深度学习(第1章——神经网络原理和Pytorch入门)
前言:
本章将讲解神经网络原理,神经元如何处理输入并输出,什么是梯度,多层感知机中梯度的计算,Pytoch自动梯度效果,如何使用原生Python实现一个简单的神经网络,以及对应Pytorch实现。

神经网络原理:
神经网络的设计灵感来源于人脑的结构和功能。人脑由数十亿个神经元组成,这些神经元通过突触相互连接,形成复杂的网络。
神经元的基本单元:
人脑的基本单元是神经元,每个神经元接收来自其他神经元的信号,并通过突触将信号传递给下一个神经元。在人工神经网络中,神经元被模拟为节点,每个节点接收输入并生成输出。
层次结构:
人脑的神经元通常以层次结构组织,信息从感知层(如视觉、听觉)传递到更高层次的处理区域。类似地,人工神经网络通常由输入层、隐藏层和输出层组成,信息在这些层之间传递和处理。
激活函数:
神经元在接收到足够的刺激后会“激活”,并产生输出。这个过程可以通过激活函数来模拟。在神经网络中,激活函数(如ReLU、Sigmoid等)决定了节点的输出,模拟了生物神经元的激活机制。
学习与适应:
人脑通过突触的强度变化来学习和记忆,这种过程称为突触可塑性。人工神经网络通过调整权重来学习,使用反向传播算法来优化网络的性能。
并行处理:
人脑能够同时处理大量信息,具有高度的并行处理能力。神经网络也能够并行处理输入数据,特别是在使用GPU等硬件加速时。
如果是初学者,可能对上面的一些名词有些陌生,不过影响不大,可以先简单的将神经网络看作一个黑盒,其在对训练数据 进行一段时间的训练后,能够对于测试数据
输出其预测值
,其中
表示一次训练的(特征,标签)对的数目,即批次,
特征空间,
的维度数目即为特征的数目,比如一个人的身高,体重两项数据对应特征空间维度为2,
,
表示标签的种类。神经网络相当于一个映射函数
。
神经元:
先看神经网络的基本单位:神经元:

每个神经元均会根据输入的特征X给出一个输出值y,神经元会对每个特征进行权衡,毕竟每个特征对最终输出的影响结果也会不同,并会将加权后的特征相加后在加上一个偏置量b,这样即使所有特征的权重都为0的情况下也会产生一个非0的输出,同时会加上一个激活函数,将无边界的输入控制在一个可控的范围,也可以结合实际生物中当刺激达到一定程度时即会产生一个电位,但这个电位有最大值(与Na+ K+离子的进出速率有关,但速率也有上限,不可能被针扎一下直接220V)因此最终可以得到以下公式:
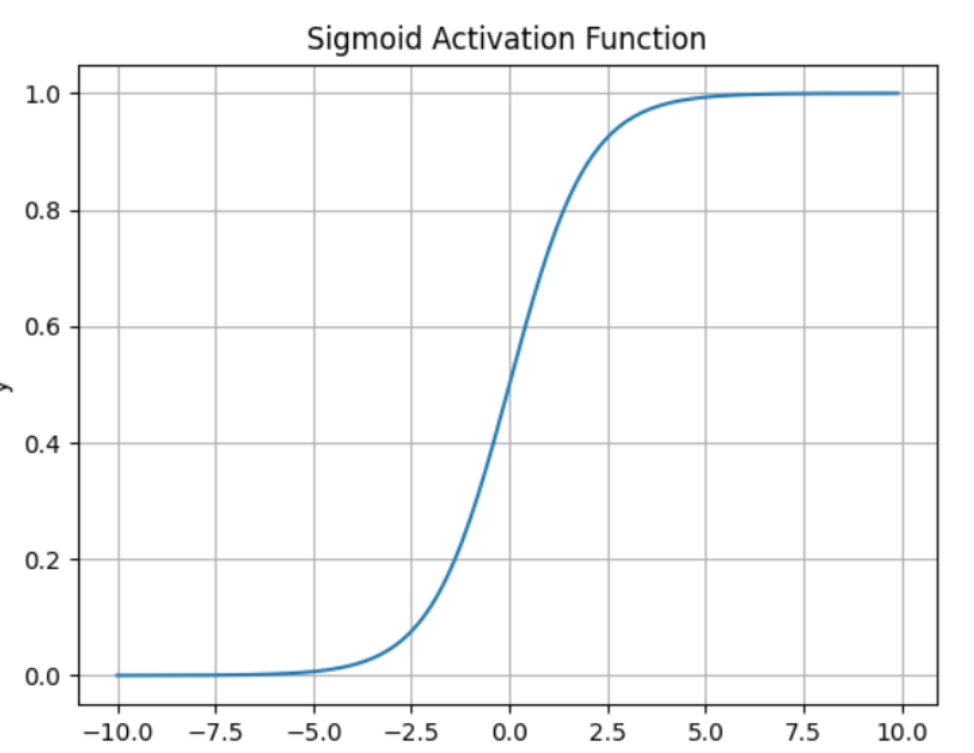
其中即为激活函数,这里拿Sigmod激活函数举例,其表达式为:
对其求导可发现:
其波形如下,能够将正负无穷的数据最终统一到0到1的范围内。
梯度:
梯度(偏导的集合)是多变量微积分中的一个基本概念,表示一个标量函数在某一点的变化率和方向。具体而言,梯度是一个向量,它指向函数在该点上升最快的方向,其大小表示函数在该方向上的变化率。
简单而言,对于的函数,先计算
相对于每个
的偏导,(如果
对于
的偏导为2,即表示
每增加1,
增加2),将
,
,
看作一个整体
,如果需要知道
相对于
的梯度,其值即为计算结果
对每个
的偏导并组成一个向量。

简单介绍上面代码,创建了一个值为(1,2,3)的向量,并开启自动梯度,开启后通过backward调用能够获取该向量经过一定变化后输出对于原向量的梯度,这里输出:
求偏导后容易得到相对于
的梯度为(2,2,2)。
多层感知机:
将多个神经元组装起来即可得到神经网络,下图是一个两层的神经网络,包含三个神经元
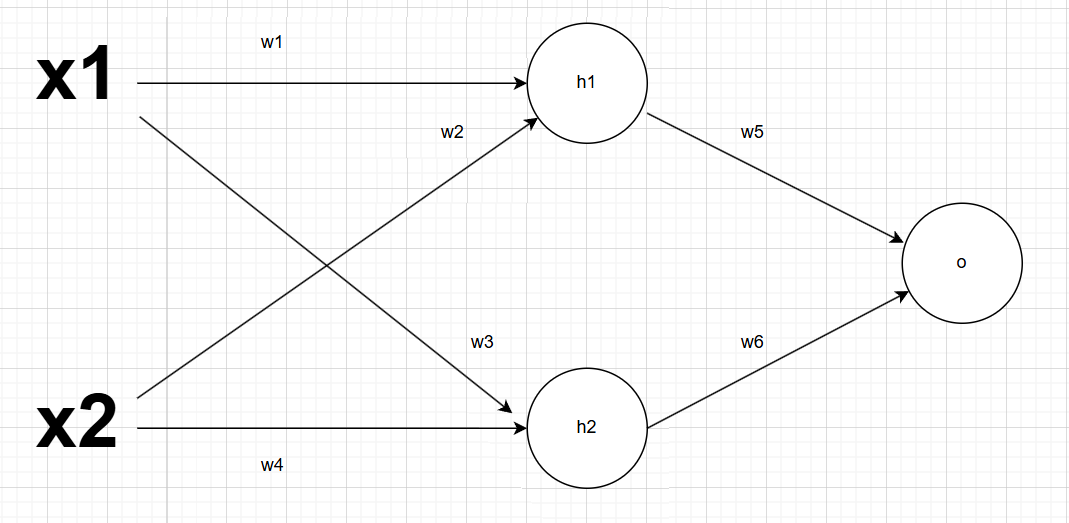
其中:
这里把看为神经网络的一层,
为神经网络的另一层,神经网络每层的输入是上一层的输出,类似生物中信号传递。尽管这里仅仅只由两层网络且使用的函数为线性变化,但由于激活函数引入非线性变化,这个神经网络以及能够模拟大部分非线性函数。
这里假设需要用上述神经网络完成一项根据身高和体重判别性别的任务,标签和数据如下:
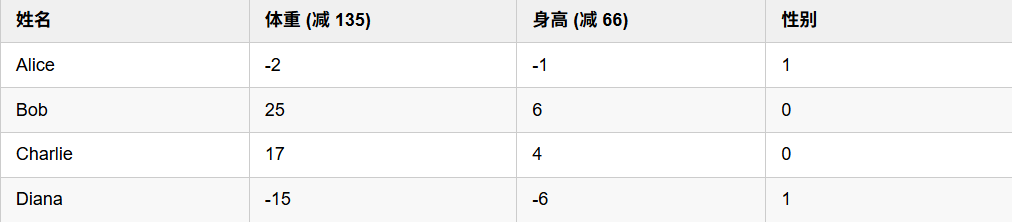
初始时随机化权重,每一对(体重,身高)输入网络后,由于最后经过一层激活函数都归一化到0到1的范围。就例如对于某次初始权重Alice(-2,-1)最终输入为0.2,这显然与正确性别1有较大差距,这里将这个差距定义为损失Loss。损失用于衡量真实标签和预测标签的差距程度,显然这个程度越小表明模型效果越好。当然由于有多个数据,可能仅仅只是这个数据记录错误将男生记录成了女生,而神经网络最终实现的效果应该是在大部分样本上取得较好效果,应该损失应该累加每组的损失。使用均方差损失,计算如下:
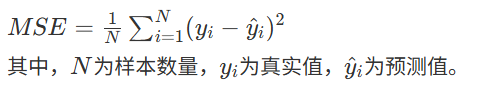
(这里如果采用距离损失则显然损失越趋近于0越好,但如果使用别的损失计算发现损失可能为负数,且损失越小越好,则可以使用Sigmod进行一次激活。)
当计算出损失后,如何通过损失优化权重,这里有前人做出了数学证明,只需要知道结论即可:用当前权重的每一个参数减一个逐渐递减的值(学习率)乘损失并更新该参数,重复无穷次最终得到的值即为让损失为0的值。不过在实践中发现,当学习率恒定取较小的值时也能取得较好的效果,当然如果太小取学习率为0.00001,当
初始值为0,真实值为1时,在上述损失始终在(0,1)的范围内时至少需要迭代100000次。但取太大又会振荡,因此需要合理选取学习率。

Python原生实现神经网络:
在知道神经网络原理后,显然最终要的是求出梯度,由于torch提供了自动梯度所以不需要手动计算,先介绍单神经元的梯度计算方式。虽然前面梯度部分也又提到,这里加深理解。
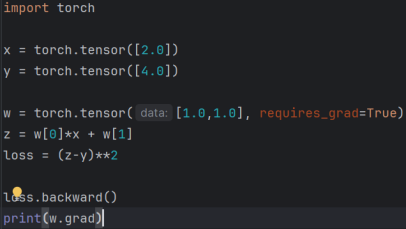
这里x可以看作一维特征,y为标签,w为神经网络初始权重(1,1),z为输出通过z的计算方式能够发现其实这里神经网络是一个简单的线性模型,损失为z和y插值的平方。梯度计算如下:
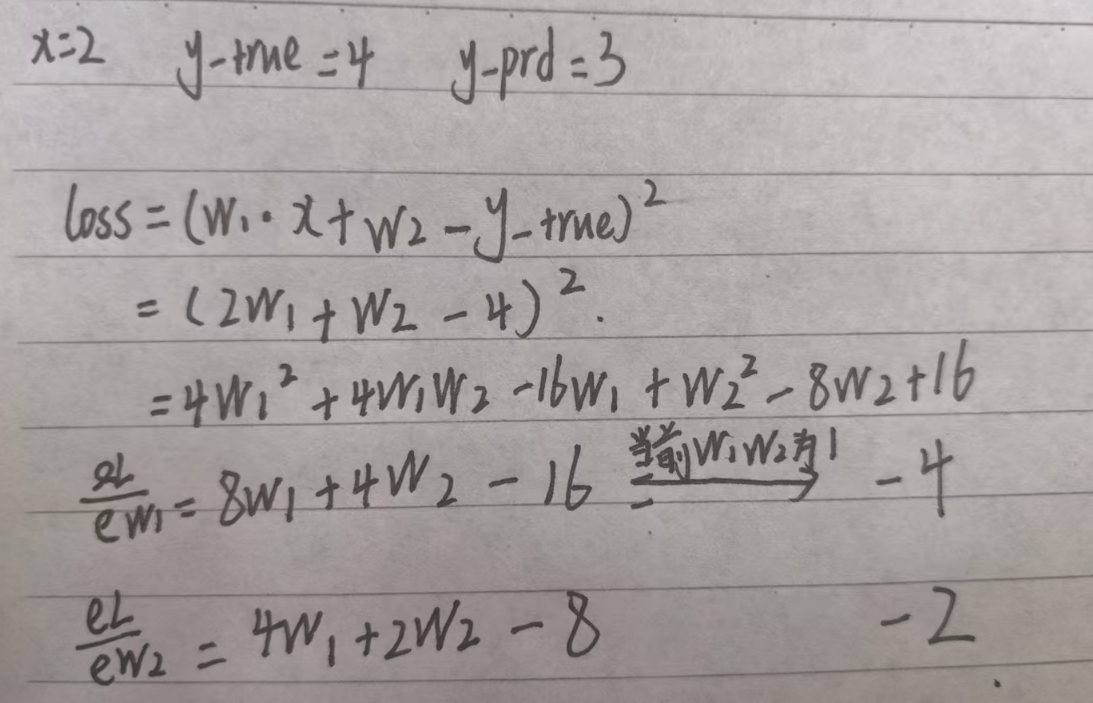
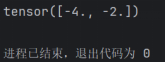
使用torch计算结果如下:
下面展示在两层神经网络中损失对于的偏导计算:

同理能够求出关于所有参数的梯度,同时能够发现其中有很多公共项能够复用,这里不再赘述。
代码如下,其中权重全部初始化为0.1,方便复现结果。
import numpy as npdef sigmoid(x):return 1 / (1 + np.exp(-x))def deriv_sigmoid(x):fx = sigmoid(x)return fx * (1 - fx)def mse_loss(y_true, y_pred):return ((y_true - y_pred) ** 2).mean()class OurNeuralNetwork:def __init__(self):# 权重,Weightsself.w1 = 0.1self.w2 = 0.1self.w3 = 0.1self.w4 = 0.1self.w5 = 0.1self.w6 = 0.1# 截距项,Biasesself.b1 = 0.1self.b2 = 0.1self.b3 = 0.1def feedforward(self, x):h1 = sigmoid(self.w1 * x[0] + self.w2 * x[1] + self.b1)h2 = sigmoid(self.w3 * x[0] + self.w4 * x[1] + self.b2)o1 = sigmoid(self.w5 * h1 + self.w6 * h2 + self.b3)return o1def train(self, data, all_y_trues):learn_rate = 0.1epochs = 1000 # 遍历整个数据集的次数for epoch in range(epochs):for x, y_true in zip(data, all_y_trues):sum_h1 = self.w1 * x[0] + self.w2 * x[1] + self.b1h1 = sigmoid(sum_h1)sum_h2 = self.w3 * x[0] + self.w4 * x[1] + self.b2h2 = sigmoid(sum_h2)sum_o1 = self.w5 * h1 + self.w6 * h2 + self.b3o1 = sigmoid(sum_o1)y_pred = o1d_L_d_ypred = -2 * (y_true - y_pred)# Neuron o1d_ypred_d_w5 = h1 * deriv_sigmoid(sum_o1)d_ypred_d_w6 = h2 * deriv_sigmoid(sum_o1)d_ypred_d_b3 = deriv_sigmoid(sum_o1)d_ypred_d_h1 = self.w5 * deriv_sigmoid(sum_o1)d_ypred_d_h2 = self.w6 * deriv_sigmoid(sum_o1)# Neuron h1d_h1_d_w1 = x[0] * deriv_sigmoid(sum_h1)d_h1_d_w2 = x[1] * deriv_sigmoid(sum_h1)d_h1_d_b1 = deriv_sigmoid(sum_h1)# Neuron h2d_h2_d_w3 = x[0] * deriv_sigmoid(sum_h2)d_h2_d_w4 = x[1] * deriv_sigmoid(sum_h2)d_h2_d_b2 = deriv_sigmoid(sum_h2)# Neuron h1self.w1 -= learn_rate * d_L_d_ypred * d_ypred_d_h1 * d_h1_d_w1self.w2 -= learn_rate * d_L_d_ypred * d_ypred_d_h1 * d_h1_d_w2self.b1 -= learn_rate * d_L_d_ypred * d_ypred_d_h1 * d_h1_d_b1# Neuron h2self.w3 -= learn_rate * d_L_d_ypred * d_ypred_d_h2 * d_h2_d_w3self.w4 -= learn_rate * d_L_d_ypred * d_ypred_d_h2 * d_h2_d_w4self.b2 -= learn_rate * d_L_d_ypred * d_ypred_d_h2 * d_h2_d_b2# Neuron o1self.w5 -= learn_rate * d_L_d_ypred * d_ypred_d_w5self.w6 -= learn_rate * d_L_d_ypred * d_ypred_d_w6self.b3 -= learn_rate * d_L_d_ypred * d_ypred_d_b3if epoch % 10 == 0:y_preds = np.apply_along_axis(self.feedforward, 1, data)loss = mse_loss(all_y_trues, y_preds)print("Epoch %d loss: %.3f" % (epoch, loss))# 定义数据集
data = np.array([[-2, -1], # Alice[25, 6], # Bob[17, 4], # Charlie[-15, -6], # Diana
])
all_y_trues = np.array([1, # Alice0, # Bob0, # Charlie1, # Diana
])network = OurNeuralNetwork()
network.train(data, all_y_trues)
emily = np.array([-7, -3])
frank = np.array([20, 2])
print("Emily: %.3f" % network.feedforward(emily))
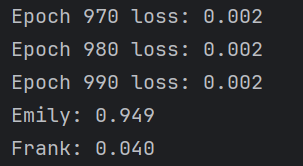
print("Frank: %.3f" % network.feedforward(frank))最终结果如下:
Pytorch实现神经网络:
import torch
import torch.nn as nn
import torch.optim as optim
import numpy as np# 定义神经网络类
class OurNeuralNetwork(nn.Module):def __init__(self):super(OurNeuralNetwork, self).__init__()# 定义两个线性层self.layer1 = nn.Linear(2, 2)self.layer2 = nn.Linear(2, 1)# 初始化权重和偏置nn.init.constant_(self.layer1.weight, 0.1)nn.init.constant_(self.layer1.bias, 0.1)nn.init.constant_(self.layer2.weight, 0.1)nn.init.constant_(self.layer2.bias, 0.1)def forward(self, x):# 第一个隐藏层h1 = torch.sigmoid(self.layer1(x))# 输出层o1 = torch.sigmoid(self.layer2(h1))return o1.flatten()# 定义数据集
data = np.array([[-2, -1], # Alice[25, 6], # Bob[17, 4], # Charlie[-15, -6], # Diana
])
all_y_trues = np.array([1, # Alice0, # Bob0, # Charlie1, # Diana
])# 将numpy数组转换为torch张量
data = torch.tensor(data, dtype=torch.float32)
all_y_trues = torch.tensor(all_y_trues, dtype=torch.float32)# 初始化网络
network = OurNeuralNetwork()# 定义损失函数和优化器
loss_fn = nn.MSELoss()
optimizer = optim.SGD(network.parameters(), lr=0.1)# 训练网络
epochs = 1000
for epoch in range(epochs):for i in range(len(data)):optimizer.zero_grad()y_pred = network(data[i])loss = loss_fn(y_pred, all_y_trues[i].unsqueeze(0))loss.backward()optimizer.step()if epoch % 10 == 0:with torch.no_grad():y_preds = network(data)loss = loss_fn(y_preds, all_y_trues)print("Epoch %d loss: %.3f" % (epoch, loss.item()))# 测试新样本
emily = torch.tensor([-7, -2], dtype=torch.float32)
frank = torch.tensor([20, 2], dtype=torch.float32)
with torch.no_grad():print("Emily (Linear): %.3f" % network(emily).item()) # 输出预测结果print("Frank (Linear): %.3f" % network(frank).item()) # 输出预测结果以下为逐段代码分析:
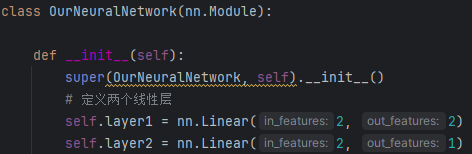
模型定义了两个线性层,第一个输入维度为2,输出维度也为2,因为前面提到每个神经元可以接受若干特征输入但只有一个特征输出,所以能够通过输出维度判断该层只有两个神经元。同理第二层只有一个神经元(当然理论上单个神经元确实可以有多个输出但有以下问题,1:与生物上单一电信号输出相悖,2:实际等效于多个神经元堆叠,3:破坏了pytoch现有框架,反向传播需要重新推导)
第一层可以看作:
其中为1*2矩阵
,
为2*2矩阵
,
为矩阵
,
为
,
第二层以此类推(打公式太麻烦了)
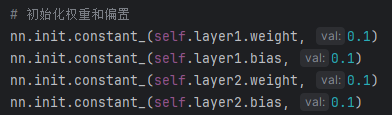
在定义完毕后,初始化所有参数为0.1,确保效果与之前原生实现一致。
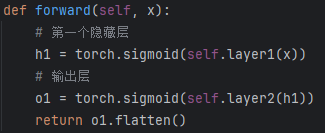
forward函数定义最终输出结果流程,这里表示输入x经过了sigmod(h1)和sigmod(o1)得到。
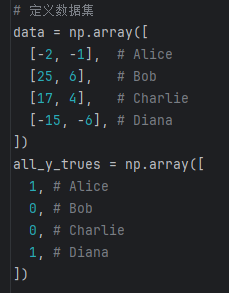
数据集。
![]()
损失。
![]()
定义优化器,优化为该神经网络的所有参数,即,学习率为0.1,即每次用当前权重减去梯度乘0.1。
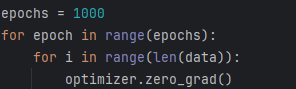
训练1000次,每轮训练前先清空梯度,因为torch的梯度计算会一直累计,不清空会将上轮训练的梯度也算进来。
![]()
计算预测值。
![]()
计算损失,损失必须为标量,所以需要unsqueeze。
![]()
计算损失相对参与损失计算的所有设置自动梯度的向量梯度,这里指上面9个权重,nn会自动为权重设置自动梯度记录。
![]()
优化器将其里面的向量根据梯度值和学习率优化。
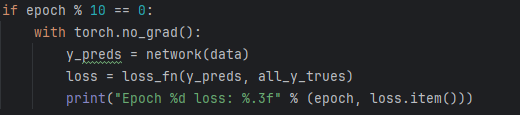
每十轮打印损失。
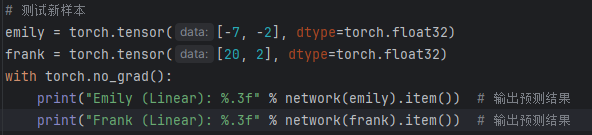
进行预测,关闭自动梯度加快预测速度。
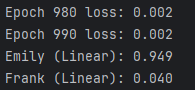
最终结果与之前原生实现一致。
相关文章:
)
深度学习(第1章——神经网络原理和Pytorch入门)
前言: 本章将讲解神经网络原理,神经元如何处理输入并输出,什么是梯度,多层感知机中梯度的计算,Pytoch自动梯度效果,如何使用原生Python实现一个简单的神经网络,以及对应Pytorch实现。 神经网络原…...

使用DeepSeek AI高效降低论文重复率
一、论文查重原理与DeepSeek降重机制 1.1 主流查重系统工作原理 文本比对算法:连续字符匹配(通常13-15字符)语义识别技术:检测同义替换和结构调整参考文献识别:区分合理引用与不当抄袭跨语言检测:中英文互译内容识别1.2 DeepSeek降重核心技术 深度语义理解:分析句子核心…...

【3D文件】3D打印迪迦奥特曼,3D打印的迪迦圣像,M78遗迹管理局,5款不同的3D打印迪迦免费下载,总有一款适合你
【3D文件】3D打印迪迦奥特曼,3D打印的迪迦圣像,M78遗迹管理局,5款不同的3D打印迪迦免费下载,总有一款适合你 资源下载: 3D文件AI生成器,机器学习生成,AI生成3D文件,3D打印迪迦奥特…...

【未解决】Spring AI 1.0.0-M6 使用 Tool Calling 报错,请求破解之法
1.报错 2.Java 代码 2.1 pom.xml <dependencyManagement><dependencies><!-- Spring AI --><dependency><groupId>org.springframework.ai</groupId><artifactId>spring-ai-bom</artifactId><version>1.0.0-M6</ver…...
)
第 2 篇:快速上手 Framer Motion(实操入门)
1. 环境准备 在开始使用 Framer Motion 之前,你需要先确保你的开发环境中已经设置好了 React 项目。我们将使用 Next.js 作为示例,如果你是使用其他 React 框架,步骤也基本相同。 1.1 创建一个 Next.js 项目 如果你还没有创建 Next.js 项目…...

如何写好合同管理系统需求分析
引言 在当今企业数字化转型的浪潮中,合同管理系统作为企业法律合规和商业运营的重要支撑工具,其需求分析的准确性和完整性直接关系到系统建设的成败。本文基于Volere需求过程方法论,结合江铃汽车集团合同管理系统需求规格说明书实践案例&…...
)
C语言自定义类型详解一:结构体(内存对齐)
结构体的声明: 结构体是一些值的集合,这些值是成员变量,结构体的每个成员可以是不同类型的变量(包括其他结构体变量) 类如:描述一个学生 struct Stu {char name[200];int age;char sex[5];//性别char id…...

GitHub配置密钥
1.生成SSH密钥 1)检查 SSH 密钥是否存在 首先,确认是否已经在本地系统中生成了 SSH 密钥对。可以通过以下命令检查: ls -al ~/.ssh 在命令输出中,应该能看到类似 id_rsa 和 id_rsa.pub 这样一对文件。如果这些文件不存在&#…...

PyTorch逻辑回归总结
目录 PyTorch逻辑回归总结神经网络基础基本结构学习路径 线性回归简单线性回归多元线性回归 逻辑回归核心原理损失函数 梯度下降法基本思想关键公式学习率影响 PyTorch实现数据准备模型构建代码优化 核心概念对比 PyTorch逻辑回归总结 神经网络基础 基本结构 输入节点隐藏节…...

Browser-use 是连接你的AI代理与浏览器的最简单方式
AI MCP 系列 AgentGPT-01-入门介绍 Browser-use 是连接你的AI代理与浏览器的最简单方式 AI MCP(大模型上下文)-01-入门介绍 AI MCP(大模型上下文)-02-awesome-mcp-servers 精选的 MCP 服务器 AI MCP(大模型上下文)-03-open webui 介绍 是一个可扩展、功能丰富且用户友好的…...

nginx自编译重现gzip和chunked的现象
前言 最近做项目,发现一个比较好玩的事,nginx的module gzip模式默认支持1KB压缩,和chunked返回,本来现在的很多框架都很完善了,但是,一些新语言框架或者一些老旧框架会不能完整支持chunked,导致…...
)
RNN - 循环神经网络(概念介绍)
RNN 潜变量自回归模型 使用潜变量 h t h_t ht 总结过去信息 p ( h t ∣ h t − 1 , x t − 1 ) p(h_t | h_{t-1}, x_{t-1}) p(ht∣ht−1,xt−1) p ( x t ∣ h t , x t − 1 ) p(x_t | h_t, x_{t-1}) p(xt∣ht,xt−1) 循环神经网络 更新隐藏状态࿱…...
)
OpenCV的详细介绍与安装(一)
1.OpenCV概述 OpenCV是一个开源的计算机视觉和机器学习软件库, 它轻量级而且高效——由一系列 C 函数和少量 C 类构成,它支持多种编程语言(如C、Python、Java),并可在Windows、Linux、macOS、Android和iOS等平台上运行…...
 Spring Boot 与 NoSQL)
50、Spring Boot 详细讲义(七) Spring Boot 与 NoSQL
七 Spring Boot 与 NoSQL 目录 MongoDB 集成Redis 集成Elasticsearch 集成1、 MongoDB 集成 1.1 MongoDB 概述 1.1.1 MongoDB 的基本概念 文档型数据库: 数据存储为类似 JSON 的文档结构(BSON 格式)。每个文档由字段和值对组成,类似于键值对。支持嵌入式文档和数组,灵活…...

微信小程序组件传参
微信小程序组件传参感觉和vue还是挺像的 父组件向子组件传参 在小程序中父组件子组件传参,主要使用properties属性。演示下: 创建组件文件夹component,创建组件demoComponent,记得创建的时候选择组件,不是page页面 …...

C++实用函数:bind
本篇来介绍了C++中bind功能。 1 std::bind 在 C++ 里,std::bind 是一个函数模板,其作用是创建一个可调用对象,该对象可绑定到一组参数上。std::bind 的函数原型如下: template< class F, class... Args > /*unspecified*/ bind( F&& f, Args&&...…...

C# 程序结构||C# 基本语法
原文:C# 程序结构_w3cschool (注:本文为教程文章,请勿标记为付费文章!特此声明) 本节我们将学习 C# 编程语言的结构,为了让大家能够对 C# 程序结构有个更好的理解,我们会先演示一个…...

分库分表-除了hash分片还有别的吗?
在分库分表的设计中,除了常见的 Hash 分片,还有多种策略根据业务场景灵活选择。以下是几种主流的分库分表策略及其应用场景、技术实现和优缺点分析,结合项目经验(如标易行投标服务平台的高并发场景)进行说明: 一、常见分库分表策略 1. 范围分片(Range Sharding) 原理:…...

单片机非耦合业务逻辑框架
在小型单片机项目开发初期,由于业务逻辑相对简单,我们往往较少关注程序架构层面的设计。 然而随着项目经验的积累,开发者会逐渐意识到模块间的耦合问题:当功能迭代时,一处修改可能引发连锁反应。 此时,构…...

WordPress - 此站点出现严重错误
本篇讲 当WordPress出现 此站点出现严重错误 时,该如何解决。 目录 1,现象 2, FAQ 3,管理Menu无法打开 下面是详细内容。 1,现象 此站点出现严重错误(このサイトで重大なエラーが発生しました&#x…...
——线程安全总结(翻新版)——定时器(Timer)线程池(ThreadPoolExecutor))
Java EE(8)——线程安全总结(翻新版)——定时器(Timer)线程池(ThreadPoolExecutor)
1.Timer 1.1Timer基本介绍 1.Timer的主要作用 任务调度:Timer允许你安排一个任务在未来的某个时间点执行,或者以固定的间隔重复执行 后台执行:Timer可以使用一个后台线程来执行任务,这意味着调度和执行任务不会阻塞主线程(主线程…...

#[特殊字符]Rhino建模教程 · 第一章:正方体建模入门
🦏Rhino建模教程 第一章:正方体建模入门 本章将从最基础的操作入手,带你一步步掌握Rhino建模的核心流程,适合新手或需要复习基础的用户。 🎯 目标:制作一个带凹槽、圆角、封盖的正方体模型,并…...

How to run ERSEM
Build ERSEM Make a “build” folder, and go into the build folder. Create “build_archer2.edit.sh” #!/usr/bin/env bash# Script for compiling FVCOM-FABM-ERSEM for ARCHER2 # # The build is split into three phases: # # 1) Build the FABM-ERSEM library. Her…...

关于QT5项目只生成一个CmakeLists.txt文件
编译器自动检测明明可以检测,Kit也没有报红 但是最后生成项目只有一个文件 一:检查cmake版本,我4.1版本cmake一直报错 cmake3.10可以用 解决之后还是有问题 把环境变量加上去:...

C++ string类
1.标准库中的string类 在 C 里,string类属于标准库的一部分,它在<string>头文件中定义,用于处理和操作字符串。 1.1string类的常用接口说明 1.1.1. string类对象的常见构造 string() (重点) 构造空的string类…...

如何使用ChatGPT撰写短视频爆款文案
短视频已经成为了互联网内容消费的重要形式,吸引观众的眼球成为内容创作者的首要任务。在短视频平台的内容过载中,如何写出一篇能够迅速吸引观众点击、分享并获得高互动的爆款文案,是每个短视频创作者都在追求的目标。今天,我们将…...

基于Tesseract与Opencv的电子发票识别[1]
本文我们将尝试使用tesseract识别电子发票上的信息并不断提高识别准确率,是一个逐渐调整的过程,仅用于记录研究过程。 图像识别:使用tesseract识别。图像预处理:使用OpenCV等图像处理库对发票图像进行预处理,如灰度化…...

数据库—函数笔记
一,数据库函数的分类 内置函数(Built-in Functions) 数据库系统自带的函数,无需额外定义即可直接调用。 聚合函数:对数据集进行计算(如 SUM, AVG, COUNT)。 字符串函数:处理文本数据…...

产品研发流程说明记录
1. 前言 在小型公司,产品研发流程通常较为简单,需求提出后经过简单评审便直接开发上线。而在中大型互联网公司,研发流程更加规范和系统,涉及多部门协作和多环节把控。本文将详细介绍一个标准的产品需求研发流程,帮助相…...

智慧城市:如同为城市装上智能大脑,开启智慧生活
智慧城市的概念随着信息技术的飞速发展而逐渐兴起,它通过集成物联网、大数据、人工智能和数字孪生等先进技术,为城市管理和居民生活带来了前所未有的智能化变革。本文将深入探讨这些核心技术及其在智慧城市的典型应用场景,展示智慧城市如何提…...

游戏测试入门知识
高内聚指的是一个模块或组件内部的功能应该紧密相关。这意味着模块内的所有元素都应该致力于实现同一个目标或功能,并且该模块应当尽可能独立完成这一任务。 低耦合则是指不同模块之间的依赖程度较低,即一个模块的变化对其它模块造成的影响尽可能小。理…...

Sentinel源码—2.Context和处理链的初始化二
大纲 1.Sentinel底层的核心概念 2.Sentinel中Context的设计思想与源码实现 3.Java SPI机制的引入 4.Java SPI机制在Sentinel处理链中的应用 5.Sentinel默认处理链ProcessorSlot的构建 4.Java SPI机制在Sentinel处理链中的应用 (1)初始化Entry会初始化处理链 (2)初始化处…...

Java基础第20天-JDBC
JDBC为访问不同的数据库提供了统一的接口,为使用者屏蔽了细节问题,程序员使用JDBC可以连接任何提供了JDBC驱动程序的数据库系统,从而完成对数据库的各种操作 ResultSet 表示数据库结果集的数据表,通常通过执行查询数据库的语句生…...

VMware下Ubuntu空间扩容
目的: Ubuntu空间剩余不足,需要对Ubuntu进行扩容。 使用工具: 使用Ubuntu系统中的gparted工具进行系统扩容。 前提: 1、电脑有多余的未分配磁盘空间,比如我的Ubuntu磁盘G盘是200G,现在快满了,…...

第十一章 网络编程
在TCP/IP协议中,“IP地址TCP或UDP端口号”唯一标识网络通讯中的一个进程。 因此可以用Socket来描述网络连接的一对一关系。 常用的Socket类型有两种:流式Socket(SOCK_STREAM)和数据报式Socket(SOCK_DGRAM)…...

Bad Request 400
之前一直以为400就是前端代码有问题 这下遇到了,发现是因为前后端不一致 后端代码注意:现在我写的int 前端请求 原因 :前后端不一致 💡 问题核心:后端 amount 类型是 int,但前端传了小数 237.31...

行业深度:金融数据治理中的 SQL2API 应用创新
金融行业作为数据密集型领域,面临着监管合规要求严苛、数据交互频次高、安全风险防控难度大等多重挑战。SQL2API 技术通过 “数据服务化 合规化” 的双重赋能,成为金融机构破解数据治理难题的核心工具,在多个关键场景实现突破性创新。 &…...

记录学习的第二十六天
还是每日一题。 今天这道题有点难度,我看着题解抄的。 之后做了两道双指针问题。 这道题本来是想用纯暴力做的,结果出错了。😓...

MySQLQ_数据库约束
目录 什么是数据库约束约束类型NOT NULL 非空约束UNIQUE 唯一约束PRIMARY KEY主键约束FOREIGN KEY外键约束CHECK约束DEFAULT 默认值(缺省)约束 什么是数据库约束 数据库约束就是对数据库添加一些规则,使数据更准确,关联性更强 比如加了唯一值约束&#…...

数据库ocp证书是什么水平
专业知识与技能:OCP 证书是对持证人在 Oracle 数据库管理、安装、配置、性能调优、备份恢复等方面专业知识和技能的权威认证。它要求考生通过一系列严格的考试,包括理论知识和实际操作能力的考核,以证明其具备扎实的 Oracle 数据库专业知识和…...

1022 Digital Library
1022 Digital Library 分数 30 全屏浏览 切换布局 作者 CHEN, Yue 单位 浙江大学 A Digital Library contains millions of books, stored according to their titles, authors, key words of their abstracts, publishers, and published years. Each book is assigned an u…...

基于Python的PC控制Robot 小程序开发历程
1、Background:用万能语言Python进行Robot 的控制一直以来是我想做的事,刚好有机会付诸实践。Just Do It~ 2、Python 代码编写: import socket import time HOST "192.168.0.1" #IP PORT 2008 #Por…...

Coze平台技术解析:零代码AI开发与智能体应用实践
【资源软件】 伏脂撺掇蒌葶苘洞座 /835a36NvQn😕 链接:https://pan.quark.cn/s/5180c62aacf7 「微信被删好友检测工具」筷莱坌教狴犴狾夺郝 链接:https://pan.quark.cn/s/fe4976448ca1 HitPaw Watermark Remover 链接:https://pan…...
)
在 K8s 上构建和部署容器化应用程序(Building and Deploying Containerized Applications on k8s)
在 Kubernetes 上构建和部署容器化应用程序 Kubernetes 是一个用于管理容器化工作负载和服务的开源平台。它提供了一个强大的框架来自动化部署、扩展和管理容器化应用程序。本博客将指导您完成在 Kubernetes 上构建和部署容器化应用程序的过程,重点介绍技术方面并使…...

【教程】如何使用Labelimg查看已经标注好的YOLO数据集标注情况
《------往期经典推荐------》 一、AI应用软件开发实战专栏【链接】 项目名称项目名称1.【人脸识别与管理系统开发】2.【车牌识别与自动收费管理系统开发】3.【手势识别系统开发】4.【人脸面部活体检测系统开发】5.【图片风格快速迁移软件开发】6.【人脸表表情识别系统】7.【…...

**Windows 系统**的常用快捷键大全
以下是 Windows 系统的常用快捷键大全,涵盖日常操作、文件管理、窗口控制、系统功能等,助你大幅提升效率: 一、基础系统操作 Win:打开/关闭「开始菜单」Win E:打开「文件资源管理器」Win D:一键显示桌面…...

L1-025 正整数A+B
L1-025 正整数AB L1-025 正整数AB - 团体程序设计天梯赛-练习集 (pintia.cn) 题解 第一次做这道题时,没有注意到num1 和 num2 是在区间 [1, 1000] 内,num1和num2的长度应该是4位数并且num1和num2不能等于0,num1和num2不能大于1000。这两个…...

Go 语言的 map 在解决哈希冲突时,主要使用了链地址法同时参考了开放地址法的思想即每个桶的 8个 key val对是连续的
总结一下 Go map 的哈希冲突解决机制。 1. 哈希表结构: Go 语言的 map 底层有两个主要结构:hmap 和 bmap,它们分别负责管理整个 map 的元数据和存储键值对的桶。 hmap:包含 map 的元数据,如桶的数量、已插入的键值对…...

未支付订单如何释放库存
在电商或交易系统中,处理未支付订单的库存释放是典型的高并发场景问题。以下是结合 Java 技术栈的完整解决方案,涵盖 设计思路、技术实现、容错机制,并基于实际项目经验(如标易行平台的标书资源预约场景)进行分析: 一、核心设计原则 最终一致性:确保库存释放与订单状态的…...

HDFS Full Block Report超限导致性能下降的原因分析
文章目录 前言发现问题失败的为什么是FBR块汇报频率的变化为什么FBR会反复失败HDFS性能下降导致Yarn负载变高的形式化分析理解线程理解IO Wait理解HDFS性能下降导致Yarn负载和使用率增高 引用 前言 我们的Yarn Cluster主要用来运行一批由Airflow定时调度的Spark Job࿰…...