基于混合编码器和边缘引导的拉普拉斯金字塔网络用于遥感变化检测
Laplacian Pyramid Network With HybridEncoder and Edge Guidance for RemoteSensing Change Detection
0、摘要
遥感变化检测(CD)是观测和分析动态土地覆盖变化的一项关键任务。许多基于深度学习的CD方法表现出强大的性能,但它们的有效性受到编码器选择和准确划定变化区域边缘的挑战的影响。在本文中,我们提出了一种混合编码器和边缘引导的拉普拉斯金字塔网络(HE-LPNet)来解决这些问题。具体来说,混合编码器结合了卷积神经网络和变压器的优势,从而提取出更细粒度的特征。同时,混合编码器结合了视觉基础模型,从而增强了整体模型的泛化。 除了特征提取,图像被处理以生成拉普拉斯金字塔,然后与混合编码器提取的特征融合,以增强像素级的显着特征。在解码器阶段,加权引导注意力被设计为选择性地将通道和空间注意力应用于融合特征,提高网络区分变化区域的能力。此外,我们提出了边缘引导损失来捕获变化区域的边缘信息。为了验证所提出的HE-LPNet的有效性,在三个高分辨率遥感CD数据集上进行了广泛的实验。实验结果表明,我们的方法优于其他最先进的CD方法。
索引术语-变化检测(CD)、边缘引导、混合编码器、拉普拉斯金字塔(LP)、遥感(RS)imag
1、引言
遥感变化检测的目的是识别同一地理区域在不同时间段[1]、[2]拍摄的两幅图像之间的变化,这一过程在火灾检测、环境监测[3]、灾害监测[4]、城市变化分析[5]和土地管理[6]等不同领域具有重要意义。然而,由于光照变化、配准错误、对象比例变化和类别不平衡等各种不利条件,处理这项任务是具有挑战性的。 因此,已经提出了许多方法来缓解这些问题,包括使用先进的深度学习技术[7]。
近年来,卷积神经网络(CNN)在计算机视觉[8]、[9]、[10]以及遥感CD[11]、[12]、[13]、[14]、[15]、[16]、[17]等领域得到了广泛的应用。大多数CD方法依赖于联合国技术评估委员会[11]或其各种改编[13]、[15]、[18]。与传统方法相比,这些方法具有多种优势,例如更高的精确度、增强的降噪能力和更好的泛化能力[19]。同时,在自然语言处理领域,基于自我注意机制的转换器[20]也取得了显著的成功。视觉转换器(VIT)[21]代表了将变压器编码器应用于图像分类领域的第一次尝试,展示了与传统CNN方法相当的性能。该转换器具有远程信息交互和语义表示能力,已在CD中得到应用。双时相图像转换器(BIT)[22]代表了将该转换器应用于遥感CD的开创性工作,它使用双时相转换器来捕获时空上下文。随后,许多变压器架构,如SwinSUNet[23]、ChangeFormer[24]、TransUNetCD[25]和轻量级结构感知转换器(LSAT)[26]被提出以应对遥感CD的挑战,表现出稳健的性能。
近年来,视觉基础模型在计算机视觉领域引起了广泛的关注。一个值得注意的例子是任意分割模型(SAM)[27],这是一个视觉基础模型,以其在图像分割中的卓越性能而闻名。SAM独特的设计使其能够在用户提供的提示指导下,准确地分割图像中任何特定的感兴趣对象,从而提供更高的灵活性和适应性。SAM独特的架构有助于跨不同场景进行更准确的细分,超越了专业模型的能力。虽然SAM在自然图像上表现出稳健的性能,但最近的研究表明,当应用于遥感图像时,其有效性有所下降[28]。这一下降是由于自然图像和遥感图像之间的数据域差距很大,导致遥感领域内不同数据集和模式的分割性能不一致。虽然在遥感领域已经提出了几种基于SAM的方法[28],[29],其在遥感CD背景下的充分探索仍然不完整。
现有的CD遥感方法具有一定的解决问题的能力,但仍存在一些不足之处,需要进一步探索。首先,如图1所示,高分辨率遥感图像中变化目标的大小差异很大,从汽车这样的微小变化到农田等更大的变化。然而,现有的大多数CD方法只使用基于CNN或转换器体系结构的特征提取,这带来了一些挑战。基于CNN的方法中卷积的局部化性质限制了它们捕获远程依赖关系的能力。由于其有限的空间范围,小的卷积核将网络的注意力引导到局部特征上,无意中将广泛的全局特征降级为次要位置。对于遥感CD,由于变化区域的大小变化很大,可靠的检测需要远距离的全球信息。虽然基于转换器的方法擅长对长期依赖关系进行建模,但它们往往通过将图像转换为一维符号来忽略空间信息。尽管在Transformers中包含了位置编码,但这些方法在实现稳健的局部特征学习方面仍然面临挑战,并且无法捕获多尺度通道特征依赖。因此,有必要探索CNN和Transform在特征提取中的结合,以发挥它们各自的优势。其次,尽管目前的遥感图像表现出足够的清晰度,但与自然图像相比,它们仍然存在不足。这一不足之处使准确划定变化区边界变得复杂。一些文献[30]、[31]、[32]使用多层特征融合来应对这一挑战。然而,如前所述,仅依靠CNN或变换作为特征提取工具是有缺点的,特别是在提取特征时没有充分考虑边缘信息。因此,这些方法不能提供全面的解决方案。
为了解决上述问题,在本文中,我们提出了一种具有混合编码器的拉普拉斯金字塔(LP)网络和边缘引导(HE-LPNet)。具体来说,我们首先提出了一种高效的混合编码器,它将CNN的强感应偏差与多尺度注意力(MSA)和Transform的标记化注意力相结合。这使得能够从不同方面聚合特征提取能力。为了利用VFM对于CD的能力,同时保留足够的可学习参数(Params)以促进域适配,我们采用MobileSAM[34]作为混合编码器中的transformer模块。MobileSAM是SAM的提炼版本。在特征提取之后,还对原始的双时间图像进行处理以获得LP[35]。 LP在不同层次上保留了图像的像素级显著特征。通过将显著特征与编码器提取的特征相结合,可以更好地恢复变化的细节。此外,加权引导注意力(WGA)被设计用于选择性地将通道和空间注意力应用于融合特征,进一步细化变化目标的定位。最后,采用边缘引导损失来约束变化区域的边界,从而使变化形状的过渡更加平滑,提高检测精度。本文的主要贡献如下。
1)我们提出了一种混合编码器,它结合了CNN的感应偏差和变压器的远程依赖性来增强特征表示。同时,混合编码器集成了MobileSAM以提高模型的泛化能力。
2)我们使用LP在双时间图像中获得像素级显着特征,这有助于补偿变化目标的详细信息。
3)在解码器阶段,WGAis设计基于不同目标的加权来实现注意力,使模型能够更准确地定位变化区域。
4)利用边缘引导损失来约束变化区域的边界,便于检索具有平滑边缘的变化建筑物的形状和细节
本文的其余部分组织如下。第二节提供了最相关研究的简明概述。第三节详细介绍了提议的HE-LPNet。第四节对实验结果、讨论和模型评估进行了全面分析。第五节对本文提出的方法进行了批判性探索。最后,第六节对本文进行了总结。
二、相关工作
A.基于深度学习的CD方法
为了解决不相关的变化和复杂的对象,最近研究的很大一部分旨在提高CNN的泛化能力。U形架构,尤其是编码器-解码器结构,因其有效的上下文建模能力而在遥感CD中很受欢迎。Daudt et al.[11]通过对双时态图像的输入法和跳过连接的探索,介绍了三种不同的基于U-net的模型,即FC-早期融合(EF)、FC-Siam-conc和FC-Siam-diff。在遥感CD中,确定不断变化的对象的大小具有挑战性。因此,使用不同大小的感受野进行变化识别至关重要。雷等人[30]引入了一个金字塔池模块,该模块巧妙地集成了来自多个卷积层的特征,有效地探索了图像上下文。该模块在更广泛的感受野和上下文的有效利用之间取得了平衡,从而提高了性能。侯等人[19]设计了一个动态初始模块,将时间数据合并到光盘中。Chen等人[31]设计了一个非局部特征金字塔网络,用于有效提取和融合多尺度特征。为了稳健地融合双时间特征,他们构建了一个基于密集连接的特征融合模块。 雷等人[32]精心设计了一种解耦卷积方法,该方法巧妙地抓住了改变实体的多尺度特征,采用循环机制进行多尺度特征提取。黄等人提出了SEIFNet[36],该方法为时空差异增强模块设计了一种双分支结构,以捕捉双时空图像的变化特征。通过自适应上下文融合模块,SEIFNet集成了层间特征,以更好地重建详细的对象信息。此外,探索并实施了许多策略来拓宽接受领域,包括采用更深层次的网络架构[37],利用扩张卷积技术[38],以及结合多样化的注意力机制[14],[16],[37],[39]。
凭借惊人的语义表示能力,Transform[20]在各种CV任务中匹配或超过CNN的性能。这些任务包括图像分类[21]、[40]、[41]、目标检测[42]、语义分割[40]、[42]、图像生成[43]、[44]和超分辨率[45]、[46]。Chen等人提出了BIT[22],用于对时空上下文进行高效和有效的建模。该模型包括一个具有变压器编码器和两个变压器解码器的轻量级结构。Song等人[47]利用一系列swin-变压器[41]模块为每个图像合成从CNN获得的多级特征图。 他们随后计算双时间图像之间的差异特征。Zhang et al.[23]引入了SwinSUNet,这是一个包含编码器、融合器和解码器的框架,所有这些组件都使用swin转换器[41]块作为其基本单元。Bandara等人引入了ChangeForm[24],这是一种在暹罗架构的上下文中融合分层变压器编码器和多层感知器(MLP)解码器的模型。这样的集成框架擅长捕捉复杂的多尺度和远程细节,这对于精确执行CD任务至关重要。雷等人[26]提出了LSAT,其中包括一个具有线性复杂性的跨维度交互式自我注意模块,以减少计算负担。 他们还引入了结构感知增强模块,用于细化差分特征和聚合细节,实现双时空遥感图像的双重增强。
然而,上述大多数方法中的特征提取器主要基于CNN或变压器架构,这导致提取的特征具有不可避免的缺陷。我们提出了一种混合编码器,将CNN的感应偏差与变压器的远程依赖相结合,以增强特征表示。
近年来,遥感图像分辨率的提高使得更多特征的检测成为可能,从而对CD模型的准确性提出了更高的要求。变化区域的边缘检测已经成为一个紧迫的挑战。HFANet[48]通过利用高频信息来增强特征定位并提高变化边界的准确性来解决这一问题。类似地,白等人[49]提出了EGRCNN,这是一种深度学习框架,将边缘估计与建筑变化预测相结合,以实现精细的边缘检测。然而,现有的边缘检测方法倾向于增加模型复杂性,同时努力解决噪声放大和泛化受限等问题。 我们提出的边缘引导损失使用预测映射和标签映射直接计算损失,从而减少计算开销,同时提供显着的性能改进。
B.拉普拉斯金字塔
LP[35]是图像处理中成熟的算法。LP方法的核心概念需要将图像线性解剖成一系列高低频分量,从而允许精确重建原始图像[35]。在尺寸为h×w的任意图像I0的情况下,LP通过计算低通预测I1😍R h 2×w 2来启动。此计算中的每个像素代表其相邻像素的加权平均值,由固定内核确定。为了实现可逆重建,LP记录高频残差h0=I0−^I0,其中^I0表示从I1导出的上采样图像。 为了进一步降低采样率和图像分辨率,LP顺序地将这些操作应用于I1,从而产生一系列高低频分量。LP已经在各种低级任务中展示了与神经网络结合的成功。一些研究人员从其巧妙的结构中汲取灵感,将其整体架构或特定的分解组件与深度学习技术相结合。示例包括超分辨率[50]、深度估计[51]和样式转换[52]中的应用。我们的目标是利用LP中固有的像素级显着性特征来增强变化目标的详细信息,并实现更精细的CD。
C.视觉基础模型
利用大规模模型作为各种专门任务的基础是当代机器学习中的一种常见策略。这种方法利用了大量的数据集,并利用了丰富的计算资源,使各种任务都有了显著的进步。著名的模型,如来自转换器的双向编码器表示[53]、生成式预先训练的转换器和SAM[27],在针对文本分类、对象检测和语义分割等特定任务进行微调时已被证明是非常有效的。这些模型利用迁移学习的好处,允许将学习的特征应用于新任务,并减少对大量数据和计算资源的需求。
SAM作为一种视觉基础模型脱颖而出,因其在图像分割方面的卓越表现而得到认可。为了将SAM应用于在遥感应用方面,已有相当多的研究人员进行了尝试。Chen等人[28]介绍了RS提示器,这是一个从编码器的中间层提取特征以构成提示器输入的模型。提示器生成包含语义类别信息的提示。丁等人[29]提出了SAM-CD,它使用冻结的Fast-SAM[54]作为编码器,并进一步完善了专门为CD量身定做的多级特征提取和结果预测组件。在本文中,我们将Mobile-SAM[34]整合到混合编码器中,以利用VFM的健壮性能并增强模型的泛化能力。
三、方法
A.体系结构概述
本文提出的HE-LPNet是一个端到端的共享权重遥感CD深度学习网络,其总体结构如图2所示。
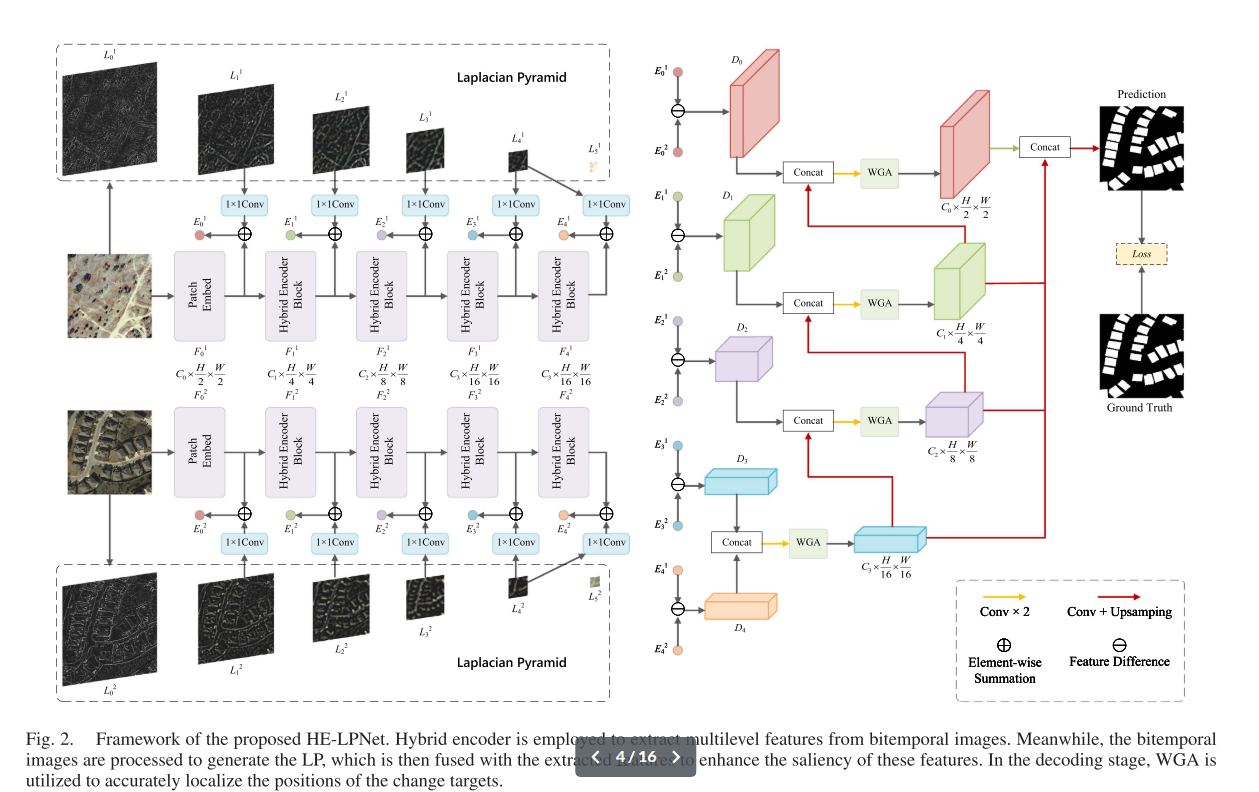
图2.所提出的HE-LPNet框架。混合编码器用于从双时态图像中提取多级特征。同时,对双时态图像进行处理以生成LP,然后将其与提取的特征融合以增强这些特征的显着性。在解码阶段,利用WGA准确定位变化目标的位置
具体来说,在编码阶段,我们将双时空遥感图像馈送到混合编码器中以提取多尺度特征。遵循UNet[11]的设计,混合编码器的结构由四个阶段组成。给定输入图像T1、T2😍RC×H×W、C、H和W分别表示图像的通道数、高度和宽度。遵循ViT[21],使用卷积词干进行补丁嵌入,该词干由两个卷积层实现。这得到的输出,表示为F1 0,F2 0😍RC0×H 2×W 2,然后通过混合编码器的四个阶段进行处理以获得层次特征。鉴于遥感图像的分辨率与标准图像相比明显较低,最后阶段取消了下采样操作,以保持输出特征分辨率与第三阶段一致。在这些阶段,特征图的空间分辨率相对于初始输入分辨率依次降低到{1/4,1/8,1/16,1/16}的比例。 我们将Stastei的输出表示为F1 i,F2 i😍RCi×H 2i+1×W 2i+1,i😍{1,2,3},F1 4,F2 4的输出维数为相同的F1 3,F2 3。同时,对双时相遥感图像进行处理,生成LP,表示为L1 i,L2 i,i😍{0,1,2,3,4,5}。随后,将金字塔图像的各个级别与混合编码器输出特征的不同级别融合,以获得增强特征E1 i,E2 i,i😍{0,1,2,3,4}。
在解码阶段,我们采用特征差分方法,对来自两个不同时间段的增强特征进行元素减法运算,然后进行赦免运算,得到表示为Di, i😍{0,1,2,3,4}的时间差分特征。时间差分特征将从深层到浅层进行级联和上采样。然后将级联特征的每一层输入到WGA中,以精确定位变化目标。每一层的结果特征也被均匀上采样以匹配最浅特征的维度,完成最终预测。
B.混合编码器
卷积的内在局限性在于它的内在局部性,使其不足以建模长期依赖关系。此外,变压器产生的单尺度特征仅依赖于标记化注意力,忽略了相互关系。因此,这种方法被证明不足以有效处理遥感图像中涉及多尺度区域的情况。为了解决上述挑战,我们引入了一种混合编码器,它包括一个MSA块、一个卷积块和一个变压器块,如图3所示。
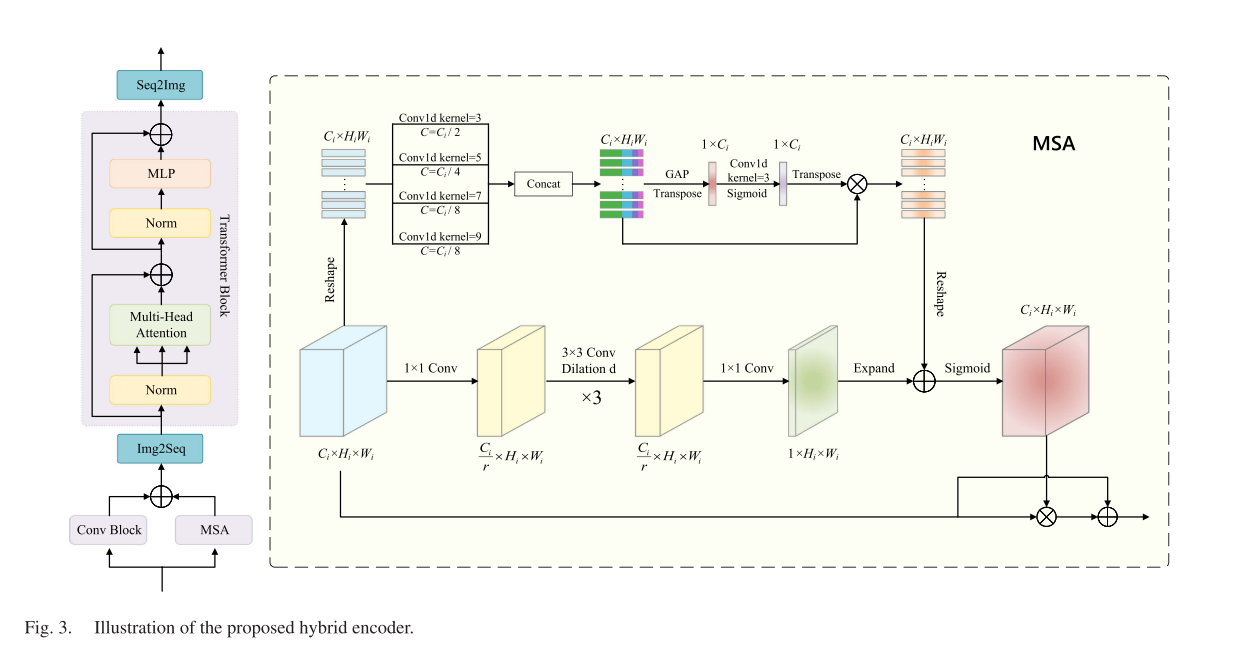
1)多尺度注意力:提出的MSA用于补充卷积和转换器块未捕获的部分信道和空间依赖关系。
对于通道注意力分支,对输入特征Fi进行初始重构,得到F i😍RCi×HiWi,F i随后进行不同核大小的一维卷积运算,以提取不同感受野下的通道信息。由于遥感图像中特征的分辨率较低,低级感受野包含了广泛的信息。我们为shallowhigh-resolution特征建立了四个不同尺度的卷积块。同时,我们将卷积块的输出通道设置为Ci/2、Ci/4、Ci/8、Ci/8,作为权重。这种设计使通道注意力能够集中在局部信息和广泛的信息上,如图3所示。 对于剩余的低分辨率特征图,我们建立核大小为1和3的两尺度卷积块,以及输出通道Ci/2、Ci/2。不同卷积块的输出随后被级联以获得Fm i,过程可以表述为
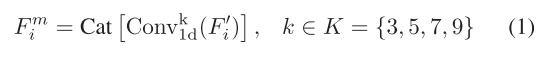
其中,Convk 1d(·)表示核大小为k的一维卷积,而Cat[·]表示特征级联操作。级联的通道特征FMi经历全局平均池的初始步骤,随后进行转置。随后,我们使用大小为3的核进行一维卷积,然后用Sigmoid函数激活输出。最后,在转置后,与FM i进行逐个元素的乘法,以获得最终的信道关注度FC i。这一过程可以描述为
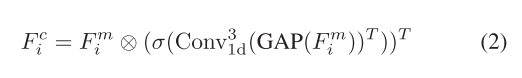
其中,GAP(·)表示全局平均池化运算,(·)T表示转置运算,σ(·)表示Sigmoid函数,⊗表示元素乘法。
空间注意力分支主要作为一个额外的补充,为更大的感受野提供空间信息。这是必不可少的,因为与MSA平行的卷积块提取丰富的局部信息。输入特征Fi首先通过1×1卷积进行压缩,以减少通道数,从而产生Fp i😍R Ci r×Hi×Wi。随后,压缩特征进行3×3卷积,膨胀值为ofd,以提取空间信息。该步骤重复三次。在上述每个卷积之后,应用批量归一化和整流线性单元(ReLU)激活。最后,采用1×1卷积获得最终的空间注意力Fs i。 这个过程可以表示为
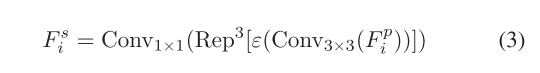
其中Conv3×3(·)和Conv1×1(·)分别表示3×3和1×1卷积层,. ε(·) 表示批量。规范化和ReLU激活。Repi[·]表示重复相同的操作i次。
在获得通道注意Fc i和空间注意Fi后,由于这两个注意图的形状不同,我们分别进行了整形和扩展操作,以恢复RCI×Hi×Wi的两个注意。随后,通过元素求和和Sigmoid运算,我们将两者结合起来,得到了MSAˆFi。最后,我们在原始输入特征Fi和MSAˆFi之间执行逐个元素的乘法。然后将得到的结果与原始输入特征通过元素求和进行组合,得到最终的输出特征FMSA i。这一过程可以用公式表示
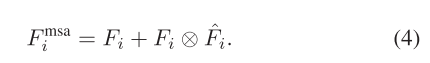
2)卷积块:利用卷积块提取局部空间特征,对空间信息进行编码。为了实现这一目标,混合编码器采用原始的ResNet-18[8]结构作为卷积块。具体地,输入特征Fi被馈送到现有卷积层中,从而产生具有编码的位置信息的局部特征Fi。
3)转换器块:转换器块采用堆叠的自我关注层,在全局语义信息建模方面具有优势,使其能够捕获长期依赖关系。为了将来自卷积块的局部提取的空间信息和来自MSA的注意信息输入到变换器块中,我们使用逐个元素求和的方法将多尺度特征FMSA i和局部内容特征Fl i整合在一起,然后将它们转换成序列形式作为变换器块的输入。这个过程可以表示为
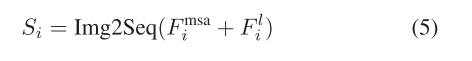
其中,Img2Seq表示将特征映射转换为一维序列的整形操作。遵循[20]中概述的架构,每个变压器模块通常由一个多头自关注(MHSA)模块和一个包含两个线性变换和高斯误差线性单元[55]激活的MLP网络组成。在各模块运行前,先进行层归一化(LN),各模块之间通过残差连接架构连接。对最终的特征序列进行变换,得到输出特征Fi+1,I级变换模块表示为
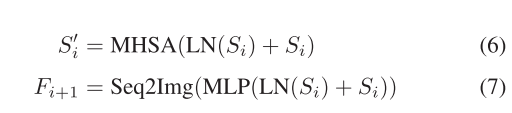
其中Seq2Img表示Img2Seq的反向操作。我们的变压器块是MobileSAM[34]使用的TinyViT[56],其中MobileSAM是从SAM[27]中提炼出来的。由于TinyViT中的参数较少,即使利用预训练的MobileSAM模型,也可以对整个模型进行端到端训练,而无需冻结模块进行额外的微调。这赋予了VFM强大的泛化能力,有助于更精确地提取CD所需的特征。
C. LP功能增强
如第II-B节所述,LP可以捕获图像的高频和低频分量,包括图像中不同域的属性。在这种情况下,图像的亮度和颜色信息表现在低频分量中,而内容细节与高频分量相关联。在遥感图像编码中,变化与图像的内容细节联系更紧密,而亮度和颜色包含的信息量较少,对图像编码的影响有限,因此我们利用LP高频信息中包含的像素级显著特征来补充混合编码器在不同层次上提取的特征。这反过来又使模型能够实现对变化区域的更精细的分割。
以输入图像T1为例,如图2所示,在将该图像送入混合编码器以提取多尺度特征的同时,还将其分解为LP,从而产生表示高频分量的集合High1=[L1 0, L1 1,L1 2,L1 3,L1 4]和表示低频分量的集合L1 5。High1的分量分辨率从H×W逐渐降低到H 16×W 16。根据[35],High1在垂直方向上高度去相关,大多数像素强度接近0,除了细节纹理保留了重要值。 我们利用高频集High1中对应于多尺度特征F1 i分辨率的分量。首先,我们使用1×1卷积压缩High1的通道。随后,经过与可学习的自适应参数Pj相乘,并与混合编码器提取的特征进行元素求和,我们得到了增强特征E1 i。这个过程可以表示为
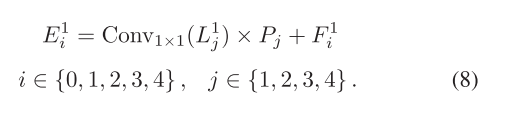
注意,在上述方程中,当i设置为0时,j应该设置为1,依此类推。由于F1 4与F1 3具有相同的维度,F1 4仍然对应于L1 4和P4
D.权重引导的注意力
来自不同层次的特征封装了独特的信息。然而,如果没有适当的指导,多层特征的融合可能会导致信息干扰,从而影响检测性能。我们提出了加权遗传算法,它根据每个通道在空间维度上的标准差为每个像素分配不同的权重,以实现选择性注意,如图4所示。具体地说,给定串联和融合的特征DF I∈RCI×Hi×Wi,I∈{0,1,2,3},首先对该特征进行重塑以获得D I∈Rci×HiWi。随后,沿着展平的空间维度计算标准差,然后应用Sigmoid运算来为每个通道分配相应的权重,从而产生W∈RCI。这一过程可以用公式表示
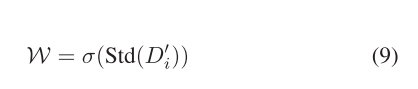
其中,std(·)表示标准差运算。然后,W首先被扩展以匹配Df i的维度,以获得Wˆ。然后,在Wˆ和df i之间执行逐个元素的乘法,并且结果被逐个元素地与df i相加,从而得到权重引导特征dg i。这一过程可以用公式表示
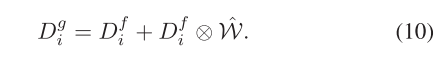
权重引导的特征Dg i将被馈送到不同的分支中,以获得通道注意力和空间注意力。对于通道注意力分支,Dg i首先进行全局平均池化并扁平化。然后,它经历一个线性层,将通道数压缩到CθR Ci r。C然后通过两个线性层,而不改变通道数和一个线性层,将通道数恢复到Ci,导致最终的通道注意力Dgc i。除了最后一个线性层,在每个线性层之后应用批量归一化和ReLU激活。该过程可以制定为
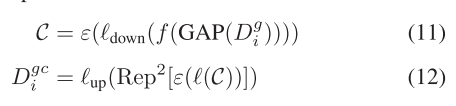
其中f(·)表示平坦操作。(·)表示线性层,而up(·)和down(·)分别表示通道数的增加和减少。
对于空间注意力分支,Dg i最初通过1×1卷积压缩,以将通道减少到Ci r,从而产生Dgr i。随后,将压缩后的特征馈送到四个并行的3×3卷积层中,每个卷积层的输出通道为Ci 4r。这些卷积层的膨胀值分别设置为1、2、3和4。这些卷积层被用来整合来自不同感受野的特征。沿着通道维度连接来自四层的输出,并通过1×1卷积获得最终的空间注意力Dgs i。 除最后1×1卷积层外,在每个卷积层之后应用批量归一化和ReLU激活。该过程可以制定为
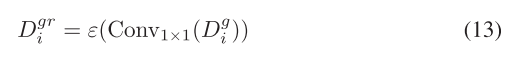
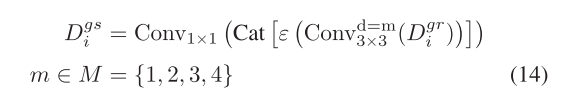
其中Convd=m 3×3(·)表示具有膨胀值m的3×3卷积层。
我们以类似于MSA的方式获得最终的输出特征。将通道注意力Dgc i和空间注意力Dgs i扩展到RCi×Hi×Wi,并使用sigmoid的元素求和获得注意力特征Dgg i。最后,我们通过以下表达式获得输出特征Dwga i
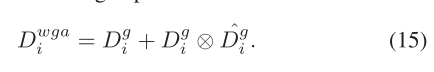
E.损失函数
1)边缘引导损失:虽然我们使用LP来补充像素级显着性特征,但图像的形状细节在编码过程中不可避免地丢失。因此,在[57]的激励下,我们开发了一种边缘引导损失,以增强对变化边缘的关注,从而准确地分割变化区域。具体来说,我们首先计算预测图像和地面实况之间相对于它们对应的局部最大池化结果的差异,该操作增强了两者的边缘信息。随后,我们计算了上述结果之间的L2距离,以实现约束并减少它们之间的差异。边缘引导损失可以表示为
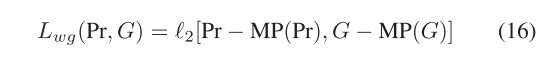
其中,MP(·)表示最大合并操作,2[·]表示L2距离。PR表示预测的变化图,而G表示相应的地面事实。
2)二值交叉熵(BCE)损失和骰子损失:在遥感CD中,网络的训练面临着显著的类不平衡问题,其中负像素数远远超过正像素数。这种不平衡会导致不充分的优化,使网络容易陷入目标函数的局部极小值。为了解决这个问题,我们使用了BCE Lbce和Dice Lost。
BCE损失可以表述为
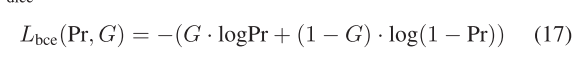
其中·表示点积操作。骰子损失可以表示为
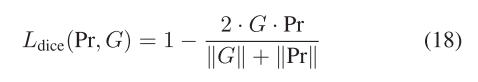
其中·表示1范数。
最终的损失函数是通过对上述三个损失函数求和得到的
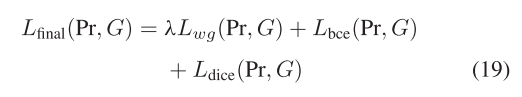
四、实验
在我们的实验中,我们使用了三个用于遥感CD的标准数据集。这些数据集的综合详细信息如下 。
1)学习、视觉和遥感(LEVIR-CD):该数据集包含从Google Earth API获得的637对图像对,每张图像的大小为1024×1024像素,空间分辨率为0.5 m。数据集的主要焦点是建筑物的变化,包括新建和毁坏的建筑物。我们将图像裁剪成大小为256×256的不重叠补丁。因此,LEVIR-C分别为训练、验证和测试阶段使用7120、1024和2048对图像补丁[58]。
2)中山大学(SYSU-CD):该数据集包含20000对双时空遥感图像块,每个块的空间尺寸为256×256,空间分辨率为0.5 m,用于训练、验证和测试的官方分割设置为6:2:2的比例,该数据集涵盖了广泛的各种复杂变化情景,包括道路扩张、新的城市结构的出现、植被的改变、郊区的增长以及建设项目的准备基础工作等实例[16]。
3)季节变化检测(SVCD):该数据集由从Google地球获得的七对季节变化图像组成,其空间分辨率从每像素3到100厘米不等。该数据集侧重于不包括季节变化的物体变化。为了便于训练,原始图像被分成小块,每个块测量256×256,并应用随机旋转。以这种方式,该数据集总共包含16000对图像对,其中10000对用于训练,3000对用于验证,3000对用于测试[33]。
B.实验设置
1)实施细节:建议的HE-LPNet使用PyTorch框架[59]实施,并从头开始训练。我们采用了一套数据增强策略来输入图像,包括随机水平翻转、选择性裁剪和时间洗牌。我们使用Adam优化器[60]训练我们的网络,动量为0.9,权重衰减为0.0001,Paramsβ1,β2分别为0.9和0.99。我们将初始学习率设置为0.0005,批量大小为32,参数λ为0.02。对于LEVIR-CD数据集和SYSU-CD数据集,模型被训练40000次迭代。对于SVCD数据集,模型被训练80000次迭代以实现足够的收敛。 所有实验均在配备Intel(R)Xeon(R)Gold 5218 CPU(2.30 GHz)和GeForce RTX 3090 GPU(24 GB内存)的系统上进行。
2)评估指标:在实验中,我们使用5个指标来评估模型的性能:精度(Pre)、召回率(Rec)、F1-得分(F1)、IoU和kappa系数(Kappa)。预度量正确识别阳性样本的能力,而记录度量捕获所有阳性样本的能力。F1是Pre和Rec的平衡度量。IoU度量预测和地面实况区域之间的重叠,而Kappa度量预测和地面实况标签之间的一致性。这些指标描述如下:

其中TP、FP、TN和FN分别表示真阳性、假阳性、真阴性和假阴性的数量。Kappa中的P表示参考数据和预测结果之间随机一致的理论可能性,可以在数学上表示为
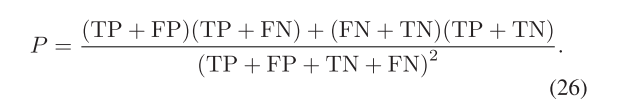
C.与最先进技术(SOTA)的比较
为了评估我们的HELPNet的有效性和效率,我们选择了几个SOTA模型作为竞争对手,包括基于CNN的方法:FC-EF[11]、FC-SD[11]、FC-SC[11]、SNUNet[37]、A2Net[61]、Changer[62]、SEIFNet[36]和三种基于变压器的方法:BIT[22]、ChangeForm[24]、TLFFNet[63]。我们使用它们公开可用的代码和默认参数来重现这些模型,以确保比较的公平性。
给出了三个遥感CD数据集上各种方法的定量评价比较 在表I中,包括Prec、Rec、F1、IoU和Kappa。我们采用两个指标来评估网络的空间复杂度和计算成本:浮点运算(FLOPs)的数量和模型Params的数量。FLOPs指标显着反映了网络推理阶段的能量消耗,而Params的数量与模型的存储需求相关。图5-7展示了三个数据集上不同方法的可视化比较。为了更好地可视化,我们使用不同的颜色来表示真阳性(白色)、假阳性(红色)、真阴性(黑色)和假阴性(蓝色)。
1)LEVIR-CD上的实验结果:通过定量比较,我们可以观察到我们提出的HE-LPNet在Rec方面略逊于TLFFNet。然而,其他指标远高于其他指标,表明HE-LPNet可以学习更多的变化特征并产生更高质量的变化图。即使与最新的方法TLFFNet、SEIFNet、A2Net和Changer相比,我们的方法在F1指标上也显示出0.11%、2.11%、0.58%和0.64%的改进。
图5选择了几个有代表性的样本进行直观的定性比较。对于大规模的建筑变化,我们提出的HE-LPNet展示了准确识别变化区域,与其他方法相比,在边界处实现了更好的性能。这归因于精心设计的边缘损失,使我们的方法能够以更高的精度精确定位对象边缘。对于小规模变化,我们的HE-LPNet在检测预方面表现出卓越的性能,优于经常忽略这些变化的其他竞争者。这验证了我们使用LP的有效性,它为模型提供了充足的详细信息。
2)SYSU-CD上的实验结果:由于数据标注粗糙,该数据集上所有方法的指标都相对较低。我们的方法在Prec和Rec中都没有达到最优结果,但在F1、IoU和Kappa分数方面脱颖而出。这表明我们的方法在Prec和Rec之间实现了优越的平衡,从而提高了各种评估指标的性能。
在定性比较中,我们的方法在识别不同表面材料的建筑物方面表现出出色的判别能力。一些变化的区域表现出与变化前非常相似的空间特征,这往往导致其他方法无法准确检测变化。然而,我们的方法即使在这种情况下也能准确检测变化。总之,定性比较结果与定量比较结果,进一步证实我们提出的HE-LPNet在SYSU-CD数据集上实现了SOTA性能。
3)在SVCD上的实验结果:从表1中的定量比较结果可以看出,我们提出的HE-LPNet在性能上比其他方法有了显著的提高。与TLFFNet、SEIFNet、Change、A2Net和ChangeFormer相比,我们的方法将F1度量分别提高了0.58%、0.96%、1.07%、0.62%和0.98%。
当前的CD方法在SVCD数据集上表现出高精度,促使我们进行详细的定性实验,以比较它们在该数据集上的性能。该数据集涵盖了广泛的对象大小,包括广阔的农田和道路上移动的车辆。图7说明了HE-LPNet在准确检测大规模变化区域边界和小物体微小变化方面的卓越能力,超越了其他方法。HE-LPNet可以检测具有挑战性的物体(如汽车)的变化,这些物体在遥感图像中通常难以识别。
4)TLFFNet与TLFFNet的比较:TLFFNet是一种结合了CNN和转换器的新型CDN方法。然而,与以往的许多方法(如BIT)类似,TLFFNet只有在利用CNN完成特征提取后,才利用转换器来提高模型的性能。这种方法限制了提取的特征,使得有效地捕获长期依赖关系变得困难。在特征提取阶段,He-LPNet集成了CNN和变换网络,使得提取的特征既能利用CNN的感应偏差,又能利用变换的长程相关性,从而获得更好的模型性能。
由于TLFFNet在WHU数据集上表现良好,我们还在该数据集上与HE-LPNet进行了比较。由于WHU数据集没有为训练、验证和测试集提供预定义的拆分,我们手动划分了数据集。为了确保公平比较,我们在WHU数据集上对HE-LPNet和TLFFNet使用相同的拆分进行了实验。HE-LPNet的结果如下:Kappa 94.54%、IoU 90.12%、F1 94.80%、Rec 94.13%和Pre95.49%。相比之下,TLFFNet的结果为:Kappa 93.82%、IoU 88.89%、F1 94.12%、Rec 92.14%和Pre96.18%。总体而言,HE-LPNet在WHU数据集上表现出优于TLFFNet的性能。
D.复杂性分析
基于表I中介绍的Params和FLOPs分析,可以观察到我们的方法在这方面并不占优势。主要原因是HE-LPNet采用混合编码器,将卷积和转换器架构都集成到特征提取阶段,导致计算资源增加。我们尽量利用较浅的卷积层和转换器块,但混合编码器仍然消耗了70%的计算资源。不同主干的详细讨论可在第IV-E1节中找到。在为本文配置的软硬件环境下,HE-LPNet取了两个在批量设置为1的Levir-CD数据集上处理测试集需要几分钟的时间,这表明尽管我们提出的方法的复杂度略高,但它仍然保持了较快的推理速度,显示了其实用价值。
E.消融研究
为了进一步验证所提出模型的每个模块和分支的贡献,本节进行了全面的烧蚀实验。我们主要关注实验中的三个指标: F1、IoU和Kappa,因为它们综合评估了模型的性能。定量结果列于表II-IV,可视化结果列于图8。
1)讨论ofDifferentBackbones:为了检查混合编码器对模型的影响,我们使用几个骨干网进行了烧蚀实验,包括ResNet18[8]、ResNet50[8]和TinyViT[56]。此外,我们调查了基于MSA和MobileSAM的预训练权重对模型性能的影响。结果在表II中给出。通过比较,很明显,使用TinyViT和ResNet18作为骨干网可以减少模型的资源消耗。然而,它显着降低了模型的性能,F1在LEVIR-CD数据集上分别下降了0.77%和0.67%。 使用ResNet50作为主干稍微提高了模型在SVCD数据集上的性能,但它导致其他两个数据集的性能下降,同时伴随着资源消耗的显着增加。这表明我们的方法在资源消耗和性能之间取得了平衡。
在不使用基于MobileSAM的预先训练的权重的情况下,可以观察到模型在所有三个数据集上的性能都有不同程度的下降,在Levir-CD、SYSU-CD和SVCD数据集上,F1分别下降了0.54%、2.32%和0.45%。这表明,向量机的权值可以增强模型的泛化能力。然而,即使不使用VFM的权重,我们的模型的性能也优于表I中比较的大多数方法,从而证明了我们的模型结构的优越性。表II还说明,混合编码器中包含MSA也在一定程度上提高了性能,这表明MSA可以补偿一些信道和空间信息。
2)LP特征增强的有效性:引入了LPI,通过利用其高频信息中包含的像素级显着特征来补充细节信息。为了进行LP的消融研究,我们去掉了将输入图像提供给LP以获得双分支频率图的步骤。在这种情况下,混合编码器提取的特征F1 i、F2 i将直接馈送到解码器。从表III中的结果可以看出,结合LP中的显着特征增强了CD能力。然而,如果不加入WGA,改进是有限的,在LEVIR-CD数据集上F1、IoU和Kappa分数分别仅增加了0.07%、0.11%和0.06%。 我们认为这是因为LP为特征添加了丰富的细节信息,但模型缺乏足够的模块来处理和消化这些信息。它从表III中可以观察到,加入WGA对特征进行处理后,模型的性能明显提高,如图8(b)和(c)所示,通过LP特征增强后,高频信息中的像素级显著性特征使特征能够更好地表示关键区域的位置信息。
3)WGA的有效性:WGA根据每个通道在空间维度上的均方差为每个像素分配不同的权重,从而实现选择性注意。为了在WGA上进行消融实验,我们在解码器阶段去掉了这个模块,直接对串联的特征进行上采样,然后将其与浅层特征相结合。与LP类似,当WGA单独使用时,改进相对较小,但与LP结合时,导致模型的大幅增强。与不使用LP和WGA相比,两者结合导致SYSU-CD数据集上的F1、IoU和Kappa分数分别增加了1.03%、1.51%和1.36%。 如图8(d)和(e)所示,融合后的特征已经定位了变化区域,但噪声仍然影响精度。通过WGA后,特征图的主要焦点集中在变化区域,大大减少了对不相关区域的关注。
4)损失函数的讨论:在本文中,我们采用了由边缘引导损失、Dice损失和BCE损失组成的混合损失。为了验证其性能,我们仅使用BCE损失、Dice损失以及这两种损失的组合来执行实验。 从表III中可以观察到,仅使用BCE损失对模型性能有显著的负面影响,仅使用Dice损失也是如此,这主要是因为CD属于二分类任务,正负样本数存在较大差异,因此结合这两个损失函数可以有效提高模型性能,同时我们观察到,在三个数据集上合并边缘引导损失导致F1分别提高了0.31%、0.48%和0.29%,证明了边缘引导损失的有效性,如图9(c)所示,边界在不使用边缘引导损失的情况下,变化区域更加模糊。相比之下,如图9(d)所示,加入边缘引导损失会导致更清晰的边界,使模型能够更准确地描绘变化区域。
5)超参数的讨论:表IV演示了损失函数中变化的超参数λ对实验结果的影响,可以观察到,在迭代次数固定的情况下,λ的不同值对实验结果有影响,当λ较小时,边缘引导损失对混合损失的贡献较小,因此对模型性能的影响有限,当λ较大时,BCE损失和Dice损失的有效性被打折,导致模型性能的负面影响。因此,为了平衡各种损失函数的比例并实现最佳模型性能,我们选择0.02作为超参数λ的值。
五、讨论
虽然HE-LPNet在遥感CD中表现出有希望的性能,但有一些局限性值得进一步讨论。首先,该模型在处理更复杂的场景时难以准确捕捉变化区域,如图10所示。在存在重叠变化区域或变化难以区分的情况下,该模型的性能显着下降。为了解决这个问题,可能需要额外的优化技术来增强模型的性能。其次,该模型仍然需要大量的oflabed数据进行训练,这使得它难以应用于一些现实世界的场景。关键的解决方案在于实现增强的检测精度,同时减少对注释数据的依赖。 在未来的工作中,开发可以用更少样本训练的高效CD方法将是提高模型可用性的关键。
结论
在本文中,我们提出了一种新颖的具有混合编码和LP特征增强的遥感CD的HE-LPNet。具体地说,混合编码器将CNN的感应偏置、MSA机制和变压器架构的优势融合在一起,将这些优势统一到一个模块中。这提高了模型捕获广泛的、多尺度的依赖关系和详细的局部空间特征的能力。此外,该模型还利用了LP高频信息中包含的像素级显著特征来补充细节信息。在解码阶段,WGA根据每个通道在空间维度上的标准差来选择性地关注每个像素,突出显示变化区域。最后,设计了一种边缘引导损失,以加强对变化的关注边缘,从而准确地分割变化区域。在具有挑战性的数据集上进行的实验显示了HE-LPNet在CD上的显著性能,在精度上超过了测试的SOTA模型。更多的消融研究进一步证明了精心设计的部件的有效性。HE-LPNet令人印象深刻的结果突显了其利用高分辨率双时相遥感图像准确检测复杂场景变化的潜力。
相关文章:

基于混合编码器和边缘引导的拉普拉斯金字塔网络用于遥感变化检测
Laplacian Pyramid Network With HybridEncoder and Edge Guidance for RemoteSensing Change Detection 0、摘要 遥感变化检测(CD)是观测和分析动态土地覆盖变化的一项关键任务。许多基于深度学习的CD方法表现出强大的性能,但它们的有效性…...

机器学习 从入门到精通 day_04
1. 决策树-分类 1.1 概念 1. 决策节点 通过条件判断而进行分支选择的节点。如:将某个样本中的属性值(特征值)与决策节点上的值进行比较,从而判断它的流向。 2. 叶子节点 没有子节点的节点,表示最终的决策结果。 3. 决策树的…...

CLAHE算法介绍
限制对比度自适应直方图增强 CLAHE 算法介绍 1. CLAHE算法框图2.直方图clip及重分配2.1 opencv自带2.2 scikit-image2.3 结果对比2.4 clip limit的性质3.插值参考文献上图来自 K. Zuiderveld: Contrast Limited Adaptive Histogram Equalization。 图中可以看到各种直方图均衡的…...

高并发的业务场景下,如何防止数据库事务死锁
一、 一致的锁定顺序 定义: 死锁的常见原因之一是不同的事务以不同的顺序获取锁。当多个事务获取了不同资源的锁,并且这些资源之间发生了互相依赖,就会形成死锁。 解决方法: 确保所有的事务在获取多个锁时,按照相同的顺序请求锁。例如,如果事务A需要锁定表A和表B,事务…...
使用Python从零实现一个端到端多模态 Transformer大模型
嘿,各位!今天咱们要来一场超级酷炫的多模态 Transformer 冒险之旅!想象一下,让一个模型既能看懂图片,又能理解文字,然后还能生成有趣的回答。听起来是不是很像超级英雄的超能力?别急,…...
(附脚本))
elestio memos SSRF漏洞复现(CVE-2025-22952)(附脚本)
免责申明: 本文所描述的漏洞及其复现步骤仅供网络安全研究与教育目的使用。任何人不得将本文提供的信息用于非法目的或未经授权的系统测试。作者不对任何由于使用本文信息而导致的直接或间接损害承担责任。如涉及侵权,请及时与我们联系,我们将尽快处理并删除相关内容。 前言…...

倚光科技:以创新之光,雕琢全球领先光学设计公司
在光学技术飞速发展的当下,每一次突破都可能为众多领域带来变革性的影响。而倚光(深圳)科技有限公司,作为光学设计公司的一颗璀璨之星,正以其卓越的创新能力和深厚的技术底蕴,引领着光学设计行业的发展潮流…...

Linux安装Elasticsearch详细教程
准备工作 下载地址:Download Elasticsearch | Elastic 下载时需要注意es与jdk版本对应关系 ES 7.x 及之前版本,选择 Java 8 ES 8.x 及之后版本,选择 Java 17 或者 Java 18,建议 Java 17,因为对应版本的 Logstash 不支持 Java 1…...

C++字符串操作详解
引言 字符串处理是编程中最常见的任务之一,而在C中,我们有多种处理字符串的方式。本文将详细介绍C中的字符串操作,包括C风格字符串和C的string类。无论你是C新手还是想巩固基础的老手,这篇文章都能帮你梳理字符串处理的关键知识点…...

PromptPro|提示词生成和管理专家
大家好,我是吾鳴。 今天吾鳴给大家分享一个实用的提示词管理网站,它的名称叫做产品化管理提示词,英文名叫做PromptPro,是一个可以帮你管理你的大模型提示词的网站,同时你也可以告诉它你的需求,让它帮你生成…...

计算机视觉图像特征提取入门:Harris角点与SIFT算法
计算机视觉图像特征提取入门:Harris角点与SIFT算法 一、前言二、Harris 角点检测算法2.1 Harris 角点的定义与直观理解2.1.1 角点的概念2.1.2 Harris 角点的判定依据 2.2 Harris 角点检测的实现步骤2.2.1 计算图像的梯度2.2.2 构建结构张量矩阵2.2.3 …...
)
swift菜鸟教程1-5(语法,变量,类型,常量,字面量)
一个朴实无华的目录 今日学习内容:1.基本语法引入空格规范输入输出 2.变量声明变量变量输出加反斜杠括号 \\( ) 3.可选(Optionals)类型可选类型强制解析可选绑定 4.常量常量声明常量命名 5.字面量整数 and 浮点数 实例字符串 实例 今日学习内容: 1.基本…...

02142数据结构导论
初学者,怎样理解这道题,怎样大白话分析 答案解析 00、概念 29、 28、 27、 26、 25、 24、 23、 22、有5个元素,其入栈次序为:A、B、C、D、E,写出以元素C、D最先出栈(即C第一个且D第二个出栈)的各种可能的出栈次序。 (来…...

如何在AMD MI300X 服务器上部署 DeepSeek R1模型?
DeepSeek-R1凭借其深度推理能力备受关注,在语言模型性能基准测试中可与顶级闭源模型匹敌。 AMD Instinct MI300X GPU可在单节点上高效运行新发布的DeepSeek-R1和V3模型。 用户通过SGLang优化,将MI300X的性能提升至初始版本的4倍,且更多优化将…...

【Django】教程-15-注册页面
【Django】教程-1-安装创建项目目录结构介绍 【Django】教程-2-前端-目录结构介绍 【Django】教程-3-数据库相关介绍 【Django】教程-4-一个增删改查的Demo 【Django】教程-5-ModelForm增删改查规则校验【正则钩子函数】 【Django】教程-6-搜索框-条件查询前后端 【Django】教程…...

OpenAI即将上线新一代重磅选手——GPT-4.1
每周跟踪AI热点新闻动向和震撼发展 想要探索生成式人工智能的前沿进展吗?订阅我们的简报,深入解析最新的技术突破、实际应用案例和未来的趋势。与全球数同行一同,从行业内部的深度分析和实用指南中受益。不要错过这个机会,成为AI领…...

参照Spring Boot后端框架实现序列化工具类
本文参照Jackson实现序列化工具类,旨在于简化开发 JacksonUtil.class public class JacksonUtil {private JacksonUtil() {}/*** 单例*/private final static ObjectMapper OBJECT_MAPPER;static {OBJECT_MAPPER new ObjectMapper();}private static ObjectMappe…...

C_内存 内存地址概念
1. 计算机内存的基本概念 计算机的内存(RAM,随机存取存储器)是用来存储程序运行时的数据和指令的地方。内存被划分为许多小单元,每个单元有一个唯一的地址,这些地址从0开始编号。 内存单元:每个内存单元通…...

Rust重定义数据库内核:从内存安全到性能革命的破界之路
Rust语言正在颠覆传统数据库开发范式,其独特的所有权系统与零成本抽象能力,为攻克C/C时代遗留的内存泄漏、并发缺陷等顽疾提供全新解决方案。本文通过TiKV、Materialize等新一代数据库核心组件的实践案例,剖析Rust如何重塑存储引擎、查询优化…...

tree 显示到二级目录
要使用 tree 命令显示到二级目录,可以通过 -L 参数指定目录层级。具体命令如下: tree -L 2 参数说明: -L 数字:控制显示的目录深度。-L 2 表示显示到第二级目录(即当前目录下的直接子目录及其内容)。 示例输出: 复制 . ├── dir1 │ ├── file1.txt │ └─…...

UE5 在UE中创建骨骼动画
文章目录 创建动画的三种方式修改骨骼动画 创建动画的三种方式 方法一 打开一个已有的动画,左上角“创建资产/创建动画/参考姿势” 这将创建一个默认的A字形的骨骼,不建议这么做 方法二 打开一个已有的动画,左上角“创建资产/创建动画/当前…...

工业相机使用笔记
目前工业相机有多种分类方式,以下是基于不同原理和特点的类别总结: 按维度分类 2D相机: 原理:通过镜头将二维平面上的物体成像在图像传感器上,传感器上的像素点阵列捕捉物体的光信号,并转换为电信号或数字…...

深度兼容性测试和自助兼容性测试的区别,如何正确的选择?
泽众云经过几年业务快速发展,特别是泽众云兼容性测试服务已成为市场热门供应商之一,也根据用户不同需求推出了超高性价比服务,主要有深度兼容性测试和自助兼容性测试两种方式。2025年上半云真机平台的机型已升级到1000,全面覆盖了…...

Windows下安装depot_tools
一、引言 Chromium和Chromium OS使用名为depot_tools的脚本包来管理检出和审查代码。depot_tools工具集包括gclient、gcl、git-cl、repo等。它也是WebRTC开发者所需的工具集,用于构建和管理WebRTC项目。本文介绍Windows系统下安装depot_tools的方法。 二、下载depo…...

学术分享:基于 ARCADE 数据集评估 Grounding DINO、YOLO 和 DINO 在血管狭窄检测中的效果
一、引言 冠状动脉疾病(CAD)作为全球主要死亡原因之一,其早期准确检测对有效治疗至关重要。X 射线冠状动脉造影(XCA)虽然是诊断 CAD 的金标准,但这些图像的人工解读不仅耗时,还易受观察者间差异…...
——什么是 IA3 微调?)
NLP高频面试题(四十一)——什么是 IA3 微调?
随着大型语言模型的广泛应用,如何高效地将这些模型适配到特定任务中,成为了研究和工程实践中的重要课题。IA3(Infused Adapter by Adding and Adjusting)微调技术,作为参数高效微调的一种新颖方法,提供了在保持模型性能的同时,显著减少可训练参数数量的解决方案。 IA3 …...

STM32 模块化开发指南 · 第 3 篇 环形缓冲区 RingBuffer 模块设计与单元测试
本文是《STM32 模块化开发实战指南》第 3 篇,聚焦于“如何设计一个高性能、稳定、安全的环形缓冲区模块”。我们将从基本结构讲起,逐步完成接口定义、边界处理、API 实现与单元测试,最终实现一个可移植、线程安全、可嵌入 UART/BLE/协议模块的通用 RingBuffer。 一、RingBuf…...

软件测试岗位:IT行业中的质量守护者
在当今数字化飞速发展的IT行业,软件如同空气般无处不在,从日常的手机应用到复杂的企业级管理系统,软件的稳定性和可靠性至关重要。而软件测试岗位的从业者,就像是软件世界的质检员,精心守护着软件的质量。 一、软件测…...

单片机方案开发 代写程序/烧录芯片 九齐/应广等 电动玩具 小家电 语音开发
在电子产品设计中,单片机(MCU)无疑是最重要的组成部分之一。无论是消费电子、智能家居、工业控制,还是可穿戴设备,小家电等,单片机的应用无处不在。 单片机,简而言之,就是将计算机…...

恐龙专利及商标维权行动,已获批TRO并冻结资金
2025年3月30日,原告Shenzhen xingyin technology co.,Ltd.,现化名为Shenzhen Z Tech Co., Ltd.委托kemet律所发起维权。目前该案件已获批TRO临时禁令,涉案账户资金已被冻结,案件详情如下: 案件基本情况:起…...

【北京市小客车调控网站-注册/登录安全分析报告】
前言 由于网站注册入口容易被黑客攻击,存在如下安全问题: 暴力破解密码,造成用户信息泄露短信盗刷的安全问题,影响业务及导致用户投诉带来经济损失,尤其是后付费客户,风险巨大,造成亏损无底洞…...

Vue 3中的 setup
Vue 3引入了Composition API,其中setup函数是这一新API的核心部分。setup函数为开发者提供了一种更灵活、更模块化的方式来组织组件逻辑。以下是关于Vue 3中setup函数的详细解释: 1. 基本概念 setup函数是组件内使用Composition API的入口点。它是一个…...

2025年实用新型专利审查周期要多久?
申请实用新型专利时,审查周期是申请人最关心的问题之一。尤其是近几年国家知识产权局不断优化流程,审查速度是否有变化?2025年申请需要等多久?本文结合最新政策和实际案例,为你全面解析! 一、实用新型专利…...

使用Python建立双缝干涉模型
引言 双缝干涉实验是物理学中经典的实验之一,它展示了光的波动性以及量子力学的奇异性。实验结果表明,当光或粒子通过两条狭缝时,它们会产生干涉现象,形成明暗相间的条纹图案。这种现象不仅说明了光的波动性,还揭示了量子力学的核心思想——粒子具有波动性。今天,我们将…...

路由交换网络专题 | 第二章 | RIP | OSPF | 路由聚合 | 路由过滤 | 静默接口
拓扑图 (1)作为企业网络边界设备,AR1 上配置什么命令,可以使 OSPF 域内所有路由都会有指向自己的默认路由。默认路由的优先级是多少。如果 OSPF 域内其他路由器同样有到达外网的路径,且优于通过 AR1 到达外网ÿ…...

python 语言 设计模式
python 语言 设计模式 设计模式是指在软件开发过程中,针对反复出现的问题所总结归纳出的通用解决方案。以下是一些常见的Python语言设计模式: 目录 python 语言 设计模式创建型模式结构型模式行为型模式创建型模式 单例模式 定义:保证一个类只有一个实例,并提供一个全局访…...

银行业务发展历史
银行业务发展历史 银行业务的发展可以追溯到古代,但其现代形式的发展可以追溯到中世纪。以下是银行业务发展的主要历史阶段: 1. 古代和中世纪时期 特点:商人提供贷款和存款服务,充当中间人转移资金,发行纸币作为支付…...

JAVA中多线程的基本用法
文章目录 一、基本概念(一)进程控制块PCB(二)并行和并发(三)进程调度1.进程的状态2.优先级3.记账信息4.上下文 (四)进程和线程1.概述2.线程为什么比进程更轻量3.进程和线程的区别和联…...

健康与好身体笔记
文章目录 保证睡眠饭后百步走,活到九十九补充钙质一副好肠胃肚子咕咕叫 健康和工作的取舍 以前对健康没概念,但是随着年龄增长,健康问题凸显出来。 持续维护该文档,健康是个永恒的话题。 保证睡眠 一是心态要好,沾枕…...
)
如何下载谷歌浏览器增强版(扩展支持版)
在日常浏览和工作中,Chrome 浏览器因其强大的性能和丰富的扩展插件,成为全球范围内使用最广泛的浏览器之一。然而,对于需要进行深度扩展管理或需要稳定扩展环境的用户来说,标准版的 Google Chrome 可能在某些方面仍显不足。这时候…...

TDDMS分布式存储管理系列文章--分片/分区/分桶详解
友情链接: 星环分布式存储TDDMS大揭秘(一)分布式存储技术推出背景以及当前存在的挑战TDDMS是什么 前情提要 通过上个系列的文章我们了解到了各节点数据副本间通过一致性算法确保每次写入在响应客户端请求之前至少被多数节点(N/2…...
:集成SSE (Server-Sent Events) 服务器实时推送)
Spring Boot(九十):集成SSE (Server-Sent Events) 服务器实时推送
1 SSE简介 Server-sent Events(SSE) 是一种基于 HTTP 协议的服务器推送技术,它允许服务器主动向客户端发送数据。与 WebSocket 不同,SSE 是单向通信,即服务器可以主动向客户端推送数据,而客户端只能接收数据。 2 SSE特点 单向通信:SSE 是服务器向客户端的单向推送,客户…...

ubuntu22.04安装ROS2 humble
参考: https://zhuanlan.zhihu.com/p/702727186 前言: 笔记本安装了ubuntu20.04安装ros一直失败,于是将系统升级为ununut22.04,然后安装ros,根据上面的教程,目前看来是有可能成功的。 系统升级为ununut…...

力扣第206场周赛
周赛链接:竞赛 - 力扣(LeetCode)全球极客挚爱的技术成长平台 1. 二进制矩阵中的特殊位置 给定一个 m x n 的二进制矩阵 mat,返回矩阵 mat 中特殊位置的数量。 如果位置 (i, j) 满足 mat[i][j] 1 并且行 i 与列 j 中…...

C++17 主要更新
C17 主要更新 C17 是继 C14 之后的重要标准更新,引入了许多提升开发效率、简化代码和增强性能的特性。以下是 C17 的主要更新,按类别分类: 1. 语言核心特性 结构化绑定(Structured Bindings) 解构元组、结构体或数组…...

k8s master节点部署
一、环境准备 1.主机准备 192.168.10.100 master.com master 192.168.10.101 node1.com node1 192.168.10.102 node2.com node2 互信 时间同步 关闭防火墙 关闭selinux 2.创建/etc/sysctl.d/k8s.conf,添加如下内容 cat > /etc/sysctl.d/k8s.conf <<EOF net.br…...
)
YOLO学习笔记 | YOLOv8 全流程训练步骤详解(2025年4月更新)
===================================================== github:https://github.com/MichaelBeechan CSDN:https://blog.csdn.net/u011344545 ===================================================== 这里写自定义目录标题 一、数据准备1. 数据标注与格式转换2. 配置文件生…...

centos7.9 升级 gcc
本片文章介绍如何升级gcc,centos7.9 仓库默认的gcc版本为:4.8.5 4.8.5-44) Copyright (C) 2015 Free Software Foundation, Inc. This is free software; see the source for copying conditions. There is NO warranty; not even for MERCHANTABILITY…...

Linux基本指令
Linux目录结构 Linux的目录结构是一个树形结构。Windows系统可以拥有多个盘符,如C盘、D盘、E盘。而Linux没有盘符这个概念,只有一个根目录/,所有文件都在它下面。如下图所示: Linux路径的描述方式 在Linux系统中,路径之间的层级…...

Google A2A协议,是为了战略性占领标准?
一、导读 2025 年 4 月 9 日,Google 正式发布了 Agent2Agent(A2A)协议。 A2A 协议致力于打破智能体之间的隔阂,让它们能够跨越框架和供应商的限制,以一种标准化、开放的方式进行沟通与协作 截止到现在,代…...