怎么使用vue3实现一个优雅的不定高虚拟列表
前言
很多同学将虚拟列表当做亮点写在简历上面,但是却不知道如何手写,那么这个就不是加分项而是减分项了。实际项目中更多的是不定高虚拟列表,这篇文章来教你不定高如何实现。
什么是不定高虚拟列表
不定高的意思很简单,就是不知道每一项item的具体高度,如下图:
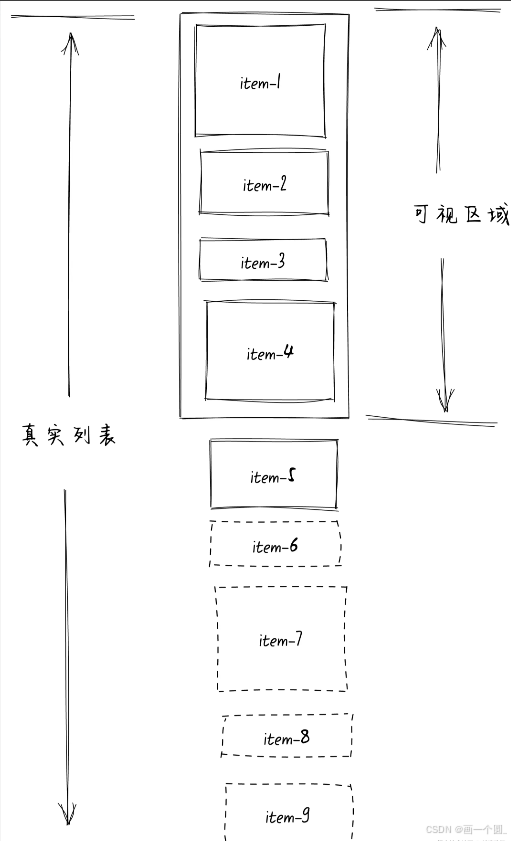
现在我们有个问题,在不定高的情况下我们就不能根据当前滚动条的scrollTop去计算可视区域里面实际渲染的第一个item的index位置,也就是start的值。
没有start,那么就无法实现在滚动的时候只渲染可视区域的那几个item了。
预估高度
既然我们不知道每个item的高度,那么就采用预估高度的方式去实现。比如这样:
const { listData, itemSize } = defineProps({// 列表数据listData: {type: Array,default: () => [],},// 预估item高度,不是真实item高度itemSize: {type: Number,default: 300,},
});
还是和上一篇一样的套路,计算出当前可视区域的高度containerHeight,然后结合预估的itemSize就可以得到当前可视区域里面渲染的item数量。代码如下:
const renderCount = computed(() => Math.ceil(containerHeight.value / itemSize));
注意:由于我们是预估的高度,所以这个renderCount的数量是不准的。
如果预估的高度比实际高太多,那么实际渲染的item数量就会不够,导致页面下方出现白屏的情况。
如果预估的高度太小,那么这里的item数量就会渲染的太多了,性能又没之前那么好。
所以预估item高度需要根据实际业务去给一个适当的值,理论上是宁可预估小点,也不预估的大了(大了会出现白屏)。
start初始值为0,并且算出了renderCount,此时我们也就知道了可视区域渲染的最后一个end的值。如下:
const end = computed(() => start.value + renderCount.value);
和上一篇一样计算end时在下方多渲染了一个item,第一个item有一部分滚出可视区域的情况时,如果不多渲染可能就会出现白屏的情况。
有了start和end,那么就知道了可视区域渲染的renderList,代码如下:
const renderList = computed(() => listData.slice(start.value, end.value + 1));
这样我们就知道了,初始化时可视区域应该渲染哪些item了,但是因为我们之前是给每个item预估高度,所以我们应该将这些高度的值纠正过来。
更新高度
为了记录不定高的list里面的每个item的高度,所以我们需要一个数组来存每个item的高度。所以我们需要定义一个positions数组来存这些值。
既然都存了每个item的高度,那么同样可以使用top、bottom这两个字段去记录每个item在列表中的开始位置和结束位置。注意bottom - top的值肯定等于height的值。
还有一个index字段记录每个item的index的值。positions定义如下:
const positions = ref<{index: number;height: number;top: number;bottom: number;}[]
>([]);
positions的初始化值为空数组,那么什么时候给这个数组赋值呢?
答案很简单,虚拟列表渲染的是props传入进来的listData。所以我们watch监听listData,加上immediate: true。这样就可以实现初始化时给positions赋值,代码如下:
watch(() => listData, initPosition, {immediate: true,
});function initPosition() {positions.value = [];listData.forEach((_item, index) => {positions.value.push({index,height: itemSize,top: index * itemSize,bottom: (index + 1) * itemSize,});});
}
遍历listData结合预估的itemSize,我们就可以得出每一个item里面的height、top、bottom这几个字段的值。
还有一个问题,我们需要一个元素来撑开滚动条。在定高的虚拟列表中我们是通过itemSize * listData.length得到的。显然这里不能那样做了,由于positions数组中存的是所有item的位置,那么最后一个item的bottom的值就是列表的真实高度。前面也是不准的,会随着我们纠正positions中的值后他就是越来越准的了。
所以列表的真实高度为:
const listHeight = computed(() => positions.value[positions.value.length - 1].bottom
);
此时positions数组中就已经记录了每个item的具体位置,虽然这个位置是错的。接下来我们就需要将这些错误的值纠正过来,如何纠正呢?
答案很简单,使用Vue的onUpdated钩子函数,这个钩子函数会在响应式状态变更而更新其 DOM 树之后调用。也就是会在renderList渲染成DOM后触发!
此时这些item已经渲染成了DOM节点,那么我们就可以遍历这些item的DOM节点拿到每个item的真实高度。都知道每个item的真实高度了,那么也就能够更新里面所有item的top和bottom了。代码如下:
<template><div ref="container" class="container" @scroll="handleScroll($event)"><div class="placeholder" :style="{ height: listHeight + 'px' }"></div><div class="list-wrapper" :style="{ transform: getTransform }"><divclass="card-item"v-for="item in renderList":key="item.index"ref="itemRefs":data-index="item.index"><span style="color: red">{{ item.index }}<img width="200" :src="item.imgUrl" alt="" /></span>{{ item.value }}</div></div></div>
</template><script setup>
onUpdated(() => {updatePosition();
});function updatePosition() {itemRefs.value.forEach((el) => {const index = +el.getAttribute("data-index");const realHeight = el.getBoundingClientRect().height;let diffVal = positions.value[index].height - realHeight;const curItem = positions.value[index];if (diffVal !== 0) {// 说明item的高度不等于预估值curItem.height = realHeight;curItem.bottom = curItem.bottom - diffVal;for (let i = index + 1; i < positions.value.length - 1; i++) {positions.value[i].top = positions.value[i].top - diffVal;positions.value[i].bottom = positions.value[i].bottom - diffVal;}}});
}
</script>
使用:data-index="item.index"将index绑定到item上面,更新时就可以通过+el.getAttribute(“data-index”)拿到对应item的index。
itemRefs中存的是所有item的DOM元素,遍历他就可以拿到每一个item,然后拿到每个item在长列表中的index和真实高度realHeight。
diffVal的值是预估的高度比实际的高度大多少,如果diffVal的值不等于0,说明预估的高度不准。此时就需要将当前item的高度height更新了,由于高度只会影响bottom的值,所以只需要更新当前item的height和bottom。
由于当前item的高度变了,假如diffVal的值为正值,说明我们预估的高度多了。此时我们需要从当前item的下一个元素开始遍历,直到遍历完整个长列表。我们预估多了,那么只需要将后面的所有item整体都向上移一移,移动的距离就是预估的差值diffVal。
所以这里需要从index + 1开始遍历,将遍历到的所有元素的top和bottom的值都减去diffVal。
将可视区域渲染的所有item都遍历一遍,将每个item的高度和位置都纠正过来,同时会将后面没有渲染到的item的top和bottom都纠正过来,这样就实现了高度的更新。理论上从头滚到尾,那么整个长列表里面的所有位置和高度都纠正完了。
开始滚动
通过前面我们已经实现了预估高度值的纠正,渲染过的item的高度和位置都是纠正过后的了。此时我们需要在滚动后如何计算出新的start的位置,以及offset偏移量的值。
还是和定高同样的套路,当滚动条在item中间滚动时复用浏览器的滚动条,从一个item滚到另外一个item时才需要更新start的值以及offset偏移量的值。
此时应该如何计算最新的start值呢?
很简单!在positions中存了两个字段分别是top和bottom,分别表示当前item的开始位置和结束位置。如果当前滚动条的scrollTop刚好在top和bottom之间,也就是scrollTop >= top && scrollTop < bottom,那么是不是就说明当前刚好滚到这个item的位置呢。
并且由于在positions数组中bottom的值是递增的,那么问题不就变成了查找第一个item的scrollTop < bottom。所以我们得出:
function getStart(scrollTop) {return positions.value.findIndex((item) => scrollTop < item.bottom);
}
每次scroll滚动都会触发一次这个查找,那么我们可以优化上面的算法吗?
positions数组中的bottom字段是递增的,这很符合二分查找的规律。不了解二分查找的同学可以看看leetcode上面的这道题: https://leetcode.cn/problems/search-insert-position/description/
所以上面的代码可以优化成这样:
function getStart(scrollTop) {let left = 0;let right = positions.value.length - 1;while (left <= right) {const mid = Math.floor((left + right) / 2);if (positions.value[mid].bottom === scrollTop) {return mid + 1;} else if (positions.value[mid].bottom < scrollTop) {left = mid + 1;} else {right = mid - 1;}}return left;
}
和定高的虚拟列表一样,当在start的item中滚动时直接复用浏览器的滚动,无需做任何事情。所以此时的offset偏移量就应该等于当前start的item的top值,也就是start的item前面的所有item加起来的高度。所以得出offset的值为:
offset.value = positions.value[start.value].top;
可能有的小伙伴会迷惑,在start的item中的滚动值为什么不算到offset偏移中去呢?
因为在start的item范围内滚动时都是直接使用的浏览器滚动,已经有了scrollTop,所以无需加到offset偏移中去。
所以我们得出当scroll事件触发时代码如下:
function handleScroll(e) {const scrollTop = e.target.scrollTop;start.value = getStart(scrollTop);offset.value = positions.value[start.value].top;
}
同样offset偏移值使用translate3d应用到可视区域的div上面,代码如下:
<template><div ref="container" class="container" @scroll="handleScroll($event)"><div class="placeholder" :style="{ height: listHeight + 'px' }"></div><div class="list-wrapper" :style="{ transform: getTransform }">...省略</div></div>
</template><script setup>
const props = defineProps({offset: {type: Number,default: 0,},
});
const getTransform = computed(() => `translate3d(0,${props.offset}px,0)`);
</script>
完整的父组件代码如下:
<template><div style="height: 100vh; width: 100vw"><VirtualList :listData="data" :itemSize="50" /></div>
</template><script setup>
import VirtualList from "./dynamic.vue";
import { faker } from "@faker-js/faker";
import { ref } from "vue";const data = ref([]);
for (let i = 0; i < 1000; i++) {data.value.push({index: i,value: faker.lorem.sentences(),});
}
</script><style>
html {height: 100%;
}
body {height: 100%;margin: 0;
}
#app {height: 100%;
}
</style>
完整的虚拟列表子组件代码如下:
<template><div ref="container" class="container" @scroll="handleScroll($event)"><div class="placeholder" :style="{ height: listHeight + 'px' }"></div><div class="list-wrapper" :style="{ transform: getTransform }"><divclass="card-item"v-for="item in renderList":key="item.index"ref="itemRefs":data-index="item.index"><span style="color: red">{{ item.index }}<img width="200" :src="item.imgUrl" alt="" /></span>{{ item.value }}</div></div></div>
</template><script setup lang="ts">
import { ref, computed, watch, onMounted, onUpdated } from "vue";
const { listData, itemSize } = defineProps({// 列表数据listData: {type: Array,default: () => [],},// 预估item高度,不是真实item高度itemSize: {type: Number,default: 300,},
});const container = ref(null);
const containerHeight = ref(0);
const start = ref(0);
const offset = ref(0);
const itemRefs = ref();
const positions = ref<{index: number;height: number;top: number;bottom: number;}[]
>([]);const end = computed(() => start.value + renderCount.value);
const renderList = computed(() => listData.slice(start.value, end.value + 1));
const renderCount = computed(() => Math.ceil(containerHeight.value / itemSize));
const listHeight = computed(() => positions.value[positions.value.length - 1].bottom
);
const getTransform = computed(() => `translate3d(0,${offset.value}px,0)`);watch(() => listData, initPosition, {immediate: true,
});function handleScroll(e) {const scrollTop = e.target.scrollTop;start.value = getStart(scrollTop);offset.value = positions.value[start.value].top;
}function getStart(scrollTop) {let left = 0;let right = positions.value.length - 1;while (left <= right) {const mid = Math.floor((left + right) / 2);if (positions.value[mid].bottom === scrollTop) {return mid + 1;} else if (positions.value[mid].bottom < scrollTop) {left = mid + 1;} else {right = mid - 1;}}return left;
}function initPosition() {positions.value = [];listData.forEach((_item, index) => {positions.value.push({index,height: itemSize,top: index * itemSize,bottom: (index + 1) * itemSize,});});
}function updatePosition() {itemRefs.value.forEach((el) => {const index = +el.getAttribute("data-index");const realHeight = el.getBoundingClientRect().height;let diffVal = positions.value[index].height - realHeight;const curItem = positions.value[index];if (diffVal !== 0) {// 说明item的高度不等于预估值curItem.height = realHeight;curItem.bottom = curItem.bottom - diffVal;for (let i = index + 1; i < positions.value.length - 1; i++) {positions.value[i].top = positions.value[i].top - diffVal;positions.value[i].bottom = positions.value[i].bottom - diffVal;}}});
}onMounted(() => {containerHeight.value = container.value.clientHeight;
});onUpdated(() => {updatePosition();
});
</script><style scoped>
.container {height: 100%;overflow: auto;position: relative;
}.placeholder {position: absolute;left: 0;top: 0;right: 0;z-index: -1;
}.card-item {padding: 10px;color: #777;box-sizing: border-box;border-bottom: 1px solid #e1e1e1;
}
</style>
这篇文章我们讲了不定高的虚拟列表如何实现,首先给每个item设置一个预估高度itemSize。然后根据传入的长列表数据listData初始化一个positions数组,数组中的top、bottom、height等属性表示每个item的位置。然后根据可视区域的高度加上itemSize算出可视区域内可以渲染多少renderCount个item。接着就是在onUpdated钩子函数中根据每个item的实际高度去修正positions数组中的值。
在滚动时查找第一个item的bottom大于scrollTop,这个item就是start的值。offset偏移的值为start的top属性。
值得一提的是如果不定高的列表中有图片就不能在onUpdated钩子函数中修正positions数组中的值,而是应该监听图片加载完成后再去修正positions数组。可以使用 ResizeObserver 去监听渲染的这一堆item,注意ResizeObserver的回调会触发两次,第一次为渲染item的时候,第二次为item中的图片加载完成后。
相关文章:

怎么使用vue3实现一个优雅的不定高虚拟列表
前言 很多同学将虚拟列表当做亮点写在简历上面,但是却不知道如何手写,那么这个就不是加分项而是减分项了。实际项目中更多的是不定高虚拟列表,这篇文章来教你不定高如何实现。 什么是不定高虚拟列表 不定高的意思很简单,就是不…...

LemonSqueezy: 1靶场渗透
LemonSqueezy: 1 来自 <LemonSqueezy: 1 ~ VulnHub> 1,将两台虚拟机网络连接都改为NAT模式 2,攻击机上做namp局域网扫描发现靶机 nmap -sn 192.168.23.0/24 那么攻击机IP为192.168.23.182,靶场IP192.168.23.225 3,对靶机进…...

2025 年山东保安员职业资格考试要点梳理
山东作为人口大省,保安市场规模庞大。2025 年考试报考条件常规。报名通过山东省各市公安机关指定的培训机构或政务服务窗口,提交资料与其他地区类似。 理论考试注重对山东地域文化特色相关安保知识的考查,如在孔庙等文化圣地安保中&#x…...

ARM处理器内核全解析:从Cortex到Neoverse的架构与区别
ARM处理器内核全解析:从Cortex到Neoverse的架构与区别 ARM作为全球领先的处理器架构设计公司,其内核产品线覆盖了从高性能计算到低功耗嵌入式应用的广泛领域。本文将全面解析ARM处理器的内核分类、架构特点、性能差异以及应用场景,帮助读者深…...

网络缓冲区
网络缓冲区分为内核缓冲区和用户态网络缓冲区 我们重点要实现用户态网络缓冲区 1.设计用户态网络缓冲区的原因 ①.生产者和消费者的速度不匹配问题, 需要缓存数据。 ②.粘包处理问题, 不能确保一次系统调用读取或写入完整数据包。 2.代码实现(cha…...
)
数据仓库的核心架构与关键技术(数据仓库系列二)
目录 一、引言 二、数据仓库的核心架构 三、数据仓库的关键技术 1 数据集成与治理 2 查询优化与性能提升 3 数据共享服务 BI:以Tableau为例 SQL2API:以麦聪QuickAPI为例 4 实时数据处理 四、技术的协同作用 五、总结与展望 六、预告 一、引言…...

基于PyQt5与OpenCV的图像处理系统设计与实现
1. 系统概述 本系统是一个集成了多种经典图像处理算法的图形用户界面(GUI)应用程序,采用Python语言开发,基于PyQt5框架构建用户界面,利用OpenCV库实现核心图像处理功能。 系统支持11种图像处理操作,每种操作都提供参数实时调节功能,并具备原始图像与处理后图像的双视图对…...

如何根据设计稿进行移动端适配:全面详解
如何根据设计稿进行移动端适配:全面详解 文章目录 如何根据设计稿进行移动端适配:全面详解1. **理解设计稿**1.1 设计稿的尺寸1.2 设计稿的单位 2. **移动端适配的核心技术**2.1 使用 viewport 元标签2.1.1 代码示例2.1.2 参数说明 2.2 使用相对单位2.2.…...
?哪个大模型更好用?)
什么是大型语言模型(LLM)?哪个大模型更好用?
什么是 LLM? ChatGPT 是一种大型语言模型 (LLM),您可能对此并不陌生。它以非凡的能力而闻名,已证明能够出色地完成各种任务,例如通过考试、生成产品内容、解决问题,甚至在最少的输入提示下编写程序。 他们的实力现已…...

集合学习内容总结
集合简介 1、Scala 的集合有三大类:序列 Seq、集Set、映射 Map,所有的集合都扩展自 Iterable 特质。 2、对于几乎所有的集合类,Scala 都同时提供了可变和不可变的版本,分别位于以下两个包 不可变集合:scala.collect…...

使用typedef和不使用的区别
使用 typedef 定义的函数指针类型 typedef sensor_drv_params_t* (*load_sensor_drv_func)(); 不使用 typedef 的函数指针声明 sensor_drv_params_t* (*load_sensor_drv_func)(); 这两者看似相似,但在语义和用途上有显著区别。下面将详细解释这两种声明的区别、各…...

基于线性回归模型的汽车燃油效率预测
基于线性回归模型的汽车燃油效率预测 1.作者介绍2.线性回归介绍2.1 线性回归简介2.2 线性回归应用场景 3.基于线性回归模型的汽车燃油效率预测实验3.1 Auto MPG Data Set数据集3.2代码调试3.3完整代码3.4结果展示 4.问题分析 基于线性回归模型的汽车燃油效率预测 1.作者介绍 郝…...

Playwright之自定义浏览器目录访问出错:BrowserType.launch: Executable doesn‘t exist
Playwright之自定义浏览器目录访问出错:BrowserType.launch: Executable doesn’t exist 问题描述: 在使用playwright进行浏览器自动化的时候,配置了自定义的浏览器目录,当按照自定义的浏览器目录启动浏览器进行操作时,…...

如何拿到iframe中嵌入的游戏数据
在 iframe 中嵌入的游戏数据是否能被获取,取决于以下几个关键因素: 1. 同源策略 浏览器的同源策略是核心限制。如果父页面和 iframe 中的内容同源(即协议、域名和端口号完全相同),那么可以直接通过 JavaScript 访问 …...

优选算法第七讲:分治
优选算法第七讲:分治 1.分治_快排1.1颜色分类1.2排序数组1.3数组中第k个最大元素1.4库存管理II 2.分治_归并2.1排序数组2.2交易逆序对的总数2.3计算右侧小于当前元素的个数2.4翻转对 1.分治_快排 1.1颜色分类 1.2排序数组 1.3数组中第k个最大元素 1.4库存管理II 2.…...

OpenBMC:BmcWeb 处理http请求4 处理路由对象
OpenBMC:BmcWeb 处理http请求2 查找路由对象-CSDN博客 Router::handle通过findRoute获取了FindRouteResponse对象foundRoute void handle(const std::shared_ptr<Request>& req,const std::shared_ptr<bmcweb::AsyncResp>& asyncResp){FindRouteResponse …...

直流电能表计量解决方案适用于光伏储能充电桩基站等场景
多场景解决方案,准确测量 01 市场规模与增长动力 全球直流表市场预测: 2025年市场规模14亿美元,CAGR超15%。 驱动因素:充电桩、光伏/储能、基站、直流配电 市场增长引擎分析: 充电桩随新能源车迅猛增长ÿ…...

x-cmd install | Slumber - 告别繁琐,拥抱高效的终端 HTTP 客户端
目录 核心优势,一览无遗安装应用场景,无限可能示例告别 GUI,拥抱终端 还在为调试 API 接口,发送 HTTP 请求而苦恼吗?还在各种 GUI 工具之间切换,只为了发送一个简单的请求吗?现在,有…...

git修改已经push的commit的message
1.修改信息 2.修改message 3.强推...

STM32 基础2
STM32中断响应过程 1、中断源发出中断请求。 2、判断处理器是否允许中断,以及该中断源是否被屏蔽。 3、中断优先级排队。 4、处理器暂停当前程序,保护断点地址和处理器的当前状态,根据中断类型号,查找中断向量表,转到…...

【STL 之速通pair vector list stack queue set map 】
考list 的比较少 --双端的啦 pair 想下,程序是什么样的. 我是我们要带着自己的思考去学习DevangLic.. #include <iostream> #include <utility> #include <string>using namespace std;int main() {// 第一部分:创建并输出两个 pair …...

深度学习篇---LSTM+Attention模型
文章目录 前言1. LSTM深入原理剖析1.1 LSTM 架构的进化理解遗忘门简介数学表达式实际作用 输入门简介数学表达式后选候选值实际作用 输出门简介数学表达式最终输出实际作用 1.2 Attention 机制的动态特性内容感知位置无关可解释性数学本质 1.3 LSTM与Attention的协同效应组合优…...

React 多个 HOC 嵌套太深,会带来哪些隐患?
在 React 中,使用多个 高阶组件(HOC,Higher-Order Component) 可能会导致组件层级变深,这可能会带来以下几个影响: 一、带来的影响 1、调试困难 由于组件被多个 HOC 包裹,React 开发者工具&am…...

企业工厂生产线马达保护装置 功能参数介绍
安科瑞刘鸿鹏 摘要 工业生产中,电压暂降(晃电)是导致电动机停机、生产中断的主要原因之一,给企业带来巨大的经济损失。本文以安科瑞晃电再起动控制器为例,探讨抗晃电保护器在生产型企业工厂中的应用,分析…...

Redis 的五种数据类型面试回答
这里简单介绍一下面试回答、我之前有详细的去学习、但是一直都觉得太多内容了、太深入了 然后面试的时候不知道从哪里讲起、于是我写了这篇CSDN帮助大家面试回答、具体的深入解析下次再说 面试官你好 我来介绍一下Redis的五种基本数据类型 有String List Set ZSet Map 五种基…...
 - 3)
多线程代码案例(定时器) - 3
定时器,是我们日常开发所常用的组件工具,类似于闹钟,设定一个时间,当时间到了之后,定时器可以自动的去执行某个逻辑 目录 Timer 的基本使用 实现一个 Timer 通过这个类,来描述一个任务 通过这个类&…...

基于大模型的GCSE预测与治疗优化系统技术方案
目录 技术方案文档:基于大模型的GCSE预测与治疗优化系统1. 数据预处理模块功能:整合多模态数据(EEG、MRI、临床指标等),标准化并生成训练集。伪代码流程图2. 大模型架构(Transformer-GNN混合模型)功能:联合建模时序信号(EEG)与空间结构(脑网络)。伪代码流程图3. 术…...

IntelliJ IDEA 中 Continue 插件使用 DeepSeek-R1 模型指南
IntelliJ IDEA 中 Continue 插件使用 DeepSeek-R1 模型指南 Continue 是一款开源的 AI 编码助手插件,支持 IntelliJ IDEA 等 JetBrains 系列 IDE。它可以通过连接多种语言模型(如 DeepSeek-R1)提供实时代码生成、问题解答和单元测试生成等功…...

Valgrind——内存调试和性能分析工具
文章目录 一、Valgrind 介绍二、Valgrind 功能和使用1. 主要功能2. 基本用法2.1 常用选项2.2 内存泄漏检测2.3 详细报告2.4 性能分析2.5 多线程错误检测 三、在 Ubuntu 上安装 Valgrind四、示例1. 检测内存泄漏2. 使用未初始化的内存3. 内存读写越界4. 综合错误 五、工具集1. M…...

京东API智能风控引擎:基于行为分析识别恶意爬虫与异常调用
京东 API 智能风控引擎基于行为分析识别恶意爬虫与异常调用,主要通过以下几种方式实现: 行为特征分析 请求频率:正常用户对 API 的调用频率相对稳定,受到网络延迟、操作速度等因素限制。若发现某个 IP 地址或用户在短时间内对同一…...

Swift 解 LeetCode 250:搞懂同值子树,用递归写出权限系统检查器
文章目录 前言问题描述简单说:痛点分析:到底难在哪?1. 子树的概念搞不清楚2. 要不要“递归”?递归从哪开始?3. 怎么“边遍历边判断”?这套路不熟 后序遍历 全局计数器遍历过程解释一下:和实际场…...

Nginx搭建API网关服务教程-系统架构优化 API统一管理
超实用!用Nginx搭建API网关服务,让你的系统架构更稳更强大!🚀 亲们,今天来给大家种草一个超级实用的API网关搭建方案啦!👀 在如今的Web系统架构中,一个稳定、高性能、可扩展的API网…...

SQL2API是什么?SQL2API与BI为何对数据仓库至关重要?
目录 一、SQL2API是什么? 二、SQL2API的历史演变:从数据共享到服务化革命 1990年代:萌芽于数据仓库的数据共享需求 2010年代初:数据中台推动服务化浪潮 2022年左右:DaaS平台的兴起 2025年代:麦聪定义…...

CentOS 7无法上网问题解决
CentOS 7无法上网问题解决 问题 配置了桥接模式以后,能够ping通本地IP但是无法ping通www.baidu.com 这里的前提是VWare上已经对虚拟机桥接模式网卡做了正确的选择,比如我现在选择的就是当前能够上外网的网卡: 问题根因 DNS未正确配置。…...
)
优化 Web 性能:使用 WebP 图片(Uses WebP Images)
在 Web 开发中,图片资源的优化是提升页面加载速度和用户体验的关键。Google 的 Lighthouse 工具在性能审计中特别推荐“使用 WebP 图片”(Uses WebP Images),因为 WebP 格式在保持视觉质量的同时显著减少文件大小。本文将基于 Chr…...

SQL121 创建索引
-- 普通索引 CREATE INDEX idx_duration ON examination_info(duration);-- 唯一索引 CREATE UNIQUE INDEX uniq_idx_exam_id ON examination_info(exam_id);-- 全文索引 CREATE FULLTEXT INDEX full_idx_tag ON examination_info(tag);描述 现有一张试卷信息表examination_in…...

Leetcode - 周赛443
目录 一、3502. 到达每个位置的最小费用二、3503. 子字符串连接后的最长回文串 I三、3504. 子字符串连接后的最长回文串 II四、3505. 使 K 个子数组内元素相等的最少操作数 一、3502. 到达每个位置的最小费用 题目链接 本题是一道脑筋急转弯,实际就是计算前缀最小…...

dolphinscheduler单机部署链接oracle
部署成功请给小编一个赞或者收藏激励小编 1、安装准备 JDK版本:1.8或者1.8oracle版本:19Coracle驱动版本:8 2、安装jdk 下载地址:https://www.oracle.com/java/technologies/downloads/#java8 下载后上传到/tmp目录下。 然后执行下面命…...

Three.js 系列专题 5:加载外部模型
内容概述 Three.js 支持加载多种 3D 文件格式(如 GLTF、OBJ、FBX),这让开发者可以直接使用专业建模软件(如 Blender、Maya)创建的复杂模型。本专题将重点介绍 GLTF 格式的加载,并调整模型的位置和材质。 学习目标 理解常见 3D 文件格式及其特点。掌握使用 GLTFLoader 加…...

【C++算法】50.分治_归并_翻转对
文章目录 题目链接:题目描述:解法C 算法代码:图解 题目链接: 493. 翻转对 题目描述: 解法 分治 策略一:计算当前元素cur1后面,有多少元素的两倍比我cur1小(降序) 利用单…...

观察者模式详解实战
观察者模式深度解析与实战案例 一、传统观察者模式痛点分析 强制接收所有通知:观察者被迫处理无关事件 事件信息不透明:状态变更缺乏上下文信息 类型安全缺失:需要手动进行类型判断和转换 扩展成本高:新增事件类型需要修改接口 …...

Light RPC:一款轻量高效的Java RPC框架实践指南
Light RPC:一款轻量高效的Java RPC框架实践指南 一、框架简介二、快速入门1. 环境准备2. 服务端配置2.1 添加依赖2.2 YAML配置2.3 接口与实现 3. 客户端配置3.1 添加依赖3.2 YAML配置3.3 客户端调用 三、核心设计解析四、适用场景与优势对比五、总结 一、框架简介 …...

国内MCP资源网站有哪些?MCP工具上哪找?
在人工智能领域,MCP(模型上下文协议)正逐渐成为连接 AI 模型与外部世界的重要桥梁。而AIbase (https://www.aibase.com/zh/repos/topic/mcp)正是探索 MCP 生态的绝佳平台,它为开发者和研究者提供了一个集中…...

在PowerBI中通过比较日期实现累加计算
#表格数据# 日期数量2025/4/712025/4/822025/4/932025/4/1042025/4/1152025/4/1262025/4/1372025/4/1482025/4/1592025/4/16102025/4/1711 #新建计算列# 列 SUMX(FILTER(表格数据,[日期]<EARLIER([日期])),表格数据[数量])...
)
十四届蓝桥杯Java省赛 B组(持续更新..)
十四届蓝桥杯Java省赛 B组 第一题:阶乘求和 📖 📚阶乘求和 第二题:幸运数字 📖 📚幸运数字 第三题:数组分割 📖 📚数组分割 说是考动态规划,但没有用…...
)
NO.73十六届蓝桥杯备战|搜索算法-剪枝与优化-记忆化搜索|数的划分|小猫爬山|斐波那契数|Function|天下第一|滑雪(C++)
剪枝与优化 剪枝,形象得看,就是剪掉搜索树的分⽀,从⽽减⼩搜索树的规模,排除掉搜索树中没有必要的分⽀,优化时间复杂度。 在深度优先遍历中,有⼏种常⻅的剪枝⽅法 排除等效冗余 如果在搜索过程中…...
)
深度学习总结(2)
神经网络的数据表示 在前面的例子中,我们的数据存储在多维NumPy数组中,也叫作张量(tensor)。一般来说,目前所有机器学习系统都使用张量作为基本数据结构。张量对这个领域非常重要,重要到TensorFlow都以它来命名。究竟什么是张量呢?张量这一概念的核心在于,它是一个数…...

STM32H7 ADC最大速率
STM32H7 ADC最大速率 硬件限制 封装 在手册 AN5354 中说明了不同封装、不同分辨率的最大速率是不一致的; BGA封装的ADC的速度要快于LQFP封装的速度的; 分辨位数越高、转换时间越长,所以ADC的最大采样速率也就最低; ADC通道模…...

MVC模型
MVC模型(Model模型,View视图,Controller控制器) 逻辑执行流程: JSP(View)----》Servlet(Controller)----》service,dao,pojo(Model&a…...

OpenGL ES -> SurfaceView + EGL实现立方体纹理贴图+透视效果
XML文件 <?xml version"1.0" encoding"utf-8"?> <com.example.myapplication.MySurfaceView xmlns:android"http://schemas.android.com/apk/res/android"android:layout_width"match_parent"android:layout_height"…...