使用labelme进行实例分割标注
前言
最近在学习实例分割算法,参考b站视频课教程,使用labelme标注数据集,在csdn找到相关教程进行数据集格式转换,按照相关目标检测网络对数据集格式的训练要求划分数据集。
1.使用labelme标注图片

在网上随便找了几张蘑菇图片,使用多边形进行标注,标签设置为mushroom,
注意:实例分割标注疑惑:一张图片同类物体不同实例,如图片中显示多个蘑菇,该标注为mushroom1, mushroom2,mushroom3;或者全都标注为mushroom
在查看了一些实例相关的文献,发现以上两种情况均存在
在使用maskrcnn的文献中,一些是同类物体不同实例:显示不同掩膜颜色; 而另一些是同类物体不同实例:显示相同掩膜颜色。
最终决定选择全部标注为mushroom的原因:
1.参考github官方labelme的实例分割标注示例
E:\Github\github\labelme-main\examples\instance_segmentation\data_annotated

图片为2011_000006.jpg
labelme json标注信息,可以看到图片中有三个人,在json标签中三个实例同一种类(人)label均为person, 因此说明label指代是类别标签,而不是实例标签, 如果标注为person1,perosn2,person3,则是说明有三种不同的类别,如果再标注另一张带有人的标签,也标注为perosn1,perosn2,则会出现 每张图片不同的人,都有一个person1, 但是实际上他们类别都是person。 因此这样标显然不合理。
{"version": "4.0.0","flags": {},"shapes": [{"label": "person","points": [[204.936170212766,108.56382978723406],[183.936170212766,141.56382978723406],[166.936170212766,150.56382978723406],[108.93617021276599,203.56382978723406],[92.93617021276599,228.56382978723406],[95.93617021276599,244.56382978723406],[105.93617021276599,244.56382978723406],[116.93617021276599,223.56382978723406],[163.936170212766,187.56382978723406],[147.936170212766,212.56382978723406],[117.93617021276599,222.56382978723406],[108.93617021276599,243.56382978723406],[100.93617021276599,325.56382978723406],[135.936170212766,329.56382978723406],[148.936170212766,319.56382978723406],[150.936170212766,295.56382978723406],[169.936170212766,272.56382978723406],[171.936170212766,249.56382978723406],[178.936170212766,246.56382978723406],[186.936170212766,225.56382978723406],[214.936170212766,219.56382978723406],[242.936170212766,157.56382978723406],[228.936170212766,146.56382978723406],[228.936170212766,125.56382978723406],[216.936170212766,112.56382978723406]],"group_id": null,"shape_type": "polygon","flags": {}},{"label": "person","points": [[271.936170212766,109.56382978723406],[249.936170212766,110.56382978723406],[244.936170212766,150.56382978723406],[215.936170212766,219.56382978723406],[208.936170212766,245.56382978723406],[214.936170212766,220.56382978723406],[188.936170212766,227.56382978723406],[170.936170212766,246.56382978723406],[170.936170212766,275.56382978723406],[221.936170212766,278.56382978723406],[233.936170212766,259.56382978723406],[246.936170212766,253.56382978723406],[245.936170212766,256.56382978723406],[242.936170212766,251.56382978723406],[262.936170212766,256.56382978723406],[304.936170212766,226.56382978723406],[297.936170212766,199.56382978723406],[308.936170212766,164.56382978723406],[296.936170212766,148.56382978723406]],"group_id": null,"shape_type": "polygon","flags": {}},{"label": "person","points": [[308.936170212766,115.56382978723406],[298.936170212766,145.56382978723406],[309.936170212766,166.56382978723406],[297.936170212766,200.56382978723406],[305.936170212766,228.56382978723406],[262.936170212766,258.56382978723406],[252.936170212766,284.56382978723406],[272.936170212766,291.56382978723406],[281.936170212766,250.56382978723406],[326.936170212766,235.56382978723406],[351.936170212766,239.56382978723406],[365.936170212766,223.56382978723406],[371.936170212766,187.56382978723406],[353.936170212766,168.56382978723406],[344.936170212766,143.56382978723406],[336.936170212766,115.56382978723406]],"group_id": null,"shape_type": "polygon","flags": {}},{"label": "chair","points": [[309.7054009819968,242.94844517184941],[282.7054009819968,251.94844517184941],[271.7054009819968,287.9484451718494],[175.70540098199677,275.9484451718494],[149.70540098199677,296.9484451718494],[151.70540098199677,319.9484451718494],[160.70540098199677,328.9484451718494],[165.54250204582655,375.38461538461536],[486.7054009819968,373.9484451718494],[498.7054009819968,336.9484451718494],[498.7054009819968,202.94844517184941],[454.7054009819968,193.94844517184941],[435.7054009819968,212.94844517184941],[368.7054009819968,224.94844517184941],[351.7054009819968,241.94844517184941]],"group_id": null,"shape_type": "polygon","flags": {}},{"label": "person","points": [[425.936170212766,82.56382978723406],[404.936170212766,109.56382978723406],[400.936170212766,114.56382978723406],[437.936170212766,114.56382978723406],[448.936170212766,102.56382978723406],[446.936170212766,91.56382978723406]],"group_id": null,"shape_type": "polygon","flags": {}},{"label": "__ignore__","points": [[457.936170212766,85.56382978723406],[439.936170212766,117.56382978723406],[477.936170212766,117.56382978723406],[474.936170212766,87.56382978723406]],"group_id": null,"shape_type": "polygon","flags": {}},{"label": "sofa","points": [[183.936170212766,140.56382978723406],[125.93617021276599,140.56382978723406],[110.93617021276599,187.56382978723406],[22.936170212765987,199.56382978723406],[18.936170212765987,218.56382978723406],[22.936170212765987,234.56382978723406],[93.93617021276599,239.56382978723406],[91.93617021276599,229.56382978723406],[110.93617021276599,203.56382978723406]],"group_id": 0,"shape_type": "polygon","flags": {}},{"label": "sofa","points": [[103.93617021276599,290.56382978723406],[58.93617021276599,303.56382978723406],[97.93617021276599,311.56382978723406]],"group_id": 0,"shape_type": "polygon","flags": {}},{"label": "sofa","points": [[348.936170212766,146.56382978723406],[472.936170212766,149.56382978723406],[477.936170212766,162.56382978723406],[471.936170212766,196.56382978723406],[453.936170212766,192.56382978723406],[434.936170212766,213.56382978723406],[368.936170212766,226.56382978723406],[375.936170212766,187.56382978723406],[353.936170212766,164.56382978723406]],"group_id": 0,"shape_type": "polygon","flags": {}},{"label": "sofa","points": [[246.936170212766,252.56382978723406],[219.936170212766,277.56382978723406],[254.936170212766,287.56382978723406],[261.936170212766,256.56382978723406]],"group_id": 0,"shape_type": "polygon","flags": {}}],"imagePath": "2011_000006.jpg","imageData": null,"imageHeight": 375,"imageWidth": 500
} 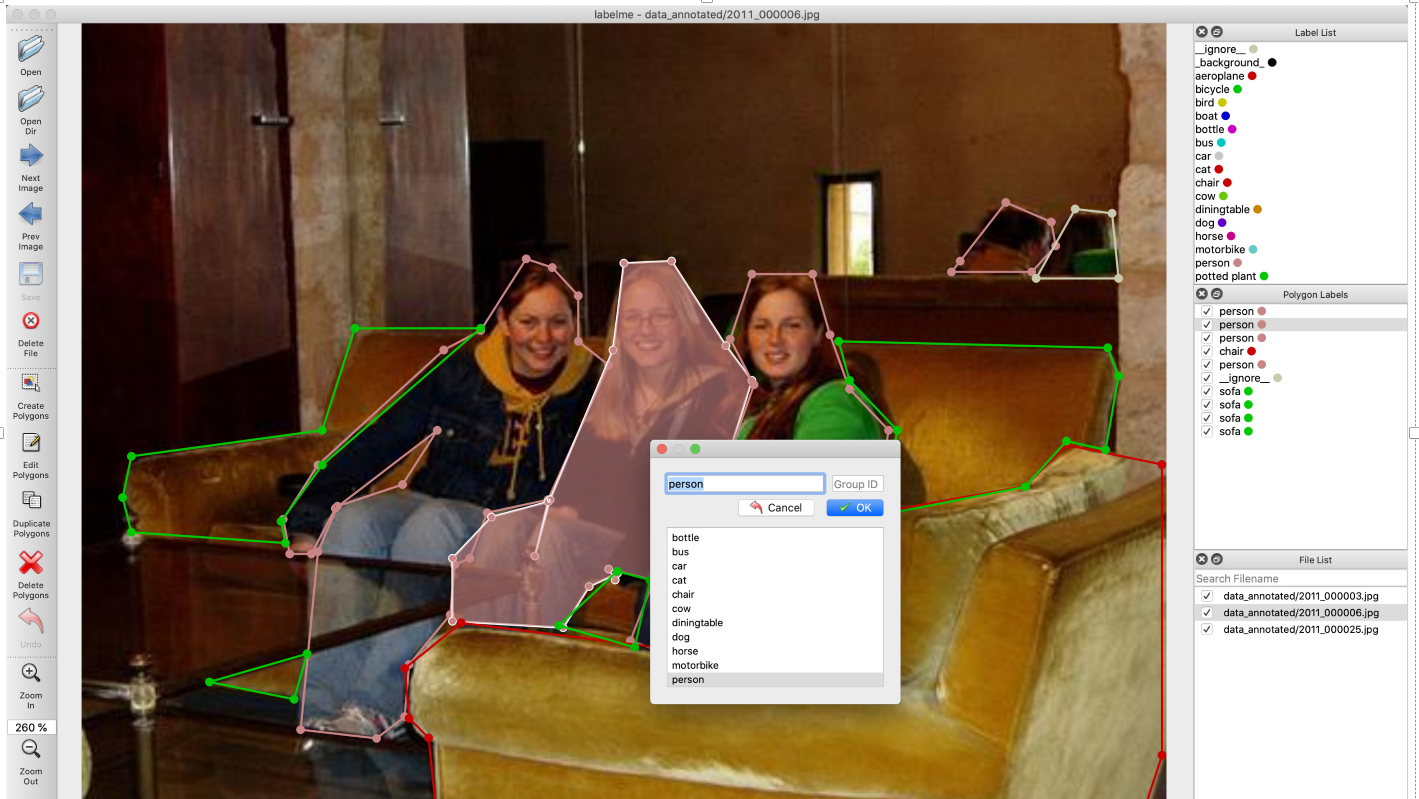
在github/labelme的官网中,作者是按上图进行标注的,三个person
2.github官方标注实例中voc数据集和coco数据集
labelme/voc数据集格式


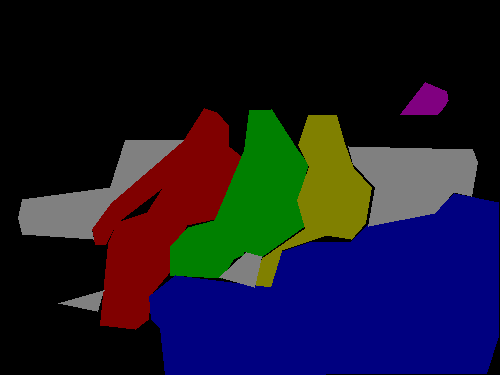
在github\labelme-main\examples\instance_segmentation\data_dataset_voc\SegmentationObject
文件中可以看到,实例分割标签中,三个人掩膜分别是不同的颜色

文件github\labelme-main\examples\instance_segmentation\data_dataset_voc\SegmentationObjectVisualization
在可视化实例分割标签中,可以看到不同人对应不同的数字和颜色
(红色1,绿色2,黄色3)
labelme/coco数据集格式

 在github\labelme-main\examples\instance_segmentation\data_dataset_coco\Visualization文件夹中可以看到三个人,掩膜显示不同的颜色,标签均显示为person
在github\labelme-main\examples\instance_segmentation\data_dataset_coco\Visualization文件夹中可以看到三个人,掩膜显示不同的颜色,标签均显示为person
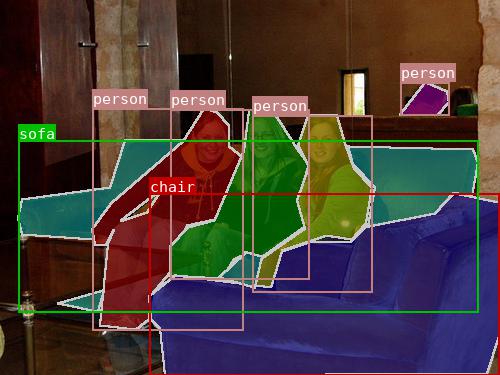
查看其annotations.json 标签文件,发现label 也都是person, 那怎么区分不同实例呢?
发现它这里是用id 来区分不同实例,每个id 代表不同种类不同实例的一个独立物体编号(不考虑背景)

观察该图片,结合 annotations.json 标签文件分析
| 图片及其 | image_id | 物体 | annotations.json 中实例对应id |
| 2011_000003.jpg | 0 | (category_id=15) person | 0 |
| person | 1 | ||
| (category_id=5) bottel | 2 | ||
| 2011_000025.jpg | 1 | (category_id=6) bus | 3 |
| bus | 4 | ||
| (category_id=7) car | 5 | ||
| 2011_000006.jpg | 2 | person | 6 |
| person | 7 | ||
| person | 8 | ||
| (category_id=9) chair | 9 | ||
| person | 10 | ||
| (category_id=18) sofa | 11 | ||
注意:group_id
labelme标注生成的json标签文件中,可以看到4个 label为sofa, 并且group_id 均为0, 这表示这4个标注部分均属于同一个实例,而不是四个相互独立的实例(因为图片显示只有一张沙发,但是由于人遮挡关系,被分割为4个部分)
在voc数据集格式实例分割标签.png中,可以看到sofa的4个部分是同一个颜色(灰色),均属于图片中第7个实例(背景是第0个实例)
在coco数据集格式annotations.json文件中可以看到, 关于sofa的标注信息,内部使用四个分割列表组成,说明该实例对象有被遮挡,而成为几个不连贯的部分; 而其它实例对象是由一个分割列表组成,说明该实例对象没有被遮挡,内部连贯。
{"id": 11, "image_id": 2, "category_id": 18, "segmentation":
[[183.936170212766, 140.56382978723406, 125.93617021276599, 140.56382978723406, 110.93617021276599, 187.56382978723406, 22.936170212765987, 199.56382978723406, 18.936170212765987, 218.56382978723406, 22.936170212765987, 234.56382978723406, 93.93617021276599, 239.56382978723406, 91.93617021276599, 229.56382978723406, 110.93617021276599, 203.56382978723406], [103.93617021276599, 290.56382978723406, 58.93617021276599, 303.56382978723406, 97.93617021276599, 311.56382978723406],[348.936170212766, 146.56382978723406, 472.936170212766, 149.56382978723406, 477.936170212766, 162.56382978723406, 471.936170212766, 196.56382978723406, 453.936170212766, 192.56382978723406, 434.936170212766, 213.56382978723406, 368.936170212766, 226.56382978723406, 375.936170212766, 187.56382978723406, 353.936170212766, 164.56382978723406], [246.936170212766, 252.56382978723406, 219.936170212766, 277.56382978723406, 254.936170212766, 287.56382978723406, 261.936170212766, 256.56382978723406]],"area": 14001.0, "bbox": [18.0, 140.0, 460.0, 172.0],"iscrowd": 0}
使用labelme自带的格式转换代码进行格式转换
在github\labelme-main\examples\instance_segmentation 文件夹下,
有两个py文件
| labelme2coco.py | 将labelme标注的json标签转换为coco数据集格式 |
| labelme2voc.py | 将labelme标注的json标签转换为voc数据集格式 |
labelme2voc.py使用

在使用labelme-多边形标注完图片后,我们将得到 图片jpg,以及 标签json (存放于data_annotated文件夹)
在转化前,需要再建立一个labels.txt文件,存放类别
注意:如果标注多个类别,该如何排序,观察labelme给示例,发现类别的排序与 coco数据集格式的 supercategory 的ID 序号对应。
labels.txt内容如下,_background_ 对应序号supercategory_id 为0, person 对应supercategory_id 为15 。
__ignore__
_background_
aeroplane
bicycle
bird
boat
bottle
bus
car
cat
chair
cow
diningtable
dog
horse
motorbike
person
potted plant
sheep
sofa
train
tv/monitorcoco数据集 annotations.json文件内容
"categories": [{"supercategory": null, "id": 0, "name": "_background_"}, {"supercategory": null, "id": 1, "name": "aeroplane"}, {"supercategory": null, "id": 2, "name": "bicycle"}, {"supercategory": null, "id": 3, "name": "bird"}, {"supercategory": null, "id": 4, "name": "boat"}, {"supercategory": null, "id": 5, "name": "bottle"}, {"supercategory": null, "id": 6, "name": "bus"}, {"supercategory": null, "id": 7, "name": "car"}, {"supercategory": null, "id": 8, "name": "cat"}, {"supercategory": null, "id": 9, "name": "chair"}, {"supercategory": null, "id": 10, "name": "cow"}, {"supercategory": null, "id": 11, "name": "diningtable"}, {"supercategory": null, "id": 12, "name": "dog"}, {"supercategory": null, "id": 13, "name": "horse"}, {"supercategory": null, "id": 14, "name": "motorbike"}, {"supercategory": null, "id": 15, "name": "person"}, {"supercategory": null, "id": 16, "name": "potted plant"}, {"supercategory": null, "id": 17, "name": "sheep"}, {"supercategory": null, "id": 18, "name": "sofa"}, {"supercategory": null, "id": 19, "name": "train"}, {"supercategory": null, "id": 20, "name": "tv/monitor"}]}因此,创建labels.txt文件内容如下:

将下面四个文件存放在同一个文件夹, 程序py文件从github\labelme-main\examples\instance_segmentation 复制
上面四个文件存放于文件夹test, 在该文件夹下打开终端, 激活虚拟环境,输入指令
python labelme2voc.py data_annotated data_dataset_voc --labels labels.txt
即可得到 VOC数据集格式
labelme2voc.py代码
#!/usr/bin/env pythonfrom __future__ import print_functionimport argparse
import glob
import os
import os.path as osp
import sysimport imgviz
import numpy as npimport labelmedef main():parser = argparse.ArgumentParser(formatter_class=argparse.ArgumentDefaultsHelpFormatter)parser.add_argument("input_dir", help="Input annotated directory")parser.add_argument("output_dir", help="Output dataset directory")parser.add_argument("--labels", help="Labels file or comma separated text", required=True)parser.add_argument("--noobject", help="Flag not to generate object label", action="store_true")parser.add_argument("--nonpy", help="Flag not to generate .npy files", action="store_true")parser.add_argument("--noviz", help="Flag to disable visualization", action="store_true")args = parser.parse_args()if osp.exists(args.output_dir):print("Output directory already exists:", args.output_dir)sys.exit(1)os.makedirs(args.output_dir)os.makedirs(osp.join(args.output_dir, "JPEGImages"))os.makedirs(osp.join(args.output_dir, "SegmentationClass"))if not args.nonpy:os.makedirs(osp.join(args.output_dir, "SegmentationClassNpy"))if not args.noviz:os.makedirs(osp.join(args.output_dir, "SegmentationClassVisualization"))if not args.noobject:os.makedirs(osp.join(args.output_dir, "SegmentationObject"))if not args.nonpy:os.makedirs(osp.join(args.output_dir, "SegmentationObjectNpy"))if not args.noviz:os.makedirs(osp.join(args.output_dir, "SegmentationObjectVisualization"))print("Creating dataset:", args.output_dir)if osp.exists(args.labels):with open(args.labels) as f:labels = [label.strip() for label in f if label]else:labels = [label.strip() for label in args.labels.split(",")]class_names = []class_name_to_id = {}for i, label in enumerate(labels):class_id = i - 1 # starts with -1class_name = label.strip()class_name_to_id[class_name] = class_idif class_id == -1:assert class_name == "__ignore__"continueelif class_id == 0:assert class_name == "_background_"class_names.append(class_name)class_names = tuple(class_names)print("class_names:", class_names)out_class_names_file = osp.join(args.output_dir, "class_names.txt")with open(out_class_names_file, "w") as f:f.writelines("\n".join(class_names))print("Saved class_names:", out_class_names_file)for filename in sorted(glob.glob(osp.join(args.input_dir, "*.json"))):print("Generating dataset from:", filename)label_file = labelme.LabelFile(filename=filename)base = osp.splitext(osp.basename(filename))[0]out_img_file = osp.join(args.output_dir, "JPEGImages", base + ".jpg")out_clsp_file = osp.join(args.output_dir, "SegmentationClass", base + ".png")if not args.nonpy:out_cls_file = osp.join(args.output_dir, "SegmentationClassNpy", base + ".npy")if not args.noviz:out_clsv_file = osp.join(args.output_dir,"SegmentationClassVisualization",base + ".jpg",)if not args.noobject:out_insp_file = osp.join(args.output_dir, "SegmentationObject", base + ".png")if not args.nonpy:out_ins_file = osp.join(args.output_dir, "SegmentationObjectNpy", base + ".npy")if not args.noviz:out_insv_file = osp.join(args.output_dir,"SegmentationObjectVisualization",base + ".jpg",)img = labelme.utils.img_data_to_arr(label_file.imageData)imgviz.io.imsave(out_img_file, img)cls, ins = labelme.utils.shapes_to_label(img_shape=img.shape,shapes=label_file.shapes,label_name_to_value=class_name_to_id,)ins[cls == -1] = 0 # ignore it.# class labellabelme.utils.lblsave(out_clsp_file, cls)if not args.nonpy:np.save(out_cls_file, cls)if not args.noviz:clsv = imgviz.label2rgb(cls,imgviz.rgb2gray(img),label_names=class_names,font_size=15,loc="rb",)imgviz.io.imsave(out_clsv_file, clsv)if not args.noobject:# instance labellabelme.utils.lblsave(out_insp_file, ins)if not args.nonpy:np.save(out_ins_file, ins)if not args.noviz:instance_ids = np.unique(ins)instance_names = [str(i) for i in range(max(instance_ids) + 1)]insv = imgviz.label2rgb(ins,imgviz.rgb2gray(img),label_names=instance_names,font_size=15,loc="rb",)imgviz.io.imsave(out_insv_file, insv)if __name__ == "__main__":main()
更改版,如果不想在终端使用命令行的形式 运行,也可以在程序中输入文件夹路径直接运行
# 2025.4.12
"""注意事项:
确保 labels.txt 文件存在且格式正确输出目录不能预先存在(脚本会自动创建)路径中的反斜杠建议使用原始字符串(字符串前加r)如果出现权限问题,请以管理员身份运行
"""# !/usr/bin/env pythonfrom __future__ import print_functionimport glob
import os
import os.path as osp
import sysimport imgviz
import numpy as npimport labelmedef main():# ====================== 需要修改的配置 ======================# 输入标注目录(包含.json文件)input_dir = r"你的标注文件目录(包含.json文件)"# 输出目录(会自动创建)output_dir = r"输出目录(会自动创建)"# 标签文件路径labels_path = r"标签文件路径(例如:labels.txt)"# 功能开关(True表示启用,False表示禁用)noobject = False # 是否不生成实例分割nonpy = False # 是否不生成.npy文件noviz = False # 是否不生成可视化结果# noobject = True # 设置为True则不生成实例分割相关文件# nonpy = True # 设置为True则不生成.npy文件# noviz = True # 设置为True则不生成可视化图片# ===========================================================# 检查输出目录if osp.exists(output_dir):print("Output directory already exists:", output_dir)sys.exit(1)os.makedirs(output_dir)# 创建子目录os.makedirs(osp.join(output_dir, "JPEGImages"))os.makedirs(osp.join(output_dir, "SegmentationClass"))if not nonpy:os.makedirs(osp.join(output_dir, "SegmentationClassNpy"))if not noviz:os.makedirs(osp.join(output_dir, "SegmentationClassVisualization"))if not noobject:os.makedirs(osp.join(output_dir, "SegmentationObject"))if not nonpy:os.makedirs(osp.join(output_dir, "SegmentationObjectNpy"))if not noviz:os.makedirs(osp.join(output_dir, "SegmentationObjectVisualization"))print("Creating dataset:", output_dir)# 读取标签with open(labels_path) as f:labels = [label.strip() for label in f if label]# 处理类别映射class_names = []class_name_to_id = {}for i, label in enumerate(labels):class_id = i - 1 # starts with -1class_name = label.strip()class_name_to_id[class_name] = class_idif class_id == -1:assert class_name == "__ignore__"continueelif class_id == 0:assert class_name == "_background_"class_names.append(class_name)class_names = tuple(class_names)print("class_names:", class_names)# 保存类别名称out_class_names_file = osp.join(output_dir, "class_names.txt")with open(out_class_names_file, "w") as f:f.write("\n".join(class_names))print("Saved class_names:", out_class_names_file)# 处理每个标注文件for filename in sorted(glob.glob(osp.join(input_dir, "*.json"))):print("Generating dataset from:", filename)label_file = labelme.LabelFile(filename=filename)base = osp.splitext(osp.basename(filename))[0]out_img_file = osp.join(output_dir, "JPEGImages", base + ".jpg")out_clsp_file = osp.join(output_dir, "SegmentationClass", base + ".png")# 生成类别标签img = labelme.utils.img_data_to_arr(label_file.imageData)imgviz.io.imsave(out_img_file, img)cls, ins = labelme.utils.shapes_to_label(img_shape=img.shape,shapes=label_file.shapes,label_name_to_value=class_name_to_id,)ins[cls == -1] = 0 # 忽略被标记的区域# 保存类别分割结果labelme.utils.lblsave(out_clsp_file, cls)if not nonpy:np.save(osp.join(output_dir, "SegmentationClassNpy", base + ".npy"), cls)if not noviz:clsv = imgviz.label2rgb(cls,imgviz.rgb2gray(img),label_names=class_names,font_size=15,loc="rb",)imgviz.io.imsave(osp.join(output_dir, "SegmentationClassVisualization", base + ".jpg"),clsv,)# 生成实例分割结果if not noobject:out_insp_file = osp.join(output_dir, "SegmentationObject", base + ".png")labelme.utils.lblsave(out_insp_file, ins)if not nonpy:np.save(osp.join(output_dir, "SegmentationObjectNpy", base + ".npy"), ins)if not noviz:instance_ids = np.unique(ins)instance_names = [str(i) for i in range(max(instance_ids) + 1)]insv = imgviz.label2rgb(ins,imgviz.rgb2gray(img),label_names=instance_names,font_size=15,loc="rb",)imgviz.io.imsave(osp.join(output_dir, "SegmentationObjectVisualization", base + ".jpg"),insv,)if __name__ == "__main__":main()data_dataset_voc文件夹内容如下:
data_dataset_voc\JPEGImages(存放jpg图片)

data_dataset_voc\SegmentationClass (存放语义分割标签)

data_dataset_voc\SegmentationClassNpy (存放语义分割标签的npy格式文件, 好像训练时没有用到)

data_dataset_voc\SegmentationClassVisualization (语义分割标签-可视化)
 data_dataset_voc\SegmentationObject (实例分割标签)
data_dataset_voc\SegmentationObject (实例分割标签)

data_dataset_voc\SegmentationObjectNpy (存放实例分割标签的npy格式文件)

data_dataset_voc\SegmentationObjectVisualization (实例分割标签-可视化)
 class_names.txt
class_names.txt
内容

至此,labelme2voc.py 内容结束,但是在使用相关实例分割网络训练(mask-rcnn)的过程中,发现还需要xml文件,需要将labelme_json标签转换为xml标签,这个后续在其他文章再说。
labelme2coco.py使用
与上述一样,
在数据集文件夹中打开终端输入命令行参数
python labelme2coco.py data_annotated data_dataset_coco --labels labels.txt或者像上述更改版代码那样,进行修改,直接输入路径值
data_dataset_coco文件夹内容如下:
data_dataset_coco|__|——JPEGImages 图片.jpg|——Visualization 可视化实例分割标签 .png|——annotations.json json标签信息 (所有图片)
data_dataset_coco\JPEGImages

data_dataset_coco\Visualization

data_dataset_coco\annotations.json
内容太长,就不展示了
参考资料:
1.github-labelme
2.labelme使用指南(转VOC、coco数据集)_哔哩哔哩_bilibili
3.deepseek.ai
相关文章:

使用labelme进行实例分割标注
前言 最近在学习实例分割算法,参考b站视频课教程,使用labelme标注数据集,在csdn找到相关教程进行数据集格式转换,按照相关目标检测网络对数据集格式的训练要求划分数据集。 1.使用labelme标注图片 在网上随便找了几张蘑菇图片&am…...

策略模式实现 Bean 注入时怎么知道具体注入的是哪个 Bean?
Autowire Resource 的区别 1.来源不同:其中 Autowire 是 Spring2.5 定义的注解,而 Resource 是 Java 定义的注解 2.依赖查找的顺序不同: 依赖注入的功能,是通过先在 Spring IoC 容器中查找对象,再将对象注入引入到当…...

PromptUp 网站介绍:AI助力,轻松创作
1. 网站定位与核心功能 promptup.net 可能是一个面向 创作者、设计师、营销人员及艺术爱好者 的AI辅助创作平台,主打 零门槛、智能化的内容生成与优化。其核心功能可能包括: AI艺术创作:通过输入关键词、选择主题或拖放模板,快速生成风格多样的数字艺术作品(如插画、海报…...

软件架构评估利器:质量效用树全解析
质量效用树是软件架构评估中的一种重要工具,它有助于系统地分析和评估软件架构在满足各种质量属性方面的表现。以下是关于质量效用树的详细介绍: 一、定义与作用 质量效用树是一种以树形结构来表示软件质量属性及其相关效用的模型。它将软件的质量目标…...
IP核时钟框架介绍)
XILINX DDR3专题---(1)IP核时钟框架介绍
1.什么是Reference Clock,这个时钟一定是200MHz吗? 2.为什么APP_DATA是128bit,怎么算出来的? 3.APP :MEM的比值一定是1:4吗? 4.NO BUFFER是什么意思? 5.什么情况下Reference Clock的时钟源可…...

ubuntu 2204 安装 vcs 2018
安装评估 系统 : Ubuntu 22.04.1 LTS 磁盘 : ubuntu 自身占用了 9.9G , 按照如下步骤 安装后 , 安装后的软件 占用 13.1G 仓库 : 由于安装 libpng12-0 , 添加了一个仓库 安装包 : 安装了多个包(lsb及其依赖包 libpng12-0)安装步骤 参考 ubuntu2018 安装 vcs2018 安装该…...

Python与去中心化存储:从理论到实战的全景指南【无标题】
Python与去中心化存储:从理论到实战的全景指南 随着区块链技术和Web3理念的兴起,去中心化存储逐渐成为构建新型互联网的核心模块之一。传统中心化存储的模式存在易被攻击、单点故障和高昂成本等问题,而去中心化存储通过分布式架构实现了更高的安全性、可靠性和数据透明度。…...

C++语言程序设计——01 C++程序基本结构
目录 编程语言一、C程序执行过程二、C基础框架三、输出语句cout换行 四、注释方法 编程语言 我们知道c是一门编程语言,它是在c语言的基础上发展而来,添加了类、对象、继承、多态等概念,我们可以称为它是一种面向对象编程的语言。 不过在学习…...
Unity UI中的Pixels Per Unit
Pixels Per Unit在图片导入到Unity的时候,将图片格式设置为Sprite的情况下会出现,其意思是精灵中的多少像素对应世界中的一个单位,默认是100 1. 对于在世界坐标中 在世界坐标中,一般对于Sprite的应用是Sprite Renderer组件 使…...
安卓开发中的后端接口调用详讲解)
(十八)安卓开发中的后端接口调用详讲解
在安卓开发中,后端接口调用是连接移动应用与服务器的重要环节,用于实现数据的获取、提交和处理。本文将详细讲解安卓开发中后端接口调用的步骤,结合代码示例和具体的使用场景,帮助你全面理解这一过程。 什么是后端接口?…...

使用freebsd-update 升级FreeBSD从FreeBSD 14.1-RELEASE-p5到FreeBSD 14.2-RELEASE
使用freebsd-update 升级FreeBSD从FreeBSD 14.1-RELEASE-p5到FreeBSD 14.2-RELEASE 先升级小版本 准备升级前,先把当前的小版本升级到顶,比如现在是FreeBSD 14.1-RELEASE-p5,先升级到最新的14.1版本,使用命令: # fr…...
)
基础排序算法(三傻排序)
1. 选择排序 原理:每次从未排序部分选出最小(或最大)元素,放到已排序部分的末尾。时间复杂度:O(n),效率低但实现简单,适合小规模数据。 //选择排序public static void selectSort(int[] arr){i…...

五分钟了解智能体
在2025年人工智能技术全面渗透社会的背景下,“智能体”(Agent)已成为推动第四次工业革命的核心概念之一。从自动驾驶汽车到医疗诊断系统,从智能家居中枢到金融量化交易平台,智能体正在重构人类与技术交互的方式。本文将…...

【机器学习】笔记| 通俗易懂讲解:生成模型和判别模型|01
博主简介:努力学习的22级计算机科学与技术本科生一枚🌸博主主页: Yaoyao2024往期回顾:【科研小白系列】这些基础linux命令,你都掌握了嘛?每日一言🌼: “脑袋想不明白的,就用脚想”—…...
)
Jieba分词的原理及应用(三)
前言 “结巴”中文分词:做最好的 Python 中文分词组件 上一篇文章讲了使用TF-IDF分类器范式进行企业级文本分类的案例。其中提到了中文场景不比英文场景,在喂给模型之前需要进行分词操作。 分词的手段有很多,其中最常用的手段还是Jieba库进行…...

神经网络背后的数学原理
神经网络背后的数学原理 数学建模神经网络数学原理 数学建模 标题民科味道满满。其实这篇小短文就是自我娱乐。 物理世界是物种多样,千姿百态。可以从不同的看待眼中的世界,包括音乐、绘画、舞蹈、雕塑等各种艺术形式。但这些主观的呈现虽然在各人眼中…...
)
常用图像滤波及色彩调节操作(Opencv)
1. 常用滤波/模糊操作 import cv2 import numpy as np import matplotlib.pyplot as plotimg cv2.imread("tmp.jpg") img cv2.cvtColor(img, cv2.COLOR_BGR2RGB) img_g cv2.GaussianBlur(img, (7,7), 0) img_mb cv2.medianBlur(img, ksize7) #中指滤波 img_bm …...

FFMPEG和opencv的编译
首先 sudo apt-get update -qq && sudo apt-get -y install autoconf automake build-essential cmake git-core libass-dev libfreetype6-dev libgnutls28-dev libmp3lame-dev libsdl2-dev libtool libva-dev libvdpau-dev libvorbis-de…...

用户登录不上linux服务器
一般出现这种问题,重新用root用户修改lsy用户的密码即可登录,但是当修改了还是登录不了的时候,去修改一个文件用root才能修改, 然后在最后添加上改用户的名字,例如 原本是只有user的,现在我加上了lsy了&a…...

【项目管理】第11章 项目成本管理-- 知识点整理
相关文档,希望互相学习,共同进步 风123456789~-CSDN博客 (一)知识总览 项目管理知识域 知识点: (项目管理概论、立项管理、十大知识域、配置与变更管理、绩效域) 对应:第6章-第19章 (二)知识笔记 第11章 项目成本管理 1.管理基础…...
)
Python中的strip()
文章目录 基本语法:示例:1. 默认移除空白字符:2. 移除指定字符:3. 不修改原字符串: 相关方法:示例: 注意事项: 在 Python 中, strip() 是一个字符串方法,用于…...
完整讲解与实战应用)
设计模式 Day 9:命令模式(Command Pattern)完整讲解与实战应用
🔄 回顾 Day 8:策略模式 在 Day 8 中我们讲解了策略模式: 用于封装多个可切换的算法逻辑,让调用者在运行时选择合适的策略。它强调的是“行为选择”,是针对“算法或行为差异”而设计。通过 PaymentStrategy、路径规划…...

【正点原子】STM32MP257 同构多核架构下的 ADC 电压采集与处理应用开发实战
在嵌入式系统中,ADC模拟电压的读取是常见的需求。如何高效、并发、且可控地完成数据采集与处理?本篇文章通过双线程分别绑定在 Linux 系统的不同 CPU 核心上,采集 /sys/bus/iio 接口的 ADC 原始值与缩放系数 scale,并在另一个核上…...

区块链从专家到小白
文章目录 含义应用场景典型特征 含义 以非对称加密算法为基础。 每个**区块(Block)**包含: 交易数据(如转账记录、合约内容)。 时间戳(记录生成时间)。 哈希值(当前区…...
)
记录centos8安装宝塔过程(两个脚本)
1、切换系统源(方便使用宝塔安装脚本下载) bash <(curl -sSL https://linuxmirrors.cn/main.sh) 2、宝塔安装脚本在宝塔的官网 宝塔面板下载,免费全能的服务器运维软件 根据自己的系统选择相应的脚本 urlhttps://download.bt.cn/insta…...

DAY 42 leetcode 151--哈希表.反转字符串中的单词
题号151 给你一个字符串 s ,请你反转字符串中 单词 的顺序。 单词 是由非空格字符组成的字符串。s 中使用至少一个空格将字符串中的 单词 分隔开。 返回 单词 顺序颠倒且 单词 之间用单个空格连接的结果字符串。 我的解法 暴力解法,先将String转为字…...

[VTK] 四元素实现旋转平移
VTK 实现旋转,有四元数的方案,也有 vtkTransform 的方案;主要示例代码如下: //构造旋转四元数vtkQuaterniond rotation;rotation.SetRotationAngleAndAxis(vtkMath::RadiansFromDegrees(90.0),0.0, 1.0, 0.0);//构造旋转点四元数v…...
2.2 分词器Tokenizer)
AI大模型:(二)2.2 分词器Tokenizer
目录 1.分词技术的发展 2.分词器原理 2.1.基于词分词 2.2.基于字符分词 2.3.基于子词分词 3.手搓Byte-Pair Encoding (BPE)分词及训练 3.1.Byte-Pair Encoding (BPE)分词原理 3.2.手搓Byte-Pair Encoding (BPE)分词器 4.如何选择已有的分词器 1. 常见子词分词器及特点…...

codeforces A. Simple Palindrome
目录 题面 代码 题面 A. 简单回文串 每个测试用例时间限制:1 秒 每个测试用例内存限制:256 兆字节 纳雷克要在幼儿园陪一些两岁的孩子度过两个小时。他想教孩子们竞技编程,他们的第一堂课是关于回文串的。 纳雷克发现孩子们只认识英文字母…...
:冯诺依曼结构)
Linux 进程基础(一):冯诺依曼结构
文章目录 一、冯诺依曼体系结构是什么?🧠二、冯诺依曼体系为何成为计算机组成的最终选择?(一)三大核心优势奠定主流地位(二)对比其他架构的不可替代性 三、存储分级:速度与容量的平衡…...
详解)
向量存储(VectorStore)详解
一、向量存储的核心概念 向量存储(VectorStore)是一种用于存储和检索高维向量数据的数据库或存储解决方案,特别适用于处理经过嵌入模型转化后的数据。与传统关系数据库不同,VectorStore 执行的是相似性搜索,而非精确匹…...
)
HCIP(网络类型)
网络类型概述 网络类型主要基于数据链路层使用的协议不同,导致数据包封装方式不同,工作方式也有所区别。根据这些特点,网络可以被分类为以下几种类型: MA网络(多点接入网络):允许同时接入多台…...

MTCNN 人脸识别
前言 此处介绍强大的 MTCNN 模块,给出demo,展示MTCNN 的 OOP, 以及ROS利用 C 节点,命令行调用脚本执行实际工作的思路。 MTCNN Script import argparse import cv2 from mtcnn import MTCNN import osclass MTCNNProcessor:def…...

一文解析DeepSeek R1模型
1. DeepSeek R1-Zero 在训练DeepSeek R1之前,深度求索团队尝试做了一个DeepSeek R1-Zero的模型,只进行强化学习而不需要监督微调,以此来强化模型自我推理的能力。 通过下图回顾下ChatGPT的做法:首先SFT,然后训练奖励…...
)
SpringMVC基础三(json)
乱码处理 编写一个表单: 编写EncodingController控制类 测试: 此乱码是在从前端传送到test方法时就已经乱了。 采用过滤器解决乱码 在web.xml中配置SpringMVC的乱码过滤器 <filter><filter-name>encoding</filter-name><filter…...

spring boot大文件与多文件下载
一、简单大文件下载: /*** 下载大文件* param path 路径* param fileName 文件名* return* throws IOException*/ public static ResponseEntity<InputStreamResource> downloadFile(String path, String fileName) throws IOException {Path filePath Path…...

事务隔离级别和MVCC
事务隔离级别 mysql是一个客户端/服务器架构的软件,对于同一个服务器来说,可以有多个客户端与之连接。每个客户端与服务器连接后就形成了一个会话。每个客户端都可以在自己的会话中向服务器发出请求语句,一个请求语句可能是某个事务的一部分…...

Ubuntu 系统深度清理:彻底卸载 Redis 服务及残留配置
Ubuntu 系统深度清理:彻底卸载 Redis 服务及残留配置 在Ubuntu系统中,Redis是一种广泛使用的内存数据存储系统,用于缓存和消息传递等场景。然而,有时候我们需要彻底卸载Redis,以清理系统资源或为其他应用腾出空间。本…...

关于群晖安装tailscale后无法直链的问题
问题是我局域网的ipv6无法正确获取到ip, 通过命令可以看到ipv6没有ip tailscale netcheck C:\Users\Administrator>tailscale netcheck 2025/04/12 23:43:34 attempting to fetch a DERPMap from https://controlplane.tailscale.comReport:* Time: 2025-04-12T15:43:38.27…...

第十二章:FreeRTOS多任务创建与删除
FreeRTOS多任务创建与删除教程 概述 本教程介绍FreeRTOS多任务的创建与删除方法,主要涉及两个核心函数: 任务创建:xTaskCreate()任务删除:vTaskDelete() 实践步骤 1. 准备工程文件 复制005工程并重命名为006 2. 创建多个任务…...
`的全面解析与应用)
JavaScript数组方法:`some()`的全面解析与应用
文章目录 JavaScript数组方法:some()的全面解析与应用一、some()方法的基本概念语法参数说明返回值 二、some()方法的核心特点三、基础用法示例示例1:检查数组中是否有大于10的元素示例2:检查字符串数组中是否包含特定子串 四、实际应用场景1…...

IntelliJ IDEA历史版本下载安装链接
IntelliJ IDEA | Other Versions 拿走,不谢O(∩_∩)O...

Rag实现流程
Rag实现流程 目录 Rag实现流程1. 加载问答链代码解释`chain_type="stuff"` 的含义其他 `chain_type` 参数选项及特点1. `map_reduce`2. `refine`3. `map_rerank`示例代码展示不同 `chain_type` 的使用其他参数类型2. 提出问题3. 检索相关文档代码解释其他参数类型4. …...

设计模式 --- 命令模式
命令模式是一种行为设计模式,它将请求封装成一个对象,从而允许你使用不同的请求、队列或日志来参数化其他对象,同时支持请求的撤销与恢复。 优点: 1.解耦调用者与接收者:输入处理无需直接调用角色方法 2.支持撤销…...

C# TCP与ip通信
一、获取本机的ip地址 // 获取本地主机名 string hostName Dns.GetHostName(); string ip "127.0.0.1"; //Console.WriteLine("本地主机名: " hostName);// 获取本地IP地址 IPAddress[] addresses Dns.GetHostAddresses(hostName); Console.WriteLine…...

如何使用 Grafana 连接 Easyearch
Grafana 介绍 Grafana 是一款开源的跨平台数据可视化与监控分析工具,专为时序数据(如服务器性能指标、应用程序日志、业务数据等)设计。它通过直观的仪表盘(Dashboards)帮助用户实时监控系统状态、分析趋势࿰…...
)
ubuntu20.04 openvino的yolov8推理(nncf量化)
1.环境配置: pip install openvino-dev(2023.0.1) pip install nncf(2.5.0) pip install ultralytics 2.模型转换及nncf量化: 1.pytorch->onnx: # Pytorch模型转换为Onnx模型 python from ultralytics import YOLO model YOLO(yolov8s.pt) # yo…...

《Python星球日记》第26天:Matplotlib 可视化
名人说:路漫漫其修远兮,吾将上下而求索。—— 屈原《离骚》 创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊) 订阅专栏:《Python星球日记》 目录 一、Matplotlib 简介1. 什么是 Matplo…...

2025蓝桥杯python A组题解
真捐款去了,好长时间没练了,感觉脑子和手都不转悠了。 B F BF BF 赛时都写假了, G G G 也只写了爆搜。 题解其实队友都写好了,我就粘一下自己的代码,稍微提点个人的理解水一篇题解 队友题解 B 思路: 我…...
(一))
OpenHarmony - 小型系统内核(LiteOS-A)(一)
OpenHarmony - 小型系统内核(LiteOS-A)(一) 一、小型系统内核概述 简介 OpenHarmony 轻量级内核是基于IoT领域轻量级物联网操作系统Huawei LiteOS内核演进发展的新一代内核,包含LiteOS-M和LiteOS-A两类内核。LiteOS-…...