机器学习常用评价指标
1. 指标说明
(1) AccuracyClassification(准确率)
• 计算方式:accuracy_score(y_true, y_pred)
• 作用:
衡量模型正确预测的样本比例(包括所有类别)。
公式:
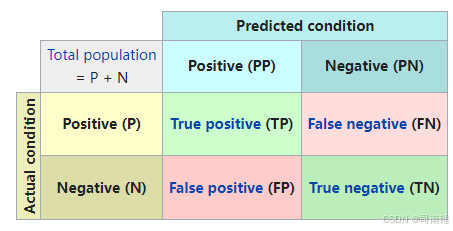
Accuracy = TP + TN TP + TN + FP + FN \text{Accuracy} = \frac{\text{TP} + \text{TN}}{\text{TP} + \text{TN} + \text{FP} + \text{FN}} Accuracy=TP+TN+FP+FNTP+TN
• 适用场景:
类别分布平衡时有效,但在类别不平衡时可能误导(例如多数类占比过高)。
(2) PrecisionClassification(精确率,宏平均)
• 计算方式:precision_score(y_true, y_pred, average='macro')
• 作用:
衡量模型预测为正的样本中实际为正的比例,按类别计算后取宏平均(各类别权重相同)。
公式(单类别):
Precision = TP TP + FP \text{Precision} = \frac{\text{TP}}{\text{TP} + \text{FP}} Precision=TP+FPTP
• 适用场景:
关注减少误报(FP),例如垃圾邮件分类中避免将正常邮件误判为垃圾邮件。
(3) RecallClassification(召回率,宏平均)
• 计算方式:recall_score(y_true, y_pred, average='macro')
• 作用:
衡量实际为正的样本中被正确预测的比例,宏平均。
公式(单类别):
Recall = TP TP + FN \text{Recall} = \frac{\text{TP}}{\text{TP} + \text{FN}} Recall=TP+FNTP
• 适用场景:
关注减少漏报(FN),例如疾病诊断中避免漏诊。
(4) F1Classification(F1分数,宏平均)
• 计算方式:f1_score(y_true, y_pred, average='macro')
• 作用:
精确率和召回率的调和平均值,平衡两者。
公式(单类别):
F 1 = 2 × Precision × Recall Precision + Recall F1 = 2 \times \frac{\text{Precision} \times \text{Recall}}{\text{Precision} + \text{Recall}} F1=2×Precision+RecallPrecision×Recall
• 适用场景:
需要同时兼顾精确率和召回率,尤其在类别不平衡时。
(5) ROCAUC(ROC曲线下面积,宏平均)
• 计算方式:roc_auc_score(y_true, y_proba, average='macro', multi_class='ovr')
• 作用:
通过多分类的One-vs-Rest策略计算AUC,衡量模型对不同类别的区分能力。
• 适用场景:
需要评估模型在不同阈值下的整体性能(如二分类或多分类概率输出)。
(6) AverageAccuracy(平均精度,AA)
• 计算方式:
对每个类别的准确率单独计算后取平均(忽略类别样本数差异)。
• 作用:
避免多数类主导整体准确率,更关注少数类的表现。
• 与Accuracy的区别:
• Accuracy:所有样本的全局正确率。
• AA:每个类别的正确率平均(更公平评估类别不平衡数据)。
(7) Kappa(Cohen’s Kappa系数)
• 计算方式:cohen_kappa_score(y_true, y_pred)
• 作用:
衡量模型预测与真实标签的一致性,排除随机猜测的影响。
公式:
κ = p o − p e 1 − p e \kappa = \frac{p_o - p_e}{1 - p_e} κ=1−pepo−pe
其中 (p_o) 是观察一致率,(p_e) 是随机一致率。
• 适用场景:
需要评估模型预测是否显著优于随机猜测(例如医学诊断或评估者间一致性)。
2. 是否存在重复?
• Accuracy vs AverageAccuracy:
• Accuracy是全局指标,AA是类别均衡的指标。两者互补,尤其在类别不平衡时需同时使用。
• 示例:若90%样本属于A类,模型全预测A类时:
◦ `Accuracy`=90%,但`AA`=50%(B类精度为0%)。 ◦ 此时`AA`更能暴露问题。
• Precision/Recall/F1(宏平均):
• 三者均基于类别宏平均,但侧重点不同(精确率、召回率、调和平均),无重复。
• 若需微平均或加权平均,需调整average参数(如average='weighted')。
• ROCAUC与其他指标:
• ROCAUC基于概率输出,其他指标基于硬标签预测,两者角度不同(概率 vs 分类结果)。
• Kappa vs Accuracy:
• Kappa考虑了随机一致性,比Accuracy更严格。例如:
◦ 若两个类别占比各50%,随机猜测的`Accuracy`=50%,`Kappa`=0。 ◦ `Kappa`能反映模型是否真正优于随机。
• 推荐组合:
• 类别平衡数据:Accuracy + F1 + ROCAUC。
• 类别不平衡数据:AA + F1(宏平均) + Kappa。
• 需减少误报:关注Precision;需减少漏报:关注Recall。
以下是针对图像分割任务的三个评价指标(PixelAccuracy、IoU、DiceCoefficient)的详细分析,包括它们的计算逻辑、适用场景以及是否存在重复或互补关系。
1. 指标说明
(1) PixelAccuracy(像素准确率)
• 计算方式:
PA = ∑ 正确预测的像素数 ∑ 总像素数 \text{PA} = \frac{\sum \text{正确预测的像素数}}{\sum \text{总像素数}} PA=∑总像素数∑正确预测的像素数
• 特点:
• 直接统计所有像素中预测正确的比例。
• 优点:计算简单,直观反映全局分割精度。
• 缺点:对类别不平衡敏感(例如背景像素占主导时,高PA可能掩盖前景类别的性能差)。
• 适用场景:
初步评估分割质量,但需结合其他指标使用。
(2) IoU(交并比,平均IoU)
• 计算方式(单类别):
IoU c = ∣ A c ∩ B c ∣ ∣ A c ∪ B c ∣ \text{IoU}_c = \frac{|A_c \cap B_c|}{|A_c \cup B_c|} IoUc=∣Ac∪Bc∣∣Ac∩Bc∣
其中 (A_c) 是真实类别 (c) 的像素集合,(B_c) 是预测类别 (c) 的像素集合。
• 宏平均:对所有类别的IoU取均值。
• 特点:
• 衡量预测区域与真实区域的重叠程度。
• 优点:对类别不平衡不敏感,直接评估分割边界质量。
• 缺点:若某类别在图像中不存在(并集为0),需特殊处理(代码中设为0)。
• 适用场景:
分割任务的核心指标,尤其关注边界准确性(如医学图像分割)。
(3) DiceCoefficient(Dice系数,平均Dice)
• 计算方式(单类别):
Dice c = 2 ∣ A c ∩ B c ∣ ∣ A c ∣ + ∣ B c ∣ \text{Dice}_c = \frac{2|A_c \cap B_c|}{|A_c| + |B_c|} Dicec=∣Ac∣+∣Bc∣2∣Ac∩Bc∣
• 与IoU的关系:(\text{Dice} = \frac{2 \times \text{IoU}}{1 + \text{IoU}})。
• 宏平均:对所有类别的Dice取均值。
• 特点:
• 类似IoU,但更强调预测与真实区域的交集。
• 优点:对分割区域的体积差异更敏感(例如小目标分割)。
• 缺点:与IoU高度相关,可能提供冗余信息。
• 适用场景:
医学图像分割(如肿瘤检测),需强调目标区域的匹配度。
2. 指标对比与潜在重复
| 指标 | 敏感性(类别不平衡) | 侧重方向 | 与IoU的关系 |
|---|---|---|---|
PixelAccuracy | 高敏感 | 全局像素正确率 | 无关 |
IoU | 低敏感 | 区域重叠精度 | 基准指标 |
DiceCoefficient | 低敏感 | 区域体积匹配度 | 与IoU强相关(数学可转换) |
• IoU vs Dice:
• 两者均衡量预测与真实区域的重叠,存在强相关性。Dice对交集更敏感,但实际应用中差异可能不显著。
• 是否冗余:
◦ 若仅需一个区域重叠指标,优先选择`IoU`(更通用)。 ◦ 若需强调小目标或医学分割,可保留`Dice`(但需注意解释时避免重复)。
• PixelAccuracy vs IoU/Dice:
• PA与后两者无直接重复,但需注意:
◦ 高`PA`可能掩盖低`IoU`(如背景主导时模型只预测背景)。 ◦ 建议同时报告`PA`和`IoU`以全面评估。
3. 改进建议
-
避免冗余:
• 若需简化指标集,可仅保留IoU(因其与Dice功能重叠)。• 若需保留
Dice,建议在文档中说明其与IoU的差异(例如对小目标的敏感性)。 -
增强鲁棒性:
• 在IoU和Dice中,对num_classes的输入增加校验(如自动推断类别数):if num_classes is None:num_classes = len(np.unique(y_true)) -
处理极端情况:
• 当某类别在真实和预测中均不存在时(union=0),当前代码返回IoU=0,但也可考虑跳过该类别(避免拉低均值)。
4. 示例场景
• 医学图像分割(类别不平衡):
• 报告IoU(评估边界) + Dice(评估体积匹配) + PA(辅助验证全局精度)。
• 街景分割(多类别平衡):
• 优先IoU + PA,可省略Dice。
总结
• 核心指标:IoU(必选),Dice(可选,与IoU二选一)。
• 辅助指标:PixelAccuracy(需结合其他指标解读)。
• 无严格重复,但需根据任务需求精简指标集以避免冗余。
1. 指标说明
(1) MSE(均方误差,Mean Squared Error)
• 公式:
MSE = 1 n ∑ i = 1 n ( y i − y ^ i ) 2 \text{MSE} = \frac{1}{n} \sum_{i=1}^n (y_i - \hat{y}_i)^2 MSE=n1i=1∑n(yi−y^i)2
• 特点:
• 对误差进行平方,放大较大误差的惩罚(对异常值敏感)。
• 输出值无单位(平方后量纲),需结合其他指标解释。
• 适用场景:
• 需要强调避免大误差的任务(如金融风险预测)。
• 与梯度下降法兼容(平方函数可导,利于优化)。
(2) RMSE(均方根误差,Root Mean Squared Error)
• 公式:
RMSE = MSE = 1 n ∑ i = 1 n ( y i − y ^ i ) 2 \text{RMSE} = \sqrt{\text{MSE}} = \sqrt{\frac{1}{n} \sum_{i=1}^n (y_i - \hat{y}_i)^2} RMSE=MSE=n1i=1∑n(yi−y^i)2
• 特点:
• 是 MSE 的平方根,恢复原始数据的单位(更直观)。
• 同样对较大误差敏感,但数值比 MSE 小(因平方根压缩)。
• 适用场景:
• 需要与目标变量同量纲的解释(如房价预测的误差以“万元”为单位)。
• 比 MSE 更贴近实际误差规模。
(3) MAE(平均绝对误差,Mean Absolute Error)
• 公式:
MAE = 1 n ∑ i = 1 n ∣ y i − y ^ i ∣ \text{MAE} = \frac{1}{n} \sum_{i=1}^n |y_i - \hat{y}_i| MAE=n1i=1∑n∣yi−y^i∣
• 特点:
• 直接计算绝对误差,对异常值不敏感(线性惩罚)。
• 单位与原始数据一致,解释性强。
• 适用场景:
• 数据中存在异常值或误差分布不均匀时(如传感器噪声)。
• 需要鲁棒性强的评估(如医疗诊断中的误差容忍)。
2. 指标对比
| 指标 | 敏感性(异常值) | 单位一致性 | 数学性质 | 典型用途 |
|---|---|---|---|---|
MSE | 高敏感 | 无 | 可导,凸函数 | 模型优化、理论分析 |
RMSE | 高敏感 | 有 | 可导,凸函数 | 结果解释、业务场景汇报 |
MAE | 低敏感 | 有 | 不可导,非光滑 | 鲁棒性评估、异常数据 |
3. 如何选择指标?
-
优先
RMSE:
• 如果需直观解释误差规模(如报告“平均误差为 5 元”),且数据较干净。 -
优先
MAE:
• 如果数据含异常值或需均衡对待所有误差(如医疗场景)。 -
优先
MSE:
• 如果模型训练需梯度下降(如神经网络),或需理论分析(如分解偏差-方差)。
4. 代码优化建议
当前实现已简洁高效,但可补充以下功能:
(1) 多输出支持
若任务是多目标回归(如预测房价和面积),可扩展为逐维度计算指标:
class MSE:def calculate(self, y_true, y_pred, axis=0):return np.mean((y_true - y_pred) ** 2, axis=axis)
(2) 加权误差
对某些样本的误差赋予不同权重(如时间序列中的近期数据更重要):
class WeightedMAE:def calculate(self, y_true, y_pred, weights):return np.average(np.abs(y_true - y_pred), weights=weights)
5. 示例场景
• 房价预测:
• 报告 RMSE=50万元(直观),同时监控 MAE 以排除极端异常影响。
• 股票价格预测:
• 使用 MSE 训练模型(惩罚大误差),但用 MAE 评估鲁棒性。
• 传感器校准:
• 优先 MAE(因噪声普遍存在,需均衡误差)。
总结
• MSE/RMSE/MAE 三者互补,无严格冗余,但需根据任务需求选择:
• 训练阶段:常用 MSE(可导性)。
• 最终评估:结合 RMSE(直观)和 MAE(鲁棒)。
• 扩展性:当前实现可支持多维度或加权计算,灵活适配复杂场景。
相关文章:

机器学习常用评价指标
1. 指标说明 (1) AccuracyClassification(准确率) • 计算方式:accuracy_score(y_true, y_pred) • 作用: 衡量模型正确预测的样本比例(包括所有类别)。 公式: Accuracy TP TN TP TN FP…...

基于ArduinoIDE的任意型号单片机 + GPS北斗BDS卫星定位
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言1.1 器件选择1.2 接线方案 二、驱动实现2.1 核心代码解析(arduino/ESP32-S3) 三、坐标解析代码四、典型问题排查总结 前言 北斗卫星导航…...

CGAL:创建点、线、三角形及其距离、关系
CGAL(Computational Geometry Algorithms Library,计算几何算法库)是一个强大的开源库,为众多几何计算问题提供了高效的解决方案,在计算几何领域应用广泛。以下将基于提供的代码示例,详细介绍如何利用 CGAL…...

STM32基础教程——软件I2C
目录 前言 I2C MPU6050 技术实现 原理图 连线图 代码实现 技术要点 I2C初始化 SCL输出和SDA输入输出控制 起始信号 停止信号 发送一个字节 读取一个字节 发送应答位 接收应答位 MPU6050初始化 指定地址写 指定地址读 读取数据寄存器 问题记录 前言 I2C …...

Xilinx FPGA | 管脚约束 / 时序约束 / 问题解析
注:本文为 “Xilinx FPGA | 管脚约束 / 时序约束 / 问题解析” 相关文章合辑。 略作重排,未整理去重。 如有内容异常,请看原文。 Xilinx FPGA 管脚 XDC 约束之:物理约束 FPGA技术实战 于 2020-02-04 17:14:53 发布 说明&#x…...

应用层自定义协议序列与反序列化
目录 一、网络版计算器 二、网络版本计算器实现 2.1源代码 2.2测试结果 一、网络版计算器 应用层定义的协议: 应用层进行网络通信能否使用如下的协议进行通信呢? 在操作系统内核中是以这种协议进行通信的,但是在应用层禁止以这种协议进行…...

大数据:数字时代的驱动力
📝个人主页🌹:一ge科研小菜鸡-CSDN博客 🌹🌹期待您的关注 🌹🌹 随着互联网和技术的迅猛发展,数据已经成为现代社会最宝贵的资源之一。大数据(Big Data)作为一种全新的信息资源,正以前所未有的方式改变着各个行业的运作模式,推动着社会的进步与创新。无论是金…...

java学习之数据结构:二、链表
本节介绍链表 目录 1.什么是链表 1.1链表定义 1.2链表分类 2.链表实现 2.1创建链表 1)手动创建 2)创建链表类进行管理链表的相关操作 2.2添加元素 1)头插法 2)尾插法 3)任意位置插入 2.3删除 2.4查找 1&…...

评估动态化烹饪工艺与营养实训室建设要点
在全民健康意识显著提升、健康饮食理念深度普及的时代背景下,烹饪工艺与营养实训室建设要点已不再局限于传统单一的技能训练模式。需以行业需求为导向,通过功能集成化设计推动革新 —— 将食品安全防控、营养科学分析、智能烹饪技术、餐饮运营管理等多元…...

Java学习手册:关系型数据库基础
一、关系型数据库概述 关系型数据库是一种基于关系模型的数据库,它将数据组织成一个或多个表(或称为关系),每个表由行和列组成。每一列都有一个唯一的名字,称为属性,表中的每一行是一个元组,代…...

吾爱出品 [Windows] EndNote 21.5.18513 汉化补丁
[Windows] EndNote 链接:https://pan.xunlei.com/s/VOPLLs6DqKNz-EoBSWVRTSmGA1?pwd9isc# Thomson Scientific公司推出了2025,本次的endnote21大概率是最后一个版本啦,现已决定进行更新。 本次采用的环境为python3.12,win11&am…...

Sentinel学习
sentinel是阿里巴巴研发的一款微服务组件,主要为用户提供服务保护,包括限流熔断等措施 (一)主要功能 流量控制(限流):比如限制1s内有多少请求能到达服务器,防止大量请求打崩服务器…...

【中间件】brpc_基础_execution_queue
execution_queue 源码 1 简介 execution_queue.h 是 Apache BRPC 中实现 高性能异步任务执行队列 的核心组件,主要用于在用户态线程(bthread)中实现任务的 异步提交、有序执行和高效调度。 该模块通过解耦任务提交与执行过程,提…...
)
Servlet(二)
软件架构 1. C/S 客户端/服务器端 2. B/S 浏览器/服务器端: 客户端零维护,开发快 资源分类 1. 静态资源 所有用户看到相同的部分,如:html,css,js 2. 动态资源 用户访问相同资源后得到的结果可能不一致,如:s…...

如何提升个人的思维能力?
提升个人的逻辑思维能力是一个系统性工程,需要长期训练和科学方法。以下是分阶段、可操作的详细建议,涵盖理论基础、日常训练和实战应用: 一、构建逻辑基础认知 1. 学习逻辑学核心理论 入门读物:《简单的逻辑学》麦克伦尼&am…...

[UVM]UVM中reg_map的作用及多个rem_map的使用案例
UVM中reg_map的作用及多个rem_map的使用案例 摘要:在 UVM (Universal Verification Methodology) 中,寄存器模型是用于验证 DUT (Design Under Test) 寄存器行为的重要工具。UVM 寄存器模型中的 uvm_reg_map(简称 reg_map)是寄存器模型的核心组成部分之一,用于定义…...

重新构想E-E-A-T:提升销售与搜索可见性的SEO策略
在2025年的数字营销环境中,谷歌的E-E-A-T(经验、专业性、权威性、可信度)已成为SEO和内容营销的核心支柱。传统的E-E-A-T优化方法通常聚焦于展示作者资质或获取反向链接,但这些策略可能不足以应对AI驱动的搜索和日益挑剔的用户需求…...
)
AI 采用金字塔(Sohn‘s AI Adoption Pyramid)
这张图是 Sohn 的 AI 采用金字塔(Sohn’s AI Adoption Pyramid) ,用于描述不同程度的 AI 应用层次,各层次意义如下: 金字塔层级 Level 1:业务角色由人类主导,AI 起辅助作用,如 AI …...

影刀RPA中新增自己的自定义指令
入门到实战明细 1. 影刀RPA自定义指令概述 1.1 定义与作用 影刀RPA的自定义指令是一种强大的功能,旨在提高流程复用率,让用户能够个性化定制指令,实现流程在不同应用之间的相互调用。通过自定义指令,用户可以将常用的、具有独立…...
驱动工具软件下载及安装教程)
驱动总裁v2.19(含离线版)驱动工具软件下载及安装教程
1.软件名称:驱动总裁 2.软件版本:2.19 3.软件大小:602 MB 4.安装环境:win7/win10/win11 5.下载地址: https://www.kdocs.cn/l/cdZMwizD2ZL1?RL1MvMTM%3D 提示:先转存后下载,防止资源丢失&am…...

SQL经典实例
第1章 检索记录 1.1 检索所有行和列 知识点:使用SELECT *快速检索表中所有列;显式列出列名(如SELECT col1, col2)提高可读性和可控性,尤其在编程场景中更清晰。 1.2 筛选行 知识点:通过WHERE子句过滤符合条…...
数学建模竞赛D题完整分析论文(共36页)(含模型、可运行代码、数据结果))
2025深圳杯(东三省)数学建模竞赛D题完整分析论文(共36页)(含模型、可运行代码、数据结果)
2025深圳杯数学建模竞赛D题完整分析论文 目录 摘 要 一、问题重述 二、问题分析 三、模型假设 四、符号定义 五、问题一模型的建立与求解 5.1 问题一模型的建立 5.1.1 问题建模背景 5.1.2 特征工程设计 5.1.3 分类模型结构与数学表达 5.2 问题一模型的求…...

大数据技术:从趋势到变革的全景探索
📝个人主页🌹:一ge科研小菜鸡-CSDN博客 🌹🌹期待您的关注 🌹🌹 在数字化时代的浪潮下,大数据已经不再是一个陌生的概念。从日常生活中的社交媒体,到企业决策支持系统,再到公共管理的大数据应用,它正在改变着我们的工作和生活方式。随着技术的进步,传统的数据…...

C++【内存管理】
C语言中的动态内存管理 int main() { int* p2(int*)calloc(4,sizeof(int)); int* p3(int*)realloc(p2,sizeof(int)*10); free(p3); }这里因为扩容数据小,所以是原地扩容,p2p3地址一样,不用free(p2) 如果扩容空间大就不是原地扩容,而是新找一块空间,然后拷贝 C内存管理方式 n…...

【Go类库分享】mcp-go Go搭建MCP服务
【Go类库分享】mcp-go Go搭建MCP服务 介绍 目前Go 生态圈有两个知名的开发 MCP 的库,一个是mark3labs/mcp-go,另一个是metoro-io/mcp-golang。 在介绍常用库之前,先来简单介绍一下mcp协议: MCP全称Model Context Protocol 模型上下文协议&a…...

人工智能发展史 — 物理学诺奖之 Hopfield 联想和记忆神经网络模型
目录 文章目录 目录1982 年,Hopfield 联想和记忆神经网络模型背景知识历史:霍普菲尔德简介神经学:大脑的联想记忆机制物理学:磁性材料的自旋玻璃理论和能量最小值函数 Hopfield 神经网络基本原理记忆存储(训练…...

Docker —— 技术架构的演进
Docker —— 技术架构的演进 技术架构演进总结单机架构优点缺点总结 应用数据分离架构优点缺点总结 应用服务集群架构1. Nginx2. HAProxy3. LVS(Linux Virtual Server)4. F5 BIG-IP对比总结选型建议 读写分离/主从分离架构1. MyCat简介 2. TDDLÿ…...

Docker与WSL2如何清理
文章目录 Docker与WSL2如何清理一、docker占据磁盘空间核心原因分析1. WSL2 虚拟磁盘的动态扩展特性2. Docker 镜像分层缓存与未清理资源 二、解决方案步骤 1:清理 Docker 未使用的资源步骤 2:手动压缩 WSL2 虚拟磁盘1. 关闭 WSL2 和 Docker Desktop2. 定…...

单片机嵌入式按键库
kw_btn库说明 本库主要满足嵌入式按键需求,集成了常用的按键响应事件:高电平、低电平、上升沿、下降沿、单击、双击、长按键事件。可以裸机运行,也可以配合实时操作系统运行。 本库开源连接地址:gitee连接 实现思路 本库采用C语…...

多多铃声 7.4| 拥有丰富的铃声曲库,满足不同用户的个性化需求,支持一键设置手机铃声
多多铃声是一款提供丰富铃声资源的应用程序,它拥有广泛的铃声曲库,涵盖各种风格和类型,能够满足不同用户的个性化需求。该应用程序支持分类浏览和热门榜单功能,让用户可以轻松找到当前最流行或自己感兴趣的铃声。此次分享的版本为…...
)
基于stm32的四旋翼飞行器:MPU6050讲解 · 上(参数读取)
大伙早上好,不知道大伙有没有飞行器情结,就是学习嵌入式就想做一个能飞的东西。小白兔不才,小白兔有啊,所以最近准备做一个简单的飞行器出来,如果失败了,那么这个系列就只能烂尾了,如果成功了&a…...

使用xlwings将excel表中将无规律的文本型数字批量转化成真正的数字
之前我写了一篇文章excel表中将无规律的文本型数字批量转化成真正的数字-CSDN博客 是使用excel自带的操作,相对繁琐。 今天使用xlwings操作,表格如下(有真正的数字,也有文本型数字,混在在一起)࿱…...

linux netlink实现用户态和内核态数据交互
1,内核态代码 #include <linux/module.h> #include <linux/netlink.h> #include <net/sock.h> #define NETLINK_TEST 31 struct sock *nl_sk NULL; static void nl_recv_msg(struct sk_buff *skb) { struct nlmsghdr *nlh; int pid; …...

学习黑客安全基础理论入门
准备安全课程内容 你已安装Kali和相关工具,并希望从基础开始学习安全。为了使课程更加互动,我会提供有趣的文本,并结合可视化内容,可能还会提供一些参考链接。内容方面,我会根据最新的中国网络安全法律作出更新&#…...

探索内容智能化的关键解决方案
北京先智先行科技有限公司拥有三款旗舰产品,分别是“先知大模型”、“先行AI商学院”以及“先知AIGC超级工场”。这三款产品在企业发展过程中扮演着重要角色。 北京先智先行科技有限公司围绕先知大模型等核心要素,构建了完备的业务体系。先知大模型私…...

学习黑客色即是空
二、Day 3 学习目标(保真版) 一句话目标: 学会用 Asset-Threat-Vulnerability-Risk (ATVR) 四件套给任何系统快速画“风险画像”,并能把它映射到黑客常说的 5 阶段攻击生命周期。 1. 30 分钟理论——ATVR 四件套 概念核心定义参考…...

【Java学习】关于springBoot的自动配置和起步依赖
关于springBoot的起步依赖:解决了spring框架中开发者配置依赖难的问题,各种依赖及版本的不同,可能引发不同的问题,使得开发者的精力大部分可能耗费在非业务代码中。所以springBoot起步依赖解决了各种依赖难的配置问题。 起步依赖…...

【LLaMA-Factory实战】1.3命令行深度操作:YAML配置与多GPU训练全解析
一、引言 在大模型微调场景中,命令行操作是实现自动化、规模化训练的核心手段。LLaMA-Factory通过YAML配置文件和多GPU分布式训练技术,支持开发者高效管理复杂训练参数,突破单机算力限制。本文将结合结构图、实战代码和生产级部署经验&#…...

【Mytais系列】介绍、核心概念
MyBatis 是一款优秀的 持久层框架,它通过简化 JDBC 操作、提供灵活的 SQL 映射能力,成为 Java 开发中处理数据库交互的核心工具之一。以下是 MyBatis 的核心框架和概念解析: 一、MyBatis 框架概述 1. 核心定位 作用:将 Java 对象…...

Vivado FPGA 开发 | 创建工程 / 仿真 / 烧录
注:本文为 “Vivado FPGA 开发 | 创建工程 / 仿真 / 烧录” 相关文章合辑。 略作重排,未整理去重。 如有内容异常,请看原文。 Vivado 开发流程(手把手教学实例)(FPGA) 不完美先生 于 2018-04-…...

PowerShell从5.1升级到7.X
文章目录 环境背景安装PowerShell 7.X其它启动PowerShell 5.1和7.X$PSVersionTable.PSVersion启动PowerShell 5.1时强制启动7.X 参考 环境 Windows 11 专业版 背景 PowerShell 5.1是Windows内置的,发布时间是2016 年。现在PowerShell版本已经到了7.5.1࿰…...

域名与官网的迷思:数字身份认证的全球困境与实践解方-优雅草卓伊凡
域名与官网的迷思:数字身份认证的全球困境与实践解方-优雅草卓伊凡 一、官网概念的法律与技术界定 1.1 官网的实质定义 当卓伊凡被问及”公司域名就是官网吗”这一问题时,他首先指出:”这相当于问’印着某公司logo的建筑就是该公司总部吗’…...

Vue实现成绩增删案例
Vue实现成绩增删案例 案例功能需求案例实现实现思路完整代码功能演示 案例小结 案例功能需求 1.通过vue渲染数据,将成绩的相关信息显示出来(学号,学科,成绩) 2.能够增加相关的成绩信息 3.能够删除相关的成绩信息 4.能…...
)
开源项目实战学习之YOLO11:ultralytics-cfg-models-rtdetr(十一)
👉 点击关注不迷路 👉 点击关注不迷路 👉 点击关注不迷路 文章大纲 1. __init__.py2. model.py3. predict.py4. train.py5. val.py ultralytics-cfg-models-rtdetr 主要与 Ultralytics 库中 RTDETR(实时目标检测模型,R…...
)
【Bootstrap V4系列】学习入门教程之 组件-按钮(Buttons)
Bootstrap V4系列 学习入门教程之 组件-按钮(Buttons) 按钮(Buttons)一、示例二、可用作按钮的 HTML 标签三、带轮廓线的按钮四、按钮的尺寸五、活动状态六、禁用状态七、按钮插件切换状态Checkbox and radio buttons (…...

【java八股文】深入浅出synchronized优化原理
🔍 开发者资源导航 🔍🏷️ 博客主页: 个人主页📚 专栏订阅: JavaEE全栈专栏 synchronized优化原理 synchronized即使悲观锁也是乐观锁,拥有自适应性。 jvm内部会统计每个锁的竞争激烈程度&…...

裴蜀定理及其证明
裴蜀定理 对于所有整数 a a a和 b b b,存在: g c d ( a , b ) a x b y gcd(a,b)axby gcd(a,b)axby 并且 a x b y axby axby一定是 g c d ( a , b ) gcd(a,b) gcd(a,b)的倍数。 证明 定义一个集合: { a x b y | a x b y &…...

单片机嵌入式CAN库
kw_can库说明 本库是针对CAN类型数据的收发设计: 主要应用于大数据量(数据处理速度高于缓存CAN_RTX_FIFO_SIZE大小)接收不丢包可快速进出接收中断可跨线程调用发送接口。 本库开源连接地址:gitee连接 实现思路 本库采用C语言…...

基于 JSP 和 Servlet 的数字信息分析小应用
Java Web 实验:基于 JSP 和 Servlet 的数字信息分析小应用 一、实验目的 实现一个简单的 Java Web 应用,通过 JSP 表单收集用户输入的文本信息,提交至 Servlet 分析其中是否包含数字,并返回结果。掌握 JSP 与 Servlet 的协同工作…...

从零认识阿里云OSS:云原生对象存储的核心价值
引言 在云计算时代,海量数据的存储与管理成为企业数字化转型的关键命题。阿里云对象存储OSS(Object Storage Service)作为云原生的分布式存储服务,凭借其独特的架构设计和丰富的功能矩阵,正在成为企业构建数据湖、管理…...