谈Linux之磁盘管理——万字详解

—— 小 峰 编 程
目录
一、硬盘的基本知识
1.了解硬盘的接口类型
2. 硬盘命名方式
3. 磁盘设备的命名
4. HP服务器硬盘
5. 硬盘的分区方式
二、 基本分区管理
1. 磁盘划分思路
2. 分区
2.1 MBR分区
2.2GPT分区
3.格式化—命令:mkfs
4.挂载
4.1手动挂载
4.2开机自动挂载之编辑/etc/fstable 或/etc/rc.local
4.3autofs自动挂载
4.4卸载设备:umount
三、逻辑卷管理(重点)
1. 逻辑卷介绍
2、逻辑卷基本概念
3. 逻辑卷LVM应用
3.1 逻辑卷创建
3.2 逻辑卷动态扩容
3.3 逻辑卷相关命令
四、RAID
1、RAID介绍
2、常见的RAID级别
2.1. RAID0
2.2. RAID1
2.3. RAID5
2.4. RAID6
2.5. RAID10
2.6 RAID01
2.7. 总结
三、软硬RAID
1. 软RAID
2. 硬RAID
四、软raid创建
1. 环境准备
2. raid的创建
创建RAID0
创建RAID1
创建RAID5
2. 保存RAID信息
3. raid停止与启动
4. raid的删除
一、硬盘的基本知识
1.了解硬盘的接口类型
2. 硬盘命名方式
| OS | IDE(并口) | SATA(串口) | SCSI |
| RHEL5 | /dev/hda | /dev/sda | /dev/sda |
| RHEL6 | /dev/sda | /dev/sda | /dev/sda |
| RHEL7 | /dev/sda | /dev/sda | /dev/sda |



3. 磁盘设备的命名
/dev/sda2
s=硬件接口类型(sata/scsi),d=disk(硬盘),a=第1块硬盘(b,第二块),2=第几个分区 /dev/hd h=IDE硬盘 /dev/hdd3/dev/vd v=虚拟硬盘 /dev/vdf7
4. HP服务器硬盘

/dev/cciss/c0d0 /dev/cciss/c0d0p1 c0第一个控制器, d0第一块磁盘, p1分区1 /dev/cciss/c0d0p2 c0第一个控制器,d0第一块磁盘, p2分区2
5. 硬盘的分区方式
MBR <2TB fdisk 4个主分区或者3个主分区+1个扩展分区(N个逻辑分区)
MBR(Master Boot Record)的缩写,由三部分组成,即:
- Bootloader(主引导程序)=446字节 、硬盘第一个扇区=512字节
引导操作系统的主程序
- DPT分区表(Disk Partition Table)=64字节
分区表保存了硬盘的分区信息,操作系统通过读取分区表内的信息,就能够获得该硬盘的分区信息。每个分区需要占用16个字节大小,保存有文件系统标识、起止柱面号、磁头号、扇区号、起始扇区位置(4个字节)、分区总扇区数目(4个字节)等内容分区表中保存的分区信息都是主分区与扩展分区的分区信息,扩展分区不能直接使用,需要在扩展分区内划分一个或多个逻辑分区后才能使用。逻辑分区的分区信息保存在扩展分区内,而不是保存在MBR分区表内,这样,就可以突破MBR分区表只能保存4个分区的限制
- 硬盘有效标志(校验位)=2个字节
GPT >2TB gdisk(parted) 128个主分区
注意:从MBR转到GPT,或从GPT转换到MBR会导致数据全部丢失!扩展阅读:http://www.eassos.cn/jiao-cheng/ying-pan/mbr-vs-gpt.php
二、 基本分区管理
1. 磁盘划分思路
- 进入分区表 ,新建分区 fdisk /dev/sdb;
- 更新分区表<刷新分区表>;
- 格式化分区——>文件系统 mkfs.ext4 /dev/sdb1;
- 挂载使用——>mount【开机自动挂载|autofs自动挂载】。
2. 分区
2.1 MBR分区
总结:
- 1. 最多只能分4个主分区,主分区编号1-4
# lsblk # df -h 查看正在挂载的设备情况 # fdisk -l 查看当前系统的所有设备分区情况硬盘容量 = 柱面数 × 盘面数(磁头数) × 扇区数 × 扇区大小(一般为512字节)
Disk /dev/sda: 10.7 GB, 10737418240 bytes--磁盘空间20971520 sectors—扇区
Sector size (logical/physical): 512 bytes / 512 bytes —扇区大小(逻辑/物理) 都是512字节。
I/O size (minimum/optimal): 512 bytes / 512 bytes—I/O 大小(最小/最大) 都是512字节。
Disk label type: dos —设备标签类型,这个磁盘分区类型,dos表示为MBR分区,gpt为gpt分区
Disk identifier: 0xf921a80d—设备识别码
启动设备 起始 结束 块 id 系统 Device Boot Start End Blocks Id System /dev/sda1 * 2048 1026047 512000 83 Linux /dev/sda2 1026048 20971519 9972736 8e Linux LVM ……
# fdisk /dev/sdbCommand(m for help): m 输出帮助信息a toggle a bootable flag 设置启动分区b edit bsd disklabel 编辑分区标签c toggle the dos compatibility flagd delete a partition 删除一个分区g create a new empty GPT partition tableG create an IRIX (SGI) partition tablel list known partition types 列出分区类型m print this menu 帮助n add a new partition 建立一个新的分区o create a new empty DOS partition table 创建一个新的空白DOS分区表p print the partition table 打印分区表q quit without saving changes 退出不保存设置s create a new empty Sun disklabel 创建一个新的空的SUN标示t change a partition’s system id 改变分区的类型u change display/entry units 改变显示的单位v verify the partition table 检查验证分区表w write table to disk and exit 保存分区表x extra functionality (experts only)
- 2. 逻辑分区大小总和不能超过扩展分区大小,逻辑分区分区编号从5开始
- 3. 如果删除扩展分区,下面的逻辑卷分区也被删除
- 4. 扩展分区的分区编号(1-4)
总结:
1. 扩展分区的大小决定了所有逻辑分区的大小
2. 删除扩展分区后下面的逻辑分区都被删除
3. 分完区后需要手动刷新分区表(partprobe/partx -d),如果刷新不成功需要重启操作系统
4. 创建分区的时候尽可能注意分区序号的连续性
2.2GPT分区
磁盘分区 常用来分区的工具有 fdisk 和 parted/ gdisk,因为 fdisk 是一个基于 MBR 的分区工具,无法支持超过 2TB 的分区需求(最新的系统里边已经升级支持),推荐使用 parted (gdisk和fdisk的使用类似,在这里我就不进行讲解了)。
- 如果没有parted命令,使用yum直接安装
yum install parted -y- 设置磁盘分区类型
parted -s /dev/xxx mklabel gpt# 注意:将xxx替换为自己lsblk出来需要处理的磁盘名称;分区类是对磁盘设置的,不是分区哦,所以不要出 现/dev/vdb1 这种part设备;mbr分区 label为 msdos.
- 创建分区
parted -s /dev/xxx mkpart part-type fs-type start end/dev/xxx :要操作的磁盘设备,例如 /dev/sda 、 /dev/sdb 等。
part-type :分区的类型,例如 primary 、 logical 或 extended 。
fs-type :文件系统的类型,例如 ext4 、 xfs 、 ntfs 等。参数可选,一般不指定, fs-type 会在格式化时指定
start 和end :分区的起始和结束位置,通常以 MB 为单位,或者使用百分比(例如 10% ) 推荐使用百分比,这样会自动处理分区对齐问题。
思考: 什么是分区对齐,分区对齐有什么作用?
答:分区对齐是指在硬盘上划分分区时,将每个分区的起始位置与硬盘的物理块边界对齐的过程。分区对齐的作用主要有以下几点:
提高性能:分区对齐可以减少硬盘读写时的寻址时间,从而提升磁盘I/O性能,减少读写延迟,提高数据传输速度。
增强硬盘寿命:分区对齐可以减少硬盘的寻址次数,降低硬盘读写的磨损程度,延长硬盘的使用寿命。
避免数据损坏:未对齐的分区可能导致部分数据跨越多个物理块,容易发生读写错误,甚至数据损坏。
总的来说,分区对齐可以优化硬盘性能,提高数据传输速度,减轻硬盘的负担,降低数据损坏的风险,是一个值得注意和遵循的硬盘管理原则
- 查看磁盘现有分区
lsblk
parted -s /dev/xxx print
fdisk -l以上三个命令都可以,请自己测试对比其中信息的差异,根据自己的需求使用。
- 删除分区
删除分区时一个非常危险的动作,在操作之前,请明确每一条命令的功能和结果 。删除分区虽然只是将分区信息删除,实际上边的文件系统,文件是没有删除的。只要你可以将源分 区信息还原(实际上就是每一个分区的起始位置和终止位置),数据就可以正常读取出来。这仅是对您 的提示,生产环境尽量不要碰到这种情况。没有特殊的需求,分区都从0%-100%,即一个磁盘只创建一个分区。这样分区被误删是比较 容易恢复的,重新按照 0%到100%大小创建分区即可。 在生产环境下目前大部分的实践是不分区,直接格式化。
parted -s /dev/xxx rm 1# 删除第一个分区,这个需要是从 parted -s /dev/xxx print 中 获取的。磁盘完成分区之后,是无法直接使用的,还需要格式化,这个过程实际上是在硬盘上创建文件系 统。
3.格式化—命令:mkfs
系统中除了 mkfs 命令外,还有上边这一批,mkfs.* 开头的命令,可以直接格式化对应的文件系 统,目前被Linux系统广泛使用的是 ext4 和 xfs 。 mkfs.ext4 这个命令就等价于 mkfs -t ext4。
mkfs.ext4 /dev/xxx 或 mkfs -t ext4 /dev/xxx
注意: 格式化是非常危险的操作,会造成数据丢失,所以请务必谨慎核对格式化的分区名称。 mkfs 格式化时,需要指定分区(lsblk 命令显示 part类型的设备),而不是磁盘,如果对一个 已经分区的磁盘直接进行格式化,会令分区丢失。
4.挂载
4.1手动挂载
- 创建新的挂载点
自己创建一个挂载点,或者挂载当前系统下的某个挂载点上。
mkdir /test- 挂载使用 mount [options] 需要挂载的设备 挂载点
mount /dev/sdb1 /test特点:系统重启后需要重新挂载;手动卸载后需要手动挂载
- -o:挂载选项 ro,sync,rw,remount
-t:文件系统类型
mount -t nfs=mount.nfs
mount -t cifs=mount.cifs
10.1.1.2 /share [smb]
mount.cifs -o user=user01,password=123 //10.1.1.2/smb /u01
mount.nfs 10.1.1.2:/share /u02remount:重新挂载一个正在挂载的设备
注意:后面可以根挂载点也可以跟设备本身;挂载设备:真实设备、设备UUID,设备的卷标
blkid /dev/xxxx 查看设备的UUID和文件系统类型
4.2开机自动挂载之编辑/etc/fstable 或/etc/rc.local
操作系统启动流程:
- 1. 硬件初始化 硬盘、内存.......
- 2. 系统初始化 /sbin/init—>xxxxxx/etc/fstab
补充:
操作系统启动流程通常包括以下步骤:
加电自检(Power-On Self-Test,POST):计算机加电时进行的自检,检查硬件是否正常工作。
BIOS启动:计算机启动时首先加载Basic Input/Output System(BIOS),进行硬件初始化、设备检测等操作。
引导加载程序(Boot Loader):BIOS将控制权交给引导加载程序,比如GRUB、LILO等。引导加载程序会加载操作系统的内核。
操作系统内核加载:引导加载程序加载操作系统内核,将控制权交给内核。
系统初始化:操作系统内核负责进行系统的初始化工作,包括初始化内存、文件系统、进程管理等。
运行init进程:操作系统内核启动一个init进程(或者Systemd等替代物),init负责系统的后续初始化和服务管理。在Linux系统中,初始的init进程是/sbin/init。
挂载文件系统:系统初始化完毕后,会根据/etc/fstab文件中的配置将需要的文件系统挂载到相应的目录上,包括根目录、/home目录等。
这是一个简要的操作系统启动流程,具体步骤可能因操作系统的版本和配置而有所不同。
- /etc/fstab文件:vim /etc/fstab ---->编辑该文件之后就可开机自动挂载
格式:
要挂载的资源路径 挂载点 文件系统类型 挂载选项 dump备份支持 文件系统检测 UUID=xxxx(自己使用blkid进行查看) / ext4 defaults 1 1
- 1段:挂载的设备(磁盘设备的文件名或设备的卷标或者是设备的UUID)
- 2段:挂载点(建议用一个空目录),建议不要将多个设备挂载到同一个挂载点上
- 3段:文件系统类型(ext3、ext4、vfat、ntfs(安装软件包)、swap等等)
- 4段:挂载选项,defaults 同时具有rw, dev, exec, acl, async,nouser等参数。
async/sync 异步/同步; auto/noauto 自动/非自动; rw/ro 读写/只读 exec/noexec 可被执行/不可被执行; remount 重新挂在一个已经挂载的文件系统,常用于修改挂载参数; user/nouser 允许/不允许其他普通用户挂载; suid/nosuid 具有/不具有suid权限:该文件系统是否允许SUID的存在; usrquota 这个是在启动文件系统的时候,让其支持磁盘配额,这个是针对用户的; grpquota 支持用户组的磁盘配额; .... mount -a 重新读取/etc/fstab文件内容
man mount 可以找到详细信息
5.5段:是否支持dump备份。dump是一个用来备份的命令,0代表不要做dump备份,1代表要每天进行dump的动作,2也代表其他不定日期的dump备份。通常这个数值不是0就是1。数字越小优先级越高。
6.6段:是否用 fsck 检验扇区。开机的过程中,系统默认会用fsck检验文件系统是否完整。0是不要检验,1表示最先检验(一般只有根目录会设定为1),2也是要检验,只是1是最先,2是其次才进行检验。
- 我本人并不建议挂载在该设备文件中,如果稍有差错就会导致一些列加载启动的问题。由于/etc/rc.local 操作系统启动后读取的最后一个文件,所以我建议大家挂载在此目录下:
vim /etc/rc.local /bin/mount -o noexec,ro /dev/sdb1 /test自动挂载 Automount:
# fsck -f /dev/sdb2 强制检验/dev/sdb2上文件系统
说明:
要挂载的资源路径可以是文件系统的UUID,设备路径,文件系统的标签 ,光盘镜像文件(iso),亦或是来自网络的共享资源等。
特点:系统重启后自动挂载;手动卸载后重启会自动挂载或者使用mount -a自动挂载
补充说明:e2label只能够对ext2~ext4的文件系统设置卷标(等同标识符)
- 便于使用卷标对卷进行管理,如挂载
e2label /dev/sdb1 mytest blkid /dev/sdb1 mount LABEL="mytest" /test
4.3autofs自动挂载
特点:挂载是由访问产生;卸载是由超时产生;依赖于后台的autofs服务。使用时触发自动挂载,超时自动卸载。
- 如何配置设备的autofs自动挂载?
1)安装autofs软件
rpm -q autofs #先查看本机有没有安装autofs yum install autofs -y2)修改/etc/auto.master文件 定义1级挂载点和超时时间,子配置文件
vi /etc/auto.master…… /misc /etc/auto.misc /test(一级目录路径) /etc/auto.test -t 120 #在文件中招上面一行,进行编辑左边所示。3)创建刚刚定义的子配置文件 二级挂载点和需要挂载设备以及文件系统类型及挂载方式
vi auto.test test1(二级目录,即就是最终挂载的目录) -fstype=ext4(系统文件类型) :/dev/sdb14)启动服务,测试验证
systemctl start autofs lsblk或 df -h cd /test/test1 lsblk或 df -h
4.4卸载设备:umount
umount /test 或 umount /dev/sdb1 umonut 挂载的文件名/挂载的设备名称最后挂载成功之后就可以使用了。
三、逻辑卷管理(重点)
1. 逻辑卷介绍
逻辑卷(LVM):它是Linux环境下对磁盘分区进行管理的一种机制,它是建立在物理存储设备之上的一个抽象层,优点在于灵活管理。
特点: 动态在线扩容(重点) 、离线裁剪 、数据条带化 、数据镜像
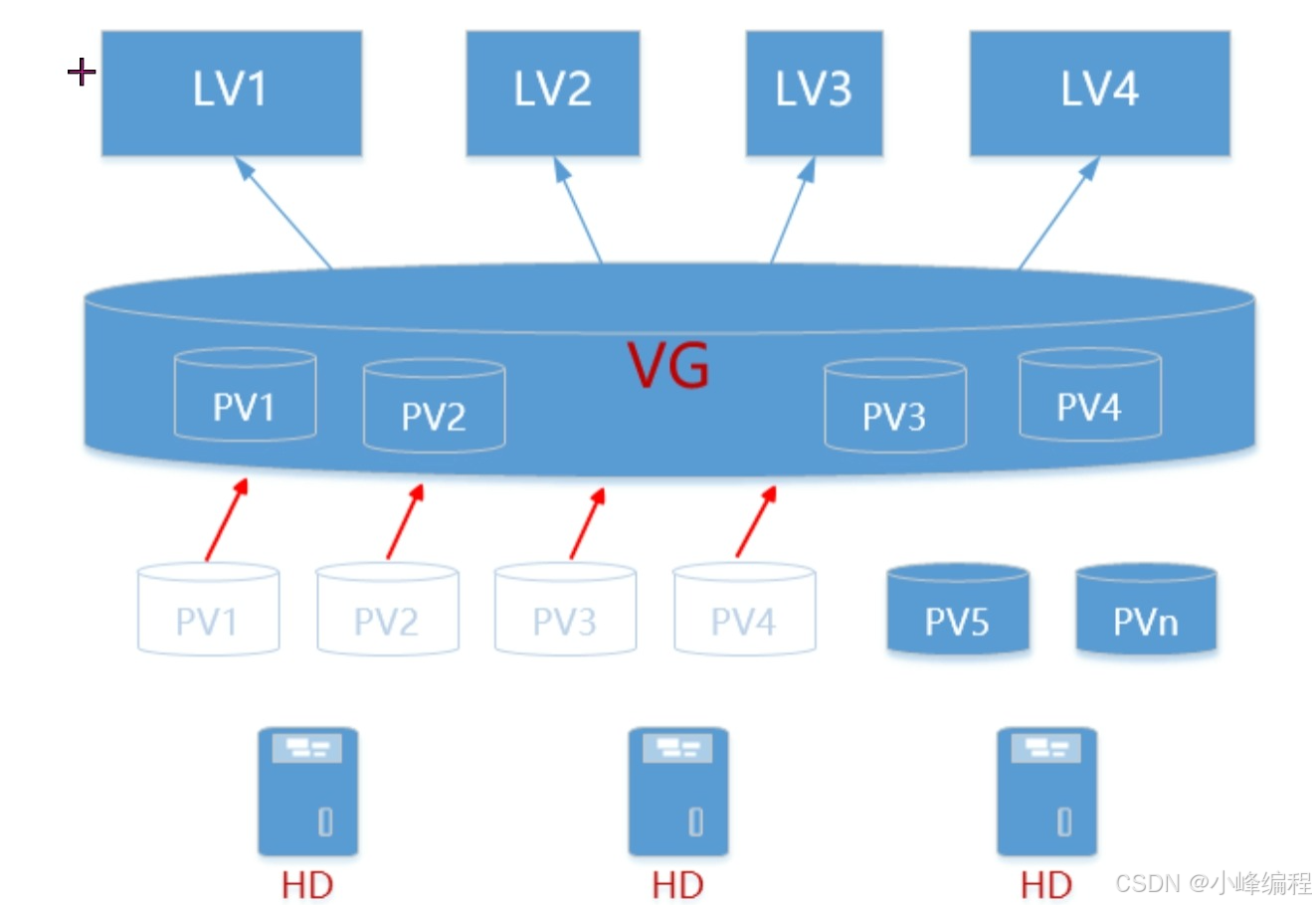
注:真实的物理设备——>逻辑上(命令创建)——>物理卷(pv)——>卷组(vg)——>逻辑卷(lv)——>逻辑卷格式化——>挂载使用。
2、逻辑卷基本概念
- 物理卷(Physical Volume,PV)
物理卷是底层真正提供容量,存放数据的设备,它可以是整个硬盘、硬盘上的分区等。
- 卷组(Volume Group, VG)
卷组建立在物理卷之上,它由一个或多个物理卷组成。即把物理卷整合起来提供容量分配。 一个LVM系统中可以只有一个卷组,也可以包含多个卷组。
- 逻辑卷(Logical Volume, LV)
逻辑卷建立在卷组之上,它是从卷组中“切出”的一块空间。它是最终用户使用的逻辑设备。逻辑卷创建之后,其大小可以伸缩。逻辑卷也被划分为被称为LE(Logical Extents) 的可被寻址的基本单位。在同一个卷组中,LE的大小和PE是相同的,并且一 一对应。
- 物理区域 PE(physical extent)
每一个物理卷被划分为称为PE(Physical Extents)的基本单元,具有唯一编号的PE是能被LVM寻址的最小单元。PE的大小可指定,默认为4 MB。 PE的大小一旦确定将不能改变,同一个卷组中的所有物理卷的PE的大小是一致的。
4MB=4096kb=4096kb/4kb=1024个block
- 说明:
- 硬盘读取数据最小单位1个扇区512字节
- 操作读取数据最小单位1个数据块=8*512字节=4096字节=4KB
- lvm寻址最小单位1个PE=4MB
3. 逻辑卷LVM应用
3.1 逻辑卷创建
需求:创建一个2.5G大小的逻辑卷
思路:
1. 物理的设备
2. 将物理设备做成物理卷
3. 创建卷组并将物理卷加入其中
4. 创建逻辑卷
5. 格式化逻辑卷
6. 挂载使用1. 物理设备的准备
sdb 8:16 0 10G 0 disk ├─sdb1 8:17 0 1024M 0 part ├─sdb2 8:18 0 1G 0 part ├─sdb3 8:19 0 1G 0 part ├─sdb4 8:20 0 1G 0 part ├─sdb5 8:21 0 1G 0 part ├─sdb6 8:22 0 1G 0 part ├─sdb7 8:23 0 1G 0 part ├─sdb8 8:24 0 1G 0 part ├─sdb9 8:25 0 1G 0 part └─sdb10 8:26 0 1023M 0 part2. 创建物理卷
pvcreate /dev/sdb1 /dev/sdb2查看物理卷:
pvs #简单查看PV VG Fmt Attr PSize PFree/dev/sda2 centos lvm2 a-- <9.51g 0/dev/sdb1 lvm2 --- 1023.98m 1023.98m/dev/sdb2 lvm2 --- 1.00g 1.00gpvdisplay /dev/sdb1 #详细查看 "/dev/sdb1" is a new physical volume of "1023.98 MiB"--- NEW Physical volume ---PV Name /dev/sdb1VG NamePV Size 1023.98 MiBAllocatable NOPE Size 0Total PE 0Free PE 0Allocated PE 0PV UUID Ta58vg-tNa9-xjPw-XAhN-wWCO-dFFt-EwZLlg3. 创建卷组并将物理卷加入其中
vgcreate vg1 /dev/sdb1 /dev/sdb2查看卷组信息:
vgs vg1 #简单查看 vgdisplay vg01 详细查看4. 创建逻辑卷
lvcreate -n lv1 -L 1.5G vg1在操作系统层面映射两个地方:
[root@bogon ~]# ll /dev/mapper/vg1-lv1 lrwxrwxrwx. 1 root root 7 Apr 7 23:02 /dev/mapper/vg1-lv1 -> ../dm-1 [root@bogon ~]# ll /dev/vg1/lv1 lrwxrwxrwx. 1 root root 7 Apr 7 23:02 /dev/vg1/lv1 -> ../dm-1查看逻辑卷的信息:
lvdisplay /dev/vg1/lv1 -n:指定逻辑卷的名字 -L:指定逻辑卷的大小 -l:指定逻辑卷的大小5. 格式化逻辑卷
mkfs.ext4 /dev/vg1/lv16. 挂载使用
1)创建一个空的挂载点
2)挂载使用
mount /dev/vg1/lv1 /test/test2
3.2 逻辑卷动态扩容
需求:将/test2目录动态扩容到3G
思路:
- 1. 查看/u01目录所对应的逻辑卷是哪一个 /dev/mapper/vg02-lv01
- 2. 查看当前逻辑卷所在的卷组vg01剩余空间是否足够
- 3. 如果vg01空间不够,得先扩容卷组,再扩容逻辑卷
- 4. 如果vg01空间足够,直接扩容逻辑卷
步骤:
1. 查看/u01目录属于哪个卷组
df -hlvs2. 卷组的剩余空间
vgs结果:当前卷组空间不足我扩容
3. 扩容逻辑卷所在的卷组
- 1)首先得有物理设备
- 2) 将物理设备做成物理卷
pvcreate /dev/sdb[3-4] pvs
- 3)将物理卷加入到卷组中(卷组扩容)
vgextend vg1 /dev/sdb[3-4] pvs vgs注意:正常情况下,应该先将物理设备创建为物理卷再加入到卷组中;如果直接加入卷组,系统会自动帮你将其做成物理卷。
4. 扩容逻辑卷
lvextend -n /dev/vg1/lv1 -L 3G # -L 3G最终的大小 或者 lvextend -L +1.5G /dev/vg1/lv1 -L +1.5G 扩容1.5G5. 查看结果
lvsLV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convertroot centos -wi-ao---- <9.51glv1 vg1 -wi-ao---- 3.00g6. 同步文件系统
resize2fs /dev/vg1/v1 #ext4文件系统类型 xfs_growfs /dev/vg1/v1 #xfs7. 再次查看验证
df -h离线裁剪逻辑卷(了解)
umount /test/test2 e2fsck -f /dev/vg1/lv1 检验文件系统 resize2fs /dev/vg1/lv1 2G 裁剪文件系统到2G lvreduce /dev/vg1/lv1 -L 2G 裁剪逻辑卷 mount /dev/vg1/lv1 /data 挂载使用
3.3 逻辑卷相关命令
- 创建物理卷:pvcreate
- 创建卷组:vgcreate
- 创建逻辑卷:lvcreate
- 删除逻辑卷:lvremove
- 删除卷组:vgremove
说明:卷组里的物理卷没有被使用才可以直接删除卷组
- 删除物理卷:pvremove
- 扩容卷组:vgextend
- 扩容逻辑卷:lvextend
- 同步文件系统:resize2fs
- 裁剪卷组:vgreduce
- 裁剪逻辑卷:lvreduce
四、RAID
1、RAID介绍
RAID(Redundant Array of Independent Disk 独立冗余磁盘阵列)技术是加州大学伯克利分校1987年提出,最初是为了组合小的廉价磁盘来代替大的昂贵磁盘,同时希望磁盘失效时不会使对数据的访问受损失而开发出一定水平的数据保护技术。RAID就是一种由多块廉价磁盘构成的冗余阵列,在操作系统下是作为一个独立的大型存储设备出现。RAID可以充分发挥出多块硬盘的优势,可以提升硬盘速度,增大容量,提供容错功能,能够确保数据安全性,易于管理的优点,在任何一块硬盘出现问题的情况下都可以继续工作,不会 受到损坏硬盘的影响。
2、常见的RAID级别
2.1. RAID0
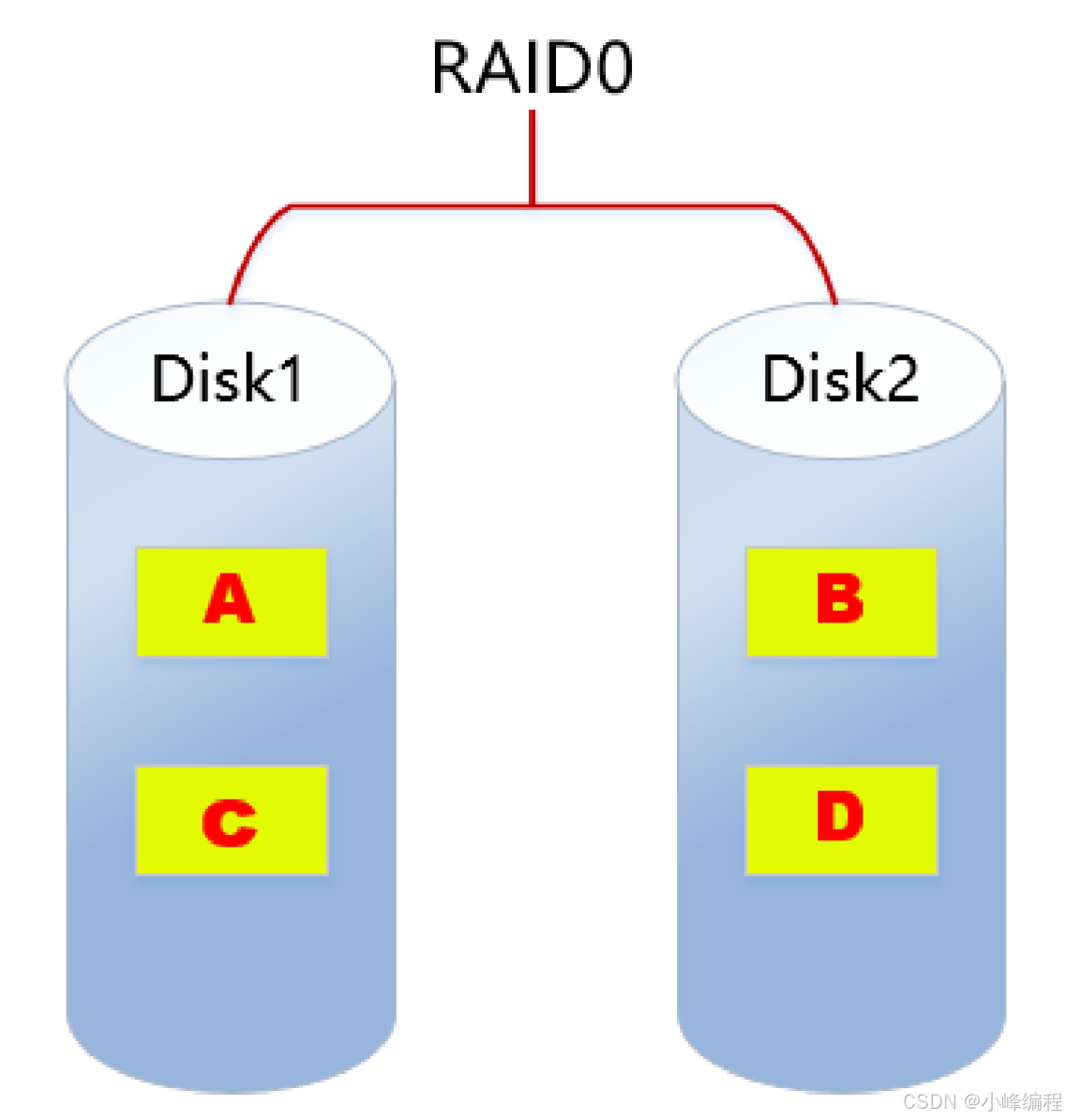
RAID0特点:
- 至少需要两块磁盘
- 数据条带化分布到磁盘,高的读写性能,100%高存储空间利用率
- 数据没有冗余策略,一块磁盘故障,数据将无法恢复
- 应用场景:对性能要求高但对数据安全性和可靠性要求不高的场景,比如音频、视频等的存储。
2.2. RAID1
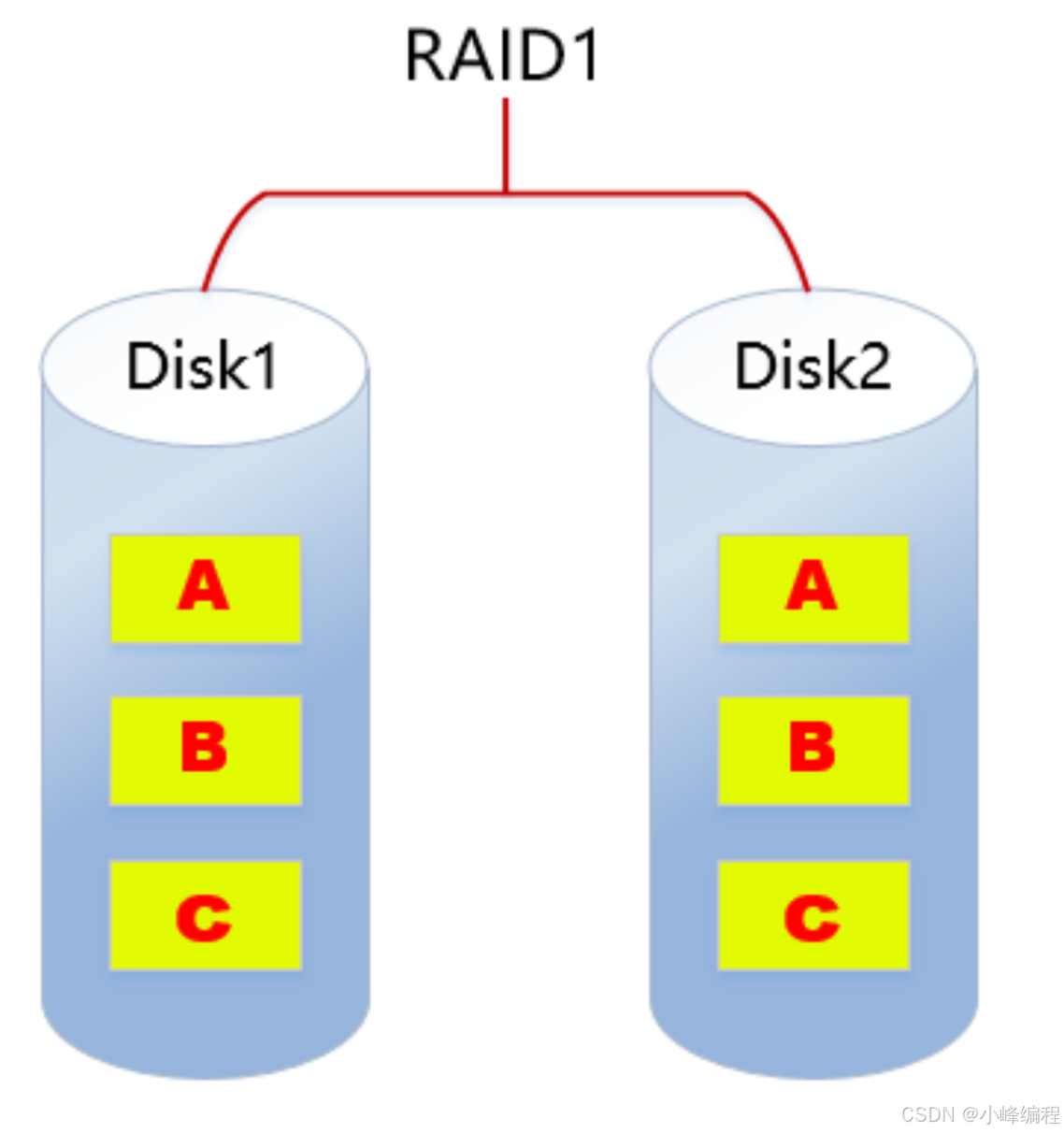
RAID1特点:
- 至少需要2块磁盘
- 数据镜像备份写到磁盘上(工作盘和镜像盘),可靠性高,磁盘利用率为50%
- 读性能可以,但写性能不佳
- 一块磁盘故障,不会影响数据的读写
- 应用场景:对数据安全可靠要求较高的场景,比如邮件系统、交易系统等。
2.3. RAID5
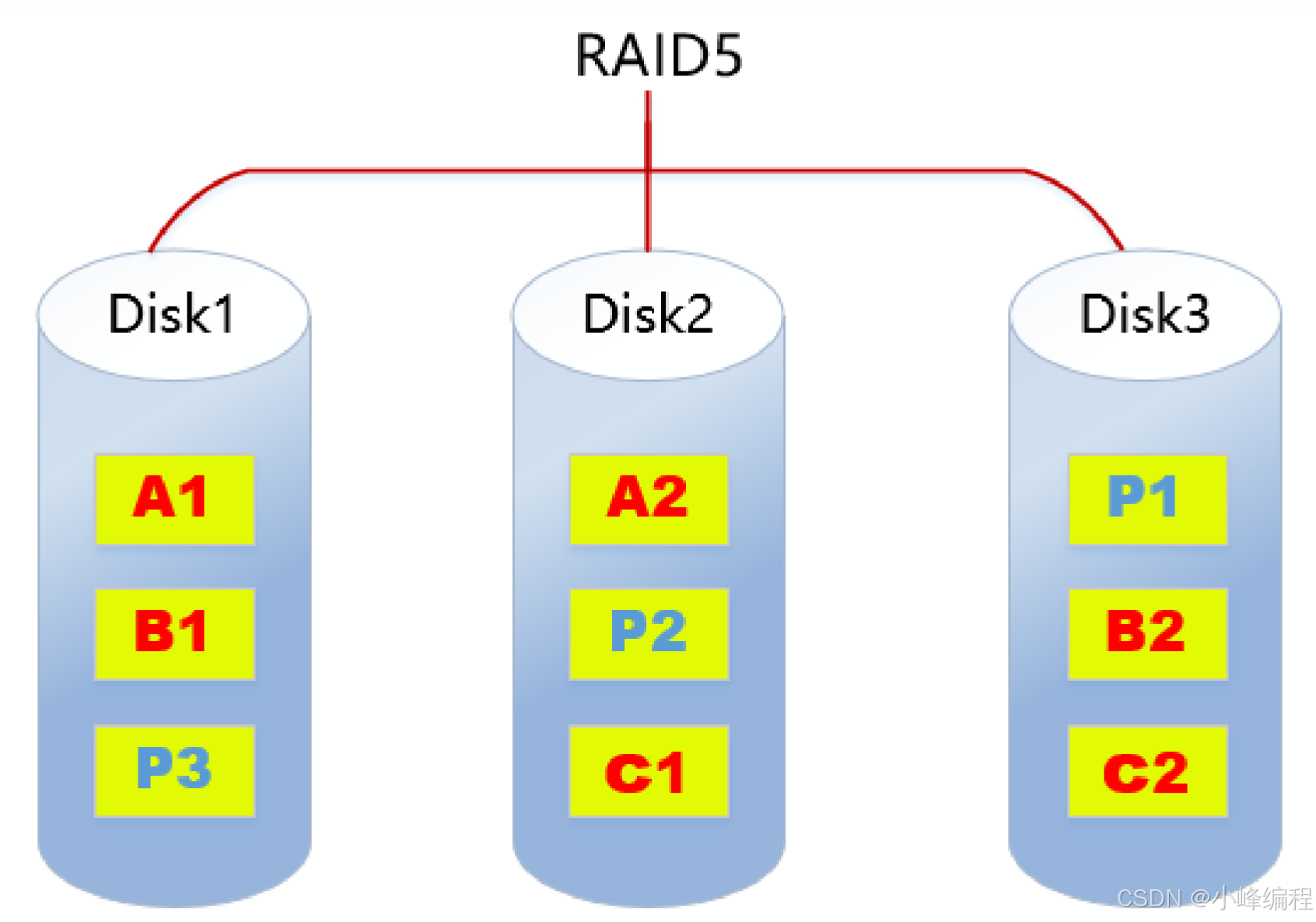
RAID5特点:
- 至少需要3块磁盘
- 数据条带化存储在磁盘,读写性能好,磁盘利用率为(n-1)/n
- 以奇偶校验(分散)做数据冗余
- 一块磁盘故障,可根据其他数据块和对应的校验数据重构损坏数据(消耗性能)
- 是目前综合性能最佳的数据保护解决方案
- 兼顾了存储性能、数据安全和存储成本等各方面因素(性价比高)
- 适用于大部分的应用场景
2.4. RAID6
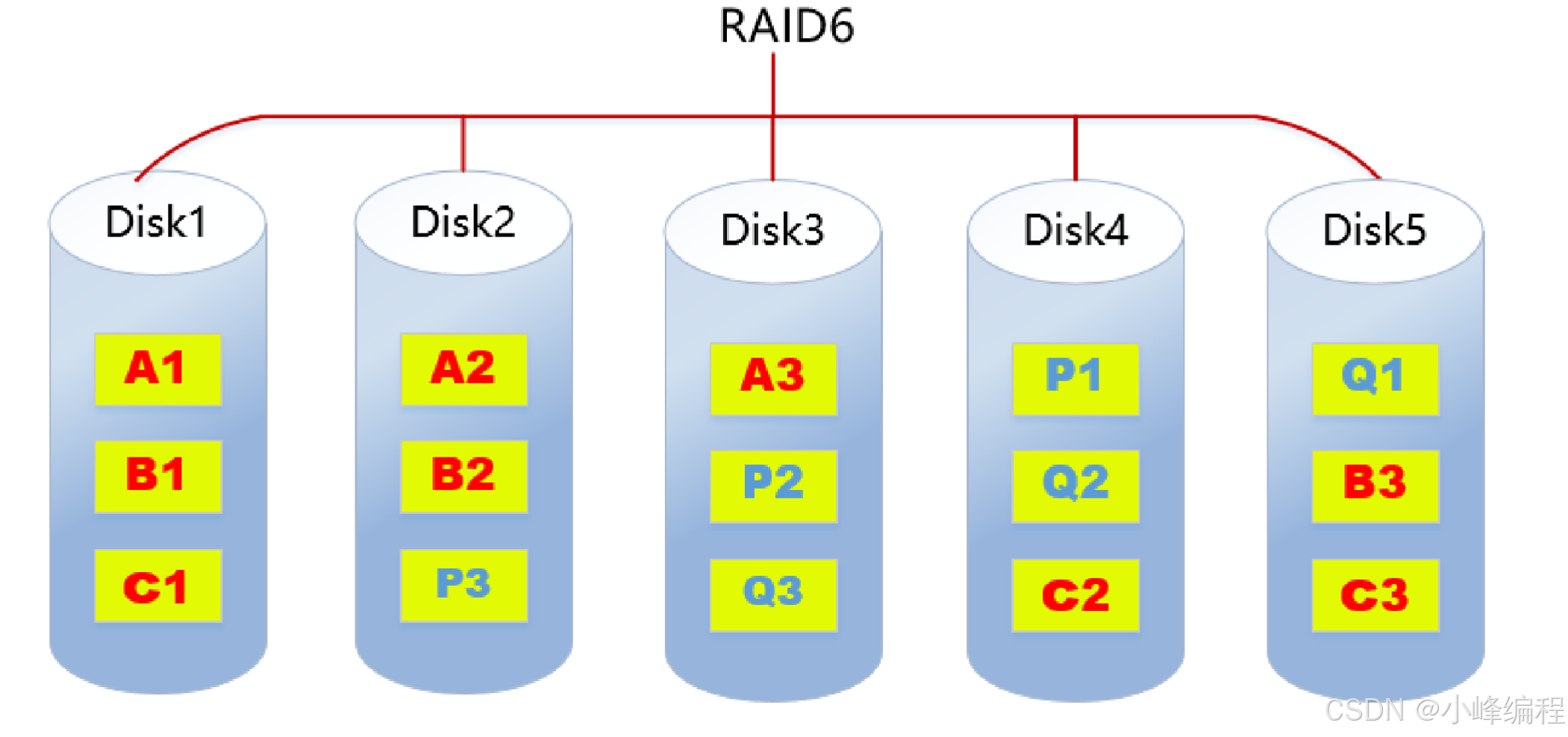
RAID6特点:
- 至少需要4块磁盘
- 数据条带化存储在磁盘,读取性能好,容错能力强
- 采用双重校验方式保证数据的安全性
- 如果2块磁盘同时故障,可以通过两个校验数据来重建两个磁盘的数据
- 成本要比其他等级高,并且更复杂
- 一般用于对数据安全性要求非常高的场合
2.5. RAID10
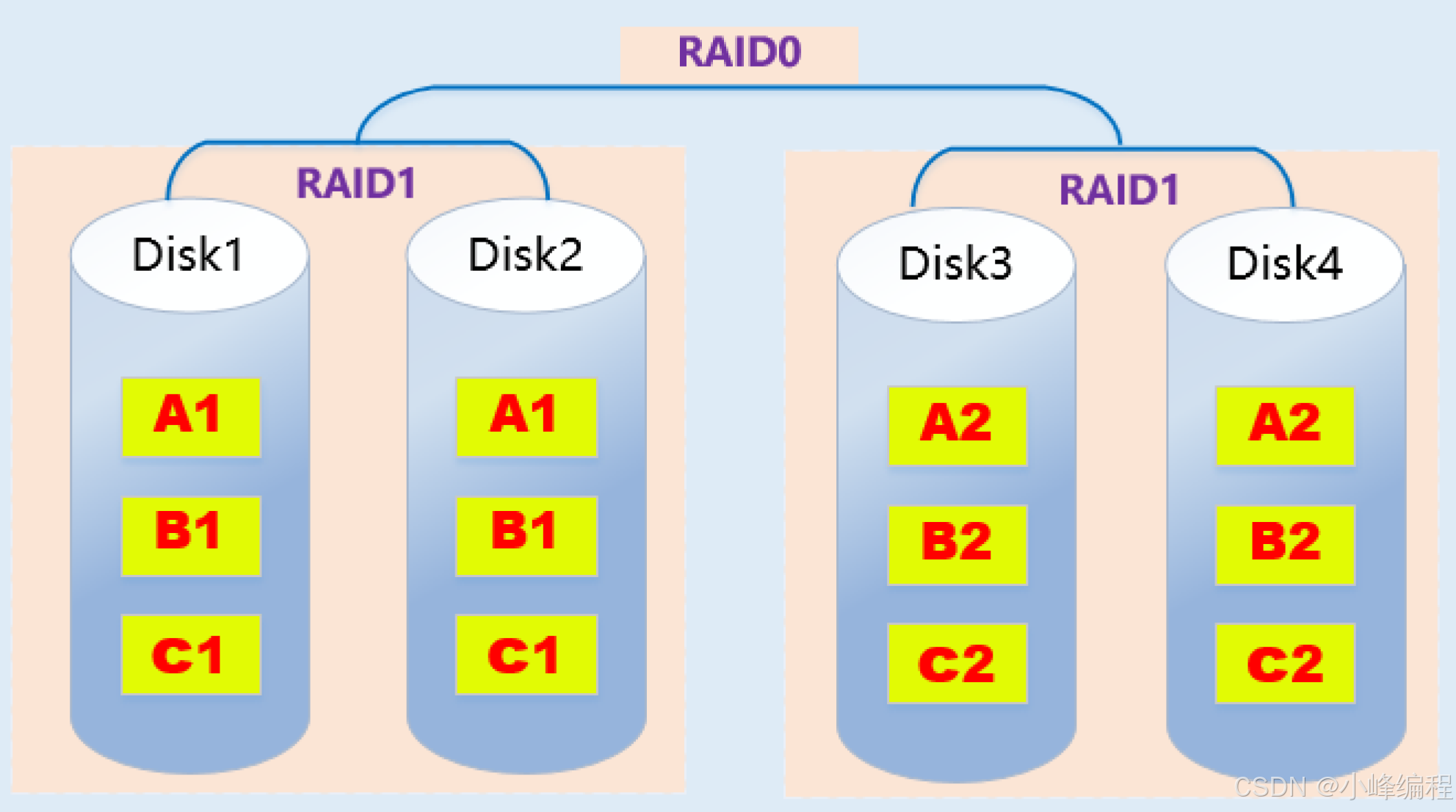
RAID10特点:
- RAID10是raid1+raid0的组合(镜像+条带化)
- 至少需要4块磁盘
- 两块硬盘为一组先做raid1,再将做好raid1的两组做raid0
- 兼顾数据的冗余(raid1镜像)和读写性能(raid0数据条带化)
- 磁盘利用率为50%,成本较高
2.6 RAID01
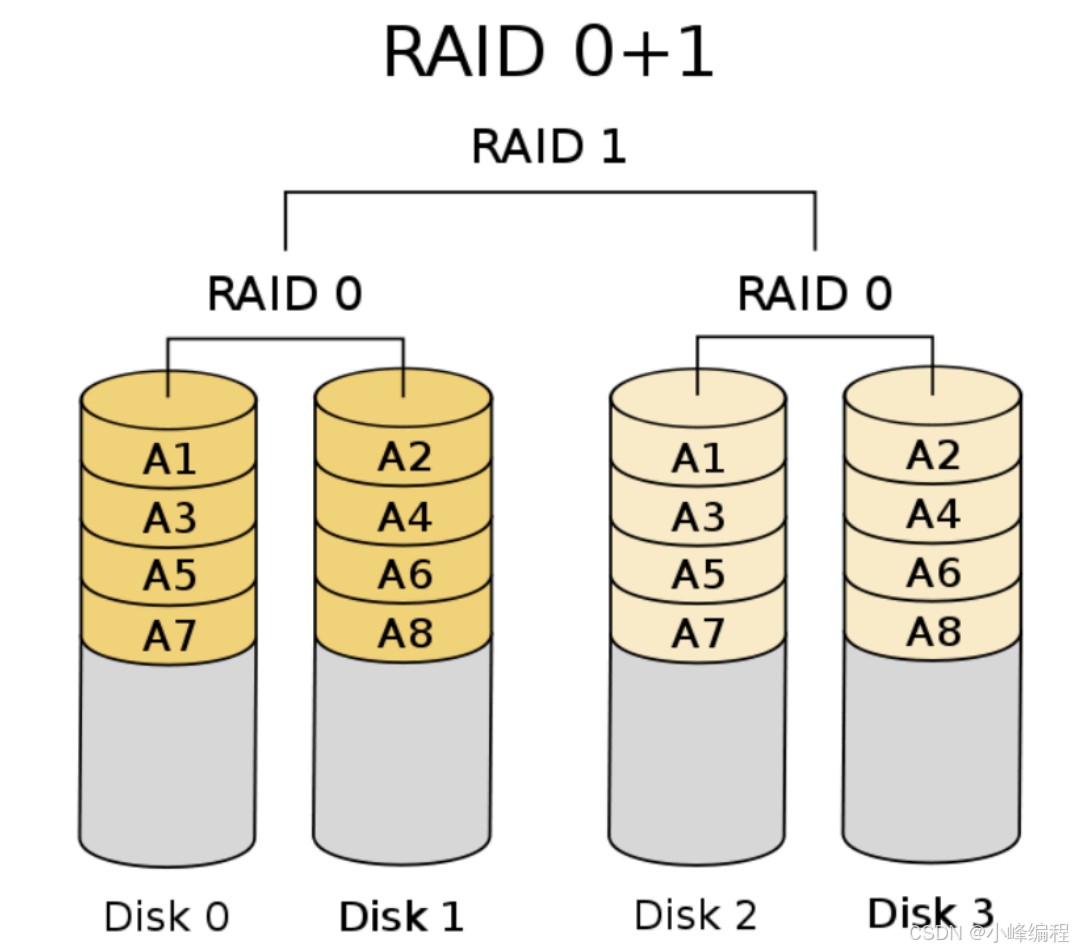
raid01与raid10的架构顺序刚好相反,raid01是先做条带再做镜像,结构如图 这种架构的安全性低于raid10,而两者由于IO数量一致。读写速度相同,使用的硬盘数量也一致。
2.7. 总结
| 类型 | 读写性能 | 可靠性 | 磁盘利用率 | 成本 |
|---|---|---|---|---|
| RAID0 | 最好 | 最低 | 100% | 较低 |
| RAID1 | 读正常;写两份数据 | 高 | 50% | 高 |
| RAID5 | 读:近似RAID0 写:多了校验 | RAID0<RAID5<RAID1 | (n-1)/n | RAID0<RAID5<RAID1 |
| RAID6 | 读:近似RAID0 写:多了双重校验 | RAID6>RAID5 | RAID6<RAID5 | RAID6>RAID1 |
| RAID10 | 读:RAID10=RAID0 写:RAID10=RAID1 | 高 | 50% | 最高 |
3、软硬RAID
3.1. 软RAID
软RAID运行于操作系统底层,将SCSI或者IDE控制器提交上来的物理磁盘,虚拟成虚拟磁盘,再提交给管理程序来进行管理。软RAID有以下特点:
- 占用内存空间
- 占用CPU资源
- 如果程序或者操作系统故障就无法运行
总结:基于以上缺陷,所以现在企业很少用软raid。
3.2. 硬RAID
通过用硬件来实现RAID功能的就是硬RAID,独立的RAID卡,主板集成的RAID芯片都是硬RAID。RAID卡就是用来实现RAID功能的板卡,通常是由I/O处理器、硬盘控制器、硬盘连接器和缓存等一系列零组件构成的。不同的RAID卡支持的RAID功能不同。支持RAlD0、RAID1、RAID4、RAID5、RAID10不等。


4、软raid创建
4.1. 环境准备
添加1个大小为10G的虚拟硬盘,并分10个分区。
4.2. raid的创建
创建RAID0
安装mdadm工具: yum -y install mdadm mdadm --create /dev/md0 --raid-devices=2 /dev/sdb1 /dev/sdb2 --level=0 mdadm -C /dev/md0 -l 0 -n 2 /dev/sdb1 /dev/sdb2 -C:创建软raid -l:指定raid级别 -n:指定raid中设备个数查看RAID信息:/proc/mdstat文件记录了所有raid信息
cat /proc/mdstat查看指定的RAID信息:
mdadm -D /dev/md0格式化挂载使用:
mkfs.ext4 /dev/md0 mount /dev/md0 /test/test1测试:
iostat -m -d /dev/sdc[12] 2 dd if=/dev/zero of=/u01/file bs=1M count=1024
创建RAID1
- 创建raid1:
mdadm -C /dev/md1 -l1 -n 2 /dev/sdc[34]
- 查看状态信息:
watch -n 1 cat /proc/mdstat #watch命令监控该文件变化情况,1秒钟显示一次 #或者直接查看 cat /proc/mdstat注:两个UU说明状态ok,一个盘故障则显示_U;F表示失效失败;_表示有一块盘失效。
- 查看raid1详细信息
mdadm -D /dev/md1
- 格式化挂载使用:
mkfs.ext4 /dev/md1 mount /dev/md1 /test/test2
- 测试验证热插拔:
1. 模拟一块盘故障(将磁盘标记为失效)
mdadm /dev/md1 -f /dev/sdb3 set /dev/sdb3 faulty in /dev/md1 -f or --fail 表示失效2. 查看raid1状态
cat /proc/mdstat3. 移除故障或者失效硬盘(热拔)
mdadm /dev/md1 -r /dev/sdb3 -r or --remove 表示移除 mdadm -D /dev/md14. 加入新的磁盘到raid1中(热插)
mdadm /dev/md1 -a /dev/sdb3 -a or --add 表示增加 cat /proc/mdstat
创建RAID5
- 创建raid5:
mdadm -C /dev/md5 -l 5 -n 3 -x 1 /dev/sdc{7,8,9,10} -x, --spare-devices= 表示指定热备盘 说明:热备盘表示当其中一块盘故障后,热备盘会立马顶上去,而不需要人为手动干预。
- 格式化挂载使用:
mkfs.ext4 /dev/md5 mount /dev/md5 /test/test3
- 测试热备磁盘作用:
1. 标记一块活动盘失效
mdadm /dev/md5 -f /dev/sdb5立即查看状态:
cat /proc/mdstat mdadm -D /dev/md52. 移除失效的盘
mdadm /dev/md5 -r /dev/sdc7 cat /proc/mdstat3. 为了日后考虑,再次添加一个热备盘到raid5中
mdadm /dev/md5 -a /dev/sdb5小练习:
1. 创建一个raid5,raid5至少由3块磁盘设备组成
2. 模拟1块设备故障,检查raid5是否可以正常使用
保存RAID信息
问:为什么要保存raid信息?
答:如果不做信息的保存,重启系统后raid不能自动被识别到(在rhel6里测试为重启后名字会变)。
1. 创建配置文件vim /etc/mdadm.conf DEVICES /dev/sdb[125678]说明:该配置文件默认没有,手动创建,里面写上做了raid的所有硬盘设备。
2. 扫描raid信息保存到配置文件
mdadm -D --scan >> /etc/mdadm.conf cat /etc/mdadm.conf DEVICES /dev/sdb[125678] DEVICES /dev/sdb[12345678] ARRAY /dev/md/0 metadata=1.2 name=localhost.localdomain:0 UUID=b5fae7c0:28c267ed:d2fcf245:638caa84 ARRAY /dev/md1 metadata=1.2 name=bogon:1 UUID=d795a5af:09c8966a:cc88b2d5:a2a68562 ARRAY /dev/md5 metadata=1.2 spares=1 name=bogon:5 UUID=9f29e214:07984db1:20b92e6c:b0604f57
raid停止与启动
- 以RAID5为例说明:
停止raid:
1. 卸载raidumount /test/test32. 使用命令停止raid
mdadm --stop /dev/md5启动raid:
1. 配置文件(/etc/mdadm.conf)存在如下启动mdadm -A /dev/md5 -A:Assemble a pre-existing array 表示装载一个已存在的raid2. 配置文件(/etc/mdadm.conf)不存在如下启动
mdadm -A /dev/md5 /dev/sdb[5678]3. 如果设备名不知道,可以去查看每个设备的raid信息,使用uuid把raid设备重新组合
mdadm -E /dev/sdb5说明:同一个raid里每个磁盘查看的UUID都是这个值 mdadm -E /dev/sdn6 通过以上方法找到后进行重新组合,如下: mdadm -A --uuid=18a60636:71c82e50:724a2a8f:e763fdcf /dev/md5
raid的删除
- 1. 卸载设备
umount /test/test3
- 2. 移除所有磁盘
mdadm /dev/md5 -f /dev/sdb[5678]mdadm /dev/md5 -r /dev/sdb[5678]
- 3. 停止raid
mdadm --stop /dev/md5
- 4. 擦出超级块(superblock)清除相关信息
mdadm --misc --zero-superblock /dev/sdb[5678]
本 篇 完 结 … …
持 续 更 新 中 … …
相关文章:

谈Linux之磁盘管理——万字详解
—— 小 峰 编 程 目录 一、硬盘的基本知识 1.了解硬盘的接口类型 2. 硬盘命名方式 3. 磁盘设备的命名 4. HP服务器硬盘 5. 硬盘的分区方式 二、 基本分区管理 1. 磁盘划分思路 2. 分区 2.1 MBR分区 2.2GPT分区 3.格式化—命令:mkfs 4.挂载 4.1手动挂…...

做好一个测试开发工程师第二阶段:java入门:idea新建一个project后默认生成的.idea/src/out文件文件夹代表什么意思?
时间:2025.4.8 一、前言 关于Java与idea工具安装不再展开,网上很多教程,可以自己去看 二、project建立后默认各文件夹代表意思 1、首先new---->project后会得到文件如图 其中: .idea文件代表:存储这个项目的历史…...

伪代码的定义与应用场景
李升伟 整理 伪代码(Pseudocode)是一种用近似自然语言(通常是英语或开发者熟悉的语言)和简单语法描述的算法逻辑工具。它介于自然语言和编程语言之间,不依赖具体语法规则,专注于表达思路,是编程…...

/sys/fs/cgroup/memory/memory.stat 关键指标说明
目录 1. **total_rss**2. **total_inactive_file**3. **total_active_file**4. **shmem**5. **其他相关指标**总结 以下是/sys/fs/cgroup/memory/memory.stat文件中一些关键指标的详细介绍,特别是与PostgreSQL相关的指标: 1. total_rss 定义࿱…...

机器学习中的聚类分析算法:原理与应用
一、什么是聚类分析? 聚类分析(Clustering Analysis)是机器学习中一种重要的无监督学习技术,它的目标是将数据集中的样本划分为若干个组(称为"簇"),使得同一簇内的样本彼此相似,而不同簇的样本差异较大。与分类不同&am…...

VUE中的路由处理
1.引入,预处理main.ts import {} from vue-router import { createRouter, createWebHistory } from vue-router import HomePages from @/pages/HomePages.vue import AboutPage from @/pages/AboutPage.vue import NewsPage from @/pages/NewsPage.vue //1. 配置路由规…...
 控制工程会用到的)
MATLAB学习笔记(二) 控制工程会用到的
MATLAB中 控制工程会用到的 基础传递函数表达传递函数 零极点式 状态空间表达式 相互转化画响应图线根轨迹Nyquist图和bode图现控部分求约旦判能控能观极点配置和状态观测 基础 传递函数表达 % 拉普拉斯变换 syms t s a f exp(a*t) %e的a次方 l laplace(f) …...

Python: 实现数据可视化分析系统
后端基于Python 开源的 Web 框架 Flask,前端页面采用 LayUI 框架以及 Echarts 图表,数据库为sqlite。系统的功能模块分为数据采集和存储模块、数据处理和分析模块、可视化展示模块和系统管理模块。情感分析方面使用LDA等主题建模技术,结合领域…...

VectorBT量化入门系列:第一章 VectorBT基础与环境搭建
VectorBT量化入门系列:第一章 VectorBT基础与环境搭建 本教程专为中高级开发者设计,系统讲解VectorBT技术在量化交易中的应用。通过结合Tushare数据源和TA-Lib技术指标,深度探索策略开发、回测优化与风险评估的核心方法。从数据获取到策略部署…...

典型反模式深度解析及重构方案
反模式 1:魔法数字/字符串(Magic Numbers/Strings) ▐ 问题场景 // 订单状态校验 if (order.getStatus() 3) { // 3代表已发货?sendNotification(); }// 折扣计算 double discount price * 0.15; // 0.15是什么?…...

神经探针与价值蓝海:AI重构需求挖掘的认知拓扑学
当产品经理的决策边界遭遇量子态的用户需求,传统需求分析工具已显露出经典物理般的局限性。Gartner 2024报告揭示:全球Top 500企业中有83%遭遇需求洞察的"测不准困境"——用户声称的需求与行为数据偏差率达47%,而未被表达的潜在需求…...

Tomcat 负载均衡
目录 二、Tomcat Web Server 2.1 Tomcat 部署 2.1.1 Tomcat 介绍 2.1.2 Tomcat 安装 2.2 Tomcat 服务管理 2.2.1 Tomcat 启停 2.2.2 目录说明 2.2.3编辑主页 2.3 Tomcat管理控制台 2.3.1开启远程管理 2.3.2 配置远程管理密码 三、负载均衡 3.1 重新编译Nginx 3.1.1 确…...

CSS >子元素选择器和空格
在 CSS 中,> 符号是 子元素选择器(Child Combinator),它用于选择某个元素的直接子元素(仅限第一层嵌套的子元素,不包含更深层的后代元素)。 语法 父元素 > 子元素 {样式规则; } 示例 …...

duckdb源码阅读学习路径图
🧭 DuckDB 最小内存源码阅读路径图 1️⃣ 数据流入口与批处理:DataChunk 项目内容✅ 目标理解 DuckDB 向量化执行的数据载体结构,如何影响内存📁 路径src/common/types/data_chunk.cpp/hpp🔍 入口函数DataChunk::Initialize, DataChunk::SetCardinality, Reset📌 优化…...

C#二叉树
C#二叉树 二叉树是一种常见的数据结构,它是由节点组成的一种树形结构,其中每个节点最多有两个子节点。二叉树的一个节点通常包含三部分:存储数据的变量、指向左子节点的指针和指向右子节点的指针。二叉树可以用于多种算法和操作,…...

BT-Basic函数之首字母W
BT-Basic函数之首字母W 文章目录 BT-Basic函数之首字母Wwaitwait for start wait wait函数使程序在执行下一个功能之前暂停指定的秒数。 语法 wait <数值表达式>参数 <数值表达式> 等待时长,以秒为单位。该值必须大于或等于0。小于25毫秒的正值会被…...

如何避免论文内容被误认为是 AI 生成的?
AIGC 检测的原理 AIGC 检测主要基于自然语言处理(NLP)和机器学习技术,通过深度分析文本内容来识别其中的 AI 生成痕迹。具体原理如下: 基础学习算法:利用机器学习算法对文本信息进行特征提取和表示,以便计…...

node.js之path常用方法
node.js之path常用方法 1.path.join([…paths]) 用于将多个路径片段拼接成一个路径,会自动处理路径分隔符,避免手动拼接时可能出现的问题 const joinedPath path.join(folder1, folder2, file.txt); console.log(joinedPath); // 输出: folder1/fol…...

【面试】C++与C override的报错阶段 RAII
文章目录 C 相对于 C 语言的主要区别**1. 面向对象编程(OOP)****2. 函数增强****3. 内存管理****4. 引用(Reference)****5. 标准模板库(STL)****6. 异常处理****7. 类型安全增强****8. 其他特性****9. 兼容…...
一次倒序遍历)
LeetCode 3396.使数组元素互不相同所需的最少操作次数:O(n)一次倒序遍历
【LetMeFly】3396.使数组元素互不相同所需的最少操作次数:O(n)一次倒序遍历 力扣题目链接:https://leetcode.cn/problems/minimum-number-of-operations-to-make-elements-in-array-distinct/ 给你一个整数数组 nums,你需要确保数组中的元素…...

机器学习课堂7用scikit-learn库训练SVM模型
1.用scikit-learn库训练SVM模型 代码 # 2-11用scikit-learn库训练SVM模型 import pandas as pd import numpy as np import matplotlib.pyplot as plt from sklearn import svm # 导入sklearn# 参数设置 m_train 250 # 训练样本数量 svm_C 100 # SVM的C值 svm_kernel …...
)
模拟考试系统(ssm+vue+mysql5.x)
模拟考试系统(ssmvuemysql5.x) 模拟考试系统是一个为考试准备和管理提供全面支持的平台。系统提供了丰富的功能模块,包括个人中心、科目管理、复习资料管理、参考文献管理、用户管理、留言板管理、试题管理、试卷管理、系统管理和考试管理。用户可以在个人中心修改…...

【计网】作业4
一. 单选题(共22题,64分) 1. (单选题)主机甲采用停止-等待协议向主机乙发送数据,数据传输速率是4kb/s,单向传播时延为30ms,忽略确认帧的发送时延。当信道利用率等于80%时,数据帧的长度为&#…...

MYSQL数据库语法补充
一,DQL基础查询 DQL(Data Query Language)数据查询语言,可以单表查询,也可以多表查询 语法: select 查询结果 from 表名 where 条件; 特点: 查询结果可以是:表中的字段…...

Java基础编程练习第38题-除法器
题目:编写一个除法器,输入被除数和除数,并将结果输出。 这道题看似很简单,实则也不难。 就是假如用户输入的类型不同怎么办呢?用户输入int或者double类型应该怎么解决。这里我们就需要用到函数的重载。 代码如下&am…...

【基于Vue3组合式API的互斥输入模式实现与实践分享】
基于Vue3组合式API的互斥输入模式实现与实践分享 目录 背景与痛点设计思路技术实现使用场景与案例遇到的问题与解决方案最佳实践总结 1. 背景与痛点 在表单交互设计中,我们经常面临这样的场景:多种输入方式互斥。例如,在评分系统中&#…...

Linux进程概念及理解
目录 冯诺依曼体系结构 操作系统(Operator System) 概念 设计OS的目的 定位 如何理解 "管理" 总结 系统调用和库函数概念 进程 基本概念 描述进程-PCB task_struct-PCB的一种 task_ struct内容分类 组织进程 查看进程 通过系统调用获取进程标示符 通过系统调用创建进…...

苹果签名是否安全
苹果开发者与运营商都对苹果签名有一定了解,那么苹果签名安全吗?下面我来跟大家聊一聊。 苹果签名能验证应用的来源,但存在一些风险,有开发者伪造签名,让用户认为此产品是可信的,这样就安装到了恶意应用&am…...
环境下,需要手动实现队列机制来替代FreeRTOS的CAN发送接收函数)
STM32在裸机(无RTOS)环境下,需要手动实现队列机制来替代FreeRTOS的CAN发送接收函数
xQueueSendToBackFromISR(ecuCanRxQueue, hcan->pRxMsg, &xHigherPriorityTaskWoken),xQueueReceive(mscCanRxQueue,&mscRxMsg,0)和xQueueSendToBack(mscCanTxQueue, &TxMessageTemp, 0 )这3个函数,在裸机下实现: 在裸机&…...

无法看到新安装的 JDK 17
在 Linux 系统中使用 update-alternatives --config java 无法看到新安装的 JDK 17,可能是由于 JDK 未正确注册到系统备选列表中。 一、原因分析 JDK 未注册到 update-alternatives update-alternatives 工具需要手动注册 JDK 路径后才能识别新版本。如果仅安装 JDK…...

JavaEE——线程的状态
目录 前言1. NEW2. TERMINATED3. RUNNABLE4. 三种阻塞状态总结 前言 本篇文章来讲解线程的几种状态。在Java中,线程的状态是一个枚举类型,Thread.State。其中一共分为了六个状态。分别为:NEW,RUNNABLE,BLOCKED,WAITING,TIMED_WAITING, TERMI…...
)
数据结构与算法-数学-(同余,线性同余方程,中国剩余定理,卡特兰数,斯特林数)
同余方程: 1.1 线性同余方程 & 乘法逆元 线性同余方程是形如 ax≡b(mod m) 的方程,可转化为 axmyb 的线性不定方程,利用扩展欧几里得算法求解。当 b1 时,x 就是 a 在模 m 意义下的乘法逆元。 代码: #include &…...

RAG 系统中的偏差是什么?
检索增强生成 (RAG) 在减少模型幻觉和增强大型语言模型 (LLM)的领域特定知识库方面已获得广泛认可。通过外部数据源佐证大型语言模型生成的信息,有助于保持模型输出的新鲜度和真实性。然而,最近在 RAG系统中的发现,突显了基于 RAG 的大型语言…...

[创业之路-362]:用确定性的团队、组织、产品开发流程和方法,应对客户、市场、竞争和商业模式的不确定性。
在充满不确定性的商业环境中,通过确定性的团队、组织、产品开发流程和方法构建核心竞争力,是应对客户、市场、竞争和商业模式变化的核心策略。以下从团队韧性、组织敏捷、产品开发闭环三个维度,结合实战方法论,提供可落地的解决方…...
)
系统与网络安全------网络通信原理(1)
资料整理于网络资料、书本资料、AI,仅供个人学习参考。 文章目录 网络通信模型协议分层计算机网络发展计算机网络功能什么是协议为什么分层邮局实例 OSI模型OSI协议模型OSI七层模型OSI七层的功能简介 TCP/IP模型OSI模型与TCP/IP模型TCP/IP协议族的组成各层PDU设备与…...

ArkTS语言基础之函数
前言 臭宝们终于来到了ArkTS基础之函数,今天我们来学习一下ArkTS的函数的相关知识,上一节中也有一些函数的基础知识。 函数声明 函数声明引入一个函数,包含其名称、参数列表、返回类型和函数体,在下面的例子中,我们声明了一个名…...

synchronized锁升级的锁对象和Mark Word
在讨论synchronized锁升级和Mark Word时,提到的"对象"通常指的是锁对象,也就是被用作synchronized同步锁的那个Java对象。 1. 什么是锁对象? 锁对象是指被用于synchronized同步代码块或方法的对象实例。例如: // 这个…...
插入排序 希尔排序 冒泡排序)
数据结构|排序算法(二)插入排序 希尔排序 冒泡排序
一、插入排序 1.算法思想 插入排序(Insertion Sort)是一种简单的排序算法,其基本思想是:将待排序的元素插入到已经有序的序列中,从而逐步构建有序序列。 具体过程如下: 把待排序的数组分为已排序和未排…...

12、主频和时钟配置实验
一、I.MX6U 时钟系统详解 1、系统时钟来源 开发板的系统时钟来源于两部分: 32.768KHz 和24MHz 的晶振,其中 32.768KHz 晶振是 I.MX6U 的 RTC 时钟源, 24MHz 晶振是 I.MX6U 内核和其它外设的时钟源。 2、7路PLL时钟源 I.MX6U 的外设有很多,不同的外设时钟源不同, NXP 将…...

DFS和BFS的模版
dfs dfs金典例题理解就是走迷宫 P1605 迷宫 - 洛谷 dfs本质上在套一个模版: ///dfs #include<bits/stdc.h> using namespace std; int a[10][10]{0}; int m,n,t,ans0; int ex,ey; int v[10][10]{0}; int dx[4]{-1,0,1,0}; int dy[4]{0,1,0,-1}; void dfs(in…...

docker镜像导出导入
在Docker中,可以很容易地导出和导入镜像,这对于备份、迁移或者在不同的环境中共享镜像非常有用。以下是操作步骤: 导出镜像 使用 docker save docker save 命令可以用来将一个或多个镜像保存到一个文件中,这个文件可以被导入到任…...

大模型Agent | 构建智能体 AI-Agent的 5大挑战,及解决方案!
源自: AINLPer(每日干货分享!!) 编辑: ShuYini 校稿: ShuYini 时间: 2025-4-7 更多:>>>>专注大模型/AIGC、学术前沿的知识分享! 引言 AI-Agent正变得越来越智能,它能够根据用户需…...

基于STM32、HAL库的IP2721 快充协议芯片简介及驱动程序设计
一、简介: IP2721是一款高性能的USB PD (Power Delivery)协议控制器芯片,主要用于USB Type-C接口的电源管理。它支持USB PD 3.0规范,能够实现多种电压和电流的协商,广泛应用于充电器、移动电源等设备。 主要特性: 支持USB PD 3.0规范 支持Type-C接口的DRP/SRC/SNK模式 内…...

荣耀90 GT信息
外观设计 屏幕:采用 6.7 英寸 AMOLED 荣耀绿洲护眼屏,超窄边框设计,其上边框 1.6mm,左右黑边 1.25mm,屏占较高,带来更广阔的视觉体验。屏幕还支持 120Hz 自由刷新率,可根据使用场景自动切换刷新…...

53. 评论日记
要自己有判断是非的能力宝子们。#小米 #小米su7 #雷军 #神操作 #小米su7ultra_哔哩哔哩_bilibili 2025年4月8日19:30:57...
之安装Dashboard和CoreDNS)
【10】搭建k8s集群系列(二进制部署)之安装Dashboard和CoreDNS
一、部署Dashboard 1.1、创建kubernetes-dashboard.yaml文件 完整的yaml配置文件信息如下: # Copyright 2017 The Kubernetes Authors. # # Licensed under the Apache License, Version 2.0 (the "License"); # you may not use this file except in …...

【算法手记12】DP25 删除相邻数字的最大分数
🦄个人主页:修修修也 🎏所属专栏:刷题 ⚙️操作环境:牛客网 目录 一.DP25 删除相邻数字的最大分数 题目详情: 题目思路: 解题代码: 结语 一.DP25 删除相邻数字的最大分数 牛客网题目链接(点击即可跳转):DP25 删除相邻数字的最大分数 题目详情: 本题详情如…...

[Godot] C#简单实现人物的控制和动画
目录 实现效果 场景搭建 脚本实现 移动 动画 完整脚本 相机跟随 总结 实现效果 场景搭建 本文章只分享了关于移动和动画的,没有给碰撞体,大家根据需要自行添加吧 相机的缩放大小可以根据自己的需要调整 我的人物动画结构是这样的,待机动…...

选择站群服务器租用的优势都有什么?
站群服务器是一种专门用于托管多个网站的服务器,是通过集中管理和资源分配,可以支持同时运行数十个甚至是数百个独立网站,站群服务器的主要特点就是让每个网站可以分配独立的IP地址,避免出现IP关联风险,通过统一控制面…...

VS Code下开发FPGA——FPGA开发体验提升__下
上一篇:IntelliJ IDEA下开发FPGA-CSDN博客 Type:Quartus 一、安装插件 在应用商店先安装Digtal IDE插件 安装后,把其他相关的Verilog插件禁用,避免可能的冲突。重启后,可能会弹出下面提示 这是插件默认要求的工具链&a…...