【“星睿O6”AI PC开发套件评测】+ tensorflow 初探
因为本次我的项目计划使用 tensorflow,所以这篇文章主要想做一个引子,介绍如何在“星睿O6”上搭建 tensorflow 的开发环境和验证测试。本文主要分为几个部分:
- 在“星睿O6”上编译安装 tensorflow
- 基于 MNIST 数据集的模型训练和评估
tensorflow 源码编译安装
在编译 tensorflow 的时候,免不了缺少一些程序,需要 apt install,为了加快 apt install 的速度,我选择了使用阿里云镜像。修改 /etc/apt/sources.list 为如下内容:
deb https://mirrors.aliyun.com/debian/ bookworm main non-free non-free-firmware contribdeb-src https://mirrors.aliyun.com/debian/ bookworm main non-free non-free-firmware contribdeb https://mirrors.aliyun.com/debian-security/ bookworm-security maindeb-src https://mirrors.aliyun.com/debian-security/ bookworm-security maindeb https://mirrors.aliyun.com/debian/ bookworm-updates main non-free non-free-firmware contribdeb-src https://mirrors.aliyun.com/debian/ bookworm-updates main non-free non-free-firmware contribdeb https://mirrors.aliyun.com/debian/ bookworm-backports main non-free non-free-firmware contribdeb-src https://mirrors.aliyun.com/debian/ bookworm-backports main non-free non-free-firmware contrib
接下来就是 tensorflow 编译构建,编译过程主要参考 Build from source | TensorFlow,为了保持稳定和本着体验最新版本的效果,我选择了 r2.19 分支, 拉取仓库后切换分支,后面在加载构建的 wheel 包后可以检查版本是否一致,git checkout r2.19。整个过程分为如下几部分:
-
安装 bazebl-sink deb 包,直接从 Releases · bazelbuild/bazelisk 下载 bazelisk-arm64.deb 包,在 “星睿”O6中
sudo dpkg -i bazelisk-arm64.deb -
安装 clang 编译器
sudo apt install clang,安装sudo apt install libhdf5-dev在打包 wheel 的时候会用到 -
配置,这里我使用默认配置
-sh-5.2$./configure You have bazel 6.5.0 installed. Please specify the location of python. [Default is /usr/bin/python3]:Found possible Python library paths:/usr/lib/python3/dist-packages/usr/local/lib/python3.11/dist-packages Please input the desired Python library path to use. Default is [/usr/lib/python3/dist-packages]Do you wish to build TensorFlow with ROCm support? [y/N]: No ROCm support will be enabled for TensorFlow.Do you wish to build TensorFlow with CUDA support? [y/N]: No CUDA support will be enabled for TensorFlow.Do you want to use Clang to build TensorFlow? [Y/n]: Clang will be used to compile TensorFlow.Please specify the path to clang executable. [Default is /usr/bin/clang]:You have Clang 14.0.6 installed.Please specify optimization flags to use during compilation when bazel option "--config=opt" is specified [Default is -Wno-sign-compare]:Would you like to interactively configure ./WORKSPACE for Android builds? [y/N]: Not configuring the WORKSPACE for Android builds.Preconfigured Bazel build configs. You can use any of the below by adding "--config=<>" to your build command. See .bazelrc for more details.--config=mkl # Build with MKL support. --config=mkl_aarch64 # Build with oneDNN and Compute Library for the Arm Architecture (ACL).--config=monolithic # Config for mostly static monolithic build.--config=numa # Build with NUMA support.--config=dynamic_kernels # (Experimental) Build kernels into separate shared objects.--config=v1 # Build with TensorFlow 1 API instead of TF 2 API. Preconfigured Bazel build configs to DISABLE default on features: --config=nogcp # Disable GCP support.--config=nonccl # Disable NVIDIA NCCL support. Configuration finished -
编译过程中,主要解决 无法正常从 github 下载软件包的问题,这里我的解决方法是批量替换使用镜像地址,比如,修改
/home/radxa/.cache/bazel/_bazel_radxa/6b12cd9b265767cc77a16c7f64b094ec/external/rules_python/python/versions.bzl的DEFAULT_RELEASE_BASE_URL = "https://github.moeyy.xyz/https://github.com/indygreg/python-build-standalone/releases/download",因为修改的较多,这里我就不一一列举了,其它的编译还是很顺利的。 -
编译 wheel 包命令:
bazel build //tensorflow/tools/pip_package:wheel --repo_env=USE_PYWRAP_RULES=1 --repo_env=WHEEL_NAME=tensorflow_cpu,编译成功的截图:
!
可以看到编译花费将近 3 个小时,不容易哦。
编译成功之后,可以看到生成的文件在如下目录

安装编译生成的 tensorflow_cpu 包简单测试下,是否正常:
python3 -m pip install tensorflow_cpu-2.19.0-cp311-cp311-linux_aarch64.whl --break-system-packages sh-5.2$ python3 Python 3.11.2 (main, Nov 30 2024, 21:22:50) [GCC 12.2.0] on linux Type "help", "copyright", "credits" or "license" for more information. >>> import tensorflow as tf >>> print("TensorFlow version:", tf.__version__) TensorFlow version: 2.19.0 >>>可以看到版本和我们切换的一致。
模型训练和评估
这一部分,主要记录下如何在 O6 上使用我们自己编译出来的 tensorflow 开始构建、训练和评估模型。这里主要根据 tensorflow 的教程 TensorFlow 2 quickstart for beginners | TensorFlow Core,开始加载逐步加载数据集、构建模型和训练评估模型。
加载数据集
因为网络原因,我手动下载了 mnist.npz 数据集,然后放在 ~/.keras/datasets/ 目录。
构建模型和训练模型
这里主要涉及到定义模型、定义损失函数以及模型训练。
完整的测试代码如下:
#!/usr/bin/python3import tensorflow as tf
from PIL import Image
import numpy as np
import matplotlib.pyplot as pltprint("TensorFlow version:", tf.__version__)# save gray_array to file
def save_grayscale_array_to_image(gray_array, filename="grayscale_image.png"):"""Saves a 2D NumPy array (representing grayscale data) to an image file.Args:gray_array (numpy.ndarray): A 2D NumPy array where each elementrepresents the intensity of a pixel (0-255).filename (str): The name of the file to save the image to.Common formats are 'png', 'jpg', 'bmp', etc."""try:# Ensure the data is in the correct format (uint8)if gray_array.dtype != np.uint8:gray_array = gray_array.astype(np.uint8)# Create a PIL Image object in grayscale ('L' mode)img = Image.fromarray(gray_array, mode='L')# Save the image to the specified filenameimg.save(filename)print(f"Grayscale image saved successfully as '{filename}'")except Exception as e:print(f"Error saving grayscale image: {e}")def plt_predict(x,y,ya):fig = plt.figure(figsize=(8, 6)) # Set the figure size to 8x6 inchesax = fig.add_subplot(1, 1, 1)ax.plot(x, y, label='predict', color='blue', linestyle='-') # Plot the first lineax.plot(x, ya, label='predict_after', color='red', linestyle='--') # Plot the first lineax.set_xlabel('X Axis') # Set the x-axis labelax.set_ylabel('Y Axis') # Set the y-axis labelax.set_title('Predict compare Waves') # Set the subplot titleax.legend() # Display the legendplt.savefig('predict.png', dpi=300)
mnist = tf.keras.datasets.mnistx = np.linspace(0, 9, 10)
# print(x)(x_train, y_train), (x_test, y_test) = mnist.load_data()
# print(type(x_train), type(x_train[0]), x_train[0], x_train[:1])
# print( x_train[0].shape, x_train[:1].shape, x_train[0].dtype)
# save_grayscale_array_to_image(x_train[0], "train0.png")x_train, x_test = x_train / 255.0, x_test / 255.0# print(type(x_train), type(x_train[0]), x_train[0])
# print(type(y_train), type(y_train[0]), y_train[0])
# print(y_train.shape, y_train[0].shape, y_train[:1].shape, y_train[0].dtype)
# exit(-1)# define the model
model = tf.keras.models.Sequential([tf.keras.layers.Flatten(input_shape=(28, 28)),tf.keras.layers.Dense(128, activation='relu'),tf.keras.layers.Dropout(0.2),tf.keras.layers.Dense(10)
])# test model before train
predictions = model(x_train[:1]).numpy()
y = tf.nn.softmax(predictions).numpy().reshape([10,])
# print(type(y), type(yz), yz.shape)
print("predictions before", y)
# print("predictions before yz", yz)# loss function
loss_fn = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True)
# print(loss_fn(y_train[:1], predictions).numpy())# construct model
model.compile(optimizer='adam',loss=loss_fn,metrics=['accuracy'])# train model
model.fit(x_train, y_train, epochs=5)# test model
predictions = model(x_train[:1]).numpy()
ya = tf.nn.softmax(predictions).numpy().reshape([10,])
# print("new predictions again", predictions)
print("predictions after", ya)
plt_predict(x,y,ya)
model.evaluate(x_test, y_test, verbose=2)
测试结果
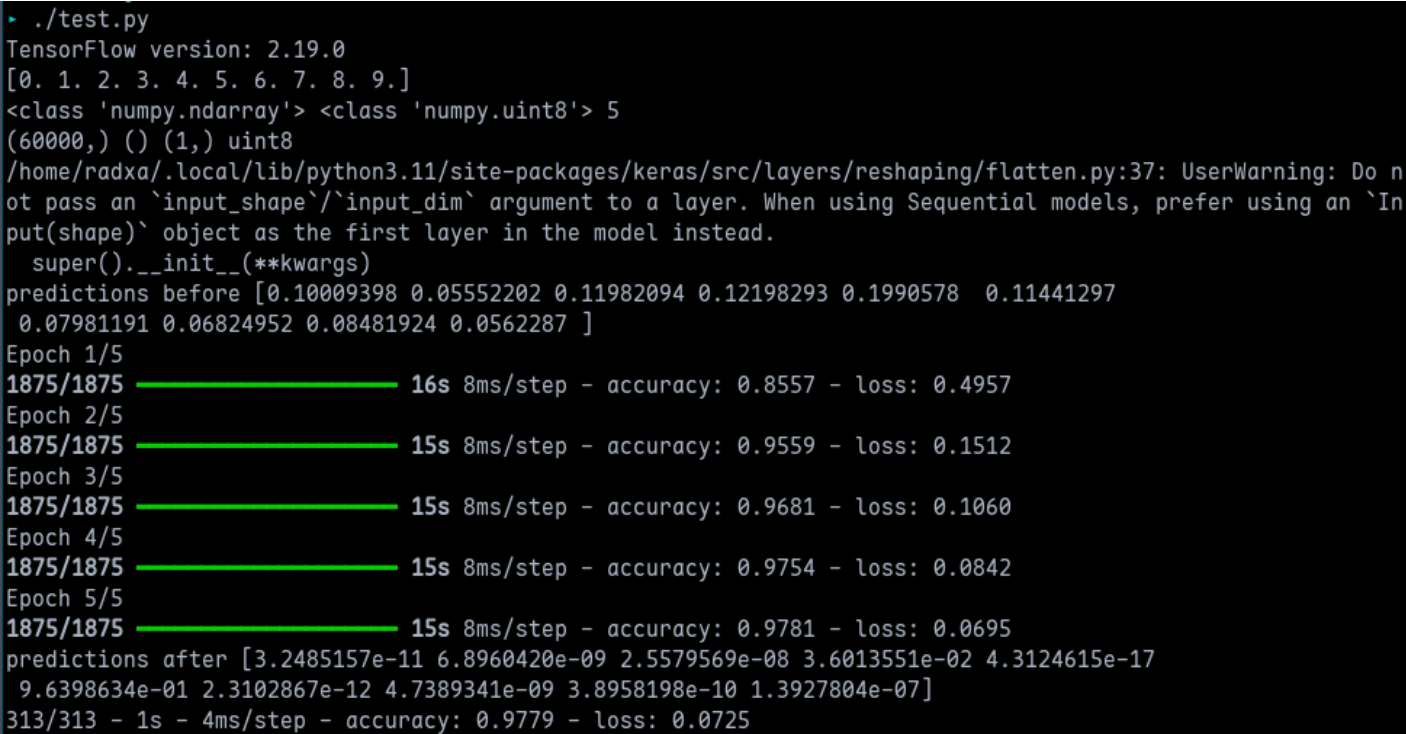
在训练的过程中,我使用 btop 查看了对CPU和内存的使用情况,内存稳定在1GB附近,CPU占用在10%附近,根据打印整个训练过程在80s左右完成。

为了更加直观的看到模型训练前后的输出结果对比,根据预测的结果,我绘制了对比曲线图如下:
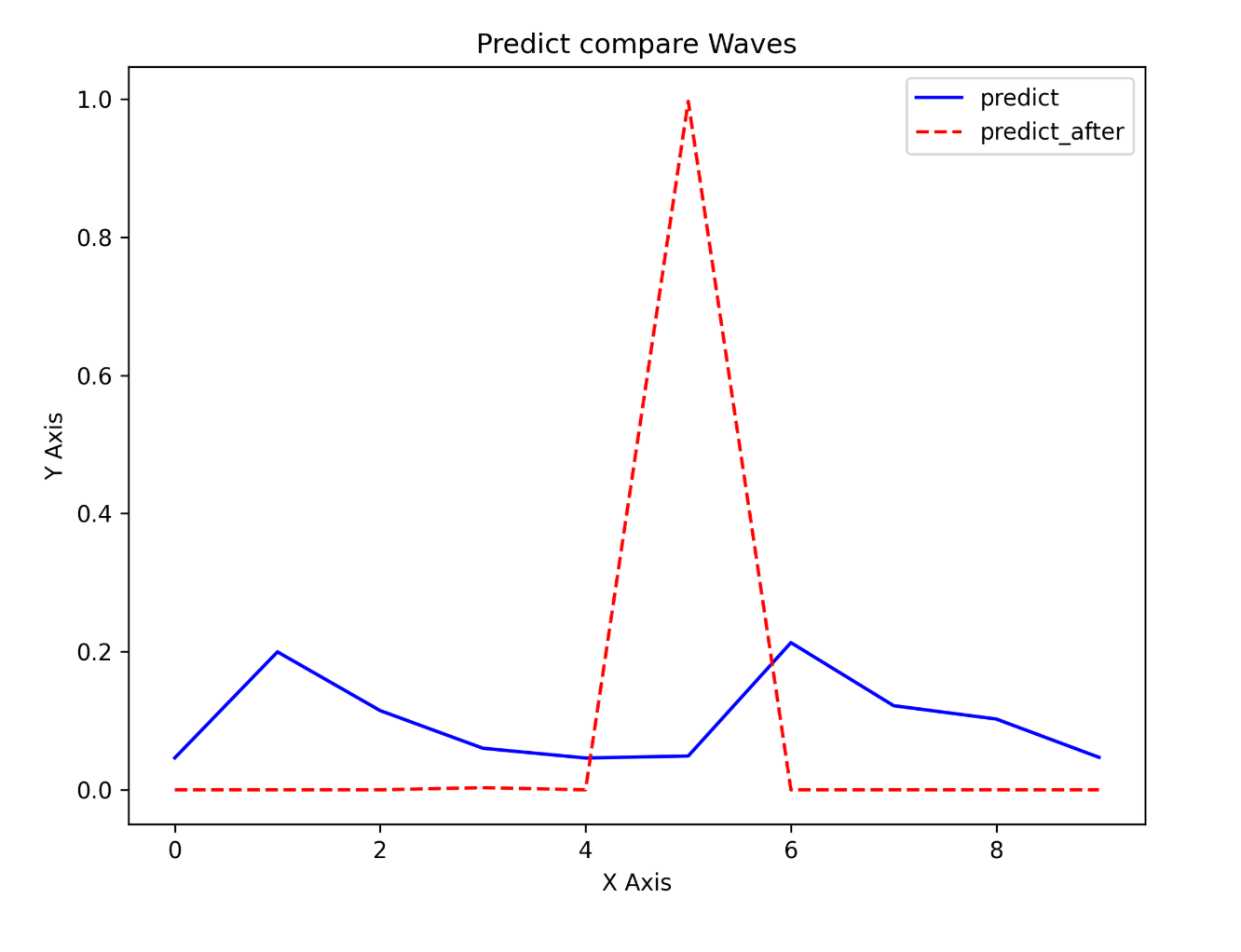
可以看到,模型训练之后,预测的结果为 5 的概率最大,我将原始数据存储为对应的灰度图,如下图所示:

可以看到是 5 的样式,从上面两个图可以看出模型训练之后相比训练之前有明显的准确度提升。
此外,想更加直观可视化的看下模型的层次图,我使用 tensorboard 进行可视化,首先是定义一个回调函数,在 fit 的时候调用,这部分改动如下:
# define callback func for tensorboard
tf_callback = tf.keras.callbacks.TensorBoard(log_dir="./logs")
# train model
model.fit(x_train, y_train, epochs=5, callbacks=[tf_callback], verbose=1)
然后重新训练,训练完成后,执行 tensorboard --logdir=logs使用 tensorboard 加载数据,接着在浏览器打开localhost:6006 就可以看到层次结构。
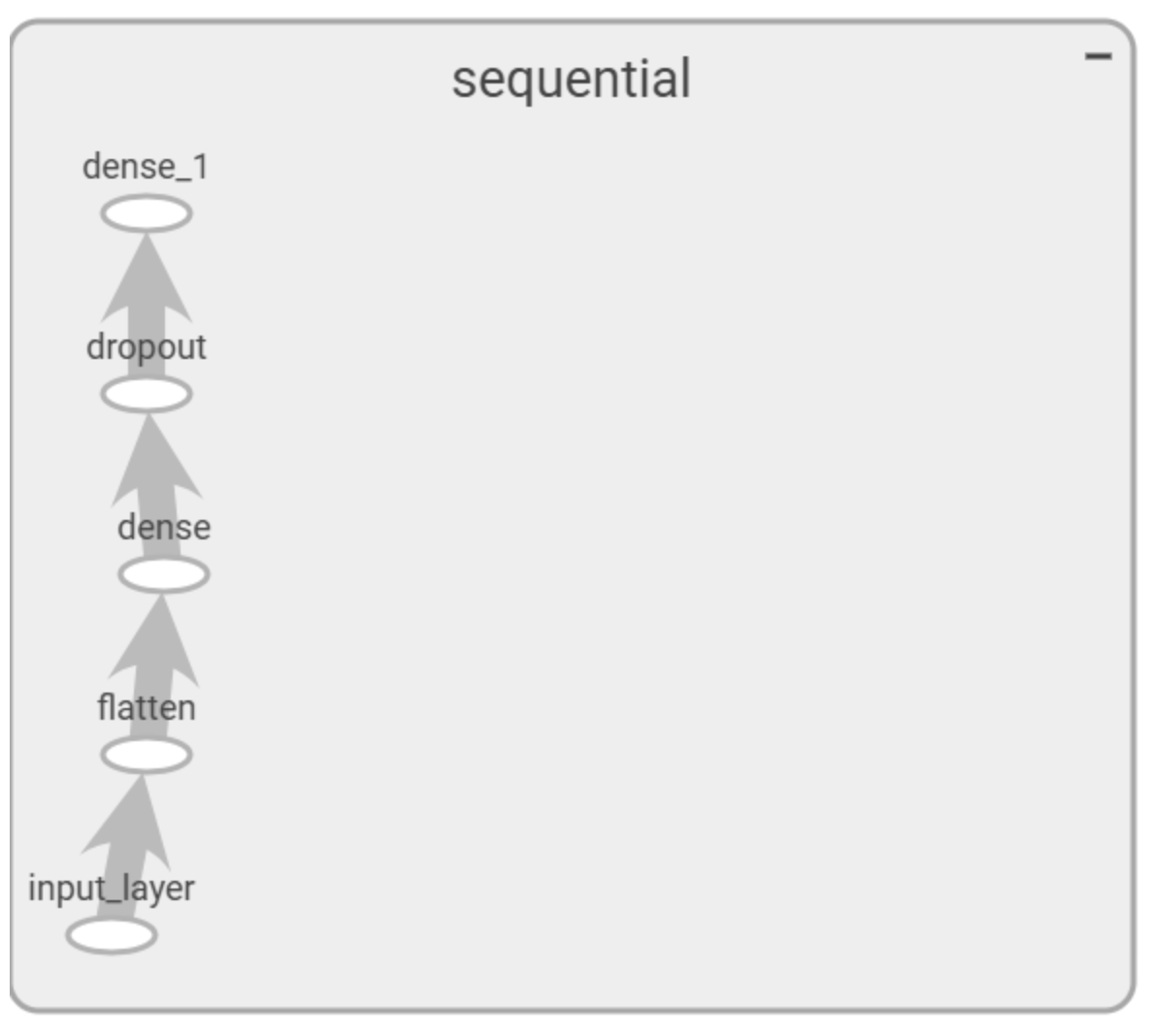
和源码中定义的层结构可以对应起来:
# define the model
model = tf.keras.models.Sequential([tf.keras.layers.Flatten(input_shape=(28, 28)),tf.keras.layers.Dense(128, activation='relu'),tf.keras.layers.Dropout(0.2),tf.keras.layers.Dense(10)
])
至此简单演示了从 tensorflow 源码编译安装到基本模型构建、训练和测试对比的一个过程。期待下一篇文章更加复杂的模型部署过程。
相关文章:

【“星睿O6”AI PC开发套件评测】+ tensorflow 初探
因为本次我的项目计划使用 tensorflow,所以这篇文章主要想做一个引子,介绍如何在“星睿O6”上搭建 tensorflow 的开发环境和验证测试。本文主要分为几个部分: 在“星睿O6”上编译安装 tensorflow基于 MNIST 数据集的模型训练和评估 tensorf…...

通义灵码全面接入Qwen3:AI编程进入智能体时代,PAI云上部署实战解析
引言:AI编程的范式革命 2025年4月30日,阿里云通义灵码宣布全面支持新一代大模型Qwen3,并同步推出编程智能体功能,标志着AI辅助开发从“工具助手”向“自主决策智能体”的跃迁。与此同时,阿里云PAI平台上线Qwen3全系列…...

如何禁止AutoCAD这类软件联网
推荐二、三方法,对其他软件影响最小 一、修改Hosts文件 Hosts文件是一个存储域名与IP地址映射关系的文本文件,通过修改Hosts文件可以将AutoCAD的域名指向本地回环地址(127.0.0.1),从而实现禁止联网的目的。具体步骤如…...

音视频项目在微服务领域的趋势场景题深度解析
音视频项目在微服务领域的趋势场景题深度解析 在互联网大厂Java求职者的面试中,经常会被问到关于音视频项目在微服务领域的应用场景的相关问题。本文通过一个故事场景来展示这些问题的实际解决方案。 第一轮提问 面试官:马架构,欢迎来到我…...

100 个 NumPy 练习
本文翻译整理自:https://github.com/rougier/numpy-100 文章目录 关于 100 个 NumPy 练习相关链接资源关键功能特性 100 个 NumPy 练习题1、导入 NumPy 包并命名为 np (★☆☆)2、打印 NumPy 版本和配置信息 (★☆☆)3、创建一个大小为 10 的空向量 (★☆☆)4、如何…...

在Carla中构建自动驾驶:使用PID控制和ROS2进行路径跟踪
机器人软件开发什么是 P、PI 和 PID 控制器?比例 (P) 控制器比例积分 (PI) 控制器比例-积分-微分 (PID) 控制器横向控制简介CARLA ROS2 集成纵向控制横向控制关键要点结论引用 机器人软件开发 …...

Windows和 macOS 上安装 `nvm` 和 Node.js 16.16.0 的详细教程。
Windows和 macOS 上安装 nvm 和 Node.js 16.16.0 的详细教程。 --- ### 1. 安装 nvm(Node Version Manager) nvm 是一个 Node.js 版本管理工具,可以轻松安装和切换不同版本的 Node.js。 #### Windows 安装 nvm 1. **下载 nvm 安装包**&#x…...

day11 python超参数调整
模型组成:模型 算法 实例化设置的外参(超参数) 训练得到的内参调参评估:调参通常需要进行两次评估。若不使用交叉验证,需手动划分验证集和测试集;但许多调参方法自带交叉验证功能,实际中可省略…...

Linux C++ xercesc xml 怎么判断路径下有没有对应的节点
在Linux环境下使用Xerces-C库处理XML文件时,判断路径下是否存在对应的节点可以通过以下几个步骤实现: 加载XML文档 首先,你需要加载XML文档。这可以通过创建一个xercesc::DOMParser对象并使用它的parse方法来实现。 #include <xercesc/…...

罗技K580蓝牙键盘连接mac pro
罗技K580蓝牙键盘,满足了我们的使用需求。最棒的是,它能够同时连接两个设备,通过按F11和F12键进行切换,简直不要太方便! 连接电脑 💻 USB连接 1、打开键盘:双手按住凹槽两边向前推࿰…...

Socket-UDP
Socket(套接字 )是计算机网络中用于实现进程间通信的重要编程接口,是对 TCP/IP 协议的封装 ,可看作是不同主机上应用进程之间双向通信端点的抽象。以下是详细介绍: 作用与地位 作为应用层与传输层、网络层协议间的中…...

【游戏ai】从强化学习开始自学游戏ai-2 使用IPPO自博弈对抗pongv3环境
文章目录 前言一、环境设计二、动作设计三、状态设计四、神经网路设计五、效果展示其他问题总结 前言 本学期的大作业,要求完成多智能体PPO的乒乓球对抗环境,这里我使用IPPO的方法来实现。 正好之前做过这个单个PPO与pong环境内置的ai对抗的训练&#…...
——机器人及舵机配置)
LeRobot 项目部署运行逻辑(三)——机器人及舵机配置
Lerobot 目前的机器人硬件以舵机类型为主,并未配置机器人正逆运动学及运动学,遥操作映射以舵机关节角度为主 因此,需要在使用前需要对舵机各项参数及初始位置进行配置 目录 1 Mobile ALOHA 配置 2 Dynamixel 配置 2.1 配置软件 2.2 SDK …...

Ubuntu20.04安装NVIDIA Warp
Ubuntu20.04安装NVIDIA Warp 安装测试 Warp的gitee网址 Warp的github网址 写在前面:建议安装前先参考readme文件自检系统驱动和cuda是否支持,个人实测建议是python3.9,但python3.8.20也可以使用。 写在前面:后续本人可能会使用这…...
)
电子病历高质量语料库构建方法与架构项目(临床情景理解模块篇)
引言 随着人工智能技术在医疗健康领域的广泛应用,电子病历(Electronic Medical Records,EMR)作为临床医疗数据的重要载体,已成为医学研究和临床决策支持的关键资源。电子病历高质量语料库的构建为医疗人工智能模型的训练和应用提供了基础支撑,其中临床情境理解模块是连接…...

WPF性能优化举例
WPF性能优化集锦 一、UI渲染性能优化 1. 虚拟化技术 ListView/GridView虚拟化: <ListView VirtualizingStackPanel.IsVirtualizing="True"VirtualizingStackPanel.VirtualizationMode="Recycling"ScrollViewer.IsDeferredScrollingEnabled=…...

【CUDA pytorch】
ev win10 3050ti 联想笔记本 nvcc --version 得到 PS C:\Users\25515> nvcc --version nvcc: NVIDIA (R) Cuda compiler driver Copyright (c) 2005-2022 NVIDIA Corporation Built on Tue_May__3_19:00:59_Pacific_Daylight_Time_2022 Cuda compilation tools, release …...

mac下载homebrew 安装和使用git
mac下载homebrew 安装和使用git 本人最近从windows换成mac,记录一下用homebrew安装git的过程 打开终端 command 空格,搜索终端 安装homebrew 在终端中输入下面命令,来安装homebrew /bin/bash -c "$(curl -fsSL https://raw.githu…...

Elasticsearch入门速通01:核心概念与选型指南
一、Elasticsearch 是什么? 一句话定义: 开源分布式搜索引擎,擅长处理海量数据的实时存储、搜索与分析,是ELK技术栈(ElasticsearchKibanaBeatsLogstash)的核心组件。 核心能力: 近实时搜索&…...
)
应对过度处方挑战:为药物推荐任务微调大语言模型(Xiangnan He)
Abstract 药物推荐系统因其有潜力根据患者的临床数据提供个性化且有效的药物组合,在医疗保健领域备受关注。然而,现有方法在适应不同的电子健康记录(EHR)系统以及有效利用非结构化数据方面面临挑战,导致其泛化能力有限…...

41 python http之requests 库
Python 的requests库就像你的 "接口助手",用几行代码就能发送 HTTP 请求,自动处理复杂的网络交互,让你告别手动拼接 URL 和解析响应的痛苦! 一、快速入门:3 步搞定基本请求 1.1 安装库:一键开启助手功能 pip install requests 1.2 发送 GET 请求 import r…...

百度网盘golang实习面经
goroutine内存泄漏的情况?如何避免? goroutine内存泄漏基本上是因为异常导致阻塞, 可以导致阻塞的情况 1 死锁, goroutine 等待的锁发生了死锁情况 2 chan没有正常被关闭,导致读取读chan的goroutine阻塞 如何避免 1 避免死锁 2 正常关闭 3 使用context管…...

super_small_toy_tpu
super_small_toy_tpu 小狼http://blog.csdn.net/xiaolangyangyang 1、基础框图 2、源码下载: GitHub - dldldlfma/super_small_toy_tpu 3、安装iverilog、vvp、gtkwave windows安装:https://bleyer.org/icarus/ ubuntu安装:sudo ap…...

Redis缓存穿透、缓存击穿与缓存雪崩:如何在.NET Core中解决
在高并发的互联网系统中,缓存技术作为优化系统性能的重要手段,已被广泛应用。然而,缓存系统本身也存在一些常见的问题,尤其是 缓存穿透、缓存击穿 和 缓存雪崩。这些问题如果处理不当,可能导致系统性能严重下降&#x…...

驱动车辆诊断测试创新 | 支持诊断测试的模拟器及数据文件转换生成
一 背景和挑战 | 背景: 随着汽车功能的日益丰富,ECU和域控制器的复杂性大大增加,导致测试需求大幅上升,尤其是在ECU的故障诊断和性能验证方面。然而,传统的实车测试方法难以满足高频率迭代和验证需求,不仅…...

VS Code技巧2:识别FreeCAD对象
在使用VS Code阅读FreeCAD代码或者FreeCAD的工作台代码时,VS Code无法识别FreeCAD对象,会提示Import “FreeCAD” could not be resolved: 问题解决如下几步即可。 第一步:确认 FreeCAD 的 Python 环境路径 在FreeCAD的Python控制…...

泰迪杯特等奖案例学习资料:基于多模态融合与边缘计算的智能温室环境调控系统
(第十二届泰迪杯数据挖掘挑战赛特等奖案例解析) 一、案例背景与核心挑战 1.1 应用场景与行业痛点 在现代设施农业中,温室环境调控直接影响作物产量与品质。传统温室管理存在以下问题: 环境参数耦合性高:温度、湿度、光照、CO₂浓度等参数相互影响,人工调控易顾此失彼。…...

猿人学web端爬虫攻防大赛赛题第13题——入门级cookie
1. F12开发者模式 刷新第一页,仔细研究发现里面有三次请求名为13的请求,根据题目提示cookie关键字,所以主要留意请求和响应的cookie值。 三次请求都带了sessionid,说明存在session(后面写代码要用session来写&#x…...

机器指标监控技术方案
文章目录 机器指标监控技术方案架构图组件简介Prometheus 简介核心特性适用场景 Grafana 简介核心特性适用场景 Alertmanager 简介核心特性适用场景 数据采集机器Node ExporterMySQL ExporterRedis ExporterES ExporterRocketMQ ExporterSpringcloud ExporterNacos 数据存储短期…...

数据库设计理论:从需求分析到实现的全流程解析
引言 在当今信息爆炸的时代,数据已成为企业和组织最宝贵的资产之一。如何有效地组织、存储和管理这些数据,是数据库设计需要解决的核心问题。一个优秀的数据库设计能够提高系统性能,确保数据一致性,降低维护成本,而糟…...
)
一文详解 Linux下的开源打印系统CUPS(Common UNIX Printing System)
文章目录 前言一、CUPS 简介二、CUPS 常用指令解析2.1 安装 CUPS2.2 启动/重启服务2.3 添加打印机(核心操作)2.4 设置默认打印机2.5 打印文件2.6 查看打印任务2.7 取消打印任务2.8 查看、移除已添加的打印机 三、调试与常见问题3.1 日志查看3.2 驱动问题…...

uniapp打包apk详细教程
目录 1.打apk包前提条件 2.获取uni-app标识 3.进入dcloud开发者后台 4.开始打包 1.打apk包前提条件 1.在HBuilderX.exe软化中,登录自己的账号 2.在dcloud官网,同样登录自己的账号。没有可以免费注册。 2.获取uni-app标识 获取方法:点…...

C++初阶-string类2
目录 1.迭代器 1.1普通迭代器的使用 1.2string::begin 1.3string::end 1.4const迭代器的使用 1.5泛型迭代器和const反向迭代器 1.6string::rbegin 1.6string::rend 1.7string::cbegin、string::cend、string::crbegin、string::crend 与begin/end、rbegin/rend的区别 …...
)
Qt QComboBox 下拉复选多选(multicombobox)
Qt QComboBox 下拉复选多选(multicombobox),备忘,待更多测试 【免费】QtQComboBox下拉复选多选(multicombobox)资源-CSDN文库...

逻辑回归之参数选择:从理论到实践
在机器学习的广阔领域中,逻辑回归作为一种经典的有监督学习算法,常用于解决分类问题。它以其简单易懂的原理和高效的计算性能,在实际应用中备受青睐。然而,要充分发挥逻辑回归的优势,参数选择是关键环节。本文将结合信…...

10、属性和数据处理---c++17
一、[[fallthrought]] 用途:在 switch 语句中标记某个分支 (case) 故意不写 break,明确告知编译器“执行穿透”是有意为之。 仅在需要向下穿透时使用,且应添加注释说明原因 #include<cstdio> #include<iostream> using namesp…...

conda管理python环境
安装conda 使用anaconda官网安装地址:https://www.anaconda.com/download/success 配置镜像环境 conda config --add channels Index of /anaconda/pkgs/main/ | 清华大学开源软件镜像站 | Tsinghua Open Source Mirror conda config --add channels Index of /an…...

【Python学习路线】零基础到项目实战系统
目录 🌟 前言技术背景与价值当前技术痛点解决方案概述目标读者说明 🧠 一、技术原理剖析核心概念图解核心作用讲解关键技术模块说明技术选型对比 💻 二、实战演示环境配置要求核心代码实现运行结果验证 ⚡ 三、性能对比测试方法论量化数据对比…...
)
C/C++核心机制深度解析:指针、结构体与动态内存管理(面试精要)
C/C核心机制深度解析:指针、结构体与动态内存管理(面试精要) 引言 在系统级编程领域,C/C语言凭借对硬件的直接操作能力和高效的内存管理机制,长期占据主导地位。面试中,指针、结构体和动态内存管理作为三…...

宇树科技举办“人型机器人格斗大赛”
2025 年 5 月至 6 月,一场全球瞩目的科技盛宴 —— 全球首场 “人形机器人格斗大赛”,将由杭州宇树科技盛大举办。届时,观众将迎来机器人格斗领域前所未有的视觉震撼。 为打造最强参赛阵容,宇树科技技术团队在过去数周里…...

getattr 的作用
getattr 是 Python 内置的一个函数,用于“动态地”获取对象的属性。**它允许你在运行时通过属性名称(字符串形式)来访问对象的属性,而不用在代码中直接硬编码属性名。**下面详细介绍该方法的用法和注意事项: ────…...
)
腾讯云服务器性能提升全栈指南(2025版)
腾讯云服务器性能提升全栈指南(2025版) 一、硬件选型与资源优化 1. 实例规格精准匹配 腾讯云服务器提供计算型CVM、内存型MEM、大数据型Hadoop等12种实例类型。根据业务特性选择: • 高并发Web应用:推荐SA3实例࿰…...

Kotlin与Jetpack Compose的详细使用指南
Kotlin与Jetpack Compose的详细使用指南,综合最新技术实践和官方文档整理: 一、环境配置与基础架构 项目创建 在Android Studio中选择Empty Compose Activity模板,默认生成包含Composable预览的MainActivity2要求Kotlin版本≥1.8.0&…...

潇洒郎: 100% 成功搭建Docker私有镜像仓库并管理、删除镜像
1、Registry Web管理界面 2、拉取Registry-Web镜像 创建配置文件 tee /opt/zwx-registry/web-config.yml <<-EOF registry:url: http://172.28.73.90:8010/v2name: registryreadonly: falseauth:enabled: false EOF 拉取docker-registry-web镜像并绑定Registry仓库 …...

【Spring Boot 注解】@ConfigurationProperties
文章目录 ConfigurationProperties注解一、简介二、依赖引入三、基本用法四、主要特性五、激活方式六,优点七、与 Value 对比 ConfigurationProperties注解 一、简介 ConfigurationProperties 是 Spring Boot 提供的一个强大注解,用于将外部配置&#…...

阿里云服务迁移实战: 06-切换DNS
概述 按前面的步骤,所有服务迁移完毕之后,最后就剩下 DNS 解析修改了。 修改解析 在域名解析处,修改域名的解析地址即可。 如果 IP 已经过户到了新账号,则不需要修改解析。 何确保业务稳定 域名解析更换时,由于 D…...

Java实现归并排序算法
1. 归并排序原理图解 归并排序是一种分治算法,其核心思想是将数组分成两半,分别对这两半进行排序,然后将排序后的两半合并。以下是归并排序的步骤: 1. 分治: - 将数组分成两半。 - 递归地对每半部分进行归并排序。 2. …...

Vue 项目中运行 `npm run dev` 时发生的过程
步骤1:找到「任务说明书」(package.json) 当你输入 npm run dev,系统首先会去查项目的 「任务说明书」(即 package.json 文件),看看 dev 这个任务具体要做什么。 示例代码(package.json 片段)…...
数据结构)
Python3(19)数据结构
在 Python 编程中,数据结构是组织和存储数据的重要方式,合理选择和使用数据结构能显著提升程序的效率和可读性。这篇博客通过丰富的代码示例深入学习 Python3 的数据结构知识,方便日后复习回顾。 一、列表(List) 1.1…...

macOS 安装了Docker Desktop版终端docker 命令没办法使用
macOS 安装了Docker Desktop版终端docker 命令没办法使用 1、检查Docker Desktop能否正常运行。 确保Docker Desktop能正常运行。 2、检查环境变量是否添加 1、添加环境变量 如果环境变量中没有包含Docker的路径,你可以手动添加。首先,找到Docker的…...