Python----机器学习(基于PyTorch的蘑菇逻辑回归)
Logistic Regression(逻辑回归)是一种用于处理二分类问题的统计学习方法。它基于线性回归 模型,通过Sigmoid函数将输出映射到[0, 1]范围内,表示概率。逻辑回归常被用于预测某个实 例属于正类别的概率。
一、数据集介绍
本例使用了一个的蘑菇数据集 Mushroom - UCI Machine Learning Repository 该数据集包含对23种有褶菌的蘑菇进行描述的假设样本。每个物种被确定为绝对可食用、绝对 有毒。后者的类别与有毒物种合并。即二元分类有毒和没毒。
数据集地址
Mushroom - UCI Machine Learning Repository
| 变量名称 | 角色 | 类型 | 描述 | 单位 | 缺失值 |
|---|---|---|---|---|---|
| 有毒 | 目标 | 分类 | 不 | ||
| Cap-Shape (盖形) | 特征 | 分类 | 钟 = b,圆锥 = c,凸 = x,扁平 = f,旋钮 = k,下沉 = s | 不 | |
| Cap-Surface (盖板表面) | 特征 | 分类 | 纤维状 = f,凹槽 = g,鳞状 = y,光滑 = S | 不 | |
| 大写字母颜色 | 特征 | 二元的 | 棕色=n,buff=b,肉桂=c,灰色=g,绿色=r,粉红色=p,紫色=u,红色=e,白色=w,黄色=y | 不 | |
| 瘀 伤 | 特征 | 分类 | 瘀伤=t,no=f | 不 | |
| 气味 | 特征 | 分类 | 杏仁=a,茴香=l,杂酚油=c,鱼=y,污秽=f,霉味=m,无=n,辛辣=p,辣=s | 不 | |
| 鳃附件 | 特征 | 分类 | attached=a,降序=d,free=f,notched=n | 不 | |
| 鳃间距 | 特征 | 分类 | close=c,crowded=w,distant=d | 不 | |
| 鳃大小 | 特征 | 分类 | 宽=b,窄=n | 不 | |
| 鳃色 | 特征 | 分类 | 黑色=k,棕色=n,buff=b,巧克力=h,灰色=g,绿色=r,橙色=o,粉红色=p,紫色=u,红色=e,白色=w,黄色=y | 不 | |
| sstem-shape | 特征 | 分类 | 放大 = e,锥度 = t | 不 | |
| 柄根 | 特征 | 分类 | 球茎=b,俱乐部=c,杯=u,等于=e,根形体=z,rooted=r,缺失=? | 是的 | |
| stalk-surface-above-ring (茎表面在环上方) | 特征 | 分类 | 纤维=f,鳞片=y,丝滑=k,光滑=S | 不 | |
| stalk-surface-below-ring (茎表面低于环) | 特征 | 分类 | 纤维=f,鳞片=y,丝滑=k,光滑=S | 不 | |
| stalk-color-above-ring (茎颜色在环上方) | 特征 | 分类 | 棕色=n,浅黄色=b,肉桂=c,灰色=g,橙色=o,粉红色=p,红色=e,白色=w,黄色=y | 不 | |
| stalk-color-below-ring (茎颜色在环下) | 特征 | 分类 | 棕色=n,浅黄色=b,肉桂=c,灰色=g,橙色=o,粉红色=p,红色=e,白色=w,黄色=y | 不 | |
| 面纱型 | 特征 | 二元的 | 部分=p,通用=u | 不 | |
| 面纱颜色 | 特征 | 分类 | 棕色=n,橙色=o,白色=w,黄色=y | 不 | |
| 环号 | 特征 | 分类 | 无=n,一=o,二=t | 不 | |
| 环型 | 特征 | 分类 | 蜘蛛网=c,倏逝=e,扩口=f,大=l,无=n,吊坠=p,护套=s,区域=z | 不 | |
| 孢子打印颜色 | 特征 | 分类 | 黑色=k,棕色=n,buff=b,巧克力=h,绿色=r,橙色=o,紫色=u,白色=w,黄色=y | 不 | |
| 人口 | 特征 | 分类 | 丰富=a,聚集=c,数量=n,分散=s,几个=v,孤儿=y | 不 | |
| 生境 | 特征 | 分类 | 草地=g,树叶=l,草地=m,路径=p,城市=u,废物=w,树林=d | 不 |
该数据集包括对应于姬松茸和鳃蘑菇科 23 种鳃蘑菇的假设样本的描述(第 500-525 页)。每个物种都被确定为绝对可食用、绝对有毒或可食用未知,因此不推荐。后一类与有毒的一类结合在一起。该指南明确指出,确定蘑菇的可食用性没有简单的规则;没有像 Poisonous Oak 和 Ivy 的 ''leaflets three, let it be'' 这样的规则。
二、设计思路
2.1、读取数据
import pandas as pd
df=pd.read_table('agaricus-lepiota.data',header=None,sep=',')
df2.2、数据清洗
import numpy as np
df=df.replace('?',np.nan)
df.dropna(axis=0,inplace=True)2.3、划分特征
X=df.iloc[:,1:]
y=df.iloc[:,0]2.4、one-hot独热编码
X=pd.get_dummies(X)2.5、划分训练集和测试集
from sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test=train_test_split(X,y,train_size=0.75,random_state=42)2.6、标准化
from sklearn.preprocessing import StandardScaler
scaler=StandardScaler()
X_train_scaler=scaler.fit_transform(X_train)
X_test_scaler=scaler.transform(X_test)2.7、特征标签
from sklearn.preprocessing import LabelEncoder
labelencoder=LabelEncoder()
y_train_labelencoder=labelencoder.fit_transform(y_train)
y_test_labelencoder=labelencoder.transform(y_test)2.8、转换为Tensor张量
import torch
X_train_tensor=torch.tensor(X_train_scaler,dtype=torch.float32)
y_train_tensor=torch.tensor(y_train_labelencoder,dtype=torch.float32)
X_test_tensor=torch.tensor(X_test_scaler,dtype=torch.float32)
y_test_tensor=torch.tensor(y_test_labelencoder,dtype=torch.float32)2.9、创建数据加载器
from torch.utils.data import DataLoader,TensorDatasettrain_dataset=TensorDataset(X_train_tensor,y_train_tensor)
train_loader=DataLoader(train_dataset,batch_size=64,shuffle=True)2.10、定义逻辑回归模型
import torch.nn as nn
class LogisticRegression(nn.Module):def __init__(self,inputsize):super().__init__()self.linear=nn.Linear(inputsize,1)def forward(self,x):return torch.sigmoid(self.linear(x))
inputsize=X_train_tensor.shape[1]
model=LogisticRegression(inputsize)2.11、定义损失函数和优化器
import torch.utils
criterion=nn.BCELoss()
optimizer=torch.optim.Adam(model.parameters(),lr=0.01)2.12、训练模型
for i in range(1,101):total_loss=0model.train()for x,y in train_loader:optimizer.zero_grad()y_hat=model(x)loss=criterion(y_hat,y.view(-1,1))loss.backward()optimizer.step()total_loss+=lossavg_loss=total_loss/len(train_loader)if i%10==0 or i==1:print(i,avg_loss.item())
2.13、模型评估
from sklearn.metrics import roc_curve,auc
with torch.no_grad():model.eval()y_pred=model(X_test_tensor)fpr,tpr,threshold=roc_curve(y_test_labelencoder,y_pred.numpy())roc_auc=auc(fpr,tpr)2.14、可视化
from matplotlib import pylab as plt
plt.figure(figsize=(10, 6))
plt.plot(fpr, tpr, color='darkorange', lw=2, label=f'AUC = {roc_auc:.2f}')
plt.plot([0, 1], [0, 1], color='navy', lw=2, linestyle='--')
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('Receiver Operating Characteristic (ROC) Curve')
plt.legend(loc='lower right')
plt.show()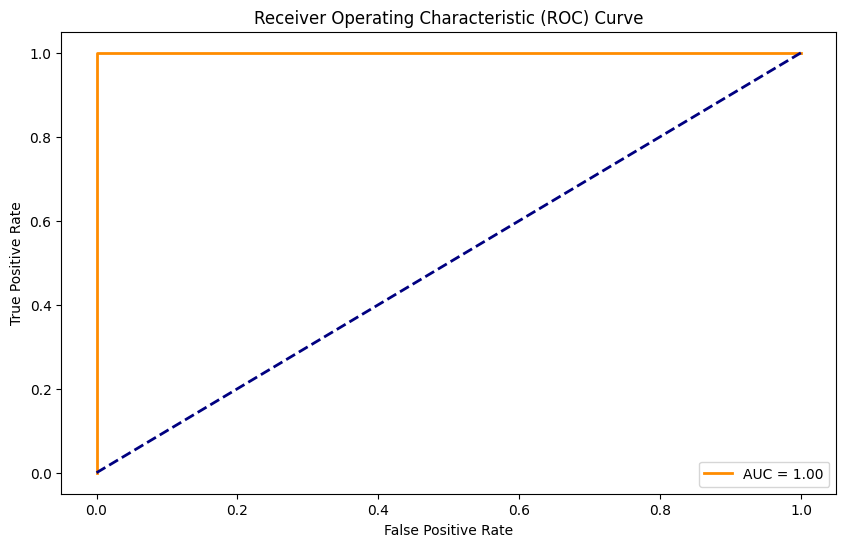
三、完整代码
import pandas as pd
from matplotlib import pylab as plt
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
import torch
import torch.nn as nn
from torch.utils.data import DataLoader, TensorDataset
from sklearn.preprocessing import LabelEncoder
import numpy as np
from sklearn.metrics import roc_curve, auc # 读取数据集,使用制表符作为分隔符
df = pd.read_table('agaricus-lepiota.data', header=None, sep=',') # 将缺失值(用"?"表示)替换为NaN并删除含缺失值的行
df = df.replace('?', np.nan)
df.dropna(axis=0, inplace=True) # 分离特征和标签
X = df.iloc[:, 1:] # 特征
y = df.iloc[:, 0] # 标签(种类:食用或有毒) # 将分类特征进行独热编码
X = pd.get_dummies(X) # 划分训练集和测试集,训练集占75%
X_train, X_test, y_train, y_test = train_test_split(X, y, train_size=0.75, random_state=42) # 数据标准化
scaler = StandardScaler()
X_train_scaler = scaler.fit_transform(X_train) # 对训练数据进行标准化
X_test_scaler = scaler.transform(X_test) # 对测试数据进行标准化 # 标签编码
labelencoder = LabelEncoder()
y_train_labelencoder = labelencoder.fit_transform(y_train) # 将训练标签编码
y_test_labelencoder = labelencoder.transform(y_test) # 将测试标签编码 # 将数据转换为PyTorch张量
X_train_tensor = torch.tensor(X_train_scaler, dtype=torch.float32) # 特征张量
y_train_tensor = torch.tensor(y_train_labelencoder, dtype=torch.float32) # 标签张量
X_test_tensor = torch.tensor(X_test_scaler, dtype=torch.float32) # 测试特征张量
y_test_tensor = torch.tensor(y_test_labelencoder, dtype=torch.float32) # 测试标签张量 # 创建训练数据集和数据加载器
train_dataset = TensorDataset(X_train_tensor, y_train_tensor)
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True) # 随机打乱数据 # 定义逻辑回归模型
class LogisticRegression(nn.Module): def __init__(self, inputsize): super().__init__() self.linear = nn.Linear(inputsize, 1) # 单层线性层 def forward(self, x): return torch.sigmoid(self.linear(x)) # 使用sigmoid激活函数 # 实例化模型
inputsize = X_train_tensor.shape[1] # 输入特征的数量
model = LogisticRegression(inputsize) # 定义损失函数和优化器
criterion = nn.BCELoss() # 二元交叉熵损失
optimizer = torch.optim.Adam(model.parameters(), lr=0.01) # Adam优化器,学习率为0.01 # 训练模型
for i in range(1, 101): total_loss = 0 # 初始化总损失 model.train() # 切换到训练模式 for x, y in train_loader: optimizer.zero_grad() # 清空上一步的梯度 y_hat = model(x) # 前向传播,得到预测值 loss = criterion(y_hat, y.view(-1, 1)) # 计算损失 loss.backward() # 反向传播,计算梯度 optimizer.step() # 更新模型参数 total_loss += loss # 累加损失 avg_loss = total_loss / len(train_loader) # 计算平均损失 if i % 10 == 0 or i == 1: print(i, avg_loss.item()) # 每10个epoch打印一次损失值 # 评估模型
with torch.no_grad(): # 关闭梯度计算,以减少内存使用 model.eval() # 切换到评估模式 y_pred = model(X_test_tensor) # 在测试数据上做预测 fpr, tpr, threshold = roc_curve(y_test_labelencoder, y_pred.numpy()) # 计算ROC曲线的假阳率和真阳率 roc_auc = auc(fpr, tpr) # 计算AUC值 # 绘制ROC曲线
plt.figure(figsize=(10, 6))
plt.plot(fpr, tpr, color='darkorange', lw=2, label=f'AUC = {roc_auc:.2f}') # 绘制ROC曲线
plt.plot([0, 1], [0, 1], color='navy', lw=2, linestyle='--') # 绘制随机猜测的对角线
plt.xlabel('假阳率 (False Positive Rate)')
plt.ylabel('真阳率 (True Positive Rate)')
plt.title('接收者操作特征 (ROC) 曲线')
plt.legend(loc='lower right')
plt.show() 设计思路
-
数据预处理:
首先读取数据集,并用
NaN替换掉缺失值(“?”),然后删除所有包含缺失值的行。分离特征和目标变量。这里特征是从第二列到最后一列,目标是第一列(表示蘑菇是否可食用)。对分类特征进行独热编码,以便模型能处理这些离散特征。 -
数据分割:
使用
train_test_split将数据集划分为训练集(75%)和测试集(25%),确保模型的训练和测试都基于不同的数据。 -
数据标准化:
利用
StandardScaler对特征数据进行标准化,使特征具有均值0和方差1,这有助于模型训练的稳定性。 -
标签编码:
对目标变量(可食用和有毒)进行标签编码,使其可以被模型处理。
-
模型构建:
定义了一个逻辑回归模型,模型结构很简单,仅包含一个线性层,使用sigmoid激活函数进行二分类。
-
模型训练:
设置二元交叉熵损失函数
BCELoss和Adam优化器进行模型训练。在训练过程中打印每10个epoch的平均损失,以监测模型收敛情况。 -
模型评估:
在测试集上进行预测,并使用
roc_curve计算假阳率和真阳率,同时计算AUC值,以评估模型的性能。 -
可视化结果:
使用Matplotlib绘制ROC曲线,便于直观展示模型分类能力,AUC越接近1表示模型效果越好。
相关文章:
)
Python----机器学习(基于PyTorch的蘑菇逻辑回归)
Logistic Regression(逻辑回归)是一种用于处理二分类问题的统计学习方法。它基于线性回归 模型,通过Sigmoid函数将输出映射到[0, 1]范围内,表示概率。逻辑回归常被用于预测某个实 例属于正类别的概率。 一、数据集介绍 本例使用了…...
)
Python----机器学习(基于PyTorch的乳腺癌逻辑回归)
Logistic Regression(逻辑回归)是一种用于处理二分类问题的统计学习方法。它基于线性回归 模型,通过Sigmoid函数将输出映射到[0, 1]范围内,表示概率。逻辑回归常被用于预测某个实 例属于正类别的概率。 一、数据集介绍 在本例中&…...

如何配置AWS EKS自动扩展组:实现高效弹性伸缩
本文详细讲解如何在AWS EKS中配置节点组(Node Group)和Pod的自动扩展,优化资源利用率并保障应用高可用。 一、准备工作 工具安装 安装并配置AWS CLI 安装eksctl(EKS管理工具) 安装kubectl(Kubernetes命令…...
)
【C++ Qt】认识Qt、Qt 项目搭建流程(图文并茂、通俗易懂)
每日激励:“不设限和自我肯定的心态:I can do all things。 — Stephen Curry” 绪论: 本章将开启Qt的学习,Qt是一个较为古老但仍然在GUI图形化界面设计中有着举足轻重的地位,因为它适合嵌入式和多种平台而被广泛使用…...

用Python打造去中心化知识产权保护系统:科技驱动创作者权益新方案
用Python打造去中心化知识产权保护系统:科技驱动创作者权益新方案 近年来,区块链技术和去中心化系统的兴起为知识产权保护提供了新的可能性。在传统模式下,知识产权保护通常依赖于集中化管理机构,这种方式不仅成本高,还可能因不透明导致权益争议。于是,我们萌生了一个设…...

CVE重要漏洞复现-Fastjson1.2.24-RCE漏洞
本文仅供网络学习,不得用于非法目的,否则后果自负 1、漏洞简介 fastjson是阿里巴巴的开源JSON解析库,它可以解析JSON格式的字符串,也可以从JSON字符串反序列化到JavaBean。即fastjson的主要功能就是将Java Bean序列化成JSON字符…...

Windows 图形显示驱动开发-WDDM 1.2功能—显示设备硬件软件认证要求
一、容器技术id技术的硬件级实现要求 1.1 EDID规范深度适配 1.物理层要求: 必须使用EDID 2.0及以上版本数据结构 容器ID需写入VSDB区块的0x50-0x6F区域,采用Little-Endian格式存储 允许的最大传输延迟:I2C总线时钟频率≤100KHz时…...

Coze流搭建--写入飞书多维表格
目标 使用coze搭建一个业务流,将业务流生产出的数据写入飞书保存 测试业务流 使用图片生成插件,配置prompt生产图片,将生产的结果写入飞书文档 coze流 运行后最终效果 搭建流程 第一步:飞书创建多维表格 注册飞书创建多维表…...

4.14:计组第三章
一、数据的强制类型转换与存储 1、边界对齐与大端小端方式 2、真-强制类型转换 二、存储器的基本知识(不包含磁盘存储器) 1、主存储器 (1)...

Vue3+Vite前端项目部署后部分图片资源无法获取、动态路径图片资源报404错误的原因及解决方案
目录 Vue3vite前端项目部署后部分图片资源无法获取、动态路径图片资源报404错误的原因及解决方案 一、情景介绍 1、问题出现的场景 2、无法加载的图片写法 二、反向代理原理简介 三、造成该现象的原因 四、解决方案 1、放弃动态渲染 2、在页面挂载的时候引入图片资源 …...

Nacos操作指南
第一章:Nacos 概述 1.1 什么是 Nacos? 定义与定位 Nacos(Naming and Configuration Service)是阿里巴巴于2018年开源的动态服务发现、配置管理和服务管理平台,现已成为微服务生态中的重要基础设施。其核心价值在于帮…...
)
2025年常见渗透测试面试题-红队面试宝典下(题目+回答)
网络安全领域各种资源,学习文档,以及工具分享、前沿信息分享、POC、EXP分享。不定期分享各种好玩的项目及好用的工具,欢迎关注。 目录 一、Java反序列化过程及利用链示例 二、大型网络渗透经验 三、Cobalt Strike的两种Dump Hash区别 四…...
)
扩增子分析|基于R语言microeco包进行微生物群落网络分析(network网络、Zi-Pi关键物种和subnet子网络图)
一、引言 microeco包是福建农林大学姚敏杰教授团队开发的扩增子测序集成分析。该包综合了扩增子测序下游分析的多种功能包括群落组成、多样性、网络分析、零模型等等。通过简单的几行代码可实现复杂的分析。因此,microeco包发表以来被学界广泛关注,截止2…...

flutter-Text等组件出现双层黄色下划线的问题
文章目录 1. 现象2. 原因3. 解决方法 1. 现象 这天我正在写Flutter项目的页面功能,突然发现我的 Text 文字出现了奇怪的样式,具体如下: 文字下面出现了双层黄色下划线文字的空格变得很大,文字的间距也变得很大 我百思不得其解&a…...

优化运营、降低成本、提高服务质量的智慧物流开源了
智慧物流视频监控平台是一款功能强大且简单易用的实时算法视频监控系统。它的愿景是最底层打通各大芯片厂商相互间的壁垒,省去繁琐重复的适配流程,实现芯片、算法、应用的全流程组合,从而大大减少企业级应用约95%的开发成本可通过边缘计算技术…...

leetcode第二题
功能函数 typedef struct ListNode {int val;struct ListNode *next; } ListNode;struct ListNode* addTwoNumbers(struct ListNode* l1, struct ListNode* l2) {ListNode *dummy (ListNode *)malloc(sizeof(ListNode));ListNode *cur dummy;int carry 0; //carry是进位值…...

QT实现带快捷键的自定义 QComboBox 控件
在现代GUI应用程序中,用户界面的设计不仅要美观,还要提供高效的交互方式。本文将介绍一个自定义的QCComboBox类,它是一个基于Qt的组合框(QComboBox),支持为每个下拉项添加快捷键。通过这些快捷键࿰…...

聊聊类模板
我们来聊聊类模板,从基础到实际例子,让你更容易理解。 什么是类模板? 类模板是一种模板,允许我们定义一个可以处理任意数据类型的类。简单来说,就是我们可以编写一个类的“蓝图”,然后在需要的时候使用不…...

使用Python进行AI图像生成:从GAN到风格迁移的完整指南
AI图像生成是一个非常有趣且前沿的领域,结合了深度学习和计算机视觉技术。以下是一些使用Python和相关库进行AI图像生成的创意和实现思路: 1. 使用GAN(生成对抗网络) 基本概念:GAN由两个神经网络组成:生成…...

Java 设计模式:外观模式详解
Java 设计模式:外观模式详解 外观模式(Facade Pattern)是一种结构型设计模式,它为复杂的子系统提供一个简化的统一接口,隐藏子系统的复杂性,使客户端更方便地使用系统。外观模式就像一个“门面”ÿ…...

微信小程序中实现某个样式值setData改变时从350rpx到200rpx的平滑过渡效果
方案一:使用 CSS Transition(推荐简单场景) WXSS /* 在对应组件的WXSS中添加 */ .transition-effect {transition: all 0.4s ease-in-out;will-change: bottom; /* 启用GPU加速 */ }WXML <!-- 修改后的WXML --> <view class"…...

LINUX基础 [四] - Linux工具
目录 软件包管理器yum Linux开发工具vim vim的基本概念 vim的三种常用模式 vim的简单配置 vim常用模式的基本操作 命令模式 底行模式 处理vim打开文件报错的问题 Linux编译器-gcc/g使用 为什么我们可以用C/C做开发呢? 预处理(进行宏替换&#x…...

Spring Cloud之远程调用OpenFeign最佳实践
目录 OpenFeign最佳实践 问题引入 Feign 继承方式 创建Module 引入依赖 编写接口 打Jar包 服务提供方 服务消费方 启动服务并访问 Feign 抽取方式 创建Module 引入依赖 编写接口 打Jar包 服务消费方 启动服务并访问 服务部署 修改pom.xml文件 观察Nacos控制…...

【QT】 常用控件【输入类】
🌈 个人主页:Zfox_ 🔥 系列专栏:Qt 目录 一:🔥 输入类控件 🦋 Line Edit -- 单行输入框🎀 录入个人信息🎀 正则表达式验证输入框数据🎀 验证两次输入密码一致…...

【Python】读取xyz坐标文件输出csv文件
Python读取xyz坐标文件输出csv文件 import sys import numpy as np import pandas as pd from tqdm import tqdm import cv2 import argparsedef read_xyz(file_path):with open(file_path, "r") as f: # 打开文件data f.readlines() # 读取文件datas []for …...
)
深度解析Redis过期字段清理机制:从源码到集群化实践 (一)
深度解析Redis过期字段清理机制:从源码到集群化实践 一、问题本质与架构设计 1.1 过期数据管理的核心挑战 Redis连接池时序图技术方案 设计规范: #mermaid-svg-Yr9fBwszePgHNnEQ {font-family:"trebuchet ms",verdana,arial,sans-se…...
)
MapReduce实验:分析和编写WordCount程序(对文本进行查重)
实验环境:已经部署好的Hadoop环境 Hadoop安装、配置与管理_centos hadoop安装-CSDN博客 实验目的:对输入文件统计单词频率 实验过程: 1、准备文件 test.txt文件,它是你需要准备的原始数据文件,存放在你的 Linux 系…...

【中大厂面试题】腾讯云 java 后端 最新面试题
腾讯云(一面) 1. spring 和 springboot的区别是什么? 配置方式的区别:Spring 应用的配置较为繁琐,通常需要编写大量的 XML 配置文件或者使用 Java 注解进行配置。例如,配置数据源、事务管理器等都需要手动…...

Redis存储“大数据对象”的常用策略及StackOverflowError错误解决方案
Hi,大家好,我是灰小猿! 在一些功能的开发中,我们一般会有一些场景需要将得到的数据先暂时的存储起来,以便后面的接口或业务使用,这种场景我们一般常用的场景就是将数据暂时存储在缓存中,之后再…...

【Vue】v-if和v-show的区别
个人博客:haichenyi.com。感谢关注 一. 目录 一–目录二–核心区别三–使用场景四–性能对比五–总结 二. 核心区别 之前将css的显示隐藏的方式的时候,就已经提到过v-show和v-if了。忘记了的可以再回头去复习复习。 (2.1)…...

南瓜颜色预测:逻辑回归在农业分类问题中的实战应用
南瓜颜色预测:逻辑回归在农业分类问题中的实战应用 摘要 本案例通过预测南瓜颜色的分类问题,全面展示了逻辑回归在农业领域的实战应用。从数据预处理到模型评估,详细介绍了Seaborn可视化、模型构建、性能优化和结果解释等关键环节。案例不仅…...

【物联网-RS-485】
物联网-RS-485 ■ RS-485 连接方式■ RS-485 半双工通讯■ RS-485 的特点■ ModBus■ ModBus-ASCII■ ModBus-RTU ■ RS-485 连接方式 ■ RS-485 半双工通讯 一线定义为A 一线定义为B RS-485传输方式:半双工通信、(逻辑1:2V ~ 6V 逻辑0&…...
)
TDengine 语言连接器(Node.js)
简介 tdengine/websocket 是 TDengine 的官方 Node.js 语言连接器。Node.js 开发人员可以通过它开发存取 TDengine 数据库的应用软件。 Node.js 连接器源码托管在 GitHub。 Node.js 版本兼容性 支持 Node.js 14 及以上版本。 支持的平台 支持所有能运行 Node.js 的平台。 …...

Git分布式版本控制工具
一、工作流程 二、常用指令 1、配置git 配置环境变量 cmd打开命令行,输入git查看是否配置成功。 设置用户名和邮箱 git config --global user.name "用户名" git config --global user.email "邮箱" 查看用户名和邮箱 git config --glob…...

The first day of vue
关于小白直接接触vue3的第1天 首先我们需要一个脚手架node.js (这个可以从官网下载,免费的,安装也比较简单,后续我也会出一个相关的安装教程,方便大家和我一起讨论,互相学习) (不知道有没有人对…...
)
C语言超详细指针知识(三)
在经过前面两篇指针知识博客学习之后,我相信你已经对指针有了一定的理解,今天将更新C语言指针最后一篇,一起来学习吧。 1.字符指针变量 在指针类型的学习中,我们知道有一种指针类型为字符指针char*,之前我们是这样使用…...

无人机气动-结构耦合技术要点与难点
一、技术要点 1. 多学科耦合建模 气动载荷与结构响应的双向耦合:气动力(如升力、阻力、力矩)导致结构变形,而变形改变气动外形,进一步影响气流分布,形成闭环反馈。 建模方法: 高精度C…...

打造现代数据基础架构:MinIO对象存储完全指南
目录 打造现代数据基础架构:MinIO对象存储完全指南1. MinIO介绍1.1 什么是对象存储?1.2 MinIO核心特点1.3 MinIO使用场景 2. MinIO部署方案对比2.1 单节点单驱动器(SNSD/Standalone)2.2 单节点多驱动器(SNMD/Standalone Multi-Drive)2.3 多节点多驱动器(…...

SpringBoot条件注解全解析:核心作用与使用场景详解
目录 引言一、条件注解的核心机制二、SpringBoot内置条件注解详解1、ConditionalOnClass和ConditionalOnMissingClass2、ConditionalOnBean和ConditionalOnMissingBean3、ConditionalOnProperty4、ConditionalOnWebApplication和ConditionalOnNotWebApplication5、ConditionalO…...

智慧酒店企业站官网-前端静态网站模板【前端练习项目】
最近又写了一个静态网站,智慧酒店宣传官网。 使用的技术 html css js 。 特别适合编程学习者进行网页制作和前端开发的实践。 项目包含七个核心模块:首页、整体解决方案、优势、全国案例、行业观点、合作加盟、关于我们。 通过该项目,小伙伴们…...

#2 物联网组成要素
从下至上,则包括了5个要素,包括 设备 / 传感器 / 网络 / 物联网服务 / 数据分析 这五个要素。为了便于理解,我们用思维导图展示 物联网构成架构 设备 能够感测和反馈并连到网络进行物联网服务的装置 传感器 传感器和网关的融合实现了物…...

UE5 物理模拟 与 触发检测
文章目录 碰撞条件开启模拟关闭模拟 多层级的MeshUE的BUG 触发触发条件 碰撞 条件 1必须有网格体组件 2网格体组件必须有网格,没有网格虽然可以开启物理模拟,但是不会有任何效果 注意开启的模拟的网格体组件会计算自己和所有子网格的mesh范围 3只有网格…...
与Lambda)
C++23 新特性静态operator[]、operator()与Lambda
文章目录 静态操作符 operator[] 和 operator()示例:静态 operator[]示例:静态 operator() 静态 Lambda 表达式(P1169R4)示例:静态 Lambda 表达式 编译器支持和总结深入静态操作符 operator[] 和 operator()性能优化代…...

C# 13新特性 - .NET 9
转载: C# 13 中的新增功能 | Microsoft Learn C# 13 包括以下新增功能。 可以使用最新的 Visual Studio 2022 版本或 .NET 9 SDK 尝试这些功能:Introduced in Visual Studio 2022 Version 17.12 and newer when using C# 13 C# 13 中的新增功能 | Micr…...

MyBatis SQL会话管理详解
目录 一、SQL会话的基本概念(一)创建SQL会话 二、SQL会话的生命周期(一)打开会话(二)执行SQL操作(三)提交事务(四)回滚事务(五)关闭会…...

Uniapp: 下拉选择框 ba-tree-picker
目录 1、效果展示2、如何使用2.1 插件市场2.2 引入插件 3、参数配置3.1 属性3.2 方法 4、遇见的问题4.1、设置下拉树的样式 1、效果展示 2、如何使用 2.1 插件市场 首先从插件市场中将插件导入到项目中 2.2 引入插件 在使用的页面引入插件 <view click"showPicke…...

【高性能缓存Redis_中间件】三、redis 精通:性能优化与生产实践
一、引言 在前两篇 Redis 消息队列的文章中,我们掌握了基础使用和高级特性。本文作为系列终篇,将聚焦生产环境的性能优化与全流程实践,请各位跟随小编的步伐一起构建高可靠、高性能的消息处理系统(文章中的演示均为Centos7的背…...
自然语言处理Hugging Face Transformers
Hugging Face Transformers 是一个基于 PyTorch 和 TensorFlow 的开源库,专注于 最先进的自然语言处理(NLP)模型,如 BERT、GPT、RoBERTa、T5 等。它提供了 预训练模型、微调工具和推理 API,广泛应用于文本分类、机器翻…...

uniapp自定义tabbar,根据角色动态显示不同tabbar,无闪动问题
🤵 作者:coderYYY 🧑 个人简介:前端程序媛,目前主攻web前端,后端辅助,其他技术知识也会偶尔分享🍀欢迎和我一起交流!🚀(评论和私信一般会回!!) 👉 个人专栏推荐:《前端项目教程以及代码》 ✨一、前言 这个需求在开发中还是很常见的,搜索了网络其他教程,…...

狂神SQL学习笔记一:初识MySQL、关系型数据库和非关系型数据库
菜鸟教程学习一半了,但是已经疲倦了,所以换一个课程学习,来提升学习质量,可能会有很多已经学习到的地方,就当是复习巩固了。 按照SQL学习课程来划分,分为45集,所以可能也会写45篇文章ÿ…...