c语言修炼秘籍 - - 禁(进)忌(阶)秘(技)术(巧)【第四式】自定义类型详解(结构体、枚举、联合)
c语言修炼秘籍 - - 禁(进)忌(阶)秘(技)术(巧)【第四式】自定义类型详解(结构体、枚举、联合)
【心法】
【第零章】c语言概述
【第一章】分支与循环语句
【第二章】函数
【第三章】数组
【第四章】操作符
【第五章】指针
【第六章】结构体
【第七章】const与c语言中一些错误代码
【禁忌秘术】
【第一式】数据的存储
【第二式】指针
【第三式】字符函数和字符串函数
【第四式】自定义类型详解(结构体、枚举、联合)
文章目录
- c语言修炼秘籍 - - 禁(进)忌(阶)秘(技)术(巧)【第四式】自定义类型详解(结构体、枚举、联合)
- 前言
- 一、结构体
- 1. 结构的基础知识
- 2. 结构的声明
- 3. 特殊的声明
- 4. 结构的自引用
- 5. 结构体变量的定义和初始化
- 6. 结构体内存对齐
- 7. 修改默认对齐数
- 8. 结构体传参
- 二、位段
- 1. 什么是位段
- 2. 位段的内存分配
- 3. 位段的跨平台问题
- 4. 位段的应用
- 三、枚举
- 1. 枚举类型的定义
- 2. 枚举的优点
- 3. 枚举的使用
- 四、联合
- 1. 联合类型的定义
- 2. 联合的特点
- 3. 联合大小的计算
- 4. 联合休的使用实例:
- 五、使用结构体实现一个通讯录
- 总结
前言
c语言中虽然定义得有许多的类型,如char、int、double等等,但是现实生活中需要描述的问题,仅仅使用这些已有类型是不够的,所以在c语言中,程序员可以根据自己的需要,定义出自己的类型结构,以满足需求。
本文会对c语言中的结构体进行详细介绍,包括:
- 结构体:
- 结构体类型的声明
- 结构的自引用
- 结构体变量的定义和初始化
- 结构体内存对齐
- 结构体传参
- 结构体实现位段(位段的填充&可移植性)
- 枚举
- 枚举类型的定义
- 枚举的优点
- 枚举的使用
- 联合
- 联合类型的定义
- 联合的特点
- 联合的使用
一、结构体
1. 结构的基础知识
结构是一些值的集合,这些值被称为成员变量。结构的每个成员可以是不同类型的变量。
与数组作区分:
虽然数组也是一组值的集合,但数组的这组值的类型相同;
2. 结构的声明
struct Tag
{member-list;
} variable-list;
// 使用关键字struct来声明一个结构体
// Tag是结构体的名字
// {}中成员变量
// {}后面的是结构体变量
例如用结构体来描述一个学生
struct Stu
{char name[20]; // 名字int age; // 年龄char sex[5]; // 性别 char id[10]; // 学号
}; // 分号不能省略
3. 特殊的声明
除了上面的声明方式外,在结构体的声明时可以不完全声明
// 还可以不声明结构体的名字,定义一个匿名结构体
struct
{member-list;
} variable-list;
// 但是通过这种方法定义的结构体,就只有在定义这里创建的几个结构体变量,之后无法定义一个新的变量,因为没有名字。struct
{int a;short b;char c;double d;
} x;// 这个结构体只有x这一个变量,无法定义新变量struct
{int a;short b;char c;double d;
} *p;
// 这个结构体只有p这一个指针变量,无法定义新变量
上面的两个结构体都省略了结构体标签Tag,那么问题来了:
// 在上面代码的基础上下面代码合法吗?
p = &x;
非法
因为编译器会将上面的两个声明当作两个完全不同的类型,所以这种行为是非法的。
4. 结构的自引用
结构体中的成员变量类型还可以是其它的结构体:
struct A
{int a;short b;char c;float d;
};struct B
{int data;struct A a;
};
那么有一个问题,一个结构体的成员变量能否是它自身呢?
struct Node
{int data;struct Node next;
};
// 这可行吗?
// 如果可行,这个结构体在内存中占多大空间呢?
// 即sizeof(struct Node)是多少
显然这种行为是不可行的,结构体中的成员变量是这个结构体,那么这个结构体在内存中占多大空间就无法确认;
正确的引用方式:
struct Node
{int data;struct Node* next;
};
// 通过指针来实现结构体的自引用
// 指针的大小是根据机器的平台决定的,这是一个确定的值,所以这个结构体在内存中占据的空间是确定的
注意,当我们使用typedef来重命名结构体时,通常都会使用不完全的结构体声明
如:
typedef struct
{int data;char ch;
} Test;
// 这是一个匿名结构体,并将其重命名为Test
那么下面代码正确吗?
typedef struct
{int data;Test* node;
} Test;
不行!
因为,是先有了这个结构体,才能将其重命名为Test,但是在结构体的成员变量中先使用Test,这样就产生了冲突,所以这种方式是不合法的;
应该使用下面的方式进行结构体的自引用;
typedef struct Node
{int data;struct Node* node;
} Node;
5. 结构体变量的定义和初始化
有了结构体类型,之后应该如何定义变量呢?
#include <stdio.h>struct Point
{int x;int y;
} p1; // 声明类型的同时定义一个变量p1struct Point p2; // 定义变量p2,struct Point是这个类型的名字// 初始化
struct Point p3 = { x, y };
// 这里的x, y表示int类型的数值
// 同数组相同,一组元素使用{}初始化赋值,可以不完全初始化,后续的成员变量会被初始化为0struct Stu // 声明类型
{char name[20]; // 名字int age; // 年龄
};
struct Stu stu = { "zhangsan" ,22 }; // 初始化struct Node
{int data; struct Point p;struct Node* next;
} n1 = { 10, { 4, 5 }, NULL }; // 结构体嵌套初始化struct Node n2 = { 20, { 3, 7 }, &n1 }; // 结构体嵌套初始化
6. 结构体内存对齐
通过上面的学习,我们已经掌握了结构体的基本使用了,但是一个结构体在内存中占据多大空间呢?它的成员变量的空间是如何分布的呢?
下面我们就来看看结构体内存对齐:
#include <stdio.h>int main()
{struct S1{char c1;int i;char c2;};printf("S1 = %d\n" , sizeof(struct S1));struct S2{char c1;char c2;int i;};printf("S2 = %d\n", sizeof(struct S2));struct S3{double d;char c;int i;};printf("S3 = %d\n", sizeof(struct S3));struct S4{char c;struct S3 s3;double d;};printf("S4 = %d\n", sizeof(struct S4));return 0;
}
S1和S2的成员变量类型相同,只是排序不同,它们在内存中占据的空间相同吗?
一个结构体在内存中占据空间的大小,是成员变量占据内存空间的大小之和吗?
运行结果:
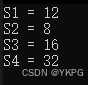
可以看到,S1和S2的大小不同;
结构体占据的内存空间大小也不等于它的成员变量占据空间之和;
那么,结构体变量的内存大小应该如何计算呢?
首先,我们先了解结构体的对齐规则:
第一个成员在与结构体变量偏移量为0的地址处;
其他成员变量要对齐到某个数字(对齐数)的整数倍的地址处;
对齐数 = 编译器默认的一个对齐数 与 该成员大小的 较小值
- VS中默认为8,例如一个int类型的成员变量的对齐数为4,一个char类型的成员变量的对齐数为1,一个空间大于8的结构体类型的对齐数为8;
结构体的总大小为最大对齐数(每个成员都有一个对齐数)的整数倍,这个结构体的对齐数就是它的最大对齐数;
如果嵌套了结构体,这个嵌套的结构体对齐到它的最大对齐数的整数倍处,结构体整体大小就是所有最大对齐数(包括嵌套的结构体的对齐数)的整数倍;
那么为什么要在内存对齐呢?(大部分资料)
- 平台原因:
不是所有的硬件平台都能够访问任意地址上的任意数据;某些硬件平台只能在某些地址处取某些特定类型的数据,否则会抛出异常; - 性能原因:
数据结构(尤其是栈)应该尽可能地在自然边界上对齐;
原因在于,为了访问未对齐的内存,处理器需要作两次内存访问;而对齐的内存访问仅需要一次访问。
例如,一个int类型,在32位机器上,一次读取能够获取4个字节,如果这个int类型的数据在内存上不对齐,就不能拿到完整的数据,需要多读取一次;
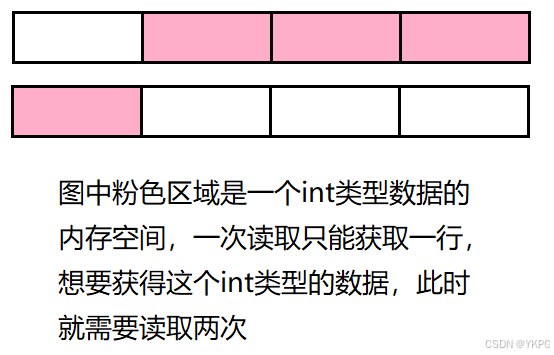
总的来说,结构体的内存对齐就是拿空间换时间的做法;
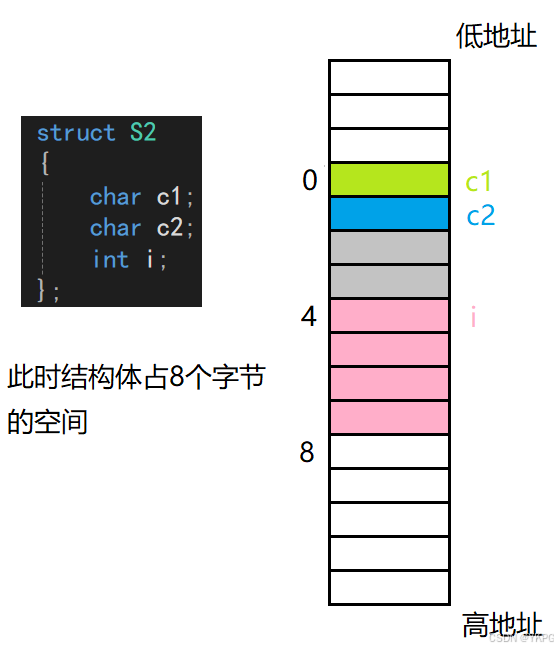
那么相同的成员类型,不同的排序顺序,结构体占据的内存空间也可能是不同的,为了节省空间,应该:让占空间小的成员尽量集中在一起
struct S1
{char c1;int i;char c2;
};struct S2
{char c1;char c2;int i;
};
// s1和S2的成员一模一样,但是它们占据的内存空间大小是不一样的
练习
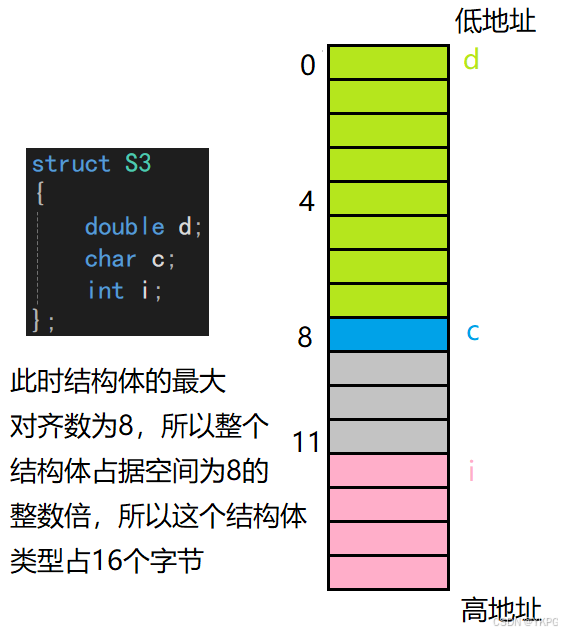
现在对这部分最开始给出的4个结构体占据的空间进行详细分析:
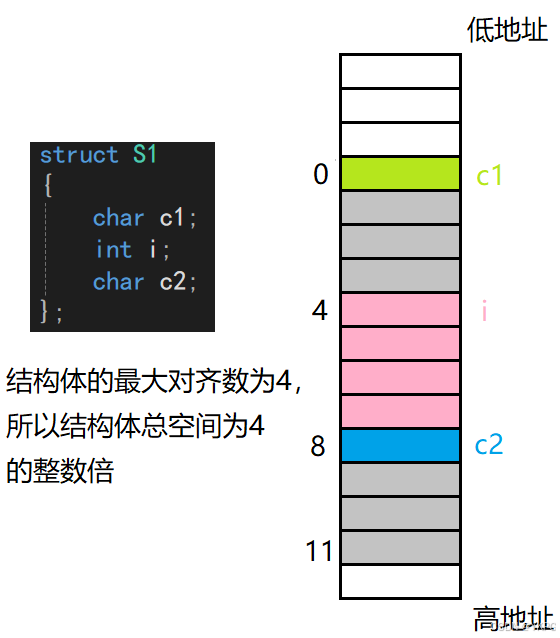
结构体的第一个成员的偏移量为0,所以c1在这个结构体的最前面占一个字节,int类型占4个字节,所以一个int类型的成员的对齐数为4,它的起始位置的偏移量为4的整数倍,所以此时需要先空3个字节,i从第四个字节开始存放,char类型占一个字节,对齐数为1,地址地址的偏移量为1的整数倍,所以可以接着继续放,最后因为结构体的总大小为所有成员的最大对齐数的整数倍,此时的最大对齐数为4,所以此时需要再补3个字节,补成12字节,所以一个S1类型的变量占12个字节;
分析同上,不再赘述;
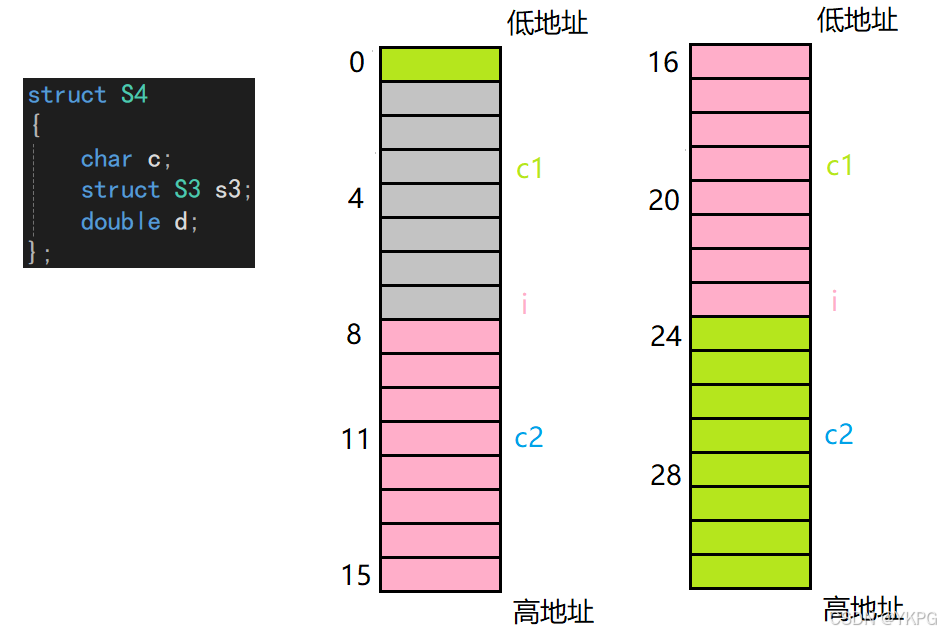
第一个成员c占1个字节,从0偏移处开始,第二个成员是一个结构体,由上面的分析得知,S3占16个字节,所以它的对齐数为8,此时需要填充7个字节,从第8字节开始,最后是一个对齐数为8的double类型,开始位置的偏移量应为8的倍数,所以S4这个类型占32个字节的空间;
7. 修改默认对齐数
使用#pragma这个预处理指令可以修改默认对齐数;
#include <stdio.h>#pragma pack(8) // 设置默认对齐数为8
struct S1
{char c1;int i;char c2;
};#pragma pack() // 取消设置的默认对齐数,还原为默认的8 -- VS中#pragma pack(1) // 将默认对齐数设为1
struct S2
{char c1;int i;char c2;
};
#pragma pack() // 还原默认对齐数int main()
{printf("%d\n", sizeof(struct S1));printf("%d\n", sizeof(struct S2));return 0;
}
分析:
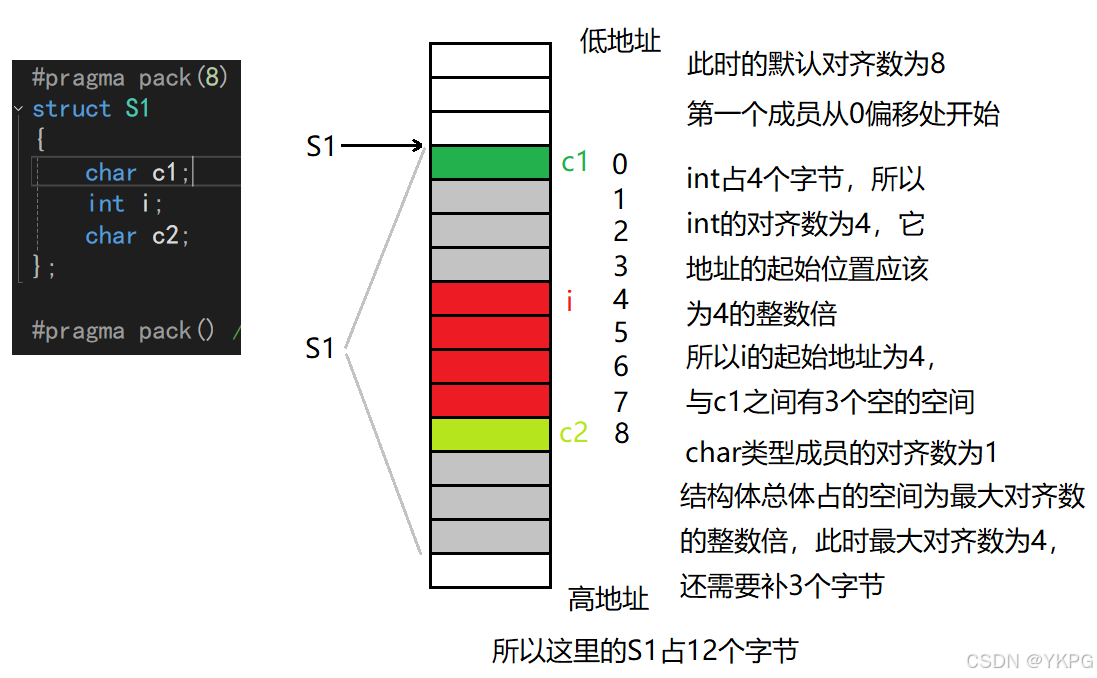
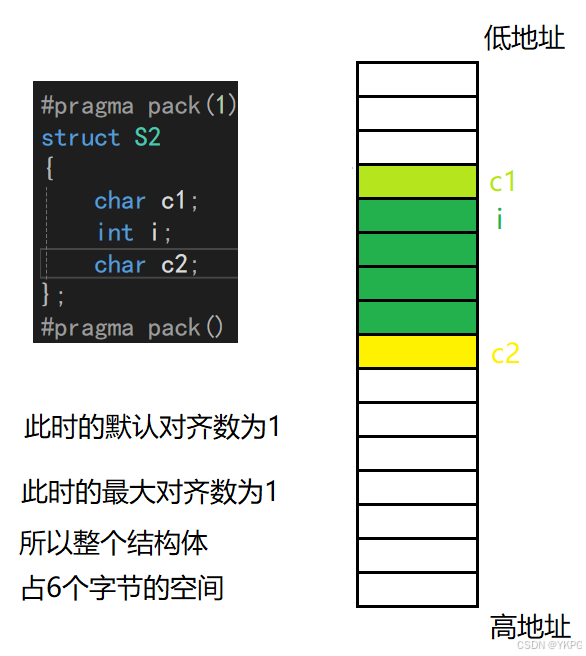
运行结果:
结构体在对齐方式不合适的时候,可以自己更改默认对齐数;
百度面试题:
写一个宏,计算结构体中某变量相对于首地址的偏移,并给出说明,参考offsetof宏的实现
#define OFFSETOF(type, member) (unsigned int)(&(((type*)0)->member))
// 将0作为一个结构体类型的指针,通过指针->访问到对应成员member,再取地址,
// 因为这个结构体类型的地址为0,所以此时这个成员的地址就相当于它的偏移量,再将这个地址转为无符号整数,
// 这样就能获取到一个结构体类型中某成员变量相对于首地址的偏移#include <stdio.h>struct Stu
{char name[20];int age; char sex[5];char id[10];
};int main()
{printf("%d\n", OFFSETOF(struct Stu, age));return 0;
}
运行结果:
注意,这里的数组的对齐数是这个数组中元素的对齐数,它是一个char类型的数组,所以这个数组的对齐数为1
这与嵌套结构体的对齐数相同,结构体的对齐数为最大对齐数,是这个结构中的成员变量的最大的对齐数,数组中元素相同,所以最大对齐数就是数组元素的对齐数;
8. 结构体传参
直接看代码,下面的代码1和代码2哪个更好
#include <stdio.h>struct S
{int data[1000];int num;
};struct S s = { { 1,2,3,4 }, 1000 };// 代码1
void print1(struct S s)
{printf("%d\n", s.num);
}// 代码2
void print2(struct S* s)
{printf("%d\n", s->num);
}int main()
{print1(s); // 传结构体print2(&s); // 传指针return 0;
}
代码1是传值调用,代码2是传址调用;
我们都知道,
传值调用,是将实参拷贝一份,函数对临时变量进行处理;
传址调用,是将实参的地址传给函数,函数能通过指针,直接对参数进行处理;
传值相比传址会多做一次拷贝,存在额外开销,当结构体类型占据空间很庞大时,这个额外开销也就随着增大;
所以从性能角度出发,代码2的传址调用更好;
所以在结构体传参时,要传结构体的地址
二、位段
1. 什么是位段
位段的声明和结构体是类似的,只有两个不同:
- 位段的成员必须是
int、unsigned int、signed int、char、unsigned char、signed char - 位段的成员名后面有一个冒号
:和一个数字
比如:
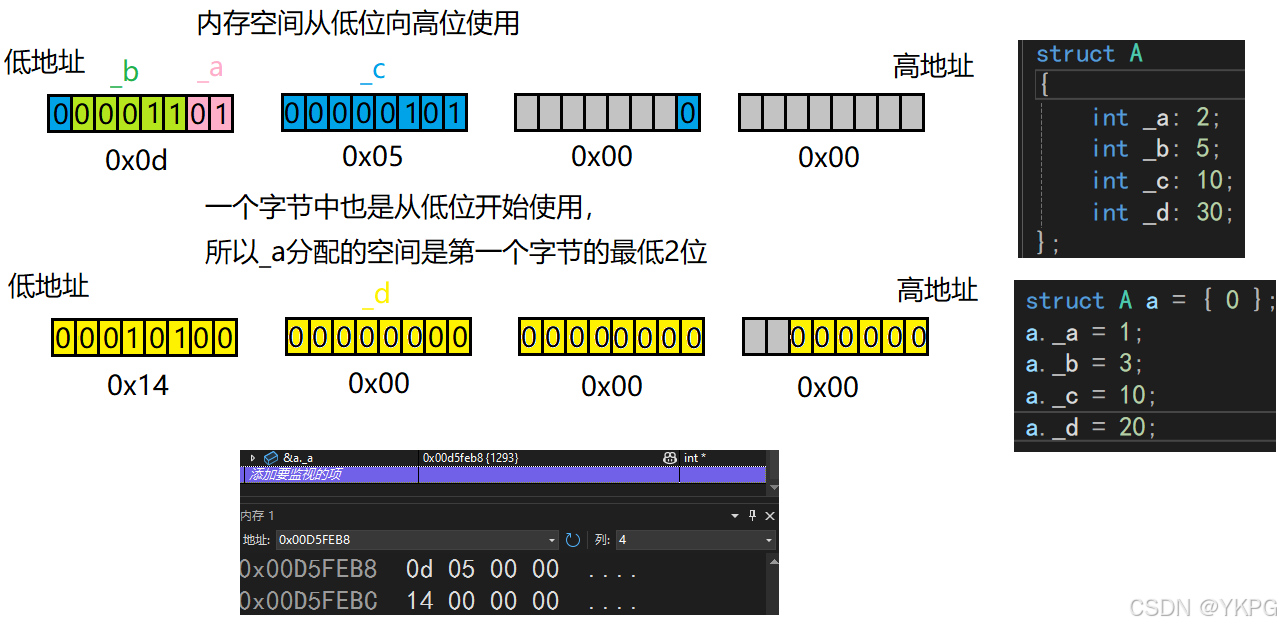
struct A
{int _a:2;int _b:5;int _c:10;int _d:30;
};
A就是一个位段类型,那么位段A占多大的内存呢?
8个字节;
怎么来的呢?
每个成员的:后面的数字表示这个成员占多少个比特位;
int表示每次分配空间都分配一个int类型的大小,也就是4个字节,然后使用这4个字节为成员分配空间,直到剩余空间不足,继续分配一个int类型的大小;
在这个例子中,先位段分配4个字节,成员_a占2个bit,此时还剩30个bit;成员_b占5个bit,此时还剩25个bit;成员_c占10个bit,此时还剩15个bit;成员_d需要30个bit,剩余的空间不足,所以再分配4个字节,此时要怎么使用呢?
是使用了剩余的15bit,再从新的32bit中分配15bit;还是直接从新的32bit中分配30bit?
正确的是后者。
所以这个位段占的空间大小为8个字节;
2. 位段的内存分配
- 位段的成员可以是
int、unsigned int、signed int或者是char类型(属于整形家族); - 位段的空间是按照需要以4个字节(int类型)或者1个字节(char类型)的方式来开辟的;
- 位段涉及很多不确定因素,所以位段是不跨平台的,注重可移植的程序应该避免使用位段;
struct S
{char a:3;char b:4;char c:5;char d:4;
};int main()
{struct S s = { 0 };s.a = 10;s.b = 12;s.c = 3;s.d = 4;return 0;
}
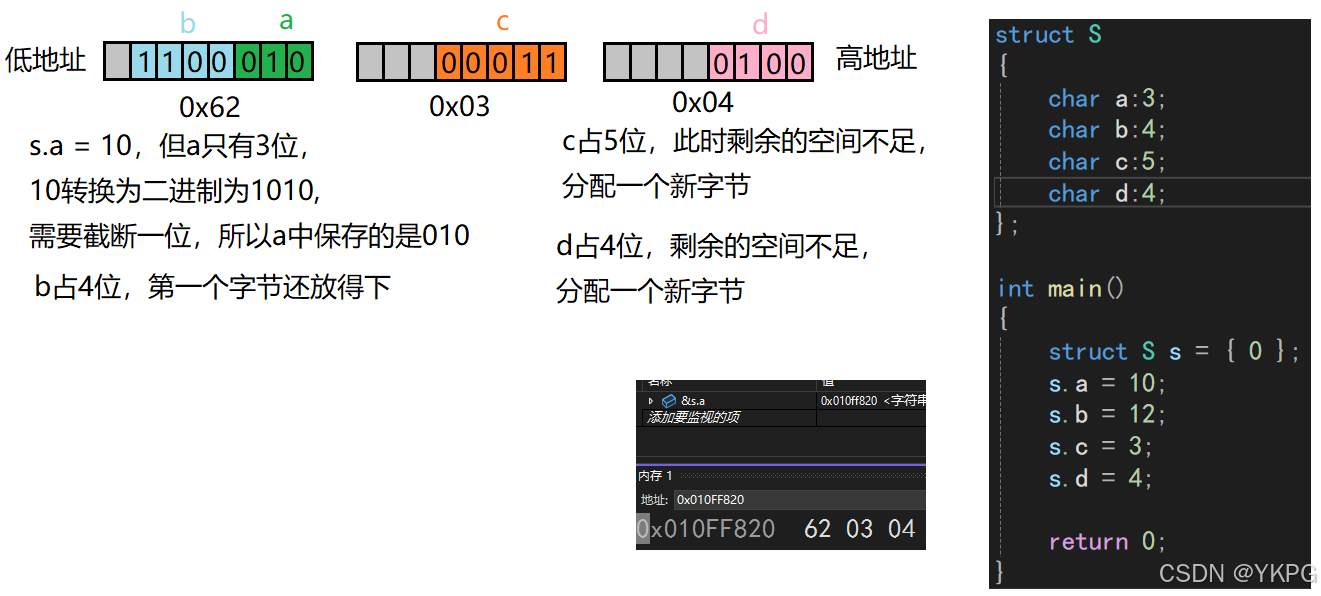
注意:
位段的成员的长度是有限制的,
char类型的成员长度不能超过8;
int类型的成员长度不能超过32;(32位或64位机器下)
3. 位段的跨平台问题
- int位段被当成有符号数还是无符号数是不确定的;
- 位段中最大位的数目是不确定。(16位机器下,最大为16,写成27,在16位机器中是会出问题的);
- 位段中的成员在内存中从左向右,还是从右向左分配标准尚未定义;
- 当一个结构包含两个位段,第二个位段成员比较大,无法容纳第一个位段剩余的位时,是舍弃剩余的位还是利用,这是不确定的;
总结
与结构相比,位段可以达到同样的效果,但是可以更好的节省空间,但是会存在跨平台问题;
4. 位段的应用
像计算机网络中的IP数据报的格式,就是使用了位段。这样节省了传递的报文的长度,使得报文的有效数据更高。具体就不展开介绍了。
注意
因为位段的成员的开始地址并不是一个字节的起始位置,只有字节是有地址的,比特位是没有地址的,所以&s._a这种行为是错误的,要输入值到一个位段的成员,是不能直接使用scanf函数的,只能将值输入到一个变量中,通过赋值,将这个值传给位段成员;
三、枚举
枚举顾名思义就是一一列举。
比如,一周有7天,从星期一到星期天是有限的7天,可以一一列举;
月份有12个月,也可以一一列举;
这里就能使用枚举了。
1. 枚举类型的定义
enum Day // 星期
{Mon,Tues,Wed,Thur,Fri,Sat,Sun
};enum Color // 颜色
{Red,Green,Blue
};enum Month // 月份
{Jan,Feb,Mar,Apr,May,Jun,Jul,Aug,Sep,Oct,Nov,Dec
};
以上定义的enum Day、enum Color、enum Month都是枚举类型。
{}中的内容是枚举类型的可能取值,也叫做枚举常量。
这些可能的取值是可确定的,默认从0开始,依次递增1,在定义的时候也可以赋初值。
如:
enum Color // 颜色
{Red, // 0Green, // 1Blue // 2
};enum Color // 颜色
{Red = 1, // 1Green = 3, // 3Blue // 4
};
枚举是一种类型(枚举类型),它的成员是常量(枚举常量),枚举常量的类型是int;
2. 枚举的优点
为什么要用枚举呢?
- 增加代码的可读性和可维护性;
- 和
#define定义的标识符比较,枚举有类型检查,更加严谨; - 防止命名污染(封装);
- 便于调试;
- 使用方便,可一次定义多个常量;
例如:前面我们写过的计算器
void menu()
{printf("*******************\n");printf("*** 1.Add 2.Sub ***\n");printf("*** 3.Mul 4.Div ***\n");printf("*** 0.exit ***\n");printf("*******************\n");
}enum Op
{exit,add,sub,mul,div
};int main()
{int input;printf("请选择:>");scanf("%d", &input);// 代码1switch (input){case 0:// 退出break;case 1:Add();break;case 2:Sub();break;case 3:Mul();break;case 4:Div();break;default:// 选错break;}// 代码2switch (input){case exit:// 退出break;case add:Add();break;case sub:Sub();break;case mul:Mul();break;case div:Div();break;default:// 选错break;}return 0;
}
这段代码中,代码1如果不看menu函数,估计没人知道case 1这些分支表示什么意思,但是代码2中使用了枚举类型,就能一眼看出每个分支是干什么的,增加了代码的可读性;
#define的功能是直接替换,并不会因为类型不同而产生不同的操作;
除此之外,#define定义的标识符常量是全局的,而枚举类型的值只能被该类型的变量访问;
从源程序到可执行程序再到执行经过的过程为:
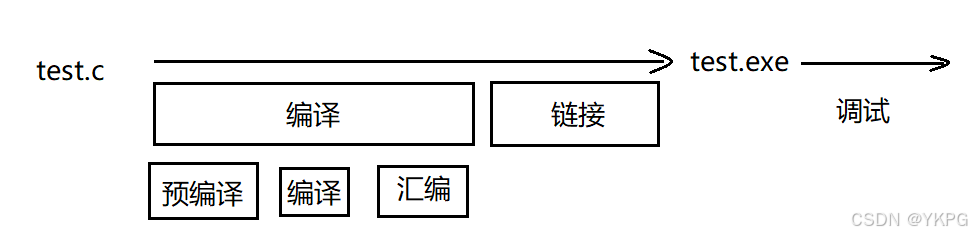
#define的替换是在预编译过程中完成的,调试无法发现#define带来的错误;
3. 枚举的使用
使用上面的Color类型:
int main()
{enum Color color1 = Blue; enum Color color2 = 2; // errreturn 0;
}
直接将int类型赋值给枚举类型是错误的,虽然Blue这个枚举常量的值也是2,但是它的类型的enum Color这个枚举类型,c语言是会对枚举类型进行类型检查的;
四、联合
1. 联合类型的定义
联合也是一种特殊的自定义类型;
这种类型定义的变量也包含一系列的成员,特征是这些成员都共用一块内存空间(所以,联合也叫共用体);
比如:
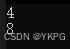
#include <stdio.h>union Un
{char ch;int i;
} ;union Un1
{double d;char ch;int i;
};int main()
{printf("%d\n", sizeof(union Un));printf("%d\n", sizeof(union Un1));return 0;
}
运行结果:
2. 联合的特点
联合的成员共用一块内存空间,这样一个联合变量的大小,至少也是最大成员的大小,因为联合至少要能保存它最大成员的值;
下面代码输出什么?
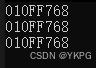
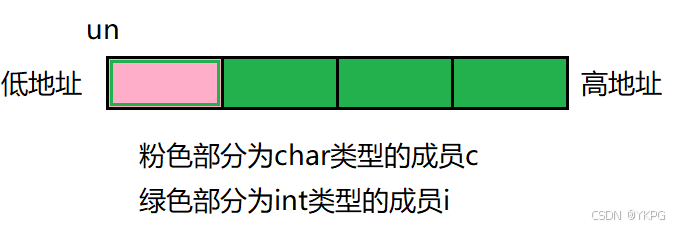
#include <stdio.h>union Un
{int i;char c;
};int main()
{union Un un;printf("%p\n", &un);printf("%p\n", &(un.i));printf("%p\n", &(un.c));return 0;
}
分析:
因为联合体变量un有两个成员i、c,这个联合变量占4个字节,通过内存地址的使用都是从低位到高位,所以i占整4个字节,c占地址最小的1个字节;
运行结果:
下面代码的输出又是什么呢?
int main()
{union Un un;un.i = 0x11223344;un.c = 0x55;printf("%x\n", un.i);return 0;
}
分析:

运行结果:

面试题
判断当前计算机的大小端存储
之前实现方式是将一个int类型的变量赋值为1,
如果机器是大端字节序,那么它在内存中的存储为(低到高):00 00 00 01;
如果机器是小端字节序,那么它在内存中的存储为(低到高):01 00 00 00;
取这个int类型变量的地址,将其转换为char*类型,访问这个指针指向的内存空间的内容(处于低位的第一字节):
如果为0,则为大端;如果为1,则为小端;
这种方法和联合的使用刚好相符,所以此时可以使用联合类型,就不需要强制类型转换了;
具体代码如下:
#include <stdio.h>union Un
{char c;int i;
};int main()
{union Un un;un.i = 1;if (un.c){printf("小端\n");}else{printf("大端\n");}return 0;
}
3. 联合大小的计算
- 联合的大小至少是最大成员的大小;
- 当最大成员大小不是最大对齐数的整数倍时,就要对齐到最大对齐数的整数倍;
举个例子:
#include <stdio.h>union Un1
{char c[5];int i;
};union Un2
{short c[7];int i;
};int main()
{// 下面代码输出什么?printf("%d\n", sizeof(union Un1));printf("%d\n", sizeof(union Un2));return 0;
}
分析:
根据上面的规则,
Un1中最大对齐数是i的对齐数4,最大成员的大小是c数组的大小5,此时5不是4的整数倍,所以此时的联合的大小为8;
Un1中最大对齐数是i的对齐数4,最大成员的大小是c数组的大小14,此时14不是4的整数倍,所以此时的联合的大小为16;
运行结果:

4. 联合休的使用实例:
使用联合体是可以节省空间的,例如:
现在要举办一个活动,要上线一个礼品兑换单,礼品兑换单有三种商品:图书、杯子、衬衫。
每种商品都有:库存量、价格、商品类型和商品类型相关的其他信息。
图书:书名、作者、页数;
杯子:设计;
衬衫:设计、可选颜色、可选尺寸;
如果不认真思考,可能就会直接使用下面类似的结构:
struct gift_list
{// 公共属性int stock_number; // 库存量double price; // 价格int item_type; // 商品类型// 特殊属性// 图书char title[20]; // 书名char author[20]; // 作者int num_pages; // 页数// 杯子char design[30]; // 设计// 衬衫// 与杯子共用设计成员属性int colors; // 颜色int sizes; // 尺寸
};
这样的结构设计非常简单,但结构中包含了所有礼品的属性,对于一个礼品来说有些属性是不需要的,使用这个结构记录数据是会浪费内存的;
上面的礼品中只有一些属性是共用,对于那些特殊属性就可以使用联合体来保存,以此来节省一些内存;
所以上面的代码可以改成:
struct gift_list
{// 公共属性int stock_number; // 库存量double price; // 价格int item_type; // 商品类型// 使用匿名联合体,在声明时定义一个变量itemunion{// 这个联合体中的成员是三个匿名结构体的变量,book、cup、shirtstruct{// 图书char title[20]; // 书名char author[20]; // 作者int num_pages; // 页数} book;struct{// 杯子char design[30]; // 设计} cup;struct{// 衬衫char design[30]; // 设计int colors; // 颜色int sizes; // 尺寸} shirt;} item;// 特殊属性
};
五、使用结构体实现一个通讯录
contact.c
#define _CRT_SECURE_NO_WARNINGS#include "contact.h"void initContact(Contact* contact)
{assert(contact);memset(contact->data, 0, MAXNUM * sizeof(Peoinfo));contact->count = 0;
}static int isFull(const Contact* contact)
{if (contact->count == MAXNUM){return 1; // 通讯录已满}return 0; // 通讯录未满
}void Add(Contact* contact)
{assert(contact);if (isFull(contact)){printf("通讯录已满,无法再增加信息\n");return;}getchar();// 没有做溢出检查printf("输入名字:>");gets((contact->data[contact->count]).name); printf("输入年龄:>");scanf("%d", &((contact->data[contact->count]).age));getchar();printf("输入性别:>");gets((contact->data[contact->count]).sex);//getchar();printf("输入电话:>");gets((contact->data[contact->count]).phone_number);//getchar();printf("输入地址:>");gets((contact->data[contact->count]).address);(contact->count)++;
}int isEmpty(const Contact* contact)
{if (contact->count == 0){return 1; // 通讯录为空}return 0;
}void Print(const Contact* contact)
{assert(contact);if (isEmpty(contact)){printf("通讯录为空\n");return;}printf("%-20s%-7s%-7s%-20s%-30s\n", "名字", "年龄", "性别", "电话", "地址");int i = 0;for (i = 0; i < contact->count; i++){printf("%-20s%-7d%-7s%-20s%-30s\n", (contact->data[i]).name,(contact->data[i]).age,(contact->data[i]).sex,(contact->data[i]).phone_number,(contact->data[i]).address);}
}static int search_by_name(const Contact* contact)
{assert(contact);if (isEmpty(contact)){printf("通讯录为空\n");return;}char buffer[20] = { 0 };printf("输入要查找人的名字:>");getchar();gets(buffer);int i = 0;for (i = 0; i < contact->count; i++){// 找到了,只能找到第一个相符的人if (strcmp((contact->data[i]).name, buffer) == 0){return i;}}return -1; // 未找到
}void Delete(Contact* contact)
{// 找到指定人// 通过名字查找int ret = search_by_name(contact);if (ret == -1){printf("没有这个人\n");return;}(contact->count)--;int i = 0;for (i = ret; i < contact->count; i++){strcpy((contact->data[i]).name, (contact->data[i + 1]).name);(contact->data[i]).age = (contact->data[i + 1]).age;strcpy((contact->data[i]).sex, (contact->data[i + 1]).sex);strcpy((contact->data[i]).phone_number, (contact->data[i + 1]).phone_number);strcpy((contact->data[i]).address, (contact->data[i + 1]).address);}
}void Modify(Contact* contact)
{assert(contact);// 找到指定人// 通过名字查找int ret = search_by_name(contact);if (ret == -1){printf("没有这个人\n");return;}printf("进行修改\n");// 没有做溢出检查printf("输入名字:>");gets((contact->data[ret]).name);printf("输入年龄:>");scanf("%d", &((contact->data[ret]).age));getchar();printf("输入性别:>");gets((contact->data[ret]).sex);//getchar();printf("输入电话:>");gets((contact->data[ret]).phone_number);//getchar();printf("输入地址:>");gets((contact->data[ret]).address);
}void Search(const Contact* contact)
{assert(contact);int ret = search_by_name(contact);if (ret == -1){printf("没有这个人\n");return;}printf("%-20s%-7s%-7s%-20s%-30s\n", "名字", "年龄", "性别", "电话", "地址");printf("%-20s%-7d%-7s%-20s%-30s\n", (contact->data[ret]).name,(contact->data[ret]).age,(contact->data[ret]).sex,(contact->data[ret]).phone_number,(contact->data[ret]).address);
}void Sort(Contact* contact)
{assert(contact);// 使用冒泡排序int i = 0;int j = 0;for (i = 0; i < (contact->count) - 1; i++){for (j = 0; j < (contact->count) - i - 1; j++){if (strcmp((contact->data[j]).name, (contact->data[j + 1]).name) > 0){char buffer[30] = { 0 };// 交换名字strcpy(buffer, (contact->data[j]).name);strcpy((contact->data[j]).name, (contact->data[j + 1]).name);strcpy((contact->data[j + 1]).name, buffer);// 交换年龄int tmp = (contact->data[j]).age;(contact->data[j]).age = (contact->data[j + 1]).age;(contact->data[j + 1]).age = tmp;// 交换性别strcpy(buffer, (contact->data[j]).sex);strcpy((contact->data[j]).sex, (contact->data[j + 1]).sex);strcpy((contact->data[j + 1]).sex, buffer);// 交换电话strcpy(buffer, (contact->data[j]).phone_number);strcpy((contact->data[j]).phone_number, (contact->data[j + 1]).phone_number);strcpy((contact->data[j + 1]).phone_number, buffer);// 交换地址strcpy(buffer, (contact->data[j]).address);strcpy((contact->data[j]).address, (contact->data[j + 1]).address);strcpy((contact->data[j + 1]).address, buffer);}}}
}
contact.h
#pragma once#include <stdio.h>
#include <string.h>
#include <assert.h>// 定义结构体、标识符常量
#define MAXNUM 1000 // 通讯录中能保存的人数typedef struct
{int age; // 年龄char name[20]; // 名字char sex[7]; // 性别char phone_number[20]; // 电话号码char address[30]; // 地址
} Peoinfo; // 保存人的信息typedef struct
{Peoinfo data[MAXNUM]; // 通讯录可以保存1000个人的信息int count; // 当前通讯录中的人数
} Contact;// 声明函数
// 初始化通讯录
void initContact(Contact*);
// 增加人的信息
void Add(Contact*);
// 打印通讯录
void Print(Contact*);
// 删除指定人的信息
void Delete(Contact*);
// 修改指定人的信息
void Modify(Contact*);
// 查找指定人的信息
void Search(Contact*);
// 排序通讯录
void Sort(Contact*);
test.c
#include "contact.h"void menu()
{printf("*******************************\n");printf("*** 1.增加信息 2.删除信息 ***\n");printf("*** 3.修改信息 4.查找信息 ***\n");printf("*** 5.排序信息 6.打印信息 ***\n");printf("*** 0.退出程序 ***\n");printf("*******************************\n");
}enum Op
{exit, // 退出程序add, // 增加信息delete, // 删除信息modify, // 修改信息search, // 查找信息sort, // 排序信息print // 打印信息
};int main()
{int input;// 通讯录Contact contact;// 初始化通讯录initContact(&contact);do{menu();printf("请选择:>");scanf("%d", &input);switch (input){case exit:printf("退出通讯录\n");break;case add:Add(&contact);break;case delete:Delete(&contact);break;case modify:Modify(&contact);break;case search:Search(&contact);break;case sort:Sort(&contact);break;case print:Print(&contact);break;default:printf("没有这个选项\n");break;}}while(input);return 0;
}
其中contact.c中的排序函数可以使用回调函数来实现让用户提供排序方法,不一定要用名字作排序;
总结
本文对c语言中会用到的结构体类型进行了详细解读,并在最后给出了一个使用结构体实现的通讯录;
相关文章:
忌(阶)秘(技)术(巧)【第四式】自定义类型详解(结构体、枚举、联合))
c语言修炼秘籍 - - 禁(进)忌(阶)秘(技)术(巧)【第四式】自定义类型详解(结构体、枚举、联合)
c语言修炼秘籍 - - 禁(进)忌(阶)秘(技)术(巧)【第四式】自定义类型详解(结构体、枚举、联合) 【心法】 【第零章】c语言概述 【第一章】分支与循环语句 【第二章】函数 【第三章】数组 【第四章】操作符 【第五章】指针 【第六章】结构体 【第七章】con…...

阿里巴巴langengine二次开发大模型平台
阿里巴巴LangEngine开源了!支撑亿级网关规模的高可用Java原生AI应用开发框架 - Leepy - 博客园 阿里国际AI应用搭建平台建设之路(上) - 框架篇 基于java二次开发 目前Spring ai、spring ai alibaba 都是java版本的二次基础能力 重要的是前端工作流 如何与 服务端的…...

获取KUKA机器人诊断文件KRCdiag的方法
有时候在进行售后问题时需要获取KUKA机器人的诊断文件KRCdiag,通过以下方法可以获取KUKA机器人的诊断文件KRCdiag: 1、将U盘插到控制柜内的任意一个USB接口; 2、依次点【主菜单】—【文件】—【存档】—【USB(控制柜)…...

聊聊Spring AI的MilvusVectorStore
序 本文主要研究一下Spring AI的MilvusVectorStore 示例 pom.xml <dependency><groupId>org.springframework.ai</groupId><artifactId>spring-ai-starter-vector-store-milvus</artifactId></dependency>配置 spring:ai:vectorstore:…...

前后端通信指南
HTTP 协议与 RESTful APIWebSocket 与实时通信一、前后端通信概述 前后端通信是现代 Web 开发的核心环节,前端(浏览器或移动端)需要向后端请求数据,并根据返回的数据渲染界面。常见的通信方式包括 HTTP 请求、RESTful API、WebSocket、GraphQL 等。 常见前后端通信方式 通…...

[特殊字符] 驱动开发硬核特训 · Day 2
主题:深入掌握 UART 与 SPI 驱动开发原理、架构与调试技术 本期围绕实际项目中应用最广泛的两类外设通信接口 —— UART(串口)与 SPI(串行外设接口),通过结构化知识点梳理,结合实际驱动开发流程…...
)
B树和B+树的区别(B Tree B+ Tree)
前言 B树和B树是数据库中常用的索引结构,它们的核心区别主要体现在数据存储方式、节点结构和适用场景上。 关键区别详解 数据存储方式: B树:所有节点均存储键值(key-data)对,数据可能分布在树的任意层级。…...
)
32--当网络接口变成“夜店门口“:802.1X协议深度解码(理论纯享版本)
当网络接口变成"夜店门口":802.1X协议深度解码 引言:网口的"保安队长"上岗记 如果把企业网络比作高端会所,那么802.1X协议就是门口那个拿着金属探测器的黑超保安。它会对着每个想进场的设备说:“请出示您的会…...

【LLM】使用MySQL MCP Server让大模型轻松操作本地数据库
随着MCP协议(Model Context Protocol)的出现,使得 LLM 应用与外部数据源和工具之间的无缝集成成为可能,本章就介绍如何通过MCP Server让LLM能够直接与本地的MySQL数据库进行交互,例如新增、修改、删除数据,…...
汽车活塞生产制造MOM建设方案(第一部分))
MOM成功实施分享(八)汽车活塞生产制造MOM建设方案(第一部分)
在制造业数字化转型的浪潮中,方案对活塞积极探索,通过实施一系列数字化举措,在生产管理、供应链协同、质量控制等多个方面取得显著成效,为行业提供了优秀范例。 1.转型背景与目标:活塞在数字化转型前面临诸多挑战&…...
:广告验证与反作弊实战技巧)
程序化广告行业(59/89):广告验证与反作弊实战技巧
程序化广告行业(59/89):广告验证与反作弊实战技巧 大家好!在程序化广告领域,想要做好投放,除了了解基本的架构和原理,还得掌握一些关键的技能,比如广告验证和反作弊。今天就和大家一…...

市场趋势分析与交易策略调整
市场趋势分析与交易策略调整 在市场交易中,趋势的判断与策略的调整至关重要。不同市场环境下,交易者需要灵活运用技术分析和资金管理手段,以提升交易的稳定性。本文将探讨市场趋势的识别方法,以及如何在不同市场环境中调整交易策略…...

安卓离线畅玩的多款棋类单机游戏推荐
软件介绍 在手游盛行的当下,不少玩家在网游激战之余,渴望一份单机游戏带来的宁静与专注。今天要为大家介绍的,便是一款能满足此类需求的安卓软件 —— 棋类大师。 它巧妙地将象棋、围棋、五子棋三种经典棋类游戏集成于一身,且具…...

论文阅读Diffusion Autoencoders: Toward a Meaningful and Decodable Representation
原文框架图: 官方代码: https://github.com/phizaz/diffae/blob/master/interpolate.ipynb 主要想记录一下模型的推理过程 : %load_ext autoreload %autoreload 2 from templates import * device cuda:1 conf ffhq256_autoenc() # pri…...

医疗信息系统的主要痛点分析
医疗信息系统的主要痛点分析 1. 数据治理问题 数据标准不统一 各医院采用不同的数据格式和编码标准诊断术语、药品编码等缺乏统一规范检验检查结果的参考值范围不一致 数据质量参差不齐 数据录入不规范,存在大量错误和缺失历史数据清洗难度大数据更新不及时 数据安…...

Pycharm v2024.3.4 Windows Python开发工具
Pycharm v2024.3.4 Windows Python开发工具 文章目录 Pycharm v2024.3.4 Windows Python开发工具一、介绍二、效果三、下载 一、介绍 JetBrains PyCharm 是一款Python集成开发环境(IDE),被广泛用于Python开发 二、效果 三、下载 百度网盘: …...

YOLOv12 从预训练迈向自主训练,第一步数据准备
视频讲解: YOLOv12 从预训练迈向自主训练,第一步数据准备 前面复现过yolov12,使用pre-trained的模型进行过测试,今天来讲下如何训练自己的模型,第一步先准备数据和训练格式 https://gitcode.com/open-source-toolkit/…...

Java 线程池全面解析
Java 线程池全面解析 一、线程池种类及优缺点 1. 常见线程池类型(通过Executors创建) 线程池类型创建方式特点适用场景缺点FixedThreadPoolExecutors.newFixedThreadPool(n)固定线程数,无界队列负载较重的服务器可能堆积大量任务导致OOMCachedThreadPoolExecutors.newCach…...
)
第七章 Python基础进阶-异常、模块与包(其五)
目录 一.异常 二.异常的捕获方法 1.捕获常规异常 2.捕获指定异常 3.捕获多个异常 4.异常else 5.异常的finally 三.异常的传递 四.Python模块 1.import导入模块 2.from导入模块 3.from模块名 import* 4.as定义别名 5.自定义模块 (1)测试模块…...
-vsg::RenderGraph的创建)
vulkanscenegraph显示倾斜模型(5.6)-vsg::RenderGraph的创建
前言 上一章深入分析了vsg::CommandGraph的创建过程及其通过子场景遍历实现Vulkan命令录制的机制。本章将在该基础上,进一步探讨Vulkan命令录制中的核心封装——vsg::RenderGraph。作为渲染流程的关键组件,RenderGraph封装了vkCmdBeginRenderPass和vkCmd…...

DelayQueue vs ScheduledThreadPool:Java定时任务的双雄争霸
定时任务管理的两种武林绝学 想象你需要管理一个跨时区的视频会议系统: DelayQueue 像一位严格的计时员,把所有会议请求按时间排序,到点才放行ScheduledThreadPool 像一位智能秘书,能主动安排、取消和调整会议时间 它们都能处理…...

Qt添加资源文件
目录 1.创建一个新项目 1.1菜单栏 添加菜单项 1.2工具栏 1.3铆接部件 1.4中心部件 1.5最终界面 2.资源文件 2.1将图片文件拷贝到项目位置下 2.2添加新文件 2.3rec.qrc文件 2.4添加前缀,添加文件 2.5使用 1.创建一个新项目 利用界面文件完成一个有菜单…...

U-Net: Convolutional Networks for BiomedicalImage Segmentation
Abstract 人们普遍认为,深度网络的成功训练需要成千上万的标注训练样本。在本文中,我们提出了一种网络和训练策略,该策略强烈依赖于数据增强,以更有效地利用现有的标注样本。该架构包括一个用于捕获上下文的收缩路径和一个用于实…...

28--当路由器开始“宫斗“:设备控制面安全配置全解
当路由器开始"宫斗":设备控制面安全配置全解 引言:路由器的"大脑保卫战" 如果把网络世界比作一座繁忙的城市,那么路由器就是路口执勤的交通警察。而控制面(Control Plane)就是警察的大脑…...

NHANES指标推荐:DI-GM
文章题目:The relationship between dietary index for gut microbiota and diabetes DOI:10.1038/s41598-025-90854-y 中文标题:肠道菌群膳食指数与糖尿病的关系 发表杂志:Sci Rep 影响因子:1区,IF3.8 发表…...

仓库规划 第32次CCF-CSP计算机软件能力认证
没什么说的暴力枚举 n*n*m 的时间复杂度 题目说选序号小的作为父亲 直接编号前往后输出 遇到合适的就break #include<bits/stdc.h> using namespace std; int n, m; int main() {cin >> n >> m;//n:仓库个数 m:位置编码的维数vector<vector<int>…...

leetcode-代码随想录-哈希表-哈希理论基础
哈希表理论基础 哈希表:或者称为散列表,是根据关键码的值而直接进行访问的数据结构。 哈希法:用于快速判断一个元素是否出现在集合里 哈希函数是⼀种映射关系,根据关键词key,经过⼀定函数关系 f 得到元素的位置。 存…...

《科学》期刊发布新成果:量子计算迎来原子 - 光腔集成新时代
《Error-detected quantum operations with neutral atoms mediated by an optical cavity》 -《Science》 2025.3.21 摘要 光镊(optical tweezers)束缚的可编程原子阵列已成为量子信息处理(quantum information processing)和量…...
)
Spring Boot 与 TDengine 的深度集成实践(一)
引言 在当今数字化时代,数据处理与存储对于各类应用的重要性不言而喻。Spring Boot 作为一款流行的 Java 开发框架,以其快速开发、约定大于配置、内嵌容器等特性,大大提升了 Java 企业级应用的开发效率,降低了开发门槛࿰…...

SpringBoot + Netty + Vue + WebSocket实现在线聊天
最近想学学WebSocket做一个实时通讯的练手项目 主要用到的技术栈是WebSocket Netty Vue Pinia MySQL SpringBoot,实现一个持久化数据,单一群聊,支持多用户的聊天界面 下面是实现的过程 后端 SpringBoot启动的时候会占用一个端口ÿ…...

数据结构实验2.3:Josephus问题求解
文章目录 一,问题描述二,基本要求三,算法设计(1)存储结构设计(2)算法设计 四,示例代码五,运行效果 一,问题描述 在现实生活以及计算机科学的一些场景中&…...

Ruby语言的代码重构
Ruby语言的代码重构:探索清晰、可维护与高效的代码 引言 在软件开发的过程中,代码的质量直接影响到项目的可维护性、扩展性和整体性能。随着时间的推移,系统的需求变化,代码可能会变得混乱和难以理解,因此࿰…...
)
CAN/FD CAN总线配置 最新详解 包含理论+实战(附带源码)
看前须知:本篇文章不会说太多理论性的内容(重点在理论结合实践),顾及实操,应用,一切理论内容支撑都是为了后续实际操作进行铺垫,重点在于读者可以看完文章应用。(也为节约读者时间&a…...

杰文字悖论:效率提升的副作用
最近,Deepseek的火爆让我们开始反思一个有趣的现象:杰文斯悖论。这是1856年,经济学家杰文斯提出来的一个有趣的现象:当技术效率提高时,资源的使用量反而会增加,而不是减少。听起来可能有点不可思议。杰文斯…...

AcWing 6118. 蛋糕游戏
贪心 为了方便描述,下面将贝茜和埃尔茜分别称为a、b。 已知蛋糕的数量为偶数个,b每次只能吃左右边界上的蛋糕,a每次操作将两个蛋糕变成一个,发现都会使蛋糕的数量减一,且a先操作将蛋糕数量从偶数变成奇数,…...

【前端】【Nuxt3】Nuxt 3 开发中因生命周期理解不足导致的常见错误分类及其解决方案
以下是 Nuxt 3 开发中因生命周期理解不足导致的常见错误分类及其解决方案,以结构化形式呈现: 一、数据获取与异步处理 错误 1:错误使用客户端钩子获取数据 问题:在 onMounted 中获取数据,导致 SSR 失效。示例&#x…...

【kubernetes】BusyBox
目录 1. 说明2. 在 Kubernetes 中的角色2.1 轻量级调试工具2.2 临时容器2.3 网络测试2.4 文件系统检查 3. 为什么选择 BusyBox?4. 常见用法5. 注意事项 1. 说明 1.BusyBox 是一个轻量级、开源的 Linux 工具集,将多种常见的 Unix 工具(如 ls、…...

Leetcode——239. 滑动窗口最大值
题解一 思路 第一次做困难的题,确实把我既困住了又难住了,确实自己一点都想不出来。 这个思路,差不多就是,自己定义一个单调队列。 添加的时候,判断是否比队列最后的元素大,如果比它大,就把…...

kubernetes configMap 存储
1.模型 首先会在每一个节点上安装一个叫 agent 端 agent 端要做的作用就是监听当前的目标配置中心的配置选项是否发送更新动作 如果有的话 我的agent 端的话要从远程的配置中心 去下载最新的配置文件 替换我当前的 再去触发nginx实现重载 当然对于后期的运维工程师 如果想去发…...

架构思维:查询分离 - 表数据量大查询缓慢的优化方案
文章目录 Pre引言案例何谓查询分离?何种场景下使用查询分离?查询分离实现思路1. 如何触发查询分离?方式一: 修改业务代码:在写入常规数据后,同步建立查询数据。方式二:修改业务代码:…...
是蓝牙协议栈中用于音频传输的一个标准化协议)
A2DP(Advanced Audio Distribution Profile)是蓝牙协议栈中用于音频传输的一个标准化协议
A2DP(Advanced Audio Distribution Profile)是蓝牙协议栈中用于音频传输的一个标准化协议,主要用于高质量音频流的无线传输。以下是A2DP协议的详细信息: 定义 A2DP协议允许音源设备(Source,简称SRC&#…...

Redisson使用详解
一、Redisson 核心特性与适用场景 Redisson 是基于 Redis 的 Java 客户端,提供分布式对象、锁、集合和服务,简化分布式系统开发。 典型应用场景: 分布式锁:防止重复扣款、超卖控制(如秒杀库存)。数据共享…...

GraalVM 24 正式发布阿里巴巴贡献重要特性 —— 支持 Java Agent 插桩
作者:林子熠、饶子昊 2025 年 3 月 18 日 Oracle 双箭齐发,正式发布了 JDK 24 和 GraalVM 24,带来了众多新特性。 JDK 24 在性能和安全性方面均有改进(特性列表链接见下),其中较大的一处改动是在 JDK 中…...
)
游戏编程模式学习(编程质量提升之路)
文章目录 前言一、命令模式(Command Pattern)1.命令模式练习场景I.需求场景 2.解耦命令与执行者3.使用命令对玩家角色和AI的操作进行统一抽象4. 命令模式的撤销实现 二、享元模式1.应用场景2.目的3.实现方式 三、原型模式1.运用场景2.实现方式 四、状态模…...

计算机视觉五大技术——深度学习在图像处理中的应用
深度学习是利用“多层神经网络”实现人工智能的一种方式 计算机视觉:“对图像中的客观对象构建明确而有意义的描述”,识别图片中的含义进行处理 1.图像分类——“图里有狗” 判断整张图片属于哪个类别,判断图片是“猫”还是“狗” 思路&a…...

Mixed Content: The page at https://xxx was loaded over HTTPS
一、核心原因分析 Mixed Content 警告是由于 HTTPS 页面中引用了 HTTP 协议的资源(如脚本、图片、iframe 等),导致浏览器因安全策略阻止加载这些非加密内容。HTTP 资源可能被中间人攻击篡改,破坏 HTTPS 页面的整体安全性。 二、推荐解决方案 1. 强制资源升级为 HTTPS •…...
transforms-pytorch4
数据通常不会直接是机器学习算法可以使用的“最终格式”。我们使用转换(transforms)来对数据进行处理,使其适合训练。 所有的 TorchVision 数据集都提供了两个参数:transform 用于修改特征,target_transform 用于修改…...

Springboot----@Role注解的作用
Role(BeanDefinition.ROLE_INFRASTRUCTURE) 是 Spring 框架中的一个注解,用于显式标记 Bean 的角色,表明该 Bean 是 Spring 容器内部的基础设施组件(如后置处理器、工具类等),而非用户直接使用的业务 Bean。其核心作用…...

SpringBoot项目报错: 缺少 Validation
目录 为什么需要Validation?如何使用Validation? 缺少validation?这不过是代码的一个小小问题,就像被风带走的一片叶子,轻轻一吹就能解决啦! 在你的项目中,如果你发现自己需要进行数据验证&…...

MySQL vs MSSQL 对比
在企业数据库管理系统中,MySQL 和 Microsoft SQL Server(MSSQL)是最受欢迎的两大选择。MySQL 是一款开源的关系型数据库管理系统(RDBMS),由 MySQL AB 开发,现归属于 Oracle 公司。而 MSSQL 是微…...