Milvus×Florence:一文读懂如何构建多任务视觉模型


近两年来多任务学习(Multi-task learning)正取代传统的单任务学习(single-task learning),逐渐成为人工智能领域的主流研究方向。其原因在于,多任务学习可以让我们以最少的人力投入,获得尽可能多的AI能力。比如ChatGPT,就是一种基于多任务学习的自然语言生成模型。通过海量的数据训练,以及针对特定任务的模型微调,ChatGPT可以拥有极高的性能以及广泛的通用性。
这种单任务向多任务的转变趋势在计算机视觉领域体现的尤为明显。传统的计算机视觉算法框架下我们往往需要针对不同的任务去创建不同的模型,比如人脸识别需要特定的算法,猫脸识别需要特定算法,花草识别又需要另一套算法。这就导致整体的训练效率低下不说,算法的可扩展性也受到了极大的限制。
针对这一问题,除了典型的ChatGPT的解法之外,微软推出了一种名叫Florence的新的计算机视觉基础模型。Florence是一种典型的多任务学习计算机视觉模型,可以完成包括图像分类、目标检测、视觉问答和视频分析在内的多种类型的视觉任务,并且在每一个子任务中的表现通常都优于传统的单任务学习模型,与此同时,scaling law也适用于Florence模型,数据规模越大,模型的智能程度也就越高。
接下来我们将重点解读Florence 模型的结构、训练方法、能力,以及对未来的AI和计算机视觉的潜在影响。
01.
传统单任务计算机视觉模型的缺陷
将各种计算机视觉任务的类型进行总结,我们可以将其简单概括为三大维度:时间、空间、模态。
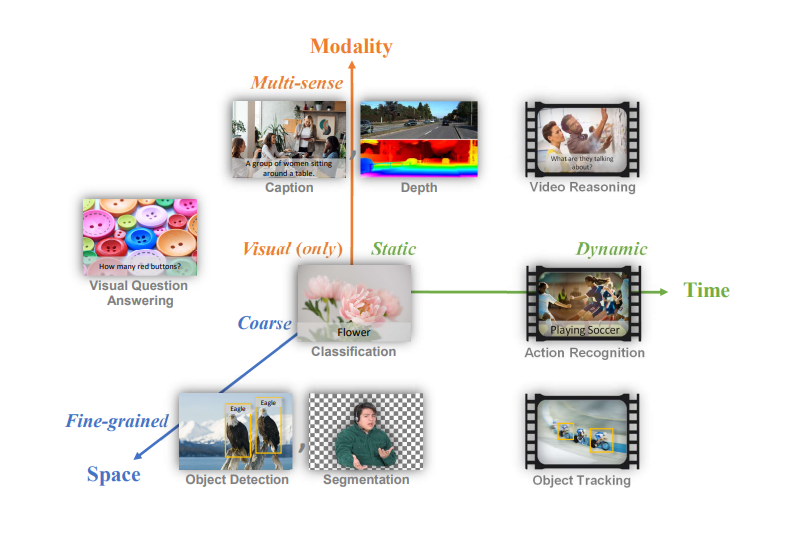
图1:映射到时空模态空间的常见计算机视觉任务
空间:既包括粗粒度的场景理解,也包括细粒度的目标检测和分割。在粗粒度层面上,有图像分类这样的任务,旨在识别图像的主要主题。细粒度分析,则包括了目标检测等任务,需要识别并定位图像中的多个目标并分割任务,这要求精确描绘目标边界。
时间:计算机视觉任务涉及静态图像和动态视频。静态任务包括图像分类、目标检测和视觉问答。动态任务涉及分析随时间变化的图像序列,例如视频中的动作识别或目标跟踪。
模态:纯视觉任务包括图像分类和目标检测,而多模态任务,则会将视觉数据与其他类型的信息相结合,例如文本(在图像描述或视觉问答中)、深度信息,甚至是一些视频分析任务中的音频。
传统意义上,我们需要针对不同任务训练不同的模型,但这种单任务学习的模式存在三大问题:
开发和部署效率低下:为每个任务创建和维护单独的模型需要大量资源且耗时。
知识迁移的困难:为一项任务优化的模型通常难以将学到的知识应用于其他的相关任务。
处理新情况的能力有限:当面对与训练数据显著不同的场景时,专用模型可能表现不佳。
02.
Florence 简介
与上文提到的单任务模型形成对比,Florence 旨在开发一个通用的基础模型,并在架构中集成了多个组件,每个组件分别解决包括图像识别、目标检测以及视觉问答和图像描述、视觉理解等不同方面任务。其最大特色是该模型利用视觉和语言理解的组合来处理和解释文本和视觉数据,使其特别适合需要多模态能力的应用。
具体来说,Florence 的多功能性源于其统一的架构,其架构有两个主要组件:Florence预训练模型(Pretrained Models)和Florence适配模型(Adaptation Models)。
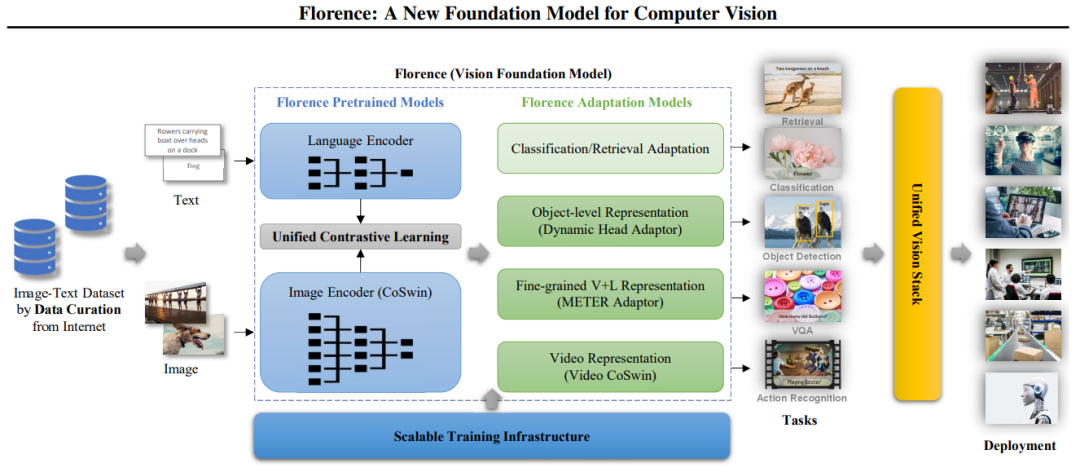
图2:构建Florence的工作流程:从数据管理到部署
2.1 Florence 预训练模型
Florence预训练模型由几个关键组件组成,用于有效处理和对齐视觉和文本数据。
语言编码器:该组件处理文本输入,允许模型理解和生成与视觉内容相关的语言。它类似于BERT或GPT等模型,但能与视觉信息一起工作。
图像编码器(CoSwin):基于CoSwin的分层视觉转换器,该编码器处理视觉信息,将原始像素数据转换为有意义的表示。它建立在自然语言处理中 transformer 的架构基础上,使其适用于图像处理。
统一对比学习:该模块对齐视觉和文本表示,使模型能够理解图像及其描述之间的关系,帮助模型学习哪些文本对应哪些图像,反之亦然。
2.2 Florence 任务适配模型
该模型旨在通过小样本和零样本迁移学习来有效适配各种不同类型任务,并通过很少的 epoch 训练进行有效部署。具体来说,该组件支持:
1. 分类/检索适配:该组件允许Florence执行图像分类和跨模态检索任务。例如,它可以将图像分类为预定义的类别,或查找与给定文本描述相匹配的图像。
2. 对象级表示 (Dynamic Head 适配器):该适配器支持细粒度的目标检测和分割任务,允许模型对图像中的内容进行分类,并定位和勾勒特定对象。
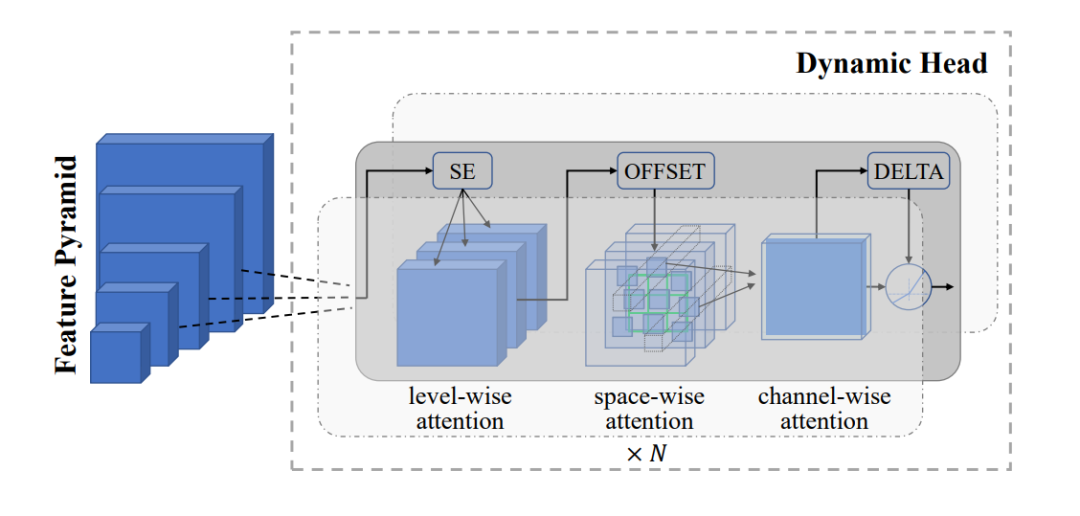
图3:用于对象级视觉表示学习的 Dynamic Head 适配器
如上图所示, Dynamic Head 适配器通过一系列注意力机制处理视觉信息:
输入是一个包含不同尺度视觉信息的特征金字塔。例如,在繁忙街景的图像中:
最大的块可能代表建筑物和道路的整体布局。
中间的街区可能会捕捉到单独的汽车和行人。
最小的块可以专注于细节,如车牌或面部特征。
适配器采用三种类型的注意力:
层次注意力(Level-wise attention, SE):侧重于金字塔不同层次的重要特征。在我们的街景中,SE可能会强调车辆检测任务中的汽车层次,或人物识别任务中的面部特征层次。
空间注意力(Space-wise attention):这涉及每个级别内的相关空间位置,由3D网格表示。例如,当寻找行人时,它可能会关注人行道区域,当检测车辆时,它可能会关注道路区域。
通道注意力(Channel-wise attention):强调了重要的特征通道,显示为最后一个块。一些通道可能更适合检测形状,而其他通道可能更适合检测颜色信息。
OFFSET和DELTA组件微调空间边界。它们有助于精确定位目标边界,例如准确勾勒街景中的汽车或人物。
这种多阶段注意力过程使模型能够通过关注不同尺度和空间位置上最相关的信息来检测和分割对象。例如,它可以同时检测像公交车这样的大型物体,像汽车这样的中型物体,以及像街景中的交通标志这样的小型物体。
3. 细粒度V+L表示(METER适配器):该模块支持视觉-语言任务,如视觉问答和图像描述。它使模型能够理解视觉和文本信息之间的复杂关系。
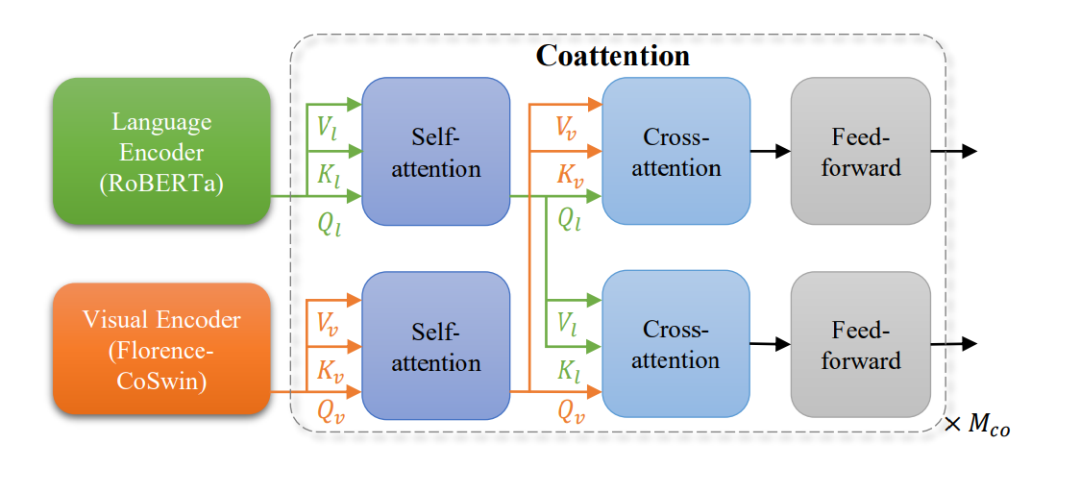
图4:用作Florence V+L适配模型的METER适配器
上图所示的METER适配器使用共同注意力机制来融合视觉和文本信息。让我们看看它的工作原理:
语言编码器(RoBERTa)处理文本输入。例如,它可能会处理以下问题:“停在消防栓旁边的汽车是什么颜色的?”
视觉编码器(Florence-CoSwin)处理视觉输入。这将分析街景的图像。
两个输入都经过单独的自注意力层,允许每种模态独立处理其信息。文本自注意力可能集中在颜色、汽车和消防栓等关键词上,而视觉自注意力可能突出显示图像中包含汽车和消防栓的区域。
这些自我注意层的输出然后输入到交叉注意层,这是视觉和文本信息结合的地方。
文本特征关注图像的相关部分(Vl、Kl、Ql箭头指向下方)。对于我们的例子,这可能会将汽车和消防栓这两个词与图像中的视觉表示联系起来。
图像特征与文本的相关部分相关(Vv、Kv、Qv箭头指向上方)。这可能涉及将汽车的视觉特征与问题中的单词颜色相关联。
最后,两个流都经过前馈层,进一步处理这些组合信息。
此过程重复Mco次,允许进行多轮细化。
这种架构允许模首先分别处理文本和图像,然后逐渐组合信息,使其能够理解视觉和文本内容之间的复杂关系。举个例子,在街景识别中,模型会显根据其靠近消防栓的位置识别正确的汽车,然后确定其颜色,并形成一个答案,例如:停在消防栓旁边的汽车是蓝色的。
4. 视频表示(Video CoSwin):该适配器扩展了Florence处理视频数据的能力,使动作识别等任务成为可能。它建立在图像处理能力上,以理解随时间变化的图像序列。
这种统一的结构使Florence只需一个基础模型和特定任务的适配器,就能处理图像分类、视频识别等一系列任务。
03.
Florence 的能力:“多才多艺”的视觉AI
Florence 的适应性在执行以下任务的能力中显而易见。
零样本图像分类
Florence 在12个数据集中展现了强大的零样本分类能力,在大多数情况下优于CLIP和FLIP等模型。它在细粒度任务上表现尤为出色,如在Standford Cars上获得93.2%的分数,在Oxford Pets上获得95.9%的分数,并以83.7%的准确率处理ImageNet等大规模数据集。这一表现表明,Florence 可以利用其对语言和视觉特征的理解,泛化识别未见类别。
线性探测分类
当在冻结特征之上使用线性分类器时,Florence 在大多数数据集上超过了 SimCLRv2、ViT 和 EfficientNet 等模型。这种在多样化和细粒度分类任务上的多功能性表明,Florence 学到的表示非常丰富且适用于新任务。
目标检测
Florence 的目标检测性能在多个数据集上进行了评估,在COCO上得分为62.4 mAP,在Object365上得分为39.3 mAP,在Visual Genome上得分为16.2 AP50。这些结果突出了它在复杂场景中分类、定位和识别多个对象的能力。
视觉问答(VQA)
Florence 在 VQAv2 数据集上取得了80.36%的准确率,显示了其整合视觉和文本信息的能力。
图文检索
Florence 在跨模态检索方面表现出色,Flickr30K数据集的结果显示图像到文本的R@1为97.2%,文本到图像的R@1为87.9%,MSCOCO数据集的图像到文本的R@1为81.8%,文本到图像的R@1为63.2%。这种对齐视觉和文本表示的能力支持强大的跨模态搜索功能。
视频动作识别
虽然是在静态图像上训练的,但 Florence 能够很好地适应视频任务,在Kinetics-400上取得了86.5%的top-1准确率,在Kinetics-600上的top-1准确率为87.8%。这表明,Florence 可以捕捉视频中的时间信息并识别动作,处理动作和序列,而无需对视频数据进行特定的训练。
有关更多评估和实验结果,请查看Florence的论文(https://arxiv.org/abs/2111.11432)。
04.
Florence和向量数据库如何增强多模态搜索
Florence 在图像-文本检索和零样本分类方面的能力,与向量数据库的优势可以互相结合,来最大化它们的潜力,创建强大的多媒体搜索和分析系统。
4.1 了解向量数据库
向量数据库是专门用于存储、索引和查询高维向量的系统,这些向量表示图像、文本或音频等复杂数据。这些向量通常由Florence等模型生成,允许在庞大的数据集中进行高效的相似性搜索。这种能力使得向量数据库非常适合应用于基于语义或内容相似性的快速准确的数据匹配。
4.2 Milvus:为规模而建的开源向量数据库
Milvus是GitHub上拥有超过30,000颗星的开源向量数据库,特别适合构建AI驱动的应用。它具有可扩展性、强大的性能和灵活的索引,非常适合管理像Florence这样的模型生成的大型复杂数据集。它提供广泛的功能,例如:
混合和多模态搜索:Milvus支持混合稀疏和密集搜索,将向量相似性搜索与标量过滤器相结合,并允许多模态搜索。
可扩展性:Milvus可以水平扩展,管理数十亿个向量,确保其与Florence处理庞大数据集的能力保持同步。
多种索引类型:Milvus拥有15种索引类型,为用户提供了优化查询速度、准确性或内存的灵活性,适合一系列应用需求。
GPU加速:Milvus利用GPU加速索引和搜索,这与Florence基于GPU的推理非常一致,并最大限度地提高了端到端系统效率。
实时更新:Milvus支持实时数据插入和更新,允许基于Florence的系统能够无缝整合新数据,而不会出现重大中断。
Florence 和 Milvus 的组合有许多应用,包括:
多模态RAG:传统的RAG系统专注于检索文本,以增强LLM的生成过程,产生更准确、更个性化的响应。多模态RAG通过使用Florence和Milvus等多模态AI模型,将图像、音频、视频等其他数据类型集成到嵌入、检索和生成过程中。
大规模视觉搜索引擎:用户可以根据详细的文本描述查找图像,或上传图像以在海量数据集中查找类似的图像。
内容推荐系统:通过存储各种内容项(图像、视频、文章)的Florence嵌入,Milvus可以根据用户偏好和行为提供个性化推荐。
自动标记和分类:Florence的零样本能力与Milvus的快速检索相结合,可以通过在数据库中找到类似的、已经标记的项目,来实现新图像的自动标记。
大规模视觉问答:在Milvus中存储image-question-answer三元组的嵌入,能快速检索有关图像的新问题的相关信息。
随着技术的发展,我们期望看到更先进的视觉AI系统,可以增强人机交互,简化AI驱动的助手。这些发展还可能导致各行各业更好的自动化,并引入新的创意和内容生产工具。
更多资源
Paper: Florence: A New Foundation Model for Computer Vision(https://arxiv.org/pdf/2111.11432)
Paper: Dynamic Head: Unifying Object Detection Heads with Attentions(https://arxiv.org/abs/2106.08322)
Paper: What Do You See? Enhancing Zero-Shot Image Classification with Multimodal Large Language Models(https://arxiv.org/abs/2405.15668)
Blog: Using Vector Search to Better Understand Computer Vision Data(https://zilliz.com/blog/use-vector-search-to-better-understand-computer-vision-data)
Demo: Similarity Search Demos Powered by Milvus(https://milvus.io/milvus-demos)
本文作者:Denis Kuria
推荐阅读



相关文章:

Milvus×Florence:一文读懂如何构建多任务视觉模型
近两年来多任务学习(Multi-task learning)正取代传统的单任务学习(single-task learning),逐渐成为人工智能领域的主流研究方向。其原因在于,多任务学习可以让我们以最少的人力投入,获得尽可能多…...

深入理解异步编程:使用 `asyncio` 和 `aiohttp` 进行并发请求
深入理解异步编程:使用 asyncio 和 aiohttp 进行并发请求 1. 异步编程简介2. 代码结构概览3. 代码详解3.1 fetch 函数3.2 fetch_all 函数3.3 main 函数3.4 主程序 4. 性能分析5. 总结 在现代的Web开发中,性能优化是一个非常重要的课题。特别是在处理大量…...

C++之虚函数
对基类中的方法进行重写; 主要是通过继承机制 V 表实现; 虚函数的引入与不加入虚函数的主要区别在于 动态多态性。通过将 Entity 类的 GetName 函数声明为 virtual,可以实现 运行时多态,这意味着程序会根据对象的实际类型调用相应…...

buildroot 制作Linux嵌入式文件系统,并添加telnet 以及ssh
在开始配置前,我们需要了解SSH和Telnet的基本概念。SSH(Secure Shell)为加密的网络协议,用于在不安全的网络中执行命令并管理网络服务。相对于SSH,Telnet是一个老旧且非加密的协议,用于进行远程登录 sshd 服…...
进程控制)
(Linux 系统)进程控制
目录 一、进程创建 1、fork函数初识 二、进程终止 1、正常终止 2、异常终止 三、进程等待 1、进程等待必要性 2、进程等待的方法: 四、获取子进程status 1、基本概念 2、进程的阻塞等待方式 3、进程的非阻塞等待方式 五、进程程序替换 1、六种替换函数…...

Redis进行性能优化可以考虑的一些策略
选择合适的数据结构 根据实际的需求选择合适的数据结构,以高效地访问和存储多个属性。 比如如果你需要存储用户的多个属性,如用户名、邮箱等,使用哈希可以比使用多个字符串键值对更节省内存 避免大key/value 较大地key和value会占用更多的…...

win10系统部署RAGFLOW+Ollama教程
本篇主要基于linux服务器部署ragflowollama,其他操作系统稍有差异但是大体一样。 一、先决条件 CPU ≥ 4核; RAM ≥ 16 GB; 磁盘 ≥ 50 GB; Docker ≥ 24.0.0 & Docker Compose ≥ v2.26.1。 如果尚未在本地计算机ÿ…...

新型大语言模型的预训练与后训练范式,Meta的Llama 3.1语言模型
前言:大型语言模型(LLMs)的发展历程可以说是非常长,从早期的GPT模型一路走到了今天这些复杂的、公开权重的大型语言模型。最初,LLM的训练过程只关注预训练,但后来逐步扩展到了包括预训练和后训练在内的完整…...

【Spark源码分析】规则框架-草稿
规则批:规则集合序列,由名称、执行策略、规则列表组成。一个规则批里使用一个执行规则。 执行策略 FixedPointOnce 规则: #mermaid-svg-1cvqR4xkYpMuAs77 {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px…...

力扣第 77 题 组合
题目描述 给定两个整数 n 和 k,返回范围 [1, n] 中所有可能的 k 个数的组合。 你可以按任意顺序返回答案。 示例 示例 1 输入: n 4, k 2输出: [[1, 2], [1, 3], [1, 4], [2, 3], [2, 4], [3, 4]]示例 2 输入: n 1, k …...
截取指定位数的字符等)
postman中获取随机数、唯一ID、时间日期(包括当前日期增减)截取指定位数的字符等
在Postman中,您可以使用内置的动态变量和编写脚本的方式来获取随机数、唯一ID、时间日期以及截取指定位数的字符。以下是具体的操作方法: 一、postman中获取随机数、唯一ID、时间日期(包括当前日期增减)截取指定位数的字符等 获取…...

【汇编】逻辑指令
文章目录 一、逻辑运算指令(一)各逻辑运算指令格式及操作(1)逻辑非指令 NOT(2)逻辑与指令 AND(3)逻辑或指令 OR(4)异或指令 XOR(5)测试…...

LinkedList的了解
一、LinkedList的定义与类型 Java中的LinkedList类是一个双向链表(Doubly Linked List)。与单向链表(Singly Linked List)不同,双向链表中的每个节点不仅包含指向下一个节点的引用,还包含指向前一个节点的…...

2411mfc,修改按钮颜色
添加消息:ON_WM_CTLCOLOR() //在OnInitDialog()方法中添加{HWND hSatateWnd GetDlgItem(IDC_CHK)->GetSafeHwnd();SetWindowTheme(hSatateWnd, _T(""), _T(""));}头文件中: afx_msg HBRUSH OnCtlColor(CDC* pDC, CWnd* pWnd, UINT nCtlColor);HBRUSH O…...
)
NLP中的主题模型:LDA(Latent Dirichlet Allocation, 潜在狄利克雷分配)
探索自然语言处理中的主题模型:LDA与狄利克雷分布 主题模型是一种用于发现文档集合中潜在主题的概率生成模型。其中,LDA(Latent Dirichlet Allocation, 潜在狄利克雷分配)是最著名的主题模型之一。在 LDA 中,狄利克雷…...

javaweb Day11
Maven高级 1.分模块设计...

pnpm的menorepo项目配置eslint和prettier
1、使用eslint脚手架安装相关依赖并生成对应配置文件 pnpm dlx eslint/create-config 自动安装了以下几个插件 生成的配置文件如下所示,和csdn其他教程里面不一样,这是因为eslint升级成9.xx版本了 需要node版本20以上 eslint 9.x 升级或使用指南…...
——线程(1)线程概念)
从0开始linux(38)——线程(1)线程概念
欢迎来到博主专栏:从0开始linux 博主ID:代码小豪 文章目录 进程与线程线程概念线程的优点线程的独立数据 进程与线程 如果要理解线程,那么进程将会时绕不开的点。首先我们回顾一下我们之前在进程章节当中是如何描述进程的? 进程&…...
)
【Linux系统编程】:进程池(简易版)
目录 1.制作游戏菜单 2.对管道进行描述和组织 3.初始化管道 3.1子进程执行任务slaver() 3.2检查管道是否创建有误 4.父进程向管道写入(控制子进程执行任务) 5.清理资源 修改初始化管道代码 6.完整代码: 1.制作游戏菜单 我们利用管道…...

uniapp实现小程序的版本更新
参考官方文档:uni.getUpdateManager() | uni-app官网 uni.getUpdateManager()是uniapp框架提供的一个API,用于管理小程序的版本更新。这个API返回一个全局唯一的版本更新管理器对象,该对象可以用于检测新版本、下载新版本以及提示用户重启应…...

嵌入式QT学习第4天:Qt 信号与槽
Linux版本号4.1.15 芯片I.MX6ULL 大叔学Linux 品人间百味 思文短情长 本章思维导图如下: 不使用 Qt Designer 的方式进行开发,用代码绘界面,可以锻炼我们的布局能力,和代码逻辑能力&#x…...

`asyncio.wait` 和 `asyncio.gather` 的区别
asyncio.wait 和 asyncio.gather 的区别 1. asyncio.wait2. asyncio.gather主要区别总结 在Python的异步编程中,asyncio.wait 和 asyncio.gather 都是用于等待多个异步任务完成的工具,但它们在功能和使用方式上有一些关键的区别。本文将详细解释这两个函…...
)
【JavaEE】多线程(2)
一、线程安全 1.1 线程安全的概念 线程是随机调度执行的,如果多线程环境下的程序运行的结果符合我们预期则说明线程安全,反之,如果遇到其他结果甚至引起了bug则说明线程不安全 1.2 经典例子与解释 下面举一个经典的线程不安全的例子&…...
)
虚拟地址空间与物理内存(Linux系统)
个人主页:敲上瘾-CSDN博客 个人专栏:Linux学习、游戏、数据结构、c语言基础、c学习、算法 目录 问题引入 一、什么是虚拟内存 二、虚拟内存的描述与组织 三、页表的优势 四、虚拟内存区域划分 问题引入 为引入今天的话题,我们先来看下面…...

iOS Arkit机器学习相关
最近在搞追踪运动物体,然后Arkit识别3d模型和图片,静止状态还不错,运动时候效果还是有点差,所以搞了下苹果的CoreML,苹果官网也有一些训练好的模型 苹果模型列表,自己参考或者使用,提供一个数据…...

Maven CMD命令
打包测试命令 在当前文件中 >mvn clean package -D maven.test.skiptrue 基本命令 mvn clean 清理目标目录(target)中的输出文件。 mvn compile 编译主源代码路径(src/main/java)下的 Java 代码。 mvn test-compile 编译测试源…...
+t265配置运行记录(ubuntu18.04+ros melodic))
DM-VIO(ROS)+t265配置运行记录(ubuntu18.04+ros melodic)
在工作中需要对DM-VIO算法进行测试,于是配置并记录了一下: 首先运行ros接口的dm-vio,一定要先配置源码 https://github.com/lukasvst/dm-vio在这个网址把源码下载下来并解压,并安装一下依赖: sudo apt-get install …...

DETR:一种新颖的端到端目标检测与分割框架
DETR:一种新颖的端到端目标检测与分割框架 摘要: 随着深度学习技术的发展,目标检测和图像分割任务取得了显著的进步。然而,传统的基于区域提名的方法在处理这些问题时存在一定的局限性。为此,Facebook AI Research&am…...

Android 输入事件拦截机制
Keyboard产生按键事件后,会通过notifyKey开始传递: frameworks\native\services\inputflinger\InputDispatcher.cpp void InputDispatcher::notifyKey(const NotifyKeyArgs* args) {...uint32_t policyFlags args->policyFlags;//只关注policyFlags…...

【Figma】中文版安装
一、软件安装包下载 打开官网链接https://www.figma.com/downloads/下载相应安装包 或使用我已下载好的链接: FigmaSetup.exe 链接: https://pan.baidu.com/s/113eQ8JRETdeOwUp2B3uieA?pwd4vep 二、安装流程 1.点击安装包 2.选择在浏览器登录 3.输入账号密码&a…...

SolarCube: 高分辨率太阳辐照预测基准数据集
太阳能作为清洁能源在减缓气候变化中的作用日益凸显,其稳定的供应对电网管理至关重要。然而,太阳辐照受云层和天气变化的影响波动较大,给光伏电力的管理带来挑战,尤其是在调度、储能和备用系统管理方面。因此,精确的太…...
)
arkTS:持久化储存UI状态的基本用法(PersistentStorage)
arkUI:持久化储存UI状态的基本用法(PersistentStorage) 1 主要内容说明2 例子2.1 持久化储存UI状态的基本用法(PersistentStorage)2.1.1 源码1的相关说明2.1.1.1 数据存储2.1.1.2 数据读取2.1.1.3 动态更新2.1.1.4 显示…...

【Canvas与雷达】点鼠标可暂停金边蓝屏雷达显示屏
【成图】 【代码】 <!DOCTYPE html> <html lang"utf-8"> <meta http-equiv"Content-Type" content"text/html; charsetutf-8"/> <head><title>点鼠标可暂停金边蓝屏雷达显示屏 Draft1</title><style typ…...

第二部分shell----二、shell 条件测试
一、基本语法 在shell程序中,用户可以使用测试语句来测试指定的条件表达式的条件的真或假。当指定的条件为 真时,整个条件测试的返回值为0;反之,如果指定的条件为假,则条件测试语句的返回值为非0值。 1.test<测试表…...

node修改文件名称
node修改名称 var fs require(fs); const events require(events); var path require(path);init(); function init() {//要遍历的文件夹所在的路径const dirPath path.resolve(__dirname, "data");//遍历目录fileDisplay(dirPath); }/*** 文件遍历* param dirP…...

Vue教程|搭建vue项目|Vue-CLI新版脚手架
一、安装Node环境 安装Node及Npm环境 Node下载地址:Node.js — Run JavaScript EverywhereNode.js is a JavaScript runtime built on Chromes V8 JavaScript engine.https://nodejs.org/en/ 安装完成后,检查安装是否成功,并检查版本,命令如下: node -v npm -v mac@Macd…...

Java设计模式
Java设计模式 一、观察者设计模式1.1 概述1.2 结构1.3 特点1. 优点2. 缺点3. 使用场景 1.4 JDK中的实现1. Observable 类2. Observer 接口3. 例子 二、模板设计模式三、单例设计模式一、懒汉式单例二、饿汉式单例 四、Builder模式4.1 概述4.2 结构4.3 具体实现4.4 使用场景 一、…...

java 接口防抖
防抖:防止重复提交 在Web系统中,表单提交是一个非常常见的功能,如果不加控制,容易因为用户的误操作或网络延迟导致同一请求被发送多次,进而生成重复的数据记录。要针对用户的误操作,前端通常会实现按钮的l…...

[C++并发编程] 线程基础
线程发起 最简单的发起一个线程。 void thread_work(std::string str) {std::cout << "str: " << std << std::endl; } //初始化并启动一个线程 std::thread t1(thread, wangzn2016); 线程等待: 线程发起后,可能新的线…...

基于若依框架和Vue2 + Element-UI 实现图片上传组件的重写与优化
背景 在使用 若依分离版Element-UI 的图片上传组件时,需要根据业务需求进行定制化处理,比如: 需要传递额外的业务参数到后端需要对上传路径进行修改需要对上传组件进行样式定制 实现步骤 1. 创建本地组件 首先在业务模块下创建本地的图片上传组件: src/views/xxx/compone…...

自定义类型: 结构体、枚举 、联合
目录 结构体 结构体类型的声明 匿名结构体 结构的自引用 结构体变量的定义和初始化 结构体成员变量的访问 结构体内存对齐 结构体传参 位段 位段类型的声明 位段的内存分配 位段的跨平台问题 位段的应用 枚举 枚举类型的定义 枚举的优点 联合体(共用体) 联合…...

力扣98:验证二叉搜索树
给你一个二叉树的根节点 root ,判断其是否是一个有效的二叉搜索树。 有效 二叉搜索树定义如下: 节点的左 子树 只包含 小于 当前节点的数。节点的右子树只包含 大于 当前节点的数。所有左子树和右子树自身必须也是二叉搜索树。 示例 1: 输入…...

Java Stream reduce 函数,聚合数据
Stream.reduce() 是 Stream 的一个聚合方法,它可以把一个 Stream 的所有元素按照自定义聚合逻辑,聚合成一个结果。 先看一个简单数字求和: public class Main {public static void main(String[] args){int sum Stream.of(1, 2…...

npm install -g@vue/cli报错解决:npm error code ENOENT npm error syscall open
这里写目录标题 报错信息1解决方案 报错信息2解决方案 报错信息1 使用npm install -gvue/cli时,发生报错,报错图片如下: 根据报错信息可以知道,缺少package.json文件。 解决方案 缺什么补什么,这里我们使用命令npm…...
部署前后端分离项目(MAC环境))
阿里云服务器(centos7.6)部署前后端分离项目(MAC环境)
Jdk17安装部署 下载地址:https://www.oracle.com/java/technologies/downloads/ 选择自己需要的jdk版本进行下载。 通过mac终端scp命令上传下载好的jdk17到服务器的/usr/local目录下 scp -r Downloads/jdk-17.0.13_linux-x64_bin.tar.gz 用户名服务器ip地址:/us…...

【机器学习】机器学习基础
什么是机器学习? 机器学习(Machine Learning, ML)是一种人工智能(AI)的分支,指计算机通过数据学习规律并做出预测或决策,而无需明确编程。它的核心目标是让机器能够从经验中学习,逐…...
)
BUUCTF—Reverse—Java逆向解密(10)
程序员小张不小心弄丢了加密文件用的秘钥,已知还好小张曾经编写了一个秘钥验证算法,聪明的你能帮小张找到秘钥吗? 注意:得到的 flag 请包上 flag{} 提交 需要用专门的Java反编译软件:jd-gui 下载文件,发现是个class文…...

基于JSP+MySQL的网上招聘系统的设计与实现
摘要 在这样一个经济飞速发展的时代,人们的生存与生活问题已成为当代社会需要关注的一个焦点。对于一个刚刚 踏入社会的年轻人来说,他对就业市场和形势了解的不够详细,同时对自己的职业规划也很模糊,这就导致大量的 时间被花费在…...

js 中 file 文件 应用
文章目录 文件上传File 对象基本属性文件上传大文件上传文件格式校验通过 type 属性校验图片格式通过文件名扩展名校验 文件解析一、处理图片文件流(以 Blob 格式接收文件流为例)二、处理文本文件流三、处理 PDF 文件流(借助 PDF.js 库来展示…...

Java 泛型详细解析
泛型的定义 泛型类的定义 下面定义了一个泛型类 Pair,它有一个泛型参数 T。 public class Pair<T> {private T start;private T end; }实际使用的时候就可以给这个 T 指定任何实际的类型,比如下面所示,就指定了实际类型为 LocalDate…...