机器学习 从入门到精通 day_04
1. 决策树-分类
1.1 概念
1. 决策节点 通过条件判断而进行分支选择的节点。如:将某个样本中的属性值(特征值)与决策节点上的值进行比较,从而判断它的流向。
2. 叶子节点 没有子节点的节点,表示最终的决策结果。
3. 决策树的深度 所有节点的最大层次数,决策树具有一定的层次结构,根节点的层次数定为0,从下面开始每一层子节点层次数增加。
4. 决策树优点:可视化 - 可解释能力-对算力要求低。
5. 决策树缺点:容易产生过拟合,所以不要把深度调整太大了。

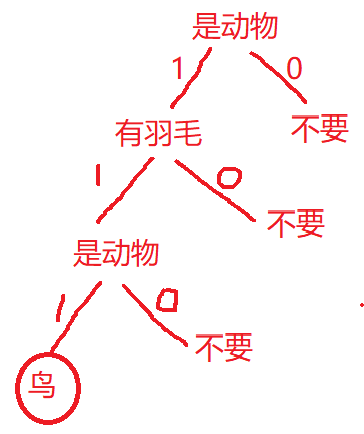
| 是动物 | 能飞 | 有羽毛 | |
| 麻雀 | 1 | 1 | 1 |
| 蝙蝠 | 1 | 1 | 0 |
| 飞机 | 0 | 1 | 0 |
| 熊猫 | 1 | 0 | 0 |
是否为动物:
| 是动物 | 能飞 | 有羽毛 | |
| 麻雀 | 1 | 1 | 1 |
| 蝙蝠 | 1 | 1 | 0 |
| 熊猫 | 1 | 0 | 0 |
是否会飞:
| 是动物 | 能飞 | 有羽毛 | |
| 麻雀 | 1 | 1 | 1 |
| 蝙蝠 | 1 | 1 | 0 |
是否有羽毛:
| 是动物 | 能飞 | 有羽毛 | |
| 麻雀 | 1 | 1 | 1 |
1.2 基于信息增益决策树的建立
信息增益决策树倾向于选择取值较多的属性,在有些情况下这类属性可能不会提供太多有价值的信息,算法只能对描述属性为离散型属性的数据集构造决策树。
根据以下信息构建一棵预测是否贷款的决策树。我们可以看到有4个影响因素:职业,年龄,收入和学历。
| 职业 | 年龄 | 收入 | 学历 | 是否贷款 | |
| 1 | 工人 | 36 | 5500 | 高中 | 否 |
| 2 | 工人 | 42 | 2800 | 初中 | 是 |
| 3 | 白领 | 45 | 3300 | 小学 | 是 |
| 4 | 白领 | 25 | 10000 | 本科 | 是 |
| 5 | 白领 | 32 | 8000 | 硕士 | 否 |
| 6 | 白领 | 28 | 13000 | 博士 | 是 |
(1)信息熵:信息熵描述的是不确定性。信息熵越大,不确定性越大。信息熵的值越小,则D的纯度越高。
假设样本集合D共有N类,第k类样本所占比例为,则D的信息熵为:
![]()
(2)信息增益:信息增益是一个统计量,用来描述一个属性区分数据样本的能力。信息增益越大,那么决策树就会越简洁。这里信息增益的程度用信息熵的变化程度来衡量, 信息增益公式:![]()
(3 )信息增益决策树建立步骤:第一步,计算根节点的信息熵上表根据是否贷款把样本分成2类样本,"是"占4/6=2/3, "否"占2/6=1/3,所以![]() ;第二步,计算属性的信息增益:
;第二步,计算属性的信息增益:
<1> "职业"属性的信息增益![]() ,在职业中,工人占1/3, 工人中,是否代款各占1/2, 所以有
,在职业中,工人占1/3, 工人中,是否代款各占1/2, 所以有![]() ,在职业中,白领占2/3, 白领中,是贷款占3/4, 不贷款占1/4, 所以有
,在职业中,白领占2/3, 白领中,是贷款占3/4, 不贷款占1/4, 所以有![]() ,所以有
,所以有![]() ,最后得到职业属性的信息增益为:
,最后得到职业属性的信息增益为:![]() 。
。
<2>" 年龄"属性的信息增益(以35岁为界)
![]()
<3> "收入"属性的信息增益(以10000为界,大于等于10000为一类)
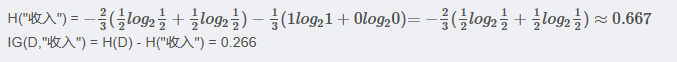
<4> "学历"属性的信息增益(以高中为界, 大于等于高中的为一类)
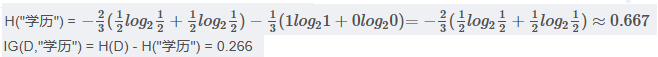
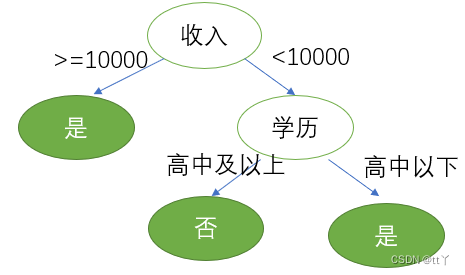
第三步,划分属性,对比属性信息增益发现,"收入"和"学历"相等,并且是最高的,所以我们就可以选择"学历"或"收入"作为第一个决策树的节点, 接下来我们继续重复1,2的做法继续寻找合适的属性节点。
1.3 基于基尼指数决策树的建立(了解)
基尼指数(Gini Index)是决策树算法中用于评估数据集纯度的一种度量,基尼指数衡量的是数据集的不纯度,或者说分类的不确定性。在构建决策树时,基尼指数被用来决定如何对数据集进行最优划分,以减少不纯度。
基尼指数的计算:对于一个二分类问题,如果一个节点包含的样本属于正类的概率是 (p),则属于负类的概率是 (1-p)。那么,这个节点的基尼指数 (Gini(p)) 定义为:
对于多分类问题,如果一个节点包含的样本属于第 k 类的概率是 p_k,则节点的基尼指数定义为:
基尼指数的意义:1. 当一个节点的所有样本都属于同一类别时,基尼指数为 0,表示纯度最高。2. 当一个节点的样本均匀分布在所有类别时,基尼指数最大,表示纯度最低。
决策树中的应用:在构建决策树时,我们希望每个内部节点的子节点能更纯,即基尼指数更小。因此,选择分割特征和分割点的目标是使子节点的平均基尼指数最小化。具体来说,对于一个特征,我们计算其所有可能的分割点对应的子节点的加权平均基尼指数,然后选择最小化这个值的分割点。这个过程会在所有特征中重复,直到找到最佳的分割特征和分割点。
例如,考虑一个数据集 (D),其中包含 (N) 个样本,特征 (A) 将数据集分割为 |D_1|和 |D_2| ,则特征 (A) 的基尼指数为:
其中 |D_1|和 |D_2| 分别是子集 D_1 和 D_2 中的样本数量。
通过这样的方式,决策树算法逐步构建一棵树,每一层的节点都尽可能地减少基尼指数,最终达到对数据集的有效分类。
案例:
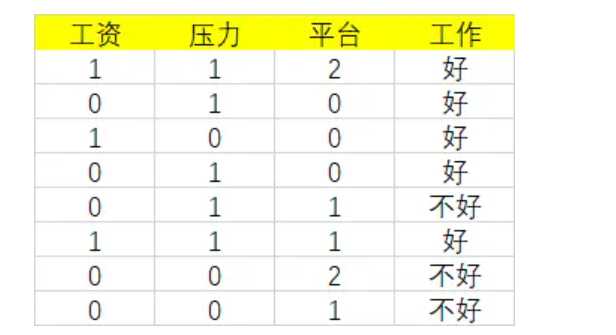
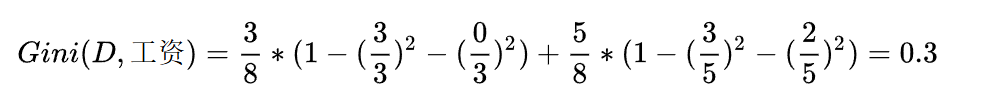
首先工资有两个取值,分别是0和1。当工资=1时,有3个样本。所以:
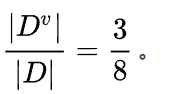
同时,在这三个样本中,工作都是好。所以:
![]()
就有了加号左边的式子:
![]()
同理,当工资=0时,有5个样本,在这五个样本中,工作有3个是不好,2个是好。就有了加号右边的式子:
![]()
同理,可得压力的基尼指数如下:
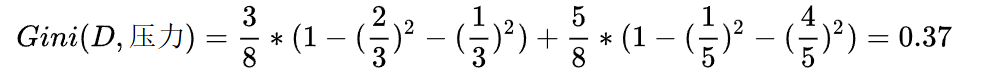
平台的基尼指数如下:
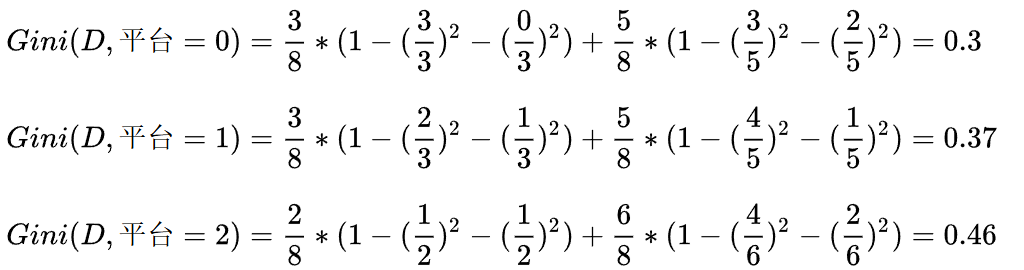
在计算时,工资和平台的计算方式有明显的不同。因为工资只有两个取值0和1,而平台有三个取值0,1,2。所以在计算时,需要将平台的每一个取值都单独进行计算。比如:当平台=0时,将数据集分为两部分,第一部分是平台=0,第二部分是平台!=0(分母是5的原因)。根据基尼指数最小准则, 我们优先选择工资或者平台=0作为D的第一特征。
我们选择工资作为第一特征,那么当工资=1时,工作=好,无需继续划分。当工资=0时,需要继续划分。
当工资=0时,继续计算基尼指数:
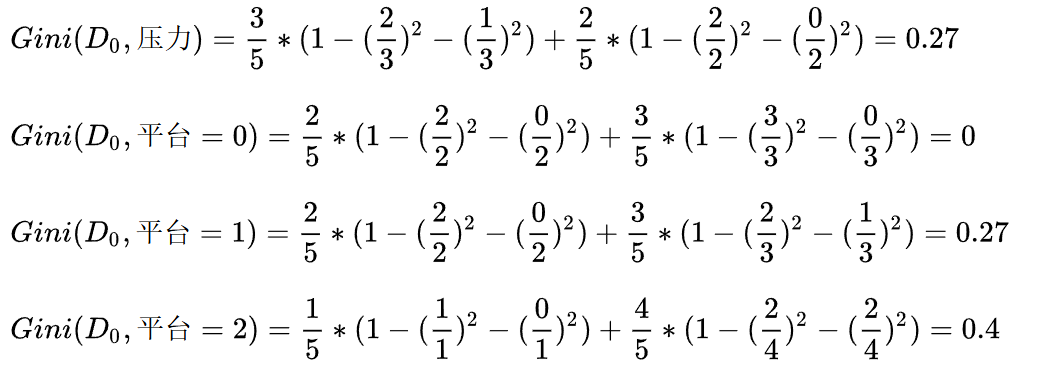
当平台=0时,基尼指数=0,可以优先选择。同时,当平台=0时,工作都是好,无需继续划分,当平台=1,2时,工作都是不好,也无需继续划分。直接把1,2放到树的一个结点就可以。
1.4 API介绍
class sklearn.tree.DecisionTreeClassifier(....)
参数:
criterion "gini" "entropy” 默认为="gini" 当criterion取值为"gini"时采用 基尼不纯度(Gini impurity)算法构造决策树,当criterion取值为"entropy”时采用信息增益( information gain)算法构造决策树.
max_depth int, 默认为=None 树的最大深度# 可视化决策树
function sklearn.tree.export_graphviz(estimator, out_file="iris_tree.dot", feature_names=iris.feature_names)
参数:estimator决策树预估器out_file生成的文档feature_names节点特征属性名
功能:把生成的文档打开,复制出内容粘贴到"http://webgraphviz.com/"中,点击"generate Graph"会生成一个树型的决策树图示例:
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.tree import DecisionTreeClassifier, export_graphviz# 1)获取数据集
iris = load_iris()# 2)划分数据集
x_train, x_test, y_train, y_test = train_test_split(iris.data, iris.target, random_state=22)#3)标准化
transfer = StandardScaler()
x_train = transfer.fit_transform(x_train)
x_test = transfer.transform(x_test)# 4)决策树预估器
estimator = DecisionTreeClassifier(criterion="entropy")estimator.fit(x_train, y_train)# 5)模型评估,计算准确率
score = estimator.score(x_test, y_test)
print("准确率为:\n", score)# 6)预测
index=estimator.predict([[2,2,3,1]])
print("预测:\n",index,iris.target_names,iris.target_names[index])# 可视化决策树
export_graphviz(estimator, out_file="iris_tree.dot", feature_names=iris.feature_names)把文件"iris_tree.dot"内容粘贴到"Webgraphviz"点击"generate Graph"决策树图:
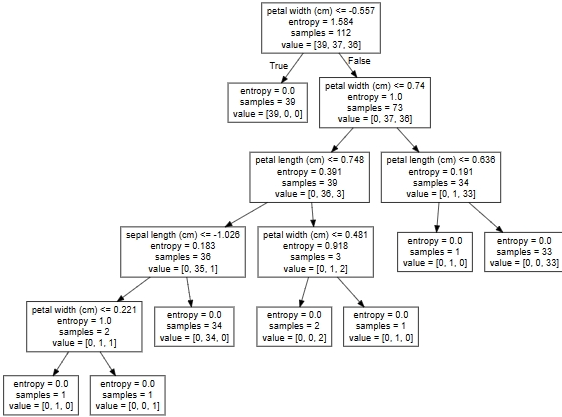
示例:
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction import DictVectorizer
from sklearn.tree import DecisionTreeClassifier, export_graphviz
# 1、获取数据
titanic = pd.read_csv("src/titanic/titanic.csv")
titanic.head()
# 筛选特征值和目标值
x = titanic[["pclass", "age", "sex"]]
y = titanic["survived"]#2、数据处理
# 1)缺失值处理, 因为其中age有缺失值。
x["age"].fillna(x["age"].mean(), inplace=True)# 2) 转换成字典, 因为其中数据必须为数字才能进行决策树,所在先转成字典,后面又字典特征抽取,这样之后的数据就会是数字了, 鸢尾花的数据本来就全部是数字,所以不需要这一步。
"""
x.to_dict(orient="records") 这个方法通常用于 Pandas DataFrame 对象,用来将 DataFrame 转换为一个列表,其中列表的每一个元素是一个字典,对应于 DataFrame 中的一行记录。字典的键是 DataFrame 的列名,值则是该行中对应的列值。
假设你有一个如下所示的 DataFrame x:A B C
0 1 4 7
1 2 5 8
2 3 6 9
执行 x.to_dict(orient="records"),你会得到这样的输出:
[{'A': 1, 'B': 4, 'C': 7},{'A': 2, 'B': 5, 'C': 8},{'A': 3, 'B': 6, 'C': 9}
]
"""
x = x.to_dict(orient="records")
# 3)、数据集划分
x_train, x_test, y_train, y_test = train_test_split(x, y, random_state=22)
# 4)、字典特征抽取
transfer = DictVectorizer()
x_train = transfer.fit_transform(x_train) #稀疏矩阵
x_test = transfer.transform(x_test)# 3)决策树预估器
estimator = DecisionTreeClassifier(criterion="entropy", max_depth=8)
estimator.fit(x_train, y_train)# 4)模型评估
# 方法1:直接比对真实值和预测值
y_predict = estimator.predict(x_test)
print("y_predict:\n", y_predict)
print("直接比对真实值和预测值:\n", y_test == y_predict)# 方法2:计算准确率
score = estimator.score(x_test, y_test)
print("准确率为:\n", score)# 6)预测
x_test = transfer.transform([{'pclass': '1rd', 'age': 22.0, 'sex': 'female'}])
index=estimator.predict(x_test)
print("预测1:\n",index)#[1] 头等舱的就可以活下来
x_test = transfer.transform([{'pclass': '3rd', 'age': 22.0, 'sex': 'female'}])
index=estimator.predict(x_test)
print("预测2:\n",index)#[0] 3等舱的活不下来# 可视化决策树
export_graphviz(estimator, out_file="titanic_tree.dot", feature_names=transfer.get_feature_names_out())2. 集成学习方法之随机森林
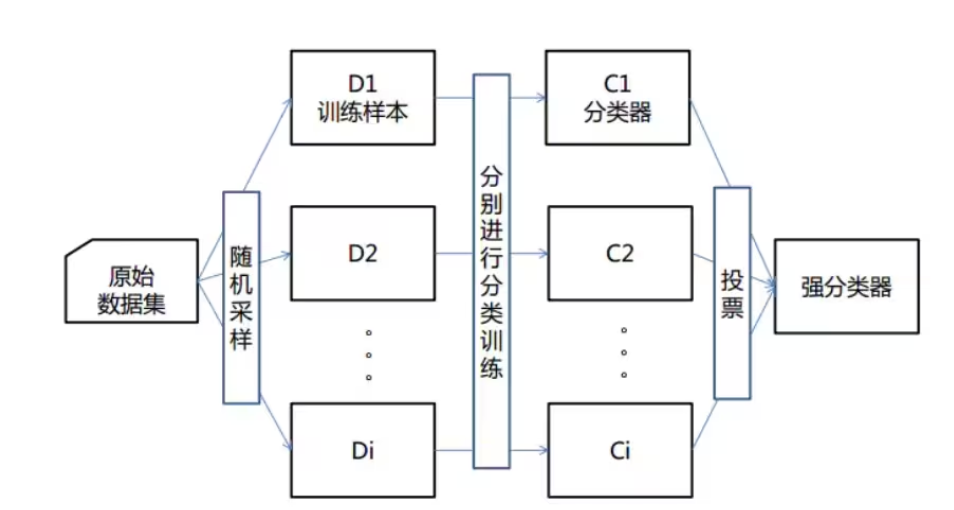
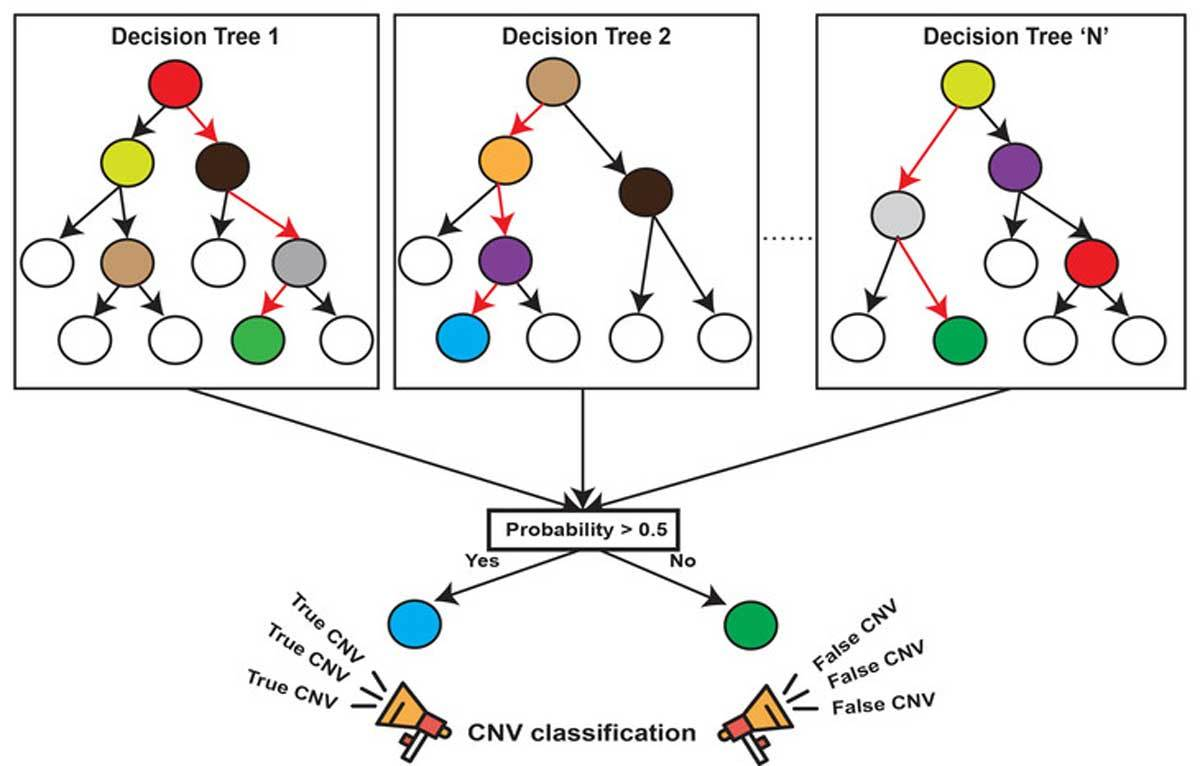
机器学习中有一种大类叫集成学习(Ensemble Learning),集成学习的基本思想就是将多个分类器组合,从而实现一个预测效果更好的集成分类器。集成算法可以说从一方面验证了中国的一句老话:三个臭皮匠,赛过诸葛亮。集成算法大致可以分为:Bagging,Boosting 和 Stacking 三大类型。
(1)每次有放回地从训练集中取出 n 个训练样本,组成新的训练集;
(2)利用新的训练集,训练得到M个子模型;
(3)对于分类问题,采用投票的方法,得票最多子模型的分类类别为最终的类别;
随机森林就属于集成学习,是通过构建一个包含多个决策树(通常称为基学习器或弱学习器)的森林,每棵树都在不同的数据子集和特征子集上进行训练,最终通过投票或平均预测结果来产生更准确和稳健的预测。这种方法不仅提高了预测精度,也降低了过拟合风险,并且能够处理高维度和大规模数据集。
2.1 算法原理
-
随机: 特征随机,训练集随机
-
样本:对于一个总体训练集T,T中共有N个样本,每次有放回地随机选择n个样本。用这n个样本来训练一个决策树。
-
特征:假设训练集的特征个数为d,每次仅选择k(k<d)个来构建决策树。
-
-
森林: 多个决策树分类器构成的分类器, 因为随机,所以可以生成多个决策树
-
处理具有高维特征的输入样本,而且不需要降维
-
使用平均或者投票来提高预测精度和控制过拟合
2.2 API 介绍
class sklearn.ensemble.RandomForestClassifier参数:
n_estimators int, default=100
森林中树木的数量。(决策树个数)criterion {“gini”, “entropy”}, default=”gini” 决策树属性划分算法选择当criterion取值为“gini”时采用 基尼不纯度(Gini impurity)算法构造决策树,当criterion取值为 “entropy” 时采用信息增益( information gain)算法构造决策树.max_depth int, default=None 树的最大深度。 示例:
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction import DictVectorizer
from sklearn.tree import export_graphviz
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import GridSearchCV# 1、获取数据
titanic = pd.read_csv("src/titanic/titanic.csv")
titanic.head()
# 筛选特征值和目标值
x = titanic[["pclass", "age", "sex"]]
y = titanic["survived"]#2、数据处理
# 1)缺失值处理
x["age"].fillna(x["age"].mean(), inplace=True)
# 2) 转换成字典
x = x.to_dict(orient="records")
# 3)、数据集划分
x_train, x_test, y_train, y_test = train_test_split(x, y, random_state=22)
# 4)、字典特征抽取
transfer = DictVectorizer()
x_train = transfer.fit_transform(x_train)
x_test = transfer.transform(x_test)'''
#3 预估: 不加网格搜索与交叉验证的代码
estimator = RandomForestClassifier(n_estimators=120, max_depth=5)
# 训练
estimator.fit(x_train, y_train)
'''#3 预估: 加网格搜索与交叉验证的代码
estimator = RandomForestClassifier()
# 参数准备 n_estimators树的数量, max_depth树的最大深度
param_dict = {"n_estimators": [120,200,300,500,800,1200], "max_depth": [5,8,15,25,30]}
# 加入网格搜索与交叉验证, cv=3表示3次交叉验证
estimator = GridSearchCV(estimator, param_grid=param_dict, cv=3)
# 训练
estimator.fit(x_train, y_train)# 5)模型评估
# 方法1:直接比对真实值和预测值
y_predict = estimator.predict(x_test)
print("y_predict:\n", y_predict)
print("直接比对真实值和预测值:\n", y_test == y_predict)# 方法2:计算准确率
score = estimator.score(x_test, y_test)
print("准确率为:\n", score)'''
加网格搜索与交叉验证的代码
print("最佳参数:\n", estimator.best_params_)
print("最佳结果:\n", estimator.best_score_)
print("最佳估计器:\n", estimator.best_estimator_)
print("交叉验证结果:\n", estimator.cv_results_)
'''
#估计运行花1min相关文章:

机器学习 从入门到精通 day_04
1. 决策树-分类 1.1 概念 1. 决策节点 通过条件判断而进行分支选择的节点。如:将某个样本中的属性值(特征值)与决策节点上的值进行比较,从而判断它的流向。 2. 叶子节点 没有子节点的节点,表示最终的决策结果。 3. 决策树的…...

CLAHE算法介绍
限制对比度自适应直方图增强 CLAHE 算法介绍 1. CLAHE算法框图2.直方图clip及重分配2.1 opencv自带2.2 scikit-image2.3 结果对比2.4 clip limit的性质3.插值参考文献上图来自 K. Zuiderveld: Contrast Limited Adaptive Histogram Equalization。 图中可以看到各种直方图均衡的…...

高并发的业务场景下,如何防止数据库事务死锁
一、 一致的锁定顺序 定义: 死锁的常见原因之一是不同的事务以不同的顺序获取锁。当多个事务获取了不同资源的锁,并且这些资源之间发生了互相依赖,就会形成死锁。 解决方法: 确保所有的事务在获取多个锁时,按照相同的顺序请求锁。例如,如果事务A需要锁定表A和表B,事务…...
使用Python从零实现一个端到端多模态 Transformer大模型
嘿,各位!今天咱们要来一场超级酷炫的多模态 Transformer 冒险之旅!想象一下,让一个模型既能看懂图片,又能理解文字,然后还能生成有趣的回答。听起来是不是很像超级英雄的超能力?别急,…...
(附脚本))
elestio memos SSRF漏洞复现(CVE-2025-22952)(附脚本)
免责申明: 本文所描述的漏洞及其复现步骤仅供网络安全研究与教育目的使用。任何人不得将本文提供的信息用于非法目的或未经授权的系统测试。作者不对任何由于使用本文信息而导致的直接或间接损害承担责任。如涉及侵权,请及时与我们联系,我们将尽快处理并删除相关内容。 前言…...

倚光科技:以创新之光,雕琢全球领先光学设计公司
在光学技术飞速发展的当下,每一次突破都可能为众多领域带来变革性的影响。而倚光(深圳)科技有限公司,作为光学设计公司的一颗璀璨之星,正以其卓越的创新能力和深厚的技术底蕴,引领着光学设计行业的发展潮流…...

Linux安装Elasticsearch详细教程
准备工作 下载地址:Download Elasticsearch | Elastic 下载时需要注意es与jdk版本对应关系 ES 7.x 及之前版本,选择 Java 8 ES 8.x 及之后版本,选择 Java 17 或者 Java 18,建议 Java 17,因为对应版本的 Logstash 不支持 Java 1…...

C++字符串操作详解
引言 字符串处理是编程中最常见的任务之一,而在C中,我们有多种处理字符串的方式。本文将详细介绍C中的字符串操作,包括C风格字符串和C的string类。无论你是C新手还是想巩固基础的老手,这篇文章都能帮你梳理字符串处理的关键知识点…...

PromptPro|提示词生成和管理专家
大家好,我是吾鳴。 今天吾鳴给大家分享一个实用的提示词管理网站,它的名称叫做产品化管理提示词,英文名叫做PromptPro,是一个可以帮你管理你的大模型提示词的网站,同时你也可以告诉它你的需求,让它帮你生成…...

计算机视觉图像特征提取入门:Harris角点与SIFT算法
计算机视觉图像特征提取入门:Harris角点与SIFT算法 一、前言二、Harris 角点检测算法2.1 Harris 角点的定义与直观理解2.1.1 角点的概念2.1.2 Harris 角点的判定依据 2.2 Harris 角点检测的实现步骤2.2.1 计算图像的梯度2.2.2 构建结构张量矩阵2.2.3 …...
)
swift菜鸟教程1-5(语法,变量,类型,常量,字面量)
一个朴实无华的目录 今日学习内容:1.基本语法引入空格规范输入输出 2.变量声明变量变量输出加反斜杠括号 \\( ) 3.可选(Optionals)类型可选类型强制解析可选绑定 4.常量常量声明常量命名 5.字面量整数 and 浮点数 实例字符串 实例 今日学习内容: 1.基本…...

02142数据结构导论
初学者,怎样理解这道题,怎样大白话分析 答案解析 00、概念 29、 28、 27、 26、 25、 24、 23、 22、有5个元素,其入栈次序为:A、B、C、D、E,写出以元素C、D最先出栈(即C第一个且D第二个出栈)的各种可能的出栈次序。 (来…...

如何在AMD MI300X 服务器上部署 DeepSeek R1模型?
DeepSeek-R1凭借其深度推理能力备受关注,在语言模型性能基准测试中可与顶级闭源模型匹敌。 AMD Instinct MI300X GPU可在单节点上高效运行新发布的DeepSeek-R1和V3模型。 用户通过SGLang优化,将MI300X的性能提升至初始版本的4倍,且更多优化将…...

【Django】教程-15-注册页面
【Django】教程-1-安装创建项目目录结构介绍 【Django】教程-2-前端-目录结构介绍 【Django】教程-3-数据库相关介绍 【Django】教程-4-一个增删改查的Demo 【Django】教程-5-ModelForm增删改查规则校验【正则钩子函数】 【Django】教程-6-搜索框-条件查询前后端 【Django】教程…...

OpenAI即将上线新一代重磅选手——GPT-4.1
每周跟踪AI热点新闻动向和震撼发展 想要探索生成式人工智能的前沿进展吗?订阅我们的简报,深入解析最新的技术突破、实际应用案例和未来的趋势。与全球数同行一同,从行业内部的深度分析和实用指南中受益。不要错过这个机会,成为AI领…...

参照Spring Boot后端框架实现序列化工具类
本文参照Jackson实现序列化工具类,旨在于简化开发 JacksonUtil.class public class JacksonUtil {private JacksonUtil() {}/*** 单例*/private final static ObjectMapper OBJECT_MAPPER;static {OBJECT_MAPPER new ObjectMapper();}private static ObjectMappe…...

C_内存 内存地址概念
1. 计算机内存的基本概念 计算机的内存(RAM,随机存取存储器)是用来存储程序运行时的数据和指令的地方。内存被划分为许多小单元,每个单元有一个唯一的地址,这些地址从0开始编号。 内存单元:每个内存单元通…...

Rust重定义数据库内核:从内存安全到性能革命的破界之路
Rust语言正在颠覆传统数据库开发范式,其独特的所有权系统与零成本抽象能力,为攻克C/C时代遗留的内存泄漏、并发缺陷等顽疾提供全新解决方案。本文通过TiKV、Materialize等新一代数据库核心组件的实践案例,剖析Rust如何重塑存储引擎、查询优化…...

tree 显示到二级目录
要使用 tree 命令显示到二级目录,可以通过 -L 参数指定目录层级。具体命令如下: tree -L 2 参数说明: -L 数字:控制显示的目录深度。-L 2 表示显示到第二级目录(即当前目录下的直接子目录及其内容)。 示例输出: 复制 . ├── dir1 │ ├── file1.txt │ └─…...

UE5 在UE中创建骨骼动画
文章目录 创建动画的三种方式修改骨骼动画 创建动画的三种方式 方法一 打开一个已有的动画,左上角“创建资产/创建动画/参考姿势” 这将创建一个默认的A字形的骨骼,不建议这么做 方法二 打开一个已有的动画,左上角“创建资产/创建动画/当前…...

工业相机使用笔记
目前工业相机有多种分类方式,以下是基于不同原理和特点的类别总结: 按维度分类 2D相机: 原理:通过镜头将二维平面上的物体成像在图像传感器上,传感器上的像素点阵列捕捉物体的光信号,并转换为电信号或数字…...

深度兼容性测试和自助兼容性测试的区别,如何正确的选择?
泽众云经过几年业务快速发展,特别是泽众云兼容性测试服务已成为市场热门供应商之一,也根据用户不同需求推出了超高性价比服务,主要有深度兼容性测试和自助兼容性测试两种方式。2025年上半云真机平台的机型已升级到1000,全面覆盖了…...

Windows下安装depot_tools
一、引言 Chromium和Chromium OS使用名为depot_tools的脚本包来管理检出和审查代码。depot_tools工具集包括gclient、gcl、git-cl、repo等。它也是WebRTC开发者所需的工具集,用于构建和管理WebRTC项目。本文介绍Windows系统下安装depot_tools的方法。 二、下载depo…...

学术分享:基于 ARCADE 数据集评估 Grounding DINO、YOLO 和 DINO 在血管狭窄检测中的效果
一、引言 冠状动脉疾病(CAD)作为全球主要死亡原因之一,其早期准确检测对有效治疗至关重要。X 射线冠状动脉造影(XCA)虽然是诊断 CAD 的金标准,但这些图像的人工解读不仅耗时,还易受观察者间差异…...
——什么是 IA3 微调?)
NLP高频面试题(四十一)——什么是 IA3 微调?
随着大型语言模型的广泛应用,如何高效地将这些模型适配到特定任务中,成为了研究和工程实践中的重要课题。IA3(Infused Adapter by Adding and Adjusting)微调技术,作为参数高效微调的一种新颖方法,提供了在保持模型性能的同时,显著减少可训练参数数量的解决方案。 IA3 …...

STM32 模块化开发指南 · 第 3 篇 环形缓冲区 RingBuffer 模块设计与单元测试
本文是《STM32 模块化开发实战指南》第 3 篇,聚焦于“如何设计一个高性能、稳定、安全的环形缓冲区模块”。我们将从基本结构讲起,逐步完成接口定义、边界处理、API 实现与单元测试,最终实现一个可移植、线程安全、可嵌入 UART/BLE/协议模块的通用 RingBuffer。 一、RingBuf…...

软件测试岗位:IT行业中的质量守护者
在当今数字化飞速发展的IT行业,软件如同空气般无处不在,从日常的手机应用到复杂的企业级管理系统,软件的稳定性和可靠性至关重要。而软件测试岗位的从业者,就像是软件世界的质检员,精心守护着软件的质量。 一、软件测…...

单片机方案开发 代写程序/烧录芯片 九齐/应广等 电动玩具 小家电 语音开发
在电子产品设计中,单片机(MCU)无疑是最重要的组成部分之一。无论是消费电子、智能家居、工业控制,还是可穿戴设备,小家电等,单片机的应用无处不在。 单片机,简而言之,就是将计算机…...

恐龙专利及商标维权行动,已获批TRO并冻结资金
2025年3月30日,原告Shenzhen xingyin technology co.,Ltd.,现化名为Shenzhen Z Tech Co., Ltd.委托kemet律所发起维权。目前该案件已获批TRO临时禁令,涉案账户资金已被冻结,案件详情如下: 案件基本情况:起…...

【北京市小客车调控网站-注册/登录安全分析报告】
前言 由于网站注册入口容易被黑客攻击,存在如下安全问题: 暴力破解密码,造成用户信息泄露短信盗刷的安全问题,影响业务及导致用户投诉带来经济损失,尤其是后付费客户,风险巨大,造成亏损无底洞…...

Vue 3中的 setup
Vue 3引入了Composition API,其中setup函数是这一新API的核心部分。setup函数为开发者提供了一种更灵活、更模块化的方式来组织组件逻辑。以下是关于Vue 3中setup函数的详细解释: 1. 基本概念 setup函数是组件内使用Composition API的入口点。它是一个…...

2025年实用新型专利审查周期要多久?
申请实用新型专利时,审查周期是申请人最关心的问题之一。尤其是近几年国家知识产权局不断优化流程,审查速度是否有变化?2025年申请需要等多久?本文结合最新政策和实际案例,为你全面解析! 一、实用新型专利…...

使用Python建立双缝干涉模型
引言 双缝干涉实验是物理学中经典的实验之一,它展示了光的波动性以及量子力学的奇异性。实验结果表明,当光或粒子通过两条狭缝时,它们会产生干涉现象,形成明暗相间的条纹图案。这种现象不仅说明了光的波动性,还揭示了量子力学的核心思想——粒子具有波动性。今天,我们将…...

路由交换网络专题 | 第二章 | RIP | OSPF | 路由聚合 | 路由过滤 | 静默接口
拓扑图 (1)作为企业网络边界设备,AR1 上配置什么命令,可以使 OSPF 域内所有路由都会有指向自己的默认路由。默认路由的优先级是多少。如果 OSPF 域内其他路由器同样有到达外网的路径,且优于通过 AR1 到达外网ÿ…...

python 语言 设计模式
python 语言 设计模式 设计模式是指在软件开发过程中,针对反复出现的问题所总结归纳出的通用解决方案。以下是一些常见的Python语言设计模式: 目录 python 语言 设计模式创建型模式结构型模式行为型模式创建型模式 单例模式 定义:保证一个类只有一个实例,并提供一个全局访…...

银行业务发展历史
银行业务发展历史 银行业务的发展可以追溯到古代,但其现代形式的发展可以追溯到中世纪。以下是银行业务发展的主要历史阶段: 1. 古代和中世纪时期 特点:商人提供贷款和存款服务,充当中间人转移资金,发行纸币作为支付…...

JAVA中多线程的基本用法
文章目录 一、基本概念(一)进程控制块PCB(二)并行和并发(三)进程调度1.进程的状态2.优先级3.记账信息4.上下文 (四)进程和线程1.概述2.线程为什么比进程更轻量3.进程和线程的区别和联…...

健康与好身体笔记
文章目录 保证睡眠饭后百步走,活到九十九补充钙质一副好肠胃肚子咕咕叫 健康和工作的取舍 以前对健康没概念,但是随着年龄增长,健康问题凸显出来。 持续维护该文档,健康是个永恒的话题。 保证睡眠 一是心态要好,沾枕…...
)
如何下载谷歌浏览器增强版(扩展支持版)
在日常浏览和工作中,Chrome 浏览器因其强大的性能和丰富的扩展插件,成为全球范围内使用最广泛的浏览器之一。然而,对于需要进行深度扩展管理或需要稳定扩展环境的用户来说,标准版的 Google Chrome 可能在某些方面仍显不足。这时候…...

TDDMS分布式存储管理系列文章--分片/分区/分桶详解
友情链接: 星环分布式存储TDDMS大揭秘(一)分布式存储技术推出背景以及当前存在的挑战TDDMS是什么 前情提要 通过上个系列的文章我们了解到了各节点数据副本间通过一致性算法确保每次写入在响应客户端请求之前至少被多数节点(N/2…...
:集成SSE (Server-Sent Events) 服务器实时推送)
Spring Boot(九十):集成SSE (Server-Sent Events) 服务器实时推送
1 SSE简介 Server-sent Events(SSE) 是一种基于 HTTP 协议的服务器推送技术,它允许服务器主动向客户端发送数据。与 WebSocket 不同,SSE 是单向通信,即服务器可以主动向客户端推送数据,而客户端只能接收数据。 2 SSE特点 单向通信:SSE 是服务器向客户端的单向推送,客户…...

ubuntu22.04安装ROS2 humble
参考: https://zhuanlan.zhihu.com/p/702727186 前言: 笔记本安装了ubuntu20.04安装ros一直失败,于是将系统升级为ununut22.04,然后安装ros,根据上面的教程,目前看来是有可能成功的。 系统升级为ununut…...

力扣第206场周赛
周赛链接:竞赛 - 力扣(LeetCode)全球极客挚爱的技术成长平台 1. 二进制矩阵中的特殊位置 给定一个 m x n 的二进制矩阵 mat,返回矩阵 mat 中特殊位置的数量。 如果位置 (i, j) 满足 mat[i][j] 1 并且行 i 与列 j 中…...

C++17 主要更新
C17 主要更新 C17 是继 C14 之后的重要标准更新,引入了许多提升开发效率、简化代码和增强性能的特性。以下是 C17 的主要更新,按类别分类: 1. 语言核心特性 结构化绑定(Structured Bindings) 解构元组、结构体或数组…...

k8s master节点部署
一、环境准备 1.主机准备 192.168.10.100 master.com master 192.168.10.101 node1.com node1 192.168.10.102 node2.com node2 互信 时间同步 关闭防火墙 关闭selinux 2.创建/etc/sysctl.d/k8s.conf,添加如下内容 cat > /etc/sysctl.d/k8s.conf <<EOF net.br…...
)
YOLO学习笔记 | YOLOv8 全流程训练步骤详解(2025年4月更新)
===================================================== github:https://github.com/MichaelBeechan CSDN:https://blog.csdn.net/u011344545 ===================================================== 这里写自定义目录标题 一、数据准备1. 数据标注与格式转换2. 配置文件生…...

centos7.9 升级 gcc
本片文章介绍如何升级gcc,centos7.9 仓库默认的gcc版本为:4.8.5 4.8.5-44) Copyright (C) 2015 Free Software Foundation, Inc. This is free software; see the source for copying conditions. There is NO warranty; not even for MERCHANTABILITY…...

Linux基本指令
Linux目录结构 Linux的目录结构是一个树形结构。Windows系统可以拥有多个盘符,如C盘、D盘、E盘。而Linux没有盘符这个概念,只有一个根目录/,所有文件都在它下面。如下图所示: Linux路径的描述方式 在Linux系统中,路径之间的层级…...

Google A2A协议,是为了战略性占领标准?
一、导读 2025 年 4 月 9 日,Google 正式发布了 Agent2Agent(A2A)协议。 A2A 协议致力于打破智能体之间的隔阂,让它们能够跨越框架和供应商的限制,以一种标准化、开放的方式进行沟通与协作 截止到现在,代…...
暴力娱乐篇29)
每日一题(小白)暴力娱乐篇29
题目比较简单,主要是判断条件这块,一定要注意在奇数的位置和偶数的位置标记,若奇数位为奇数偶数位为偶数才能计数加一,否则都是跳过。 ①接收数据n ②循环n次,拆解n,每次拆解记录ans ③拆解n为若干次x&a…...