Elasticsearch:加快 HNSW 图的合并速度
作者:来自 Elastic Thomas Veasey 及 Mayya Sharipova

过去,我们曾讨论过搜索多个 HNSW 图时所面临的一些挑战,以及我们是如何缓解这些问题的。当时,我们也提到了一些计划中的改进措施。本文正是这项工作的成果汇总。
你可能会问,为什么要使用多个图?这是 Lucene 中架构选择的一个副作用:不可变段(immutable segments)。正如大多数架构决策一样,它既有优点也有缺点。例如,我们最近正式发布了无服务器版本的 Elasticsearch。在这个背景下,我们从不可变段中获得了非常显著的优势,包括高效的索引复制、索引计算与查询计算的解耦,以及它们各自的自动扩展能力。对于向量量化,段合并让我们有机会更新参数,以更好地适应数据特性。在这个方向上,我们认为通过测量数据特性并重新评估索引选择,还可以带来其他优势。
本文将探讨我们为显著减少构建多个 HNSW 图的开销,特别是为了降低图合并成本所做的工作。
背景
为了保持可管理的段(segment)数量,Lucene 会定期检查是否需要合并段。这基本上是检查当前段数量是否超过了一个由基础段大小和合并策略决定的目标段数。如果超过了这个限制,Lucene 就会将若干段合并,直到约束条件不再被违反。这个过程在其他文档中已有详细描述。
Lucene 倾向于合并相似大小的段,因为这样可以实现写放大的对数增长。对于向量索引来说,写放大指的是同一个向量被插入图的次数。Lucene 通常尝试将大约 10 个段合并成一组。因此,向量大约会被插入图 1 + 9/10 × log₁₀(n/n₀) 次,其中 n 是索引中的总向量数量,n₀ 是每个基础段的预期向量数量。由于这种对数增长,即便在非常大的索引中,写放大仍能保持在个位数。然而,合并图所花费的总时间与写放大呈线性关系。
在合并 HNSW 图时,我们已经采用了一个小的优化:保留最大段的图,并将其他段的向量插入这个图。这就是上述公式中 9/10 系数的原因。接下来我们将展示,如何通过利用所有参与合并的图中的信息,显著提高这一过程的效率。
图合并
之前,我们保留了最大的图,并插入了其他图中的向量,忽略了包含它们的图。我们在下面利用的关键见解是,每个我们丢弃的图包含了它所包含的向量的相似性信息。我们希望利用这些信息来加速插入至少一部分向量。
我们专注于将一个较小的图 插入到一个较大的图
的问题,因为这是一个原子操作,我们可以用它来构建任何合并策略。
该策略是找到一个小图中顶点的子集 来插入到大图中。然后,我们利用这些顶点在小图中的连接性来加速插入剩余的顶点
。以下我们用
和
分别表示小图和大图中顶点
的邻居。该过程的示意如下。

我们使用下文将讨论的一个过程(第1行)来计算集合 。然后,使用标准的 HNSW 插入过程(第2行)将
中的每个顶点插入到大图中。对于尚未插入的每个顶点,我们会找到其已插入的邻居及这些邻居在大图中的邻居(第 4 和第 5 行)。接着,使用以这个集合为种子的 FAST-SEARCH-LAYER 过程(第 6 行),从 HNSW 论文中的 SELECT-NEIGHBORS-HEURISTIC 中找到候选集合(第 7 行)。实际上,我们是在替换 INSERT 方法(论文中的算法1)中的 SEARCH-LAYER 过程,其他部分保持不变。最后,将刚插入的顶点加入集合 J(第8行)。
显然,为了使这个过程有效,每个 中的顶点必须至少有一个邻居在 J 中。实际上,我们要求对于每个
,都有
,其中
,即最大层连接数。我们观察到,在实际的 HNSW 图中,顶点度数的分布差异很大。下图展示了 Lucene HNSW 图底层中顶点度数的典型累计密度函数。

我们尝试了使用固定值的 和将其设为顶点度数的函数这两种方法。第二种选择带来了更大的加速,并对召回率的影响较小,因此我们选择了以下公式:
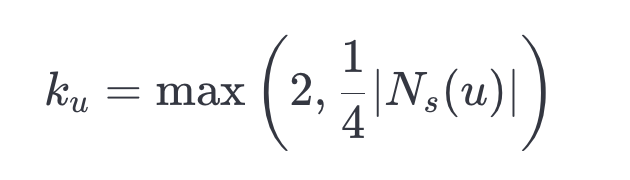
请注意, 是顶点
在小图中的度数。设定下限为 2 意味着我们将插入所有度数小于 2 的顶点。
一个简单的计数论证表明,如果我们仔细选择 ,我们只需要直接将约
的顶点插入到大图
中。具体而言,我们对图的边进行着色,如果我们将它的一个端点插入到
中。然后我们知道,为了确保
中的每个顶点都有至少
个邻居在 J 中,我们需要着色至少
条边。此外,我们预期:
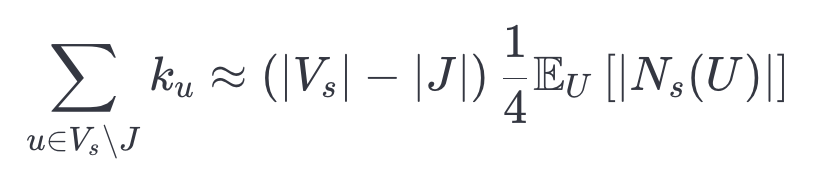
这里, 是小图中顶点的平均度数。对于每个顶点
,我们最多会着色
条边。因此,我们预期着色的总边数最多为
。我们希望通过仔细选择
,能够着色接近这个数量的边。因此,为了覆盖所有的顶点,
需要满足:
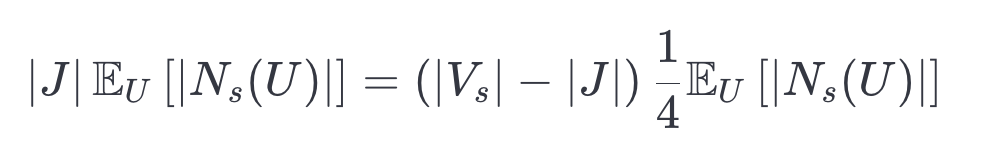
这意味着:
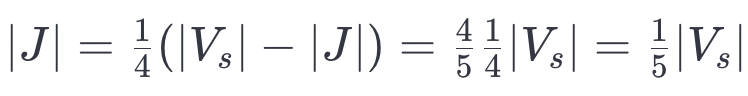
提供 SEARCH-LAYER 支配了运行时间,这表明我们可以在合并时间上实现最多 5 倍的加速。考虑到写入放大效应的对数增长,这意味着即使对于非常大的索引,我们的构建时间通常也仅仅是构建一个图时的两倍。
这种策略的风险在于我们可能会损害图的质量。最初,我们尝试了一个无操作的 FAST-SEARCH-LAYER。我们发现这会导致图质量下降,特别是在合并到单个段时,召回率作为延迟的函数会降低。然后我们探索了使用有限图搜索的各种替代方案。最终,最有效的选择是最简单的。使用 SEARCH-LAYER,但设置一个较低的 ef_construction。通过这种参数设置,我们能够在保持优良图质量的同时,减少约一半的合并时间。
计算连接集
找到一个好的连接集可以表述为一个图覆盖问题。贪心启发式算法是一种简单有效的启发式方法,用于逼近最优的图覆盖。我们采用的方法是使用贪心启发式算法,一次选择一个顶点将其加入到 中,使用以下定义的每个候选顶点的增益:
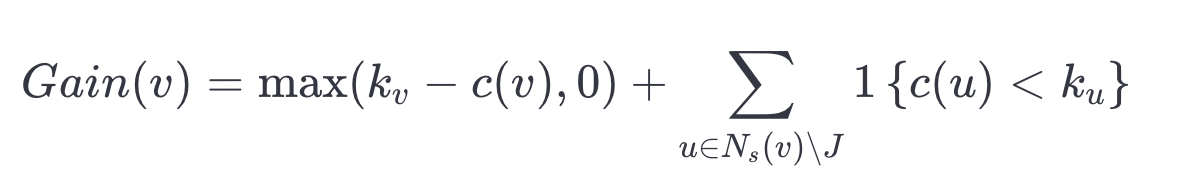
在这里, 表示向量
在
中的邻居数量,
是指示函数。增益包括我们加入到
中的顶点的邻居数量变化,即
,因为通过加入一个覆盖较少的顶点,我们可以获得更多的增益。增益计算在下图中对于中央橙色节点进行了说明。

我们为每个顶点 维护以下状态:
-
是否过时(stale)
-
它的增益
-
在
中相邻顶点的计数,记作
-
一个在 [0, 1] 范围内的随机数,用于打破平局。
计算加入集合的伪代码如下。

我们首先在第 1-5 行初始化状态。
在主循环的每次迭代中,我们首先提取最大增益的顶点(第 8 行),并在存在平局时随机打破平局。在做任何修改之前,我们需要检查该顶点的增益是否过时。特别地,每次我们将一个顶点添加到 中时,会影响其他顶点的增益:
-
由于它的所有邻居在
-
如果它的任何邻居现在已经完全覆盖,那么它们所有邻居的增益都可能发生变化(第14-16行)。
我们以懒惰的方式重新计算增益,因此只有在我们要将一个顶点插入到 中时,才会重新计算该顶点的增益(第18-20行)。
请注意,我们只需要跟踪我们已添加到 中的顶点的总增益,以决定何时退出。此外,尽管
,至少会有一个顶点具有非零增益,因此我们始终会取得进展。
结果
我们在4个数据集上进行了实验,涵盖了我们支持的三种距离度量(欧几里得、余弦和内积),并采用了两种类型的量化方法:1)int8 —— 每个维度使用1字节的整数;2)BBQ —— 每个维度使用一个比特。
实验 1:int8 量化
从基准到候选方案(提出的改进)的平均加速比为:
-
索引时间加速:1.28×
-
强制合并加速:1.72×
这对应于以下运行时间的划分:

为了完整性,以下是各项时间数据:
-
quora-E5-small; 522931 文档;384 维度;余弦度量
基准:索引时间:112.41s,强制合并:113.81s
候选:索引时间:81.55s,强制合并:70.87s -
cohere-wikipedia-v2; 100万文档;768 维度;余弦度量
基准:索引时间:158.1s,强制合并:425.20s
候选:索引时间:122.95s,强制合并:239.28s -
gist; 960 维度,100万文档;欧几里得度量
基准:索引时间:141.82s,强制合并:536.07s
候选:索引时间:119.26s,强制合并:279.05s -
cohere-wikipedia-v3; 100万文档;1024 维度;内积度量
基准:索引时间:211.86s,强制合并:654.97s
候选:索引时间:168.22s,强制合并:414.12s
下面是与基准进行对比的召回率与延迟图,比较了候选方案(虚线)与基准在两种检索深度下的表现:recall@10 和 recall@100,分别针对具有多个分段的索引(即索引所有向量后默认合并策略的最终结果)以及强制合并为单个分段的索引。曲线越高且越靠左表示性能越好,这意味着在较低的延迟下获得更高的召回率。
从下面的图表可以看出,在多个分段索引上,候选方案在 Cohere v3 数据集上的表现更好,对于其他所有数据集,曲线稍差但几乎可比。当合并为单个分段后,所有数据集的召回曲线几乎相同。




实验 2:BBQ 量化
从基准到候选方案的平均加速比为:
-
索引时间加速:1.33×
-
强制合并加速:1.34×
以下是具体的细分:

为完整性考虑,以下是时间数据:
-
quora-E5-small; 522931 个文档; 384 维度; 余弦度量
基准:索引时间:70.71秒,强制合并:59.38秒
候选方案:索引时间:58.25秒,强制合并:40.15秒 -
cohere-wikipedia-v2; 100 万个文档; 768 维度; 余弦度量
基准:索引时间:203.08秒,强制合并:107.27秒
候选方案:索引时间:142.27秒,强制合并:85.68秒 -
gist; 960 维度,100 万个文档; 欧氏度量
基准:索引时间:110.35秒,强制合并:323.66秒
候选方案:索引时间:105.52秒,强制合并:202.20秒 -
cohere-wikipedia-v3; 100 万个文档; 1024 维度; 内积度量
基准:索引时间:313.43秒,强制合并:165.98秒
候选方案:索引时间:190.63秒,强制合并:159.95秒
从多个段索引的图表可以看到,候选方案在几乎所有数据集上表现更好,除了 cohere v2 数据集,基准略优。对于单个段索引,所有数据集的召回曲线几乎相同。




总的来说,我们的实验涵盖了不同的数据集特征、索引设置和检索场景。实验结果表明,我们能够在保持强大的图质量和搜索性能的同时,实现显著的索引和合并加速,这些结果在各种测试场景中表现一致。
结论
本文讨论的算法将在即将发布的 Lucene 10.2 版本中提供,并将在基于该版本的 Elasticsearch 发布中可用。用户将在这些新版本中受益于改进的合并性能和缩短的索引构建时间。这个变化是我们不断努力使 Lucene 和 Elasticsearch 成为一个快速高效的向量搜索数据库的一部分。
自己亲自体验向量搜索,通过这款自定进度的搜索 AI 实践学习。你可以开始免费的云试用或立即在本地机器上尝试 Elastic。
原文:Speeding up merging of HNSW graphs - Elasticsearch Labs
相关文章:

Elasticsearch:加快 HNSW 图的合并速度
作者:来自 Elastic Thomas Veasey 及 Mayya Sharipova 过去,我们曾讨论过搜索多个 HNSW 图时所面临的一些挑战,以及我们是如何缓解这些问题的。当时,我们也提到了一些计划中的改进措施。本文正是这项工作的成果汇总。 你可能会问…...

Elasticsearch单节点安装手册
Elasticsearch单节点安装手册 以下是一份 Elasticsearch 单节点搭建手册,适用于 Linux 系统(如 CentOS/Ubuntu),供学习和测试环境使用。 Elasticsearch 单节点搭建手册 1. 系统要求 操作系统:Linux(Cent…...

前端用户列表与后端分页协同设计
分页实现方案 在现代Web应用中,用户列表展示与分页是一个常见的功能需求。前端与后端通过API协同工作,使用PageHelper等工具实现高效分页。 例如: 后端实现 (使用PageHelper) public PageResult DishPage(DishPageQueryDTO dishPageQuery…...

MyBatis的第四天学习笔记下
10.MyBatis参数处理 10.1 项目信息 模块名:mybatis-007-param数据库表:t_student表结构: id: 主键name: 姓名age: 年龄height: 身高sex: 性别birth: 出生日期 sql文件: create table t_student ( id bigint auto_increm…...

三类人解决困境的方法
有一个视频讲述了三类人解决困境的方法,视频中有持续流出干净水源的水龙头,一杯装满脏水的玻璃杯。第一类普通人是拿着玻璃杯放到水龙头下不断接水,水龙头一直开着的第二类高手是把脏水倒到水池里,然后打开水龙头接水,…...

蓝桥杯第十一届省赛C++B组真题解析
蓝桥杯第十一届省赛CB组真题解析 八、回文日期https://www.lanqiao.cn/problems/348/learning 方法一:暴力枚举所有的日期,记录有多少个回文日期。 #include <bits/stdc.h> using namespace std; int month[13]{0,31,28,31,30,31,30,31,31,30,31…...

Tailscale 的工作原理*
Tailscale 的核心原理基于 WireGuard VPN,它实现了端到端加密的 点对点(P2P)连接,但在必要时会通过 中继服务器(DERP) 进行中转。整体来说,它是一个 零配置的 Mesh VPN,让所有设备看…...

PyTorch张量范数计算终极指南:从基础到高阶实战
在深度学习领域,张量范数计算是模型正则化、梯度裁剪、特征归一化的核心技术。本文将以20代码实例,深度剖析torch.norm的9大核心用法,并揭示其在Transformer模型中的关键应用场景。 🚀 快速入门(5分钟掌握核心操作&…...

Innovus DRC Violation和Calibre DRC Violation分析和修复案例
今天把小编昨天帮助社区训练营学员远程协助的一个经典案例分享给大家。希望能够帮助到更多需要帮助的人。如果各位想跟小编来系统学习数字后端设计实现的,可以联系小编。 数字IC后端手把手实战教程 | Innovus verify_drc VIA1 DRC Violation解析及脚本自动化修复方…...
)
数据库7(数据定义语句,视图,索引)
1.数据定义语句 SQL数据定义语言(DDL)用于定义和管理数据库结构,包括创建、修改和删除 数据库对象。常见的DDL语句包括CREATE、DROP和ALTER。 它的操作的是对象,区分操作数据的语句:INSERT,DELETE,UPDATE 示例&#x…...

Cadence 修改 铜和pin脚 连接属性 和 光绘参数修改
光绘层叠设置,参考 光绘参数修改, 中英文对照...

秒杀业务的实现过程
一.后台创建秒杀的活动场次信息,并关联到要秒杀的商品或服务; 二.通过定时任务,将秒杀的活动信息和商品服务信息存储到redis; 三.在商品展示页的显眼位置加载秒杀活动信息; 四.用户参与秒杀,创建订单,将…...
时实时获取 COCO 指标(AP):2025最新配置与代码详解 (小白友好 + B站视频))
✅ Ultralytics YOLO 训练(Train)时实时获取 COCO 指标(AP):2025最新配置与代码详解 (小白友好 + B站视频)
✅ YOLO获取COCO指标(4): 训练(Train)启用COCO API评估(实时监控AP指标)| 发论文必看! | Ultralytics | 小白友好 文章目录 一、问题定位二、原理分析三、解决方案与实践案例步骤 1: 在 model.train() 调用中设置 save_jsonTrue步骤 2: 修改 …...
)
java基础 流(Stream)
Stream Stream 的核心概念核心特点 Stream 的操作分类中间操作(Intermediate Operations)终止操作(Terminal Operations) Stream 的流分类顺序流(Sequential Stream)并行流(Parallel Stream&…...

基于springboot+vue的课程管理系统
一、系统架构 前端:vue | element-ui 后端:springboot | mybatis-plus 环境:jdk1.8 | mysql8 | maven | node v16.20.2 | idea 二、代码及数据 三、功能介绍 01. 登录 02. 管理员-首页 03. 管理员-系管理 04. 管理员-专业管理 05. 管…...

android14 keycode 上报 0 解决办法
驱动改完后发现上报了keycode=0 04-07 13:02:33.201 2323 2662 D WindowManager: interceptKeyTq keycode=0 interactive=false keyguardActive=true policyFlags=2000000 04-07 13:02:33.458 2323 2662 D WindowManager: interceptKeyTq keycode=0 interactive=false key…...

小说现代修仙理论
修仙理论 灵魂感应与感知强化:通过特定的修炼方法,感应自身灵魂,以此提升感知能力,使修炼者对周围环境及自身状态的察觉更为敏锐。 生物电的感知与运用 生物电感知:修炼者需凝神静气,感知体内生物…...

6.综合练习1-创建文件
题目: 分析: 本例中使用mkdirs方法创建aaa文件夹。 题目要求是"在当前模块下的aaa文件夹",此时在左侧的目录中,是没有aaa文件夹的,所以要先创建a.txt文件的父级路径aaa文件夹,由于是在当前模块下…...

PostgreSQL的内存管理机制
目录 V1.0PostgreSQL的内存管理机制文件系统缓存作为二级缓存内存切换机制性能影响总结 V2.0PostgreSQL 内存管理机制:双缓存体系验证与笔记完善1. 现有描述验证2. 完善后的内存管理笔记2.1 双缓存体系2.2 其他关键内存区域2.3 验证方法 3. 注意事项 V1.0 PostgreS…...

ReplicaSet、Deployment功能是怎么实现的?
在Kubernetes中,ReplicaSet 和 Deployment 是用于管理 Pod 副本的关键对象。它们各自的功能和实现机制如下: 1. ReplicaSet 功能 管理 Pod 副本:确保指定数量的 Pod 副本一直在运行。如果有 Pod 副本崩溃或被删除,ReplicaSet 会…...

544 eff.c:1761处loop vect 分析
2.6 带有mask的向量数学函数 gcc 支持的svml向量数学函数 32652 GCC currently emits calls to code{vmldExp2}, 32653 code{vmldLn2}, code{vmldLog102}, code{vmldPow2}, 32654 code{vmldTanh2}, code{vmldTan2}, code{vmldAtan2}, code{vmldAtanh2}, 32655 code{vmldCbrt2}…...

搜狗拼音输入法纯净优化版:去广告,更流畅输入体验15.2.0.1758
前言 搜狗输入法电脑版无疑是装机必备的神器。它打字精准,词库丰富全面,功能强大,极大地提升了输入效率。最新版的搜狗拼音输入法更是借助AI技术,让打字变得既准确又高效。而搜狗输入法的去广告精简优化版,通过移除广…...

YOLOv11改进 | YOLOv11引入MobileNetV4
前言: 主要是对该文章YOLOv11改进 | YOLOv11引入MobileNetV4进行复现,以及对一些问题进行解答 1、mobilenetv4核心代码 from typing import Optional import torch import torch.nn as nn import torch.nn.functional as F__all__ [MobileNetV4ConvLa…...

Java中的ArrayList方法
1. 创建 ArrayList 实例 你可以通过多种方式创建 ArrayList 实例: <JAVA> ArrayList<String> list new ArrayList<>(); // 创建一个空的 ArrayList ArrayList<String> list new ArrayList<>(10); // 创建容量为 10 的 ArrayList …...

wordpress 利用 All-in-One WP Migration全站转移
导出导入站点 在插件中查询 All-in-One WP Migration备份并导出全站数据 导入 注意事项: 1.导入部分限制50MB 宝塔解决方案,其他类似,修改php.ini配置文件即可 2. 全站转移需要修改域名 3. 大文件版本,大于1G的可以参考我的…...
全攻略)
零基础教程:Windows电脑安装Linux系统(双系统/虚拟机)全攻略
一、安装方式选择 方案对比表 特性双系统安装虚拟机安装性能原生硬件性能依赖宿主机资源分配磁盘空间需要独立分区(建议50GB)动态分配(默认20GB起)内存占用独占全部内存需手动分配(建议4GB)启动方式开机选…...

聚焦AI与大模型创新,紫光云如何引领云计算行业快速演进?
【全球云观察 | 科技热点关注】 随着近年来AI与大模型的兴起,云计算行业正在发生着一场大变局。 “在2025年春节期间,DeepSeek两周火爆全球,如何进行私域部署成了企业关心的问题。”紫光云公司总裁王燕平强调指出,AI与…...

mapreduce 过程中,maptask的partitioner是在map阶段中具体什么阶段分区的?
在MapReduce的Map阶段中,Partitioner(分区器)的作用发生在map函数输出键值对之后,但在数据被写入磁盘(spill到本地文件)之前。具体流程如下: 分区发生的具体阶段: Map函数处理完成 当…...

找到字符串中所以字母异位词 --- 滑动窗口
目录 一:题目 二:算法原理 三:代码实现 一:题目 题目链接:438. 找到字符串中所有字母异位词 - 力扣(LeetCode) 二:算法原理 三:代码实现 版本一:无co…...

密码破解工具
1. 引言 密码是信息安全的核心之一,而攻击者往往利用各种工具和技术来破解密码。密码破解工具可以分为 离线破解(Offline Cracking) 和 在线破解(Online Cracking) 两大类: 离线破解:攻击者已经获取了加密的密码哈希(hash),可以在本地进行破解,无需与目标系统交互。…...

路由策略在双点双向路由重发布的应用
一、背景叙述 路由重发布通常是解决两个不同路由协议之间的互通问题,也就是路由双向引入。有时候,单点路由重发布在大规模网络中压力较大,缺乏冗余性,于是就有了双点双向路由重发布 问题:但是双点双向路由重发布也会…...

在Python软件中集成智能体:以百度文心一言和阿里通义千问为例
摘要 本文旨在探讨如何在Python软件中集成智能体,具体以百度文心一言和阿里通义千问等大模型生成的智能体为例。文章详细介绍了集成这些智能体的方法,包括环境准备、API调用、代码实现等步骤,并提供了相关的示例代码。通过集成这些智能体&…...

day22 学习笔记
文章目录 前言一、遍历1.行遍历2.列遍历3.直接遍历 二、排序三、去重四、分组 前言 通过今天的学习,我掌握了对Pandas的数据类型进行基本操作,包括遍历,去重,排序,分组 一、遍历 1.行遍历 intertuples方法用于遍历D…...

谈Linux之磁盘管理——万字详解
—— 小 峰 编 程 目录 一、硬盘的基本知识 1.了解硬盘的接口类型 2. 硬盘命名方式 3. 磁盘设备的命名 4. HP服务器硬盘 5. 硬盘的分区方式 二、 基本分区管理 1. 磁盘划分思路 2. 分区 2.1 MBR分区 2.2GPT分区 3.格式化—命令:mkfs 4.挂载 4.1手动挂…...

做好一个测试开发工程师第二阶段:java入门:idea新建一个project后默认生成的.idea/src/out文件文件夹代表什么意思?
时间:2025.4.8 一、前言 关于Java与idea工具安装不再展开,网上很多教程,可以自己去看 二、project建立后默认各文件夹代表意思 1、首先new---->project后会得到文件如图 其中: .idea文件代表:存储这个项目的历史…...

伪代码的定义与应用场景
李升伟 整理 伪代码(Pseudocode)是一种用近似自然语言(通常是英语或开发者熟悉的语言)和简单语法描述的算法逻辑工具。它介于自然语言和编程语言之间,不依赖具体语法规则,专注于表达思路,是编程…...

/sys/fs/cgroup/memory/memory.stat 关键指标说明
目录 1. **total_rss**2. **total_inactive_file**3. **total_active_file**4. **shmem**5. **其他相关指标**总结 以下是/sys/fs/cgroup/memory/memory.stat文件中一些关键指标的详细介绍,特别是与PostgreSQL相关的指标: 1. total_rss 定义࿱…...

机器学习中的聚类分析算法:原理与应用
一、什么是聚类分析? 聚类分析(Clustering Analysis)是机器学习中一种重要的无监督学习技术,它的目标是将数据集中的样本划分为若干个组(称为"簇"),使得同一簇内的样本彼此相似,而不同簇的样本差异较大。与分类不同&am…...

VUE中的路由处理
1.引入,预处理main.ts import {} from vue-router import { createRouter, createWebHistory } from vue-router import HomePages from @/pages/HomePages.vue import AboutPage from @/pages/AboutPage.vue import NewsPage from @/pages/NewsPage.vue //1. 配置路由规…...
 控制工程会用到的)
MATLAB学习笔记(二) 控制工程会用到的
MATLAB中 控制工程会用到的 基础传递函数表达传递函数 零极点式 状态空间表达式 相互转化画响应图线根轨迹Nyquist图和bode图现控部分求约旦判能控能观极点配置和状态观测 基础 传递函数表达 % 拉普拉斯变换 syms t s a f exp(a*t) %e的a次方 l laplace(f) …...

Python: 实现数据可视化分析系统
后端基于Python 开源的 Web 框架 Flask,前端页面采用 LayUI 框架以及 Echarts 图表,数据库为sqlite。系统的功能模块分为数据采集和存储模块、数据处理和分析模块、可视化展示模块和系统管理模块。情感分析方面使用LDA等主题建模技术,结合领域…...

VectorBT量化入门系列:第一章 VectorBT基础与环境搭建
VectorBT量化入门系列:第一章 VectorBT基础与环境搭建 本教程专为中高级开发者设计,系统讲解VectorBT技术在量化交易中的应用。通过结合Tushare数据源和TA-Lib技术指标,深度探索策略开发、回测优化与风险评估的核心方法。从数据获取到策略部署…...

典型反模式深度解析及重构方案
反模式 1:魔法数字/字符串(Magic Numbers/Strings) ▐ 问题场景 // 订单状态校验 if (order.getStatus() 3) { // 3代表已发货?sendNotification(); }// 折扣计算 double discount price * 0.15; // 0.15是什么?…...

神经探针与价值蓝海:AI重构需求挖掘的认知拓扑学
当产品经理的决策边界遭遇量子态的用户需求,传统需求分析工具已显露出经典物理般的局限性。Gartner 2024报告揭示:全球Top 500企业中有83%遭遇需求洞察的"测不准困境"——用户声称的需求与行为数据偏差率达47%,而未被表达的潜在需求…...

Tomcat 负载均衡
目录 二、Tomcat Web Server 2.1 Tomcat 部署 2.1.1 Tomcat 介绍 2.1.2 Tomcat 安装 2.2 Tomcat 服务管理 2.2.1 Tomcat 启停 2.2.2 目录说明 2.2.3编辑主页 2.3 Tomcat管理控制台 2.3.1开启远程管理 2.3.2 配置远程管理密码 三、负载均衡 3.1 重新编译Nginx 3.1.1 确…...

CSS >子元素选择器和空格
在 CSS 中,> 符号是 子元素选择器(Child Combinator),它用于选择某个元素的直接子元素(仅限第一层嵌套的子元素,不包含更深层的后代元素)。 语法 父元素 > 子元素 {样式规则; } 示例 …...

duckdb源码阅读学习路径图
🧭 DuckDB 最小内存源码阅读路径图 1️⃣ 数据流入口与批处理:DataChunk 项目内容✅ 目标理解 DuckDB 向量化执行的数据载体结构,如何影响内存📁 路径src/common/types/data_chunk.cpp/hpp🔍 入口函数DataChunk::Initialize, DataChunk::SetCardinality, Reset📌 优化…...

C#二叉树
C#二叉树 二叉树是一种常见的数据结构,它是由节点组成的一种树形结构,其中每个节点最多有两个子节点。二叉树的一个节点通常包含三部分:存储数据的变量、指向左子节点的指针和指向右子节点的指针。二叉树可以用于多种算法和操作,…...

BT-Basic函数之首字母W
BT-Basic函数之首字母W 文章目录 BT-Basic函数之首字母Wwaitwait for start wait wait函数使程序在执行下一个功能之前暂停指定的秒数。 语法 wait <数值表达式>参数 <数值表达式> 等待时长,以秒为单位。该值必须大于或等于0。小于25毫秒的正值会被…...

如何避免论文内容被误认为是 AI 生成的?
AIGC 检测的原理 AIGC 检测主要基于自然语言处理(NLP)和机器学习技术,通过深度分析文本内容来识别其中的 AI 生成痕迹。具体原理如下: 基础学习算法:利用机器学习算法对文本信息进行特征提取和表示,以便计…...