【NLP 面经 9.逐层分解Transformer】
如果我能给你短暂的开心
—— 25.4.7
一、Transformer 整体结构
1.Tranformer的整体结构
Transformer 的整体结构,左图Encoder和右图Decoder,下图是Transformer用于中英文翻译的整体结构:
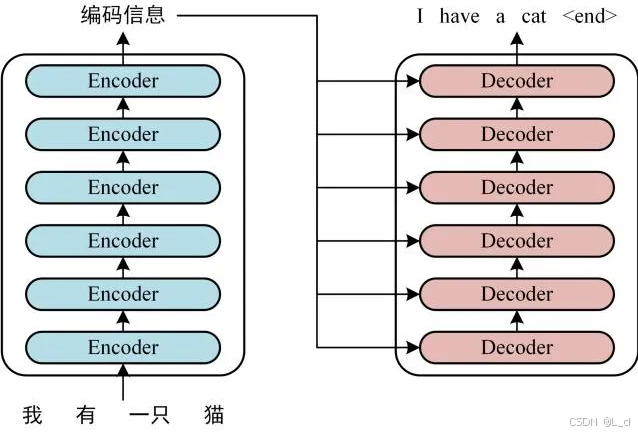
可以看到 Transformer 由 Encoder 和 Decoder 两个部分组成,Encoder 和 Decoder 都包含 6 个 block
2.Transformer的工作流程
第一步:获取输入句子的每一个单词的表示向量 X,X由单词的 Embedding(Embedding就是从原始数据中提取出来的特征Feature)和单词位置的 Embedding 相加得到

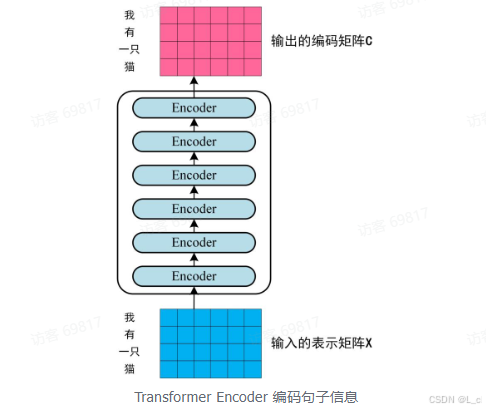
第二步:将得到的单词表示向量矩阵(如上图所示,每一行是一个单词的表示X)传入 Encoder中,经过 6 个 Encoder block 后可以得到句子所有单词的编码信息矩阵 C
如下图,单词向量矩阵用 X_n×d 表示,n 是句子中单词个数,d 是表示向量的维度(d = 512).每一个 Encoder block 输出的矩阵维度与输入完全一致
第三步:将 Encoder 输出的编码信息矩阵 C 传递到 Decoder 中,Decoder 依次会根据当前翻译过的单词 1 ~ i 翻译下一个单词 i + 1,如下图所示,在使用的过程中,翻译到单词 i + 1时候需要通过 Mask(掩盖)操作遮盖住 i + 1 之后的单词
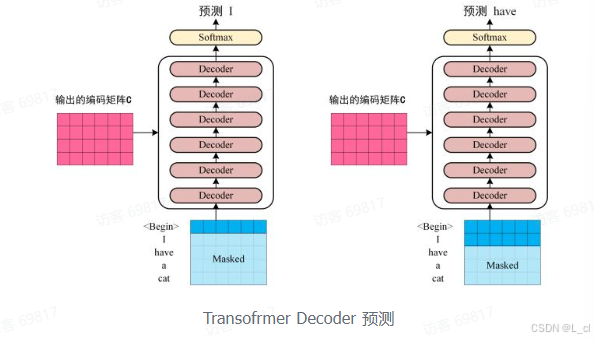
上图 Decoder 接收了 Encoder 的编码矩阵C,然后首先输入一个翻译开始符 "<Begin>",预测第一个单词 "I",然后输入翻译开始符 "<Begin>" 和单词 "I”,预测单词 "have",以此类推。这是 Transformer 使用时候的大致流程,接下来是里面各个部分的细节
二、Transformer的输入
Transformer 中单词的输入表示 x 由 单词 Embedding 和 位置 Embedding(Positional Encoding)相加得到
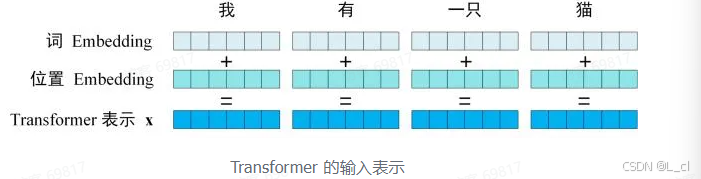
1.单词 Embedding
单词的 Embedding 有很多种方式可以获取,例如可以采用 Word2Vec、Glove 等算法预训练得到,也可以在 Transformer 中训练得到
2.位置 Embedding
Transformer 中除了单词的 Embedding,还需要使用位置 Embedding 表示单词出现在句子中的位置。因为 Transformer 不采用 RNN 的结构,而是使用全局信息,不能利用单词的顺序信息,而这部分信息对于 NLP 来说非常重要。所以 Transformer 中使用位置 Embedding 保存单词在序列中的相对或绝对位置。
位置 Embedding 用 PE 表示,PE 的维度与单词 Embedding 是一样的,PE可以通过训练得到,也可以使用某种公式计算得到,在Transformer中使用公式计算得到
计算公式:

其中,pos 表示单词在句子中的位置,d 表示 PE的维度(与词Embedding一样),2i 表示偶数的维度,2i + 1 表示奇数的维度(即 2i ≤ d,2i + 1 ≤ d)。使用这种公式计算 PE 有以下好处:
使 PE 能够适应比训练集里面所有句子更长的句子,假设训练集里面最长的句子是有20个单词,突然来了一个长度为21的句子,则是用公式计算的方法可以计算出第21位的 Embedding
可以让模型容易地计算出相对位置,对于固定长度的间距 k、PE(pos + k) 可以用 PE(pos) 计算得到,因为:sin(A+B) = sin(A) * cos(B) + cos(A) * sin(B),cos(A + B) = cos(A) * cos(B) - sin(A) * sin(B)
三、Self-Attention 自注意力机制
Transformer的内部结构图:
左侧为 Encoder block
右侧为 Decoder block
红色圈中的部分为 Multi-Head Attention,是由多个 Self-Attention 组成的
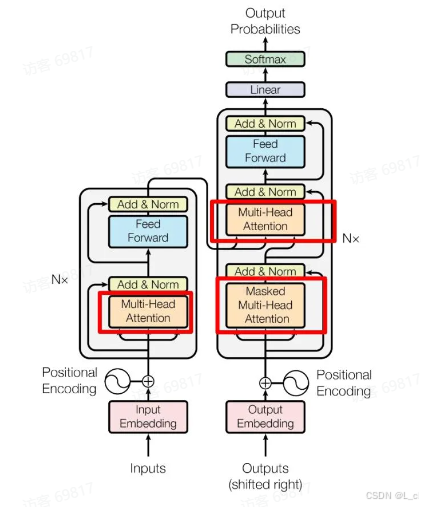
Encoder block 包含一个 Multi-Head Attention
Decoder block 包含两个 Multi-Head Attention(其中有一个用到Masked)
Multi-Head Attention 上方还包括一个 Add & Norm 层
Add 表示残差链接(Residual Connection)用于防止网络退化
Norm 表示 Layer Normalization,用于对每一层的激活值进行归一化
因为 Self-Attention 是 Transformer 的重点,所以我们重点关注 Multi-Head Attention 以及 Self-Attention
1.Self-Attention 结构
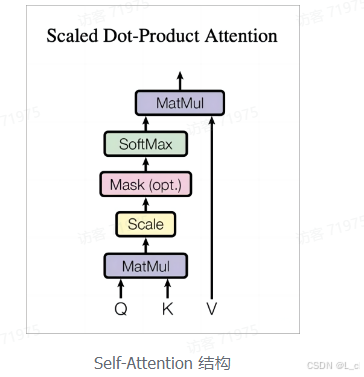
上图是 Self-Attention 的结构,在计算的时候需要用到矩阵Q(查询),K(键值),V(值)。在实际中,Self-Attention 接收的是输入(单词的表示向量 x组成的矩阵 X)或者上一个Encoder block的输出,而Q,K,V正是通过 Self-Attention 的输入进行线性变换得到的
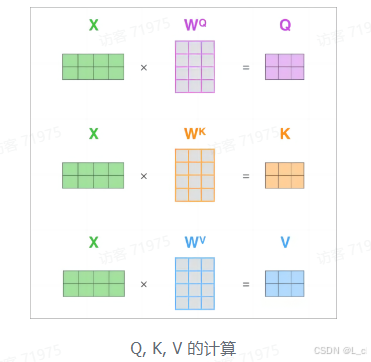
2.Q、K、V的计算
Self-Attention的输入用矩阵X表示,则可以使用线性变换矩阵W_Q、W_K、W_V计算得到Q、K、V,计算如下图所示:注意 X、Q、K、V的每一行都表示一个单词
代码实现
nn.Linear():实现全连接层的线性变换,计算公式为 y = xA^T + b,其中 A 是权重矩阵,b 是偏置项。适用于输入输出的最后一维特征变换,支持任意维度输入(如2D、3D张量),仅对最后一维进行线性映射
| 参数名 | 类型 | 必选 | 默认值 | 说明 |
|---|---|---|---|---|
in_features | int | 是 | - | 输入张量最后一维的特征数(如输入形状 (batch, 20),则 in_features=20) |
out_features | int | 是 | - | 输出张量最后一维的特征数(如输出形状 (batch, 30),则 out_features=30) |
bias | bool | 否 | True | 是否添加可学习的偏置项。若设为 False,则 y = xA^T。 |
.permute():调整张量的维度顺序,不改变数据内容,仅重新排列轴顺序。例如将形状 (batch, height, width, channel) 转换为 (batch, channel, height, width),常用于适配不同层的数据格式(如CNN输入与全连接层的对接)
| 参数名 | 类型 | 必选 | 默认值 | 说明 |
|---|---|---|---|---|
dims | int 可变参数 | 是 | - | 新维度的顺序,需指定所有维度索引(如原维度顺序是 (0,1,2),调用 .permute(2,0,1) 后变为 (2,0,1)) |
torch.bmm():执行批量矩阵乘法,适用于三维张量(形状为 (batch, n, m) 和 (batch, m, p)),逐个批次计算两个矩阵的乘积。常用于注意力机制中的 Q@K^T 操作或全连接层的批量并行计算
| 参数名 | 类型 | 必选 | 默认值 | 说明 |
|---|---|---|---|---|
input | Tensor | 是 | - | 输入张量,形状为 (batch, n, m),每个批次包含一个 n×m 矩阵。 |
mat2 | Tensor | 是 | - | 输入张量,形状为 (batch, m, p),每个批次包含一个 m×p 矩阵。 |
out | Tensor | 否 | None | 可选输出张量,用于存储结果,形状为 (batch, n, p)。 |
import numpy as np
from math import sqrt
import torch
from torch import nnclass Self_Attention(nn.Module):# input: batch size * seq_len * input_dim# q: batch size * input_dim * dim k# k: batch_size * input_dim * dim k# v: batch size * input_dim * dim_vdef __init__(self, input_dim, dim_k, dim_v):super(Self_attention, self):self.q = nn.Linear(input_dim, dim_k)self.k = nn.Linear(input_dim, dim_k)self.v = nn.Linear(input_dim, dim_v)self.__norm_fact = 1 / sqrt(dim_k)def forward(self, x):Q = self.q(x) # Q: batch_size * seq_len * dim_kK = self.k(x) # K: batch_size * seq_len * dim_kV = self.v(x) # V: batch_size * seq_len * dim_v# Q * K.T(): batch_size * seq_len * seq_lenattn = nn.Softmax(Q, K.permute(0, 2, 1)) * self.__norm_fact# Q * K.T() * V: batch_size * seq_len * dim_voutput = torch.bmm(attn, v)return outputX = torch.randn(4, 3, 2)
print(X)
self_attn = Self_Attention(2, 4, 5) # input_dim:2 k_dim: 4 v_dim: 5
res = self_attn(X)
print(res.shape) # [4, 3, 5]3.Self-Attention 的输出
得到矩阵 Q、K、V 之后就可以计算出 Self-Attention 的输出了,计算的公式如下:

公式中计算矩阵Q 和 K每一行向量的内积,为了防止内积过大,因此除以d_k的平方根。Q乘以K的转置后,得到的矩阵行列数都为 n,n 为句子单词数,这个矩阵可以表示单词之间的 attention 强度。下图为 Q 乘以 K_T,1234表示的是句子中的单词
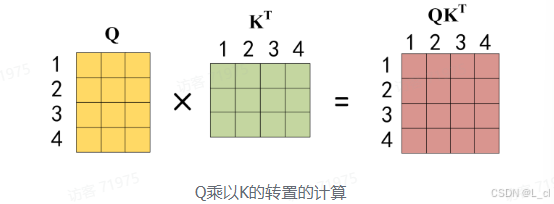
得到 Q*K_T 之后,使用 Softmax 计算每一个单词对于其他单词的 attention 系数,公式中的 Softmax 是对矩阵的每一行进行 Softmax,即每一行的和都变为1
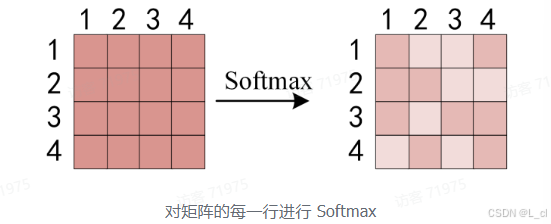
得到 Softmax 矩阵之后可以和 V 相乘,得到最终的输出 Z
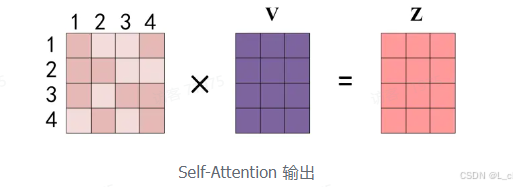
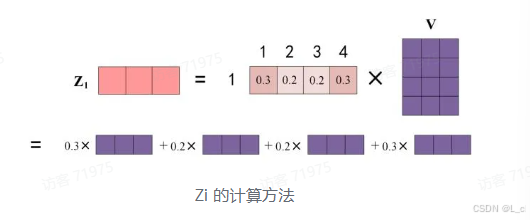
上图中 Softmax 矩阵的第 1 行表示单词 1 与其他所有单词的 attention 系数,最终单词 1 的输出 Z1 等于所有单词 i 的值 V_i,根据 attention 系数的比例加在一起得到,如下图所示:
4.Multi-Head Attention
在上一步,我们已经直到怎么通过 Self-Attention 计算得到输出矩阵 Z,而 Multi-Head Attention 是由多个 Self-Attention 组合形成的,下图是论文中 Multi-Head Attention 的结构图
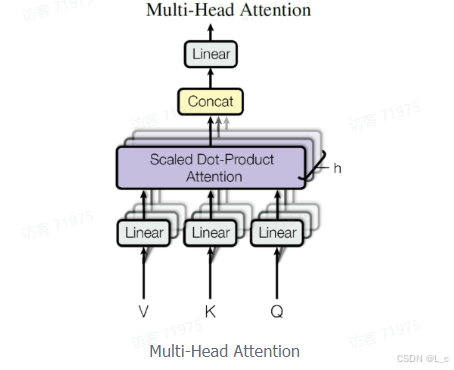
从上图可以看到 Multi-Head Attention 包含多个 Self-Attention 层,首先将输入 X 分别传递到 h 个不同的 Self-Attention 中,计算得到 h 个输出矩阵 Z。下图是 h = 8 时候的情况,此时会得到 8 个输出矩阵 Z
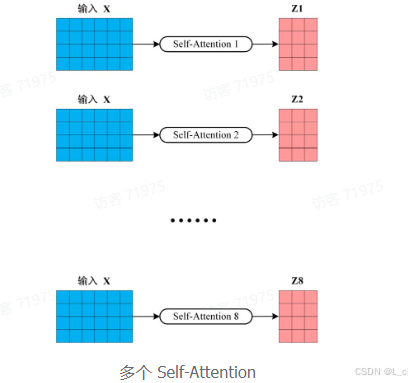
得到 8 个输出矩阵,Z1 到 Z8 之后,Multi-Head Attention 将它们拼接在一起(Concat),然后传入一个 Linear 层,得到 Multi-Head Attention 最终的输出 Z
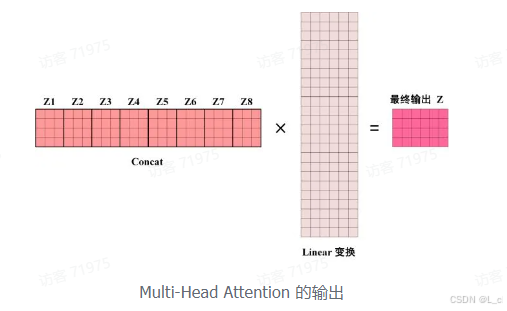
可以看到 Multi-Head Attention 输出的矩阵 Z 与其输入的矩阵 X 的维度是一样的
5.代码实现
nn.Linear():对输入数据执行线性变换 y=xA^T+b,常用于神经网络的特征映射和分类层
| 参数名 | 类型 | 必选 | 默认值 | 说明 |
|---|---|---|---|---|
in_features | int | 是 | 无 | 输入特征维度(如BERT隐藏层768) |
out_features | int | 是 | 无 | 输出特征维度(如词汇表30522) |
bias | bool | 否 | True | 是否启用偏置项 |
device | str | 否 | None | 张量存储设备(CPU/GPU) |
dtype | dtype | 否 | None | 张量数据类型(如float32) |
张量.reshape():在不改变数据顺序的前提下调整张量维度,支持自动推断维度(-1)
| 参数名 | 类型 | 必选 | 默认值 | 说明 |
|---|---|---|---|---|
shape | tuple 或 int | 是 | 无 | 目标形状(如(6, -1)) |
张量.shape:返回张量的维度信息元组,如 (batch_size, seq_len, hidden_dim)
张量.size():返回张量的维度信息(与.shape等效)或指定维度的长度
| 参数名 | 类型 | 必选 | 默认值 | 说明 |
|---|---|---|---|---|
dim | int | 否 | None | 指定维度索引(可选) |
nn.Softmax():将输入转换为概率分布(总和为1),常用于分类任务
| 参数名 | 类型 | 必选 | 默认值 | 说明 |
|---|---|---|---|---|
dim | int | 否 | -1 | 应用Softmax的维度索引 |
torch.matmul():支持多维张量的矩阵乘法,包含广播机制
| 参数名 | 类型 | 必选 | 默认值 | 说明 |
|---|---|---|---|---|
input | Tensor | 是 | 无 | 输入张量(如矩阵A) |
other | Tensor | 是 | 无 | 输入张量(如矩阵B) |
out | Tensor | 否 | None | 输出张量(可选) |
permute():重新排列张量的维度顺序,常用于处理图像或序列数据
| 参数名 | 类型 | 必选 | 默认值 | 说明 |
|---|---|---|---|---|
dims | int序列 | 是 | 无 | 新维度顺序(如(2,0,1)) |
torch.rand():生成区间 [0,1) 内均匀分布的随机数张量
| 参数名 | 类型 | 必选 | 默认值 | 说明 |
|---|---|---|---|---|
size | tuple 或 int | 是 | 无 | 张量形状(如(2,3)) |
dtype | dtype | 否 | None | 数据类型(如torch.float32) |
device | str | 否 | None | 存储设备(如'cuda') |
# Muti-head Attention 机制的实现
from math import sqrt
import torch
import torch.nn as nnclass Self_Attention_Muti_Head(nn.Module):# input: batch_size , seq_len , input_dim def __init__(self, input_dim, dim_k, dim_v, nums_head):super(Attention_Muti_Head, self).__init__()assert dim_k % nums_head == 0 # 确保dim_k可被头数整除assert dim_v % nums_head == 0 # 确保dim_v可被头数整除# q: batch_size , input_dim , dim_kself.q = nn.Linear(input_dim, dim_k) # Q线性变换层# k: batch_size , input_dim , dim_kself.k = nn.Linear(input_dim, dim_k) # K线性变换层# v: batch_size , input_dim , dim_vself.v = nn.Linear(input_dim, dim_v) # V线性变换层self.nums_head = nums_head # 头数self.dim_k = dim_k # 总键维度self.dim_v = dim_v # 总值维度self._norm_fact = 1 / sqrt(dim_k) # 缩放因子# x: batch_size, seq_len, input_dimdef forward(self, x):# Q: batch_size, seq_len, dim_kQ = self.q(x).reshape(-1, x.shape[0], x.shape[1], self.dim_k // self.nums_head)# K: batch_size, seq_len, dim_kK = self.k(x).reshape(-1, x.shape[0], x.shape[1], self.dim_k // self.nums_head)# V: batch_size, seq_len, dim_vV = self.v(x).reshape(-1, x.shape[0], x.shape[1], self.dim_v // self.nums_head)print(x.shape)print(Q.size())# batch_size, num_heads, seq_len, seq_lenattn_scores = (torch.matmul(Q, K, permute(0, 1, 3, 2))attn_weights = nn.Softmax(dim = -1)(attn_scores)# Q: batch_size * num_heads * seq_len * d_k# K.T():batch_size * num_heads * d_k * seq_len# Q * K.T(): batch_size * seq_len * seq_lenoutput - torch.matmul(attn, V).reshape(x.shape[0], x.shape[1], -1)# Q * K.T(): V # batch_size * seq_len * dim_vreturn outputx = torch.rand(1, 3, 4)
print(x)
attn = Self_Attention_Multi_Head(4, 4, 4, 2)
y = attn(x)
print(y.shape)四、Encoder 结构
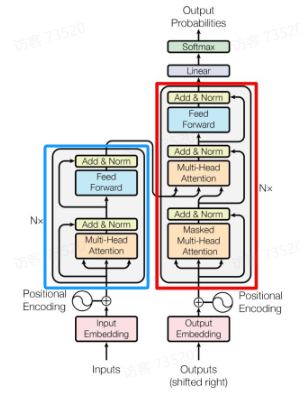
蓝色部分是 Transformer 的 Encoder block 结构,可以看到是由 Multi-Head Attention,Add & Norm,Feed Forward组成的,上文介绍了Multi-Head Attention 的计算过程,现在了解一下 Add & Norm 和 Feed Forward 部分
1.Add & Norm
Add & Norm 层由 Add 和 Norm 两部分组成,其计算公式如下:
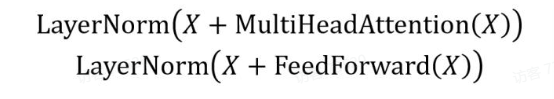
其中 X 表示 Multi-Head Attention 或者 Feed Forward 的输入,MultiHeadAttention(X) 和 FeedForward(X) 表示输出(输出与输入 X 维度是一样的,所以可以相加)
Add 指 X + Multi Head Attention(X),是一种残差连接,通常用于解决多层网络训练的问题,可以让网络只关注当前差异的部分,在 ResNet 中经常用到
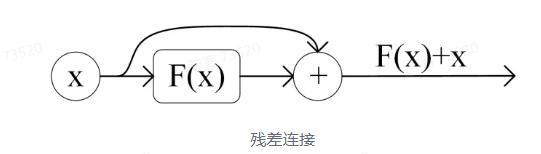
Norm 指 Layer Normalization,通常用于 RNN 结构,Layer Normalization 会将每一层神经元的输入都转成均值方差都一样的,这样可以加快收敛
2.Feed Forward
Feed Forward 层比较简单,是一个两层的全连接层,第一层的激活函数为 Relu,第二层不使用激活函数,对应的公式如下:
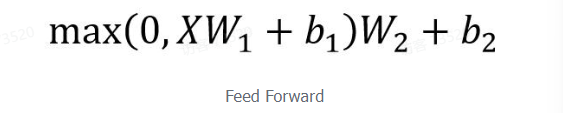
X 是输入,Feed Forward 最终得到的输出矩阵的维度与 X 一致
3.组成 Encoder
通过上面描述的 Multi-Head Attention,Feed Forward,Add & Norm 就可以构造出一个 Encoder block,Encoder block 接收输入矩阵 X_(n × d),并输出一个矩阵 O_(n × d)。通过多个 Encoder block 叠加就可以组成 Encoder
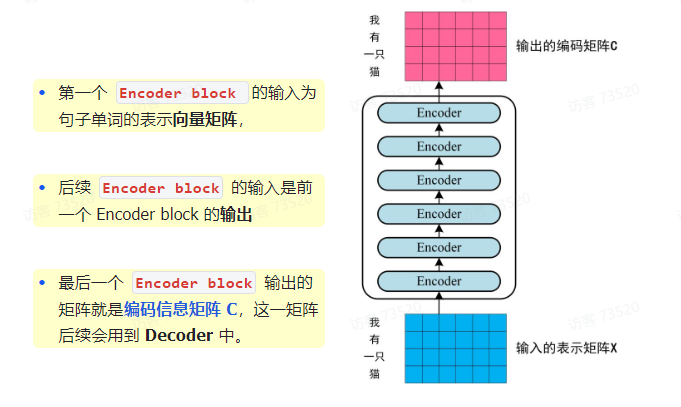
五、Decoder 结构
Transformer Decoder block
红色部分为 Transformer 的 Decoder block 结构,与 Encoder block 相似,但是存在一些区别:
① 包含两个 Multi-Head Attention 层
② 第一个 Multi-Head Attention 层采用了 Masked 操作
③ 第二个 Multi-Head Attention 层的 K,V 矩阵使用 Encoder 的编码信息矩阵C进行计算,而 Q 使用上一个 Decoder block 的输出计算
④ 最后有一个 Softmax 层计算下一个翻译单词的概率
1.第一个 Multi-Head Attention
Decoder block 的第一个 Multi-Head Attention 采用了 Masked 操作,因为在翻译的过程中是顺序翻译的,即翻译完第 i 个单词,才可以翻译第 i + 1 个单词。通过 Masked 操作可以防止第 i 个单词知道 i + 1 个单词之后的信息。下面以 “我有一只猫” 翻译成 “I have a cat” 为例,了解一下 Masked 操作
在 Decoder 的时候,是需要根据之前的翻译,求解当前最有可能的翻译,如下图所示,首先根据输入 “<Begin>” 预测出第一个单词为 “I”,然后根据输入 “<Begin> I” 预测下一个单词 “have”。

Decoder 可以在训练的过程中使用 Teacher Forcing 并且并行化训练,即将正确的单词序列 (<Begin> I have a cat)和对应输出(I have a cat <end>) 传递到 Decoder。那么在预测第 i 个输出时,就要将第 i + 1 之后的单词掩盖住
注意 Mask 操作是在 Self-Attention 的 Softmax 之前使用的,下面用 0 1 2 3 4 5 分别表示 <Begin> I have a cat <end>。
第一步:
1.下图是 Decoder 的输入矩阵 和 Mask 矩阵,输入矩阵包含 “<Begin> I have a cat"(0 1 2 3 4 5)五个单词的表示向量,Mask 是一个 5 × 5 的矩阵。在 Mask 可以发现单词 0 只能使用单词 0 的信息,而单词 1 可以使用单词 0、1的信息,即只能使用之前的信息
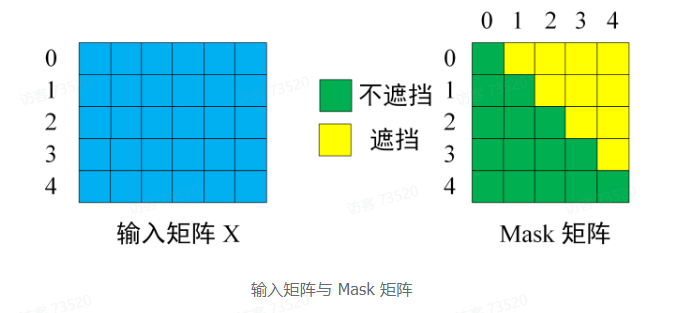
第二步:
2.接下来的操作和之前的 Self-Attention 一样,通过输入矩阵 X 计算得到 Q、K、V矩阵,然后计算 Q 和 K^T 的乘积 QK^T
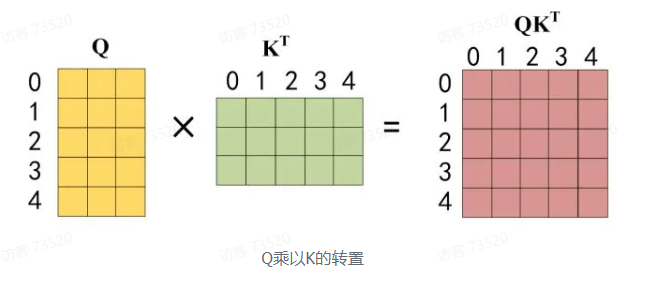
第三步:
3.在得到 QK^T之后,需要进行 Softmax,计算 attention score,我们在 Softmax 之前需要使用 Mask 矩阵遮挡住每一个单词之后的信息,遮挡操作如下:

得到 Mask QK^T,之后在 Mask QK^T 上进行 Softmax,每一行的和都为 1,但是单词 0 在 单词 1,2,3,4 上的 attentionn score 都为 0
第四步:
4.使用 Mask QK^T 与 矩阵V 相乘,得到输出 Z,则单词 1 的输出向量 Z_1 是只包含单词 1 的信息的
第五步:
5.通过上述步骤就可以得到一个 Mask Self-Attention 的输出矩阵 Z_i,然后和 Encoder 类似,通过 Multi-Head Attention 拼接多个输出 Z_i,然后计算得到第一个 Multi-Head Attention 的输出 Z,Z 与 输入X维度一样
2.第二个 Multi-Head Attention
Decoder block 第二个 Multi-Head Attention 变化不大,主要的区别在于其中 Self-Attention 的 K、V 矩阵不是使用上一个 Decoder block 的输出计算的,而是使用 Encoder 的编码信息矩阵 C 计算的
根据 Encoder 的输出 C 计算得到 K、V,根据上一个 Decoder block 的输出 Z 计算 Q(如果是第一个 Decoder block,则使用输入矩阵 X 进行计算),后续的计算方法与之前描述的一致
这样做的好处是在 Decoder 的时候,每一位单词都可以利用到 Encoder 所有单词的信息(这些信息无需 Mask)。
3.Softmax 预测输出单词
Decoder block 最后的部分是利用 Softmax 预测下一个单词,在之前的网络层我们可以得到一个最终的输出 Z,因为 Mask 的存在,使得 单词 0 的输出 Z_0 只包含单词 0 的信息,如下:
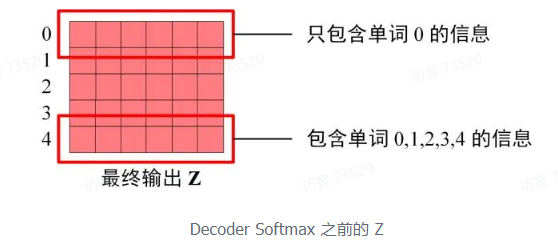
Softmax 根据输出矩阵的每一行预测下一个单词:
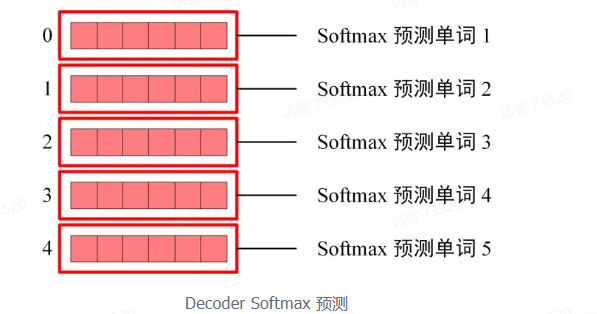
这就是 Decoder block 的定义,与 Encoder 一样,Decoder 是由多个 Decoder block 组合而成
六、Transformer 总结
1.Transformer 与 RNN 不同,可以比较好的并行训练。
2.Transformer 本身是不能利用单词的顺序信息的。因此需要在输入中添加位置 Embedding,否则 Transformer 就是一个词袋模型了。
3.Transformer 的重点是 Self-Attention 结构,其中用到的 Q、K、V 矩阵通过输出进行线性变换得到。
4.Transformer 中 Multi-Head Attention 中有多个 Self-Attention,可以捕获单词之间多种维度上的相关系数 attention score。
相关文章:

【NLP 面经 9.逐层分解Transformer】
如果我能给你短暂的开心 —— 25.4.7 一、Transformer 整体结构 1.Tranformer的整体结构 Transformer 的整体结构,左图Encoder和右图Decoder,下图是Transformer用于中英文翻译的整体结构: 可以看到 Transformer 由 Encoder 和 Decoder 两个…...
(5))
Diffusion Policy Visuomotor Policy Learning via Action Diffusion官方项目解读(二)(5)
运行官方代码库中提供的Colab代码:vision-based environment(二)(5) Network十八、类SinusoidalPosEmb,继承自nn.Module十八.1 def __init__()十八.2 def forward()总体说明 十九、类Downsample1dÿ…...

西门子S7-1200PLC 工艺指令PID_Temp进行控温
1.硬件需求: 西门子PLC:CPU 1215C DC/DC/DC PLC模块:SM 1231 TC模块 个人电脑:已安装TIA Portal V17软件 加热套:带加热电源线以及K型热电偶插头 固态继电器:恩爵 RT-SSK4A2032-08S-F 其他࿱…...

【深度学习:理论篇】--Pytorch进阶教程
目录 1.神经网络 1.1.torch.nn 核心模块 1.2.定义神经网络 1.3.损失函数 1.4.反向传播 1.5.梯度更新 2.图片分类器 2.1.数据加载 2.2.卷积神经网络 2.3.优化器和损失 2.4.训练网络 2.5.测试网络 2.6.GPU上训练 3.数据并行训练--多块GPU 3.1.导入和参数 3.2.构造…...
基础)
卷积神经网络(CNN)基础
目录 一、应用场景 二、卷积神经网络的结构 1. 输入层(Input Layer) 2. 卷积层(Convolutional Layer) 3. 池化层(Pooling Layer) 最大池化(max_pooling)或平均池化(…...

第 28 场 蓝桥入门赛 JAVA 完整题解
前言 本文总结了六个编程题目的解题思路与核心考点,涵盖基础语法、逻辑分析、贪心算法、数学推导等知识点。每个题目均从问题本质出发,通过巧妙的算法设计或数学优化降低复杂度,展现了不同场景下的编程思维与解题技巧。以下为各题的详细考点解…...

Python 网络请求利器:requests 包详解与实战
诸神缄默不语-个人技术博文与视频目录 文章目录 一、前言二、安装方式三、基本使用1. 发起 GET 请求2. 发起 POST 请求 四、requests请求调用常用参数1. URL2. 数据data3. 请求头 headers4. 参数 params5. 超时时间 timeout6. 文件上传 file:上传纯文本文件流7. jso…...

聊透多线程编程-线程基础-1.进程、线程基础概念
目录 一、进程 二、线程 三、进程与线程的关系 四、进程与线程的比较 注:本文多张图片来源于网络,如有侵权,请联系删除 一、进程 1. 进程的定义 进程是指在系统中正在运行的一个应用程序的实例,是操作系统进行资源分配和调…...

Android:Android Studio右侧Gradle没有assembleRelease等选项
旧版as是“Do not build Gradle task list during Gradle sync” 操作这个选项。 参考这篇文章:Android Studio Gradle中没有Task任务,没有Assemble任务,不能方便导出aar包_gradle 没有task-CSDN博客 在as2024版本中,打开Setting…...

LeetcodeBST2JAVA
235.二叉搜索树的最近公共祖先 给定一个二叉搜索树, 找到该树中两个指定节点的最近公共祖先。 百度百科中最近公共祖先的定义为:“对于有根树 T 的两个结点 p、q,最近公共祖先表示为一个结点 x,满足 x 是 p、q 的祖先且 x 的深度尽可能大&…...

如何创建单独的城市活码?活码能永久使用吗?
如何创建单独的城市活码 创建单独的城市活码通常需要借助专业的第三方工具,以下是具体步骤: 1.选择合适的工具 推荐使用专业的活码生成工具。 2.注册并登录 访问官网,完成注册并登录。 3.创建活码 在首页点击“创建活码”按钮。输入活码…...
应用)
用户画像(https://github.com/memodb-io/memobase)应用
1.下载项目的源代码,我们要先启动后端,用docker启动 cd src/server cp .env.example .env cp ./api/config.yaml.example ./api/config.yaml 这里我的配置内容如下config.yaml(因为我是调用的符合openai格式的大模型,所以我没改,如果要是别的大模型的话,需要自己再做兼容…...

基于形状补全和形态测量描述符的腓骨游离皮瓣下颌骨重建自动规划|文献速递-深度学习医疗AI最新文献
Title 题目 Automated planning of mandible reconstruction with fibula free flap basedon shape completion and morphometric descriptors 基于形状补全和形态测量描述符的腓骨游离皮瓣下颌骨重建自动规划 01 文献速递介绍 因创伤、骨髓炎和肿瘤而接受下颌骨节段切除术…...

Python3笔记之号称替代pip的uv包管理器
uv是什么? uv,这是一个由 Astral 团队开发的极快速的Python包和项目管理工具,用Rust语言编写。它集成了多种功能,旨在替代pip、pip-tools、pipx、poetry、pyenv、twine、virtualenv等多个工具,提供更高效、更全面的Py…...

面试如何应用大模型
在面试中,如果被问及如何应用大模型,尤其是面向政务、国有企业或大型传统企业的数字化转型场景,你可以从以下几个角度进行思考和回答: 1. 确定应用大模型的目标与痛点 首先,明确应用大模型的业务目标,并结合企业的实际需求分析可能面临的痛点。这些企业通常会关注如何提…...

贪心算法:部分背包问题深度解析
简介: 该Java代码基于贪心算法实现了分数背包问题的求解,核心通过单位价值降序排序和分阶段装入策略实现最优解。首先对Product数组执行双重循环冒泡排序,按wm(价值/重量比)从高到低重新排列物品;随后分两阶段装入:循环…...

Java程序的基本规则
java程序的基本规则 1.1 java程序的组成形式 Java程序是一种纯粹的面向对象的程序设计语言,因此Java程序 必须以类(class)的形式存在,类(class)是Java程序的最小程序 单位。Java程序不允许可执行性语句…...

机器学习-线性回归模型
机器学习-线性回归模型 线性模型笔记1、向量化2、线性回归模型公式3、损失函数(代价函数)4、梯度下降法5、Python 实现示例 6、使用 sklearn 实现线性回归模型✅ 基本步骤如下:📦 示例代码: 7、numpy中的切片X[n,:]是取…...
)
Linux 入门指令(1)
(1)ls指令 ls -l可以缩写成 ll 同时一个ls可以加多个后缀 比如 ll -at (2)pwd指令 (3)cd指令 cd .是当前目录 (4)touch指令 (5)mkdir指令 (6)rmdir和rm…...

密码学基础——AES算法
目录 一、算法背景 AES算法与Rijndael算法 二、算法特点 1.安全性高 2.效率高 3.灵活性好 三、算法说明 3.1状态、种子密钥和轮数的概念 (1)状态(State) 定义 结构:通常状态是一个 4N 字节的矩阵࿰…...

淘宝API与小程序深度联动:商品详情页“一键转卖”功能开发
要实现淘宝 API 与小程序深度联动,开发商品详情页 “一键转卖” 功能,可按以下步骤进行: 1. 前期准备 淘宝开放平台接入:在淘宝开放平台注册开发者账号,创建应用,获取 App Key 和 App Secret,…...

深入解析 C++ 设计模式:原理、实现与应用
一、引言 在 C 编程的广袤领域中,设计模式犹如闪耀的灯塔,为开发者指引着构建高效、可维护软件系统的方向。设计模式并非神秘莫测的代码魔法,实际上,我们在日常编程中或许早已与之打过交道。简单来说,设计模式常常借助…...

配置与管理代理服务器
安装squid Squid软件包在标准yum存储库中可用,因此,我们正在使用yum命令安装Squid代理。 [rootserver ~]# dnf install -y squid //安装 [rootserver ~]#systemctl enable --now squid.service [rootserver ~]#systemctl status squid.serv…...

RuntimeError: CUDA error: invalid device function
CUDA内核编译时的架构设置与当前GPU不兼容导致 -- The CUDA compiler identification is NVIDIA 11.5.119 (实际为 12.6) 解决方案: 1. 查看显卡计算能力 2. CMakeLists.txt 修改 set_target_properties(my_library PROPERTIESCUDA_AR…...

vulnhub:sunset decoy
靶机下载地址https://www.vulnhub.com/entry/sunset-decoy,505/ 渗透过程 简单信息收集 nmap 192.168.56.0/24 -Pn # 确定靶机ip:192.168.56.121 nmap 192.168.56.121 -A -T4 # 得到开放端口22,80 在80端口得到save.zip,需要密码解压。 john破解压缩…...

MySQL日期时间类型详解:DATE、TIME和DATETIME的用法与区别
在数据库设计中,正确处理日期和时间数据是至关重要的。MySQL提供了多种数据类型来存储时间信息,其中最常用的三种是DATE、TIME和DATETIME。本文将详细介绍这三种类型的特性、区别以及实际应用场景。 一、基本数据类型介绍 1. DATE类型 用途࿱…...

js异步机制
1、什么是异步机制?为什么js需要异步机制? 异步机制和同步机制是相对应的,异步是指:当代码按照顺序执行到一些比较耗时的操作,不会立刻执行,而是将这些操作推到一个队列中等待合适的时机从队列中取出任务执…...

Pycharm常用快捷键总结
主要是为了记录windows下的PyCharm的快捷键,里面的操作都试过了功能描述会增加备注。 文件操作 快捷键功能描述Ctrl N新建文件Ctrl Shift N根据名称查找文件Ctrl O打开文件Ctrl S保存当前文件Ctrl Shift S另存为Alt F12打开终端(Terminal&…...

巧记英语四级单词 Unit2-下【晓艳老师版】
mit传递(send 送)、 superiority n.优势,优越性 超越别人的东西就是自己的优势govern v.统治 government政府 统治的机构administer v.管理,治理 minister 大臣 部长,mini-小人,一再的做大臣 部长…...

走进底层 - JVM工作原理入门指南
走进底层 - JVM工作原理入门指南 Java 之所以能够实现“一次编写,到处运行”(Write Once, Run Anywhere, WORA),核心在于 Java 虚拟机(JVM, Java Virtual Machine)。JVM 是 Java 程序的运行环境,…...

windows 10频繁通知A字“出现了问题,无法安装功能。”
一、故障突现 windows 10频繁通知A字“出现了问题,无法安装功能。” 编辑文档时发现黑体、楷体gb_2312等常用字体,在字体列表中失踪,原来设置好的字体也显示失效。 二、起因分析 回想了一下,是3月27日安装了 2025-适用于Windows…...

基础环境配置
1.GitGerritjenkins Linux 远程登录 | 菜鸟教程 https://zhuanlan.zhihu.com/p/22766058062 2.Samba 配置 3.软件安装 (1)MobaXterm (2)Vscode (3)Xmind (4) Audacity Aud…...

ROS2——foxy apt打包离线安装deb包
需要从A设备复制ROS2环境到B设备,且B设备有可能没网络,所以选择制作离线资源包 1. 本机安装指令 本机环境ubuntu20.04,安装ros2-foxy版本,直接输入以下指令,基本不会遇到问题 这里安装的是ros-base版本,不…...
-clickhouse与hdfs)
大数据学习(104)-clickhouse与hdfs
🍋🍋大数据学习🍋🍋 🔥系列专栏: 👑哲学语录: 用力所能及,改变世界。 💖如果觉得博主的文章还不错的话,请点赞👍收藏⭐️留言📝支持一…...

大数据 - 1. 概述
早期的计算机(上世纪70年代前) 是相互独立的,各自处理各自的数据上世纪70年代后,出现了基于TCP/IP协议的小规模的计算机互联互通。上世纪90年代后,全球互联的互联网出现。当全球互联网逐步建成(2000年左右&…...
 static成员(上))
CD25.【C++ Dev】类和对象(16) static成员(上)
目录 1.static成员变量 问题:实现一个类,计算程序中创建出了多少个类对象 设计思路 代码示例 版本1 版本2 static成员 特点1.static成员为静态成员,为所有类对象所共享(在某种程度上可以理解为全局的,用类去封装"全局变量"),存放在静态区,则不属于某个具体的…...

C语言今天开始了学习
好多年没有弄了,还是捡起来弄下吧 用的vscode 建议大家参考这个配置 c语言vscode配置 c语言这个语言简单,但是今天听到了一个消息说python 不知道怎么debug。人才真多啊...

Mockito如何对静态方法进行测试
在 Mockito 中,直接对静态方法进行模拟是困难的,因为 Mockito 的设计理念是优先通过依赖注入(DI)管理对象,而静态方法破坏了这种设计(难以解耦)。不过,从 Mockito 3.4.0 版本开始,通过 mockStatic 方法支持了对静态方法的模拟(需配合 mockito-inline 依赖)。 从 Mo…...

Three.js 入门实战:安装、基础概念与第一个场景⭐
学习本章节你不必要追求细节,你只需要了解基本的3D场景需要哪些元素组成,如何通过组成3D场景的元素属性调整来控制3D物体或者场景即可。 在上一篇文章中我们初识了 Three.js,今天我们正式进入实战环节 🎯 前置准备: …...
)
【QT】QT的消息盒子和对话框(自定义对话框)
QT的消息盒子和对话框(自定义对话框) 一、消息盒子QMessageBox1、弹出警告盒子示例代码:现象: 2、致命错误盒子示例代码:现象: 3、帮助盒子示例代码:现象: 4、示例代码: …...

QT面试题:内存管理与对象生命周期
题目: 在Qt中,当一个父对象被销毁时,其子对象是否会被自动释放?请结合Qt的内存管理机制说明原因,并解释在什么情况下可能导致内存泄漏。如何避免这类问题? 参考答案 父子对象的内存管理机制 …...

linux查询inode使用率
在 Linux 中,inode 用于存储文件和目录的元数据(如权限、所有者、时间戳等)。当文件系统的 inode 被耗尽时,即使磁盘空间充足,系统也会提示 No space left on device。以下是查询 inode 使用率的详细方法: …...

算法基础—二分算法
目录 一、⼆分查找例题 1 牛可乐和魔法封印 2 A-B 数对 3 烦恼的高考志愿 二、 ⼆分答案 1 木材加⼯ 2 砍树 3 跳石头 ⼆分算法的原理以及模板其实是很简单的,主要的难点在于问题中的各种各样的细节问题。因此,⼤多数情况下,只是背会…...

2024年第十五届蓝桥杯CC++大学A组--成绩统计
2024年第十五届蓝桥杯C&C大学A组--成绩统计 题目: 动态规划, 对于该题,考虑动态规划解法,先取前k个人的成绩计算其方差,并将成绩记录在数组中,记录当前均值,设小蓝已检查前i-1个人的成绩&…...

家居实用品:生活中的艺术,家的温馨源泉
在快节奏的现代生活中,家居实用品不仅是日常所需的工具,更是营造温馨家居氛围、提升生活品质的关键元素。它们以其独特的魅力,默默地融入我们的日常生活,成为连接物质世界与精神世界的桥梁。 走进家门,首先映入眼帘的或…...

TCP重传率高与传输延迟问题
目录标题 排查步骤:TCP重传率高与传输延迟问题v1.0通过 rate(node_netstat_Tcp_RetransSegs[3m]) 排查 TCP 重传问题的步骤1. **指标含义与初步分析**2. **关联指标排查**3. **定位具体问题源**4. **解决方案**5. **验证与监控** v2.0一、基础检查二、网络层分析三、…...

超越简单检索:探索知识图谱与大型语言模型的协同进化之路
摘要: 大型语言模型(LLM)在自然语言处理领域取得了革命性进展,但其在事实准确性、复杂推理和可解释性方面仍面临挑战,“幻觉”现象是其固有局限性的体现。知识图谱(KG)作为结构化人类知识的载体,…...

汽车的四大工艺
文章目录 冲压工艺核心流程关键技术 焊接工艺核心流程 涂装工艺核心流程 总装工艺核心流程终检与测试静态检查动态检查四轮定位制动转鼓测试淋雨测试总结 简单总结下汽车的四大工艺(从网上找了一张图,感觉挺全面的)。 冲压工艺 将金属板材通过…...

研发效能实践:技术评审会生存指南
文章目录 🚨开篇暴击:为什么你的评审会像「菜鸡互啄」?⚙️第一章:Google Design Sprint——5天把争议变成共识📅 Day 1-5 实操手册Map the Problem(画地图)Sketch Solutions…...

js 拷贝
在 JavaScript 中,拷贝对象和数组时需要特别注意,因为对象和数组是引用类型,直接赋值只会复制引用,而不是实际的数据。以下是几种常见的拷贝方法及其应用场景: 1. 浅拷贝(Shallow Copy) 浅拷贝…...