Docker —— 技术架构的演进
Docker —— 技术架构的演进
- 技术架构演进总结
- 单机架构
- 优点
- 缺点
- 总结
- 应用数据分离架构
- 优点
- 缺点
- 总结
- 应用服务集群架构
- 1. Nginx
- 2. HAProxy
- 3. LVS(Linux Virtual Server)
- 4. F5 BIG-IP
- 对比总结
- 选型建议
- 读写分离/主从分离架构
- 1. MyCat
- 简介
- 2. TDDL(Taobao Distributed Data Layer)
- 简介
- 3. Amoeba
- 简介
- 4. Cobar
- 简介
- 对比总结
- 选型建议
- 延伸:现代替代方案
- 引入缓存——冷热分离架构
- Redis 详细介绍
- 1. Redis 核心特性
- (1) 高性能内存数据库
- 垂直分库
- 1. Greenplum
- 定位
- 适用场景
- 缺点
- 2. TiDB
- 定位
- 适用场景
- 缺点
- 3. PostgreSQL XC(XL)
- 定位
- 适用场景
- 缺点
- 4. HAWQ
- 定位
- 适用场景
- 缺点
- 对比总结
- 选型建议
- 延伸阅读
- 业务拆分——微服务
- Spring Cloud 和 Dubbo 介绍
- 1. Spring Cloud
- 2. Dubbo
- 3. 对比总结
- 4. 现代演进
- 容器化引入——容器编排架构
- 通俗解释:Docker 是啥?为啥要用它?
- 1. Docker 是干什么的?
- 2. 为啥要引入 Docker?
- 问题1:环境不一致,导致“在我电脑能跑,上线就崩”
- 问题2:服务器资源浪费
- 问题3:部署慢到怀疑人生
- 问题4:应用之间互相打架
- 3. Docker 的核心概念
- 4. 举个栗子:用 Docker 部署网站
- 5. 总结:Docker 的好处
- 通俗解释:Kubernetes(K8S)是啥?为啥需要它?
- 1. 先举个现实中的例子
- 2. K8S 到底是干嘛的?
- 3. 为什么需要 K8S?
- 问题1:手动管理1000个容器?累死!
- 问题2:流量突增,服务崩了怎么办?
- 问题3:如何保证服务永不宕机?
- 4. K8S 的核心功能
- 5. 举个实际例子
- 6. 和Docker的关系
- 7. 总结:K8S 的优势
- 几种架构的比较
- 技术架构演进对比表
- 关键演进逻辑
- 选型建议
相信大家之前已经对Docker这个东西有过耳闻,没有系统性的了解过的话对它的概念可能还只是停留在对这个名词的认识上,我们今天的主要任务就是对Docker进行一个简单初步的了解。
不过在了解Docker之前,我们先了解一下互连网技术架构的演进,这样可以帮助我们更加深入的了解引入Docker的重要性和必要性。
技术架构演进总结
单机架构
- 单机架构
- 特点:所有服务(应用和数据库)部署在一台服务器上。
- 适用场景:初期用户量少,快速验证业务。
- 引入的软件:
- Web服务器:Tomcat、Netty、Nginx、Apache
- 数据库:MySQL、Oracle、PostgreSQL、SQL Server
我们初学者做一个什么XXX管理系统之类的,所用的就是单机架构,我们的服务器和数据库是装在一个电脑上的:
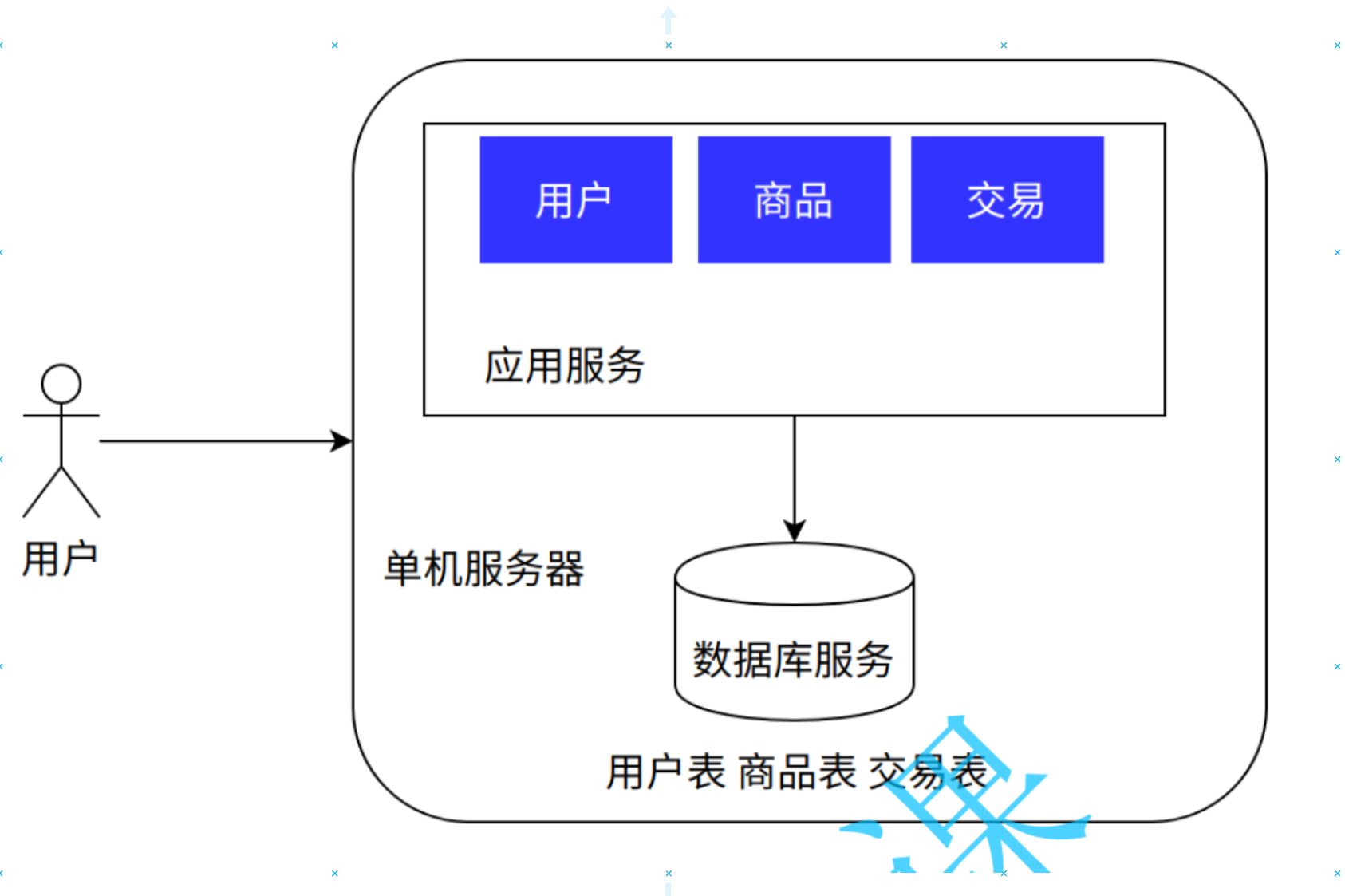
单机架构是一种简单直接的技术架构,适用于系统初期或访问量较小的场景。以下是单机架构的优缺点分析:
优点
-
简单易实现:
- 开发难度低:单机架构的系统结构简单,开发团队无需考虑复杂的分布式问题,如网络通信、数据一致性等,开发周期短,能够快速将系统投入市场。
- 部署简单:所有组件(应用服务和数据库)都部署在同一台服务器上,部署过程简单快捷,运维成本低。
- 维护方便:由于系统结构简单,出现问题时排查和修复相对容易,不需要跨多个服务器进行调试。
-
性能开销小:
- 低延迟:应用服务和数据库在同一台服务器上,数据访问的延迟较低,因为不需要通过网络传输数据。
- 资源利用集中:所有资源(如CPU、内存、磁盘I/O)都集中在一个服务器上,资源分配和管理相对简单。
-
成本低:
- 硬件成本低:初期只需一台服务器即可满足需求,无需额外购买多台服务器或复杂的网络设备。
- 运维成本低:无需专业的运维团队,单机系统的运维相对简单,减少了人力成本。
缺点
-
可扩展性差:
- 性能瓶颈:随着用户访问量的增加,单机系统的性能会迅速达到瓶颈。一旦服务器的CPU、内存或磁盘I/O等资源耗尽,系统将无法继续处理更多的请求。
- 难以水平扩展:单机架构无法通过增加更多的服务器来提升系统的处理能力,只能通过升级硬件(垂直扩展),但硬件性能提升的成本高且有上限。
-
可用性低:
- 单点故障:如果服务器出现故障(如硬件故障、网络问题、操作系统崩溃等),整个系统将无法正常工作,没有冗余机制来保证系统的高可用性。
- 维护困难:对服务器进行维护(如升级、打补丁等)时,需要停机操作,这会影响用户体验。
-
资源利用率低:
- 资源浪费:在业务量低谷时,服务器的资源可能会大量闲置,无法充分利用,导致资源浪费。
- 难以应对突发流量:单机架构难以应对突发的高并发请求,容易导致系统崩溃或响应缓慢。
总结
单机架构适用于系统初期或访问量较小的场景,其优点在于简单、易实现、成本低,适合快速验证业务和上线。然而,随着业务的发展和用户量的增加,单机架构的缺点(如可扩展性差、可用性低)会逐渐显现,因此需要逐步向更复杂的分布式架构演进。
应用数据分离架构
- 应用数据分离架构
- 特点:将数据库服务独立部署到另一台服务器,减轻单机压力。
- 适用场景:用户量增长,硬件资源接近极限。
- 引入的软件:无新软件,但需配置网络通信(如JDBC)。
简单来说,就是把数据库放到另外一台电脑上了:
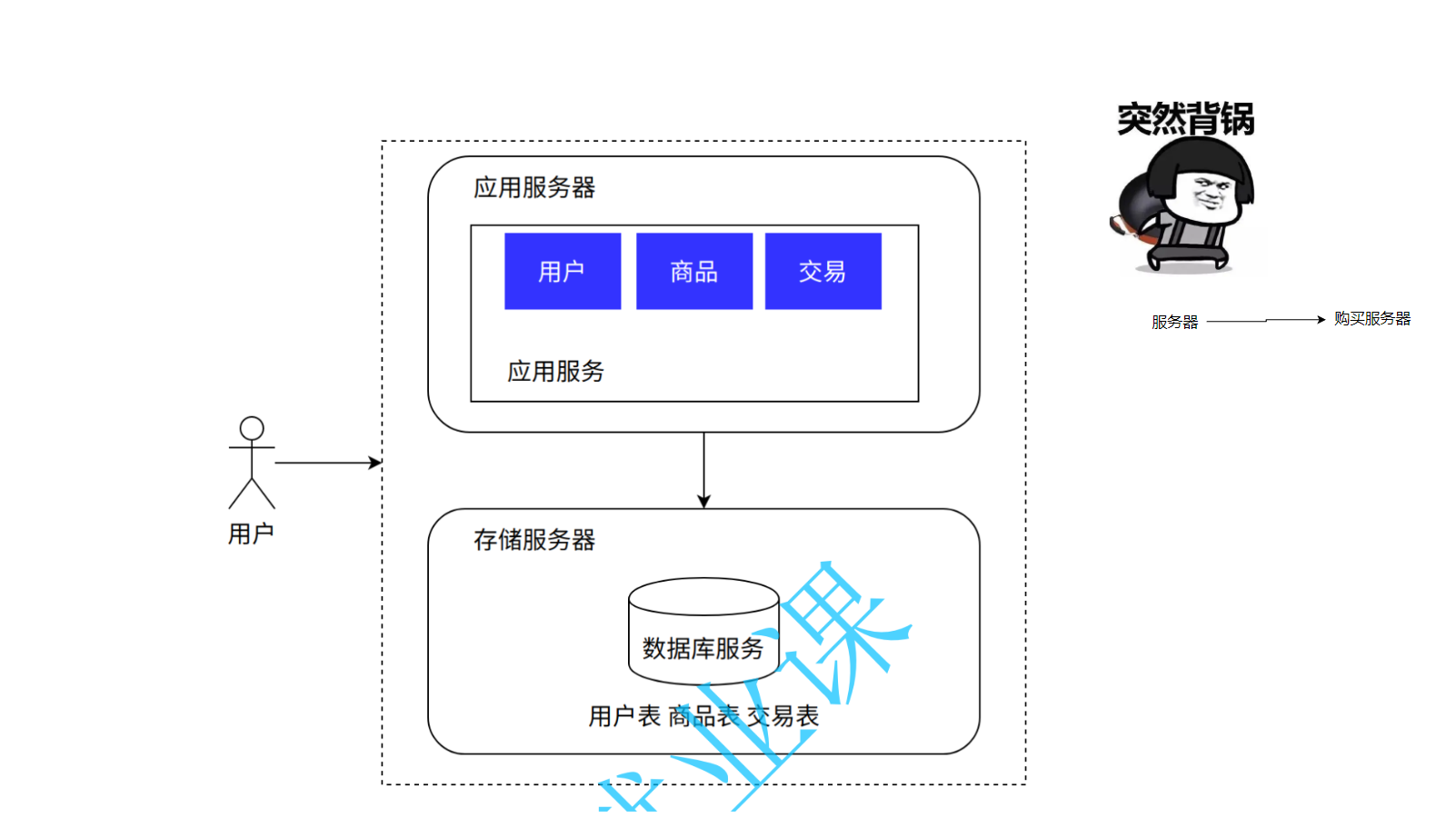
应用数据分离架构是将应用服务和数据库服务部署在不同的服务器上,通过网络进行通信。这种架构在系统访问量逐步上升时,能够有效提升系统的承载能力。以下是应用数据分离架构的优缺点分析:
优点
-
提升性能:
- 资源隔离:应用服务和数据库服务分别部署在不同的服务器上,可以独立分配资源(CPU、内存、磁盘I/O等),避免资源竞争,提高系统的整体性能。
- 负载均衡:通过将应用服务和数据库服务分离,可以为数据库服务单独配置高性能的服务器,进一步提升数据库的处理能力。
-
扩展性增强:
- 灵活扩展:当系统访问量增加时,可以单独对应用服务或数据库服务进行扩展,例如增加应用服务器的数量或升级数据库服务器的硬件配置,而不影响另一部分。
- 逐步优化:可以根据系统的实际需求,逐步优化应用服务和数据库服务的性能,而不需要对整个系统进行大规模的重构。
-
运维效率提升:
- 独立管理:应用服务和数据库服务的运维可以独立进行,便于运维团队分别管理和维护,减少运维复杂性。
- 故障隔离:如果应用服务或数据库服务出现故障,可以单独排查和修复,不会相互影响,提高了系统的可用性。
-
安全性增强:
- 数据保护:数据库服务部署在独立的服务器上,可以通过网络防火墙等安全措施,更好地保护数据的安全性。
- 访问控制:可以对数据库服务进行更严格的访问控制,限制只有授权的应用服务才能访问数据库,降低安全风险。
缺点
-
网络开销增加:
- 通信延迟:应用服务和数据库服务通过网络通信,相比单机架构,增加了网络延迟,可能会影响系统的响应速度。
- 网络带宽要求:随着系统访问量的增加,应用服务和数据库服务之间的数据交互量也会增加,对网络带宽的要求更高,否则可能会出现网络瓶颈。
-
复杂性增加:
- 配置复杂:需要配置网络通信、数据库连接池等,增加了系统的配置复杂性。
- 管理难度:需要管理多台服务器,包括应用服务器和数据库服务器,增加了运维管理的难度和成本。
-
成本增加:
- 硬件成本:需要额外购买一台或多台服务器来部署数据库服务,增加了硬件成本。
- 运维成本:需要专业的运维人员来管理多台服务器,增加了人力成本。
-
数据一致性问题:
- 分布式事务:如果应用服务和数据库服务之间需要进行分布式事务处理,可能会增加数据一致性的复杂性,需要额外的机制来保证数据的完整性和一致性。
总结
应用数据分离架构通过将应用服务和数据库服务分离,有效提升了系统的性能和扩展性,同时增强了运维效率和安全性。然而,这种架构也带来了网络开销增加、复杂性提升、成本上升以及数据一致性问题等挑战。在实际应用中,这种架构适用于系统访问量逐步上升,但尚未达到需要大规模分布式架构的场景。通过合理配置和优化,可以在中等规模的系统中实现较好的性能和稳定性。
应用服务集群架构
- 应用服务集群架构
- 特点:通过负载均衡将流量分发到多台应用服务器,水平扩展。
- 适用场景:单台应用服务器无法承载高并发请求。
- 引入的软件:
- 负载均衡:Nginx、HAProxy、LVS、F5
随着用户的增长,一台服务器肯定是不够用的了,所以我们就会扩展很多的服务器,然后通过负载均衡算法,每次挑选一台当前压力最小的服务器来提供服务:
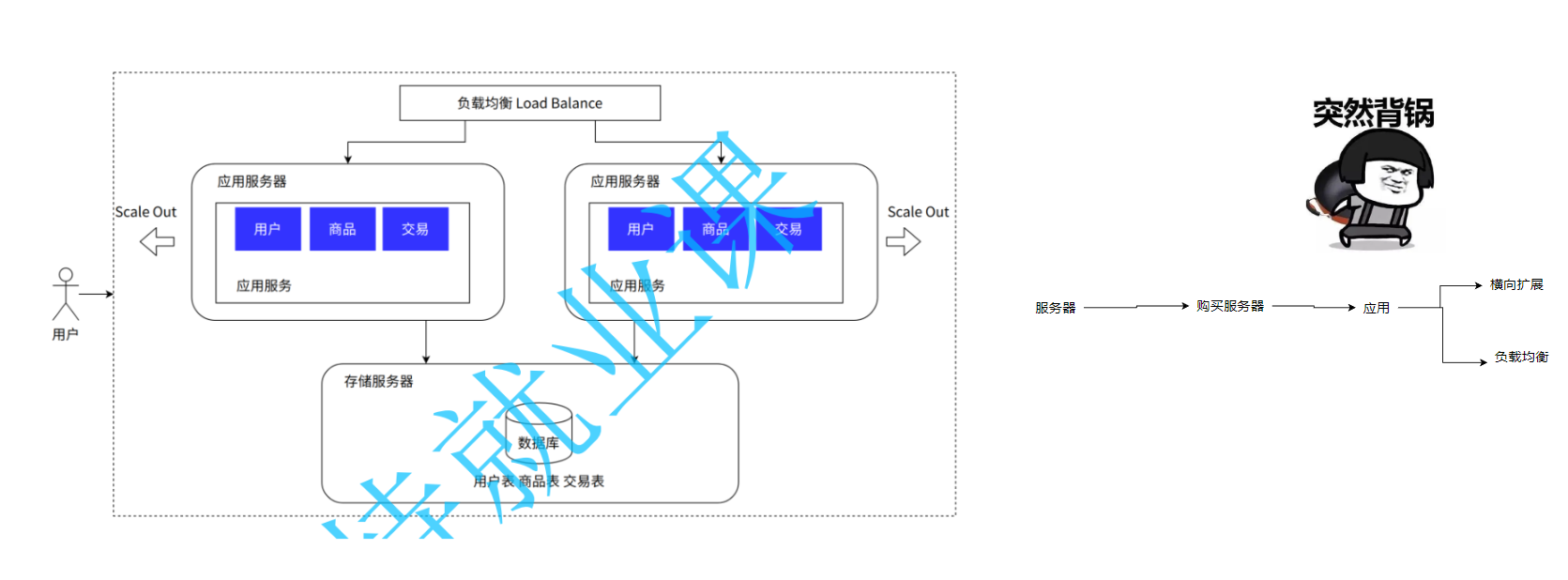
引入的东西就变多了:
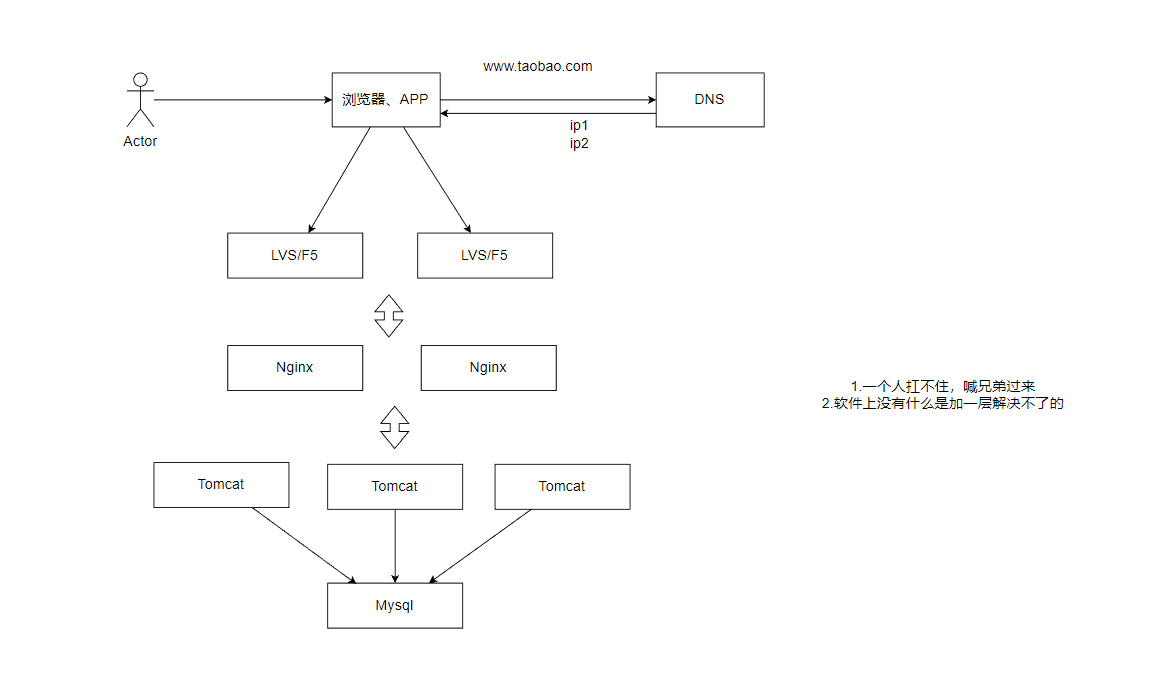
我们都来了解一下:
以下是 Nginx、HAProxy、LVS、F5 这四种负载均衡技术的详细介绍和对比:
1. Nginx
- 类型:基于应用层(Layer 7)的反向代理和负载均衡器,也可支持部分传输层(Layer 4)功能。
- 特点:
- 轻量级、高性能,支持高并发(事件驱动模型,单机可处理数万并发连接)。
- 支持 HTTP/HTTPS、TCP/UDP 协议的负载均衡。
- 内置缓存、SSL/TLS 终止、URL 重写、静态文件服务等功能。
- 配置简单,支持动态模块扩展(如 Lua 脚本)。
- 负载均衡算法:
- 轮询(Round-Robin)、加权轮询(Weighted Round-Robin)
- IP 哈希(IP Hash)、最小连接(Least Connections)等。
- 适用场景:
- Web 应用负载均衡(如 HTTP/HTTPS 流量分发)。
- 动静分离、API 网关、反向代理。
- 缺点:
- 对 TCP 层负载均衡的支持较弱(不如 LVS)。
- 长连接场景下性能可能不如 LVS 或 HAProxy。
2. HAProxy
- 类型:专注于传输层(Layer 4)和应用层(Layer 7)的负载均衡器。
- 特点:
- 高性能,支持百万级并发(基于事件驱动和多线程模型)。
- 支持 TCP(如数据库负载均衡)和 HTTP 模式。
- 丰富的健康检查机制(如主动探测后端服务状态)。
- 灵活的 ACL(访问控制列表)规则,可定制流量路由策略。
- 负载均衡算法:
- 轮询、加权轮询、最小连接、源 IP 哈希等。
- 支持动态权重调整(如根据服务器负载自动分配流量)。
- 适用场景:
- 高并发 Web 服务、数据库读写分离、微服务网关。
- 需要精细流量控制的场景(如灰度发布)。
- 缺点:
- 配置相对复杂(需手动定义后端健康检查策略)。
- 无内置缓存功能(需配合其他工具如 Redis)。
3. LVS(Linux Virtual Server)
- 类型:基于内核的传输层(Layer 4)负载均衡,工作在 Linux 内核态。
- 特点:
- 极高性能(数据包直接转发,无需用户态-内核态切换)。
- 支持 NAT(网络地址转换)、DR(直接路由)、TUN(隧道)三种模式。
- 无单点故障(可结合 Keepalived 实现高可用)。
- 负载均衡算法:
- 轮询、加权轮询、最小连接、目标 IP 哈希等。
- 适用场景:
- 超大规模流量分发(如视频直播、CDN 边缘节点)。
- 需要低延迟、高吞吐的 TCP/UDP 负载均衡(如游戏服务器)。
- 缺点:
- 仅支持 Layer 4,无法解析 HTTP 协议(不能基于 URL 或 Cookie 路由)。
- 配置复杂,需依赖 Linux 内核调优。
4. F5 BIG-IP
- 类型:商业硬件负载均衡器(支持 Layer 4 和 Layer 7)。
- 特点:
- 企业级功能:高级 SSL 加速、DDoS 防护、WAF(Web 应用防火墙)。
- 可视化管理和监控(通过 GUI 或 REST API)。
- 支持全局负载均衡(GSLB),跨数据中心流量调度。
- 负载均衡算法:
- 轮询、加权轮询、最小连接、响应时间优先等。
- 适用场景:
- 对安全性和可靠性要求极高的企业级应用(如金融、政务)。
- 需要一体化解决方案(负载均衡 + 安全 + 流量分析)。
- 缺点:
- 价格昂贵(硬件设备 + 按功能模块授权)。
- 灵活性较低(依赖厂商支持)。
对比总结
| 特性 | Nginx | HAProxy | LVS | F5 BIG-IP |
|---|---|---|---|---|
| 工作层级 | Layer 7/4 | Layer 7/4 | Layer 4 | Layer 7/4 |
| 性能 | 高(HTTP 优化) | 极高(TCP 优化) | 极致(内核转发) | 高(硬件加速) |
| 配置复杂度 | 简单 | 中等 | 复杂 | 中等(GUI 支持) |
| 扩展性 | 高(模块化) | 中等 | 低(依赖内核) | 低(商业闭源) |
| 成本 | 免费开源 | 免费开源 | 免费开源 | 昂贵(商业硬件) |
| 典型场景 | Web 反向代理 | TCP/HTTP 负载 | 超大规模 TCP | 企业级全功能 |
选型建议
- Web 应用:优先选 Nginx 或 HAProxy(HTTP 层灵活路由)。
- 高性能 TCP 服务:选 LVS(如数据库、游戏服务器)。
- 企业级需求:预算充足时选 F5(安全 + 负载均衡一体化)。
- 云原生环境:可结合 Kubernetes Ingress(Nginx/HAProxy)或 Service Mesh(如 Istio)。
读写分离/主从分离架构
- 读写分离/主从分离架构
- 特点:数据库主库处理写请求,从库处理读请求,分担压力。
- 适用场景:数据库读写压力不均衡(如读多写少)。
- 引入的软件:
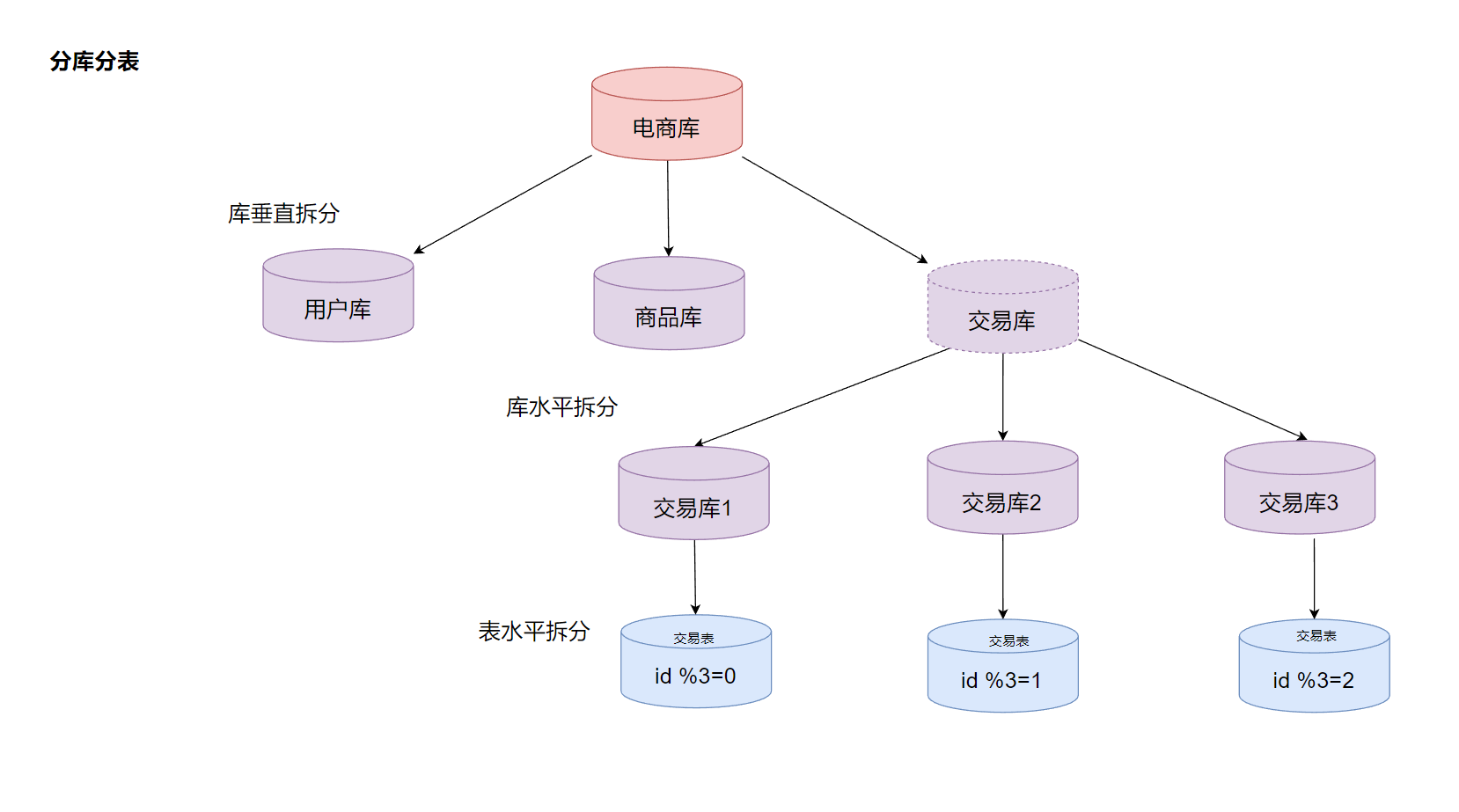
- 数据库中间件:MyCat、TDDL、Amoeba、Cobar (让应用层无需关心数据如何分布,像访问单库一样操作分布式数据库。)
之前的架构数据库同时担任了写和读的角色,在这个架构中,写专门有一个数据库,读专门有一个数据库:
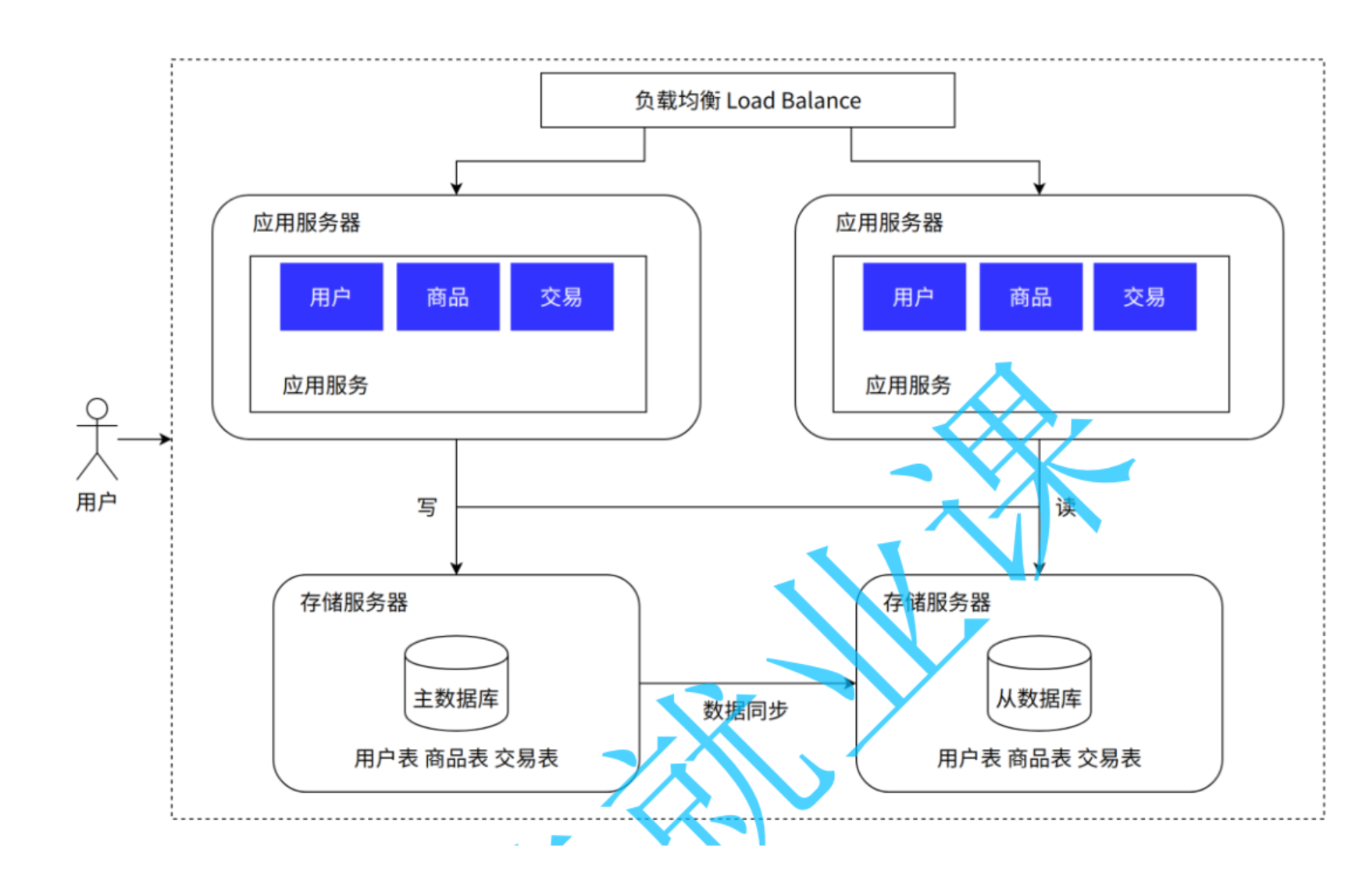
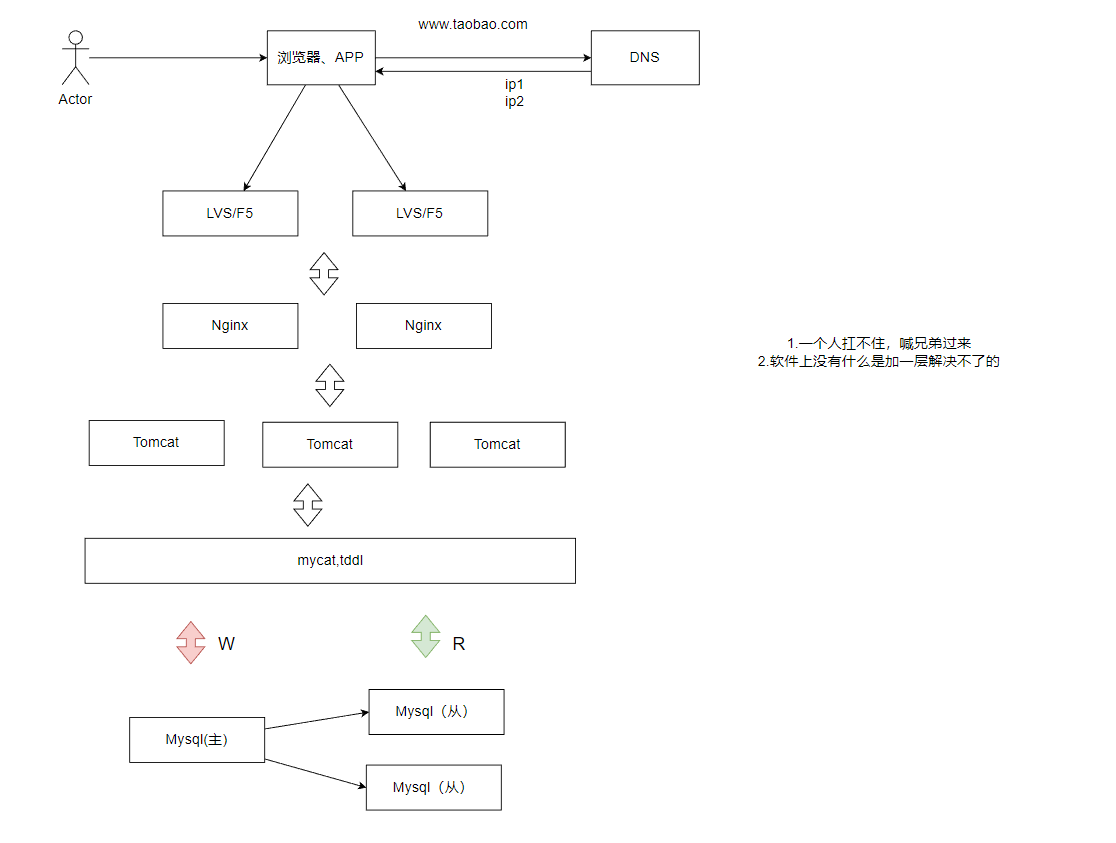
同时也引入了一些东西,我们也来了解一下:
以下是 MyCat、TDDL、Amoeba、Cobar 的详细介绍和对比,它们都是用于数据库中间件或分库分表的工具,主要用于解决数据库扩展性、读写分离、分库分表等问题。
1. MyCat
简介
- 定位:开源的分布式数据库中间件,基于阿里Cobar二次开发,支持分库分表、读写分离、数据分片等。
- 核心功能:
- 分库分表:支持水平拆分(按字段分片)、垂直拆分(按业务分库)。
- 读写分离:自动路由读请求到从库,写请求到主库。
- SQL 兼容性:支持 MySQL 协议,兼容大部分 SQL 语法(如 JOIN、子查询)。
- 分布式事务:弱一致性事务(最终一致性),支持 XA 事务(需额外配置)。
- 适用场景:
- 需要分库分表的高并发 OLTP 系统(如电商订单库)。
- 替代传统单库 MySQL,提升数据库扩展性。
- 缺点:
- 复杂查询(如多表 JOIN)性能较差。
- 运维成本较高(需管理分片规则、数据迁移等)。
2. TDDL(Taobao Distributed Data Layer)
简介
- 定位:阿里自研的数据库中间件(非开源,仅内部使用),后来部分能力开放为 DRDS(分布式关系数据库服务)。
- 核心功能:
- 动态数据源路由:根据 SQL 类型(读/写)自动选择主库或从库。
- 分库分表:支持按范围、哈希等方式分片。
- SQL 解析与优化:对复杂 SQL 进行改写,提升分库分表查询效率。
- 适用场景:
- 阿里内部高并发业务(如淘宝订单、支付系统)。
- 需要强可控性的企业级分库分表方案。
- 缺点:
- 不开源,普通用户无法直接使用。
- 依赖阿里云 DRDS 商业化产品。
3. Amoeba
简介
- 定位:早期的开源数据库代理(类似 MySQL Proxy),支持读写分离和分库分表。
- 核心功能:
- 读写分离:自动路由读请求到从库。
- 分库分表:支持简单规则(如按 ID 取模分片)。
- 轻量级:基于 Java 开发,部署简单。
- 适用场景:
- 小规模读写分离需求(如早期 Web 应用)。
- 不适合复杂分片规则或高并发场景。
- 缺点:
- 功能较简单,不支持复杂 SQL 优化。
- 社区不活跃,已逐渐被 MyCat、ShardingSphere 取代。
4. Cobar
简介
- 定位:阿里早期开源的数据库中间件,MyCat 的前身,现已停止维护。
- 核心功能:
- 分库分表:支持按哈希、范围等方式分片。
- 读写分离:自动路由读/写请求。
- MySQL 协议兼容:应用无需修改代码即可接入。
- 历史地位:
- 是 MyCat 的基础,推动了分库分表中间件的发展。
- 缺点:
- 已停止更新,被 MyCat 和 ShardingSphere 取代。
对比总结
| 特性 | MyCat | TDDL (DRDS) | Amoeba | Cobar (已淘汰) |
|---|---|---|---|---|
| 开源情况 | 开源 | 阿里内部(部分开放 DRDS) | 开源 | 开源(已停止维护) |
| 分库分表 | 支持(灵活分片规则) | 支持(企业级优化) | 简单分片 | 支持(基础分片) |
| 读写分离 | 支持 | 支持 | 支持 | 支持 |
| SQL 兼容性 | 较好(兼容大部分 MySQL 语法) | 强(阿里优化) | 一般 | 一般 |
| 适用场景 | 高并发 OLTP | 超大规模企业级系统 | 小规模读写分离 | 历史项目 |
| 现状 | 活跃(社区维护) | 阿里云 DRDS 商业化 | 逐渐淘汰 | 已被 MyCat 取代 |
选型建议
- 需要开源分库分表 → MyCat(功能全面,社区活跃)。
- 企业级高可用方案 → 阿里云 DRDS(基于 TDDL,但需付费)。
- 简单读写分离 → Amoeba(仅适合老旧小系统)。
- Cobar 已淘汰,无需考虑。
延伸:现代替代方案
- ShardingSphere(Apache 顶级项目):
- 比 MyCat 更活跃,支持多数据库(MySQL/PostgreSQL/Oracle)。
- 提供 Sharding-JDBC(嵌入式分库分表)和 Sharding-Proxy(独立中间件)。
- Vitess(YouTube 开源):
- 适合超大规模 MySQL 集群,云原生设计(K8s 友好)。
如果需要更现代的解决方案,建议优先考虑 ShardingSphere 或 Vitess。
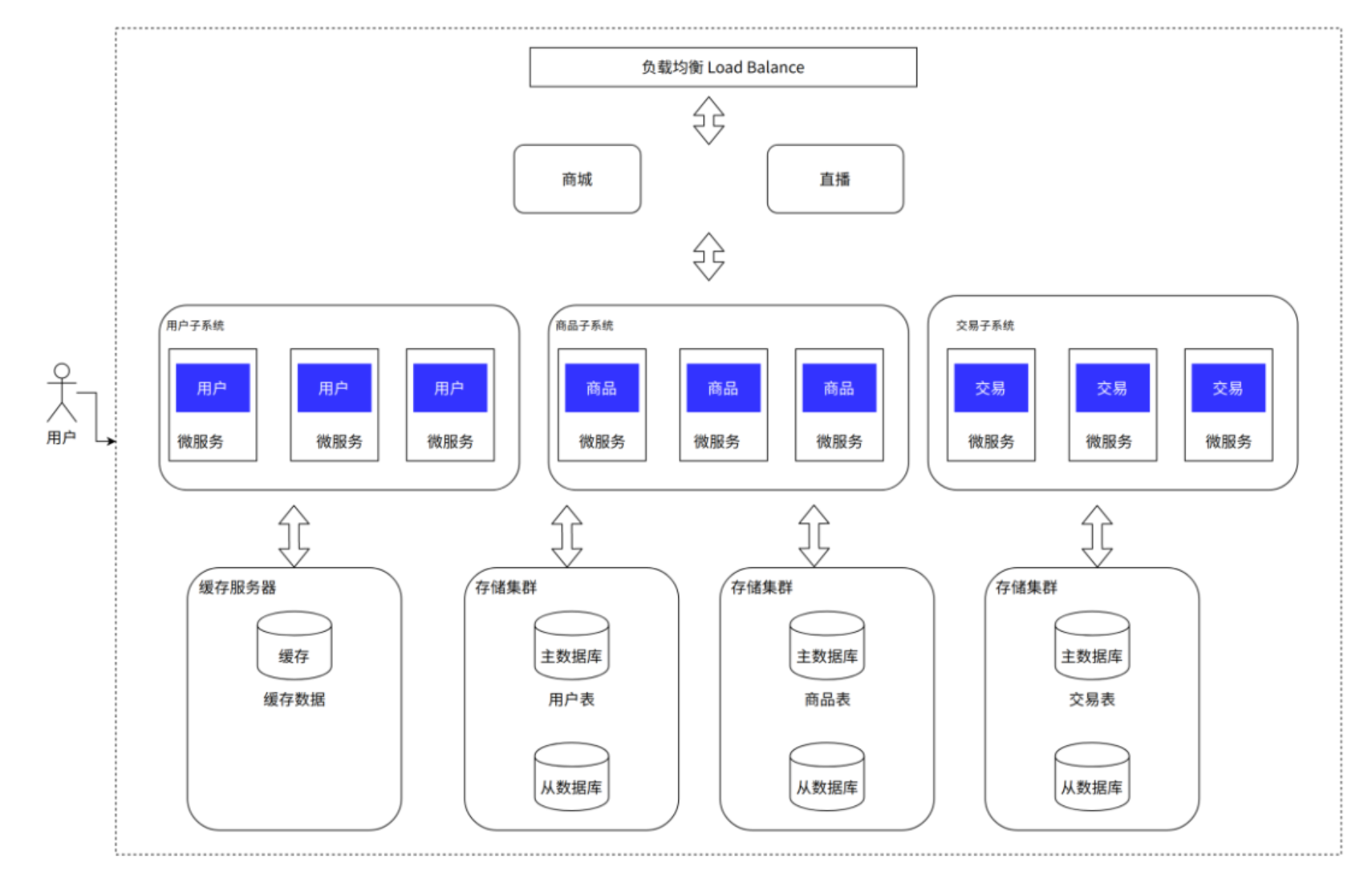
引入缓存——冷热分离架构
- 引入缓存——冷热分离架构
- 特点:使用缓存存储热点数据,减少数据库访问。
- 适用场景:存在高频访问的热点数据(如热门商品)。
- 引入的软件:
- 缓存工具:Memcached、Redis
这样的目的是,如果一些数据经常被访问,就放在缓存里,不用直接访问数据库,大大提升访问效率:
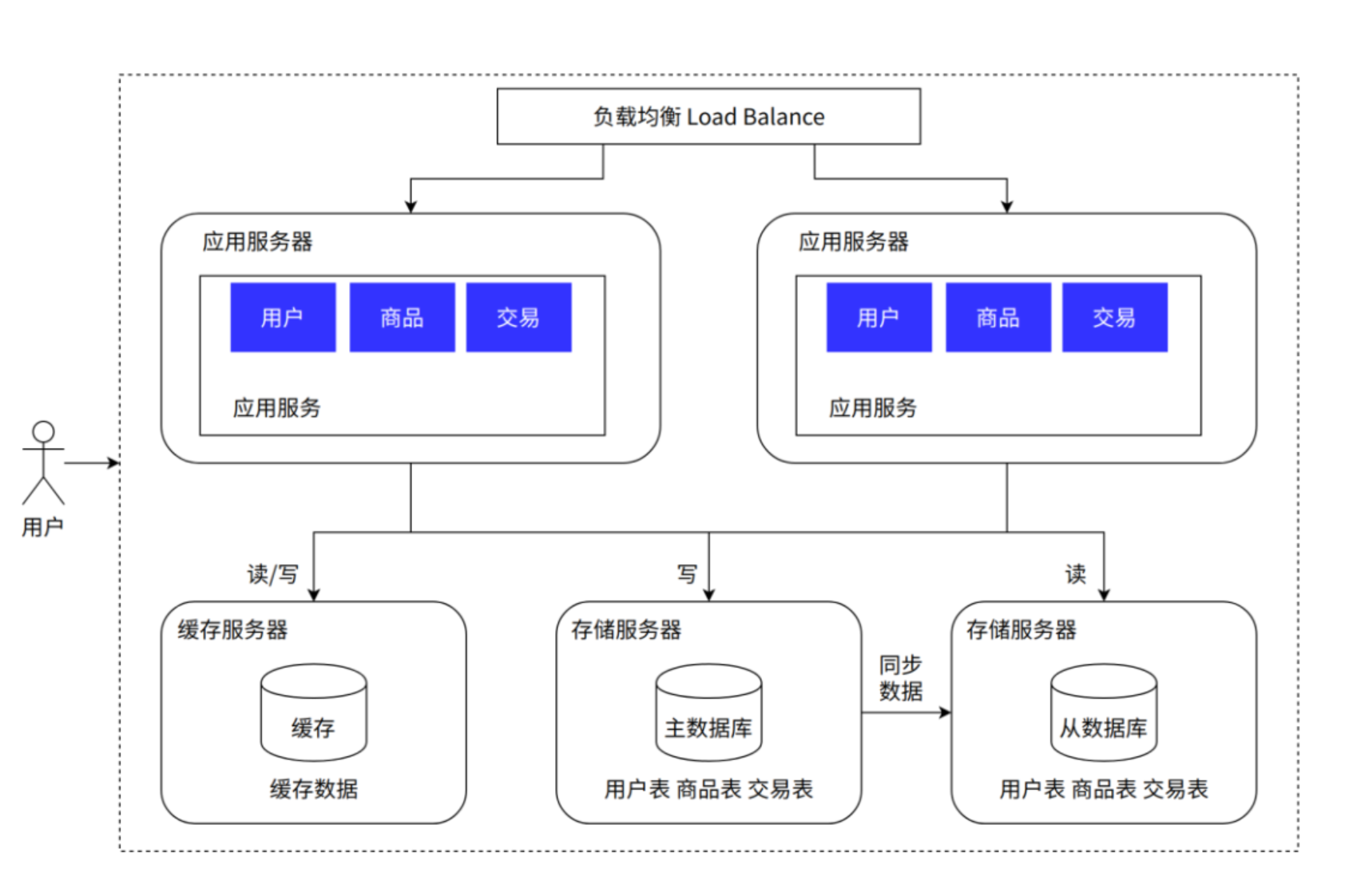
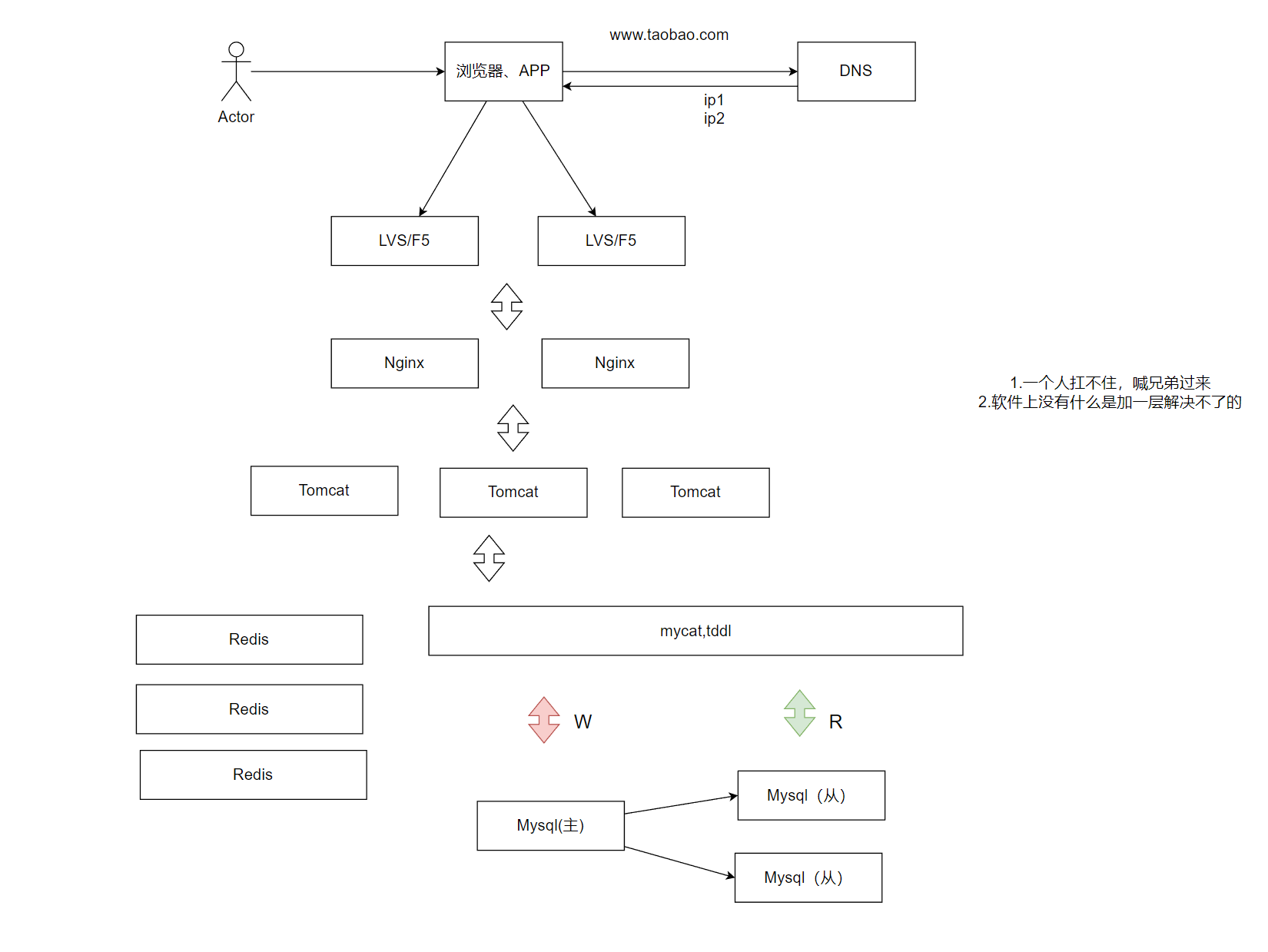
高速缓存的话,就是Redis最有名气了:
Redis 详细介绍
Redis(Remote Dictionary Server)是一个开源的、基于内存的 键值存储数据库(Key-Value Store),同时支持 持久化 和 多种数据结构,广泛应用于 缓存、消息队列、实时分析、会话存储 等场景。
1. Redis 核心特性
(1) 高性能内存数据库
- 内存存储:数据主要存储在内存中,读写速度极快(10万+ QPS)。
- 单线程模型:避免多线程竞争,通过 I/O 多路复用(epoll/kqueue)实现高并发。
- 支持持久化:
- RDB(快照):定时全量备份,适合灾难恢复。
- AOF(日志追加):记录所有写操作,数据更安全但文件较大。
如果需要 替代 MySQL 的部分功能(如缓存、实时计算),Redis 是最佳选择之一!
垂直分库
- 垂直分库
- 特点:按业务拆分数据库,分散数据存储压力。
- 适用场景:单库数据量过大,查询性能下降。
- 引入的软件:
- 分布式数据库:Greenplum、TiDB、PostgreSQL XC、HAWQ
简单来说是将不同业务模块的数据存储到独立的数据库中。
Greenplum、TiDB、PostgreSQL XC、HAWQ 的详细介绍,它们都属于 分布式数据库 或 大规模并行处理(MPP)数据库,主要用于解决海量数据分析和高并发事务处理的场景。
1. Greenplum
定位
- 类型:基于 PostgreSQL 的 MPP(大规模并行处理)分析型数据库。
- 核心特点:
- 列存储 & 行存储:支持混合存储模型,适合 OLAP(分析型查询)。
- 分布式计算:数据分片(Sharding)到多个节点,并行计算。
- SQL 兼容:完全兼容 PostgreSQL 语法,支持复杂查询(如窗口函数、CTE)。
- 生态工具:集成 Apache MADlib(机器学习库)、GPText(全文检索)。
适用场景
- 数据仓库:企业级大数据分析(如日志分析、用户行为分析)。
- ETL 处理:支持 TB/PB 级数据的高效聚合和转换。
缺点
- 不适合高并发 OLTP:设计目标是分析型负载,事务性能较弱。
- 运维复杂:需手动管理数据分布策略。
2. TiDB
定位
- 类型:分布式 HTAP 数据库(Hybrid Transactional/Analytical Processing)。
- 核心特点:
- 水平扩展:通过 Raft 协议实现数据分片,支持自动扩容。
- 强一致性:基于 Percolator 模型的分布式事务(ACID)。
- 兼容 MySQL:语法和协议兼容,可无缝替代 MySQL。
- 实时分析:通过 TiFlash(列存引擎)支持 OLAP 查询。
适用场景
- 高并发 OLTP:如电商订单、支付系统。
- 实时数仓:事务和分析混合负载(HTAP)。
缺点
- 资源消耗大:依赖 TiKV(分布式 KV 存储),内存和 SSD 需求高。
- 复杂查询性能有限:相比 Greenplum,OLAP 能力较弱。
3. PostgreSQL XC(XL)
定位
- 类型:基于 PostgreSQL 的 分布式关系型数据库。
- 核心特点:
- 写扩展:支持多节点写入(不同于 Greenplum 的单写多读)。
- 全局事务:通过两阶段提交(2PC)保证分布式事务一致性。
- 透明分片:应用无需感知数据分布(通过协调节点路由)。
适用场景
- 分布式 OLTP:需要跨节点写入的事务系统(如多租户 SaaS)。
- 替代分库分表:避免业务层手动分片。
缺点
- 社区活跃度低:已逐步被 Citus(PostgreSQL 插件)取代。
- 性能瓶颈:协调节点可能成为单点。
4. HAWQ
定位
- 类型:基于 Greenplum 的 SQL-on-Hadoop 引擎(现为 Apache HAWQ)。
- 核心特点:
- HDFS 集成:直接查询 Hadoop 数据(Parquet/ORC 格式)。
- MPP 架构:类似 Greenplum,但优化了 Hadoop 生态兼容性。
- 支持 ANSI SQL:兼容 PostgreSQL 语法。
适用场景
- 大数据分析:替代 Hive,提供更快的交互式查询。
- 混合架构:需同时访问 HDFS 和传统数据库的场景。
缺点
- 依赖 Hadoop:需部署 HDFS/YARN,架构较重。
- 社区停滞:已逐渐被 Presto/Spark SQL 取代。
对比总结
| 数据库 | 类型 | 核心优势 | 适用场景 | 缺点 |
|---|---|---|---|---|
| Greenplum | MPP 分析型 | 海量数据分析,PostgreSQL 兼容 | 数据仓库、OLAP | 事务性能弱,运维复杂 |
| TiDB | 分布式 HTAP | 高并发 OLTP + 实时分析 | 电商、金融核心系统 | 资源消耗大,OLAP 能力中等 |
| PostgreSQL XC | 分布式 OLTP | 多节点写入,兼容 PostgreSQL | 多租户 SaaS、分布式事务 | 社区停滞,协调节点瓶颈 |
| HAWQ | SQL-on-Hadoop | 直接查询 HDFS,MPP 加速 | Hadoop 生态中的交互式分析 | 依赖 Hadoop,已边缘化 |
选型建议
- 需要替代传统数仓 → Greenplum(强 OLAP 能力)。
- 高并发 OLTP + 实时分析 → TiDB(HTAP 场景首选)。
- 多节点写入的 PostgreSQL → 考虑 Citus(PostgreSQL 插件,比 XC 更活跃)。
- Hadoop 生态分析 → Presto/Spark SQL(HAWQ 已逐渐淘汰)。
延伸阅读
- Citus:PostgreSQL 的分布式扩展,适合分片和实时分析。
- ClickHouse:专攻 OLAP 的列存数据库,比 Greenplum 更轻量。
- OceanBase:阿里自研的分布式数据库,类似 TiDB 但闭源。
这些数据库的竞争本质是 OLTP vs OLAP 和 SQL 兼容性 vs 扩展性 的权衡,根据业务需求选择即可。
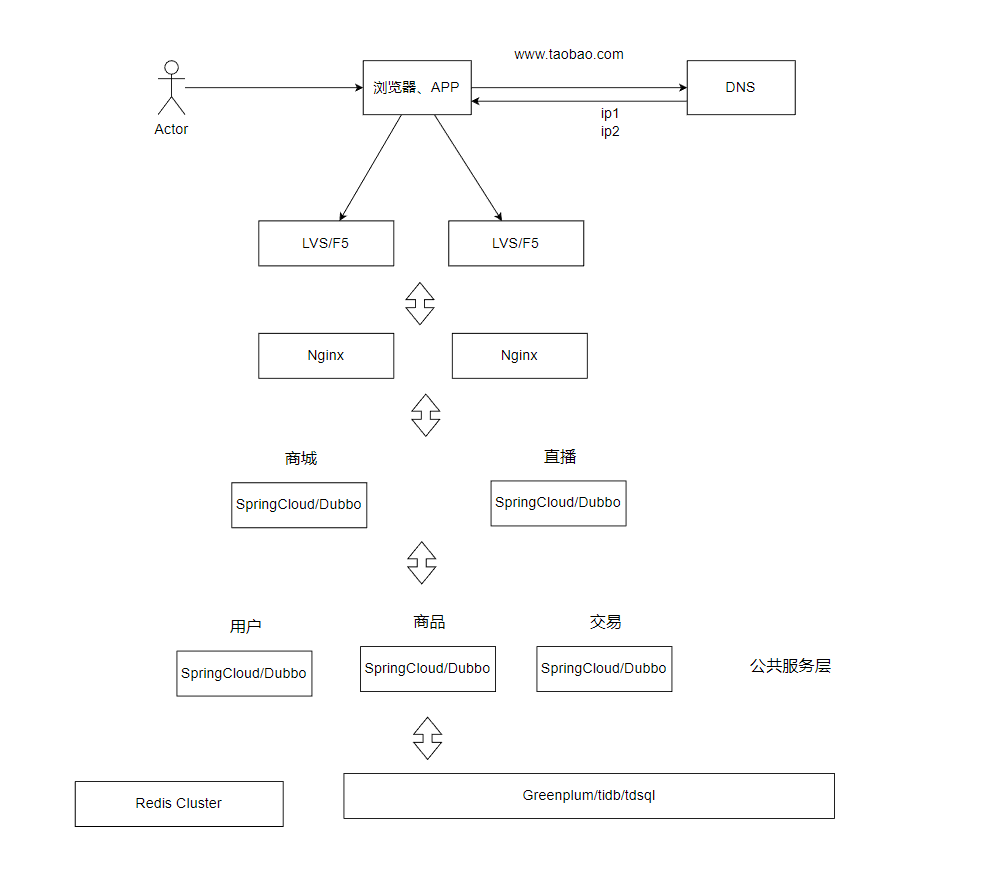
业务拆分——微服务
- 业务拆分——微服务
- 特点:将系统拆分为独立维护的微服务,通过网关或消息总线通信。
- 适用场景:业务复杂,团队规模扩大,需独立开发和部署。
- 引入的软件:
- 微服务框架:Spring Cloud、Dubbo
将单体应用拆分为多个独立的、松耦合的服务,每个服务负责一个特定的业务功能(如用户服务、订单服务)。
Spring Cloud 和 Dubbo 介绍
1. Spring Cloud
定位:
- 微服务全家桶,提供了一套完整的分布式系统解决方案(如服务发现、配置中心、熔断器等)。
- 基于 Spring 生态,与 Spring Boot 深度集成,适合 Java 技术栈。
核心组件:
| 组件 | 功能 | 类似竞品 |
|---|---|---|
| Eureka | 服务注册与发现(已逐步被替代) | Nacos、Consul |
| Ribbon | 客户端负载均衡 | Dubbo LB |
| Feign | 声明式 HTTP 客户端(RESTful 调用) | Dubbo RPC |
| Hystrix | 熔断降级(已停更,推荐 Resilience4J) | Sentinel |
| Zuul/Gateway | API 网关(路由、限流) | Kong、APISIX |
| Config | 分布式配置中心 | Nacos、Apollo |
| Sleuth/Zipkin | 分布式链路追踪 | SkyWalking |
优点:
- 开箱即用:组件丰富,覆盖微服务全场景。
- 生态强大:与 Spring 无缝整合,社区活跃。
缺点:
- 性能较低:基于 HTTP/REST,通信效率不如 RPC。
- 配置复杂:组件多,学习成本高。
适用场景:
- 企业级微服务架构(尤其是 Java 技术栈)。
- 需要快速搭建完整微服务体系的团队。
2. Dubbo
定位:
- 高性能 RPC 框架,专注于服务间的远程调用(核心解决通信问题)。
- 阿里开源,后捐赠给 Apache,支持多语言(Java、Go、Rust 等)。
核心功能:
| 功能 | 说明 | Spring Cloud 对应方案 |
|---|---|---|
| RPC 调用 | 基于 Netty 的高性能二进制通信 | Feign(HTTP) |
| 负载均衡 | 内置多种算法(随机、轮询、一致性哈希) | Ribbon |
| 服务注册发现 | 支持 Zookeeper、Nacos 等 | Eureka/Nacos |
| 容错机制 | 失败自动重试、快速失败等 | Hystrix |
| 服务治理 | 流量控制、动态路由、权重调整 | Gateway + Sentinel |
优点:
- 性能极致:二进制协议(如 Dubbo2/Triple),吞吐量比 HTTP 高 50% 以上。
- 轻量灵活:可单独使用 RPC,也可整合其他组件(如 Nacos 做注册中心)。
缺点:
- 功能单一:需自行整合配置中心、网关等(常与 Spring Cloud Alibaba 搭配)。
- 多语言支持较新:非 Java 语言生态仍在完善。
适用场景:
- 高并发、低延迟的内部服务调用(如电商核心交易系统)。
- 已有注册中心(如 Zookeeper),需轻量级 RPC 框架。
3. 对比总结
| 维度 | Spring Cloud | Dubbo |
|---|---|---|
| 核心目标 | 提供微服务全家桶解决方案 | 专注高性能 RPC 通信 |
| 通信协议 | HTTP/REST(文本,性能较低) | 自定义二进制协议(性能高) |
| 服务治理 | 需整合多个组件(如 Gateway + Sentinel) | 内置流量控制、负载均衡等 |
| 生态整合 | 与 Spring 生态无缝兼容 | 需搭配其他组件(如 Nacos) |
| 适用场景 | 需要完整微服务能力的企业 | 追求高性能的内部服务调用 |
4. 现代演进
- Spring Cloud Alibaba:
- 整合了 Dubbo + Nacos + Sentinel,提供“Spring Cloud 体验 + Dubbo 性能”。
- Dubbo 3.0:
- 支持 Triple 协议(兼容 gRPC)、应用级服务发现,更适合云原生。
选型建议:
- 如果团队熟悉 Spring,需要快速搭建微服务 → Spring Cloud。
- 如果追求极致性能,且已有注册中心 → Dubbo。
- 折中方案 → Spring Cloud Alibaba + Dubbo。
容器化引入——容器编排架构
- 容器化引入——容器编排架构
- 特点:使用容器技术(Docker)和编排工具(K8S)动态管理服务。
- 适用场景:需动态扩缩容、提高资源利用率、简化运维。
- 引入的软件:
- 容器化工具:Docker
- 容器编排:Kubernetes(K8S)
接下来我们来介绍一下Docker:
通俗解释:Docker 是啥?为啥要用它?
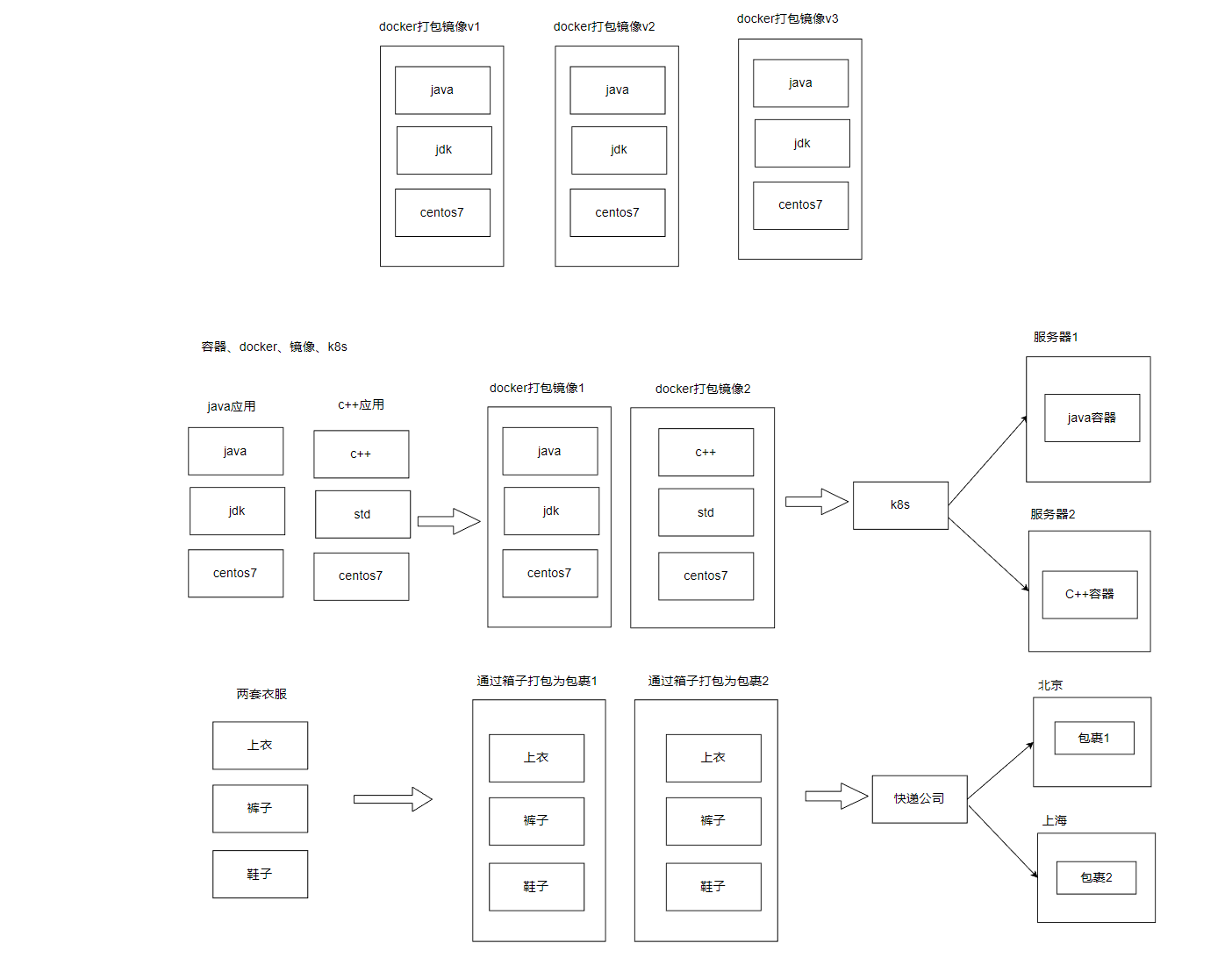
1. Docker 是干什么的?
想象你要搬家,家里有一堆家具、电器、衣服、玩具……
- 传统方式:
你得一件件拆开、打包、搬到新家,再重新组装——费时费力,还容易出错(比如忘带螺丝刀)。 - 用 Docker:
直接把整个房间(包括家具、电器、甚至墙纸)打包成一个“集装箱”,运到新家后,拆开就能用,和原来一模一样!
Docker 就是这个“集装箱”:
- 它把 应用程序 + 运行环境(比如代码、数据库、配置文件)一起打包成一个轻量级的“箱子”(镜像)。
- 这个箱子可以在任何地方(Windows/Mac/Linux/云服务器)秒级启动,完全不用操心环境问题。
2. 为啥要引入 Docker?
问题1:环境不一致,导致“在我电脑能跑,上线就崩”
- 传统开发:
程序员A用 Windows,程序员B用 Mac,服务器是 Linux……每个人的软件版本还不同,动不动就报错:“缺个库”“版本不对”。 - 用 Docker:
所有人直接用同一个“集装箱”(镜像),里面环境一模一样,彻底告别“玄学bug”。
问题2:服务器资源浪费
- 传统部署:
每个应用独占一台虚拟机(VM),比如跑一个网站就用一个 VM,CPU 和内存根本用不满,浪费钱。 - 用 Docker:
多个“集装箱”可以共享一台机器的操作系统,像乐高一样灵活拼装,省下90%的硬件成本。
问题3:部署慢到怀疑人生
- 传统上线:
装系统 → 配环境 → 调试依赖 → 启动服务……一下午过去了。 - 用 Docker:
一行命令docker run,1秒启动服务,还能一键批量部署100台服务器。
问题4:应用之间互相打架
- 传统方式:
两个程序需要不同版本的 Python,装一起直接冲突,只能二选一。 - 用 Docker:
每个程序住自己的“集装箱”,互相隔离,Python 2 和 Python 3 可以和谐共存。
3. Docker 的核心概念
| 名词 | 类比 | 作用 |
|---|---|---|
| 镜像(Image) | 集装箱的“设计图纸” | 包含应用和环境的只读模板(比如“带MySQL的Ubuntu镜像”)。 |
| 容器(Container) | 根据图纸造出的“真实集装箱” | 镜像运行时的实例(一个镜像可以启动多个容器)。 |
| Dockerfile | 集装箱的“施工说明书” | 用代码定义如何构建镜像(比如“先装Ubuntu,再装MySQL”)。 |
4. 举个栗子:用 Docker 部署网站
- 打包:把你的网站代码 + Nginx + Python 环境打包成一个镜像。
- 运输:把这个镜像上传到服务器(就像把集装箱运到码头)。
- 运行:在服务器上执行
docker run,网站秒级上线!
传统方式 vs Docker 方式:
- 传统:配环境2小时,启动5分钟,还可能失败。
- Docker:配环境1次(做成镜像),以后每次启动只要1秒。
5. 总结:Docker 的好处
- 环境一致:开发、测试、生产环境完全一致,告别“跑不起来”。
- 秒级部署:一点按钮,服务就能全球上线。
- 省钱:一台服务器能跑100个容器,相当于省了99台虚拟机。
- 隔离安全:一个容器崩了,不会影响其他容器。
一句话:
Docker 就像“软件界的集装箱”,让开发、部署、运维变得像搭积木一样简单!
通俗解释:Kubernetes(K8S)是啥?为啥需要它?
1. 先举个现实中的例子
想象你开了一家网红奶茶店,生意爆火,现在要在全城开100家分店。
- 问题来了:
- 怎么确保每家店的奶茶口味一致?
- 怎么自动调配原料(比如某款奶茶突然爆单)?
- 怎么监控所有店铺,万一某家店机器坏了怎么办?
Kubernetes(K8S)就是你的“超级奶茶总部”,它能:
- 自动管理所有分店(服务器)。
- 智能调度原料(计算资源)。
- 保证奶茶口味一致(服务标准化)。
- 故障自愈(某家店停电了,自动换另一家顶上)。
2. K8S 到底是干嘛的?
简单说:
- 它是一个自动化运维机器人,专门帮你管理成千上万的“集装箱”(Docker容器)。
- 它的核心任务是:把一堆服务器变成一台“超级计算机”,让你像用一台机器一样轻松管理海量服务。
类比Docker:
- Docker 是“集装箱”(打包应用),K8S 是“港口调度系统”(管理集装箱)。
3. 为什么需要 K8S?
问题1:手动管理1000个容器?累死!
- 不用K8S:
你得手动登录每台服务器,启动容器、监控状态、处理故障……运维工程师直接辞职。 - 用K8S:
告诉它“我要跑100个微信后台容器”,它会自动分配服务器、监控状态、故障重启,你只管喝茶。
问题2:流量突增,服务崩了怎么办?
- 不用K8S:
半夜爬起来加服务器,手忙脚乱。 - 用K8S:
设定规则“CPU超过80%自动扩容”,流量暴增时,K8S自动新建容器扛住压力。
问题3:如何保证服务永不宕机?
- 不用K8S:
一台服务器挂了,上面的服务全凉。 - 用K8S:
它会自动把挂掉的服务挪到其他健康服务器,用户毫无感知。
4. K8S 的核心功能
| 功能 | 类比奶茶店 | 技术解释 |
|---|---|---|
| 自动部署 | 新店开张,总部一键配齐所有设备 | 根据配置文件(YAML)自动部署容器 |
| 弹性伸缩 | 爆款奶茶卖光了?立刻调10台机器生产 | 根据CPU/内存负载,自动增减容器数量 |
| 服务发现 | 顾客不管去哪家店,都能买到同款奶茶 | 自动分配IP和域名,服务间直接通信 |
| 自愈能力 | 某店咖啡机坏了?立刻换备用机器 | 容器崩溃后自动重启或迁移到其他节点 |
| 负载均衡 | 让所有店铺的顾客排队时间均匀 | 把用户请求智能分发给空闲的容器 |
5. 举个实际例子
场景:你开发了一个短视频APP(类似抖音)。
- 不用K8S:
- 用户多了,你得手动加服务器、部署服务、调试网络……天天救火。
- 用K8S:
- 写个配置文件:“需要100个视频处理容器,50个用户服务容器”。
- K8S自动分配服务器、监控流量、扩容缩容、处理故障。
- 你只需要关注业务代码,其他全交给K8S。
6. 和Docker的关系
- Docker:负责“打包”应用(像集装箱)。
- K8S:负责“调度”集装箱(像智能港口系统)。
- 组合效果:
- Docker让应用可移植,K8S让应用自动化运维。
7. 总结:K8S 的优势
- 省人力:不用雇100个运维工程师。
- 省钱:服务器利用率提升50%以上。
- 高可用:服务24小时不宕机。
- 标准化:开发、测试、生产环境完全一致。
一句话:
Kubernetes 是云时代的操作系统,让你像管理一台电脑一样管理整个数据中心!
补充:名字里的“8”是缩写,因为 Kubernetes 中间有8个字母(
K+ubernete+s)。
几种架构的比较
以下是 单机架构、应用数据分离、读写分离、缓存架构、垂直分库、水平分库、微服务架构、容器化(Docker/K8S) 的详细对比表格,涵盖核心目标、适用场景、优缺点及技术组件:
技术架构演进对比表
| 架构类型 | 核心目标 | 适用场景 | 优点 | 缺点 | 关键技术/工具 |
|---|---|---|---|---|---|
| 单机架构 | 快速验证业务,简单部署 | - 初创项目 - 低并发(<1000 QPS) - 学生项目/毕业设计 | - 开发简单 - 无分布式复杂度 - 成本低 | - 单点故障 - 性能瓶颈(CPU/内存/磁盘) - 无法扩展 | - Web服务器:Tomcat/Nginx - 数据库:MySQL/PostgreSQL |
| 应用数据分离 | 缓解单机资源压力 | - 数据库负载高 - 初期用户增长(1万~10万 QPS) | - 读写分离雏形 - 硬件成本低 | - 应用层仍是单点 - 数据库未优化 | - 独立数据库服务器 - 网络通信优化(JDBC连接池) |
| 读写分离 | 分担数据库读压力 | - 读多写少(如资讯网站) - 读请求占比>80% | - 提升读性能 - 从库可水平扩展 | - 主库单点写入压力 - 数据同步延迟 | - 主从复制:MySQL Replication - 中间件:MyCat/ShardingSphere |
| 缓存架构 | 拦截热点查询,降低数据库负载 | - 热点数据访问(如商品详情页) - 高并发查询(如秒杀) | - 响应极快(Redis 10万+ QPS) - 减轻数据库压力 | - 缓存一致性难题 - 缓存穿透/雪崩风险 | - 缓存:Redis/Memcached - 策略:缓存预热、布隆过滤器 |
| 垂直分库 | 按业务拆分数据库,降低单库复杂度 | - 业务模块多且独立(如电商拆用户库、订单库) - 单库表数量过多(>100张表) | - 业务解耦 - 单库性能提升 | - 跨库JOIN困难 - 分布式事务复杂 | - 分库策略:按业务划分 - 工具:Spring Cloud Alibaba(Seata) |
| 水平分库分表 | 解决单表数据量过大问题 | - 单表数据超千万行 - 高并发写入(如订单表) | - 数据分散存储 - 理论上无限扩展 | - 分片键设计复杂 - 跨分片查询性能差 | - 分片中间件:MyCat/ShardingSphere - 数据库:TiDB/CockroachDB |
| 微服务架构 | 业务解耦,独立开发部署 | - 大型系统(团队>20人) - 多业务线需快速迭代(如美团外卖、滴滴打车) | - 技术栈灵活(不同服务用不同语言) - 独立扩缩容 | - 分布式事务难题 - 运维复杂度高(需服务网格、链路追踪) | - 框架:Spring Cloud/Dubbo - 组件:Nacos(注册中心)、Sentinel(限流)、Zipkin(链路追踪) |
| 容器化(Docker) | 环境一致性,快速部署 | - 开发/测试/生产环境统一 - 需动态扩缩容(如应对促销活动) | - 一次构建,到处运行 - 资源利用率高(共享OS内核) | - 网络配置复杂 - 存储管理挑战 | - Docker镜像 - 编排工具:Docker Compose |
| Kubernetes(K8S) | 自动化运维,管理海量容器 | - 云原生应用 - 超大规模集群(如抖音/淘宝后台) - 需高可用和自愈能力 | - 自动扩缩容 - 服务自愈 - 跨主机调度 | - 学习曲线陡峭 - 中小团队可能过度设计 | - 核心概念:Pod/Deployment/Service - 生态:Helm(包管理)、Prometheus(监控) |
关键演进逻辑
- 从单机到分布式:
- 单机 → 数据分离 → 读写分离 → 分库分表,逐步解决数据库瓶颈。
- 从单体到微服务:
- 业务复杂后,拆分为独立服务,但引入分布式事务和运维挑战。
- 从物理机到云原生:
- Docker 解决环境一致性问题,K8S 解决大规模调度问题。
选型建议
- 初创公司:单机 → 应用数据分离 → 缓存。
- 中型系统:读写分离 + 垂直分库 → 微服务。
- 大型系统:水平分库 + K8S + 服务网格(如Istio)。
通过这张表格,可以清晰看到每种架构的演进动机和技术权衡,实际项目中常需混合使用(如微服务+分库分表+K8S)。
相关文章:

Docker —— 技术架构的演进
Docker —— 技术架构的演进 技术架构演进总结单机架构优点缺点总结 应用数据分离架构优点缺点总结 应用服务集群架构1. Nginx2. HAProxy3. LVS(Linux Virtual Server)4. F5 BIG-IP对比总结选型建议 读写分离/主从分离架构1. MyCat简介 2. TDDLÿ…...

Docker与WSL2如何清理
文章目录 Docker与WSL2如何清理一、docker占据磁盘空间核心原因分析1. WSL2 虚拟磁盘的动态扩展特性2. Docker 镜像分层缓存与未清理资源 二、解决方案步骤 1:清理 Docker 未使用的资源步骤 2:手动压缩 WSL2 虚拟磁盘1. 关闭 WSL2 和 Docker Desktop2. 定…...

单片机嵌入式按键库
kw_btn库说明 本库主要满足嵌入式按键需求,集成了常用的按键响应事件:高电平、低电平、上升沿、下降沿、单击、双击、长按键事件。可以裸机运行,也可以配合实时操作系统运行。 本库开源连接地址:gitee连接 实现思路 本库采用C语…...

多多铃声 7.4| 拥有丰富的铃声曲库,满足不同用户的个性化需求,支持一键设置手机铃声
多多铃声是一款提供丰富铃声资源的应用程序,它拥有广泛的铃声曲库,涵盖各种风格和类型,能够满足不同用户的个性化需求。该应用程序支持分类浏览和热门榜单功能,让用户可以轻松找到当前最流行或自己感兴趣的铃声。此次分享的版本为…...
)
基于stm32的四旋翼飞行器:MPU6050讲解 · 上(参数读取)
大伙早上好,不知道大伙有没有飞行器情结,就是学习嵌入式就想做一个能飞的东西。小白兔不才,小白兔有啊,所以最近准备做一个简单的飞行器出来,如果失败了,那么这个系列就只能烂尾了,如果成功了&a…...

使用xlwings将excel表中将无规律的文本型数字批量转化成真正的数字
之前我写了一篇文章excel表中将无规律的文本型数字批量转化成真正的数字-CSDN博客 是使用excel自带的操作,相对繁琐。 今天使用xlwings操作,表格如下(有真正的数字,也有文本型数字,混在在一起)࿱…...

linux netlink实现用户态和内核态数据交互
1,内核态代码 #include <linux/module.h> #include <linux/netlink.h> #include <net/sock.h> #define NETLINK_TEST 31 struct sock *nl_sk NULL; static void nl_recv_msg(struct sk_buff *skb) { struct nlmsghdr *nlh; int pid; …...

学习黑客安全基础理论入门
准备安全课程内容 你已安装Kali和相关工具,并希望从基础开始学习安全。为了使课程更加互动,我会提供有趣的文本,并结合可视化内容,可能还会提供一些参考链接。内容方面,我会根据最新的中国网络安全法律作出更新&#…...

探索内容智能化的关键解决方案
北京先智先行科技有限公司拥有三款旗舰产品,分别是“先知大模型”、“先行AI商学院”以及“先知AIGC超级工场”。这三款产品在企业发展过程中扮演着重要角色。 北京先智先行科技有限公司围绕先知大模型等核心要素,构建了完备的业务体系。先知大模型私…...

学习黑客色即是空
二、Day 3 学习目标(保真版) 一句话目标: 学会用 Asset-Threat-Vulnerability-Risk (ATVR) 四件套给任何系统快速画“风险画像”,并能把它映射到黑客常说的 5 阶段攻击生命周期。 1. 30 分钟理论——ATVR 四件套 概念核心定义参考…...

【Java学习】关于springBoot的自动配置和起步依赖
关于springBoot的起步依赖:解决了spring框架中开发者配置依赖难的问题,各种依赖及版本的不同,可能引发不同的问题,使得开发者的精力大部分可能耗费在非业务代码中。所以springBoot起步依赖解决了各种依赖难的配置问题。 起步依赖…...

【LLaMA-Factory实战】1.3命令行深度操作:YAML配置与多GPU训练全解析
一、引言 在大模型微调场景中,命令行操作是实现自动化、规模化训练的核心手段。LLaMA-Factory通过YAML配置文件和多GPU分布式训练技术,支持开发者高效管理复杂训练参数,突破单机算力限制。本文将结合结构图、实战代码和生产级部署经验&#…...

【Mytais系列】介绍、核心概念
MyBatis 是一款优秀的 持久层框架,它通过简化 JDBC 操作、提供灵活的 SQL 映射能力,成为 Java 开发中处理数据库交互的核心工具之一。以下是 MyBatis 的核心框架和概念解析: 一、MyBatis 框架概述 1. 核心定位 作用:将 Java 对象…...

Vivado FPGA 开发 | 创建工程 / 仿真 / 烧录
注:本文为 “Vivado FPGA 开发 | 创建工程 / 仿真 / 烧录” 相关文章合辑。 略作重排,未整理去重。 如有内容异常,请看原文。 Vivado 开发流程(手把手教学实例)(FPGA) 不完美先生 于 2018-04-…...

PowerShell从5.1升级到7.X
文章目录 环境背景安装PowerShell 7.X其它启动PowerShell 5.1和7.X$PSVersionTable.PSVersion启动PowerShell 5.1时强制启动7.X 参考 环境 Windows 11 专业版 背景 PowerShell 5.1是Windows内置的,发布时间是2016 年。现在PowerShell版本已经到了7.5.1࿰…...

域名与官网的迷思:数字身份认证的全球困境与实践解方-优雅草卓伊凡
域名与官网的迷思:数字身份认证的全球困境与实践解方-优雅草卓伊凡 一、官网概念的法律与技术界定 1.1 官网的实质定义 当卓伊凡被问及”公司域名就是官网吗”这一问题时,他首先指出:”这相当于问’印着某公司logo的建筑就是该公司总部吗’…...

Vue实现成绩增删案例
Vue实现成绩增删案例 案例功能需求案例实现实现思路完整代码功能演示 案例小结 案例功能需求 1.通过vue渲染数据,将成绩的相关信息显示出来(学号,学科,成绩) 2.能够增加相关的成绩信息 3.能够删除相关的成绩信息 4.能…...
)
开源项目实战学习之YOLO11:ultralytics-cfg-models-rtdetr(十一)
👉 点击关注不迷路 👉 点击关注不迷路 👉 点击关注不迷路 文章大纲 1. __init__.py2. model.py3. predict.py4. train.py5. val.py ultralytics-cfg-models-rtdetr 主要与 Ultralytics 库中 RTDETR(实时目标检测模型,R…...
)
【Bootstrap V4系列】学习入门教程之 组件-按钮(Buttons)
Bootstrap V4系列 学习入门教程之 组件-按钮(Buttons) 按钮(Buttons)一、示例二、可用作按钮的 HTML 标签三、带轮廓线的按钮四、按钮的尺寸五、活动状态六、禁用状态七、按钮插件切换状态Checkbox and radio buttons (…...

【java八股文】深入浅出synchronized优化原理
🔍 开发者资源导航 🔍🏷️ 博客主页: 个人主页📚 专栏订阅: JavaEE全栈专栏 synchronized优化原理 synchronized即使悲观锁也是乐观锁,拥有自适应性。 jvm内部会统计每个锁的竞争激烈程度&…...

裴蜀定理及其证明
裴蜀定理 对于所有整数 a a a和 b b b,存在: g c d ( a , b ) a x b y gcd(a,b)axby gcd(a,b)axby 并且 a x b y axby axby一定是 g c d ( a , b ) gcd(a,b) gcd(a,b)的倍数。 证明 定义一个集合: { a x b y | a x b y &…...

单片机嵌入式CAN库
kw_can库说明 本库是针对CAN类型数据的收发设计: 主要应用于大数据量(数据处理速度高于缓存CAN_RTX_FIFO_SIZE大小)接收不丢包可快速进出接收中断可跨线程调用发送接口。 本库开源连接地址:gitee连接 实现思路 本库采用C语言…...

基于 JSP 和 Servlet 的数字信息分析小应用
Java Web 实验:基于 JSP 和 Servlet 的数字信息分析小应用 一、实验目的 实现一个简单的 Java Web 应用,通过 JSP 表单收集用户输入的文本信息,提交至 Servlet 分析其中是否包含数字,并返回结果。掌握 JSP 与 Servlet 的协同工作…...

从零认识阿里云OSS:云原生对象存储的核心价值
引言 在云计算时代,海量数据的存储与管理成为企业数字化转型的关键命题。阿里云对象存储OSS(Object Storage Service)作为云原生的分布式存储服务,凭借其独特的架构设计和丰富的功能矩阵,正在成为企业构建数据湖、管理…...
B题【颜色转换】原论文讲解)
2025年深圳杯数学建模(东三省)B题【颜色转换】原论文讲解
大家好呀,从发布赛题一直到现在,总算完成了2025年深圳杯数学建模(东三省)B题【颜色转换】完整的成品论文。 给大家看一下目录吧: 目录 摘 要: 一、问题重述 二.问题分析 2.1问题一 2.2问…...

开源语音合成和转换项目
开源语音合成和转换项目 大模型出来以后,语音合成和转换方面也有了很大的变化。在语音转换文字方面有Whisper、SeamlessM4T等;在语音合成方面有ChatTTS(中英文)、Orpheus TTS(仅仅支持英文)、Amphion&…...

考研408《计算机组成原理》复习笔记,第二章计算机性能
一、计算机各项性能指标 1、计算机系统整体的性能指标: 从宏观上看,整个计算机是由软件硬件共同性能决定的,但是【最主要的决定性的影响】还是来自于【硬件】 因为计算机组成原理主要讲【硬件】,那么我们也仅考虑【硬件性能】 2…...

智能决策支持系统的基本概念与理论体系
决策支持系统是管理科学的一个分支,原本与人工智能属于不同的学科范畴,但自20世纪80年代以来,由于专家系统在许多方面取得了成功,于是人们开始考虑把人工智能技术用于计算机管理中来。在用计算机所进行的各种管理中,如…...

什么是运算符重载
运算符重载,就是对已有的运算符重新进行定义,赋予其另一种功能,以适应不同的数据类型,本质上是函数重载。以下为您详细介绍: 实现原理与方式 - 原理:把指定的运算表达式转化为对运算符函数的调用࿰…...

自定义Dockerfile,发布springboot项目
(1) 上传jar包 把hello项目打成一个可执行的jar包 hello-1.0-SNAPSHOT.jar,把这个jar包上传到linux中 (2) 创建文件,文件名my_hello(就是一个Dockerfile),内容如下 #1.定义父镜像(定义当前工程依赖的环境):…...

什么是多租户系统
随着云计算和 SaaS(Software as a Service)模式的普及,多租户架构(Multi-Tenant Architecture)成为 SaaS 产品设计中的核心模式之一。多租户架构允许多个用户(租户)共享同一套基础设施和应用&am…...

摩尔缠论课程合集完整版核心课程前置课程圈子问答星球圈子摩尔缠论三个阶段
一、教程描述 这是一套摩尔缠论课程合集(完整版),内容非常系统并且极为全面,包括视频、图片和文档等不同文件类型,摩尔缠论共有三个版本,有些类似软件版本迭代,后一版本是前一版本的升级和进化…...

java学习之数据结构:三、八大排序
主要介绍学过的各种排序算法 目录 1.插入排序 1.1直接插入排序 1.2希尔排序 2.选择排序 2.1直接选择排序 2.2堆排序 3.交换排序 3.1冒泡排序 3.2快速排序 4.归并排序 5.基数排序 1.插入排序 1.1直接插入排序 基本思想:就是将待排序的数据按照其元素值的…...

Docker Compose:服务编排:批量管理多个容器
通过docker compose进行容器批量管理:一次性启动四个容器(nginx,tomcat,redis,mysql) (1) 创建docker-compose目录 mkdir ~/docker-compose cd ~/docker-compose (2&…...

微服务设计约束
相较于单体应用,微服务架构在提升开发、部署等环节灵活性的同时,也提升了在运维、监控环节的复杂性。结合实践总结,微服务架构的设计有以下四条设计约束遵循: (1)微服务个体约束 一个设计良好的微服务应用,所完成的功…...

C语言中的自定义类型 —— 结构体.位段.联合体和枚举
自定义类型 1. 前言2. 结构体2.1 结构体的声明2.2 结构体变量的定义和初始化2.3 结构体的特殊声明2.4 结构体的自引用2.5 结构体的内存对齐2.6 修改默认对齐数2.7 结构体传参 3. 位段4. 联合体5. 枚举6. 结言 1. 前言 在C语言中已经为用过户提供了内置类型,如&…...

【序列贪心】摆动序列 / 最长递增子序列 / 递增的三元子序列 / 最长连续递增序列
⭐️个人主页:小羊 ⭐️所属专栏:贪心算法 很荣幸您能阅读我的文章,诚请评论指点,欢迎欢迎 ~ 目录 摆动序列最长递增子序列递增的三元子序列最长连续递增序列 摆动序列 摆动序列 贪心策略:统计出所有的极大值和极小…...

从零开发一个B站视频数据统计Chrome插件
从零开发一个B站视频数据统计Chrome插件 前言 B站(哔哩哔哩)作为国内最大的弹幕视频网站之一,视频的播放量、点赞、投币、收藏等数据对于内容创作者和数据分析者来说非常重要。本文将带你一步步实现一个Chrome插件,自动统计并展…...

【Python实战】飞机大战
开发一个飞机大战游戏是Python学习的经典实战项目,尤其适合结合面向对象编程和游戏框架(如Pygame)进行实践。以下是游戏设计的核心考虑因素和模块划分建议: 一、游戏设计核心考虑因素 性能优化 Python游戏需注意帧率控制ÿ…...

WebAPI项目从Newtonsoft.Json迁移到System.Text.Json踩坑备忘
1.控制器层方法返回类型不能为元组 控制器层方法返回类型为元组时,序列化结果为空。 因为元组没有属性只有field,除非使用IncludeFields参数专门指定,否则使用System.Text.Json进行序列化时不会序列化field var options new JsonSerializ…...

人工智能助力工业制造:迈向智能制造的未来
在当今数字化转型的浪潮中,人工智能(AI)技术正逐渐成为推动工业制造领域变革的核心力量。智能制造作为工业 4.0 的重要组成部分,通过将 AI 技术与传统制造工艺深度融合,正在重塑整个生产流程,提高生产效率、…...

影楼精修-露齿笑算法解析
注意,为避免侵权,本文图片均为AIGC生成或网络公开数据; 像素蛋糕-露齿笑 在介绍本文之前,先说一下,其实露齿笑特效,并非像素蛋糕首创,早在几年前,face app就率先推出了这个效果&am…...
)
【iview】es6变量结构赋值(对象赋值)
变量的解构赋值 以iview的src/index.js中Vue.prototype.$IVIEW改造为例练习下怎么使用变量的解构赋值 原来的写法: const install function(Vue, opts {}) {if (install.installed) return;locale.use(opts.locale);locale.i18n(opts.i18n);Object.keys(iview).fo…...

在Windows系统中使用Docker发布镜像到镜像仓库
在Windows系统中使用Docker发布镜像到镜像仓库的步骤如下: 步骤 1:安装并配置Docker 安装Docker Desktop • 下载Docker Desktop for Windows并安装。 • 确保启用WSL 2或Hyper-V后端(根据系统版本选择)。 验证Docker运行状态 打…...

糖尿病筛查常识---秋浦四郎
糖尿病筛查可以早期发现糖尿病或糖尿病前期(血糖异常但未达到糖尿病标准),以利于及时干预,预防并发症。因为许多人患上糖尿病时没有明显症状,但已经开始对身体造成损害,有了明显糖尿病症状才检查发现糖尿病…...

CSS 预处理器 Sass
目录 Sass 一、Sass 是什么? 二、核心功能详解 1. 变量(Variables) 2. 嵌套(Nesting) 3. 混合宏(Mixins) 4. 继承(Inheritance) 5. 运算(Operations&…...

Mybatisplus:一些常用功能
自动驼峰 mybatis-plus:configuration:# 开启驼峰命名规则,默认true开启map-underscore-to-camel-case: true# 控制台日志打印,便于查看SQLlog-impl: org.apache.ibatis.logging.stdout.StdOutImpl TableName 作用:表名注解,标识…...

Golang WaitGroup 用法 源码阅读笔记
使用 sync.WaitGroup可以用来阻塞等待一组并发任务完成 下面是如何使用sync.WaitGroup的使用 最重要的就是不能并发调用Add()和Wait() var wg sync.WaitGroupfor ... {wg.Add(1) // 不能和wg.Wait()并发执行go func() {// 不能在启动的函数里面执行wg.Add(), 否则会panicde…...

第二章:一致性基础 A Primer on Memory Consistency and Cache Coherence - 2nd Edition
在本章中,我们将介绍足够多的缓存一致性知识,以便理解一致性模型是如何与缓存相互作用的。我们在 2.1 节首先给出在本入门教程中所考虑的系统模型。为了简化本章以及后续章节的阐述,我们选择了尽可能简单的系统模型,该模型足以说明…...

C++类_移动构造函数
std::move 的主要用途是在对象所有权转移时,触发移动构造函数或移动赋值运算符,避免不必要的深拷贝,提升性能。 移动构造函数 和 移动赋值运算符, std::move转换为右值,匹配到移动构造函数和移动赋值运算符。…...