图论整理复习
回溯:
模板:
void backtracking(参数) {if (终止条件) {存放结果;return;}for (选择:本层集合中元素(树中节点孩子的数量就是集合的大小)) {处理节点;backtracking(路径,选择列表); // 递归回溯,撤销处理结果}
}77.组合:
给定两个整数 n 和 k,返回范围 [1, n] 中所有可能的 k 个数的组合。
你可以按 任何顺序 返回答案。
示例 1:
输入:n = 4, k = 2 输出: [[2,4],[3,4],[2,3],[1,2],[1,3],[1,4], ]
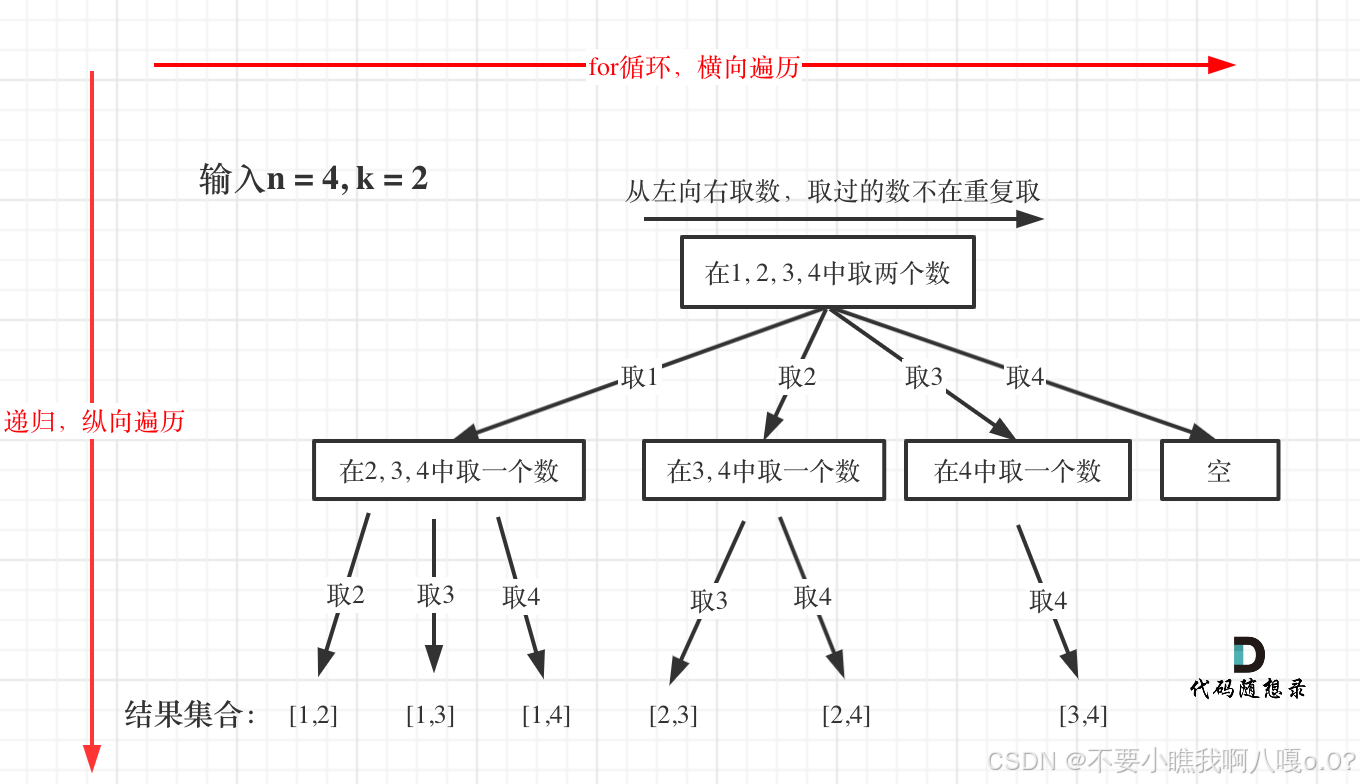
主要记忆:横向为for循环控制,纵向遍历为递归控制,在每次递归操作之后要加上回溯的操作,也就是绘图递归前的那一步操作。
class Solution {
public:vector<int> path;vector<vector<int>> res;void backtrack(int n, int k, int sindex){if(path.size() == k){res.push_back(path);return;}for(int i = sindex; i <= n; i++){path.push_back(i);backtrack(n, k, i + 1);path.pop_back();}}vector<vector<int>> combine(int n, int k) {backtrack(n, k, 1);return res;}
};216:组合总和
找出所有相加之和为 n 的 k 个数的组合,且满足下列条件:
- 只使用数字1到9
- 每个数字 最多使用一次
返回 所有可能的有效组合的列表 。该列表不能包含相同的组合两次,组合可以以任何顺序返回。
示例 1:
输入: k = 3, n = 7 输出: [[1,2,4]] 解释: 1 + 2 + 4 = 7 没有其他符合的组合了。
class Solution {
public:vector<int> path;vector<vector<int>> res;int sum = 0;void backtrack(int n, int k, int sindex){if(sum == n && path.size() == k){res.push_back(path);return;}for(int i = sindex; i <= 9; i++){path.push_back(i);sum += i;backtrack(n, k, i + 1);sum -= i;path.pop_back();}}vector<vector<int>> combinationSum3(int k, int n) {backtrack(n, k, 1);return res;}
};DFS:
模板:
记录每一个符合的区域,需要用到回溯的思想,在每一次进入递归回溯后需要进行复位操作:
#include <iostream>
#include <vector>
using namespace std;vector<vector<int> > result; // 收集符合条件的路径
vector<int> path; // 1节点到终点的路径
vector<bool> visited; // 标记节点是否被访问过void dfs(const vector<vector<int> >& graph, int x, int n) {// 停止搜索的条件:// 1. 搜索到了已经搜索过的节点(在path中的节点)// 2. 搜索到了不符合需求的节点(这里不需要特别判断,因为for循环会自动处理无出边的情况)if (x == n) { // 找到符合条件的一条路径result.push_back(path);return;}for (int i = 1; i <= n; i++) { // 遍历节点x链接的所有节点if (graph[x][i] == 1 && !visited[i]) { // 找到x链接的且未访问过的节点visited[i] = true; // 标记为已访问path.push_back(i); // 遍历到的节点加入到路径中来dfs(graph, i, n); // 进入下一层递归path.pop_back(); // 回溯,撤销本节点visited[i] = false; // 回溯,取消访问标记}}
}int main() {int n, m, s, t;cin >> n >> m;// 节点编号从1到n,所以申请 n+1 这么大的数组vector<vector<int> > graph(n + 1, vector<int>(n + 1, 0));visited.resize(n + 1, false); // 初始化visited数组while (m--) {cin >> s >> t;// 使用邻接矩阵 表示无向图,1 表示 s 与 t 是相连的graph[s][t] = 1;}visited[1] = true; // 起点标记为已访问path.push_back(1); // 无论什么路径已经是从1节点出发dfs(graph, 1, n); // 开始遍历// 输出结果if (result.size() == 0) {cout << -1 << endl;}for (size_t i = 0; i < result.size(); i++) {for (size_t j = 0; j < result[i].size() - 1; j++) {cout << result[i][j] << " ";}cout << result[i][result[i].size() - 1] << endl;}return 0;
}547:省份数量
有 n 个城市,其中一些彼此相连,另一些没有相连。如果城市 a 与城市 b 直接相连,且城市 b 与城市 c 直接相连,那么城市 a 与城市 c 间接相连。
省份 是一组直接或间接相连的城市,组内不含其他没有相连的城市。
给你一个 n x n 的矩阵 isConnected ,其中 isConnected[i][j] = 1 表示第 i 个城市和第 j 个城市直接相连,而 isConnected[i][j] = 0 表示二者不直接相连。
返回矩阵中 省份 的数量。
示例 1:

输入:isConnected = [[1,1,0],[1,1,0],[0,0,1]] 输出:2
class Solution {
public:// 需要额外添加一个visited矩阵来确定当前遍历到的点是否已经走过,进行剪枝,提前终止递归,作为递归停止的条件void dfs(vector<vector<int>>& isConnected, int x, vector<bool>& visited){if(visited[x]){return;}visited[x] = true;for(int i = 0; i < isConnected.size(); i++){if(isConnected[x][i] == 1 && !visited[i]){dfs(isConnected, i, visited);}}}int findCircleNum(vector<vector<int>>& isConnected) {vector<bool> visited(isConnected.size(), false);int res = 0;for(int i = 0; i < isConnected.size(); i++){if(!visited[i]){dfs(isConnected, i, visited);res++;}}return res;}
};200:岛屿数量
给你一个由 '1'(陆地)和 '0'(水)组成的的二维网格,请你计算网格中岛屿的数量。
岛屿总是被水包围,并且每座岛屿只能由水平方向和/或竖直方向上相邻的陆地连接形成。
此外,你可以假设该网格的四条边均被水包围。
示例 1:
输入:grid = [["1","1","1","1","0"],["1","1","0","1","0"],["1","1","0","0","0"],["0","0","0","0","0"] ] 输出:1
class Solution {
public:// 定义四个方向的偏移量:下、右、上、左int opt[4][2] = {{1, 0}, {0, 1}, {-1, 0}, {0, -1}};// DFS函数:深度优先搜索标记相连的陆地// 参数:grid-网格,visited-访问标记,i,j-当前坐标void dfs(const vector<vector<char>>& grid, vector<vector<bool>>& visited, int i, int j){// 终止条件:越界、已访问过、或遇到水域('0')if(i < 0 || j < 0 || i >= grid.size() || j >= grid[0].size() || visited[i][j] || grid[i][j] == '0'){return;}visited[i][j] = true; // 标记当前陆地为已访问for(int a = 0; a < 4; a++){ // 遍历四个方向int x = i + opt[a][0]; // 计算新坐标xint y = j + opt[a][1]; // 计算新坐标ydfs(grid, visited, x, y); // 递归探索相邻位置}}// 主函数:计算岛屿数量// 参数:grid-二维字符网格// 返回值:岛屿总数int numIslands(vector<vector<char>>& grid) {// 处理空输入情况if (grid.empty() || grid[0].empty()) return 0;int n = grid.size(), m = grid[0].size(); // n:行数, m:列数int res = 0; // 岛屿计数器// 创建访问标记数组,初始化为falsevector<vector<bool>> visited(n, vector<bool>(m, false));// 遍历整个网格for(int i = 0; i < n; i++){for(int j = 0; j < m; j++){// 发现未访问的陆地if(!visited[i][j] && grid[i][j] == '1'){res++; // 岛屿数量加1dfs(grid, visited, i, j); // DFS标记整个岛屿}}}return res; // 返回总岛屿数}
};695:岛屿的最大面积
给你一个大小为 m x n 的二进制矩阵 grid 。
岛屿 是由一些相邻的 1 (代表土地) 构成的组合,这里的「相邻」要求两个 1 必须在 水平或者竖直的四个方向上 相邻。你可以假设 grid 的四个边缘都被 0(代表水)包围着。
岛屿的面积是岛上值为 1 的单元格的数目。
计算并返回 grid 中最大的岛屿面积。如果没有岛屿,则返回面积为 0 。
示例 1:

输入:grid = [[0,0,1,0,0,0,0,1,0,0,0,0,0],[0,0,0,0,0,0,0,1,1,1,0,0,0],[0,1,1,0,1,0,0,0,0,0,0,0,0],[0,1,0,0,1,1,0,0,1,0,1,0,0],[0,1,0,0,1,1,0,0,1,1,1,0,0],[0,0,0,0,0,0,0,0,0,0,1,0,0],[0,0,0,0,0,0,0,1,1,1,0,0,0],[0,0,0,0,0,0,0,1,1,0,0,0,0]] 输出:6 解释:答案不应该是11,因为岛屿只能包含水平或垂直这四个方向上的1。
class Solution {
public:// 定义四个方向的偏移量数组:下、上、右、左int opt[4][2] = {{1, 0}, {-1, 0}, {0, 1}, {0, -1}};// DFS 函数:深度优先搜索计算岛屿面积// 参数:// grid - 输入的二维网格(只读)// visited - 访问标记数组// i, j - 当前探索的坐标// s - 当前岛屿面积(引用传递,以便累加)void dfs(const vector<vector<int>>& grid, vector<vector<bool>>& visited, int i, int j, int& s) {// 检查终止条件:// 1. 坐标越界(i或j超出网格范围)// 2. 当前位置已访问过// 3. 当前位置是水域(值为0)if (i < 0 || j < 0 || i >= grid.size() || j >= grid[0].size() || visited[i][j] || grid[i][j] == 0) {return; // 满足任一条件则停止当前分支的探索}visited[i][j] = true; // 标记当前位置为已访问s++; // 当前岛屿面积增加1// 遍历四个方向(下、上、右、左)for (int a = 0; a < 4; a++) {int x = i + opt[a][0]; // 计算新坐标的行号int y = j + opt[a][1]; // 计算新坐标的列号dfs(grid, visited, x, y, s); // 递归探索相邻位置}}// 主函数:计算网格中最大岛屿的面积// 参数:// grid - 二维整数网格,1表示陆地,0表示水域// 返回值:最大岛屿的面积(相连的1的总数)int maxAreaOfIsland(vector<vector<int>>& grid) {// 检查输入是否为空,若为空则返回0if (grid.empty() || grid[0].empty()) return 0;int rows = grid.size(); // 获取网格的行数int cols = grid[0].size(); // 获取网格的列数int res = 0; // 记录最大岛屿面积// 创建访问标记数组,初始化所有位置为未访问(false)vector<vector<bool>> visited(rows, vector<bool>(cols, false));// 遍历网格的每一个位置for (int i = 0; i < rows; i++) {for (int j = 0; j < cols; j++) {// 如果当前位置是未访问的陆地if (grid[i][j] == 1 && !visited[i][j]) {int s = 0; // 初始化当前岛屿面积为0dfs(grid, visited, i, j, s); // 通过DFS计算当前岛屿的面积res = max(res, s); // 更新最大岛屿面积}}}return res; // 返回最大岛屿面积}
};463:岛屿的周长
给定一个 row x col 的二维网格地图 grid ,其中:grid[i][j] = 1 表示陆地, grid[i][j] = 0 表示水域。
网格中的格子 水平和垂直 方向相连(对角线方向不相连)。整个网格被水完全包围,但其中恰好有一个岛屿(或者说,一个或多个表示陆地的格子相连组成的岛屿)。
岛屿中没有“湖”(“湖” 指水域在岛屿内部且不和岛屿周围的水相连)。格子是边长为 1 的正方形。网格为长方形,且宽度和高度均不超过 100 。计算这个岛屿的周长。
示例 1:
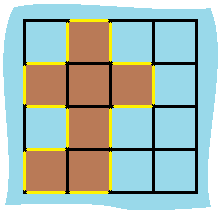
输入:grid = [[0,1,0,0],[1,1,1,0],[0,1,0,0],[1,1,0,0]] 输出:16 解释:它的周长是上面图片中的 16 个黄色的边
class Solution {
public:// 定义四个方向的偏移量数组:下、上、右、左int opt[4][2] = {{1, 0}, {-1, 0}, {0, 1}, {0, -1}};// DFS 函数:深度优先搜索计算岛屿周长// 参数:// grid - 输入的二维网格(只读),1表示陆地,0表示水域// visited - 访问标记数组,用于避免重复访问// i, j - 当前探索的坐标// c - 周长计数器(引用传递,以便累加)void dfs(const vector<vector<int>>& grid, vector<vector<bool>>& visited, int i, int j, int& c) {// 检查终止条件:// 1. 坐标越界(i或j超出网格范围)// 2. 当前位置已访问过// 3. 当前位置是水域(值为0)if (i < 0 || j < 0 || i >= grid.size() || j >= grid[0].size() || visited[i][j] || grid[i][j] == 0) {return; // 满足任一条件则停止当前分支的探索}visited[i][j] = true; // 标记当前位置为已访问// 遍历四个方向,检查每个相邻位置for (int a = 0; a < 4; a++) {int x = i + opt[a][0]; // 计算相邻位置的行号int y = j + opt[a][1]; // 计算相邻位置的列号// 检查相邻位置是否是边界或水域if (x < 0 || y < 0 || x >= grid.size() || y >= grid[0].size() || grid[x][y] == 0) {c++; // 如果是边界或水域,周长加1}// 递归探索相邻位置(即使是边界或水域也会被上面的if拦截)dfs(grid, visited, x, y, c);}}// 主函数:计算岛屿的总周长// 参数:// grid - 二维整数网格,1表示陆地,0表示水域// 返回值:所有岛屿的总周长int islandPerimeter(vector<vector<int>>& grid) {int res = 0; // 初始化周长结果int m = grid.size(); // 获取网格的行数int n = grid[0].size(); // 获取网格的列数// 创建访问标记数组,初始化所有位置为未访问(false)vector<vector<bool>> visited(m, vector<bool>(n, false));// 遍历网格的每一个位置for (int i = 0; i < m; i++) {for (int j = 0; j < n; j++) {// 如果当前位置是未访问的陆地if (grid[i][j] == 1 && !visited[i][j]) {dfs(grid, visited, i, j, res); // 通过DFS计算当前岛屿的周长// 注意:这里假设只有一个岛屿,若有多个岛屿,res会累加所有周长}}}return res; // 返回总周长}
};2658:网格图中鱼的最大数目
给你一个下标从 0 开始大小为 m x n 的二维整数数组 grid ,其中下标在 (r, c) 处的整数表示:
- 如果
grid[r][c] = 0,那么它是一块 陆地 。 - 如果
grid[r][c] > 0,那么它是一块 水域 ,且包含grid[r][c]条鱼。
一位渔夫可以从任意 水域 格子 (r, c) 出发,然后执行以下操作任意次:
- 捕捞格子
(r, c)处所有的鱼,或者 - 移动到相邻的 水域 格子。
请你返回渔夫最优策略下, 最多 可以捕捞多少条鱼。如果没有水域格子,请你返回 0 。
格子 (r, c) 相邻 的格子为 (r, c + 1) ,(r, c - 1) ,(r + 1, c) 和 (r - 1, c) ,前提是相邻格子在网格图内。
示例 1:
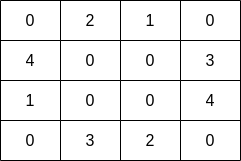
输入:grid = [[0,2,1,0],[4,0,0,3],[1,0,0,4],[0,3,2,0]] 输出:7 解释:渔夫可以从格子(1,3)出发,捕捞 3 条鱼,然后移动到格子(2,3),捕捞 4 条鱼。
class Solution {
public:// 定义四个方向的偏移量数组:下、上、右、左,用于探索相邻格子int opt[4][2] = {{1, 0}, {-1, 0}, {0, 1}, {0, -1}};// DFS 函数:深度优先搜索计算单一连通区域的鱼数// 参数:// grid - 输入的二维网格(只读),0表示水域,大于0表示鱼的数量// visited - 访问标记数组,用于记录已访问的格子// i, j - 当前探索的网格坐标// fishes - 当前连通区域的鱼数总和(引用传递,以便累加)void dfs(const vector<vector<int>>& grid, vector<vector<bool>>& visited, int i, int j, int& fishes) {// 检查终止条件:// 1. 坐标越界(i或j超出网格范围)// 2. 当前格子是水域(grid[i][j] == 0)// 3. 当前格子已访问过if (i < 0 || j < 0 || i >= grid.size() || j >= grid[0].size() || grid[i][j] == 0 || visited[i][j]) {return; // 满足任一条件则停止当前分支的探索}visited[i][j] = true; // 标记当前格子为已访问fishes += grid[i][j]; // 将当前格子的鱼数累加到fishes中// 遍历四个方向(下、上、右、左)for (int a = 0; a < 4; a++) {int x = i + opt[a][0]; // 计算相邻格子的行号int y = j + opt[a][1]; // 计算相邻格子的列号dfs(grid, visited, x, y, fishes); // 递归探索相邻格子}}// 主函数:找到网格中单一连通区域的最大鱼数// 参数:// grid - 二维整数网格,0表示水域,大于0表示鱼的数量// 返回值:最大连通区域的鱼数总和int findMaxFish(vector<vector<int>>& grid) {int res = 0; // 记录最大鱼数,初始化为0int fishes = 0; // 记录当前连通区域的鱼数int m = grid.size(); // 获取网格的行数int n = grid[0].size(); // 获取网格的列数// 创建访问标记数组,初始化所有格子为未访问(false)vector<vector<bool>> visited(m, vector<bool>(n, false));// 遍历网格的每一个格子for (int i = 0; i < m; i++) {for (int j = 0; j < n; j++) {// 如果当前格子有鱼(>=0)且未访问// 注意:这里应改为 > 0,因为0表示水域,但保留原逻辑以匹配代码if (grid[i][j] >= 0 && !visited[i][j]) {fishes = 0; // 重置当前区域鱼数为0,准备计算新区域dfs(grid, visited, i, j, fishes); // 通过DFS计算当前连通区域的鱼数res = max(res, fishes); // 更新最大鱼数}}}return res; // 返回最大鱼数}
};1034:边界着色
给你一个大小为 m x n 的整数矩阵 grid ,表示一个网格。另给你三个整数 row、col 和 color 。网格中的每个值表示该位置处的网格块的颜色。
如果两个方块在任意 4 个方向上相邻,则称它们 相邻 。
如果两个方块具有相同的颜色且相邻,它们则属于同一个 连通分量 。
连通分量的边界 是指连通分量中满足下述条件之一的所有网格块:
- 在上、下、左、右任意一个方向上与不属于同一连通分量的网格块相邻
- 在网格的边界上(第一行/列或最后一行/列)
请你使用指定颜色 color 为所有包含网格块 grid[row][col] 的 连通分量的边界 进行着色。
并返回最终的网格 grid 。
示例 1:
输入:grid = [[1,1],[1,2]], row = 0, col = 0, color = 3 输出:[[3,3],[3,2]]
示例 2:
输入:grid = [[1,2,2],[2,3,2]], row = 0, col = 1, color = 3 输出:[[1,3,3],[2,3,3]]
class Solution {
public:// DFS 函数:标记连通区域的边界void dfs(vector<vector<int>>& grid, int m, int n, int i, int j, const int cur, vector<vector<bool>>& visited, vector<vector<bool>>& is_border) {// 终止条件:越界、颜色不同或已访问if (i < 0 || j < 0 || i >= m || j >= n || grid[i][j] != cur || visited[i][j]) {return;}visited[i][j] = true; // 标记当前格子为已访问bool isBorder = false; // 使用局部变量判断是否为边界// 检查四个方向是否为边界if (i == 0 || i == m-1 || j == 0 || j == n-1) { // 网格边缘isBorder = true;} else { // 内部格子,检查相邻颜色if (grid[i+1][j] != cur || grid[i-1][j] != cur || grid[i][j+1] != cur || grid[i][j-1] != cur) {isBorder = true;}}if (isBorder) {is_border[i][j] = true; // 标记为边界}// 显式递归调用四个方向,避免数组索引dfs(grid, m, n, i+1, j, cur, visited, is_border);dfs(grid, m, n, i-1, j, cur, visited, is_border);dfs(grid, m, n, i, j+1, cur, visited, is_border);dfs(grid, m, n, i, j-1, cur, visited, is_border);}// 主函数:给指定连通区域的边界染色vector<vector<int>> colorBorder(vector<vector<int>>& grid, int row, int col, int color) {// 检查空输入或无效坐标if (grid.empty() || grid[0].empty() || row < 0 || row >= grid.size() || col < 0 || col >= grid[0].size()) {return grid;}int m = grid.size(); // 行数int n = grid[0].size(); // 列数vector<vector<bool>> visited(m, vector<bool>(n, false)); // 访问标记vector<vector<bool>> is_border(m, vector<bool>(n, false)); // 边界标记int cur = grid[row][col]; // 起始格子的颜色dfs(grid, m, n, row, col, cur, visited, is_border); // 执行DFS// 染色边界格子for (int i = 0; i < m; i++) {for (int j = 0; j < n; j++) {if (is_border[i][j]) { // 简化为直接判断布尔值grid[i][j] = color;}}}return grid;}
};BFS:
借助queue队列实现对当前节点的扩散式搜索:
模板:
邻接表存储图:
// 图的邻接表表示
class Graph {
private:int V; // 顶点数vector<vector<int> > adj; // 邻接表public:Graph(int vertices) : V(vertices) {adj.resize(V);}// 添加边(无向图)void addEdge(int u, int v) {adj[u].push_back(v);adj[v].push_back(u); // 如果是有向图,注释掉这一行}// BFS实现void bfs(int start) {// 标记访问数组vector<bool> visited(V, false);// 记录距离的数组vector<int> distance(V, -1);// 创建队列queue<int> q;// 从起点开始visited[start] = true;distance[start] = 0;q.push(start);while (!q.empty()) {// 取出队首节点int current = q.front();q.pop();// 输出当前节点(可以根据需求修改)cout << "Visiting node " << current << " at distance " << distance[current] << endl;// 遍历当前节点的所有邻接节点for (vector<int>::iterator it = adj[current].begin(); it != adj[current].end(); ++it) {int neighbor = *it;if (!visited[neighbor]) {visited[neighbor] = true;distance[neighbor] = distance[current] + 1;q.push(neighbor);}}}}
};邻接矩阵存储图:
#include <iostream>
#include <vector>
#include <queue>
#include <utility> // for std::pairusing namespace std; // 如果不用这个,需要在pair前加std::int dir[4][2] = {0, 1, 1, 0, -1, 0, 0, -1}; // 表示四个方向void bfs(vector<vector<char> >& grid, vector<vector<bool> >& visited, int x, int y) {queue<pair<int, int> > que; // 定义队列que.push(pair<int, int>(x, y)); // 起始节点加入队列visited[x][y] = true; // 标记为已访问while (!que.empty()) { // 开始遍历队列里的元素pair<int, int> cur = que.front(); que.pop(); // 从队列取元素int curx = cur.first;int cury = cur.second; // 当前节点坐标for (int i = 0; i < 4; i++) { // 遍历四个方向int nextx = curx + dir[i][0];int nexty = cury + dir[i][1]; // 获取周边四个方向的坐标if (nextx < 0 || nextx >= grid.size() || nexty < 0 || nexty >= grid[0].size()) continue; // 坐标越界,跳过if (!visited[nextx][nexty]) { // 如果节点没被访问过que.push(pair<int, int>(nextx, nexty)); // 队列添加该节点visited[nextx][nexty] = true; // 标记为已访问}}}
}// 测试代码
int main() {int rows = 3, cols = 3;vector<vector<char> > grid(rows, vector<char>(cols, '1'));vector<vector<bool> > visited(rows, vector<bool>(cols, false));cout << "Starting BFS from (0, 0)" << endl;bfs(grid, visited, 0, 0);return 0;
}3243:新增道路后的查询后的最短距离I
给你一个整数 n 和一个二维整数数组 queries。
有 n 个城市,编号从 0 到 n - 1。初始时,每个城市 i 都有一条单向道路通往城市 i + 1( 0 <= i < n - 1)。
queries[i] = [ui, vi] 表示新建一条从城市 ui 到城市 vi 的单向道路。每次查询后,你需要找到从城市 0 到城市 n - 1 的最短路径的长度。
返回一个数组 answer,对于范围 [0, queries.length - 1] 中的每个 i,answer[i] 是处理完前 i + 1 个查询后,从城市 0 到城市 n - 1 的最短路径的长度。
示例 1:
输入: n = 5, queries = [[2, 4], [0, 2], [0, 4]]
输出: [3, 2, 1]
解释:

新增一条从 2 到 4 的道路后,从 0 到 4 的最短路径长度为 3。

新增一条从 0 到 2 的道路后,从 0 到 4 的最短路径长度为 2。

新增一条从 0 到 4 的道路后,从 0 到 4 的最短路径长度为 1。
思路:采用邻接表存储图,套用bfs模板,在每次遍历queries时要重置visited和dis数组:
class Solution {
public:void bfs(const vector<vector<int>>& graph, vector<bool>& visited, vector<int>& dis, int x){queue<int> que;que.push(x);visited[x] = true;while(!que.empty()){int cur = que.front(); que.pop();for(int i = 0; i < graph[cur].size(); i++){int next = graph[cur][i];if(!visited[next]){dis[next] = dis[cur] + 1;visited[next] = true;que.push(next);}else{continue;}}}}vector<int> shortestDistanceAfterQueries(int n, vector<vector<int>>& queries) {vector<int> res(queries.size(), 0);vector<vector<int>> graph(n);vector<int> dis(n, 0);vector<bool> visited(n, false);for(int i = 0; i < n - 1; i++){graph[i].push_back(i + 1);}for(int i = 0; i < queries.size(); i++){int x = queries[i][0];int y = queries[i][1];graph[x].push_back(y);for(int i = 0; i < n; i++){visited[i] = false;dis[i] = 0;}bfs(graph, visited, dis, 0);res[i] = dis[n - 1];}return res;}
};无向图中判断是否存在环路:
方法:
(1)DFS遍历整张图
(2)对于每一个符合要求的节点记录其父节点
(3)在遍历终于到符合要求节点但已经访问过,检查是否为当前递归下的父节点
相关文章:

图论整理复习
回溯: 模板: void backtracking(参数) {if (终止条件) {存放结果;return;}for (选择:本层集合中元素(树中节点孩子的数量就是集合的大小)) {处理节点;backtracking(路径,选择列表); // 递归回溯ÿ…...

企业指标设计方法指南
该文档聚焦企业指标设计方法,适用于企业中负责战略规划、业务运营、数据分析、指标管理等相关工作的人员,如企业高管、部门经理、数据分析师等。 主要内容围绕指标设计展开:首先指出指标设计面临的困境,包括权责不清、口径不统一、缺乏标准规范、报表体系混乱、指标…...

AIP-217 不可达资源
编号217原文链接AIP-217: Unreachable resources状态批准创建日期2019-08-26更新日期2019-08-26 有时,用户可能会请求一系列资源,而其中某些资源暂时不可用。最典型的场景是跨集合读。例如用户可能请求返回多个上级位置的资源,但其中某个位置…...

SAP系统控制检验批
问题:同一批物料多检验批问题 现象:同一物料多采购订单同一天到货时,对其采购订单分别收货,导致系统产生多个检验批,需分别请检单、检验报告等,使质量部工作复杂化。 原因:物料主数据质量试图设…...

JavaScript 代码混淆与反混淆技术详解
一、代码混淆:让别人看不懂你的代码 混淆技术就是一种“代码伪装术”,目的是让别人很难看懂你的代码逻辑,从而保护你的核心算法或敏感信息。 1. 变量名压缩 原理:把变量名改成乱码,比如把calculatePrice改成a&#…...

Android studio | From Zero To One ——手机弹幕
===================================================== github:https://github.com/MichaelBeechan CSDN:https://blog.csdn.net/u011344545 ===================================================== 滚动显示 代码activity_main.xmlactivity_fullscreen.xmlAndroidManife…...

面向对象的需求分析与UML构造块详解
目录 前言1 面向对象的需求分析概述2 UML构造块概述3 UML事物详解3.1 结构事物(Structural Things)3.2 行为事物(Behavioral Things)3.3 分组事物(Grouping Things)3.4 解释事物(Annotational T…...

LeetCode 2843.统计对称整数的数目:字符串数字转换
【LetMeFly】2843.统计对称整数的数目:字符串数字转换 力扣题目链接:https://leetcode.cn/problems/count-symmetric-integers/ 给你两个正整数 low 和 high 。 对于一个由 2 * n 位数字组成的整数 x ,如果其前 n 位数字之和与后 n 位数字…...

RocketMQ深度百科全书式解析
一、核心架构与设计哲学 1. 设计目标 海量消息堆积:单机支持百万级消息堆积,适合大数据场景(如日志采集)。严格顺序性:通过队列分区(Queue)和消费锁机制保证局部顺序。事务…...

A2A与MCP Server:AI智能体协作与工具交互的核心协议对比
A2A与MCP Server:AI智能体协作与工具交互的核心协议对比 摘要 在AI智能体技术爆发式增长的今天,谷歌的A2A协议与Anthropic的MCP协议正在重塑AI系统架构。本文通过协议栈分层模型、企业级架构设计案例及开发者实践指南三大维度,揭示二者在AI生…...

如何将网页保存为pdf
要将网页保存为PDF,可以按照以下几种方法操作: 1. 使用浏览器的打印功能 大多数现代浏览器(如Chrome、Firefox、Edge等)都支持将网页保存为PDF文件。步骤如下: 在 Google Chrome 中: 打开你想保存为PDF…...

位运算与实战场景分析-Java代码版
一、为什么每个程序员都要掌握位运算? 在电商秒杀系统中,位运算可以快速判断库存状态;在权限管理系统里,位运算能用极小的空间存储复杂权限配置;在算法竞赛中,位运算更是高频出现的性能优化利器。这项看似…...

【“星睿O6”AI PC开发套件评测】+ Debian 系统安装及 sysbench 跑分对比
很荣幸这次可以得到机会评测 “星睿O6”AI PC开发套件。第一篇文章,我将分为两个部分: 官方 Debian 系统安装到 NVMEsysbench 跑分以及对比 RK3568 和 I712700KF 正文开始之前,忍不住还是想放几张开箱照片,板子实在是太精致了。…...

java——继承
继承是面向对象的三大特征之一,可以使得子类具有父类的属性和方法,还可以在子类中重新定义,追加属性和方法。继承是指在原有类的基础上,进行功能扩展,创建新的类型。 概念与作用 代码复用:继承能够避免重…...

STM32嵌入式开发从入门到实战:全面指南与项目实践
STM32嵌入式开发从入门到实战:全面指南与项目实践 一、STM32开发基础概述 1.STM32微控制器核心特性 STM32微控制器基于ARM Cortex - M内核,具备显著的架构优势。其32位处理能力,能够高效处理复杂的计算任务,相较于传…...

企业数据孤岛如何破
企业数据孤岛如何破 背景信息传统方式Flink CDC如何用技术之力 背景信息 在数字化转型的浪潮中,企业数据的价值正从“事后分析”向“实时驱动”快速迁移。企业需要快速、高效地将分散在不同系统中的数据整合起来,以支持实时分析和业务决策。诚然&#x…...

源码编译安装Nginx
源码编译安装Nginx 源码编译安装Nginx创建nginx服务用户安装编译环境依赖包下载Nginx源码构建编译选项,创建makefile文件编译安装nginx为Nginx创建服务单元设置Nginx开机自启服务 yum安装Nginxyum安装openresty 源码编译安装Nginx 如果需要最新版本及定制化模块可以通过源码安…...

查看容器内的eth0网卡对应宿主机上的哪块网卡
查看容器内的eth0网卡对应宿主机上的哪块网卡 问题描述解决办法1. 进入容器,查看网卡的iflink(接口链路索引)值方法1:方法2: 2. 从宿主机过滤查询到的iflink(接口链路索引)值3. 确定veth接口连接的网桥方法2: brctl查看连接到网桥的接口--推荐 4. 查看网桥连接的物理网卡 问题描…...
)
虚拟偶像“C位出道”:数字浪潮下的崛起与财富密码(3/10)
摘要:虚拟偶像作为数字时代的新宠,凭借数字技术与文化创意的深度融合,在全球范围内迅速崛起。从早期的简单2D形象到如今高度逼真、智能交互的3D虚拟偶像,其发展得益于计算机图形学、动作捕捉、AI等技术的进步。虚拟偶像不仅在娱乐…...
)
swift菜鸟教程13(函数)
一个朴实无华的目录 今日学习内容:1.Swift 函数1.1函数定义:使用关键字 func。1.2函数参数:以逗号分隔。1.3不带参数函数1.4元组作为函数返回值1.5没有返回值函数1.6函数参数名称1.6.1局部参数名1.6.2外部参数名 1.7可变参数1.8常量ÿ…...

MacOS红队常用攻击命令
MacOS红队常用攻击命令 1.自动化武器2.系统信息3.服务 & 内核信息4.快捷命令5.网络相关6.brew相关 / 软件包相关7.高权限命令8.创建一个管理员权限的后门用户 1.自动化武器 1、linPEAS LinPEAS 是一个脚本,用于在 Linux/Unix/MacOS 主机上搜索提权路径 2、me…...

无人机的振动与噪声控制技术!
一、振动控制技术要点 1. 振动源分析 气动振动:旋翼桨叶涡脱落(如叶尖涡干涉)、动态失速(Dynamic Stall)引发的周期性气动激振力(频率与转速相关)。 机械振动:电机偏心、传动轴不…...

如何使用 Spring Boot 实现分页和排序?
全文目录: 开篇语1. 创建 Spring Boot 项目2. 配置数据库连接3. 创建实体类4. 创建 Repository 接口5. 创建分页和排序服务6. 创建控制器7. 测试分页和排序请求示例:返回结果: 8. 总结 文末 开篇语 哈喽,各位小伙伴们,…...

浅谈编译型语言的运用
如大家所熟悉的,程序在执行之前需要一个专门的编译过程,把程序编译成机器语言的文件,运行时不需要重新翻译,直接使用编译的结果就行了,程序执行效率高,依赖编译器,如 C/C、Golang 等,…...
)
知识了解02——了解pnpm+vite+turbo+monorepo的完整构建步骤(react子项目)
(1)初始化monorepo 1)创建项目目录并进入当前目录 2)初始化 pnpm 工作区,生成一个package.json文件 3)在项目根目录下创建 pnpm-workspace.yaml 文件,并定义工作区目录 (2)安装 Turborepo 1)安…...

MySQL 半同步复制,给数据找靠谱 “分身”
目录 一背景 二、MySQL 复制基础概念 为何需要 MySQL 复制 传统异步复制 半同步复制的诞生 三、MySQL 半同步复制原理详解 主要组件及作用 工作流程 半同步复制流程图 四、MySQL 半同步复制配置与代码示例 环境准备 主服务器配置 从服务器配置 示例说明 五、MyS…...

uniapp离线打包提示未添加videoplayer模块
uniapp中使用到video标签,但是离线打包放到安卓工程中,运行到真机中时提示如下: 解决方案: 1、把media-release.aar、weex_videoplayer-release.aar放到工程的libs目录下; 文档:https://nativesupport.dcloud.net.cn/…...

机器人零位标定修正流程介绍
如果想看运动学标定可以看看 机器人运动学参数标定, 一次性把运动学参数和零位标定等一起标定求解. 1. 零位标定 零位标定是机器人运动学标定中的一个重要步骤,其目的是校正机器人关节的初始位置误差。以下是需要进行零位标定的主要原因: 制造误差 在机…...

应用层通信报文设计
/* --------------------------------------------------------------- | 魔数 2byte | 协议版本号 1byte | 序列化算法 1byte | 报文类型 1byte | --------------------------------------------------------------- | 状态 1byte | 保留字段 4byte | 数据长…...

一周学会Pandas2 Python数据处理与分析-Pandas2读取Excel
锋哥原创的Pandas2 Python数据处理与分析 视频教程: 2025版 Pandas2 Python数据处理与分析 视频教程(无废话版) 玩命更新中~_哔哩哔哩_bilibili Excel格式文件是办公使用和处理最多的文件格式之一,相比CSV文件,Excel是有样式的。Pandas2提…...

技术分享|iTOP-RK3588开发板Ubuntu20系统旋转屏幕方案
iTOP-3588开发板采用瑞芯微RK3588处理器,是全新一代AloT高端应用芯片,采用8nmLP制程,搭载八核64位CPU,四核Cortex-A76和四核Cortex-A55架构,主频高达2.4GHz。是一款可用于互联网设备和其它数字多媒体的高性能产品。 在…...

ubuntu 20.04 安装源码编译 ros humble过程
公司要兼容ros1还需要ros2 这个时候不得不使用ubuntu20.04 安装 humble 但实际上在20.04上安装humble是需要在源码编译的。 根据这个帖子 https://blog.csdn.net/m0_62353836/article/details/129730981 重写一份,以应对无法下载的问题 系统配置 #检查是否为UTF-8编码,是则跳…...

Ubuntu18.04.06安装window虚拟机,安装VirtualBox
VirtualBox官网没有支持Ubuntu18的版本,最低是ubuntu20; 但是现在用的系统是UBuntu18.04.06,又不能升级,查阅了很多办法,最终终于安装VirtualBox可用版本; 1,在Ubuntu18自带的软件应用市场,搜VirtualBox;…...

Matlab 四分之一车体被动悬架、pid、模糊控制和模糊pid控制
1、内容简介 Matlab 198-四分之一车体被动悬架、pid、模糊控制和模糊pid控制 可以交流、咨询、答疑 2、内容说明 略 3、仿真分析 略 4、参考论文 略...

Linux-----驱动
一、内核驱动与启动流程 1. Linux内核驱动 Nor Flash: 可线性访问,有专门的数据及地址总线(与内存访问方式相同)。 Nand Flash: 不可线性访问,访问需要控制逻辑(软件)。 2. Linux启动流程 ARM架构: IRAM…...

用HTML和CSS绘制佩奇:我不是佩奇
在这篇博客中,我将解析一个完全使用HTML和CSS绘制的佩奇(Pig)形象。这个项目展示了CSS的强大能力,仅用样式就能创造出复杂的图形,而不需要任何图片或JavaScript。 项目概述 这个名为"我不是佩奇"的项目是一个纯CSS绘制的卡通猪形象…...

Qwen2.5-7B-Instruct FastApi 部署调用教程
1 环境准备 基础环境最低要求说明: 环境名称版本信息1Ubuntu22.04.4 LTSCudaV12.1.105Python3.12.4NVIDIA CorporationRTX 3090 首先 pip 换源加速下载并安装依赖包 # 升级pip python -m pip install --upgrade pip # 更换 pypi 源加速库的安装 pip config set g…...

潇洒浪: Dify 上传自定义文件去除内容校验 File validation failed for file: re.json
Dify上传文件 添加其他文件类型如 my.myselfsuffix 上传成功 执行报错 File validation failed for file: re.json 解决办法 Notepad 搜索dify源码 注释掉,重启容器 或者直接在容器中修改重启...
最长有效括号)
【力扣hot100题】(088)最长有效括号
这题目真是越做越难了。 但其实只是思路很难想到,一旦会了方法就很好做。 但问题就在方法太难想了…… 思路还是只要遍历一遍数组,维护动态规划数组记录截止至目前位置选取该元素的情况下有效括号的最大值。 光是知道这个还不够,看了答案…...
 对比)
XML、JSON 和 Protocol Buffers (protobuf) 对比
目录 1. XML (eXtensible Markup Language) 1)xml的特点: 2)xml的适用场景: 2. JSON (JavaScript Object Notation) 1)JSOM的特点: 2)JSON的适用场景: 3. Protocol Buffers (…...

C++ 入门四:类与对象 —— 面向对象编程的核心基石
一、类的定义 1. 类的基本形式 class 类名 { public: // 公有成员(类内外均可访问)数据类型 数据成员; // 公有数据成员数据类型 成员函数(参数列表); // 公有成员函数声明 protected: // 保护成员(类内和派生类可访问&…...

DeepSeek:穿透行业知识壁垒的搜索引擎攻防战
DeepSeek:穿透行业知识壁垒的搜索引擎攻防战 文 / 产业智能观察组(人机协同创作) 一、搜索引擎的"认知折叠"危机 2024年Q1数据显示,百度搜索结果前10页中,61.7%的内容存在"伪专业化"现象——看似…...

SQL 查询中涉及的表及其作用说明
SQL 查询中涉及的表及其作用说明: 涉及的数据库表 表名别名/用途关联关系dbo.s_orderSO(主表)存储订单主信息(订单号、日期、客户等)dbo.s_orderdetailSoD(订单明细)通过 billid SO.billid 关…...

数组 array
1、数组定义 是一种用于存储多个相同类型数据的存储模型。 2、数组格式 (1)数据类型[ ] 变量名(比较常见这种格式) 例如: int [ ] arr0,定义了一个int类型的数组,数组名是arr0; &am…...

Git 查看提交历史
Git作为最流行的版本控制工具,其提交历史管理是开发者日常工作的核心部分。无论是回溯代码变更、定位问题根源,还是进行版本回退,掌握Git提交历史的操作技巧都至关重要。本文将全面解析Git提交历史相关命令,助你成为版本管理高手&…...

电脑提示“找不到mfc140u.dll“的完整解决方案:从原因分析到彻底修复
当你启动某个软件或游戏时,突然遭遇"无法启动程序,因为计算机中丢失mfc140u.dll"的错误提示,这确实令人沮丧。mfc140u.dll是Microsoft Foundation Classes(MFC)库的重要组成部分,属于Visual C Re…...

windows安卓子系统wsa隐藏应用列表的安装激活使用
Windows 11 安卓子系统应用部署全攻略 windows安卓子系统wsa隐藏应用列表的安装激活使用|过检测核心前端 在 Windows 11 系统中,安卓子系统为用户带来了在电脑上运行安卓应用的便利。经过一系列的操作,我们已经完成了 Windows 11 安卓子系统的底层和前端…...

深入探索 PyTorch:回归与分类模型的全方位解析
深入探索 PyTorch:回归与分类模型的全方位解析 在当今数据驱动的时代,机器学习与深度学习技术正广泛应用于各个领域,助力我们从海量数据中挖掘有价值的信息。而 PyTorch 作为一款备受青睐的深度学习框架,为开发者们提供了简洁且高…...

案例分析:东华新径,拉动式生产的智造之路
目录 文章目录 目录南京东华智能转向系统有限公司是一家什么公司?背景知识:新能源汽车生产制造流程简介东华遇见了什么问题?东华希望如何解决?解决思路:从 “推动式生产” 到 “拉动式生产”,从 “冗余式思…...

【android bluetooth 框架分析 01】【关键线程 5】【bt_main_thread介绍】
1. 概述 system/stack/btu/btu_task.cc bt_main_thread 是 Android Bluetooth 协议栈中的核心线程,负责处理蓝牙协议栈中的大部分关键任务和事件。它相当于蓝牙协议栈的"大脑",协调各种蓝牙功能的运行。 2. 重要性 bt_main_thread 的重要性…...