开源项目实战学习之YOLO11:ultralytics-cfg-models-rtdetr(十一)
👉 点击关注不迷路
👉 点击关注不迷路
👉 点击关注不迷路
文章大纲
- 1. __init__.py
- 2. model.py
- 3. predict.py
- 4. train.py
- 5. val.py
-
ultralytics-cfg-models-rtdetr 主要与
Ultralytics 库中 RTDETR(实时目标检测模型,Real-Time Detection with Efficient Transformers)模型相关,涉及到模型的配置、定义和相关功能实现 -
优点
- 高效的检测性能: RTDETR 在各种目标检测任务中表现出较高的准确性,能够精确地定位和识别多种不同类型的目标物体。它采用了先进的神经网络架构和算法,能够学习到丰富的图像特征。
- 实时性好: RTDETR 模型
适用于对实时性要求较高的场景,如视频监控、自动驾驶等,能够及时对视频流中的目标进行检测和响应。 - 灵活的模型配置: Ultralytics 库提供了灵活的配置选项,用户可以根据自己的需求和硬件条件,对 RTDETR 模型进行不同规模和复杂度的配置。例如,可以调整模型的层数、通道数等参数,以在检测精度和推理速度之间进行权衡,满足不同应用场景的需求。
- 易于使用和部署: Ultralytics 库提供了简洁易用的 API,使得用户能够方便地进行模型的训练、推理和评估。同时,RTDETR 模型可以方便地部署到多种不同的平台上,包括 CPU、GPU 以及一些嵌入式设备,具有较好的跨平台性和可移植性。
-
缺点
- 对小目标检测能力有限: 检测小目标局限性。小目标在图像中所占像素较少,特征不明显,容易被模型忽略或误判。这可能导致在
一些包含大量小目标的场景中,检测精度有所下降。 - 对复杂背景适应性不足:
当图像背景较为复杂,例如存在大量干扰物、遮挡或光线变化较大时,RTDETR 模型的性能可能会受到一定影响。复杂的背景可能会干扰模型对目标特征的提取,导致目标定位不准确或漏检。 - 训练数据要求较高: 为了充分发挥 RTDETR 模型的性能,
需要使用大量高质量的标注数据进行训练。如果训练数据的数量不足或质量不高,模型可能无法学习到足够的特征,从而影响检测效果。此外,收集和标注大量高质量的数据需要耗费大量的人力和时间成本。
- 对小目标检测能力有限: 检测小目标局限性。小目标在图像中所占像素较少,特征不明显,容易被模型忽略或误判。这可能导致在
-
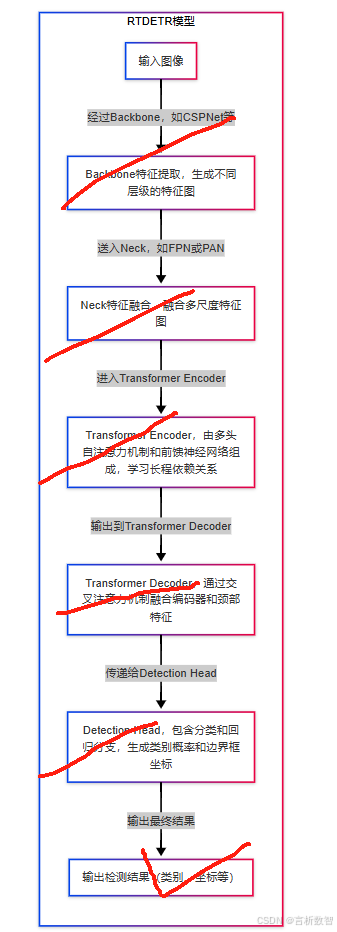
RTDETR模型的网络结构简要流程图
1. init.py
-
# 从当前包的 model 模块中导入 RTDETR 类 # RTDETR 类可能是实现 RTDETR(Real - Time Detection Transformer)模型的核心类, # 用于定义模型的结构、前向传播逻辑等,是整个目标检测模型的基础定义 from .model import RTDETR# 从当前包的 predict 模块中导入 RTDETRPredictor 类 # RTDETRPredictor 类负责使用训练好的 RTDETR 模型进行预测操作, # 它可能包含了对输入数据的预处理、调用模型进行推理以及对输出结果的后处理等功能, # 可以将其理解为一个用于执行预测任务的工具类 from .predict import RTDETRPredictor# 从当前包的 val 模块中导入 RTDETRValidator 类 # RTDETRValidator 类主要用于对 RTDETR 模型进行验证评估, # 它会在验证数据集上运行模型,计算各种评估指标(如 mAP 等), # 以评估模型的性能和泛化能力,帮助开发者了解模型的优劣 from .val import RTDETRValidator# __all__ 是一个特殊的列表,用于控制当使用 from <package> import * 语句时导入的对象 # 这里指定了三个对象,当使用上述导入语句时,会导入 RTDETRPredictor、RTDETRValidator 和 RTDETR 这三个对象 # 这种方式可以明确地控制模块的公共接口,避免不必要的对象被导入 __all__ = "RTDETRPredictor", "RTDETRValidator", "RTDETR"
2. model.py
-
# 从 ultralytics 库的 engine.model 模块导入 Model 类 # Model 类是 ultralytics 框架中模型的基类,提供了模型的基本功能和接口 from ultralytics.engine.model import Model# 从 ultralytics 库的 nn.tasks 模块导入 RTDETRDetectionModel 类 # RTDETRDetectionModel 类是用于目标检测任务的 RTDETR 模型的具体实现 from ultralytics.nn.tasks import RTDETRDetectionModel# 从当前包的 predict 模块导入 RTDETRPredictor 类 # RTDETRPredictor 类用于使用训练好的 RTDETR 模型进行预测操作 from .predict import RTDETRPredictor# 从当前包的 train 模块导入 RTDETRTrainer 类 # RTDETRTrainer 类用于对 RTDETR 模型进行训练 from .train import RTDETRTrainer# 从当前包的 val 模块导入 RTDETRValidator 类 # RTDETRValidator 类用于对 RTDETR 模型进行验证评估 from .val import RTDETRValidator# 定义 RTDETR 类,继承自 Model 类 class RTDETR(Model):def __init__(self, model: str = "rtdetr-l.pt") -> None:"""初始化 RTDETR 模型。参数:model (str): 模型文件的路径或名称,默认为 "rtdetr-l.pt""""# 调用父类 Model 的构造函数,传入模型文件和任务类型# 这里指定任务类型为 "detect",表示目标检测任务super().__init__(model=model, task="detect")@propertydef task_map(self) -> dict:"""获取任务映射字典,该字典将任务类型映射到相应的预测器、验证器、训练器和模型类。返回:dict: 任务映射字典"""return {"detect": {# 预测器类,用于进行预测操作"predictor": RTDETRPredictor,# 验证器类,用于进行验证评估"validator": RTDETRValidator,# 训练器类,用于进行模型训练"trainer": RTDETRTrainer,# 模型类,用于定义 RTDETR 目标检测模型的结构"model": RTDETRDetectionModel,}}
3. predict.py
LetterBox- 对图像进行填充和缩放操作,使图像符合模型输入的尺寸要求
# 导入 PyTorch 库,用于深度学习中的张量计算和模型操作 import torch# 从 ultralytics 库的 data.augment 模块导入 LetterBox 类 # LetterBox 类用于对图像进行填充和缩放操作,使图像符合模型输入的尺寸要求 from ultralytics.data.augment import LetterBox# 从 ultralytics 库的 engine.predictor 模块导入 BasePredictor 类 # BasePredictor 是预测器的基类,自定义的预测器类可以继承该类并实现特定的预测逻辑 from ultralytics.engine.predictor import BasePredictor# 从 ultralytics 库的 engine.results 模块导入 Results 类 # Results 类用于存储和管理预测结果 from ultralytics.engine.results import Results# 从 ultralytics 库的 utils 模块导入 ops 工具模块 # ops 模块包含了一些常用的操作函数,如坐标转换、张量处理等 from ultralytics.utils import ops# 定义 RTDETRPredictor 类,继承自 BasePredictor 类 class RTDETRPredictor(BasePredictor):def postprocess(self, preds, img, orig_imgs):"""对模型的预测结果进行后处理,将预测结果转换为最终的检测结果。参数:preds (list or torch.Tensor): 模型的预测结果,可能是一个列表或张量img (torch.Tensor): 经过预处理后的输入图像张量orig_imgs (list or torch.Tensor): 原始输入图像,可能是列表或张量返回:list: 包含最终检测结果的列表,每个元素是一个 Results 对象"""# 如果 preds 不是列表或元组类型,将其转换为包含该元素和 None 的列表# 这是为了统一处理 PyTorch 推理和导出推理的不同输出格式if not isinstance(preds, (list, tuple)):preds = [preds, None]# 获取预测结果张量最后一个维度的大小nd = preds[0].shape[-1]# 将预测结果的最后一个维度拆分为两部分,前 4 个元素为边界框坐标,其余为类别分数bboxes, scores = preds[0].split((4, nd - 4), dim=-1)# 如果原始图像不是列表类型,将其从 PyTorch 张量转换为 NumPy 数组的批量形式if not isinstance(orig_imgs, list):orig_imgs = ops.convert_torch2numpy_batch(orig_imgs)# 初始化一个空列表,用于存储最终的检测结果results = []# 遍历每个预测结果、原始图像和图像路径for bbox, score, orig_img, img_path in zip(bboxes, scores, orig_imgs, self.batch[0]):# 将边界框坐标从 [x, y, w, h] 格式转换为 [x1, y1, x2, y2] 格式bbox = ops.xywh2xyxy(bbox)# 获取每个预测框的最大类别分数和对应的类别索引max_score, cls = score.max(-1, keepdim=True)# 根据置信度阈值筛选出置信度高于阈值的预测框idx = max_score.squeeze(-1) > self.args.conf# 如果指定了要检测的类别,则进一步筛选出属于指定类别的预测框if self.args.classes is not None:idx = (cls == torch.tensor(self.args.classes, device=cls.device)).any(1) & idx# 根据筛选条件过滤出符合要求的预测框,将边界框坐标、最大类别分数和类别索引拼接在一起pred = torch.cat([bbox, max_score, cls], dim=-1)[idx]# 获取原始图像的高度和宽度oh, ow = orig_img.shape[:2]# 将预测框的坐标缩放回原始图像的尺寸pred[..., [0, 2]] *= owpred[..., [1, 3]] *= oh# 创建一个 Results 对象,包含原始图像、图像路径、类别名称和预测框信息# 并将其添加到结果列表中results.append(Results(orig_img, path=img_path, names=self.model.names, boxes=pred))# 返回最终的检测结果列表return resultsdef pre_transform(self, im):"""对输入图像进行预处理,主要是进行填充和缩放操作。参数:im (list): 输入图像列表返回:list: 经过预处理后的图像列表"""# 创建一个 LetterBox 对象,指定图像尺寸、不自动调整和使用填充缩放方式letterbox = LetterBox(self.imgsz, auto=False, scale_fill=True)# 对输入图像列表中的每个图像应用 LetterBox 变换return [letterbox(image=x) for x in im]
4. train.py
- RANK 通常用于分布式训练中表示当前进程的编号,colorstr 用于给字符串添加颜色,方便日志输出
# 从 copy 模块导入 copy 函数,用于创建对象的浅拷贝 from copy import copy# 从 ultralytics 库的 models.yolo.detect 模块导入 DetectionTrainer 类 # DetectionTrainer 是用于目标检测模型训练的基类,提供了训练的基本流程和方法 from ultralytics.models.yolo.detect import DetectionTrainer# 从 ultralytics 库的 nn.tasks 模块导入 RTDETRDetectionModel 类 # RTDETRDetectionModel 是 RTDETR 目标检测模型的具体实现类 from ultralytics.nn.tasks import RTDETRDetectionModel# 从 ultralytics 库的 utils 模块导入 RANK 和 colorstr # RANK 通常用于分布式训练中表示当前进程的编号 # colorstr 用于给字符串添加颜色,方便日志输出 from ultralytics.utils import RANK, colorstr# 从当前包的 val 模块导入 RTDETRDataset 和 RTDETRValidator 类 # RTDETRDataset 用于构建 RTDETR 模型训练和验证所需的数据集 # RTDETRValidator 用于对 RTDETR 模型进行验证评估 from .val import RTDETRDataset, RTDETRValidator# 定义 RTDETRTrainer 类,继承自 DetectionTrainer 类 class RTDETRTrainer(DetectionTrainer):def get_model(self, cfg=None, weights=None, verbose=True):"""获取用于训练的 RTDETR 模型。参数:cfg: 模型配置文件,默认为 Noneweights: 预训练模型的权重文件路径,默认为 Noneverbose: 是否打印详细信息,默认为 True返回:RTDETRDetectionModel: 初始化好的 RTDETR 模型"""# 创建 RTDETRDetectionModel 实例# cfg 是模型配置,nc 是类别数量,从数据配置中获取,ch 是输入通道数,同样从数据配置中获取# verbose 控制是否打印详细信息,只有当 RANK 为 -1 时才打印(通常表示非分布式训练时)model = RTDETRDetectionModel(cfg, nc=self.data["nc"], ch=self.data["channels"], verbose=verbose and RANK == -1)# 如果提供了预训练权重文件路径,则加载权重if weights:model.load(weights)# 返回初始化好的模型return modeldef build_dataset(self, img_path, mode="val", batch=None):"""构建用于训练或验证的数据集。参数:img_path: 图像数据的路径mode: 模式,可选值为 "train" 或 "val",默认为 "val"batch: 批量大小,默认为 None返回:RTDETRDataset: 构建好的数据集"""return RTDETRDataset(# 图像数据的路径img_path=img_path,# 图像的尺寸,从参数配置中获取imgsz=self.args.imgsz,# 批量大小batch_size=batch,# 是否进行数据增强,当 mode 为 "train" 时进行增强augment=mode == "train",# 超参数配置,从参数配置中获取hyp=self.args,# 是否使用矩形训练,这里设置为 Falserect=False,# 是否缓存数据,从参数配置中获取,默认为 Nonecache=self.args.cache or None,# 是否单类别训练,从参数配置中获取,默认为 Falsesingle_cls=self.args.single_cls or False,# 日志前缀,添加颜色,方便区分训练和验证模式prefix=colorstr(f"{mode}: "),# 要检测的类别,从参数配置中获取classes=self.args.classes,# 数据配置data=self.data,# 数据使用比例,训练模式下从参数配置中获取,验证模式下为 1.0fraction=self.args.fraction if mode == "train" else 1.0,)def get_validator(self):"""获取用于验证模型的验证器。返回:RTDETRValidator: 初始化好的验证器"""# 定义损失函数的名称,后续在日志中可能会用到self.loss_names = "giou_loss", "cls_loss", "l1_loss"# 创建 RTDETRValidator 实例# test_loader 是测试数据加载器,save_dir 是保存结果的目录,args 是参数配置的浅拷贝return RTDETRValidator(self.test_loader, save_dir=self.save_dir, args=copy(self.args))
5. val.py
v8_transforms是一组预定义的数据增强变换# 导入 PyTorch 库,用于深度学习中的张量计算、模型构建和训练等操作 import torch# 从 ultralytics 库的 data 模块导入 YOLODataset 类 # YOLODataset 是用于处理 YOLO 系列模型数据集的基类 from ultralytics.data import YOLODataset# 从 ultralytics 库的 data.augment 模块导入 Compose、Format 和 v8_transforms # Compose 用于组合多个数据增强操作;Format 用于格式化数据;v8_transforms 是一组预定义的数据增强变换 from ultralytics.data.augment import Compose, Format, v8_transforms# 从 ultralytics 库的 models.yolo.detect 模块导入 DetectionValidator 类 # DetectionValidator 是用于目标检测模型验证的基类 from ultralytics.models.yolo.detect import DetectionValidator# 从 ultralytics 库的 utils 模块导入 colorstr 和 ops # colorstr 用于给字符串添加颜色,便于日志输出;ops 包含一些常用的操作函数,如坐标转换等 from ultralytics.utils import colorstr, ops# 定义 __all__ 变量,指定当使用 from module import * 语句时,要导入的对象 __all__ = ("RTDETRValidator",) # tuple or list# 定义 RTDETRDataset 类,继承自 YOLODataset 类 class RTDETRDataset(YOLODataset):def __init__(self, *args, data=None, **kwargs):"""初始化 RTDETRDataset 类。参数:*args: 可变位置参数,传递给父类的构造函数data: 数据集相关的数据,默认为 None**kwargs: 可变关键字参数,传递给父类的构造函数"""# 调用父类的构造函数进行初始化super().__init__(*args, data=data, **kwargs)def load_image(self, i, rect_mode=False):"""加载指定索引的图像。参数:i: 图像的索引rect_mode: 是否使用矩形模式加载图像,默认为 False返回:加载好的图像"""# 调用父类的 load_image 方法加载图像return super().load_image(i=i, rect_mode=rect_mode)def build_transforms(self, hyp=None):"""构建数据增强变换。参数:hyp: 超参数配置,默认为 None返回:组合好的数据增强变换"""if self.augment:# 如果进行数据增强且不是矩形模式,设置 mosaic 和 mixup 的比例hyp.mosaic = hyp.mosaic if self.augment and not self.rect else 0.0hyp.mixup = hyp.mixup if self.augment and not self.rect else 0.0# 使用 v8_transforms 构建数据增强变换,开启拉伸transforms = v8_transforms(self, self.imgsz, hyp, stretch=True)else:# 如果不进行数据增强,使用空的组合变换# transforms = Compose([LetterBox(new_shape=(self.imgsz, self.imgsz), auto=False, scale_fill=True)])transforms = Compose([])# 在变换列表末尾添加 Format 变换,用于格式化数据transforms.append(Format(bbox_format="xywh", # 边界框格式为 xywhnormalize=True, # 对图像进行归一化return_mask=self.use_segments, # 是否返回掩码return_keypoint=self.use_keypoints, # 是否返回关键点batch_idx=True, # 是否返回批次索引mask_ratio=hyp.mask_ratio, # 掩码比例mask_overlap=hyp.overlap_mask # 掩码重叠度))return transforms# 定义 RTDETRValidator 类,继承自 DetectionValidator 类 class RTDETRValidator(DetectionValidator):def build_dataset(self, img_path, mode="val", batch=None):"""构建用于验证的数据集。参数:img_path: 图像数据的路径mode: 模式,可选值为 "val"(验证),默认为 "val"batch: 批量大小,默认为 None返回:RTDETRDataset 实例,即构建好的数据集"""return RTDETRDataset(img_path=img_path, # 图像数据路径imgsz=self.args.imgsz, # 图像尺寸batch_size=batch, # 批量大小augment=False, # 不进行数据增强hyp=self.args, # 超参数配置rect=False, # 不使用矩形模式cache=self.args.cache or None, # 是否缓存数据prefix=colorstr(f"{mode}: "), # 日志前缀,添加颜色data=self.data # 数据集相关数据)def postprocess(self, preds):"""对模型的预测结果进行后处理。参数:preds: 模型的预测结果返回:后处理后的预测结果"""if not isinstance(preds, (list, tuple)):# 如果预测结果不是列表或元组类型,将其转换为包含该元素和 None 的列表# 以统一处理 PyTorch 推理和导出推理的不同输出格式preds = [preds, None]# 获取预测结果的批次大小、数量和最后一个维度的大小bs, _, nd = preds[0].shape# 将预测结果的最后一个维度拆分为边界框坐标和类别分数两部分bboxes, scores = preds[0].split((4, nd - 4), dim=-1)# 将边界框坐标乘以图像尺寸bboxes *= self.args.imgsz# 初始化输出列表,每个元素是一个全零张量,用于存储每个样本的预测结果outputs = [torch.zeros((0, 6), device=bboxes.device)] * bsfor i, bbox in enumerate(bboxes):# 将边界框坐标从 xywh 格式转换为 xyxy 格式bbox = ops.xywh2xyxy(bbox)# 获取每个预测框的最大类别分数和对应的类别索引score, cls = scores[i].max(-1)# 将边界框坐标、最大类别分数和类别索引拼接在一起pred = torch.cat([bbox, score[..., None], cls[..., None]], dim=-1)# 按置信度降序排序,以便正确计算内部指标pred = pred[score.argsort(descending=True)]# 筛选出置信度高于阈值的预测结果outputs[i] = pred[score > self.args.conf]return outputsdef _prepare_batch(self, si, batch):"""准备一个批次的数据。参数:si: 样本索引batch: 批次数据返回:准备好的样本数据字典"""# 根据样本索引筛选出当前样本的数据idx = batch["batch_idx"] == sicls = batch["cls"][idx].squeeze(-1) # 类别标签bbox = batch["bboxes"][idx] # 边界框坐标ori_shape = batch["ori_shape"][si] # 原始图像形状imgsz = batch["img"].shape[2:] # 图像尺寸ratio_pad = batch["ratio_pad"][si] # 缩放和填充比例if len(cls):# 如果有类别标签,将边界框坐标从 xywh 格式转换为 xyxy 格式bbox = ops.xywh2xyxy(bbox)# 将边界框坐标转换到原始图像空间bbox[..., [0, 2]] *= ori_shape[1]bbox[..., [1, 3]] *= ori_shape[0]return {"cls": cls, "bbox": bbox, "ori_shape": ori_shape, "imgsz": imgsz, "ratio_pad": ratio_pad}def _prepare_pred(self, pred, pbatch):"""准备预测结果,将其转换到原始图像空间。参数:pred: 预测结果pbatch: 准备好的批次数据返回:转换到原始图像空间的预测结果"""# 克隆预测结果,避免修改原始数据predn = pred.clone()# 将预测结果的边界框坐标转换到原始图像空间predn[..., [0, 2]] *= pbatch["ori_shape"][1] / self.args.imgszpredn[..., [1, 3]] *= pbatch["ori_shape"][0] / self.args.imgszreturn predn.float()
相关文章:
)
开源项目实战学习之YOLO11:ultralytics-cfg-models-rtdetr(十一)
👉 点击关注不迷路 👉 点击关注不迷路 👉 点击关注不迷路 文章大纲 1. __init__.py2. model.py3. predict.py4. train.py5. val.py ultralytics-cfg-models-rtdetr 主要与 Ultralytics 库中 RTDETR(实时目标检测模型,R…...
)
【Bootstrap V4系列】学习入门教程之 组件-按钮(Buttons)
Bootstrap V4系列 学习入门教程之 组件-按钮(Buttons) 按钮(Buttons)一、示例二、可用作按钮的 HTML 标签三、带轮廓线的按钮四、按钮的尺寸五、活动状态六、禁用状态七、按钮插件切换状态Checkbox and radio buttons (…...

【java八股文】深入浅出synchronized优化原理
🔍 开发者资源导航 🔍🏷️ 博客主页: 个人主页📚 专栏订阅: JavaEE全栈专栏 synchronized优化原理 synchronized即使悲观锁也是乐观锁,拥有自适应性。 jvm内部会统计每个锁的竞争激烈程度&…...

裴蜀定理及其证明
裴蜀定理 对于所有整数 a a a和 b b b,存在: g c d ( a , b ) a x b y gcd(a,b)axby gcd(a,b)axby 并且 a x b y axby axby一定是 g c d ( a , b ) gcd(a,b) gcd(a,b)的倍数。 证明 定义一个集合: { a x b y | a x b y &…...

单片机嵌入式CAN库
kw_can库说明 本库是针对CAN类型数据的收发设计: 主要应用于大数据量(数据处理速度高于缓存CAN_RTX_FIFO_SIZE大小)接收不丢包可快速进出接收中断可跨线程调用发送接口。 本库开源连接地址:gitee连接 实现思路 本库采用C语言…...

基于 JSP 和 Servlet 的数字信息分析小应用
Java Web 实验:基于 JSP 和 Servlet 的数字信息分析小应用 一、实验目的 实现一个简单的 Java Web 应用,通过 JSP 表单收集用户输入的文本信息,提交至 Servlet 分析其中是否包含数字,并返回结果。掌握 JSP 与 Servlet 的协同工作…...

从零认识阿里云OSS:云原生对象存储的核心价值
引言 在云计算时代,海量数据的存储与管理成为企业数字化转型的关键命题。阿里云对象存储OSS(Object Storage Service)作为云原生的分布式存储服务,凭借其独特的架构设计和丰富的功能矩阵,正在成为企业构建数据湖、管理…...
B题【颜色转换】原论文讲解)
2025年深圳杯数学建模(东三省)B题【颜色转换】原论文讲解
大家好呀,从发布赛题一直到现在,总算完成了2025年深圳杯数学建模(东三省)B题【颜色转换】完整的成品论文。 给大家看一下目录吧: 目录 摘 要: 一、问题重述 二.问题分析 2.1问题一 2.2问…...

开源语音合成和转换项目
开源语音合成和转换项目 大模型出来以后,语音合成和转换方面也有了很大的变化。在语音转换文字方面有Whisper、SeamlessM4T等;在语音合成方面有ChatTTS(中英文)、Orpheus TTS(仅仅支持英文)、Amphion&…...

考研408《计算机组成原理》复习笔记,第二章计算机性能
一、计算机各项性能指标 1、计算机系统整体的性能指标: 从宏观上看,整个计算机是由软件硬件共同性能决定的,但是【最主要的决定性的影响】还是来自于【硬件】 因为计算机组成原理主要讲【硬件】,那么我们也仅考虑【硬件性能】 2…...

智能决策支持系统的基本概念与理论体系
决策支持系统是管理科学的一个分支,原本与人工智能属于不同的学科范畴,但自20世纪80年代以来,由于专家系统在许多方面取得了成功,于是人们开始考虑把人工智能技术用于计算机管理中来。在用计算机所进行的各种管理中,如…...

什么是运算符重载
运算符重载,就是对已有的运算符重新进行定义,赋予其另一种功能,以适应不同的数据类型,本质上是函数重载。以下为您详细介绍: 实现原理与方式 - 原理:把指定的运算表达式转化为对运算符函数的调用࿰…...

自定义Dockerfile,发布springboot项目
(1) 上传jar包 把hello项目打成一个可执行的jar包 hello-1.0-SNAPSHOT.jar,把这个jar包上传到linux中 (2) 创建文件,文件名my_hello(就是一个Dockerfile),内容如下 #1.定义父镜像(定义当前工程依赖的环境):…...

什么是多租户系统
随着云计算和 SaaS(Software as a Service)模式的普及,多租户架构(Multi-Tenant Architecture)成为 SaaS 产品设计中的核心模式之一。多租户架构允许多个用户(租户)共享同一套基础设施和应用&am…...

摩尔缠论课程合集完整版核心课程前置课程圈子问答星球圈子摩尔缠论三个阶段
一、教程描述 这是一套摩尔缠论课程合集(完整版),内容非常系统并且极为全面,包括视频、图片和文档等不同文件类型,摩尔缠论共有三个版本,有些类似软件版本迭代,后一版本是前一版本的升级和进化…...

java学习之数据结构:三、八大排序
主要介绍学过的各种排序算法 目录 1.插入排序 1.1直接插入排序 1.2希尔排序 2.选择排序 2.1直接选择排序 2.2堆排序 3.交换排序 3.1冒泡排序 3.2快速排序 4.归并排序 5.基数排序 1.插入排序 1.1直接插入排序 基本思想:就是将待排序的数据按照其元素值的…...

Docker Compose:服务编排:批量管理多个容器
通过docker compose进行容器批量管理:一次性启动四个容器(nginx,tomcat,redis,mysql) (1) 创建docker-compose目录 mkdir ~/docker-compose cd ~/docker-compose (2&…...

微服务设计约束
相较于单体应用,微服务架构在提升开发、部署等环节灵活性的同时,也提升了在运维、监控环节的复杂性。结合实践总结,微服务架构的设计有以下四条设计约束遵循: (1)微服务个体约束 一个设计良好的微服务应用,所完成的功…...

C语言中的自定义类型 —— 结构体.位段.联合体和枚举
自定义类型 1. 前言2. 结构体2.1 结构体的声明2.2 结构体变量的定义和初始化2.3 结构体的特殊声明2.4 结构体的自引用2.5 结构体的内存对齐2.6 修改默认对齐数2.7 结构体传参 3. 位段4. 联合体5. 枚举6. 结言 1. 前言 在C语言中已经为用过户提供了内置类型,如&…...

【序列贪心】摆动序列 / 最长递增子序列 / 递增的三元子序列 / 最长连续递增序列
⭐️个人主页:小羊 ⭐️所属专栏:贪心算法 很荣幸您能阅读我的文章,诚请评论指点,欢迎欢迎 ~ 目录 摆动序列最长递增子序列递增的三元子序列最长连续递增序列 摆动序列 摆动序列 贪心策略:统计出所有的极大值和极小…...

从零开发一个B站视频数据统计Chrome插件
从零开发一个B站视频数据统计Chrome插件 前言 B站(哔哩哔哩)作为国内最大的弹幕视频网站之一,视频的播放量、点赞、投币、收藏等数据对于内容创作者和数据分析者来说非常重要。本文将带你一步步实现一个Chrome插件,自动统计并展…...

【Python实战】飞机大战
开发一个飞机大战游戏是Python学习的经典实战项目,尤其适合结合面向对象编程和游戏框架(如Pygame)进行实践。以下是游戏设计的核心考虑因素和模块划分建议: 一、游戏设计核心考虑因素 性能优化 Python游戏需注意帧率控制ÿ…...

WebAPI项目从Newtonsoft.Json迁移到System.Text.Json踩坑备忘
1.控制器层方法返回类型不能为元组 控制器层方法返回类型为元组时,序列化结果为空。 因为元组没有属性只有field,除非使用IncludeFields参数专门指定,否则使用System.Text.Json进行序列化时不会序列化field var options new JsonSerializ…...

人工智能助力工业制造:迈向智能制造的未来
在当今数字化转型的浪潮中,人工智能(AI)技术正逐渐成为推动工业制造领域变革的核心力量。智能制造作为工业 4.0 的重要组成部分,通过将 AI 技术与传统制造工艺深度融合,正在重塑整个生产流程,提高生产效率、…...

影楼精修-露齿笑算法解析
注意,为避免侵权,本文图片均为AIGC生成或网络公开数据; 像素蛋糕-露齿笑 在介绍本文之前,先说一下,其实露齿笑特效,并非像素蛋糕首创,早在几年前,face app就率先推出了这个效果&am…...
)
【iview】es6变量结构赋值(对象赋值)
变量的解构赋值 以iview的src/index.js中Vue.prototype.$IVIEW改造为例练习下怎么使用变量的解构赋值 原来的写法: const install function(Vue, opts {}) {if (install.installed) return;locale.use(opts.locale);locale.i18n(opts.i18n);Object.keys(iview).fo…...

在Windows系统中使用Docker发布镜像到镜像仓库
在Windows系统中使用Docker发布镜像到镜像仓库的步骤如下: 步骤 1:安装并配置Docker 安装Docker Desktop • 下载Docker Desktop for Windows并安装。 • 确保启用WSL 2或Hyper-V后端(根据系统版本选择)。 验证Docker运行状态 打…...

糖尿病筛查常识---秋浦四郎
糖尿病筛查可以早期发现糖尿病或糖尿病前期(血糖异常但未达到糖尿病标准),以利于及时干预,预防并发症。因为许多人患上糖尿病时没有明显症状,但已经开始对身体造成损害,有了明显糖尿病症状才检查发现糖尿病…...

CSS 预处理器 Sass
目录 Sass 一、Sass 是什么? 二、核心功能详解 1. 变量(Variables) 2. 嵌套(Nesting) 3. 混合宏(Mixins) 4. 继承(Inheritance) 5. 运算(Operations&…...

Mybatisplus:一些常用功能
自动驼峰 mybatis-plus:configuration:# 开启驼峰命名规则,默认true开启map-underscore-to-camel-case: true# 控制台日志打印,便于查看SQLlog-impl: org.apache.ibatis.logging.stdout.StdOutImpl TableName 作用:表名注解,标识…...

Golang WaitGroup 用法 源码阅读笔记
使用 sync.WaitGroup可以用来阻塞等待一组并发任务完成 下面是如何使用sync.WaitGroup的使用 最重要的就是不能并发调用Add()和Wait() var wg sync.WaitGroupfor ... {wg.Add(1) // 不能和wg.Wait()并发执行go func() {// 不能在启动的函数里面执行wg.Add(), 否则会panicde…...

第二章:一致性基础 A Primer on Memory Consistency and Cache Coherence - 2nd Edition
在本章中,我们将介绍足够多的缓存一致性知识,以便理解一致性模型是如何与缓存相互作用的。我们在 2.1 节首先给出在本入门教程中所考虑的系统模型。为了简化本章以及后续章节的阐述,我们选择了尽可能简单的系统模型,该模型足以说明…...

C++类_移动构造函数
std::move 的主要用途是在对象所有权转移时,触发移动构造函数或移动赋值运算符,避免不必要的深拷贝,提升性能。 移动构造函数 和 移动赋值运算符, std::move转换为右值,匹配到移动构造函数和移动赋值运算符。…...

Spring AI 实战:第一章、Spring AI入门之DeepSeek调用
引言:当Spring遇上AI,会擦出怎样的火花? 作为一名Java开发者,是否曾经眼红Python阵营那些花里胡哨的AI应用?是否在对接各种大模型API时,被五花八门的接口规范搞得头大?好消息是,Spr…...

fastapi+vue中的用户权限管理设计
数据库设计:RBAC数据模型 这是一个典型的基于SQLAlchemy的RBAC权限系统数据模型实现,各模型分工明确,共同构成完整的权限管理系统。 图解说明: 实体关系: 用户(USER)和角色(ROLE)通过 USER_ROLE 中间表实现多对多关系…...

Space Engineers 太空工程师 [DLC 解锁] [Steam] [Windows]
Space Engineers 太空工程师 [DLC 解锁] [Steam] [Windows] 需要有游戏正版基础本体,安装路径不能带有中文,或其它非常规拉丁字符; DLC 版本 至最新全部 DLC 后续可能无法及时更新文章,具体最新版本见下载文件说明 DLC 解锁列表&…...

随机变量数字特征
主要介绍一维随机变量期望和方差、二维随机变量期望和方差、以及协方差相关公式,及推导。 一维随机变量 以一个抛硬币的场景作为例子,如下: 抛掷两枚均匀硬币,如果两枚都是正面向上,则赢得2元,否则就输掉…...

C++总结01-类型相关
一、数据存储 1.程序数据段 • 静态(全局)数据区:全局变量、静态变量 • 堆内存:程序员手动分配、手动释放 • 栈内存:编译器自动分配、自动释放 • 常量区:编译时大小、值确定不可修改 2.程序代码段 •…...

【多线程】七、POSIX信号量 环形队列的生产者消费者模型
文章目录 Ⅰ. 信号量一、POSIX 信号量的概念二、POSIX 信号量的类型区别三、POSIX 信号量与 SystemV 信号量的区别Ⅱ. 线程信号量基本原理一、为什么要引入信号量❓二、PV 操作三、POSIX 信号量的实现原理四、CAS操作介绍Ⅲ. POSIX未命名信号量接口一、初始化无名信号量二、销毁…...

二维码批量识别—混乱多张二维码识别-物品分拣—-未来之窗-仙盟创梦IDE
仙盟模型 用途 精准分拣:快速准确识别物品上复杂或多个二维码,依据码中信息(如目的地、品类等)实现物品自动化分拣,提高分拣效率与准确性。库存管理:识别入库、出库物品二维码,更新库存数据&am…...

《TensorFlow 与 TensorFlow Lite:协同驱动 AI 应用全景》
《TensorFlow 与 TensorFlow Lite:协同驱动 AI 应用全景》 摘要 :在机器学习技术浪潮中,TensorFlow 与 TensorFlow Lite 作为 Google 技术栈的核心组件,分别占据云端训练与端侧部署的关键位置。本文将系统梳理二者架构特性、功能…...

Spring AI 实战:第三章、Spring AI结构化输出之告别杂乱无章
引言:当程序员遇上剧荒 “周末看什么?” 这个看似简单的问题,往往能让我们在各大影视平台间反复横跳半小时,最后无奈选择重刷《老友记》。本期让我们用技术解决这个"世纪难题":让大模型成为你的私人影视推荐…...
)
ros2 humble 控制真实机械臂(以lerobot为例)
基础版 0.确保串口访问权限 sudo chmod 666 /dev/ttyARM0 # 确保串口访问权限 1.下载 lerobot 驱动功能包 git clone https://gitee.com/kong-yue1/lerobot_devices.git 2.编写控制节点(完整代码) 主要功能是与 Feetech 电机总线进行通信&#…...

REINFORCE蒙特卡罗策略梯度算法详解:python从零实现
🧠 向所有学习者致敬! “学习不是装满一桶水,而是点燃一把火。” —— 叶芝 我的博客主页: https://lizheng.blog.csdn.net 🌐 欢迎点击加入AI人工智能社区! 🚀 让我们一起努力,共创…...

模拟SIP终端向Freeswitch注册用户
1、简介 使用go语言编写一个程序,模拟SIP-T58终端在Freeswitch上注册用户 2、思路 以客户端向服务端Freeswitch发起REGISTER请求,告知服务器当前的联系地址构造SIP REGISTER请求 创建UDP连接,连接到Freeswitch的5060端口发送初始的REGISTER请…...

Elasticsearch 中的索引模板:如何使用可组合模板
作者:来自 Elastic Kofi Bartlett 探索可组合模板以及如何创建它们。 更多阅读: Elasticsearch:可组合的 Index templates - 7.8 版本之后 想获得 Elastic 认证吗?查看下一期 Elasticsearch Engineer 培训的时间! El…...

一篇文章看懂时间同步服务
Linux 系统时间与时区管理 一、时间与时钟类型 时钟类型说明管理工具系统时钟由 Linux 内核维护的软件时钟,基于时区配置显示时间timedatectl硬件时钟 (RTC)主板上的物理时钟,通常以 UTC 或本地时间存储,用于系统启动时初始化时间hwclock …...

Mysql常用语句汇总
Mysql语句分类 DDL: 数据定义语言,用来定义数据库对象(数据库、表、字段)DML: 数据操作语言,用来对数据库表中的数据进行增删改DQL: 数据查询语言,用来查询数据库中表的记录DCL: 数据控制语言,用来创建数据…...

迭代器的思想和实现细节
1. 迭代器的本质 迭代器是一种行为类似指针的对象,它可能是指针(如 std::vector 的迭代器),也可能是封装了指针的类(如 std::list 的迭代器)。如果是指针那天然就可以用下面的运算,如果是类&am…...

[Vue]编程式导航
在 Vue 中,编程式导航是通过 JavaScript 代码(而非 <router-link> 标签)动态控制路由跳转的核心方式。这个方法依赖于 Vue Router 提供的 API,能更灵活地处理复杂场景(如异步操作、条件跳转等)。 一、…...