《Not All Tokens Are What You Need for Pretraining》全文翻译
《Not All Tokens Are What You Need for Pretraining》
不是所有的词元都是预训练所需
摘要
先前的语言模型预训练方法通常对所有训练词元均匀地应用下一词预测损失。对此常规做法提出挑战,我们认为“语料库中的并非所有词元对于语言模型训练同等重要”。我们的初步分析考察了语言模型的词元级训练动态,揭示了不同词元的损失表现存在显著差异。基于这些洞见,我们提出了一种新的语言模型RHO-1。不同于传统语言模型对语料中的每个下一词进行学习,RHO-1采用选择性语言建模(Selective Language Modeling,SLM),仅在与目标分布匹配的有用词元上进行训练。该方法首先利用参考模型为词元打分,然后仅针对高分词元聚焦损失进行训练。在15B OpenWebMath语料上的持续预训练中,RHO-1在9个数学任务的少样本准确率上实现高达 30 % 30\% 30%的绝对提升。微调后,RHO-1-1B与7B模型在MATH数据集上分别达到 40.6 % 40.6\% 40.6%与 51.8 % 51.8\% 51.8%的最新水平——其训练词元数量仅为DeepSeekMath的3%。此外,在80B通用词元上的持续预训练中,RHO-1在15个多样任务上平均提升 6.8 % 6.8\% 6.8%,显著提高了数据效率和语言模型预训练表现。
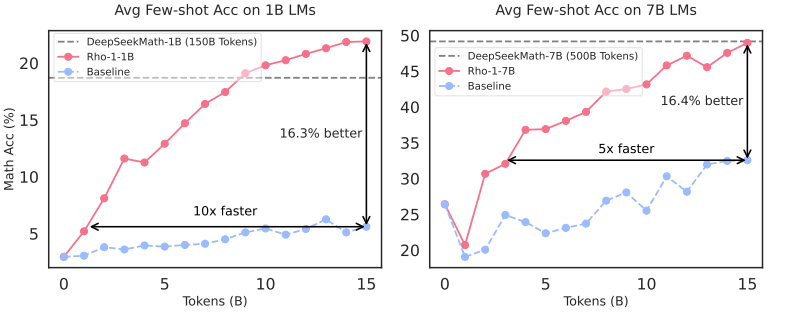
图1:我们对1B和7B语言模型使用15B OpenWebMath词元进行持续预训练。RHO-1应用我们提出的选择性语言建模(SLM),而基线模型则采用因果语言建模(CLM)。SLM在GSM8k和MATH数据集的平均少样本准确率提升超过16%,且达到基线性能的速度快5-10倍。
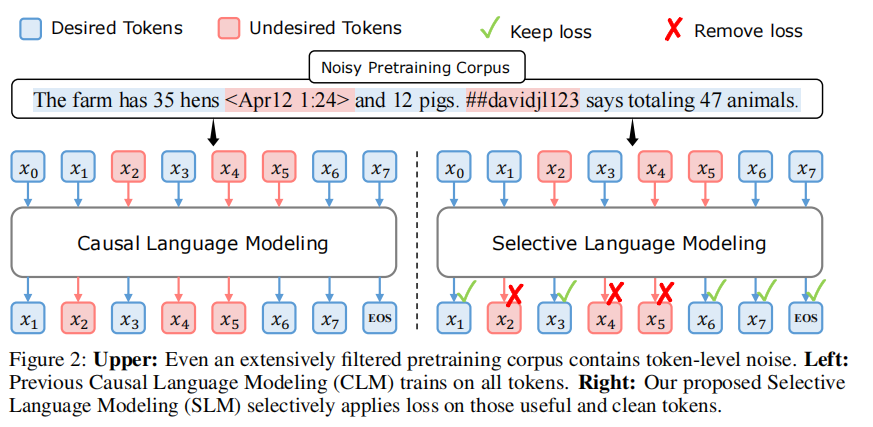
图2:上图:即使经过广泛过滤的预训练语料库依然包含词元级噪声。左图:先前的因果语言建模(CLM)在所有词元上训练。右图:我们提出的选择性语言建模(SLM)仅对有用且干净的词元施加损失。
1 引言
扩展模型参数和数据集规模持续提升大规模语言模型(LLM)的下一词预测准确率,推动人工智能取得显著进展 [Kaplan 等,2020;Brown 等,2020;OpenAI,2023;Team 等,2023]。然而,训练所有可用数据并非总是最优或可行。因此,数据过滤实践变得尤为重要,使用多种启发式和分类器 [Brown 等,2020;Wenzek 等,2019] 来筛选训练文档。这些技术显著提升了数据质量和模型表现。
但即便经过细致的文档级过滤,高质量数据集中仍含大量噪声词元,可能妨碍训练,见图2上图所示。去除这些词元可能改变文本含义,而过度严格的过滤会丢失有用数据 [Welbl 等,2021;Muennighoff 等,2024] 并带来偏差 [Dodge 等,2021;Longpre 等,2023]。研究显示,网页数据的分布并不完全匹配下游任务的理想分布 [Tay 等,2022;Wettig 等,2023]。例如,常见语料中的词元可能含有幻觉内容或难以预测的高度歧义部分。对所有词元施加相同损失,导致在非关键词元上的计算效率低下,或限制LLM向更高智能迈进的潜力。
为了探索语言模型如何在词元级别学习,我们首先观察了训练动态,尤其是预训练中词元损失的演变。在 § 2.1 \S 2.1 §2.1,我们评估了不同检查点模型的词元困惑度,并将词元归类为不同类型。结果显示,显著的损失减小仅集中于部分词元。“易学词元”已经被掌握,而部分“难学词元”表现为波动损失且难以收敛,导致大量无效梯度更新。
基于上述分析,我们提出了RHO-1模型,采用新颖的选择性语言建模(SLM)目标 3 ^{3} 3。如图4所示,该方法输入完整序列,并有选择地忽略不希望的词元损失。具体流程:首先,SLM在高质量语料上训练参考模型(Reference Model,RM),该模型为词元评分,实现对不干净及无关词元的自然筛除;其次,使用RM为语料中每个词元计算损失评分(§2.2);最后,仅训练那些训练模型损失明显高于RM的词元,即有较高“剩余损失”的词元,有选择地学习最有益的内容(§2.2)。
综合实验证明,SLM极大提升训练时的数据效率和下游任务表现。此外,我们发现SLM有效定位与目标分布相关的词元,进而改善困惑度表现。
3 { }^{3} 3 “RHO”代表选择性建模更高信息“密度( ρ \rho ρ)”的词元。
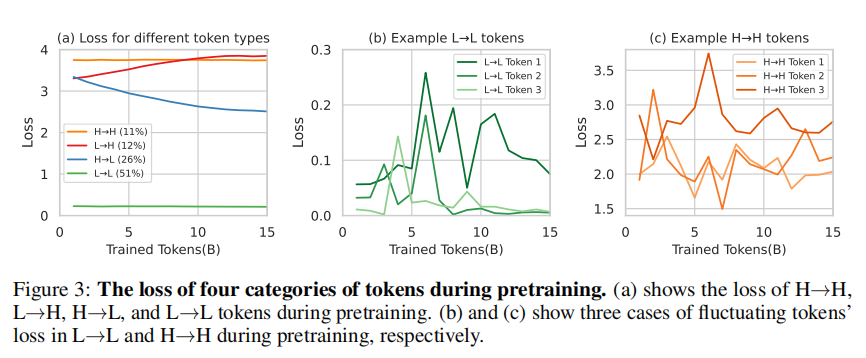
图3:预训练期间四类词元的损失变化。(a)展示了 H → H \mathrm{H} \rightarrow \mathrm{H} H→H、 L → H \mathrm{L} \rightarrow \mathrm{H} L→H、 H → L \mathrm{H} \rightarrow \mathrm{L} H→L和 L → L \mathrm{L} \rightarrow \mathrm{L} L→L词元的损失轨迹;(b)与(c)分别展示 L → L \mathrm{L} \rightarrow \mathrm{L} L→L与 H → H \mathrm{H} \rightarrow \mathrm{H} H→H词元损失波动的三种典型情况。
在数学持续预训练中(§3.2),1B和7B的RHO-1均较CLM基线在GSM8k和MATH任务中提升超过16%。图1显示,SLM以高达10倍的速度达到基线准确率。值得注意的是,RHO-1-7B仅用15B词元(选出10.5B词元)实现了与预训练了500B词元的DeepSeekMath-7B相当的性能,展现了极高效率。微调后,RHO-1-1B和7B在MATH上分别获得 40.6 % 40.6\% 40.6%和 51.8 % 51.8\% 51.8%。此外,§3.3验证SLM在通用持续预训练中的有效性:Tinyllama-1B在80B词元上预训练,SLM使15个基准平均性能提升 6.8 % 6.8\% 6.8%,其中代码与数学任务提升超10%。§3.4展示,在缺少高质量参考数据时,可基于自引用的SLM策略,带来下游任务均值最高 3.3 % 3.3\% 3.3%的提升。
2 选择性语言建模
2.1 并非所有词元同等重要:词元损失的训练动态}
我们首先深入考察单个词元在标准预训练中的损失变化。以Tinyllama-1B在OpenWebMath的15B词元持续预训练为例,每训练1B词元保存一个检查点。使用约32万词元的验证集测评各检查点的词元损失。图3(a)显示,词元分为四类:保持高损失 ( H → H ) (\mathrm{H} \rightarrow \mathrm{H}) (H→H)、损失上升 ( L → H ) (\mathrm{L} \rightarrow \mathrm{H}) (L→H)、损失下降 ( H → L ) (\mathrm{H} \rightarrow \mathrm{L}) (H→L)与持续低损失 ( L → L ) (\mathrm{L} \rightarrow \mathrm{L}) (L→L)(详细定义参见§D.1)。仅 26 % 26\% 26%词元表现显著损失下降,多数词元 ( 51 % ) (51\%) (51%)已被模型掌握。 11 % 11\% 11%词元持续难学,可能受固有不确定性驱动 [Hüllermeier 和 Waegeman,2021]。另外有 12 % 12\% 12%词元训练中损失意外上升。
第二,许多词元损失伴随训练呈现明显波动,难以收敛。图3(b)与©显示部分 L → L \mathrm{L} \rightarrow \mathrm{L} L→L及 H → H \mathrm{H} \rightarrow \mathrm{H} H→H词元损失存在高方差(§D.2对原因内容做了可视化分析,确认多数为噪声词元,支持我们的假设)。
由此可见,词元损失曲线非整体损失的平滑下降,训练动态复杂。若能选取模型需重点学习的词元,或可稳定训练过程,提升数据利用效率。

2.2 选择性语言建模
总体思路 受文档级过滤中参考模型的启发,我们提出了词元级数据选择管线“选择性语言建模(Selective Language Modeling, SLM)”,流程如图4。首先在高质量语料上训练参考模型(RM),用于评估待训练语料中每一词元的损失得分。然后仅针对有较高“剩余损失”的词元训练语言模型。直觉为高剩余损失词元更具可学习性,且与目标分布更匹配,有效排除低质量或无关词元。下面详细介绍。
参考模型训练 选用代表期望目标分布的高质量语料,训练参考模型RM,采用标准交叉熵损失。基于RM计算预训练语料中每个词元 x i x_i xi的参考损失 L R M \mathcal{L}_{\mathrm{RM}} LRM,公式为:
L R M ( x i ) = − log P ( x i ∣ x < i ) (1) \mathcal{L}_{\mathrm{RM}}(x_i) = -\log P(x_i | x_{<i}) \tag{1} LRM(xi)=−logP(xi∣x<i)(1)
此评分反映词元在参考分布下的困难程度,供后续筛选使用。
选择性预训练 标准的因果语言建模(CLM)损失为:
L C L M ( θ ) = − 1 N ∑ i = 1 N log P ( x i ∣ x < i ; θ ) (2) \mathcal{L}_{\mathrm{CLM}}(\theta) = -\frac{1}{N}\sum_{i=1}^N \log P(x_i | x_{<i}; \theta) \tag{2} LCLM(θ)=−N1i=1∑NlogP(xi∣x<i;θ)(2)
其中 θ \theta θ为模型参数, N N N为序列长度, x i x_i xi为第 i i i个词元, x < i x_{<i} x<i为其之前的词元。
SLM区别于CLM,针对与RM差异较大的词元重点施加损失。定义当前训练模型在词元 x i x_i xi上的损失为 L θ ( x i ) \mathcal{L}_\theta(x_i) Lθ(xi),则余量损失为:
L Δ ( x i ) = L θ ( x i ) − L R M ( x i ) (3) \mathcal{L}_\Delta(x_i) = \mathcal{L}_\theta(x_i) - \mathcal{L}_{\mathrm{RM}}(x_i) \tag{3} LΔ(xi)=Lθ(xi)−LRM(xi)(3)
引入词元选择比例 k % k\% k%,只选取拥有最高余量损失的前 k % k\% k%词元参与训练,交叉熵损失计算为:
L S L M ( θ ) = − 1 N × k % ∑ i = 1 N I k % ( x i ) ⋅ log P ( x i ∣ x < i ; θ ) (4) \mathcal{L}_{\mathrm{SLM}}(\theta) = -\frac{1}{N \times k\%} \sum_{i=1}^N I_{k\%}(x_i) \cdot \log P(x_i | x_{<i}; \theta) \tag{4} LSLM(θ)=−N×k%1i=1∑NIk%(xi)⋅logP(xi∣x<i;θ)(4)
这里, I k % ( x i ) I_{k\%}(x_i) Ik%(xi)为指示函数:
$$I_{k%}(x_i) = \begin{cases}
1 & \text{若 } x_i \text{拥有前 } k% \text{ 最高评分} \
0 & \text{否则}
\end{cases} \tag{5}$$
默认情况下,我们使用 L Δ \mathcal{L}_\Delta LΔ作为评分函数 S S S,保证损失仅施加在模型学习最有益的词元上。实际中,可对一个批次词元按余量损失排序,只计算前 k % k\% k%词元损失,无额外预训练成本,实现高效整合。

3 实验}
我们在数学及通用领域均执行了持续预训练,并设计了消融实验及多维度分析验证SLM的有效性。
3.1 实验设置}
参考模型训练 数学参考模型使用0.5B高质量数学相关词元组成的语料,混合了基于GPT的合成数据 [Yu 等,2024;Huang 等,2024] 与人工筛选数据 [Yue 等,2024;Ni 等,2024]。通用参考模型则从开源数据集(如Tulu-v2 [Ivison 等,2023]、OpenHermes-2.5 [Teknium,2023]等)编纂1.9B词元语料。参考模型训练3轮,学习率:1B模型 5 e 5e 5e- 5 5 5,7B模型 1 e 1e 1e- 5 5 5,采用余弦衰减策略。最大序列长度1B模型设2048,7B模型设4096,批次中包含多个样本。主实验中持续预训练模型与参考模型均以相同基础模型初始化。
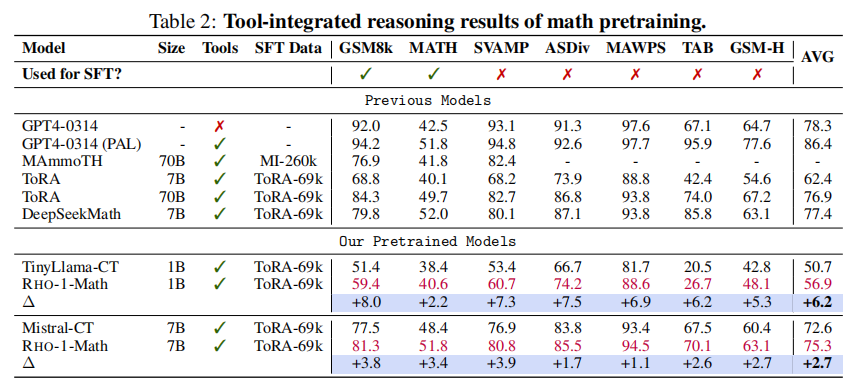
图4:选择性语言建模(SLM)管线示意。SLM通过聚焦预训练中的有价值且干净的词元,优化语言模型性能。主要三步包括:(步骤1) 在高质量数据上训练参考模型;(步骤2) 利用参考模型为语料中的每个词元评分;(步骤3) 只针对评分较高的词元进行训练。
预训练语料 数学领域采用OpenWebMath(OWM)数据集 [Paster 等,2023],约14B词元,采自Common Crawl中数学相关网页。通用领域以SlimPajama [Daria 等,2023]和StarCoderData [Li 等,2023a](均属于Tinyllama语料)联合OpenWebMath,共计训练80B词元,比例 6 : 3 : 1 6:3:1 6:3:1。
预训练配置 数学预训练基于Tinyllama-1.1B [Zhang 等,2024]和Mistral-7B [Jiang 等,2023]模型,学习率分别为 8 e 8e 8e- 5 5 5和 2 e 2e 2e- 5 5 5。1.1B模型在 32 × 32 \times 32× H100 80G GPU下,15B词元约需3.5小时,50B词元约12小时。7B模型训练15B词元约18小时。通用领域Tinyllama-1.1B学习率设 1 e 1e 1e- 4 4 4,在相同硬件下训练80B词元约19小时。批量大小统一为1M词元。词元选择比例,Tinyllama-1.1B为60%,Mistral-7B为70%。
基线设置 以采用常规因果语言建模的持续预训练模型(Tinyllama-CT和Mistral-CT)为主要基线。另与Gemma [Team 等,2024]、Qwen1.5 [Bai 等,2023]、Phi-1.5 [Li 等,2023b]、DeepSeekLLM [DeepSeek-AI,2024]、DeepSeekMath [Shao 等,2024]、CodeLlama [Roziere 等,2023]、Mistral [Jiang 等,2023]、Minerva [Lewkowycz 等,2022]、Tinyllama [Zhang 等,2024]、LLemma [Azerbayev 等,2023]及InternLM2-Math [Ying 等,2024]等知名强基线比较。微调结果对比包括MAmmoTH [Yue 等,2024]和ToRA [Gou 等,2024]。
评测配置 普通任务采用lm-eval-harness 4 { }^{4} 4 [Gao 等,2023],数学任务自研评测套件 5 { }^{5} 5。推理加速采用vllm (v0.3.2) [Kwon 等,2023]。详见附录E。
3.2 数学预训练结果}
少样本链式思维推理 采用少样本链式思维(CoT)提示,遵循前沿工作 [Wei 等,2022a;Lewkowycz 等,2022;Azerbayev 等,2023;Shao 等,2024]。如表1,RHO-1-Math比直接持续预训练平均提升16.5%(1B模型)和10.4%(7B模型)。训练多轮后,平均少样本准确率进一步提升至40.9%。与基于500B数学词元预训练的DeepSeekMath-7B相比,RHO-1-7B使用仅15B词元(10.5B选中词元)实现了相当效果,彰显高效性。
工具集成推理 微调基于69k ToRA语料(含1.6万条GPT-4生成的工具集成推理轨迹和5.3万条LLaMA生成的答案增强样本)。结果见表2,RHO-1-1B与7B在MATH任务分别达到40.6%和51.8%的最新性能。部分未见训练任务(如TabMWP和GSM-Hard)RHO-1亦表现出良好的泛化能力,平均少样本准确率分别提升6.2%和2.7%。
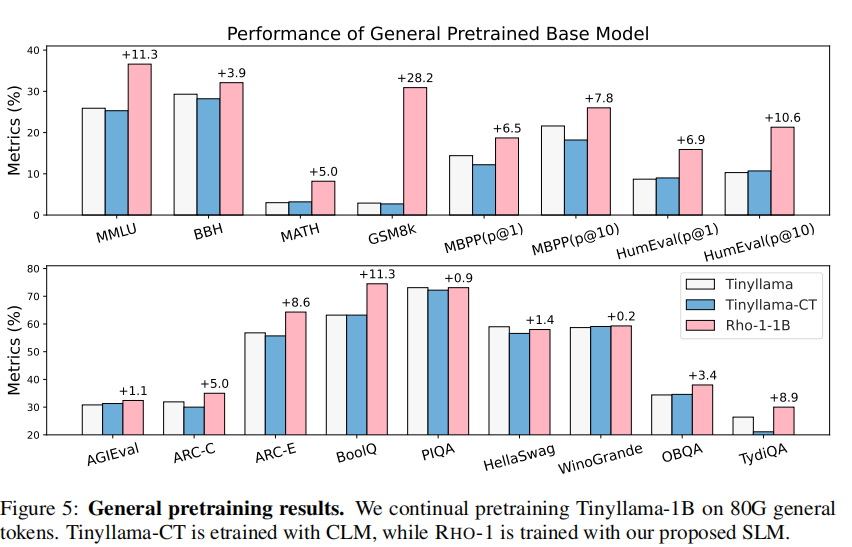
图5:通用预训练结果。持续预训练Tinyllama-1B共80G通用词元。Tinyllama-CT采用CLM训练,RHO-1采用我们提出的SLM训练。
3.3 通用预训练结果}
我们在80B通用词元上持续训练Tinyllama-1.1B验证SLM有效性。图5显示,尽管Tinyllama已就大部分词元充分训练,SLM仍比常规持续预训练平均提升6.8%(15个基准),代码和数学任务提升超10%。
3.4 自引用实验}
本节展示SLM无需额外高质量数据,仅凭预训练语料即可辅助模型训练效果提升。以OpenWebMath(OWM,Proof-Pile的子集)训练参考模型为例,评估OWM和PPile中词元,筛选后用于训练。此场景假定无下游相关数据,是常见现实情况。我们推测关键非评分准确性,而为过滤噪声词元。因此设计两种评分函数:参考模型损失 L R M \mathcal{L}_{\mathrm{RM}} LRM与下一词信息熵 H R M \mathcal{H}_{\mathrm{RM}} HRM(衡量下一词不确定度)。详情见附录H。
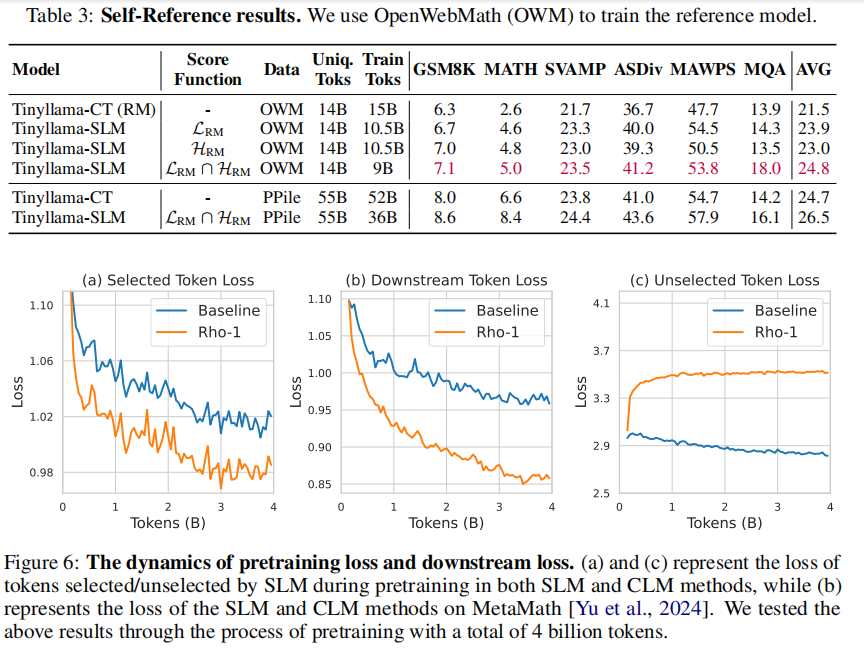
实验表明,使用仅OWM训练的参考模型亦可有效指导同语料预训练,平均下游性能提升 + 2.4 % +2.4\% +2.4%。单用信息熵作为评分函数获得类似结果。两种评分函数交集训练即筛选词元更精炼(减少40%)且性能更优,提升 + 3.3 % +3.3\% +3.3%。在仅用OWM训练参考模型情况下,SLM在PPile预训练仍带来 + 1.8 % +1.8\% +1.8%提升且用词元数减少30%。详见附录H。
3.5 消融与分析}
选择词元损失与下游性能更契合 我们利用参考模型筛词,并评估训练后验证集及下游损失。如图6所示,经过4B词元预训练统计,RHO-1在选中词元上的损失下降明显,较传统预训练对下游损失影响更显著,后者虽训练初期损失下降但对下游帮助有限。因此,选词训练更有效。
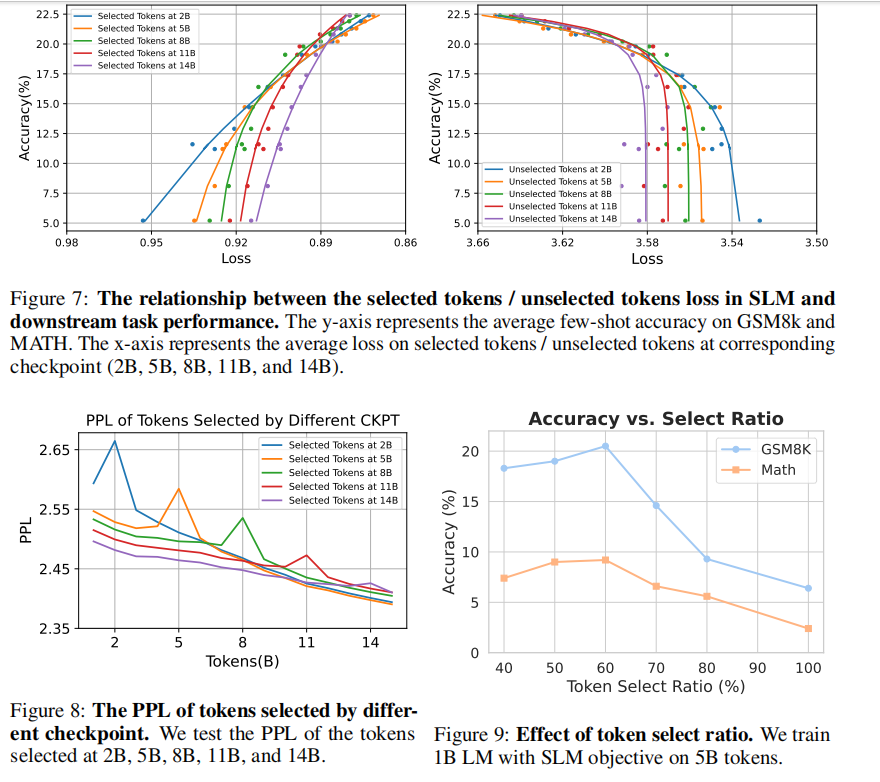
图6:(a)与©为SLM与CLM方法下预训练时,选中/未选词元的损失变化,(b)为SLM及CLM在MetaMath上的损失对比。训练4B词元。
图7揭示SLM选中词元损失与下游任务表现成幂律关系,验证[ Gadre 等,2024 ]结果。SLM选中词元的损失下降促进性能提升,未选词元则负面影响模型表现,表明非所有词元损失均需降低方能获益。
图7:SLM中选中词元/未选词元损失与下游少样本准确率关系。纵轴为GSM8k与MATH平均准确率,横轴为相关检查点(2B、5B、8B、11B及14B)对应词元平均损失。
SLM筛选词元分析 为洞察SLM工作机制,我们可视化RHO-1训练中词元选择动态 (§G.1,蓝色表示实际被训练的词元)。观察表明,SLM筛选的词元与数学语义高度关联,令模型专注于语料中数学相关信息部分。
此外,我们分析不同训练检查点筛选词元差异,并测试词元在不同检查点上的困惑度。图8显示,后期筛选的词元训练后期困惑度趋高,早期困惑度较低,暗示模型优先优化未充分学习词元,提升学习效率。我们注意词元困惑度存在阶段性的“二次下降”现象 [Nakkiran 等,2021],体现SLM依余量损失动态筛选最急需学习的词元。
图8:不同时期(2B、5B、8B、11B、14B)筛选词元的困惑度(PPL)随训练进程变化。
选词比例影响 我们探究SLM中词元选择比例对训练效果的影响。该比例多基于启发式定义,类似Masked Language Model (MLM) 的mask比例设定 [Devlin 等,2019;Liu 等,2019]。图9显示,约60%的词元被选中时,训练效果最佳。
图9:词元选择比例对1B模型在5B词元上训练性能影响。
4 结论
本文提出选择性语言建模(SLM)方法,通过选择更适合当前训练阶段的词元训练新的语言模型RHO-1。通过对预训练过程中词元损失的细致分析,发现词元价值存在显著差异,并非所有词元对模型训练同等重要。我们在数学及通用领域的实验和分析充分验证了SLM的有效性,强调了词元级别在LLM预训练中的关键地位。未来,从词元视角提升预训练效率与表现值得深入研究。
致谢
郑浩林、陈林感谢国家重点研发计划(编号2022ZD0160501)、国家自然科学基金(编号62372390、62432011)支持。耿志斌、杨宇久感谢深圳市科技计划(JCYJ20220818101001004)及平安科技(深圳)有限公司“图神经网络项目”支持。
相关文章:

《Not All Tokens Are What You Need for Pretraining》全文翻译
《Not All Tokens Are What You Need for Pretraining》 不是所有的词元都是预训练所需 摘要 先前的语言模型预训练方法通常对所有训练词元均匀地应用下一词预测损失。对此常规做法提出挑战,我们认为“语料库中的并非所有词元对于语言模型训练同等重要”。我们的…...

vscode终端运行windows服务器的conda出错
远程windows服务器可以运行,本地vscode不能。 打开vscode settings.json文件 添加conda所在路径...
)
使用基数树优化高并发内存池(替代加锁访问的哈希表和红黑树)
前言: 本篇旨在熟悉 基于tcmalloc的高性能并发内存池项目之后,对于最后的优化进行的笔记梳理,项目完整代码 可点击:项目代码 进行查看。 优化思想风暴: 为了方便根据页号查找到对应的span, 这里我们可以使用红黑树或…...

【bash】.bashrc
查看当前路径文件数量 alias file_num"ls -l | grep ^- | wc -l"查看文件大小 alias file_size"du -sh"alias ll alias ll"ls -ltrh"cd的同时执行ll alias cdcdls; function cdls() {builtin cd "$1" && ll }自定义prompt…...

自我生成,自我训练:大模型用合成数据实现“自我学习”机制实战解析
目录 自我生成,自我训练:大模型用合成数据实现“自我学习”机制实战解析 一、什么是自我学习机制? 二、实现机制:如何用合成数据实现自我训练? ✅ 方式一:Prompt强化生成 → 自我采样再训练 ✅ 方式二…...

Linux的命令格式,运行级别,找回root密码,Linux用户的分类,绝对路径和相对路径,硬链接和软链接,实用按键
目录 Linux的命令格式 运行级别 运行级别说明 切换运行级别 指定默认的运行级别 找回root密码 找回root密码 可能会出现的问题 Linux的用户分类 绝对路径和相对路径 硬链接和软链接 实用按键 Linux的命令格式 Linux的命令格式: command [-options] [par…...

C# JSON
在C#中,你可以使用System.Text.Json或Newtonsoft.Json库来解析JSON字符串。以下是使用这两种库分别解析你提供的JSON字符串的示例。 1. 使用 System.Text.Json System.Text.Json 是 .NET Core 3.0 及以上版本中包含的内置JSON库。以下是如何使用它来解析你的JSON字…...

入门-C编程基础部分:6、常量
飞书文档https://x509p6c8to.feishu.cn/wiki/MnkLwEozRidtw6kyeW9cwClbnAg C 常量 常量是固定值,在程序执行期间不会改变,可以让我们编程更加规范。 常量可以是任何的基本数据类型,比如整数常量、浮点常量、字符常量,或字符串字…...

数字时代的AI与大数据:用高级AI开发技术革新大数据管理
李升伟 编译 在当今数字时代,数据的爆炸式增长令人惊叹 从社交媒体互动到物联网设备的传感器数据,企业正被海量信息淹没。但如何将这种无序的数据洪流转化为有价值的洞察?答案在于人工智能(AI)开发技术的革新&#x…...

数据结构与算法入门 Day 0:程序世界的基石与密码
🌟数据结构与算法入门 Day 0:程序世界的基石与密码🔑 ps:接受到了不少的私信反馈,说应该先把前置的知识内容做一个梳理,所以把昨天的文章删除了,重新开启今天的博文写作 Hey 小伙伴们ÿ…...

20250416在荣品的PRO-RK3566开发板的Android13下编译native C的应用程序的步骤
mm编译的简略步骤以及详细LOG,仅供参考: rootrootrootroot-X99-Turbo:~/hailuo_temp/Android13.0$ source build/envsetup.sh rootrootrootroot-X99-Turbo:~/hailuo_temp/Android13.0$ lunch 57. rk3566_t-userdebug Pick from common choices abo…...

Pikachu靶场——Cross-Site Scripting
使用ubantu-linux虚拟机通过docker镜像本地搭建 一,反射型xss(get) 1,观察靶场环境,功能是提交你最喜欢的NBA球星 2,可以通过burp suite抓包分析一下 通过GET请求提交输入的姓名,这是及其危险的 3,尝试使用…...
)
ArkTS组件的三个通用(通用事件、通用属性、通用手势)
文章目录 通用事件点击事件 onClick触摸事件 onTouch挂载、卸载事件拖拽事件按键事件 onKeyEvent焦点事件鼠标事件悬浮事件组件区域变化事件 onAreaChange组件尺寸变化事件组件可见区域变化事件组件快捷键事件自定义事件分发自定义事件拦截 通用属性尺寸设置位置设置布局约束边…...

双token实现无感刷新
一、方案说明 1. 核心流程 用户登录 提交账号密码 → 服务端验证 → 返回Access Token(前端存储) Refresh Token(HttpOnly Cookie) 业务请求 请求头携带Access Token → 服务端验证有效性 → 有效则返回数据 Token过…...

UE5游戏分辨率设置和窗口模式
第一种方法: 在项目配置Config文件夹下新建 DefaultGameUserSettings.ini 输入代码 [/Script/Engine.GameUserSettings] bUseVSyncFalse ResolutionSizeX1960 ResolutionSizeY1080 LastUserConfirmedResolutionSizeX800 LastUserConfirmedResolutionSizeY600 WindowPosX-1 …...

Java 线程中断 Interrupted
线程中断是 Java 中的一种协作机制,用于通知线程应该停止当前工作并退出。 中断就好比其它线程跟当前线程打了个招呼,告诉他可以执行中断操作。其他线程通过调用该线程的interrupt()方法对其进行中断操作。 中断并不会直接终止线程,而是设置…...

Android Jetpack是什么与原生android 有什么区别
Android Jetpack是什么 Android Jetpack是Google推出的一套开发组件工具集,旨在帮助开发者更高效地构建高质量的Android应用。它包含多个库和工具,被分为架构、用户界面、行为和基础四大类。以下是一些Android Jetpack的示例: 架构组件 ViewModel:用于以生命周期的方式管理…...

从0~1写一个starer启动器
从0到1编写一个Spring Boot Starter 前言 使用过Spring框架的伙伴都知道,虽然Spring在一定程度上帮助我们简化了集成其他框架,但在集成框架的同时仍少不了大量的XML配置,这些繁琐的工作无疑会加重我们的工作任务。而Spring Boot相较于Sprin…...
)
prime-2 靶场笔记(vuInhub靶场)
前言: 在本次靶场环境中涉及的知识点,主要包含LFI和SMB以及Lxd组提权,具体内容包括主机探测、端口扫描、目录扫描、wpscan扫描、反弹shell、一句话木马、容器、linux各种提权和维持。 环境介绍: 本靶场使用了kali(192…...
)
Node.js 中的 Buffer(缓冲区)
下面是关于 Node.js 中的 Buffer(缓冲区) 的系统总结,涵盖了定义、创建、读取修改、溢出处理、中文编码问题以及字符串转换等关键用法👇 🧱 一、什么是 Buffer? Buffer 是 Node.js 提供的用于处理二进制数…...

如何学习嵌入式
写这个文章是用来学习的,记录一下我的学习过程。希望我能一直坚持下去,我只是一个小白,只是想好好学习,我知道这会很难,但我还是想去做! 本文写于:2025.04.16 请各位前辈能否给我提点建议,或者学习路线指导一下 STM32单片机学习总…...
 使用HIDL方法)
高版本Android (AIDL HAL) 使用HIDL方法
目录 修改步骤和编译方法 注意事项 Android 11 引入了使用 AIDL 实现 HAL 的功能。 后续Android新版本,HAL默认切到了使用AIDL. 因此当导入旧HIDL实现方式时,需要做一些修改。 1.将HAL HIDL模块拷贝到相应目录,进行编译 source build/envsetup.sh lunch xxx mmm 模块路径 1.…...
 vpc-flow 数据抽样)
Cribl (实验) vpc-flow 数据抽样
先看文档: Firewall Logs: VPC Flow Logs, Cisco ASA, Etc. | Cribl Docs Firewall Logs: VPC Flow Logs, Cisco ASA, Etc. Recipe for Sampling Firewall Logs Firewall logs are another source of important operational (and security) data. Typical examples include Ama…...

RK3568 更换显示logo
文章目录 1、环境介绍2、替换logo 1、环境介绍 硬件:飞凌ok3568-c开发板 软件:原厂rk356x sdk 屏幕:1024*600 hdmi屏 2、替换logo 这是一件提无语的事。本来替换logo是很平常的一件事。即替换kernel目录下的logo图片即可: 但…...

修改wsl中发行版Ubuntu的主机名
我wsl2中装了两个ubuntu的发行版本,默认下主机名和我的windows主机名都一样,而且包含大写字母,在配置其他应用时经常会出问题,按照下面的顺序修改了一下: 1、打开ubuntu发行版 现在显示包含大写字母和数字的主机名。 …...
)
Python学习之路(三)
将 Python 与数据库对接是开发过程中常见的任务,可以使用多种数据库(如 SQLite、MySQL、PostgreSQL、Oracle、MongoDB 等)。以下是一些常见的数据库及其与 Python 的对接方法,包括安装库、连接数据库、执行查询和操作数据的示例。…...

多功能门禁系统的设计
本课题为多功能门禁系统的设计,其系统架构如图2.1所示,整个系统由STM32F103单片机和MaixBit开发板两部分构成,其中MaixBit是基于K210芯片的开发板,在此主要负责人脸的录入,识别,液晶显示等功能,…...

C/C++---头文件保护机制
在 C 和 C 编程里,头文件保护机制是一种防止头文件被重复包含的技术,它主要借助 #ifndef、#define 和 #endif 这些预处理指令来达成,也可以使用 #pragma once 这一编译器特定指令。下面详细阐述这一机制: 1. 头文件重复包含的问题…...
)
双指针算法(一)
目录 一、力扣——283、移动零 二、力扣——1089、复写零 三、力扣——11、盛最多的水 四、力扣——202、快乐数 一、力扣——283、移动零 题目如下: 这里我们用双指针算法,用的是双指针的思想,我们在这道题在数组下操作可以用数组下标。…...

LNMP架构部署论坛
目录 1.安装Nginx服务 1.系统初始化 2.安装工具包及依赖包 3.创建运行用户 4.编译安装 5.优化路径 6.添加 Nginx 系统服 2.安装MySQL服务 1.确定GLIBC版本 2.上传二进制压缩包并解压 3. 创建运行用户 4. 创建 mysql 配置文件 5.更改mysql安装目录和配…...

微信小程序边框容器带三角指向
效果图 .wxml <view class"tb"><view class"tb-pointer" style"--n:{{n}}rpx;" /> </view> <button bind:tap"addPixel">增加三角一个像素</button>.js Page({data: {n:16,},addPixel(){this.setData…...

RISCV Hardware Performance Monitor 和 Sscofpmf 扩展
文章目录 前言RISCV的HPMSscofpmf 扩展总结 前言 Perf 全名是 Performance Event,应用可以利用 PMU (Performance Monitoring Unit)、tracepoint 和核心内部的特殊计数器(counter)来进行统计,另外还能同时分析运行中的核心代码&a…...
的轨迹仿真,主要用于模拟升力体在不同飞行阶段(初始滑翔段、滑翔段、下压段)的运动轨迹)
MATLAB脚本实现了一个三自由度的通用航空运载器(CAV-H)的轨迹仿真,主要用于模拟升力体在不同飞行阶段(初始滑翔段、滑翔段、下压段)的运动轨迹
%升力体:通用航空运载器CAV-H %读取数据1 升力系数 alpha = [10 15 20]; Ma = [3.5 5 8 10 15 20 23]; alpha1 = 10:0.1:20; Ma1 = 3.5:0.1:23; [Ma1, alpha1] = meshgrid(Ma1, alpha1); CL = readmatrix(simulation.xlsx, Sheet, Sheet1, Range, B2:H4); CL1 = interp2(…...
结合osg及osgEarth实现地图选点功能)
GIS开发笔记(4)结合osg及osgEarth实现地图选点功能
一、实现效果:在地球上点击某个点后,显示该点的坐标。 二、实现原理: viewer添加事件处理器类,类中响应鼠标左键事件,获取坐标点显示。 三、参考代码: #pragma once#include <osgGA/GUIEventHandler> #include...
find_shape_model_clutter)
halcon模板匹配(五)find_shape_model_clutter
目录 一、find_shape_model_clutter例程目的二、默认模板匹配的过程三、定义杂波区域四、设置模型的杂波区域 一、find_shape_model_clutter例程目的 如下图所示,这个例程是想找到左图所示区域内的目标,要求上下临近区域无目标。 默认参数匹配结果 二…...

openGauss使用指南与SQL转换注意事项
openGauss 使用指南与SQL转换注意事项 基本说明 openGauss数据库内核基于PostgreSQL(pgsql),因此可以将SQL Server语句转换为pgsql语句。可以使用AI工具辅助转换,但需注意以下关键差异点。 数据类型转换注意事项 字符串类型处理 nvarchar转换&#…...
—组件基础》)
前端基础之《Vue(5)—组件基础》
一、什么是组件化 1、理解组件化 组件是HTML的扩展,使用粒度较小的HTML元素封装成粒度更大的标签(Vue组件)。可以实现快速开发、代码复用、提升可维护性。 相当于盖房子,用预制板,不是用一块块砖,一天可以…...
)
责任链模式(Chain of Responsibility Pattern)
责任链模式(Chain of Responsibility Pattern)是一种行为型设计模式,它允许将请求沿着处理者链进行传递,直到有一个处理者能够处理该请求为止。在这个模式中,多个处理者对象会形成一个链条,每个处理者都有机会处理请求,或者将请求传递给链条中的下一个处理者。这种模式将…...
:数组作为函数参数,注意事项与实践)
C++算法(9):数组作为函数参数,注意事项与实践
C编程中,数组作为函数参数传递是一个常见但容易出错的操作。本文将详细介绍数组作为函数参数时需要注意的关键问题,帮助开发者避免常见的陷阱。 主要注意事项 1. 数组作为参数的本质 参数声明形式实际传递内容大小信息int arr[]数组首地址丢失int arr[…...
)
特性(Attribute)
特性(Attribute)的概念 定义 特性是用于向代码元素(类、方法、属性等)添加元数据的类,继承自 System.Attribute。 元数据提供程序化的描述信息,供运行时或工具(如编译器、反射)使…...

使用CubeMX新建SysTick延时函数工程——使用中断,不使用HAL_Delay
具体操作步骤看这里:STM32CubeMX学习笔记(4)——系统延时使用_cubemx systick-CSDN博客 1、SysTick 初始化函数 SysTick 初始化函数由用户编写,里面调用了 SysTick_Config() 这个固件库函数,通过设置该固件 库函数的形…...
从零开始实现 MobileViT 注意力机制——轻量级Transformer Vision Model 的新思路
从零开始实现 MobileViT 注意力机制——轻量级Transformer Vision Model 的新思路 近年来,计算机视觉领域中 Transformer 模型的崛起为图像处理带来了新的活力。特别是在 ViT(Vision Transformer)模型提出之后,Transformer 在图像…...

Doris部署生产集群最低要求的部署方案
Doris生产集群最低部署方案(2025年4月版) 一、节点规划与数量 1. FE节点(Frontend) 数量:至少 3个节点(1个Follower 2个 Observer),确保高可用(HA)。角色分…...

如何实现“一机两用” 寻求安全与效率的完美平衡
#### 一机两用的背景 在数字化时代,无论是企业还是政府部门,都面临着既要处理内部敏感数据,又要访问互联网获取资源的双重需求。这种需求催生了“一机两用”的模式,即同一台终端设备既要连接内网处理核心业务,又要能够…...

楼宇自控系统如何为现代建筑打造安全、舒适、节能方案
在科技飞速发展的当下,现代建筑对功能和品质的要求日益提升。楼宇自控系统作为建筑智能化的核心技术,宛如一位智慧的“管家”,凭借先进的技术手段,为现代建筑精心打造安全、舒适、节能的全方位解决方案,让建筑真正成为…...

Xilinx 7系列fpga在线升级和跳转
一、常见跳转方式 1,一般FPGA只要上电,就会自动从外部flash的0地址加载程序。 2,而我们所谓的在线式升级就是在flash0地址放一个程序(boot/golden image),然后在后面再放一个程序(app/update …...

【LangChain核心组件】Callbacks机制深度剖析与实战指南
目录 一、通俗解释(举个🌰) 二、具体能干啥? 三、怎么用?(一句话说透) 四、小结 五、为什么Callbacks是LangChain的灵魂组件? 六、Callbacks核心API解析 1、 基础回调处理器 …...

回调函数用法详细讲解
目录 一、通过几个例子,浅谈一下我的学习见解! 二、typedef关键字用法回顾 1)基本语法 2)主要用途 1、为基本数据类型定义别名 2、为复杂类型定义别名 >>1.数组类型 >>2.指针类型 >>3.结构体类型 >…...

Nature子刊:科学家绘制与全身性癫痫发作相关的大脑网络图谱,为新的脑刺激疗法铺平道路
癫痫是一种古老的神经系统疾病,其历史可以追溯到数千年前。在古代,癫痫患者常被误解为受到神灵的惩罚或灵魂的附体,这种误解导致患者在社会中遭受歧视和排斥。然而,随着现代医学的发展,我们逐渐揭开了癫痫的神秘面纱&a…...

postman使用技巧
postman使用技巧 pre-request需求:三方对接的接口需要在请求头中添加如下参数pre-request 中获取环境变量中的变量值pre-request 中添加请求头 参考: pre-request 需求:三方对接的接口需要在请求头中添加如下参数 Accept: application/json…...