YOLOv11改进 | YOLOv11引入MobileNetV4
前言:
主要是对该文章YOLOv11改进 | YOLOv11引入MobileNetV4进行复现,以及对一些问题进行解答
1、mobilenetv4核心代码
from typing import Optional
import torch
import torch.nn as nn
import torch.nn.functional as F__all__ = ['MobileNetV4ConvLarge', 'MobileNetV4ConvSmall', 'MobileNetV4ConvMedium', 'MobileNetV4HybridMedium', 'MobileNetV4HybridLarge']MNV4ConvSmall_BLOCK_SPECS = {"conv0": {"block_name": "convbn","num_blocks": 1,"block_specs": [[3, 32, 3, 2]]},"layer1": {"block_name": "convbn","num_blocks": 2,"block_specs": [[32, 32, 3, 2],[32, 32, 1, 1]]},"layer2": {"block_name": "convbn","num_blocks": 2,"block_specs": [[32, 96, 3, 2],[96, 64, 1, 1]]},"layer3": {"block_name": "uib","num_blocks": 6,"block_specs": [[64, 96, 5, 5, True, 2, 3],[96, 96, 0, 3, True, 1, 2],[96, 96, 0, 3, True, 1, 2],[96, 96, 0, 3, True, 1, 2],[96, 96, 0, 3, True, 1, 2],[96, 96, 3, 0, True, 1, 4],]},"layer4": {"block_name": "uib","num_blocks": 6,"block_specs": [[96, 128, 3, 3, True, 2, 6],[128, 128, 5, 5, True, 1, 4],[128, 128, 0, 5, True, 1, 4],[128, 128, 0, 5, True, 1, 3],[128, 128, 0, 3, True, 1, 4],[128, 128, 0, 3, True, 1, 4],]},"layer5": {"block_name": "convbn","num_blocks": 2,"block_specs": [[128, 960, 1, 1],[960, 1280, 1, 1]]}
}MNV4ConvMedium_BLOCK_SPECS = {"conv0": {"block_name": "convbn","num_blocks": 1,"block_specs": [[3, 32, 3, 2]]},"layer1": {"block_name": "fused_ib","num_blocks": 1,"block_specs": [[32, 48, 2, 4.0, True]]},"layer2": {"block_name": "uib","num_blocks": 2,"block_specs": [[48, 80, 3, 5, True, 2, 4],[80, 80, 3, 3, True, 1, 2]]},"layer3": {"block_name": "uib","num_blocks": 8,"block_specs": [[80, 160, 3, 5, True, 2, 6],[160, 160, 3, 3, True, 1, 4],[160, 160, 3, 3, True, 1, 4],[160, 160, 3, 5, True, 1, 4],[160, 160, 3, 3, True, 1, 4],[160, 160, 3, 0, True, 1, 4],[160, 160, 0, 0, True, 1, 2],[160, 160, 3, 0, True, 1, 4]]},"layer4": {"block_name": "uib","num_blocks": 11,"block_specs": [[160, 256, 5, 5, True, 2, 6],[256, 256, 5, 5, True, 1, 4],[256, 256, 3, 5, True, 1, 4],[256, 256, 3, 5, True, 1, 4],[256, 256, 0, 0, True, 1, 4],[256, 256, 3, 0, True, 1, 4],[256, 256, 3, 5, True, 1, 2],[256, 256, 5, 5, True, 1, 4],[256, 256, 0, 0, True, 1, 4],[256, 256, 0, 0, True, 1, 4],[256, 256, 5, 0, True, 1, 2]]},"layer5": {"block_name": "convbn","num_blocks": 2,"block_specs": [[256, 960, 1, 1],[960, 1280, 1, 1]]}
}MNV4ConvLarge_BLOCK_SPECS = {"conv0": {"block_name": "convbn","num_blocks": 1,"block_specs": [[3, 24, 3, 2]]},"layer1": {"block_name": "fused_ib","num_blocks": 1,"block_specs": [[24, 48, 2, 4.0, True]]},"layer2": {"block_name": "uib","num_blocks": 2,"block_specs": [[48, 96, 3, 5, True, 2, 4],[96, 96, 3, 3, True, 1, 4]]},"layer3": {"block_name": "uib","num_blocks": 11,"block_specs": [[96, 192, 3, 5, True, 2, 4],[192, 192, 3, 3, True, 1, 4],[192, 192, 3, 3, True, 1, 4],[192, 192, 3, 3, True, 1, 4],[192, 192, 3, 5, True, 1, 4],[192, 192, 5, 3, True, 1, 4],[192, 192, 5, 3, True, 1, 4],[192, 192, 5, 3, True, 1, 4],[192, 192, 5, 3, True, 1, 4],[192, 192, 5, 3, True, 1, 4],[192, 192, 3, 0, True, 1, 4]]},"layer4": {"block_name": "uib","num_blocks": 13,"block_specs": [[192, 512, 5, 5, True, 2, 4],[512, 512, 5, 5, True, 1, 4],[512, 512, 5, 5, True, 1, 4],[512, 512, 5, 5, True, 1, 4],[512, 512, 5, 0, True, 1, 4],[512, 512, 5, 3, True, 1, 4],[512, 512, 5, 0, True, 1, 4],[512, 512, 5, 0, True, 1, 4],[512, 512, 5, 3, True, 1, 4],[512, 512, 5, 5, True, 1, 4],[512, 512, 5, 0, True, 1, 4],[512, 512, 5, 0, True, 1, 4],[512, 512, 5, 0, True, 1, 4]]},"layer5": {"block_name": "convbn","num_blocks": 2,"block_specs": [[512, 960, 1, 1],[960, 1280, 1, 1]]}
}def mhsa(num_heads, key_dim, value_dim, px):if px == 24:kv_strides = 2elif px == 12:kv_strides = 1query_h_strides = 1query_w_strides = 1use_layer_scale = Trueuse_multi_query = Trueuse_residual = Truereturn [num_heads, key_dim, value_dim, query_h_strides, query_w_strides, kv_strides,use_layer_scale, use_multi_query, use_residual]MNV4HybridConvMedium_BLOCK_SPECS = {"conv0": {"block_name": "convbn","num_blocks": 1,"block_specs": [[3, 32, 3, 2]]},"layer1": {"block_name": "fused_ib","num_blocks": 1,"block_specs": [[32, 48, 2, 4.0, True]]},"layer2": {"block_name": "uib","num_blocks": 2,"block_specs": [[48, 80, 3, 5, True, 2, 4],[80, 80, 3, 3, True, 1, 2]]},"layer3": {"block_name": "uib","num_blocks": 8,"block_specs": [[80, 160, 3, 5, True, 2, 6],[160, 160, 0, 0, True, 1, 2],[160, 160, 3, 3, True, 1, 4],[160, 160, 3, 5, True, 1, 4, mhsa(4, 64, 64, 24)],[160, 160, 3, 3, True, 1, 4, mhsa(4, 64, 64, 24)],[160, 160, 3, 0, True, 1, 4, mhsa(4, 64, 64, 24)],[160, 160, 3, 3, True, 1, 4, mhsa(4, 64, 64, 24)],[160, 160, 3, 0, True, 1, 4]]},"layer4": {"block_name": "uib","num_blocks": 12,"block_specs": [[160, 256, 5, 5, True, 2, 6],[256, 256, 5, 5, True, 1, 4],[256, 256, 3, 5, True, 1, 4],[256, 256, 3, 5, True, 1, 4],[256, 256, 0, 0, True, 1, 2],[256, 256, 3, 5, True, 1, 2],[256, 256, 0, 0, True, 1, 2],[256, 256, 0, 0, True, 1, 4, mhsa(4, 64, 64, 12)],[256, 256, 3, 0, True, 1, 4, mhsa(4, 64, 64, 12)],[256, 256, 5, 5, True, 1, 4, mhsa(4, 64, 64, 12)],[256, 256, 5, 0, True, 1, 4, mhsa(4, 64, 64, 12)],[256, 256, 5, 0, True, 1, 4]]},"layer5": {"block_name": "convbn","num_blocks": 2,"block_specs": [[256, 960, 1, 1],[960, 1280, 1, 1]]}
}MNV4HybridConvLarge_BLOCK_SPECS = {"conv0": {"block_name": "convbn","num_blocks": 1,"block_specs": [[3, 24, 3, 2]]},"layer1": {"block_name": "fused_ib","num_blocks": 1,"block_specs": [[24, 48, 2, 4.0, True]]},"layer2": {"block_name": "uib","num_blocks": 2,"block_specs": [[48, 96, 3, 5, True, 2, 4],[96, 96, 3, 3, True, 1, 4]]},"layer3": {"block_name": "uib","num_blocks": 11,"block_specs": [[96, 192, 3, 5, True, 2, 4],[192, 192, 3, 3, True, 1, 4],[192, 192, 3, 3, True, 1, 4],[192, 192, 3, 3, True, 1, 4],[192, 192, 3, 5, True, 1, 4],[192, 192, 5, 3, True, 1, 4],[192, 192, 5, 3, True, 1, 4, mhsa(8, 48, 48, 24)],[192, 192, 5, 3, True, 1, 4, mhsa(8, 48, 48, 24)],[192, 192, 5, 3, True, 1, 4, mhsa(8, 48, 48, 24)],[192, 192, 5, 3, True, 1, 4, mhsa(8, 48, 48, 24)],[192, 192, 3, 0, True, 1, 4]]},"layer4": {"block_name": "uib","num_blocks": 14,"block_specs": [[192, 512, 5, 5, True, 2, 4],[512, 512, 5, 5, True, 1, 4],[512, 512, 5, 5, True, 1, 4],[512, 512, 5, 5, True, 1, 4],[512, 512, 5, 0, True, 1, 4],[512, 512, 5, 3, True, 1, 4],[512, 512, 5, 0, True, 1, 4],[512, 512, 5, 0, True, 1, 4],[512, 512, 5, 3, True, 1, 4],[512, 512, 5, 5, True, 1, 4, mhsa(8, 64, 64, 12)],[512, 512, 5, 0, True, 1, 4, mhsa(8, 64, 64, 12)],[512, 512, 5, 0, True, 1, 4, mhsa(8, 64, 64, 12)],[512, 512, 5, 0, True, 1, 4, mhsa(8, 64, 64, 12)],[512, 512, 5, 0, True, 1, 4]]},"layer5": {"block_name": "convbn","num_blocks": 2,"block_specs": [[512, 960, 1, 1],[960, 1280, 1, 1]]}
}MODEL_SPECS = {"MobileNetV4ConvSmall": MNV4ConvSmall_BLOCK_SPECS,"MobileNetV4ConvMedium": MNV4ConvMedium_BLOCK_SPECS,"MobileNetV4ConvLarge": MNV4ConvLarge_BLOCK_SPECS,"MobileNetV4HybridMedium": MNV4HybridConvMedium_BLOCK_SPECS,"MobileNetV4HybridLarge": MNV4HybridConvLarge_BLOCK_SPECS
}def make_divisible(value: float,divisor: int,min_value: Optional[float] = None,round_down_protect: bool = True,
) -> int:"""This function is copied from here"https://github.com/tensorflow/models/blob/master/official/vision/modeling/layers/nn_layers.py"This is to ensure that all layers have channels that are divisible by 8.Args:value: A `float` of original value.divisor: An `int` of the divisor that need to be checked upon.min_value: A `float` of minimum value threshold.round_down_protect: A `bool` indicating whether round down more than 10%will be allowed.Returns:The adjusted value in `int` that is divisible against divisor."""if min_value is None:min_value = divisornew_value = max(min_value, int(value + divisor / 2) // divisor * divisor)# Make sure that round down does not go down by more than 10%.if round_down_protect and new_value < 0.9 * value:new_value += divisorreturn int(new_value)def conv_2d(inp, oup, kernel_size=3, stride=1, groups=1, bias=False, norm=True, act=True):conv = nn.Sequential()padding = (kernel_size - 1) // 2conv.add_module('conv', nn.Conv2d(inp, oup, kernel_size, stride, padding, bias=bias, groups=groups))if norm:conv.add_module('BatchNorm2d', nn.BatchNorm2d(oup))if act:conv.add_module('Activation', nn.ReLU6())return convclass InvertedResidual(nn.Module):def __init__(self, inp, oup, stride, expand_ratio, act=False, squeeze_excitation=False):super(InvertedResidual, self).__init__()self.stride = strideassert stride in [1, 2]hidden_dim = int(round(inp * expand_ratio))self.block = nn.Sequential()if expand_ratio != 1:self.block.add_module('exp_1x1', conv_2d(inp, hidden_dim, kernel_size=3, stride=stride))if squeeze_excitation:self.block.add_module('conv_3x3',conv_2d(hidden_dim, hidden_dim, kernel_size=3, stride=stride, groups=hidden_dim))self.block.add_module('red_1x1', conv_2d(hidden_dim, oup, kernel_size=1, stride=1, act=act))self.use_res_connect = self.stride == 1 and inp == oupdef forward(self, x):if self.use_res_connect:return x + self.block(x)else:return self.block(x)class UniversalInvertedBottleneckBlock(nn.Module):def __init__(self,inp,oup,start_dw_kernel_size,middle_dw_kernel_size,middle_dw_downsample,stride,expand_ratio):"""An inverted bottleneck block with optional depthwises.Referenced from here https://github.com/tensorflow/models/blob/master/official/vision/modeling/layers/nn_blocks.py"""super().__init__()# Starting depthwise conv.self.start_dw_kernel_size = start_dw_kernel_sizeif self.start_dw_kernel_size:stride_ = stride if not middle_dw_downsample else 1self._start_dw_ = conv_2d(inp, inp, kernel_size=start_dw_kernel_size, stride=stride_, groups=inp, act=False)# Expansion with 1x1 convs.expand_filters = make_divisible(inp * expand_ratio, 8)self._expand_conv = conv_2d(inp, expand_filters, kernel_size=1)# Middle depthwise conv.self.middle_dw_kernel_size = middle_dw_kernel_sizeif self.middle_dw_kernel_size:stride_ = stride if middle_dw_downsample else 1self._middle_dw = conv_2d(expand_filters, expand_filters, kernel_size=middle_dw_kernel_size, stride=stride_,groups=expand_filters)# Projection with 1x1 convs.self._proj_conv = conv_2d(expand_filters, oup, kernel_size=1, stride=1, act=False)# Ending depthwise conv.# this not used# _end_dw_kernel_size = 0# self._end_dw = conv_2d(oup, oup, kernel_size=_end_dw_kernel_size, stride=stride, groups=inp, act=False)def forward(self, x):if self.start_dw_kernel_size:x = self._start_dw_(x)# print("_start_dw_", x.shape)x = self._expand_conv(x)# print("_expand_conv", x.shape)if self.middle_dw_kernel_size:x = self._middle_dw(x)# print("_middle_dw", x.shape)x = self._proj_conv(x)# print("_proj_conv", x.shape)return xclass MultiQueryAttentionLayerWithDownSampling(nn.Module):def __init__(self, inp, num_heads, key_dim, value_dim, query_h_strides, query_w_strides, kv_strides,dw_kernel_size=3, dropout=0.0):"""Multi Query Attention with spatial downsampling.Referenced from here https://github.com/tensorflow/models/blob/master/official/vision/modeling/layers/nn_blocks.py3 parameters are introduced for the spatial downsampling:1. kv_strides: downsampling factor on Key and Values only.2. query_h_strides: vertical strides on Query only.3. query_w_strides: horizontal strides on Query only.This is an optimized version.1. Projections in Attention is explict written out as 1x1 Conv2D.2. Additional reshapes are introduced to bring a up to 3x speed up."""super().__init__()self.num_heads = num_headsself.key_dim = key_dimself.value_dim = value_dimself.query_h_strides = query_h_stridesself.query_w_strides = query_w_stridesself.kv_strides = kv_stridesself.dw_kernel_size = dw_kernel_sizeself.dropout = dropoutself.head_dim = key_dim // num_headsif self.query_h_strides > 1 or self.query_w_strides > 1:self._query_downsampling_norm = nn.BatchNorm2d(inp)self._query_proj = conv_2d(inp, num_heads * key_dim, 1, 1, norm=False, act=False)if self.kv_strides > 1:self._key_dw_conv = conv_2d(inp, inp, dw_kernel_size, kv_strides, groups=inp, norm=True, act=False)self._value_dw_conv = conv_2d(inp, inp, dw_kernel_size, kv_strides, groups=inp, norm=True, act=False)self._key_proj = conv_2d(inp, key_dim, 1, 1, norm=False, act=False)self._value_proj = conv_2d(inp, key_dim, 1, 1, norm=False, act=False)self._output_proj = conv_2d(num_heads * key_dim, inp, 1, 1, norm=False, act=False)self.dropout = nn.Dropout(p=dropout)def forward(self, x):batch_size, seq_length, _, _ = x.size()if self.query_h_strides > 1 or self.query_w_strides > 1:q = F.avg_pool2d(self.query_h_stride, self.query_w_stride)q = self._query_downsampling_norm(q)q = self._query_proj(q)else:q = self._query_proj(x)px = q.size(2)q = q.view(batch_size, self.num_heads, -1, self.key_dim) # [batch_size, num_heads, seq_length, key_dim]if self.kv_strides > 1:k = self._key_dw_conv(x)k = self._key_proj(k)v = self._value_dw_conv(x)v = self._value_proj(v)else:k = self._key_proj(x)v = self._value_proj(x)k = k.view(batch_size, self.key_dim, -1) # [batch_size, key_dim, seq_length]v = v.view(batch_size, -1, self.key_dim) # [batch_size, seq_length, key_dim]# calculate attn scoreattn_score = torch.matmul(q, k) / (self.head_dim ** 0.5)attn_score = self.dropout(attn_score)attn_score = F.softmax(attn_score, dim=-1)context = torch.matmul(attn_score, v)context = context.view(batch_size, self.num_heads * self.key_dim, px, px)output = self._output_proj(context)return outputclass MNV4LayerScale(nn.Module):def __init__(self, init_value):"""LayerScale as introduced in CaiT: https://arxiv.org/abs/2103.17239Referenced from here https://github.com/tensorflow/models/blob/master/official/vision/modeling/layers/nn_blocks.pyAs used in MobileNetV4.Attributes:init_value (float): value to initialize the diagonal matrix of LayerScale."""super().__init__()self.init_value = init_valuedef forward(self, x):gamma = self.init_value * torch.ones(x.size(-1), dtype=x.dtype, device=x.device)return x * gammaclass MultiHeadSelfAttentionBlock(nn.Module):def __init__(self,inp,num_heads,key_dim,value_dim,query_h_strides,query_w_strides,kv_strides,use_layer_scale,use_multi_query,use_residual=True):super().__init__()self.query_h_strides = query_h_stridesself.query_w_strides = query_w_stridesself.kv_strides = kv_stridesself.use_layer_scale = use_layer_scaleself.use_multi_query = use_multi_queryself.use_residual = use_residualself._input_norm = nn.BatchNorm2d(inp)if self.use_multi_query:self.multi_query_attention = MultiQueryAttentionLayerWithDownSampling(inp, num_heads, key_dim, value_dim, query_h_strides, query_w_strides, kv_strides)else:self.multi_head_attention = nn.MultiheadAttention(inp, num_heads, kdim=key_dim)if self.use_layer_scale:self.layer_scale_init_value = 1e-5self.layer_scale = MNV4LayerScale(self.layer_scale_init_value)def forward(self, x):# Not using CPE, skipped# input normshortcut = xx = self._input_norm(x)# multi queryif self.use_multi_query:x = self.multi_query_attention(x)else:x = self.multi_head_attention(x, x)# layer scaleif self.use_layer_scale:x = self.layer_scale(x)# use residualif self.use_residual:x = x + shortcutreturn xdef build_blocks(layer_spec):if not layer_spec.get('block_name'):return nn.Sequential()block_names = layer_spec['block_name']layers = nn.Sequential()if block_names == "convbn":schema_ = ['inp', 'oup', 'kernel_size', 'stride']for i in range(layer_spec['num_blocks']):args = dict(zip(schema_, layer_spec['block_specs'][i]))layers.add_module(f"convbn_{i}", conv_2d(**args))elif block_names == "uib":schema_ = ['inp', 'oup', 'start_dw_kernel_size', 'middle_dw_kernel_size', 'middle_dw_downsample', 'stride','expand_ratio', 'msha']for i in range(layer_spec['num_blocks']):args = dict(zip(schema_, layer_spec['block_specs'][i]))msha = args.pop("msha") if "msha" in args else 0layers.add_module(f"uib_{i}", UniversalInvertedBottleneckBlock(**args))if msha:msha_schema_ = ["inp", "num_heads", "key_dim", "value_dim", "query_h_strides", "query_w_strides", "kv_strides","use_layer_scale", "use_multi_query", "use_residual"]args = dict(zip(msha_schema_, [args['oup']] + (msha)))layers.add_module(f"msha_{i}", MultiHeadSelfAttentionBlock(**args))elif block_names == "fused_ib":schema_ = ['inp', 'oup', 'stride', 'expand_ratio', 'act']for i in range(layer_spec['num_blocks']):args = dict(zip(schema_, layer_spec['block_specs'][i]))layers.add_module(f"fused_ib_{i}", InvertedResidual(**args))else:raise NotImplementedErrorreturn layersclass MobileNetV4(nn.Module):def __init__(self, model):# MobileNetV4ConvSmall MobileNetV4ConvMedium MobileNetV4ConvLarge# MobileNetV4HybridMedium MobileNetV4HybridLarge"""Params to initiate MobilenNetV4Args:model : support 5 types of models as indicated in"https://github.com/tensorflow/models/blob/master/official/vision/modeling/backbones/mobilenet.py""""super().__init__()assert model in MODEL_SPECS.keys()self.model = modelself.spec = MODEL_SPECS[self.model]# conv0self.conv0 = build_blocks(self.spec['conv0'])# layer1self.layer1 = build_blocks(self.spec['layer1'])# layer2self.layer2 = build_blocks(self.spec['layer2'])# layer3self.layer3 = build_blocks(self.spec['layer3'])# layer4self.layer4 = build_blocks(self.spec['layer4'])# layer5self.layer5 = build_blocks(self.spec['layer5'])self.width_list = [i.size(1) for i in self.forward(torch.randn(1, 3, 640, 640))]def forward(self, x):x0 = self.conv0(x)x1 = self.layer1(x0)x2 = self.layer2(x1)x3 = self.layer3(x2)x4 = self.layer4(x3)# x5 = self.layer5(x4)# x5 = nn.functional.adaptive_avg_pool2d(x5, 1)return [x1, x2, x3, x4]def MobileNetV4ConvSmall():model = MobileNetV4('MobileNetV4ConvSmall')return modeldef MobileNetV4ConvMedium():model = MobileNetV4('MobileNetV4ConvMedium')return modeldef MobileNetV4ConvLarge():model = MobileNetV4('MobileNetV4ConvLarge')return modeldef MobileNetV4HybridMedium():model = MobileNetV4('MobileNetV4HybridMedium')return modeldef MobileNetV4HybridLarge():model = MobileNetV4('MobileNetV4HybridLarge')return modelif __name__ == "__main__":# Generating Sample imageimage_size = (1, 3, 640, 640)image = torch.rand(*image_size)# Modelmodel = MobileNetV4HybridLarge()out = model(image)for i in range(len(out)):print(out[i].shape)2、YOLOv11中添加MobileNetV4方式
注:进行这一步时,要在ultralytics安装包所在文件夹里进行修改,否则会出现以下报错信息:
WARNING ⚠️ no model scale passed. Assuming scale='n'. Traceback (most recent call last): File "/home/jetson/Desktop/ultralytics/data/train.py", line 13, in <module> model = YOLO(model_yaml_path, task='classify').load(pre_model_name) File "/usr/local/lib/python3.10/dist-packages/ultralytics/models/yolo/model.py", line 23, in __init__ super().__init__(model=model, task=task, verbose=verbose) File "/usr/local/lib/python3.10/dist-packages/ultralytics/engine/model.py", line 144, in __init__ self._new(model, task=task, verbose=verbose) File "/usr/local/lib/python3.10/dist-packages/ultralytics/engine/model.py", line 255, in _new self.model = (model or self._smart_load("model"))(cfg_dict, verbose=verbose and RANK == -1) # build model File "/usr/local/lib/python3.10/dist-packages/ultralytics/nn/tasks.py", line 437, in __init__ self._from_yaml(cfg, ch, nc, verbose) File "/usr/local/lib/python3.10/dist-packages/ultralytics/nn/tasks.py", line 450, in _from_yaml self.model, self.save = parse_model(deepcopy(self.yaml), ch=ch, verbose=verbose) # model, savelist File "/usr/local/lib/python3.10/dist-packages/ultralytics/nn/tasks.py", line 1018, in parse_model else globals()[m] KeyError: 'MobileNetV4ConvSmall'
2.1 在ultralytics/nn下新建Extramodule文件夹,并在Extramodule里创建MobileNetV4.py
在MobileNetV4.py文件里添加给出的MobileNetV4代码
添加完MobileNetV4代码后,在ultralytics/nn/Extramodule/__init__.py文件中引用
from .MobileNetV4 import *2.2 在ultralytics/nn/tasks.py里引用
from .Extramodule import *(1)在tasks.py找到parse_model函数(ctrl+f 可以直接搜索parse_model位置),添加:
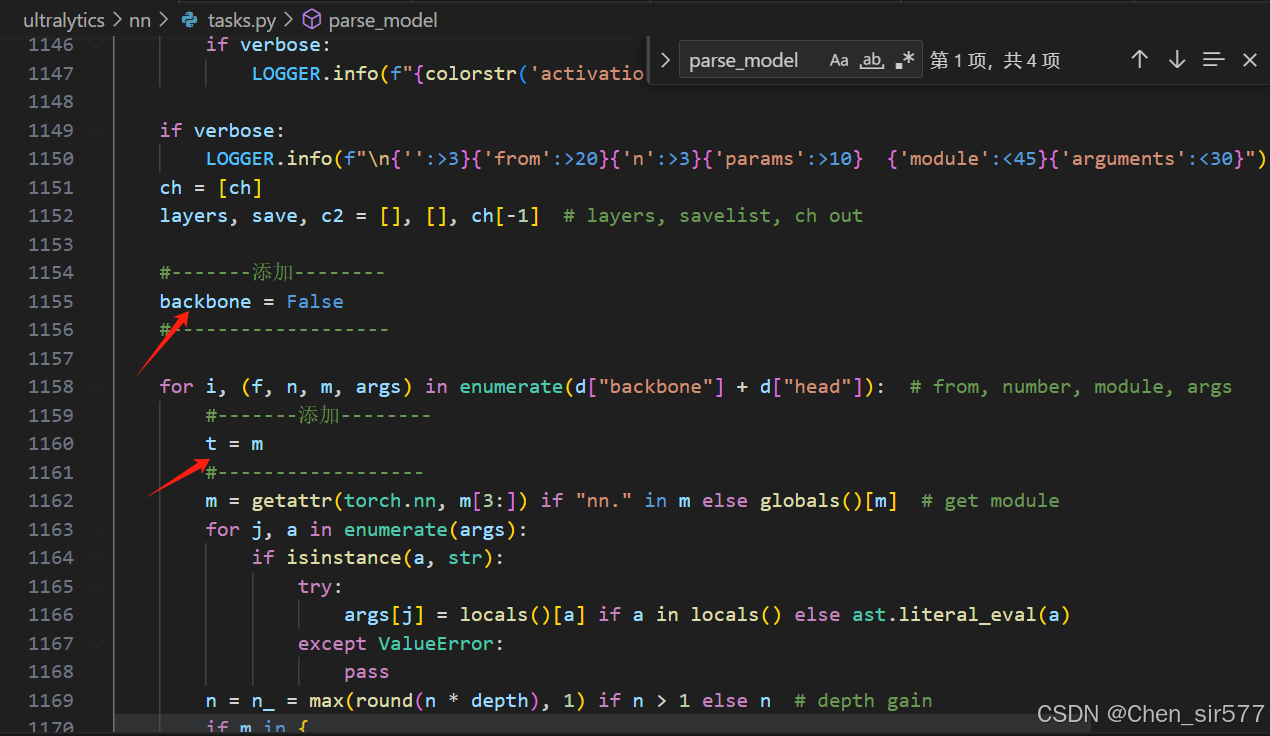
(2)添加主干代码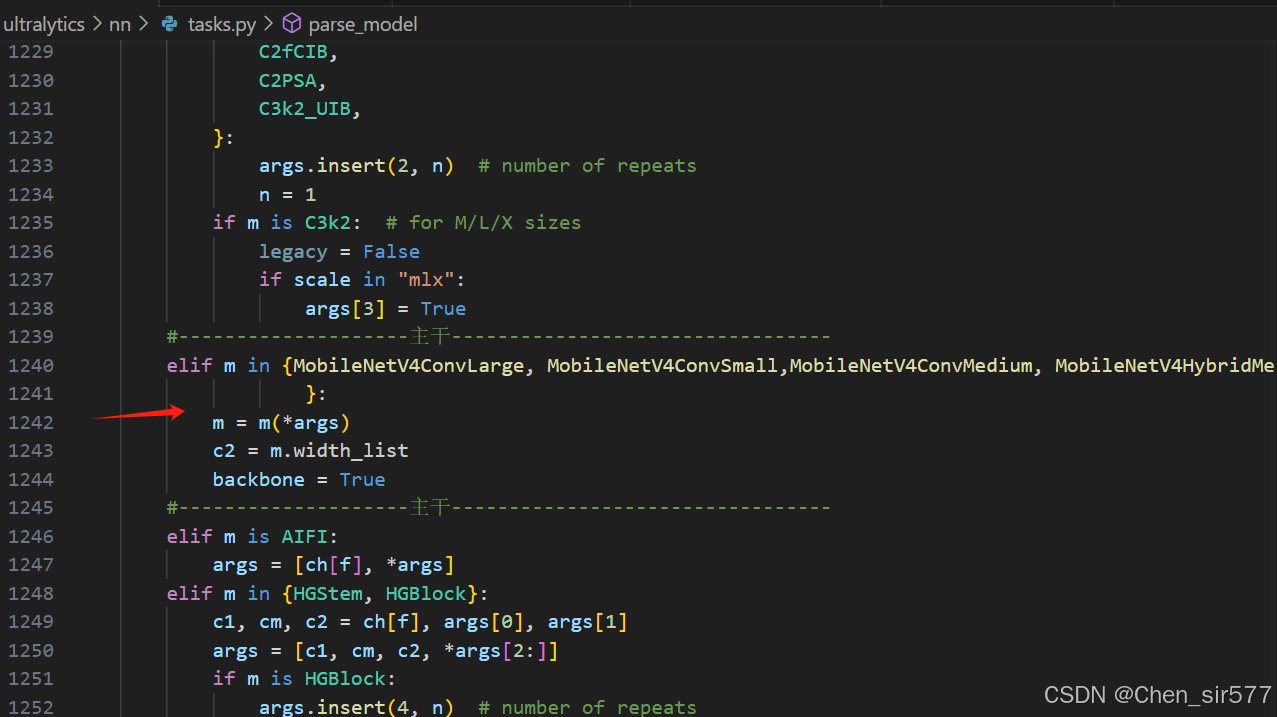
elif m in {MobileNetV4ConvLarge, MobileNetV4ConvSmall,MobileNetV4ConvMedium, MobileNetV4HybridMedium, MobileNetV4HybridLarge}:m = m(*args)c2 = m.width_listbackbone = True (3)将elif m is AIFI 到parse_model函数的结尾:以下的代码全部替换成我给的
elif m is AIFI:args = [ch[f], *args]elif m in {HGStem, HGBlock}:c1, cm, c2 = ch[f], args[0], args[1]args = [c1, cm, c2, *args[2:]]if m is HGBlock:args.insert(4, n) # number of repeatsn = 1elif m is ResNetLayer:c2 = args[1] if args[3] else args[1] * 4elif m is nn.BatchNorm2d:args = [ch[f]]elif m is Concat:c2 = sum(ch[x] for x in f)elif m in {Detect, WorldDetect, Segment, Pose, OBB, ImagePoolingAttn, v10Detect}:args.append([ch[x] for x in f])if m is Segment:args[2] = make_divisible(min(args[2], max_channels) * width, 8)elif m is RTDETRDecoder: # special case, channels arg must be passed in index 1args.insert(1, [ch[x] for x in f])elif m is CBLinear:c2 = args[0]c1 = ch[f]args = [c1, c2, *args[1:]]elif m is CBFuse:c2 = ch[f[-1]]else:c2 = ch[f]if isinstance(c2, list):m_ = mm_.backbone = Trueelse:m_ = nn.Sequential(*(m(*args) for _ in range(n))) if n > 1 else m(*args) # modulet = str(m)[8:-2].replace('__main__.', '') # module typem.np = sum(x.numel() for x in m_.parameters()) # number paramsm_.i, m_.f, m_.type = i + 4 if backbone else i, f, t # attach index, 'from' index, typeif verbose:LOGGER.info(f'{i:>3}{str(f):>20}{n_:>3}{m.np:10.0f} {t:<45}{str(args):<30}') # printsave.extend(x % (i + 4 if backbone else i) for x in ([f] if isinstance(f, int) else f) if x != -1) # append to savelistlayers.append(m_)if i == 0:ch = []if isinstance(c2, list):ch.extend(c2)if len(c2) != 5:ch.insert(0, 0)else:ch.append(c2)return nn.Sequential(*layers), sorted(save)(4)在tasks.py找到_predict_once函数,替换为:
def _predict_once(self, x, profile=False, visualize=False, embed=None):"""Perform a forward pass through the network.Args:x (torch.Tensor): The input tensor to the model.profile (bool): Print the computation time of each layer if True, defaults to False.visualize (bool): Save the feature maps of the model if True, defaults to False.embed (list, optional): A list of feature vectors/embeddings to return.Returns:(torch.Tensor): The last output of the model."""y, dt, embeddings = [], [], [] # outputsfor m in self.model:if m.f != -1: # if not from previous layerx = y[m.f] if isinstance(m.f, int) else [x if j == -1 else y[j] for j in m.f] # from earlier layersif profile:self._profile_one_layer(m, x, dt)if hasattr(m, 'backbone'):x = m(x)if len(x) != 5: # 0 - 5x.insert(0, None)for index, i in enumerate(x):if index in self.save:y.append(i)else:y.append(None)x = x[-1] # 最后一个输出传给下一层else:x = m(x) # runy.append(x if m.i in self.save else None) # save outputif visualize:feature_visualization(x, m.type, m.i, save_dir=visualize)if embed and m.i in embed:embeddings.append(nn.functional.adaptive_avg_pool2d(x, (1, 1)).squeeze(-1).squeeze(-1)) # flattenif m.i == max(embed):return torch.unbind(torch.cat(embeddings, 1), dim=0)return x(5)在ultralytics/models/yolo/detect/train.py里找到build_dataset函数,替换为:
def build_dataset(self, img_path, mode="train", batch=None):"""Build YOLO Dataset.Args:img_path (str): Path to the folder containing images.mode (str): `train` mode or `val` mode, users are able to customize different augmentations for each mode.batch (int, optional): Size of batches, this is for `rect`. Defaults to None."""gs = max(int(de_parallel(self.model).stride.max() if self.model else 0), 32)return build_yolo_dataset(self.args, img_path, batch, self.data, mode=mode, rect=False, stride=gs)注:这里修改的是目标检测任务,如果是分类任务则不需要这个步骤。
3. 新建一个MobileNetV4.yaml文件
注:(1)这边有两个版本,版本1和版本2效果不一样,由于我只是进行复现,并没有过多的了解其原理,若有大佬了解,麻烦指出该两个版本的不同点、
(2)这里可以直接替换原yolo11-cls.yaml文件,这样训练可以通过yolo11n/s/m/l-cls.yaml选择大小。这里是分类任务,目标检测任务同理。
版本1:
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLO11 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect# Parameters
nc: 7 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolo11n.yaml' will call yolo11.yaml with scale 'n'# [depth, width, max_channels]n: [0.50, 0.25, 1024] # summary: 319 layers, 2624080 parameters, 2624064 gradients, 6.6 GFLOPss: [0.50, 0.50, 1024] # summary: 319 layers, 9458752 parameters, 9458736 gradients, 21.7 GFLOPsm: [0.50, 1.00, 512] # summary: 409 layers, 20114688 parameters, 20114672 gradients, 68.5 GFLOPsl: [1.00, 1.00, 512] # summary: 631 layers, 25372160 parameters, 25372144 gradients, 87.6 GFLOPsx: [1.00, 1.50, 512] # summary: 631 layers, 56966176 parameters, 56966160 gradients, 196.0 GFLOPs# YOLO11n backbone
backbone:# [from, repeats, module, args]- [-1, 1, MobileNetV4ConvSmall, []] # 4- [-1, 1, SPPF, [1024, 5]] # 5- [-1, 2, C2PSA, [1024]] # 6# YOLO11n head
head:- [-1, 1, Classify, [nc]] # Classify版本2:
# Ultralytics YOLO ??, AGPL-3.0 license
# YOLO11 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolo11n.yaml' will call yolo11.yaml with scale 'n'# [depth, width, max_channels]n: [0.50, 0.25, 1024] # summary: 319 layers, 2624080 parameters, 2624064 gradients, 6.6 GFLOPss: [0.50, 0.50, 1024] # summary: 319 layers, 9458752 parameters, 9458736 gradients, 21.7 GFLOPsm: [0.50, 1.00, 512] # summary: 409 layers, 20114688 parameters, 20114672 gradients, 68.5 GFLOPsl: [1.00, 1.00, 512] # summary: 631 layers, 25372160 parameters, 25372144 gradients, 87.6 GFLOPsx: [1.00, 1.50, 512] # summary: 631 layers, 56966176 parameters, 56966160 gradients, 196.0 GFLOPs# 0-P1/2
# 1-P2/4
# 2-P3/8
# 3-P4/16
# 4-P5/32# YOLO11n backbone
backbone:# [from, repeats, module, args]- [-1, 1, MobileNetV4ConvSmall, []] # 4- [-1, 1, SPPF, [1024, 5]] # 5- [-1, 2, C2PSA, [1024]] # 6# YOLO11n head
head:- [-1, 1, nn.Upsample, [None, 2, "nearest"]]- [[-1, 3], 1, Concat, [1]] # cat backbone P4- [-1, 2, C3k2, [512, False]] # 9- [-1, 1, nn.Upsample, [None, 2, "nearest"]]- [[-1, 2], 1, Concat, [1]] # cat backbone P3- [-1, 2, C3k2, [256, False]] # 12 (P3/8-small)- [-1, 1, Conv, [256, 3, 2]]- [[-1, 9], 1, Concat, [1]] # cat head P4- [-1, 2, C3k2, [512, False]] # 15 (P4/16-medium)- [-1, 1, Conv, [512, 3, 2]]- [[-1, 6], 1, Concat, [1]] # cat head P5- [-1, 2, C3k2, [1024, True]] # 18 (P5/32-large)- [[12, 15, 18], 1, Detect, [nc]] # Detect(P3, P4, P5)4、模型训练
#coding:utf-8
from ultralytics import YOLO# 模型配置文件
model_yaml_path = "ultralytics/cfg/models/11/MobileNetV4.yaml"
# 数据集配置文件
data = "KDEF"
#预训练模型
pre_model_name = 'yolo11s-cls.pt'if __name__ == '__main__':#加载预训练模型model = YOLO(model_yaml_path, task='classify').load(pre_model_name)#训练模型results = model.train(data=data,epochs=100,batch=16,name='train_emoKDEF_MobileNetV4_s',)配置自己的数据集和训练参数即可。
版本1的训练结果:

如图所示就是成功啦,可以看到GFLOPs相较于yolo11s-cls的12.2 GFLOPs下降了许多。
版本2的训练结果
相关文章:

YOLOv11改进 | YOLOv11引入MobileNetV4
前言: 主要是对该文章YOLOv11改进 | YOLOv11引入MobileNetV4进行复现,以及对一些问题进行解答 1、mobilenetv4核心代码 from typing import Optional import torch import torch.nn as nn import torch.nn.functional as F__all__ [MobileNetV4ConvLa…...

Java中的ArrayList方法
1. 创建 ArrayList 实例 你可以通过多种方式创建 ArrayList 实例: <JAVA> ArrayList<String> list new ArrayList<>(); // 创建一个空的 ArrayList ArrayList<String> list new ArrayList<>(10); // 创建容量为 10 的 ArrayList …...

wordpress 利用 All-in-One WP Migration全站转移
导出导入站点 在插件中查询 All-in-One WP Migration备份并导出全站数据 导入 注意事项: 1.导入部分限制50MB 宝塔解决方案,其他类似,修改php.ini配置文件即可 2. 全站转移需要修改域名 3. 大文件版本,大于1G的可以参考我的…...
全攻略)
零基础教程:Windows电脑安装Linux系统(双系统/虚拟机)全攻略
一、安装方式选择 方案对比表 特性双系统安装虚拟机安装性能原生硬件性能依赖宿主机资源分配磁盘空间需要独立分区(建议50GB)动态分配(默认20GB起)内存占用独占全部内存需手动分配(建议4GB)启动方式开机选…...

聚焦AI与大模型创新,紫光云如何引领云计算行业快速演进?
【全球云观察 | 科技热点关注】 随着近年来AI与大模型的兴起,云计算行业正在发生着一场大变局。 “在2025年春节期间,DeepSeek两周火爆全球,如何进行私域部署成了企业关心的问题。”紫光云公司总裁王燕平强调指出,AI与…...

mapreduce 过程中,maptask的partitioner是在map阶段中具体什么阶段分区的?
在MapReduce的Map阶段中,Partitioner(分区器)的作用发生在map函数输出键值对之后,但在数据被写入磁盘(spill到本地文件)之前。具体流程如下: 分区发生的具体阶段: Map函数处理完成 当…...

找到字符串中所以字母异位词 --- 滑动窗口
目录 一:题目 二:算法原理 三:代码实现 一:题目 题目链接:438. 找到字符串中所有字母异位词 - 力扣(LeetCode) 二:算法原理 三:代码实现 版本一:无co…...

密码破解工具
1. 引言 密码是信息安全的核心之一,而攻击者往往利用各种工具和技术来破解密码。密码破解工具可以分为 离线破解(Offline Cracking) 和 在线破解(Online Cracking) 两大类: 离线破解:攻击者已经获取了加密的密码哈希(hash),可以在本地进行破解,无需与目标系统交互。…...

路由策略在双点双向路由重发布的应用
一、背景叙述 路由重发布通常是解决两个不同路由协议之间的互通问题,也就是路由双向引入。有时候,单点路由重发布在大规模网络中压力较大,缺乏冗余性,于是就有了双点双向路由重发布 问题:但是双点双向路由重发布也会…...

在Python软件中集成智能体:以百度文心一言和阿里通义千问为例
摘要 本文旨在探讨如何在Python软件中集成智能体,具体以百度文心一言和阿里通义千问等大模型生成的智能体为例。文章详细介绍了集成这些智能体的方法,包括环境准备、API调用、代码实现等步骤,并提供了相关的示例代码。通过集成这些智能体&…...

day22 学习笔记
文章目录 前言一、遍历1.行遍历2.列遍历3.直接遍历 二、排序三、去重四、分组 前言 通过今天的学习,我掌握了对Pandas的数据类型进行基本操作,包括遍历,去重,排序,分组 一、遍历 1.行遍历 intertuples方法用于遍历D…...

谈Linux之磁盘管理——万字详解
—— 小 峰 编 程 目录 一、硬盘的基本知识 1.了解硬盘的接口类型 2. 硬盘命名方式 3. 磁盘设备的命名 4. HP服务器硬盘 5. 硬盘的分区方式 二、 基本分区管理 1. 磁盘划分思路 2. 分区 2.1 MBR分区 2.2GPT分区 3.格式化—命令:mkfs 4.挂载 4.1手动挂…...

做好一个测试开发工程师第二阶段:java入门:idea新建一个project后默认生成的.idea/src/out文件文件夹代表什么意思?
时间:2025.4.8 一、前言 关于Java与idea工具安装不再展开,网上很多教程,可以自己去看 二、project建立后默认各文件夹代表意思 1、首先new---->project后会得到文件如图 其中: .idea文件代表:存储这个项目的历史…...

伪代码的定义与应用场景
李升伟 整理 伪代码(Pseudocode)是一种用近似自然语言(通常是英语或开发者熟悉的语言)和简单语法描述的算法逻辑工具。它介于自然语言和编程语言之间,不依赖具体语法规则,专注于表达思路,是编程…...

/sys/fs/cgroup/memory/memory.stat 关键指标说明
目录 1. **total_rss**2. **total_inactive_file**3. **total_active_file**4. **shmem**5. **其他相关指标**总结 以下是/sys/fs/cgroup/memory/memory.stat文件中一些关键指标的详细介绍,特别是与PostgreSQL相关的指标: 1. total_rss 定义࿱…...

机器学习中的聚类分析算法:原理与应用
一、什么是聚类分析? 聚类分析(Clustering Analysis)是机器学习中一种重要的无监督学习技术,它的目标是将数据集中的样本划分为若干个组(称为"簇"),使得同一簇内的样本彼此相似,而不同簇的样本差异较大。与分类不同&am…...

VUE中的路由处理
1.引入,预处理main.ts import {} from vue-router import { createRouter, createWebHistory } from vue-router import HomePages from @/pages/HomePages.vue import AboutPage from @/pages/AboutPage.vue import NewsPage from @/pages/NewsPage.vue //1. 配置路由规…...
 控制工程会用到的)
MATLAB学习笔记(二) 控制工程会用到的
MATLAB中 控制工程会用到的 基础传递函数表达传递函数 零极点式 状态空间表达式 相互转化画响应图线根轨迹Nyquist图和bode图现控部分求约旦判能控能观极点配置和状态观测 基础 传递函数表达 % 拉普拉斯变换 syms t s a f exp(a*t) %e的a次方 l laplace(f) …...

Python: 实现数据可视化分析系统
后端基于Python 开源的 Web 框架 Flask,前端页面采用 LayUI 框架以及 Echarts 图表,数据库为sqlite。系统的功能模块分为数据采集和存储模块、数据处理和分析模块、可视化展示模块和系统管理模块。情感分析方面使用LDA等主题建模技术,结合领域…...

VectorBT量化入门系列:第一章 VectorBT基础与环境搭建
VectorBT量化入门系列:第一章 VectorBT基础与环境搭建 本教程专为中高级开发者设计,系统讲解VectorBT技术在量化交易中的应用。通过结合Tushare数据源和TA-Lib技术指标,深度探索策略开发、回测优化与风险评估的核心方法。从数据获取到策略部署…...

典型反模式深度解析及重构方案
反模式 1:魔法数字/字符串(Magic Numbers/Strings) ▐ 问题场景 // 订单状态校验 if (order.getStatus() 3) { // 3代表已发货?sendNotification(); }// 折扣计算 double discount price * 0.15; // 0.15是什么?…...

神经探针与价值蓝海:AI重构需求挖掘的认知拓扑学
当产品经理的决策边界遭遇量子态的用户需求,传统需求分析工具已显露出经典物理般的局限性。Gartner 2024报告揭示:全球Top 500企业中有83%遭遇需求洞察的"测不准困境"——用户声称的需求与行为数据偏差率达47%,而未被表达的潜在需求…...

Tomcat 负载均衡
目录 二、Tomcat Web Server 2.1 Tomcat 部署 2.1.1 Tomcat 介绍 2.1.2 Tomcat 安装 2.2 Tomcat 服务管理 2.2.1 Tomcat 启停 2.2.2 目录说明 2.2.3编辑主页 2.3 Tomcat管理控制台 2.3.1开启远程管理 2.3.2 配置远程管理密码 三、负载均衡 3.1 重新编译Nginx 3.1.1 确…...

CSS >子元素选择器和空格
在 CSS 中,> 符号是 子元素选择器(Child Combinator),它用于选择某个元素的直接子元素(仅限第一层嵌套的子元素,不包含更深层的后代元素)。 语法 父元素 > 子元素 {样式规则; } 示例 …...

duckdb源码阅读学习路径图
🧭 DuckDB 最小内存源码阅读路径图 1️⃣ 数据流入口与批处理:DataChunk 项目内容✅ 目标理解 DuckDB 向量化执行的数据载体结构,如何影响内存📁 路径src/common/types/data_chunk.cpp/hpp🔍 入口函数DataChunk::Initialize, DataChunk::SetCardinality, Reset📌 优化…...

C#二叉树
C#二叉树 二叉树是一种常见的数据结构,它是由节点组成的一种树形结构,其中每个节点最多有两个子节点。二叉树的一个节点通常包含三部分:存储数据的变量、指向左子节点的指针和指向右子节点的指针。二叉树可以用于多种算法和操作,…...

BT-Basic函数之首字母W
BT-Basic函数之首字母W 文章目录 BT-Basic函数之首字母Wwaitwait for start wait wait函数使程序在执行下一个功能之前暂停指定的秒数。 语法 wait <数值表达式>参数 <数值表达式> 等待时长,以秒为单位。该值必须大于或等于0。小于25毫秒的正值会被…...

如何避免论文内容被误认为是 AI 生成的?
AIGC 检测的原理 AIGC 检测主要基于自然语言处理(NLP)和机器学习技术,通过深度分析文本内容来识别其中的 AI 生成痕迹。具体原理如下: 基础学习算法:利用机器学习算法对文本信息进行特征提取和表示,以便计…...

node.js之path常用方法
node.js之path常用方法 1.path.join([…paths]) 用于将多个路径片段拼接成一个路径,会自动处理路径分隔符,避免手动拼接时可能出现的问题 const joinedPath path.join(folder1, folder2, file.txt); console.log(joinedPath); // 输出: folder1/fol…...

【面试】C++与C override的报错阶段 RAII
文章目录 C 相对于 C 语言的主要区别**1. 面向对象编程(OOP)****2. 函数增强****3. 内存管理****4. 引用(Reference)****5. 标准模板库(STL)****6. 异常处理****7. 类型安全增强****8. 其他特性****9. 兼容…...
一次倒序遍历)
LeetCode 3396.使数组元素互不相同所需的最少操作次数:O(n)一次倒序遍历
【LetMeFly】3396.使数组元素互不相同所需的最少操作次数:O(n)一次倒序遍历 力扣题目链接:https://leetcode.cn/problems/minimum-number-of-operations-to-make-elements-in-array-distinct/ 给你一个整数数组 nums,你需要确保数组中的元素…...

机器学习课堂7用scikit-learn库训练SVM模型
1.用scikit-learn库训练SVM模型 代码 # 2-11用scikit-learn库训练SVM模型 import pandas as pd import numpy as np import matplotlib.pyplot as plt from sklearn import svm # 导入sklearn# 参数设置 m_train 250 # 训练样本数量 svm_C 100 # SVM的C值 svm_kernel …...
)
模拟考试系统(ssm+vue+mysql5.x)
模拟考试系统(ssmvuemysql5.x) 模拟考试系统是一个为考试准备和管理提供全面支持的平台。系统提供了丰富的功能模块,包括个人中心、科目管理、复习资料管理、参考文献管理、用户管理、留言板管理、试题管理、试卷管理、系统管理和考试管理。用户可以在个人中心修改…...

【计网】作业4
一. 单选题(共22题,64分) 1. (单选题)主机甲采用停止-等待协议向主机乙发送数据,数据传输速率是4kb/s,单向传播时延为30ms,忽略确认帧的发送时延。当信道利用率等于80%时,数据帧的长度为&#…...

MYSQL数据库语法补充
一,DQL基础查询 DQL(Data Query Language)数据查询语言,可以单表查询,也可以多表查询 语法: select 查询结果 from 表名 where 条件; 特点: 查询结果可以是:表中的字段…...

Java基础编程练习第38题-除法器
题目:编写一个除法器,输入被除数和除数,并将结果输出。 这道题看似很简单,实则也不难。 就是假如用户输入的类型不同怎么办呢?用户输入int或者double类型应该怎么解决。这里我们就需要用到函数的重载。 代码如下&am…...

【基于Vue3组合式API的互斥输入模式实现与实践分享】
基于Vue3组合式API的互斥输入模式实现与实践分享 目录 背景与痛点设计思路技术实现使用场景与案例遇到的问题与解决方案最佳实践总结 1. 背景与痛点 在表单交互设计中,我们经常面临这样的场景:多种输入方式互斥。例如,在评分系统中&#…...

Linux进程概念及理解
目录 冯诺依曼体系结构 操作系统(Operator System) 概念 设计OS的目的 定位 如何理解 "管理" 总结 系统调用和库函数概念 进程 基本概念 描述进程-PCB task_struct-PCB的一种 task_ struct内容分类 组织进程 查看进程 通过系统调用获取进程标示符 通过系统调用创建进…...

苹果签名是否安全
苹果开发者与运营商都对苹果签名有一定了解,那么苹果签名安全吗?下面我来跟大家聊一聊。 苹果签名能验证应用的来源,但存在一些风险,有开发者伪造签名,让用户认为此产品是可信的,这样就安装到了恶意应用&am…...
环境下,需要手动实现队列机制来替代FreeRTOS的CAN发送接收函数)
STM32在裸机(无RTOS)环境下,需要手动实现队列机制来替代FreeRTOS的CAN发送接收函数
xQueueSendToBackFromISR(ecuCanRxQueue, hcan->pRxMsg, &xHigherPriorityTaskWoken),xQueueReceive(mscCanRxQueue,&mscRxMsg,0)和xQueueSendToBack(mscCanTxQueue, &TxMessageTemp, 0 )这3个函数,在裸机下实现: 在裸机&…...

无法看到新安装的 JDK 17
在 Linux 系统中使用 update-alternatives --config java 无法看到新安装的 JDK 17,可能是由于 JDK 未正确注册到系统备选列表中。 一、原因分析 JDK 未注册到 update-alternatives update-alternatives 工具需要手动注册 JDK 路径后才能识别新版本。如果仅安装 JDK…...

JavaEE——线程的状态
目录 前言1. NEW2. TERMINATED3. RUNNABLE4. 三种阻塞状态总结 前言 本篇文章来讲解线程的几种状态。在Java中,线程的状态是一个枚举类型,Thread.State。其中一共分为了六个状态。分别为:NEW,RUNNABLE,BLOCKED,WAITING,TIMED_WAITING, TERMI…...
)
数据结构与算法-数学-(同余,线性同余方程,中国剩余定理,卡特兰数,斯特林数)
同余方程: 1.1 线性同余方程 & 乘法逆元 线性同余方程是形如 ax≡b(mod m) 的方程,可转化为 axmyb 的线性不定方程,利用扩展欧几里得算法求解。当 b1 时,x 就是 a 在模 m 意义下的乘法逆元。 代码: #include &…...

RAG 系统中的偏差是什么?
检索增强生成 (RAG) 在减少模型幻觉和增强大型语言模型 (LLM)的领域特定知识库方面已获得广泛认可。通过外部数据源佐证大型语言模型生成的信息,有助于保持模型输出的新鲜度和真实性。然而,最近在 RAG系统中的发现,突显了基于 RAG 的大型语言…...

[创业之路-362]:用确定性的团队、组织、产品开发流程和方法,应对客户、市场、竞争和商业模式的不确定性。
在充满不确定性的商业环境中,通过确定性的团队、组织、产品开发流程和方法构建核心竞争力,是应对客户、市场、竞争和商业模式变化的核心策略。以下从团队韧性、组织敏捷、产品开发闭环三个维度,结合实战方法论,提供可落地的解决方…...
)
系统与网络安全------网络通信原理(1)
资料整理于网络资料、书本资料、AI,仅供个人学习参考。 文章目录 网络通信模型协议分层计算机网络发展计算机网络功能什么是协议为什么分层邮局实例 OSI模型OSI协议模型OSI七层模型OSI七层的功能简介 TCP/IP模型OSI模型与TCP/IP模型TCP/IP协议族的组成各层PDU设备与…...

ArkTS语言基础之函数
前言 臭宝们终于来到了ArkTS基础之函数,今天我们来学习一下ArkTS的函数的相关知识,上一节中也有一些函数的基础知识。 函数声明 函数声明引入一个函数,包含其名称、参数列表、返回类型和函数体,在下面的例子中,我们声明了一个名…...

synchronized锁升级的锁对象和Mark Word
在讨论synchronized锁升级和Mark Word时,提到的"对象"通常指的是锁对象,也就是被用作synchronized同步锁的那个Java对象。 1. 什么是锁对象? 锁对象是指被用于synchronized同步代码块或方法的对象实例。例如: // 这个…...
插入排序 希尔排序 冒泡排序)
数据结构|排序算法(二)插入排序 希尔排序 冒泡排序
一、插入排序 1.算法思想 插入排序(Insertion Sort)是一种简单的排序算法,其基本思想是:将待排序的元素插入到已经有序的序列中,从而逐步构建有序序列。 具体过程如下: 把待排序的数组分为已排序和未排…...

12、主频和时钟配置实验
一、I.MX6U 时钟系统详解 1、系统时钟来源 开发板的系统时钟来源于两部分: 32.768KHz 和24MHz 的晶振,其中 32.768KHz 晶振是 I.MX6U 的 RTC 时钟源, 24MHz 晶振是 I.MX6U 内核和其它外设的时钟源。 2、7路PLL时钟源 I.MX6U 的外设有很多,不同的外设时钟源不同, NXP 将…...