数据结构--线性表
单链表的基本操作
1.清空单链表
- 链表仍然存在,但链表中无元素,成为空链表(头指针和头链表仍存在)
- 算法思路:依次释放所有结点,并将头结点指针设置为空
2.返回表长
3.取值–取单链表中第i个元素
- 因为存储方式为顺序存储,所以需要依次扫描
4.按值查找
- 返回该元素所在的位置
- 返回该元素对应的下标索引
5.插入结点
算法分析:
- 先找到第i个元素位置
- 将i-1元素的指针指向新节点
- 新节点的指针域指向原先第i个
- 结点数量自增1
不能直接更换2-3步的顺序,否则会导致第i个元素的位置丢失
6.删除第i个结点
7.查找、插a入和删除的时间复杂度分析
- 查找:
- 因为线性来拿吧只能顺序存取,即在查找时要从头指针找起,所以时间复杂度为O(n)
- 插入和删除
- 因线性链表不需要移动元素,只要修改指针,所以一般时间复杂度为O(n)
8.头插法建立单链表
算法分析:
- 从一个空表开始,重复读入数据
- 生成新结点,将数据存入新结点的数据域中
- 从最后一个结点开始依次将各节点插入链表前端
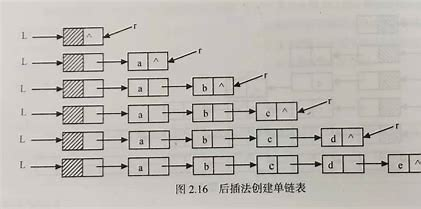
- 时间复杂度O(n)
9.尾插法创建单链表
- 从一个空表开始,将新结点诸葛插入链表尾部,尾指针r指向链表的尾结点
- 初始时r均指向头结点,每读入一个数据元素则申请一个新结点,将新结点插入到尾结点后,r指向新结点
代码
#include<stdio.h>
#include<malloc.h>
#include<stdlib.h>
#include<string.h>
struct Lnode { //链表结点的类型定义char name[10];int score;struct Lnode* next;
};
int init_Lnode(Lnode* L); //单链表的初始化
int isLnode(Lnode* L); //判断是否为空,0表示空,1表示非空
int destroyLnode(Lnode* L); //销毁单链表
int deleteLnode(Lnode* L); //清空单链表
int lengthLnode(Lnode* L); //求表长
int getLnode(Lnode* L, int i, Lnode& e); //取值,求第i个元素
Lnode* findLnode(Lnode* L, int i, char* name1, int score); //按照值查找,返回第一个元素的位置
int insertLnode(Lnode* L, char* name2, int score); //在第i个位置前增添一个
int denLnode(Lnode* L, int n); //删除第n个元素的结点
void creatLnode_1(Lnode* L, int n); //利用头插法创建链表
void creatLnode_2(Lnode* L, int n); //利用尾插法创建链表
int main() {}
int init_Lode(Lnode *L) {L = (Lnode*)malloc(sizeof(Lnode));if (!L) return 0;L->next = NULL;return 1;
}
int isLnode(Lnode* L) {if (!L->next) return 0;return 1;
}
int destroyLonde(Lnode* L) {Lnode* p;while (L->next) {p = L;L = L->next;free(p);}return 1;
}
int deleteLnode(Lnode* L) {Lnode* p = L->next;Lnode* q;while (p) {q = p->next;free(p);p = q;}L->next = NULL;return 1;
}
int lengthLnode(Lnode* L) {int sum = 0;if (!isLnode(L)) return sum;Lnode* p = L->next;while (p) {sum++;p = p->next;}free(p);return sum;
}
int getLnode(Lnode* L, int i, Lnode& e) {Lnode *p = L->next;int j = 1;while (p && j < i) {p = p->next;j++;}if (!p || j>i) return 0;e = *p;return 1;
}
Lnode* findLnode(Lnode* L, int i, char* name1, int score) {Lnode* p = L->next;while (p) {if (strcmp(p->name, name1) && p->score == score) {break;}p = p->next;}return p;
}int insertLnode(Lnode* L, char* name2, int score, int n) {int i = 0;Lnode* p = L;if (n<1 || n>lengthLnode(L) + 1) {printf("error");return 0;}while (i < n) {p = p->next;i++;}Lnode* s = (Lnode*)malloc(sizeof(Lnode));strcpy_s(s->name, name2);s->score = score;s->next = p->next;p->next = s;return 1;
}
int denLnode(Lnode* L, int n) {int i = 0;Lnode* p = L;if (n<1 || n>lengthLnode(L)) {printf("error");return 0;}while (i < n-1) {p = p->next;i++;}Lnode* s = p->next;p->next = p->next->next;free(s);return 1;
}
void creatLnode_1(Lnode* L, int n) {L = (Lnode*)malloc(sizeof(Lnode));L->next = NULL;Lnode* p;for (int i = 0; i < n; i++) {p= (Lnode*)malloc(sizeof(Lnode));scanf_s("输入姓名:%d", &p->name);scanf_s("输入成绩:%d", &p->score);p->next = L->next;L->next = p;}
}
void creatLnode_2(Lnode* L, int n) {L = (Lnode*)malloc(sizeof(Lnode));L->next = NULL;Lnode* p, * r;r = L;for (int i = 0; i < n; i++) {p = (Lnode*)malloc(sizeof(Lnode));scanf_s("输入姓名:%d", &p->name);scanf_s("输入成绩:%d", &p->score);p->next = NULL;r->next = p;r = p; }
}
循环链表
-
即头尾相接的一个链表,表中最后一个结点的指针域指向头结点,使整个链表闭合成为一个环
-
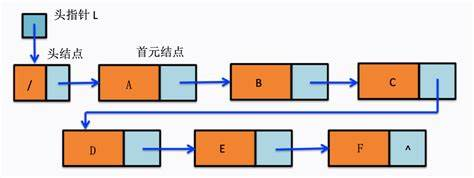
-
优点:从表中任意结点出发均可找到表中其他结点
-
注意:循环链表中没有NULL,所以遍历时终止条件为是否等于头指针
-
空表:头指针指向自己
-
在循环链表中操作首尾元素时用的最多的是尾指针,因为头指针要找最后一个元素比较麻烦,时间复杂度高
两个循环链表的合并
- 操作步骤:
- p存表头结点
- Tb表头连接到Ta表尾
- 释放Tb表头结点
- Tb表尾指向Ta表头
- 伪代码如下:
LinkList Connect(LinkList Ta, LinkList Tb) { //Ta和Tb均为尾指针p = Ta->next; Ta->next = Tb->next->next;free(Tb->next);Tb->next = p;return Tb;
}
双向链表
前面链表如果需要找到某一个元素的前驱结点比较麻烦,但如果我们采用双向链表就比较方便,时间复杂度O(n)->O(1)
结构体定义伪代码如下:
typedef struct DulNode {Elemtype data;struct Dulnode* prior, * next;
};
- 空表:前驱后继均为NULL
- 对称性:
- p->next->prior = p = p->prior->next;
- 在双向链表中有些操作如(Listlength)等只涉及以后方向的指针,所以算法鱼线性链表相同。
- 但在插入删除时,许哟啊同时修改两个方向的指针,两者的时间复杂度为O(n)
双向循环链表:
- 头结点的前驱指针指向链表的最后一个结点
- 最后一个结点的后继指针指向头结点
双向链表的插入
算法分析:
- s->prior = p->prior
- p->prior->next = s
- s->next = p
- p->prior = s
伪代码如下:
int Listinsert_dul(LinkList& L, int i, Elemtype e) { //Elemtype为题目所需压要的数据类型if (!(p = GetElem_dul(L, i))) return 0; //将p指向第i个元素s = new DulLnode; s->data = e;s->prior = p->prior;p->prior->next = s;s->next = p;p->prior = s;return 1;
}
双向链表的删除
算法分析:
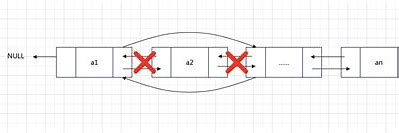
- p->prior->next = p->next;
- p->next->prior = p->prior
伪代码如下:
int Listinsert_dul(LinkList& L, int i, Elemtype &e) { //Elemtype为题目所需压要的数据类型if (!(p = GetElem_dul(L, i))) return 0; //将p指向第i个元素e = p->data;p->prior->next = p->next->prior;p->next->prior = p->prior->next;free(p);return 1;
}
- 如果知道要删除的位置,那么时间复杂度为O(1),但为了查找第i个元素的位置所以总的时间复杂度为O(n)
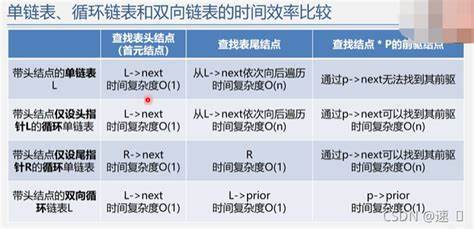
单链表、循环链表和双向链表的时间效率比较
顺序表和链表的比较
链表的优点:
- 结点空间可以动态申请和释放
- 逻辑次序通过结点的指针表示,插入和删除时不需要移动大量的数据元素
缺点:
- 每个指针域需要额外的占用空间
- 存储密度比较小
- 非随机存取结构,对结点的操作都要从头指针沿着指针链查找,增加了算法的复杂度
存储密度指结点中数据本身所占系结点总空间的比重,即数据所占空间/结点总空间
一般存储密度越大,存储空间的利用率越高
线性表的合并
问题描述:
- 假设利用两个线性表La和Lb分别表示两个集合A和B,现要求一个新的集合A = A∪B
- 如La = (7,5,3,11),Lb = (2,6,3) —>La = (7,5,3,11,2,6)
- 算法分析:
- 依次取出Lb的元素并在La中查找
- 如果有,直接跳过该元素
- 如果没有,则插入到La的表尾
- 依次取出Lb的元素并在La中查找
伪代码如下:
void union(List& a, LIst b) {a_len = Listlength(a);b_len = Listlength(b);for (int i = 0; i < b_len; i++) {GetElem(b, i, e);if (!Locate(a, e)) {Listinsert(&a, ++a_len, e); //即添加完后元素个数自增1}}
}
有序表的合并(顺序表)
已知La和Lb中的数据元素按照非递减有序排列合并为一个新的线性表Lc,且Lc中的元素也是按照值非递减有序排列
La=(1,7,8) Lb=(2,4,6,8,10,11)
–》Lc=(1,2,4,6,7,8,8,10,11)
算法步骤:
- 创建一个空表Lc
- 依次从La和Lb中摘取值较小的结点插入到Lc表的最后,直至某方变为一个空表为止
- 继续从另一个表中读取剩余元素
void MergeList1(List a, List b, List& c) {pa = a.elem;pb = b.elem; //pa和pb分别指向第一个元素c.length = a.length + b.length;c.elem = new elem[c.length];pa_last = pa.elem + pa.length - 1;pb_last = pb.elem + pb.length - 1;while (pa <= pa_last && pb <= pb_last) {if (*pa <= *pb) *pc++ = *pa++;else *pc++ = *pb++;}while (pa <= pa_last) {*pc++ = *pa++;}while (pb <= pb_last) {*pc++ = *pb++;}
}
有序表的合并(链表)
算法步骤上同
伪代码:
void MergeList2(List a, List b, List& c) {pa = a->next;pb = b->next;pc = c = a;while (a && b) {if (a->data < b->data) {pc->next = pa;pc = pa;pa = pa->next;}else {pc->next = pb;pc = pb;pb= pb->next;}}pc->next = a ? a : b;delete(b);
}
实战:多项式相加运算
typedef struct aaa {float p; //系数int e; //指数
};
typedef struct bbb{aaa data;struct bbb* next;
}*List;
void add(List a, List b) {Lnode* p1 = a->next;Lnode* p2 = b->next;Lnode* pa = a;while (p1 && p2) {if (p1->data.e == p2->data.e) {p1->data.e += p2->data.e;if (p1->data.e == 0) {p1 = p1->next;p2 = p2->next;}else {pa->next = p1;pa = p1;p1 = p1->next;p2 = p2->next;continue;}}else if (p1->data.e < p2->data.e) {pa->next = p1;pa = p1; p1 = p1->next;}else {pa->next = p2;pa = p2;p2 = p2->next;}}if (p1) pa->next = p1;if (p2) pa->next = p2;
}实战:稀疏多项式的运算
算法分析(顺序表):
- 先将两个多项式转化为存储为线性表形式
- 创建一个新的数组
- 分别遍历比较两个线性表的每一项
- 指数相同,对应系数相加,若其和不为0,则在新数组中增加一个新项
- 指数不同,将指数较小的项复制到新数组中
- 一个多项式遍历完毕后,将另外一个剩余项依次复制进新数组即可
- 问题:新数组应该多大?
- 存储空间分配不灵活
- 运算空间复杂度高
线性表分析大同小异,算法分析略
结点结构体的定义:
struct polynode{int coef;int exp;polynode *next;
}polynode,polylist;
尾插法创建线性表:
polylist polycreate() { //尾插法polynode *head,*rear,*s;int c,e;head=(polynode *)malloc(sizeof(polynode));rear=head;scanf("%d %d",&c,&e);while(c!=0){s=(polynode *)malloc(sizeof(polynode));s->coef=c;s->exp=e;rear->next=s;rear=s; scanf("%d %d",&c,&e);}rear->next=NULL;//将表的最后一个结点的next置NULL,以表示结束return (head);
}实现两个多项式相加:
void polyadd(polylist polya, polylist polyb){
//将两个多项式相加,然后将和多项式存放在polya中,并将polyb删除polynode* p, * q, * tail, * temp;int sum;p = polya->next;q = polyb->next;tail = polya;//tail指向和多项式的尾结点while (p != NULL && q != NULL) {if (p->exp < q->exp){tail->next = p;tail = p;p = p->next;}else if (p->exp == q->exp){sum = p->coef + q->coef;if (sum != 0)//若系数和非0,则系数和置入结点p,释放结点q,并将指针后移{p->coef = sum;tail->next = p;tail = p;p = p->next;temp = q;q = q->next;free(temp);}else {//若系数和为0.删除p,q,并将指针指向下一个结点temp = p;p = p->next;free(temp);temp = q;q = q->next;free(temp);}}else {tail->next = q;tail = q;q = q->next;}}if (p != NULL){tail->next = p;tail = p;p = p->next;}else {tail->next = q;tail = q;q = q->next;}
}
实战:图书管理系统
略
sum = p->coef + q->coef;
if (sum != 0)
//若系数和非0,则系数和置入结点p,释放结点q,并将指针后移
{
p->coef = sum;
tail->next = p;
tail = p;
p = p->next;
temp = q;
q = q->next;
free(temp);
}
else {
//若系数和为0.删除p,q,并将指针指向下一个结点
temp = p;
p = p->next;
free(temp);
temp = q;
q = q->next;
free(temp);
}
}
else {
tail->next = q;
tail = q;
q = q->next;
}
}
if (p != NULL){
tail->next = p;
tail = p;
p = p->next;
}
else {
tail->next = q;
tail = q;
q = q->next;
}
}
## 实战:图书管理系统略相关文章:

数据结构--线性表
单链表的基本操作 1.清空单链表 链表仍然存在,但链表中无元素,成为空链表(头指针和头链表仍存在)算法思路:依次释放所有结点,并将头结点指针设置为空 2.返回表长 3.取值–取单链表中第i个元素 因为存储…...

电商用户购物行为分析:基于K-Means聚类与分类验证的完整流程
随着电商行业的快速发展,用户行为分析成为企业优化营销策略、提升用户体验的重要手段。通过分析用户的购物行为数据,企业可以挖掘出用户群体的消费特征和行为模式,从而制定更加精准的营销策略。本文将详细介绍一个基于Python实现的电商用户购物行为分析系统,涵盖数据预处理…...

《车辆人机工程-汽车驾驶显示装置》实验报告
汽思考题 汽车显示装置有哪些? 汽车显示装置是车辆与驾驶员、乘客交互的重要界面,主要用于信息展示、功能控制和安全辅助。以下是常见的汽车显示装置分类及具体类型: 一、驾驶舱核心显示装置 1. 仪表盘(Instrument Cluster&am…...

三维点云投影二维图像的原理及实现
转自个人博客:三维点云投影二维图像的原理及实现 1. 概述 1.1 原理概述 三维点云模型是由深度相机采集深度信息和RGB信息进行生成的,深度相机能直接获取到深度图和二维RGB图像,也就是说利用相机原本的关系就可以把深度信息投影回二维图像&a…...

使用Golang打包jar应用
文章目录 背景Go 的 go:embed 功能介绍与打包 JAR 文件示例1. go:embed 基础介绍基本特性基本语法 2. 嵌入 JAR 文件示例项目结构代码实现 3. 高级用法:嵌入多个文件或目录4. 使用注意事项5. 实际应用场景6. 完整示例:运行嵌入的JAR 背景 想把自己的一个…...

MySQL数据过滤、转换与标准化
数据处理是数据库操作的重要组成部分,尤其是在大量数据中查找、转换和规范化目标信息的过程中。为了确保数据的有效性与一致性,MySQL提供了一系列数据过滤、转换与标准化的功能。 本教程将深入探讨数据过滤和转换的基本方法及应用,内容涵盖数…...

Linux中安装sentinel
拉取镜像 #我默认拉取最新的 sentinel 镜像 docker pull bladex/sentinel-dashboard 创建容器 docker run --name sentinel -d -p 8858:8858 bladex/sentinel-dashboard 检查是否成功 docker ps 浏览器访问 默认账号密码是 sentinel/sentinel 成功了 开放sentinel端口或者关…...
)
大模型压缩训练(知识蒸馏)
AI的计算结果不是一个数值,而是一个趋势 一、模型压缩简介 1、深度学习(Deep Learning)因其计算复杂度或参数冗余,在一些场景和设备上限制了相应的模型部署,需要借助模型压缩、优化加速、异构计算等方法突破瓶颈。 …...

Matlab绘制函数方程图形
Matlab绘制函数方程图形: 多项式计算: polyval 函数 Values of Polynomials: polyval ( ) 绘制方程式图形: 代码如下: >> a[9,-5,3,7]; x-2:0.01:5; fpolyval(a,x); plot(x,f,LineWidth,2); xlabel(x); ylabel(f(x))…...

dify windos,linux下载安装部署,提供百度云盘地址
dify下载安装 dify1.0.1 windos安装包百度云盘地址 通过网盘分享的文件:dify-1.0.1.zip 链接: 百度网盘 请输入提取码 提取码: 1234 dify安装包 linux安装包百度云盘地址 通过网盘分享的文件:dify-1.0.1.tar.gz 链接: 百度网盘 请输入提取码 提取码…...
)
优化方法介绍(一)
优化方法介绍(一) 本博客是一个系列博客,主要是介绍各种优化方法,使用 matlab 实现,包括方法介绍,公式推导和优化过程可视化 1 失败案例介绍 本文在编写最速下降法的时候使用了经典的求解函数框架,并使用了自适应步长(alpha)机制,即加入参数flag,当出现梯度下降的情…...

Centos7.9 升级内核,安装RTX5880驱动
系统镜像下载 https://vault.centos.org/7.9.2009/isos/x86_64/CentOS-7-x86_64-DVD-2009.iso 系统安装步骤省略 开始安装显卡驱动 远程登录查看内核 [root192 ~]# uname -a Linux 192.168.119.166 3.10.0-1160.el7.x86_64 #1 SMP Mon Oct 19 16:18:59 UTC 2020 x86_64 x8…...

计算轴承|滚动轴承故障频率
一、轴承故障频率概述 在旋转机械故障诊断中,轴承故障频率(BPFO、BPFI、BSF、FTF)是重要的分析依据。通过计算这些特征频率,可以帮助工程师: 识别轴承故障类型(内圈/外圈/滚动体故障)制定振动…...

Python 数据分析01 环境搭建教程
Python 数据分析01 环境搭建教程 一、安装 Python 环境 访问 Python 官方网站 Python 官网,选择适合你操作系统的 Python 版本进行下载。下载完成后,运行安装程序。在安装过程中,建议选择“Add Python to PATH”选项,这样可以在…...
:近年发展动态与技术标准演进)
程序化广告行业(80/89):近年发展动态与技术标准演进
程序化广告行业(80/89):近年发展动态与技术标准演进 大家好!在技术领域探索的过程中,我深刻认识到知识分享的力量,它能让我们在学习的道路上加速前行。写这篇博客,就是希望能和大家一起深入剖析…...

Node.js cluster模块详解
Node.js cluster 模块详解 cluster 模块允许你轻松创建共享同一服务器端口的子进程(worker),充分利用多核 CPU 的性能。它是 Node.js 实现高并发的重要工具。 核心概念 主进程(Master):负责管理工作进程…...
(含模型、可运行代码))
2025年认证杯数学建模C题完整分析论文(共39页)(含模型、可运行代码)
2025年认证杯数学建模竞赛C题完整分析论文 目录 摘要 一、问题重述 二、问题分析 三、模型假设 四、 模型建立与求解 4.1问题1 4.1.1问题1解析 4.1.2问题1模型建立 4.1.3问题1求解代码 4.1.4问题1求解结果 4.2问题2 4.2.1问题2解析 4.2.2问题2模型建…...

PostgreSQL 的 COPY 命令
PostgreSQL 的 COPY 命令 PostgreSQL 的 COPY 命令是高效数据导入导出的核心工具,性能远超常规 INSERT 语句。以下是 COPY 命令的深度解析: 一 COPY 命令基础 1.1 基本语法对比 命令类型语法示例执行位置文件访问权限服务器端COPYCOPY table FROM /p…...

MySQL进阶-存储引擎索引
目录 一:存储引擎 MySQL体系结构 存储引擎介绍 存储引擎特点 InnoDB MyISAM Memory 区别及特点 存储引擎选择 索引 索引概述 介绍 演示 特点 索引结构 概述 二叉树 B-Tree BTree Hash 索引分类 索引分类 聚集索引&二级索引 一࿱…...

为什么需要Refresh Token?
后端服务性能 一种方案是在服务器端保存 Token 状态,用户每次操作都会自动刷新(推迟) Token 的过期时间——Session 就是采用这种策略来保持用户登录状态的。然而仍然存在这样一个问题,在前后端分离、单页 App 这些情况下&#x…...

基于3A4000及CentOS的银河麒麟V10离线源码编译安装VLC
碰到过的一个具体问题: 源码安装vlc-3.0.x版本,需要注意的是,不要安装ffmpeg-5及以上的版本,即只支持ffmpeg-4的版本,因此,要安装vlc-3.0版本,一个重要的依赖时就会ffmpeg-4。报错没有revision…...

Windows for Redis 后台服务运行
下载 redis 安装包 地址:https://github.com/tporadowski/redis/releases 解压zip压缩包,执行 redis-server.exe 即可以窗口模式运行(窗口关闭则服务关闭) 运行窗口可以看到,端口是 6379 我这里使用 nvaicat 客服端测…...

前端工程化-包管理NPM-package.json 和 package-lock.json 详解
package.json 和 package-lock.json 详解 1.package.json 基本概念 package.json 是 Node.js 项目的核心配置文件,它定义了项目的基本信息、依赖项、脚本命令等。 主要字段 基本信息字段 name: 项目名称(必填) version: 项目版本…...

如何在 Linux 中彻底终止被 `Ctrl+Z` 挂起的进程?
问题场景 在 Linux 终端操作时,你是否曾遇到过这样的情况? 当运行一个命令(如 ping www.baidu.com)时,不小心按下了 CtrlZ,屏幕上显示类似以下内容: ^Z [2] 已停止 ping www.b…...

人工智能100问☞第3问:深度学习的核心原理是什么?
目录 一、通俗解释 二、专业解析 三、权威参考 深度学习的核心原理是通过构建多层神经网络结构,逐层自动提取并组合数据特征,利用反向传播算法优化参数,从而实现对复杂数据的高层次抽象和精准预测。 一、通俗解释 深度学习的核心原理,就像是教计算机像婴儿…...
)
基于若依和elementui实现文件上传(导入Excel表)
基于若依和elementui实现文件上传(导入Excel表) 前端部分: 若依封装了Apache的poi功能,实现文件的上传和下载 若依使用的是JS语法,需要改造为JS语法才能使用 若依如何解决跨域的问题: 在前端的配置文件中…...
)
2025年第十六届蓝桥杯省赛真题解析 Java B组(简单经验分享)
之前一年拿了国二后,基本就没刷过题了,实力掉了好多,这次参赛只是为了学校的加分水水而已,希望能拿个省三吧 >_< 目录 1. 逃离高塔思路代码 2. 消失的蓝宝思路代码 3. 电池分组思路代码 4. 魔法科考试思路代码 5. 爆破思路…...

OpenHarmony人才认证证书
OpenHarmony人才认证体系目前支持初级工程师认证,要求了解OpenHarmony开源项目、生态进展及系统移植等基础知识,熟练掌握OpenHarmony的ArkUI、分布式软总线、分布式硬件、分布式数据管理等基础能力使用,具备基础的开发能力。 考试流程可参考O…...

Docker--利用dockerfile搭建mysql主从集群和redis集群
Docker镜像制作的命令 链接 Docker 镜像制作的注意事项 链接 搭建mysql主从集群 mysql主从同步的原理 MySQL主从同步(Replication)是一种实现数据冗余和高可用性的技术,通过将主数据库(Master)的变更操作同步到一个…...

LLaMA-Factory双卡4090微调DeepSeek-R1-Distill-Qwen-14B医学领域
unsloth单卡4090微调DeepSeek-R1-Distill-Qwen-14B医学领域后,跑通一下多卡微调。 1,准备2卡RTX 4090 2,准备数据集 医学领域 pip install -U huggingface_hub export HF_ENDPOINThttps://hf-mirror.com huggingface-cli download --resum…...

使用ZSH美化Windows系统Git Bash
此前,我们讲解了一种借助 Windows Subsystem for Linux(WSL)让用户在 Windows 操作系统中运用 Linux Shell 命令,进而高效地实现文件访问、编译等开发工作。 Windows系统命令行的最佳实践 | 听到微笑的博客 这种借助 Windows Su…...

如何使用PyCharm自动化测试
如何使用PyCharm自动化测试 1.打开PyCharm右击文件,点击新建项目 按照如图配置,然后点击创建 2.创建好后,点击文件,然后点击设置 按照如图步骤,查看selenium和webdriver-manager是否存在 3.以上都完成后按照如图创…...

56.评论日记
2025年4月12日22:06:08 小米事故下的众生相_哔哩哔哩_bilibili...

EMI滤波器和ESD保护等效参数汇总
EMI 共模抑制与ESD设计参考用,特别是工业和机器人,伺服器类产品,特别关注,提高产品稳定性 基带接口 通道数 线性小信号等效参数 数字端口时钟频率 备注 Rline Cline 电池反接 1 — 240Pf — 过压和电池反接保护 …...

java -jar与java -cp的区别
java -jar与java -cp 1、情景描述2、情景分析3、两者区别 通常情况下,我们会看到以下两种命令启动的Java程序: java -jar xxx.jar [args] java -cp xxx.jar mainclass [args]这两种用法有什么区别呢? 1、情景描述 1)Java打包单个…...
)
蓝桥杯嵌入式十五届模拟三(串口、双ADC)
一.LED 先配置LED的八个引脚为GPIO_OutPut,锁存器PD2也是,然后都设置为起始高电平,生成代码时还要去解决引脚冲突问题 二.按键 按键配置,由原理图按键所对引脚要GPIO_Input 生成代码,在文件夹中添加code文件夹&#…...
-第四天)
04-算法打卡-数组-二分查找-leetcode(69)-第四天
1 题目地址 69. x 的平方根 - 力扣(LeetCode)69. x 的平方根 - 给你一个非负整数 x ,计算并返回 x 的 算术平方根 。由于返回类型是整数,结果只保留 整数部分 ,小数部分将被 舍去 。注意:不允许使用任何内…...

SpringBoot项目:部门管理系统
文章目录 1、工程搭建1.1 创建项目1.2 创建数据库1.3 准备基础代码1.4 准备mapper接口1.5 准备service层1.6 准备controller层2、接口开发2.1 查询部门2.1.1 接口开发1、工程搭建 1.1 创建项目 主要内容: 创建Springboot工程引入web开发起步依赖、mybatis、mysql驱动、lombok…...

MyBatis-Plus 扩展功能
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 逻辑删除一、配置逻辑删除字段方式一:全局配置(推荐)方式二:实体类注解配置 二、逻辑删除流程三、完整代码示例1. 实…...

service和endpoints是如何关联的?
在Kubernetes中,Service 和 Endpoints 是两个密切关联的对象,它们共同实现了服务发现和负载均衡的功能。以下是它们之间的关联和工作原理: 1. Service 的定义 Service 是一种抽象,定义了一组逻辑上相关的 Pod,以及用…...

MyBatis-plus 快速入门
提示:MyBatis-Plus(MP)是一个 MyBatis的增强版 文章目录 前言使用MybatisPlus的基本步骤1、引入MybatisPlus依赖代替Mybatis依赖2、定义Mapper接口并继承BaseMapper他是怎么知道哪张表,哪些字段呢 3、实体类注解4、根据需要添加配…...

【PySpark大数据分析概述】03 PySpark大数据分析
【作者主页】Francek Chen 【专栏介绍】 ⌈ ⌈ ⌈PySpark大数据分析与应用 ⌋ ⌋ ⌋ PySpark作为Apache Spark的Python API,融合Python易用性与Spark分布式计算能力,专为大规模数据处理设计。支持批处理、流计算、机器学习 (MLlib) 和图计算 (GraphX)&am…...

C# --- IEnumerable 和 IEnumerator
C# --- IEnumerable 和 IEnumerator IEnumerableIEnumeratorIEnumerable 和 IEnumerator 的作用手动实现 IEnumerableIEnumerable vs. IQueryable为什么有了ienumerator还需要ienumerable IEnumerable 在C#中,IEnumerable 是一个核心接口,用于表示一个可…...

Excel VBA 运行时错误1004’:方法‘Open’作用于对象‘Workbooks’时失败 的解决方法
使用Excel编写VBA脚本时出现如下错误: 运行时错误1004’: 方法‘Open’作用于对象‘Workbooks’时失败 我的功能是打开一系列excel文件从中自动复制数据到汇总excel的各个指定的sheet中,来源的excel是从网站上下载的。 出现这个问题后从网上查找各种办…...
-第三天)
03-算法打卡-数组-二分查找-leetcode(34)-第三天
1 题目地址 34. 在排序数组中查找元素的第一个和最后一个位置 - 力扣(LeetCode)34. 在排序数组中查找元素的第一个和最后一个位置 - 给你一个按照非递减顺序排列的整数数组 nums,和一个目标值 target。请你找出给定目标值在数组中的开始位置…...
)
利用python从零实现Byte Pair Encoding(BPE)
喜欢可以到我的主页订阅专栏哟(^U^)ノ~YO 第一章:自然语言处理与分词技术基础 1.1 自然语言处理的核心挑战 自然语言处理(Natural Language Processing, NLP)作为人工智能领域的重要分支,其核心目标是实现计算机对人类语言的理解与生成。在深度学习技术快速发展的今…...

Redis的分布式锁
Redis的分布式锁 一.分布式锁的简介二.分布式锁的实现1.基本实现2.引入过期时间3.引入校验ID4.引入Lua5.引入看门狗(watch dog)6.引入RedLock算法 一.分布式锁的简介 在一个分布式的系统中, 会涉及到多个节点访问一个公共资源的情况,此时就需要通过锁的…...

SpringBoot分布式项目中实现智能邮件提醒系统
一、应用场景与需求分析 在电商、OA、客服等系统中,邮件提醒是用户触达的重要方式。本文针对以下典型需求进行方案设计: 多类型支持:订单超时、服务到期、待办通知等场景动态内容:支持纯文本/HTML/模板引擎内容格式智能重发:24小时未处理自动升级提醒级别高可用性:分布式…...
)
LSTM-SVM长短期记忆神经网络结合支持向量机组合模型多特征分类预测/故障诊断,适合新手小白研究学习(Matlab完整源码和数据)
LSTM-SVM长短期记忆神经网络结合支持向量机组合模型多特征分类预测/故障诊断,适合新手小白研究学习(Matlab完整源码和数据) 目录 LSTM-SVM长短期记忆神经网络结合支持向量机组合模型多特征分类预测/故障诊断,适合新手小白研究学习…...
?)
【图像处理基石】什么是抗锯齿(Anti-Aliasing)?
1. 抗锯齿的定义与作用 抗锯齿(Anti-Aliasing, AA)是一种用于消除数字图像中因采样不足导致的边缘锯齿现象的技术。锯齿(Jaggies)通常出现在高分辨率信号以低分辨率呈现时,例如3D图形渲染或图像缩放过程中。抗锯齿通过…...