Streamlit性能优化:缓存与状态管理实战
目录
📌 核心特性
📌 运行原理
(1)全脚本执行
(2)差异更新
📌 缓存机制
❓为什么使用缓存?
使用@st.cache_data的优化方案
缓存适用场景
使用st.session_state的优化方案
📌总结
Streamlit 是一个开源的 Python 库,专为快速构建数据科学和机器学习 Web 应用而设计。它无需前端开发经验,通过简单 API 即可创建交互式界面,适合原型开发和数据展示
📌 核心特性
- 极简代码:用纯 Python 实现界面交互
- 实时预览:保存代码后自动刷新页面
- 丰富组件:支持图表、表格、滑块、文件上传等
- 无缝集成:兼容 Pandas、Matplotlib、PyTorch 等主流库
安装Streamlit
pip3 install streamlit先通过一个简单的Hello World案例来了解Streamlit
import streamlit as st# 显示标题
st.title("Hello World,I'm echola")# 显示文本
st.write("这是一个由Streamlit搭建的Web平台")
运行:
streamlit run hello.py结果:
 是不是很强悍,三行代码搞定一个Web应用
是不是很强悍,三行代码搞定一个Web应用
📌 运行原理
Streamlit 的运行逻辑围绕脚本的线性执行和响应式更新展开,其核心设计是让开发者以极简的方式构建交互式应用。以下是关键逻辑分步解析:
1、启动Web服务器
- Streamlit 启动一个本地 Web 服务器,默认监听 8501 端口
- 打开浏览器并导航到 http://localhost:8501,展示应用界面
2、解析和执行脚本:
- Streamlit 解析 hello.py 文件,生成抽象语法树(AST)
- 动态执行脚本中的代码,按照顺序执行每个 Streamlit 组件(如 st.title 和 st.write)
3、组件渲染
- 每个 Streamlit 组件(如 st.title 和 st.write)会被注册到当前页面的状态中
- 页面会根据组件的顺序和内容进行渲染
4、实时更新:
- 基于Websocket通信:浏览器与服务器保持长连接,脚本输出的文本、图表等实时推送至前端
- 增量更新机制:Streamlit只能对比前后两次执行的输出差异,仅向浏览器发送差异部分,也就是只更新变化的部分(而非刷新整个页面),Streamlit 会自动重新运行政整个脚本(而非局部更新)并更新页面,确保了开发过程中的高效性和实时性
上述增量更新可能会有一点矛盾,简而言之就是,「全脚本执行 + 差异更新」的设计,让 Streamlit 在开发便捷性(无需手动管理更新)和运行效率(局部渲染)之间取得了完美平衡
(1)全脚本执行
⚠️:也要避免全局作用域的冗余计算(需用缓存优化)
下来使用一个简单的案例,来模拟Streamlit加载全脚本的耗时过程
import time
import streamlit as st# 全脚本执行部分:以下代码每次交互都会运行
st.title("TimeOut Example") # ✅ 标题会重复渲染,但 Streamlit 会优化为"增量更新"# 局部增量执行:以下代码仅在按钮点击时触发
if st.button("Click me"):processing_bar = st.progress(0) # 每次点击时新建进度条with st.spinner("Loading..."):for percent_complete in range(100):time.sleep(0.05)processing_bar.progress(percent_complete + 1)st.success("Loading completed!")
当用户点击按钮时,触发 if 条件判断,显示加载提示框 "Loading..."。开始模拟耗时操作,通过循环和 time.sleep 模拟耗时。每次循环中,更新进度条的值,进度条从0%逐渐增加到100%
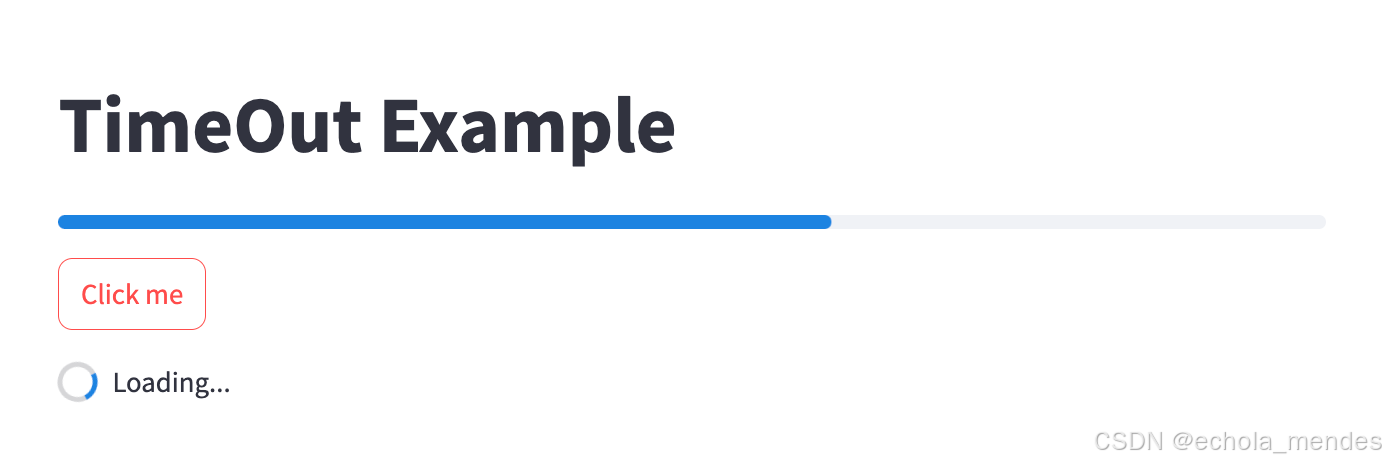
直至耗时完成5s后,隐藏加载提示框,显示成功消息框”Loading completed“

再次点击【Click me】, 重复上述效果图
可以从上述效果中看出,无论是页面首次加载、按钮点击,还是其他组件交互(如下拉框选择),Streamlit都会从头到尾重新执行整个脚本
虽然脚本会全量执行,但Streamlit内部通过智能的组件状态管理和缓存机制,只更页面中发生变化的部分(如按钮触发的进度条),而不是刷新整个页面
接下来会使用缓存机制进行优化
(2)差异更新
可以高效渲染(减少网络传输数据量和浏览器渲染开销)和无缝体验(用户输入状态,如:文本框焦点、滚动条位置,不会因为局部更新而丢失)
⚠️:也要关注复杂UI的组件键(Key)的稳定性
📌 缓存机制
❓为什么使用缓存?
🔴 问题:每次点击click按钮时,代码会从执行整个耗时操作(for循环+time.sleep),即使操作结果不变
🥀 缓存的作用:将耗时操作的结果缓存起来,后续重复调用时直接读取缓存,避免重复计算
解决重复计算问题:通过装饰器@st.cache_data(缓存数据)或@st.cache_resource(缓存资源如模型、数据库连接),避免脚本执行导致的重复计算
@st.cache_data
def heavy_computation():# 此函数仅在输入参数或代码变更时重新执行return result使用@st.cache_data的优化方案
那优化一下上面提到的问题
import time
import streamlit as stst.title("Optimize Example")# 缓存耗时操作的结束(假设操作是无参数)
@st.cache_data
def expensive_operation():# 模拟耗时操作(例如:数据计算)result = []for _ in range(100):time.sleep(0.05) # 假设这是实际的计算步骤result.append(_) # 模拟中间结果return resultif st.button("Click me"):processing_bar = st.progress(0) # 每次点击时新建进度条with st.spinner("Loading..."):# 获取数据(首次点击执行耗时操作,后续点击直接读缓存)data = expensive_operation()for percent_complete in range(len(data)):processing_bar.progress(percent_complete + 1)st.success("Loading completed!")
首次点击【Click me】,会出现

大概5s后,执行完成
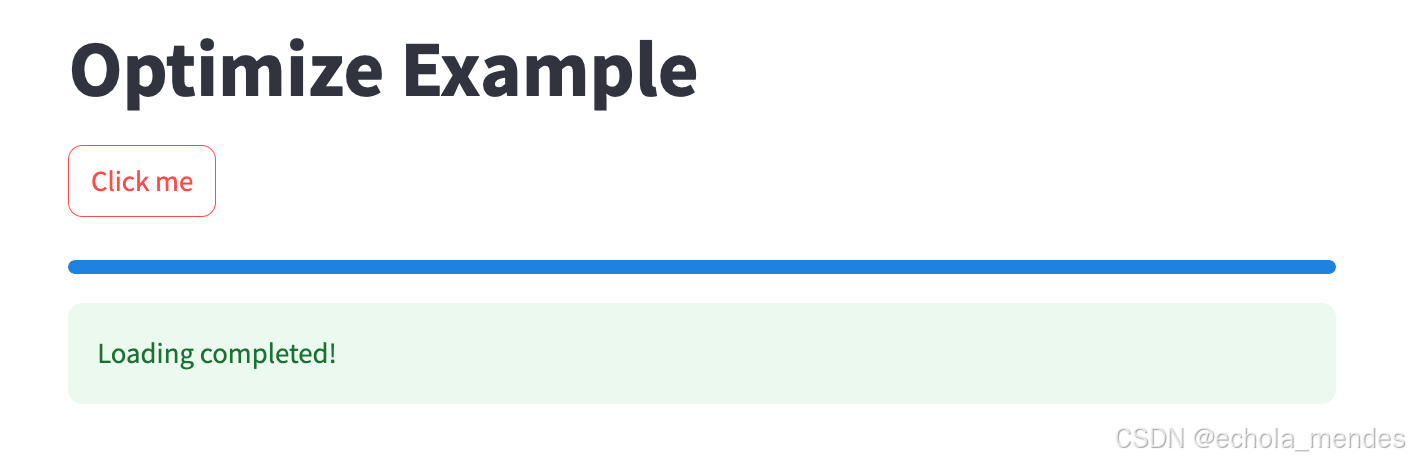 重复点击【Click me】 ,不会重复加载进度条,由于直接读取缓存结果,无需重复计算,数据已缓存,进度条会快速更新到100%
重复点击【Click me】 ,不会重复加载进度条,由于直接读取缓存结果,无需重复计算,数据已缓存,进度条会快速更新到100%
通过 @st.cache_data 装饰器缓存耗时操作的结果,避免每次点击按钮时都重新执行耗时操作
不是所有耗时操作都必须使用缓存
缓存适用场景
- 需要缓存的场景:
- 耗时操作的结果是 静态的(例如读取文件、初始化模型、复杂计算)。
- 操作结果 不依赖外部变量或用户输入。
- 不适用缓存场景:
- 操作结果 依赖动态参数(例如用户输入的变量),此时需通过函数参数触发缓存更新。
- 操作需要 实时更新(例如每次点击都需重新计算)
如果耗时操作 依赖参数,可以通过函数参数控制缓存版本:
@st.cache_data
def expensive_operation(param1, param2):# 根据参数执行不同计算results = []for _ in range(100):time.sleep(0.05)results.append(param1 + param2 + _)return results# 在按钮点击时传入参数
data = expensive_operation(10, 20) # 参数不同会生成不同缓存可以看出:
- 缓存机制:通过
@st.cache_data缓存静态计算结果,减少重复执行。 - 进度条优化:将耗时操作与进度条更新分离,首次加载缓存后,后续交互可快速完成
那上述代码就没有什么问题了吗?
⚠️接下来分析原代码存在的弊端:
- 进度条重复创建:每次点击按钮都会新建processing_bar,导致多次点击时进度条堆叠
- 无法阻止重复提交:在耗时操作执行期间,用户仍可多次点击按钮,导致逻辑混乱
- 状态丢失:进度完成后的状态(如success提示)无法持久化
使用st.session_state的优化方案
1、保存进度条实例
if "processing_bar" not in st.session_state:st.session_state.processing_bar = None # 初始化进度条容器if st.button("Click me"):# 仅在第一次点击时创建进度条if not st.session_state.processing_bar:st.session_state.processing_bar = st.progress(0)# 后续操作复用已有进度条with st.spinner("Loading..."):data = expensive_operation()for i in range(len(data)):st.session_state.processing_bar.progress(i + 1)# 完成后清空引用st.session_state.processing_bar = Nonest.success("Done!")2. 防止重复提交
if "is_processing" not in st.session_state:st.session_state.is_processing = False # 状态锁if st.button("Click me") and not st.session_state.is_processing:st.session_state.is_processing = True # 锁定try:# 执行耗时操作...finally:st.session_state.is_processing = False # 释放3. 持久化完成状态
if "load_complete" not in st.session_state:st.session_state.load_complete = Falseif st.button("Click me"):# 执行操作...st.session_state.load_complete = Trueif st.session_state.load_complete:st.success("数据已加载完成!")st.balloons() # 显示动画效果完整优化代码
import time
import streamlit as stst.title("Optimized Example")# 初始化会话状态
if "processing_bar" not in st.session_state:st.session_state.processing_bar = None
if "is_processing" not in st.session_state:st.session_state.is_processing = False
if "load_complete" not in st.session_state:st.session_state.load_complete = False@st.cache_data
def expensive_operation():result = []for _ in range(100):time.sleep(0.05)result.append(_)return resultif st.button("Click me") and not st.session_state.is_processing:st.session_state.is_processing = Truetry:# 创建或复用进度条if not st.session_state.processing_bar:st.session_state.processing_bar = st.progress(0)with st.spinner("Loading..."):data = expensive_operation()for i in range(len(data)):st.session_state.processing_bar.progress(i + 1)st.session_state.load_complete = Truefinally:st.session_state.is_processing = Falsest.session_state.processing_bar = None # 重置进度条if st.session_state.load_complete:st.success("操作成功!")st.balloons()关键作用总结
| 会话状态项 | 功能说明 |
|---|---|
processing_bar | 保持进度条对象引用,防止重复创建 |
is_processing | 实现类似互斥锁,防止重复提交 |
load_complete | 持久化完成状态,实现跨脚本执行记忆 |
通过 st.session_state 实现了:
- 状态持久化:在 Streamlit 的全脚本重执行机制中保持关键状态
- 资源管理:避免 DOM 元素重复创建
- 交互安全:防止用户误操作导致的逻辑冲突
这种模式特别适合需要保持复杂交互状态的场景(如多步骤表单、长任务处理)
📌总结
通过 缓存机制 减少重复计算,结合 st.session_state 管理会话状态,Streamlit 可以高效处理复杂交互场景,同时保持代码简洁和用户体验流畅。这种优化策略尤其适合需要频繁交互、状态保持或耗时操作的 Web 应用开发
相关文章:

Streamlit性能优化:缓存与状态管理实战
目录 📌 核心特性 📌 运行原理 (1)全脚本执行 (2)差异更新 📌 缓存机制 ❓为什么使用缓存? 使用st.cache_data的优化方案 缓存适用场景 使用st.session_state的优化方案 &…...

楼宇自控系统凭何成为建筑稳定、高效、安全运行的关键
在现代建筑领域,随着建筑规模的不断扩大和功能的日益复杂,建筑的稳定、高效、安全运行成为了至关重要的课题。楼宇自控系统犹如建筑的“智慧大脑”,凭借其卓越的功能和技术,在这三个关键方面发挥着不可替代的作用,成为…...

【学习自用】配置文件中的配置项
server.port服务器端口,常被用于指定应用程序运行时所监听的端口号spring.datasource.url用于配置数据源的数据库连接URLspring.datasource.username用于指定连接数据库的用户名spring.datasource.password用于配置数据源时设置数据库连接密码的属性mybatis.mapper-…...

《解码 C/C++ 关键字:科技编程的核心指令集》
序号语言关键字原型实现原理功能返回值类型使用示例注意事项应用场景1Cautoauto 数据类型 变量名;函数调用时在栈上分配内存,函数结束自动释放声明自动变量,变量生命周期限于函数执行期间无c<br>void func() {<br> auto int num 10;<br&…...

Linux 性能调优之CPU调优认知
写在前面 博文内容为《性能之巅 系统、企业与云可观测性(第2版)》CPU 章节课后习题答案整理内容涉及: CPU 术语,指标认知CPU 性能问题分析解决CPU 资源负载特征分析应用程序用户态CPU用量分析理解不足小伙伴帮忙指正对每个人而言,真正的职责只有一个:找到自我。然后在心中…...

《P2660 zzc 种田》
题目背景 可能以后 zzc 就去种田了。 题目描述 田地是一个巨大的矩形,然而 zzc 每次只能种一个正方形,而每种一个正方形时 zzc 所花的体力值是正方形的周长,种过的田不可以再种,zzc 很懒还要节约体力去泡妹子,想花最少的体力值…...
介绍)
Model Context Protocol(MCP)介绍
“Model Context Protocol(MCP)”是近年来在多模态大模型或可扩展智能系统中出现的一个概念,其主要目标是为大模型提供结构化的上下文管理和动态记忆机制。它解决的是在长时间对话、多轮交互、任务切换等复杂情境中,模型如何理解“…...

解决使用PendingIntent.getBroadcast时出现java.lang.IllegalArgumentException异常的问题
当app为targetSdk31及以上,并且在Android12及以上系统中调用PendingIntent.getBroadcast(context, 0, intent, 0)接口时会抛出异常: java.lang.IllegalArgumentException: com.haier.uhome.uplus.seasia: Targeting S (version 31 and above) requires …...

创建一个简单的HTML游戏站
创建一个简单的HTML游戏站涉及多个步骤,包括规划网站结构、设计用户界面、编写游戏逻辑以及测试和部署。下面是一个详细的步骤指南: 1. 规划网站结构 确定目标受众:了解你的目标用户群体。选择游戏类型:决定你要开发的游戏类型&…...

AIDD-人工智能药物设计-TCMP-12个公开的中药数据库
12个公开的中药数据库 数据库是中药网络药理学研究不可或缺的数据来源之一。目前已经建立了若干中药数据库,提供有关中药的各方面信息,包括疾病、方剂、草药或天然产物、生物活性成分和靶点。这些数据库成为中医药与现代生物医学之间的桥梁,…...

基于大模型的阵发性室上性心动过速风险预测与治疗方案研究
目录 一、引言 1.1 研究背景与意义 1.2 研究目的与目标 1.3 研究方法与数据来源 二、阵发性室上性心动过速概述 2.1 定义与分类 2.2 发病机制与流行病学 2.3 临床表现与诊断方法 三、大模型在阵发性室上性心动过速预测中的应用 3.1 大模型技术原理与特点 3.2 模型构…...

基于金字塔视觉变换的类引导网络高分辨率遥感图像高效语义分割
Class-Guidance Network Based on the Pyramid Vision Transformer for Efficient Semantic Segmentation of High-Resolution Remote Sensing Images 摘要 多分类语义分割中类之间的小差异和类内的大变化是全卷积神经网络的“编码器-解码器”结构没有完全解决的问题&#…...

高级:数据库面试题全攻略
一、引言 数据库是软件开发中不可或缺的组件,面试官通过相关问题,考察候选人对数据库核心概念的理解、实际应用能力以及在复杂场景下的问题解决能力。本文将深入解读数据库的索引、事务、锁机制等常见面试问题,结合实际开发场景,…...

如何避免Python爬虫重复抓取相同页面?
在网络爬虫开发过程中,重复抓取相同页面是一个常见但必须解决的问题。重复抓取不仅会浪费网络带宽和计算资源,降低爬虫效率,还可能导致目标网站服务器过载,甚至触发反爬机制。本文将深入探讨Python爬虫中避免重复抓取的多种技术方…...

LeetCode.02.04.分割链表
分割链表 给你一个链表的头节点 head 和一个特定值 x ,请你对链表进行分隔,使得所有 小于 x 的节点都出现在 大于或等于 x 的节点之前。 你不需要 保留 每个分区中各节点的初始相对位置。 示例 1: 输入:head [1,4,3,2,5,2], x …...

鸿蒙开发_ARKTS快速入门_语法说明_渲染控制---纯血鸿蒙HarmonyOS5.0工作笔记012
然后我们再来看渲染控制 首先看条件渲染,其实就是根据不同的状态,渲染不同的UI界面 比如下面这个暂停 开启播放的 可以看到就是通过if 这种条件语句 修改状态变量的值 然后我们再来看这个, 下面点击哪个,上面横线就让让他显示哪个 去看一下代码 可以看到,有两个状态变量opt…...

MOP数据库中的EXPLAIN用法
EXPLAIN 是 SQL 中的一个非常有用的工具,主要用于分析查询语句的执行计划。执行计划能展示数据库在执行查询时的具体操作步骤,像表的读取顺序、使用的索引情况、数据的访问方式等,这有助于我们对查询性能进行优化。 语法 不同的数据库系统&…...

软考 系统架构设计师系列知识点 —— 设计模式之抽象工厂模式
本文内容参考: 软考 系统架构设计师系列知识点之设计模式(2)_系统架构设计师中考设计模式吗-CSDN博客 https://baike.baidu.com/item/%E6%8A%BD%E8%B1%A1%E5%B7%A5%E5%8E%82%E6%A8%A1%E5%BC%8F/2361182 特此致谢! Abstract Fac…...

告别水下模糊!SU-YOLO:轻量化+尖峰神经网络,用“类脑计算”实现水下目标毫秒级识别
目录 一、摘要 二、引言 三、相关工作 SNN 物体检测 水下物体探测 水下图像去噪 归一化 四、方法 水下尖峰YOLO 尖峰干扰器 SU-Block SpikeSPP 编码器和检测头 分批归一化 五、Coovally AI模型训练与应用平台 六、实验结果 数据集和实施细节 数据集 实施细节…...

Three.js 系列专题 8:实战项目 - 构建一个小型 3D 游戏
内容概述 本专题将通过一个实战项目展示 Three.js 的综合应用。游戏包含迷宫生成、角色移动、相机控制和简单的物理碰撞检测(可选)。这将帮助你将之前学到的知识融会贯通。 学习目标 整合几何体、光照、动画和交互知识。实现基本的游戏逻辑和用户控制。可选:使用 Cannon.j…...
)
嵌入式笔试(一)
C语言和嵌入式软件 面试题(共10题 时间30分钟) 1. 请写出下面声明的含义。 int(*s[10])(int);定义了一个数组为s包含十个元素,每个元素都是函数指针,函数的参数为一个int类型,返回值也是int类型2. 选择题 设有一台计算机,它有一条加法指令,每次可计算三个数的和。如果要…...

spark 的流量统计案例
创建一个目录为data...

局域网访问 Redis 方法
局域网访问 Redis 方法 默认情况下,Redis 只允许本机 (127.0.0.1) 访问。如果你想让局域网中的其他设备访问 Redis,需要 修改 Redis 配置,并确保 防火墙放行端口。 方法 1:修改 Redis 配置 1. 修改 redis.conf(或 me…...

LeetCode题五:合并两个有序链表
基本思路其实就是:先建立一个空链表,然后将尾节点放在头结点上; 如果第一个链表节点值较小,那么先将list1插入新链表中,然后将尾节点后移;相同的,第二个也需要比较;移动新链表的指针…...

深入探索 `malloc`:内存分配失败的原因及正确使用规范
文章目录 一、malloc 内存分配失败的常见原因1. 内存不足2. 内存越界访问3. 内存碎片化4. 系统限制5. 错误的使用方式 二、如何正确使用 malloc1. 检查返回值2. 释放内存3. 避免内存越界4. 优化内存使用5. 调整系统参数6. 使用高效的内存分配器 三、总结 在 C 语言中࿰…...

处理Excel的python库openpyxl、xlrd、xlwt、panda区别
openpyxl、xlrd、xlwt、pandas 都能处理 Excel 表格,但用途和适合的场景不同。今天做个总结: 库名功能支持格式读写支持样式备注openpyxl全面的.xlsx处理库.xlsx(Excel2007)✅✅✅首选xlrd读取.xls文件的老牌工具.xls(…...

【C++11】特殊类的设计 单例模式 类型转换
目录 一、特殊类的设计: 1、设计一个不能够拷贝的类: 2、设计一个只能在堆上创建的类 3、设计一个只能在栈上创建的类 4、设计一个不能被继承的类: 二、单例模式: 设计一个只能创建一个对象的类: 饿汉模式&…...
带论文文档1万字以上,文末可获取,系统界面在最后面。)
基于vue框架的助农特色农产品销售系统i7957(程序+源码+数据库+调试部署+开发环境)带论文文档1万字以上,文末可获取,系统界面在最后面。
系统程序文件列表 项目功能:用户,商品分类,农产品信息,特价商品,爱心捐赠 开题报告内容 基于Vue框架的助农特色农产品销售系统开题报告 一、研究背景与意义 (一)研究背景 随着乡村振兴战略的深入实施,特色农产品作为农村经济的重要组成部…...
:ls 命令深入剖析与实践应用(期末、期中复习必备))
Linux 学习笔记(3):ls 命令深入剖析与实践应用(期末、期中复习必备)
前言 一、ls 命令基础语法 命令示例 二、工作目录与 HOME 目录 1.工作目录 2.HOME 目录 三、结语 前言 在 Linux 系统的学习旅程中,基础命令的掌握是迈向熟练操作的关键一步。其中,ls 命令作为我们探索系统文件和目录结构的常用工具,有着…...

最简CNN based RNN源码
1.源码: GitCode - 全球开发者的开源社区,开源代码托管平台 最终的效果: 数据集是20个周期,1024点sin(x)加了偏置。其中用于训练的有1024-300点。最后300点用来进行测试。上面的右侧输出的,其实对应左侧x73之后的波形࿰…...

大模型是如何把向量解码成文字输出的
hidden state 向量 当我们把一句话输入模型后,例如 “Hello world”: token IDs: [15496, 995]经过 Embedding Transformer 层后,会得到每个 token 的中间表示,形状为: hidden_states: (batch_size, seq_len, hidd…...

Elasticsearch:加快 HNSW 图的合并速度
作者:来自 Elastic Thomas Veasey 及 Mayya Sharipova 过去,我们曾讨论过搜索多个 HNSW 图时所面临的一些挑战,以及我们是如何缓解这些问题的。当时,我们也提到了一些计划中的改进措施。本文正是这项工作的成果汇总。 你可能会问…...

Elasticsearch单节点安装手册
Elasticsearch单节点安装手册 以下是一份 Elasticsearch 单节点搭建手册,适用于 Linux 系统(如 CentOS/Ubuntu),供学习和测试环境使用。 Elasticsearch 单节点搭建手册 1. 系统要求 操作系统:Linux(Cent…...

前端用户列表与后端分页协同设计
分页实现方案 在现代Web应用中,用户列表展示与分页是一个常见的功能需求。前端与后端通过API协同工作,使用PageHelper等工具实现高效分页。 例如: 后端实现 (使用PageHelper) public PageResult DishPage(DishPageQueryDTO dishPageQuery…...

MyBatis的第四天学习笔记下
10.MyBatis参数处理 10.1 项目信息 模块名:mybatis-007-param数据库表:t_student表结构: id: 主键name: 姓名age: 年龄height: 身高sex: 性别birth: 出生日期 sql文件: create table t_student ( id bigint auto_increm…...

三类人解决困境的方法
有一个视频讲述了三类人解决困境的方法,视频中有持续流出干净水源的水龙头,一杯装满脏水的玻璃杯。第一类普通人是拿着玻璃杯放到水龙头下不断接水,水龙头一直开着的第二类高手是把脏水倒到水池里,然后打开水龙头接水,…...

蓝桥杯第十一届省赛C++B组真题解析
蓝桥杯第十一届省赛CB组真题解析 八、回文日期https://www.lanqiao.cn/problems/348/learning 方法一:暴力枚举所有的日期,记录有多少个回文日期。 #include <bits/stdc.h> using namespace std; int month[13]{0,31,28,31,30,31,30,31,31,30,31…...

Tailscale 的工作原理*
Tailscale 的核心原理基于 WireGuard VPN,它实现了端到端加密的 点对点(P2P)连接,但在必要时会通过 中继服务器(DERP) 进行中转。整体来说,它是一个 零配置的 Mesh VPN,让所有设备看…...

PyTorch张量范数计算终极指南:从基础到高阶实战
在深度学习领域,张量范数计算是模型正则化、梯度裁剪、特征归一化的核心技术。本文将以20代码实例,深度剖析torch.norm的9大核心用法,并揭示其在Transformer模型中的关键应用场景。 🚀 快速入门(5分钟掌握核心操作&…...

Innovus DRC Violation和Calibre DRC Violation分析和修复案例
今天把小编昨天帮助社区训练营学员远程协助的一个经典案例分享给大家。希望能够帮助到更多需要帮助的人。如果各位想跟小编来系统学习数字后端设计实现的,可以联系小编。 数字IC后端手把手实战教程 | Innovus verify_drc VIA1 DRC Violation解析及脚本自动化修复方…...
)
数据库7(数据定义语句,视图,索引)
1.数据定义语句 SQL数据定义语言(DDL)用于定义和管理数据库结构,包括创建、修改和删除 数据库对象。常见的DDL语句包括CREATE、DROP和ALTER。 它的操作的是对象,区分操作数据的语句:INSERT,DELETE,UPDATE 示例&#x…...

Cadence 修改 铜和pin脚 连接属性 和 光绘参数修改
光绘层叠设置,参考 光绘参数修改, 中英文对照...

秒杀业务的实现过程
一.后台创建秒杀的活动场次信息,并关联到要秒杀的商品或服务; 二.通过定时任务,将秒杀的活动信息和商品服务信息存储到redis; 三.在商品展示页的显眼位置加载秒杀活动信息; 四.用户参与秒杀,创建订单,将…...
时实时获取 COCO 指标(AP):2025最新配置与代码详解 (小白友好 + B站视频))
✅ Ultralytics YOLO 训练(Train)时实时获取 COCO 指标(AP):2025最新配置与代码详解 (小白友好 + B站视频)
✅ YOLO获取COCO指标(4): 训练(Train)启用COCO API评估(实时监控AP指标)| 发论文必看! | Ultralytics | 小白友好 文章目录 一、问题定位二、原理分析三、解决方案与实践案例步骤 1: 在 model.train() 调用中设置 save_jsonTrue步骤 2: 修改 …...
)
java基础 流(Stream)
Stream Stream 的核心概念核心特点 Stream 的操作分类中间操作(Intermediate Operations)终止操作(Terminal Operations) Stream 的流分类顺序流(Sequential Stream)并行流(Parallel Stream&…...

基于springboot+vue的课程管理系统
一、系统架构 前端:vue | element-ui 后端:springboot | mybatis-plus 环境:jdk1.8 | mysql8 | maven | node v16.20.2 | idea 二、代码及数据 三、功能介绍 01. 登录 02. 管理员-首页 03. 管理员-系管理 04. 管理员-专业管理 05. 管…...

android14 keycode 上报 0 解决办法
驱动改完后发现上报了keycode=0 04-07 13:02:33.201 2323 2662 D WindowManager: interceptKeyTq keycode=0 interactive=false keyguardActive=true policyFlags=2000000 04-07 13:02:33.458 2323 2662 D WindowManager: interceptKeyTq keycode=0 interactive=false key…...

小说现代修仙理论
修仙理论 灵魂感应与感知强化:通过特定的修炼方法,感应自身灵魂,以此提升感知能力,使修炼者对周围环境及自身状态的察觉更为敏锐。 生物电的感知与运用 生物电感知:修炼者需凝神静气,感知体内生物…...

6.综合练习1-创建文件
题目: 分析: 本例中使用mkdirs方法创建aaa文件夹。 题目要求是"在当前模块下的aaa文件夹",此时在左侧的目录中,是没有aaa文件夹的,所以要先创建a.txt文件的父级路径aaa文件夹,由于是在当前模块下…...

PostgreSQL的内存管理机制
目录 V1.0PostgreSQL的内存管理机制文件系统缓存作为二级缓存内存切换机制性能影响总结 V2.0PostgreSQL 内存管理机制:双缓存体系验证与笔记完善1. 现有描述验证2. 完善后的内存管理笔记2.1 双缓存体系2.2 其他关键内存区域2.3 验证方法 3. 注意事项 V1.0 PostgreS…...