【机器学习】笔记| 通俗易懂讲解:生成模型和判别模型|01

- 博主简介:努力学习的22级计算机科学与技术本科生一枚🌸
- 博主主页: @Yaoyao2024
- 往期回顾:【科研小白系列】这些基础linux命令,你都掌握了嘛?
- 每日一言🌼: “脑袋想不明白的,就用脚想”——《走吧,张小砚》🌺
0、前言|声明
本篇博客是基于Generative and Discriminative Models这篇英文文章翻译(更多是用我个人自己的语言去理解和讲解)而来,加上博主本人的理解、思考和笔记,供大家参考和学习使用。
在此也非常感谢原作者团队的内容~!
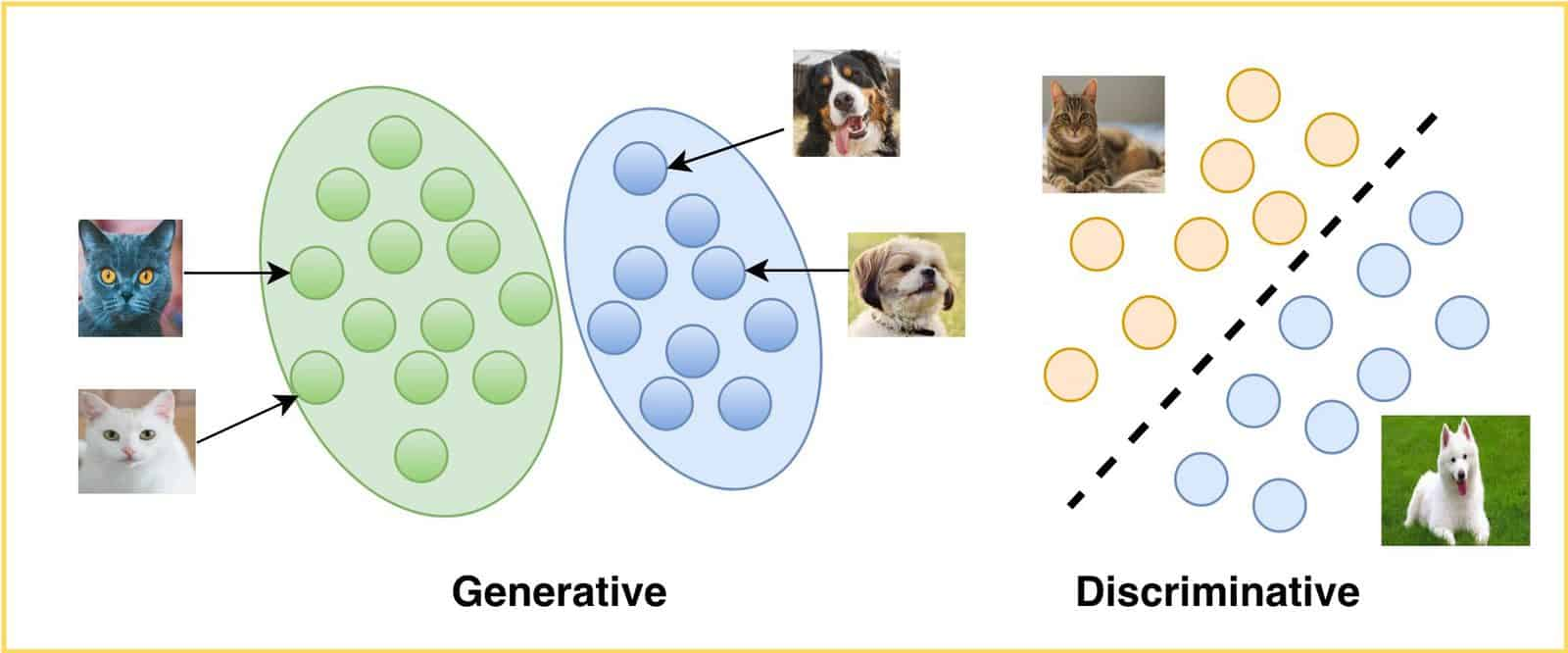
在解决大部分深度学习和机器学习问题时,解决思路通常来源于:判别模型和生成模型。也就是说,这两种模型的方法,给许多实际问题提供了 基础的概念框架和思考方向。
基于这两种模型的特征、方法、应用场景的不同,其实也可以很容易将其区分开来:
- Discriminative Models: 比如上图右侧,将一个图片样本(内容为猫或者狗)区分开来,这就是判别模型所需要做的。
- Generative Models:左侧,如何从一个样本点的分布中,进行采样,然后生成想要的猫或狗,这属于生成模型。
随着神经网络越来越多的被采用到,与其相关的生成式领域和判别式领域都在发展壮大。因此,为了去学习和理解这些算法,我们必须学习基础的相关理论知识,以及掌握所有的建模方法。
这样才能更好的去运用和改进这些方法,在实际运用中发挥更大的作用。
首先,你只需要对机器学习和深度学习有基本的熟悉。一旦你建立了基础,就可以进入更高级的主题,比如生成对抗网络或GAN。如果你以前处理过图像分类(判别)或图像重建(生成)问题,那可能是一个bonus。不了解幕后的一切以及问题是如何建模的也没关系。
如前所述,没有专有技术或对事物如何工作的深刻理解是可以的。这篇文章将讨论细节并提供对以下方面的直观理解:
1. 判别式建模——Discriminative Modelling
1.1:判别建模能做什么?是什么?⭐
💐判别式模型的应用:
大家,包括我自己,比较熟悉的那当然是:分类(Classification)和回归预测(Regression)。但是,很多很多任务都是会使用的判别模型:
- Object Detection|目标检测(物体检测)
- Semantic Segmentation| 语义分割
- panoptic segmentation| 全景建模
- keypoint detection| 关键点检测
- language modelling| 语言建模
下面四张图片展示了在图像领域,最常见和最有趣的实际应用
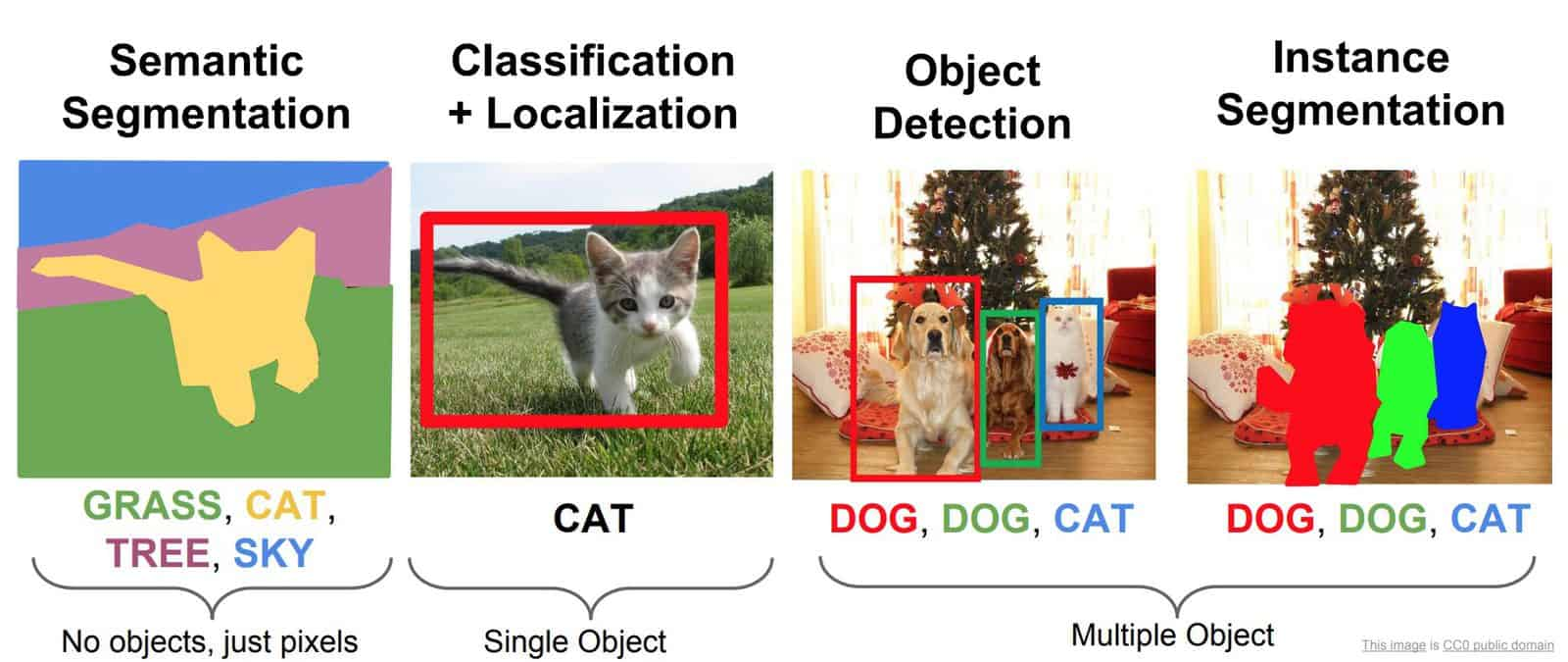
Semantic Segmentation(语义分割):将图像中每个像素(pixel)分配到预先定义的语义类别中,关注的是像素所属的类别信息,不区分同一类别的不同个体(objects)。 比如:在一张街景图片中,包含多个人和多个车,语义分割则会把所有是“人”的像素标记为“人”,所有车标记为“车”,不进行这些类别内的个体区分。Classification+Localization(分类+回归定位):首先将这个图片样本进行分类,然后识别定位出这个图片中的个体Object。因为对图片是单分类,所有识别到的Object也是单个的。Object Detection(目标检测):给定输入的图片,将图片中不同的Object进行识别定位,然后分类。这样可以detect到一张图片的多个object。Instance Segmentation(实例分割):不仅要识别出每个像素所属的语义类别,还要区分同一类别的不同个体实例。在上述街道图像中,实例分割会为每一个人、每一辆车单独进行标记,例如 “人 1”“人 2”“车 1”“车 2” 等,能够精确地分割出每个独立的目标对象。
🍹判别式模型属于:监督学习 | Supervised Learning
下面以分类任务举例来说明:
在分类任务中,训练时候,给定的数据是带标签(每个标签代表图像属于哪个类别)的。模型学习的目标是:将输入(图片)按照类别划分。比如上文中讲到如何将猫和狗两个不同的类别的输入区分开。 这种具有分类能力的模型,通常也被称为Classifiers——分类器。作用就是:将输入的图片样本 X \text{X} X 与类别(训练的时候给定的label) Y \text{Y} Y进行映射,并且去发现图片样本 x ∈ X x\in X x∈X属于类别标签 y ∈ Y y\in Y y∈Y 的概率。
那么作为这样一个有分类能力的分类器,它具体学习(建模)出来的是什么呢?——decision bundaries(决策边界)。
决策边界,可以简单理解为一个函数,具有判别能力的函数。给定输入X,根据这个函数的结果,我们可以判断出X属于哪个类别。判别函数可以是线性的,也可以是非线性的。
💁🏻♀️图片本身是HxWxC多维数据,经过特征编码后,维度可以压缩。不同图像,作为一个样本点,都处在高维空间的某一点。比如下面这张图,为了方便表示,图像是2维的(这里的2维指的是只需要每个维度一个值,二维向量,即可表示一个图像),每一张图片作为一个样本点落在了这个空间。分类模型就是找出一个线性或者非线性的决策边界函数(红线),来将下图中的红绿灯和车分别开来。
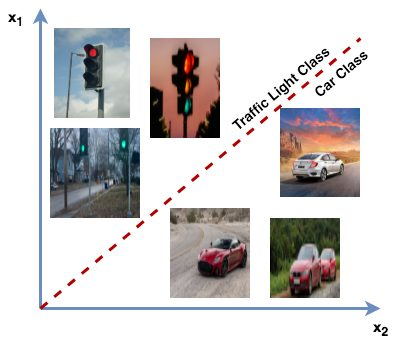
通过上图我们可以看到,影响最终得到的决策函数的,主要是离决策边界很近的点,因为这些靠近边界的数据点对确定边界的准确位置最为关键。它们处于类别之间的“模糊地带”,模型因为需要准确的将类别分开,所以它们会更多考虑这些点的贡献,来对其进行分析从而精确地确定决策边界。
相反,远离决策边界的数据点(离群点;Outliers),相对来说并不太重要。这是因为这些数据点很明显地属于某一个类别了,它们对于确定决策边界的位置和形状贡献比较小,对于进一步优化决策边界的作用不大。
💁🏻♀️ 将图像样本点投射到高维空间进行观察,每一个样本点,可以认为是图像总体分布(未知)的进行采样,得到随机变量(具体取值也就是训练集里的一张张图像)。根据《概率论和数理统计》,由多个从未知分布采样的随机变量,它们独立且同分布,则通过“参数估计”的方法可以得知原总体分布。但是这里的问题是,原总体分布本身是未知的(我们不知道红绿灯,汽车,是满足什么样子的一个分布,写不出它的概率密度函数 P ( X ) P(X) P(X))。
但是,对于分类器,这本身就不重要。分类器根本不关心你的分布是什么。我只需要你现在已有的数据样本点,我找出一个决策边界,把已有的样本点划分开来。它不会关心你这个样本点是满足与哪个分布函数,更不知道如何产生一个图片样本。(知道了分布,也就知道如何从图像分布中采样出样本点,生成图像。但分类器是没有这个功能的)
😸判别式模型在分类样本时候,也会对数据特征进行学习(特征编码):
在尝试对属于类别标签y的样本x进行分类时, 判别式模型会间接地学习数据集中的某些特征,这些特征可以理解为对高维复杂图像数据进行压缩和提取出来的更有利于图像分类的特征。
举例来说,一辆汽车有四个圆形的轮子,且长度大于宽度。而交通信号灯是垂直的,且有三个圆环。这些特征,帮助模型区分汽车和交通信号灯这两个类别。模型通过学习这些特征来确定分类的依据。当遇到新的样本时,就可以根据样本是否具有这些特征,来判断它属于哪个类别。
🌻判别模型的类型:
根据是否能够给出输入数据样本属于某一类别的概率,我们可以将模型分为两类:
-
概率型(Probabilistic):
- “logistic regression” 逻辑回归是一种常见的概率型判别式模型。它通过对输入特征进行加权求和,并应用逻辑函数(sigmoid 函数)来输出样本属于某一类别的概率。
- “a deep neural network, which models P (Y|X)” 深度神经网络也是概率型判别式模型的一种,它对条件概率 P (Y|X) 进行建模。这里 P (Y|X) 表示在给定特征 X 的情况下,样本属于类别 Y 的概率。深度神经网络通过多层神经元的计算和学习,可以自动提取复杂的特征表示,从而估计这个条件概率。
-
非概率型(Non-probabilistic)
- “Support Vector Machine (SVM), which tries to learn the mappings directly from the data points to the classes with a hyperplane.” 支持向量机(SVM)是一种非概率型的判别式模型。它试图通过找到一个超平面,直接学习从数据点到类别的映射关系。SVM 的目标是找到一个能将不同类别的数据点尽可能分开的超平面,使得不同类别之间的间隔最大,从而实现对数据的分类。
🪧判别式建模的核心概念:
“Discriminative modelling learns to model the conditional probability of class label y given set of features x as P (Y|X).” 建模学习对给定一组特征 x 时类别标签 y 的条件概率进行建模,即建模为 P (Y|X)。这是判别式模型的核心思想,它关注的是根据输入的特征来预测样本所属的目标类别,通过学习这种条件概率关系来实现分类任务。
💁🏻♀️在判别式建模中,X 代表的是输入的特征集合,它可以是图像的各种特征(比如像素值、纹理、颜色等),也可以是其他类型数据的特征,比如在自然语言处理中是文本的词向量等;Y 代表的是输出的目标,不仅仅局限于类别标签,确实可以是位置信息(如目标检测中物体在图像中的方框位置坐标),还可以是其他任何与输入特征有条件依赖关系的输出结果,例如在回归任务中是一个连续的数值。判别式模型重点在于学习从特征 X 到目标 Y 的映射关系,也就是 (P(Y|X)),只要存在这样的条件依赖关系,就可以运用判别式建模的思路来处理问题。
2.2:学习典型的判别模型
一些判别式模型如下:
- 支持向量机:Support Vector Machine
- 逻辑回归:Logistic Regression
- k 近邻算法(kNN):k-Nearest Neighbour
- 随机森林:Ramdom Forest
- 深度神经网络(如 AlexNet、VGGNet 和 ResNet 等)
让我们研究一些判别式模型,并探究它们的显著特点。
2.2.1:支持向量机Support Vector Machine
支持向量机(SVM)是一种非参数的监督学习技术,在工程师群体中非常受欢迎,因为它能以显著更少的计算量产生出色的结果。作为一种机器学习算法,它既可以应用于分类问题(输出是离散确定性的),也能应用于回归问题(输出是连续的)。它被广泛应用于文本分类、图像分类、蛋白质和基因分类等领域。
著名的基于深度学习的目标检测模型,即基于卷积神经网络的区域检测模型(R-CNN),使用支持向量机来对边界框中的目标进行分类。在这篇论文Rich feature hierarchies for accurate object detection and semantic segmentation Tech report (v5) 中,作者们使用了特定类别的线性支持向量机来对图像中的每个区域进行分类。
数据的线性可分与非线性可分:
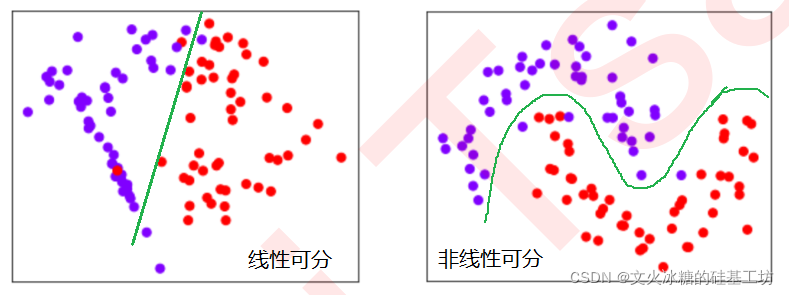
在上述图形中,特征值(X1, X2) 是平面上的连续点,标签值Y是点的颜色,是离散的。当分类数据的分布上可以使用一条直线来将两类数据分开时,我们就说数据是线性可分的。反之,数据不是线性可分的。
🪧SVM既可以分离线性可分的数据,也可以分离线性不可分的数据。
-
对于线性不可分的数据,会用到
Kernel-trick(大名鼎鼎的“核函数”),核函数就是将数据点从当前维度的空间映射的更高维,从而实现线性可分。 -
如果没有核函数,也就是所谓的线性SVM,它的目标是在特征空间中找到一个超平面,这个超平面要将不同类别的数据点分隔开,并且要使得这个超平面与个类别中离它最近的数据点(即支持向量)之间的间隔最大,这样找到的超平面就是线性可分问题的最优解决方案。
-
最特征空间中,那些处于数据点边界位置,对确定超平面位置起关键作用的点被称为支持向量。它们决定了超平面的位置和方向,因为超平面的位置是由这些支持向量来确定的,其他远离超平面的数据点对超平面的位置没有影响。
-
根据支持向量之间的相对位置关系,可以计算得出最大间隔(margin) 的大小。然后在最大间隔点的中间点处,绘制出最优超平面,这个超平面能够以最佳方式将不同类别的数据点分割开来,使得分类效果最优,泛化能力更强。
下图展示了核技巧技术以及维度空间的图像,利用(这些)核技巧和维度空间,支持向量机(SVM)能够轻松得以实现。
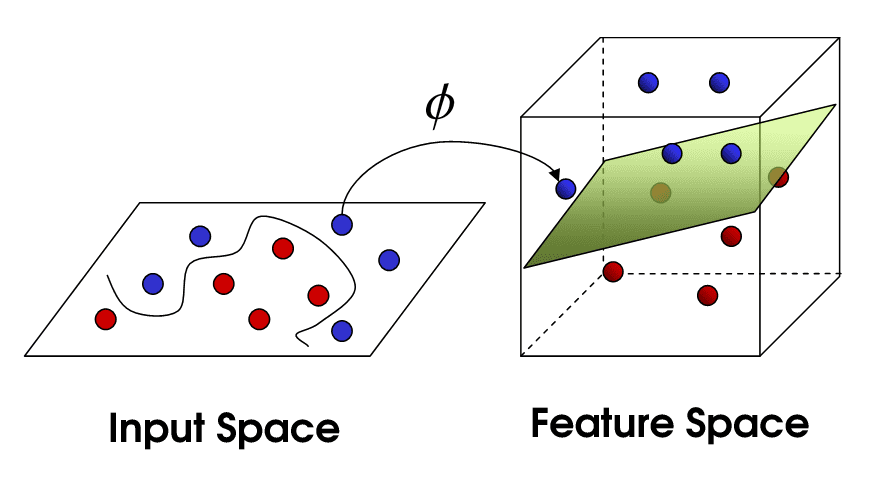
超平面是N-1维,其中N是给定数据集中存在的特征数。例如,如果数据集有两个特征(二维输入空间),A线将指示决策边界。
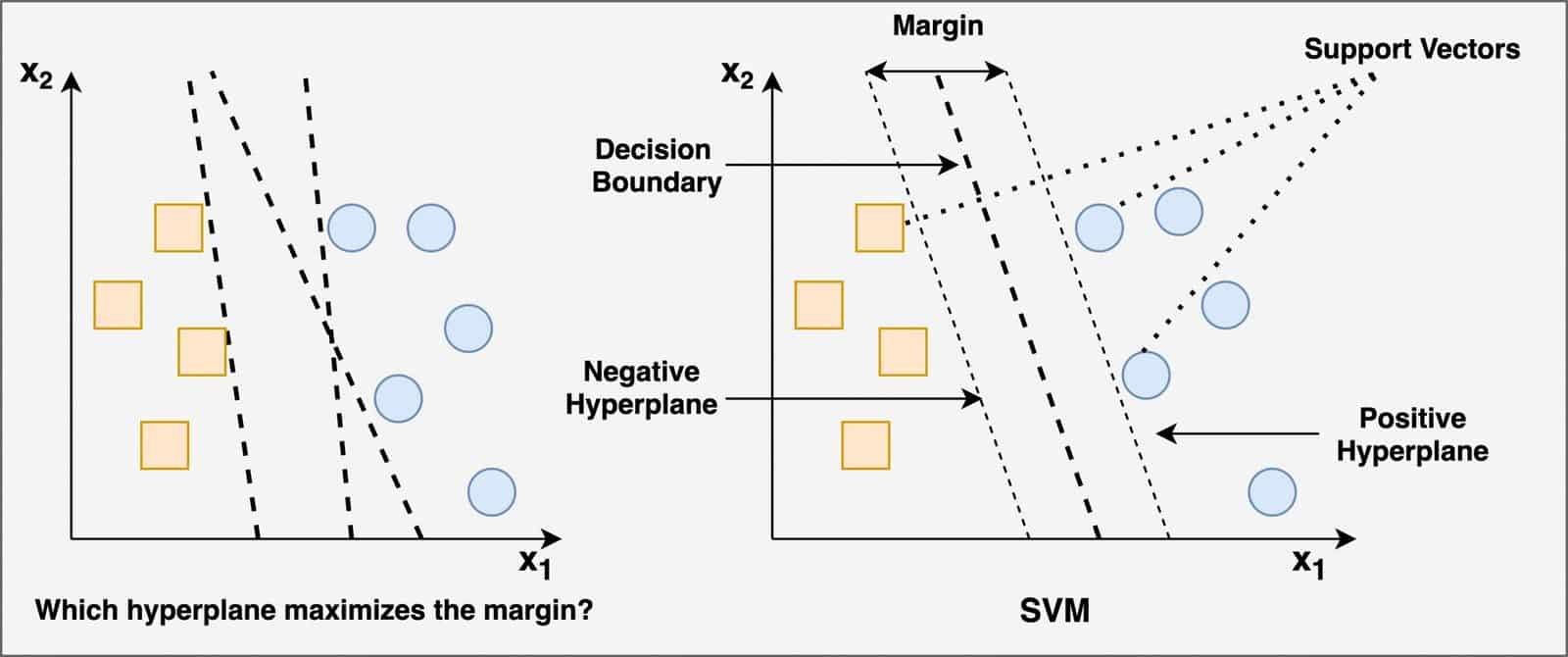
🧚🏻♀️为什么我们要找到使得支持向量具有最大间隔的超平面?
因为:具有最大间隔的决策边界它增加了泛化的机会,工作的最好。它给边界附近的数据点留有足够的自由度,减少错误分类的机会。另一方面,具有较小间隔的决策边界通常会导致过度拟合。
下图描述了如何选择超平面,最终选择的超平面最大化了数据点之间的间隔。
当数据点不能以线性方式分隔时,就会使用非线性支持向量机(Non-Linear SVM)。核函数或核技巧有助于为所有训练数据获得一个新的超平面。如上图所示, 输入空间被投影到一个更高维度的特征空间中,这样一来,在新超平面上的数据点分布将会是线性的。各种核技巧,比如多项式核函数和径向基函数,被用于通过支持向量机来解决非线性分类问题。
支持向量机可以直接现成使用。只需从 scikit-learn(sklearn)库中导入支持向量机模块即可。
from sklearn import svm
2.2.2:随机森林Random Forest
和SVM一样,随机森林同样属于判别式建模。它是机器学习的方法,也是在执行分类和回归的最流行和最强大的机器学习算法之一。随机森林称为Kaggle社区的热门,因为它帮助赢得了许多比赛。
随机森林,是决策树模型(Decision-tree models)的集合。因此,在理解随机森林之前,我们要知道——决策树算法 Decision Trees。
微软训练了一个深度随机决策森林分类器,从单深度图像中预测身体关节的3D位置。没有时间信息,使用了数十万张训练图像。-> Real-Time Human Pose Recognition in Parts from Single Depth Images
🦝那么,什么是决策树算法呢?
下图展示了一个决策树的结构和工作原理:
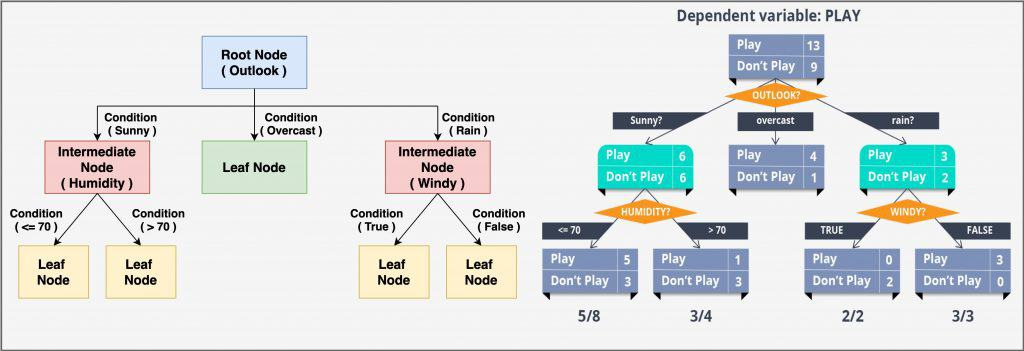
和SVM一样,一个决策树是无参数的监督学习算法,同样可以用在分类和回归任务当中。但是,主要还是用于分类。决策树可以渐进地将数据从大类到小类别进行逐渐的分类,直到得到最终的目标类别(标签)。一旦它学会怎么用label对训练数据进行建模,那么当输入测试数据的时候,它也能得到对应的label(目标类别)。
决策树是一个树形的分类器,由一个根节点、内部决策节点和叶子节点(代表最终的分类结果)构成。
其中整个算法包含的数据可以由树结构来表示:
- 内部决策节点:代表一个决策条件,是对每一个特征熟悉的测试。
- 每一条边:代表决策的结果
- 叶子节点:最终分类的目标类别,也就是训练时候输入数据对应的标签。
决策树大致上可以分为两种类别:
- 当目标类别(标签)是离散的,即预测结果是离散的(也就是上图中展示的例子):
- 它预测的结果是离散的两个类别:
play和do not play - 考虑到的特征属性有:
outlook( sunny, windy, rainy ),humidity, andwindy. 决策树从这些属性中进行学习。当把每一个数据传递到对应的节点,最终向下决策,得到一个叶子节点,代表分类的结果。
- 它预测的结果是离散的两个类别:
- 预测的目标是连续取值:比如通过房屋的不同特征来预测房价。
通过上图,我们知道,不同的决策节点,根据属性的不同取值,有对应不同的边:
- binary:属性只有两个取值情况(对应的决策节点下面只有两条边)
- multiway:属性有多个取值情况,如( sunny, rainy, overcast )。
决策树算法的关键是构建一棵完整的决策树,构建的过程也就是训练的过程。寻找并且构建最优决策树,一旦构建完成,当测试数据到来时候,输入决策树,则可以给出分类结果。
决策树的生成:
决策树会分析所有的数据特征,以找出那些能够将训练数据分割成子集,从而得出最佳分类结果的特征。训练阶段还会确定哪些数据属性将成为根节点、分支节点和中间节点。数据会被递归地分割,直到树达到叶节点为止。决策树如何进行分割是由基尼不纯度(Gini Impurity)或熵(Entropy)这两个用于选择中间(条件)节点的标准所决定的。
决策树通常使用基尼不纯度度量来创建决策点,这些决策点展示了数据被分割得有多精细。
- 当所有的观测值都属于同一个标签时,这是一种完美的分类,此时基尼不纯度为零(这是最佳情况)。
- 当观测值在各个标签之间平均分配时,基尼不纯度的值为一(这是最差情况)。
在python中,决策树模块可以直接从sklearn库中导入:
from sklearn.tree import DecisionTreeClassifier
连接完了决策树,现在让我们来学习随机森林算法:
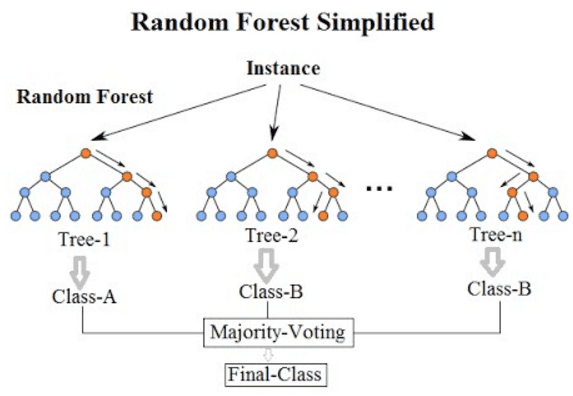
构建随机森林的方法其实也很简单粗暴,就是将多棵能够进行目标类别判别的决策树进行合并(就像上图那样)。因为一个决策树分类器可能很弱,但是当我们把很弱的几个分类器集合起来,然后让他们进行分类判别,然后少数服从多数,就可以让得到的结果更准确且模型泛化能力更强(改善了方差)。这里提到的 “改善了方差”,是因为随机森林通过集成多个决策树,减少了单个决策树可能出现的过拟合问题(方差较大意味着模型对训练数据的波动过于敏感),使得模型在不同数据集上的表现更加稳定和一致。
同样的,使用随机森林算法:
from sklearn.ensemble import RandomForestClassifier
由于随机森林算法采用自助抽样(bootstrap samples)进行训练,因此可以从数据集中有放回地抽取随机样本或数据点。
自助抽样是一种重采样技术,在训练随机森林时,从原始数据集中有放回地抽取样本。有放回意味着每次抽取一个数据点后,会将其放回数据集,这样同一个数据点在一次抽样过程中可能被多次选中。通过这种方式,可以生成多个不同的训练子集,每个子集用于训练一棵决策树。这种方法增加了训练数据的多样性,有助于提高模型的泛化能力。
为了集成决策树,随机森林采用了装袋法(bagging method)。不过,这与传统的装袋法略有不同。在随机森林中,并非使用所有特征,而是抽取特征的随机子集来训练每棵树。随机特征选择使树之间具有更高的独立性。这样,每棵树都能从数据集中捕获独特的信息,进而提高模型的准确性并缩短训练时间。在集成所有的树之后,它使用多数投票法计算最终输出。获得最多票数的标签被视为最终预测结果。
传统的装袋法通常会使用所有特征来训练每个弱学习器。而随机森林在训练每棵决策树时,不仅对数据进行有放回抽样,还会随机选择特征的子集。例如,假设原始数据集有 100 个特征,在训练每棵树时,可能只随机选择其中的 10 个特征来进行训练。
2.2.3:线性回归Linear Regression
根据它的名称:它是属于监督学习算法+回归模型。输入变量,得到连续的输出。
同时,作为有参数的机器学习算法,它的部分参数在训练过程中学习得到。
-
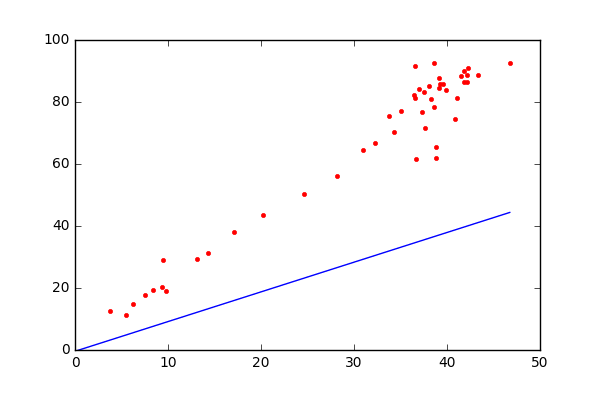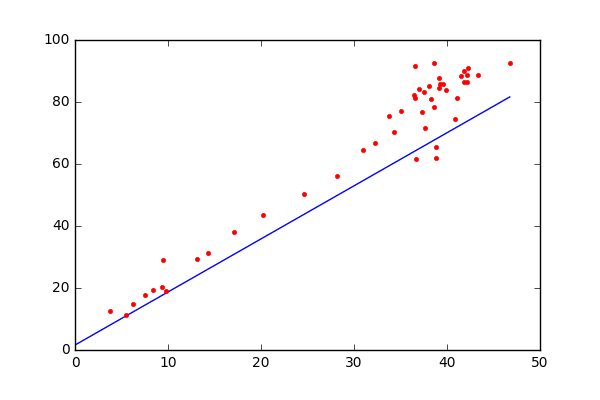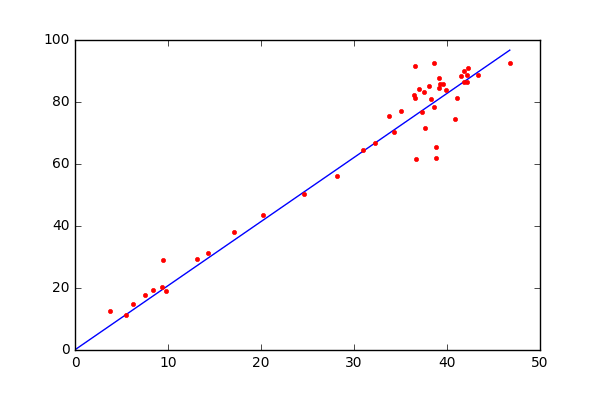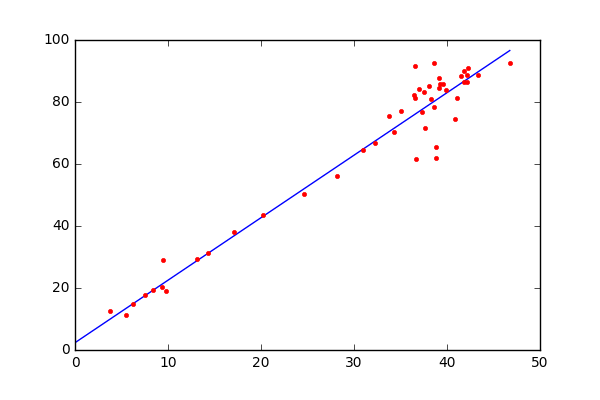
线性回归的目标:寻找一个线性的决策边界,是建立自变量和因变量之间的线性关系的统计方法。当我们在特征空间找到一条直线(在二维空间)或一个超平面(在多维空间),这个直线或超平面就是所谓的线性决策边界(decision bundary)。通过这个边界,我们可以根据输入自变量的值,来预测因变量的值。
-
线性回归的原理基础:基于我们熟知的线性函数 y = m x + b . y=mx+b. y=mx+b. 。这个方程描述的二维空间的一条参数,其中 m m m和 b b b是待确定的参数。线性回归的任务就是通过这些数据点+统计学方法来估计出最优的参数值。使得这条直线能够尽可能拟合原始数据
- 因变量y:它是我们想要预测的变量,在图像中通常对应纵轴。例如在上述房价预测的例子中,y就是房价,我们希望根据其他因素(自变量)来预测房价的值。
- 斜率m:表示直线的倾斜程度,它反映了自变量x的变化对因变量y变化的影响程度。在房价预测中,如果m的值较大,说明房屋面积每增加一个单位,房价的增加幅度较大;反之,如果m的值较小,房价随面积增加的幅度就较小。
- 自变量x:是用来预测因变量y的输入变量,在图像中对应横轴。在房价预测中,x可以是房屋的面积、房间数量等因素。
- y轴截距b:是直线与y轴的交点,它表示当自变量x为0时,因变量y的值。在实际问题中,b可能有具体的物理意义,也可能只是为了使直线能够更好地拟合数据而引入的一个参数。
2.2.4:逻辑回归Logistic Regression
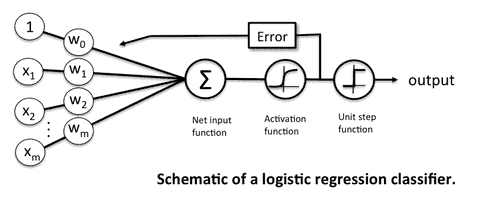
逻辑回归其实是在线性回归基础上进行改进的。和线性回归一样,它也是参数化的监督学习方法。通常用来分类问题。
它是一种广义的线性机器学习算法,因为其结果依赖于特征和参数的线性组合。在逻辑回归中,首先会对输入特征进行线性的加权求和。就像线性回归中的 (y = mx + b) 形式,只不过后续会有进一步的处理。
逻辑回归虽然名字里有 “回归”,但它主要用于解决分类问题,而不是像传统的线性回归那样用于预测连续值。这可能会让初学者产生混淆。
逻辑回归是在线性回归的基础上引入了逻辑函数(也称为 sigmoid 函数)。线性回归得到的结果是连续的,可能取值范围为负无穷到正无穷,而分类问题通常需要一个离散的输出(如 0 或 1 表示不同类别)。
加入逻辑函数的目的是将线性回归得到的连续输出转换为取值在 0 到 1 之间的确定性概率值。逻辑函数的公式为 σ ( z ) = 1 1 + e − z \sigma(z)=\frac{1}{1 + e^{-z}} σ(z)=1+e−z1,其中 z z z 是线性回归的输出。通过逻辑函数,将 z z z 映射到 0 到 1 的区间,这个概率值可以解释为样本属于某一类别的概率。例如,当概率值大于 0.5 时,可以将样本分类为正类;当概率值小于 0.5 时,分类为负类。
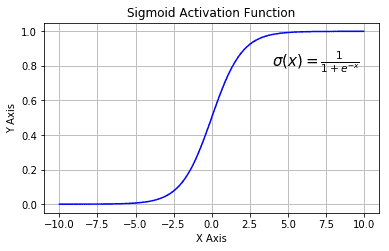
上图展示了逻辑函数(Logistic Function),也被一般称为sigmoid激活函数,它接受一个实数x并且将其压缩到0~1之间;将大负数转换为0,将大正数转换为1.
逻辑回归可以被看成是改进的线性回归,其等式可以被写作 y = σ ( m x + b ) , y=\sigma(mx+b), y=σ(mx+b),,其中 σ \sigma σ是sigmoid激活函数。
和线性回归一样,这里在训练过程中,通过计算预测值和真实标签之间的损失loss,来不断更新上述等式中的参数值。其中二元交叉熵函数(Binary Cross-Entropy Function)被用作损失函数。
L ( y , y ^ ) = − [ y log ( y ^ ) + ( 1 − y ) log ( 1 − y ^ ) ] L(y,\hat{y})=-[y\log(\hat{y})+(1-y)\log(1-\hat{y})] L(y,y^)=−[ylog(y^)+(1−y)log(1−y^)]
以对猫和狗的图像进行分类这个简单的例子来说。逻辑回归会接收输入图像 x x x,并输出一个介于 0 到 1 之间的值。假设猫的真实标签为 0,狗的真实标签为 1。当你输入一张猫的图像时,模型预测输出为 0.2。随后,会在真实标签 0 和预测输出 0.2 之间计算损失,并相应地更新模型的参数。
从 sklearn 库中导入逻辑回归模块:
from sklearn.linear_model import LogisticRegression# 创建逻辑回归模型实例
model = LogisticRegression()
2.2.5:深度神经网络Deep Neural Network
要理解神经网络的线性判别方法,我们需要先理解上面的线性和逻辑回归的方法。
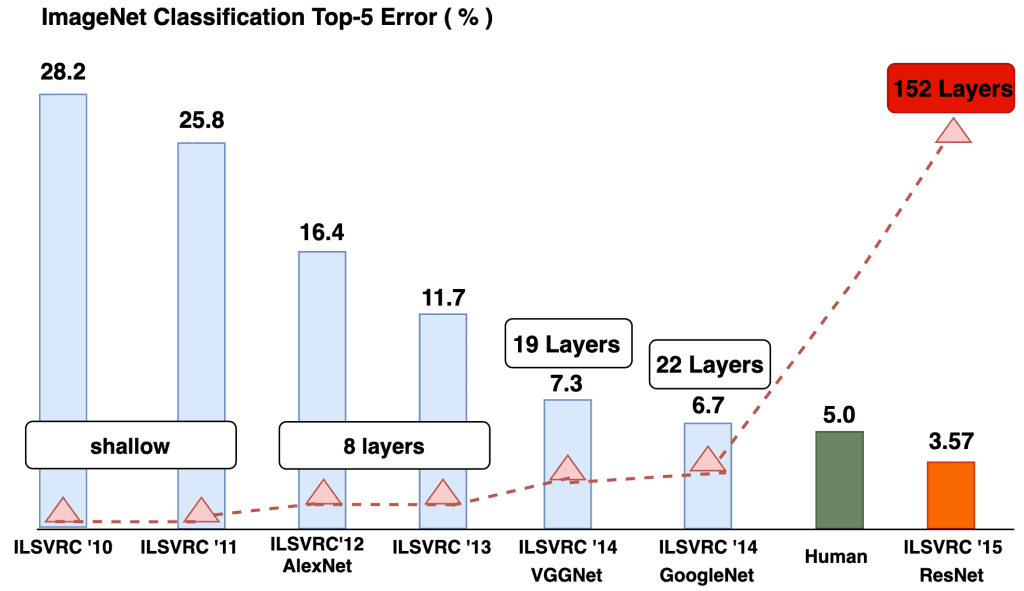
上图展示了通常被称为深度学习的深度神经网络在这些年来取得了多大的进展。分类领域的情况是以著名的 ImageNet 大规模视觉识别挑战赛(ILSVRC)作为衡量基准的。你会发现,机器(残差网络 ResNet)实现了前 5 分类错误率为 3.57% 的成绩,并且超越了与人类表现相关的 5% 的错误率。这难道不令人惊叹吗?上图还说明了另一个有趣的观点:随着神经网络中层数的增加,模型的性能也随之提升。
深度神经网络(DNN)是引人注目的复杂架构,旨在模仿人脑。自2012年以来,卷积神经网络(CNN)的性能大大优于手工描述符和浅层网络。
手工描述符(LBP、SIFT)是使用手动、预定义算法提取的特征,用于调整在数据集中没有很好地泛化的几个参数。
- 传统的机器学习方法中,常常使用手工设计的特征描述符来提取数据的特征。例如,在图像处理领域,像 SIFT(尺度不变特征变换)、HOG(方向梯度直方图)等就是典型的手工特征描述符。这些描述符是由人类根据对数据的理解和经验设计出来的,在提取特征时,需要明确地定义特征提取的规则和步骤,是一种显式的特征提取方式。不过,手工设计特征往往需要大量的专业知识和领域经验,并且对于不同类型的数据和任务,可能需要设计不同的特征描述符,缺乏通用性。
- 神经网络是一种基于数据驱动的模型,在训练过程中,它会自动学习数据中的特征。神经网络通过多层的神经元结构,从输入数据中逐步提取出更高级、更抽象的特征。例如,在图像分类任务中,神经网络的底层可能学习到边缘、纹理等简单特征,而高层则可以学习到物体的形状、部件等更复杂的特征。这种特征学习方式不需要人工显式地定义特征提取规则,而是让模型自己从数据中发现特征,因此在不同类型的数据和任务上具有更好的通用性。
浅层(shallow) 神经网络与深层神经网络对比:浅层神经网络并不 “深”,通常只有一个隐藏层。而深层神经网络则可能多达 152 层(如残差网络架构)。
神经网络被誉为优秀的函数逼近器,它有三种类型的层:输入层、隐藏层和输出层。所有的奇妙之处都发生在隐藏层。
-
逻辑回归可以看作是一个简单的单层神经网络,它只有输入层和输出层,没有隐藏层。逻辑回归通过线性组合输入特征并使用 sigmoid 函数将结果映射到 0 到 1 之间,用于二分类问题。
-
深层神经网络可以看作是多个逻辑回归单元的堆叠,每个隐藏层的神经元都类似于一个逻辑回归单元。通过多层的堆叠,深层神经网络能够学习到更复杂的非线性关系。
-
在逻辑回归中,使用 sigmoid 函数引入非线性,将线性组合的结果转换为概率值。然而,sigmoid 函数存在梯度消失的问题,当输入值过大或过小时,函数的导数趋近于 0,导致在反向传播过程中梯度传递困难,影响模型的训练效果。
-
深层神经网络通常使用更高效的激活函数,如 ReLU、PReLU 和 Swish 等。这些激活函数在一定程度上解决了梯度消失的问题,能够加快模型的训练速度,提高模型的性能。
关于更多激活函数和全面的理解,可以看这篇post->Activation Functions in Deep Learning – A Complete Overview

上图是卷积神经网络(CNN)层的滤波器filter(卷积核)可视化。
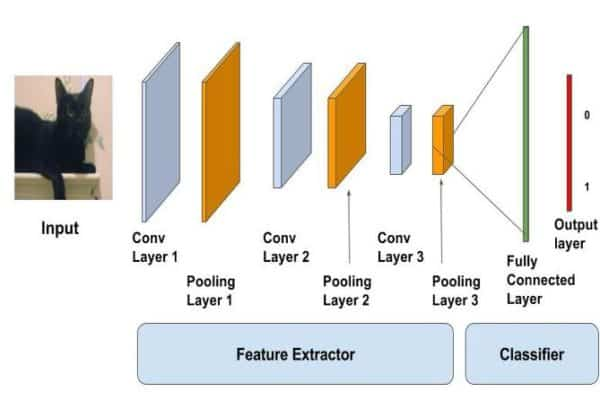
在深度神经网络(DNN)中,图像分类任务首先由卷积神经网络层来执行,这些层负责学习图像的特征。接下来,全连接层会聚合这些特征,并输出一个分类分数(即输入图像是一只猫的概率)。当然,在图像被成功分类之前,还有很多其他的操作步骤。
如果想要深入了解使用卷积神经网络进行图像分类的相关内容Convolutional Neural Network (CNN): A Complete Guide
在卷积神经网络的初始层(如上述可视化所示)会学习像垂直、水平和对角线(局部模式)这样的低级特征。随着向网络更深处推进,所学习到的特征会变得更加抽象(全局模式)。
2.2.6:比较|总结
💐Support Vector Machine ( SVM ):
- SVM可以被用于分类和回归任务,它是监督学习算法。
- SVM在训练数据有限,并且特征数量多的数据集上表现更好。
- 它使用多项式核、径向基函数(RBF)核和 sigmoid 核等核技巧来解决复杂的非线性问题。你不仅可以定义自定义核函数,还能添加一些核函数来实现更复杂的决策边界。
- 使用合页损失函数(hinge loss)以获得更高的准确性(不过它也有自身的缺陷)。
- 支持向量机仅支持二分类。对于多分类问题,需要设置多个支持向量机模型。
- 像软间隔调整这样的超参数有助于达到足够的准确性。
- 支持向量机内存效率高,因为最大间隔是由支持向量推导出来的,也就是说,只涉及数据点的一个子集。
- 作为一种非概率模型,它不会输出预测的概率或用于概率估计。
- 在 CPU 上进行训练,可以在多个核心上并行化。显然,大型数据集需要更多的训练时间
- 其目标函数是凸函数,这意味着不存在局部最优解,使用拉格朗日乘子法而不是(深度神经网络中使用的)梯度下降法来进行优化。
💐随机森林:
- 随机森林可以解决分类和回归任务,是一种监督学习算法。
- 与支持向量机不同,它可以进行多分类。
- 还会为预测给出一个概率分数。
- 当数据集变大时,随机森林是更优的选择
- 泛化能力好,当多个弱决策树森林组合在一起时不会出现过拟合。
- 如果决策树森林的数量非常庞大,训练速度会较慢。然而,如果训练数据量很大,我们会发现它的训练速度比支持向量机快。
- 它还支持隐式特征选择,并且能直观地告诉你哪些特征是重要的。
💐深度神经网络(DNN):
- 用途和学习方式:和另外两种模型一样,深度神经网络也可以解决分类和回归问题。在应用于监督学习(如图像分类)时使用标签,而在无监督学习(如图像生成)中则不需要标签。
- 数据适应性:深度神经网络表现良好,尤其是当你有大量数据的时候。
- 优化方式:与支持向量机不同,深度神经网络的目标函数是非凸的,可能存在多个局部最优解。使用梯度下降法来优化训练误差。
- 计算需求:计算量非常大,网络深度越高,对计算能力的要求就越高。你需要在 GPU(图形处理单元)上进行训练。
- 特征提取:当试图从原始数据中提取有意义的特征时,这种方法效果最佳。你不需要依赖像局部二值模式或梯度直方图这样的手工设计的特征。
- 超参数调整:为了获得最佳结果,你确实需要仔细调整神经网络的超参数。在使用训练数据时,它们的泛化能力良好。
- 应用领域:在数百万个应用中得到使用,其中更突出的应用领域包括计算机视觉、自然语言处理/理解、医学成像、语音处理和时间序列。
参考
- Generative and Discriminative Models
- 线性数据与非线性数据的区别
- 详解SVM模型——核函数是怎么回事
相关文章:

【机器学习】笔记| 通俗易懂讲解:生成模型和判别模型|01
博主简介:努力学习的22级计算机科学与技术本科生一枚🌸博主主页: Yaoyao2024往期回顾:【科研小白系列】这些基础linux命令,你都掌握了嘛?每日一言🌼: “脑袋想不明白的,就用脚想”—…...
)
Jieba分词的原理及应用(三)
前言 “结巴”中文分词:做最好的 Python 中文分词组件 上一篇文章讲了使用TF-IDF分类器范式进行企业级文本分类的案例。其中提到了中文场景不比英文场景,在喂给模型之前需要进行分词操作。 分词的手段有很多,其中最常用的手段还是Jieba库进行…...

神经网络背后的数学原理
神经网络背后的数学原理 数学建模神经网络数学原理 数学建模 标题民科味道满满。其实这篇小短文就是自我娱乐。 物理世界是物种多样,千姿百态。可以从不同的看待眼中的世界,包括音乐、绘画、舞蹈、雕塑等各种艺术形式。但这些主观的呈现虽然在各人眼中…...
)
常用图像滤波及色彩调节操作(Opencv)
1. 常用滤波/模糊操作 import cv2 import numpy as np import matplotlib.pyplot as plotimg cv2.imread("tmp.jpg") img cv2.cvtColor(img, cv2.COLOR_BGR2RGB) img_g cv2.GaussianBlur(img, (7,7), 0) img_mb cv2.medianBlur(img, ksize7) #中指滤波 img_bm …...

FFMPEG和opencv的编译
首先 sudo apt-get update -qq && sudo apt-get -y install autoconf automake build-essential cmake git-core libass-dev libfreetype6-dev libgnutls28-dev libmp3lame-dev libsdl2-dev libtool libva-dev libvdpau-dev libvorbis-de…...

用户登录不上linux服务器
一般出现这种问题,重新用root用户修改lsy用户的密码即可登录,但是当修改了还是登录不了的时候,去修改一个文件用root才能修改, 然后在最后添加上改用户的名字,例如 原本是只有user的,现在我加上了lsy了&a…...

【项目管理】第11章 项目成本管理-- 知识点整理
相关文档,希望互相学习,共同进步 风123456789~-CSDN博客 (一)知识总览 项目管理知识域 知识点: (项目管理概论、立项管理、十大知识域、配置与变更管理、绩效域) 对应:第6章-第19章 (二)知识笔记 第11章 项目成本管理 1.管理基础…...
)
Python中的strip()
文章目录 基本语法:示例:1. 默认移除空白字符:2. 移除指定字符:3. 不修改原字符串: 相关方法:示例: 注意事项: 在 Python 中, strip() 是一个字符串方法,用于…...
完整讲解与实战应用)
设计模式 Day 9:命令模式(Command Pattern)完整讲解与实战应用
🔄 回顾 Day 8:策略模式 在 Day 8 中我们讲解了策略模式: 用于封装多个可切换的算法逻辑,让调用者在运行时选择合适的策略。它强调的是“行为选择”,是针对“算法或行为差异”而设计。通过 PaymentStrategy、路径规划…...

【正点原子】STM32MP257 同构多核架构下的 ADC 电压采集与处理应用开发实战
在嵌入式系统中,ADC模拟电压的读取是常见的需求。如何高效、并发、且可控地完成数据采集与处理?本篇文章通过双线程分别绑定在 Linux 系统的不同 CPU 核心上,采集 /sys/bus/iio 接口的 ADC 原始值与缩放系数 scale,并在另一个核上…...

区块链从专家到小白
文章目录 含义应用场景典型特征 含义 以非对称加密算法为基础。 每个**区块(Block)**包含: 交易数据(如转账记录、合约内容)。 时间戳(记录生成时间)。 哈希值(当前区…...
)
记录centos8安装宝塔过程(两个脚本)
1、切换系统源(方便使用宝塔安装脚本下载) bash <(curl -sSL https://linuxmirrors.cn/main.sh) 2、宝塔安装脚本在宝塔的官网 宝塔面板下载,免费全能的服务器运维软件 根据自己的系统选择相应的脚本 urlhttps://download.bt.cn/insta…...

DAY 42 leetcode 151--哈希表.反转字符串中的单词
题号151 给你一个字符串 s ,请你反转字符串中 单词 的顺序。 单词 是由非空格字符组成的字符串。s 中使用至少一个空格将字符串中的 单词 分隔开。 返回 单词 顺序颠倒且 单词 之间用单个空格连接的结果字符串。 我的解法 暴力解法,先将String转为字…...

[VTK] 四元素实现旋转平移
VTK 实现旋转,有四元数的方案,也有 vtkTransform 的方案;主要示例代码如下: //构造旋转四元数vtkQuaterniond rotation;rotation.SetRotationAngleAndAxis(vtkMath::RadiansFromDegrees(90.0),0.0, 1.0, 0.0);//构造旋转点四元数v…...
2.2 分词器Tokenizer)
AI大模型:(二)2.2 分词器Tokenizer
目录 1.分词技术的发展 2.分词器原理 2.1.基于词分词 2.2.基于字符分词 2.3.基于子词分词 3.手搓Byte-Pair Encoding (BPE)分词及训练 3.1.Byte-Pair Encoding (BPE)分词原理 3.2.手搓Byte-Pair Encoding (BPE)分词器 4.如何选择已有的分词器 1. 常见子词分词器及特点…...

codeforces A. Simple Palindrome
目录 题面 代码 题面 A. 简单回文串 每个测试用例时间限制:1 秒 每个测试用例内存限制:256 兆字节 纳雷克要在幼儿园陪一些两岁的孩子度过两个小时。他想教孩子们竞技编程,他们的第一堂课是关于回文串的。 纳雷克发现孩子们只认识英文字母…...
:冯诺依曼结构)
Linux 进程基础(一):冯诺依曼结构
文章目录 一、冯诺依曼体系结构是什么?🧠二、冯诺依曼体系为何成为计算机组成的最终选择?(一)三大核心优势奠定主流地位(二)对比其他架构的不可替代性 三、存储分级:速度与容量的平衡…...
详解)
向量存储(VectorStore)详解
一、向量存储的核心概念 向量存储(VectorStore)是一种用于存储和检索高维向量数据的数据库或存储解决方案,特别适用于处理经过嵌入模型转化后的数据。与传统关系数据库不同,VectorStore 执行的是相似性搜索,而非精确匹…...
)
HCIP(网络类型)
网络类型概述 网络类型主要基于数据链路层使用的协议不同,导致数据包封装方式不同,工作方式也有所区别。根据这些特点,网络可以被分类为以下几种类型: MA网络(多点接入网络):允许同时接入多台…...

MTCNN 人脸识别
前言 此处介绍强大的 MTCNN 模块,给出demo,展示MTCNN 的 OOP, 以及ROS利用 C 节点,命令行调用脚本执行实际工作的思路。 MTCNN Script import argparse import cv2 from mtcnn import MTCNN import osclass MTCNNProcessor:def…...

一文解析DeepSeek R1模型
1. DeepSeek R1-Zero 在训练DeepSeek R1之前,深度求索团队尝试做了一个DeepSeek R1-Zero的模型,只进行强化学习而不需要监督微调,以此来强化模型自我推理的能力。 通过下图回顾下ChatGPT的做法:首先SFT,然后训练奖励…...
)
SpringMVC基础三(json)
乱码处理 编写一个表单: 编写EncodingController控制类 测试: 此乱码是在从前端传送到test方法时就已经乱了。 采用过滤器解决乱码 在web.xml中配置SpringMVC的乱码过滤器 <filter><filter-name>encoding</filter-name><filter…...

spring boot大文件与多文件下载
一、简单大文件下载: /*** 下载大文件* param path 路径* param fileName 文件名* return* throws IOException*/ public static ResponseEntity<InputStreamResource> downloadFile(String path, String fileName) throws IOException {Path filePath Path…...

事务隔离级别和MVCC
事务隔离级别 mysql是一个客户端/服务器架构的软件,对于同一个服务器来说,可以有多个客户端与之连接。每个客户端与服务器连接后就形成了一个会话。每个客户端都可以在自己的会话中向服务器发出请求语句,一个请求语句可能是某个事务的一部分…...

Ubuntu 系统深度清理:彻底卸载 Redis 服务及残留配置
Ubuntu 系统深度清理:彻底卸载 Redis 服务及残留配置 在Ubuntu系统中,Redis是一种广泛使用的内存数据存储系统,用于缓存和消息传递等场景。然而,有时候我们需要彻底卸载Redis,以清理系统资源或为其他应用腾出空间。本…...

关于群晖安装tailscale后无法直链的问题
问题是我局域网的ipv6无法正确获取到ip, 通过命令可以看到ipv6没有ip tailscale netcheck C:\Users\Administrator>tailscale netcheck 2025/04/12 23:43:34 attempting to fetch a DERPMap from https://controlplane.tailscale.comReport:* Time: 2025-04-12T15:43:38.27…...

第十二章:FreeRTOS多任务创建与删除
FreeRTOS多任务创建与删除教程 概述 本教程介绍FreeRTOS多任务的创建与删除方法,主要涉及两个核心函数: 任务创建:xTaskCreate()任务删除:vTaskDelete() 实践步骤 1. 准备工程文件 复制005工程并重命名为006 2. 创建多个任务…...
`的全面解析与应用)
JavaScript数组方法:`some()`的全面解析与应用
文章目录 JavaScript数组方法:some()的全面解析与应用一、some()方法的基本概念语法参数说明返回值 二、some()方法的核心特点三、基础用法示例示例1:检查数组中是否有大于10的元素示例2:检查字符串数组中是否包含特定子串 四、实际应用场景1…...

IntelliJ IDEA历史版本下载安装链接
IntelliJ IDEA | Other Versions 拿走,不谢O(∩_∩)O...

Rag实现流程
Rag实现流程 目录 Rag实现流程1. 加载问答链代码解释`chain_type="stuff"` 的含义其他 `chain_type` 参数选项及特点1. `map_reduce`2. `refine`3. `map_rerank`示例代码展示不同 `chain_type` 的使用其他参数类型2. 提出问题3. 检索相关文档代码解释其他参数类型4. …...

设计模式 --- 命令模式
命令模式是一种行为设计模式,它将请求封装成一个对象,从而允许你使用不同的请求、队列或日志来参数化其他对象,同时支持请求的撤销与恢复。 优点: 1.解耦调用者与接收者:输入处理无需直接调用角色方法 2.支持撤销…...

C# TCP与ip通信
一、获取本机的ip地址 // 获取本地主机名 string hostName Dns.GetHostName(); string ip "127.0.0.1"; //Console.WriteLine("本地主机名: " hostName);// 获取本地IP地址 IPAddress[] addresses Dns.GetHostAddresses(hostName); Console.WriteLine…...

如何使用 Grafana 连接 Easyearch
Grafana 介绍 Grafana 是一款开源的跨平台数据可视化与监控分析工具,专为时序数据(如服务器性能指标、应用程序日志、业务数据等)设计。它通过直观的仪表盘(Dashboards)帮助用户实时监控系统状态、分析趋势࿰…...
)
ubuntu20.04 openvino的yolov8推理(nncf量化)
1.环境配置: pip install openvino-dev(2023.0.1) pip install nncf(2.5.0) pip install ultralytics 2.模型转换及nncf量化: 1.pytorch->onnx: # Pytorch模型转换为Onnx模型 python from ultralytics import YOLO model YOLO(yolov8s.pt) # yo…...

《Python星球日记》第26天:Matplotlib 可视化
名人说:路漫漫其修远兮,吾将上下而求索。—— 屈原《离骚》 创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊) 订阅专栏:《Python星球日记》 目录 一、Matplotlib 简介1. 什么是 Matplo…...

2025蓝桥杯python A组题解
真捐款去了,好长时间没练了,感觉脑子和手都不转悠了。 B F BF BF 赛时都写假了, G G G 也只写了爆搜。 题解其实队友都写好了,我就粘一下自己的代码,稍微提点个人的理解水一篇题解 队友题解 B 思路: 我…...
(一))
OpenHarmony - 小型系统内核(LiteOS-A)(一)
OpenHarmony - 小型系统内核(LiteOS-A)(一) 一、小型系统内核概述 简介 OpenHarmony 轻量级内核是基于IoT领域轻量级物联网操作系统Huawei LiteOS内核演进发展的新一代内核,包含LiteOS-M和LiteOS-A两类内核。LiteOS-…...

Neo4j GDS-13-neo4j GDS 库中节点插入算法实现
neo4j GDS 系列 Neo4j APOC-01-图数据库 apoc 插件介绍 Neo4j GDS-01-graph-data-science 图数据科学插件库概览 Neo4j GDS-02-graph-data-science 插件库安装实战笔记 Neo4j GDS-03-graph-data-science 简单聊一聊图数据科学插件库 Neo4j GDS-04-图的中心性分析介绍 Neo…...

js中this的指向问题
前言: 在js中,this出现的位置多种多样,你会不会迷糊呢?this到底指代的是哪个对象?这篇文章带你搞懂不同场景下this的指向问题。 this出现场景: 从作用域的角度来讲,this出现的位置无非就是两…...

【3dSwap】3D-Aware Face Swapping
文章目录 3D-Aware Face Swapping背景points贡献方法从2D图像推断3D先验通过潜在代码操纵进行人脸交换联合枢轴调整目标函数实验与二维人脸交换方法比较进一步分析3D感知人脸交换消融实验局限性3D-Aware Face Swapping 会议/期刊:CVPR 2023 作者: code:https://lyx0208.gi…...

基于STM32的智能门禁系统
2.1系统方案设计 本课题为基于STM32的智能门禁系统的设计,其系统架构如图2.1所示,整个系统由STM32F103单片机和MaixBit开发板两部分构成,其中MaixBit是基于K210芯片的开发板,在此主要负责人脸的录入,识别,…...

用链表、信号,实现简易MP3项目
链表实现MP3 #include <sys/types.h> #include <sys/stat.h> #include <fcntl.h> #include <unistd.h> #include <time.h> #include <dirent.h> #include <sys/stat.h> #include <sys/types.h> #include <glob.h> #inc…...

YOLO检测目标后实现距离测量
当我们使用YOLO检测器得到检测结果后,我们如何计算检测的物体距离相机的位置呢? 目前,有三种较为主流的距离计算方法,分别是单目测距、双目测距以及基于深度估计的测距方法。 单目测距 工作原理:单目测距使用一个摄像…...

js 效果展示 拿去练手
自学完整功能,拿去练手。 鼠标移动放大 通过网盘分享的文件:图片放大 链接: https://pan.baidu.com/s/1w8SjtKi4kUNDnZtRDfYMeQ?pwd95p6 提取码: 95p6 通过网盘分享的文件:图片动画效果 链接: https://pan.baidu.com/s/1Pjphx-Cc4HQQNNujr…...

【算法】 欧拉函数与欧拉降幂 python
欧拉函数 欧拉函数 ϕ ( n ) \phi(n) ϕ(n) 表示小于等于 n 的正整数中与 n 互质的数的个数。即: ϕ ( n ) ∣ { k ∈ Z ∣ 1 ≤ k ≤ n , gcd ( k , n ) 1 } ∣ \phi(n) \left| \{ k \in \mathbb{Z}^ \mid 1 \leq k \leq n, \gcd(k, n) 1 \} \right| ϕ(n)…...

Qt触摸屏隐藏鼠标指针
Qt触摸屏隐藏鼠标指针 Chapter1 Qt触摸屏隐藏鼠标指针 Chapter1 Qt触摸屏隐藏鼠标指针 使用Qt开发的屏幕软件HMI不需要显示鼠标,qt设置,可以在只启动HMI的时候隐藏光标,退出时再显示。 1.如果只希望在某个 widget 中不显示鼠标指针…...

QT聊天项目DAY01
1.新建初始项目 2.修改UI格式 运行效果 3.创建登录界面 设计登录界面UI 设计布局 调整布局间距 往水平布局中拖入标签和文本输入框 更换控件名称并固定高度 添加窗口部件 往现有的资源文件中导入图片 添加水平布局 4.设置登陆界面为主窗口的核心组件 #pragma once#include &l…...

Stable Diffusion +双Contronet:从 ControlNet 边缘图到双条件融合:实现服装图像生成的技术演进——项目学习记录
前言 学习记录contronet优化:最近,我基于 diffusers 库的 ControlNet,探索了如何通过 Canny 边缘图控制服装图像生成,并逐步升级到融合颜色图的双条件模型。有不断的问题、解决和进步,从最初的边缘图生成到最终实现 2…...

【Hadoop入门】Hadoop生态之Spark简介
1 什么是Spark? Apache Spark 是一个开源的分布式计算框架,专为处理大规模数据而设计。它提供了高效、通用的集群计算能力,支持内存计算,能够显著提高数据处理和分析的速度。Spark 已经成为大数据处理领域的重要工具,广…...

深度学习学习笔记
目录 摘要 Abstracts 简介 Hourglass Module(Hourglass 模块) 网络结构 Intermediate Supervision(中间监督) 训练过程细节 评测结果 摘要 本周阅读了《Stacked Hourglass Networks for Human Pose Estimation》…...