BERT - BertTokenizer, BertModel API模型微调
本节代码将展示如何在预训练的BERT模型基础上进行微调,以适应特定的下游任务。
⭐学习建议直接看文章最后的需复现代码,不懂得地方再回看
微调是自然语言处理中常见的方法,通过在预训练模型的基础上添加额外的层,并在特定任务的数据集上进行训练,可以快速适应新的任务。以下是从模型微调的角度对代码的详细说明:
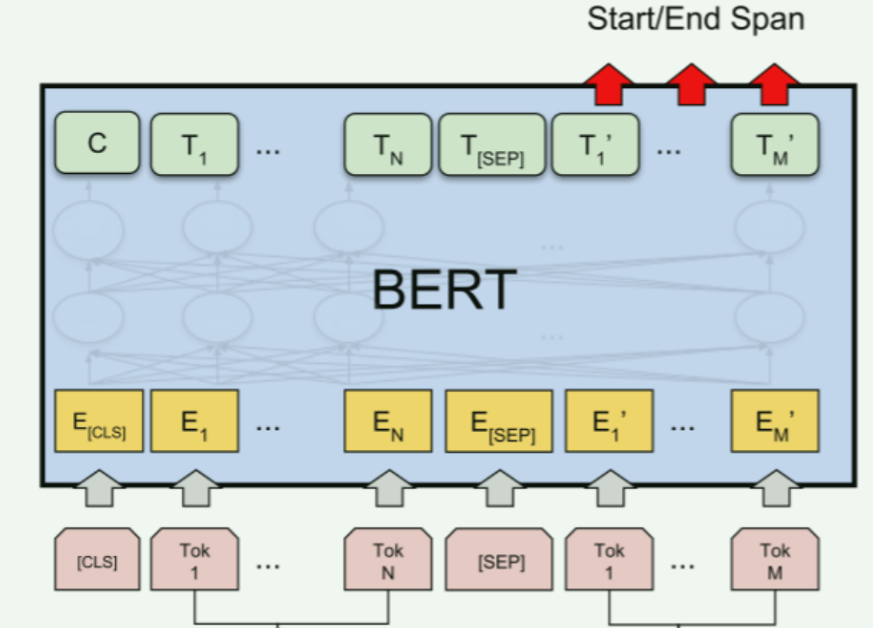
1. 加载预训练模型
self.bert = BertModel.from_pretrained(model_path)-
预训练模型:使用
transformers库的BertModel.from_pretrained方法加载一个预训练的BERT模型。model_path是预训练模型的路径或名称,例如"bert-base-chinese"。 -
优势:
-
预训练模型已经在大规模语料上进行了训练,学习了通用的语言表示。
-
微调可以利用这些预训练的参数,快速适应新的任务,通常只需要较少的数据和训练时间。
-
2. 添加任务特定的头
self.mlm_head = nn.Linear(d_model, vocab_size)
self.nsp_head = nn.Linear(d_model, 2)-
MLM头:
mlm_head是一个线性层,用于预测被掩盖的单词。输入是BERT模型的输出,输出是词汇表大小的预测概率。 -
NSP头:
nsp_head是一个线性层,用于预测两个句子是否相邻。输入是BERT模型的[CLS]标记的输出,输出是二分类的概率。
3. 前向传播
def forward(self, mlm_tok_ids, seg_ids, mask):bert_out = self.bert(mlm_tok_ids, seg_ids, mask)output = bert_out.last_hidden_statecls_token = output[:, 0, :]mlm_logits = self.mlm_head(output)nsp_logits = self.nsp_head(cls_token)return mlm_logits, nsp_logits-
BERT模型的输出:
-
bert_out.last_hidden_state:BERT模型的输出,形状为(batch_size, seq_len, d_model)。 -
[CLS]标记的输出:output[:, 0, :],用于NSP任务。
-
-
任务特定的输出:
-
mlm_logits:MLM任务的预测结果。 -
nsp_logits:NSP任务的预测结果。
-
4. 数据处理
class BERTDataset(Dataset):def __init__(self, nsp_dataset, tokenizer: BertTokenizer, max_length):self.nsp_dataset = nsp_datasetself.tokenizer = tokenizerself.max_length = max_lengthself.cls_id = tokenizer.cls_token_idself.sep_id = tokenizer.sep_token_idself.pad_id = tokenizer.pad_token_idself.mask_id = tokenizer.mask_token_iddef __getitem__(self, idx):sent1, sent2, nsp_label = self.nsp_dataset[idx]sent1_ids = self.tokenizer.encode(sent1, add_special_tokens=False)sent2_ids = self.tokenizer.encode(sent2, add_special_tokens=False)tok_ids = [self.cls_id] + sent1_ids + [self.sep_id] + sent2_ids + [self.sep_id]seg_ids = [0]*(len(sent1_ids)+2) + [1]*(len(sent2_ids) + 1)mlm_tok_ids, mlm_labels = self.build_mlm_dataset(tok_ids)mlm_tok_ids = self.pad_to_seq_len(mlm_tok_ids, 0)seg_ids = self.pad_to_seq_len(seg_ids, 2)mlm_labels = self.pad_to_seq_len(mlm_labels, -100)mask = (mlm_tok_ids != 0)return {"mlm_tok_ids": mlm_tok_ids,"seg_ids": seg_ids,"mask": torch.tensor(mask, dtype=torch.long),"mlm_labels": mlm_labels,"nsp_labels": torch.tensor(nsp_label)}-
数据处理:
-
将文本数据转换为词索引(
tok_ids)。 -
添加特殊标记(
[CLS]和[SEP])。 -
生成段嵌入(
seg_ids)。 -
生成MLM任务的数据(
mlm_tok_ids和mlm_labels)。 -
填充或截断序列到固定长度(
max_length)。
-
-
掩码:生成掩码,用于标记哪些位置是有效的输入(非填充部分)。
5. 训练过程
for epoch in range(epochs):for batch in tqdm(trainloader, desc="Training"):batch_mlm_tok_ids = batch["mlm_tok_ids"]batch_seg_ids = batch["seg_ids"]batch_mask = batch["mask"]batch_mlm_labels = batch["mlm_labels"]batch_nsp_labels = batch["nsp_labels"]mlm_logits, nsp_logits = model(batch_mlm_tok_ids, batch_seg_ids, batch_mask)loss_mlm = loss_fn(mlm_logits.view(-1, vocab_size), batch_mlm_labels.view(-1))loss_nsp = loss_fn(nsp_logits, batch_nsp_labels)loss = loss_mlm + loss_nsploss.backward()optim.step()optim.zero_grad()print("Epoch: {}, MLM Loss: {}, NSP Loss: {}".format(epoch, loss_mlm, loss_nsp))-
训练步骤:
-
前向传播:将输入数据通过模型,得到MLM和NSP任务的预测结果。
-
计算损失:分别计算MLM和NSP任务的损失。
-
反向传播:计算梯度并更新模型参数。
-
优化器:使用Adam优化器,学习率设置为
1e-3。
-
-
进度条:使用
tqdm显示训练进度,使训练过程更加直观。
6. 微调的优势
-
快速适应新任务:预训练模型已经学习了通用的语言表示,微调可以快速适应新的任务,通常只需要较少的数据和训练时间。
-
节省计算资源:从头训练BERT模型需要大量的计算资源和时间,而微调只需要在预训练模型的基础上进行少量的训练。
-
更好的性能:预训练模型在大规模数据上进行了训练,通常具有更好的性能。微调可以进一步提升模型在特定任务上的表现。
需复现代码
import re
import math
import torch
import random
import torch.nn as nnfrom tqdm import tqdm
from transformers import BertTokenizer, BertModel
from torch.utils.data import Dataset, DataLoaderclass BERT(nn.Module):def __init__(self, vocab_size, d_model, seq_len, N_blocks, num_heads, dropout, dff):super().__init__()self.bert = BertModel.from_pretrained(model_path)self.mlm_head = nn.Linear(d_model, vocab_size)self.nsp_head = nn.Linear(d_model, 2)def forward(self, mlm_tok_ids, seg_ids, mask):bert_out = self.bert(mlm_tok_ids, seg_ids, mask)output = bert_out.last_hidden_statecls_token = output[:, 0, :]mlm_logits = self.mlm_head(output)nsp_logits = self.nsp_head(cls_token)return mlm_logits, nsp_logitsdef read_data(file):with open(file, "r", encoding="utf-8") as f:data = f.read().strip().replace("\n", "")corpus = re.split(r'[。,“”:;!、]', data)corpus = [sentence for sentence in corpus if sentence.strip()]return corpusdef create_nsp_dataset(corpus):nsp_dataset = []for i in range(len(corpus)-1):next_sentence = corpus[i+1]rand_id = random.randint(0, len(corpus) - 1)while abs(rand_id - i) <= 1:rand_id = random.randint(0, len(corpus) - 1)negt_sentence = corpus[rand_id]nsp_dataset.append((corpus[i], next_sentence, 1)) # 正样本nsp_dataset.append((corpus[i], negt_sentence, 0)) # 负样本return nsp_datasetclass BERTDataset(Dataset):def __init__(self, nsp_dataset, tokenizer: BertTokenizer, max_length):self.nsp_dataset = nsp_datasetself.tokenizer = tokenizerself.max_length = max_lengthself.cls_id = tokenizer.cls_token_idself.sep_id = tokenizer.sep_token_idself.pad_id = tokenizer.pad_token_idself.mask_id = tokenizer.mask_token_iddef __len__(self):return len(self.nsp_dataset)def __getitem__(self, idx):sent1, sent2, nsp_label = self.nsp_dataset[idx]sent1_ids = self.tokenizer.encode(sent1, add_special_tokens=False)sent2_ids = self.tokenizer.encode(sent2, add_special_tokens=False)tok_ids = [self.cls_id] + sent1_ids + [self.sep_id] + sent2_ids + [self.sep_id]seg_ids = [0]*(len(sent1_ids)+2) + [1]*(len(sent2_ids) + 1)mlm_tok_ids, mlm_labels = self.build_mlm_dataset(tok_ids)mlm_tok_ids = self.pad_to_seq_len(mlm_tok_ids, 0)seg_ids = self.pad_to_seq_len(seg_ids, 2)mlm_labels = self.pad_to_seq_len(mlm_labels, -100)mask = (mlm_tok_ids != 0)return {"mlm_tok_ids": mlm_tok_ids,"seg_ids": seg_ids,"mask": torch.tensor(mask, dtype=torch.long),"mlm_labels": mlm_labels,"nsp_labels": torch.tensor(nsp_label)}def pad_to_seq_len(self, seq, pad_value):seq = seq[:self.max_length]pad_num = self.max_length - len(seq)return torch.tensor(seq + pad_num * [pad_value], dtype=torch.long)def build_mlm_dataset(self, tok_ids):mlm_tok_ids = tok_ids.copy()mlm_labels = [-100] * len(tok_ids)for i in range(len(tok_ids)):if tok_ids[i] not in [self.cls_id, self.sep_id, self.pad_id]:if random.random() < 0.15:mlm_labels[i] = tok_ids[i]if random.random() < 0.8:mlm_tok_ids[i] = self.mask_idelif random.random() < 0.9:mlm_tok_ids[i] = random.randint(106, self.tokenizer.vocab_size - 1)return mlm_tok_ids, mlm_labelsif __name__ == "__main__":data_file = "4.10-BERT/背影.txt"model_path = "/Users/azen/Desktop/llm/models/bert-base-chinese"tokenizer = BertTokenizer.from_pretrained(model_path)corpus = read_data(data_file)max_length = 25 # len(max(corpus, key=len))print("Max length of dataset: {}".format(max_length))nsp_dataset = create_nsp_dataset(corpus)trainset = BERTDataset(nsp_dataset, tokenizer, max_length)batch_size = 16trainloader = DataLoader(trainset, batch_size, shuffle=True)vocab_size = tokenizer.vocab_sized_model = 768N_blocks = 2num_heads = 12dropout = 0.1dff = 4*d_modelmodel = BERT(vocab_size, d_model, max_length, N_blocks, num_heads, dropout, dff)lr = 1e-3optim = torch.optim.Adam(model.parameters(), lr=lr)loss_fn = nn.CrossEntropyLoss()epochs = 20for epoch in range(epochs):for batch in tqdm(trainloader, desc = "Training"):batch_mlm_tok_ids = batch["mlm_tok_ids"]batch_seg_ids = batch["seg_ids"]batch_mask = batch["mask"]batch_mlm_labels = batch["mlm_labels"]batch_nsp_labels = batch["nsp_labels"]mlm_logits, nsp_logits = model(batch_mlm_tok_ids, batch_seg_ids, batch_mask)loss_mlm = loss_fn(mlm_logits.view(-1, vocab_size), batch_mlm_labels.view(-1))loss_nsp = loss_fn(nsp_logits, batch_nsp_labels)loss = loss_mlm + loss_nsploss.backward()optim.step()optim.zero_grad()print("Epoch: {}, MLM Loss: {}, NSP Loss: {}".format(epoch, loss_mlm, loss_nsp))passpass相关文章:

BERT - BertTokenizer, BertModel API模型微调
本节代码将展示如何在预训练的BERT模型基础上进行微调,以适应特定的下游任务。 ⭐学习建议直接看文章最后的需复现代码,不懂得地方再回看 微调是自然语言处理中常见的方法,通过在预训练模型的基础上添加额外的层,并在特定任务的…...

通过代码获取接口文档工具
通过代码获取接口文档工具 介绍使用到的技术使用说明核心源码演示截图工具源码 介绍 1.通过前后端代码来生成规格化的接口文档 2.支持拖拽上传或点击选择文件,可以一次选择多个文件或选择文件夹 3.用户选择前后端代码,工具调用GPT解析,得到规…...

不再卡顿!如何根据使用需求挑选合适的电脑内存?
电脑运行内存多大合适?在选购或升级电脑时,除了关注处理器的速度、硬盘的容量之外,内存(RAM)的大小也是决定电脑性能的一个重要因素。但究竟电脑运行内存多大才合适呢?这篇文章将帮助你理解不同使用场景下适…...

leetcode589 N叉树的前序遍历
前序遍历的顺序是:根节点 -> 子节点1 -> 子节点2 -> ... -> 子节点N 递归: class Solution { private:void traverse(Node* cur, vector<int>& res){if(cur NULL) return;res.push_back(cur->val);for(Node* child: cur->…...

游戏引擎学习第216天
回顾并为当天做准备 你可以看到,游戏现在正在运行。如果我没记错的话,我们之前把调试系统关闭了,留下一个状态,让任何想要在这段时间内进行实验的人可以自由操作,因为我们还没有完全完成这个系统。所以这样做是为了确…...

JavaSE反射机制干货
1.反射(Relection) 理解 定义:程序运行状态,动态地获取程序信息及调用程序功能即为java反射机制 2.获取class对象 掌握 2.1 Java代码的3个阶段 Java代码在计算机中经历的三个阶段:Source源代码阶段-Class类对象阶段-Runt…...

[特殊字符] 第十一讲 | 空间回归模型实战:SAR / SEM / GWR逐个击破
📘 专栏:科研统计方法实战分享 | 地学/农学人的数据分析工具箱 ✍️ 作者:平常心0715 🔑 本讲关键词:空间滞后模型(SAR)、空间误差模型(SEM)、地理加权回归(G…...

AI前沿周报:2025年3月技术深度解析
以下是基于2024-2025年AI技术前沿动态的深度技术周报示例,结合行业最新突破与研究进展,突出技术原理与应用场景分析: AI前沿周报:2025年3月技术深度解析 时间范围:2025年3月1日-3月31日 本期焦点:模型透明…...

aidigu开源微博项目程序,PHP开发的开源微博系统,自媒体个人创业、网盘推广首先
一、软件介绍 文末提供程序和源码下载学习 PHP开发的开源微博系统,采用PHP MySQL开发,框架采用ThinkPHP5.1,用户登录后拥有专属ID,支持表情、关注用户,网盘分享等功能,支持图片上传,视频上传,网盘存储分享…...
和PyTorch TabNet之TabNetRegressor)
Tabnet介绍(Decision Manifolds)和PyTorch TabNet之TabNetRegressor
Tabnet介绍(Decision Manifolds)和PyTorch TabNet之TabNetRegressor Decision ManifoldsTabNet1.核心思想2. 架构组成3. 工作流程4. 优点PyTorch TabNetTabNetRegressor参数1. 模型相关参数`n_d``n_a``n_steps``gamma``cat_idxs``cat_dims``cat_emb_dim`2. 训练相关参数`opti…...

格瑞普Tattu正式成为2025年中国无人机竞速联赛官方赞助商!
格瑞普Tattu正式成为2025年中国无人机竞速联赛官方赞助商! 为飞手赋能,为赛事护航! Tattu是深圳市格瑞普电池有限公司(Grepow)旗下的子品牌之一,专注为无人机、FPV和模型爱好者提供专业可靠的电池和充电器等一站式电源解决方案。凭借卓越的放电性能、稳…...

PySide6 监测设备变更事件
在PySide6中监听系统事件,判断是否有串口设备插拔,进而当串口状态变更时,实现列表数据实时更新。 在Qt中,可以使用 nativeEvent 接口来完成这一操作: [virtual protected] bool QWidget::nativeEvent(const QByteArray…...

嵌入式系统的历史与发展
目录 引言 一、嵌入式系统的早期萌芽 1、首个现代嵌入式系统 2、早期未成形嵌入式系统的应用 二、以单片机为主的初级阶段 1、工业领域应用 2、大型家电领域应用 三、处理器升级与多样化应用阶段 1、数字化电子化设备涌现 (1)智能仪表…...

mysql调试记录
ALTER USER rootlocalhost IDENTIFIED WITH mysql_native_password BY password; 该命令在调试python使用pymysql连接数据库出现错误时, 报错为pymysql.err.OperationalError: (1045, "Access denied for user rootlocalhost (using password: NO)") m…...

【后端开发】Spring MVC阶段总结
文章目录 快捷引入依赖lombok的使用Lombok依赖Lombok使用Lombok注解 三层架构分层的目的MVC与分层的区别三层架构分层的好处 企业命名规范常见命名命名风格介绍大驼峰风格小驼峰风格包名 常见注解Cookie与Session 快捷引入依赖 这个方法可以快捷引入依赖,但是引入依…...

netty-socketio + springboot 消息推送服务
netty-socketio springboot 消息推送服务 后端1. 目录结构:代码pom文件:application.yml:SocketIOConfig:PushMessage:ISocketIOServiceSocketIOServiceImpl:pushMessageController:启动类&…...
)
基于 JavaWeb 的 SSM 在线视频教育系统设计和实现(源码+文档+部署讲解)
技术范围:SpringBoot、Vue、SSM、HLMT、Jsp、PHP、Nodejs、Python、爬虫、数据可视化、小程序、安卓app、大数据、物联网、机器学习等设计与开发。 主要内容:免费功能设计、开题报告、任务书、中期检查PPT、系统功能实现、代码编写、论文编写和辅导、论文…...

同时打开多个Microchip MPLAB X IDE
0.引用 Microchip 32位MCU CAN驱动图文教程-附源码 - 哔哩哔哩 https://bbs.21ic.com/icview-3391426-1-1.html https://bbs.21ic.com/icview-3393632-1-1.html 1.前言 工作中接触到使用Microchip 的 MPLAB X IDE 开发工具,使用的MCU是Microchip SAMD21J18A MCU…...

dify 500错误
问题 升级到1.2.0 后所有页面接口均报错500, 环境: docker 本地部署 version:1.2.0 解决办法 1.首先关闭服务 docker compose down2.找到docker-compose.yaml里的plugin_daemon,参照下面修改参数 plugin_daemon:environment:PLUGIN_MAX_EXECUTION…...

WPF设计标准学习记录26
画刷名称功能说明SolidColorBrush使用单一的连续颜色填充区域LinearGradientBrush使用线性渐变绘制区域。RadialGradientBrush使用径向渐变绘制区域。 焦点定义渐变的开始,而圆定义渐变的终点。ImageBrush使用图像绘制区域。VisualBrush使用一个视图绘制区域。BitmapCacheBrus…...
,getchar(),getline(),cin.get line()异同点)
cin,cin.get(),getchar(),getline(),cin.get line()异同点
文章目录 1.cin2.cin.get()3.getchar()4.cin.getline()5.getline() 1.cin (1)cin>>等价于cin.operator>>(),即调用成员函数operator>>()进行读取数据。 (2)当cin>>从缓冲区中读取数据时&…...

7# 5多线-7 不会停
7# 5多线-7 不会停 分析,明显线接错了,打自动时也能手动启停,打手动无法启停,这时远程只能启ka3,无法启ka4。排查手自转换2上没接线,接到8上了(13和12接错了,也就是sac的5和6接错了)…...

基于混合编码器和边缘引导的拉普拉斯金字塔网络用于遥感变化检测
Laplacian Pyramid Network With HybridEncoder and Edge Guidance for RemoteSensing Change Detection 0、摘要 遥感变化检测(CD)是观测和分析动态土地覆盖变化的一项关键任务。许多基于深度学习的CD方法表现出强大的性能,但它们的有效性…...

机器学习 从入门到精通 day_04
1. 决策树-分类 1.1 概念 1. 决策节点 通过条件判断而进行分支选择的节点。如:将某个样本中的属性值(特征值)与决策节点上的值进行比较,从而判断它的流向。 2. 叶子节点 没有子节点的节点,表示最终的决策结果。 3. 决策树的…...

CLAHE算法介绍
限制对比度自适应直方图增强 CLAHE 算法介绍 1. CLAHE算法框图2.直方图clip及重分配2.1 opencv自带2.2 scikit-image2.3 结果对比2.4 clip limit的性质3.插值参考文献上图来自 K. Zuiderveld: Contrast Limited Adaptive Histogram Equalization。 图中可以看到各种直方图均衡的…...

高并发的业务场景下,如何防止数据库事务死锁
一、 一致的锁定顺序 定义: 死锁的常见原因之一是不同的事务以不同的顺序获取锁。当多个事务获取了不同资源的锁,并且这些资源之间发生了互相依赖,就会形成死锁。 解决方法: 确保所有的事务在获取多个锁时,按照相同的顺序请求锁。例如,如果事务A需要锁定表A和表B,事务…...
使用Python从零实现一个端到端多模态 Transformer大模型
嘿,各位!今天咱们要来一场超级酷炫的多模态 Transformer 冒险之旅!想象一下,让一个模型既能看懂图片,又能理解文字,然后还能生成有趣的回答。听起来是不是很像超级英雄的超能力?别急,…...
(附脚本))
elestio memos SSRF漏洞复现(CVE-2025-22952)(附脚本)
免责申明: 本文所描述的漏洞及其复现步骤仅供网络安全研究与教育目的使用。任何人不得将本文提供的信息用于非法目的或未经授权的系统测试。作者不对任何由于使用本文信息而导致的直接或间接损害承担责任。如涉及侵权,请及时与我们联系,我们将尽快处理并删除相关内容。 前言…...

倚光科技:以创新之光,雕琢全球领先光学设计公司
在光学技术飞速发展的当下,每一次突破都可能为众多领域带来变革性的影响。而倚光(深圳)科技有限公司,作为光学设计公司的一颗璀璨之星,正以其卓越的创新能力和深厚的技术底蕴,引领着光学设计行业的发展潮流…...

Linux安装Elasticsearch详细教程
准备工作 下载地址:Download Elasticsearch | Elastic 下载时需要注意es与jdk版本对应关系 ES 7.x 及之前版本,选择 Java 8 ES 8.x 及之后版本,选择 Java 17 或者 Java 18,建议 Java 17,因为对应版本的 Logstash 不支持 Java 1…...

C++字符串操作详解
引言 字符串处理是编程中最常见的任务之一,而在C中,我们有多种处理字符串的方式。本文将详细介绍C中的字符串操作,包括C风格字符串和C的string类。无论你是C新手还是想巩固基础的老手,这篇文章都能帮你梳理字符串处理的关键知识点…...

PromptPro|提示词生成和管理专家
大家好,我是吾鳴。 今天吾鳴给大家分享一个实用的提示词管理网站,它的名称叫做产品化管理提示词,英文名叫做PromptPro,是一个可以帮你管理你的大模型提示词的网站,同时你也可以告诉它你的需求,让它帮你生成…...

计算机视觉图像特征提取入门:Harris角点与SIFT算法
计算机视觉图像特征提取入门:Harris角点与SIFT算法 一、前言二、Harris 角点检测算法2.1 Harris 角点的定义与直观理解2.1.1 角点的概念2.1.2 Harris 角点的判定依据 2.2 Harris 角点检测的实现步骤2.2.1 计算图像的梯度2.2.2 构建结构张量矩阵2.2.3 …...
)
swift菜鸟教程1-5(语法,变量,类型,常量,字面量)
一个朴实无华的目录 今日学习内容:1.基本语法引入空格规范输入输出 2.变量声明变量变量输出加反斜杠括号 \\( ) 3.可选(Optionals)类型可选类型强制解析可选绑定 4.常量常量声明常量命名 5.字面量整数 and 浮点数 实例字符串 实例 今日学习内容: 1.基本…...

02142数据结构导论
初学者,怎样理解这道题,怎样大白话分析 答案解析 00、概念 29、 28、 27、 26、 25、 24、 23、 22、有5个元素,其入栈次序为:A、B、C、D、E,写出以元素C、D最先出栈(即C第一个且D第二个出栈)的各种可能的出栈次序。 (来…...

如何在AMD MI300X 服务器上部署 DeepSeek R1模型?
DeepSeek-R1凭借其深度推理能力备受关注,在语言模型性能基准测试中可与顶级闭源模型匹敌。 AMD Instinct MI300X GPU可在单节点上高效运行新发布的DeepSeek-R1和V3模型。 用户通过SGLang优化,将MI300X的性能提升至初始版本的4倍,且更多优化将…...

【Django】教程-15-注册页面
【Django】教程-1-安装创建项目目录结构介绍 【Django】教程-2-前端-目录结构介绍 【Django】教程-3-数据库相关介绍 【Django】教程-4-一个增删改查的Demo 【Django】教程-5-ModelForm增删改查规则校验【正则钩子函数】 【Django】教程-6-搜索框-条件查询前后端 【Django】教程…...

OpenAI即将上线新一代重磅选手——GPT-4.1
每周跟踪AI热点新闻动向和震撼发展 想要探索生成式人工智能的前沿进展吗?订阅我们的简报,深入解析最新的技术突破、实际应用案例和未来的趋势。与全球数同行一同,从行业内部的深度分析和实用指南中受益。不要错过这个机会,成为AI领…...

参照Spring Boot后端框架实现序列化工具类
本文参照Jackson实现序列化工具类,旨在于简化开发 JacksonUtil.class public class JacksonUtil {private JacksonUtil() {}/*** 单例*/private final static ObjectMapper OBJECT_MAPPER;static {OBJECT_MAPPER new ObjectMapper();}private static ObjectMappe…...

C_内存 内存地址概念
1. 计算机内存的基本概念 计算机的内存(RAM,随机存取存储器)是用来存储程序运行时的数据和指令的地方。内存被划分为许多小单元,每个单元有一个唯一的地址,这些地址从0开始编号。 内存单元:每个内存单元通…...

Rust重定义数据库内核:从内存安全到性能革命的破界之路
Rust语言正在颠覆传统数据库开发范式,其独特的所有权系统与零成本抽象能力,为攻克C/C时代遗留的内存泄漏、并发缺陷等顽疾提供全新解决方案。本文通过TiKV、Materialize等新一代数据库核心组件的实践案例,剖析Rust如何重塑存储引擎、查询优化…...

tree 显示到二级目录
要使用 tree 命令显示到二级目录,可以通过 -L 参数指定目录层级。具体命令如下: tree -L 2 参数说明: -L 数字:控制显示的目录深度。-L 2 表示显示到第二级目录(即当前目录下的直接子目录及其内容)。 示例输出: 复制 . ├── dir1 │ ├── file1.txt │ └─…...

UE5 在UE中创建骨骼动画
文章目录 创建动画的三种方式修改骨骼动画 创建动画的三种方式 方法一 打开一个已有的动画,左上角“创建资产/创建动画/参考姿势” 这将创建一个默认的A字形的骨骼,不建议这么做 方法二 打开一个已有的动画,左上角“创建资产/创建动画/当前…...

工业相机使用笔记
目前工业相机有多种分类方式,以下是基于不同原理和特点的类别总结: 按维度分类 2D相机: 原理:通过镜头将二维平面上的物体成像在图像传感器上,传感器上的像素点阵列捕捉物体的光信号,并转换为电信号或数字…...

深度兼容性测试和自助兼容性测试的区别,如何正确的选择?
泽众云经过几年业务快速发展,特别是泽众云兼容性测试服务已成为市场热门供应商之一,也根据用户不同需求推出了超高性价比服务,主要有深度兼容性测试和自助兼容性测试两种方式。2025年上半云真机平台的机型已升级到1000,全面覆盖了…...

Windows下安装depot_tools
一、引言 Chromium和Chromium OS使用名为depot_tools的脚本包来管理检出和审查代码。depot_tools工具集包括gclient、gcl、git-cl、repo等。它也是WebRTC开发者所需的工具集,用于构建和管理WebRTC项目。本文介绍Windows系统下安装depot_tools的方法。 二、下载depo…...

学术分享:基于 ARCADE 数据集评估 Grounding DINO、YOLO 和 DINO 在血管狭窄检测中的效果
一、引言 冠状动脉疾病(CAD)作为全球主要死亡原因之一,其早期准确检测对有效治疗至关重要。X 射线冠状动脉造影(XCA)虽然是诊断 CAD 的金标准,但这些图像的人工解读不仅耗时,还易受观察者间差异…...
——什么是 IA3 微调?)
NLP高频面试题(四十一)——什么是 IA3 微调?
随着大型语言模型的广泛应用,如何高效地将这些模型适配到特定任务中,成为了研究和工程实践中的重要课题。IA3(Infused Adapter by Adding and Adjusting)微调技术,作为参数高效微调的一种新颖方法,提供了在保持模型性能的同时,显著减少可训练参数数量的解决方案。 IA3 …...

STM32 模块化开发指南 · 第 3 篇 环形缓冲区 RingBuffer 模块设计与单元测试
本文是《STM32 模块化开发实战指南》第 3 篇,聚焦于“如何设计一个高性能、稳定、安全的环形缓冲区模块”。我们将从基本结构讲起,逐步完成接口定义、边界处理、API 实现与单元测试,最终实现一个可移植、线程安全、可嵌入 UART/BLE/协议模块的通用 RingBuffer。 一、RingBuf…...

软件测试岗位:IT行业中的质量守护者
在当今数字化飞速发展的IT行业,软件如同空气般无处不在,从日常的手机应用到复杂的企业级管理系统,软件的稳定性和可靠性至关重要。而软件测试岗位的从业者,就像是软件世界的质检员,精心守护着软件的质量。 一、软件测…...