《CBOW 词向量转化实战:让自然语言处理 “读懂” 文字背后的含义》
文章目录
- 前言
- 一、自然语言模型
- 统计语言模型存在的问题
- 总结:这两个问题的本质,第一个是"容量问题":模型记忆力有限;第二个是"理解力问题":模型缺乏抽象能力。
- 二、词向量转换
- 1.onehot编码
- 编码过程
- onehot独热编码存在的问题
- 总结
- 2.词嵌入
- (1)Word2Vec
- CBOW模型
- Skip_Gram模型
- 3、词嵌入模型的训练
- (1)模型训练的过程
- (2)损失函数的选择
- 三、CBOW模型实现词嵌入
- 完整代码展示
- 总结
前言
在自然语言处理领域,让计算机理解人类语言的语义一直是研究难点。传统的独热编码等词表示方法,仅能孤立标识单词,无法体现词间语义联系。
词向量转换与词嵌入技术的诞生打破了这一困局。它们将离散单词映射为连续向量,挖掘单词间语义关联,把单词嵌入低维空间,使语义相近的词自然聚类。如今,这项技术已深度融入文本分类、机器翻译等任务,成为 NLP 模型理解语义的核心基础。接下来,我们将深入解析其原理、方法及应用。
一、自然语言模型
语言模型是自然语言处理的关键技术,常见类型包括传统统计语言模型和神经网络语言模型。传统统计语言模型中的 N - gram 模型,基于统计计算文本中连续 N 个词出现的概率以预测下一词,如二元语法计算词对概率,其优势在于简单高效,但存在无法处理长距离语义依赖、数据稀疏等问题;神经网络语言模型中,递归神经网络语言模型(RNN - LM)能捕捉长期依赖关系,却面临梯度消失与爆炸难题,影响长序列处理效果,长短时记忆网络语言模型(LSTM - LM)作为 RNN 改进版,通过门控机制优化信息流动,可有效处理长序列,例如记住长句开头关键信息辅助后续处理,门控循环单元语言模型(GRU - LM)则简化 RNN 结构,合并部分门和状态,在部分任务中效果良好且计算效率更高。
统计语言模型存在的问题
1、由于参数空间的爆炸式增长,它无法处理(N>3)的数据。
举例理解:
中文有成千上万的词汇,四词组合的可能性超过100亿种(相当于给每个汉字搭配3个伙伴的所有可能性)。即使你每天背100个组合,也要273万年才能背完——这就是参数空间的爆炸式增长。统计语言模型就像一个只能死记硬背的学生,当需要记忆的组合超过三词时,它的"大脑"就完全装不下了。
2、没有考虑词与词之间内在的联系性。
假设你学过:
“小狗在公园奔跑"和"小猫在草地跳跃”,但从未学过"小猫在公园奔跑"。
人类会自动联想:既然"小狗"和"小猫"都是宠物,"奔跑"和"跳跃"都是动作,那么新句子应该合理。但传统统计模型就像一个只认字面意思的机器人:
它认为"小狗"和"小猫"是完全不同的词,“奔跑"和"跳跃"也没有任何关联,只要没亲眼见过"小猫在公园奔跑"这个具体组合,就认为概率为零。
这就好比只允许用完全相同模具做蛋糕,稍微改动形状就被判定为"不可能”,而不知道面粉、鸡蛋这些原料之间本来就有通用性。
总结:这两个问题的本质,第一个是"容量问题":模型记忆力有限;第二个是"理解力问题":模型缺乏抽象能力。
二、词向量转换
1.onehot编码
One-Hot 编码(独热编码)是一种将离散型分类变量(如文字、符号、类别标签)转换为数值型向量的方法。它的核心思想是为每个类别分配一个唯一的二进制向量,向量中只有一位是 1(表示当前类别),其余均为 0。机器学习模型(如神经网络、逻辑回归)只能处理数值数据,无法直接使用文本或类别标签。编码的目的是将非数值信息转化为数值形式。
假设你需要将“我爱中国”这些自然语言输入计算机,但计算机只能处理数字。如果想让计算机能够认识这些文字,则需要通过 One-Hot 编码后:
我 → [1, 0, 0,0]
爱 → [0, 1, 0,0]
中→ [0, 0, 1,0]
国→ [0,0, 0, 1]
每个汉字对应一个“独一无二”的二进制向量,就像为每个类别分配了一个“身份证号”。
编码过程
步骤 1:确定所有可能的类别,例如动物类别为 [猫, 狗, 鸟]。
步骤 2:为每个类别分配一个位置索引,例如:猫→0,狗→1,鸟→2。
步骤 3:生成二进制向量,向量的长度等于类别总数,仅在对应索引位置设为 1,其余为 0。
onehot独热编码存在的问题
1、维度灾难:当类别数量极大时(例如 10,000 个城市),编码后的特征维度爆炸,导致计算效率下降。
例子:假设我们有一个语料库,语料库总共有4960个汉字,将这4960个词转换为onehot向量,矩阵非常稀疏,出现维度灾难。例如有一句话为“我爱北京天安门”,传入神经网络输入层的数据为:7x4960的矩阵,这个矩阵是由0和1组成的矩阵,随着语料库的增加,这个矩代表每一个汉字所需的维度也越多,出现了维度爆炸问题。
2、无法表达相似性:所有类别被视为完全独立,例如“猫”和“狗”的相似性无法体现(它们的向量距离相同)。
总结
One-Hot 编码是处理离散特征的基础方法,核心是通过二进制向量唯一标识每个类别。虽然简单有效,但在高基数(类别多)场景下需谨慎使用,此时可考虑嵌入(Embedding)或特征哈希(Hashing)等优化方案。
2.词嵌入
为了解决维度灾难,通过神经网络训练,将每个词都映射到一个较短的词向量上来。词向量的维度一般需要在训练时自己来指定。现在很常见的例如300维。
例如有一句话为“我爱北京天安门”,通过神经网络训练后的数据为:
[0.62,0.12,0.01,0,0,0,0,….,0]
[0.1,0.12,0.001,0,0,0,0,….,0]
[0,0,0.01,0.392,0.39, 0,….,0]
[0,0,0,1,0,0.01,0.123,….,0.11]
“我爱北京天安门”这句话的矩阵由7x4960转换为7x300,可以看出矩阵中维度的数字已经不再是0和1,而是变为了浮点数。
这种将高维度的词表示转换为低维度的词表示的方法,我们称之为词嵌入(word embedding)。
(1)Word2Vec
Google研究团队里的Tomas Mikolov等人于2013年的《Distributed Representations ofWords and Phrases and their Compositionality》以及后续的《Efficient Estimation of Word Representations in Vector Space》两篇文章中提出的一种高效训练词向量的模型,也就是word2vec。
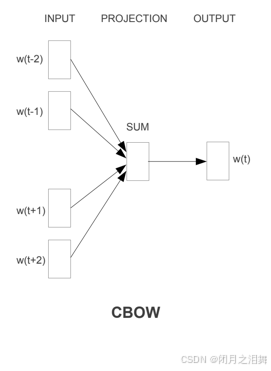
Word2Vec的两种模型结构,CBOW(Continuous Bag-of-Words):根据上下文预测中心词。Skip-Gram:根据中心词预测上下文。
CBOW模型
CBOW模型是以上下文词汇预测当前词,即用ω(t−2)、ω(t−1)、 ω(t+1)、 ω(t+2)预测ω(t)。

假设此时要预测“由”,即通过“我命”和“我不”来预测,中间字”由“。
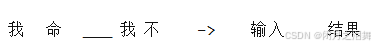
Skip_Gram模型
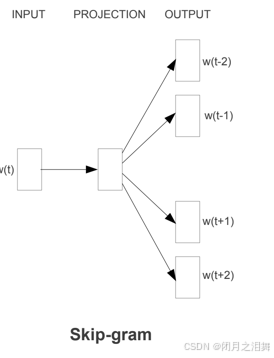
Skip_Gram模型是以当前词预测其上下文词汇,即用ω(t)预测ω(t−2)、ω(t−1)、 ω(t+1)、 ω(t+2)。
假设此时要使用“由”,预测“我命”和“我不”的内容。

3、词嵌入模型的训练
(1)模型训练的过程
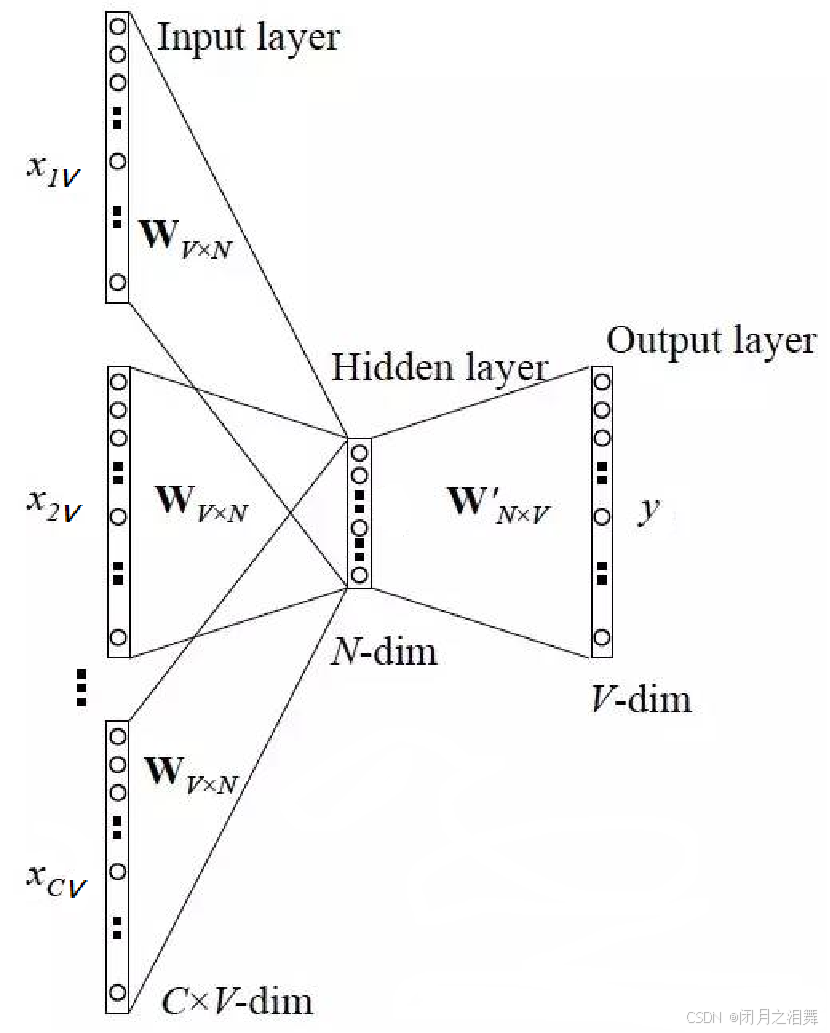
1、当前词的上下文词语的one-hot编码输入到输入层。
2、这些词分别乘以同一个矩阵WVN后分别得到各自的1N 向量。
3、将多个这些1N 向量取平均为一个1N 向量。
4、将这个1N 向量乘矩阵 W’VN ,变成一个1V 向量。
5、将1V 向量softmax归一化后输出取每个词的概率向量1V
6、将概率值最大的数对应的词作为预测词。
7、将预测的结果1V 向量和真实标签1V 向量(真实标签中的V个值中有一个是1,其他是0)计算误差
8、在每次前向传播之后反向传播误差,不断调整 WVN和 W’V*N矩阵的值。
假定语料库中一共有4960个词,则词编码为4960个01组合,现在压缩为300维。
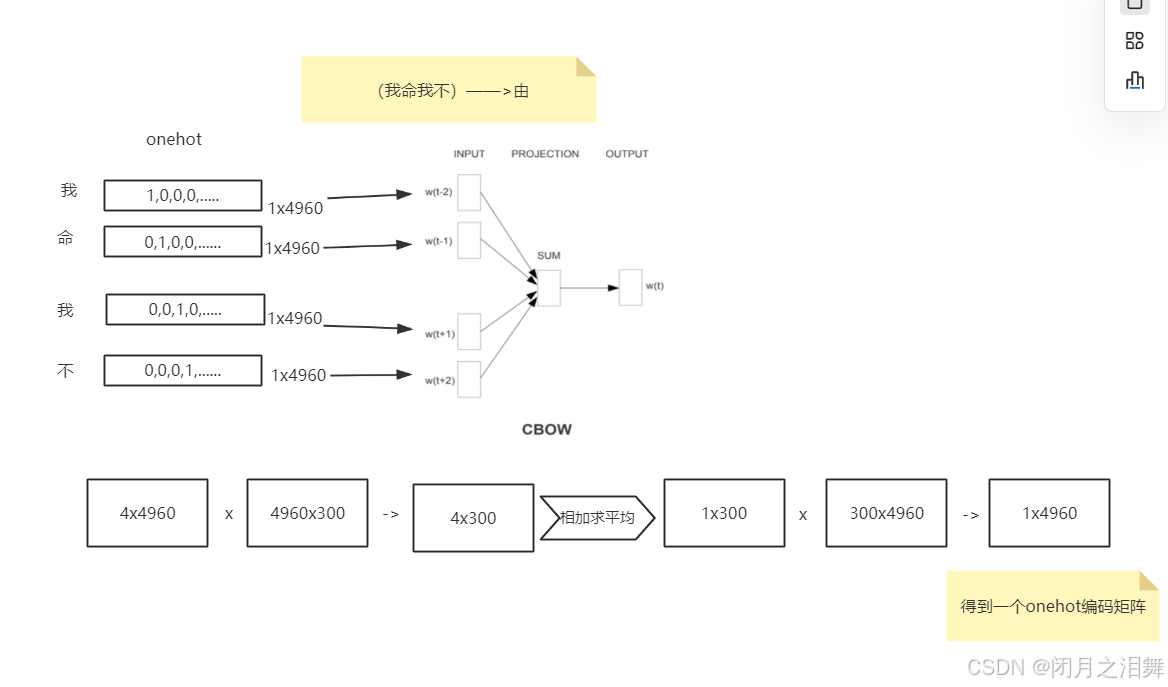

当新来一个字时,我们可以将这个字的onehot向量与CBOW中训练得到的矩阵相乘就可以实现词嵌入,将词向量的维度由4960维降到300维。
(2)损失函数的选择

softmax交叉熵损失函数实现多分类,公式为:
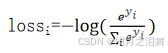
三、CBOW模型实现词嵌入
1、导入必要的库
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim#
from tqdm import tqdm,trange#显示进度条
import numpy as np
2、读取文本,创建词库
CONTEXT_SIZE=2 #设置词左边和右边选择的个数(即上下文词汇个数)raw_text ="""We are about to study the idea of a computational process.Computational processes are abstract beings that inhabit computers.As they evolve, processes manipulate other abstract things called data.The evolution of a process is directed by a pattern of rulescalled a program. People create programs to direct processes. In effectwe conjure the spirits of the computer with our spells.""".split()#语料库#中文的语句,你可以选择分词,也可以选择分字
vocab = set(raw_text)#集合。词库,里面内容独一无人
vocab_size = len(vocab)
word_to_idx = {word:i for i, word in enumerate(vocab)} #for循环的复合写法,第1次循环,i得到的索引号,word 第1个年
idx_to_word = {i: word for i, word in enumerate(vocab)}3、构造CBOW网络的输入和输出
data =[]#获取上下文词,将上下文词作为输入,目标词作为输出。构建训练数据集。
for i in range(CONTEXT_SIZE, len(raw_text)-CONTEXT_SIZE):#(2,60)context =([raw_text[i-(2-j)]for j in range(CONTEXT_SIZE)]+[raw_text[i+j+ 1] for j in range(CONTEXT_SIZE)])#获取上下文词(['we"'are"'to''study'])target = raw_text[i] #获取目标词'about'data.append((context,target)) #将上下文词和目标词保存到data中[((['we"'are 'to''study'])'about')]
4、定义文本转onehot的函数
def make_context_vector(context,word_to_idx):#将上下文词转换为one-hotidxs =[word_to_idx[w] for w in context]return torch.tensor(idxs,dtype=torch.long)#
5、定义CBOW网络
class CBOW(nn.Module):def __init__(self,vocab_size,embedding_dim):super(CBOW,self).__init__()self.embeddings=nn.Embedding(vocab_size,embedding_dim)self.proj=nn.Linear(embedding_dim,128)self.output=nn.Linear(128,vocab_size)def forward(self,inputs):embeds=sum(self.embeddings(inputs)).view(1,-1)out=F.relu(self.proj(embeds))out=self.output(out)nll_prob=F.log_softmax(out,dim=-1)return nll_prob
6、优化器损失函数初始化,加载模型到设备中
device='cuda' if torch.cuda.is_available() else 'mps' if torch.backends.mps.is_available() else 'cpu'model=CBOW(vocab_size,10).to(device) #将模型加载到设备中,设置CBOW网络的输入和输出vocab_size是指语料库的大小,10是指你要将语料库压缩到多少维。optimizer=optim.Adam(model.parameters(),lr=0.001) #创建优化器loss_funcation=nn.NLLLoss() #损失函数初始化
7、模型的训练
losses=[]
model.train()for epoch in tqdm(range(200)):for context,target in data:context_vector=make_context_vector(context,word_to_idx).to(device)target=torch.tensor([word_to_idx[target]]).to(device)train_predict=model(context_vector)loss=loss_funcation(train_predict,target)optimizer.zero_grad()loss.backward()optimizer.step()
8、预测
context=['People','create','to','direct']
context_vector=make_context_vector(context,word_to_idx).to(device)model.eval()
predict=model(context_vector)
max_idx=int(predict.argmax(1))
print(idx_to_word[max_idx])完整代码展示
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim#
from tqdm import tqdm,trange#显示进度条
import numpy as np
#任务:已经有了语料库,
# 1、构造训练数据集,(单词,词库,)#真实的单词模型,
# 每一个单词的词性,你训练大量的输入文本,
CONTEXT_SIZE=2 #设置词左边和右边选择的个数(即上下文词汇个数)raw_text ="""We are about to study the idea of a computational process.Computational processes are abstract beings that inhabit computers.As they evolve, processes manipulate other abstract things called data.The evolution of a process is directed by a pattern of rulescalled a program. People create programs to direct processes. In effectwe conjure the spirits of the computer with our spells.""".split()#语料库#中文的语句,你可以选择分词,也可以选择分字
vocab = set(raw_text)#集合。词库,里面内容独一无人
vocab_size = len(vocab)
word_to_idx = {word:i for i, word in enumerate(vocab)} #for循环的复合写法,第1次循环,i得到的索引号,word 第1个年
idx_to_word = {i: word for i, word in enumerate(vocab)}data =[]#获取上下文词,将上下文词作为输入,目标词作为输出。构建训练数据集。
for i in range(CONTEXT_SIZE, len(raw_text)-CONTEXT_SIZE):#(2,60)context =([raw_text[i-(2-j)]for j in range(CONTEXT_SIZE)]+[raw_text[i+j+ 1] for j in range(CONTEXT_SIZE)])#获取上下文词(['we"'are"'to''study'])target = raw_text[i] #获取目标词'about'data.append((context,target)) #将上下文词和目标词保存到data中[((['we"'are 'to''study'])'about')]
def make_context_vector(context,word_to_idx):#将上下文词转换为one-hotidxs =[word_to_idx[w] for w in context]return torch.tensor(idxs,dtype=torch.long)#class CBOW(nn.Module):def __init__(self,vocab_size,embedding_dim):super(CBOW,self).__init__()self.embeddings=nn.Embedding(vocab_size,embedding_dim)self.proj=nn.Linear(embedding_dim,128)self.output=nn.Linear(128,vocab_size)def forward(self,inputs):embeds=sum(self.embeddings(inputs)).view(1,-1)out=F.relu(self.proj(embeds))out=self.output(out)nll_prob=F.log_softmax(out,dim=-1)return nll_probdevice='cuda' if torch.cuda.is_available() else 'mps' if torch.backends.mps.is_available() else 'cpu'model=CBOW(vocab_size,10).to(device)optimizer=optim.Adam(model.parameters(),lr=0.001)loss_funcation=nn.NLLLoss()losses=[]
model.train()for epoch in tqdm(range(200)):total_loss=0for context,target in data:context_vector=make_context_vector(context,word_to_idx).to(device)target=torch.tensor([word_to_idx[target]]).to(device)train_predict=model(context_vector)loss=loss_funcation(train_predict,target)optimizer.zero_grad()loss.backward()optimizer.step()total_loss+=loss.item()losses.append(total_loss)print(losses)context=['People','create','to','direct']
context_vector=make_context_vector(context,word_to_idx).to(device)model.eval()
predict=model(context_vector)
max_idx=int(predict.argmax(1))
print(idx_to_word[max_idx])总结
统计语言模型受限于记忆容量与语义抽象能力,One-Hot 编码的稀疏性与语义孤立问题促使词嵌入技术诞生。Word2Vec 通过 CBOW 和 Skip-Gram 模型,基于上下文共现学习低维语义向量,并借助负采样等优化方法实现高效训练,完成了从符号表示到语义建模的跨越。然而,静态词嵌入难以捕捉序列数据的时序依赖与长期关联,而 ** 循环神经网络(RNN)** 及其改进变体 LSTM(长短期记忆网络)通过动态建模序列中的状态传递与记忆机制,弥补了这一缺陷,成为处理时序数据的核心技术。从词嵌入到 RNN/LSTM,自然语言处理逐步构建起从 “词级语义表示” 到 “序列动态建模” 的完整体系,为后续复杂任务奠定了关键基础。
相关文章:

《CBOW 词向量转化实战:让自然语言处理 “读懂” 文字背后的含义》
文章目录 前言一、自然语言模型统计语言模型存在的问题总结:这两个问题的本质,第一个是"容量问题":模型记忆力有限;第二个是"理解力问题":模型缺乏抽象能力。 二、词向量转换1.onehot编码编码过程…...

网络变更:APIC 节点替换
Draft 一、同版本硬件更换 1. 查看 APIC 状态 System > Controllers > (any APIC) > Cluster APIC1> acidiag avread // APIC 参数 2. 下线故障设备 Actions > Decommission 3. 物理移除故障设备,连接目标 APIC 4. 根据第一步中的配置参数配置目…...

Java在excel中导出动态曲线图DEMO
1、环境 JDK8 POI 5.2.3 Springboot2.7 2、DEMO pom <dependency><groupId>org.apache.poi</groupId><artifactId>poi-ooxml</artifactId><version>5.2.3</version></dependency><dependency><groupId>commons…...
)
Python爬虫爬取图片并存储到MongoDB(注意:仅尝试存储一条空的示例数据到MongoDB,验证MongoDB的联通性)
以下是一个使用Python爬取图片并存储到MongoDB的示例实现,包含详细步骤说明: import requests from bs4 import BeautifulSoup from pymongo import MongoClient from datetime import datetime import os import re# 配置信息 mongoIP mongodb://root…...
)
Qt —— 在Linux下试用QWebEngingView出现的Js错误问题解决(附上四种解决办法)
错误提示:js: A parser-blocking, cross site (i.e. different eTLD+1) script, https:xxxx, is invoked via document.write. The network request for this script MAY be blocked by the browser in this or a future page load due to poor network connectivity. If bloc…...

240424 leetcode exercises II
240424 leetcode exercises II jarringslee 文章目录 240424 leetcode exercises II[148. 排序链表](https://leetcode.cn/problems/sort-list/)🔁分治 & 归并排序法1. 找中点并断开2. 合并两个有序链表3. 主函数:递归拆分与合并 [24. 两两交换链表…...

STM32实现2小时延时的最佳方法探讨
在嵌入式系统开发中,特别是使用STM32这类微控制器时,实现精确的长时间延时是一项常见但具有挑战性的任务。延时的方法选择不仅影响系统的性能和功耗,还关系到系统的稳定性和可靠性。本文将探讨在STM32上实现2小时延时的几种方法,并…...

G3学习笔记
🍨 本文为🔗365天深度学习训练营 中的学习记录博客🍖 原作者:K同学啊 准备工作 import torch import numpy as np import torch.nn as nn import torch.optim as optim from torchvision import datasets, transforms from torc…...
)
初识Redis · 主从复制(上)
目录 前言: 主从模式 模拟主从模式 连接信息 slaveof命令 nagle算法 Nagle算法的工作原理: 具体实现: 优点: 缺点: 使用场景: 拓扑结构 前言: 主从复制这里算得上是一个大头了&…...
题解)
欧拉计划 Project Euler55(利克瑞尔数)题解
欧拉计划 Project Euler 55 题解 题干思路code 题干 思路 直接暴力找即可,若使用其他语言要注意溢出的问题,这里我使用的手写大数加法 code // 249 #include <bits/stdc.h>using namespace std;using ll long long;string add(const string&am…...

关于nginx,负载均衡是什么?它能给我们的业务带来什么?怎么去配置它?
User 关于nginx,我还想知道,负载均衡是什么?它能为我的业务带来什么?怎么去配置它? Assistant 负载均衡是 Nginx 另一个非常强大的功能,也是构建高可用、高性能应用的关键技术之一。我们来详细了解一下。 …...

【项目管理】进度网络图 笔记
项目管理-相关文档,希望互相学习,共同进步 风123456789~-CSDN博客 (一)知识总览 项目管理知识域 知识点: (项目管理概论、立项管理、十大知识域、配置与变更管理、绩效域) 对应&…...

【C++QT】Buttons 按钮控件详解
文章目录 一、QPushButton 基础按钮控件二、QToolButton 轻量工具按钮控件三、QRadioButton 互斥选择控件四、QCheckBox 状态选择控件五、QCommandLinkButton 引导式按钮控件六、QDialogButtonBox 对话框按钮布局控件七、实践与选型建议八、总结如果这篇文章对你有所帮助&#…...

威雅利电子|业界领先的高隔离度用于5G基站的吸收式SPDT开关“NT1819“
业界领先的高隔离度 用于5G基站的吸收式SPDT开关"NT1819" 为了实现智能社会,已经启动了5G服务。这样,高速、低延迟、大容量的数据通信成为可能,也给我们的生活和工业发展带来了巨大的变化。 在5G基站有很多天线,每个天…...

【DNS】BIND 9的配置
该文档围绕BIND 9的配置与区域文件展开,介绍了BIND 9配置文件及区域文件的相关知识,以及权威名称服务器、解析器的相关内容,还阐述了负载均衡和区域文件的详细知识,具体如下: 基础配置文件: named.conf&am…...

高可靠性厚铜板制造的关键设备与工艺投入
随着科技的不断发展,电子设备越来越普及,对电路板的需求也越来越大。厚铜板电路板作为一种高性能、高可靠性的电路板,受到了广泛的关注和应用。那么,作为一家厚铜板电路板供应商,如何投入线路板生产呢?本文…...

m365是什么,和o365的区别
M365(Microsoft 365)是微软推出的基于云的办公套件,包含多种生产力工具,旨在帮助个人和企业提高工作效率。它包括经典的办公软件,如Word、Excel、PowerPoint、Outlook等,还提供协作和云存储服务,…...

【Pandas】pandas DataFrame dot
Pandas2.2 DataFrame Binary operator functions 方法描述DataFrame.add(other)用于执行 DataFrame 与另一个对象(如 DataFrame、Series 或标量)的逐元素加法操作DataFrame.add(other[, axis, level, fill_value])用于执行 DataFrame 与另一个对象&…...

技术服务业-首套运营商网络路由5G SA测试专网在深光搭建完成并对外提供服务
深光为了更好的服务蜂窝无线技术及运营商测试认证相关业务,搭建了技术服务业少有的5G测试专网,可独立灵活配置、完整端到端5G(含RedCap、LAN)的网络架构。 通过走真正运营商网络路由的方式,使终端设备的测试和运营商网…...

GrassRouter 小草MULE多5G多链路聚合通信路由设备在应急场景的聚合效率测试报告及解决方案
在应急通信场景中,快速、稳定、高效的通信链路是保障救援工作顺利开展的关键。MULE(Multi-Link Unified Link Enhancement)多链路聚合路由通信设备作为一种新型的通信技术解决方案,通过聚合多条通信链路(如4G/5G、卫星…...

解释器模式:自定义语言解析与执行的设计模式
解释器模式:自定义语言解析与执行的设计模式 一、模式核心:定义语言文法并实现解释器处理句子 在软件开发中,当需要处理特定领域的语言(如数学表达式、正则表达式、自定义配置语言)时,可以通过解释器模式…...
)
第十二章 Python语言-大数据分析PySpark(终)
目录 一. PySpark前言介绍 二.基础准备 三.数据输入 四.数据计算 1.数据计算-map方法 2.数据计算-flatMap算子 3.数据计算-reduceByKey方法 4.数据计算-filter方法 5.数据计算-distinct方法 6.数据计算-sortBy方法 五.数据输出 1.输出Python对象 (1&am…...

Oracle数据库巡检脚本
1.查询实例信息 SELECT INST_ID, INSTANCE_NAME, TO_CHAR(STARTUP_TIME, YYYY-MM-DD HH24:MI:SS) AS STARTUP_TIME FROM GV$INSTANCE ORDER BY INST_ID; 2.查看是否归档 archive log list 3.查看数据库参数 SELECT NAME , TYPE , VALUE FROM V$PARAMETER ORDER BY NAME; 4.…...

示例:Spring JDBC编程式事务
以下是一个完整的 Spring JDBC 编程式事务示例,包含批量插入、事务管理、XML 配置和单元测试: 1. 项目依赖(pom.xml) <dependencies><!-- Spring JDBC --><dependency><groupId>org.springframework<…...

Happens-Before 原则
Happens-Before 规则 Happens-Before是JMM的核心概念之一,是一种可见性模型,保障多线程环境下前一个操作的结果相对于后续操作是可见的。 程序顺序性,同一线程中前面代码的操作happens-before后续的任意操作。volatile变量规则,…...
提交代码更新?)
怎样通过互联网访问内网 SVN (版本管理工具)提交代码更新?
你有没有遇到过这种情况:在公司或者家里搭了个 SVN 服务器(用来存代码的),但出门在外想提交代码时,发现连不上? 这是因为 SVN 通常跑在内网,外网直接访问不了。 这时候就需要 “内网穿透” ——…...
)
Verilog 语法 (一)
Verilog 是硬件描述语言,在编译下载到 FPGA 之后, FPGA 会生成电路,所以 Verilog 全部是并行处理与运行的;C 语言是软件语言,编译下载到单片机 /CPU 之后,还是软件指令,而不会根据你的代…...
 如何进行 SQL 优化?)
针对 Spring Boot 应用中常见的查询场景 (例如:分页查询、关联查询、聚合查询) 如何进行 SQL 优化?
通用优化原则(适用于所有场景): 索引是基础: 确保 WHERE、JOIN、ORDER BY、GROUP BY 涉及的关键列都有合适的索引(单列或联合索引)。避免 SELECT *: 只查询业务需要的列,减少数据传输量和内存消耗。覆盖索…...

shadcn/radix-ui的tooltip高度定制arrow位置
尝试了半天,后来发现,不支持。。。。。就是不支持 那箭头只能居中 改side和align都没用,下面有在线实例 https://codesandbox.io/p/sandbox/radix-ui-slider-forked-zgn7hj?file%2Fsrc%2FApp.tsx%3A69%2C21 但是呢, 第一如果…...

ROS-真机向虚拟机器人映射
问题描述 ROS里的虚拟机械臂可以实现和真实机械臂的位置同步,真实机械臂如何动,ROS里的虚拟机械臂就如何动 效果 步骤 确保库卡机械臂端安装有EthernetKRL辅助软件和KUKAVARPROXY 6.1.101(它是一个 TCP/IP 服务器 ,可通过网络实…...
)
ap无法上线问题定位(交换机发包没有剥掉pvid tag)
一中学,新开的40台appoe交换机核心交换机旁挂ac出口路由的组网,反馈ap无法上线,让协助解决。 组网如下: 排查过程: 检查ac的配置,没有发现问题 发现配置没有问题,vlan1000配置子接口ÿ…...

Linux基础
03.Linux基础 了解VMware备份的两种方式 了解Linux系统文件系统 掌握Linux基础命令 备份操作系统 为什么要备份系统? 数据安全:防止因硬件故障、软件错误等原因导致的数据丢失。 系统恢复:快速恢复系统至正常状态,减少停机时…...

python函数与模块
目录 一:函数 1.无参函数 2.带参数函数 2.函数中变量中的作用域 4.内建函数 二:模块与包 1.模块 (1)模块定义 (2)模块导入 2.包 (1)包的使用 (2)_…...

线上助农产品商城小程序源码介绍
基于ThinkPHPFastAdminUniApp开发的线上助农产品商城小程序源码,旨在为农产品销售搭建一个高效、便捷的线上平台,助力乡村振兴。 一、技术架构 该小程序源码采用了ThinkPHP作为后端框架,FastAdmin作为快速开发框架,UniApp作为跨…...

个人博客后台管理开发日志
技术栈:Vue3 Ts node.js mySQL pinia axios 3月14日 一、数据表梳理 用户(user) ID名字邮箱密码 头像 地址 创建 时间 总览有本地文件、博客文章、摄影图库、随笔随记,这些板块也有对应的分类,我们要把这些分类…...

[论文阅读]REPLUG: Retrieval-Augmented Black-Box Language Models
REPLUG: Retrieval-Augmented Black-Box Language Models REPLUG: Retrieval-Augmented Black-Box Language Models - ACL Anthology NAACL-HLT 2024 在这项工作中,我们介绍了RePlug(Retrieve and Plug),这是一个新的检索增强型…...

Matlab 基于共面螺旋管或共面亥姆霍兹谐振器的超薄低频吸声板
经典吸声材料的吸声性能严格依赖于材料的厚度,要达到完全吸声,至少需要四分之一波长。在本文中,我们报道了一种厚度约为波长百分之一的超薄吸声板,可以完全吸收声能。其策略是将四分之一波长的减声管弯曲并缠绕成二维共面减声管&a…...

济南国网数字化培训班学习笔记-第二组-4节-输电线路工程安全管理
输电线路工程安全管理 安全标识 颜色 禁止红、警示黄、指令蓝、提示绿 安全器具 定义 安全工器具通常专指“电力安全工器具”,是防止触电、灼伤、坠落、摔跌、腐蚀、窒息等事故,保障工作人员人身安全的各种专用工具和器具 分类 个体防护设备 防…...

【C语言】数据在内存中的存储:从整数到浮点数的奥秘
前言 在计算机的世界里,数据的存储和表示是编程的基础。今天,我们就来深入探讨一下数据在内存中的存储方式,包括整数和浮点数的存储细节,以及大小端字节序的奥秘。这些内容不仅对理解计算机系统至关重要,还能帮助我们…...

白鲸开源WhaleStudio与崖山数据库管理系统YashanDB完成产品兼容互认证
近日,北京白鲸开源科技有限公司与深圳计算科学研究院联合宣布,双方已完成产品兼容互认证。此次认证涉及深圳计算科学研究院自主研发的崖山数据库管理系统YashanDB V23和北京白鲸开源科技有限公司的核心产品WhaleStudio V2.6。经过严格的测试与验证&#…...
)
图论---朴素Prim(稠密图)
O( n ^2 ) 题目通常会提示数据范围: 若 V ≤ 500,两种方法均可(朴素Prim更稳)。 若 V ≤ 1e5,必须用优先队列Prim vector 存图。 // 最小生成树 —朴素Prim #include<cstring> #include<iostream> #i…...

借助deepseek和vba编程实现一张表格数据转移到多张工作簿的表格中
核心目标 将工作表中的内容按村社名称分类放入对应位置的目标工作簿的第一个工作表的对应位置 deepseek提问方式 你是一个擅长vba编程的专家,核心目标是奖工作表中的部分内容按下列要求写入对应工作簿的第一个工作表中。第一,在工作表A列中筛选出相…...

springboot整合redis实现缓存
一、redis 二、spring boot 整合redis 三、基于注解的Redis缓存实现 使用Cacheable、CachePut、CacheEvict注解定制缓存管理 对CommentService类中的方法进行修改使用Cacheable、CachePut、CacheEvict三个注解定制缓存管理,修改后的方法如下 Cacheable(cacheNam…...

git tag使用场景和实践
背景 每次上线一个迭代,为了区分本次代码的分支是哪个迭代,可以给分支打上tag,这样利于追踪分支所属迭代,如果devops没有自动给分支打tag,需要自己来打 操作 1.查看当前tag git tag2.给分支打tag git tag <tag…...

十分钟恢复服务器攻击——群联AI云防护系统实战
场景描述 服务器遭遇大规模DDoS攻击,导致服务不可用。通过群联AI云防护系统的分布式节点和智能调度功能,快速切换流量至安全节点,清洗恶意流量,10分钟内恢复业务。 技术实现步骤 1. 启用智能调度API触发节点切换 群联系统提供RE…...

国产紫光同创FPGA视频采集转SDI编码输出,基于HSSTHP高速接口,提供2套工程源码和技术支持
目录 1、前言工程概述免责声明 2、相关方案推荐我已有的所有工程源码总目录----方便你快速找到自己喜欢的项目紫光同创FPGA相关方案推荐本博已有的 SDI 编解码方案本方案在Xilinx--Artix7系列FPGA上的应用本方案在Xilinx--Kintex系列FPGA上的应用本方案在Xilinx--Zynq系列FPGA上…...

最小生成树-prim、kruskal算法
目录 prim算法 kruskal算法 题目练习 (1)AcWing 858. Prim算法求最小生成树 - AcWing (2)859. Kruskal算法求最小生成树 - AcWing题库编辑 学习之前建议温习一下迪杰斯特拉算法和并查集~ 先简单认识下最小生成树:…...

【硬核干货】JetBrains AI Assistant 干货笔记
快进来抄作业,小编呕心沥血整理的 JetBrains AI Assistant 超干货笔记! 原文链接:【硬核干货】JetBrains AI Assistant 干货笔记 关于晓数神州 晓数神州坚持以“客户为中心”的宗旨,为客户提供专业的解决方案和技术服务ÿ…...

强化学习核心原理及数学框架
1. 定义与核心思想 强化学习(Reinforcement Learning, RL)是一种通过智能体(Agent)与环境(Environment)的持续交互来学习最优决策策略的机器学习范式。其核心特征为: 试错学习&#x…...

C# 综合示例 库存管理系统4 classMod类
版权声明:本文为博主原创文章,转载请在显著位置标明本文出处以及作者网名,未经作者允许不得用于商业目的 在《库存管理系统》中使用classMod类来保存全局变量。 变量定义和含义,请详见下面的源代码: public class classMod { //数据库路径...