【Scrapy】简单项目实战--爬取dangdang图书信息
目录
一、基本步骤
1、新建项目 :新建一个新的爬虫项目
2、明确目标 (items.py):明确你想要抓取的目标
3、制作爬虫 (spiders/xxspider.py):制作爬虫开始爬取网页
4、存储内容 (pipelines.py):设计管道存储爬取内容
5、运行爬虫
二、实战:爬取当当图书
接下来介绍一个简单的项目,完成一遍 Scrapy 抓取流程。
一、基本步骤
1、新建项目 :新建一个新的爬虫项目
1 创建一个scrapy项目
scrapy startproject mySpider(文件夹名称)2、明确目标 (items.py):明确你想要抓取的目标
选择你需要爬取的内容,例如作者名字、小说名、封面图片等
在items.py文件中定义
3、制作爬虫 (spiders/xxspider.py):制作爬虫开始爬取网页
生成一个爬虫
scrapy genspider 爬虫文件的名字 要爬的网页
eg:[不需要加https]
https://www.baidu.com/ --> baidu.com
https://www.douban.com/ --> douban.com
scrapy genspider baidu www.baidu.com
EG 爬虫文件解释:
import scrapy
class BaiduSpider(scrapy.Spider):# 爬虫的名字 一般运行爬虫的时候 使用的值name = 'baidu'# 允许访问的域名allowed_domains = ['www.baidu.com']# 起始的url地址 指的是第一次要访问的域名# start_urls 是在allowed_domains的前面添加一个http://# 是在allowed_domains的后面添加一个/# 如果以html结尾 就不用加/ 否则网站进不去 报错start_urls = ['http://www.baidu.com/']# 是执行了start_urls之后 执行的方法# 方法中的response 就是返回的那个对象# 相当于 response = urllib.request.urlopen()# response = requests.get()def parse(self, response):pass
4、 配置中间件(middlewares.py防反爬)
# middlewares.py 添加随机请求头和代理
import random
from fake_useragent import UserAgentclass CustomMiddleware:def process_request(self, request, spider):# 随机UA(伪装不同浏览器)request.headers['User-Agent'] = UserAgent().random# 使用代理IP(示例用阿布云代理)request.meta['proxy'] = "http://http-dyn.abuyun.com:9020"request.headers['Proxy-Authorization'] = basic_auth_header('H01234567890123D', '0123456789012345')【本项目没有防反爬机制,不用管这个文件】
4、存储内容 (pipelines.py):设计管道存储爬取内容
如果想使用管道的话 那么就必须在settings中开启管道
ITEM_PIPELINES = {# 管道可以有很多个 那么管道是有优先级 优先级的范围是1到1000 值越小优先级越高'scrapy_dangdang.pipelines.ScrapyDangdangPipeline': 300,
}# 将在settings.py中这段话取消注释,则打开了通道。
然后去pippelines.py中设计管道:
class ScrapyDangdangPipeline:def open_spider(self,spider):self.fp = open('book.json','w',encoding='utf-8')# item就是yield后面的对象def process_item(self, item, spider): self.fp.write(str(item))return itemdef close_spider(self,spider):self.fp.close()
5、运行爬虫
在cmd中输入:scrapy crawl 爬虫的名字eg:scrapy crawl baidu
二、实战:爬取当当图书
创建项目
上一节我们已经创建好了文件夹
创建好文件夹之后,通过cd mySprider进入到文件夹内部,创建通过scrapy genspider 爬虫程序了,这里创建爬虫文件,scrapy genspider dang category.dangdang.com

爬虫文件已经创建完成,通过mySprider,spiders目录下看到创建好的db文件。
明确目标 (items.py):明确你想要抓取的目标
-
确定需要下载的数据,去items.py文件中添加。这里我们准备存储图片、名字和价格
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.htmlimport scrapyclass MyspiderItem(scrapy.Item):# define the fields for your item here like:# name = scrapy.Field()src = scrapy.Field()# 名字name = scrapy.Field()# 价格price = scrapy.Field()pass去爬虫文件中去爬取我们需要的内容了(这里是在dang.py文件中)
import scrapy
from ..items import MyspiderItemclass DangSpider(scrapy.Spider):# 爬虫的名字 一般运行爬虫的时候 使用的值name = 'dang'# 允许访问的域名# 如果是多页下载的话 那么必须要调整的是allowed_domains的范围 一般情况下只写域名allowed_domains = ['category.dangdang.com']# 起始的url地址 指的是第一次要访问的域名# start_urls 是在allowed_domains的前面添加一个http://# 是在allowed_domains的后面添加一个/# 如果以html结尾 就不用加/start_urls = ['http://category.dangdang.com/cp01.01.02.00.00.00.html']base_url = 'http://category.dangdang.com/pg'page = 1# 是执行了start_urls之后 执行的方法# 方法中的response 就是返回的那个对象# 相当于 response = urllib.request.urlopen()# response = requests.get()def parse(self, response):# pipelines 下载数据# items 定义数据结构的# src = //ul[@id="component_59"]/li//img/@src# alt = //ul[@id="component_59"]/li//img/@alt# price = //ul[@id="component_59"]/li//p[@class="price"]/span[1]/text()# 所有的seletor的对象 都可以再次调用xpath方法li_list = response.xpath('//ul[@id="component_59"]/li')for li in li_list:# 第一张图片和其他的图片的标签是属性是不一样的# 第一张图片src是可以使用的 其他图片的地址data-originalsrc = li.xpath('.//img/@data-original').extract_first()if src:src = srcelse:src = li.xpath('.//img/@src').extract_first()name = li.xpath('.//img/@alt').extract_first()price = li.xpath('.//p[@class="price"]/span[1]/text()').extract_first()book = MyspiderItem(src=src,name=name,price=price)# 获取一个book就交给pipelinesyield book# 每一页爬取的业务逻辑都是一样的# 所以我们只需要将执行的那个页的请求再次调用parse方法就可以了if self.page < 100:self.page = self.page + 1url = self.base_url + str(self.page) + '-cp01.01.02.00.00.00.html'# 怎么去调用parse方法# scrapy.Request就是scrpay的get方法# url就是请求地址# callback是你要执行的那个函数 注意不需要加圆括号yield scrapy.Request(url=url,callback=self.parse)
通过解析拿到数据之后,我们就可以去通道中添加保存的方法了(pippelines.py)
去settings.py在打开通道和添加通道,完成之后进行下一步
ITEM_PIPELINES = {# 管道可以有很多个 那么管道是有优先级 优先级的范围是1到1000 值越小优先级越高'mySpider.pipelines.ScrapyDangdangPipeline': 300,'mySpider.pipelines.DangDangDownloadPiepline': 301,
}
注意

黄色框起来的是你的文件名,自行修改!
- 通道打开后,在pippelines.py完成下列操作
import os
# 如果想使用管道的话 那么就必须在settings中开启管道
class ScrapyDangdangPipeline:def open_spider(self,spider):self.fp = open('book.json','w',encoding='utf-8')# item就是yield后面的book对象def process_item(self, item, spider):# 一下这种模式不推荐 因为每传递一个对象 那么就打开一次文件对文件的操作过于频繁# # write方法必须要写一个字符串 而不能是其他的对象# # w模式 会每一个对象都打开一次文件 覆盖之前的内容# with open('book.json','a',encoding='utf-8') as fp:# fp.write(str(item))self.fp.write(str(item))return itemdef close_spider(self,spider):self.fp.close()# 多条管道开启# 定义管道类# 在settings中开启管道# 'scrapy_dangdang.pipelines.DangDangDownloadPiepline': 301,
import urllib.requestclass DangDangDownloadPiepline:def process_item(self,item,spider):url = 'http:' + item.get('src')if not os.path.exists('./books/'):os.mkdir('./books/')filename = './books/' + item.get('name') + '.jpg'urllib.request.urlretrieve(url=url,filename=filename)return item
- 最后在cmd中输入:scrapy crawl dang
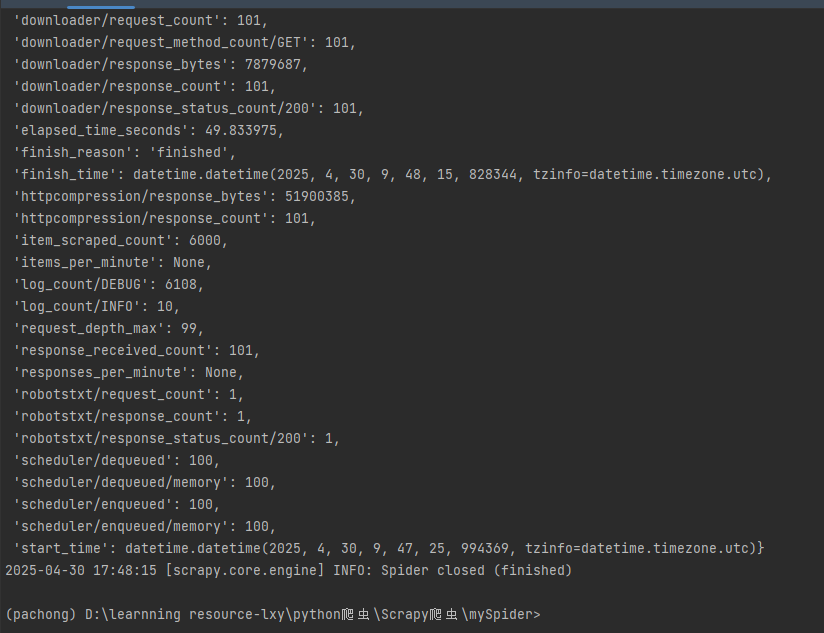
- 完成之后就开始下载了,全部完成之后你就会看到多了book.json文件和books文件夹在自己的项目中。里面有数据,则表示项目成功了。
运行结果
三、总结
一定要记得!!在setting开启管道设置 ,设置的时候注意路径名称,在这卡了半天
✅ spiders/ 里的爬虫逻辑(怎么抓,主要抓取数据的文件)
✅ pipelines.py 里的存储逻辑,处理抓到的数据(怎么存,定义文件存储方式等等)
✅ settings.py 里的配置参数(怎么调优)总的来说,简单一点的爬虫用scrapy实现时需要先创建好项目-->明确要爬取的目标--->分析页面,看看数据存在什么标签中,写爬取的py文件--->看看是否有反爬机制--->在管道文件中添加对数据的处理方式。
相关文章:

【Scrapy】简单项目实战--爬取dangdang图书信息
目录 一、基本步骤 1、新建项目 :新建一个新的爬虫项目 2、明确目标 (items.py):明确你想要抓取的目标 3、制作爬虫 (spiders/xxspider.py):制作爬虫开始爬取网页 4、存储内容 (p…...

Linux架构篇、第1章_01架构的介绍HTTP HTTPS 协议全面解析
题目:HTTP/HTTPS 协议全面解析:原理、区别与状态码详解 版本号: 1.0,0 作者: 老王要学习 日期: 2025.04.30 适用环境: 服务器 文档说明 本文围绕 HTTP/HTTPS 协议展开,详细介绍了协议的基本概念、工作原理、两者之间的区别以及常见的状态码…...
)
Python 刷题记录(持续更新)
Python 刷题记录(持续更新) 主要是 PythonTip 里的题目 刷题网站 【PythonTip】1.分秒转换 def convert_to_seconds(minutes):second minutes * 60return second# 输入分钟 input_minutes int(input())# 调用函数 print(convert_to_seconds(input…...

核心技能:ArcGIS洪水灾害普查、风险评估及淹没制图
查看原文>>>ArcGIS 在洪水灾害普查、风险评估及淹没制图中的实践技术应用 【内容简述】: 水旱灾害风险普查是全国自然灾害综合风险普查的重要组成部分。其中,我国有超过 60%的国土面积、90%以上的人口均受到不同程度的洪水威胁,重…...

MySQL explain
1 EXPLAIN执行结果下各字段含义 (1) id 含义:标识查询中每个 SELECT 子句的唯一编号。规则:相同 id:按从上到下的顺序执行。不同 id:值越大,优先级越高(先执行)。NULL:表示该行是 …...
★★★★★)
数据结构每日一题day14(链表)★★★★★
题目描述:试编写算法将带头结点的单链表就地逆置,所谓“就地”就是空间复杂度为O(1)。 算法思想: 1.初始化: 定义三个指针 prev、curr、next,分别表示前驱节点、当前节点和后继节点。 prev 初始化为 NULL…...

Java继承中super的使用方法
super 关键字在 Java 中用于访问父类的成员(包括字段、方法和构造函数)。当你在子类中调用父类的方法或访问父类的成员变量时,super 是必不可少的工具。 🔑 super 的基本用法 1. 调用父类的构造方法 在子类的构造方法中&#x…...

2025东三省B题深圳杯B题数学建模挑战赛数模思路代码文章教学
完整内容请看文章最下面的推广群 一、问题一的模型构建与优化(RGB颜色空间转换模型) 基础模型(线性映射模型)/高斯过程回归模型(GPR): 针对高清视频源(BT2020标准)与普通…...

K8S - GitOps 入门实战 - 自动发布与秒级回滚
引言 传统运维依赖手动执行 kubectl apply或脚本推送应用,存在环境差异、操作记录缺失、回滚缓慢等痛点。 GitOps以 Git 为唯一可信源,通过声明式配置和版本化回滚,重构 Kubernetes 交付流程,带来以下优势: • 环境…...

第六章 流量特征分析-常见攻击事件 tomcat wp
1、在web服务器上发现的可疑活动,流量分析会显示很多请求,这表明存在恶意的扫描行为,通过分析扫描的行为后提交攻击者IP flag格式:flag{ip},如:flag{127.0.0.1} 可看见有大量的IP为:14.0.0.120的ip攻击10.0.0.112。 2、找到攻击者…...

Axure RP 快速上手指南:安装配置与实战技巧
以下是Axure RP的中文安装与使用指南: 1. 下载Axure RP Axure RP提供下载地址:https://pan.quark.cn/s/cc957c429c1c 2. 安装Axure RP Windows系统: 双击下载的 .exe 文件。 按提示完成安装(接受协议、选择安装路径等ÿ…...
)
【Dockerfile】Dockerfile打包Tomcat及TongWeb应用镜像(工作实践踩坑教学)
文章目录 前言准备工作目录结构准备基础镜像准备dockerfile开发(TongWeb)dockerfile开发(Tomcat)dockerfile镜像命令(排查问题基本够用) 更多相关内容可查看 前言 本文仅应用于完成此项工作,后…...

第16届蓝桥STEMA真题剖析-2025年1月12日Scratch初/中级组
[导读]:超平老师的《Scratch蓝桥杯真题解析100讲》已经全部完成,后续会不定期解读蓝桥杯真题,这是Scratch蓝桥真题解析系列教程第223讲。 第16届第4次蓝桥STEMA已于2025年1月12日正式落下帷幕,比赛仍然采取线上形式。这是Scratch…...

文件读取操作
如果需要从文件读入数据,并把输出数据保存为文件,需要使用文件读取。 freopen为file reopen,意为文件重新打开,实现重定向标准输入输出第一个参数为文件名可以修改,输入文件为.in,输出文件为.out第二个参数…...

服务容错治理框架resilience4jsentinel基础应用---微服务的限流/熔断/降级解决方案
写在前文:hystrix停止维护,不做总结; 本文主要总结sentinel和resilience4j这两个框架;另外额外补充面试可能会问到的限流算法; 目录 限流算法 漏桶算法 计数器算法 令牌桶算法 resilience4j与sentinel resilie…...

信创系统图形界面开发指南:技术选择与实践详解
信创系统图形界面开发指南:技术选择与实践详解 🧑 博主简介:CSDN博客专家、CSDN平台优质创作者,高级开发工程师,数学专业,10年以上C/C, C#, Java等多种编程语言开发经验,拥有高级工程师证书&…...

六、UI自动化测试06--PO设计模式
目录 一、PO 设计模式1. v1 版本1.1 v1.11.2 v1.2 2. v2 版本3. ⽅法封装套路4. v3 版本4.1 浏览器对象管理类的实现4.2 浏览器对象管理类的优化4.3 浏览器对象管理类的使⽤4.4 获取弹窗信息⽅法的封装 5. PO 设计模式6. v4 版本6.1 PO⻚⾯元素封装步骤6.2 测试⽤例的最终代码样…...
)
电子病历高质量语料库构建方法与架构项目(智能数据目录篇)
电子病历高质量语料库的构建是医疗人工智能发展的基础性工作,而智能数据目录作为数据治理的核心组件,能够有效管理这些语料资源。本文将系统阐述电子病历高质量语料库的构建方法与架构,特别聚焦于智能数据目录的设计与实现,包括数据目录的功能定位、元数据管理、构建步骤以…...

DeepSeek最新大模型发布-DeepSeek-Prover-V2-671B
2025 年 4 月 30 日,DeepSeek 开源了新模型 DeepSeek-Prover-V2-671B,该模型聚焦数学定理证明任务,基于混合专家架构,使用 Lean 4 框架进行形式化推理训练,参数规模达 6710 亿,结合强化学习与大规模合成数据…...

论文公式根据章节自动编号教程
目录 一、操作前提二、具体操作步骤 插入公式编号添加括号(如需) 问答 摘要: 在撰写论文等文档时,让公式根据章节自动编号能大幅提升排版效率。 一、操作前提 先将每一章标题设置为多级标题。可点击Word“多级列表” - “定义…...

「Mac畅玩AIGC与多模态10」开发篇06 - 使用自定义翻译插件开发智能体应用
一、概述 本篇介绍如何在 macOS 环境下,通过编写自定义 OpenAPI Schema,将无需认证的翻译服务接入 Dify 平台,并开发基于实时翻译的智能体应用。本案例培养单提参数 API 调用技巧,实现智能体的实时转换能力。 二、环境准备 1. 确认本地开发环境 macOS 系统Dify 平台已成…...
:Boosting及提升树)
大连理工大学选修课——机器学习笔记(8):Boosting及提升树
Boosting及提升树 Boosting概述 Bootstrap强调的是抽样方法 不同的数据集彼此独立,可并行操作 Boosting注重数据集改造 数据集之间存在强依赖关系,只能串行实现 处理的结果都是带来了训练集改变,从而得到不同的学习模型 Boosting基本思…...
(十七)标准库)
OpenHarmony - 小型系统内核(LiteOS-A)(十七)标准库
OpenHarmony - 小型系统内核(LiteOS-A)(十七) 二十一、标准库 OpenHarmony内核使用musl libc库,支持标准POSIX接口,开发者可基于POSIX标准接口开发内核之上的组件及应用。 标准库接口框架 图1 POSIX接口…...

vscode详细配置Go语言相关插件
文章目录 vscode详细配置Go语言1.插件介绍1.1 BetterCommments1.2GitGraph1.3Go1.4GoComment1.5goctl1.6Lowlight Go Errors1.7Markdown1.8Material Icon Theme1.9Preetier2.0Project Manager其它插件 2.settings.json文件 vscode详细配置Go语言 1.插件介绍 1.1 BetterCommme…...

如何解决服务器文件丢失或损坏的问题
当服务器文件丢失或损坏时,需采取系统化的恢复和预防措施。以下是分步骤解决方案: --- ### **一、紧急恢复措施** #### 1. **检查文件系统完整性** bash # 对未挂载的分区进行检查(需先umount) fsck -y /dev/sdX # 针对ext4文…...

【C++11】包装器:function 和 bind
📝前言: 这篇文章我们来讲讲C11——包装器:function和bind,对于每个包装器主要讲解: 原型基本语法使用示例 🎬个人简介:努力学习ing 📋个人专栏:C学习笔记 🎀…...

芯知识|小体积语音芯片方案WTV/WT2003H声音播放ic应用解析
在智能硬件设备趋向微型化的背景下,语音芯片方案厂家针对小体积设备开发了多款超小型语音芯片方案,其中WTV系列和WT2003H系列凭借其QFN封装设计、高性能与高集成度,成为微型设备语音方案的理想选择。以下从封装特性、功能优势及典型应用场景三…...

第三部分:特征提取与目标检测
像边缘、角点、特定的纹理模式等都是图像的特征。提取这些特征是许多计算机视觉任务的关键第一步,例如图像匹配、对象识别、图像拼接等。目标检测则是在图像中找到特定对象(如人脸、汽车等)的位置。 本部分将涵盖以下关键主题: …...

MySQL bin目录下的可执行文件
文章目录 MySQL bin目录下的可执行文件1.mysqldump2.mysqladmin3.mysqlcheck4.mysqlimport5.mysqlshow6.mysqlbinlog7.常用可执行文件 MySQL bin目录下的可执行文件 1.mysqldump mysqldump 是 MySQL 的数据库备份工具。对数据备份、迁移或恢复非常重要。 备份整个数据库&…...
)
第四部分:赋予网页健壮的灵魂 —— TypeScript(中)
目录 4 类与面向对象:构建复杂的组件4.1 类的定义与成员4.2 继承 (Inheritance)4.3 接口实现 (Implements)4.4 抽象类 (Abstract Class)4.5 静态成员 (Static Members) 5 更高级的类型:让类型系统更灵活5.1 联合类型 (|)5.2 交叉类型 (&)5.3 字面量类…...

Learning vtkjs之ImageMarchingCubes
体积 等值面处理 介绍 vtkImageMarchingCubes - 对体积进行等值面处理 给定一个指定的等值,使用Marching Cubes算法生成一个等值面。 效果 新建了一个球,对比一下原始的(透明的)和ISO的效果 核心代码 参数部分 const updat…...

【“星睿O6”AI PC开发套件评测】+ tensorflow 初探
因为本次我的项目计划使用 tensorflow,所以这篇文章主要想做一个引子,介绍如何在“星睿O6”上搭建 tensorflow 的开发环境和验证测试。本文主要分为几个部分: 在“星睿O6”上编译安装 tensorflow基于 MNIST 数据集的模型训练和评估 tensorf…...

通义灵码全面接入Qwen3:AI编程进入智能体时代,PAI云上部署实战解析
引言:AI编程的范式革命 2025年4月30日,阿里云通义灵码宣布全面支持新一代大模型Qwen3,并同步推出编程智能体功能,标志着AI辅助开发从“工具助手”向“自主决策智能体”的跃迁。与此同时,阿里云PAI平台上线Qwen3全系列…...

如何禁止AutoCAD这类软件联网
推荐二、三方法,对其他软件影响最小 一、修改Hosts文件 Hosts文件是一个存储域名与IP地址映射关系的文本文件,通过修改Hosts文件可以将AutoCAD的域名指向本地回环地址(127.0.0.1),从而实现禁止联网的目的。具体步骤如…...

音视频项目在微服务领域的趋势场景题深度解析
音视频项目在微服务领域的趋势场景题深度解析 在互联网大厂Java求职者的面试中,经常会被问到关于音视频项目在微服务领域的应用场景的相关问题。本文通过一个故事场景来展示这些问题的实际解决方案。 第一轮提问 面试官:马架构,欢迎来到我…...

100 个 NumPy 练习
本文翻译整理自:https://github.com/rougier/numpy-100 文章目录 关于 100 个 NumPy 练习相关链接资源关键功能特性 100 个 NumPy 练习题1、导入 NumPy 包并命名为 np (★☆☆)2、打印 NumPy 版本和配置信息 (★☆☆)3、创建一个大小为 10 的空向量 (★☆☆)4、如何…...

在Carla中构建自动驾驶:使用PID控制和ROS2进行路径跟踪
机器人软件开发什么是 P、PI 和 PID 控制器?比例 (P) 控制器比例积分 (PI) 控制器比例-积分-微分 (PID) 控制器横向控制简介CARLA ROS2 集成纵向控制横向控制关键要点结论引用 机器人软件开发 …...

Windows和 macOS 上安装 `nvm` 和 Node.js 16.16.0 的详细教程。
Windows和 macOS 上安装 nvm 和 Node.js 16.16.0 的详细教程。 --- ### 1. 安装 nvm(Node Version Manager) nvm 是一个 Node.js 版本管理工具,可以轻松安装和切换不同版本的 Node.js。 #### Windows 安装 nvm 1. **下载 nvm 安装包**&#x…...

day11 python超参数调整
模型组成:模型 算法 实例化设置的外参(超参数) 训练得到的内参调参评估:调参通常需要进行两次评估。若不使用交叉验证,需手动划分验证集和测试集;但许多调参方法自带交叉验证功能,实际中可省略…...

Linux C++ xercesc xml 怎么判断路径下有没有对应的节点
在Linux环境下使用Xerces-C库处理XML文件时,判断路径下是否存在对应的节点可以通过以下几个步骤实现: 加载XML文档 首先,你需要加载XML文档。这可以通过创建一个xercesc::DOMParser对象并使用它的parse方法来实现。 #include <xercesc/…...

罗技K580蓝牙键盘连接mac pro
罗技K580蓝牙键盘,满足了我们的使用需求。最棒的是,它能够同时连接两个设备,通过按F11和F12键进行切换,简直不要太方便! 连接电脑 💻 USB连接 1、打开键盘:双手按住凹槽两边向前推࿰…...

Socket-UDP
Socket(套接字 )是计算机网络中用于实现进程间通信的重要编程接口,是对 TCP/IP 协议的封装 ,可看作是不同主机上应用进程之间双向通信端点的抽象。以下是详细介绍: 作用与地位 作为应用层与传输层、网络层协议间的中…...

【游戏ai】从强化学习开始自学游戏ai-2 使用IPPO自博弈对抗pongv3环境
文章目录 前言一、环境设计二、动作设计三、状态设计四、神经网路设计五、效果展示其他问题总结 前言 本学期的大作业,要求完成多智能体PPO的乒乓球对抗环境,这里我使用IPPO的方法来实现。 正好之前做过这个单个PPO与pong环境内置的ai对抗的训练&#…...
——机器人及舵机配置)
LeRobot 项目部署运行逻辑(三)——机器人及舵机配置
Lerobot 目前的机器人硬件以舵机类型为主,并未配置机器人正逆运动学及运动学,遥操作映射以舵机关节角度为主 因此,需要在使用前需要对舵机各项参数及初始位置进行配置 目录 1 Mobile ALOHA 配置 2 Dynamixel 配置 2.1 配置软件 2.2 SDK …...

Ubuntu20.04安装NVIDIA Warp
Ubuntu20.04安装NVIDIA Warp 安装测试 Warp的gitee网址 Warp的github网址 写在前面:建议安装前先参考readme文件自检系统驱动和cuda是否支持,个人实测建议是python3.9,但python3.8.20也可以使用。 写在前面:后续本人可能会使用这…...
)
电子病历高质量语料库构建方法与架构项目(临床情景理解模块篇)
引言 随着人工智能技术在医疗健康领域的广泛应用,电子病历(Electronic Medical Records,EMR)作为临床医疗数据的重要载体,已成为医学研究和临床决策支持的关键资源。电子病历高质量语料库的构建为医疗人工智能模型的训练和应用提供了基础支撑,其中临床情境理解模块是连接…...

WPF性能优化举例
WPF性能优化集锦 一、UI渲染性能优化 1. 虚拟化技术 ListView/GridView虚拟化: <ListView VirtualizingStackPanel.IsVirtualizing="True"VirtualizingStackPanel.VirtualizationMode="Recycling"ScrollViewer.IsDeferredScrollingEnabled=…...

【CUDA pytorch】
ev win10 3050ti 联想笔记本 nvcc --version 得到 PS C:\Users\25515> nvcc --version nvcc: NVIDIA (R) Cuda compiler driver Copyright (c) 2005-2022 NVIDIA Corporation Built on Tue_May__3_19:00:59_Pacific_Daylight_Time_2022 Cuda compilation tools, release …...

mac下载homebrew 安装和使用git
mac下载homebrew 安装和使用git 本人最近从windows换成mac,记录一下用homebrew安装git的过程 打开终端 command 空格,搜索终端 安装homebrew 在终端中输入下面命令,来安装homebrew /bin/bash -c "$(curl -fsSL https://raw.githu…...

Elasticsearch入门速通01:核心概念与选型指南
一、Elasticsearch 是什么? 一句话定义: 开源分布式搜索引擎,擅长处理海量数据的实时存储、搜索与分析,是ELK技术栈(ElasticsearchKibanaBeatsLogstash)的核心组件。 核心能力: 近实时搜索&…...