GPT - GPT(Generative Pre-trained Transformer)模型框架
本节代码主要为实现了一个简化版的 GPT(Generative Pre-trained Transformer)模型。GPT 是一种基于 Transformer 架构的语言生成模型,主要用于生成自然语言文本。
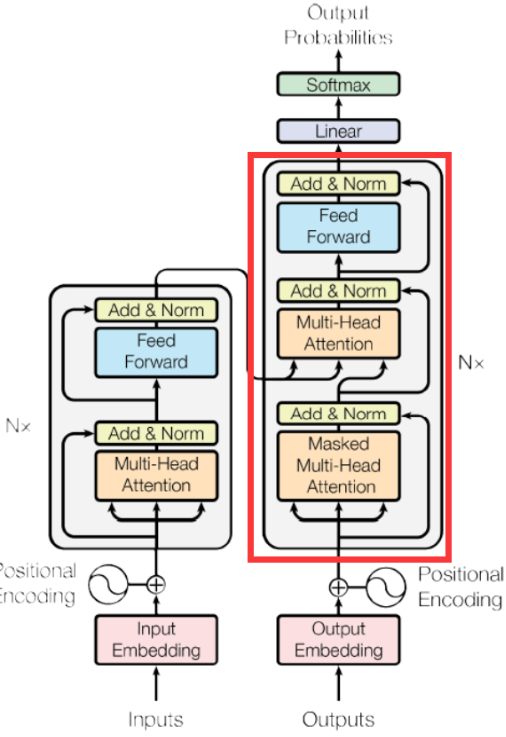
1. 模型结构
初始化部分
class GPT(nn.Module):def __init__(self, vocab_size, d_model, seq_len, N_blocks, dff, dropout):super().__init__()self.emb = nn.Embedding(vocab_size, d_model)self.pos = nn.Embedding(seq_len, d_model)self.layers = nn.ModuleList([TransformerDecoderBlock(d_model, dff, dropout)for i in range(N_blocks)])self.fc = nn.Linear(d_model, vocab_size)-
vocab_size:词汇表的大小,即模型可以处理的唯一词元(token)的数量。 -
d_model:模型的维度,表示嵌入和内部表示的维度。 -
seq_len:序列的最大长度,即输入序列的最大长度。 -
N_blocks:Transformer 解码器块的数量。 -
dff:前馈网络(Feed-Forward Network, FFN)的维度。 -
dropout:Dropout 的概率,用于防止过拟合。
组件说明
-
self.emb:词嵌入层,将输入的词元索引映射到d_model维的向量空间。 -
self.pos:位置嵌入层,将序列中每个位置的索引映射到d_model维的向量空间。位置嵌入用于给模型提供序列中每个词元的位置信息。 -
self.layers:一个模块列表,包含N_blocks个TransformerDecoderBlock。每个块是一个 Transformer 解码器层,包含多头注意力机制和前馈网络。 -
self.fc:一个线性层,将解码器的输出映射到词汇表大小的维度,用于生成最终的词元概率分布。
2. 前向传播
def forward(self, x, attn_mask=None):emb = self.emb(x)pos = self.pos(torch.arange(x.shape[1]))x = emb + posfor layer in self.layers:x = layer(x, attn_mask)return self.fc(x)步骤解析
-
词嵌入和位置嵌入:
-
self.emb(x):将输入的词元索引x转换为词嵌入表示emb,形状为(batch_size, seq_len, d_model)。 -
self.pos(torch.arange(x.shape[1])):生成位置嵌入pos,形状为(seq_len, d_model)。torch.arange(x.shape[1])生成一个从 0 到seq_len-1的序列,表示每个位置的索引。 -
x = emb + pos:将词嵌入和位置嵌入相加,得到最终的输入表示x。位置嵌入的加入使得模型能够区分序列中不同位置的词元。
-
-
Transformer 解码器层:
-
for layer in self.layers:将输入x逐层传递给每个TransformerDecoderBlock。 -
x = layer(x, attn_mask):每个解码器块会处理输入x,并应用因果掩码attn_mask(如果提供)。因果掩码确保模型在解码时只能看到当前及之前的位置,而不能看到未来的信息。
-
-
输出层:
-
self.fc(x):将解码器的输出x传递给线性层self.fc,生成最终的输出。输出的形状为(batch_size, seq_len, vocab_size),表示每个位置上每个词元的预测概率。
-
截止到本篇文章GPT简单复现完成,下面将附完整代码,方便理解代码整体结构
import math
import torch
import random
import torch.nn as nnfrom tqdm import tqdm
from torch.utils.data import Dataset, DataLoader'''
仿 nn.TransformerDecoderLayer 实现
'''class MultiHeadAttention(nn.Module):def __init__(self, d_model, num_heads, dropout):super().__init__()self.num_heads = num_headsself.d_k = d_model // num_headsself.q_project = nn.Linear(d_model, d_model)self.k_project = nn.Linear(d_model, d_model)self.v_project = nn.Linear(d_model, d_model)self.o_project = nn.Linear(d_model, d_model)self.dropout = nn.Dropout(dropout)def forward(self, x, attn_mask=None):batch_size, seq_len, d_model = x.shapeQ = self.q_project(x).view(batch_size, seq_len, self.num_heads, self.d_k).transpose(1, 2)K = self.q_project(x).view(batch_size, seq_len, self.num_heads, self.d_k).transpose(1, 2)V = self.q_project(x).view(batch_size, seq_len, self.num_heads, self.d_k).transpose(1, 2)atten_scores = Q @ K.transpose(2, 3) / math.sqrt(self.d_k)if attn_mask is not None:attn_mask = attn_mask.unsqueeze(1)atten_scores = atten_scores.masked_fill(attn_mask == 0, -1e9)atten_scores = torch.softmax(atten_scores, dim=-1)out = atten_scores @ Vout = out.transpose(1, 2).contiguous().view(batch_size, seq_len, d_model)out = self.o_project(out)return self.dropout(out)class TransformerDecoderBlock(nn.Module):def __init__(self, d_model, dff, dropout):super().__init__()self.linear1 = nn.Linear(d_model, dff)self.activation = nn.GELU()# self.activation = nn.ReLU()self.dropout = nn .Dropout(dropout)self.linear2 = nn.Linear(dff, d_model)self.norm1 = nn.LayerNorm(d_model)self.norm2 = nn.LayerNorm(d_model)self.norm3 = nn.LayerNorm(d_model)self.dropout1 = nn.Dropout(dropout)self.dropout2 = nn.Dropout(dropout)self.dropout3 = nn.Dropout(dropout)self.mha_block1 = MultiHeadAttention(d_model, num_heads, dropout)self.mha_block2 = MultiHeadAttention(d_model, num_heads, dropout)def forward(self, x, mask=None):x = self.norm1(x + self.dropout1(self.mha_block1(x, mask)))x = self.norm2(x + self.dropout2(self.mha_block2(x, mask)))x = self.norm3(self.linear2(self.dropout(self.activation(self.linear1(x)))))return xclass GPT(nn.Module):def __init__(self, vocab_size, d_model, seq_len, N_blocks, dff, dropout):super().__init__()self.emb = nn.Embedding(vocab_size, d_model)self.pos = nn.Embedding(seq_len, d_model)self.layers = nn.ModuleList([TransformerDecoderBlock(d_model, dff, dropout)for i in range(N_blocks)])self.fc = nn.Linear(d_model, vocab_size)def forward(self, x, attn_mask=None):emb = self.emb(x)pos = self.pos(torch.arange(x.shape[1]))x = emb + posfor layer in self.layers:x = layer(x, attn_mask)return self.fc(x)def read_data(file, num=1000):with open(file, "r", encoding="utf-8") as f:data = f.read().strip().split("\n")res = [line[:24] for line in data[:num]]return resdef tokenize(corpus):vocab = {"[PAD]": 0, "[UNK]": 1, "[BOS]": 2, "[EOS]": 3, ",": 4, "。": 5, "?": 6}for line in corpus:for token in line:vocab.setdefault(token, len(vocab))idx2word = list(vocab)return vocab, idx2wordclass Tokenizer:def __init__(self, vocab, idx2word):self.vocab = vocabself.idx2word = idx2worddef encode(self, text):ids = [self.token2id(token) for token in text]return idsdef decode(self, ids):tokens = [self.id2token(id) for id in ids]return tokensdef id2token(self, id):token = self.idx2word[id]return tokendef token2id(self, token):id = self.vocab.get(token, self.vocab["[UNK]"])return idclass Poetry(Dataset):def __init__(self, poetries, tokenizer: Tokenizer):self.poetries = poetriesself.tokenizer = tokenizerself.pad_id = self.tokenizer.vocab["[PAD]"]self.bos_id = self.tokenizer.vocab["[BOS]"]self.eos_id = self.tokenizer.vocab["[EOS]"]def __len__(self):return len(self.poetries)def __getitem__(self, idx):poetry = self.poetries[idx]poetry_ids = self.tokenizer.encode(poetry)input_ids = torch.tensor([self.bos_id] + poetry_ids)input_msk = causal_mask(input_ids)label_ids = torch.tensor(poetry_ids + [self.eos_id])return {"input_ids": input_ids,"input_msk": input_msk,"label_ids": label_ids}def causal_mask(x):mask = torch.triu(torch.ones(x.shape[0], x.shape[0]), diagonal=1) == 0return maskdef generate_poetry(method="greedy", top_k=5):model.eval()with torch.no_grad():input_ids = torch.tensor(vocab["[BOS]"]).view(1, -1)while input_ids.shape[1] < seq_len:output = model(input_ids, None)probabilities = torch.softmax(output[:, -1, :], dim=-1)if method == "greedy":next_token_id = torch.argmax(probabilities, dim=-1)elif method == "top_k":top_k_probs, top_k_indices = torch.topk(probabilities[0], top_k)next_token_id = top_k_indices[torch.multinomial(top_k_probs, 1)]if next_token_id == vocab["[EOS]"]:breakinput_ids = torch.cat([input_ids, next_token_id.view(1, 1)], dim=1)return input_ids.squeeze()if __name__ == "__main__":file = "/Users/azen/Desktop/llm/LLM-FullTime/dataset/text-generation/poetry_data.txt"poetries = read_data(file, num=2000)vocab, idx2word = tokenize(poetries)tokenizer = Tokenizer(vocab, idx2word)trainset = Poetry(poetries, tokenizer)batch_size = 16trainloader = DataLoader(trainset, batch_size=batch_size, shuffle=True)d_model = 512seq_len = 25 # 有特殊标记符num_heads = 8dropout = 0.1dff = 4*d_modelN_blocks = 2model = GPT(len(vocab), d_model, seq_len, N_blocks, dff, dropout)lr = 1e-4optim = torch.optim.Adam(model.parameters(), lr=lr)loss_fn = nn.CrossEntropyLoss()epochs = 100for epoch in range(epochs):for batch in tqdm(trainloader, desc="Training"):batch_input_ids = batch["input_ids"]batch_input_msk = batch["input_msk"]batch_label_ids = batch["label_ids"]output = model(batch_input_ids, batch_input_msk)loss = loss_fn(output.view(-1, len(vocab)), batch_label_ids.view(-1))loss.backward()optim.step()optim.zero_grad()print("Epoch: {}, Loss: {}".format(epoch, loss))res = generate_poetry(method="top_k")text = tokenizer.decode(res)print("".join(text))pass
相关文章:
GPT - GPT(Generative Pre-trained Transformer)模型框架
本节代码主要为实现了一个简化版的 GPT(Generative Pre-trained Transformer)模型。GPT 是一种基于 Transformer 架构的语言生成模型,主要用于生成自然语言文本。 1. 模型结构 初始化部分 class GPT(nn.Module):def __init__(self, vocab…...
:如何选择合适的访谈对象)
数据中台、BI业务访谈(三):如何选择合适的访谈对象
大家在日常中有没有遇到这种情况,感觉所有的事情都准备的很充分了,反复的演练,结果一上去就发现事情完全没有按照自己预想的来。智者千虑,必有一失。满满自信的去,结果是铩羽归来。 这种情况很正常,就跟打…...

计算机网络-TCP可靠传输机制
计算机网络-TCP可靠传输机制 3. TCP可靠传输机制3.1 序列号与确认号机制3.1.1 序列号与确认号的基本概念3.1.2 序列号与确认号的工作原理3.1.3 序列号与确认号在Linux内核中的实现TCP控制块中的序列号和确认号字段序列号的初始化发送数据时的序列号处理接收数据时的确认号处理 …...

计算机网络- 传输层安全性
传输层安全性 7. 传输层安全性7.1 传输层安全基础7.1.1 安全需求机密性(Confidentiality)完整性(Integrity)真实性(Authenticity)不可否认性(Non-repudiation) 7.1.2 常见安全威胁窃…...

【C++取经之路】lambda和bind
目录 引言 lambda语法 lambda捕获列表解析 1)值捕获 2)引用捕获 3)隐式捕获 lambda的工作原理 lambda进阶用法 泛型lambda 立即调用 lambda 与 function bind语法 bind的调用逻辑 bind核心用途 绑定参数 调整参数顺序 bind的…...

AF3 ProteinDataset类的初始化方法解读
AlphaFold3 protein_dataset模块 ProteinDataset 类主要负责从结构化的蛋白质数据中构建一个可供模型训练/推理使用的数据集,ProteinDataset 类的 __init__ 方法用于初始化一个蛋白质数据集对象。 源代码: def __init__(self,dataset_folder,features_folder="./data/t…...
)
博客园账户注册全流程指南(附常见问题)
博客园账户注册全流程指南(附常见问题) 引言 博客园作为国内老牌技术社区,是程序员们分享知识、交流技术的圣地。本文将手把手教你完成从注册到开通博客的全流程,附常见问题解答,助你轻松开启技术博客之旅。 一、注…...

算法复习笔记
算法复习 最大公约数枚举abc反序数 模拟xxx定律打印数字菱形今年的第几天?vector完数VS盈数剩下的树 排序和查找顺序查找二分查找找位置 字符串统计单词浮点数加法 线性数据结构队列约瑟夫问题(队列)计算表达式(栈) 递…...
)
spring boot 引入fastjson,com.alibaba.fastjson不存在(Springboot-测试项目)
spring boot 引入fastjson,com.alibaba.fastjson不存在(Springboot-测试项目) 先解决最初的的包不找到问题,适用所有包找不到跟进。 <mirrors><!-- mirror| Specifies a repository mirror site to use instead of a g…...
含万字文档+运行说明文档)
新闻推荐系统(springboot+vue+mysql)含万字文档+运行说明文档
新闻推荐系统(springbootvuemysql)含万字文档运行说明文档 该系统是一个新闻推荐系统,分为管理员和用户两个角色。管理员模块包括个人中心、用户管理、排行榜管理、新闻管理、我的收藏管理和系统管理等功能。管理员可以通过这些功能进行用户信息管理、查看和编辑用…...

UE4 踩坑记录
1、Using git status to determine working set for adaptive non-unity build 我删除了一个没用的资源,结果就报这个错,原因就是这条命令导致的, 如果这个项目是git项目, ue编译时会优先通过 git status检查哪些文件被修改&#…...

【解决方案】vscode 不小心打开了列选择模式,选择时只能选中同一列的数据。
vscode 不小心打开了列选择模式,选择时只能选中同一列的数据。 解决方案: 1.通过命令面板关闭: 按下 Ctrl Shift P(Windows/Linux)或 Cmd Shift P(macOS),输入 切换列选择模式…...

国标GB28181视频平台EasyCVR如何搭建汽车修理厂远程视频网络监控方案
一、背景分析 近年我国汽车保有量持续攀升,与之相伴的汽车保养维修需求也逐渐提高。随着社会经济的发展,消费者对汽车维修服务质量的要求越来越高,这使得汽车维修店的安全防范与人员管理问题面临着巨大挑战。 多数汽车维修店分布分散&#…...

【Go】windows下的Go安装与配置,并运行第一个Go程序
【Go】windows下的Go安装与配置,并运行第一个Go程序 安装环境:windows10 64位 安装版本:go1.16 windows/amd64 一、安装配置步骤 1.到官方网址下载安装包 https://golang.google.cn/dl/ 默认情况下 .msi 文件会安装在 c:\Go 目录下。可自行配…...

Linux 线程:从零构建多线程应用:系统化解析线程API与底层设计逻辑
线程 线程的概述 在之前,我们常把进程定义为 程序执行的实例,实际不然,进程实际上只是维护应用程序的各种资源,并不执行什么。真正执行具体任务的是线程。 那为什么之前直接执行a.out的时候,没有这种感受呢…...

榕壹云无人共享系统:基于SpringBoot+MySQL+UniApp的物联网共享解决方案
无人共享经济下的技术革新 随着无人值守经济模式的快速发展,传统共享设备面临管理成本高、效率低下等问题。榕壹云无人共享系统依托SpringBoot+MySQL+UniApp技术栈,结合物联网与移动互联网技术,为商家提供低成本、高可用的无人化运营解决方案。本文将详细解析该系统的技术架…...
:电子书免费下载)
技术书籍推荐(002):电子书免费下载
20. 利用Python进行数据分析 免费 电子书 PDF 下载 书籍简介: 本书聚焦于使用Python进行数据处理和分析。详细介绍了Python中用于数据分析的重要库,如NumPy(提供高效的数值计算功能,包括数组操作、数学函数等)、panda…...
)
安全序列(DP)
#include <bits/stdc.h> using namespace std; const int MOD1e97; const int N1e65; int f[N]; int main() {int n,k;cin>>n>>k;f[0]1;for(int i1;i<n;i){f[i]f[i-1]; // 不放桶:延续前一位的所有方案if(i-k-1>0){f[i](f[i]f[i-k…...
)
数据可视化 —— 堆形图应用(大全)
一、案例一:温度堆积图 # 导入 matplotlib 库中的 pyplot 模块,这个模块提供了类似于 MATLAB 的绘图接口, # 方便我们创建各种类型的可视化图表,比如折线图、柱状图、散点图等 import matplotlib.pyplot as plt # 导入 numpy 库&…...
)
利用 pyecharts 实现地图的数据可视化——第七次人口普查数据的2d、3d展示(关键词:2d 、3d 、map、 geo、涟漪点)
参考文档:链接: link_pyecharts 官方文档 1、map() 传入省份全称,date_pair 是列表套列表 [ [ ],[ ] … ] 2、geo() 传入省份简称,date_pair 是列表套元组 [ ( ),( ) … ] 1、准备数据 population_data:简称经纬度 population_da…...

字节跳动开源 LangManus:不止是 Manus 平替,更是下一代 AI 自动化引擎
当 “AI 自动化” 成为科技领域最炙手可热的关键词,我们仿佛置身于一场激动人心的变革前夜。各行各业都在翘首以盼,期待 AI 技术能够真正解放生产力,将人类从繁琐重复的工作中解脱出来。在这个充满无限可能的时代,字节跳动悄然发布…...

第十四届蓝桥杯大赛软件赛省赛C/C++ 大学 A 组真题
文章目录 1 幸运数题目描述:答案:4430091 代码: 2 有奖问答题目描述:重点:答案:8335366 代码: 3 平方差题目描述:思路:数学找规律代码: 4 更小的数题目描述&a…...

springboot+tabula解析pdf中的表格数据
场景 在日常业务需求中,往往会遇到解析pdf数据获取文本的需求,常见的做法是使用 pdfbox 来做,但是它只适合做一些简单的段落文本解析,无法处理表格这种复杂类型,因为单元格中的文本有换行的情况,无法对应到…...

静态链接part1
比较多这一部分,包含了编译和链接,书还没看完就先记录一下其中编译的一部分 编译 gcc编译分为预处理、编译、汇编、链接四个步骤 预处理 也称预编译,主要处理的是源代码文件中以“#”开始的预编译指令,这里简单讲一下规则&…...

golang通过STMP协议发送邮件功能详细操作
一.简介 在 Go 语言中接入 IMAP 和 SMTP 服务来进行邮件的发送和接收操作,可以通过使用一些现有的第三方库来简化操作,常见的库有 go-imap 和 gomail,它们可以帮助我们连接和操作 IMAP 邮箱(读取邮件)以及通过 SMTP 发送邮件 二.实现 1. IMA…...

分布式锁在秒杀场景中的Python实现与CAP权衡
目录 一、分布式锁的前世今生 二、秒杀系统的 “硬核” 挑战 三、Python 实现分布式锁的 “实战演练” Redis 实现:快准狠 ZooKeeper 实现:稳如老狗 数据库实现:老实本分 四、CAP 理论的 “三角恋” 五、性能优化的 “锦囊妙计” 锁粒度控制:粗细有道 超时机制:别…...

数据驱动的温暖守护:智慧康养平台如何实现 “千人千面” 的精准照护?
在当今数字化时代,七彩喜智慧康养平台借助数据的力量,正逐步打破传统养老服务模式的局限,实现 “千人千面” 的精准照护。 通过收集、分析和利用大量与老年人相关的数据,这些平台能够深入了解每位老人的独特需求,并据…...

基于SSM的校园美食交流系统
作者:计算机学姐 开发技术:SpringBoot、SSM、Vue、MySQL、JSP、ElementUI、Python、小程序等,“文末源码”。 专栏推荐:前后端分离项目源码、SpringBoot项目源码、Vue项目源码、SSM项目源码、微信小程序源码 精品专栏:…...

多线程进阶
进阶的内容,就关于线程的面试题为主了,涉及到的内容在工作中使用较少,但面试会考!!! 锁的策略 加锁的过程中,在处理冲突的过程中,涉及到的一些不同的处理方法,此处的锁…...

聊一聊接口测试时遇到第三方服务时怎么办
目录 一、使用 Mock 或 Stub 模拟第三方服务 二、利用第三方服务的沙箱(Sandbox)环境 三、测试隔离与数据清理 四、处理异步回调 五、容错与异常测试 六、契约测试 在我们进行接口测试时,有的时候会遇到要调用第三方服务即外部的API&am…...

《Python星球日记》第22天:NumPy 基础
名人说:路漫漫其修远兮,吾将上下而求索。—— 屈原《离骚》 创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊) 目录 一、NumPy 简介1. 什么是 NumPy?为什么使用 NumPy?2. 安…...

Spring Boot 中 Bean 的生命周期详解
Spring Boot 中 Bean 的生命周期详解 一、引言 在 Spring Boot 应用中,Bean 是构成应用程序的基础组件。理解 Bean 的生命周期对于开发高效、稳定的 Spring Boot 应用至关重要。本文将深入探讨 Spring Boot 中 Bean 的完整生命周期过程。 二、Bean 生命周期的基本…...

结构化需求分析:功能、数据与行为的全景建模
目录 前言1 功能模型:数据流图(DFD)的结构与应用1.1 数据流图的基本构成要素1.2 数据流图的层次化设计1.3 数据流图的建模价值 2 数据模型:ER图揭示数据结构与关系2.1 ER图的基本组成2.2 建模过程与注意事项2.3 数据模型的价值体现…...

OpenCompass模型评估
OpenCompass面向大模型的开源方和使用者, 提供开源、高效、全面的大模型评测开放平台。 一、OpenCompass文档 1.基础安装 使用Conda准备 OpenCompass 运行环境: conda create --name opencompass python3.10 -y conda activate opencompass2. 安装 Op…...

基于51单片机语音实时采集系统
基于51单片机语音实时采集 (程序+原理图+PCB+设计报告) 功能介绍 具体功能: 系统由STC89C52单片机ISD4004录音芯片LM386功放模块小喇叭LCD1602按键指示灯电源构成 1.可通过按键随时选择相应的录音进行播…...

NeuroImage:膝关节炎如何影响大脑?静态与动态功能网络变化全解析
膝骨关节炎(KOA)是导致老年人活动受限和残疾的主要原因之一。这种疾病不仅引起关节疼痛,还会显著影响患者的生活质量。然而,目前对于KOA患者大脑功能网络的异常变化及其与临床症状之间的关系尚不清楚。 2024年4月10日,…...

高级java每日一道面试题-2025年4月01日-微服务篇[Nacos篇]-Nacos集群的数据一致性是如何保证的?
如果有遗漏,评论区告诉我进行补充 面试官: Nacos集群的数据一致性是如何保证的? 我回答: Nacos 集群数据一致性保障机制详解 在 Java 高级面试中,Nacos 集群的数据一致性保障是考察分布式系统核心能力的关键点。以下是 Nacos 通过多种机制和技术确保…...

阿里云 OSS 在 ZKmall开源商城的应用实践
ZKmall开源商城通过深度整合阿里云OSS(对象存储服务),构建了高效、安全的文件存储与管理体系,支撑商品图片、用户上传内容等非结构化数据的存储与分发。结合阿里云OSS的技术特性与ZKmall的微服务架构,其实践方案可总结…...

【Linux】线程池与封装线程
目录 一、线程池: 1、池化技术: 2、线程池优点: 3、线程池应用场景: 4、线程池实现: 二、封装线程: 三、单例模式: 四、其他锁: 五、读者写者问题 一、线程池: …...

protobuf的应用
1.版本和引用 syntax "proto3"; // proto2 package tutorial; // package类似C命名空间 // 可以引用本地的,也可以引用include里面的 import "google/protobuf/timestamp.proto"; // 已经写好的proto文件是可以引用 我们版本选择pr…...
)
linux shell编程之条件语句(二)
目录 一. 条件测试操作 1. 文件测试 2. 整数值比较 3. 字符串比较 4. 逻辑测试 二. if 条件语句 1. if 语句的结构 (1) 单分支 if 语句 (2) 双分支 if 语句 (3) 多分支 if 语句 2. if 语句应用示例 (1) 单分支 if 语句应用 (2) 双分支 if 语句应用 (3) 多分支 …...

图论整理复习
回溯: 模板: void backtracking(参数) {if (终止条件) {存放结果;return;}for (选择:本层集合中元素(树中节点孩子的数量就是集合的大小)) {处理节点;backtracking(路径,选择列表); // 递归回溯ÿ…...

企业指标设计方法指南
该文档聚焦企业指标设计方法,适用于企业中负责战略规划、业务运营、数据分析、指标管理等相关工作的人员,如企业高管、部门经理、数据分析师等。 主要内容围绕指标设计展开:首先指出指标设计面临的困境,包括权责不清、口径不统一、缺乏标准规范、报表体系混乱、指标…...

AIP-217 不可达资源
编号217原文链接AIP-217: Unreachable resources状态批准创建日期2019-08-26更新日期2019-08-26 有时,用户可能会请求一系列资源,而其中某些资源暂时不可用。最典型的场景是跨集合读。例如用户可能请求返回多个上级位置的资源,但其中某个位置…...

SAP系统控制检验批
问题:同一批物料多检验批问题 现象:同一物料多采购订单同一天到货时,对其采购订单分别收货,导致系统产生多个检验批,需分别请检单、检验报告等,使质量部工作复杂化。 原因:物料主数据质量试图设…...

JavaScript 代码混淆与反混淆技术详解
一、代码混淆:让别人看不懂你的代码 混淆技术就是一种“代码伪装术”,目的是让别人很难看懂你的代码逻辑,从而保护你的核心算法或敏感信息。 1. 变量名压缩 原理:把变量名改成乱码,比如把calculatePrice改成a&#…...

Android studio | From Zero To One ——手机弹幕
===================================================== github:https://github.com/MichaelBeechan CSDN:https://blog.csdn.net/u011344545 ===================================================== 滚动显示 代码activity_main.xmlactivity_fullscreen.xmlAndroidManife…...

面向对象的需求分析与UML构造块详解
目录 前言1 面向对象的需求分析概述2 UML构造块概述3 UML事物详解3.1 结构事物(Structural Things)3.2 行为事物(Behavioral Things)3.3 分组事物(Grouping Things)3.4 解释事物(Annotational T…...

LeetCode 2843.统计对称整数的数目:字符串数字转换
【LetMeFly】2843.统计对称整数的数目:字符串数字转换 力扣题目链接:https://leetcode.cn/problems/count-symmetric-integers/ 给你两个正整数 low 和 high 。 对于一个由 2 * n 位数字组成的整数 x ,如果其前 n 位数字之和与后 n 位数字…...

RocketMQ深度百科全书式解析
一、核心架构与设计哲学 1. 设计目标 海量消息堆积:单机支持百万级消息堆积,适合大数据场景(如日志采集)。严格顺序性:通过队列分区(Queue)和消费锁机制保证局部顺序。事务…...