第十二章 Python语言-大数据分析PySpark(终)
目录
一. PySpark前言介绍
二.基础准备
三.数据输入
四.数据计算
1.数据计算-map方法
2.数据计算-flatMap算子
3.数据计算-reduceByKey方法
4.数据计算-filter方法
5.数据计算-distinct方法
6.数据计算-sortBy方法
五.数据输出
1.输出Python对象
(1)collect算子
(2)reduce算子
(3)take算子
(4)count算子
2.输出到文件中
六.分布式集群运行(作者谈感受)
此章节主要讲解PySpark技术其中内容分为:前言介绍、基础准备、数据输入、数据计算、数据输出、分布式集群运行。
基础准备主要是:“安装PySpark”和PySpark执行环境入口对象,理解PySpark的编程模型。
分布式集群运行这一章,作者并未学到liunx还有专门的大数据因此无法演示。
一. PySpark前言介绍
Spark的定义:Apache Spark是用于大规模数据(large-scala data)处理的统一(unified)分析引擎

简单来说,Spark是一款分布式的计算框架,用于调度成百上千的服务器集群,计算TB、PB乃至EB级别的海量数据

学习PySpark技术的目的:由于Python应用场景和就业方向是十分丰富的,其中,最为亮点的方向为:“大数据开发”和“人工智能”

总结:
1.什么是Spark、什么是PySpark
- Spark是Apache基金会旗下的顶级开源项目,用于对海量数据进行大规模分布式计算。
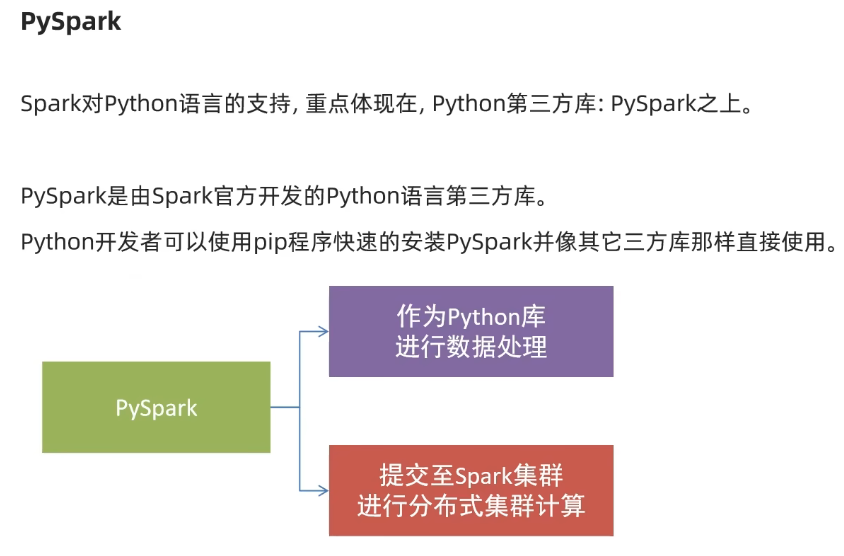
- PySpark是Spark的Python实现,是Spark为Python开发者提供的编程入口,用于以Python代码完成Spark任务的开发
- PySpark不仅可以作为Python第三方库使用,也可以将程序提交的Spark集群环境中,调度大规模集群进行执行。
二.基础准备
PySpark库的安装
同其它的Python第三方库一样,PySpark同样可以使用pip程序进行安装。
在”CMD”命令提示符程序内,输入:
pip install pyspark
或使用国内代理镜像网站(清华大学源)
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple pyspark
构建PySpark执行环境入口对象
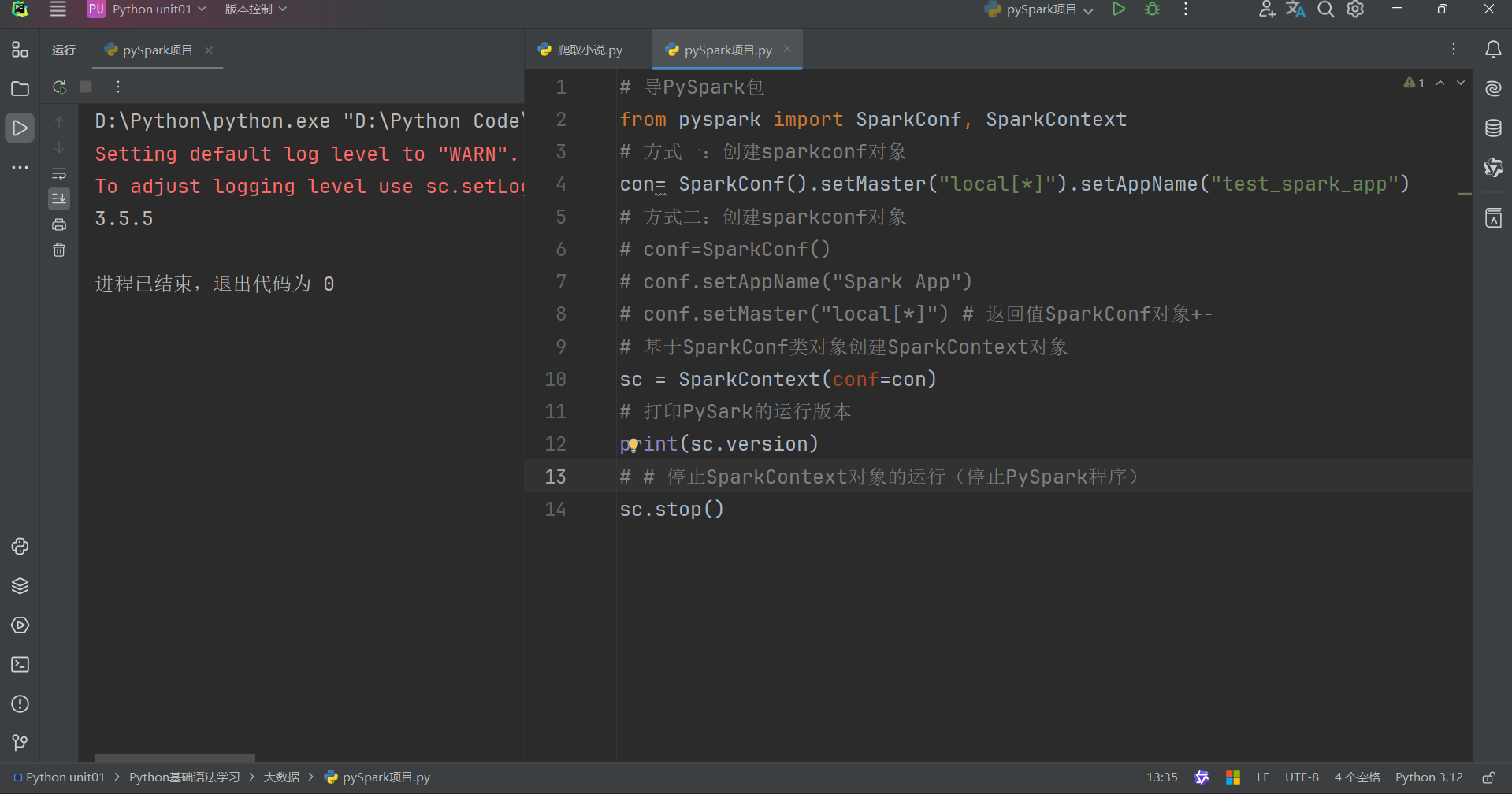
想要使用PySpark库完成数据处理,首先需要构建一个执行环境入口对象。
PySpark的执行环境入口对象是:类SparkContext 的类对象

以下是示例代码如下:
注:
若输出结果是cmd �����ڲ����ⲿ���Ҳ���ǿ����еij��� ���������ļ���
Java gateway process exited before sending its port number
则需要你去环境变量添加JDK和在path中添加“C:\Windows\System32”即可,作者亲测有效。后面可能还需要hadoop的配置,可自行b站,作者也是找半天配半天,甚至这个问题也是靠了我们CSDN大佬的各种解决方法得出来,我只能说CSDN是国内最好用的平台。
PySpark的编程模型
SparkContext类对象,是PySpark编程中一切功能的入口。
PySpark的编程,主要分为如下三大步骤:

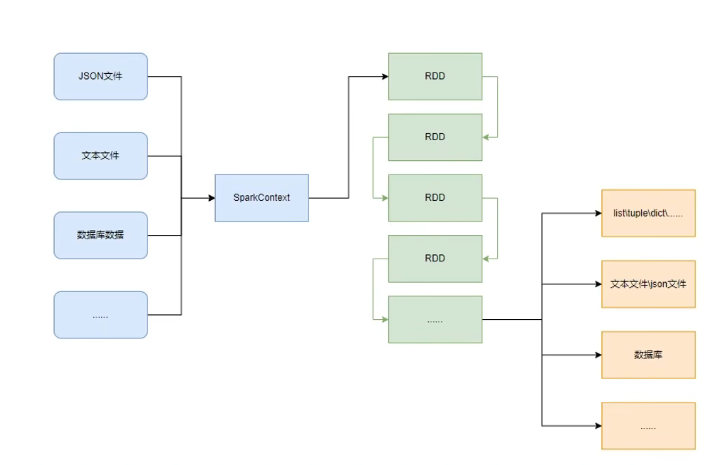
- 通过SparkContext对象,完成数据输入
- 输入数据后得到RDD对象,对RDD对象进行迭代计算
- 最终通过RDD对象的成员方法,完成数据输出工作
总结:
1.如何安装PySpark库
pip install pyspark
2.为什么要构建SparkContext对象作为执行入口
PySpark的功能都是从SparkContext对象作为开始
3.PySpark的编程模型是?
数据输入:通过5parkContext完成数据读取
数据计算:读取到的数据转换为RDD对象,调用RDD的成员方法完成
计算
数据输出:调用RDD的数据输出相关成员方法,将结果输出到list、元组、字典、文本文件、数据库等
三.数据输入
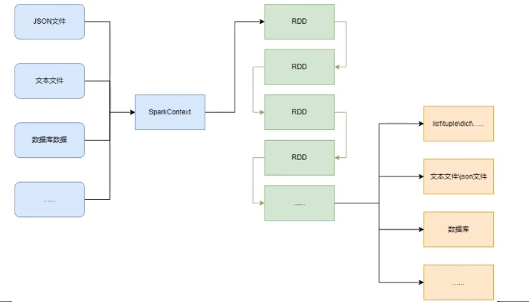
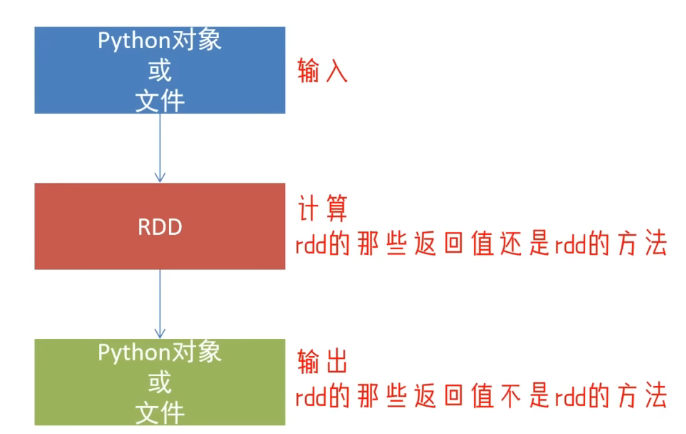
RDD对象
如图可见,PySpark支持多种数据的输入,在输入完成后,都会得到一个:RDD类的对象
RDD全称为:弹性分布式数据集(ResilientDistributed Datasets)
PySpark针对数据的处理,都是以RDD对象作为载体,即:
- 数据存储在RDD内
- 各类数据的计算方法,也都是RDD的成员方法
- RDD的数据计算方法,返回值依旧是RDD对象
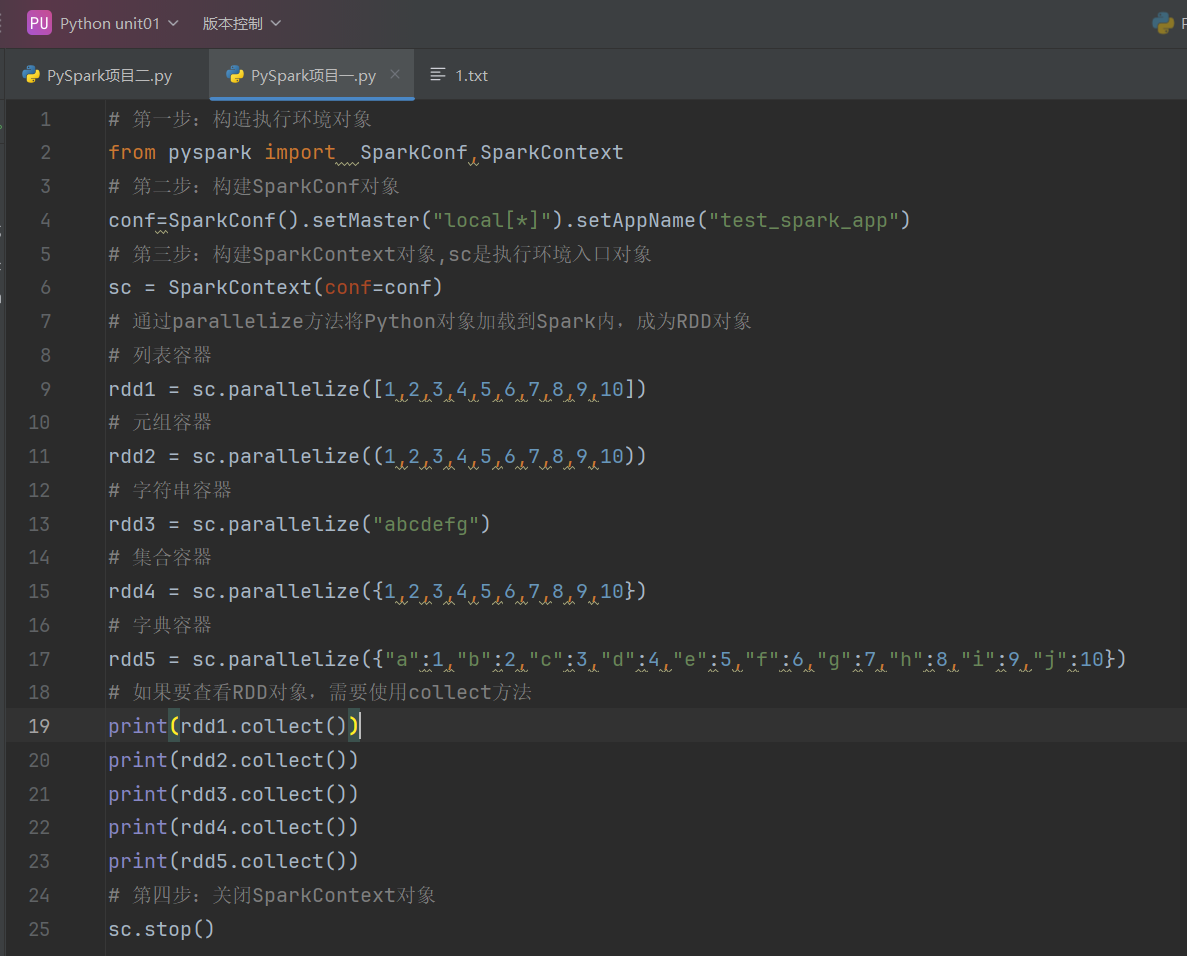
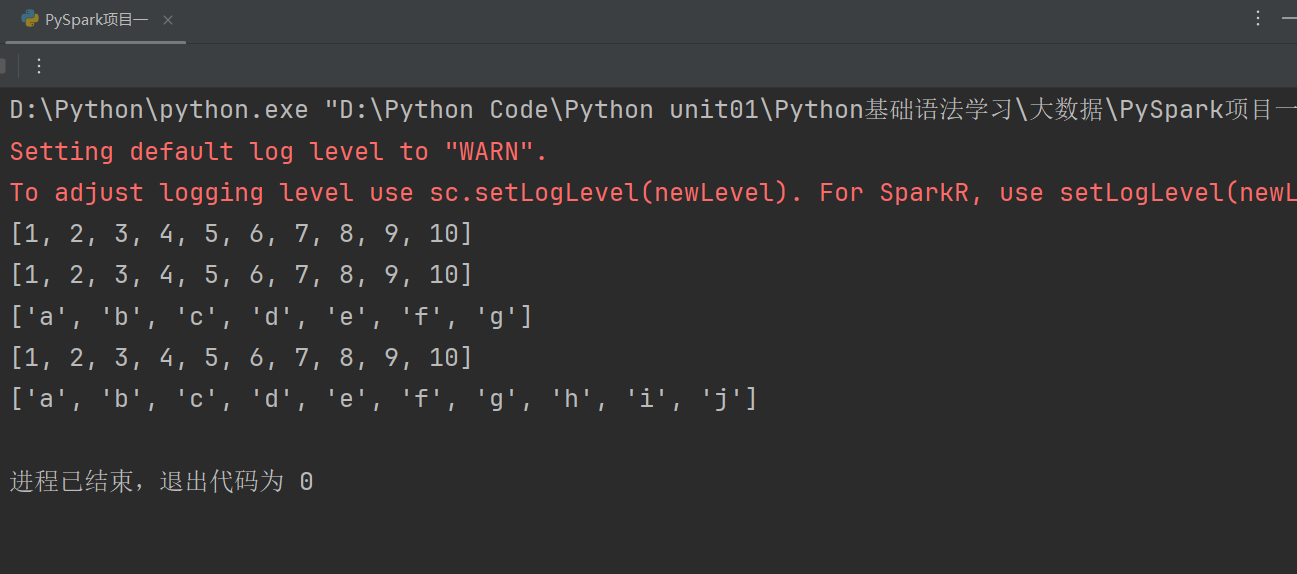
PySpark支持通过SparkContext对象的parallelize成员方法,将:
- list
- tuple
- set
- dict
- str
转换为PySpark的RDD对象

注意:
- 字符串会被拆分出1个个的字符,存入RDD对象
- 字典仅有key会被存入RDD对象
代码示例如下:
读取文件转RDD对象
PySpark也支持通过SparkContext入口对象,来读取文件,来构建出RDD对象。

代码演示如下:
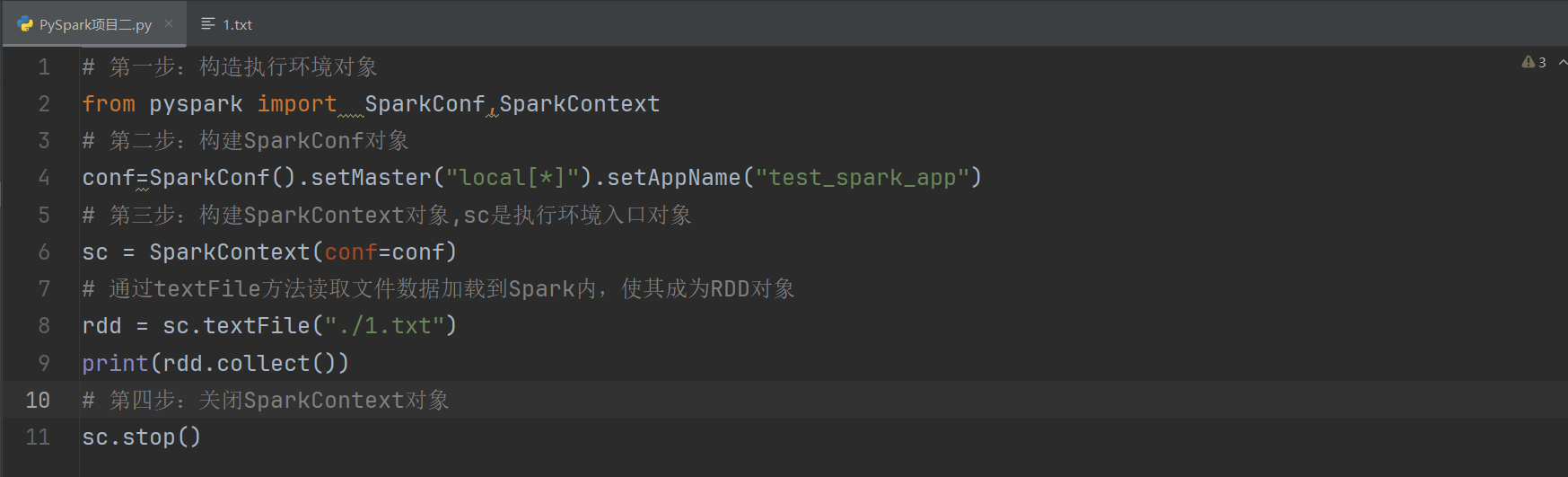

总结:
1.RDD对象是什么?为什么要使用它?
RDD对象称之为分布式弹性数据集,是PySpark中数据计算的载体,它可以:
- 提供数据存储
- 提供数据计算的各类方法
- 数据计算的方法,返回值依旧是RDD(RDD选代计算)
后续对数据进行各类计算,都是基于RDD对象进行
2.如何输入数据到Spark(即得到RDD对象)
- 通过SparkContext的parallelize成员方法,将Python数据容器转换为RDD对象
- 通过SparkContext的textFile成员方法,读取文本文件得到RDD对象
四.数据计算
此小节分为:map方法、flatMap方法、reduceByKey方法、filter方法、distinct方法、sortBy方法。
1.数据计算-map方法
PySpark的数据计算,都是基于RDD对象来进行的,那么如何进行呢?
自然是依赖,RDD对象内置丰富的:成员方法(算子)
map算子
功能: map算子,是将RDD的数据 一条条处理( 处理的逻辑 基于map算子中接收的处理函数),返回新的RDD
语法:

示例代码演示如下:
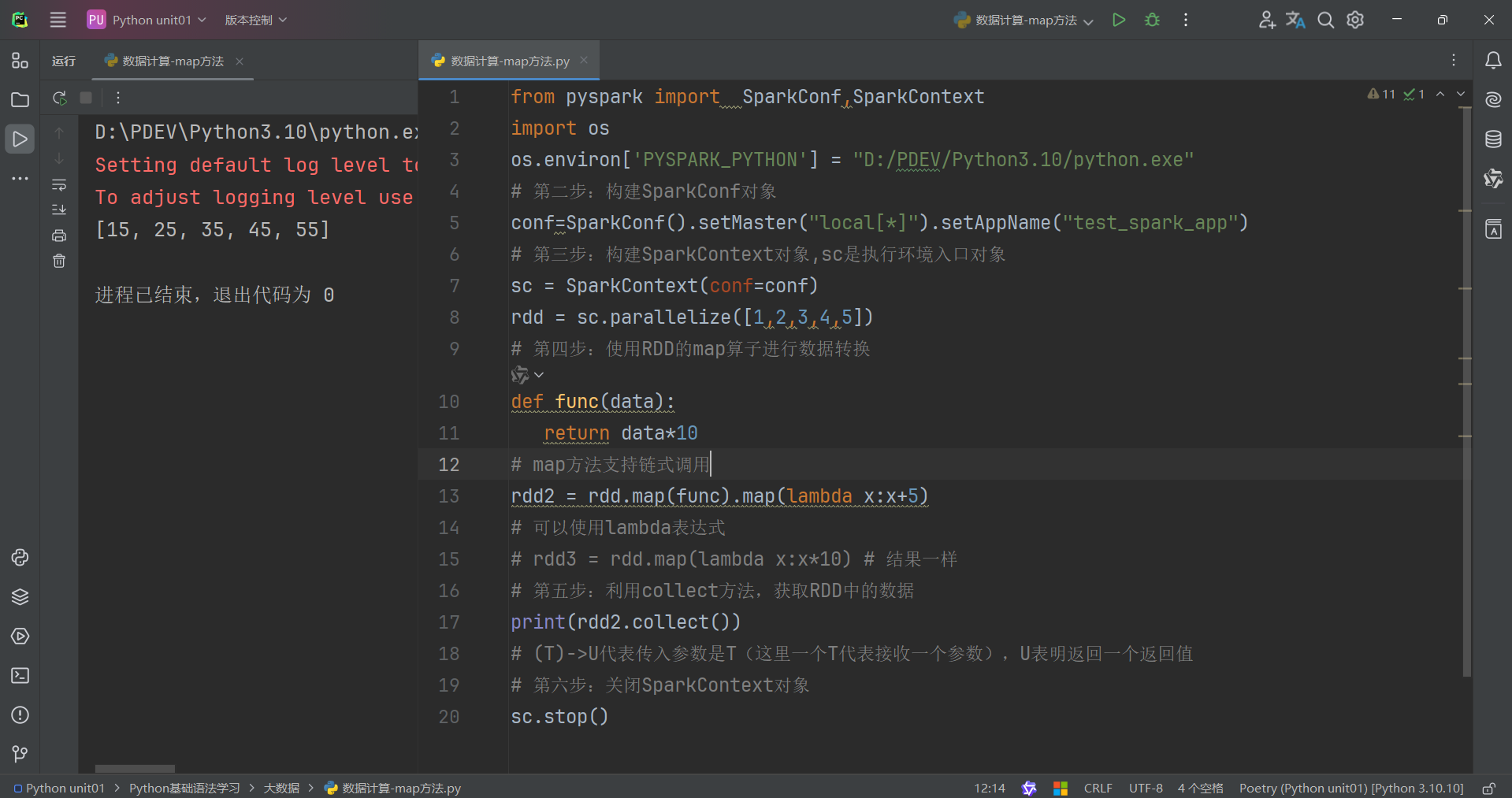
map方法会根据你序列的数据进行一个一个计算,并且返回新的rdd。
因此它也支持链式调用。
注:
这里使用map方法有两个注意地方,作者花大量时间解决这个。一个就是看看自己的Python解释器一定要是3.10及以下的3.11及最新不能使用,作者已经测试过了。如果你报错,就一定要将Python解释器装一个3.10然后再换上3.10。这是第一个地方。
第二个地方一定要在前面加上import OS导入OS包。并且要在最前面加上:os.environ['PYSPARK_PYTHON'] = "D:/PDEV/Python3.10/python.exe"
这个路径一定要根据你电脑Python解释器上面填写,根据自己电脑配置解释器的位置进行调配。以上是最主要会导致你程序报错的原因。
总结:
1.map算子(成员方法)
- 接受一个处理函数,可用lambda表达式快速编写
- 对RDD内的元素逐个处理,并返回一个新的RDD
2.链式调用
- 对于返回值是新RDD的算子,可以通过链式调用的方
- 式多次调用算子
2.数据计算-flatMap算子
flatMap算子的功能: 对rdd执行map操作,然后进行解除嵌套操作
解除嵌套:

代码如下:

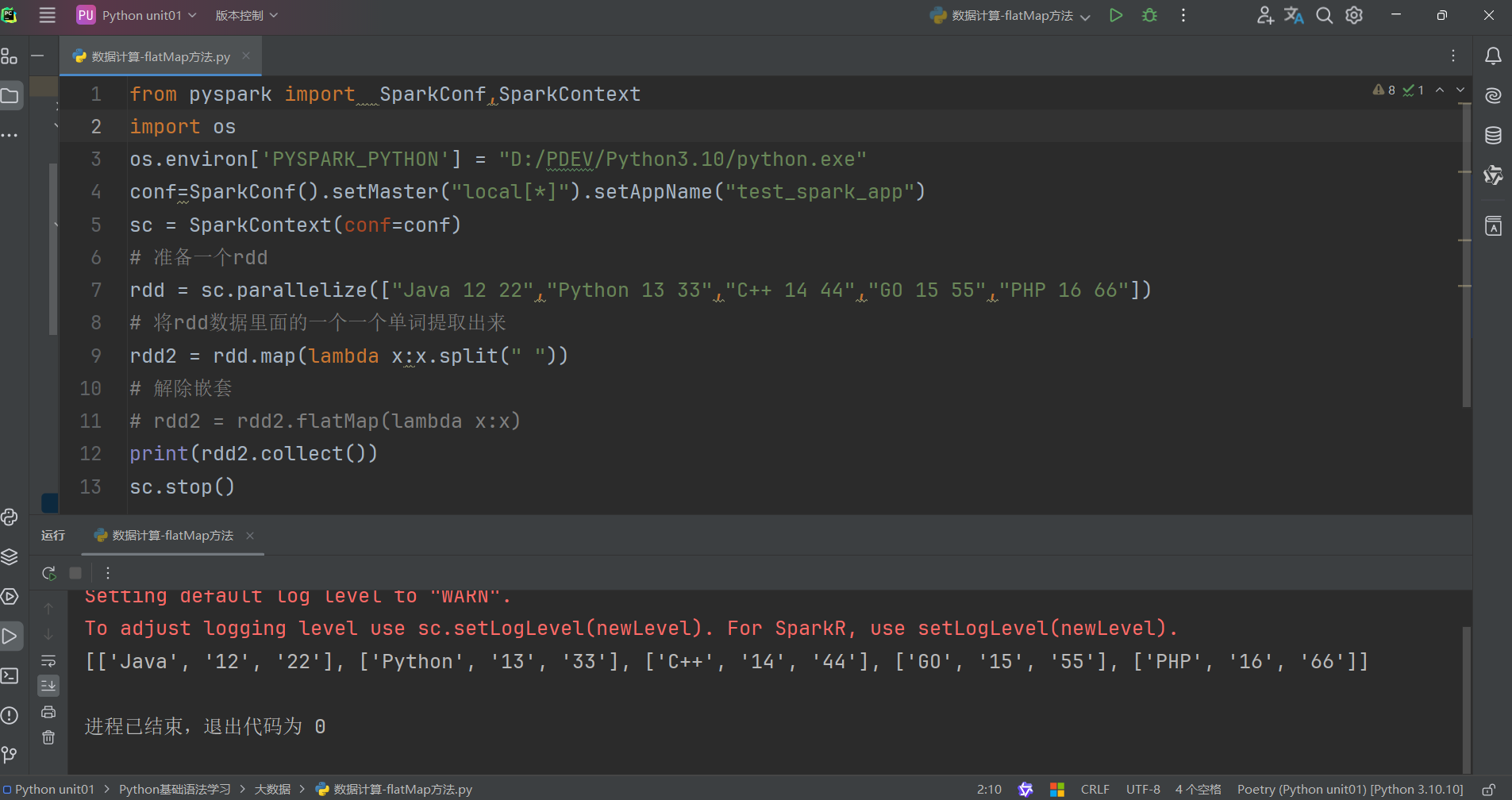
代码演示如下:
未使用flatMap方法代码如下:
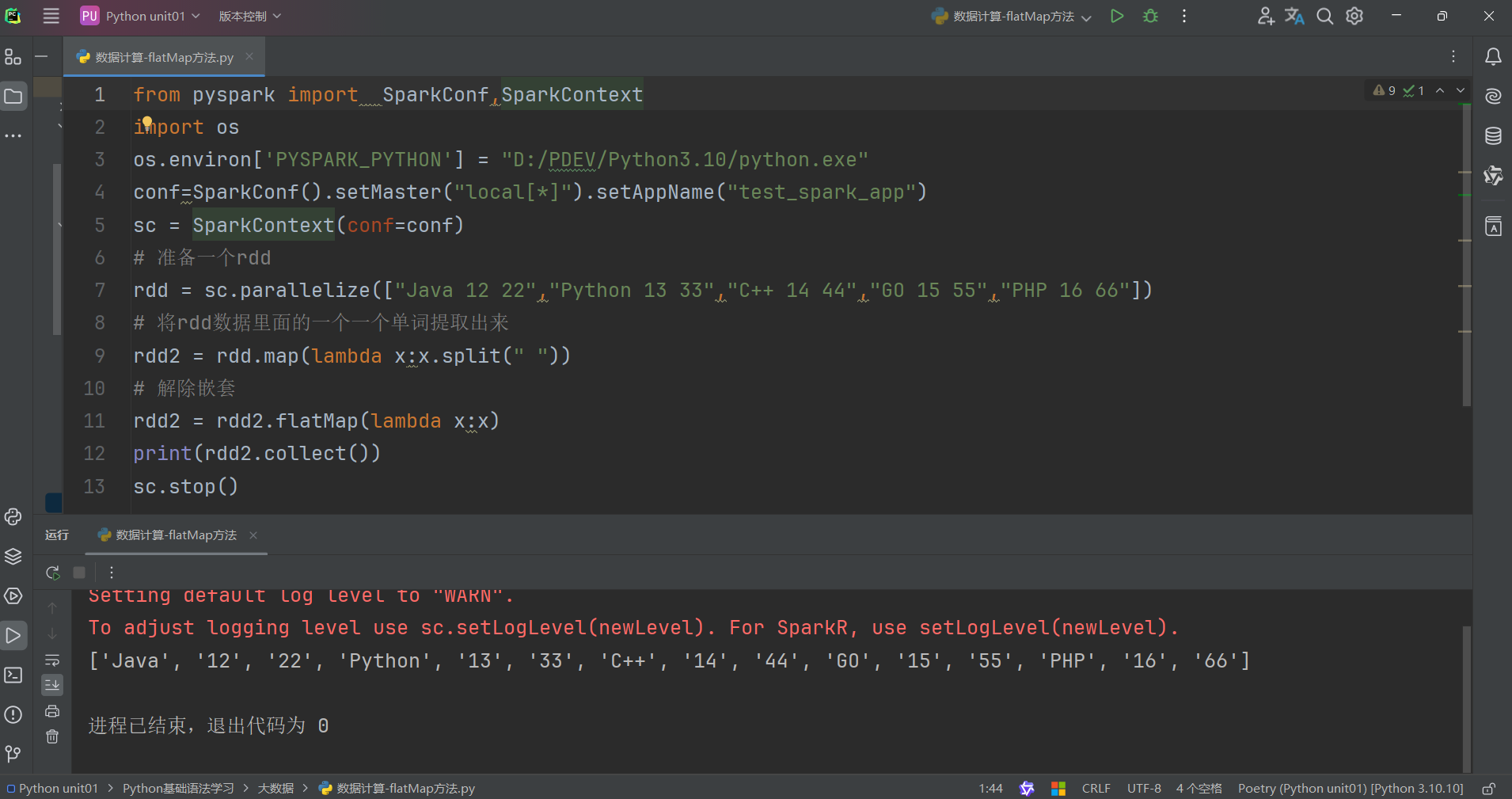
使用flatMap方法解除嵌套代码如下:
总结:
1.flatMap算子
- 计算逻辑和map一样
- 可以比map多出,解除一层嵌套的功能
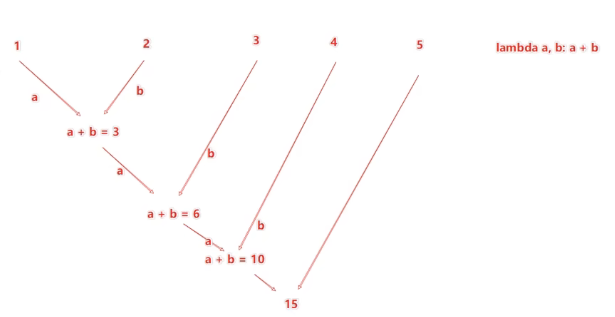
3.数据计算-reduceByKey方法
reduceByKey算子的功能:针对KV型 RDD,自动按照key分组,然后根据你提供的聚合逻辑,完成组内数据(value)的聚合操作。
注:KV型指的是存储数据是二元元组就称为KV型。
用法:



注:
rdd中存放的是二元元组,元组元素有2个,第一个元素可以视作字典的键,第二个是键入的值。通过reduceByKey方法可以根据键来整合数据的运算操作,这就是聚合。
reduceByKey中接收的函数,只负责聚合,不理会分组。
分组是自动 by key 来分组的。
二元元组,几元元组指的是元组内部的元素个数有几个就称作几元元组。
reduceBeKey中的聚合逻辑是:
比如,有[1,2,3,4,5],然后聚合函数是:lambda a,b:a+b
代码演示如下:
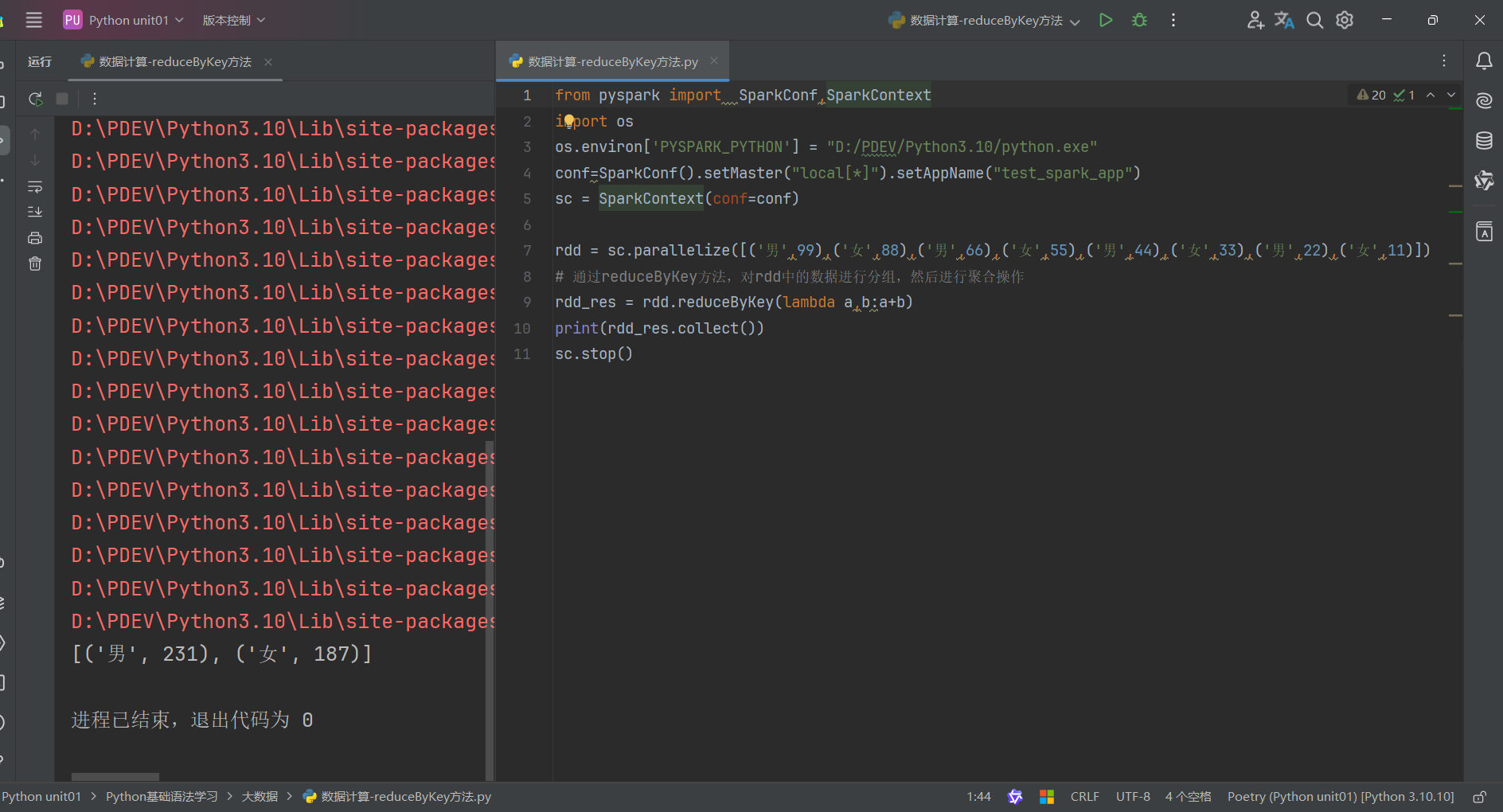
总结:
1.reduceByKey算子
接受一个处理函数,对数据进行两两计算
4.数据计算-filter方法
Filter方法的功能:过滤想要的数据进行保留
语法:
![]()
返回的是True的数据被保留,False的数据被丢弃。
代码如下:

代码演示如下:

总结:
1.filter算子
- 接受一个个处理函数,可用lambda快速编写
- 函数对RDD数据逐个处理,得到True的保留至返回值的RDD中
5.数据计算-distinct方法
distinct算子
功能:对RDD数据进行去重,返回新RDD
语法: ![]()
代码演示如下:
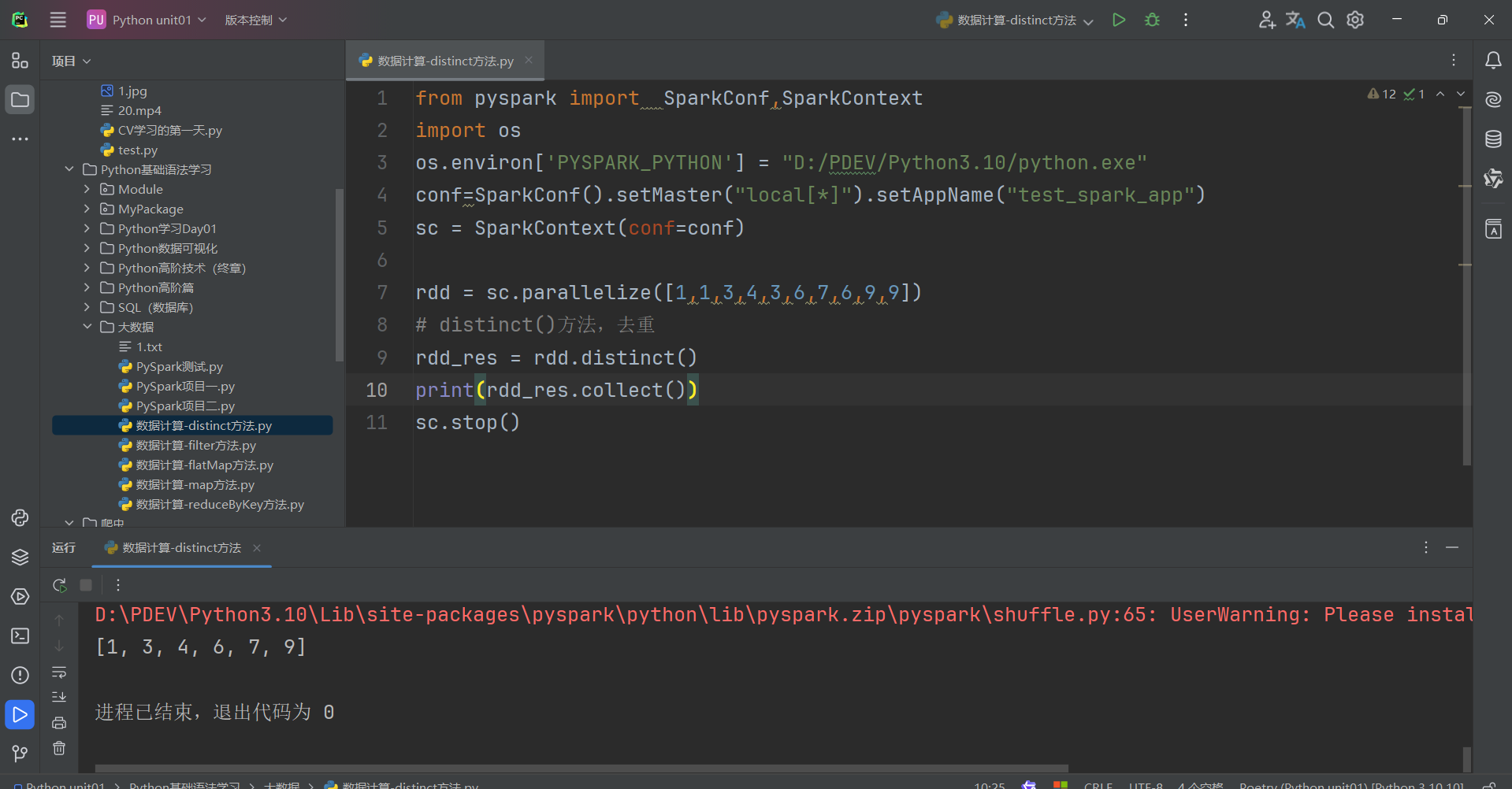
总结:
1.distinct算子
- 完成对RDD内数据的去重操作
6.数据计算-sortBy方法
sortBy算子功能:对RDD数据进行排序,基于你指定的排序依据。
语法:

代码演示如下:
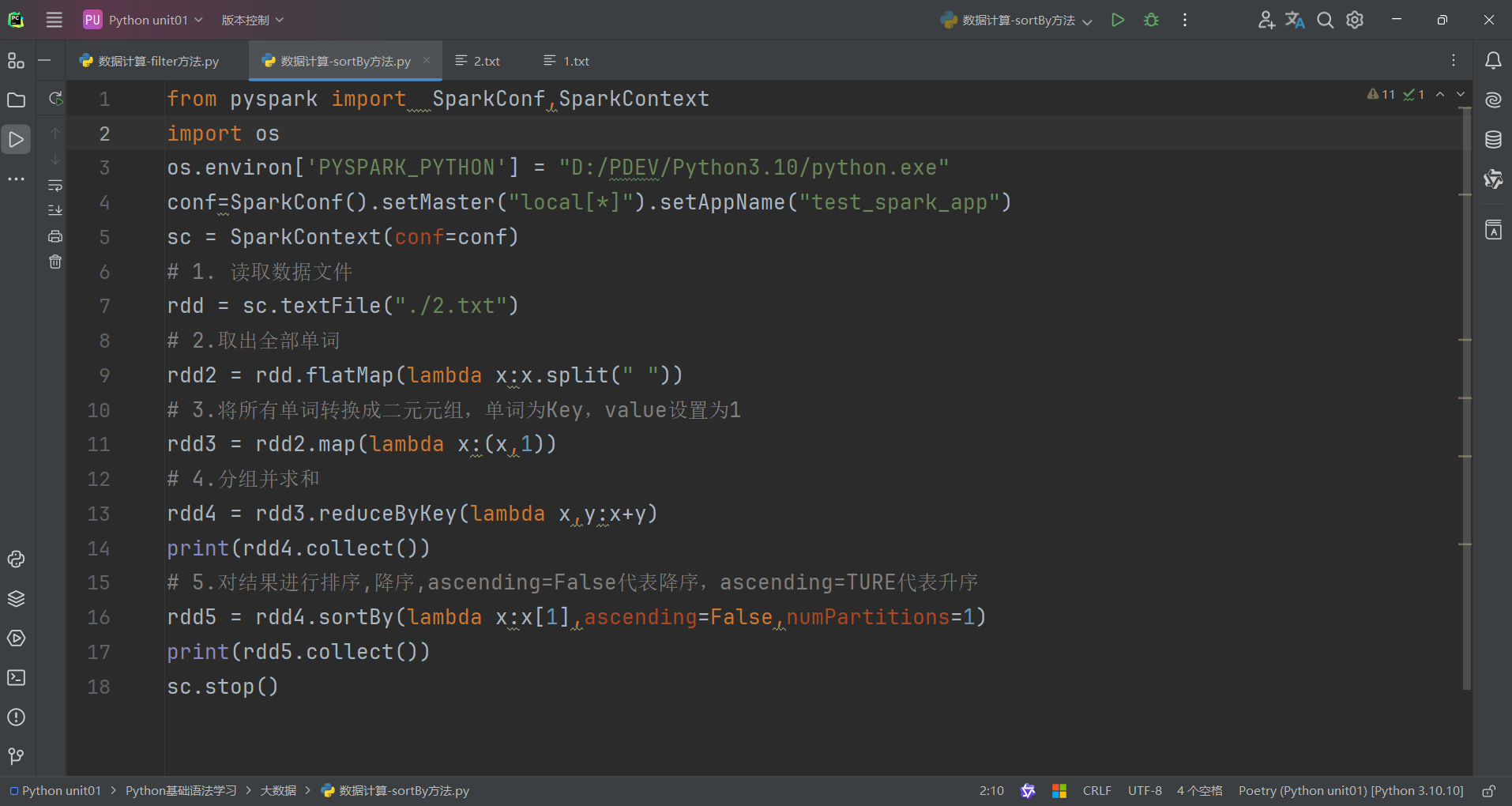
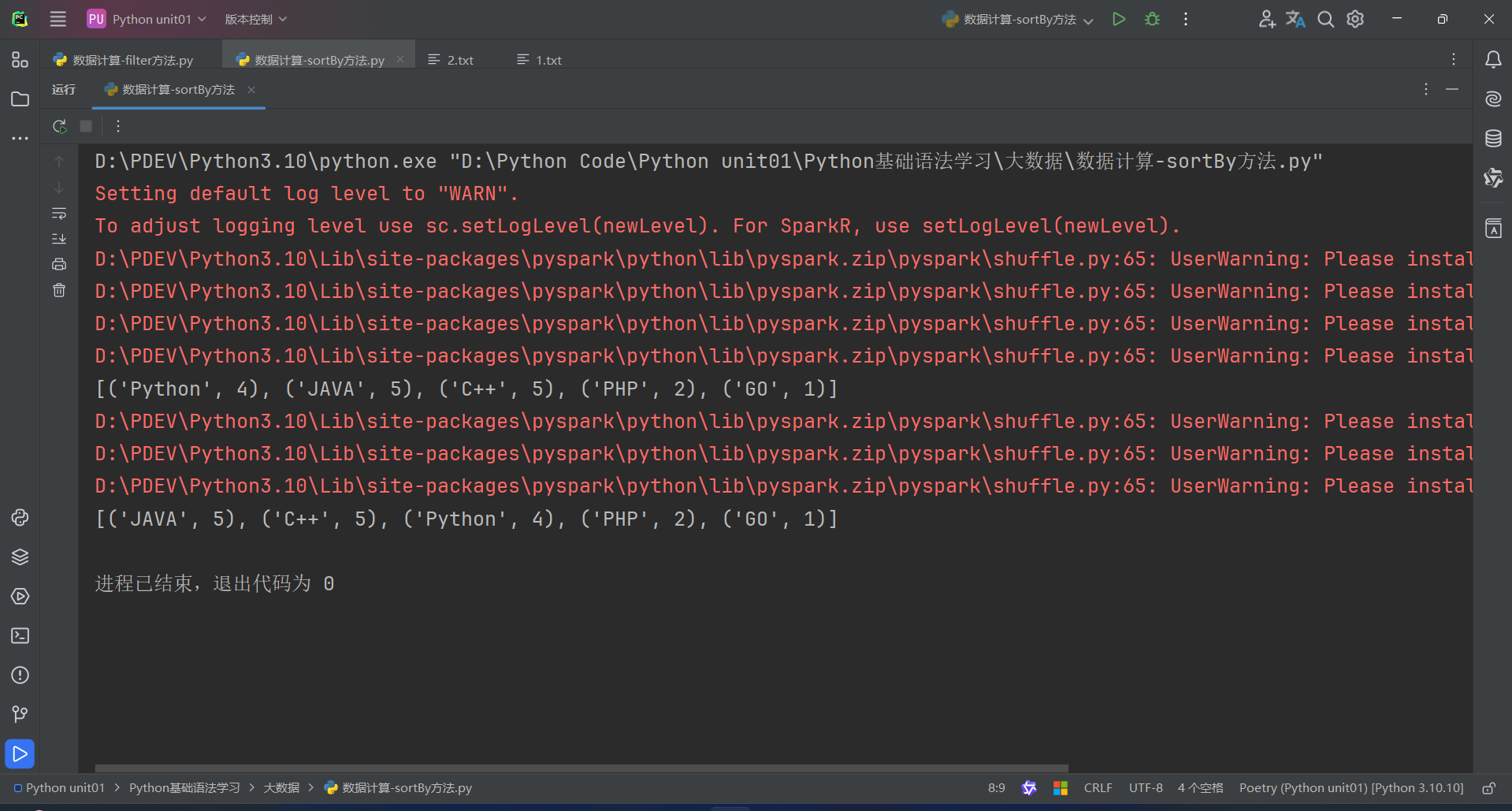
1.sortBy算子
- 接收一个处理函数,可用lambda快速编写
- 函数表示用来决定排序的依据
- 可以控制升序或降序
- 全局排序需要设置分区数为1
五.数据输出
此小节分为:输出为Python对象和输出到文件中。
1.输出Python对象
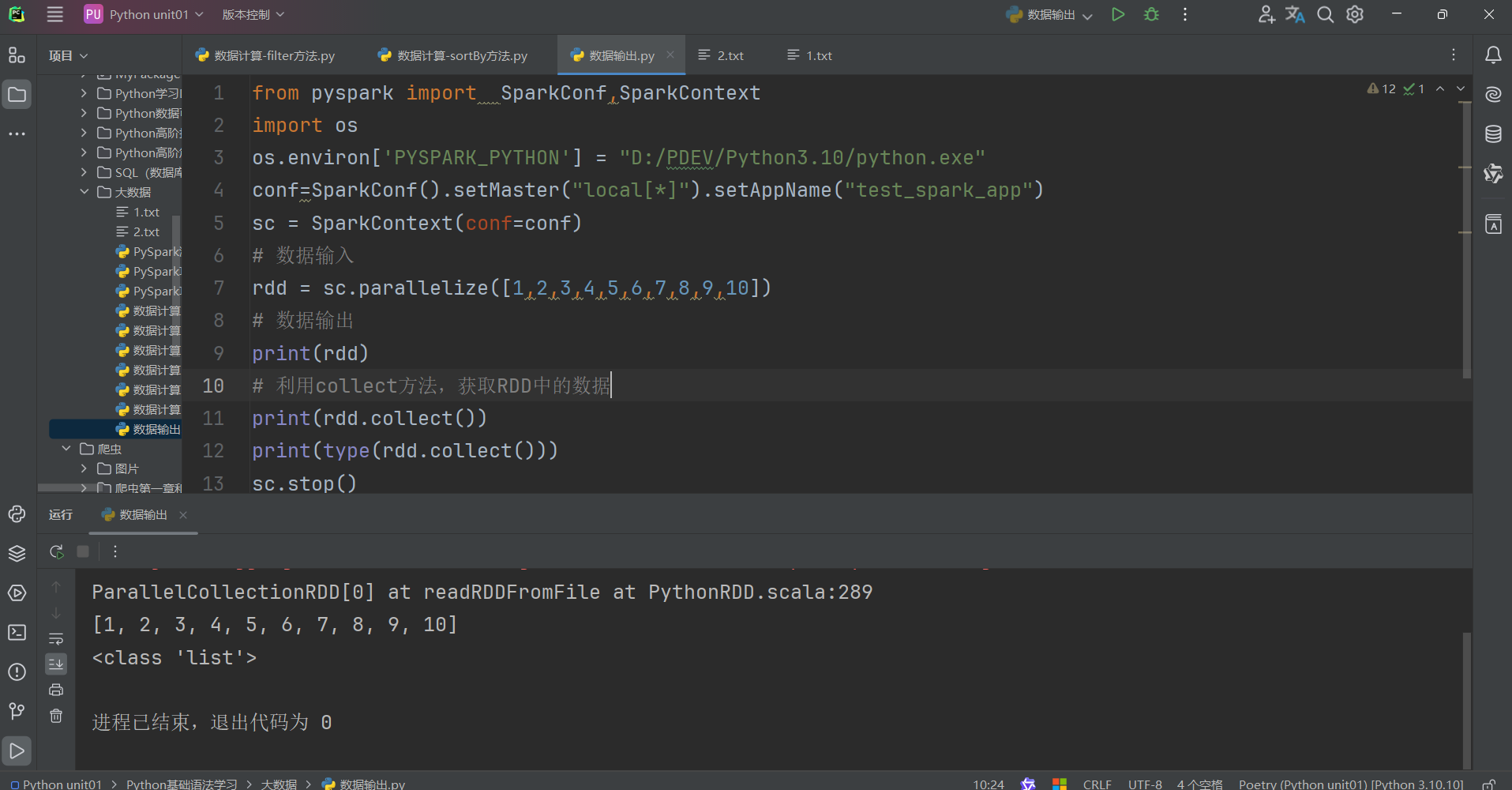
数据输出
数据输入:
- sc.parallelize
- sc.textFile
数据计算:
- rdd.map
- rdd.flatMap
- rdd.reduceByKey
- ………
(1)collect算子
collect算子的功能:将RDD各个分区内的数据,统一收集到Driver中,形成一个List对象。
用法:
![]()
返回值是一个List
(2)reduce算子
reduce算子功能: 对RDD数据集按照你传入的逻辑进行聚合
语法:


返回值等同于计算函数的返回值
代码演示如下:
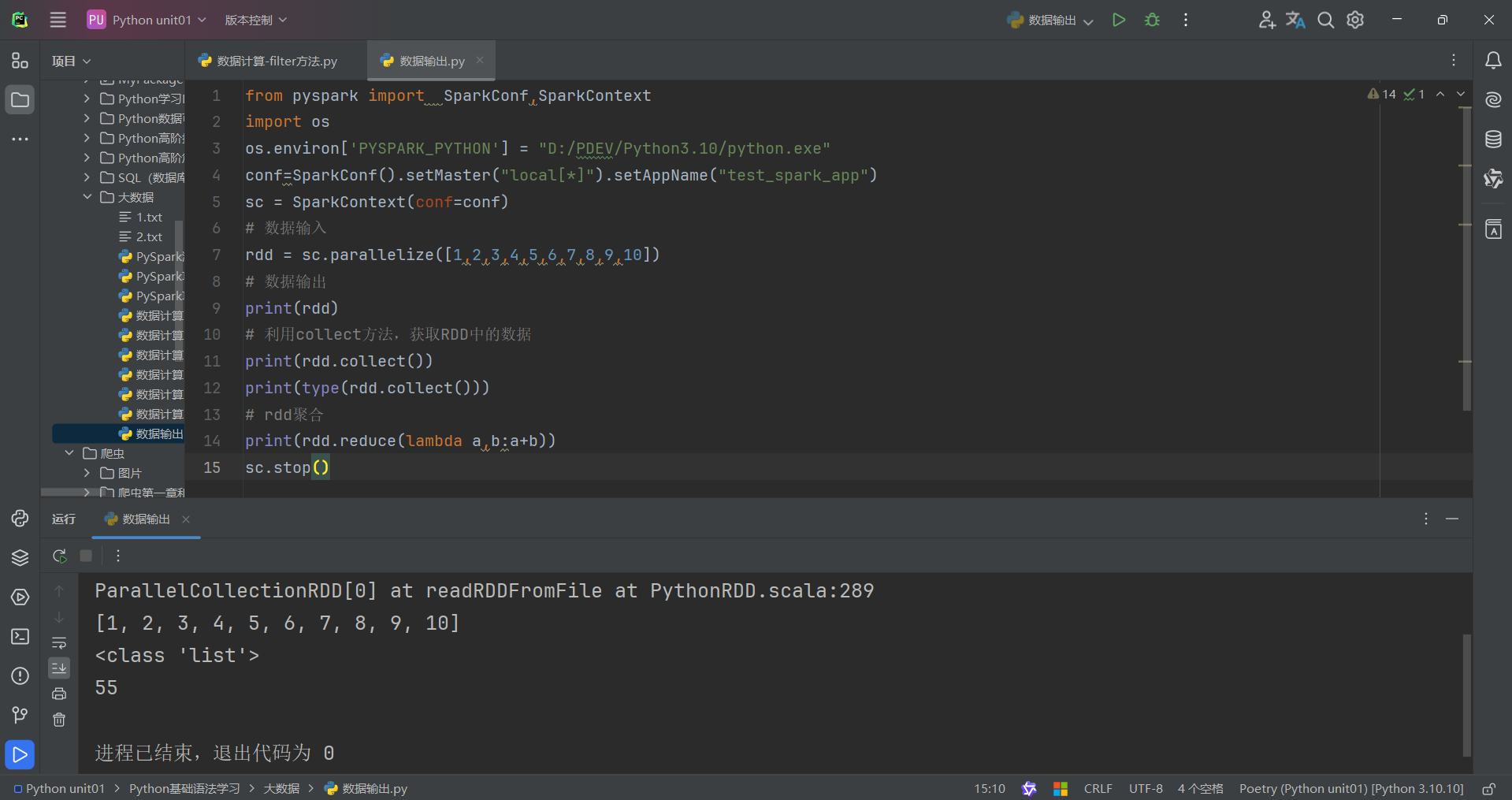
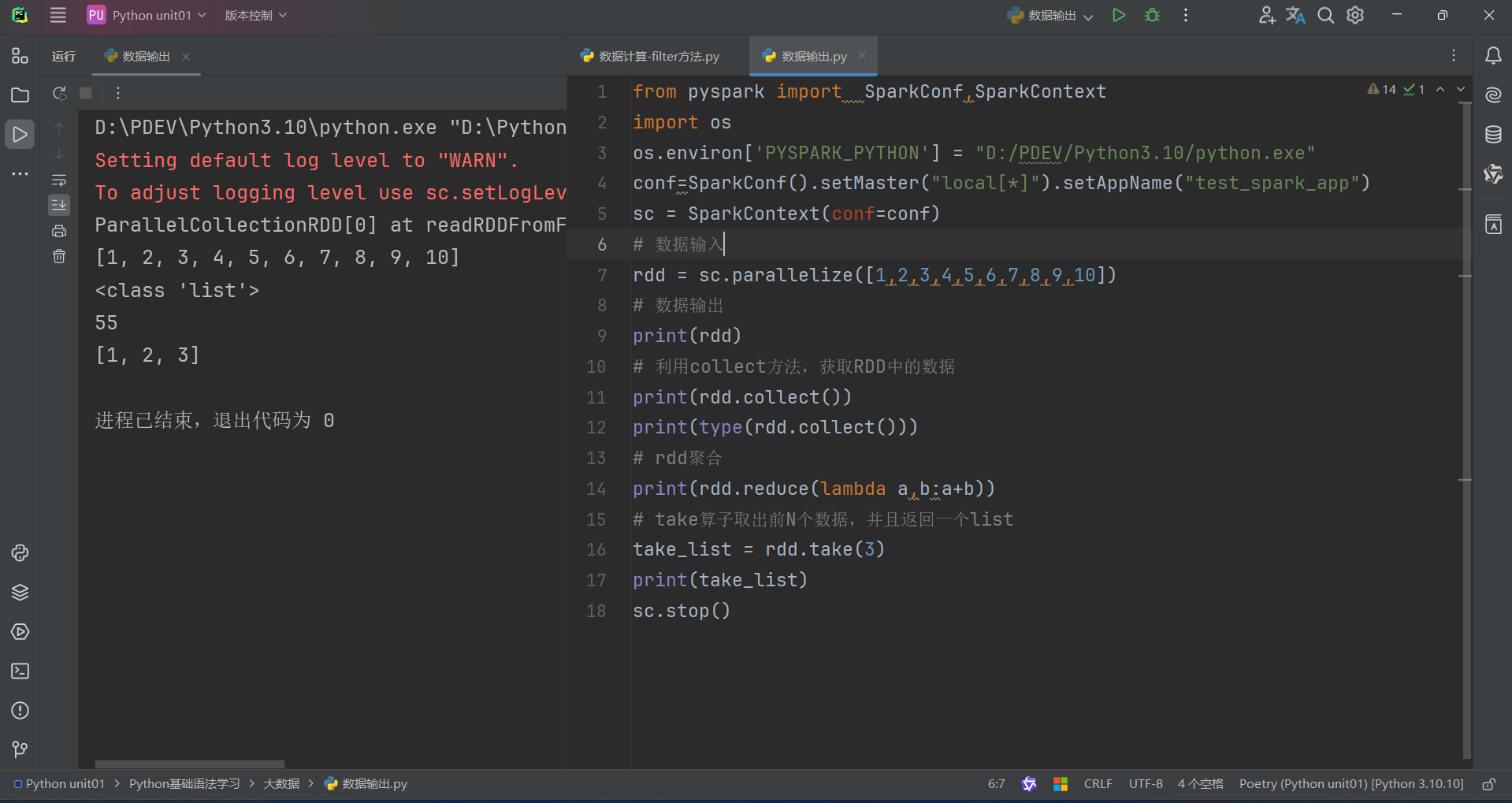
(3)take算子
take算子的功能:取RDD的前N个元素,组成list返回给你
用法:

代码如下:
(4)count算子
count算子的功能:计算RDD有多少条数据,返回值是一个数字
用法:

代码演示如下:
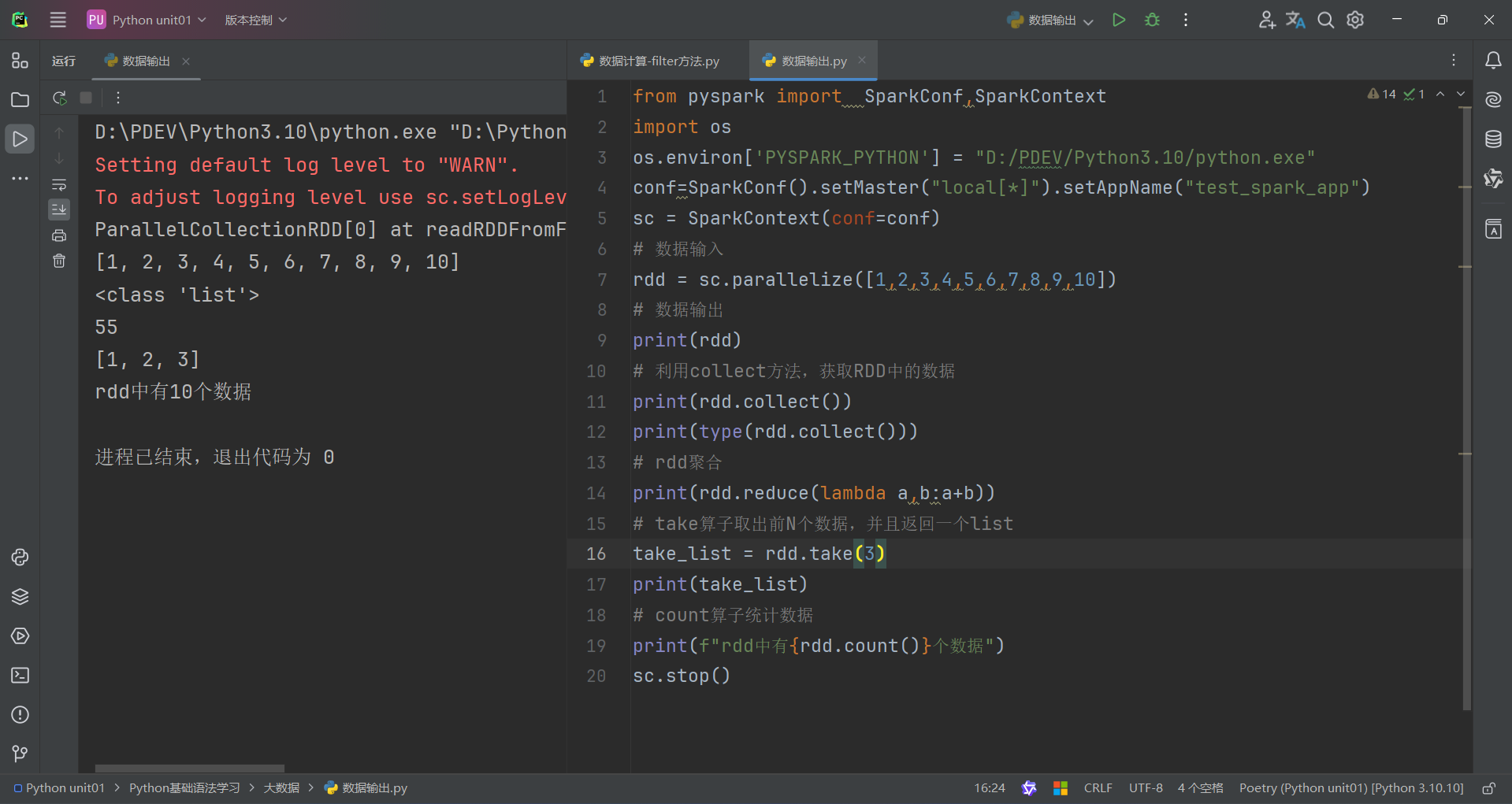
总结:
1.Spark的编程流程就是:
- 将数据加载为RDD(数据输入)
- 对RDD进行计算(数据计算)
- 将RDD转换为Python对象(数据输出)
2.数据输出的方法
- collect:将RDD内容转换为list
- reduce:对RDD内容进行自定义聚合
- take:取出RDD的前N个元素组成list
- count:统计RDD元素个数
数据输出可用的方法是很多的,本小节简单的介绍了4个
2.输出到文件中
(1)saveAsTextFile算子
saveAsTextFile算子的功能: 将RDD的数据写入文本文件中
支持 本地写出,hdfs等文件系统
代码:

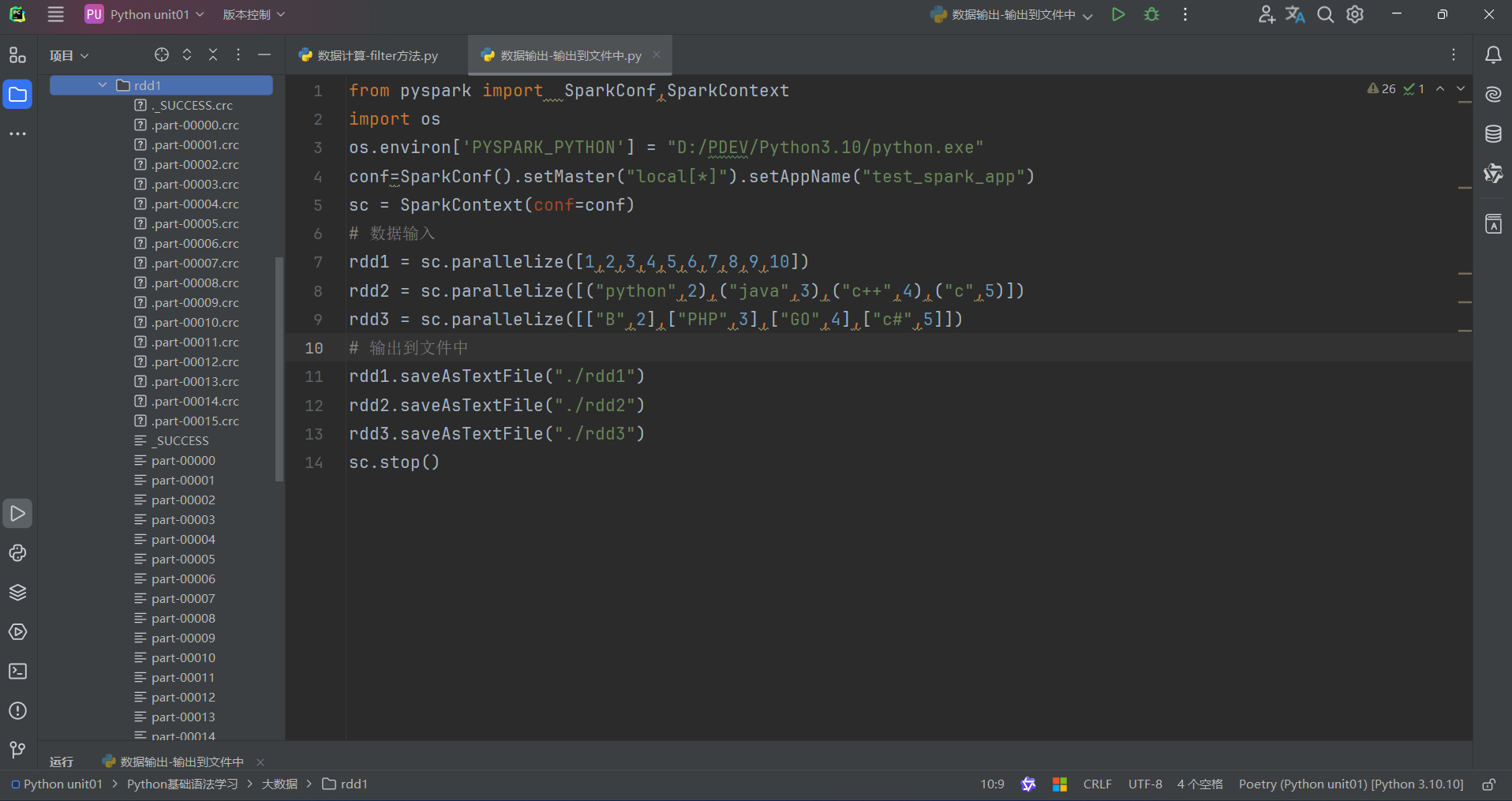
注:
这里需要配置hadoop,作者也是花了大量时间去配置这个东西,它操作太繁琐,首先你需要有JAVA的JDK并且最好是JDK8,最新版本可能导致不兼容,然后由于我使用的Windows系统还需要去改动一些项目文件中的代码,这里作者只能说都是泪。由于作者是计科专业不是大数据专业,校内也未给我们开设过Python的课程,这些配置纯由作者一点一滴配置完成,吃过苦头,受过折磨得出的经验。
注意事项
调用保存文件的算子,需要配置Hadoop依赖
下载Hadoop安装包
- http://archive.apache.org/dist/hadoop/common/hadoop-3.0.0/hadoop-3.0.0.tar.gz
解压到电脑任意位置
在Python代码中使用os模块配置:os.environ['HADOOP_HOME”]='HADOOP解压文件夹路径
下载winutils.exe,并放入Hadoop解压文件夹的bin目录内
- https://raw.githubusercontent.com/steveloughran/winutils/master/hadoop-3.0.0/bin/winutils.exe
下载hadoop.dll,并放入:C:/Windows/System32 文件夹内
- https://raw.githubusercontent.com/steveloughran/winutils/master/hadoop-3.0.0/bin/hadoop.dll
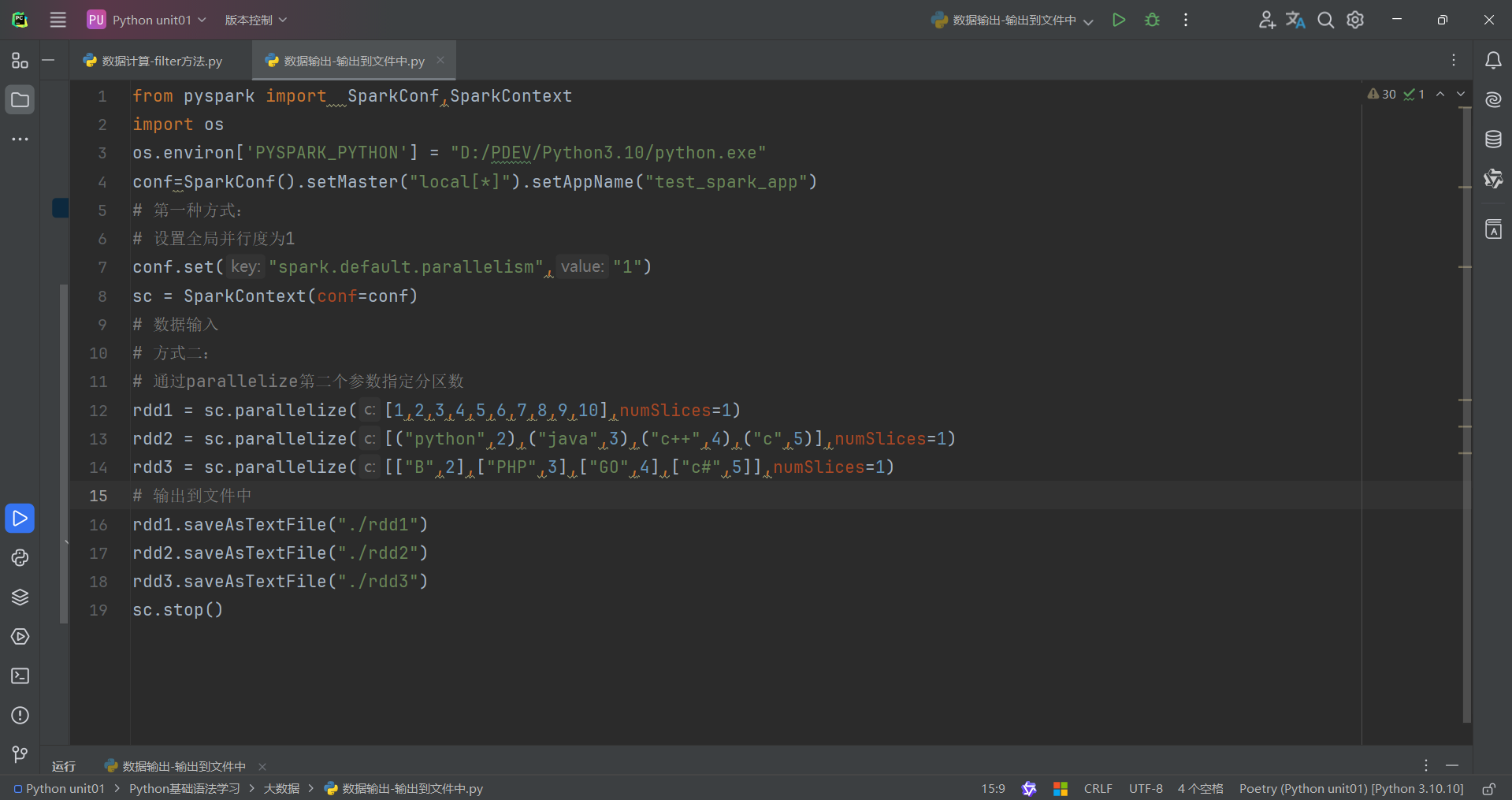
回归正题,由于作者电脑是CPU是15核,所以生成15个分区,这15个分区存储的数据有一些有,有一些没有。因此我们想要修改RDD分区为1有如下方式:

代码演示如下:
总结:
1.RDD输出到文件的方法
- rdd.saveAsTextFile(路径)
- 输出的结果是一个文件夹
- 有几个分区就输出多少个结果文件
2.如何修改RDD分区
SparkConf对象设置conf.set("spark.default.parallelism","1")
创建RDD的时候,sc.parallelize方法传入numSlices参数为1
六.分布式集群运行(作者谈感受)
分布式集群需要Linux系统,作者还没学,不过作者已经配置好了分布式集群,后续若用到我会在此补充。未来作者还是会去学习Linux系统。希望我未来在企业能用到这个吧。尽力了这一节作者没法演示了,作者才大一新生,还是一个双非排名靠后的本科,通过自身学习一步一步学,无导师指导甚至前辈指导都没有,作者都是一个人钻研,一钻研可能就是几天甚至半个月,这个环境配置作者一直没有放弃一直在整配置,用过AI去寻求帮助,但是AI都不太行,我认为AI对比于人来说,可能人优势还是非常大,人的优势就是能过灵活随机应变并且拥有真正解决问题的能力,AI是一贯的套路,甚至它们给的方法不一定对于实际问题有合理解决的方法,所以我认为AI很代替真正能够善于解决问题的人,它们现在只是一个辅助工具,未来AI是什么样的我不清楚,但是我知道的是人的潜力是AI永远代替不了的,我通过不断钻研学习,尽管今天的技术也许我这辈子用不到,但是我对于计算机的热爱,还是比较浓厚的我愿意花很大的时间在这个上面,我学了很多的东西尽管很杂乱,也许因为杂乱我可能很快忘了它们但是我知道这个印象永远在我脑海,因为我花了很多的时间在某一关卡,一卡可能是一天甚至一周乃至一个月,但是我没放弃过去思考这些问题,我认为只要是问题总会有突破口,计算机需要你花很多的时间,我听过很多说计算机如今行业不行了,但是我不在意因为热爱一件事情不一定要去思考它未来怎么样,只要一直走下去迟早这个技术会在你手里发光发热,而不是因为自己懒惰和自己不想去找到属于自己的兴趣爱好以及道路而放弃,可以不热爱学习,但是一定要热爱自己有兴趣的事情。
注:
这一节作者没法演示,只能讲我这学过来的感受从C语言的一点不会到Python、JAVA、C++这些语言我都学过了。未来我更新的东西会很多也很杂乱,不知道未来在企业能否用到,甚至高薪,但是走一步看一步吧。未来我还会继续更新我的学习,大学四年是一个学习积累非常好的一个机会。
相关文章:
)
第十二章 Python语言-大数据分析PySpark(终)
目录 一. PySpark前言介绍 二.基础准备 三.数据输入 四.数据计算 1.数据计算-map方法 2.数据计算-flatMap算子 3.数据计算-reduceByKey方法 4.数据计算-filter方法 5.数据计算-distinct方法 6.数据计算-sortBy方法 五.数据输出 1.输出Python对象 (1&am…...

Oracle数据库巡检脚本
1.查询实例信息 SELECT INST_ID, INSTANCE_NAME, TO_CHAR(STARTUP_TIME, YYYY-MM-DD HH24:MI:SS) AS STARTUP_TIME FROM GV$INSTANCE ORDER BY INST_ID; 2.查看是否归档 archive log list 3.查看数据库参数 SELECT NAME , TYPE , VALUE FROM V$PARAMETER ORDER BY NAME; 4.…...

示例:Spring JDBC编程式事务
以下是一个完整的 Spring JDBC 编程式事务示例,包含批量插入、事务管理、XML 配置和单元测试: 1. 项目依赖(pom.xml) <dependencies><!-- Spring JDBC --><dependency><groupId>org.springframework<…...

Happens-Before 原则
Happens-Before 规则 Happens-Before是JMM的核心概念之一,是一种可见性模型,保障多线程环境下前一个操作的结果相对于后续操作是可见的。 程序顺序性,同一线程中前面代码的操作happens-before后续的任意操作。volatile变量规则,…...
提交代码更新?)
怎样通过互联网访问内网 SVN (版本管理工具)提交代码更新?
你有没有遇到过这种情况:在公司或者家里搭了个 SVN 服务器(用来存代码的),但出门在外想提交代码时,发现连不上? 这是因为 SVN 通常跑在内网,外网直接访问不了。 这时候就需要 “内网穿透” ——…...
)
Verilog 语法 (一)
Verilog 是硬件描述语言,在编译下载到 FPGA 之后, FPGA 会生成电路,所以 Verilog 全部是并行处理与运行的;C 语言是软件语言,编译下载到单片机 /CPU 之后,还是软件指令,而不会根据你的代…...
 如何进行 SQL 优化?)
针对 Spring Boot 应用中常见的查询场景 (例如:分页查询、关联查询、聚合查询) 如何进行 SQL 优化?
通用优化原则(适用于所有场景): 索引是基础: 确保 WHERE、JOIN、ORDER BY、GROUP BY 涉及的关键列都有合适的索引(单列或联合索引)。避免 SELECT *: 只查询业务需要的列,减少数据传输量和内存消耗。覆盖索…...

shadcn/radix-ui的tooltip高度定制arrow位置
尝试了半天,后来发现,不支持。。。。。就是不支持 那箭头只能居中 改side和align都没用,下面有在线实例 https://codesandbox.io/p/sandbox/radix-ui-slider-forked-zgn7hj?file%2Fsrc%2FApp.tsx%3A69%2C21 但是呢, 第一如果…...

ROS-真机向虚拟机器人映射
问题描述 ROS里的虚拟机械臂可以实现和真实机械臂的位置同步,真实机械臂如何动,ROS里的虚拟机械臂就如何动 效果 步骤 确保库卡机械臂端安装有EthernetKRL辅助软件和KUKAVARPROXY 6.1.101(它是一个 TCP/IP 服务器 ,可通过网络实…...
)
ap无法上线问题定位(交换机发包没有剥掉pvid tag)
一中学,新开的40台appoe交换机核心交换机旁挂ac出口路由的组网,反馈ap无法上线,让协助解决。 组网如下: 排查过程: 检查ac的配置,没有发现问题 发现配置没有问题,vlan1000配置子接口ÿ…...

Linux基础
03.Linux基础 了解VMware备份的两种方式 了解Linux系统文件系统 掌握Linux基础命令 备份操作系统 为什么要备份系统? 数据安全:防止因硬件故障、软件错误等原因导致的数据丢失。 系统恢复:快速恢复系统至正常状态,减少停机时…...

python函数与模块
目录 一:函数 1.无参函数 2.带参数函数 2.函数中变量中的作用域 4.内建函数 二:模块与包 1.模块 (1)模块定义 (2)模块导入 2.包 (1)包的使用 (2)_…...

线上助农产品商城小程序源码介绍
基于ThinkPHPFastAdminUniApp开发的线上助农产品商城小程序源码,旨在为农产品销售搭建一个高效、便捷的线上平台,助力乡村振兴。 一、技术架构 该小程序源码采用了ThinkPHP作为后端框架,FastAdmin作为快速开发框架,UniApp作为跨…...

个人博客后台管理开发日志
技术栈:Vue3 Ts node.js mySQL pinia axios 3月14日 一、数据表梳理 用户(user) ID名字邮箱密码 头像 地址 创建 时间 总览有本地文件、博客文章、摄影图库、随笔随记,这些板块也有对应的分类,我们要把这些分类…...

[论文阅读]REPLUG: Retrieval-Augmented Black-Box Language Models
REPLUG: Retrieval-Augmented Black-Box Language Models REPLUG: Retrieval-Augmented Black-Box Language Models - ACL Anthology NAACL-HLT 2024 在这项工作中,我们介绍了RePlug(Retrieve and Plug),这是一个新的检索增强型…...

Matlab 基于共面螺旋管或共面亥姆霍兹谐振器的超薄低频吸声板
经典吸声材料的吸声性能严格依赖于材料的厚度,要达到完全吸声,至少需要四分之一波长。在本文中,我们报道了一种厚度约为波长百分之一的超薄吸声板,可以完全吸收声能。其策略是将四分之一波长的减声管弯曲并缠绕成二维共面减声管&a…...

济南国网数字化培训班学习笔记-第二组-4节-输电线路工程安全管理
输电线路工程安全管理 安全标识 颜色 禁止红、警示黄、指令蓝、提示绿 安全器具 定义 安全工器具通常专指“电力安全工器具”,是防止触电、灼伤、坠落、摔跌、腐蚀、窒息等事故,保障工作人员人身安全的各种专用工具和器具 分类 个体防护设备 防…...

【C语言】数据在内存中的存储:从整数到浮点数的奥秘
前言 在计算机的世界里,数据的存储和表示是编程的基础。今天,我们就来深入探讨一下数据在内存中的存储方式,包括整数和浮点数的存储细节,以及大小端字节序的奥秘。这些内容不仅对理解计算机系统至关重要,还能帮助我们…...

白鲸开源WhaleStudio与崖山数据库管理系统YashanDB完成产品兼容互认证
近日,北京白鲸开源科技有限公司与深圳计算科学研究院联合宣布,双方已完成产品兼容互认证。此次认证涉及深圳计算科学研究院自主研发的崖山数据库管理系统YashanDB V23和北京白鲸开源科技有限公司的核心产品WhaleStudio V2.6。经过严格的测试与验证&#…...
)
图论---朴素Prim(稠密图)
O( n ^2 ) 题目通常会提示数据范围: 若 V ≤ 500,两种方法均可(朴素Prim更稳)。 若 V ≤ 1e5,必须用优先队列Prim vector 存图。 // 最小生成树 —朴素Prim #include<cstring> #include<iostream> #i…...

借助deepseek和vba编程实现一张表格数据转移到多张工作簿的表格中
核心目标 将工作表中的内容按村社名称分类放入对应位置的目标工作簿的第一个工作表的对应位置 deepseek提问方式 你是一个擅长vba编程的专家,核心目标是奖工作表中的部分内容按下列要求写入对应工作簿的第一个工作表中。第一,在工作表A列中筛选出相…...

springboot整合redis实现缓存
一、redis 二、spring boot 整合redis 三、基于注解的Redis缓存实现 使用Cacheable、CachePut、CacheEvict注解定制缓存管理 对CommentService类中的方法进行修改使用Cacheable、CachePut、CacheEvict三个注解定制缓存管理,修改后的方法如下 Cacheable(cacheNam…...

git tag使用场景和实践
背景 每次上线一个迭代,为了区分本次代码的分支是哪个迭代,可以给分支打上tag,这样利于追踪分支所属迭代,如果devops没有自动给分支打tag,需要自己来打 操作 1.查看当前tag git tag2.给分支打tag git tag <tag…...

十分钟恢复服务器攻击——群联AI云防护系统实战
场景描述 服务器遭遇大规模DDoS攻击,导致服务不可用。通过群联AI云防护系统的分布式节点和智能调度功能,快速切换流量至安全节点,清洗恶意流量,10分钟内恢复业务。 技术实现步骤 1. 启用智能调度API触发节点切换 群联系统提供RE…...

国产紫光同创FPGA视频采集转SDI编码输出,基于HSSTHP高速接口,提供2套工程源码和技术支持
目录 1、前言工程概述免责声明 2、相关方案推荐我已有的所有工程源码总目录----方便你快速找到自己喜欢的项目紫光同创FPGA相关方案推荐本博已有的 SDI 编解码方案本方案在Xilinx--Artix7系列FPGA上的应用本方案在Xilinx--Kintex系列FPGA上的应用本方案在Xilinx--Zynq系列FPGA上…...

最小生成树-prim、kruskal算法
目录 prim算法 kruskal算法 题目练习 (1)AcWing 858. Prim算法求最小生成树 - AcWing (2)859. Kruskal算法求最小生成树 - AcWing题库编辑 学习之前建议温习一下迪杰斯特拉算法和并查集~ 先简单认识下最小生成树:…...

【硬核干货】JetBrains AI Assistant 干货笔记
快进来抄作业,小编呕心沥血整理的 JetBrains AI Assistant 超干货笔记! 原文链接:【硬核干货】JetBrains AI Assistant 干货笔记 关于晓数神州 晓数神州坚持以“客户为中心”的宗旨,为客户提供专业的解决方案和技术服务ÿ…...

强化学习核心原理及数学框架
1. 定义与核心思想 强化学习(Reinforcement Learning, RL)是一种通过智能体(Agent)与环境(Environment)的持续交互来学习最优决策策略的机器学习范式。其核心特征为: 试错学习&#x…...

C# 综合示例 库存管理系统4 classMod类
版权声明:本文为博主原创文章,转载请在显著位置标明本文出处以及作者网名,未经作者允许不得用于商业目的 在《库存管理系统》中使用classMod类来保存全局变量。 变量定义和含义,请详见下面的源代码: public class classMod { //数据库路径...

[C] 第6章 C51函数
文章目录 C51函数函数概述从函数定义角度分类从函数有无返回值分类从函数有无参数 函数定义的一般形式C51无参函数的一般形式C51有参函数的一般形式 函数的形式参数和实际参数形式参数实际参数函数的返回值一般形式为: 函数的形参和实参的特点 函数的调用函数的调用…...

docker 配置代理
docker 配置代理有 2 中方法 1.Daemon configuration 直接在 /etc/docker/daemon.json 文件中配置 {"proxies": {"http-proxy": "http://proxy.example.com:3128","https-proxy": "https://proxy.example.com:3129",&quo…...

Redis 深度解析:从核心原理到生产实践
Redis 深度解析:从核心原理到生产实践 一、Redis 核心定位与数据结构 1. 核心能力矩阵深度解析 Redis 作为高性能内存数据库,核心能力覆盖缓存、数据存储、消息中间件等场景,其设计哲学围绕速度优先、内存高效、功能丰富展开: …...

从零搭建高可用分布式限流组件:设计模式与Redis令牌桶实践
一、需求背景与设计目标 在分布式系统中,面对突发流量时需要一种精准可控的流量控制手段。我们的组件需要具备: 多维度限流(用户/IP/服务节点/自定义表达式)分布式环境下精准控制开箱即用的Spring Boot Starter集成高扩展性的架…...

基于霍尔效应传感器的 BLDC 电机梯形控制方案详解
基于霍尔效应传感器的 BLDC 电机梯形控制方案解读 使用霍尔效应传感器的无刷直流(BLDC)电机梯形控制 一、系统核心架构与技术优势 (一)BLDC 电机与霍尔传感器控制原理 BLDC 电机作为永磁同步电机的一种,其核心特征是转子反电动势为梯形波,定子电流为 120 电角度宽度的矩…...

Pikachu靶场-File Inclusion
文件包含漏洞(File Inclusion Vulnerability)是Web应用程序中的一种常见安全漏洞,通常由于开发者未对用户输入进行严格过滤,导致攻击者能够包含并执行恶意文件。这种漏洞主要分为两种类型: 1. 漏洞类型 本地文件包含&a…...
以测试服务器安全性)
如何模拟黑客攻击(Red Teaming)以测试服务器安全性
模拟黑客攻击(Red Teaming)是评估服务器安全性的有效方法,但需严格遵循**合法授权**和**道德准则**。以下是专业且安全的操作流程: --- ### **1. 前期准备** - **法律授权** - 获得目标系统的**书面授权**,明确测…...

分页查询优惠券
文章目录 概要整体架构流程技术细节小结 概要 接口分析 一个典型的带过滤条件的分页查询,非常简单。按照Restful风格设计即可,我们关注的点有两个: 请求参数 返回值格式 请求参数包含两部分,一个是分页参数,另一…...

QTcpSocket 和 QUdpSocket 来实现基于 TCP 和 UDP 的网络通信
在 Qt 中,您可以通过 QTcpSocket 和 QUdpSocket 来实现基于 TCP 和 UDP 的网络通信。以下是如何使用 Qt 实现这两种通信方式的简要示例。 1. TCP 网络通信 TCP 是面向连接的协议,确保数据的可靠传输。下面是一个简单的 TCP 客户端和服务器示例。 TCP …...

从岗位依附到能力生态:AI革命下“什么叫就业”的重构与价值
在人工智能(AI)技术深刻重塑社会生产关系的当下,“就业”这一概念正经历着从“职业绑定”到“能力变现”的范式转移。本文将从传统就业观的解构、AI赋能艺术教育的价值逻辑、以及未来就业形态的进化方向三个维度,探讨技术驱动下就业的本质变革,并揭示AI技术如何通过教育创…...

2025上海车展 | 移远通信全栈车载智能解决方案重磅亮相,重构“全域智能”出行新范式
2025年4月23日至5月2日,第二十一届上海国际汽车工业展览会在国家会展中心(上海)盛大启幕。作为车载智能解决方案领域的领军企业,移远通信以“全域智能 驭见未来”为主题,携丰富的车载解决方案及客户终端惊艳亮相8.2馆8…...

LVGL在VScode的WSL2中仿真
目录 一、前言 二、开始部署 1.拉取github的库 2.在WSL安装一些必要的库或者包 3.开始编译 三、注意事项 一、前言 相信有不少兄弟因为苦于没有外设而无法学习LVGL,这里我提供一种WSL中仿真LVGL工程的方法。结果图如下: 二、开始部署 1.拉取github…...

React-组件和props
1、类组件 import React from react; class ClassApp extends React.Component {constructor(props) {super(props);this.state{};}render() {return (<div><h1>这是一个类组件</h1><p>接收父组件传过来的值:{this.props.name}</p>&…...

驱动开发系列53 - 一个OpenGL应用程序是如何调用到驱动厂商GL库的
一:概述 一个 OpenGL 应用程序调用 GPU 驱动的过程,主要是通过动态链接库(libGL.so)来完成的。本文从上到下梳理一下整个调用链,包含 GLVND、Mesa 或厂商驱动之间的关系。 二:调用关系 1. 首先一个 OpenGL 应用程序(比如游戏或图形渲染软件)在运行时会调用 OpenGL 提供…...
)
【python】一文掌握 markitdown 库的操作(用于将文件和办公文档转换为Markdown的Python工具)
更多内容请见: python3案例和总结-专栏介绍和目录 文章目录 一、markitdown概述1.1 markitdown介绍1.2 MarkItDown支持的文件1.3 为什么是Markdown?二、markitdown安装2.1 pip方式安装2.2 源码安装2.3 docker方式安装三、基本使用3.1 命令行方式3.2 可选依赖项配置3.3 插件方…...

【网络入侵检测】基于Suricata源码分析NFQ IPS模式实现
【作者主页】只道当时是寻常 【专栏介绍】Suricata入侵检测。专注网络、主机安全,欢迎关注与评论。 1. 概要 👋 本文聚焦于 Suricata 7.0.10 版本源码,深入剖析其 NFQ(Netfilter Queue)模式的实现原理。通过系统性拆解初始化阶段的配置流程、数据包监听机制的构建逻辑,以…...
)
驱动开发硬核特训 · Day 19:从字符设备出发,掌握 Linux 驱动的实战路径(含 gpio-leds 控制示例)
视频教程请关注 B 站:“嵌入式 Jerry” 一、背景说明:字符设备驱动的角色定位 在 Linux 内核驱动体系中,**字符设备驱动(Character Device Driver)**扮演着关键的桥梁作用,它直接向用户空间程序提供 read/…...

项目——高并发内存池
目录 项目介绍 做的是什么 要求 内存池介绍 池化技术 内存池 解决的问题 设计定长内存池 高并发内存池整体框架设计 ThreadCache ThreadCache整体设计 哈希桶映射对齐规则 ThreadCache TLS无锁访问 CentralCache CentralCache整体设计 CentralCache结构设计 C…...

几种查看PyTorch、cuda 和 Python 版本方法
在检查 PyTorch、cuda 和 Python 版本时,除了直接使用 torch.__version__ 和 sys.version,我们还可以通过其他方式实现相同的功能 方法 1:直接访问属性(原始代码) import torch import sysprint("PyTorch Versi…...

如何实现跟踪+分割的高效协同?SiamMask中的多任务损失设计
如何实现跟踪分割的高效协同?SiamMask中的多任务损失设计 一、引言二、三大分支损失函数详解2.1 分类分支损失2.2 回归分支损失2.3 Mask分支损失 三、损失加权策略与系数选择3.1 常见超参数设定3.2 动态权重(可选) 四、训练实践:平…...

MODBUS转EtherNetIP边缘计算网关配置优化:Logix5000与ATV340高效数据同步与抗干扰方案
一、行业背景 智能制造是当前工业发展的趋势,智能工厂通过集成各种自动化设备和信息技术,实现生产过程的智能化、自动化和高效化。在某智能工厂中,存在大量采用ModbusTCP协议的设备,如智能传感器、变频器等,而工厂的主…...