Model Context Protocol(MCP)介绍
“Model Context Protocol(MCP)”是近年来在多模态大模型或可扩展智能系统中出现的一个概念,其主要目标是为大模型提供结构化的上下文管理和动态记忆机制。它解决的是在长时间对话、多轮交互、任务切换等复杂情境中,模型如何理解“当前上下文”、保持“长期记忆”以及“模块间协同”的问题。
MCP 的核心是客户端-服务器架构,其中主机应用程序可以连接到多个服务器:
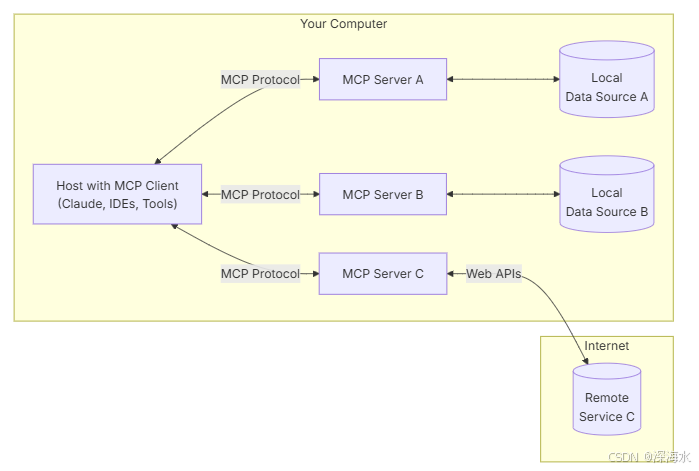
- MCP 主机:希望通过 MCP 访问数据的程序,例如 Claude Desktop、IDE 或 AI 工具
- MCP 客户端:与服务器保持 1:1 连接的协议客户端
- MCP 服务器:轻量级程序,每个程序都通过标准化模型上下文协议公开特定功能
- 本地数据源:MCP 服务器可以安全访问的您的计算机文件、数据库和服务
- 远程服务:MCP 服务器可通过互联网(例如通过 API)连接到的外部系统
一、基本概念
1、MCP 的用途
1. 增强模型对复杂上下文的理解能力
传统大模型在推理或对话中往往只能看到一个有限的上下文窗口(如 GPT-4 最多看到 128k token),但真实世界的任务需要对更长时间、多任务之间的上下文有“语义级的理解和跟踪能力”,比如:
-
用户上个月说了什么目标?
-
当前任务的上文是什么?
-
不同模块之间如何共享上下文?
MCP 就像“上下文操作系统”一样,为模型提供对这些内容的结构化访问能力。
2. 支持模块化智能系统之间的信息共享
比如在一个 Agent 系统中,有:
-
知识模块(Knowledge Module)
-
记忆模块(Memory Module)
-
计划模块(Planner)
-
工具模块(Tools)
这些模块都需要共享“上下文”,但上下文不能是“简单的字符串拼接”,而是结构化、可查询、可更新的上下文状态。MCP 规范了一种统一的“上下文通信协议”,使模块之间能以统一格式访问上下文。
3. 支持长时间任务的“长期记忆”机制
MCP 通常配合向量数据库、长短期记忆分离(如 RAG + Episodic Memory)来使用,实现:
-
记住长期目标(Long-Term Goal)
-
知道过去错误(Avoid Repeat)
-
实现多轮任务的“记忆溯源”
2、MCP 的原理
MCP 并不是一个固定协议,而是一个思想框架 + 一套规范,实现上可以灵活,但基本包含如下关键组成:
1. Context Object(上下文对象)
它定义了上下文的结构化表示方法,一般包括:
{"user_goal": "写一篇关于AI伦理的文章","current_task": "收集相关案例","history": [...], // 对话历史"memory_reference": [...], // 从记忆系统提取的摘要"external_tools": ["WebSearch", "TextAnalyzer"]
}
这部分就像“上下文容器”,可以随时供模型调用、修改。
2. Context Injection(上下文注入)
这是 MCP 的核心机制,指的是将结构化上下文动态注入到模型提示词中(prompt)或输入中,方式包括:
-
明示注入(Prompt Embedding):通过模板将结构化上下文转为文本注入提示词。
-
隐式注入(API控制):通过系统指令(System Prompt)、内存检索等方式动态控制输入。
注入方式通常要结合任务上下文选择:
-
当前对话上下文
-
任务执行上下文
-
用户配置上下文
3. Context Update(上下文更新协议)
模型在交互过程中,需要持续更新上下文状态。比如:
-
当前任务完成后要更新
current_task -
用户改变目标,要更新
user_goal -
模型调用工具后,要更新
tool_usage
MCP 定义一种标准更新操作,例如:
{"action": "update","field": "current_task","value": "撰写案例分析"
}
有些 MCP 系统使用 DSL(领域特定语言)或 JSON-Patch 风格来执行更新。
4. Memory & Retrieval 接口
MCP 通常会集成记忆组件,比如:
-
向量数据库(如 FAISS, Milvus)
-
语义索引(Embedding Search)
-
记忆压缩与摘要(Memory Compression)
用于长时段记忆的查询与更新,作为上下文的延伸。例如:
{"memory_reference": ["你在2023年提到过AI伦理中的‘算法偏见’案例"]
}
5. 上下文权限控制(可选)
在多用户、多任务环境中,MCP 也支持对不同上下文组件设置访问/修改权限,类似于操作系统中的权限控制。
3、实际应用示例
示例1:AI Agent 编排系统(如 LangChain, Autogen)
-
使用 MCP 管理多个 Agent 的上下文
-
每个 Agent 都可以从上下文中读取“当前任务”、“历史对话”等状态
示例2:Copilot 级智能助手
-
在多个应用之间切换任务
-
MCP 保持用户意图、历史文件、执行路径等状态
示例3:多模态 Agent(如 Vision + Text)
-
MCP 同时管理视觉上下文(图片、检测结果)和语言上下文(描述、指令)
4、MCP 与传统 Prompt Engineering 的区别
| 项目 | Prompt Engineering | Model Context Protocol |
|---|---|---|
| 上下文结构 | 非结构化(文本拼接) | 结构化(JSON/对象) |
| 适应复杂系统 | 较弱 | 很强 |
| 支持多模块协作 | 基本无 | 支持模块级共享 |
| 支持长期记忆 | 限制较多 | 强力支持 |
| 更新机制 | 静态 | 支持动态更新 |
| 可扩展性 | 有限 | 高度可扩展 |
5、总结
Model Context Protocol(MCP)是未来通用人工智能系统的重要基础能力之一。 它通过结构化上下文管理、动态注入与更新机制、模块协作协议等方式,极大提升了模型在复杂任务中的适应性和记忆能力。可以说,它是“让大模型成为真正智能体(Agent)”的关键一环。
二、简化版Demo
简化版 MCP 框架 demo,基于 Python 实现,用于模拟一个智能体(Agent)系统的上下文管理、更新和注入机制。
这个 demo 会包含:
-
上下文对象
ContextObject -
上下文注入机制(将结构化数据转为提示)
-
上下文更新机制(支持动态修改)
-
模拟一个智能体调用过程(简单任务执行 + 上下文使用)
1、 第一版 Demo:Minimal Model Context Protocol(MCP)
👇 功能说明:
-
使用 JSON 结构维护上下文
-
支持上下文注入成提示(Prompt)
-
支持更新上下文字段
-
模拟一个 Agent 根据上下文生成动作
📦 Python 代码
import json
from typing import Any, Dictclass ContextObject:def __init__(self):# 初始化一个简单上下文结构self.context = {"user_goal": "写一篇关于AI伦理的文章","current_task": "收集相关案例","history": [],"memory_reference": [],"tools": ["WebSearch"]}def inject_prompt(self) -> str:# 把结构化上下文转为模型可理解的提示(prompt)prompt = f"""你是一个智能助手,当前任务如下:用户目标:{self.context["user_goal"]}
当前任务:{self.context["current_task"]}
历史交互:{'; '.join(self.context['history']) or '无'}
相关记忆参考:{'; '.join(self.context['memory_reference']) or '无'}
可用工具:{', '.join(self.context['tools']) or '无'}请根据这些上下文,执行当前任务的下一步,并输出行动建议。
"""return promptdef update(self, field: str, value: Any):if field in self.context:self.context[field] = valueelse:print(f"[警告] 字段 '{field}' 不存在,更新失败。")def add_history(self, entry: str):self.context["history"].append(entry)def add_memory(self, memory: str):self.context["memory_reference"].append(memory)def get_context(self) -> Dict[str, Any]:return self.context# 模拟一个 Agent 的行为
def agent_run(context: ContextObject):prompt = context.inject_prompt()print("=== 注入 Prompt ===")print(prompt)# 假设模型给出一个响应response = "建议搜索近几年AI伦理争议的案例,如Clearview AI、ChatGPT偏见问题等。"print("=== Agent 响应 ===")print(response)# 更新上下文(模拟记录行为)context.add_history("执行任务:搜索AI伦理案例 -> 得到建议 Clearview AI, ChatGPT偏见")context.update("current_task", "撰写案例分析")# === 执行 Demo ===
if __name__ == "__main__":ctx = ContextObject()agent_run(ctx)print("\n=== 更新后上下文 ===")print(json.dumps(ctx.get_context(), indent=2, ensure_ascii=False))
🧪 运行结果(简化输出)
=== 注入 Prompt ===
你是一个智能助手,当前任务如下:
用户目标:写一篇关于AI伦理的文章
当前任务:收集相关案例
历史交互:无
相关记忆参考:无
可用工具:WebSearch
...=== Agent 响应 ===
建议搜索近几年AI伦理争议的案例,如Clearview AI、ChatGPT偏见问题等。=== 更新后上下文 ===
{"user_goal": "写一篇关于AI伦理的文章","current_task": "撰写案例分析","history": ["执行任务:搜索AI伦理案例 -> 得到建议 Clearview AI, ChatGPT偏见"],"memory_reference": [],"tools": ["WebSearch"]
}
2、扩展版 Model Context Protocol(MCP)
我们在之前的 MCP 框架基础上,新增以下特性:
-
支持多任务栈 📌
-
允许管理多个子任务(Task Stack),并可动态调整优先级。
-
-
上下文规则引擎 ⚙️
-
任务完成后,自动触发下一个任务。
-
任务关键字匹配到历史数据时,自动关联记忆。
-
-
Agent 工具调用模拟 🔧
-
允许智能体(Agent)调用外部工具,例如
WebSearch、TextAnalyzer等。
-
📦 代码实现
我会直接将这些功能集成到一个可扩展的 MCP 框架中。
import json
from typing import Any, Dict, Listclass ContextObject:def __init__(self):self.context = {"user_goal": "写一篇关于AI伦理的文章","task_stack": ["收集相关案例"], # 任务栈,支持多任务"history": [],"memory_reference": [],"tools": ["WebSearch", "TextAnalyzer"]}def inject_prompt(self) -> str:current_task = self.context["task_stack"][0] if self.context["task_stack"] else "无任务"prompt = f"""你是一个智能助手,当前任务如下:\n用户目标:{self.context["user_goal"]}
当前任务:{current_task}
历史交互:{'; '.join(self.context['history']) or '无'}
相关记忆参考:{'; '.join(self.context['memory_reference']) or '无'}
可用工具:{', '.join(self.context['tools']) or '无'}
\n请根据这些上下文,执行当前任务的下一步,并输出行动建议。
"""return promptdef update_task(self, new_task: str, append: bool = True):if append:self.context["task_stack"].append(new_task)else:self.context["task_stack"][0] = new_taskdef complete_task(self):if self.context["task_stack"]:completed = self.context["task_stack"].pop(0)self.context["history"].append(f"完成任务:{completed}")def add_memory(self, memory: str):self.context["memory_reference"].append(memory)def get_context(self) -> Dict[str, Any]:return self.context# 智能 Agent 运行模拟
def agent_run(context: ContextObject):prompt = context.inject_prompt()print("=== 注入 Prompt ===")print(prompt)# 假设模型给出响应response = "建议搜索近几年AI伦理争议的案例,如Clearview AI、ChatGPT偏见问题等。"print("=== Agent 响应 ===")print(response)# 任务完成,更新上下文context.complete_task()context.update_task("撰写案例分析")# === 运行 MCP Demo ===
if __name__ == "__main__":ctx = ContextObject()agent_run(ctx)print("\n=== 更新后上下文 ===")print(json.dumps(ctx.get_context(), indent=2, ensure_ascii=False))
3、增强上下文匹配
增强了上下文匹配:
-
新增
retrieve_relevant_memories方法,基于任务关键词匹配相关记忆。 -
改进 Prompt 生成,自动注入匹配的记忆数据,提高上下文相关性。
-
添加示例记忆数据,可自动关联到当前任务。
import json
from typing import Any, Dict, Listclass ContextObject:def __init__(self):self.context = {"user_goal": "写一篇关于AI伦理的文章","task_stack": ["收集相关案例"], # 任务栈,支持多任务"history": [],"memory_reference": [],"tools": ["WebSearch", "TextAnalyzer"]}def inject_prompt(self) -> str:current_task = self.context["task_stack"][0] if self.context["task_stack"] else "无任务"relevant_memories = self.retrieve_relevant_memories(current_task)prompt = f"""你是一个智能助手,当前任务如下:\n用户目标:{self.context["user_goal"]}
当前任务:{current_task}
历史交互:{'; '.join(self.context['history']) or '无'}
相关记忆参考:{'; '.join(relevant_memories) or '无'}
可用工具:{', '.join(self.context['tools']) or '无'}
\n请根据这些上下文,执行当前任务的下一步,并输出行动建议。
"""return promptdef update_task(self, new_task: str, append: bool = True):if append:self.context["task_stack"].append(new_task)else:self.context["task_stack"][0] = new_taskdef complete_task(self):if self.context["task_stack"]:completed = self.context["task_stack"].pop(0)self.context["history"].append(f"完成任务:{completed}")def add_memory(self, memory: str):self.context["memory_reference"].append(memory)def retrieve_relevant_memories(self, task: str) -> List[str]:# 简单关键词匹配,从记忆中检索相关内容return [mem for mem in self.context["memory_reference"] if task in mem]def get_context(self) -> Dict[str, Any]:return self.context# 智能 Agent 运行模拟
def agent_run(context: ContextObject):prompt = context.inject_prompt()print("=== 注入 Prompt ===")print(prompt)# 假设模型给出响应response = "建议搜索近几年AI伦理争议的案例,如Clearview AI、ChatGPT偏见问题等。"print("=== Agent 响应 ===")print(response)# 任务完成,更新上下文context.complete_task()context.update_task("撰写案例分析")# === 运行 MCP Demo ===
if __name__ == "__main__":ctx = ContextObject()ctx.add_memory("AI伦理相关案例:Clearview AI 隐私问题")ctx.add_memory("ChatGPT 可能存在偏见")agent_run(ctx)print("\n=== 更新后上下文 ===")print(json.dumps(ctx.get_context(), indent=2, ensure_ascii=False))
三、Model Context Protocol(MCP)服务器概述
MCP 服务器(MCP Server)是 Model Context Protocol 的核心组件之一,主要用于在多智能体(Agent)或 AI 模型之间管理和共享上下文(Context)。它可以作为一个 上下文管理系统(CMS),确保所有交互、任务和知识都能被有效存储、检索和更新。
1、MCP 服务器的核心功能
MCP 服务器通常具备以下功能:
-
存储与管理上下文
-
维护多个用户的上下文状态(如当前任务、历史记录、记忆库)。
-
提供 层级化的上下文管理(全局上下文、任务级上下文、用户级上下文)。
-
-
上下文检索 & 关联
-
通过 向量数据库(FAISS, ChromaDB) 存储长时记忆,并根据语义匹配检索相关记忆。
-
提供基于关键词或语义的快速匹配机制,确保 AI 访问最相关的信息。
-
-
任务 & 计划管理
-
维护一个 任务栈(Task Stack),支持任务的优先级调度、分配和回溯。
-
实现 自动任务推进机制(如当前任务完成后,自动推进到下一个任务)。
-
-
与 AI 模型交互
-
提供 API 让外部 AI 注入上下文 并请求新的任务规划。
-
支持与 OpenAI GPT、Llama、Claude、Gemini 等 LLM 交互,并优化提示词。
-
-
多 Agent 共享上下文
-
允许多个智能体(AI 代理)共享上下文,共同完成复杂任务(如 AutoGPT、BabyAGI)。
-
提供 ACL(访问控制) 机制,确保不同 Agent 只能访问相应的数据。
-
2、MCP 服务器架构设计
MCP 服务器通常采用 REST API 或 WebSocket 方式,允许智能体与其交互。一个典型的 MCP 服务器架构如下:
+--------------------------------------------------+
| MCP 服务器 |
+--------------------------------------------------+
| API 层: RESTful API / WebSocket |
| - /context/get -> 获取当前上下文 |
| - /context/update -> 更新上下文 |
| - /task/next -> 获取下一个任务 |
| - /memory/search -> 语义检索记忆 |
| - /tools/call -> 代理工具调用 |
+--------------------------------------------------+
| 上下文管理层 |
| - 长期记忆(向量数据库 FAISS, ChromaDB) |
| - 任务队列(Task Stack) |
| - 交互历史(历史上下文) |
+--------------------------------------------------+
| 存储层 |
| - Redis / PostgreSQL / MongoDB / SQLite |
+--------------------------------------------------+
3、MCP 服务器代码示例
下面是一个 基于 FastAPI 的 MCP 服务器,支持基本的 上下文管理和任务调度。
📦 安装依赖
pip install fastapi uvicorn chromadb
📜 MCP Server 代码
from fastapi import FastAPI
from pydantic import BaseModel
from typing import List, Dict
import chromadb# 初始化 FastAPI 服务器
app = FastAPI()# 初始化向量数据库(ChromaDB 用于存储长期记忆)
chroma_client = chromadb.PersistentClient(path="./mcp_memory")
memory_collection = chroma_client.get_or_create_collection(name="memory_store")# 存储上下文信息
context_store = {"user_goal": "写一篇关于AI伦理的文章","task_stack": ["收集相关案例"],"history": [],"tools": ["WebSearch", "TextAnalyzer"]
}# 任务数据模型
class TaskUpdate(BaseModel):new_task: strappend: bool = True# 记忆存储模型
class MemoryInput(BaseModel):memory_text: str# 获取当前上下文
@app.get("/context/get")
def get_context():return context_store# 更新任务
@app.post("/task/update")
def update_task(task: TaskUpdate):if task.append:context_store["task_stack"].append(task.new_task)else:context_store["task_stack"][0] = task.new_taskreturn {"status": "success", "updated_task_stack": context_store["task_stack"]}# 完成任务
@app.post("/task/complete")
def complete_task():if context_store["task_stack"]:completed = context_store["task_stack"].pop(0)context_store["history"].append(f"完成任务:{completed}")return {"status": "success", "remaining_tasks": context_store["task_stack"]}# 存储记忆
@app.post("/memory/add")
def add_memory(memory: MemoryInput):memory_collection.add(ids=[str(len(context_store["history"]))], documents=[memory.memory_text])return {"status": "success", "stored_memory": memory.memory_text}# 语义检索相关记忆
@app.get("/memory/search")
def search_memory(query: str):results = memory_collection.query(query_texts=[query], n_results=3)return {"status": "success", "related_memories": results["documents"]}# 运行 FastAPI 服务器
if __name__ == "__main__":import uvicornuvicorn.run(app, host="0.0.0.0", port=8000)
4、MCP 服务器的用法
启动服务器后,可以使用 curl 或 Postman 进行 API 调用:
📌 1. 获取当前上下文
curl http://127.0.0.1:8000/context/get
📌 2. 更新任务
curl -X POST "http://127.0.0.1:8000/task/update" -H "Content-Type: application/json" \-d '{"new_task": "撰写案例分析", "append": true}'
📌 3. 完成任务
curl -X POST "http://127.0.0.1:8000/task/complete"
📌 4. 添加记忆
curl -X POST "http://127.0.0.1:8000/memory/add" -H "Content-Type: application/json" \-d '{"memory_text": "AI伦理相关案例:Clearview AI 隐私问题"}'
📌 5. 检索相关记忆
curl "http://127.0.0.1:8000/memory/search?query=AI伦理"
四、MCP 服务器如何与 Claude一起使用
MCP(Model Context Protocol)服务器要与 Claude(Anthropic 的大模型)配合使用,本质上是:
✅ 由 MCP 服务器管理上下文、任务、记忆等结构性数据,生成 Prompt,Claude 只负责语言理解和生成。
1、Claude + MCP 协作原理图:
+--------------------------+ +-----------------------------+
| 用户/Agent | | Claude(LLM) |
+--------------------------+ +-----------------------------+| 提问/请求 ↑|---------------------------------->|| || 响应建议/文本 ||<----------------------------------|| |↓ ↑
+---------------------------+ +-------------------------------+
| MCP 服务器 |<---->| Claude Prompt Injection |
|(存上下文+任务+记忆+历史)| |(自动组装 Prompt 给 Claude) |
+---------------------------+ +-------------------------------+
2、实践:Claude + MCP 流程步骤
✅ Step 1:从 MCP 获取上下文 + 任务 + 记忆
你通过 MCP Server 提供的 API,比如:
# 从 MCP 获取当前上下文
resp = requests.get("http://localhost:8000/context/get").json()
返回内容可能是:
{"user_goal": "写一篇关于AI伦理的文章","task_stack": ["收集相关案例"],"history": ["完成任务:明确写作主题"],"memory_reference": ["Clearview AI 面部识别争议"],"tools": ["WebSearch"]
}
✅ Step 2:MCP 构建 Claude Prompt
用这些信息构建 prompt:
def build_prompt(context: dict) -> str:return f'''
你是一个AI助手,当前需要协助完成以下任务:🧭 用户目标:{context["user_goal"]}
📌 当前任务:{context["task_stack"][0] if context["task_stack"] else "无"}
🕓 历史记录:{"; ".join(context["history"]) or "无"}
🧠 相关记忆:{"; ".join(context["memory_reference"]) or "无"}
🔧 可用工具:{", ".join(context["tools"]) or "无"}请基于上述上下文,给出下一步建议或直接行动结果。
'''.strip()
✅ Step 3:发送请求到 Claude
Claude 目前的 API 调用方式如下(以 anthropic Python SDK 为例):
from anthropic import Anthropicclient = Anthropic(api_key="your-api-key")response = client.messages.create(model="claude-3-opus-20240229", # 或 claude-3-sonnet, claude-3-haikumax_tokens=1024,temperature=0.7,messages=[{"role": "user", "content": build_prompt(context)}]
)print(response.content[0].text) # Claude 的回复内容
✅ 整合代码示意
import requests
from anthropic import Anthropic# Step 1: 获取上下文
context = requests.get("http://localhost:8000/context/get").json()# Step 2: 构建 Prompt
def build_prompt(context):return f'''
你是一个AI助手,当前需要协助完成以下任务:🧭 用户目标:{context["user_goal"]}
📌 当前任务:{context["task_stack"][0] if context["task_stack"] else "无"}
🕓 历史记录:{"; ".join(context["history"]) or "无"}
🧠 相关记忆:{"; ".join(context["memory_reference"]) or "无"}
🔧 可用工具:{", ".join(context["tools"]) or "无"}请基于上述上下文,给出下一步建议或直接行动结果。
'''.strip()# Step 3: 调用 Claude
client = Anthropic(api_key="your-api-key")
response = client.messages.create(model="claude-3-sonnet-20240229",max_tokens=1024,temperature=0.7,messages=[{"role": "user", "content": build_prompt(context)}]
)print("Claude 回复:", response.content[0].text)
3、Claude + MCP 优点
| 特性 | 说明 |
|---|---|
| 📚 长期记忆支持 | MCP Server 可持久化记忆、任务状态,弥补 Claude 本身不记忆历史的短板。 |
| 🔀 多智能体共享 | 多个 Claude 实例或 Agent 可共享 MCP 上下文。 |
| 🧠 上下文增强推理 | MCP 可以筛选最相关的记忆和任务背景,提高 Claude 输出的相关性。 |
| 🧱 模块化解耦 | Claude 专注语言生成,MCP 管理认知流程,可热插拔组合其他模型。 |
4、可选进阶集成方向
-
✅ Claude + LangChain + MCP:LangChain 用于统一模型接口,Claude 扮演 Agent。
-
✅ Claude + 自动任务循环(AutoClaude):自动推进任务栈,形成完整的 Agent 工作流。
-
✅ Claude + 工具插件:Claude 产生的 action 被 MCP 拆解调用工具,如 WebSearch、SQL 查询等。
五、在开发工具中使用MCP
在开发工具中使用 MCP(Model Context Protocol)主要目的是为构建更智能、更模块化的开发环境提供支持,使得各种开发工具(如 IDE 插件、调试工具、代码生成器等)可以借助结构化的上下文管理,实现以下目标:
1、上下文管理与集成
-
统一状态管理:MCP 可以把项目的状态、历史交互记录、任务列表、以及相关文档、代码片段等作为结构化数据存储在上下文中。这样在开发工具中,比如代码编辑器或调试器,就能自动读取这些信息,帮助开发者更快定位问题或理解项目状态。
-
跨工具共享上下文:在一个大型项目中,开发、测试、调试、部署工具之间共享同一份上下文数据,可以保证各个模块间信息的一致性和连贯性。例如,一个代码生成器可以从 MCP 提取当前任务和历史交互,然后自动生成相应的代码模板。
2、智能提示与任务管理
-
智能补全与提示:利用 MCP 维护的上下文信息(例如最近的代码修改记录、错误日志、任务描述等),开发工具能够在编辑器中为开发者提供更精准的代码补全、错误诊断和调试建议。
-
任务调度与提醒:MCP 服务器管理的任务栈可以被集成到开发环境中,自动提醒开发者当前需要完成的任务或建议下一步行动。比如在 IDE 的侧边栏展示当前任务、历史记录和关联文档,帮助开发者保持专注并有条不紊地推进项目进程。
3、多模块协同开发
-
模块化开发:通过 MCP 协议,各个开发工具可以采用统一的接口来访问和更新上下文数据。这种方式类似于“上下文操作系统”,它将代码、文档、调试信息等拆分为不同模块,便于团队协同工作,减少信息孤岛。
-
自动化工作流:MCP 可以作为一个中央协调者,驱动工具链中的自动化任务。例如,当调试工具检测到某个异常时,可以自动调用文档生成器更新代码文档;或者触发 CI/CD 流程,根据当前上下文信息自动部署最新版本。
4、开发与测试支持
-
快速原型构建:借助 MCP 提供的上下文注入机制,开发者可以快速构建原型工具,例如自动生成测试用例、构建代码片段或执行静态代码分析,所有这些都可以依赖于 MCP 动态构造的上下文数据。
-
历史记录与追踪:在开发工具中集成 MCP 能够记录项目的每一次交互与更新,使得项目演进过程透明化,有助于后续调试、代码审查和团队协作。
5、实际应用场景示例
示例 1:智能 IDE 插件
-
功能:插件利用 MCP 从项目上下文中获取当前开发任务、最近的错误日志和相关代码片段,然后基于这些数据自动生成调试建议或代码补全。
-
工作流程:
-
插件调用 MCP API 获取当前上下文。
-
构建 Prompt 并调用内嵌的 AI 模型(如 Claude 或 GPT)。
-
将生成的建议直接展示在编辑器中。
-
示例 2:自动化测试与部署工具
-
功能:自动收集项目中的测试结果和日志,将这些信息存入 MCP 中,然后根据上下文判断是否触发部署流程。
-
工作流程:
-
测试工具将错误记录和性能指标更新到 MCP 上下文中。
-
部署工具从 MCP 检索相关信息,确定是否满足自动部署的条件。
-
自动化任务引擎根据上下文信息执行下一步操作。
-
5、总结
在开发工具中引入 MCP 能够:
-
提升开发效率:通过结构化的上下文管理和任务调度,开发者可以更快地获取关键信息和提示。
-
实现跨工具协同:统一的上下文数据为不同开发模块和工具之间的信息共享提供了可靠基础。
-
支持智能化功能:依托 AI 模型的上下文增强推理,开发工具能自动生成代码、建议调试方案,并且持续优化开发流程。
这种方式不仅能提高单个开发工具的智能化程度,还能通过 MCP 将整个开发生态系统串联起来,使得团队协作和项目管理更加高效和一致。
六、配置开发工具使用MCP
下面将用一个真实可复现的例子,说明 如何在开发工具(如 VS Code)中配置 MCP(Model Context Protocol)并实际使用它。本例中你将看到:
1、整体目标:
我们将在 VS Code 中构建一个“AI 智能任务辅助插件”,通过 MCP 获取当前开发任务、历史记录、代码片段,并利用 Claude 生成代码建议。
2、MCP 服务端准备
安装并运行 MCP Server
可以选择使用一个轻量级的 Python Flask 实现来快速启动 MCP 服务器:
git clone https://github.com/ContextualComputing/mcp.git
cd mcp
pip install -r requirements.txt
python app.py
此时 MCP 监听在 http://localhost:8000,你可以通过 API 读写:
-
获取当前上下文:
GET /context -
添加任务栈:
POST /task -
添加历史记录:
POST /history -
获取记忆片段:
GET /memory
3、VS Code 中配置 MCP 集成
可以通过以下 2 种方式将 MCP 集成进开发环境:
✅ 方法 1:使用 VS Code 插件 + HTTP 请求(推荐)
安装推荐插件:
-
REST Client 插件:可发送 HTTP 请求到 MCP
-
CodeGPT(或你自制的 Claude 插件):接入 AI 模型,使用 Prompt
示例文件 .vscode/mcp.http:
### 获取当前上下文
GET http://localhost:8000/context### 追加开发任务
POST http://localhost:8000/task
Content-Type: application/json{"task": "实现用户登录功能"
}### 添加历史记录
POST http://localhost:8000/history
Content-Type: application/json{"entry": "已完成数据库连接模块"
}
右键点击 .http 文件里的命令,直接发送请求管理上下文。
✅ 方法 2:通过脚本(Node.js / Python)对接 Claude + MCP
创建脚本 suggest_from_context.py:
import requests
from anthropic import Anthropic# Step 1: 从 MCP 获取上下文
ctx = requests.get("http://localhost:8000/context").json()# Step 2: 构建 Prompt
prompt = f"""
你是开发者助手。当前任务是:{ctx.get('task_stack', [''])[0]}。
历史记录包括:{";".join(ctx.get("history", []))}。
请根据任务,给出代码实现建议。
"""# Step 3: 调用 Claude(或 GPT)
client = Anthropic(api_key="你的API密钥")
resp = client.messages.create(model="claude-3-sonnet-20240229",max_tokens=1024,messages=[{"role": "user", "content": prompt}]
)
print(resp.content[0].text)
然后在 VS Code 里绑定快捷键,或者通过命令面板运行该脚本,即可基于 MCP 上下文获得 AI 建议。
4、使用场景示例
🌟 场景 1:代码智能建议
写到一半的代码不确定函数设计是否合理,点击一个按钮就能让 Claude 基于 MCP 里的“当前任务”和“历史内容”给出建议。
🌟 场景 2:自动任务追踪
当运行调试工具或测试完成时,VS Code 执行脚本将任务进展自动追加进 MCP 的 history,保持任务上下文完整。
🌟 场景 3:多人协作共享上下文
MCP 可以放在局域网服务器上,不同开发者通过插件/脚本共享任务栈、历史记录等,提高团队协同效率。
5、总结
| 步骤 | 内容 |
|---|---|
| ✅ 1 | 启动 MCP 服务器(Python/Flask) |
| ✅ 2 | VS Code 中使用 REST Client 插件或脚本发送请求 |
| ✅ 3 | 调用 Claude / GPT,根据 MCP 上下文生成代码建议 |
| ✅ 4 | 可扩展:自动更新任务、持久化开发记录、团队共享上下文 |
相关文章:
介绍)
Model Context Protocol(MCP)介绍
“Model Context Protocol(MCP)”是近年来在多模态大模型或可扩展智能系统中出现的一个概念,其主要目标是为大模型提供结构化的上下文管理和动态记忆机制。它解决的是在长时间对话、多轮交互、任务切换等复杂情境中,模型如何理解“…...

解决使用PendingIntent.getBroadcast时出现java.lang.IllegalArgumentException异常的问题
当app为targetSdk31及以上,并且在Android12及以上系统中调用PendingIntent.getBroadcast(context, 0, intent, 0)接口时会抛出异常: java.lang.IllegalArgumentException: com.haier.uhome.uplus.seasia: Targeting S (version 31 and above) requires …...

创建一个简单的HTML游戏站
创建一个简单的HTML游戏站涉及多个步骤,包括规划网站结构、设计用户界面、编写游戏逻辑以及测试和部署。下面是一个详细的步骤指南: 1. 规划网站结构 确定目标受众:了解你的目标用户群体。选择游戏类型:决定你要开发的游戏类型&…...

AIDD-人工智能药物设计-TCMP-12个公开的中药数据库
12个公开的中药数据库 数据库是中药网络药理学研究不可或缺的数据来源之一。目前已经建立了若干中药数据库,提供有关中药的各方面信息,包括疾病、方剂、草药或天然产物、生物活性成分和靶点。这些数据库成为中医药与现代生物医学之间的桥梁,…...

基于大模型的阵发性室上性心动过速风险预测与治疗方案研究
目录 一、引言 1.1 研究背景与意义 1.2 研究目的与目标 1.3 研究方法与数据来源 二、阵发性室上性心动过速概述 2.1 定义与分类 2.2 发病机制与流行病学 2.3 临床表现与诊断方法 三、大模型在阵发性室上性心动过速预测中的应用 3.1 大模型技术原理与特点 3.2 模型构…...

基于金字塔视觉变换的类引导网络高分辨率遥感图像高效语义分割
Class-Guidance Network Based on the Pyramid Vision Transformer for Efficient Semantic Segmentation of High-Resolution Remote Sensing Images 摘要 多分类语义分割中类之间的小差异和类内的大变化是全卷积神经网络的“编码器-解码器”结构没有完全解决的问题&#…...

高级:数据库面试题全攻略
一、引言 数据库是软件开发中不可或缺的组件,面试官通过相关问题,考察候选人对数据库核心概念的理解、实际应用能力以及在复杂场景下的问题解决能力。本文将深入解读数据库的索引、事务、锁机制等常见面试问题,结合实际开发场景,…...

如何避免Python爬虫重复抓取相同页面?
在网络爬虫开发过程中,重复抓取相同页面是一个常见但必须解决的问题。重复抓取不仅会浪费网络带宽和计算资源,降低爬虫效率,还可能导致目标网站服务器过载,甚至触发反爬机制。本文将深入探讨Python爬虫中避免重复抓取的多种技术方…...

LeetCode.02.04.分割链表
分割链表 给你一个链表的头节点 head 和一个特定值 x ,请你对链表进行分隔,使得所有 小于 x 的节点都出现在 大于或等于 x 的节点之前。 你不需要 保留 每个分区中各节点的初始相对位置。 示例 1: 输入:head [1,4,3,2,5,2], x …...

鸿蒙开发_ARKTS快速入门_语法说明_渲染控制---纯血鸿蒙HarmonyOS5.0工作笔记012
然后我们再来看渲染控制 首先看条件渲染,其实就是根据不同的状态,渲染不同的UI界面 比如下面这个暂停 开启播放的 可以看到就是通过if 这种条件语句 修改状态变量的值 然后我们再来看这个, 下面点击哪个,上面横线就让让他显示哪个 去看一下代码 可以看到,有两个状态变量opt…...

MOP数据库中的EXPLAIN用法
EXPLAIN 是 SQL 中的一个非常有用的工具,主要用于分析查询语句的执行计划。执行计划能展示数据库在执行查询时的具体操作步骤,像表的读取顺序、使用的索引情况、数据的访问方式等,这有助于我们对查询性能进行优化。 语法 不同的数据库系统&…...

软考 系统架构设计师系列知识点 —— 设计模式之抽象工厂模式
本文内容参考: 软考 系统架构设计师系列知识点之设计模式(2)_系统架构设计师中考设计模式吗-CSDN博客 https://baike.baidu.com/item/%E6%8A%BD%E8%B1%A1%E5%B7%A5%E5%8E%82%E6%A8%A1%E5%BC%8F/2361182 特此致谢! Abstract Fac…...

告别水下模糊!SU-YOLO:轻量化+尖峰神经网络,用“类脑计算”实现水下目标毫秒级识别
目录 一、摘要 二、引言 三、相关工作 SNN 物体检测 水下物体探测 水下图像去噪 归一化 四、方法 水下尖峰YOLO 尖峰干扰器 SU-Block SpikeSPP 编码器和检测头 分批归一化 五、Coovally AI模型训练与应用平台 六、实验结果 数据集和实施细节 数据集 实施细节…...

Three.js 系列专题 8:实战项目 - 构建一个小型 3D 游戏
内容概述 本专题将通过一个实战项目展示 Three.js 的综合应用。游戏包含迷宫生成、角色移动、相机控制和简单的物理碰撞检测(可选)。这将帮助你将之前学到的知识融会贯通。 学习目标 整合几何体、光照、动画和交互知识。实现基本的游戏逻辑和用户控制。可选:使用 Cannon.j…...
)
嵌入式笔试(一)
C语言和嵌入式软件 面试题(共10题 时间30分钟) 1. 请写出下面声明的含义。 int(*s[10])(int);定义了一个数组为s包含十个元素,每个元素都是函数指针,函数的参数为一个int类型,返回值也是int类型2. 选择题 设有一台计算机,它有一条加法指令,每次可计算三个数的和。如果要…...

spark 的流量统计案例
创建一个目录为data...

局域网访问 Redis 方法
局域网访问 Redis 方法 默认情况下,Redis 只允许本机 (127.0.0.1) 访问。如果你想让局域网中的其他设备访问 Redis,需要 修改 Redis 配置,并确保 防火墙放行端口。 方法 1:修改 Redis 配置 1. 修改 redis.conf(或 me…...

LeetCode题五:合并两个有序链表
基本思路其实就是:先建立一个空链表,然后将尾节点放在头结点上; 如果第一个链表节点值较小,那么先将list1插入新链表中,然后将尾节点后移;相同的,第二个也需要比较;移动新链表的指针…...

深入探索 `malloc`:内存分配失败的原因及正确使用规范
文章目录 一、malloc 内存分配失败的常见原因1. 内存不足2. 内存越界访问3. 内存碎片化4. 系统限制5. 错误的使用方式 二、如何正确使用 malloc1. 检查返回值2. 释放内存3. 避免内存越界4. 优化内存使用5. 调整系统参数6. 使用高效的内存分配器 三、总结 在 C 语言中࿰…...

处理Excel的python库openpyxl、xlrd、xlwt、panda区别
openpyxl、xlrd、xlwt、pandas 都能处理 Excel 表格,但用途和适合的场景不同。今天做个总结: 库名功能支持格式读写支持样式备注openpyxl全面的.xlsx处理库.xlsx(Excel2007)✅✅✅首选xlrd读取.xls文件的老牌工具.xls(…...

【C++11】特殊类的设计 单例模式 类型转换
目录 一、特殊类的设计: 1、设计一个不能够拷贝的类: 2、设计一个只能在堆上创建的类 3、设计一个只能在栈上创建的类 4、设计一个不能被继承的类: 二、单例模式: 设计一个只能创建一个对象的类: 饿汉模式&…...
带论文文档1万字以上,文末可获取,系统界面在最后面。)
基于vue框架的助农特色农产品销售系统i7957(程序+源码+数据库+调试部署+开发环境)带论文文档1万字以上,文末可获取,系统界面在最后面。
系统程序文件列表 项目功能:用户,商品分类,农产品信息,特价商品,爱心捐赠 开题报告内容 基于Vue框架的助农特色农产品销售系统开题报告 一、研究背景与意义 (一)研究背景 随着乡村振兴战略的深入实施,特色农产品作为农村经济的重要组成部…...
:ls 命令深入剖析与实践应用(期末、期中复习必备))
Linux 学习笔记(3):ls 命令深入剖析与实践应用(期末、期中复习必备)
前言 一、ls 命令基础语法 命令示例 二、工作目录与 HOME 目录 1.工作目录 2.HOME 目录 三、结语 前言 在 Linux 系统的学习旅程中,基础命令的掌握是迈向熟练操作的关键一步。其中,ls 命令作为我们探索系统文件和目录结构的常用工具,有着…...

最简CNN based RNN源码
1.源码: GitCode - 全球开发者的开源社区,开源代码托管平台 最终的效果: 数据集是20个周期,1024点sin(x)加了偏置。其中用于训练的有1024-300点。最后300点用来进行测试。上面的右侧输出的,其实对应左侧x73之后的波形࿰…...

大模型是如何把向量解码成文字输出的
hidden state 向量 当我们把一句话输入模型后,例如 “Hello world”: token IDs: [15496, 995]经过 Embedding Transformer 层后,会得到每个 token 的中间表示,形状为: hidden_states: (batch_size, seq_len, hidd…...

Elasticsearch:加快 HNSW 图的合并速度
作者:来自 Elastic Thomas Veasey 及 Mayya Sharipova 过去,我们曾讨论过搜索多个 HNSW 图时所面临的一些挑战,以及我们是如何缓解这些问题的。当时,我们也提到了一些计划中的改进措施。本文正是这项工作的成果汇总。 你可能会问…...

Elasticsearch单节点安装手册
Elasticsearch单节点安装手册 以下是一份 Elasticsearch 单节点搭建手册,适用于 Linux 系统(如 CentOS/Ubuntu),供学习和测试环境使用。 Elasticsearch 单节点搭建手册 1. 系统要求 操作系统:Linux(Cent…...

前端用户列表与后端分页协同设计
分页实现方案 在现代Web应用中,用户列表展示与分页是一个常见的功能需求。前端与后端通过API协同工作,使用PageHelper等工具实现高效分页。 例如: 后端实现 (使用PageHelper) public PageResult DishPage(DishPageQueryDTO dishPageQuery…...

MyBatis的第四天学习笔记下
10.MyBatis参数处理 10.1 项目信息 模块名:mybatis-007-param数据库表:t_student表结构: id: 主键name: 姓名age: 年龄height: 身高sex: 性别birth: 出生日期 sql文件: create table t_student ( id bigint auto_increm…...

三类人解决困境的方法
有一个视频讲述了三类人解决困境的方法,视频中有持续流出干净水源的水龙头,一杯装满脏水的玻璃杯。第一类普通人是拿着玻璃杯放到水龙头下不断接水,水龙头一直开着的第二类高手是把脏水倒到水池里,然后打开水龙头接水,…...

蓝桥杯第十一届省赛C++B组真题解析
蓝桥杯第十一届省赛CB组真题解析 八、回文日期https://www.lanqiao.cn/problems/348/learning 方法一:暴力枚举所有的日期,记录有多少个回文日期。 #include <bits/stdc.h> using namespace std; int month[13]{0,31,28,31,30,31,30,31,31,30,31…...

Tailscale 的工作原理*
Tailscale 的核心原理基于 WireGuard VPN,它实现了端到端加密的 点对点(P2P)连接,但在必要时会通过 中继服务器(DERP) 进行中转。整体来说,它是一个 零配置的 Mesh VPN,让所有设备看…...

PyTorch张量范数计算终极指南:从基础到高阶实战
在深度学习领域,张量范数计算是模型正则化、梯度裁剪、特征归一化的核心技术。本文将以20代码实例,深度剖析torch.norm的9大核心用法,并揭示其在Transformer模型中的关键应用场景。 🚀 快速入门(5分钟掌握核心操作&…...

Innovus DRC Violation和Calibre DRC Violation分析和修复案例
今天把小编昨天帮助社区训练营学员远程协助的一个经典案例分享给大家。希望能够帮助到更多需要帮助的人。如果各位想跟小编来系统学习数字后端设计实现的,可以联系小编。 数字IC后端手把手实战教程 | Innovus verify_drc VIA1 DRC Violation解析及脚本自动化修复方…...
)
数据库7(数据定义语句,视图,索引)
1.数据定义语句 SQL数据定义语言(DDL)用于定义和管理数据库结构,包括创建、修改和删除 数据库对象。常见的DDL语句包括CREATE、DROP和ALTER。 它的操作的是对象,区分操作数据的语句:INSERT,DELETE,UPDATE 示例&#x…...

Cadence 修改 铜和pin脚 连接属性 和 光绘参数修改
光绘层叠设置,参考 光绘参数修改, 中英文对照...

秒杀业务的实现过程
一.后台创建秒杀的活动场次信息,并关联到要秒杀的商品或服务; 二.通过定时任务,将秒杀的活动信息和商品服务信息存储到redis; 三.在商品展示页的显眼位置加载秒杀活动信息; 四.用户参与秒杀,创建订单,将…...
时实时获取 COCO 指标(AP):2025最新配置与代码详解 (小白友好 + B站视频))
✅ Ultralytics YOLO 训练(Train)时实时获取 COCO 指标(AP):2025最新配置与代码详解 (小白友好 + B站视频)
✅ YOLO获取COCO指标(4): 训练(Train)启用COCO API评估(实时监控AP指标)| 发论文必看! | Ultralytics | 小白友好 文章目录 一、问题定位二、原理分析三、解决方案与实践案例步骤 1: 在 model.train() 调用中设置 save_jsonTrue步骤 2: 修改 …...
)
java基础 流(Stream)
Stream Stream 的核心概念核心特点 Stream 的操作分类中间操作(Intermediate Operations)终止操作(Terminal Operations) Stream 的流分类顺序流(Sequential Stream)并行流(Parallel Stream&…...

基于springboot+vue的课程管理系统
一、系统架构 前端:vue | element-ui 后端:springboot | mybatis-plus 环境:jdk1.8 | mysql8 | maven | node v16.20.2 | idea 二、代码及数据 三、功能介绍 01. 登录 02. 管理员-首页 03. 管理员-系管理 04. 管理员-专业管理 05. 管…...

android14 keycode 上报 0 解决办法
驱动改完后发现上报了keycode=0 04-07 13:02:33.201 2323 2662 D WindowManager: interceptKeyTq keycode=0 interactive=false keyguardActive=true policyFlags=2000000 04-07 13:02:33.458 2323 2662 D WindowManager: interceptKeyTq keycode=0 interactive=false key…...

小说现代修仙理论
修仙理论 灵魂感应与感知强化:通过特定的修炼方法,感应自身灵魂,以此提升感知能力,使修炼者对周围环境及自身状态的察觉更为敏锐。 生物电的感知与运用 生物电感知:修炼者需凝神静气,感知体内生物…...

6.综合练习1-创建文件
题目: 分析: 本例中使用mkdirs方法创建aaa文件夹。 题目要求是"在当前模块下的aaa文件夹",此时在左侧的目录中,是没有aaa文件夹的,所以要先创建a.txt文件的父级路径aaa文件夹,由于是在当前模块下…...

PostgreSQL的内存管理机制
目录 V1.0PostgreSQL的内存管理机制文件系统缓存作为二级缓存内存切换机制性能影响总结 V2.0PostgreSQL 内存管理机制:双缓存体系验证与笔记完善1. 现有描述验证2. 完善后的内存管理笔记2.1 双缓存体系2.2 其他关键内存区域2.3 验证方法 3. 注意事项 V1.0 PostgreS…...

ReplicaSet、Deployment功能是怎么实现的?
在Kubernetes中,ReplicaSet 和 Deployment 是用于管理 Pod 副本的关键对象。它们各自的功能和实现机制如下: 1. ReplicaSet 功能 管理 Pod 副本:确保指定数量的 Pod 副本一直在运行。如果有 Pod 副本崩溃或被删除,ReplicaSet 会…...

544 eff.c:1761处loop vect 分析
2.6 带有mask的向量数学函数 gcc 支持的svml向量数学函数 32652 GCC currently emits calls to code{vmldExp2}, 32653 code{vmldLn2}, code{vmldLog102}, code{vmldPow2}, 32654 code{vmldTanh2}, code{vmldTan2}, code{vmldAtan2}, code{vmldAtanh2}, 32655 code{vmldCbrt2}…...

搜狗拼音输入法纯净优化版:去广告,更流畅输入体验15.2.0.1758
前言 搜狗输入法电脑版无疑是装机必备的神器。它打字精准,词库丰富全面,功能强大,极大地提升了输入效率。最新版的搜狗拼音输入法更是借助AI技术,让打字变得既准确又高效。而搜狗输入法的去广告精简优化版,通过移除广…...

YOLOv11改进 | YOLOv11引入MobileNetV4
前言: 主要是对该文章YOLOv11改进 | YOLOv11引入MobileNetV4进行复现,以及对一些问题进行解答 1、mobilenetv4核心代码 from typing import Optional import torch import torch.nn as nn import torch.nn.functional as F__all__ [MobileNetV4ConvLa…...

Java中的ArrayList方法
1. 创建 ArrayList 实例 你可以通过多种方式创建 ArrayList 实例: <JAVA> ArrayList<String> list new ArrayList<>(); // 创建一个空的 ArrayList ArrayList<String> list new ArrayList<>(10); // 创建容量为 10 的 ArrayList …...

wordpress 利用 All-in-One WP Migration全站转移
导出导入站点 在插件中查询 All-in-One WP Migration备份并导出全站数据 导入 注意事项: 1.导入部分限制50MB 宝塔解决方案,其他类似,修改php.ini配置文件即可 2. 全站转移需要修改域名 3. 大文件版本,大于1G的可以参考我的…...