【第三十三周】BLIP论文阅读笔记
BLIP
- 摘要
- Abstract
- 文章信息
- 引言
- 方法
- MED
- 预训练
- CapFilt
- 关键代码
- 实验结果
- 总结
摘要
本博客介绍了BLIP(Bootstrapping Language-Image Pre-training),这是一种创新的视觉-语言预训练框架,旨在通过统一模型架构和高效数据增强策略,同时解决现有视觉-语言模型在理解与生成任务上的割裂性以及网络数据噪声对性能的制约。其核心思想包含两方面:模型层面提出多模态混合编码器-解码器(MED),通过共享参数支持三种模式——单模态编码器(对齐全局特征)、跨模态编码器(细粒度匹配)和跨模态解码器(生成描述),联合优化图像-文本对比(ITC)、匹配(ITM)和语言建模(LM)损失,从而统一理解(如检索)与生成(如描述)任务;数据层面设计Captioning 和 Filtering(CapFilt)方法,利用预训练(使用网上获取的有噪声的数据)的MED生成合成描述(Captioner模块)并过滤原始网络文本与合成文本中的噪声(Filter模块),从噪声数据中提炼高质量训练样本。实验表明,BLIP在图像-文本检索、图像描述生成等任务上达到SOTA,且零样本迁移至视频任务时表现优异。其优势在于通过灵活架构与数据增强突破多任务瓶颈,但数据清洗的计算成本较高,且未深入时序建模。未来可探索多轮数据增强、生成多样性优化及视频-语言扩展,进一步释放模型潜力。
Abstract
This blog introduces BLIP (Bootstrapping Language-Image Pre-training), an innovative vision-language pre-training framework designed to address the limitations of existing models in unifying understanding and generation tasks, while mitigating performance degradation caused by noisy web data. Its core innovations lie in two aspects: Model-wise, it proposes a Multimodal Mixture of Encoder-Decoder (MED) architecture that supports three modes—unimodal encoders (for global feature alignment via image-text contrastive loss, ITC), cross-modal encoders (for fine-grained matching via image-text matching loss, ITM), and cross-modal decoders (for caption generation via language modeling loss, LM)—jointly optimized to bridge understanding (e.g., retrieval) and generation (e.g., captioning). Data-wise, it introduces Captioning and Filtering (CapFilt), a bootstrapping strategy where a pre-trained MED generates synthetic captions (via the Captioner module) and filters noise from both web-derived and synthetic texts (via the Filter module), thereby distilling high-quality training data. Experiments demonstrate BLIP’s state-of-the-art performance on tasks like image-text retrieval and captioning, along with strong zero-shot transfer to video-language tasks. While its flexible architecture and data enhancement overcome multi-task bottlenecks, challenges include higher computational costs in data purification and limited exploration of temporal modeling. Future directions may explore iterative data augmentation rounds, optimizing generation diversity, and extending to video-language domains to unlock further potential.
文章信息
Title:BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation
Author:Junnan Li, Dongxu Li, Caiming Xiong, Steven Hoi.
Source:https://arxiv.org/abs/2201.12086
引言
CLIP 之后,各种视觉语言与训练模型(Vision-Language Pre-training, VLP)相继被提出,显著提高了各种视觉语言任务的性能。然而,现有的 VLP 方法主要存在以下两个问题:
- 模型的角度:BLIP之前的大多数方法要么是基于编码器的模型,要么就是基于编码器-解码器的模型,但基于编码器的模型难以完成文本生成任务,基于编码器-解码器的模型难以完成图像-文本检索任务。
- 数据角度:大多数方法的数据是来自网络上的,尽管通过扩大数据集对模型性能的提升有帮助,但直接从网上获取的数据有噪声,有噪声的文本对视觉-语言学习来说是次优的。
为了让 VLP 同时具有图文多模态的理解和生成能力,BLIP提出一种全新的多模态混合架构 MED(Multimodal mixture of Encoder and Decoder),为了去除网络上获得的数据的噪声,BLIP在预训练完成的 MED 基础上引入了 CapFilt。
方法
BLIP 全称是 Bootstrapping Language-Image Pre-training,是一种统一视觉语言理解与生成的预训练模型。BLIP的网络架构如下图所示:

MED
BLIP 采用了基于 编码器 - 解码器的多模态混合结构 (Multimodal mixture of Encoder-Decoder, MED),其包括两个单模态编码器:图像编码器和文本编码器,两个多模态编码器:基于图像的文本编码器和解码器。
- 单模态图像编码器:其实就是一个VIT,将输入图像分割成一个个的 Patch 并将它们编码为一系列 Image Embedding,并使用额外的 [CLS] token 来表示全局的图像特征。
- 单模态文本编码器:基于BERT架构,其中 [CLS] token 附加到文本输入的开头以总结句子。作用是提取文本特征做对比学习。
- 以图像为基础的文本编码器:在 Text Encoder 的 self-attention 层和前馈网络之间加入 交叉注意 (cross-attention, CA) 层用来注入视觉信息,并将 [Encode] token 加到输入文本的开头以以标识特定任务。作用是根据 ViT 给的图片特征和文本输入做二分类,判断图文是否匹配。
- 以图像为基础的文本解码器:与Image-grounded text encoder 不同的是,双向自注意力层换为了causal self-attention(因果关系注意力),并将 [Decode] token 和 [EOS] token 加到输入文本的开头和结尾以标识序列的开始和结束。作用是生成符合图像的文本描述。
lmage Encoder、Text Encoder、Image-grounded text encoder、Image-grounded text decoder 三个模块的结构比较相似,而且共享了部分参数(架构图中相同颜色的部分,比如三个模块的Feed Foward的颜色一样,共享参数)。另外,每个 image-text 在输入时,image 部分只需要过一个 ViT 模型,text 部分需要过3次文本模型。
预训练
预训练时需要共同优化三个目标,包括两个理解任务的目标函数和一个生成任务的目标函数,具体如下:
- 图文对比损失(Image-Text Contrastive Loss, ITC):ITC作用于单模态的图像编码器和文本编码器,通过对比学习对齐图像和文本的特征空间(类似于CLIP)。具体方法为最大化正样本图像 - 文本对的相似度且最小化负样本图像 - 文本对的相似度,使匹配的图文对在特征空间中更接近,非匹配对更远离。另外,这里用到了ALBEF 中的动量编码器,其目的是产生一些伪标签以辅助模型的训练。
- 图文匹配损失 (Image-Text Matching Loss, ITM):ITM作用于单模态图像编码器和多模态的基于图像的文本编码器,通过学习图像 - 文本对的联合表征实现视觉和语言之间的细粒度对齐。具体方法是通过一个二分类任务,预测图像文本对是正样本还是负样本(图文对是否匹配)。另外,这里用到了ALBEF 中的 hard negative mining 技术以更好地捕捉负样本信息。
- 语言建模损失(Language Modeling Loss, LM):LM作用于单模态图像编码器和多模态的基于图像的文本解码器(生成任务),目标是根据给定的图像以自回归方式来生成关于文本的描述。具体方法是通过优化交叉熵损失函数,训练模型以自回归的方式最大化文本的概率。
CapFilt
高质量的人工注释图像-文本对 { ( I h , T h ) } \{(I_h,T_h)\} {(Ih,Th)}(如CoCo)的数量有限,所以之前的方法都是用网上获取的大量图像-文本对 { ( I w , T w ) } \{(I_w,T_w)\} {(Iw,Tw)}作为训练数据,但这些网络数据中的文本难以精准地描述图像内容,存在大量噪声。

如上图,图片是巧克力蛋糕,而其文本却不是对图片的描述,属于噪声数据。
BLIP 提出 CapFilt 的机制来从有大量噪声的数据中获取质量更高的数据。其具体方法和步骤如下图:

CapFilt 包含两个模块,过滤模块 Filter 和生成文本模块 Captioner:
- Filter:用于去除噪声图文对,基于文本编码器 Image-grounded text encoder 实现,使用 ITC 和 ITM 损失函数在 COCO 数据集上进行微调。
- Captioner:用于生成给定图像的描述文本,基于文本解码器 Image-grounded text decoder 实现,使用 LM 损失函数在 COCO 数据集上进行微调。

BLIP 先使用含有噪声的网络数据集进行预训练;
再用COCO数据集对 Image-grounded text encoder 和 Image-grounded text decoder 进行微调,得到 Filter 和 Captioner ,然后利用 Captioner 生成图片对应的生成描述文本( T s T_s Ts),Filter 对网上获取的图文对进行过滤,去除其认为不匹配的图文对,同时对 Captioner 生成的图像文本对 { ( I w , T s ) } \{(I_w,T_s)\} {(Iw,Ts)}进行过滤,最终得到高质量的数据集 { ( I w , T w ) } + { ( I w , T s ) } \{(I_w,T_w)\}+\{(I_w,T_s)\} {(Iw,Tw)}+{(Iw,Ts)}(这里的数据都是经过过滤的);
过滤后的数据加上高质量的COCO数据集 { ( I h , T h ) } \{(I_h,T_h)\} {(Ih,Th)},作为训练集,重新训练一个BLIP(从头训练),得到一个高性能的 BLIP。
关键代码
BLIP_Base 类:实现了 Text Encoder 和 Image-grounded Text Encoder ,当 mode 为 ‘multimodal’ 时实现的是Image-grounded Text Encoder。
class BLIP_Base(nn.Module):def __init__(self, med_config = 'configs/med_config.json', image_size = 224,vit = 'base',vit_grad_ckpt = False,vit_ckpt_layer = 0, ):"""Args:med_config (str): 混合编码器 - 解码器模型的配置文件路径image_size (int): 输入图像的大小vit (str): 视觉Transformer的模型大小""" super().__init__()# 创建视觉编码器self.visual_encoder, vision_width = create_vit(vit,image_size, vit_grad_ckpt, vit_ckpt_layer)# 初始化分词器self.tokenizer = init_tokenizer() # 从JSON文件加载Bert配置med_config = BertConfig.from_json_file(med_config)# 设置编码器宽度med_config.encoder_width = vision_width# 创建文本编码器self.text_encoder = BertModel(config=med_config, add_pooling_layer=False) def forward(self, image, caption, mode):# 确保模式参数为 'image', 'text', 'multimodal' 之一assert mode in ['image', 'text', 'multimodal'], "mode parameter must be image, text, or multimodal"# 对输入的文本进行分词处理text = self.tokenizer(caption, return_tensors="pt").to(image.device) if mode=='image': # 返回图像特征image_embeds = self.visual_encoder(image) return image_embedselif mode=='text':# 返回文本特征text_output = self.text_encoder(text.input_ids, attention_mask = text.attention_mask, return_dict = True, mode = 'text') return text_output.last_hidden_stateelif mode=='multimodal':# 返回多模态特征image_embeds = self.visual_encoder(image) image_atts = torch.ones(image_embeds.size()[:-1],dtype=torch.long).to(image.device) text.input_ids[:,0] = self.tokenizer.enc_token_idoutput = self.text_encoder(text.input_ids,attention_mask = text.attention_mask,encoder_hidden_states = image_embeds,encoder_attention_mask = image_atts, return_dict = True,) return output.last_hidden_state
VisionTransformer 类:实现 image encoder
class VisionTransformer(nn.Module):""" Vision TransformerA PyTorch impl of : `An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale` -https://arxiv.org/abs/2010.11929"""def __init__(self, img_size=224, patch_size=16, in_chans=3, num_classes=1000, embed_dim=768, depth=12,num_heads=12, mlp_ratio=4., qkv_bias=True, qk_scale=None, representation_size=None,drop_rate=0., attn_drop_rate=0., drop_path_rate=0., norm_layer=None, use_grad_checkpointing=False, ckpt_layer=0):"""Args:img_size (int, tuple): 输入图像的大小patch_size (int, tuple): 图像块的大小in_chans (int): 输入通道数num_classes (int): 分类头的类别数embed_dim (int): 嵌入维度depth (int): Transformer的深度num_heads (int): 注意力头的数量mlp_ratio (int): MLP隐藏维度与嵌入维度的比例qkv_bias (bool): 是否启用qkv的偏置qk_scale (float): 覆盖默认的qk缩放比例representation_size (Optional[int]): 启用并设置表示层的大小drop_rate (float): 丢弃率attn_drop_rate (float): 注意力丢弃率drop_path_rate (float): 随机深度率norm_layer: (nn.Module): 归一化层"""super().__init__()self.num_features = self.embed_dim = embed_dim # 为了与其他模型保持一致norm_layer = norm_layer or partial(nn.LayerNorm, eps=1e-6)# 图像块嵌入层self.patch_embed = PatchEmbed(img_size=img_size, patch_size=patch_size, in_chans=in_chans, embed_dim=embed_dim)num_patches = self.patch_embed.num_patches# 分类标记self.cls_token = nn.Parameter(torch.zeros(1, 1, embed_dim))# 位置嵌入self.pos_embed = nn.Parameter(torch.zeros(1, num_patches + 1, embed_dim))# 位置丢弃层self.pos_drop = nn.Dropout(p=drop_rate)# 随机深度衰减规则dpr = [x.item() for x in torch.linspace(0, drop_path_rate, depth)] self.blocks = nn.ModuleList([Block(dim=embed_dim, num_heads=num_heads, mlp_ratio=mlp_ratio, qkv_bias=qkv_bias, qk_scale=qk_scale,drop=drop_rate, attn_drop=attn_drop_rate, drop_path=dpr[i], norm_layer=norm_layer,use_grad_checkpointing=(use_grad_checkpointing and i>=depth-ckpt_layer))for i in range(depth)])# 归一化层self.norm = norm_layer(embed_dim)# 初始化位置嵌入和分类标记trunc_normal_(self.pos_embed, std=.02)trunc_normal_(self.cls_token, std=.02)self.apply(self._init_weights)
BLIP_Decoder 类:实现image-grounded decoder
class BLIP_Decoder(nn.Module):def __init__(self, med_config = 'configs/med_config.json', image_size = 384,vit = 'base',vit_grad_ckpt = False,vit_ckpt_layer = 0,prompt = 'a picture of ',):"""Args:med_config (str): 混合编码器 - 解码器模型的配置文件路径image_size (int): 输入图像的大小vit (str): 视觉Transformer的模型大小prompt (str): 提示文本""" super().__init__()# 创建图像编码器self.visual_encoder, vision_width = create_vit(vit, image_size, vit_grad_ckpt, vit_ckpt_layer)# 初始化分词器self.tokenizer = init_tokenizer() # 从JSON文件加载Bert配置med_config = BertConfig.from_json_file(med_config)# 设置编码器宽度med_config.encoder_width = vision_width# 创建文本解码器self.text_decoder = BertLMHeadModel(config=med_config) self.prompt = promptself.prompt_length = len(self.tokenizer(self.prompt).input_ids) - 1def forward(self, image, caption):# 获取图像特征image_embeds = self.visual_encoder(image) image_atts = torch.ones(image_embeds.size()[:-1], dtype=torch.long).to(image.device)# 对输入的文本进行分词处理text = self.tokenizer(caption, padding='longest', truncation=True, max_length=40, return_tensors="pt").to(image.device) text.input_ids[:, 0] = self.tokenizer.bos_token_id# 生成解码器的目标标签decoder_targets = text.input_ids.masked_fill(text.input_ids == self.tokenizer.pad_token_id, -100) decoder_targets[:, :self.prompt_length] = -100# 进行解码操作decoder_output = self.text_decoder(text.input_ids, attention_mask = text.attention_mask, encoder_hidden_states = image_embeds,encoder_attention_mask = image_atts, labels = decoder_targets,return_dict = True, ) # 获取语言模型损失loss_lm = decoder_output.lossreturn loss_lmdef generate(self, image, sample=False, num_beams=3, max_length=30, min_length=10, top_p=0.9, repetition_penalty=1.0):# 获取图像特征image_embeds = self.visual_encoder(image)if not sample:# 复制图像特征以进行波束搜索image_embeds = image_embeds.repeat_interleave(num_beams, dim=0)image_atts = torch.ones(image_embeds.size()[:-1], dtype=torch.long).to(image.device)model_kwargs = {"encoder_hidden_states": image_embeds, "encoder_attention_mask": image_atts}# 生成提示文本的输入IDprompt = [self.prompt] * image.size(0)input_ids = self.tokenizer(prompt, return_tensors="pt").input_ids.to(image.device) input_ids[:, 0] = self.tokenizer.bos_token_idinput_ids = input_ids[:, :-1] if sample:# 核采样outputs = self.text_decoder.generate(input_ids=input_ids,max_length=max_length,min_length=min_length,do_sample=True,top_p=top_p,num_return_sequences=1,eos_token_id=self.tokenizer.sep_token_id,pad_token_id=self.tokenizer.pad_token_id, repetition_penalty=1.1, **model_kwargs)else:# 波束搜索outputs = self.text_decoder.generate(input_ids=input_ids,max_length=max_length,min_length=min_length,num_beams=num_beams,eos_token_id=self.tokenizer.sep_token_id,pad_token_id=self.tokenizer.pad_token_id, repetition_penalty=repetition_penalty,**model_kwargs) captions = [] for output in outputs:# 解码生成的文本caption = self.tokenizer.decode(output, skip_special_tokens=True) captions.append(caption[len(self.prompt):])return captions
实验结果
下表对比了不同数据集上的预训练模型的性能
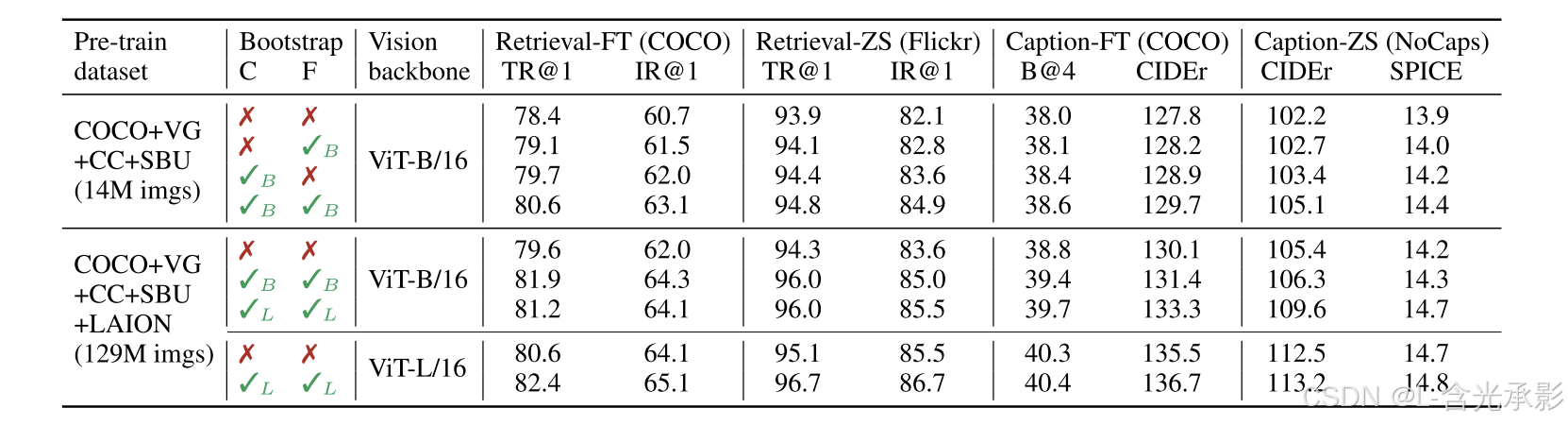
当模型一样时,使用更大的数据集,一般会带来更好的性能。当使用一样的数据集时,更大的模型效果更好。另外,论文提出的CapFilt对模型性能提升有帮助,特别是Captioner。
另外,第一次预训练模型和微调是为了得到Captioner和Filter,从而获得质量更高、更大的数据集,此次的模型与第二次预训练的模型没有任何关系,第二次训练得到的模型才是最终的模型。
总结
BLIP是一种创新的视觉-语言预训练框架,旨在统一跨模态理解(如图像检索)与生成(如图像描述)任务,同时解决网络数据噪声对模型性能的负面影响。其核心架构多模态混合编码器-解码器(MED)通过共享参数实现三种模式:单模态编码器(用于图像-文本对比学习ITC对齐全局特征)、基于图像的文本编码器(通过图像-文本匹配损失ITM学习细粒度对齐)和基于图像的文本解码器(通过语言建模损失LM生成描述),三者联合优化以支持多任务学习。BLIP提出Captioning & Filtering(CapFilt)策略:首先利用预训练的MED生成合成描述(Captioner模块),再通过过滤模块(Filter)剔除原始网络文本和合成文本中的噪声样本,最终结合高质量数据重新训练模型,显著提升跨模态对齐能力。BLIP的优势在于通过统一架构和高效数据增强实现了多任务SOTA性能,且零样本迁移能力强;缺点可能在于大规模数据清洗的计算成本较高,且对复杂时空建模(如视频任务)尚未深入。未来方向可探索多轮数据增强、多模态生成多样性优化,以及结合时序建模扩展至视频-语言领域。
相关文章:

【第三十三周】BLIP论文阅读笔记
BLIP 摘要Abstract文章信息引言方法MED预训练CapFilt 关键代码实验结果总结 摘要 本博客介绍了BLIP(Bootstrapping Language-Image Pre-training),这是一种创新的视觉-语言预训练框架,旨在通过统一模型架构和高效数据增强策略&am…...

如何配置osg编译使支持png图标加载显示
步骤如下: 1.下载osg代码 git clone https://github.com/openscenegraph/OpenSceneGraph.git cd OpenSceneGraph 2.开始配置编译 mkdir build cd build cmake … -DBUILD_OSG_PLUGINS_BY_DEFAULT1 -DBUILD_OSG_PLUGIN_PNG1 3.编译与安装 make make install 4.在安装…...
)
234. 回文链表(java)
个人理解: 1.先找到链表的中间节点,将链表分为前后两部分 方法:设置快慢指针,初始都指向头节点,慢指针每次走一步,快指针每次走两步。循环结束条件为:快指针后两个元素不为空,此时慢…...

面试:结构体默认是对齐的嘛?如何禁止对齐?
是的。 结构体默认是对齐的。结构体对齐是为了优化内存访问速度和减少CPU访问内存时的延迟。结构体对齐的规则如下: 某数据类型的变量存放的地址需要按有效对齐字节剩下的字节数可以被该数据类型所占字节数整除,char可以放在任意位置,int存…...

Leetcode837.新21点
目录 题目算法标签: 数学, 概率, 动态规划思路代码 题目 837. 新 21 点 算法标签: 数学, 概率, 动态规划 思路 定义状态表示为 f [ i ] f[i] f[i], 表示分数达到 i i i的时候的概率, 分析状态计算, 假设当前的分数是 i i i, 抽取到的牌得分数是 x x x, 那么当前状态就会转移…...

【C到Java的深度跃迁:从指针到对象,从过程到生态】第四模块·Java特性专精 —— 第十五章 泛型:类型系统的元编程革命
一、从C的void*到Java类型安全 1.1 C泛型的原始实现 C语言通过void*和宏模拟泛型,存在严重安全隐患: 典型泛型栈实现: #define DECLARE_STACK(type) \ struct stack_##type { \ type* data; \ int top; \ int capacity; \ }; #de…...

纯净无噪,智见未来——MAGI-1本地部署教程,自回归重塑数据本质
一、MAGI-1简介 MAGI-1 是一种逐块生成视频的自回归去噪模型,而非一次性生成完整视频。每个视频块(含 24 帧)通过整体去噪处理,当前块达到特定去噪阈值后,立即启动下一块的生成。这种流水线设计支持 最多 4 个块的并发…...

BG开发者日志0427:故事的起点
1、4月26日晚上,BG项目的gameplay部分开发完毕,后续是细节以及试玩版优化。 开发重心转移到story部分,目前刚开始, 确切地说以前是长期搁置状态,因为过去的四个月中gameplay部分优先开发。 --- 2、BG这个项目的起点…...

直播预告|TinyVue 组件库高级用法:定制你的企业级UI体系
TinyVue 是一个跨端跨框架的企业级 UI 组件库,基于 renderless 无渲染组件设计架构,实现了一套代码同时支持 Vue2 和 Vue3,支持 PC 和移动端,包含 100 多个功能丰富的精美组件,可帮助开发者高效开发 Web 应用。 4 月 …...

基于Jamba模型的天气预测实战
深入探索Mamba模型架构与应用 - 商品搜索 - 京东 DeepSeek大模型高性能核心技术与多模态融合开发 - 商品搜索 - 京东 由于大气运动极为复杂,影响天气的因素较多,而人们认识大气本身运动的能力极为有限,因此以前天气预报水平较低 。预报员在预…...

Customizing Materials Management with SAP ERP Operations
Customizing Materials Management with SAP ERP Operations...

使用 NServiceBus 在 .NET 中构建分布式系统
在 .NET 中,NServiceBus 依然是构建可靠、可扩展、异步消息驱动架构的强大工具。本文将为你讲解如何在 .NET 环境下集成 NServiceBus,帮助你理解其核心概念及配置方法,并快速上手构建基于消息的系统。 一、NServiceBus 简介 NServiceBus …...

【Linux网络与网络编程】13.五种 IO 模型
前言 在前面的学习中,有一个问题一直没有展开来说,即 IO 问题。 IO 到底有多少种方式呢?什么是高效的 IO 呢? IO 本质上就是 INPUT 和 OUTPUT 。在网络中 INPUT 就是从网卡中获取数据,而 OUTPUT 就是向网卡中发送数据…...

Java后端开发day37--源码解析:TreeMap可变参数--集合工具类:Collections
(以下内容全部来自上述课程) 1. TreeMap 1.1 须知 1.1.1 Entry 节点初始为黑色:提高代码阅读性 1.1.2 TreeMap中的成员变量 comparator:比较规则root:红黑树根节点的地址值size:集合的长度和红黑树…...

海关 瑞数 后缀分析 rs
声明 本文章中所有内容仅供学习交流使用,不用于其他任何目的,抓包内容、敏感网址、数据接口等均已做脱敏处理,严禁用于商业用途和非法用途,否则由此产生的一切后果均与作者无关! 逆向过程 部分python代码 cp execj…...
)
【合新通信】---Mini单路光模块(Mini SFF/USOT)
产品特性 l 高可靠、全金属外壳、抗振动设计 l 紧凑的结构设计, 超小模块尺寸 l 可插拔标准LC单模光纤连接器接口,方便动态和灵活的配置数据连接 l 每通道工作速率可达1.25Gbps,速率可向下兼容 l 单路发射光纤通道,内置1310nm波长光发射…...
:LeetCode 49. 字母异位词分组(Group Anagrams)详解)
Java详解LeetCode 热题 100(02):LeetCode 49. 字母异位词分组(Group Anagrams)详解
文章目录 1. 题目描述2. 理解题目3. 解法一:排序法3.1 思路3.2 Java代码实现3.3 代码详解3.4 复杂度分析3.5 适用场景4. 解法二:计数法4.1 思路4.2 Java代码实现4.3 代码详解4.4 复杂度分析4.5 适用场景5. 解法三:字符串哈希法5.1 思路5.2 Java代码实现5.3 代码详解5.4 复杂…...
)
【每日随笔】文化属性 ① ( 天机 | 强势文化与弱势文化 | 文化属性的形成与改变 | 强势文化 具备的特点 )
文章目录 一、文化属性1、天机2、文化属性的强势文化与弱势文化强势文化弱势文化 二、文化属性的形成与改变1、文化属性形成2、文化属性改变3、文化知识的阶层 三、强势文化 具备的 特点 一、文化属性 1、天机 如果想要 了解这个世界的 底层架构 , 就需要掌握 洞察事物本质 的能…...

Java + Seleium4.X + TestNG自动化技术
系列文章目录 文章目录 系列文章目录前言一、 Java版Selenium自动化测试框架介绍和原理1.1 什么是Seleium1.2 特点1.3 注意点 二、安装SeleiumChrome环境 创建Maven项目2.1 安装Seleium Chrome环境2.2 Maven环境 三、Selenium4.X UI元素定位实战3.1 ID选择器3.2 Name选择器3.…...

Spark SQL核心概念与编程实战:从DataFrame到DataSet的结构化数据处理
一、Spark-SQL是什么 Spark SQL 是 Spark 用于结构化数据(structured data)处理的 Spark 模块。 二、Hive and SparkSQL SparkSQL 的前身是 Shark,Shark是给熟悉 RDBMS 但又不理解 MapReduce 的技术人员提供的快速上手的工具。 Hive 是早期唯一运行在 Hadoop 上的 S…...

electron-vite 应用打包自定义图标不显示问题
// 修改electron-builder.yml ... win:executableName: xxx //可执行文件名称icon: build/icon.ico //你的图标路径 ...打包后,自定义图标不显示原因: 1 cannot execute causeexit status 2,安装包无法生成 用管理员身份运行,win11右击开始…...

AI中Token的理解与使用总结
AI中Token的理解与使用总结 什么是Token 在AI领域,特别是自然语言处理(NLP)中,Token是指将文本分割成的最小处理单元。Tokenization(分词)是将原始文本分解为Token的过程。 Token的几种形式 单词级Token:以单词为基本单位 示例:“Hello world” → [“Hello”, “world”…...
)
C++/SDL 进阶游戏开发 —— 双人塔防(代号:村庄保卫战 14)
🎁个人主页:工藤新一 🔍系列专栏:C面向对象(类和对象篇) 🌟心中的天空之城,终会照亮我前方的路 🎉欢迎大家点赞👍评论📝收藏⭐文章 文章目录 二…...

全栈量子跃迁:当Shor算法破解RSA时,我们如何用晶格密码重构数字世界的信任基岩?
一、量子威胁的降维打击 1. Shor算法的毁灭性力量 # Shor算法量子电路简化示例(Qiskit实现) from qiskit import QuantumCircuit from qiskit.circuit.library import QFTdef shor_circuit(n: int, a: int) -> QuantumCircuit:qc QuantumCircuit(2…...

python实战项目65:drissionpage采集boss直聘数据
python实战项目65:drissionpage采集boss直聘数据 一、需求简介二、流程分析三、完整代码一、需求简介 boss直聘网站近期改版,改版之后代码需要做相应的升级维护。drissionpage采集网页数据是一种不错的方式,笔者认为比Selenium好用,使用方法大家可以自行查阅资料。boss直聘…...

常用的性能提升手段--提纲
上一篇文章里,介绍了提升性能的一种优化手段:池化。 这篇文章来归纳整理一下其他的常见的提升性能的手段 1. 缓存 (Caching) 缓存可以说是计算机领域的万金油了,它无处不在。 举个最简单的例子,CPU -> L1,L2,L3 Cache -> 内存 。 CPU的处理速度要比内存快几个数量…...

天梯——现代战争
第一次做的时候,直接暴力,显然最后超时。 暴力代码如下: #include<bits/stdc.h> using namespace std; const int N10005; bool mark1[N]{0},mark2[N]{0}; int p[N][N]; int main(){int n,m,k,a,b;cin>>n>>m>>k;fo…...
 D. Baggage Claim(建图))
Codeforces Round 1021 (Div. 2) D. Baggage Claim(建图)
每周五篇博客:(4/5) https://codeforces.com/contest/2098/problem/D 题意 每个机场都有一个行李索赔区,巴尔贝索沃机场也不例外。在某个时候,Sheremetyevo的一位管理员提出了一个不寻常的想法:将行李索…...

常用第三方库:shared_preferences数据持久化
常用第三方库:shared_preferences数据持久化 前言 shared_preferences是Flutter中最常用的轻量级数据持久化解决方案,它提供了一个简单的key-value存储机制,适合存储用户配置、应用设置等小型数据。本文将从实战角度深入讲解shared_prefere…...

项目驱动 CAN-bus现场总线基础教程》随笔
阅读:《项目驱动 CAN-bus现场总线基础教程》 仲裁段的实现 有感而发 感觉出人意外之处 感觉出人意外之处 最近在阅读入门的CAN相关书籍时,在介绍仲裁段是如何实现各节点之间,通讯仲裁功能的章节中,有如下一段描述: …...

WPF之XAML基础
文章目录 XAML基础:深入理解WPF和UWP应用开发的核心语言1. XAML简介XAML与XML的关系 2. XAML语法基础元素语法属性语法集合语法附加属性 3. XAML命名空间命名空间映射关系 4. XAML标记扩展静态资源引用数据绑定相对资源引用常见标记扩展对比 5. XAML与代码的关系XAM…...

测试基础笔记第十四天
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 一、字符串1.字符串2.字符串切片3.查找find()4.去除两端空白字符 strip5.字符串转换大小写 lower、upper5.拆分 split()6.字符串的其他常见方…...
:LeetCode 1. 两数之和(Two Sum)详解)
Java详解LeetCode 热题 100(01):LeetCode 1. 两数之和(Two Sum)详解
文章目录 1. 题目描述2. 理解题目3. 解法一:暴力枚举法3.1 思路3.2 Java代码实现3.3 代码详解3.4 复杂度分析3.5 适用场景 4. 解法二:哈希表法4.1 思路4.2 Java代码实现4.3 代码详解4.4 复杂度分析4.5 适用场景 5. 解法三:两遍哈希表法5.1 思…...

机器学习之三:归纳学习
正如人们有各种各样的学习方法一样,机器学习也有多种学习方法。若按学习时所用的方法进行分类,则机器学习可分为机械式学习、指导式学习、示例学习、类比学习、解释学习等。这是温斯顿在1977年提出的一种分类方法。 有关机器学习的基本概念,…...

AI声像融合守护幼儿安全——打骂/异常声音报警系统的智慧防护
幼儿园是孩子们快乐成长的摇篮,但打骂、哭闹或尖叫等异常事件可能打破这份宁静,威胁幼儿的身心安全。打骂/异常声音报警系统,依托尖端的AI声像融合技术,结合语音识别、情绪分析与视频行为检测,为幼儿园筑起一道智能安全…...

2024ICPC网络赛第二场题解
文章目录 F. Tourist(签到)I. Strange Binary(思维)J. Stacking of Goods(思维)A. Gambling on Choosing Regionals(签到)G. Game(数学)L. 502 Bad Gateway(数学)E. Escape(BFS)C. Prefix of Suffixes(kmp结论)K. match(01trie分治多项式乘法组合数) 题目链接 F. Tourist(签到…...

风控策略引擎架构设计全解析:构建智能实时决策系统
摘要 本文深入探讨现代风控策略引擎的核心架构设计,结合金融反欺诈、电商交易风控等典型场景,详细解析实时决策、规则引擎、特征计算等关键技术模块的实现方案。通过分层架构设计、分布式计算优化、策略动态编排等创新方法,展示如何构建支撑每秒万级决策的高可用风控系统。…...

TensorFlow 安装全攻略
选择 TensorFlow 的原因: TensorFlow 是一个端到端平台,它提供多个抽象级别,因此您可以根据自己的需求选择合适的级别。您可以使用高阶 Keras API 构建和训练模型,该 API 让您能够轻松地开始使用 TensorFlow 和机器学习。如果您需…...

Dijkstra 算法代码步骤[leetcode.743网络延迟时间]
有 n 个网络节点,标记为 1 到 n。 给你一个列表 times,表示信号经过 有向 边的传递时间。 times[i] (ui, vi, wi),其中 ui 是源节点,vi 是目标节点, wi 是一个信号从源节点传递到目标节点的时间。 现在,…...

Ubuntu22.04/24.04 P104-100 安装驱动和 CUDA Toolkit
硬件环境 使用一块技嘉 B85m-DS3H 安装 P104-100, CPU是带集成显卡的i5-4690. 先在BIOS中设置好显示设备优先使用集成显卡(IGX). 然后安装P104-100开机. 登入Ubuntu 后查看硬件信息, 检查P104-100是否已经被检测到 # PCI设备 lspci -v | grep -i nvidia lspci | grep NVIDIA …...

Golang 学习指南
目录 变量与常量数据类型与控制结构常用数据结构函数与错误处理指针与并发Gin 框架与 go mod小结与参考资料 1. 变量与常量 变量(var) 用于定义可变的值。可以指定类型,也可以自动推断类型。示例:var name string "Golang…...
)
Ubuntu 磁盘空间占用清理(宝塔)
目录 前言1. 基本知识2. 实战 前言 🤟 找工作,来万码优才:👉 #小程序://万码优才/r6rqmzDaXpYkJZF 爬虫神器,无代码爬取,就来:bright.cn 本身自搭建了一个宝塔,突然一下子多了好些空…...

AntBio: 2025 AACR Meeting - Charting New Oncology Frontiers Together
AntBio cordially invites you to attend the 2025 AACR Annual Meeting and jointly chart a new course in oncology research! The global benchmark for cancer research and therapeutics—the 2025 American Association for Cancer Research (AACR) Annual Meeting—wi…...

数模学习:二,MATLAB的基本语法使用
注释代码: (1)在每行语句后面加上分号,则不显示该行代码的运算结果。 在每行代码前加%,则该行代码会被注释掉 (2) 多行注释: 选中要注释的多行语句,按快捷键Ctrl R (3) 取消注释: 选中要注释的多行语句…...

【Webpack \ Vite】多环境配置
环境变量脚本命令 如何通过不同的环境变量或不同的配置文件进行项目区分,动态加载配置。通常,使用环境变量是最简单且灵活的方法,因为它不需要改变构建命令或创建多个配置文件 环境变量 在根目录下创建 .env.xxx 文件,为不同的环…...

已知漏洞打补丁
. 打补丁 根据MS漏洞编号或者CVE漏洞编号都可以找到对应的HotfixID。 1.根据MS漏洞编号可以使用:https://learn.microsoft.com/zh-cn/security-updates/securitybulletins/securitybulletins 即可找到KB编号。 2.根据CVE漏洞编号可以使用:https://cve…...
、火星坐标系(GCJ02)、百度地图(BD09)坐标系转换Java代码)
WGS84(GPS)、火星坐标系(GCJ02)、百度地图(BD09)坐标系转换Java代码
在做基于百度地图、高德地图等电子地图做为地图服务的二次开发时,通常需要将具有WGS84等坐标的矢量数据(如行政区划、地名、河流、道路等GIS地理空间数据)添加到地图上面。 然而,在线地图大多使用的是火星坐标系,需要…...

R语言操作n
1.加载安装vegan包 2.查看data(varechem)和data(varespec),探索其维度和结构 3.基于varespec构建物种互作网络,输出gml文件并采用gephi可视化为图片,输出pdf,阈值为r>0.6,p<0.05 4.基于varespec和varechem构建物种-环境互作…...

ChatGPT与DeepSeek在科研论文撰写中的整体科研流程与案例解析
随着人工智能技术的快速发展,大语言模型如ChatGPT和DeepSeek在科研领域展现出强大的潜力,尤其是在论文撰写方面。本文旨在介绍如何利用ChatGPT和DeepSeek提升科研论文撰写的效率与质量,并提供一个具体案例,详细阐述其技术流程及公…...

VScode在 Markdown 编辑器中预览
1. 使用在线 Mermaid 编辑器 步骤: 打开 Mermaid Live Editor。将你 .md 文件中的 Mermaid 代码(从 mermaid 到结束的代码块)复制粘贴到编辑器的左侧输入框。编辑器会自动在右侧生成可视化的 ER 图。你可以点击右上角的下载按钮,…...