整理一些大模型部署相关的知识
不一定有什么用, 不经常用还会忘掉.
之前被人问到一次,脑子卡壳回答不出要点, 非常尴尬!
在此记录一下使用心得, 偶尔回来翻看!
一 并行方式
1.1 数据并行 (Data Parallelism)
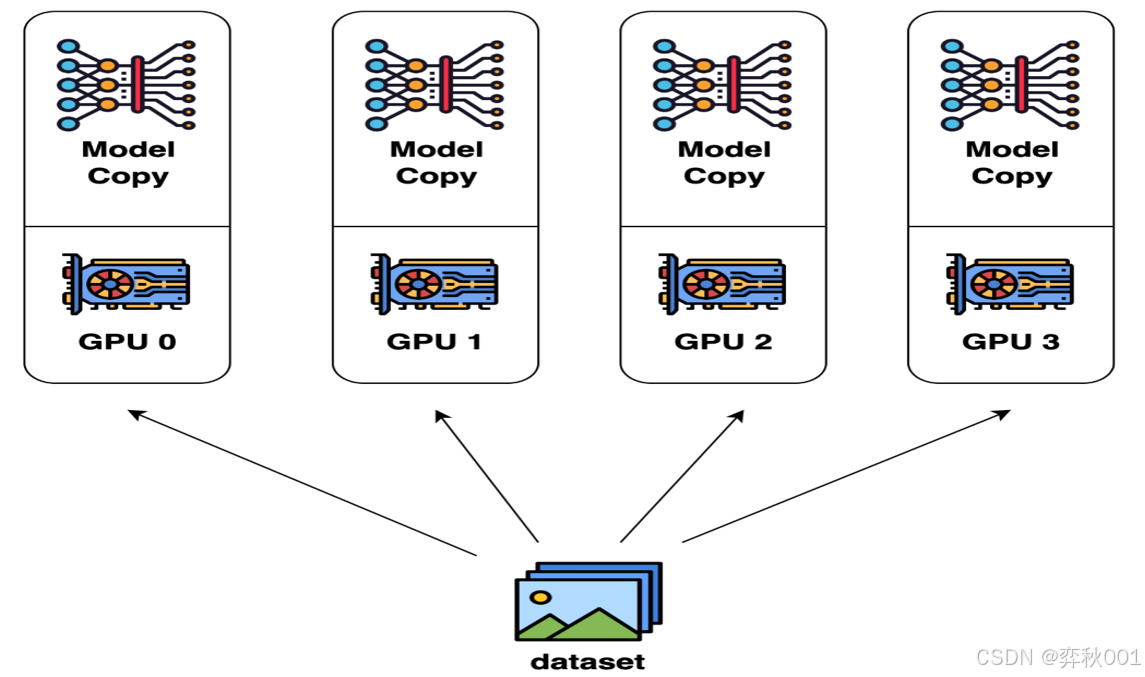
主要用于模型训练阶段, 即将多个完整的模型副本分布到多个gpu上, 每个gpu运行一部分数据数据, 每个设备独立地计算前向传播和反向传播,然后在每一轮迭代结束时,设备之间通过通信(比如nccl, gloo等), 将计算结果收集起来, 并通过某种归约运算(比如求和、取平均、最大值、最小值等)合并成一个全局结果, 之后广播机制向所有节点gpu发这个全局结果,同步梯度并更新模型参数, 从而确保每个节点都拥有相同的最终数据.
这是一种扩展batch_size的手段, 例如共有16个gpu, 每个gpu运行2个batch_size的数据, 那么总共的batch_size=2*16=32.
DP(Data Parallelism)与DDP(Distributed Data Parallelism)原理都是如此, 只是它们的通讯方式不同.
这种方式在模型规模小时有优势, 不过大模型时代已经被淘汰了, 因为常见显卡通常只要24G显存, A100也不过80G显存, 根本无法训练72B及以上规模的模型.
另外缺点也比较明显:通信开销较大,特别是在节点数量增加时。
我测试过在4张rtx titanx全量微调qwen2.5-vl-7B模型, 1000条多模态数据用了5天才完成2000+ step, 被deepspeed等新型训练方式吊打.
1.2 模型并行(Model Parallelism)
主要用于模型训练阶段, 适用于超大规模的模型. 没用过, 也不推荐使用. 因为实现复杂,通信开销大,效率较低.
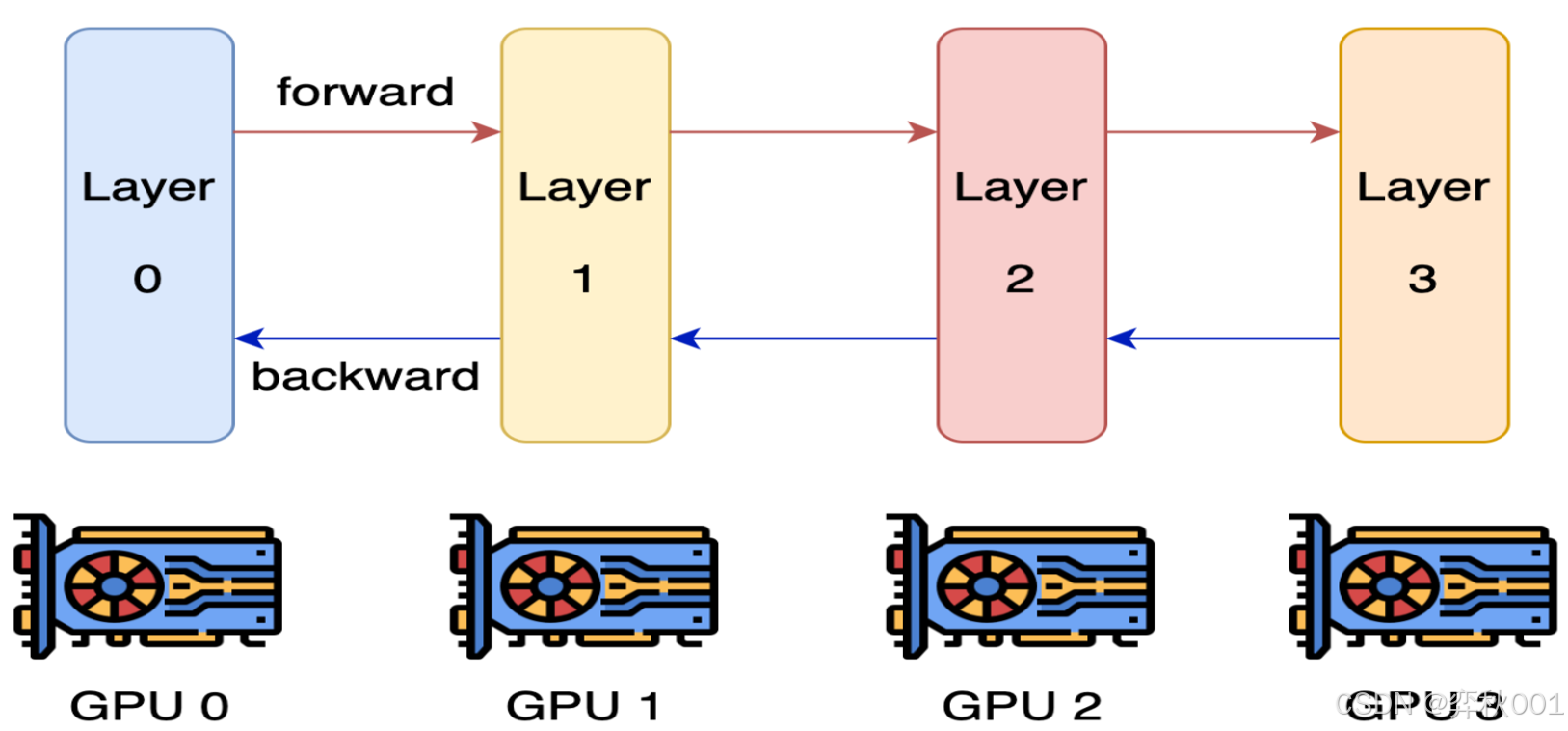
处理思路是模型按层分割成若干块,每块都交给一个gpu, 前一个模块计算完成后, 计算结果传递给下一个gpu, 依次进行前向,反向传播. 过程中涉及多次通信传递, 更重要的是, 同一时间只有一个gpu在工作, 极大浪费计算资源, 效率低下.
1.3 流水线并行 (Pipeline Parallelism)
流水线并行可以认为是数据并行与模型并行的混合体.
根据前面知识可知, 数据并行是在每个gpu上独立运行一份数据, 模型并行是将模型切分到多个gpu上依次执行数据.
流水线并行则是将模型按层或模块顺序切分成多个阶段,每个阶段分配到不同的计算节点上,形成流水线。
看起来挺复杂, 不过看下面的流程图就非常容易理解了.
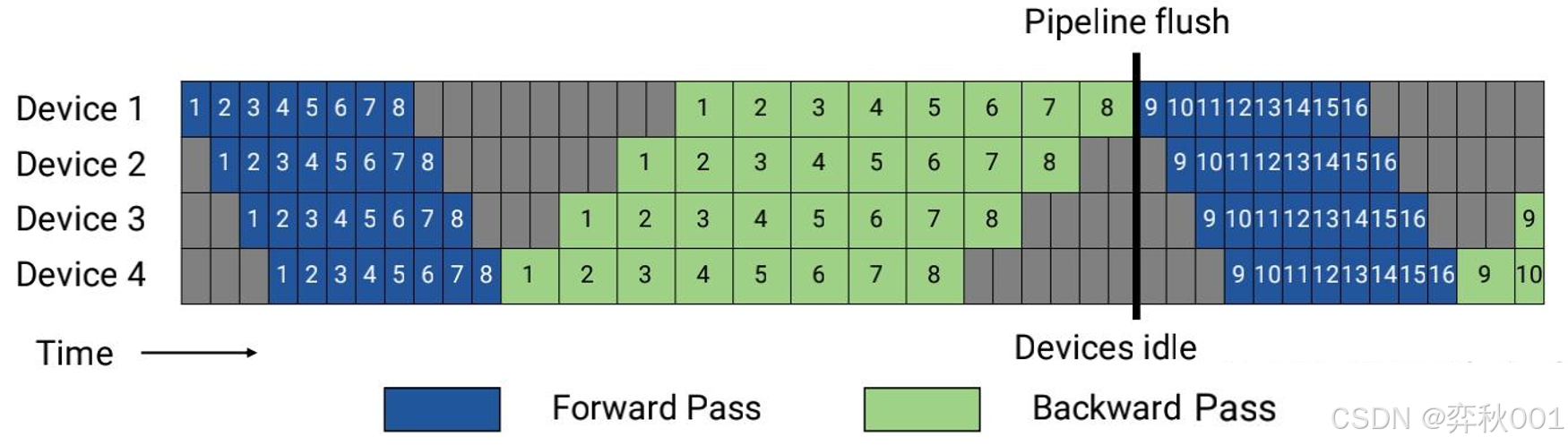
模型被切分到4个device上
如上图所示,原来的一个batch,拆分成了8个微批次.
- ① 首先在device1上运行第一份数据, 执行完成后传递给device2, 直至传递给device4完成计算.
- ② device1计算完成第一份数据后, 紧接着执行第二份数据, 完成后再传递给device2, 依次类推完成剩余数据计算.
- ③ 都计算完成后从device4依次执行反向传播计算, 更新模型梯度.
通过以上描述可知, 这种方法结合了数据并行和模型并行的有点
另外图中灰色区域是正向/反向计算间隔区域, 是gpu空闲时间, 被称为空泡率,减少空泡区域可以提高并行效率. 通常都是对反向传播
部分进行优化. 想了解细节可以参考以下文章:
https://zhuanlan.zhihu.com/p/32724741626

1.4 张量并行 (Tensor Parallelism)
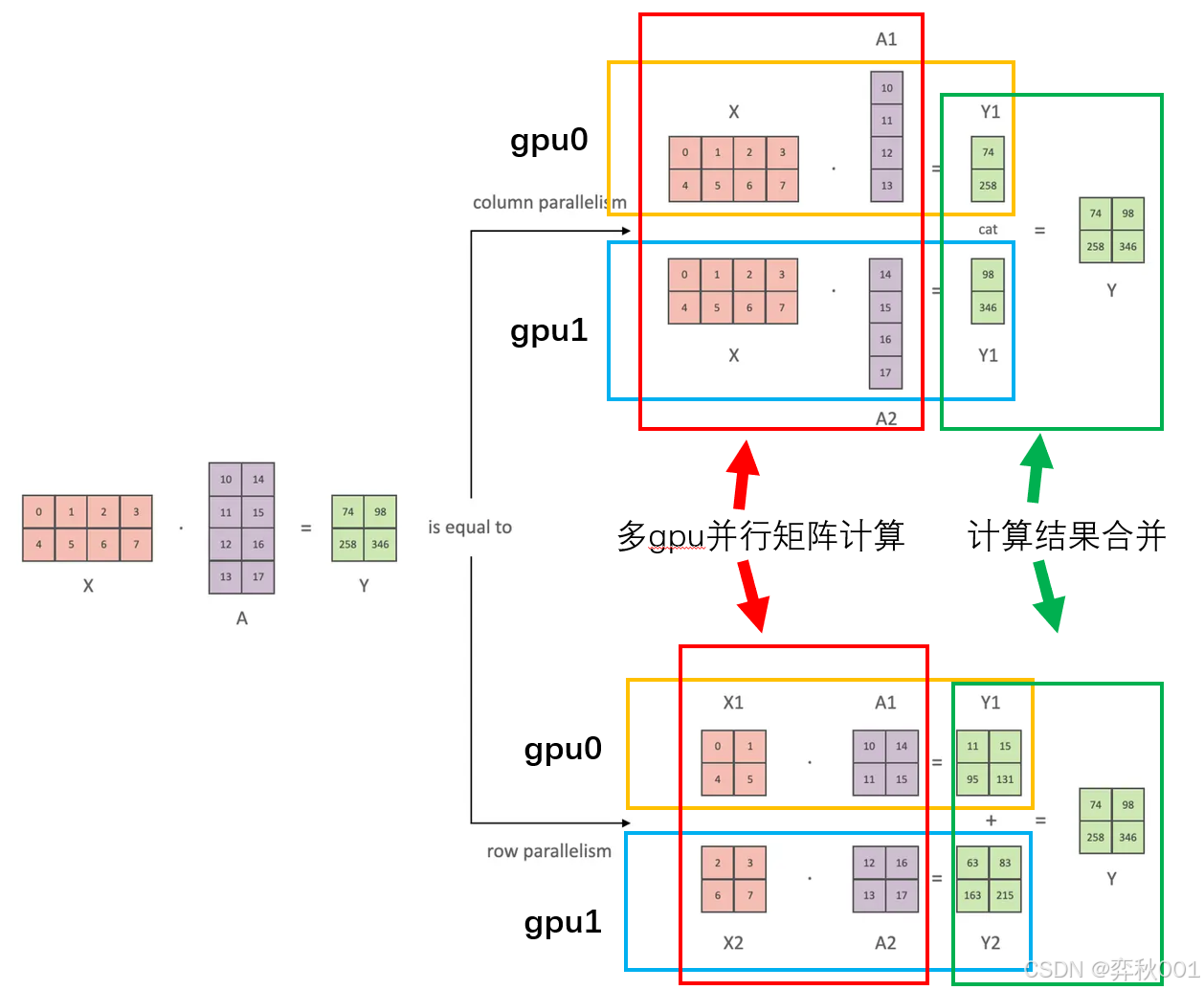
张量并行将模型的张量(如权重矩阵)按维度切分到不同的计算节点上。
通常是将大型张量按行或列切分,每个节点处理切分后的子张量。需要通过集合通信操作(如AllGather或AllReduce)来合并结果
如大模型的attention通常由多个head组成, 此时就可以将多个head计算分配到不同gpu上.
例如某个attention由16个head组成, 分配到8张gpu上, 则每张gpu只负责计算2个head attention, 可以极大加速计算效率.
另外矩阵的行切分和列切分对最后结果合并有影响.
列切分的结构直接cat拼接在一起. 行切分则是结果相加.
1.5 3D并行
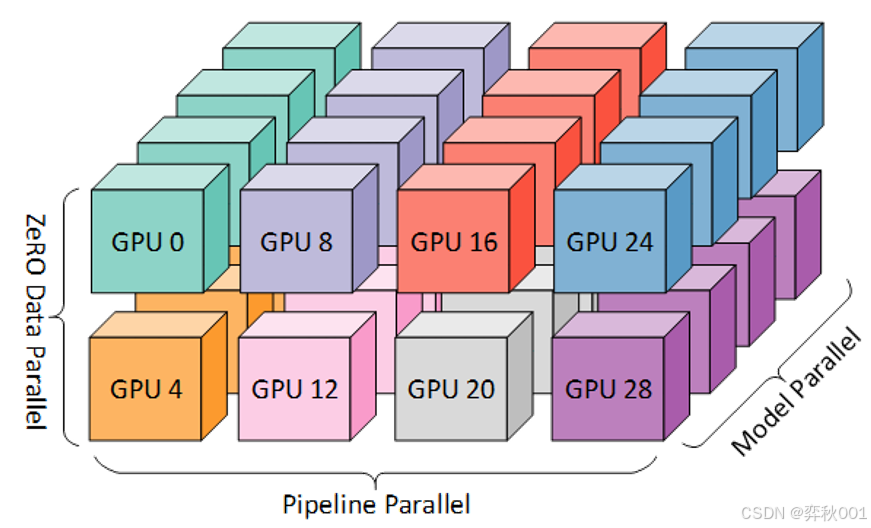
3D并行是一种特定的混合并行实现方式,由微软在DeepSpeed框架中提出,专指同时使用以下三种并行策略的组合:
- 数据并行(Data Parallelism, DP):拆分批次数据到不同设备,独立计算梯度后同步。
- 流水线并行(Pipeline Parallelism, PP):将模型按层切分到不同设备,按流水线方式分阶段计算。
- 张量并行(Tensor Parallelism, TP):将单个层的矩阵运算(如注意力头、FFN层)拆分到多设备。
3D并行常用于训练超大规模的大模型, 在部署推理时很少使用, 因为DP通信开销大, 还会出现DP冗余显存占用的情况.
目前主流推理架构, 比如vllm, tensorrt-LLM等都只实现PP+TP的方式, 使用其他方式来优化对数据的出来,比如PagedAttention好Continuous Batching等技术.
二 常见的推理技术
在(一)中提到了各种并行技术, 实际也是一种推理优化方案, 更详细的推理优化技术, 这里谈下自己的使用体验.
2.1 并发优化
并发优化的目的是提高吞吐量, 提高硬件利用率以及降低请求延迟
比较有代表性的技术有以下三个:
- dynamic batching(动态批处理) : 是指允许将一个或多个推理请求组合成单个批次(必须动态创建)以最大化吞吐量的功能. 从定义可知, 整个批次必须全部完成后才能返回结果, 对实时响应时间有很大影响, 这种技术在 Triton Inference Server有使用. 我没用过, 不做评价, 但从描述可知, 不适合做流式输出, 有很大的应用限制.
- continuous batching(连续批处理): 以token/迭代为粒度进行批处理,动态插入新请求到正在运行的批次中, 已完成请求可立即返回,无需等待整个批次.简单地说, 就是消除了padding, 让每个batch都装满, 极大提升了计算效率. Continuous Batching已成为现代大模型推理服务(如vLLM、TGI, Tensorrt-LLM等)的标准配置,能显著提高GPU利用率和系统吞吐量
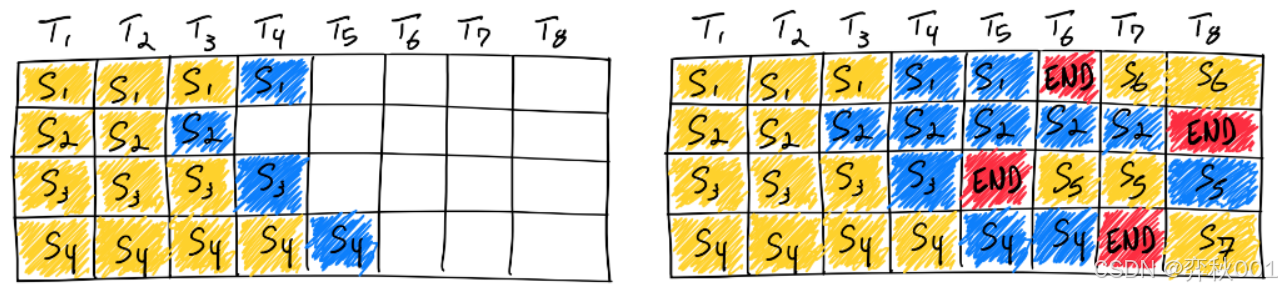
- Async Serving(异步服务): 目的是减少I/O等待浪费, 优化高并发连接管理. 代表性技术如FastAPI, 与vllm等推理架构的异步引擎AsyncLLMEngine组合使用, 有互补作用, 我在工程化实践证明效果很好.
2.2 显存优化
目的是提升显存利用率, 增大推理吞吐量,提升推理并发能力.
关于显存优化,我接触到的只有flash-attn和PagedAttention
2.21 flash-attn
flash-attn, 准确地说, 这是GPU硬件对attention的优化技术, 原理是通过利用更高速的上层存储计算单元,减少对低速更下层存储器的访问次数,来提升模型的训练,推理性能.
flash-attn核心是对Self-Attention的计算进行分块计算. 开始阶段, flash-attn将输入矩阵分割成多个小块,然后对这些小块进行多次遍历。在每次遍历中,它计算当前块的softmax归一化值,并将其存储在内存中。通过逐步累加这些归一化值,最终得到整个注意力矩阵的结果,而无需在内存中存储整个注意力矩阵.
在前向传播中计算每个块的softmax归一化值,并将这些值存储在内存中。在后向传播中,它只需要利用这些存储的归一化因子和输入矩阵Q,K,V来重新计算注意力矩阵,而不需要重新计算整个注意力矩阵。这种方法显著减少了后向传播的计算量, 提升计算效率
更多细节参考这里:
https://www.zhihu.com/question/611236756/answer/86383686403
另外, flash-attn对硬件有要求, 需要 Ampere架构及以上, 2080ti, rtx titianx不支持, 非常可惜.
flash-attn的安装也是一个问题, 从源码编译很很多坑, 推荐直接使用别人已经编译好的版本:
https://github.com/Dao-AILab/flash-attention/releases
2.22 PagedAttention
PagedAttention是vllm中应用的技术, 这是一个很棒的推理技术, 其他推理架构也融入PagedAttention, 比如TensorRT-LLM, llama.cpp等架构, 反正好的技术大家都会相互借鉴. 该技术主要针对KV Cache 显存瓶颈 进行优化, 核心思想是动态分配, 这个过程有点类似C/C++中的指针操作, 指针只存储数据地址, 具体数据在单独的数据块中:
- 按需申请显存块,避免预分配浪费
- 非连续存储:允许一个请求的KV Cache分散在不同物理块中
- 共享机制:多个请求可共享相同前缀的KV Cache(如提示词相同)
在我之前的文章有更完整描述, 这里不展开了:
vllm源码解析(一):整体架构与推理代码
此时,不得不吐槽一下vllm中对PagedAttention的实现, 改了很多版本, 我最初读的是0.5.4, 现在的版本是0.8.2, 完全重构了主体逻辑架构, 不敢再理解源码了, 怕再被知识清零,白费工夫.
2.3 算子优化
原理是将多个连续操作合并为一个内核(Kernel),减少内存读写和内核启动开销, 例如在attention计算中,针对多查询注意力结构的QKV通用矩阵乘法(GEMM)横向算子融合,以及多层感知机(MLP)中的全连接层(FC)+激活融合.
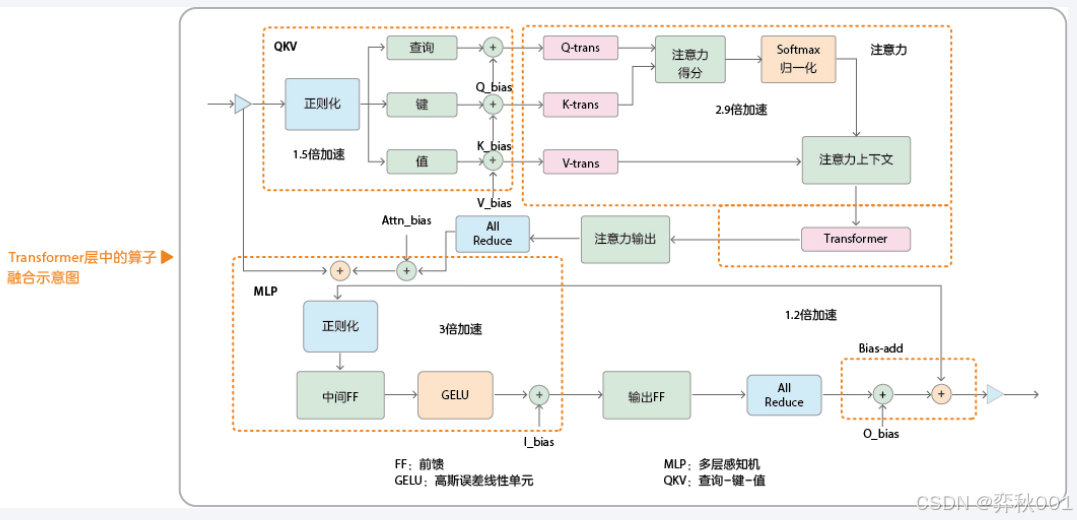
这种优化方案太过底层, 与硬件设备强相关, 通常都是针对当前硬件的定制性优化.
工作中几乎用不到这项技术, 因为投入的技术/时间成本与回报完全不对等.
印象中, 只有一些推理/计算架构在搞,比如CUDA Kernel, FlashAttention, TensorRT-LLM, pytorch等, 距离我们太过遥远了.
2.4 分布式优化
分布式优化技术 是解决单机资源不足、提升吞吐量和降低延迟的关键手段, 现在有商用价值的大模型至少7B, 好一点的有32B,72B甚至更高, 单个gpu很难加载, 分布式技术已经训练/推理的必选项了.
这项技术主要分两部分: 通信优化和并行技术
通信技术比如NCCL和GLOO等, 使用时常从这二者选择, 对它们的优化没搞过, 不做评价.
并行技术在(一)中有详细介绍, 在使用时最常用的方案是流水线并行+张量并行, 目前所有推理都支持这两种并行技术,比如vllm ,tensorrt-llm, TGI, llama.cpp等. 这里分享下这两种技术组合使用的心得.
根据我的使用经验和pipeline-parallel-size自身原理, pipeline-parallel-size越大, 产生的空泡率越高, 好处是对微batch的处理速度变快, 但不应超过输入数据batch的大小.
tensor-parallel-size是将单个矩阵运算(如GEMM)在多个设备之间并行计算, 如tensor-parallel-size=8, 相当于每个gpu计算2个head, 充分利用gpu计算性能, 但代价也有, 就是每个attention的计算结果需要8卡直接同步, 通信效率较低.
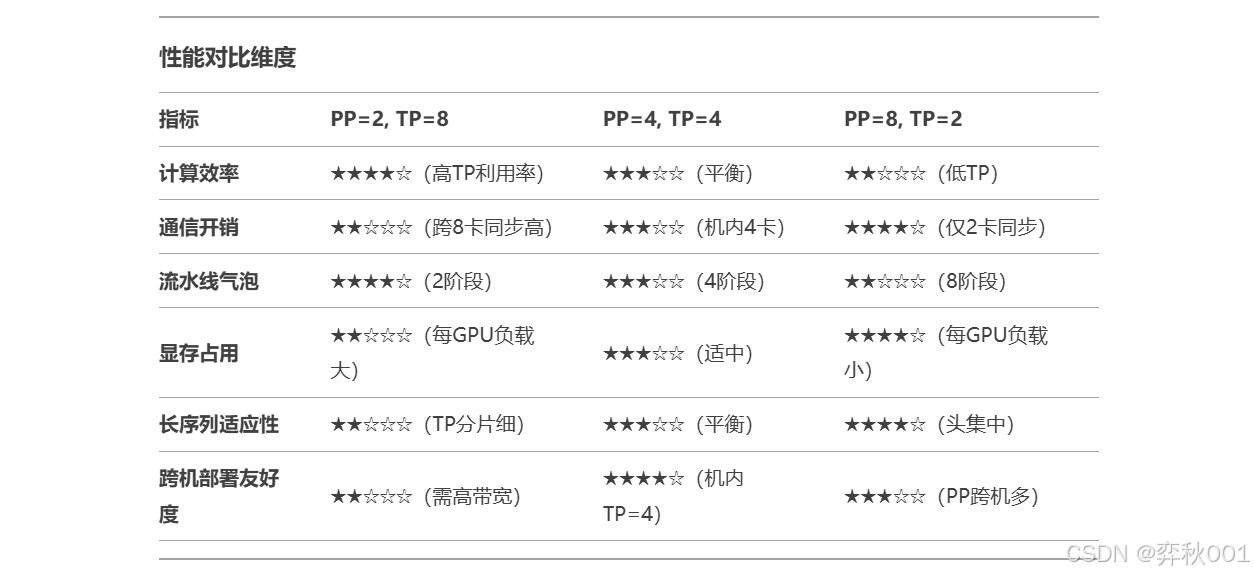
所以具体工作中, 把所有可用的组合全部尝试一遍才是挑选针对当前设备最靠谱的方案, 这里给出部分配置的历史经验
假设一个大模型有32层layers, attention 有16个head. 目前有2台机器, 每台机器8张显卡, 设置不同的pipeline-parallel-size和tensor-parallel-size对推理性能有什么影响, 有以下三组参数:
- pipeline-parallel-size=2和tensor-parallel-size=8
- pipeline-parallel-size=4和tensor-parallel-size=4
- pipeline-parallel-size=8和tensor-parallel-size=2
2.5 低比特量化
就是常说的量化技术, 目前常用方案有autogptq, autoawq等, 还有直接的int4,Int8量化,不过这种方式效果与量化前差异很大, 目前用的较少了. 量化只是减小模型尺寸, 但推理速度不一定变快, 因为经过反量化操作再参与矩阵计算.
gptq是训练后量化, 逐层量化, 原理是先量化第一层, 调整后面所有层参数以最小化损失. 之后量化第二层, 固定第一,第二层再次调整后面所有层参数以最小化损失. 通过描述可知这中需要校准数据集的参与, 校准集选取和数据对量化效果有很大影响. 我操作过gptq的量化, 100张和300张校准集效果差不多, 当把数据增加到1000张,效果反而变差了.
个人更喜欢使用awq技术, 是一种感知量化, 认为模型权重只有1%的参数重要, 不参与量化, 其他不重要的权重参数才参会量化, 也需要校准集参与, 但对数据没有gptq那么敏感, 实践证明awq比gptq好用, 目前, 新出的大模型都使用awq作为量化手段, 已经很能说明问题.
kv-cache是推理阶段的量化, 将推理过程中产生kv-cache处理为int4/int8类型, 减少显存占用, 这种优化手段已经集成到各种推理架构中了,如vllm ,tensorrt-llm等.
2.6 其他优化技术
这类算法都可归类为投机算法
使用一个同类型的尺寸更小的模型模型进行推理, 称为草稿模型
- 先把当前query输入草稿模型,让其快速生成“草稿”
- 让目标模型并行地检查草稿,判断每个token是否可以被接受
例如可以选择qwen2-3B作为草稿模型, 以qwen-72B作为目标模型, 检查的速度可比生成的速度快多了, 虽然不一定每次都准确, 但只有中一个token就大赚.
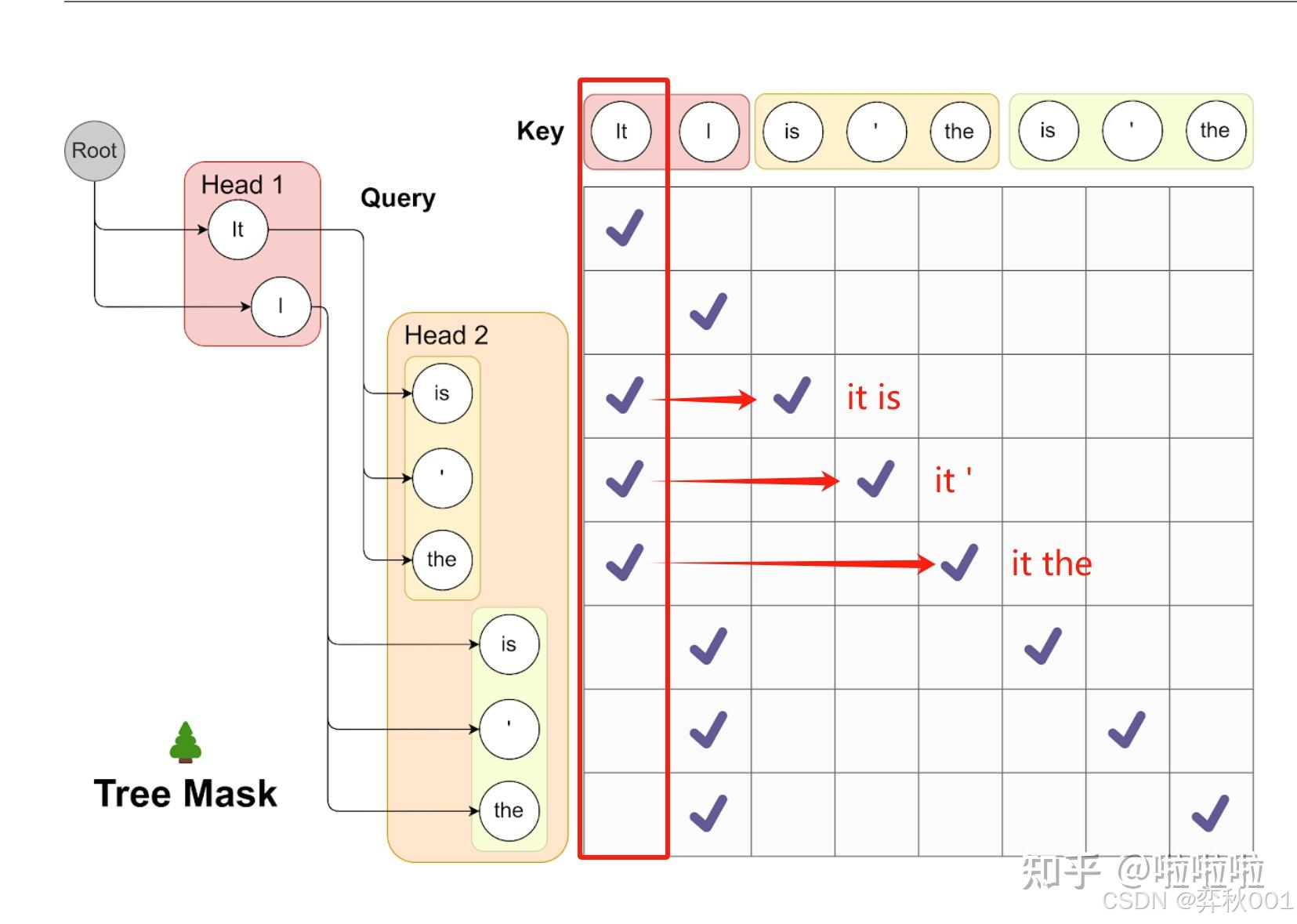
简单了解下Medusa(多头美杜莎)的工作机制.
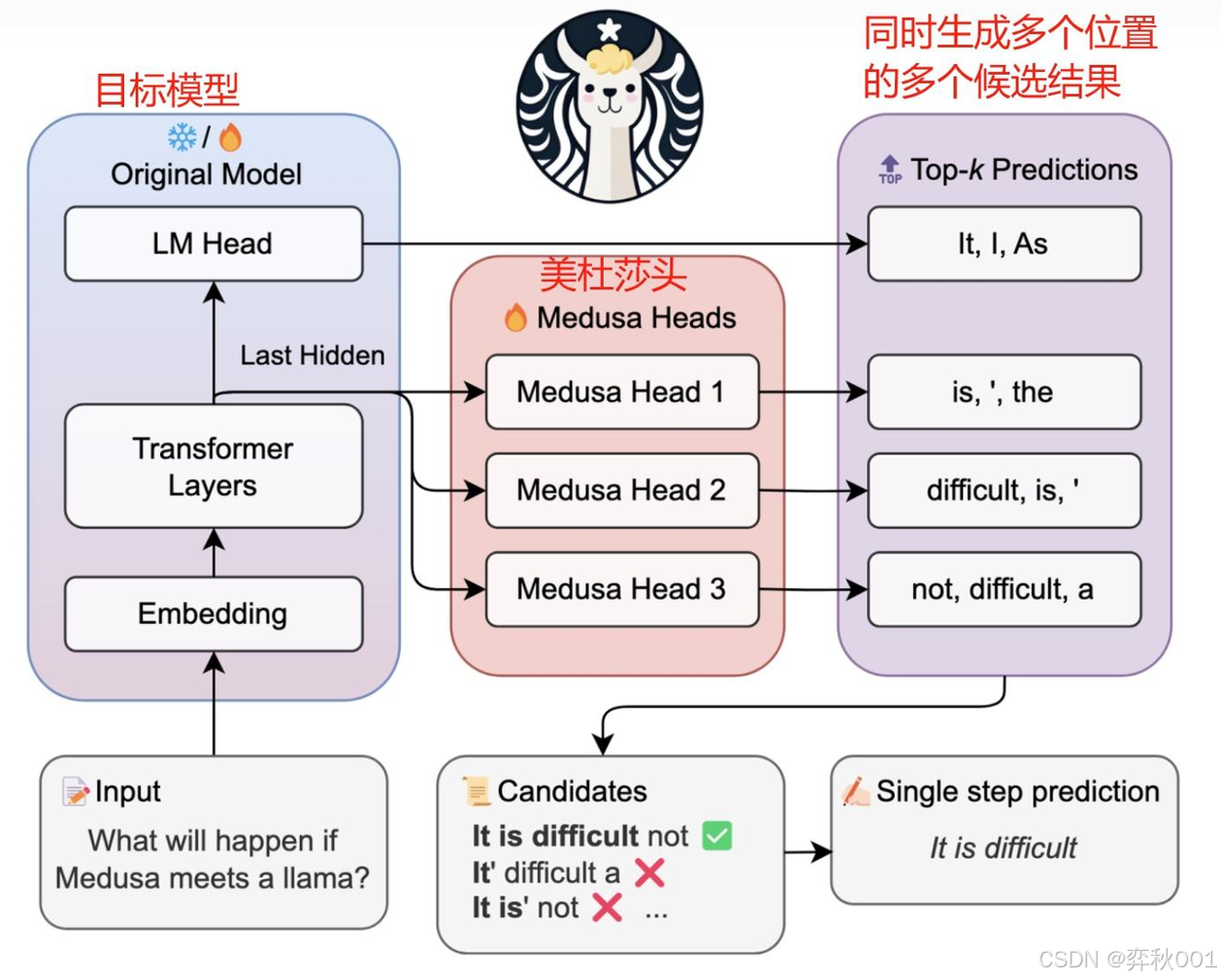
美杜莎在原始大模型(如LLaMA、Qwen)的基础上,在最后的输出层添加多个轻量级多头预测模块(Medusa Heads),通常由几层小型FFN(前馈网络)组成,用于并行生成候选Token
推理流程:
- 首Token生成:主干模型生成第1个Token yt。
- 候选Token预测:美杜莎头基于 yt 并行预测 k 个候选Token {yt+1,yt+2,…,yt+k}。
- 验证候选Token:主干模型对候选序列进行验证,保留正确部分。
- 接受或回退:若候选Token全部验证正确,则直接跳过后续计算,继续预测下一组。若部分错误,则回退到最后一个正确Token的位置重新生成。
多头美杜莎使用了【树形Attention】来一次性地生成每条路径的概率,极大地提高了验证草稿token的速度, 当头数为8时, 看报告说有4倍的推理加速, 不过需要训练模型, 有机会要验证一下.
三 推理架构参数解析
前面提到的各种推理优化方法, 都已经集成到推理架构中, 这里以vllm为例, 说下部分重要参数意义:
- –gpu-memory-utilization: 默认设置为 0.9,但如果显存较小,或多个显卡分布式时,有显卡在运行其他程序,可能会导致 Out of Memory 错误, 根据可用显存进行设置
- –tensor-parallel-size, pipeline-parallel-size: 根据上面介绍可知,分别是张量并行和流水线并行数量
- dtype: 加载权重的类型, huggingface下载的模型默认使用bfloat16, 如果当前显卡不支持, 需要手动改为float16
- max-model-len: 模型在处理输入时能够考虑的历史信息的总长度。通过max-model-len控制,不添加此参数时,系统将尝试使用最大可能的序列长度. 这个设置非常占用显存, 同时, 若进行多轮对话, 还需要把这个值设的比较大, 不然中途会报错.
- max-num-seqs: 每个 batch 中最多同时处理的序列(请求)数量. 它指定了 每次连续推理(batch)时并发处理的最大请求数。这个值越大,吞吐量(QPS)可能越高,所以在并发场景下可以适当设大这个值, 但同时也会占用更多的显存和系统资源.
- enable-prefix-caching: 单轮对话中system prompt是相同的,多轮对话中每一轮对话要依赖历史对话,对它们的KV Cache进行缓存,就不用每次重新计算. 现在vllm对前缀缓存时block级别, 即使有prompt不同, 也能使用部分kv-cache缓存.
- enforce-eager: 用于控制vLLM是否始终使用PyTorch的eager模式(即时执行模式),默认为False,vLLM会默认使用eager模式和CUDA图的混合模式来执行操作,这种混合模式旨在提供最大的性能和灵活性. 当enforce-eager为True时, CUDA图, 推理性能变差, 但会极大减小显存消耗, 有些时候这个参数很有用.
其他参数还有很多, 但影响性能的主要就这么多了
最后, 不得不感慨, 想在工作中单独探索某项优化手段对性能的提升, 那个时代已经不在了, 现在是各种推理架构的天下, 如vllm, tensorrt-llm, IMdeploy,llama.cpp等, 优化方案也是在这些架构上二次开发.

相关文章:

整理一些大模型部署相关的知识
不一定有什么用, 不经常用还会忘掉. 之前被人问到一次,脑子卡壳回答不出要点, 非常尴尬! 在此记录一下使用心得, 偶尔回来翻看! 一 并行方式 1.1 数据并行 (Data Parallelism) 主要用于模型训练阶段, 即将多个完整的模型副本分布到多个gpu上, 每个gpu运行一部分数据数据, 每个…...
 [第191~200题](持续更新))
算法刷题记录——LeetCode篇(2.10) [第191~200题](持续更新)
更新时间:2025-04-04 算法题解目录汇总:算法刷题记录——题解目录汇总技术博客总目录:计算机技术系列博客——目录页 优先整理热门100及面试150,不定期持续更新,欢迎关注! 198. 打家劫舍 你是一个专业的…...

蓝桥杯备赛 Day 19 加练dfs
是否需要回溯? 输入参数有哪几个(当前dfs和下一个dfs什么会变?)? 是否需要返回值? 一.1158: 八皇后 P1158 - 八皇后 - New Online Judge (ecustacm.cn) 学习: 1.dfs输入为层数,即行号i,因为是每行只放一个,下一个dfs就是i1 2…...

蓝桥杯-卡java排序
问题描述 本题是一道针对 Java 中 Arrays.sort 的题目,因此只有一个数据,该数据可以把 int 类型的数组在使用 Arrays.sort 后卡成 O(n2)O(n2)。 给定一个有 nn 个正整数的序列 aa,你需要将其升序排序后输出。 输入格式 第一行输入一个正整…...

内存管理模块
在 Linux 内核中,内存管理是一个复杂而关键的组成部分。内核空间的虚拟地址被划分为多个区域,每个区域有其特定的用途和映射机制。本文将详细介绍 直接映射区(Direct Mapping Area)、vmalloc 区、永久内核映射区(Perma…...

Spring RestTemplate修仙指南:从HTTP萌新到请求大能的终极奥义
各位在Spring生态摸爬滚打的道友们!今天要解锁的是Spring官方御用HTTP法宝——RestTemplate!这货堪称Java界的"御剑飞行术",虽然官方已推荐WebClient接棒,但江湖上仍有80%项目在用这员老将!准备好一键起飞了…...

cpp经典数论问题
题目如下 思路 代码如下...

Redis 线程模型:单线程也能快如闪电?
目录 一、核心思想:快刀斩乱麻的“单线程”高手 🦸♂️二、为什么是“单线程”?🤔三、单线程如何做到高性能?✨ “I/O 多路复用”是关键!四、真的一直都只有“一个线程”吗?并不完全是&#x…...

游戏引擎学习第208天
运行游戏并回顾我们的情况 今天,我们将继续完成之前中断的调试输出工作。最近的工作偏离了一些,展示了如何进行元编程的实践,主要涉及了一个小的解析器。尽管这个解析器本身是一个玩具,但它展示了如何完成一个完整的循环…...
(箭头函数不绑定自己的this,而是继承上下文的this;不能用于造函数)JavaScript =>)
JavaScript箭头函数介绍(=>)(箭头函数不绑定自己的this,而是继承上下文的this;不能用于造函数)JavaScript =>
文章目录 JavaScript箭头函数全解析箭头函数的基本语法简洁语法特性隐式返回值对象字面量返回 词法绑定的this不适用箭头函数的场景对象方法构造函数DOM事件处理 高级用法在数组方法中的应用链式调用柯里化函数 性能考量1. 作为回调函数时减少创建闭包的开销2. 简化代码结构&am…...

数据对象:DTO、DO、PO和 BO的区别和关系
在Java开发中,DTO(Data Transfer Object)、DO(Domain Object)、PO(Persistent Object)和BO(Business Object)是常用的数据对象概念,下面为你详细介绍并给出简…...

Java内存模型详解:堆、栈、方法区
1. 堆(Heap) 作用:存放所有对象实例及数组,是垃圾回收的主要区域。 结构: 新生代(Young Generation): Eden区:新创建的对象首先分配在此。 Survivor区(From…...

ubuntu 20.04 编译运行LeGo_LOAM 跑数据集 并且保存pcl文件
1.搭建文件目录,clone代码,编译 mkdir -p Lego_LOAM/src cd Lego_LOAM/src git clone https://github.com/RobustFieldAutonomyLab/LeGO-LOAM.git cd .. catkin_make -j1 错误1:: fatal error: opencv/cv.h: 没有那个文件或目录 13 | #include <opencv/cv.h…...

CMake使用教程
CMake是开源、跨平台的构建工具,可以让我们通过编写简单的配置文件去生成本地的Makefile,这个配置文件是独立于运行平台和编译器的,这样就不用亲自去编写Makefile了,而且配置文件可以直接拿到其它平台上使用,无需修改,非常方便。 使用命令行执行CMakeLists.txt,对文件进…...

快速上手Linux进程管理
一.理解进程和线程 1.1 什么是进程 它表示一个正在执行的程序实例。在操作系统中,进程是系统进行资源分配和调度的基本单位。每个进程都有自己独立的内存空间、代码、数据和系统资源,如打开的文件、使用的硬件设备等。 进程的主要特点包括:…...

pytorch框架实现cnn四种天气图片多分类问题-添加dropout和bn层
目录 1.导包 2.加载数据、拼接训练、测试文件夹 3. 查看当前目录下的所有文件名,以列表的形式输出 4.原数据集dataset中存在的数据的目标类别 5.创建train和test目录 及其需要分类的子文件夹 6.使用torchvision 的transforms进行数据预处理 6.1数据统一缩放resize、To…...

swift-11-init、deinit、可选链、协议、元类型
一、required 二、属性观察器 三、可失败初始化器 可以用init!定义隐式解包的可失败初始化器 可失败初始化器可以调用非可失败初始化器,非可失败初始化器调用可失败初始化器需要进行解包 如果初始化器调用一个可失败初始化器导致初始化失败 ,那么整个初…...
搜索插入位置)
【力扣hot100题】(062)搜索插入位置
感觉自己对二分法还是没有很好掌握,主要在于边界问题,只会基本的搜索,如果要搜索比目标值大的第一个索引或者比目标值小的最后一个索引(或者换一些花里胡哨的题目)就完全不会了。 class Solution { public:int search…...

TCPIP详解 卷1协议 三 链路层
3.1——以太网和IEEE802局域网/城域网标准 以太网这个术语通常指一套标准,由DEC,Intel公司和Xerox公司在1980年首次发布,并在1982年加以修订。第一个常见格式的以太网,目前被称为10Mb/s以太网或共享以太网。它被IEEE采纳为802.3标…...

以太网安全
前言: 端口隔离可实现同一VLAN内端口之间的隔离。用户只需要将端口加入到隔离组中,就可以实现隔离组内端口之间的二层数据的隔离端口安全是一种在交换机接入层实施的安全机制,旨在通过控制端口的MAC地址学习行为,确保仅授权设备能…...

linux如何查看当前系统的资源占用情况
在 Linux 系统中,有多个命令可以查看当前系统的资源占用情况。以下是一些常用的命令及其说明: 1. 查看内存使用情况:free free -h-h 参数表示以人类可读的格式显示(如 MB, GB)。输出示例: to…...
)
人脸识别系统(人脸识别、前后端交互、Python项目)
基于Flask、Face_Recognition的人脸识别系统 项目介绍 基于flask、face_recognition的人脸识别系统。 本项目采用Face_Recognition库内置的ResNet-34预训练模型,其已对LFW公开数据集进行预训练而得到的模型。利用ResNet-34预训练模型,可使用少量已知人…...
)
2025 ArkTS语言开发入门之前言(二)
2025 ArkTS语言开发入门之前言(二) 前言 在上一节,咱们学习了如何下载并安装ArkTS的集成开发环境,这时候有的臭宝会发现,左边的这些叽里咕噜的是什么?下面,我来带着臭宝们来学习一下这些是什么…...
)
VLAN(虚拟局域网)
一、vlan概述 VLAN(virtual local area network)是一种通过逻辑方式划分网络的技术,允许将一个物理网络划分为多个独立的虚拟网络。每一个vlan是一个广播域,不同vlan之间的通信需要通过路由器或三层交换机 [!注意] vlan是交换机独有的技术,P…...

2025.4.6总结
今日记录:今天玩的有些累,先是去护肤店护理了脸部,然后去汉口江滩那看了看美景,吹吹江风。节假日去玩,光是挤一个半小时地铁都感觉累。还好上下班期间不用挤地铁,不然还真受不了。 假期小结 1.消费&#…...

【清明折柳】写在扬马三周目后
黄绿之间,方寸之外。 文章目录 楔子解耦到离散螃蟹与毒药文本的力量朝花夕拾后记 楔子 “——就像物理学家通过演绎与归纳将宏微世界的运转规律浓缩到数学公式中时,如今的人工智能也在试图量化整个人类文明。” “——只是,使用的是昂贵、笨…...
)
P1258 小车问题(二分)
题目描述 甲、乙两人同时从 A 地出发要尽快同时赶到 B 地。出发时 A 地有一辆小车,可是这辆小车除了驾驶员外只能带一人。已知甲、乙两人的步行速度一样,且小于车的速度。问:怎样利用小车才能使两人尽快同时到达。 输入格式 仅一行&#x…...

一个基于ragflow的工业文档智能解析和问答系统
工业复杂文档解析系统 一个基于ragflow的工业文档智能解析和问答系统,支持多种文档格式的解析、知识库管理和智能问答功能。 系统功能 1. 文档管理 支持多种格式文档上传(PDF、Word、Excel、PPT、图片等)文档自动解析和分块处理实时处理进度显示文档解析结果预览批量文档…...

负指数二项式展开
转载:负指数二项式展开_二项式负数次幂的展开式-CSDN博客...

CentOS 7服务器上快速安装mamba函数库
本次预配置虚拟环境为cuda 11.8torch 2.2.2python 3.10 1. 创建conda虚拟环境:conda create -n mamba python3.10 激活环境:conda activate mamba 2. 安装Pytorch环境: conda install pytorch2.2.2 torchvision0.17.2 torchaudio2.2.2 py…...
:添加 CPCA通道先验卷积注意力机制)
ResNet改进(18):添加 CPCA通道先验卷积注意力机制
1. CPCA 模块 CPCA(Channel Prior Convolutional Attention)是一种结合通道先验信息的卷积注意力机制,旨在通过显式建模通道间关系来增强特征表示能力。 核心思想 CPCA的核心思想是将通道注意力机制与卷积操作相结合,同时引入通道先验知识,通过以下方式优化特征学习: 通…...

代码随想录算法训练营--打卡day6
一.四数相加 1.题目链接 454. 四数相加 II - 力扣(LeetCode) 2.思路 使用 HashSet 无法记录每种和出现的次数,当不同的 (nums1[i], nums2[j]) 组合得到相同的和时,会出现统计错误。这里应该使用 HashMap 来记录和以及其出现的…...

edge webview2 runtime跟Edge浏览器软件安装包双击无反应解决方法
软件安装报错问题有需要远程文章末尾获取联系方式,可以帮你远程处理各类安装报错。 一 、edge webview2 runtime跟Edge浏览器软件安装包双击无反应 在安装edge webview2 runtime跟Edge浏览器双击无反应没有出现安装界面。这个可能是 新版本的Edge WebView2 Runti…...

Xorg 内存上涨的根源探究
Xorg 内存上涨的根源探究 起因 在同一客户端进程内显示多股视频源,通过SDL创建窗口渲染,由于网络抖动视频源出现频繁断流现象导致,渲染任务反复重启,从而导致SDL渲染窗口反复创建释放,最后导致Xorg内存持续上涨 排查准备 Xorg是什么? Xorg(X.Org Server)是 X Wind…...

Neo4j基本命令使用
neo4j neo4j简介安装可视化管理后台登录 Cyphercreatematchmergecreate创建关系merge创建关系wheredelete sort命令字符串函数toUpper()函数toLower()函数substring()函数replace()函数 聚合函数count()函数max()函数min()函数sum()函数avg()函数索引index python 中使用neo4j …...

Python爬虫教程009:requests的基本使用以及get和post请求的使用
文章目录 5.1 基本使用5.2 get请求5.3 post请求5.1 基本使用 在 Python 爬虫开发中,requests 是一个非常流行、简单易用的 HTTP 库,用于发送网络请求。它可以让你方便地抓取网页内容、提交表单、上传文件等。 🔧安装: pip install requestsresponse的属性及类型: resp…...

SQL练习
目录 1.查询" 01 "课程比" 02 "课程成绩高的学生的信息及课程分数 2.查询平均成绩大于等于 60 分的同学的学生编号和学生姓名和平均成绩 3.查询在 SC 表存在成绩的学生信息 4.查询所有同学的学生编号、学生姓名、选课总数、所有课程的总成绩(没成绩的显…...

ubuntu20.04 复现fastlio2 并运行数据包
1.搭建文件目录和拷贝代码 mkdir -p Fastlio2/src cd Fastlio2/src git clone https://github.com/hku-mars/FAST_LIO.git git clone https://github.com/Livox-SDK/livox_ros_driver.git 2.到工作空间下编译 cd .. catkin_make 报错1: 解决方案1: …...

Windows安装 PHP 8 和mysql9,win下使用phpcustom安装php8.4.5和mysql9
百度搜索官网并下载phpcustom,然后启动环境,点击网站管理 里面就有php8最新版,可以点mysql设置切mysql9最新版,如果你用最新版无法使用,说明你的php程序不支持最新版的mysql MySQL 9.0 引入了一些新的 SQL 模式和语法变…...

【失配树 KMP+树上倍增】P5829失配树|省选-
本文涉及知识点 较难理解的字符串查找算法KMP 树上倍增 P5829 【模板】失配树 题目描述 给定一个字符串 s s s,定义它的 k k k 前缀 p r e k \mathit{pre}_k prek 为字符串 s 1 … k s_{1\dots k} s1…k, k k k 后缀 s u f k \mathit{suf}_…...
)
机器学习模型性能提升教程(特征工程和模型优化)
特征工程和模型优化是提升机器学习模型性能的核心步骤,以下从特征工程和模型优化两个维度,结合具体案例展开说明: 一、特征工程 特征工程的核心目标是从原始数据中提取更有价值的信息,常见方法包括特征选择、特征构造和特征转换。…...

跨域问题前端解决
由于浏览器的同源策略,前后端分离的项目,调试的时候总是会遇到跨域的问题,这里通过修改前端代码解决跨域问题。 首先先查看前端代码的根目录下,有没有vue.config.js文件, 若有,使用方法1,若没有此文件&…...

每天五分钟深度学习框架pytorch:搭建LSTM完成时间序列的预测
本文重点 前面一篇文章我们使用了pytorch搭建了循环神经网络LSTM然后完成了手写字体识别的任务,本文我们使用LSTM完成一个时间序列的任务。 数据集介绍 数据集如图所示,其中有一列是时间,然后还有一列是对应时间的起飞航班数,它可以看成是一个时间序列,通过前面t时间的起…...

Autosar应用层开发基础——Arxml制作
Davinci软件的主要作用 (1) AUTOSAR 软件架构设计 图形化建模:支持 SWC(Software Component)设计、接口定义、端口连接等。 分层架构管理:清晰划分 应用层(SWC) 和 基础软件层(BSW)…...
)
Word 页眉设置(不同章节不同页眉)
需求分析 要给文档设置页眉,但是要不同的页眉不同的页眉 问题点:一旦设置页眉 每个页眉都是一样的 现在要设置不一样的 设置了页眉但是整个文章的页眉都一样 问题解决 取消链接 前一节(不和前面的页眉同步更新) 小结 不同的…...

Redis的Java客户端的使用
Redis 的 Java 客户端使用 C 追求极致的性能, 而 Java没有这样的追求. Redis 在官网公开了所使用的应用层协议 (RESP). 任何一个第三方都可以通过这个协议, 来实现出一个和 Redis 服务器通信的客户端程序. 已经有很多大佬, 做好了库, 可以让我们直接调用 (不必关注 RESP 协议…...

双向链表示例
#include <stdio.h> #include <stdlib.h>// 定义双向链表节点结构体 typedef struct list {int data; // 数据部分struct list *next; // 指向下一个节点的指针struct list *prev; // 指向前一个节点的指针 } list_t;// 初始化链表,将链表的…...

Unity如何把一个物体下物体复制很多到别的物体下
C# 脚本批量复制 如果需批量复制到多个父物体下,推荐用脚本实现: using UnityEngine;public class CopyChildren : MonoBehaviour {// 原父物体(拖拽赋值)public Transform sourceParent;// 目标父物体数组(可拖拽多个…...

Java Properties 类详解
Java Properties 类详解 Properties 是 Java 中用于处理 键值对配置文件 的特殊类,继承自 Hashtable<Object,Object>。以下是其核心知识点: 1. 核心特性 特性说明存储格式纯文本文件(.properties),每行 keyval…...

进程内存分布--之理论知识
一个由C/C编译的程序占用的内存分为以下几个部分 : 1、栈区(stack):由编译器自动分配释放 ,存放函数调用函数的参数值,局部变量的值等。其操作方式类似于数据结构中的栈。 2、堆区(heap…...