【Python使用】嘿马推荐系统全知识和项目开发教程第2篇:1.4 案例--基于协同过滤的电影推荐,1.5 推荐系统评估【附代码

教程总体简介:1.1 推荐系统简介 学习目标 1 推荐系统概念及产生背景 2 推荐系统的工作原理及作用 3 推荐系统和Web项目的区别 1.3 推荐算法 1 推荐模型构建流程 2 最经典的推荐算法:协同过滤推荐算法(Collaborative Filtering) 3 相似度计算(Similarity Calculation) 4 协同过滤推荐算法代码实现: 二 根据用户行为数据创建ALS模型并召回商品 2.0 用户行为数据拆分 2.1 预处理behavior_log数据集 2.2 根据用户对类目偏好打分训练ALS模型 三 CTR预估数据准备 3.1 分析并预处理raw_sample数据集 1.3 Hadoop优势 4.4 大数据产品与互联网产品结合 4.5 大数据应用--数据分析 4.6 数据分析案例 5.3 HBase 的安装与Shell操作 1 HBase的安装 2.3 HDFS设计思路 4.3 Hive 函数 1 内置运算符 2 内置函数 3 Hive 自定义函数和 Transform MapReduce实战 3.3.1 利用MRJob编写和运行MapReduce代码 3.3.2 运行MRJOB的不同方式 3.3.3 mrjob 实现 topN统计(实验) spark-core RDD常用算子练习 3.1 RDD 常用操作 3.2 RDD Transformation算子 3.4 Spark RDD两类算子执行示意 3、JSON数据的处理 3.1 介绍 3.2 实践 3.1 静态json数据的读取和操作 5.4 HappyBase操作Hbase 4.4 hive综合案例 四 LR实现CTR预估 4.1 Spark逻辑回归(LR)训练点击率预测模型 4、数据清洗 5.6 HBase组件 1、sparkStreaming概述 spark-core实战 5.1通过spark实现ip地址查询 五 离线推荐数据缓存 5.1离线数据缓存之离线召回集 1.4 案例--基于协同过滤的电影推荐 1 User-Based CF 预测电影评分 3 spark 安装部署及standalone模式介绍 1 spark 安装部署 3 spark 集群相关概念 六 实时产生推荐结果 6.1 推荐任务处理 推荐系统基础 Hadoop Hive HBase Spark SQL 1.6 推荐系统的冷启动问题 2 处理推荐系统冷启动问题的常用方法 一 个性化电商广告推荐系统介绍 1.2 项目效果展示 1.3 项目实现分析 1.4 点击率预测(CTR--Click-Through-Rate)概念 资源调度框架 YARN 3.1.1 什么是YARN 3.1.2 YARN产生背景 3.1.3 YARN的架构和执行流程 基于回归模型的协同过滤推荐 基于矩阵分解的CF算法 基于矩阵分解的CF算法实现(二):BiasSvd 基于内容的推荐算法(Content-Based) 基于内容的电影推荐:物品画像 基于TF-IDF的特征提取技术 基于内容的电影推荐:为用户产生TOP-N推荐结果 2、DataFrame 分布式处理框架 MapReduce 3.2.1 什么是MapReduce
完整笔记资料代码:https://gitee.com/yinuo112/Backend/tree/master/Python/嘿马推荐系统全知识和项目开发教程/note.md
感兴趣的小伙伴可以自取哦~
全套教程部分目录:

部分文件图片:
1.4 案例--基于协同过滤的电影推荐
学习目标
- 应用基于用户的协同过滤实现电影评分预测
- 应用基于物品的协同过滤实现电影评分预测
1 User-Based CF 预测电影评分
-
数据集下载
-
下载地址:[MovieLens Latest Datasets Small](
-
建议下载[ml-latest-small.zip](
-
加载ratings.csv,转换为用户-电影评分矩阵并计算用户之间相似度
| |
- 预测用户对物品的评分 (以用户1对电影1评分为例)
评分公式
| |
- 封装成方法 预测任意用户对任意电影的评分
| |
- 为某一用户预测所有电影评分
| |
- 根据评分为指定用户推荐topN个电影
| |
2 Item-Based CF 预测电影评分
- 加载ratings.csv,转换为用户-电影评分矩阵并计算用户之间相似度
| |
- 预测用户对物品的评分 (以用户1对电影1评分为例)
评分公式
| |
- 封装成方法 预测任意用户对任意电影的评分
| |
- 为某一用户预测所有电影评分
| |
- 根据评分为指定用户推荐topN个电影
| |
3
1.5 推荐系统评估
学习目标
- 了解推荐系统的常用评估指标
- 了解推荐系统的评估方法
1 推荐系统的评估指标
- 好的推荐系统可以实现用户, 服务提供方, 内容提供方的共赢
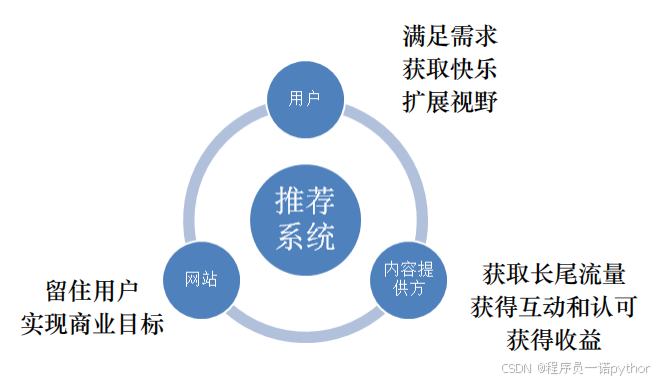
- 评估数据来源显示反馈和隐式反馈
| 显式反馈 | 隐式反馈 | |
|---|---|---|
- 常用评估指标
• 准确性 • 信任度 • 满意度 • 实时性 • 覆盖率 • 鲁棒性 • 多样性 • 可扩展性 • 新颖性 • 商业⽬标 • 惊喜度 • ⽤户留存
-
准确性 (理论角度) Netflix 美国录像带租赁
-
评分预测
- RMSE MAE
-
topN推荐
- 召回率 精准率
-
-
准确性 (业务角度)
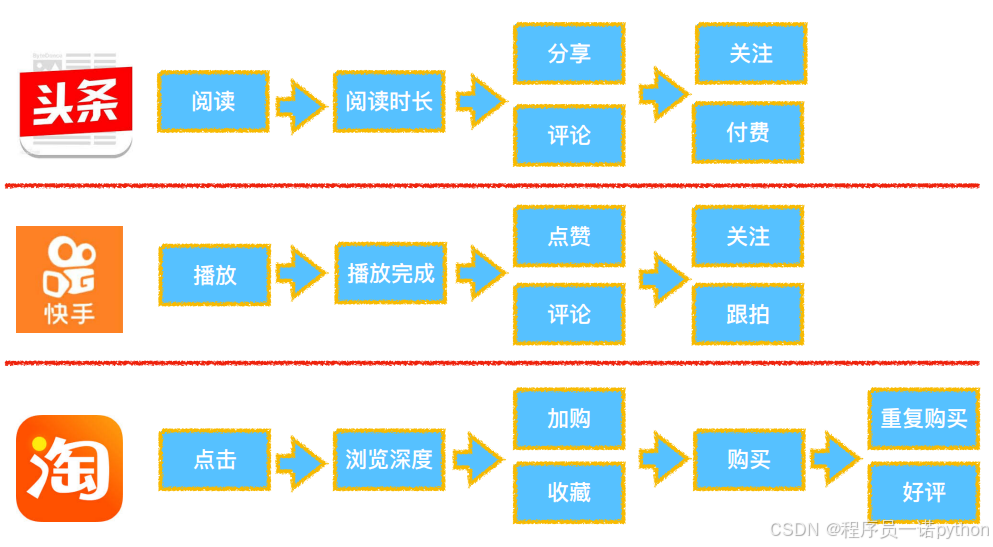
-
覆盖度
- 信息熵 对于推荐越大越好
- 覆盖率
-
多样性&新颖性&惊喜性
- 多样性:推荐列表中两两物品的不相似性。(相似性如何度量?
- 新颖性:未曾关注的类别、作者;推荐结果的平均流⾏度
- 惊喜性:历史不相似(惊)但很满意(喜)
- 往往需要牺牲准确性
- 使⽤历史⾏为预测⽤户对某个物品的喜爱程度
- 系统过度强调实时性
-
Exploitation & Exploration 探索与利用问题
- Exploitation(开发 利用):选择现在可能最佳的⽅案
- Exploration(探测 搜索):选择现在不确定的⼀些⽅案,但未来可能会有⾼收益的⽅案
- 在做两类决策的过程中,不断更新对所有决策的不确定性的认知,优化 长期的⽬标
-
EE问题实践
- 兴趣扩展: 相似话题, 搭配推荐
- 人群算法: userCF 用户聚类
- 平衡个性化推荐和热门推荐比例
- 随机丢弃用户行为历史
- 随机扰动模型参数
-
EE可能带来的问题
- 探索伤害用户体验, 可能导致用户流失
- 探索带来的长期收益(留存率)评估周期长, KPI压力大
- 如何平衡实时兴趣和长期兴趣
- 如何平衡短期产品体验和长期系统生态
- 如何平衡大众口味和小众需求
2 推荐系统评估方法
-
评估方法
-
问卷调查: 成本高
-
离线评估:
- 只能在用户看到过的候选集上做评估, 且跟线上真实效果存在偏差
- 只能评估少数指标
- 速度快, 不损害用户体验
-
在线评估: 灰度发布 & A/B测试 50% 全量上线
- 实践: 离线评估和在线评估结合, 定期做问卷调查
相关文章:

【Python使用】嘿马推荐系统全知识和项目开发教程第2篇:1.4 案例--基于协同过滤的电影推荐,1.5 推荐系统评估【附代码
教程总体简介:1.1 推荐系统简介 学习目标 1 推荐系统概念及产生背景 2 推荐系统的工作原理及作用 3 推荐系统和Web项目的区别 1.3 推荐算法 1 推荐模型构建流程 2 最经典的推荐算法:协同过滤推荐算法(Collaborative Filtering) 3 …...

Linux makefile的一些语法
一、定义变量 1. 变量的基本语法 在 makefile 中,变量的定义和使用非常类似于编程语言中的变量。变量的定义格式(最好不要写空格)如下: VARIABLE_NAMEvalue 或者 VARIABLE_NAME:value 表示延迟赋值,变量的值在引…...
(A-D))
Educational Codeforces Round 177 (Rated for Div. 2)(A-D)
题目链接:Dashboard - Educational Codeforces Round 177 (Rated for Div. 2) - Codeforces A. Cloudberry Jam 思路 小数学推导问题,直接输出n*2即可 代码 void solve(){int n;cin>>n;cout<<n*2<<"\n"; } B. Large A…...

第十八节课:Python编程基础复习
课程复习 前三周核心内容回顾 第一周:Python基本语法元素 基础语法:缩进、注释、变量命名、保留字数据类型:字符串、整数、浮点数、列表程序结构:赋值语句、分支语句(if)、函数输入输出:inpu…...

动物多导生理信号采集分析系统技术简析
一 技术参数 通道数:通道数量决定了系统能够同时采集的生理信号数量。如中南大学湘雅医学院的生物信号采集系统可达 128 通道,OmniPlex 多导神经信号采集分析系统支持 16、32、64、128 通道在体记录。不过,这个也要看具体的应用场景ÿ…...

Linux——Linux系统调用函数练习
一、实验名称 Linux系统调用函数练习 二、实验环境 阿里云服务器树莓派 三、实验内容 1. 远程登录阿里云服务器 2. 创建目录 操作步骤: mkdir ~/xmtest2 cd ~/xmtest2结果: 成功创建并进入homework目录。 3. 编写C代码 操作步骤: …...

列表与列表项
认识列表和列表项 FreeRTOS 中的 列表(List) 和 列表项(ListItem)是其内核实现的核心数据结构,广泛用于任务调度、队列管理、事件组、信号量等模块。它们通过双向链表实现,支持高效的元素插入、删除和遍历…...
手动初始化)
mofish软件(MacOS版本)手动初始化
mofish软件手动初始化MacOS 第一步,打开终端 command空格键唤起搜索页面,输入终端,点击打开终端 第二步,进入mofish配置目录,删除初始化配置文件 在第一步打开的终端中输入如下命令后按回车键,删除mofish配置文件 …...
)
基于javaweb的SpringBoot图片管理系统图片相册系统设计与实现(源码+文档+部署讲解)
技术范围:SpringBoot、Vue、SSM、HLMT、Jsp、PHP、Nodejs、Python、爬虫、数据可视化、小程序、安卓app、大数据、物联网、机器学习等设计与开发。 主要内容:免费功能设计、开题报告、任务书、中期检查PPT、系统功能实现、代码编写、论文编写和辅导、论文…...

密码学基础——DES算法
前面的密码学基础——密码学文章中介绍了密码学相关的概念,其中简要地对称密码体制(也叫单钥密码体制、秘密密钥体制)进行了解释,我们可以知道单钥体制的加密密钥和解密密钥相同,单钥密码分为流密码和分组密码。 流密码࿰…...

我与数学建模之波折
我知道人生是起起伏伏,但没想到是起起伏伏伏伏伏伏 因为简单讲讲,所以我没讲很多生活上的细节,其实在7月我和l学长一起在外面租房子备赛。这个时间节点其实我不太愿意讲,但是逃不了,那段时间因其他事情导致我那段时间…...
)
离线部署kubesphere(已有k8s和私有harbor的基础上)
前言说明:本文是在已有k8s集群和私有仓库harbor上进行离线安装kubesphere;官网的离线教程写都很详细,但是在部署部份把搭建集群和搭建仓库也写一起了,跟着做踩了点坑,这里就记录下来希望可以帮助到需要的xdm。 1.根据官…...

量子计算入门:Qiskit实战量子门电路设计
引言:量子计算的编程基石 量子门是量子计算的基本操作单元,其通过操控量子比特的叠加与纠缠实现并行计算。IBM开发的Qiskit框架为量子算法设计与模拟提供了强大工具。本文将从量子门基础、Qiskit实战、量子隐形传态案例三个维度,结合代码解析…...

AIGC8——大模型生态与开源协作:技术竞逐与普惠化浪潮
引言:大模型发展的分水岭时刻 2024年成为AI大模型发展的关键转折点:OpenAI的GPT-4o实现多模态实时交互,中国DeepSeek-MoE-16b模型以1/8成本达到同类90%性能,而开源社区如Mistral、LLama 3持续降低技术门槛。这场"闭源商业巨…...

FPGA练习
文章目录 一、状态机思想写一个 LED流水灯的FPGA代码二、 CPLD和FPGA芯片的主要技术区别是什么? 它们各适用于什么场合?1、CPLD适用场景2、FPGA适用场景 三、 在hdlbitsFPGA教程网站上进行学习1、练习题12、练习题2练习题3练习题4练习题5 一、状态机思想…...

阿里云服务器遭遇DDoS攻击有争议?
近年来,阿里云服务器频繁遭遇DDoS攻击的事件引发广泛争议。一方面,用户质疑其防御能力不足,导致服务中断甚至被迫进入“黑洞”(清洗攻击流量的隔离机制),轻则中断半小时,重则长达24小时…...

leetcode-代码随想录-哈希表-有效的字母异位词
题目 题目链接:242. 有效的字母异位词 - 力扣(LeetCode) 给定两个字符串 s 和 t ,编写一个函数来判断 t 是否是 s 的 字母异位词。 输入: s "anagram", t "nagaram" 输出: true输入: s "rat",…...

kotlin中主构造函数是什么
一 Kotlin 中的主构造函数 主构造函数(Primary Constructor)是 Kotlin 类声明的一部分,用于在 创建对象时初始化类的属性。它不像 Java 那样是一个函数体,而是紧跟在类名后面。 主构造函数的基本定义 class Person(val name: S…...

Julia语言的测试覆盖率
Julia语言的测试覆盖率探讨 引言 在现代软件开发中,测试是确保软件质量的重要环节。随着软件的复杂度不断增加,测试覆盖率作为衡量测试质量的一个重要指标,受到了越来越多开发者的关注。Julia语言作为一种高性能的动态编程语言,…...
)
Apache httpclient okhttp(2)
学习链接 Apache httpclient & okhttp(1) Apache httpclient & okhttp(2) okhttp github okhttp官方使用文档 okhttp官方示例代码 OkHttp使用介绍 OkHttp使用进阶 译自OkHttp Github官方教程 SpringBoot 整合okHttp…...
)
BUUCTF-web刷题篇(10)
19.EasyMD5 md5相关内容总结: ①string md5(&str,raw) $str:需要计算的字符串; raw:指定十六进制或二进制输出格式。计算成功,返回md5值,计算失败,返回false。 raw参数为true:16个字符的二进制格式&…...

CCF GESP C++编程 五级认证真题 2025年3月
C 五级 2025 年 03 月 题号 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 答案 A A B B D C A D A B C A A D B 1 单选题 第 1 题 链表不具备的特点是( )。 A. 可随机访问任何一个元素 B. 插入、删除操作不需要移动元素 C. 无需事先估计存储空间大小 D. 所需存储空间与存储元素个数成…...

【AI学习】MCP的简单快速理解
最近,AI界最火热的恐怕就是MCP了。作为一个新的知识点,学习的开始,先摘录一些信息,从发展历程、通俗介绍到具体案例,这样可以快速理解MCP。 MCP发展历程 来自i陆三金 Anthropic 开发者关系负责人 Alex Albert&#…...

文档处理利器Docling,基于LangChain打造RAG应用
大家好,人工智能应用持续发展,对文档信息的有效处理、理解与检索提出了更高要求。大语言模型虽已在诸多领域发挥重要作用,但在文档处理方面仍有提升空间。 本文将详细阐述如何整合Docling 和 LangChain,创建检索增强生成…...

深度学习图像分类数据集—枣子水果成熟度分类
该数据集为图像分类数据集,适用于ResNet、VGG等卷积神经网络,SENet、CBAM等注意力机制相关算法,Vision Transformer等Transformer相关算法。 数据集信息介绍:3种枣子水果成熟度数据:g,r,y&#…...
 | string类的使用)
第五讲(上) | string类的使用
string类的使用 一、string和C风格字符串的对比二、string类的本质三、string常用的API(注意只讲解最常用的接口)Member constants(成员常数)npos Member functionsIterators——迭代器Capacity——容量reserve和resizeElement ac…...

医药流通行业AI大模型冲击下的IT从业者转型路径分析
医药流通行业AI大模型冲击下的IT从业者转型路径分析 一、行业背景与技术变革趋势 在2025年的医药流通领域,AI技术正以指数级速度重塑行业格局。国家药监局数据显示,全国药品流通企业数量已从2018年的1.3万家缩减至2024年的8,900家,行业集中…...

【新能源汽车整车动力学模型深度解析:面向MATLAB/Simulink仿真测试工程师的硬核指南】
1. 前言 作为MATLAB/Simulink仿真测试工程师,掌握新能源汽车整车动力学模型的构建方法和实现技巧至关重要。本文将提供一份6000+字的深度技术解析,涵盖从基础理论到Simulink实现的完整流程。内容经过算法优化设计,包含12个核心方程、6大模块实现和3种验证方法,满足SEO流量…...
)
Android Fresco 框架动态图支持模块源码深度剖析(七)
上一期 Android Fresco 框架兼容模块源码深度剖析(六) 本人掘金号,欢迎点击关注:https://juejin.cn/user/4406498335701950 一、引言 在 Android 开发中,高效处理和展示动态图(如 GIF、WebP 动画等)是一个常见需求。…...

蓝桥杯专项复习——双指针
目录 双指针算法:双指针算法-CSDN博客 最长连续不重复子序列 P8783 [蓝桥杯 2022 省 B] 统计子矩阵 双指针优化思路:当存在重复枚举时,可以考虑是否能使用双指针进行优化 双指针算法:双指针算法-CSDN博客 最长连续不重复子序列…...

详解大模型四类漏洞
关键词:大模型,大模型安全,漏洞研究 1. 引入 promptfoo(参考1)是一款开源大语言模型(LLM)测试工具,能对 LLM 应用进行全面漏洞测试,它可检测包括安全风险、法律风险在内…...

【HC-05蓝牙模块】基础AT指令测试
一、视频课程 HC-05 蓝牙模块 第2讲 二、视频课件...
)
文件操作(c语言)
本关任务:给定程序的功能是:从键盘输入若干行文本(每行不超过 80 个字符),写到文件myfile4.txt中,用 -1(独立一行)作为字符串输入结束的标志。然后将文本的内容读出显示在屏幕上。文…...

Apache Camel指南-第四章:路由径构建之异常处理
摘要 Apache的骆驼提供几种不同的机制,让您在处理不同的粒度级别的例外:您可以通过处理一个路线中的异常doTry,doCatch以及doFinally; 或者您可以指定要采取什么行动每种类型的异常,并应用此规则的所有路由RouteBuilder使用onExc…...

赚钱模拟器--百宝库v0.1.0
#include<bits/stdc.h> #include<windows.h> using namespace std; int n; void welcome(); void zhuye(); int main(){welcome();zhuye();return 0; }void welcome(){cout<<"欢迎您使用更多资源-百宝库v0.1.0"<<endl;system("pause&q…...
工作流程介绍)
SSL证书自动化管理(ACME协议)工作流程介绍
SSL证书自动化管理(ACME协议)是一种用于自动化管理SSL/TLS证书的协议,以下是其详细介绍: 一、ACME协议概述 ACME协议由互联网安全研究小组(ISRG)设计开发,旨在实现SSL证书获取流程的自动化。通…...

推理模型与普通大模型如何选择?
👏作者简介:大家好,我是爱吃芝士的土豆倪,24届校招生Java选手,很高兴认识大家📕系列专栏:Spring原理、JUC原理、Kafka原理、分布式技术原理、数据库技术、JVM原理、AI应用🔥如果感觉…...

人工智能与计算机技术融合下的高中教育数字化教学模式探索
一、引言 1.1 研究背景与意义 1.1.1 教育数字化转型的国家战略需求 在当今时代,数字化浪潮正席卷全球,深刻改变着人们的生产生活方式。教育领域作为培养未来人才的重要阵地,也不可避免地受到数字化的影响。教育数字化转型已成为世界各国的…...
)
P2762 太空飞行计划问题 (网络流、最大权闭合子图问题)
P2762 太空飞行计划问题 思路: 今日网络流 这个题思路其实很简单,先说结论:源点连所有实验,容量为收益;实验连接对应仪器,容量为无穷;所有仪器连汇点,容量为费用(注意是…...

对用户登录设计测试用例
一、功能测试 1、正确用户名和密码 输入正确的用户名和密码,点击提交,验证是否成功登录。 2、错误用户名或密码 输入错误的用户名或密码,验证登录失败,并提示“用户名或密码错误”。 3、登录…...
忌(阶)秘(技)术(巧)【第四式】自定义类型详解(结构体、枚举、联合))
c语言修炼秘籍 - - 禁(进)忌(阶)秘(技)术(巧)【第四式】自定义类型详解(结构体、枚举、联合)
c语言修炼秘籍 - - 禁(进)忌(阶)秘(技)术(巧)【第四式】自定义类型详解(结构体、枚举、联合) 【心法】 【第零章】c语言概述 【第一章】分支与循环语句 【第二章】函数 【第三章】数组 【第四章】操作符 【第五章】指针 【第六章】结构体 【第七章】con…...

阿里巴巴langengine二次开发大模型平台
阿里巴巴LangEngine开源了!支撑亿级网关规模的高可用Java原生AI应用开发框架 - Leepy - 博客园 阿里国际AI应用搭建平台建设之路(上) - 框架篇 基于java二次开发 目前Spring ai、spring ai alibaba 都是java版本的二次基础能力 重要的是前端工作流 如何与 服务端的…...

获取KUKA机器人诊断文件KRCdiag的方法
有时候在进行售后问题时需要获取KUKA机器人的诊断文件KRCdiag,通过以下方法可以获取KUKA机器人的诊断文件KRCdiag: 1、将U盘插到控制柜内的任意一个USB接口; 2、依次点【主菜单】—【文件】—【存档】—【USB(控制柜)…...

聊聊Spring AI的MilvusVectorStore
序 本文主要研究一下Spring AI的MilvusVectorStore 示例 pom.xml <dependency><groupId>org.springframework.ai</groupId><artifactId>spring-ai-starter-vector-store-milvus</artifactId></dependency>配置 spring:ai:vectorstore:…...

前后端通信指南
HTTP 协议与 RESTful APIWebSocket 与实时通信一、前后端通信概述 前后端通信是现代 Web 开发的核心环节,前端(浏览器或移动端)需要向后端请求数据,并根据返回的数据渲染界面。常见的通信方式包括 HTTP 请求、RESTful API、WebSocket、GraphQL 等。 常见前后端通信方式 通…...

[特殊字符] 驱动开发硬核特训 · Day 2
主题:深入掌握 UART 与 SPI 驱动开发原理、架构与调试技术 本期围绕实际项目中应用最广泛的两类外设通信接口 —— UART(串口)与 SPI(串行外设接口),通过结构化知识点梳理,结合实际驱动开发流程…...
)
B树和B+树的区别(B Tree B+ Tree)
前言 B树和B树是数据库中常用的索引结构,它们的核心区别主要体现在数据存储方式、节点结构和适用场景上。 关键区别详解 数据存储方式: B树:所有节点均存储键值(key-data)对,数据可能分布在树的任意层级。…...
)
32--当网络接口变成“夜店门口“:802.1X协议深度解码(理论纯享版本)
当网络接口变成"夜店门口":802.1X协议深度解码 引言:网口的"保安队长"上岗记 如果把企业网络比作高端会所,那么802.1X协议就是门口那个拿着金属探测器的黑超保安。它会对着每个想进场的设备说:“请出示您的会…...

【LLM】使用MySQL MCP Server让大模型轻松操作本地数据库
随着MCP协议(Model Context Protocol)的出现,使得 LLM 应用与外部数据源和工具之间的无缝集成成为可能,本章就介绍如何通过MCP Server让LLM能够直接与本地的MySQL数据库进行交互,例如新增、修改、删除数据,…...
汽车活塞生产制造MOM建设方案(第一部分))
MOM成功实施分享(八)汽车活塞生产制造MOM建设方案(第一部分)
在制造业数字化转型的浪潮中,方案对活塞积极探索,通过实施一系列数字化举措,在生产管理、供应链协同、质量控制等多个方面取得显著成效,为行业提供了优秀范例。 1.转型背景与目标:活塞在数字化转型前面临诸多挑战&…...