告别水下模糊!SU-YOLO:轻量化+尖峰神经网络,用“类脑计算”实现水下目标毫秒级识别

目录
一、摘要
二、引言
三、相关工作
SNN 物体检测
水下物体探测
水下图像去噪
归一化
四、方法
水下尖峰YOLO
尖峰干扰器
SU-Block
SpikeSPP
编码器和检测头
分批归一化
五、Coovally AI模型训练与应用平台
六、实验结果
数据集和实施细节
数据集
实施细节
计算成本
时间步长
对比实验
消融实验
SU-YOLO模块的有效性
SpikeDenoiser的效果
SeBN的有效性
残块替换
混淆矩阵和精度-召回曲线
池化和激活顺序
时间步长
七、结论

论文题目:SU-YOLO: Spiking Neural Network for Efficient Underwater Object Detection
论文链接:https://arxiv.org/pdf/2503.24389
一、摘要
水下物体探测对于海洋研究和工业安全检查至关重要。然而,复杂的光学环境和有限的水下设备资源给实现高精度和低功耗带来了巨大挑战。为了解决这些问题,提出了一种尖峰神经网络(SNN)模型——尖峰水下YOLO(SU-YOLO)。利用SNN的轻量级和高能效特性,SU-YOLO采用了一种新颖的基于尖峰的水下图像识别方法,该方法完全基于整数加法,能以最小的计算开销提高特征图的质量。此外,我们还引入了分批归一化(Separated Batch Normalization,SEBN)技术,该技术可在多个时间步长内对特征图进行独立归一化,并与残差结构进行优化整合,从而更有效地捕捉SNN的时间动态。重新设计的尖峰残差块将跨阶段部分网络(CSPNet)与YOLO架构整合在一起,以减轻尖峰退化并增强模型的特征提取能力。在URPC2019水下数据集上的实验结果表明,SU-YOLO在6.97M个参数下实现了78.8%的mAP,能耗为2.98 mJ,在检测精度和计算效率上都超越了主流SNN模型。这些结果凸显了SNN在工程应用中的潜力。
二、引言
水下探测应用广泛,包括水生生物探测、设施安全检查和打捞作业。随着遥控潜水器(ROV)和自动潜航器(AUV)的发展,无人探测方法正逐渐取代传统的人工探测方法,其中物体探测起着至关重要的作用。然而,水下光学环境复杂,图像亮度低、噪声大,因此水下物体检测比一般物体检测更具挑战性。此外,由于遥控潜水器和自动潜航器的尺寸和功率限制,必须采用轻量级检测模型以尽量减少资源消耗,从而使任务更加复杂。这些因素使得水下物体检测成为计算机视觉领域的一个高难度研究领域。
目前已经提出了几种针对水下物体检测进行优化的算法,如 YOLOv9s-UI,与基线模型相比,这些算法的精度有所提高。然而,在这些模型中加入注意力机制往往会增加计算复杂度,使其不适合像AUV这样资源有限的设备。为了解决这个问题,人们引入了轻量级模型[3, 4],以减少参数数量和计算需求。遗憾的是,与最先进的一般物体检测模型相比,这些简化通常会导致较低的检测精度。
尖峰神经网络(SNN)为实现低计算量和高精度提供了一种很有前景的方法。作为第三代神经网络[5, 6, 7],尖峰神经网络的灵感来源于大脑中的神经元通信机制。与传统的人工神经网络(ANN)不同,SNN通过离散的尖峰而不是连续的值来传输信息,这大大降低了计算成本和能耗。最近的研究探索了将 SNNs 应用于物体检测,包括Spiking-YOLO、EMS-YOLO和SpikeYOLO。然而,这些研究主要侧重于一般物体检测,缺乏针对水下条件的优化,如图像预处理和噪声抑制,从而限制了它们在水下环境中的性能。
为了解决这些局限性,我们提出了基SNN的水下物体检测模型SU-YOLO,该模型建立在YOLO框架之上。鉴于YOLOv9目前已成为一个稳定、高性能的物体检测框架,SU-YOLO采用其拾取网络作为基准。首先,为了适应水下设备的能耗限制,我们简化了网络结构,将其转换为尖峰架构,以实现最小的功耗。在此过程中,我们发现SNN中常用的传统 ResNet结构即使在浅层网络中也会导致尖峰退化;因此,我们重新设计了基于CSPNet结构的轻量级SU-Blocks作为基本单元。其次,考虑到现有的SNNs缺乏有效的图像去噪方法,我们开发了一种新型的尖峰水下图像去噪模块。该模块处理的是特征图而不是原始图像,可同时去除正噪声和负噪声,从而提高检测精度。此外,现有的批量归一化(BN)方法要么忽略SNN的时间动态,从而丢失潜在信息,要么忽略网络中的残余结构,导致神经元过度充电和激活。为了克服这些问题,我们提出了一种优化的归一化方法。
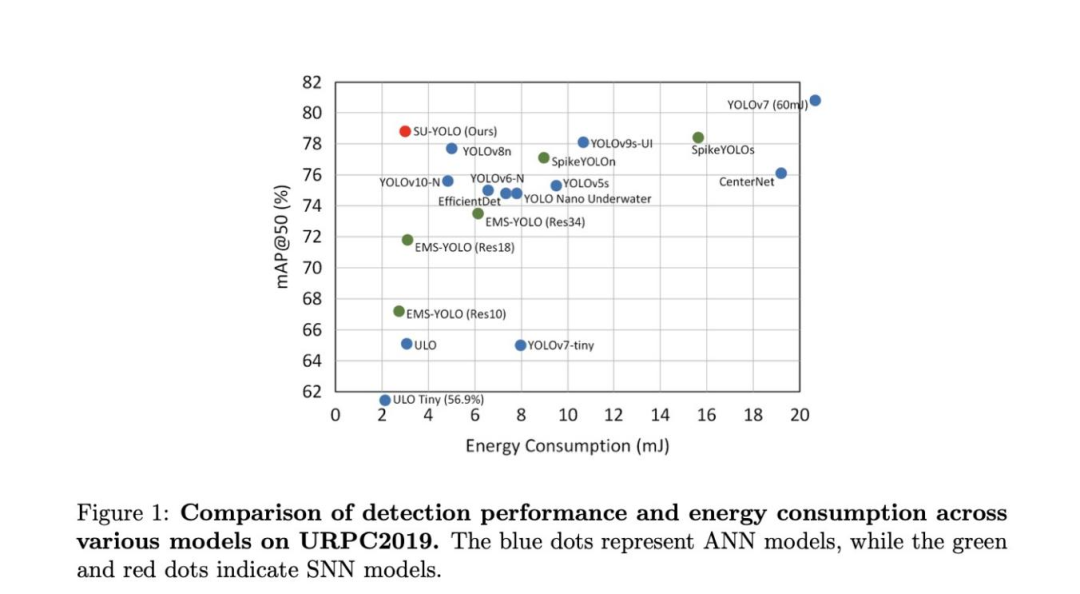
据我们所知,所提出的SU-YOLO是首个专为水下物体检测而设计的SNN。如图 1 所示,我们的方法显著提高了SNN在水下物体检测中的性能,在6.97M参数的URPC2019上实现了78.8%的mAP0.5,能耗为2.98 mJ,超过了现有轻量级SNN和多个ANN模型的性能。
这项工作的主要贡献有四个方面:
-
开发了一种基于YOLO框架的轻量级SNN模型,该模型支持直接训练,同时有效减轻了尖峰退化。该模型在水下物体检测方面的表现优于现有的SNN和几种ANN,只需四个时间步骤就能达到最佳精度。
-
设计了一种与尖峰兼容的新型水下图像去噪方法,可无缝集成到SNN架构中。这种方法只需整数加法计算,以最小的计算开销显著提高了图像质量。
-
为SNNs提出了一种改进的批量归一化方法,称为SeBN,该方法可将各时间步长的特征图沿通道维度串联起来,进行BN运算。SeBN针对残差结构进行了优化,其性能优于经典BN和替代方法(如 tdBN)。
-
在URPC2019和UDD水下图像数据集上的实验验证了SNN用于水下物体检测的可行性和卓越性能。
三、相关工作
-
SNN 物体检测
物体检测是计算机视觉中的一个基本问题。自R-CNN问世以来,基于深度学习的物体检测方法中,ANNs占据了主导地位。Spiking-YOLO的开发标志着SNN首次成功应用于物体检测。Spiking-YOLO采用ANN-SNN转换方法,通过将预先训练好的ANN转换为SNN,用尖峰发射率表示激活值。然而,这种方法需要超过1000个时间步骤才能准确表示原始值,从而降低了SNN的计算效率。FSHNN和Spike Calibration等方法通过优化网络结构,将所需时间步数减少到300步,从而缓解了这一问题。最近,Fast-SN引入了带符号的中频神经元模型和层级微调机制,以解决ANN-SNN转换中的量化和累积误差问题,进一步将时间步数压缩到3步。然而,Fast-SNN中使用负尖峰计算损害了尖峰的二进制性质,导致尖峰网络结构不标准。
转换的另一种方法是直接训练SNN,但由于尖峰点火函数的不可分性,这种方法面临着挑战。Lee等人将膜电位视为可微分参数,从而解决了这一问题,这使得梯度计算和深度可训练SNN的开发成为可能。随后的代梯度方法使用了sigmoid和arctangent等函数,进一步促进SN的训练。著名的例子包括时空反向传播算法(STBP)和基于尖峰的反向传播算法。
训练方法的进步推动了基于SNN的物体检测研究。EMS-YOLO采用完全尖峰ResNet,解决了之前在MS-ResNet和SEW-ResNet中观察到的非尖峰计算问题,并在一般物体检测中表现出强劲的性能。同样,SpikeYOLO引入了I-LIF尖峰神经元,将非尖峰计算转换为尖峰计算,从而提高了检测精度。然而,这些方法主要用于一般物体检测,由于存在模糊物体和严重噪声等挑战,在水下场景中的表现并不理想。
-
水下物体探测
由于复杂的水下环境和水下设备的性能限制,水下物体探测尤其具有挑战性。一些研究试图克服这些挑战。例如,Song等人开发了一种基于Mask R-CNN的算法,该算法采用多尺度视网膜增强和迁移学习来提高检测精度。然而,这些两阶段物体检测方法通常会产生很高的计算成本。
相比之下,单阶段检测算法(如YOLO系列)具有更简单的架构和更低的计算要求,因此更适用于资源有限的水下设备。Zhang等人提出了一种基于YOLOv4的轻量级水下检测网络,该网络结合了基于注意力的特征融合,以更少的参数实现了与原始模型相当的精度。Zhang等人利用新的去符号块和MLLE图像增强技术对YOLOv5进行了进一步改进,其性能超过了YOLOv7和YOLOv8。TC-YOLO是YOLOv5的扩展,它集成了Transformer自我注意机制,大大增强了水下物体的特征提取能力。尽管取得了这些进步,但注意力机制的加入增加了计算负荷,限制了它们在资源有限环境中的适用性。ULO等轻量级模型减少了参数数量和计算成本(3.94M个参数和3.42 GFLOPs),但在URPC上仍只能达到65.13%的 mAP,落后于主流物体检测模型。这些局限性促使我们提出了基于SNN的水下物体检测模型SU-YOLO。
-
水下图像去噪
图像去噪对于水下物体检测至关重要。传统的去噪方法,包括均值滤波、高斯滤波和非局部均值(NLM),往往会模糊噪声和物体边界,从而导致精细细节的丢失。针对这些缺点,Li等人提出了一种结合去噪的自适应色彩和对比度增强(ACCE)框架,该框架利用频域分解和变异优化来提高视觉质量。You等人采用基于小波变换的方法,在边缘检测之前对图像进行去噪,利用多分辨率分析更好地保留边缘细节。虽然这些方法有所改进,但往往难以在不使图像明显模糊的情况下去除复杂噪声。最近也有人提出了深度学习方法。例如,Tian等人提出了交叉变换器去噪网络(CTNet),它结合了变换器和CNN来进行图像去噪,在具有复杂噪声的图像中具有显著优势。Ju等人提出了一种基于补丁的去噪扩散模型来解决图像模糊和色彩失真问题,该模型能有效克服水下悬浮颗粒和光吸收问题。然而,这些方法通常涉及密集的浮点运算或需要运行单独的模型,因此与SNN架构的兼容性较差。因此,我们设计了一种专门针对SNN的轻量级水下图像去噪方法。
-
归一化
BN被广泛应用于人工神经网络中,通过对输入统计数据进行归一化处理,减轻内部协变量的偏移,从而防止训练过程中梯度消失或爆炸。然而,对于包含额外时间维度的SNN,传统BN的效果较差。目前已提出了几种改进的归一化技术。NeuNorm在更新膜电位之前沿着通道维度对输入特征进行归一化,但它并不能完全解决梯度消失问题。Temporal dimension BN(tdBN)对所有时间步长的输入进行归一化,从而同时考虑时间和空间维度。SpikingJelly框架也通过将时间维度扁平化为批次维度来应用BN。
虽然这些方法很有前景,但我们的实验表明,独立地对每个时间步进行归一化处理,而不是跨时间步合并特征,会产生更好的性能。BNTT和TEBN等方法沿用了这一设计,但没有考虑局部并行结构(如快捷连接),也没有考虑SNN中批量融合的需要。为了解决这些问题,我们提出了一种优化的归一化方法SeBN,下文将详细介绍这种方法。
四、方法
-
水下尖峰YOLO
我们的模型基于YOLO框架,由SU-Block1、SU-Block2、SpikeSPP、Encoder、SpikeDenoiser和DetectHead模块组成,如图2所示。
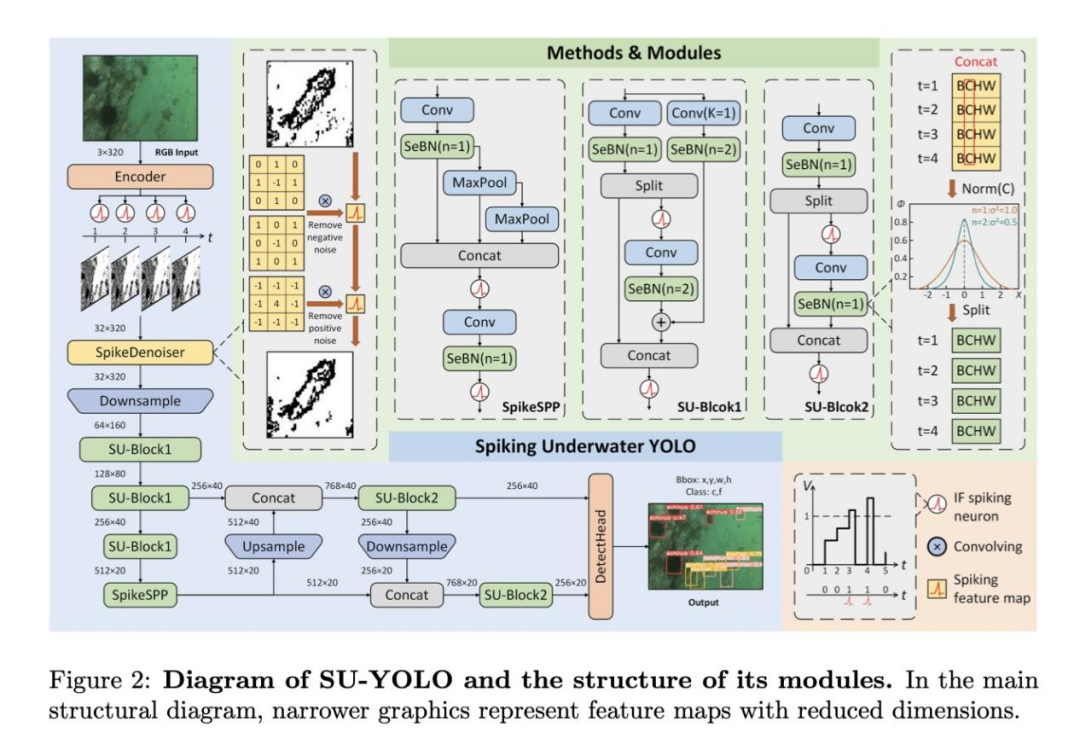
这些组件都经过精心设计和优化,以提高在水下环境中的探测性能。在前向传递过程中,归一化的RGB图像数据(比例范围为 [0,1])以浮点数值的形式输入网络,然后通过编码器模块中的积分发射(IF)神经元转换为尖峰输出。然后,SpikeDenoiser执行图像去噪和下采样。随后,由三个通道维度不断增加的SU-Block1残差块组成的主干网对生成的特征图进行处理。使用SpikeSPP模块提取多尺度特征,然后在Neck中进行特征融合,最后由DetectHead生成最终预测结果。
SU-YOLO中,所有尖峰神经元都是作为中频神经元实现的。与Leaky IF(LIF)神经元不同,IF神经元不会出现膜电压随时间衰减的现象。它们的数学表述更简单,计算成本更低,从而降低了总体功耗。IF神经元模型的描述如下:
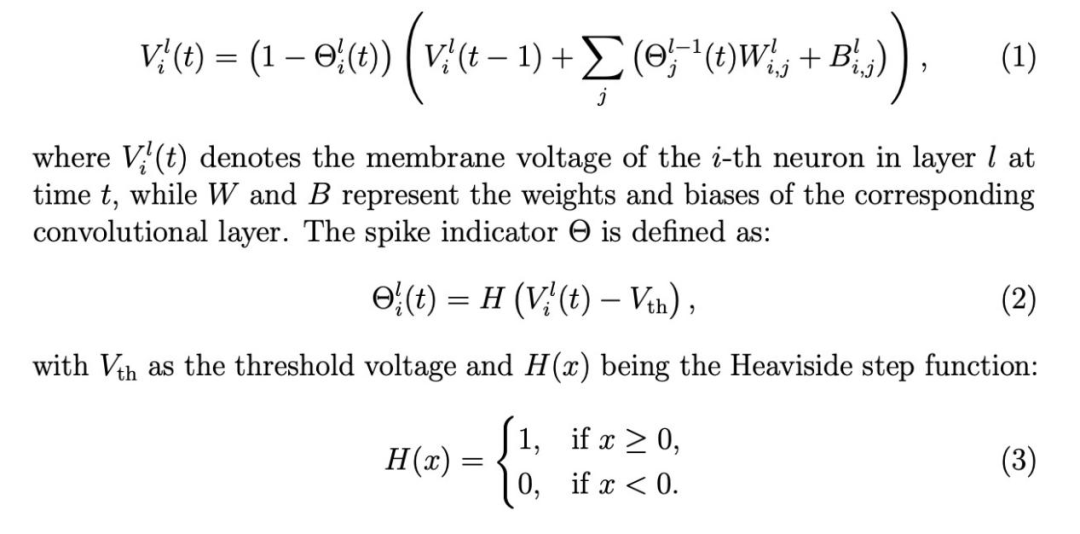
-
尖峰干扰器
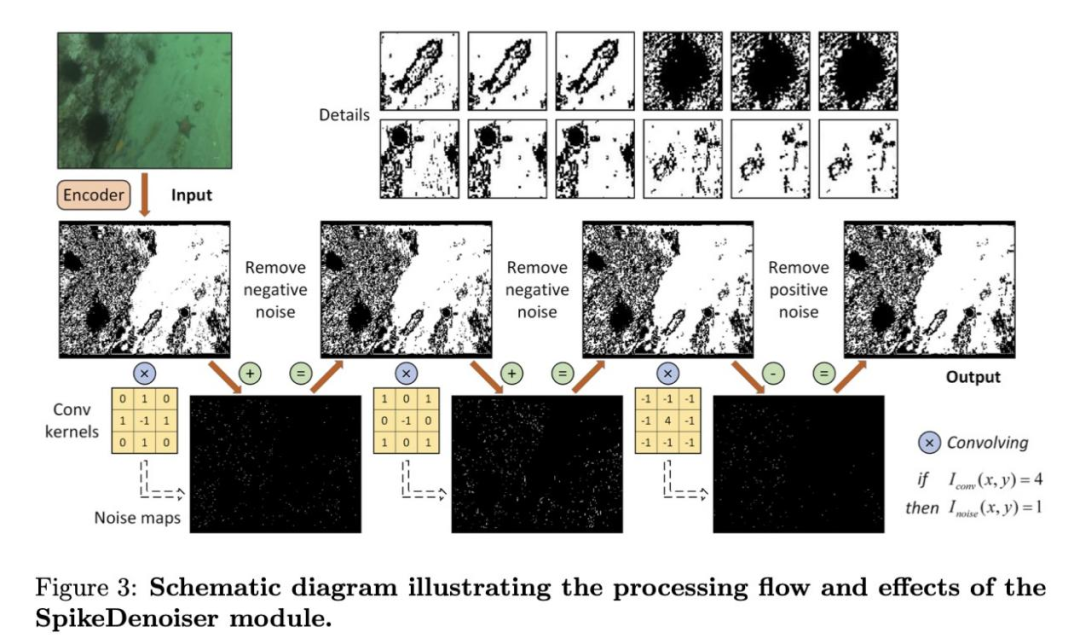
噪声会严重降低水下物体检测的性能。现有的基于SNN的方法以一般物体检测为目标,缺乏专门的去噪技术,因此在水下环境中很容易受到噪声干扰。为了克服这一局限性,同时保留网络的完全尖峰特性,我们提出了一种直接对特征图进行操作的去噪方法。在SNN中,特征图的二进制性质会导致水下盐和胡椒噪声以孤立像素的形式出现,与其邻近像素相比,这些像素的二进制值是倒置的。为了有效地提取和修正这些孤立点,我们采用了三种具有以下核定义的卷积滤波器:

用尖峰编码的输入特征图依次与K1、K2和K3卷积。如果卷积结果等于 4,则当前像素被反转。这一过程的数学表达式为
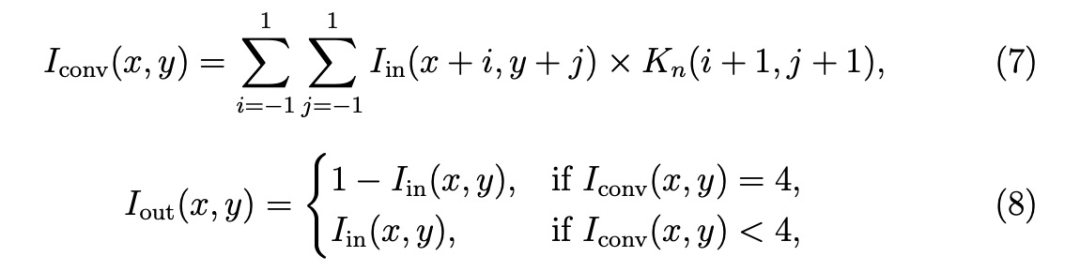
其中,Iin(x, y) 是坐标 (x, y) 处的像素值,Iconv(x, y) 是卷积结果,Iout(x, y) 是输出结果。这里,Kn(n=1、2、3)表示相应的卷积核。
如图3所示,该方法主要是填补缺失像素(负噪点)和去除孤立像素(正噪点)。内核 K1和K2识别并填充中心为0而周围像素为1的像素,而K3则针对并去除中心为1而周围像素为0的孤立像素。实验结果表明,采用激进的方法填充负噪声,再结合保守的策略去除正噪声,可以获得最佳的去噪性能。值得注意的是,SpikeDenoiser只在推理过程中运行,计算成本极低,对于一幅320×320的图像,计算成本不到0.1 GSOPs和0.01 mJ,同时将UDD的mAP提高了3.5%。这种方法保持了网络的完全尖峰特性,因为输入和输出特征图都保持二进制,运算完全依赖整数加法,与浮点加法和乘法相比,能耗分别降低了9倍和37倍。它与各种SNN架构的兼容性使其成为水下图像去噪的通用解决方案。
-
SU-Block
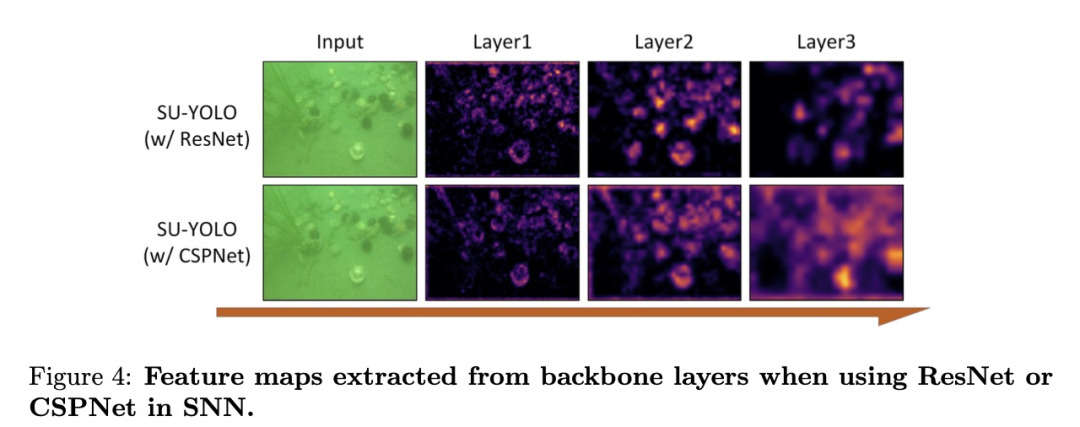
SU-Block1和SU-Block2是我们模型中的基本残差块。由于设备性能的限制,水下物体检测通常需要浅层、计算效率高的网络。虽然ResNet 在现有的SNN [9, 29, 30] 中被广泛使用,但水下图像固有的低质量限制了浅层ResNet架构的特征提取能力,导致检测精度降低。相比之下,CSPNet(交叉阶段部分网络)即使在具有挑战性的成像条件下,也能以较浅的网络深度提供增强的特征表示,从而在降低计算成本的同时保持较高的精度。此外,我们观察到,简单的ResNet结构在SNN中会出现尖峰退化(见图 4),因为随着网络深度的增加,点燃率会降低,这可能会导致关键物体特征的丢失。然而,CSPNet通过在整个骨干网中保持神经元的稳定活动,有效缓解了这种退化现象。因此,我们在CSPNet架构的基础上设计了SU-Block。
SU-Block1用于主干网的特征提取、缩放和通道扩展,集成了CSPNet和捷径连接(见图 2)。其定义如下:
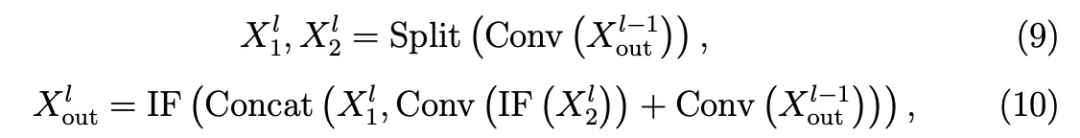
其中,Xl 表示第l层的输出,IF(-)表示 IF 神经元输出激活,Conv(-)表示卷积层,Split(-)将输入沿通道维度平均分割,Concat(-)将输入沿通道维度合并。
经过3×3卷积后,特征图被分成两组。其中一组保持不变,另一组则进行额外的3×3卷积,以进一步提取特征。然后将两组特征图合并、激活并输出。为了弥补第二组中残余路径的缺失,引入了捷径连接以保持梯度流。Neck中用于特征融合的SU-Block2采用了类似的设计,但没有下采样或额外的残差连接,从而提高了参数效率。其定义如下:
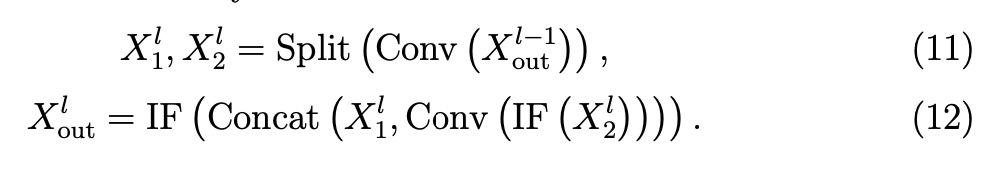
-
SpikeSPP
SpikeSPP模块是空间金字塔池化(SPP)的简化版,如图 5 所示。
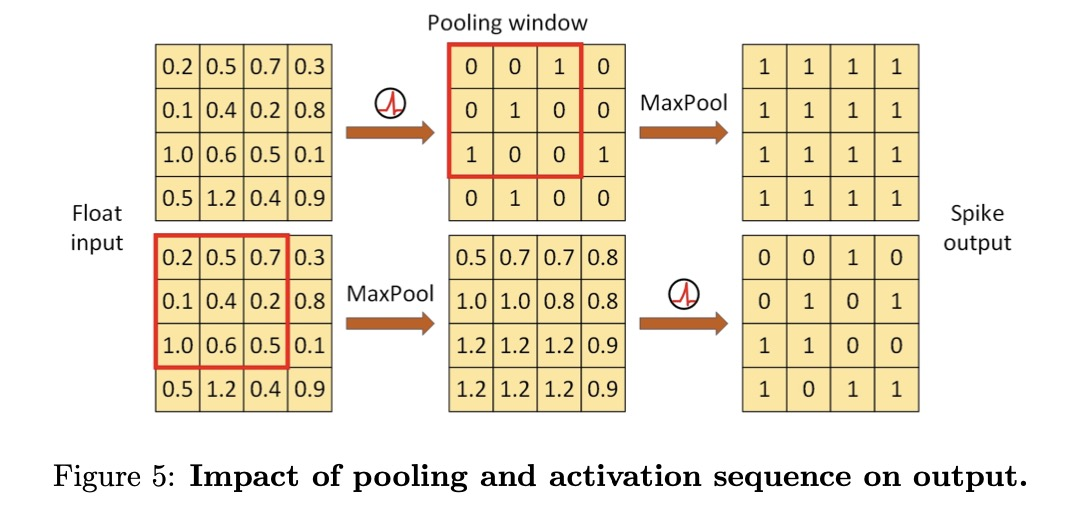
其操作定义如下:
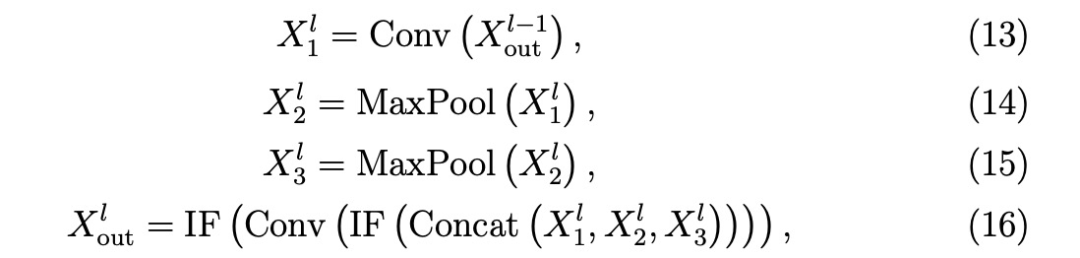
其中,MaxPool(-)表示最大池化,Concat(-)表示沿通道维度的连接。虽然SPP可提供多级池化以提取多尺度特征,但由于尖峰的二进制性质,激活后的池化可能会导致SNN中的大量信息丢失。在水下物体检测中,椒盐噪声非常普遍,激活前的池化可以更好地保存信息。实验结果进一步表明,去掉第三个最大池化层可以在不影响性能的情况下减少计算负荷。由此产生的特征随后被传递给中频神经元,中频神经元以适当的发射率产生尖峰。
-
编码器和检测头
编码器模块将浮点输入图像转换为尖峰图像。它使用传统的卷积和 BN 进行初步特征提取和归一化。生成的特征图被复制 T 次并通过尖峰神经元,产生二进制尖峰输出,完成图像编码过程。
DetectHead采用了YOLOv9的解耦头设计,并进行了修改,以处理基于尖峰的输入和输出。独立的卷积层计算类概率和边界框坐标。多层次特征融合是通过接受来自两个SU-Block2模块的输入来实现的,从而捕捉到更丰富的特征。在DetectHead的最后一个尖峰神经元中,膜电位阈值被设置为无穷大,使其能够在每个时间步长内累积所有浮点数值,从而确保更准确的预测。此外,SeB中的参数n设置为时间步数T,从而缩小了单步输出的范围并稳定了累积的膜电位,从而提高了梯度稳定性。最终的网络输出是通过读取这些神经元的膜电位得到的。
-
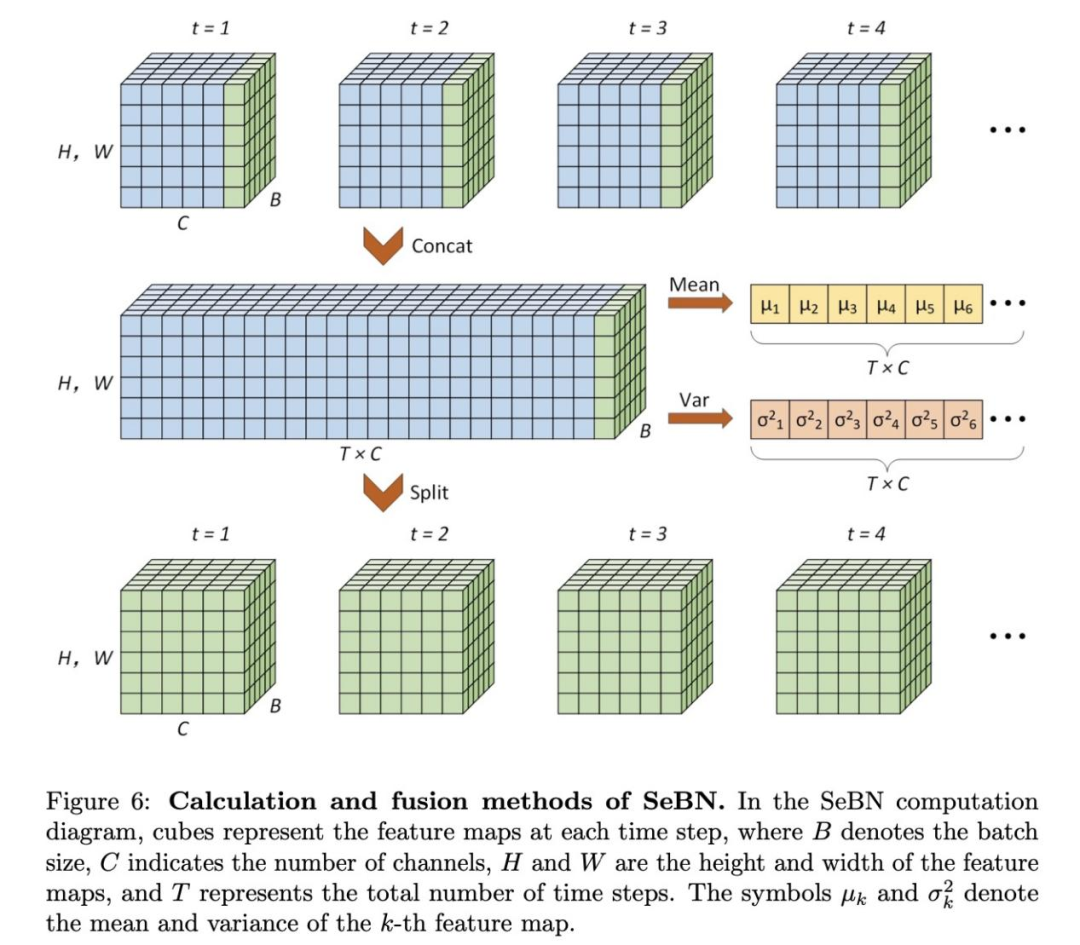
分批归一化
在SNN中,每个尖峰神经元在每个时间步都独立充电和点火,这意味着突触前输入可能随时间呈现不同的分布特征。对所有时间步长的特征图进行归一化处理可以将它们强制归入单一分布,从而掩盖这些差异。通过为每个时间步分配不同的归一化参数,网络可以保留这些时间变化,从而增强其信息容量和表现力。此外,残差网络结构需要在求和之前仔细调整数据分布,以防止神经元过度充电和过度尖峰发射。为了解决这些问题,我们提出了分批归一化(Separated Batch Normalization,SeBN)方法,该方法在优化与残余结构整合的同时,对各时间步的特征图进行独立归一化。SeBN的定义如下:
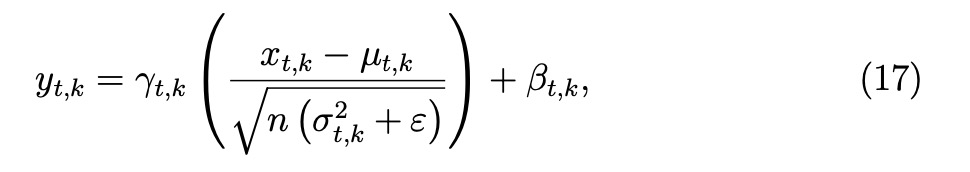
五、Coovally AI模型训练与应用平台
如果你也想要进行模型训练或模型改进,Coovally平台满足你的要求!
Coovally平台整合了国内外开源社区1000+模型算法和各类公开识别数据集,无论是YOLO系列模型还是Transformer系列视觉模型算法,平台全部包含,均可一键下载助力实验研究与产业应用。
而且在该平台上,无需配置环境、修改配置文件等繁琐操作,一键上传数据集,使用模型进行训练与结果预测,全程高速零代码!
具体操作步骤可参考:YOLO11全解析:从原理到实战,全流程体验下一代目标检测
平台链接:https://www.coovally.com
如果你想要另外的模型算法和数据集,欢迎后台或评论区留言,我们找到后会第一时间与您分享!
六、实验结果
-
数据集和实施细节
-
数据集
为了评估我们的模型在水下物体检测方面的性能,我们在URPC2019和UDD数据集上进行了实验。URPC2019数据集是在2019年水下机器人采摘大赛期间发布的,包含4707张标注过的水下图像,涵盖扇贝、海星、海参和海胆四种物体类别。该数据集分为包含3,767幅图像的训练集、包含695幅图像的验证集和包含245幅图像的测试集。UDD数据集包含2,227幅带标签的水下图像,有三个类别(扇贝、鳕鱼和棘鱼),分为包含1,827幅图像的训练集和包含 400幅图像的验证集。
在涉及SeBN的实验中,我们还使用了Pascal VOC 2012数据集,该数据集由11,540张标注了20个物体类别的图像组成。该数据集分为5,717张训练图像和5,823张带有物体检测注释的验证图像。
-
实施细节
所有实验均在单个NVIDIA RTX 2080Ti (22GB) GPU(搭配 AMD Ryzen 5600 CPU和32GB内存)上进行,运行Ubuntu 22.04 LTS、Python 3.8和PyTorch 2.0.0。在训练中,我们模型中的所有神经元都是使用SpikingJelly框架实现的中频神经元,其复位电位Vrst=0,阈值电位Vth=1.0。我们使用SGD优化器,学习率为0.001,批量大小为16,输入图像大小为320×320。模型训练了300次。
-
计算成本
在传统的人工神经网络中,计算成本是以FLOPs(浮点运算次数)来衡量的,它代表浮点运算(加法或乘法)的次数。然而,由于SNN通过离散的尖峰进行通信,计算FLOPs就不那么简单了。相反,我们使用突触运算(SOPs)作为计算成本的度量。SOPs考虑了每一层的卷积操作和前几层的尖峰发射,同时还考虑了神经元充电时的浮点加法。FLOPs和SOPs的公式定义如下:
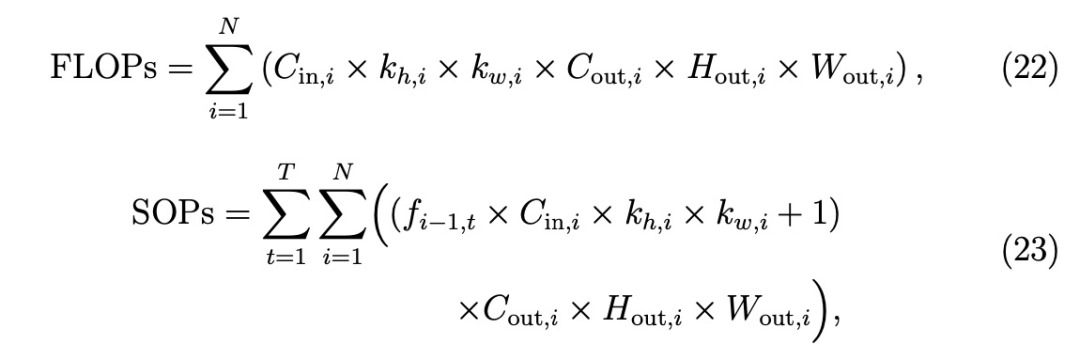
-
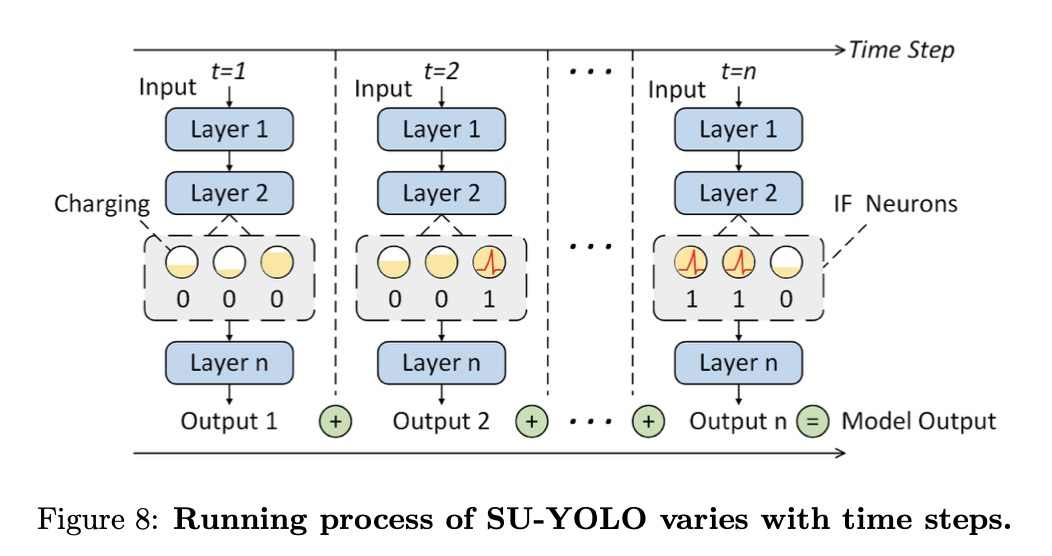
时间步长
在SNN中,时间步长是时间处理的离散单位,在此期间,神经元状态(如膜电位和尖峰生成)和突触动态会得到更新。如图 8 所示,更多的时间步数会增加尖峰发射,从而增强网络的表现力。然而,这也增加了计算开销,降低了推理速度。因此,在检测精度相当的情况下,需要较少时间步骤的方法在能效和实时性方面更具优势。
-
对比实验
我们在URPC2019和UDD上将我们的模型与现有方法进行了比较,结果汇总于表1。我们直接训练的SNN优于通过ANN-SNN转换获得的模型,同时使用的时间步骤更少。与现有的直接训练的SNN相比,我们的模型用更少的参数实现了更高的mAP。此外,它的性能还可与轻量级ANN相媲美。
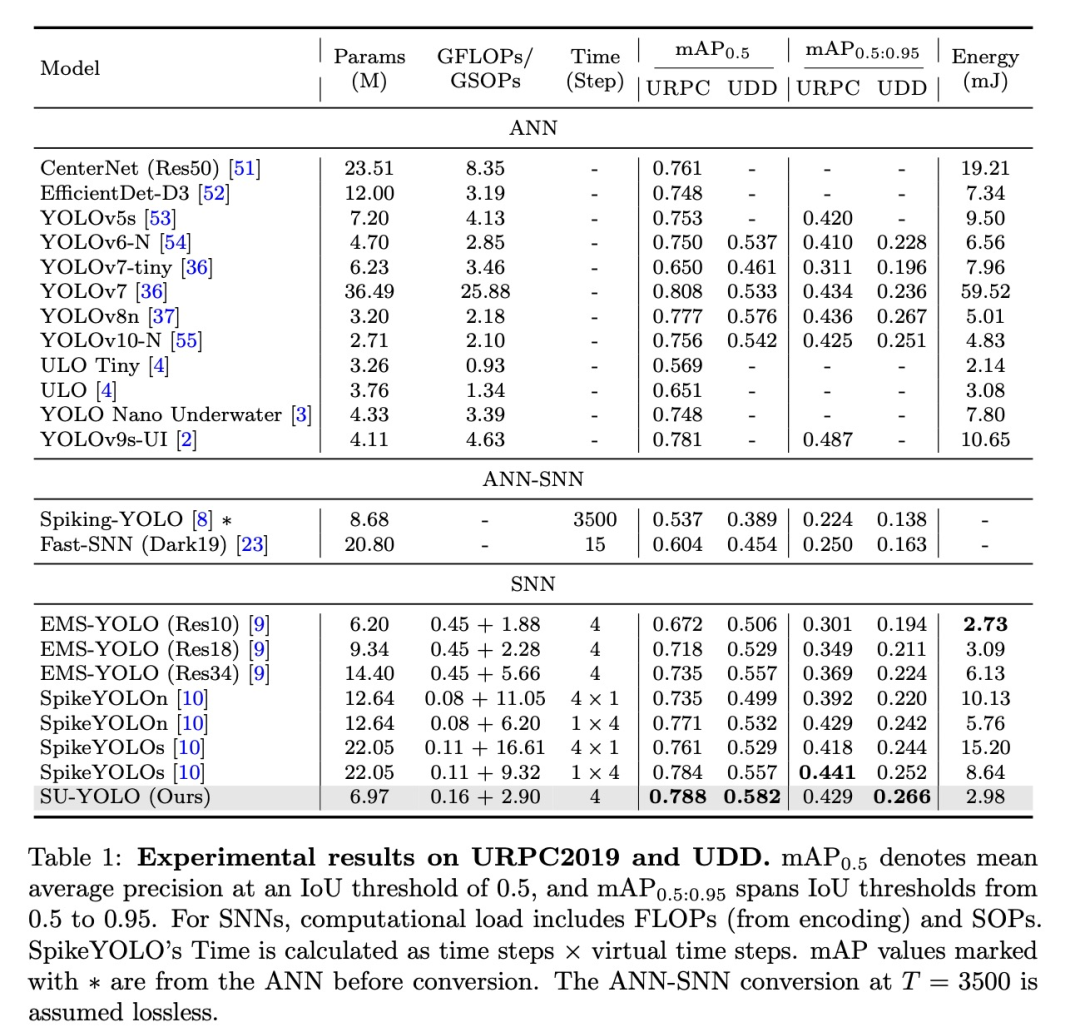
EMS-YOLO目前是基于SNN的物体检测基准。在URPC2019上,基于ResNet10的最轻版本EMS-YOLO的mAP0.5为0.672,能耗为2.73 mJ,而使用ResNet34的较大版本的 mAP0.5为0.735。SpikeYOLO进一步提高了性能,在使用一个时间步和四个虚拟时间步时,mAP0.5达到0.784,能耗为8.64 mJ。我们的方法超越了这些结果,在仅使用 6.97M参数和2.90 GSOPs计算负荷的情况下,mAP0.5达到0.788,而能耗仅为2.98 mJ,在水下物体检测方面明显优于其他SNN方法。
我们还将我们的模型与几种ANN进行了比较。虽然我们的mAP略低于YOLOv7等先进模型,但能耗仅为YOLOv7的5%。与具有类似能耗特征的轻量级ANN相比,我们的模型表现出更高的性能。UDD的其他实验证实,我们的模型始终优于其他方法。
-
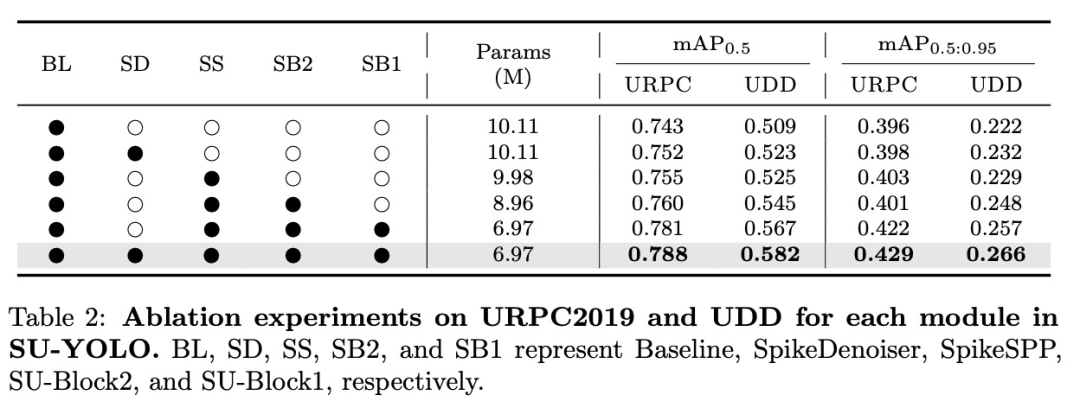
消融实验
为了验证我们提出的模块的有效性,我们使用与对比实验相同的参数设置进行了一系列消融实验。
-
SU-YOLO模块的有效性
我们首先用YOLOv9中的基本残差块RepNCSPELAN4替换 SU- Block1和SU-Block2,用SpikeSPP替换SPPELAN,并用尖峰神经元替换所有激活函数,以保持完全尖峰网络,从而评估了改进模块的效果。在所有配置中,包括特征图的数量和大小在内的整体网络结构保持一致,以作为基线。如表 2所示,每个模块都逐步减少了参数数量并提高了准确度。在应用了所有改进后,mAP0.5提高了4.5%,mAP0.5:0.95提高了3.3%。此外,独立引入SpikeDenoiser模块后,mAP0.5比基线提高了0.9%。
-
SpikeDenoiser的效果
为了评估计算成本,我们在表3中比较了传统图像去噪方法和我们提出的SpikeDenoiser。
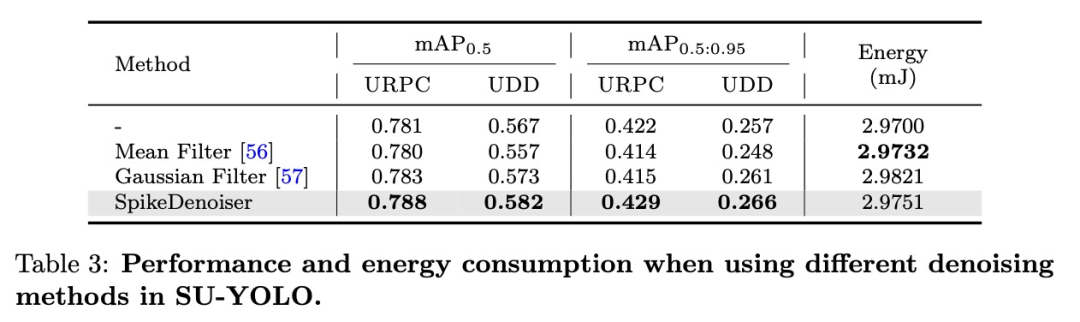
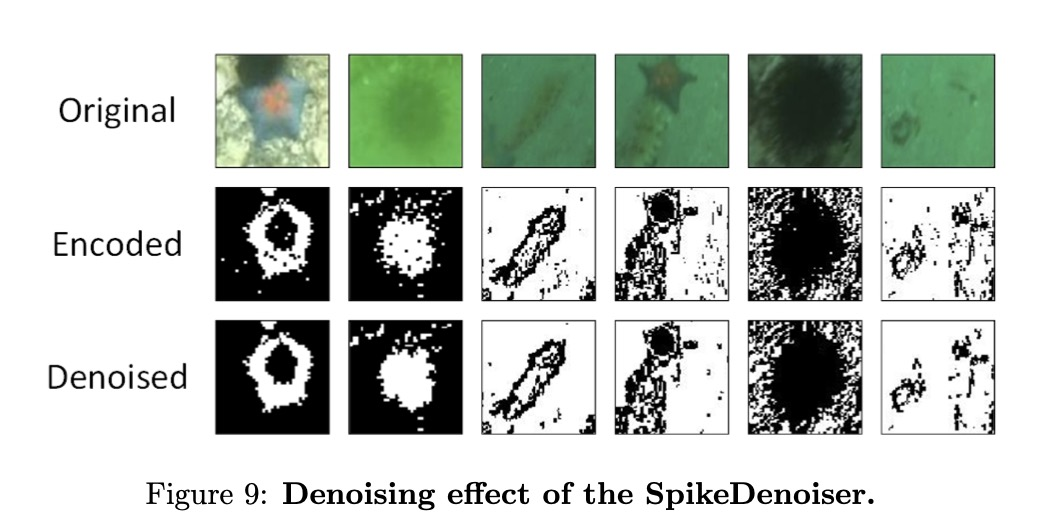
为了公平起见,我们在网络输入之前对原始图像应用了均值滤波器和高斯滤波器,以保持网络的二值性。实验结果表明,均值滤波器可能由于其强烈的模糊效果而降低了mAP,而高斯滤波器则通过更好地保留边缘信息而略微提高了准确度。相比之下,SpikeDenoiser在两个数据集上都能显著改善 mAP,而额外的能量消耗却微乎其微。图9中的可视化结果进一步表明,SpikeDenoiser能有效去除特征图中的噪声,为骨干网络提供更清晰的输入。
-
SeBN的有效性
我们将新型SeBN与传统BN方法进行了比较,如表4所示。使用标准BN的模型表现相对较差,而tdBN和TEBN则有适度改善。
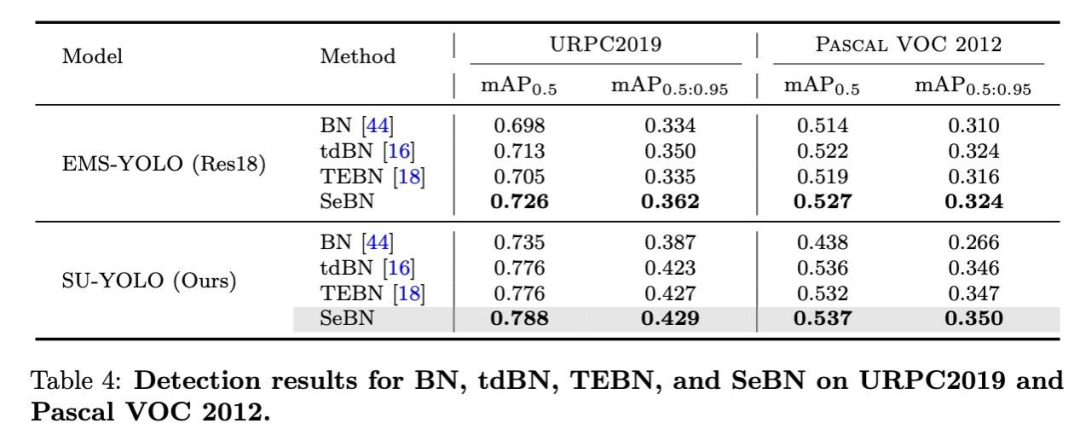
值得注意的是,在大量使用残差块的EMS-YOLO模型中,TEBN的表现不如tdBN,这可能是由于它对残差结构中元素求和处理不当。相比之下,在SU-YOLO模型中,残差块较少TEBN和tdBN表现出相似的性能;用SeBN取代TEBN和tdBN可进一步提高检测精度。我们还在EMS-YOLO和Pascal VOC 2012上对SeBN进行了评估,以检测一般物体,结果发现SeBN始终获得最高的mAP。这些结果表明SeBN具有广泛的适用性,可以很好地推广到其他数据集和 SNN 架构。
为了说明SeBN与其他归一化方法之间的差异,我们在图10中对数据分布进行了可视化处理。这些分布来自SU-YOLO第3层最后残差块之后的输出。结果显示,BN和TEBN的分布具有明显的不稳定性,其平均值和方差在不同的时间步长之间波动明显。特别是,TEBN在t=1时的方差高达2.76,这可能是由于未优化的残差添加放大了输出范围。虽然tdBN的波动较小,但其方差明显偏离了理想的标准正态分布。相比之下,SeBN在每个时间步长上都保持了近似N(0,1)的稳定分布。通过对各时间步长的平均值进行整体比较,进一步证实了SeBN优越的稳定性和性能。
-
残块替换
残差块是特征提取的核心,对检测精度有重大影响。为了评估我们设计的SU-Block的性能,我们在保持整体网络结构不变的情况下,试验了不同的残差块。我们在URPC2019上计算了不同残差块的平均尖峰发射率。如表5所示,采用CSPNet结构的SU-Block的点燃率分别为12.7%、15.4% 和18.8%,高于采用ResNet结构的EMS-Block的点燃率(15.2%、11.9%和11.5%)。这一观察结果与我们的可视化分析相吻合: SU-块能有效缓解尖峰退化,释放更多尖峰,从而增强特征提取。此外,表5显示,使用SU块的SU-YOLO实现了78.8%的出色 mAP0.5,明显高于使用EMS块或ANN版本中使用的残差块所获得的结果。
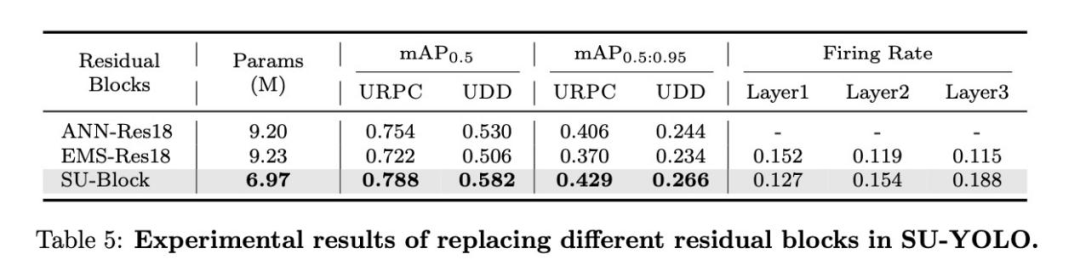
图11显示了检测结果示例,突出表明SU-Block模型检测到了更多物体。这些结果表明,在水下物体检测方面,SU-Block可以达到甚至超过相同规模的ANN残差块的性能。结合SNN的低功耗特性,完全SNN结构可能比混合ANN-SNN架构更具优势。

-
混淆矩阵和精度-召回曲线
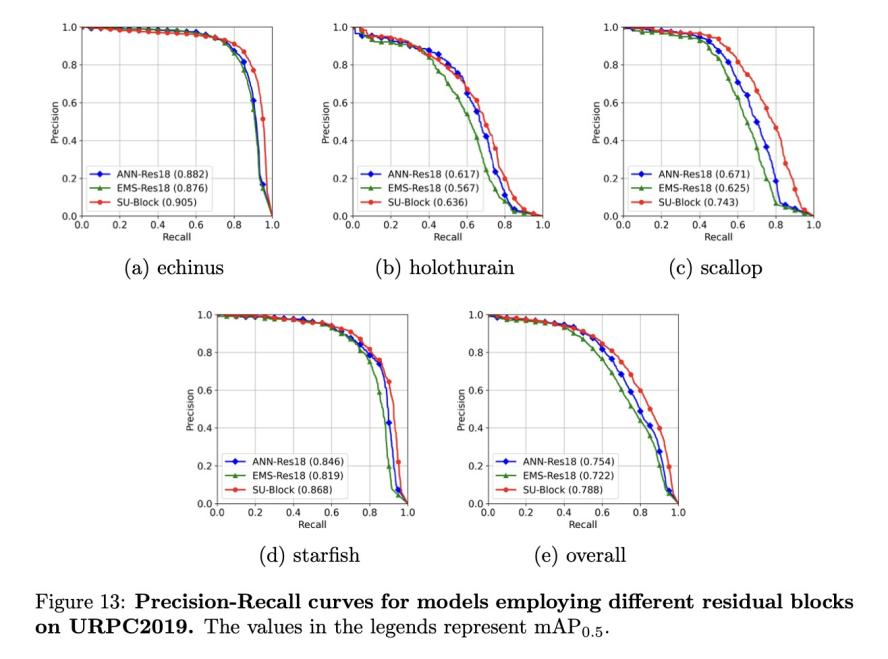
图12中的混淆矩阵说明了模型的分类性能。对于海星和棘鱼,所有三种模型都达到了较高的准确率;然而,对全齿螯虾和扇贝的检测准确率较低,这可能是因为它们的颜色较浅,与水的背景相融合,因而难以区分。值得注意的是,SU-Block 模型在所有物体类别中都表现出了最高的准确率,尤其是在扇贝检测方面分别比ANN-Res18和EMS-Res18高出12%和16%。这表明SU-Block具有卓越的特征提取能力,能够检测到不太显眼的物体。
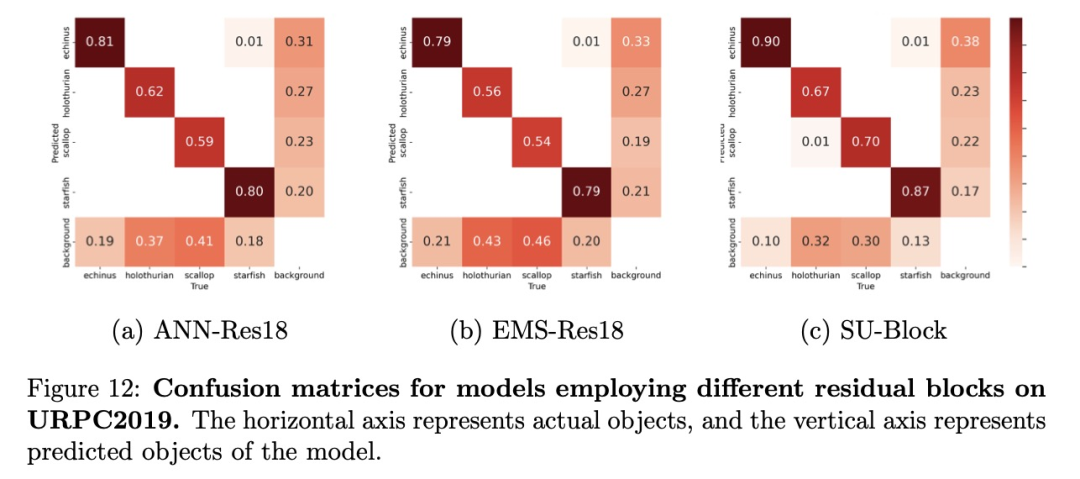
图13中的精度-召回曲线进一步凸显了SU-Block模型的卓越性能,尤其是在扇贝检测方面,其总体mAP0.5为 78.8%,而ANN-Res18为75.4%,EMS-Block为 72.2%。
-
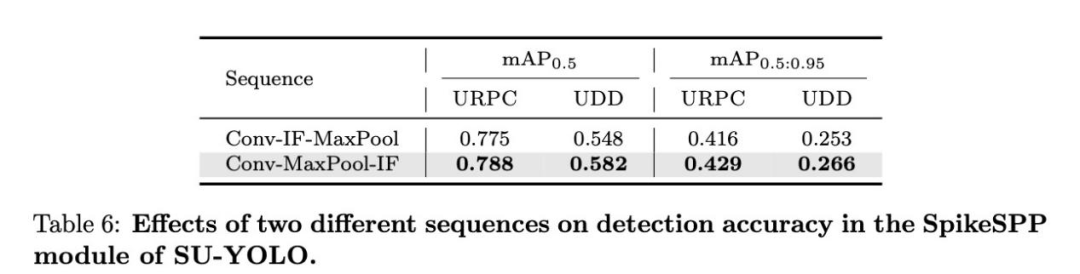
池化和激活顺序
在基于SNN的物体检测中,最大池化和激活操作的顺序对模型性能有很大影响。我们对两种情况进行了实验比较。如图14所示,当在SpikeSPP中先进行池化再进行激活时,生成的特征图会保留更多细节。

表6中的定量结果也证实了这一观察结果:将池化层置于中频神经元之前,URPC2019上的mAP0.5提高了1.3%,UDD上的mAP0.5提高了3.4%,从而证实了我们的分析。
-
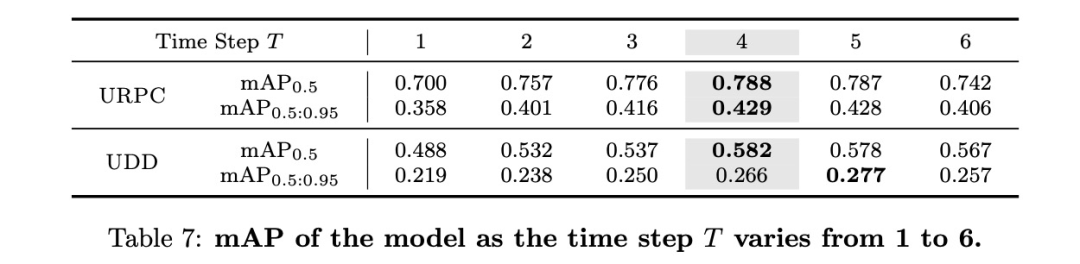
时间步长
SNN中时间步长的选择直接影响性能和计算负荷。如表7所示,当时间步长T设为4时,SU-YOLO可达到最佳精度。因此,我们采用4个时间步长来实现检测精度和功耗之间的最佳平衡。
七、结论
在本研究中,我们提出了用于水下物体检测的轻量级SNN模型SU-YOLO,该模型专为资源有限的平台而设计。为了应对水下图像中的噪声挑战,我们开发了一种基于尖峰的图像去噪方法,该方法在实验中被证明非常有效。此外,我们还引入了SeBN,这是一种针对SNN独特特性而定制的新型批量归一化方法,其性能优于现有的归一化技术。SU-YOLO中精心设计的模块极大地增强了水下环境中的检测能力,实验结果表明,我们的模型在当前的水下物体检测SNN方法中达到了最先进的性能。然而,我们关于能效的结论仍然是理论性的,因为它们是基于估计而非实际硬件测量得出的。
在未来的工作中,我们的目标是进一步提高SU-YOLO的性能,并在物理硬件系统上实现它,以获得更可靠的检测结果。这一进步将促进SNN在工程中的实际应用,并推动水下物体探测技术的进步。此外,我们还计划通过将SU-YOLO架构的适用性扩展到更多数据集和应用中,探索将其推广到更广泛的物体检测任务中。

相关文章:

告别水下模糊!SU-YOLO:轻量化+尖峰神经网络,用“类脑计算”实现水下目标毫秒级识别
目录 一、摘要 二、引言 三、相关工作 SNN 物体检测 水下物体探测 水下图像去噪 归一化 四、方法 水下尖峰YOLO 尖峰干扰器 SU-Block SpikeSPP 编码器和检测头 分批归一化 五、Coovally AI模型训练与应用平台 六、实验结果 数据集和实施细节 数据集 实施细节…...

Three.js 系列专题 8:实战项目 - 构建一个小型 3D 游戏
内容概述 本专题将通过一个实战项目展示 Three.js 的综合应用。游戏包含迷宫生成、角色移动、相机控制和简单的物理碰撞检测(可选)。这将帮助你将之前学到的知识融会贯通。 学习目标 整合几何体、光照、动画和交互知识。实现基本的游戏逻辑和用户控制。可选:使用 Cannon.j…...
)
嵌入式笔试(一)
C语言和嵌入式软件 面试题(共10题 时间30分钟) 1. 请写出下面声明的含义。 int(*s[10])(int);定义了一个数组为s包含十个元素,每个元素都是函数指针,函数的参数为一个int类型,返回值也是int类型2. 选择题 设有一台计算机,它有一条加法指令,每次可计算三个数的和。如果要…...

spark 的流量统计案例
创建一个目录为data...

局域网访问 Redis 方法
局域网访问 Redis 方法 默认情况下,Redis 只允许本机 (127.0.0.1) 访问。如果你想让局域网中的其他设备访问 Redis,需要 修改 Redis 配置,并确保 防火墙放行端口。 方法 1:修改 Redis 配置 1. 修改 redis.conf(或 me…...

LeetCode题五:合并两个有序链表
基本思路其实就是:先建立一个空链表,然后将尾节点放在头结点上; 如果第一个链表节点值较小,那么先将list1插入新链表中,然后将尾节点后移;相同的,第二个也需要比较;移动新链表的指针…...

深入探索 `malloc`:内存分配失败的原因及正确使用规范
文章目录 一、malloc 内存分配失败的常见原因1. 内存不足2. 内存越界访问3. 内存碎片化4. 系统限制5. 错误的使用方式 二、如何正确使用 malloc1. 检查返回值2. 释放内存3. 避免内存越界4. 优化内存使用5. 调整系统参数6. 使用高效的内存分配器 三、总结 在 C 语言中࿰…...

处理Excel的python库openpyxl、xlrd、xlwt、panda区别
openpyxl、xlrd、xlwt、pandas 都能处理 Excel 表格,但用途和适合的场景不同。今天做个总结: 库名功能支持格式读写支持样式备注openpyxl全面的.xlsx处理库.xlsx(Excel2007)✅✅✅首选xlrd读取.xls文件的老牌工具.xls(…...

【C++11】特殊类的设计 单例模式 类型转换
目录 一、特殊类的设计: 1、设计一个不能够拷贝的类: 2、设计一个只能在堆上创建的类 3、设计一个只能在栈上创建的类 4、设计一个不能被继承的类: 二、单例模式: 设计一个只能创建一个对象的类: 饿汉模式&…...
带论文文档1万字以上,文末可获取,系统界面在最后面。)
基于vue框架的助农特色农产品销售系统i7957(程序+源码+数据库+调试部署+开发环境)带论文文档1万字以上,文末可获取,系统界面在最后面。
系统程序文件列表 项目功能:用户,商品分类,农产品信息,特价商品,爱心捐赠 开题报告内容 基于Vue框架的助农特色农产品销售系统开题报告 一、研究背景与意义 (一)研究背景 随着乡村振兴战略的深入实施,特色农产品作为农村经济的重要组成部…...
:ls 命令深入剖析与实践应用(期末、期中复习必备))
Linux 学习笔记(3):ls 命令深入剖析与实践应用(期末、期中复习必备)
前言 一、ls 命令基础语法 命令示例 二、工作目录与 HOME 目录 1.工作目录 2.HOME 目录 三、结语 前言 在 Linux 系统的学习旅程中,基础命令的掌握是迈向熟练操作的关键一步。其中,ls 命令作为我们探索系统文件和目录结构的常用工具,有着…...

最简CNN based RNN源码
1.源码: GitCode - 全球开发者的开源社区,开源代码托管平台 最终的效果: 数据集是20个周期,1024点sin(x)加了偏置。其中用于训练的有1024-300点。最后300点用来进行测试。上面的右侧输出的,其实对应左侧x73之后的波形࿰…...

大模型是如何把向量解码成文字输出的
hidden state 向量 当我们把一句话输入模型后,例如 “Hello world”: token IDs: [15496, 995]经过 Embedding Transformer 层后,会得到每个 token 的中间表示,形状为: hidden_states: (batch_size, seq_len, hidd…...

Elasticsearch:加快 HNSW 图的合并速度
作者:来自 Elastic Thomas Veasey 及 Mayya Sharipova 过去,我们曾讨论过搜索多个 HNSW 图时所面临的一些挑战,以及我们是如何缓解这些问题的。当时,我们也提到了一些计划中的改进措施。本文正是这项工作的成果汇总。 你可能会问…...

Elasticsearch单节点安装手册
Elasticsearch单节点安装手册 以下是一份 Elasticsearch 单节点搭建手册,适用于 Linux 系统(如 CentOS/Ubuntu),供学习和测试环境使用。 Elasticsearch 单节点搭建手册 1. 系统要求 操作系统:Linux(Cent…...

前端用户列表与后端分页协同设计
分页实现方案 在现代Web应用中,用户列表展示与分页是一个常见的功能需求。前端与后端通过API协同工作,使用PageHelper等工具实现高效分页。 例如: 后端实现 (使用PageHelper) public PageResult DishPage(DishPageQueryDTO dishPageQuery…...

MyBatis的第四天学习笔记下
10.MyBatis参数处理 10.1 项目信息 模块名:mybatis-007-param数据库表:t_student表结构: id: 主键name: 姓名age: 年龄height: 身高sex: 性别birth: 出生日期 sql文件: create table t_student ( id bigint auto_increm…...

三类人解决困境的方法
有一个视频讲述了三类人解决困境的方法,视频中有持续流出干净水源的水龙头,一杯装满脏水的玻璃杯。第一类普通人是拿着玻璃杯放到水龙头下不断接水,水龙头一直开着的第二类高手是把脏水倒到水池里,然后打开水龙头接水,…...

蓝桥杯第十一届省赛C++B组真题解析
蓝桥杯第十一届省赛CB组真题解析 八、回文日期https://www.lanqiao.cn/problems/348/learning 方法一:暴力枚举所有的日期,记录有多少个回文日期。 #include <bits/stdc.h> using namespace std; int month[13]{0,31,28,31,30,31,30,31,31,30,31…...

Tailscale 的工作原理*
Tailscale 的核心原理基于 WireGuard VPN,它实现了端到端加密的 点对点(P2P)连接,但在必要时会通过 中继服务器(DERP) 进行中转。整体来说,它是一个 零配置的 Mesh VPN,让所有设备看…...

PyTorch张量范数计算终极指南:从基础到高阶实战
在深度学习领域,张量范数计算是模型正则化、梯度裁剪、特征归一化的核心技术。本文将以20代码实例,深度剖析torch.norm的9大核心用法,并揭示其在Transformer模型中的关键应用场景。 🚀 快速入门(5分钟掌握核心操作&…...

Innovus DRC Violation和Calibre DRC Violation分析和修复案例
今天把小编昨天帮助社区训练营学员远程协助的一个经典案例分享给大家。希望能够帮助到更多需要帮助的人。如果各位想跟小编来系统学习数字后端设计实现的,可以联系小编。 数字IC后端手把手实战教程 | Innovus verify_drc VIA1 DRC Violation解析及脚本自动化修复方…...
)
数据库7(数据定义语句,视图,索引)
1.数据定义语句 SQL数据定义语言(DDL)用于定义和管理数据库结构,包括创建、修改和删除 数据库对象。常见的DDL语句包括CREATE、DROP和ALTER。 它的操作的是对象,区分操作数据的语句:INSERT,DELETE,UPDATE 示例&#x…...

Cadence 修改 铜和pin脚 连接属性 和 光绘参数修改
光绘层叠设置,参考 光绘参数修改, 中英文对照...

秒杀业务的实现过程
一.后台创建秒杀的活动场次信息,并关联到要秒杀的商品或服务; 二.通过定时任务,将秒杀的活动信息和商品服务信息存储到redis; 三.在商品展示页的显眼位置加载秒杀活动信息; 四.用户参与秒杀,创建订单,将…...
时实时获取 COCO 指标(AP):2025最新配置与代码详解 (小白友好 + B站视频))
✅ Ultralytics YOLO 训练(Train)时实时获取 COCO 指标(AP):2025最新配置与代码详解 (小白友好 + B站视频)
✅ YOLO获取COCO指标(4): 训练(Train)启用COCO API评估(实时监控AP指标)| 发论文必看! | Ultralytics | 小白友好 文章目录 一、问题定位二、原理分析三、解决方案与实践案例步骤 1: 在 model.train() 调用中设置 save_jsonTrue步骤 2: 修改 …...
)
java基础 流(Stream)
Stream Stream 的核心概念核心特点 Stream 的操作分类中间操作(Intermediate Operations)终止操作(Terminal Operations) Stream 的流分类顺序流(Sequential Stream)并行流(Parallel Stream&…...

基于springboot+vue的课程管理系统
一、系统架构 前端:vue | element-ui 后端:springboot | mybatis-plus 环境:jdk1.8 | mysql8 | maven | node v16.20.2 | idea 二、代码及数据 三、功能介绍 01. 登录 02. 管理员-首页 03. 管理员-系管理 04. 管理员-专业管理 05. 管…...

android14 keycode 上报 0 解决办法
驱动改完后发现上报了keycode=0 04-07 13:02:33.201 2323 2662 D WindowManager: interceptKeyTq keycode=0 interactive=false keyguardActive=true policyFlags=2000000 04-07 13:02:33.458 2323 2662 D WindowManager: interceptKeyTq keycode=0 interactive=false key…...

小说现代修仙理论
修仙理论 灵魂感应与感知强化:通过特定的修炼方法,感应自身灵魂,以此提升感知能力,使修炼者对周围环境及自身状态的察觉更为敏锐。 生物电的感知与运用 生物电感知:修炼者需凝神静气,感知体内生物…...

6.综合练习1-创建文件
题目: 分析: 本例中使用mkdirs方法创建aaa文件夹。 题目要求是"在当前模块下的aaa文件夹",此时在左侧的目录中,是没有aaa文件夹的,所以要先创建a.txt文件的父级路径aaa文件夹,由于是在当前模块下…...

PostgreSQL的内存管理机制
目录 V1.0PostgreSQL的内存管理机制文件系统缓存作为二级缓存内存切换机制性能影响总结 V2.0PostgreSQL 内存管理机制:双缓存体系验证与笔记完善1. 现有描述验证2. 完善后的内存管理笔记2.1 双缓存体系2.2 其他关键内存区域2.3 验证方法 3. 注意事项 V1.0 PostgreS…...

ReplicaSet、Deployment功能是怎么实现的?
在Kubernetes中,ReplicaSet 和 Deployment 是用于管理 Pod 副本的关键对象。它们各自的功能和实现机制如下: 1. ReplicaSet 功能 管理 Pod 副本:确保指定数量的 Pod 副本一直在运行。如果有 Pod 副本崩溃或被删除,ReplicaSet 会…...

544 eff.c:1761处loop vect 分析
2.6 带有mask的向量数学函数 gcc 支持的svml向量数学函数 32652 GCC currently emits calls to code{vmldExp2}, 32653 code{vmldLn2}, code{vmldLog102}, code{vmldPow2}, 32654 code{vmldTanh2}, code{vmldTan2}, code{vmldAtan2}, code{vmldAtanh2}, 32655 code{vmldCbrt2}…...

搜狗拼音输入法纯净优化版:去广告,更流畅输入体验15.2.0.1758
前言 搜狗输入法电脑版无疑是装机必备的神器。它打字精准,词库丰富全面,功能强大,极大地提升了输入效率。最新版的搜狗拼音输入法更是借助AI技术,让打字变得既准确又高效。而搜狗输入法的去广告精简优化版,通过移除广…...

YOLOv11改进 | YOLOv11引入MobileNetV4
前言: 主要是对该文章YOLOv11改进 | YOLOv11引入MobileNetV4进行复现,以及对一些问题进行解答 1、mobilenetv4核心代码 from typing import Optional import torch import torch.nn as nn import torch.nn.functional as F__all__ [MobileNetV4ConvLa…...

Java中的ArrayList方法
1. 创建 ArrayList 实例 你可以通过多种方式创建 ArrayList 实例: <JAVA> ArrayList<String> list new ArrayList<>(); // 创建一个空的 ArrayList ArrayList<String> list new ArrayList<>(10); // 创建容量为 10 的 ArrayList …...

wordpress 利用 All-in-One WP Migration全站转移
导出导入站点 在插件中查询 All-in-One WP Migration备份并导出全站数据 导入 注意事项: 1.导入部分限制50MB 宝塔解决方案,其他类似,修改php.ini配置文件即可 2. 全站转移需要修改域名 3. 大文件版本,大于1G的可以参考我的…...
全攻略)
零基础教程:Windows电脑安装Linux系统(双系统/虚拟机)全攻略
一、安装方式选择 方案对比表 特性双系统安装虚拟机安装性能原生硬件性能依赖宿主机资源分配磁盘空间需要独立分区(建议50GB)动态分配(默认20GB起)内存占用独占全部内存需手动分配(建议4GB)启动方式开机选…...

聚焦AI与大模型创新,紫光云如何引领云计算行业快速演进?
【全球云观察 | 科技热点关注】 随着近年来AI与大模型的兴起,云计算行业正在发生着一场大变局。 “在2025年春节期间,DeepSeek两周火爆全球,如何进行私域部署成了企业关心的问题。”紫光云公司总裁王燕平强调指出,AI与…...

mapreduce 过程中,maptask的partitioner是在map阶段中具体什么阶段分区的?
在MapReduce的Map阶段中,Partitioner(分区器)的作用发生在map函数输出键值对之后,但在数据被写入磁盘(spill到本地文件)之前。具体流程如下: 分区发生的具体阶段: Map函数处理完成 当…...

找到字符串中所以字母异位词 --- 滑动窗口
目录 一:题目 二:算法原理 三:代码实现 一:题目 题目链接:438. 找到字符串中所有字母异位词 - 力扣(LeetCode) 二:算法原理 三:代码实现 版本一:无co…...

密码破解工具
1. 引言 密码是信息安全的核心之一,而攻击者往往利用各种工具和技术来破解密码。密码破解工具可以分为 离线破解(Offline Cracking) 和 在线破解(Online Cracking) 两大类: 离线破解:攻击者已经获取了加密的密码哈希(hash),可以在本地进行破解,无需与目标系统交互。…...

路由策略在双点双向路由重发布的应用
一、背景叙述 路由重发布通常是解决两个不同路由协议之间的互通问题,也就是路由双向引入。有时候,单点路由重发布在大规模网络中压力较大,缺乏冗余性,于是就有了双点双向路由重发布 问题:但是双点双向路由重发布也会…...

在Python软件中集成智能体:以百度文心一言和阿里通义千问为例
摘要 本文旨在探讨如何在Python软件中集成智能体,具体以百度文心一言和阿里通义千问等大模型生成的智能体为例。文章详细介绍了集成这些智能体的方法,包括环境准备、API调用、代码实现等步骤,并提供了相关的示例代码。通过集成这些智能体&…...

day22 学习笔记
文章目录 前言一、遍历1.行遍历2.列遍历3.直接遍历 二、排序三、去重四、分组 前言 通过今天的学习,我掌握了对Pandas的数据类型进行基本操作,包括遍历,去重,排序,分组 一、遍历 1.行遍历 intertuples方法用于遍历D…...

谈Linux之磁盘管理——万字详解
—— 小 峰 编 程 目录 一、硬盘的基本知识 1.了解硬盘的接口类型 2. 硬盘命名方式 3. 磁盘设备的命名 4. HP服务器硬盘 5. 硬盘的分区方式 二、 基本分区管理 1. 磁盘划分思路 2. 分区 2.1 MBR分区 2.2GPT分区 3.格式化—命令:mkfs 4.挂载 4.1手动挂…...

做好一个测试开发工程师第二阶段:java入门:idea新建一个project后默认生成的.idea/src/out文件文件夹代表什么意思?
时间:2025.4.8 一、前言 关于Java与idea工具安装不再展开,网上很多教程,可以自己去看 二、project建立后默认各文件夹代表意思 1、首先new---->project后会得到文件如图 其中: .idea文件代表:存储这个项目的历史…...

伪代码的定义与应用场景
李升伟 整理 伪代码(Pseudocode)是一种用近似自然语言(通常是英语或开发者熟悉的语言)和简单语法描述的算法逻辑工具。它介于自然语言和编程语言之间,不依赖具体语法规则,专注于表达思路,是编程…...

/sys/fs/cgroup/memory/memory.stat 关键指标说明
目录 1. **total_rss**2. **total_inactive_file**3. **total_active_file**4. **shmem**5. **其他相关指标**总结 以下是/sys/fs/cgroup/memory/memory.stat文件中一些关键指标的详细介绍,特别是与PostgreSQL相关的指标: 1. total_rss 定义࿱…...