【深度学习】#9 现代循环神经网络
主要参考学习资料:
《动手学深度学习》阿斯顿·张 等 著
【动手学深度学习 PyTorch版】哔哩哔哩@跟李牧学AI
概述
- 门控循环单元和长短期记忆网络利用门控机制实现对序列输入的选择性记忆。
- 深度循环神经网络堆叠多个循环神经网络层以实现更强的表达能力和特征提取能力。
- 双向循环神经网络同时捕捉过去和未来两个方向的依赖关系。
- 序列到序列类任务的输入和输出均为可变长度序列,主要使用编码器-解码器架构。
- 束搜索是一种在解码器选择输出序列时兼顾精确度和计算量的搜索方法。
目录
- 门控循环单元(GRU)
- 重置门和更新门
- 候选隐状态
- 隐状态
- 长短期记忆网络(LSTM)
- 遗忘门
- 输入门和候选记忆
- 输出门
- 深度循环神经网络(DRNN)
- 双向循环神经网络(BiRNN)
- 序列到序列(Seq2Seq)
- 编码器-解码器架构
- 编码器
- 解码器
- 预测序列的评估
- 束搜索
- 贪心搜索
- 穷举搜索
- 束搜索
门控循环单元(GRU)
在序列数据中,通常不是所有的信息都同等重要,我们需要提炼出关键信息,过滤掉无关的内容,门控机制则受此启发而来。当判断出重要信息时,信息从开启的门流出,当信息可以被遗忘时,则被关闭的门隔断。最早的相关方法为长短期记忆网络(LSTM),而门控循环单元(GRU)作为其简化变体,先行学习更易于理解。
重置门和更新门
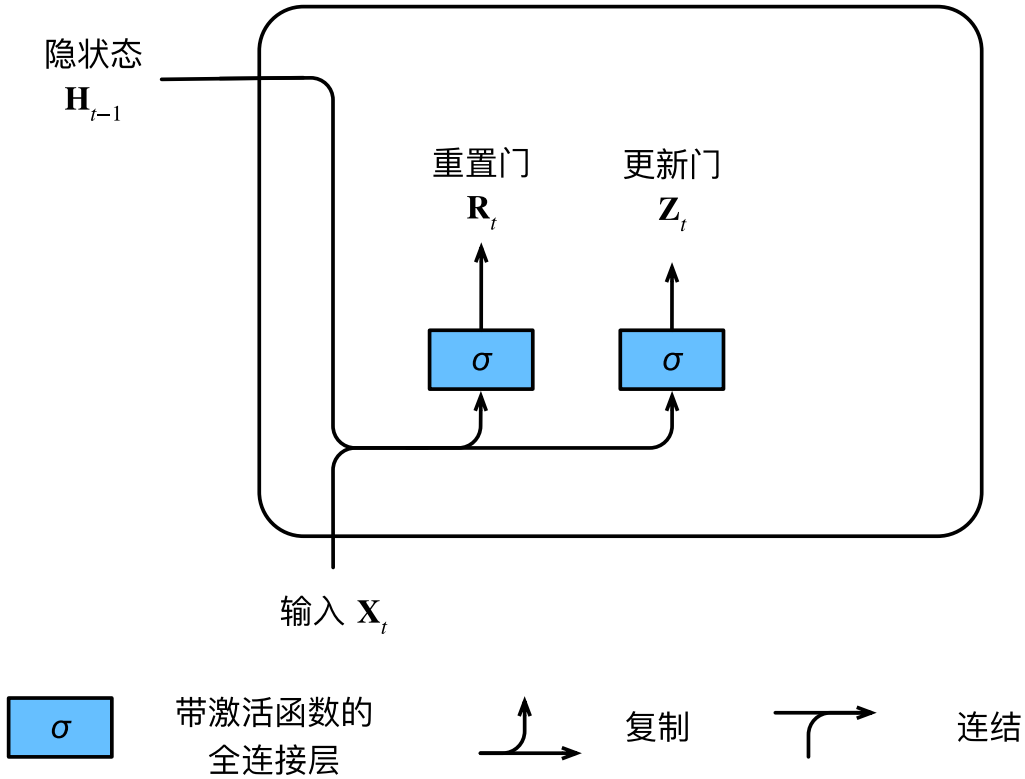
GRU包含重置门和更新门两个门控,它们都以当前时间步的输入和前一个时间步的隐状态作为输入,并通过sigmoid激活函数将各自的输出压缩到区间 ( 0 , 1 ) (0,1) (0,1)中,而输出将作为比例系数应用到后续计算中。换言之,重置门和更新门先根据输入给出筛选信息的方法,而筛选的实际操作是在之后进行的。
对于在时间步 t t t的小批量输入 X t ∈ R n × d \mathbf{X}_t \in \mathbb{R}^{n \times d} Xt∈Rn×d( n n n个样本,每个样本 d d d个输入),前一个时间步的隐状态 H t − 1 ∈ R n × h \mathbf H_{t-1}\in\mathbb R^{n\times h} Ht−1∈Rn×h( h h h个隐藏单元),重置门 R t ∈ R n × h \mathbf R_t\in\mathbb R^{n\times h} Rt∈Rn×h和更新门 Z t ∈ R n × h \mathbf Z_t\in\mathbb R^{n\times h} Zt∈Rn×h的计算如下:
R t = σ ( X t W x r + H t − 1 W h r + b r ) \mathbf{R}_t=\sigma(\mathbf{X}_t\mathbf{W}_{xr}+\mathbf{H}_{t-1}\mathbf{W}_{hr}+\mathbf{b}_r) Rt=σ(XtWxr+Ht−1Whr+br)
Z t = σ ( X t W x z + H t − 1 W h z + b z ) \mathbf{Z}_t=\sigma(\mathbf{X}_t\mathbf{W}_{xz}+\mathbf{H}_{t-1}\mathbf{W}_{hz}+\mathbf{b}_z) Zt=σ(XtWxz+Ht−1Whz+bz)
其中 W x r , W x z ∈ R d × h \mathbf{W}_{xr}, \mathbf{W}_{xz} \in \mathbb{R}^{d \times h} Wxr,Wxz∈Rd×h和 W h r , W h z ∈ R h × h \mathbf{W}_{hr}, \mathbf{W}_{hz} \in \mathbb{R}^{h \times h} Whr,Whz∈Rh×h为权重参数, b r , b z ∈ R 1 × h \mathbf{b}_r, \mathbf{b}_z \in \mathbb{R}^{1 \times h} br,bz∈R1×h为偏置参数。
候选隐状态
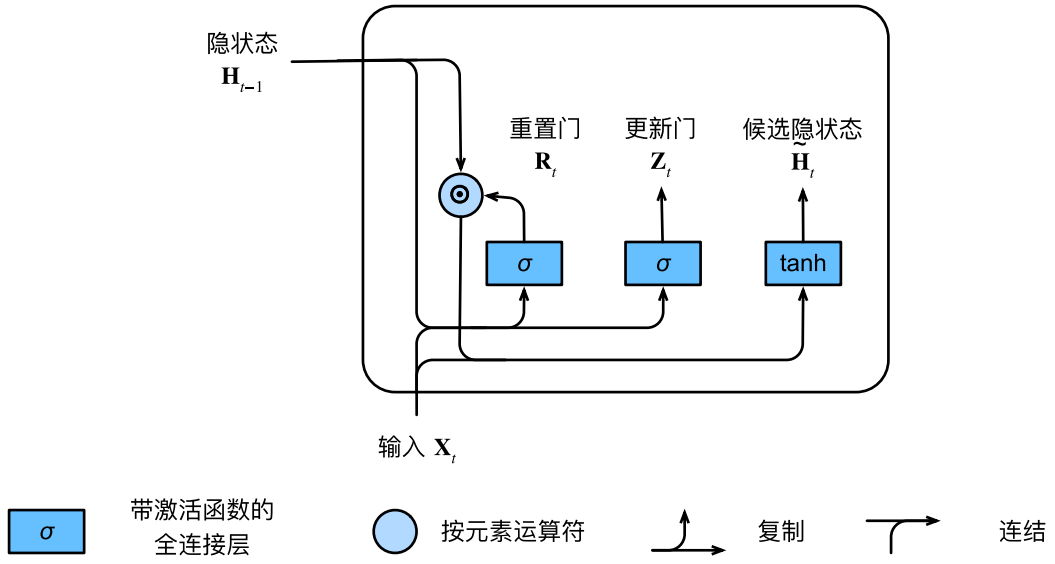
接下来我们将重置门 R t \mathbf R_t Rt应用到常规RNN的隐状态更新公式中,得到的隐状态被称为候选隐状态:
H ~ t = tanh ( X t W x h + ( R t ⊙ H t − 1 ) W h h + b h ) \widetilde{\mathbf{H}}_t = \tanh(\mathbf{X}_t \mathbf{W}_{xh} + \left(\mathbf{R}_t \odot \mathbf{H}_{t-1}\right) \mathbf{W}_{hh} + \mathbf{b}_h) H t=tanh(XtWxh+(Rt⊙Ht−1)Whh+bh)
其中 W x h ∈ R d × h \mathbf{W}_{xh} \in \mathbb{R}^{d \times h} Wxh∈Rd×h和 W h h ∈ R h × h \mathbf{W}_{hh} \in \mathbb{R}^{h \times h} Whh∈Rh×h是权重参数, b h ∈ R 1 × h \mathbf{b}_h \in \mathbb{R}^{1 \times h} bh∈R1×h是偏置参数(关于参数及其维度均可由字母及输入输出维度关系推得,此后不再赘述),符号 ⊙ \odot ⊙是按元素乘法。激活函数 tanh \tanh tanh将输出压缩到区间 ( − 1 , 1 ) (-1,1) (−1,1)中,既能避免数值爆炸,又能通过正负号增强信息表达。
R t \mathbf R_t Rt中的每个元素都在区间 ( 0 , 1 ) (0,1) (0,1)中,当其与 H t − 1 \mathbf{H}_{t-1} Ht−1中对应的元素相乘时,可以决定保留该元素的比例。它筛选过去的经验来作为理解新信息的参考。
隐状态

最后我们使用更新门 Z t \mathbf Z_t Zt将旧的隐状态 H t − 1 \mathbf H_{t-1} Ht−1(对过去信息的记忆)和候选隐状态 H ~ t \widetilde{\mathbf{H}}_t H t(对新信息的理解)加权求和,得到最终的隐状态(同时也是输出):
H t = Z t ⊙ H t − 1 + ( 1 − Z t ) ⊙ H ~ t \mathbf{H}_t = \mathbf{Z}_t \odot \mathbf{H}_{t-1} + (1 - \mathbf{Z}_t) \odot \widetilde{\mathbf{H}}_t Ht=Zt⊙Ht−1+(1−Zt)⊙H t
当 Z t \mathbf Z_t Zt接近 1 1 1时,模型倾向于忽略新的信息,保留旧的记忆,从而跳过依赖链中的当前时间步;当 Z t \mathbf Z_t Zt接近 0 0 0时,模型倾向于让新的信息覆盖旧的记忆。该方法与ResNet的残差连接有异曲同工之处。
总而言之,重置门有助于捕获序列中的短期依赖关系,更新门有助于捕获序列中的长期依赖关系。这使得模型能更灵活地处理依赖关系的同时,还通过对信息的筛选降低了梯度传播路径的复杂性,避免其被不必要的分支稀释,缓解了梯度消失和梯度爆炸的问题。
长短期记忆网络(LSTM)
长短期记忆网络(LSTM)比GRU出现得更早,但设计更为复杂。
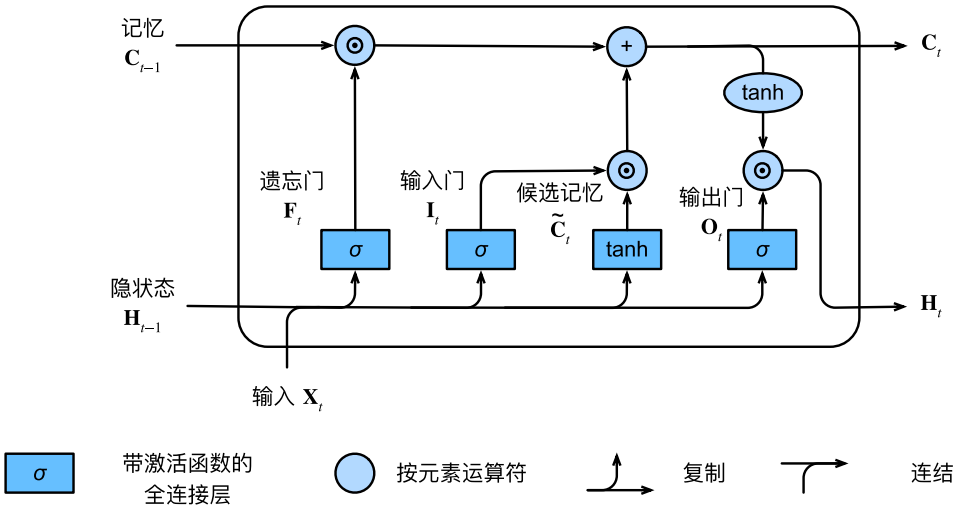
LSTM在隐状态之外引入了另一条在神经元之间传递的信息流,称为记忆元。可以将隐状态(同时也是输出)理解为短期记忆或对当前预测有用的信息,而记忆元则代表长期记忆。除此之外,LSTM包含遗忘门、输入门和输出门三个门控和候选记忆元计算,其中遗忘门、输入门和候选记忆元负责从短期记忆提炼信息以更新长期记忆,而输出门负责捕获长期依赖应用于当前预测。
遗忘门
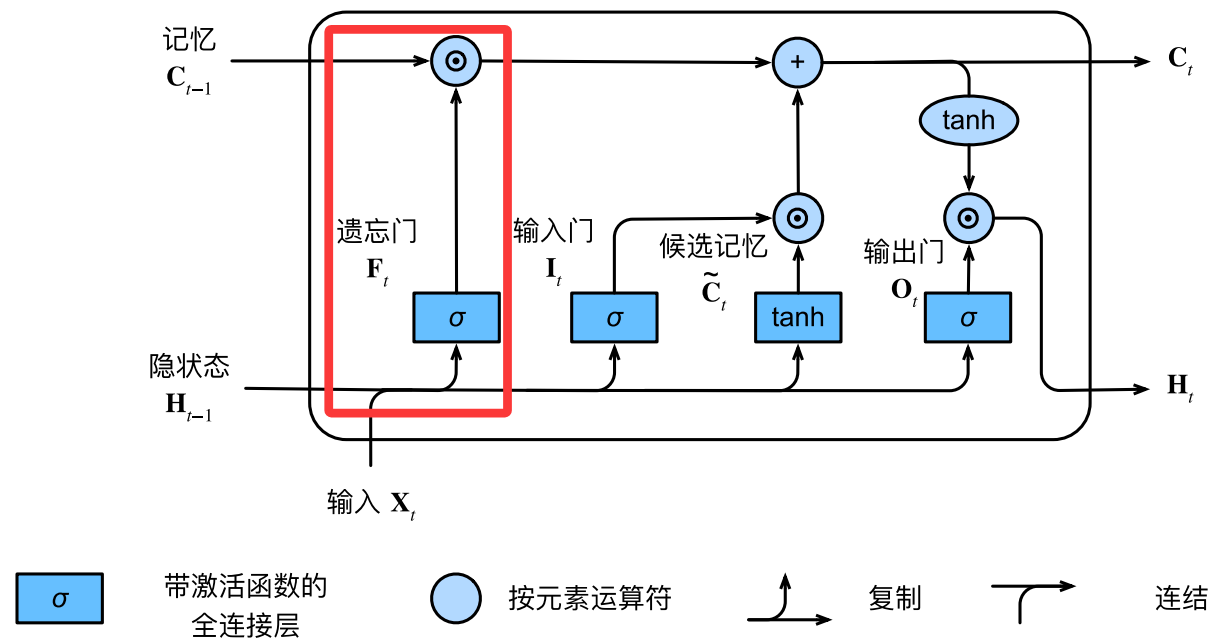
对于在时间步 t t t的小批量输入 X t ∈ R n × d \mathbf{X}_t \in \mathbb{R}^{n \times d} Xt∈Rn×d( n n n个样本,每个样本 d d d个输入),前一个时间步的隐状态 H t − 1 ∈ R n × h \mathbf H_{t-1}\in\mathbb R^{n\times h} Ht−1∈Rn×h( h h h个隐藏单元),遗忘门 F t ∈ R n × h \mathbf{F}_t \in \mathbb{R}^{n \times h} Ft∈Rn×h的计算如下:
F t = σ ( X t W x f + H t − 1 W h f + b f ) \mathbf{F}_t = \sigma(\mathbf{X}_t \mathbf{W}_{xf} + \mathbf{H}_{t-1} \mathbf{W}_{hf} + \mathbf{b}_f) Ft=σ(XtWxf+Ht−1Whf+bf)
和GRU同样地,sigmoid激活函数将其压缩到区间 ( 0 , 1 ) (0,1) (0,1)得到一个比例系数,它通过乘法作用于长期记忆,决定应该遗忘哪些信息( C t 0 \mathbf{C}_{t0} Ct0为博主自行用于表示记忆元计算的中间状态的变量名):
C t 0 = F t ⊙ C t − 1 \mathbf{C}_{t0} = \mathbf{F}_t \odot \mathbf{C}_{t-1} Ct0=Ft⊙Ct−1
输入门和候选记忆
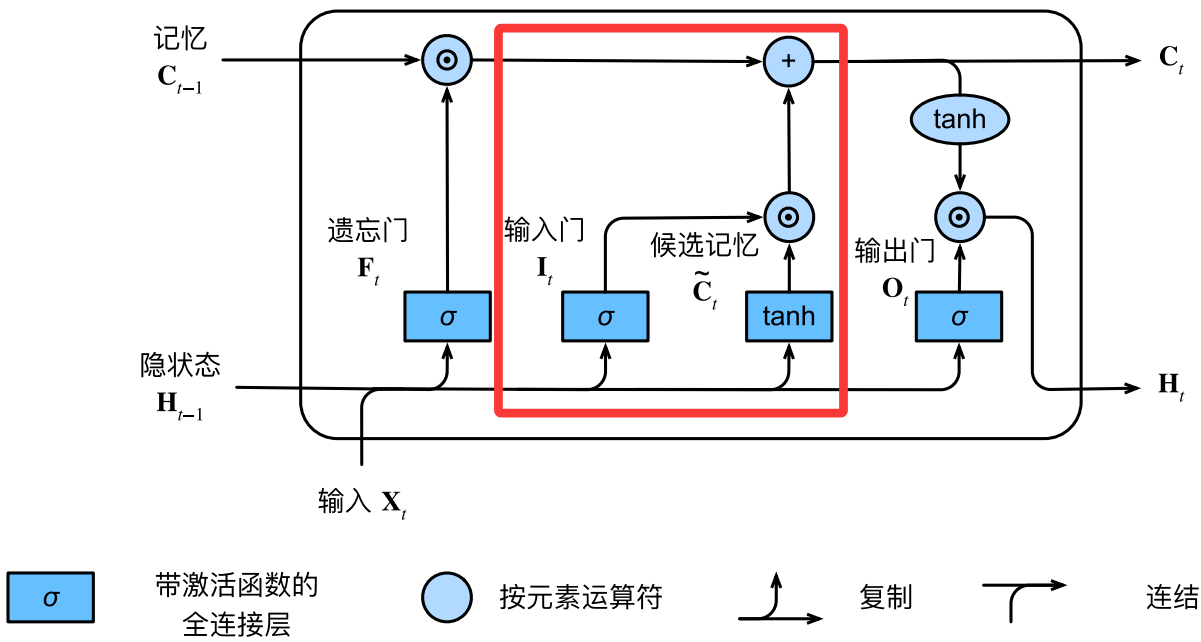
候选记忆元 C ~ t ∈ R n × h \widetilde{\mathbf{C}}_t \in \mathbb{R}^{n \times h} C t∈Rn×h和GRU的候选隐状态类似,表征一种在短期记忆基础上对新信息的理解,其计算如下:
C ~ t = tanh ( X t W x c + H t − 1 W h c + b c ) \widetilde{\mathbf{C}}_t = \text{tanh}(\mathbf{X}_t \mathbf{W}_{xc} + \mathbf{H}_{t-1} \mathbf{W}_{hc} + \mathbf{b}_c) C t=tanh(XtWxc+Ht−1Whc+bc)
输入门 I t ∈ R n × h \mathbf{I}_t \in \mathbb{R}^{n \times h} It∈Rn×h则作为候选记忆元的比例系数,决定了对新信息的哪些理解可以进入长期记忆,其计算如下:
I t = σ ( X t W x i + H t − 1 W h i + b i ) \mathbf{I}_t = \sigma(\mathbf{X}_t \mathbf{W}_{xi} + \mathbf{H}_{t-1} \mathbf{W}_{hi} + \mathbf{b}_i) It=σ(XtWxi+Ht−1Whi+bi)
将输入门作用于候选记忆元,得到的信息流入长期记忆,我们有这一阶段记忆元的更新公式如下:
C t = C t 0 + I t ⊙ C ~ t = F t ⊙ C t − 1 + I t ⊙ C ~ t \mathbf{C}_t = \mathbf{C}_{t0} + \mathbf{I}_t \odot \tilde{\mathbf{C}}_t= \mathbf{F}_t \odot \mathbf{C}_{t-1} + \mathbf{I}_t \odot \tilde{\mathbf{C}}_t Ct=Ct0+It⊙C~t=Ft⊙Ct−1+It⊙C~t
输出门
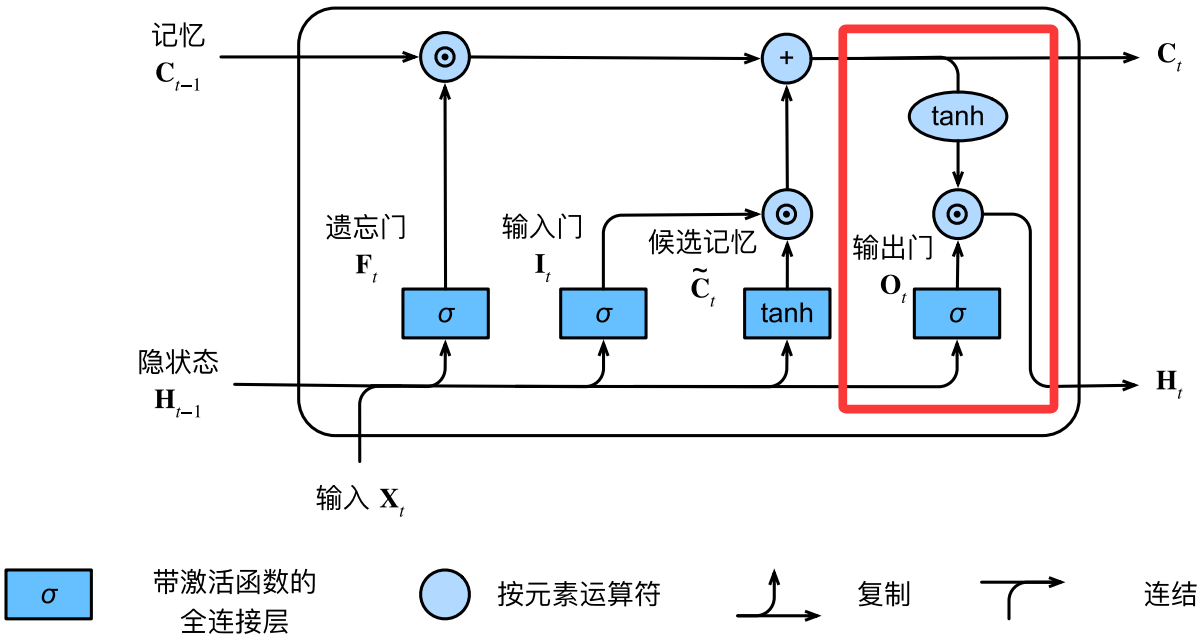
输出门用于捕获长期记忆中对当前预测较为关键的依赖信息并更新短期记忆,其计算如下:
O t = σ ( X t W x o + H t − 1 W h o + b o ) \mathbf{O}_t = \sigma(\mathbf{X}_t \mathbf{W}_{xo} + \mathbf{H}_{t-1} \mathbf{W}_{ho} + \mathbf{b}_o) Ot=σ(XtWxo+Ht−1Who+bo)
记忆元在被输出门筛选得到下一个隐状态之前,还会经过tanh激活函数以防数值爆炸:
H t = O t ⊙ tanh ( C t ) \mathbf{H}_t = \mathbf{O}_t \odot \tanh(\mathbf{C}_t) Ht=Ot⊙tanh(Ct)
现在,我们将LSTM的计算过程总结如下:
F t = σ ( X t W x f + H t − 1 W h f + b f ) \mathbf{F}_t = \sigma(\mathbf{X}_t \mathbf{W}_{xf} + \mathbf{H}_{t-1} \mathbf{W}_{hf} + \mathbf{b}_f) Ft=σ(XtWxf+Ht−1Whf+bf)
I t = σ ( X t W x i + H t − 1 W h i + b i ) \mathbf{I}_t = \sigma(\mathbf{X}_t \mathbf{W}_{xi} + \mathbf{H}_{t-1} \mathbf{W}_{hi} + \mathbf{b}_i) It=σ(XtWxi+Ht−1Whi+bi)
O t = σ ( X t W x o + H t − 1 W h o + b o ) \mathbf{O}_t = \sigma(\mathbf{X}_t \mathbf{W}_{xo} + \mathbf{H}_{t-1} \mathbf{W}_{ho} + \mathbf{b}_o) Ot=σ(XtWxo+Ht−1Who+bo)
C ~ t = tanh ( X t W x c + H t − 1 W h c + b c ) \widetilde{\mathbf{C}}_t = \text{tanh}(\mathbf{X}_t \mathbf{W}_{xc} + \mathbf{H}_{t-1} \mathbf{W}_{hc} + \mathbf{b}_c) C t=tanh(XtWxc+Ht−1Whc+bc)
C t = F t ⊙ C t − 1 + I t ⊙ C ~ t \mathbf{C}_t = \mathbf{F}_t \odot \mathbf{C}_{t-1} + \mathbf{I}_t \odot \tilde{\mathbf{C}}_t Ct=Ft⊙Ct−1+It⊙C~t
H t = O t ⊙ tanh ( C t ) \mathbf{H}_t = \mathbf{O}_t \odot \tanh(\mathbf{C}_t) Ht=Ot⊙tanh(Ct)
总而言之,LSTM将长短期记忆分流处理、相互作用,短期记忆帮助长期记忆选择性遗忘和记忆,而长期记忆帮助短期记忆重新捕获和当下有关的长期依赖关系。短期记忆涉及了更多的参数,但数值范围被压缩以防数值爆炸;长期记忆的数值没有限制,但涉及的运算更为简洁。LSTM虽然比GRU复杂,但二者在大多数任务上的表现差不多。
对于序列中过长距离的依赖,LSTM和GRU的训练成本都是相当高的,在下一章将介绍更高级的替代模型Transformer。
深度循环神经网络(DRNN)
上一章只讨论了单隐藏层的RNN。通过将多层RNN堆叠在一起,我们可以得到具有更强表达能力和特征抽象能力的深度RNN(DRNN)。
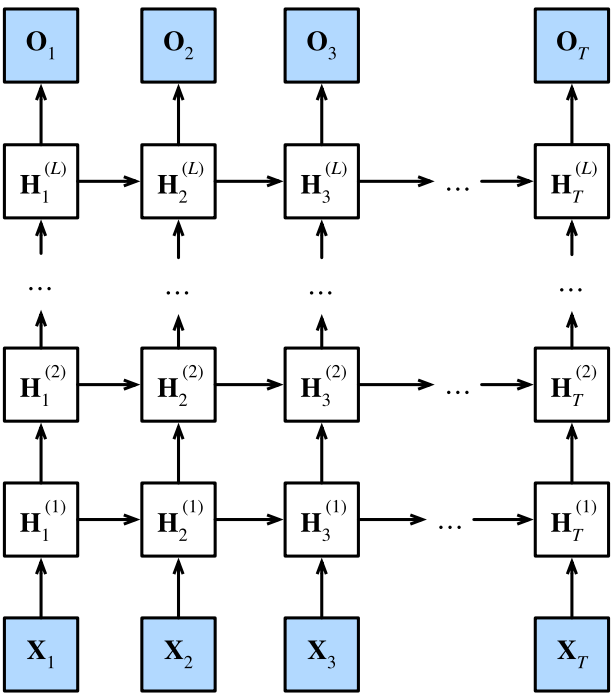
在深度RNN的隐藏层中,每一层接收来自上一层的隐状态和自己上一个时间步的隐状态来更新自己当前时间步的隐状态(除了第一层),又将自己更新后的隐状态作为输入传给下一层和下一个时间步的自己。
对于在时间步 t t t的小批量输入 H t ( 0 ) = X t ∈ R n × d \mathbf{H}_t^{(0)} = \mathbf{X}_t \in \mathbb{R}^{n \times d} Ht(0)=Xt∈Rn×d( n n n个样本,每个样本 d d d个输入),设第 l l l个隐藏层( l = 1 , ⋯ , L l=1,\cdots,L l=1,⋯,L)的隐状态为 H t ( l ) ∈ R n × h \mathbf{H}_t^{(l)} \in \mathbb{R}^{n \times h} Ht(l)∈Rn×h( h h h个隐藏单元),使用的激活函数为 ϕ l \phi_l ϕl,且设输出层变量为 O t ∈ R n × q \mathbf{O}_t \in \mathbb{R}^{n \times q} Ot∈Rn×q( q q q个输出单元),则每个隐藏层的隐状态计算如下:
H t ( l ) = ϕ l ( H t ( l − 1 ) W x h ( l ) + H t − 1 ( l ) W h h ( l ) + b h ( l ) ) \mathbf{H}_t^{(l)} = \phi_l(\mathbf{H}_t^{(l-1)} \mathbf{W}_{xh}^{(l)} + \mathbf{H}_{t-1}^{(l)} \mathbf{W}_{hh}^{(l)} + \mathbf{b}_h^{(l)}) Ht(l)=ϕl(Ht(l−1)Wxh(l)+Ht−1(l)Whh(l)+bh(l))
最终输出层的计算为:
O t = H t ( L ) W h q + b q \mathbf{O}_t = \mathbf{H}_t^{(L)} \mathbf{W}_{hq} + \mathbf{b}_q Ot=Ht(L)Whq+bq
其中隐藏层数 L L L和每层的隐藏单元数 h h h都是超参数。此外,将LSTM和GRU计算隐状态的公式(输入替换为上一层的输出)即可实现深层LSTM和深层GRU,其中深层LSTM的记忆单元仍在层内传递。
双向循环神经网络(BiRNN)
在序列学习中,我们以往假定的目标是在给定观测的情况下对下一个输出进行预测。但除此之外,还有一种任务是根据上下文预测序列中间空缺的信息,这使得模型需要捕捉过去和未来两个方向上的依赖关系,而目前为止,RNN只会观测过去的信息。
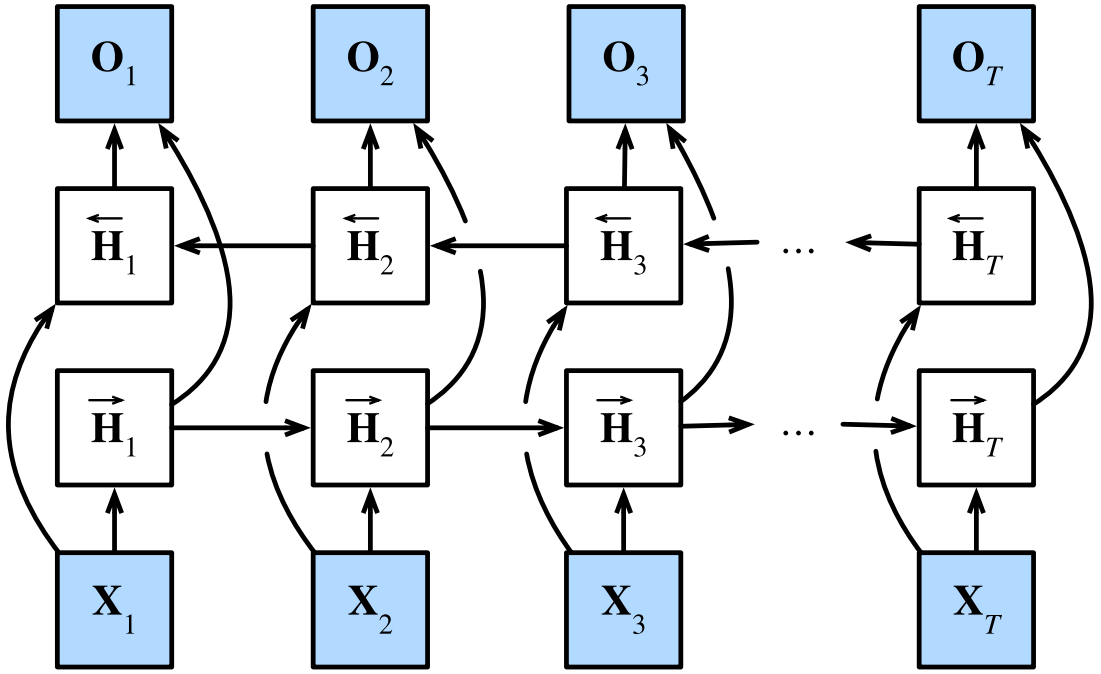
双向RNN(BiRNN)在传统RNN的基础上添加了反向传递信息的隐藏层。输入会分别进入前向隐藏层和反向隐藏层进行处理,而输出层则将前向隐状态和反向隐状态连接起来进行计算。
对于在时间步 t t t的小批量输入 X t ∈ R n × d \mathbf{X}_t \in \mathbb{R}^{n \times d} Xt∈Rn×d( n n n个样本,每个样本 d d d个输入),设该时间步的前向隐状态和反向隐状态分别为 H → t ∈ R n × h \overrightarrow{\mathbf{H}}_t \in \mathbb{R}^{n \times h} Ht∈Rn×h和 H ← t ∈ R n × h \overleftarrow{\mathbf{H}}_t \in \mathbb{R}^{n \times h} Ht∈Rn×h( h h h个隐藏单元,两个方向上的数目可以是不同的),则其计算如下:
H → t = ϕ ( X t W x h ( f ) + H → t − 1 W h h ( f ) + b h ( f ) ) \overrightarrow{\mathbf{H}}_t = \phi(\mathbf{X}_t \mathbf{W}_{xh}^{(f)} + \overrightarrow{\mathbf{H}}_{t-1} \mathbf{W}_{hh}^{(f)} + \mathbf{b}_h^{(f)}) Ht=ϕ(XtWxh(f)+Ht−1Whh(f)+bh(f))
H ← t = ϕ ( X t W x h ( b ) + H ← t + 1 W h h ( b ) + b h ( b ) ) \overleftarrow{\mathbf{H}}_t = \phi(\mathbf{X}_t \mathbf{W}_{xh}^{(b)} + \overleftarrow{\mathbf{H}}_{t+1} \mathbf{W}_{hh}^{(b)} + \mathbf{b}_h^{(b)}) Ht=ϕ(XtWxh(b)+Ht+1Whh(b)+bh(b))
参数的上标 ( f ) (f) (f)和 ( b ) (b) (b)分别表示前向和反向。
将前向隐状态 H → t \overrightarrow{\mathbf{H}}_t Ht和反向隐状态 H ← t \overleftarrow{\mathbf{H}}_t Ht连接得到进入输出层(在深度BiRNN中进入下一个双向隐藏层)的隐状态 H t ∈ R n × 2 h \mathbf{H}_t \in \mathbb{R}^{n \times 2h} Ht∈Rn×2h,最终输出层的输出 O t ∈ R n × q \mathbf{O}_t \in \mathbb{R}^{n \times q} Ot∈Rn×q( q q q个输出单元)计算如下:
O t = H t W h q + b q \mathbf{O}_t = \mathbf{H}_t \mathbf{W}_{hq} + \mathbf{b}_q Ot=HtWhq+bq
由于BiRNN需要同时进行前向和反向的隐状态计算,因此需要完整的序列才能计算每一个时间步的输出。在填充序列空缺任务中,其预测值为对应时间步的输出,而在序列标注任务中,最终的输出会结合所有时间步的输出给出。
BiRNN不适用于单向预测,因为这样的测试缺少在训练中能够利用的未来的信息,大大降低了模型的精确度。还有一个严重的问题是,双向递归使得梯度求解的链条变得非常长,导致模型的计算速度非常慢。
序列到序列(Seq2Seq)
在一类重要的自然语言处理任务中,输入和输出都是不定长的序列,例如机器翻译和对话,它们被称为序列到序列(Seq2Seq)类学习任务,这些是序列转换模型的核心问题。
编码器-解码器架构
为了处理上述类型的输入和输出,深度学习引入了通信领域中编码与解码的概念。为了避免信息在传输过程中被干扰失真,在传输前需要先将信号编码为易于传输的形式,然后在接收时将信号解码还原。
Seq2Seq使用包含两个主要组件的架构。第一个组件是编码器,它接收一个长度可变的序列作为输入,并将其转换为具有固定形状的编码状态;第二个组件是解码器,它将固定形状的编码状态映射到长度可变的序列。这被称为编码器-解码器架构。
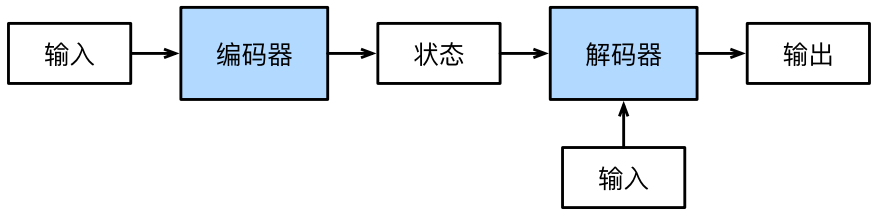
编码器
编码器将长度可变的输入序列转换成形状固定的上下文变量 c \mathbf c c,并将输入序列的信息在该上下文变量中进行编码。以用RNN设计的编码器为例,考虑单个样本,在编码之前,RNN先遍历序列 { x t } \{\mathbf x_t\} {xt}计算出每一个时间步 t t t的隐状态 h t \mathbf h_t ht:
h t = f ( x t , h t − 1 ) \mathbf{h}_t = f(\mathbf{x}_t, \mathbf{h}_{t-1}) ht=f(xt,ht−1)
编码过程则以所有时间步的隐状态作为输入,通过选定的函数 q q q将其转换为上下文变量:
c = q ( h 1 , ⋯ , h T ) \mathbf{c} = q(\mathbf{h}_1, \cdots, \mathbf{h}_T) c=q(h1,⋯,hT)
上下文变量是从输入序列中提取出的特征表示,一种简单的选择是令 c = h T \mathbf{c} = \mathbf{h}_T c=hT,直接使用最后时间步的隐状态作为上下文变量。
解码器
解码器使用来自编码器的上下文变量初始化自己的隐状态,并作为之后输出的参考。假设使用另一个RNN作为解码器,对于解码过程,在输出序列的时间步 t ′ t' t′,解码器将连接自己上一个时间步的输出 y t ′ − 1 \mathbf y_{t'-1} yt′−1和上下文变量 c \mathbf c c作为输入来更新自己上一个时间步的隐状态 s t ′ − 1 \mathbf s_{t'-1} st′−1(使用 s \mathbf s s与解码器的隐状态区分开)为 s t ′ \mathbf s_{t'} st′:
s t ′ = g ( y t ′ − 1 , c , s t ′ − 1 ) \mathbf{s}_{t^\prime} = g(y_{t^\prime-1}, \mathbf{c}, \mathbf{s}_{t^\prime-1}) st′=g(yt′−1,c,st′−1)
随后解码器通过输出层计算在时间步 t ′ t' t′的输出 y t ′ \mathbf y_{t'} yt′,这个过程也是将隐状态映射为词表大小的矩阵,以便对其进行softmax操作转化成各个词元作为预测结果的条件概率,最终给出条件概率最大的词元。只要给解码器一个初始的输入 y 1 \mathbf y_1 y1,解码器就能通过对后续时间步的预测输出序列,直到其判断序列可以终止。
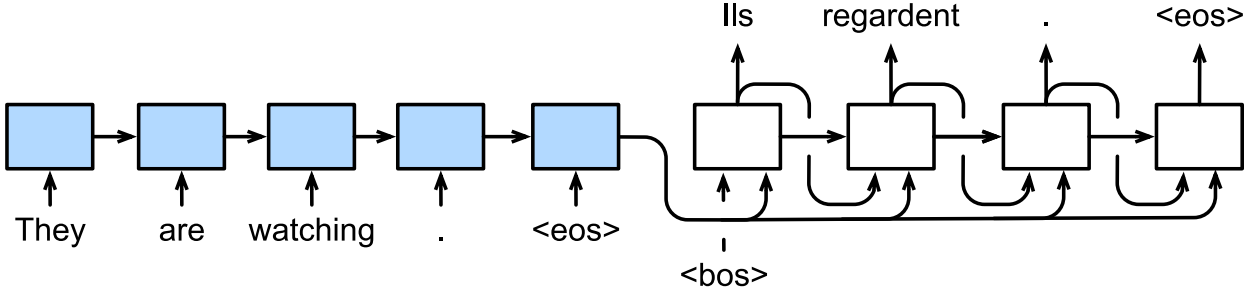
上图给出了在机器翻译中编码器-解码器架构是如何工作的,其中 <bos> \texttt{<bos>} <bos>和 <eos> \texttt{<eos>} <eos>分别为序列开始词元和序列结束词元。编码器提炼待翻译序列的信息送往解码器,解码器接收 <bos> \texttt{<bos>} <bos>作为起点,根据编码信息和已翻译出的内容继续预测翻译内容的下一个词元,直到预测出 <eos> \texttt{<eos>} <eos>作为翻译内容的结束。而在训练过程中,解码器会直接接收标签序列作为输入以从中进行学习。
预测序列的评估
对于以可变长度序列为输出的预测,我们可以通过与真实的标签序列进行比较来评估。BLEU(Bilingual Evaluation Understudy)最先被用于评估机器翻译的结果,但现在已经被广泛用于度量输出序列的质量。其定义如下:
B L E U = exp ( min ( 0 , 1 − l e n label l e n pred ) ) ∏ n = 1 k p n 1 / 2 n \mathrm{BLEU}=\exp\left(\min\left(0, 1 - \frac{\mathrm{len}_{\text{label}}}{\mathrm{len}_{\text{pred}}}\right)\right) \displaystyle\prod_{n=1}^k p_n^{1/2^n} BLEU=exp(min(0,1−lenpredlenlabel))n=1∏kpn1/2n
从右往左看, p n p_n pn表示 n n n元语法(连续 n n n个词元组成的序列)的精确率,其计算步骤如下:
- 分别统计标签序列和预测序列中的所有 n n n元语法(包括重复出现的项);
- 将标签序列的 n n n元语法与预测序列的 n n n元语法一一匹配,每项只能被匹配一次,统计匹配次数;
- 将匹配次数除以预测序列中 n n n元语法的总数(包括重复出现的项)。
例如对于标签序列 { A , B , C , C , D } \{A,B,C,C,D\} {A,B,C,C,D}和预测序列 { A , B , B , C } \{A,B,B,C\} {A,B,B,C}, p 1 = 3 4 p_1=\displaystyle\frac34 p1=43, p 2 = 2 3 \displaystyle p_2=\frac23 p2=32, p 3 = p 4 = 0 p_3=p_4=0 p3=p4=0。
由于 n n n越大, n n n元语法的匹配难度也越大, B L E U \mathrm{BLEU} BLEU通过 p n 1 / 2 n p_n^{1/2^n} pn1/2n为更长的 n n n元语法的精确率赋予了更大的权重(底数小于 1 1 1时,指数越小幂越大),再将所有的精确率累乘。
最后,越短的预测序列,其 n n n元语法的总数越小,获得的 p n p_n pn越大,因此 B L E U \mathrm{BLEU} BLEU通过系数 exp ( min ( 0 , 1 − l e n label l e n pred ) ) \exp\left(\min\left(0, 1 - \frac{\mathrm{len}_{\text{label}}}{\mathrm{len}_{\text{pred}}}\right)\right) exp(min(0,1−lenpredlenlabel))对其进行惩罚。当预测序列长度小于标签序列时, e e e的负数次幂会降低评估结果。而当预测序列长度大于标签序列时,精确率则会下降。只有当预测序列与标签序列完全相同时, B L E U = 1 \mathrm{BLEU}=1 BLEU=1。
束搜索
本节讨论解码器在选择词元作为输出时的策略问题。
贪心搜索
在上一节中,解码器直接在所有词元中选择条件概率最大的作为输出,即采取贪心搜索:
y t ′ = argmax y ∈ Y P ( y ∣ y 1 , … , y t ′ − 1 , c ) y_{t'} = \operatorname*{argmax}_{y \in \mathcal{Y}} P(y \mid y_1, \ldots, y_{t'-1}, \mathbf{c}) yt′=argmaxy∈YP(y∣y1,…,yt′−1,c)
一旦输出序列包含了 <eos> \texttt{<eos>} <eos>或到达其最大长度 T ′ T' T′,则输出完成。
这种策略带来的问题是,在当前时间步条件概率最大的词元,长远来看,在其后的几个时间步中,以该词元为起点的预测序列并不一定是所有预测序列中条件概率最高的,即局部最优不一定带来总体最优。
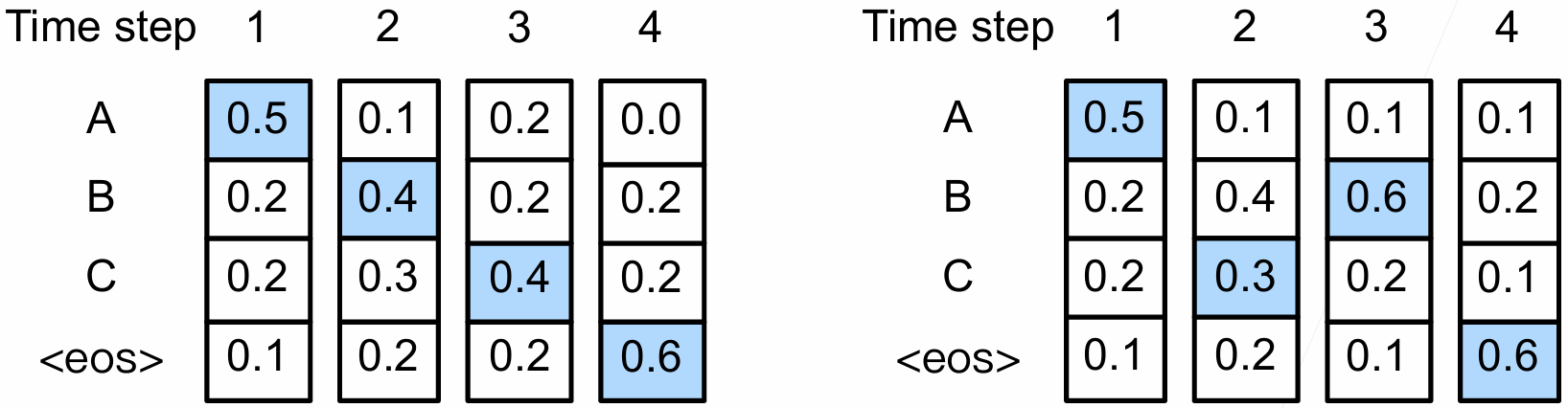
在上图所示的例子中,横向为不同时间步,纵向为不同词元。左侧使用贪心算法得到的预测序列为ABC,其概率为 0.5 × 0.4 × 0.4 × 0.6 = 0.048 0.5\times0.4\times0.4\times0.6=0.048 0.5×0.4×0.4×0.6=0.048,而右侧在第 2 2 2个时间步未使用贪心算法,得到的预测序列为ACB ,其概率为 0.5 × 0.3 × 0.6 × 0.6 = 0.054 0.5\times0.3\times0.6\times0.6=0.054 0.5×0.3×0.6×0.6=0.054(第 3 3 3、 4 4 4个时间步的概率分布不一样是因为第 2 2 2个时间步选择的概率条件不一样),优于贪心算法。
穷举搜索
如果想获得最优序列,我们可以考虑穷举搜索,即穷举所有可能的输出序列及其条件概率,计算输出条件概率最大的那一个。
穷举搜索虽然能保证选择的最优性,但其计算量 O ( ∣ Y ∣ T ′ ) O(|Y|^{T'}) O(∣Y∣T′)大得惊人( ∣ Y ∣ |Y| ∣Y∣为词表大小),在计算机上运行是几乎不可能的。
束搜索
束搜索介于贪心搜索和穷举搜索之间,兼顾精确度和计算成本。
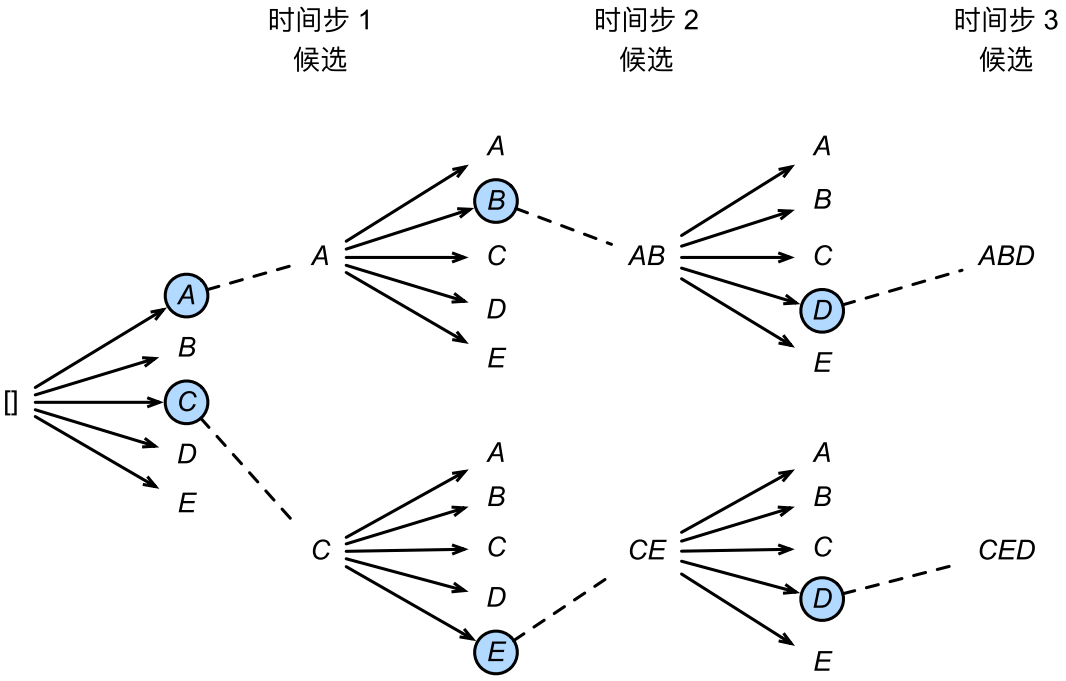
束搜索在每个时间步 t t t做选择时,会同时选中条件概率最大的 k k k个词元作为候选输出,超参数 k k k是束搜索的束宽。在下一个时间步,从这 k k k个词元衍生出来的所有分支总共有 k ∣ Y ∣ k|Y| k∣Y∣个选择( ∣ Y ∣ |Y| ∣Y∣为词表大小),而束搜索会继续同时选中这所有 k ∣ Y ∣ k|Y| k∣Y∣个选择中条件概率最大的 k k k个词元,以此类推。在预测的过程中,束搜索将始终保持有 k k k个候选输出序列,如果一条候选序列遇到 <eos> \texttt{<eos>} <eos>则停止延伸,剩余可扩展的候选序列数量会相应地减少。所有候选序列均完成后则终止束搜索。
最后我们将从最终候选输出序列集合中选择分数最高的序列作为输出序列,每个候选的分数计算如下:
1 L α log P ( y 1 , … , y L ∣ c ) = 1 L α ∑ t ′ = 1 L log P ( y t ′ ∣ y 1 , … , y t ′ − 1 , c ) \displaystyle\frac{1}{L^\alpha} \log P(y_1, \ldots, y_{L}\mid \mathbf{c}) = \frac{1}{L^\alpha} \sum_{t'=1}^L \log P(y_{t'} \mid y_1, \ldots, y_{t'-1}, \mathbf{c}) Lα1logP(y1,…,yL∣c)=Lα1t′=1∑LlogP(yt′∣y1,…,yt′−1,c)
由于条件概率由概率累乘而来,容易产生数值下溢,因此在计算时取对数处理。除此之外,在候选序列中,长序列的条件概率会显著小于短序列,为了给予补偿,我们使用系数 1 L α \displaystyle\frac1{L^\alpha} Lα1,其中 L L L为序列长度, α \alpha α一般取 0.75 0.75 0.75。对数运算结果为负数,对于更大的 L L L,该系数使最终分数更大。
束搜索的计算量为 O ( k ∣ Y ∣ T ′ ) O(k|Y|T') O(k∣Y∣T′),即每个时间步需要遍历 k ∣ Y ∣ k|Y| k∣Y∣项,其计算成本介于贪心搜索和穷举搜索之间。通过灵活地选择束宽,束搜索可以在精确度和计算成本之间权衡。
相关文章:

【深度学习】#9 现代循环神经网络
主要参考学习资料: 《动手学深度学习》阿斯顿张 等 著 【动手学深度学习 PyTorch版】哔哩哔哩跟李牧学AI 概述 门控循环单元和长短期记忆网络利用门控机制实现对序列输入的选择性记忆。深度循环神经网络堆叠多个循环神经网络层以实现更强的表达能力和特征提取能力。…...

《CBOW 词向量转化实战:让自然语言处理 “读懂” 文字背后的含义》
文章目录 前言一、自然语言模型统计语言模型存在的问题总结:这两个问题的本质,第一个是"容量问题":模型记忆力有限;第二个是"理解力问题":模型缺乏抽象能力。 二、词向量转换1.onehot编码编码过程…...

网络变更:APIC 节点替换
Draft 一、同版本硬件更换 1. 查看 APIC 状态 System > Controllers > (any APIC) > Cluster APIC1> acidiag avread // APIC 参数 2. 下线故障设备 Actions > Decommission 3. 物理移除故障设备,连接目标 APIC 4. 根据第一步中的配置参数配置目…...

Java在excel中导出动态曲线图DEMO
1、环境 JDK8 POI 5.2.3 Springboot2.7 2、DEMO pom <dependency><groupId>org.apache.poi</groupId><artifactId>poi-ooxml</artifactId><version>5.2.3</version></dependency><dependency><groupId>commons…...
)
Python爬虫爬取图片并存储到MongoDB(注意:仅尝试存储一条空的示例数据到MongoDB,验证MongoDB的联通性)
以下是一个使用Python爬取图片并存储到MongoDB的示例实现,包含详细步骤说明: import requests from bs4 import BeautifulSoup from pymongo import MongoClient from datetime import datetime import os import re# 配置信息 mongoIP mongodb://root…...
)
Qt —— 在Linux下试用QWebEngingView出现的Js错误问题解决(附上四种解决办法)
错误提示:js: A parser-blocking, cross site (i.e. different eTLD+1) script, https:xxxx, is invoked via document.write. The network request for this script MAY be blocked by the browser in this or a future page load due to poor network connectivity. If bloc…...

240424 leetcode exercises II
240424 leetcode exercises II jarringslee 文章目录 240424 leetcode exercises II[148. 排序链表](https://leetcode.cn/problems/sort-list/)🔁分治 & 归并排序法1. 找中点并断开2. 合并两个有序链表3. 主函数:递归拆分与合并 [24. 两两交换链表…...

STM32实现2小时延时的最佳方法探讨
在嵌入式系统开发中,特别是使用STM32这类微控制器时,实现精确的长时间延时是一项常见但具有挑战性的任务。延时的方法选择不仅影响系统的性能和功耗,还关系到系统的稳定性和可靠性。本文将探讨在STM32上实现2小时延时的几种方法,并…...

G3学习笔记
🍨 本文为🔗365天深度学习训练营 中的学习记录博客🍖 原作者:K同学啊 准备工作 import torch import numpy as np import torch.nn as nn import torch.optim as optim from torchvision import datasets, transforms from torc…...
)
初识Redis · 主从复制(上)
目录 前言: 主从模式 模拟主从模式 连接信息 slaveof命令 nagle算法 Nagle算法的工作原理: 具体实现: 优点: 缺点: 使用场景: 拓扑结构 前言: 主从复制这里算得上是一个大头了&…...
题解)
欧拉计划 Project Euler55(利克瑞尔数)题解
欧拉计划 Project Euler 55 题解 题干思路code 题干 思路 直接暴力找即可,若使用其他语言要注意溢出的问题,这里我使用的手写大数加法 code // 249 #include <bits/stdc.h>using namespace std;using ll long long;string add(const string&am…...

关于nginx,负载均衡是什么?它能给我们的业务带来什么?怎么去配置它?
User 关于nginx,我还想知道,负载均衡是什么?它能为我的业务带来什么?怎么去配置它? Assistant 负载均衡是 Nginx 另一个非常强大的功能,也是构建高可用、高性能应用的关键技术之一。我们来详细了解一下。 …...

【项目管理】进度网络图 笔记
项目管理-相关文档,希望互相学习,共同进步 风123456789~-CSDN博客 (一)知识总览 项目管理知识域 知识点: (项目管理概论、立项管理、十大知识域、配置与变更管理、绩效域) 对应&…...

【C++QT】Buttons 按钮控件详解
文章目录 一、QPushButton 基础按钮控件二、QToolButton 轻量工具按钮控件三、QRadioButton 互斥选择控件四、QCheckBox 状态选择控件五、QCommandLinkButton 引导式按钮控件六、QDialogButtonBox 对话框按钮布局控件七、实践与选型建议八、总结如果这篇文章对你有所帮助&#…...

威雅利电子|业界领先的高隔离度用于5G基站的吸收式SPDT开关“NT1819“
业界领先的高隔离度 用于5G基站的吸收式SPDT开关"NT1819" 为了实现智能社会,已经启动了5G服务。这样,高速、低延迟、大容量的数据通信成为可能,也给我们的生活和工业发展带来了巨大的变化。 在5G基站有很多天线,每个天…...

【DNS】BIND 9的配置
该文档围绕BIND 9的配置与区域文件展开,介绍了BIND 9配置文件及区域文件的相关知识,以及权威名称服务器、解析器的相关内容,还阐述了负载均衡和区域文件的详细知识,具体如下: 基础配置文件: named.conf&am…...

高可靠性厚铜板制造的关键设备与工艺投入
随着科技的不断发展,电子设备越来越普及,对电路板的需求也越来越大。厚铜板电路板作为一种高性能、高可靠性的电路板,受到了广泛的关注和应用。那么,作为一家厚铜板电路板供应商,如何投入线路板生产呢?本文…...

m365是什么,和o365的区别
M365(Microsoft 365)是微软推出的基于云的办公套件,包含多种生产力工具,旨在帮助个人和企业提高工作效率。它包括经典的办公软件,如Word、Excel、PowerPoint、Outlook等,还提供协作和云存储服务,…...

【Pandas】pandas DataFrame dot
Pandas2.2 DataFrame Binary operator functions 方法描述DataFrame.add(other)用于执行 DataFrame 与另一个对象(如 DataFrame、Series 或标量)的逐元素加法操作DataFrame.add(other[, axis, level, fill_value])用于执行 DataFrame 与另一个对象&…...

技术服务业-首套运营商网络路由5G SA测试专网在深光搭建完成并对外提供服务
深光为了更好的服务蜂窝无线技术及运营商测试认证相关业务,搭建了技术服务业少有的5G测试专网,可独立灵活配置、完整端到端5G(含RedCap、LAN)的网络架构。 通过走真正运营商网络路由的方式,使终端设备的测试和运营商网…...

GrassRouter 小草MULE多5G多链路聚合通信路由设备在应急场景的聚合效率测试报告及解决方案
在应急通信场景中,快速、稳定、高效的通信链路是保障救援工作顺利开展的关键。MULE(Multi-Link Unified Link Enhancement)多链路聚合路由通信设备作为一种新型的通信技术解决方案,通过聚合多条通信链路(如4G/5G、卫星…...

解释器模式:自定义语言解析与执行的设计模式
解释器模式:自定义语言解析与执行的设计模式 一、模式核心:定义语言文法并实现解释器处理句子 在软件开发中,当需要处理特定领域的语言(如数学表达式、正则表达式、自定义配置语言)时,可以通过解释器模式…...
)
第十二章 Python语言-大数据分析PySpark(终)
目录 一. PySpark前言介绍 二.基础准备 三.数据输入 四.数据计算 1.数据计算-map方法 2.数据计算-flatMap算子 3.数据计算-reduceByKey方法 4.数据计算-filter方法 5.数据计算-distinct方法 6.数据计算-sortBy方法 五.数据输出 1.输出Python对象 (1&am…...

Oracle数据库巡检脚本
1.查询实例信息 SELECT INST_ID, INSTANCE_NAME, TO_CHAR(STARTUP_TIME, YYYY-MM-DD HH24:MI:SS) AS STARTUP_TIME FROM GV$INSTANCE ORDER BY INST_ID; 2.查看是否归档 archive log list 3.查看数据库参数 SELECT NAME , TYPE , VALUE FROM V$PARAMETER ORDER BY NAME; 4.…...

示例:Spring JDBC编程式事务
以下是一个完整的 Spring JDBC 编程式事务示例,包含批量插入、事务管理、XML 配置和单元测试: 1. 项目依赖(pom.xml) <dependencies><!-- Spring JDBC --><dependency><groupId>org.springframework<…...

Happens-Before 原则
Happens-Before 规则 Happens-Before是JMM的核心概念之一,是一种可见性模型,保障多线程环境下前一个操作的结果相对于后续操作是可见的。 程序顺序性,同一线程中前面代码的操作happens-before后续的任意操作。volatile变量规则,…...
提交代码更新?)
怎样通过互联网访问内网 SVN (版本管理工具)提交代码更新?
你有没有遇到过这种情况:在公司或者家里搭了个 SVN 服务器(用来存代码的),但出门在外想提交代码时,发现连不上? 这是因为 SVN 通常跑在内网,外网直接访问不了。 这时候就需要 “内网穿透” ——…...
)
Verilog 语法 (一)
Verilog 是硬件描述语言,在编译下载到 FPGA 之后, FPGA 会生成电路,所以 Verilog 全部是并行处理与运行的;C 语言是软件语言,编译下载到单片机 /CPU 之后,还是软件指令,而不会根据你的代…...
 如何进行 SQL 优化?)
针对 Spring Boot 应用中常见的查询场景 (例如:分页查询、关联查询、聚合查询) 如何进行 SQL 优化?
通用优化原则(适用于所有场景): 索引是基础: 确保 WHERE、JOIN、ORDER BY、GROUP BY 涉及的关键列都有合适的索引(单列或联合索引)。避免 SELECT *: 只查询业务需要的列,减少数据传输量和内存消耗。覆盖索…...

shadcn/radix-ui的tooltip高度定制arrow位置
尝试了半天,后来发现,不支持。。。。。就是不支持 那箭头只能居中 改side和align都没用,下面有在线实例 https://codesandbox.io/p/sandbox/radix-ui-slider-forked-zgn7hj?file%2Fsrc%2FApp.tsx%3A69%2C21 但是呢, 第一如果…...

ROS-真机向虚拟机器人映射
问题描述 ROS里的虚拟机械臂可以实现和真实机械臂的位置同步,真实机械臂如何动,ROS里的虚拟机械臂就如何动 效果 步骤 确保库卡机械臂端安装有EthernetKRL辅助软件和KUKAVARPROXY 6.1.101(它是一个 TCP/IP 服务器 ,可通过网络实…...
)
ap无法上线问题定位(交换机发包没有剥掉pvid tag)
一中学,新开的40台appoe交换机核心交换机旁挂ac出口路由的组网,反馈ap无法上线,让协助解决。 组网如下: 排查过程: 检查ac的配置,没有发现问题 发现配置没有问题,vlan1000配置子接口ÿ…...

Linux基础
03.Linux基础 了解VMware备份的两种方式 了解Linux系统文件系统 掌握Linux基础命令 备份操作系统 为什么要备份系统? 数据安全:防止因硬件故障、软件错误等原因导致的数据丢失。 系统恢复:快速恢复系统至正常状态,减少停机时…...

python函数与模块
目录 一:函数 1.无参函数 2.带参数函数 2.函数中变量中的作用域 4.内建函数 二:模块与包 1.模块 (1)模块定义 (2)模块导入 2.包 (1)包的使用 (2)_…...

线上助农产品商城小程序源码介绍
基于ThinkPHPFastAdminUniApp开发的线上助农产品商城小程序源码,旨在为农产品销售搭建一个高效、便捷的线上平台,助力乡村振兴。 一、技术架构 该小程序源码采用了ThinkPHP作为后端框架,FastAdmin作为快速开发框架,UniApp作为跨…...

个人博客后台管理开发日志
技术栈:Vue3 Ts node.js mySQL pinia axios 3月14日 一、数据表梳理 用户(user) ID名字邮箱密码 头像 地址 创建 时间 总览有本地文件、博客文章、摄影图库、随笔随记,这些板块也有对应的分类,我们要把这些分类…...

[论文阅读]REPLUG: Retrieval-Augmented Black-Box Language Models
REPLUG: Retrieval-Augmented Black-Box Language Models REPLUG: Retrieval-Augmented Black-Box Language Models - ACL Anthology NAACL-HLT 2024 在这项工作中,我们介绍了RePlug(Retrieve and Plug),这是一个新的检索增强型…...

Matlab 基于共面螺旋管或共面亥姆霍兹谐振器的超薄低频吸声板
经典吸声材料的吸声性能严格依赖于材料的厚度,要达到完全吸声,至少需要四分之一波长。在本文中,我们报道了一种厚度约为波长百分之一的超薄吸声板,可以完全吸收声能。其策略是将四分之一波长的减声管弯曲并缠绕成二维共面减声管&a…...

济南国网数字化培训班学习笔记-第二组-4节-输电线路工程安全管理
输电线路工程安全管理 安全标识 颜色 禁止红、警示黄、指令蓝、提示绿 安全器具 定义 安全工器具通常专指“电力安全工器具”,是防止触电、灼伤、坠落、摔跌、腐蚀、窒息等事故,保障工作人员人身安全的各种专用工具和器具 分类 个体防护设备 防…...

【C语言】数据在内存中的存储:从整数到浮点数的奥秘
前言 在计算机的世界里,数据的存储和表示是编程的基础。今天,我们就来深入探讨一下数据在内存中的存储方式,包括整数和浮点数的存储细节,以及大小端字节序的奥秘。这些内容不仅对理解计算机系统至关重要,还能帮助我们…...

白鲸开源WhaleStudio与崖山数据库管理系统YashanDB完成产品兼容互认证
近日,北京白鲸开源科技有限公司与深圳计算科学研究院联合宣布,双方已完成产品兼容互认证。此次认证涉及深圳计算科学研究院自主研发的崖山数据库管理系统YashanDB V23和北京白鲸开源科技有限公司的核心产品WhaleStudio V2.6。经过严格的测试与验证&#…...
)
图论---朴素Prim(稠密图)
O( n ^2 ) 题目通常会提示数据范围: 若 V ≤ 500,两种方法均可(朴素Prim更稳)。 若 V ≤ 1e5,必须用优先队列Prim vector 存图。 // 最小生成树 —朴素Prim #include<cstring> #include<iostream> #i…...

借助deepseek和vba编程实现一张表格数据转移到多张工作簿的表格中
核心目标 将工作表中的内容按村社名称分类放入对应位置的目标工作簿的第一个工作表的对应位置 deepseek提问方式 你是一个擅长vba编程的专家,核心目标是奖工作表中的部分内容按下列要求写入对应工作簿的第一个工作表中。第一,在工作表A列中筛选出相…...

springboot整合redis实现缓存
一、redis 二、spring boot 整合redis 三、基于注解的Redis缓存实现 使用Cacheable、CachePut、CacheEvict注解定制缓存管理 对CommentService类中的方法进行修改使用Cacheable、CachePut、CacheEvict三个注解定制缓存管理,修改后的方法如下 Cacheable(cacheNam…...

git tag使用场景和实践
背景 每次上线一个迭代,为了区分本次代码的分支是哪个迭代,可以给分支打上tag,这样利于追踪分支所属迭代,如果devops没有自动给分支打tag,需要自己来打 操作 1.查看当前tag git tag2.给分支打tag git tag <tag…...

十分钟恢复服务器攻击——群联AI云防护系统实战
场景描述 服务器遭遇大规模DDoS攻击,导致服务不可用。通过群联AI云防护系统的分布式节点和智能调度功能,快速切换流量至安全节点,清洗恶意流量,10分钟内恢复业务。 技术实现步骤 1. 启用智能调度API触发节点切换 群联系统提供RE…...

国产紫光同创FPGA视频采集转SDI编码输出,基于HSSTHP高速接口,提供2套工程源码和技术支持
目录 1、前言工程概述免责声明 2、相关方案推荐我已有的所有工程源码总目录----方便你快速找到自己喜欢的项目紫光同创FPGA相关方案推荐本博已有的 SDI 编解码方案本方案在Xilinx--Artix7系列FPGA上的应用本方案在Xilinx--Kintex系列FPGA上的应用本方案在Xilinx--Zynq系列FPGA上…...

最小生成树-prim、kruskal算法
目录 prim算法 kruskal算法 题目练习 (1)AcWing 858. Prim算法求最小生成树 - AcWing (2)859. Kruskal算法求最小生成树 - AcWing题库编辑 学习之前建议温习一下迪杰斯特拉算法和并查集~ 先简单认识下最小生成树:…...

【硬核干货】JetBrains AI Assistant 干货笔记
快进来抄作业,小编呕心沥血整理的 JetBrains AI Assistant 超干货笔记! 原文链接:【硬核干货】JetBrains AI Assistant 干货笔记 关于晓数神州 晓数神州坚持以“客户为中心”的宗旨,为客户提供专业的解决方案和技术服务ÿ…...

强化学习核心原理及数学框架
1. 定义与核心思想 强化学习(Reinforcement Learning, RL)是一种通过智能体(Agent)与环境(Environment)的持续交互来学习最优决策策略的机器学习范式。其核心特征为: 试错学习&#x…...