大数据概念介绍
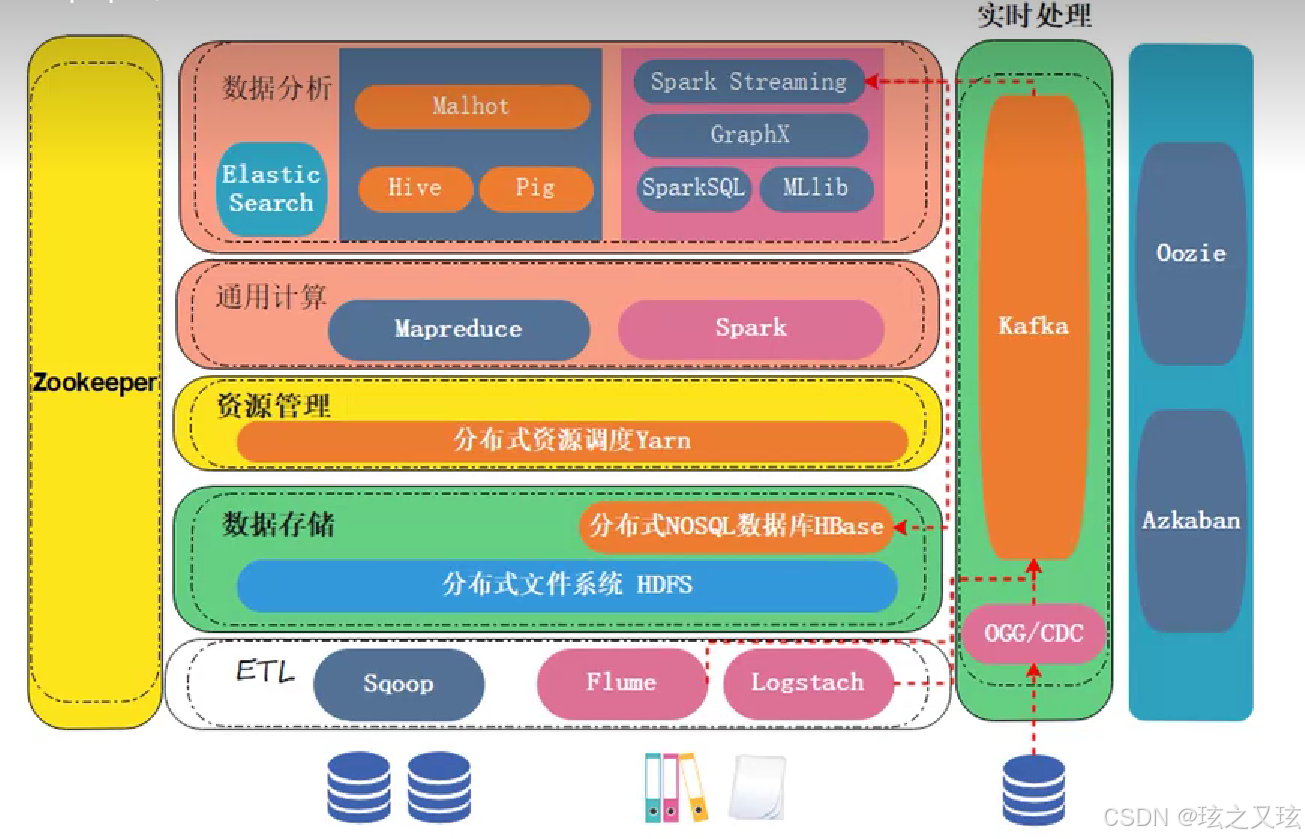
这节课给大家讲一下大数据的生态架构,
大数据有很多的产品琳琅满目,
大家看到图上就知道产品很多,
那这些产品它们各自的功能是什么,
它们又是怎么样相互配合,
来完成一整套的数据存储,
包括分析计算这样的一些任务,
这节课就要给大家进行一个分析,
那我们按照数据处理的流程,
从下往上给大家进行依次的讲解,
首先我们看数据源,
数据有结构化数据,
就是存在我们数据库里的数据,
以二维表的形式进行存储,
还有一些非结构化半结构化数据,
比如日志JASON属于半结构化图片,
视频音频属于非结构化,
对于结构化数据来说,
把这个数据抽取到大数据的数据存储平台,
这里用的比较多的或者主流的选型是HDFS,
因为它已经非常成熟了,
经过很多年的一个打磨,
scoop会通过GDBC的方式连接到我们的数据库,
对数据库进行直接抽取,
然后做一个导出,
COBE在抽取的时候一般是T加一的,
什么叫T加一呢,
就是今天产生的数据,
我们可能明天才能导到我们大数据平台,
它的时效性呢比较低一些,
你像我们数据仓库,
它其实是每天凌晨零点,
会把昨天新生成的数据统一进行一个导入,
那对于这种非结构化半结构化数据,
它们其实就是文件嘛,
图片视频日志JASON,
那这种文件呢一般来说它们会实时产生,
比如说监控的摄像头,
它会实时产生图片或者视频,
实时产生的数据进行实时抽取,
这个时候呢肯定就不能用coop了,
这些数据会通过flume或者log stench,
进行一个实时的监控,
一旦这些非结构化半结块数据产生,
他们就会立即抽取放到大数据的存储平台,
但是按照我们前面讲过的一个知识点,
实时产生的数据在架构设计上来说,
我们要先给它推送到一个消息队列中进行缓冲,
起到一个抗压的作用,
这个消息队列常用的选型就是卡夫卡,
它能抗住压力,
抗住压力以后,
实时产生的数据,
一定是要先经过大数据平台的处理,
处理完以后把结果存到我们的数据存储平台,
这样才能发挥这个实时数据的一个价值,
所以这种实时数据它不是直接往大数据平台存,
而是先经过消息队列缓存抗压,
然后大数据平台处理得到的结果再存起来,
那有的同学这个时候想了,
那我结构化的数据,
如果他也想进行实时的一个抽取,
可不可以呢,
也可以,
这个时候他要用到另外一种技术手段,
目前呢有两种,
一种是CDC,
一种是OGGOGG是oracle特有的,
CDC呢是开源的,
它们可以监控我们数据库里的结构化数据,
数据一旦发生变化,
他们就会监控到,
然后把变动的数据呢哎抽到卡夫卡里,
再交给大数据平台进行一个处理,
他们为什么能够进行实时的一个监控呢,
他们监控的是数据库的日志,
比如说MYSQL会有blog,
其他数据库呢有他们特有的这种日志文件,
我们在对数据库做一些数据,
新增或者修改的操作的时候,
会先把这样的一个操作记录在日志中,
保证一个容灾之后呢,
再往数据库里面进行一个写入,
我们直接监控数据库的日志,
数据的实时的变更,
我们就可以立马获取到,
而且不影响数据库的性能,
因为它这个日志本身就是一个文件,
这是CDC和OGG他做的一个事情,
日志拿到之后再进入KAFKA,
所以在数据源这里,
结构化数据可以使用T加一的方式,
隔一段时间抽一次导入到大数据平台,
非结构化半结构化数据,
也可以通过flume和LOGSTASH,
定时把它们抽到大数据平台,
当然他们应用的场景更多的是实时去抽取,
抽取到消息队列卡夫卡中,
结构化数据,
通过CDCOGG也实时抽取到卡夫卡,
这样的话,
我们不管是结构化数据还是非结构化,
半结构数据,
都可以满足T加一的和实时抽取的需要,
那数据呢最终会存储到我们的HT fs中,
但HDFS它本质上是一个文件系统,
我们用起来呢不太好用,
生产中呢没有见过,
我们直接把数据存到文件系统里面,
我们一般会选择把数据存到数据库里,
那AHBASE就是一个分布式的NOSQL数据库,
它是基于HDFS建立的,
虽然说数据最终它也是存在HDFS里,
但是它上层搭建了一个数据库,
那这个数据库呢用起来易用性会更好,
这样的话,
你抽取过来的数据可以直接存到DFS里,
也可以存到HBASE中,
就看具体的应用场景来具体对待,
那数据存储起来以后,
我们要基于这个数据做一些运算,
运算的时候,
我们可以用MAPREDUCE,
也可以用spark,
My reduce,
它计算起来要慢一些,
那spark呢相对快一些,
不管使用哪一种计算框架,
它们的计算任务要移动到我们的数据节点,
进行一个运算,
怎么能够把计算任务分发到数据节点呢,
就要通过中间这个资源管理层它的一些框架,
那这里最常用的呢是我们的分布式资源调度框,
架样E2,
这个框架,
它在部署的时候是和我们的数据存储的框架,
部署在一起的,
比如说我们底层的HT fs,
它是用来做存储的,
它有三个节点,
那我们样呢它也装在这三个节点上,
而且管理的这三个节点的计算资源,
你比如说CPU内存还有一些环境变量,
那我们的MAPREDUCE和spark,
计算任务要移动到数据节点进行运算,
这个时候呢,
要就可以直接在数据节点上,
分配给这些计算任务,
一些计算资源,
他们就可以顺利的紧贴数据运算,
运算完成之后呢,
药又可以把资源进行一个回收,
所以大数据的移动计算这一块的实现,
就是通过资源管理层它来完成的,
虽然我们在做计算的时候呢,
有了Mac reduce,
有了spark,
但是用起来还是不够好用,
易用性还是不够好,
为什么呢,
因为我们在开发的时候,
针对于这种结构化数据,
一般我们习惯用什么,
用circle那一些非结构化半结构化数据呢,
我们习惯用一些API,
但是现在你把数据抽取到大数据平台以后,
这些circle啊API都不能用了啊,
你只能用它提供的map reduce和spark,
去进行一个数据处理啊,
对于我们来说就很难用,
而且之前我们的业务系统用的circle啊,
用的一些API,
你是不是都要进行一个迁移啊,
那迁移的时候这个工作量就很大了,
为了让我们的数据开发或者数据分析,
这样的一个过程更加易用,
大数据,
这里其实提供了很多的一些易用框架,
比方说have,
它其实完成的就是帮你把circle,
转换成底层的MAPREDUCE,
当然呢have也可以转换成spark,
计算的效率会更高,
这样的话,
你原来的结构化数据存到的大数据平台,
之前是用circle的,
现在呢依然可以用SQL,
由have帮你把circle转换成通用计算,
转换完成之后,
通用计算的map reduce或者spark,
再通过资源管理调度到我们的数据节点,
紧贴数据完成整个计算任务,
那pig呢也是啊,
pig有它的一些API,
你使用它的API,
它会把这些API呢转换成MAPREDUCE,
当然pig呢比较早呢就停止维护了,
包括mail hot,
他是做这个机器学习的,
你用它提供的机器学习的API,
然后呢他帮你转换成MAREDUCE,
所以数据分析这一层,
它们完全是用于提高我们易用性,
而诞生的一些框架,
而根据它们转换的计算任务的不同,
那如果默认是转换map reduce的,
他们就属于HADO生态圈的,
因为哈DOP包含三个组件,
除了hdfs map reduce之外,
在哈DOBE2点X的时候呢增加了一个样,
他们三个是哈do,
那默认兼容HADOP的就属于HADOBE生态卷,
当然呢有一些框架其实刚开始诞生的时候呢,
是兼容HADOBE的,
后面呢因为spark它的性能更高,
用的公司呢更多一些,
所以他都不生态圈,
有一些框架,
比如说HEVE,
它也可以运行在spark上面,
当然spark也有它的一些生态,
spark circle帮你把circle转换成spark任务,
m l lib是做机器学习的,
group差是做图计算的,
spark streaming呢是做流计算的,
就实时处理的,
我们一般称为实时流处理或者实时流计算,
它计算得到的结果,
然后我们把结果给它存到HDFS里或者h base里,
当然呢我们一般会存储在HBASE里,
因为这个实时的这个结果如果存到HDFS里的话,
它会产生一些小文件问题,
那HDFS对于小文件来说是很敏感的,
它很容易把管理节点的内存给占满,
而且呢也会导致后续计算的一个效率下降,
所以实时计算完得到的结果呢会存到HBASE中,
h base虽然说数据最终成为HT fs,
但是呢它是一个数据库,
它解决了这个小文件问题啊,
它并没有小文件问题带来的这些隐患,
这一部分呢是spark生态圈,
那我们之后再做开发的时候,
大部分同学呢可能直接用spark或者map reduce,
进行编程,
相对会比较少一些,
我们可能更多的是用上层的易用性,
比较高的组件来进行一些相关的开发,
还有一些呢是独立开发的,
你比如说elastic search,
它是做搜索与检索的,
数据存到elastic search里面以后,
可以进行一些模糊查询,
精确匹配,
语音匹配等一些操作,
那为什么说它是独立的呢,
因为elastic search有它自己的通用计算,
也有他自己的资源管理,
包括数据存储成,
所以它并不依赖HADOP啊,
他也不依赖spark这个产品里面,
它本身就包含这几层,
所以呢它属于一个独立的产品,
最左边呢有一个ROKEEPER,
OKEEPER呢,
对大数据的各个产品其实是非常重要的,
很多产品比如说HDFSHBASE都要依赖,
你就keeper,
那它是干嘛的呢,
它是一个分布式的协调服务,
因为大数据的产品它都是分布式,
也就是运行在多个节点上的,
那比方说我们某一个大数据组件,
它突然新增了一个节点上来,
ROKEEPER呢就会识别到,
然后通知我们之前的三个节点,
说你现在的集群规模变成了四,
突然这个节点挂掉了,
zg per也会通知另外三个节点说好,
你现在有一个节点挂掉了,
节点数现在变成了三,
包括说我们的集群里面有多个管理节点,
但是呢这些管理节点它只有一个,
能够管理当前集群,
其他的呢都是备用节点,
那这样的话究竟由谁来进行管理,
谁来做备份,
ZOKEEPER可以进行一个选举,
比如说选第一个作为当前的管理节点,
另外两个做备份管理节点挂掉以后,
LUKEEPER又可以从剩下的两个备用节点里面,
再选出一个来啊,
让他来进行集群的一个接管,
所以LUKEEPER的作用其实是很大的,
我们用到的这些大数据产品,
只要想要在分布式环境下进行协调,
都可以依赖ROOKER啊来完成这样的一个诉求,
而且像一些组件呢是必须依赖ROKEEPER的,
比如说卡夫卡,
他在搭建之前,
ROKEEPER必须要进行一个安装,
最右边呢有两个任务的调度组件,
一个叫UZI,
一个叫阿兹卡班,
阿兹卡班呢相对比较新一些,
他俩是用来调度我们的计算任务的,
你比如说我们在大数据集群里面的任务,
他如果有一个先后顺序,
比如说任务一完成以后呢,
我们任务二才可以执行,
任务二执行完成以后哎,
在任务三如果有一个严格的先后顺序,
可以由UZI和阿兹卡班来进行一个限定,
再一个计算任务,
如果我们要进行定时,
比如说让他每天凌晨零点的时候进行一个执行,
就可以由UZI或者阿兹卡班来完成,
所以他们主要是来完成这种任务流,
的管理和调度的,
OK那大数据的整个产品就先介绍到这里啊,
谢谢大家
相关文章:

大数据概念介绍
这节课给大家讲一下大数据的生态架构, 大数据有很多的产品琳琅满目, 大家看到图上就知道产品很多, 那这些产品它们各自的功能是什么, 它们又是怎么样相互配合, 来完成一整套的数据存储, 包括分析计算这样的一些任务, 这节课就要给大家进行一个分析, 那我们按照数据处理…...
)
Linux(2025.3.15)
1、将/etc/passwd,/etc/shadow,/etc/group文件复制到/ceshi; 操作: (1)在根目录下创建ceshi目录; (2)复制; 结果: 2、找到/etc/ssh目录下ssh开头的所有文件并将其复制到…...

centosububntu设置开机自启动
一、centos 1.将脚本放到/etc/rc.d/init.d路径下 2.给脚本授权 sudo chmod -R 777 脚本名称 3.添加脚本至开机启动项中 sudo chkconfig --add 脚本名称 4.开启脚本 sudo chkconfig 脚本名称 on 5.查看开机启动项中是否包含该脚本 ls /etc/rc.d/rc*.d 二、ubuntu 1.在…...
)
基于大模型与动态接口调用的智能系统(知识库实现)
目录 引言 1、需求背景 2、实现原理 3、实现步骤 3.1 构建知识库接口调用提示模板 3.2 动态接口配置加载 3.3 智能参数提取链 3.4 接口智能路由 3.5 建议生成链 3.6 组合完整工作流 3.7 展示效果 总结 引言 在医疗信息化快速发展的今天,我们开发了一个智能问诊系…...

23种设计模式-行为型模式-迭代器
文章目录 简介问题解决代码设计关键点: 总结 简介 迭代器是一种行为设计模式,让你能在不暴露集合底层表现形式(列表、栈和树等)的情况下遍历集合中所有的元素。 问题 集合是编程中最常使用的数据类型之一。 大部分集合使用简单列表存储元素。但有些集…...

【Java集合】ArrayList源码深度分析
参考笔记: java ArrayList源码分析(深度讲解)-CSDN博客 【源码篇】ArrayList源码解析-CSDN博客 目录 1.前言 2. ArrayList简介 3. ArrayList类的底层实现 4. ArrayList的源码Debug 4.1 使用空参构造 (1)开始De…...

ISIS单区域抓包分析
一、通用头部报文 Intra Domain Routing Protocol Discriminator:域内路由选择协议鉴别符:这里是ISIS System ID Length:NSAP地址或NET中System ID区域的长度。值为0时,表示System ID区域的长度为6字节。值为255时,表…...

关键业务数据如何保持一致?主数据管理的最佳实践!
随着业务规模的扩大和系统复杂性的增加,如何确保关键业务数据的一致性成为许多企业面临的重大挑战。数据不一致可能导致决策失误、运营效率低下,甚至影响客户体验。因此,主数据管理(Master Data Management,简称MDM&am…...

ISIS单区域配置
一、什么是ISIS单区域 ISIS(Intermediate System to Intermediate System,中间系统到中间系统)单区域是指使用ISIS路由协议时,所有路由器都位于同一个区域(Area)内的网络配置。 二、实验拓扑 三、实验目的…...

Visual Basic语言的物联网
Visual Basic语言在物联网中的应用 引言 物联网(IoT)作为一种新兴的技术趋势,正在深刻地改变我们的生活方式与工业制造过程。在众多编程语言中,Visual Basic(VB)凭借其简单易用的特性,逐渐成为…...
)
【小沐杂货铺】基于Three.JS绘制三维数字地球Earth(GIS 、WebGL、vue、react)
🍺三维数字地球系列相关文章如下🍺:1【小沐学GIS】基于C绘制三维数字地球Earth(456:OpenGL、glfw、glut)第一期2【小沐学GIS】基于C绘制三维数字地球Earth(456:OpenGL、glfw、glut)第二期3【小沐…...

Vite环境下解决跨域问题
在 Vite 开发环境中,可以通过配置代理来解决跨域问题。以下是具体步骤: 在项目根目录下找到 vite.config.js 文件:如果没有,则需要创建一个。配置代理:在 vite.config.js 文件中,使用 server.proxy 选项来…...

嵌入式Linux开发环境搭建,三种方式:虚拟机、物理机、WSL
目录 总结写前面一、Linux虚拟机1 安装VMware、ubuntu18.042 换源3 改中文4 中文输入法5 永不息屏6 设置 root 密码7 安装 terminator8 安装 htop(升级版top)9 安装 Vim10 静态IP-虚拟机ubuntu11 安装 ssh12 安装 MobaXterm (SSH)…...

React项目在ts文件中使用router实现跳转
前言: 默认你已经进行了router的安装,目前到了配置http请求的步骤,在配置token失效或其他原因,需要实现路由跳转。在普通的 TypeScript 文件中无法直接使用Router的 useNavigate Hook。Hook 只能在 React 组件或自定义 Hook 中调用…...

Java中的正则表达式Lambda表达式
正则表达式&&Lambda表达式 正则表达式和Lambda表达式是Java编程中两个非常实用的特性。正则表达式用于字符串匹配与处理,而Lambda表达式则让函数式编程在Java中变得更加简洁。本文将介绍它们的基本用法,并结合示例代码帮助理解。同时要注意&…...

【idea设置文件头模板】
概述 设置模板,在创建java类时,统一添加内容(作者、描述、创建时间等等自定义内容),给java类添加格式统一的备注信息。 1、在settings 中找到File and Code Templates 选择File Header 2、模板内容示例 /*** Author hweiyu* Descriptio…...

我与数学建模之顺遂!
下面一段时期是我一段真正走进数模竞赛的时期。 在大二上学期结束之后,就开始张罗队友一起报名参加美赛,然后同时开始学LaTeX和Matlab,当时就是买了本Matlab的书,把书上的例题还有课后题全部做完了,然后用latex将书上…...

【Python使用】嘿马推荐系统全知识和项目开发教程第2篇:1.4 案例--基于协同过滤的电影推荐,1.5 推荐系统评估【附代码
教程总体简介:1.1 推荐系统简介 学习目标 1 推荐系统概念及产生背景 2 推荐系统的工作原理及作用 3 推荐系统和Web项目的区别 1.3 推荐算法 1 推荐模型构建流程 2 最经典的推荐算法:协同过滤推荐算法(Collaborative Filtering) 3 …...

Linux makefile的一些语法
一、定义变量 1. 变量的基本语法 在 makefile 中,变量的定义和使用非常类似于编程语言中的变量。变量的定义格式(最好不要写空格)如下: VARIABLE_NAMEvalue 或者 VARIABLE_NAME:value 表示延迟赋值,变量的值在引…...
(A-D))
Educational Codeforces Round 177 (Rated for Div. 2)(A-D)
题目链接:Dashboard - Educational Codeforces Round 177 (Rated for Div. 2) - Codeforces A. Cloudberry Jam 思路 小数学推导问题,直接输出n*2即可 代码 void solve(){int n;cin>>n;cout<<n*2<<"\n"; } B. Large A…...

第十八节课:Python编程基础复习
课程复习 前三周核心内容回顾 第一周:Python基本语法元素 基础语法:缩进、注释、变量命名、保留字数据类型:字符串、整数、浮点数、列表程序结构:赋值语句、分支语句(if)、函数输入输出:inpu…...

动物多导生理信号采集分析系统技术简析
一 技术参数 通道数:通道数量决定了系统能够同时采集的生理信号数量。如中南大学湘雅医学院的生物信号采集系统可达 128 通道,OmniPlex 多导神经信号采集分析系统支持 16、32、64、128 通道在体记录。不过,这个也要看具体的应用场景ÿ…...

Linux——Linux系统调用函数练习
一、实验名称 Linux系统调用函数练习 二、实验环境 阿里云服务器树莓派 三、实验内容 1. 远程登录阿里云服务器 2. 创建目录 操作步骤: mkdir ~/xmtest2 cd ~/xmtest2结果: 成功创建并进入homework目录。 3. 编写C代码 操作步骤: …...

列表与列表项
认识列表和列表项 FreeRTOS 中的 列表(List) 和 列表项(ListItem)是其内核实现的核心数据结构,广泛用于任务调度、队列管理、事件组、信号量等模块。它们通过双向链表实现,支持高效的元素插入、删除和遍历…...
手动初始化)
mofish软件(MacOS版本)手动初始化
mofish软件手动初始化MacOS 第一步,打开终端 command空格键唤起搜索页面,输入终端,点击打开终端 第二步,进入mofish配置目录,删除初始化配置文件 在第一步打开的终端中输入如下命令后按回车键,删除mofish配置文件 …...
)
基于javaweb的SpringBoot图片管理系统图片相册系统设计与实现(源码+文档+部署讲解)
技术范围:SpringBoot、Vue、SSM、HLMT、Jsp、PHP、Nodejs、Python、爬虫、数据可视化、小程序、安卓app、大数据、物联网、机器学习等设计与开发。 主要内容:免费功能设计、开题报告、任务书、中期检查PPT、系统功能实现、代码编写、论文编写和辅导、论文…...

密码学基础——DES算法
前面的密码学基础——密码学文章中介绍了密码学相关的概念,其中简要地对称密码体制(也叫单钥密码体制、秘密密钥体制)进行了解释,我们可以知道单钥体制的加密密钥和解密密钥相同,单钥密码分为流密码和分组密码。 流密码࿰…...

我与数学建模之波折
我知道人生是起起伏伏,但没想到是起起伏伏伏伏伏伏 因为简单讲讲,所以我没讲很多生活上的细节,其实在7月我和l学长一起在外面租房子备赛。这个时间节点其实我不太愿意讲,但是逃不了,那段时间因其他事情导致我那段时间…...
)
离线部署kubesphere(已有k8s和私有harbor的基础上)
前言说明:本文是在已有k8s集群和私有仓库harbor上进行离线安装kubesphere;官网的离线教程写都很详细,但是在部署部份把搭建集群和搭建仓库也写一起了,跟着做踩了点坑,这里就记录下来希望可以帮助到需要的xdm。 1.根据官…...

量子计算入门:Qiskit实战量子门电路设计
引言:量子计算的编程基石 量子门是量子计算的基本操作单元,其通过操控量子比特的叠加与纠缠实现并行计算。IBM开发的Qiskit框架为量子算法设计与模拟提供了强大工具。本文将从量子门基础、Qiskit实战、量子隐形传态案例三个维度,结合代码解析…...

AIGC8——大模型生态与开源协作:技术竞逐与普惠化浪潮
引言:大模型发展的分水岭时刻 2024年成为AI大模型发展的关键转折点:OpenAI的GPT-4o实现多模态实时交互,中国DeepSeek-MoE-16b模型以1/8成本达到同类90%性能,而开源社区如Mistral、LLama 3持续降低技术门槛。这场"闭源商业巨…...

FPGA练习
文章目录 一、状态机思想写一个 LED流水灯的FPGA代码二、 CPLD和FPGA芯片的主要技术区别是什么? 它们各适用于什么场合?1、CPLD适用场景2、FPGA适用场景 三、 在hdlbitsFPGA教程网站上进行学习1、练习题12、练习题2练习题3练习题4练习题5 一、状态机思想…...

阿里云服务器遭遇DDoS攻击有争议?
近年来,阿里云服务器频繁遭遇DDoS攻击的事件引发广泛争议。一方面,用户质疑其防御能力不足,导致服务中断甚至被迫进入“黑洞”(清洗攻击流量的隔离机制),轻则中断半小时,重则长达24小时…...

leetcode-代码随想录-哈希表-有效的字母异位词
题目 题目链接:242. 有效的字母异位词 - 力扣(LeetCode) 给定两个字符串 s 和 t ,编写一个函数来判断 t 是否是 s 的 字母异位词。 输入: s "anagram", t "nagaram" 输出: true输入: s "rat",…...

kotlin中主构造函数是什么
一 Kotlin 中的主构造函数 主构造函数(Primary Constructor)是 Kotlin 类声明的一部分,用于在 创建对象时初始化类的属性。它不像 Java 那样是一个函数体,而是紧跟在类名后面。 主构造函数的基本定义 class Person(val name: S…...

Julia语言的测试覆盖率
Julia语言的测试覆盖率探讨 引言 在现代软件开发中,测试是确保软件质量的重要环节。随着软件的复杂度不断增加,测试覆盖率作为衡量测试质量的一个重要指标,受到了越来越多开发者的关注。Julia语言作为一种高性能的动态编程语言,…...
)
Apache httpclient okhttp(2)
学习链接 Apache httpclient & okhttp(1) Apache httpclient & okhttp(2) okhttp github okhttp官方使用文档 okhttp官方示例代码 OkHttp使用介绍 OkHttp使用进阶 译自OkHttp Github官方教程 SpringBoot 整合okHttp…...
)
BUUCTF-web刷题篇(10)
19.EasyMD5 md5相关内容总结: ①string md5(&str,raw) $str:需要计算的字符串; raw:指定十六进制或二进制输出格式。计算成功,返回md5值,计算失败,返回false。 raw参数为true:16个字符的二进制格式&…...

CCF GESP C++编程 五级认证真题 2025年3月
C 五级 2025 年 03 月 题号 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 答案 A A B B D C A D A B C A A D B 1 单选题 第 1 题 链表不具备的特点是( )。 A. 可随机访问任何一个元素 B. 插入、删除操作不需要移动元素 C. 无需事先估计存储空间大小 D. 所需存储空间与存储元素个数成…...

【AI学习】MCP的简单快速理解
最近,AI界最火热的恐怕就是MCP了。作为一个新的知识点,学习的开始,先摘录一些信息,从发展历程、通俗介绍到具体案例,这样可以快速理解MCP。 MCP发展历程 来自i陆三金 Anthropic 开发者关系负责人 Alex Albert&#…...

文档处理利器Docling,基于LangChain打造RAG应用
大家好,人工智能应用持续发展,对文档信息的有效处理、理解与检索提出了更高要求。大语言模型虽已在诸多领域发挥重要作用,但在文档处理方面仍有提升空间。 本文将详细阐述如何整合Docling 和 LangChain,创建检索增强生成…...

深度学习图像分类数据集—枣子水果成熟度分类
该数据集为图像分类数据集,适用于ResNet、VGG等卷积神经网络,SENet、CBAM等注意力机制相关算法,Vision Transformer等Transformer相关算法。 数据集信息介绍:3种枣子水果成熟度数据:g,r,y&#…...
 | string类的使用)
第五讲(上) | string类的使用
string类的使用 一、string和C风格字符串的对比二、string类的本质三、string常用的API(注意只讲解最常用的接口)Member constants(成员常数)npos Member functionsIterators——迭代器Capacity——容量reserve和resizeElement ac…...

医药流通行业AI大模型冲击下的IT从业者转型路径分析
医药流通行业AI大模型冲击下的IT从业者转型路径分析 一、行业背景与技术变革趋势 在2025年的医药流通领域,AI技术正以指数级速度重塑行业格局。国家药监局数据显示,全国药品流通企业数量已从2018年的1.3万家缩减至2024年的8,900家,行业集中…...

【新能源汽车整车动力学模型深度解析:面向MATLAB/Simulink仿真测试工程师的硬核指南】
1. 前言 作为MATLAB/Simulink仿真测试工程师,掌握新能源汽车整车动力学模型的构建方法和实现技巧至关重要。本文将提供一份6000+字的深度技术解析,涵盖从基础理论到Simulink实现的完整流程。内容经过算法优化设计,包含12个核心方程、6大模块实现和3种验证方法,满足SEO流量…...
)
Android Fresco 框架动态图支持模块源码深度剖析(七)
上一期 Android Fresco 框架兼容模块源码深度剖析(六) 本人掘金号,欢迎点击关注:https://juejin.cn/user/4406498335701950 一、引言 在 Android 开发中,高效处理和展示动态图(如 GIF、WebP 动画等)是一个常见需求。…...

蓝桥杯专项复习——双指针
目录 双指针算法:双指针算法-CSDN博客 最长连续不重复子序列 P8783 [蓝桥杯 2022 省 B] 统计子矩阵 双指针优化思路:当存在重复枚举时,可以考虑是否能使用双指针进行优化 双指针算法:双指针算法-CSDN博客 最长连续不重复子序列…...

详解大模型四类漏洞
关键词:大模型,大模型安全,漏洞研究 1. 引入 promptfoo(参考1)是一款开源大语言模型(LLM)测试工具,能对 LLM 应用进行全面漏洞测试,它可检测包括安全风险、法律风险在内…...

【HC-05蓝牙模块】基础AT指令测试
一、视频课程 HC-05 蓝牙模块 第2讲 二、视频课件...
)
文件操作(c语言)
本关任务:给定程序的功能是:从键盘输入若干行文本(每行不超过 80 个字符),写到文件myfile4.txt中,用 -1(独立一行)作为字符串输入结束的标志。然后将文本的内容读出显示在屏幕上。文…...