大连理工大学选修课——机器学习笔记(8):Boosting及提升树
Boosting及提升树
Boosting概述
- Bootstrap强调的是抽样方法
不同的数据集彼此独立,可并行操作
- Boosting注重数据集改造
数据集之间存在强依赖关系,只能串行实现
处理的结果都是带来了训练集改变,从而得到不同的学习模型
Boosting基本思想
boosting样本集中,初始权重均等;根据上一个弱模型预测结果修改错分样本的权重。
- 生成具有不同样本权重的新数据集
- 训练新的弱学习模型
循环操作,生成n个不同的数据集
-
新数据集依次递进生成
-
训练n个不同的学习模型
-
根据组合策略生成强学习模型

Boosting的基本问题
- 如何计算预测的错误率
- 如何设置弱学习模型的权重系数
- 如何更新训练样本的权重
- 如何选择集成学习的组合策略
Boosting的常用方法
- AdaBoost 自适应提升
- Gradient Boosting 梯度提升
- Extreme Gradient Boosting 极端梯度提升
常用的弱学习模型
- 决策树
- GBDT(Gradient Boosting DecisionTree)
- XGBDT(eXtreme Gradient Boosting DecisionTree)
AdaBoost
- 加法模型:强学习模型是弱学习模型的线性组合
- 损失函数是指数型函数
- 学习算法是正向分步算法
- 采用“正向激励+递进”机制
- 也是需要根据损失函数自动调节
AdaBoost的特点
- 不是人为地调节训练样本权重,通过损失函数自适应权重调节
- 弱学习模型也有各自的权重
- 调节投票权大小
- 也是需要根据损失函数自动调节
分类误差率
-
对于样本集 X = { ( x 1 , y 1 ) , ( x 2 , y 2 ) , ⋯ , ( x N , y N ) } X=\{(x_1,y_1),(x_2,y_2),\cdots,(x_N,y_N)\} X={(x1,y1),(x2,y2),⋯,(xN,yN)}
-
建立K个弱学习模型,第k个模型的训练样本权重
D ( k ) = ( w k 1 , w k 2 , ⋯ , w k N ) D(k)=(w_{k1},w_{k2},\cdots,w_{kN}) D(k)=(wk1,wk2,⋯,wkN)
-
权重的初始化
w 1 i = 1 N ; i = 1 , 2 , ⋯ , N w_{1i}=\frac{1}{N};\qquad i=1,2,\cdots,N w1i=N1;i=1,2,⋯,N
-
样本的权重对应一种概率分布
∑ i = 1 N w k i = 1 \sum_{i=1}^Nw_{ki}=1 i=1∑Nwki=1
-
定义二值分类问题的误差,假定二值 [ − 1 , 1 ] [-1,1] [−1,1]
- 第k个弱学习模型的加权误差率
e k = P ( G k ( x i ) ≠ y i ) = ∑ i = 1 N w k i I ( G k ( x i ) ≠ y i ) I ( G k ( x i ) ≠ y i ) = 1 e_k=P(G_k(x_i)\neq y_i)=\sum_{i=1}^Nw_{ki}I(G_k(x_i)\neq y_i)\\ I(G_k(x_i)\neq y_i)=1 ek=P(Gk(xi)=yi)=i=1∑NwkiI(Gk(xi)=yi)I(Gk(xi)=yi)=1
即:
e k = P ( G k ( x i ) ≠ y i ) = ∑ y i ≠ G k ( x i ) N w k i e_k=P(G_k(x_i)\neq y_i)=\sum_{y_i\neq G_k(x_i)}^Nw_{ki} ek=P(Gk(xi)=yi)=yi=Gk(xi)∑Nwki
AdaBoost的组合策略
学习模型通过正向分布算法获得
每一轮都会生成新的弱模型,第k轮对应的强模型定义为:
f k ( x ) = ∑ i = 1 k α i G i ( x ) f_k(x)=\sum_{i=1}^k\alpha_iG_i(x) fk(x)=i=1∑kαiGi(x)
由当前所有的弱模型的线性组合而成,最终的强学习模型:
f ( x ) = s i g n ( ∑ k = 1 K α k G k ( x ) ) f(x)=sign(\sum_{k=1}^K\alpha_kG_k(x)) f(x)=sign(k=1∑KαkGk(x))
弱学习模型的权重
第k轮:
f k ( x ) = ∑ i = 1 k α i G i ( x ) = f k − 1 ( x ) + α k G k ( x ) f_k(x)=\sum_{i=1}^k\alpha_iG_i(x)=f_{k-1}(x)+\alpha_kG_k(x) fk(x)=i=1∑kαiGi(x)=fk−1(x)+αkGk(x)
求解:
( α k , G k ( x ) ) = a r g m i n ∑ i = 1 N e x p [ − y i ( f k − 1 ( x i ) + α G ( x i ) ) ] (\alpha_k,G_k(x))=arg\ min\ \sum_{i=1}^Nexp[-y_i(f_{k-1}(x_i)+\alpha G(x_i))] (αk,Gk(x))=arg min i=1∑Nexp[−yi(fk−1(xi)+αG(xi))]
令 w ‾ k i = e x p [ − y i [ f k − 1 ( x i ) ] \overline w_{ki}=exp[-y_i[f_{k-1}(x_i)] wki=exp[−yi[fk−1(xi)]
且 G k ∗ = a r g m i n ∑ i = 1 N w ‾ k i I ( y i ≠ G ( x i ) ) G_k^*=arg\ min\sum_{i=1}^N\overline w_{ki}I(y_i\neq G(x_i)) Gk∗=arg min∑i=1NwkiI(yi=G(xi))
则:
∑ i = 1 N w ‾ k i e [ − y i α G ( x i ) ] = ∑ y i = G k ( x i ) w ‾ k i e ( − α ) + ∑ y i ≠ G i ( x i ) w ‾ k i e ( α ) = ( e ( α ) − e − α ) ∑ i = 1 N w ‾ k i I ( y i ≠ G ( x i ) ) + e − α ∑ i = 1 N w ‾ k i ( α k ) = a r g m i n ( ( e α − e − α ) ∑ i = 1 N w ‾ k i I ( y i ≠ G ( x i ) ) + e − α ∑ i = 1 N w ‾ k i ) \sum_{i=1}^N\overline w_{ki}\ e^{[-y_i\alpha}G(x_i)]=\sum_{y_i=G_k(x_i)}\overline w_{ki}e^{(-\alpha)}+\sum_{y_i\neq G_i(x_i)}\overline w_{ki}\ e^{(\alpha)}\\=(e^{(\alpha)}-e^{-\alpha})\sum_{i=1}^N\overline w_{ki}I(y_i\neq G(x_i))+e^{-\alpha}\sum_{i=1}^N\overline w_{ki}\\ (\alpha_k)=arg\ min((e^\alpha-e^{-\alpha})\sum_{i=1}^N\overline w_{ki}I(y_i\neq G(x_i))+e^{-\alpha}\sum_{i=1}^N\overline w_{ki}) i=1∑Nwki e[−yiαG(xi)]=yi=Gk(xi)∑wkie(−α)+yi=Gi(xi)∑wki e(α)=(e(α)−e−α)i=1∑NwkiI(yi=G(xi))+e−αi=1∑Nwki(αk)=arg min((eα−e−α)i=1∑NwkiI(yi=G(xi))+e−αi=1∑Nwki)
对 α \alpha α求导,令导数为0,得: α k ∗ = 1 2 l n 1 − e k e k \alpha_k^*=\frac{1}{2}ln\frac{1-e_k}{e_k} αk∗=21lnek1−ek
其中, e k = ∑ i = 1 N w k i I ( y i ≠ G ( x i ) ) e_k=\sum_{i=1}^Nw_{ki}I(y_i\neq G(x_i)) ek=∑i=1NwkiI(yi=G(xi))
强学习模型权重
f k ( x ) = ∑ i = 1 k α i G i ( x ) = f k − 1 ( x ) + α k G k ( x ) f_k(x)=\sum_{i=1}^k\alpha_iG_i(x)=f_{k-1}(x)+\alpha_kG_k(x) fk(x)=i=1∑kαiGi(x)=fk−1(x)+αkGk(x)
w ‾ k + 1 = w ‾ k i Z k e y i α k G k ( x ) {\overline w_{k+1}}=\frac{\overline w_{ki}}{Z_k}e^{y_i\alpha_kG_k(x)} wk+1=ZkwkieyiαkGk(x)
AdaBoost的回归分析
- 计算错误率
- 第k个弱模型的最大误差 E k = m a x ∣ y i − G k ( x i ) ∣ E_k=max|y_i-G_k(x_i)| Ek=max∣yi−Gk(xi)∣
- 每个样本的误差 e k i = ∣ y i − G k ( x i ) ∣ E k e_{ki}=\frac{|y_i-G_k(x_i)|}{E_k} eki=Ek∣yi−Gk(xi)∣
- 第k个弱模型的错误率 e k = ∑ i = 1 N w k i e k i e_k=\sum_{i=1}^Nw_{ki}e_{ki} ek=∑i=1Nwkieki
- 权重的更新
- 第k个弱模型的权重 α k = e k 1 − e k \alpha_k=\frac{e_k}{1-e_k} αk=1−ekek
- 每个样本的权重更新 w k + 1 = w k i Z k α k 1 − e k i w_{k+1}=\frac{ w_{ki}}{Z_k}\alpha_k^{1-ek_i} wk+1=Zkwkiαk1−eki, ( Z k = ∑ i = 1 N w k i α k 1 − e k i ) (Z_k=\sum_{i=1}^Nw_{ki}\alpha_k^{1-e_{ki}}) (Zk=∑i=1Nwkiαk1−eki)
- 组合策略
- 对加权的弱学习器,取权重中位数对应的弱学习器,作为强学习器的方法。
- 最终的强回归器为 f ( x ) = G k ∗ ( x ) f(x)=G_k^*(x) f(x)=Gk∗(x)
- 其中 G k ∗ ( x ) G_k^*(x) Gk∗(x)是K个弱模型权重中位数对应的模型
AdaBoost的正则化
- 为了防止过拟合,可以引入正则化
对于强学习模型而言:
f k ( x ) = f k − 1 ( x ) + α k G k ( x ) f_k(x)=f_{k-1}(x)+\alpha_kG_k(x) fk(x)=fk−1(x)+αkGk(x)
改进模型:
f k ( x ) = f k − 1 ( x ) + v α k G k ( x ) f_k(x)=f_{k-1}(x)+v\alpha_kG_k(x) fk(x)=fk−1(x)+vαkGk(x)
其中,v为正则化参数,在此也称为步长(或者学习率),调节弱模型的生成。
AdaBoost的分类算法描述(二值)


AdaBoost的分类算法描述(多值)

AdaBoost回归算法描述
以AdaBoost R2为例

Gradient Boosting Tree
Boosting的本质:采用加法模型与正向激励算法
对弱学习模型的要求:学习能力差的模型,输出结果低方差,高偏差
弱模型采用决策树:
- 提升树(Boosting Tree)
- 采用CART(二叉树)
- 深度1-5即可,不宜太大
梯度提升树
初始化
f 0 ( x ) = a r g m i n ∑ i = 1 N L ( y i , c ) f_0(x)=arg\ min\sum_{i=1}^NL(y_i,c) f0(x)=arg mini=1∑NL(yi,c)
第m步残差
r m i = − ( ∂ L ( y i , f ( x i ) ) ∂ f ( x i ) ) f ( x ) = f x − 1 ( x ) r_{mi}=-(\frac{\partial L(y_i,f(x_i))}{\partial f(x_i)})_{f(x)=f_{x-1}(x)} rmi=−(∂f(xi)∂L(yi,f(xi)))f(x)=fx−1(x)
利用 ( x i , r m i ) ( i = 1 , 2 , ⋯ , N ) (x_i,r_{mi})(i=1,2,\cdots,N) (xi,rmi)(i=1,2,⋯,N),可以拟合一棵CART回归树
对于叶子结点
c m j = a r g m i n ∑ L ( y i , f m − 1 ( x i ) + c ) c_{mj}=arg\ min\sum L(y_i,f_{m-1}(x_i)+c) cmj=arg min∑L(yi,fm−1(xi)+c)
第m步的强模型
f m ( x ) = f m − 1 ( x ) + ∑ c m j I ( x ∈ R m j ) f_m(x)=f_{m-1}(x)+\sum c_{mj}I(x\in R_{mj}) fm(x)=fm−1(x)+∑cmjI(x∈Rmj)
最终的强模型
f ^ ( x ) = f M ( x ) = f 0 ( x ) + ∑ m = 1 M ∑ j = 1 J c m i I ( x ∈ R m j ) \hat f(x)=f_M(x)=f_0(x)+\sum_{m=1}^M\sum_{j=1}^Jc_{mi}I(x\in R_{mj}) f^(x)=fM(x)=f0(x)+m=1∑Mj=1∑JcmiI(x∈Rmj)
对于分类树,与回归树的损失函数不同
如果采用指数函数,提升树退化为AdaBoost
也可采用逻辑回归函数
- 对数似然损失函数
- 二值分类和多值分类有不同的表示形式
对于二值分类
-
损失函数
L ( y , f ( x ) ) = l o g ( 1 + e − y f ( x ) ) , y ∈ { − 1 , 1 } L(y,f(x))=log(1+e^{-yf(x)}),\quad y\in \{-1,1\} L(y,f(x))=log(1+e−yf(x)),y∈{−1,1}
-
残差计算
r m j = − ( ∂ L ( y i , f ( x i ) ) ∂ f ( x i ) ) = y i 1 + e y i ( x i ) r_{mj}=-(\frac{\partial L(y_i,f(x_i))}{\partial f(x_i)})=\frac{y_i}{1+e^{y_i(x_i)}} rmj=−(∂f(xi)∂L(yi,f(xi)))=1+eyi(xi)yi
-
对于为你和残差构建的决策树
c m j = a r g m i n ∑ l o g ( 1 + e − y i ( f m − 1 ( x i ) + c ) ) c_{mj}=arg\ min\sum log(1+e^{-y_i(f_{m-1}(x_i)+c)}) cmj=arg min∑log(1+e−yi(fm−1(xi)+c))
最优值的近似计算
c m j ≈ ∑ r m j ∑ ∣ r m j ∣ ( 1 − ∣ r m j ∣ ) c_{mj}\approx\frac{\sum r_{mj}}{\sum\ |r_{mj}|(1-|r_{mj}|)} cmj≈∑ ∣rmj∣(1−∣rmj∣)∑rmj
对于多值分类
-
对应K个分类的损失函数
L ( y , f ( x ) ) = ∑ k = 1 K y k l o g p k ( x ) L(y,f(x))=\sum_{k=1}^Ky_klog\ p_k(x) L(y,f(x))=k=1∑Kyklog pk(x)
如果输出样本类别为k,则 y k = 1 y_k=1 yk=1
-
第k类的概率的表达式为
p k ( x ) = e f k ( x ) / ∑ l = 1 K e f l ( x ) p_k(x)=e^{f_k(x)}/\sum_{l=1}^Ke^{f_l(x)} pk(x)=efk(x)/l=1∑Kefl(x)
-
计算残差
r m i l = − ( ∂ L ( y i , f ( x i ) ∂ f ( x i ) ) f k ( x ) = f l , m − 1 ( x ) = y i l − p l , m − 1 ( x i ) r_{mil}=-(\frac{\partial L(y_i,f(x_i)}{\partial f(x_i)})_{f_k(x)=f_{l,m-1}(x)}=y_{il}-p_{l,m-1}(x_i) rmil=−(∂f(xi)∂L(yi,f(xi))fk(x)=fl,m−1(x)=yil−pl,m−1(xi)
上式对应样本i对应类别l的真实概率和第m-1轮预测概率的差值
-
对于决策树优化
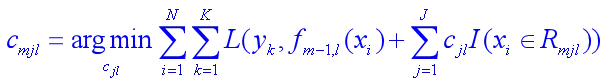
最优值的近似计算
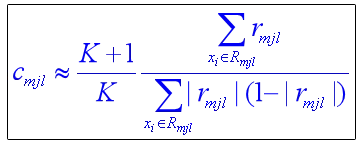
梯度提升树的其它常用损失函数
指数损失函数
L ( y , f ( x ) ) = e − y f ( x ) L(y,f(x))=e^{-yf(x)} L(y,f(x))=e−yf(x)
使用该函数,提升树退化为AdaBoost
绝对误差
L ( y , f ( x ) ) = ∣ y − f ( x ) ∣ L(y,f(x))=|y-f(x)| L(y,f(x))=∣y−f(x)∣
对应的负梯度误差
s i g n ( y i − f ( x i ) ) sign(y_i-f(x_i)) sign(yi−f(xi))
Huber损失函数
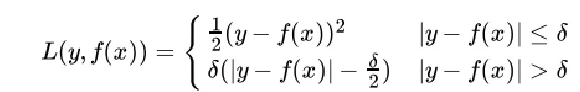
均方差和绝对差的折中产物,用于处理异常点
对应的负梯度误差:
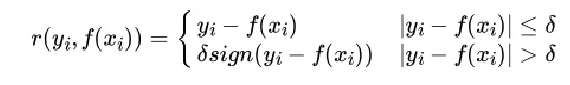
Qutantile(分位数)损失函数
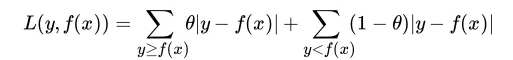
也能有效处理异常点
对应的负梯度误差
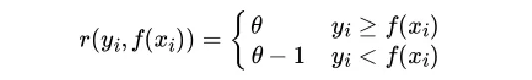
梯度提升树的正则化
方法一:
f k ( x ) = f k − 1 ( x ) + v h k ( x ) f_k(x)=f_{k-1}(x)+vh_k(x) fk(x)=fk−1(x)+vhk(x)
与AdaBoost算法手段相同
方法二:
采用采样比,取值为 ( 0 , 1 ] (0,1] (0,1]
用部分样本去拟合决策树,克服过拟合
此时的模型称为随机梯度提升树
可以实现部分并行,从而提升执行效率
梯度提升树总结
- 优点
- 可灵活处理各类数据
- 在相对少的调参情况下,预测准确率也可以比较高
- 对异常值鲁棒性强
相关文章:
:Boosting及提升树)
大连理工大学选修课——机器学习笔记(8):Boosting及提升树
Boosting及提升树 Boosting概述 Bootstrap强调的是抽样方法 不同的数据集彼此独立,可并行操作 Boosting注重数据集改造 数据集之间存在强依赖关系,只能串行实现 处理的结果都是带来了训练集改变,从而得到不同的学习模型 Boosting基本思…...
(十七)标准库)
OpenHarmony - 小型系统内核(LiteOS-A)(十七)标准库
OpenHarmony - 小型系统内核(LiteOS-A)(十七) 二十一、标准库 OpenHarmony内核使用musl libc库,支持标准POSIX接口,开发者可基于POSIX标准接口开发内核之上的组件及应用。 标准库接口框架 图1 POSIX接口…...

vscode详细配置Go语言相关插件
文章目录 vscode详细配置Go语言1.插件介绍1.1 BetterCommments1.2GitGraph1.3Go1.4GoComment1.5goctl1.6Lowlight Go Errors1.7Markdown1.8Material Icon Theme1.9Preetier2.0Project Manager其它插件 2.settings.json文件 vscode详细配置Go语言 1.插件介绍 1.1 BetterCommme…...

如何解决服务器文件丢失或损坏的问题
当服务器文件丢失或损坏时,需采取系统化的恢复和预防措施。以下是分步骤解决方案: --- ### **一、紧急恢复措施** #### 1. **检查文件系统完整性** bash # 对未挂载的分区进行检查(需先umount) fsck -y /dev/sdX # 针对ext4文…...

【C++11】包装器:function 和 bind
📝前言: 这篇文章我们来讲讲C11——包装器:function和bind,对于每个包装器主要讲解: 原型基本语法使用示例 🎬个人简介:努力学习ing 📋个人专栏:C学习笔记 🎀…...

芯知识|小体积语音芯片方案WTV/WT2003H声音播放ic应用解析
在智能硬件设备趋向微型化的背景下,语音芯片方案厂家针对小体积设备开发了多款超小型语音芯片方案,其中WTV系列和WT2003H系列凭借其QFN封装设计、高性能与高集成度,成为微型设备语音方案的理想选择。以下从封装特性、功能优势及典型应用场景三…...

第三部分:特征提取与目标检测
像边缘、角点、特定的纹理模式等都是图像的特征。提取这些特征是许多计算机视觉任务的关键第一步,例如图像匹配、对象识别、图像拼接等。目标检测则是在图像中找到特定对象(如人脸、汽车等)的位置。 本部分将涵盖以下关键主题: …...

MySQL bin目录下的可执行文件
文章目录 MySQL bin目录下的可执行文件1.mysqldump2.mysqladmin3.mysqlcheck4.mysqlimport5.mysqlshow6.mysqlbinlog7.常用可执行文件 MySQL bin目录下的可执行文件 1.mysqldump mysqldump 是 MySQL 的数据库备份工具。对数据备份、迁移或恢复非常重要。 备份整个数据库&…...
)
第四部分:赋予网页健壮的灵魂 —— TypeScript(中)
目录 4 类与面向对象:构建复杂的组件4.1 类的定义与成员4.2 继承 (Inheritance)4.3 接口实现 (Implements)4.4 抽象类 (Abstract Class)4.5 静态成员 (Static Members) 5 更高级的类型:让类型系统更灵活5.1 联合类型 (|)5.2 交叉类型 (&)5.3 字面量类…...

Learning vtkjs之ImageMarchingCubes
体积 等值面处理 介绍 vtkImageMarchingCubes - 对体积进行等值面处理 给定一个指定的等值,使用Marching Cubes算法生成一个等值面。 效果 新建了一个球,对比一下原始的(透明的)和ISO的效果 核心代码 参数部分 const updat…...

【“星睿O6”AI PC开发套件评测】+ tensorflow 初探
因为本次我的项目计划使用 tensorflow,所以这篇文章主要想做一个引子,介绍如何在“星睿O6”上搭建 tensorflow 的开发环境和验证测试。本文主要分为几个部分: 在“星睿O6”上编译安装 tensorflow基于 MNIST 数据集的模型训练和评估 tensorf…...

通义灵码全面接入Qwen3:AI编程进入智能体时代,PAI云上部署实战解析
引言:AI编程的范式革命 2025年4月30日,阿里云通义灵码宣布全面支持新一代大模型Qwen3,并同步推出编程智能体功能,标志着AI辅助开发从“工具助手”向“自主决策智能体”的跃迁。与此同时,阿里云PAI平台上线Qwen3全系列…...

如何禁止AutoCAD这类软件联网
推荐二、三方法,对其他软件影响最小 一、修改Hosts文件 Hosts文件是一个存储域名与IP地址映射关系的文本文件,通过修改Hosts文件可以将AutoCAD的域名指向本地回环地址(127.0.0.1),从而实现禁止联网的目的。具体步骤如…...

音视频项目在微服务领域的趋势场景题深度解析
音视频项目在微服务领域的趋势场景题深度解析 在互联网大厂Java求职者的面试中,经常会被问到关于音视频项目在微服务领域的应用场景的相关问题。本文通过一个故事场景来展示这些问题的实际解决方案。 第一轮提问 面试官:马架构,欢迎来到我…...

100 个 NumPy 练习
本文翻译整理自:https://github.com/rougier/numpy-100 文章目录 关于 100 个 NumPy 练习相关链接资源关键功能特性 100 个 NumPy 练习题1、导入 NumPy 包并命名为 np (★☆☆)2、打印 NumPy 版本和配置信息 (★☆☆)3、创建一个大小为 10 的空向量 (★☆☆)4、如何…...

在Carla中构建自动驾驶:使用PID控制和ROS2进行路径跟踪
机器人软件开发什么是 P、PI 和 PID 控制器?比例 (P) 控制器比例积分 (PI) 控制器比例-积分-微分 (PID) 控制器横向控制简介CARLA ROS2 集成纵向控制横向控制关键要点结论引用 机器人软件开发 …...

Windows和 macOS 上安装 `nvm` 和 Node.js 16.16.0 的详细教程。
Windows和 macOS 上安装 nvm 和 Node.js 16.16.0 的详细教程。 --- ### 1. 安装 nvm(Node Version Manager) nvm 是一个 Node.js 版本管理工具,可以轻松安装和切换不同版本的 Node.js。 #### Windows 安装 nvm 1. **下载 nvm 安装包**&#x…...

day11 python超参数调整
模型组成:模型 算法 实例化设置的外参(超参数) 训练得到的内参调参评估:调参通常需要进行两次评估。若不使用交叉验证,需手动划分验证集和测试集;但许多调参方法自带交叉验证功能,实际中可省略…...

Linux C++ xercesc xml 怎么判断路径下有没有对应的节点
在Linux环境下使用Xerces-C库处理XML文件时,判断路径下是否存在对应的节点可以通过以下几个步骤实现: 加载XML文档 首先,你需要加载XML文档。这可以通过创建一个xercesc::DOMParser对象并使用它的parse方法来实现。 #include <xercesc/…...

罗技K580蓝牙键盘连接mac pro
罗技K580蓝牙键盘,满足了我们的使用需求。最棒的是,它能够同时连接两个设备,通过按F11和F12键进行切换,简直不要太方便! 连接电脑 💻 USB连接 1、打开键盘:双手按住凹槽两边向前推࿰…...

Socket-UDP
Socket(套接字 )是计算机网络中用于实现进程间通信的重要编程接口,是对 TCP/IP 协议的封装 ,可看作是不同主机上应用进程之间双向通信端点的抽象。以下是详细介绍: 作用与地位 作为应用层与传输层、网络层协议间的中…...

【游戏ai】从强化学习开始自学游戏ai-2 使用IPPO自博弈对抗pongv3环境
文章目录 前言一、环境设计二、动作设计三、状态设计四、神经网路设计五、效果展示其他问题总结 前言 本学期的大作业,要求完成多智能体PPO的乒乓球对抗环境,这里我使用IPPO的方法来实现。 正好之前做过这个单个PPO与pong环境内置的ai对抗的训练&#…...
——机器人及舵机配置)
LeRobot 项目部署运行逻辑(三)——机器人及舵机配置
Lerobot 目前的机器人硬件以舵机类型为主,并未配置机器人正逆运动学及运动学,遥操作映射以舵机关节角度为主 因此,需要在使用前需要对舵机各项参数及初始位置进行配置 目录 1 Mobile ALOHA 配置 2 Dynamixel 配置 2.1 配置软件 2.2 SDK …...

Ubuntu20.04安装NVIDIA Warp
Ubuntu20.04安装NVIDIA Warp 安装测试 Warp的gitee网址 Warp的github网址 写在前面:建议安装前先参考readme文件自检系统驱动和cuda是否支持,个人实测建议是python3.9,但python3.8.20也可以使用。 写在前面:后续本人可能会使用这…...
)
电子病历高质量语料库构建方法与架构项目(临床情景理解模块篇)
引言 随着人工智能技术在医疗健康领域的广泛应用,电子病历(Electronic Medical Records,EMR)作为临床医疗数据的重要载体,已成为医学研究和临床决策支持的关键资源。电子病历高质量语料库的构建为医疗人工智能模型的训练和应用提供了基础支撑,其中临床情境理解模块是连接…...

WPF性能优化举例
WPF性能优化集锦 一、UI渲染性能优化 1. 虚拟化技术 ListView/GridView虚拟化: <ListView VirtualizingStackPanel.IsVirtualizing="True"VirtualizingStackPanel.VirtualizationMode="Recycling"ScrollViewer.IsDeferredScrollingEnabled=…...

【CUDA pytorch】
ev win10 3050ti 联想笔记本 nvcc --version 得到 PS C:\Users\25515> nvcc --version nvcc: NVIDIA (R) Cuda compiler driver Copyright (c) 2005-2022 NVIDIA Corporation Built on Tue_May__3_19:00:59_Pacific_Daylight_Time_2022 Cuda compilation tools, release …...

mac下载homebrew 安装和使用git
mac下载homebrew 安装和使用git 本人最近从windows换成mac,记录一下用homebrew安装git的过程 打开终端 command 空格,搜索终端 安装homebrew 在终端中输入下面命令,来安装homebrew /bin/bash -c "$(curl -fsSL https://raw.githu…...

Elasticsearch入门速通01:核心概念与选型指南
一、Elasticsearch 是什么? 一句话定义: 开源分布式搜索引擎,擅长处理海量数据的实时存储、搜索与分析,是ELK技术栈(ElasticsearchKibanaBeatsLogstash)的核心组件。 核心能力: 近实时搜索&…...
)
应对过度处方挑战:为药物推荐任务微调大语言模型(Xiangnan He)
Abstract 药物推荐系统因其有潜力根据患者的临床数据提供个性化且有效的药物组合,在医疗保健领域备受关注。然而,现有方法在适应不同的电子健康记录(EHR)系统以及有效利用非结构化数据方面面临挑战,导致其泛化能力有限…...

41 python http之requests 库
Python 的requests库就像你的 "接口助手",用几行代码就能发送 HTTP 请求,自动处理复杂的网络交互,让你告别手动拼接 URL 和解析响应的痛苦! 一、快速入门:3 步搞定基本请求 1.1 安装库:一键开启助手功能 pip install requests 1.2 发送 GET 请求 import r…...

百度网盘golang实习面经
goroutine内存泄漏的情况?如何避免? goroutine内存泄漏基本上是因为异常导致阻塞, 可以导致阻塞的情况 1 死锁, goroutine 等待的锁发生了死锁情况 2 chan没有正常被关闭,导致读取读chan的goroutine阻塞 如何避免 1 避免死锁 2 正常关闭 3 使用context管…...

super_small_toy_tpu
super_small_toy_tpu 小狼http://blog.csdn.net/xiaolangyangyang 1、基础框图 2、源码下载: GitHub - dldldlfma/super_small_toy_tpu 3、安装iverilog、vvp、gtkwave windows安装:https://bleyer.org/icarus/ ubuntu安装:sudo ap…...

Redis缓存穿透、缓存击穿与缓存雪崩:如何在.NET Core中解决
在高并发的互联网系统中,缓存技术作为优化系统性能的重要手段,已被广泛应用。然而,缓存系统本身也存在一些常见的问题,尤其是 缓存穿透、缓存击穿 和 缓存雪崩。这些问题如果处理不当,可能导致系统性能严重下降&#x…...

驱动车辆诊断测试创新 | 支持诊断测试的模拟器及数据文件转换生成
一 背景和挑战 | 背景: 随着汽车功能的日益丰富,ECU和域控制器的复杂性大大增加,导致测试需求大幅上升,尤其是在ECU的故障诊断和性能验证方面。然而,传统的实车测试方法难以满足高频率迭代和验证需求,不仅…...

VS Code技巧2:识别FreeCAD对象
在使用VS Code阅读FreeCAD代码或者FreeCAD的工作台代码时,VS Code无法识别FreeCAD对象,会提示Import “FreeCAD” could not be resolved: 问题解决如下几步即可。 第一步:确认 FreeCAD 的 Python 环境路径 在FreeCAD的Python控制…...

泰迪杯特等奖案例学习资料:基于多模态融合与边缘计算的智能温室环境调控系统
(第十二届泰迪杯数据挖掘挑战赛特等奖案例解析) 一、案例背景与核心挑战 1.1 应用场景与行业痛点 在现代设施农业中,温室环境调控直接影响作物产量与品质。传统温室管理存在以下问题: 环境参数耦合性高:温度、湿度、光照、CO₂浓度等参数相互影响,人工调控易顾此失彼。…...

猿人学web端爬虫攻防大赛赛题第13题——入门级cookie
1. F12开发者模式 刷新第一页,仔细研究发现里面有三次请求名为13的请求,根据题目提示cookie关键字,所以主要留意请求和响应的cookie值。 三次请求都带了sessionid,说明存在session(后面写代码要用session来写&#x…...

机器指标监控技术方案
文章目录 机器指标监控技术方案架构图组件简介Prometheus 简介核心特性适用场景 Grafana 简介核心特性适用场景 Alertmanager 简介核心特性适用场景 数据采集机器Node ExporterMySQL ExporterRedis ExporterES ExporterRocketMQ ExporterSpringcloud ExporterNacos 数据存储短期…...

数据库设计理论:从需求分析到实现的全流程解析
引言 在当今信息爆炸的时代,数据已成为企业和组织最宝贵的资产之一。如何有效地组织、存储和管理这些数据,是数据库设计需要解决的核心问题。一个优秀的数据库设计能够提高系统性能,确保数据一致性,降低维护成本,而糟…...
)
一文详解 Linux下的开源打印系统CUPS(Common UNIX Printing System)
文章目录 前言一、CUPS 简介二、CUPS 常用指令解析2.1 安装 CUPS2.2 启动/重启服务2.3 添加打印机(核心操作)2.4 设置默认打印机2.5 打印文件2.6 查看打印任务2.7 取消打印任务2.8 查看、移除已添加的打印机 三、调试与常见问题3.1 日志查看3.2 驱动问题…...

uniapp打包apk详细教程
目录 1.打apk包前提条件 2.获取uni-app标识 3.进入dcloud开发者后台 4.开始打包 1.打apk包前提条件 1.在HBuilderX.exe软化中,登录自己的账号 2.在dcloud官网,同样登录自己的账号。没有可以免费注册。 2.获取uni-app标识 获取方法:点…...

C++初阶-string类2
目录 1.迭代器 1.1普通迭代器的使用 1.2string::begin 1.3string::end 1.4const迭代器的使用 1.5泛型迭代器和const反向迭代器 1.6string::rbegin 1.6string::rend 1.7string::cbegin、string::cend、string::crbegin、string::crend 与begin/end、rbegin/rend的区别 …...
)
Qt QComboBox 下拉复选多选(multicombobox)
Qt QComboBox 下拉复选多选(multicombobox),备忘,待更多测试 【免费】QtQComboBox下拉复选多选(multicombobox)资源-CSDN文库...

逻辑回归之参数选择:从理论到实践
在机器学习的广阔领域中,逻辑回归作为一种经典的有监督学习算法,常用于解决分类问题。它以其简单易懂的原理和高效的计算性能,在实际应用中备受青睐。然而,要充分发挥逻辑回归的优势,参数选择是关键环节。本文将结合信…...

10、属性和数据处理---c++17
一、[[fallthrought]] 用途:在 switch 语句中标记某个分支 (case) 故意不写 break,明确告知编译器“执行穿透”是有意为之。 仅在需要向下穿透时使用,且应添加注释说明原因 #include<cstdio> #include<iostream> using namesp…...

conda管理python环境
安装conda 使用anaconda官网安装地址:https://www.anaconda.com/download/success 配置镜像环境 conda config --add channels Index of /anaconda/pkgs/main/ | 清华大学开源软件镜像站 | Tsinghua Open Source Mirror conda config --add channels Index of /an…...

【Python学习路线】零基础到项目实战系统
目录 🌟 前言技术背景与价值当前技术痛点解决方案概述目标读者说明 🧠 一、技术原理剖析核心概念图解核心作用讲解关键技术模块说明技术选型对比 💻 二、实战演示环境配置要求核心代码实现运行结果验证 ⚡ 三、性能对比测试方法论量化数据对比…...
)
C/C++核心机制深度解析:指针、结构体与动态内存管理(面试精要)
C/C核心机制深度解析:指针、结构体与动态内存管理(面试精要) 引言 在系统级编程领域,C/C语言凭借对硬件的直接操作能力和高效的内存管理机制,长期占据主导地位。面试中,指针、结构体和动态内存管理作为三…...

宇树科技举办“人型机器人格斗大赛”
2025 年 5 月至 6 月,一场全球瞩目的科技盛宴 —— 全球首场 “人形机器人格斗大赛”,将由杭州宇树科技盛大举办。届时,观众将迎来机器人格斗领域前所未有的视觉震撼。 为打造最强参赛阵容,宇树科技技术团队在过去数周里…...