使用Python从零实现一个端到端多模态 Transformer大模型
嘿,各位!今天咱们要来一场超级酷炫的多模态 Transformer 冒险之旅!想象一下,让一个模型既能看懂图片,又能理解文字,然后还能生成有趣的回答。听起来是不是很像超级英雄的超能力?别急,咱们这就来实现它!
🧠 向所有学习者致敬!
“学习不是装满一桶水,而是点燃一把火。” —— 叶芝
我的博客主页: https://lizheng.blog.csdn.net
🌐 欢迎点击加入AI人工智能社区!
🚀 让我们一起努力,共创AI未来! 🚀
好的!让我来完成这个任务,我会用幽默风趣的笔触把这篇文档翻译成符合 CSDN 博文要求的 Markdown 格式。现在就让我们开始吧!Step 0: 准备工作 —— 导入库、加载模型、定义数据、设置视觉模型
Step 0.1: 导入所需的库
在这一部分,咱们要准备好所有需要的工具,就像准备一场冒险的装备一样。我们需要 torch 和它的子模块(nn、F、optim),还有 torchvision 来获取预训练的 ResNet 模型,PIL(Pillow)用来加载图片,math 用来做些数学计算,os 用来处理文件路径,还有 numpy 来创建一些虚拟的图片数据。这些工具就像是咱们的瑞士军刀,有了它们,咱们就能搞定一切!
import torch
import torch.nn as nn
from torch.nn import functional as F
import torch.optim as optim
import torchvision
import torchvision.transforms as transforms
from PIL import Image
import math
import os
import numpy as np # 用来创建虚拟图片
为了保证代码的可重复性,咱们还设置了随机种子,这样每次运行代码的时候都能得到一样的结果。这就好像是给代码加了一个“魔法咒语”,让每次运行都像复制粘贴一样稳定。
torch.manual_seed(42) # 使用不同的种子会有不同的结果
np.random.seed(42)
接下来,咱们检查一下 PyTorch 和 Torchvision 的版本,确保一切正常。这就好像是在出发前检查一下装备是否完好。
print(f"PyTorch version: {torch.__version__}")
print(f"Torchvision version: {torchvision.__version__}")
print("Libraries imported.")
最后,咱们设置一下设备(如果有 GPU 就用 GPU,没有就用 CPU)。这就好像是给代码选择了一个超级加速器,让运行速度飞起来!
device = 'cuda' if torch.cuda.is_available() else 'cpu'
print(f"Using device: {device}")
Step 0.2: 加载预训练的文本模型
咱们之前训练了一个字符级的 Transformer 模型,现在要把它的权重和配置加载过来,这样咱们的模型就有了处理文本的基础。这就像是给咱们的多模态模型注入了一颗强大的文本处理“心脏”。
model_load_path = 'saved_models/transformer_model.pt'
if not os.path.exists(model_load_path):raise FileNotFoundError(f"Error: Model file not found at {model_load_path}. Please ensure 'transformer2.ipynb' was run and saved the model.")loaded_state_dict = torch.load(model_load_path, map_location=device)
print(f"Loaded state dictionary from '{model_load_path}'.")
从加载的模型中,咱们提取了超参数(比如 vocab_size、d_model、n_layers 等)和字符映射表(char_to_int 和 int_to_char)。这些参数就像是模型的“基因”,决定了它的行为和能力。
config = loaded_state_dict['config']
loaded_vocab_size = config['vocab_size']
d_model = config['d_model']
n_heads = config['n_heads']
n_layers = config['n_layers']
d_ff = config['d_ff']
loaded_block_size = config['block_size'] # 文本模型的最大序列长度
d_k = d_model // n_headschar_to_int = loaded_state_dict['tokenizer']['char_to_int']
int_to_char = loaded_state_dict['tokenizer']['int_to_char']
Step 0.3: 定义特殊标记并更新词汇表
为了让模型能够处理多模态数据,咱们需要添加一些特殊的标记:
<IMG>:用来表示图像输入的占位符。<PAD>:用来填充序列,让序列长度一致。<EOS>:表示句子结束的标记。
这就像是给模型的词汇表添加了一些新的“魔法单词”,让模型能够理解新的概念。
img_token = "<IMG>"
pad_token = "<PAD>"
eos_token = "<EOS>" # 句子结束标记
special_tokens = [img_token, pad_token, eos_token]
接下来,咱们把这些特殊标记添加到现有的字符映射表中,并更新词汇表的大小。这就像是给模型的词汇表扩容,让它能够容纳更多的“魔法单词”。
current_vocab_size = loaded_vocab_size
for token in special_tokens:if token not in char_to_int:char_to_int[token] = current_vocab_sizeint_to_char[current_vocab_size] = tokencurrent_vocab_size += 1vocab_size = current_vocab_size
pad_token_id = char_to_int[pad_token] # 保存 PAD 标记的 ID,后面要用
Step 0.4: 定义样本多模态数据
咱们创建了一个小的、虚拟的(图像,提示,回答)三元组数据集。为了简单起见,咱们用 PIL/Numpy 生成了一些虚拟图片(比如纯色的方块和圆形),并给它们配上了一些描述性的提示和回答。这就像是给模型准备了一些“练习题”,让它能够学习如何处理图像和文本的组合。
sample_data_dir = "sample_multimodal_data"
os.makedirs(sample_data_dir, exist_ok=True)image_paths = {"red": os.path.join(sample_data_dir, "red_square.png"),"blue": os.path.join(sample_data_dir, "blue_square.png"),"green": os.path.join(sample_data_dir, "green_circle.png") # 加入形状变化
}# 创建红色方块
img_red = Image.new('RGB', (64, 64), color = 'red')
img_red.save(image_paths["red"])
# 创建蓝色方块
img_blue = Image.new('RGB', (64, 64), color = 'blue')
img_blue.save(image_paths["blue"])
# 创建绿色圆形(用 PIL 的绘图功能近似绘制)
img_green = Image.new('RGB', (64, 64), color = 'white')
from PIL import ImageDraw
draw = ImageDraw.Draw(img_green)
draw.ellipse((4, 4, 60, 60), fill='green', outline='green')
img_green.save(image_paths["green"])
接下来,咱们定义了一些数据样本,每个样本包括一个图片路径、一个提示和一个回答。这就像是给模型准备了一些“问答对”,让它能够学习如何根据图片和提示生成正确的回答。
sample_training_data = [{"image_path": image_paths["red"], "prompt": "What color is the shape?", "response": "red." + eos_token},{"image_path": image_paths["blue"], "prompt": "Describe the image.", "response": "a blue square." + eos_token},{"image_path": image_paths["green"], "prompt": "What shape is shown?", "response": "a green circle." + eos_token},{"image_path": image_paths["red"], "prompt": "Is it a circle?", "response": "no, it is a square." + eos_token},{"image_path": image_paths["blue"], "prompt": "What is the main color?", "response": "blue." + eos_token},{"image_path": image_paths["green"], "prompt": "Describe this.", "response": "a circle, it is green." + eos_token}
]
Step 0.5: 加载预训练的视觉模型(特征提取器)
咱们从 torchvision 加载了一个预训练的 ResNet-18 模型,并移除了它的最后分类层(fc)。这就像是给模型安装了一个“视觉眼睛”,让它能够“看”图片并提取出有用的特征。
vision_model = torchvision.models.resnet18(weights=torchvision.models.ResNet18_Weights.DEFAULT)
vision_feature_dim = vision_model.fc.in_features # 获取原始 fc 层的输入维度
vision_model.fc = nn.Identity() # 替换分类器为恒等映射
vision_model = vision_model.to(device)
vision_model.eval() # 设置为评估模式
Step 0.6: 定义图像预处理流程
在把图片喂给 ResNet 模型之前,咱们需要对图片进行预处理。这就像是给图片“化妆”,让它符合模型的口味。咱们用 torchvision.transforms 来定义一个预处理流程,包括调整图片大小、裁剪、转换为张量并归一化。
image_transforms = transforms.Compose([transforms.Resize(256), # 调整图片大小,短边为 256transforms.CenterCrop(224), # 中心裁剪 224x224 的正方形transforms.ToTensor(), # 转换为 PyTorch 张量(0-1 范围)transforms.Normalize(mean=[0.485, 0.456, 0.406], # 使用 ImageNet 的均值std=[0.229, 0.224, 0.225]) # 使用 ImageNet 的标准差
])
Step 0.7: 定义新的超参数
咱们定义了一些新的超参数,专门用于多模态设置。这就像是给模型设置了一些新的“规则”,让它知道如何处理图像和文本的组合。
block_size = 64 # 设置多模态序列的最大长度
num_img_tokens = 1 # 使用 1 个 <IMG> 标记来表示图像特征
learning_rate = 3e-4 # 保持 AdamW 的学习率不变
batch_size = 4 # 由于可能占用更多内存,减小批量大小
epochs = 2000 # 增加训练周期
eval_interval = 500
最后,咱们重新创建了一个因果掩码,以适应新的序列长度。这就像是给模型的注意力机制设置了一个“遮挡板”,让它只能看到它应该看到的部分。
causal_mask = torch.tril(torch.ones(block_size, block_size, device=device)).view(1, 1, block_size, block_size)
Step 1: 数据准备用于多模态训练
Step 1.1: 提取样本数据的图像特征
咱们遍历 sample_training_data,对于每个唯一的图像路径,加载图像,应用定义的变换,并通过冻结的 vision_model 获取特征向量。这就像是给每个图像提取了一个“特征指纹”,让模型能够理解图像的内容。
extracted_image_features = {} # 用来存储 {image_path: feature_tensor}unique_image_paths = set(d["image_path"] for d in sample_training_data)
print(f"Found {len(unique_image_paths)} unique images to process.")for img_path in unique_image_paths:try:img = Image.open(img_path).convert('RGB') # 确保图像是 RGB 格式except FileNotFoundError:print(f"Error: Image file not found at {img_path}. Skipping.")continueimg_tensor = image_transforms(img).unsqueeze(0).to(device) # 应用预处理并添加批量维度with torch.no_grad():feature_vector = vision_model(img_tensor) # 提取特征向量extracted_image_features[img_path] = feature_vector.squeeze(0) # 去掉批量维度并存储print(f" Extracted features for '{os.path.basename(img_path)}', shape: {extracted_image_features[img_path].shape}")
Step 1.2: 对提示和回答进行分词
咱们用更新后的 char_to_int 映射(现在包括 <IMG>、<PAD>、<EOS>)将文本提示和回答转换为整数 ID 序列。这就像是把文本翻译成模型能够理解的“数字语言”。
tokenized_samples = []
for sample in sample_training_data:prompt_ids = [char_to_int[ch] for ch in sample["prompt"]]response_text = sample["response"]if response_text.endswith(eos_token):response_text_without_eos = response_text[:-len(eos_token)]response_ids = [char_to_int[ch] for ch in response_text_without_eos] + [char_to_int[eos_token]]else:response_ids = [char_to_int[ch] for ch in response_text]tokenized_samples.append({"image_path": sample["image_path"],"prompt_ids": prompt_ids,"response_ids": response_ids})
Step 1.3: 创建填充的输入/目标序列和掩码
咱们把图像表示、分词后的提示和分词后的回答组合成一个输入序列,为 Transformer 准备。这就像是把图像和文本“打包”成一个序列,让模型能够同时处理它们。
prepared_sequences = []
ignore_index = -100 # 用于 CrossEntropyLoss 的忽略索引for sample in tokenized_samples:img_ids = [char_to_int[img_token]] * num_img_tokensinput_ids_no_pad = img_ids + sample["prompt_ids"] + sample["response_ids"][:-1] # 输入预测回答target_ids_no_pad = ([ignore_index] * len(img_ids)) + ([ignore_index] * len(sample["prompt_ids"])) + sample["response_ids"]current_len = len(input_ids_no_pad)pad_len = block_size - current_lenif pad_len < 0:print(f"Warning: Sample sequence length ({current_len}) exceeds block_size ({block_size}). Truncating.")input_ids = input_ids_no_pad[:block_size]target_ids = target_ids_no_pad[:block_size]pad_len = 0current_len = block_sizeelse:input_ids = input_ids_no_pad + ([pad_token_id] * pad_len)target_ids = target_ids_no_pad + ([ignore_index] * pad_len)attention_mask = ([1] * current_len) + ([0] * pad_len)prepared_sequences.append({"image_path": sample["image_path"],"input_ids": torch.tensor(input_ids, dtype=torch.long),"target_ids": torch.tensor(target_ids, dtype=torch.long),"attention_mask": torch.tensor(attention_mask, dtype=torch.long)})
最后,咱们把所有的序列组合成张量,方便后续的批量处理。这就像是把所有的“练习题”打包成一个整齐的“试卷”。
all_input_ids = torch.stack([s['input_ids'] for s in prepared_sequences])
all_target_ids = torch.stack([s['target_ids'] for s in prepared_sequences])
all_attention_masks = torch.stack([s['attention_mask'] for s in prepared_sequences])
all_image_paths = [s['image_path'] for s in prepared_sequences]
Step 2: 模型调整和初始化
Step 2.1: 重新初始化嵌入层和输出层
由于咱们添加了特殊标记(<IMG>、<PAD>、<EOS>),词汇表大小发生了变化。这就像是给模型的词汇表“扩容”,咱们需要重新初始化嵌入层和输出层,以适应新的词汇表大小。
new_token_embedding_table = nn.Embedding(vocab_size, d_model).to(device)
original_weights = loaded_state_dict['token_embedding_table']['weight'][:loaded_vocab_size, :]
with torch.no_grad():new_token_embedding_table.weight[:loaded_vocab_size, :] = original_weights
token_embedding_table = new_token_embedding_table
输出层也需要重新初始化,以适应新的词汇表大小。
new_output_linear_layer = nn.Linear(d_model, vocab_size).to(device)
original_out_weight = loaded_state_dict['output_linear_layer']['weight'][:loaded_vocab_size, :]
original_out_bias = loaded_state_dict['output_linear_layer']['bias'][:loaded_vocab_size]
with torch.no_grad():new_output_linear_layer.weight[:loaded_vocab_size, :] = original_out_weightnew_output_linear_layer.bias[:loaded_vocab_size] = original_out_bias
output_linear_layer = new_output_linear_layer
Step 2.2: 初始化视觉投影层
咱们创建了一个新的线性层,用来将提取的图像特征投影到 Transformer 的隐藏维度(d_model)。这就像是给图像特征和文本特征之间架起了一座“桥梁”,让它们能够互相理解。
vision_projection_layer = nn.Linear(vision_feature_dim, d_model).to(device)
Step 2.3: 加载现有的 Transformer 块层
咱们从加载的状态字典中重新加载 Transformer 块的核心组件(LayerNorms、QKV/Output Linears for MHA、FFN Linears)。这就像是把之前训练好的模型的“核心部件”重新组装起来。
layer_norms_1 = []
layer_norms_2 = []
mha_qkv_linears = []
mha_output_linears = []
ffn_linear_1 = []
ffn_linear_2 = []for i in range(n_layers):ln1 = nn.LayerNorm(d_model).to(device)ln1.load_state_dict(loaded_state_dict['layer_norms_1'][i])layer_norms_1.append(ln1)qkv_linear = nn.Linear(d_model, 3 * d_model, bias=False).to(device)qkv_linear.load_state_dict(loaded_state_dict['mha_qkv_linears'][i])mha_qkv_linears.append(qkv_linear)output_linear_mha = nn.Linear(d_model, d_model).to(device)output_linear_mha.load_state_dict(loaded_state_dict['mha_output_linears'][i])mha_output_linears.append(output_linear_mha)ln2 = nn.LayerNorm(d_model).to(device)ln2.load_state_dict(loaded_state_dict['layer_norms_2'][i])layer_norms_2.append(ln2)lin1 = nn.Linear(d_model, d_ff).to(device)lin1.load_state_dict(loaded_state_dict['ffn_linear_1'][i])ffn_linear_1.append(lin1)lin2 = nn.Linear(d_ff, d_model).to(device)lin2.load_state_dict(loaded_state_dict['ffn_linear_2'][i])ffn_linear_2.append(lin2)
最后,咱们加载了最终的 LayerNorm 和位置编码。这就像是给模型的“大脑”安装了最后的“保护层”。
final_layer_norm = nn.LayerNorm(d_model).to(device)
final_layer_norm.load_state_dict(loaded_state_dict['final_layer_norm'])
positional_encoding = loaded_state_dict['positional_encoding'].to(device)
Step 2.4: 定义优化器和损失函数
咱们收集了所有需要训练的参数,包括新初始化的视觉投影层和重新调整大小的嵌入/输出层。这就像是给模型的“训练引擎”添加了所有的“燃料”。
all_trainable_parameters = list(token_embedding_table.parameters())
all_trainable_parameters.extend(list(vision_projection_layer.parameters()))
for i in range(n_layers):all_trainable_parameters.extend(list(layer_norms_1[i].parameters()))all_trainable_parameters.extend(list(mha_qkv_linears[i].parameters()))all_trainable_parameters.extend(list(mha_output_linears[i].parameters()))all_trainable_parameters.extend(list(layer_norms_2[i].parameters()))all_trainable_parameters.extend(list(ffn_linear_1[i].parameters()))all_trainable_parameters.extend(list(ffn_linear_2[i].parameters()))
all_trainable_parameters.extend(list(final_layer_norm.parameters()))
all_trainable_parameters.extend(list(output_linear_layer.parameters()))
接下来,咱们定义了 AdamW 优化器来管理这些参数,并定义了 Cross-Entropy 损失函数,确保忽略填充标记和非目标标记(比如提示标记)。这就像是给模型的训练过程设置了一个“指南针”,让它知道如何朝着正确的方向前进。
optimizer = optim.AdamW(all_trainable_parameters, lr=learning_rate)
criterion = nn.CrossEntropyLoss(ignore_index=ignore_index)
Step 3: 多模态训练循环(内联)
Step 3.1: 训练循环结构
咱们开始训练模型啦!在每个训练周期中,咱们随机选择一批数据,提取对应的图像特征、输入 ID、目标 ID 和注意力掩码,然后进行前向传播、计算损失、反向传播和参数更新。这就像是让模型在“训练场”上反复练习,直到它能够熟练地处理图像和文本的组合。
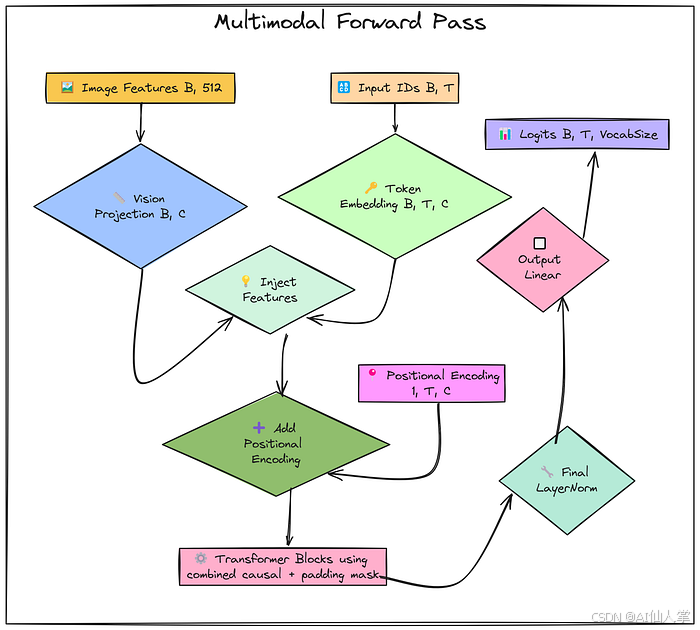
losses = []for epoch in range(epochs):indices = torch.randint(0, num_sequences_available, (batch_size,))xb_ids = all_input_ids[indices].to(device)yb_ids = all_target_ids[indices].to(device)batch_masks = all_attention_masks[indices].to(device)batch_img_paths = [all_image_paths[i] for i in indices.tolist()]try:batch_img_features = torch.stack([extracted_image_features[p] for p in batch_img_paths]).to(device)except KeyError as e:print(f"Error: Missing extracted feature for image path {e}. Ensure Step 1.1 completed correctly. Skipping epoch.")continueB, T = xb_ids.shapeC = d_modelprojected_img_features = vision_projection_layer(batch_img_features)projected_img_features = projected_img_features.unsqueeze(1)text_token_embeddings = token_embedding_table(xb_ids)combined_embeddings = text_token_embeddings.clone()combined_embeddings[:, 0:num_img_tokens, :] = projected_img_featurespos_enc_slice = positional_encoding[:, :T, :]x = combined_embeddings + pos_enc_slicepadding_mask_expanded = batch_masks.unsqueeze(1).unsqueeze(2)combined_attn_mask = causal_mask[:,:,:T,:T] * padding_mask_expandedfor i in range(n_layers):x_input_block = xx_ln1 = layer_norms_1[i](x_input_block)qkv = mha_qkv_linears[i](x_ln1)qkv = qkv.view(B, T, n_heads, 3 * d_k).permute(0, 2, 1, 3)q, k, v = qkv.chunk(3, dim=-1)attn_scores = (q @ k.transpose(-2, -1)) * (d_k ** -0.5)attn_scores_masked = attn_scores.masked_fill(combined_attn_mask == 0, float('-inf'))attention_weights = F.softmax(attn_scores_masked, dim=-1)attention_weights = torch.nan_to_num(attention_weights)attn_output = attention_weights @ vattn_output = attn_output.permute(0, 2, 1, 3).contiguous().view(B, T, C)mha_result = mha_output_linears[i](attn_output)x = x_input_block + mha_resultx_input_ffn = xx_ln2 = layer_norms_2[i](x_input_ffn)ffn_hidden = ffn_linear_1[i](x_ln2)ffn_activated = F.relu(ffn_hidden)ffn_output = ffn_linear_2[i](ffn_activated)x = x_input_ffn + ffn_outputfinal_norm_output = final_layer_norm(x)logits = output_linear_layer(final_norm_output)B_loss, T_loss, V_loss = logits.shapeif yb_ids.size(1) != T_loss:if yb_ids.size(1) > T_loss:targets_reshaped = yb_ids[:, :T_loss].contiguous().view(-1)else:padded_targets = torch.full((B_loss, T_loss), ignore_index, device=device)padded_targets[:, :yb_ids.size(1)] = yb_idstargets_reshaped = padded_targets.view(-1)else:targets_reshaped = yb_ids.view(-1)logits_reshaped = logits.view(-1, V_loss)loss = criterion(logits_reshaped, targets_reshaped)optimizer.zero_grad()if not torch.isnan(loss) and not torch.isinf(loss):loss.backward()optimizer.step()else:print(f"Warning: Invalid loss detected (NaN or Inf) at epoch {epoch+1}. Skipping optimizer step.")loss = Noneif loss is not None:current_loss = loss.item()losses.append(current_loss)if epoch % eval_interval == 0 or epoch == epochs - 1:print(f" Epoch {epoch+1}/{epochs}, Loss: {current_loss:.4f}")elif epoch % eval_interval == 0 or epoch == epochs - 1:print(f" Epoch {epoch+1}/{epochs}, Loss: Invalid (NaN/Inf)")
最后,咱们绘制了训练损失曲线,以直观地展示模型的训练过程。这就像是给模型的训练过程拍了一张“进度照”,让咱们能够清楚地看到它的进步。
import matplotlib.pyplot as plt
plt.figure(figsize=(20, 3))
plt.plot(losses)
plt.title("Training Loss Over Epochs")
plt.xlabel("Epoch")
plt.ylabel("Loss")
plt.grid(True)
plt.show()
Step 4: 多模态生成(内联)
Step 4.1: 准备输入图像和提示
咱们选择了一个图像(比如绿色圆形)和一个文本提示(比如“Describe this image:”),对图像进行预处理,提取其特征,并将其投影到训练好的视觉投影层。这就像是给模型准备了一个“输入套餐”,让它能够根据图像和提示生成回答。
test_image_path = image_paths["green"]
test_prompt_text = "Describe this image: "
接下来,咱们对图像进行预处理,提取特征,并将其投影到训练好的视觉投影层。
try:test_img = Image.open(test_image_path).convert('RGB')test_img_tensor = image_transforms(test_img).unsqueeze(0).to(device)with torch.no_grad():test_img_features_raw = vision_model(test_img_tensor)vision_projection_layer.eval()with torch.no_grad():test_img_features_projected = vision_projection_layer(test_img_features_raw)print(f" Processed image: '{os.path.basename(test_image_path)}'")print(f" Projected image features shape: {test_img_features_projected.shape}")
except FileNotFoundError:print(f"Error: Test image not found at {test_image_path}. Cannot generate.")test_img_features_projected = None
最后,咱们对提示进行分词,并将其与图像特征组合成初始上下文。这就像是把图像和提示“打包”成一个序列,让模型能够开始生成回答。
img_id = char_to_int[img_token]
prompt_ids = [char_to_int[ch] for ch in test_prompt_text]
initial_context_ids = torch.tensor([[img_id] * num_img_tokens + prompt_ids], dtype=torch.long, device=device)
print(f" Tokenized prompt: '{test_prompt_text}' -> {initial_context_ids.tolist()}")
Step 4.2: 生成循环(自回归解码)
咱们开始生成回答啦!在每个步骤中,咱们准备当前的输入序列,提取嵌入,注入图像特征,添加位置编码,创建注意力掩码,然后通过 Transformer 块进行前向传播。这就像是让模型根据当前的“输入套餐”生成下一个“魔法单词”。
generated_sequence_ids = initial_context_ids
with torch.no_grad():for _ in range(max_new_tokens):current_ids_context = generated_sequence_ids[:, -block_size:]B_gen, T_gen = current_ids_context.shapeC_gen = d_modelcurrent_token_embeddings = token_embedding_table(current_ids_context)gen_combined_embeddings = current_token_embeddingsif img_id in current_ids_context[0].tolist():img_token_pos = 0gen_combined_embeddings[:, img_token_pos:(img_token_pos + num_img_tokens), :] = test_img_features_projectedpos_enc_slice_gen = positional_encoding[:, :T_gen, :]x_gen = gen_combined_embeddings + pos_enc_slice_gengen_causal_mask = causal_mask[:,:,:T_gen,:T_gen]for i in range(n_layers):x_input_block_gen = x_genx_ln1_gen = layer_norms_1[i](x_input_block_gen)qkv_gen = mha_qkv_linears[i](x_ln1_gen)qkv_gen = qkv_gen.view(B_gen, T_gen, n_heads, 3 * d_k).permute(0, 2, 1, 3)q_gen, k_gen, v_gen = qkv_gen.chunk(3, dim=-1)attn_scores_gen = (q_gen @ k_gen.transpose(-2, -1)) * (d_k ** -0.5)attn_scores_masked_gen = attn_scores_gen.masked_fill(gen_causal_mask == 0, float('-inf'))attention_weights_gen = F.softmax(attn_scores_masked_gen, dim=-1)attention_weights_gen = torch.nan_to_num(attention_weights_gen)attn_output_gen = attention_weights_gen @ v_genattn_output_gen = attn_output_gen.permute(0, 2, 1, 3).contiguous().view(B_gen, T_gen, C_gen)mha_result_gen = mha_output_linears[i](attn_output_gen)x_gen = x_input_block_gen + mha_result_genx_input_ffn_gen = x_genx_ln2_gen = layer_norms_2[i](x_input_ffn_gen)ffn_hidden_gen = ffn_linear_1[i](x_ln2_gen)ffn_activated_gen = F.relu(ffn_hidden_gen)ffn_output_gen = ffn_linear_2[i](ffn_activated_gen)x_gen = x_input_ffn_gen + ffn_output_genfinal_norm_output_gen = final_layer_norm(x_gen)logits_gen = output_linear_layer(final_norm_output_gen)logits_last_token = logits_gen[:, -1, :]probs = F.softmax(logits_last_token, dim=-1)next_token_id = torch.multinomial(probs, num_samples=1)generated_sequence_ids = torch.cat((generated_sequence_ids, next_token_id), dim=1)if next_token_id.item() == eos_token_id:print(" <EOS> token generated. Stopping.")breakelse:print(f" Reached max generation length ({max_new_tokens}). Stopping.")
Step 4.3: 解码生成的序列
最后,咱们把生成的序列 ID 转换回人类可读的字符串。这就像是把模型生成的“魔法单词”翻译回人类的语言。
final_ids_list = generated_sequence_ids[0].tolist()
decoded_text = ""
for id_val in final_ids_list:if id_val in int_to_char:decoded_text += int_to_char[id_val]else:decoded_text += f"[UNK:{id_val}]"print(f"--- Final Generated Output ---")
print(f"Image: {os.path.basename(test_image_path)}")
response_start_index = num_img_tokens + len(test_prompt_text)
print(f"Prompt: {test_prompt_text}")
print(f"Generated Response: {decoded_text[response_start_index:]}")
Step 6: 保存模型状态(可选)
为了保存咱们训练好的多模态模型,咱们需要把所有模型组件和配置保存到一个字典中,然后用 torch.save() 保存到文件中。这就像是给模型拍了一张“全家福”,让它能够随时被加载和使用。
save_dir = 'saved_models'
os.makedirs(save_dir, exist_ok=True)
save_path = os.path.join(save_dir, 'multimodal_model.pt')multimodal_state_dict = {'config': {'vocab_size': vocab_size,'d_model': d_model,'n_heads': n_heads,'n_layers': n_layers,'d_ff': d_ff,'block_size': block_size,'num_img_tokens': num_img_tokens,'vision_feature_dim': vision_feature_dim},'tokenizer': {'char_to_int': char_to_int,'int_to_char': int_to_char},'token_embedding_table': token_embedding_table.state_dict(),'vision_projection_layer': vision_projection_layer.state_dict(),'positional_encoding': positional_encoding,'layer_norms_1': [ln.state_dict() for ln in layer_norms_1],'mha_qkv_linears': [l.state_dict() for l in mha_qkv_linears],'mha_output_linears': [l.state_dict() for l in mha_output_linears],'layer_norms_2': [ln.state_dict() for ln in layer_norms_2],'ffn_linear_1': [l.state_dict() for l in ffn_linear_1],'ffn_linear_2': [l.state_dict() for l in ffn_linear_2],'final_layer_norm': final_layer_norm.state_dict(),'output_linear_layer': output_linear_layer.state_dict()
}torch.save(multimodal_state_dict, save_path)
print(f"Multi-modal model saved to {save_path}")
加载保存的多模态模型
加载保存的模型状态字典后,咱们可以根据配置和 tokenizer 重建模型组件,并加载它们的状态字典。这就像是把之前保存的“全家福”重新组装起来,让模型能够随时被使用。
model_load_path = 'saved_models/multimodal_model.pt'
loaded_state_dict = torch.load(model_load_path, map_location=device)
print(f"Loaded state dictionary from '{model_load_path}'.")config = loaded_state_dict['config']
vocab_size = config['vocab_size']
d_model = config['d_model']
n_heads = config['n_heads']
n_layers = config['n_layers']
d_ff = config['d_ff']
block_size = config['block_size']
num_img_tokens = config['num_img_tokens']
vision_feature_dim = config['vision_feature_dim']
d_k = d_model // n_headschar_to_int = loaded_state_dict['tokenizer']['char_to_int']
int_to_char = loaded_state_dict['tokenizer']['int_to_char']causal_mask = torch.tril(torch.ones(block_size, block_size, device=device)).view(1, 1, block_size, block_size)token_embedding_table = nn.Embedding(vocab_size, d_model).to(device)
token_embedding_table.load_state_dict(loaded_state_dict['token_embedding_table'])vision_projection_layer = nn.Linear(vision_feature_dim, d_model).to(device)
vision_projection_layer.load_state_dict(loaded_state_dict['vision_projection_layer'])positional_encoding = loaded_state_dict['positional_encoding'].to(device)layer_norms_1 = []
mha_qkv_linears = []
mha_output_linears = []
layer_norms_2 = []
ffn_linear_1 = []
ffn_linear_2 = []for i in range(n_layers):ln1 = nn.LayerNorm(d_model).to(device)ln1.load_state_dict(loaded_state_dict['layer_norms_1'][i])layer_norms_1.append(ln1)qkv_dict = loaded_state_dict['mha_qkv_linears'][i]has_qkv_bias = 'bias' in qkv_dictqkv = nn.Linear(d_model, 3 * d_model, bias=has_qkv_bias).to(device)qkv.load_state_dict(qkv_dict)mha_qkv_linears.append(qkv)out_dict = loaded_state_dict['mha_output_linears'][i]has_out_bias = 'bias' in out_dictout = nn.Linear(d_model, d_model, bias=has_out_bias).to(device)out.load_state_dict(out_dict)mha_output_linears.append(out)ln2 = nn.LayerNorm(d_model).to(device)ln2.load_state_dict(loaded_state_dict['layer_norms_2'][i])layer_norms_2.append(ln2)ff1_dict = loaded_state_dict['ffn_linear_1'][i]has_ff1_bias = 'bias' in ff1_dictff1 = nn.Linear(d_model, d_ff, bias=has_ff1_bias).to(device)ff1.load_state_dict(ff1_dict)ffn_linear_1.append(ff1)ff2_dict = loaded_state_dict['ffn_linear_2'][i]has_ff2_bias = 'bias' in ff2_dictff2 = nn.Linear(d_ff, d_model, bias=has_ff2_bias).to(device)ff2.load_state_dict(ff2_dict)ffn_linear_2.append(ff2)final_layer_norm = nn.LayerNorm(d_model).to(device)
final_layer_norm.load_state_dict(loaded_state_dict['final_layer_norm'])output_dict = loaded_state_dict['output_linear_layer']
has_output_bias = 'bias' in output_dict
output_linear_layer = nn.Linear(d_model, vocab_size, bias=has_output_bias).to(device)
output_linear_layer.load_state_dict(output_dict)print("Multi-modal model components loaded successfully.")
使用加载的模型进行推理
加载模型后,咱们可以用它来进行推理。这就像是让模型根据图像和提示生成回答,就像一个超级智能的机器人一样。
def generate_with_image(image_path, prompt, max_new_tokens=50):"""Generate text response for an image and prompt"""token_embedding_table.eval()vision_projection_layer.eval()for i in range(n_layers):layer_norms_1[i].eval()mha_qkv_linears[i].eval()mha_output_linears[i].eval()layer_norms_2[i].eval()ffn_linear_1[i].eval()ffn_linear_2[i].eval()final_layer_norm.eval()output_linear_layer.eval()image = Image.open(image_path).convert('RGB')img_tensor = image_transforms(image).unsqueeze(0).to(device)with torch.no_grad():img_features_raw = vision_model(img_tensor)img_features_projected = vision_projection_layer(img_features_raw)img_id = char_to_int[img_token]prompt_ids = [char_to_int[ch] for ch in prompt]context_ids = torch.tensor([[img_id] + prompt_ids], dtype=torch.long, device=device)for _ in range(max_new_tokens):context_ids = context_ids[:, -block_size:]# [Generation logic goes here - follow the same steps as in Step 4.2]# [Logic to get next token]# [Logic to check for EOS and break]# [Logic to decode and return the result]
结语
通过这篇文章,咱们实现了一个端到端的多模态 Transformer 模型,能够处理图像和文本的组合,并生成有趣的回答。虽然这个实现比较基础,但它展示了如何将视觉和语言信息融合在一起,为更复杂的应用奠定了基础。希望这篇文章能激发你对多模态人工智能的兴趣,让你也能创造出自己的超级智能模型!
相关文章:
使用Python从零实现一个端到端多模态 Transformer大模型
嘿,各位!今天咱们要来一场超级酷炫的多模态 Transformer 冒险之旅!想象一下,让一个模型既能看懂图片,又能理解文字,然后还能生成有趣的回答。听起来是不是很像超级英雄的超能力?别急,…...
(附脚本))
elestio memos SSRF漏洞复现(CVE-2025-22952)(附脚本)
免责申明: 本文所描述的漏洞及其复现步骤仅供网络安全研究与教育目的使用。任何人不得将本文提供的信息用于非法目的或未经授权的系统测试。作者不对任何由于使用本文信息而导致的直接或间接损害承担责任。如涉及侵权,请及时与我们联系,我们将尽快处理并删除相关内容。 前言…...

倚光科技:以创新之光,雕琢全球领先光学设计公司
在光学技术飞速发展的当下,每一次突破都可能为众多领域带来变革性的影响。而倚光(深圳)科技有限公司,作为光学设计公司的一颗璀璨之星,正以其卓越的创新能力和深厚的技术底蕴,引领着光学设计行业的发展潮流…...

Linux安装Elasticsearch详细教程
准备工作 下载地址:Download Elasticsearch | Elastic 下载时需要注意es与jdk版本对应关系 ES 7.x 及之前版本,选择 Java 8 ES 8.x 及之后版本,选择 Java 17 或者 Java 18,建议 Java 17,因为对应版本的 Logstash 不支持 Java 1…...

C++字符串操作详解
引言 字符串处理是编程中最常见的任务之一,而在C中,我们有多种处理字符串的方式。本文将详细介绍C中的字符串操作,包括C风格字符串和C的string类。无论你是C新手还是想巩固基础的老手,这篇文章都能帮你梳理字符串处理的关键知识点…...

PromptPro|提示词生成和管理专家
大家好,我是吾鳴。 今天吾鳴给大家分享一个实用的提示词管理网站,它的名称叫做产品化管理提示词,英文名叫做PromptPro,是一个可以帮你管理你的大模型提示词的网站,同时你也可以告诉它你的需求,让它帮你生成…...

计算机视觉图像特征提取入门:Harris角点与SIFT算法
计算机视觉图像特征提取入门:Harris角点与SIFT算法 一、前言二、Harris 角点检测算法2.1 Harris 角点的定义与直观理解2.1.1 角点的概念2.1.2 Harris 角点的判定依据 2.2 Harris 角点检测的实现步骤2.2.1 计算图像的梯度2.2.2 构建结构张量矩阵2.2.3 …...
)
swift菜鸟教程1-5(语法,变量,类型,常量,字面量)
一个朴实无华的目录 今日学习内容:1.基本语法引入空格规范输入输出 2.变量声明变量变量输出加反斜杠括号 \\( ) 3.可选(Optionals)类型可选类型强制解析可选绑定 4.常量常量声明常量命名 5.字面量整数 and 浮点数 实例字符串 实例 今日学习内容: 1.基本…...

02142数据结构导论
初学者,怎样理解这道题,怎样大白话分析 答案解析 00、概念 29、 28、 27、 26、 25、 24、 23、 22、有5个元素,其入栈次序为:A、B、C、D、E,写出以元素C、D最先出栈(即C第一个且D第二个出栈)的各种可能的出栈次序。 (来…...

如何在AMD MI300X 服务器上部署 DeepSeek R1模型?
DeepSeek-R1凭借其深度推理能力备受关注,在语言模型性能基准测试中可与顶级闭源模型匹敌。 AMD Instinct MI300X GPU可在单节点上高效运行新发布的DeepSeek-R1和V3模型。 用户通过SGLang优化,将MI300X的性能提升至初始版本的4倍,且更多优化将…...

【Django】教程-15-注册页面
【Django】教程-1-安装创建项目目录结构介绍 【Django】教程-2-前端-目录结构介绍 【Django】教程-3-数据库相关介绍 【Django】教程-4-一个增删改查的Demo 【Django】教程-5-ModelForm增删改查规则校验【正则钩子函数】 【Django】教程-6-搜索框-条件查询前后端 【Django】教程…...

OpenAI即将上线新一代重磅选手——GPT-4.1
每周跟踪AI热点新闻动向和震撼发展 想要探索生成式人工智能的前沿进展吗?订阅我们的简报,深入解析最新的技术突破、实际应用案例和未来的趋势。与全球数同行一同,从行业内部的深度分析和实用指南中受益。不要错过这个机会,成为AI领…...

参照Spring Boot后端框架实现序列化工具类
本文参照Jackson实现序列化工具类,旨在于简化开发 JacksonUtil.class public class JacksonUtil {private JacksonUtil() {}/*** 单例*/private final static ObjectMapper OBJECT_MAPPER;static {OBJECT_MAPPER new ObjectMapper();}private static ObjectMappe…...

C_内存 内存地址概念
1. 计算机内存的基本概念 计算机的内存(RAM,随机存取存储器)是用来存储程序运行时的数据和指令的地方。内存被划分为许多小单元,每个单元有一个唯一的地址,这些地址从0开始编号。 内存单元:每个内存单元通…...

Rust重定义数据库内核:从内存安全到性能革命的破界之路
Rust语言正在颠覆传统数据库开发范式,其独特的所有权系统与零成本抽象能力,为攻克C/C时代遗留的内存泄漏、并发缺陷等顽疾提供全新解决方案。本文通过TiKV、Materialize等新一代数据库核心组件的实践案例,剖析Rust如何重塑存储引擎、查询优化…...

tree 显示到二级目录
要使用 tree 命令显示到二级目录,可以通过 -L 参数指定目录层级。具体命令如下: tree -L 2 参数说明: -L 数字:控制显示的目录深度。-L 2 表示显示到第二级目录(即当前目录下的直接子目录及其内容)。 示例输出: 复制 . ├── dir1 │ ├── file1.txt │ └─…...

UE5 在UE中创建骨骼动画
文章目录 创建动画的三种方式修改骨骼动画 创建动画的三种方式 方法一 打开一个已有的动画,左上角“创建资产/创建动画/参考姿势” 这将创建一个默认的A字形的骨骼,不建议这么做 方法二 打开一个已有的动画,左上角“创建资产/创建动画/当前…...

工业相机使用笔记
目前工业相机有多种分类方式,以下是基于不同原理和特点的类别总结: 按维度分类 2D相机: 原理:通过镜头将二维平面上的物体成像在图像传感器上,传感器上的像素点阵列捕捉物体的光信号,并转换为电信号或数字…...

深度兼容性测试和自助兼容性测试的区别,如何正确的选择?
泽众云经过几年业务快速发展,特别是泽众云兼容性测试服务已成为市场热门供应商之一,也根据用户不同需求推出了超高性价比服务,主要有深度兼容性测试和自助兼容性测试两种方式。2025年上半云真机平台的机型已升级到1000,全面覆盖了…...

Windows下安装depot_tools
一、引言 Chromium和Chromium OS使用名为depot_tools的脚本包来管理检出和审查代码。depot_tools工具集包括gclient、gcl、git-cl、repo等。它也是WebRTC开发者所需的工具集,用于构建和管理WebRTC项目。本文介绍Windows系统下安装depot_tools的方法。 二、下载depo…...

学术分享:基于 ARCADE 数据集评估 Grounding DINO、YOLO 和 DINO 在血管狭窄检测中的效果
一、引言 冠状动脉疾病(CAD)作为全球主要死亡原因之一,其早期准确检测对有效治疗至关重要。X 射线冠状动脉造影(XCA)虽然是诊断 CAD 的金标准,但这些图像的人工解读不仅耗时,还易受观察者间差异…...
——什么是 IA3 微调?)
NLP高频面试题(四十一)——什么是 IA3 微调?
随着大型语言模型的广泛应用,如何高效地将这些模型适配到特定任务中,成为了研究和工程实践中的重要课题。IA3(Infused Adapter by Adding and Adjusting)微调技术,作为参数高效微调的一种新颖方法,提供了在保持模型性能的同时,显著减少可训练参数数量的解决方案。 IA3 …...

STM32 模块化开发指南 · 第 3 篇 环形缓冲区 RingBuffer 模块设计与单元测试
本文是《STM32 模块化开发实战指南》第 3 篇,聚焦于“如何设计一个高性能、稳定、安全的环形缓冲区模块”。我们将从基本结构讲起,逐步完成接口定义、边界处理、API 实现与单元测试,最终实现一个可移植、线程安全、可嵌入 UART/BLE/协议模块的通用 RingBuffer。 一、RingBuf…...

软件测试岗位:IT行业中的质量守护者
在当今数字化飞速发展的IT行业,软件如同空气般无处不在,从日常的手机应用到复杂的企业级管理系统,软件的稳定性和可靠性至关重要。而软件测试岗位的从业者,就像是软件世界的质检员,精心守护着软件的质量。 一、软件测…...

单片机方案开发 代写程序/烧录芯片 九齐/应广等 电动玩具 小家电 语音开发
在电子产品设计中,单片机(MCU)无疑是最重要的组成部分之一。无论是消费电子、智能家居、工业控制,还是可穿戴设备,小家电等,单片机的应用无处不在。 单片机,简而言之,就是将计算机…...

恐龙专利及商标维权行动,已获批TRO并冻结资金
2025年3月30日,原告Shenzhen xingyin technology co.,Ltd.,现化名为Shenzhen Z Tech Co., Ltd.委托kemet律所发起维权。目前该案件已获批TRO临时禁令,涉案账户资金已被冻结,案件详情如下: 案件基本情况:起…...

【北京市小客车调控网站-注册/登录安全分析报告】
前言 由于网站注册入口容易被黑客攻击,存在如下安全问题: 暴力破解密码,造成用户信息泄露短信盗刷的安全问题,影响业务及导致用户投诉带来经济损失,尤其是后付费客户,风险巨大,造成亏损无底洞…...

Vue 3中的 setup
Vue 3引入了Composition API,其中setup函数是这一新API的核心部分。setup函数为开发者提供了一种更灵活、更模块化的方式来组织组件逻辑。以下是关于Vue 3中setup函数的详细解释: 1. 基本概念 setup函数是组件内使用Composition API的入口点。它是一个…...

2025年实用新型专利审查周期要多久?
申请实用新型专利时,审查周期是申请人最关心的问题之一。尤其是近几年国家知识产权局不断优化流程,审查速度是否有变化?2025年申请需要等多久?本文结合最新政策和实际案例,为你全面解析! 一、实用新型专利…...

使用Python建立双缝干涉模型
引言 双缝干涉实验是物理学中经典的实验之一,它展示了光的波动性以及量子力学的奇异性。实验结果表明,当光或粒子通过两条狭缝时,它们会产生干涉现象,形成明暗相间的条纹图案。这种现象不仅说明了光的波动性,还揭示了量子力学的核心思想——粒子具有波动性。今天,我们将…...

路由交换网络专题 | 第二章 | RIP | OSPF | 路由聚合 | 路由过滤 | 静默接口
拓扑图 (1)作为企业网络边界设备,AR1 上配置什么命令,可以使 OSPF 域内所有路由都会有指向自己的默认路由。默认路由的优先级是多少。如果 OSPF 域内其他路由器同样有到达外网的路径,且优于通过 AR1 到达外网ÿ…...

python 语言 设计模式
python 语言 设计模式 设计模式是指在软件开发过程中,针对反复出现的问题所总结归纳出的通用解决方案。以下是一些常见的Python语言设计模式: 目录 python 语言 设计模式创建型模式结构型模式行为型模式创建型模式 单例模式 定义:保证一个类只有一个实例,并提供一个全局访…...

银行业务发展历史
银行业务发展历史 银行业务的发展可以追溯到古代,但其现代形式的发展可以追溯到中世纪。以下是银行业务发展的主要历史阶段: 1. 古代和中世纪时期 特点:商人提供贷款和存款服务,充当中间人转移资金,发行纸币作为支付…...

JAVA中多线程的基本用法
文章目录 一、基本概念(一)进程控制块PCB(二)并行和并发(三)进程调度1.进程的状态2.优先级3.记账信息4.上下文 (四)进程和线程1.概述2.线程为什么比进程更轻量3.进程和线程的区别和联…...

健康与好身体笔记
文章目录 保证睡眠饭后百步走,活到九十九补充钙质一副好肠胃肚子咕咕叫 健康和工作的取舍 以前对健康没概念,但是随着年龄增长,健康问题凸显出来。 持续维护该文档,健康是个永恒的话题。 保证睡眠 一是心态要好,沾枕…...
)
如何下载谷歌浏览器增强版(扩展支持版)
在日常浏览和工作中,Chrome 浏览器因其强大的性能和丰富的扩展插件,成为全球范围内使用最广泛的浏览器之一。然而,对于需要进行深度扩展管理或需要稳定扩展环境的用户来说,标准版的 Google Chrome 可能在某些方面仍显不足。这时候…...

TDDMS分布式存储管理系列文章--分片/分区/分桶详解
友情链接: 星环分布式存储TDDMS大揭秘(一)分布式存储技术推出背景以及当前存在的挑战TDDMS是什么 前情提要 通过上个系列的文章我们了解到了各节点数据副本间通过一致性算法确保每次写入在响应客户端请求之前至少被多数节点(N/2…...
:集成SSE (Server-Sent Events) 服务器实时推送)
Spring Boot(九十):集成SSE (Server-Sent Events) 服务器实时推送
1 SSE简介 Server-sent Events(SSE) 是一种基于 HTTP 协议的服务器推送技术,它允许服务器主动向客户端发送数据。与 WebSocket 不同,SSE 是单向通信,即服务器可以主动向客户端推送数据,而客户端只能接收数据。 2 SSE特点 单向通信:SSE 是服务器向客户端的单向推送,客户…...

ubuntu22.04安装ROS2 humble
参考: https://zhuanlan.zhihu.com/p/702727186 前言: 笔记本安装了ubuntu20.04安装ros一直失败,于是将系统升级为ununut22.04,然后安装ros,根据上面的教程,目前看来是有可能成功的。 系统升级为ununut…...

力扣第206场周赛
周赛链接:竞赛 - 力扣(LeetCode)全球极客挚爱的技术成长平台 1. 二进制矩阵中的特殊位置 给定一个 m x n 的二进制矩阵 mat,返回矩阵 mat 中特殊位置的数量。 如果位置 (i, j) 满足 mat[i][j] 1 并且行 i 与列 j 中…...

C++17 主要更新
C17 主要更新 C17 是继 C14 之后的重要标准更新,引入了许多提升开发效率、简化代码和增强性能的特性。以下是 C17 的主要更新,按类别分类: 1. 语言核心特性 结构化绑定(Structured Bindings) 解构元组、结构体或数组…...

k8s master节点部署
一、环境准备 1.主机准备 192.168.10.100 master.com master 192.168.10.101 node1.com node1 192.168.10.102 node2.com node2 互信 时间同步 关闭防火墙 关闭selinux 2.创建/etc/sysctl.d/k8s.conf,添加如下内容 cat > /etc/sysctl.d/k8s.conf <<EOF net.br…...
)
YOLO学习笔记 | YOLOv8 全流程训练步骤详解(2025年4月更新)
===================================================== github:https://github.com/MichaelBeechan CSDN:https://blog.csdn.net/u011344545 ===================================================== 这里写自定义目录标题 一、数据准备1. 数据标注与格式转换2. 配置文件生…...

centos7.9 升级 gcc
本片文章介绍如何升级gcc,centos7.9 仓库默认的gcc版本为:4.8.5 4.8.5-44) Copyright (C) 2015 Free Software Foundation, Inc. This is free software; see the source for copying conditions. There is NO warranty; not even for MERCHANTABILITY…...

Linux基本指令
Linux目录结构 Linux的目录结构是一个树形结构。Windows系统可以拥有多个盘符,如C盘、D盘、E盘。而Linux没有盘符这个概念,只有一个根目录/,所有文件都在它下面。如下图所示: Linux路径的描述方式 在Linux系统中,路径之间的层级…...

Google A2A协议,是为了战略性占领标准?
一、导读 2025 年 4 月 9 日,Google 正式发布了 Agent2Agent(A2A)协议。 A2A 协议致力于打破智能体之间的隔阂,让它们能够跨越框架和供应商的限制,以一种标准化、开放的方式进行沟通与协作 截止到现在,代…...
暴力娱乐篇29)
每日一题(小白)暴力娱乐篇29
题目比较简单,主要是判断条件这块,一定要注意在奇数的位置和偶数的位置标记,若奇数位为奇数偶数位为偶数才能计数加一,否则都是跳过。 ①接收数据n ②循环n次,拆解n,每次拆解记录ans ③拆解n为若干次x&a…...

瀚天天成闯港交所上市:业绩波动明显,十分依赖少数客户和供应商
撰稿|张君 来源|贝多财经 近日,瀚天天成电子科技(厦门)股份有限公司(下称“瀚天天成”)递交招股书,报考港交所主板上市。据贝多财经了解,瀚天天成曾计划在上海证券交易所科创板上市࿰…...

全国产压力传感器常见的故障有哪些?
全国产压力传感器常见的故障如哪些呢?来和武汉利又德的小编一起了解一下,主要包括以下几类: 零点漂移 表现:在没有施加压力或处于初始状态时,传感器的输出值偏离了设定的零点。例如,压力为零时,…...
基础:从LeNet到ResNet)
计算机视觉卷积神经网络(CNN)基础:从LeNet到ResNet
计算机视觉卷积神经网络(CNN)基础:从LeNet到ResNet 一、前言二、卷积神经网络基础概念2.1 卷积层2.1.1 卷积运算原理2.1.2 卷积核的作用与参数 2.2 池化层2.2.1 最大池化与平均池化2.2.2 池化层的优势与应用 2.3 全连接层2.3…...