自定义类型: 结构体、枚举 、联合
目录
结构体
结构体类型的声明
匿名结构体
结构的自引用
结构体变量的定义和初始化
结构体成员变量的访问
结构体内存对齐
结构体传参
位段
位段类型的声明
位段的内存分配
位段的跨平台问题
位段的应用
枚举
枚举类型的定义
枚举的优点
联合体(共用体)
联合类型的定义
联合体的特点
联合体的大小
联合体的应用
结构体
结构体类型的声明
之前学习到的数据类型我们称之为内置类型,如int, double, char, float等,后续还学习了数组,数组是一组相同类型元素的集合,但描述一个事物通常需要用到不同的类型,比如要描述一个学生,有年龄,姓名,学号等,就会出现各种类型的字段,这些叫做结构体的成员,结构体的每个成员额可以是不同的变量类型!
struct Stu是一个自定义的结构体类型, struct是结构体关键字,Stu是结构体标签(tag)
struct Stu
{char name[20];//名字int age;//年龄char sex[5];//性别char id[20];//学号
};在使用时我们感觉结构体类型太长了,可以typedef进行类型重定义
typedef struct Stu
{char name[20];//名字int age;//年龄char sex[5];//性别char id[20];//学号
}stu;
匿名结构体
在声明结构体类型的时候,可以不完全的声明,也就是省略掉结构体标签, 称之为匿名结构体
struct
{char name[20];//名字int age;//年龄char sex[5];//性别char id[20];//学号
};建议不要使用匿名结构体,可读性不是很好,就按照最标准的 struct + 结构体标签 来创建结构体
结构的自引用
在结构中包含一个类型为该结构本身的成员是否可以呢?
struct Node
{int data;struct Node next;
};
这样写是不可以的,因为sizeof(struct Node)是无法计算的,用该结构体类型创建变量时开辟的空间大小也就是未知的,因此是错误的写法
struct Node
{int data;struct Node* next;
};
这样写就是可以的,第二个成员变量是一个结构体指针,固定大小是4/8个字节, 这也是数据结构中链表的每个节点的结构体定义方式
typedef struct
{int data;Node* next;
}Node;
这样写是不可以的,因为定义结构体类型时第二个成员变量用到了typedef后的类型,而此时结构体还没有创建完成,而结构体要创建完成,第二个成员变量就应该定义完成了,这就是先有鸡还是先有蛋的问题了!
typedef struct Node
{int data;struct Node* next;
}Node;这样写就是可以的,第二个成员变量定义时使用的是 struct Node, 已经有该类型了!
结构体变量的定义和初始化
●定义全局变量并初始化
#include <stdio.h>//声明结构体类型的同时初始化变量(定义+赋初值)
struct Stu
{char name[20];//名字int age;//年龄char sex[5];//性别char id[20];//学号
}s1 = { "zhangsan", 18, "mail", "20221931" }; //全局变量struct Stu s2; //全局变量int main()
{s2 = { "lisi", 20, "femail", "31931313"};return 0;
}
●定义局部变量并初始化
#include <stdio.h>
struct Stu
{char name[20];//名字int age;//年龄char sex[5];//性别char id[20];//学号
};
int main()
{struct Stu s = { "wangmazi", 23, "mail", "39133113" };return 0;
}● 结构体的嵌套定义
#include <stdio.h>
struct score
{int x;char ch;
};
struct Stu
{char name[20];//名字int age;//年龄char sex[5];//性别char id[20];//学号struct score s; //嵌套结构体
};
int main()
{struct Stu s = { "wangmazi", 23, "mail", "39133113", {10, 'q'}};return 0;
}结构体成员变量的访问
● 结构体变量.成员变量
● 结构体指针变量->成员变量
● (*结构体指针变量).成员变量
#include <stdio.h>
struct score
{int x;char ch;
};
struct Stu
{char name[20];//名字int age;//年龄char sex[5];//性别char id[20];//学号struct score sc; //嵌套结构体
};
int main()
{struct Stu s = { "wangmazi", 23, "mail", "39133113", {10, 'q'}};//1.结构体变量.成员变量printf("%s %d %s %s %d %c\n", s.name, s.age, s.sex, s.id, s.sc.x, s.sc.ch);//2.结构体指针变量->成员变量struct Stu* p = &s;printf("%s %d %s %s %d %c\n", p->name, p->age, p->sex, p->id, p->sc.x, p->sc.ch);//3.*(结构体指针变量).成员变量printf("%s %d %s %s %d %c\n", (*p).name, (*p).age, (*p).sex, (*p).id, (*p).sc.x, (*p).sc.ch);return 0;
}
结构体内存对齐
现在我们来讨论一下结构体的大小,结构体中包含了若干个成员变量,结构体的大小是所有成员变量大小相加吗???
#include <stdio.h>
struct s1
{char c1;int i;char c2;
};
int main()
{printf("%d\n", sizeof(struct s1)); //12return 0;
}显然不是,结构体中的成员变量并不是挨着连续存放的,而是要遵守一定的对齐规则!
结构体内存对齐规则
1.第一个成员在与结构体变量偏移量为0的地址处
2.其他成员变量要对齐到某个数字(对齐数)的整数倍的地址处
对齐数 = 编译器默认的一个对齐数 与 该成员大小的较小值。 VS中默认的一个对齐数值为8
3.结构体总大小为最大对齐数(每个成员变量都有一个对齐数)的整数倍。
4.如果嵌套了结构体的情况,嵌套的结构体对齐到自己的最大对齐数的整数倍处,结构体的整 体大小就是所有最大对齐数(含嵌套结构体的对齐数)的整数倍
画图解释上面结构体的大小是12:

结构体嵌套计算大小:
#include <stdio.h>
struct S3
{double d;char c;int i;
};
struct S4
{char c1;struct S3 s3;double d;
};
int main()
{printf("%d\n", sizeof(struct S3)); //16printf("%d\n", sizeof(struct S4)); //32return 0;
}

计算出 struct S3 的所有成员的最大对齐数是8,因此struct S3 的起始位置就是8的整数倍,然后strcut s3 内部的成员变量存放规则依旧遵守前三条规则,最后检查整体结构体的大小是所有成员(包括嵌套结构体成员)大小的整数倍,也就是32个字节
为啥存在结构体内存对齐?
1. 平台原因(移植原因):
不是所有的硬件平台都能访问任意地址上的任意数据的;某些硬件平台只能在某些地址处取某些特 定类型的数据,否则抛出硬件异常。
2. 性能原因:
数据结构(尤其是栈)应该尽可能地在自然边界上对齐。 原因在于,为了访问未对齐的内存,处理器需要作两次内存访问;而对齐的内存访问仅需要一次访问。
举个例子: 对于下列结构体:
struct S
{char c; int i;
};
总体来说: 结构体的内存对齐是拿空间来换取时间的做法。
那在设计结构体的时候,我们既要满足对齐,又要节省空间,如何做到:
让占用空间小的成员尽量集中在一起
struct S1
{char c1;int i;char c2;
};struct S2
{char c1;char c2;int i;
};s1结构体和s2结构体的成员变量是完全一样的,但是s2结构体的两个char类型变量在一起,所以同样遵守结构体内存对齐规则前提下,s2是更加节省空间的!
修改默认对齐数
● 使用 #pragma pack() 预处理指令修改默认对齐数
#include <stdio.h>
#pragma pack(1) //修改默认对齐数
struct S1
{char c1;int i;char c2;
};
#pragma pack() //恢复默认对齐数int main()
{printf("%d\n", sizeof(struct S1)); //6return 0;
}
结构体传参
#include <stdio.h>
#include <stddef.h>
struct S
{int data[1000];int num;
};void print1(struct S ss)
{for (int i = 0; i < 3; i++){printf("%d ", ss.data[i]);}printf("%d\n", ss.num);
}void print2(const struct S* ps)
{for (int i = 0; i < 3; i++){printf("%d ", ps->data[i]);}printf("%d\n", ps->num);
}int main()
{struct S s = { {1, 2, 3}, 100 };print1(s);print2(&s);return 0;
}
代码中有两种传参方式,可以采用代码一(传值传参),也可以采用代码二(传址传参),那么使用哪一个好呢???
建议使用传址传参,理由如下:
1. 传值传参,参数需要压栈,会有时间和空间上的系统开销
2. 如果结构体对象过大,参数压栈的系统开销比较大,导致性能下降
3. 如果要修改外部的结构体,就只能传址传参了; 如果不想修改,传址传参的形参加上const即可
位段
位段类型的声明
1.位段的成员必须是 int、unsigned int 、signed int 、char 等等, 总之,必须属于整形家族
2.位段的成员名后边有一个冒号和一个数字(表示成员占几个比特位)
//位段
struct A
{int _a : 2;int _b : 5;int _c : 10;int _d : 30;
};
可以看到,位段是一种节省空间的方式,int是占据4个字节,32个比特位,但是比如int flag 变量,用来标识真假,我们只需要两种状态,01 / 10, 只需要两个比特位就够了,也有很多其他类似的场景,因此使用位段可以节省空间
位段的内存分配
1. 位段的空间上是按照需要以4个字节( int )或者1个字节( char )的方式来开辟的。
#include <stdio.h>
//位段
struct A
{int _a : 2;int _b : 5;int _c : 10;int _d : 30;
};
int main()
{printf("%d\n", sizeof(struct A)); //8return 0;
}
上述代码中,struct A中的成员都是 int 类型的,因此先开辟4个字节,先把前三个成员(17个比特位)存下来,还剩余了15个比特位,不够存储_d,于是再开辟4个字节,_d就能存下了! 于是最终结构体的大小就是8个字节, 32个比特位
问题是_d的空间如何分配,是先使用剩余的15个比特位,再使用15个比特位呢? 还是直接使用新开辟的4个字节(32个比特位)中的30个比特位呢?? 答案是 不确定!
2. 位段涉及很多不确定因素,位段是不跨平台的,注重可移植的程序应该避免使用位段。
#include <stdio.h>
//位段
struct S
{char a : 3;char b : 4;char c : 5;char d : 4;
};
int main()
{struct S s = { 0 };s.a = 10;s.b = 12;s.c = 3;s.d = 4;printf("%d\n", sizeof(s)); //3return 0;
}
假设:
1.每一个字节的空间存放时从右向左存放
2.当这1个字节不够下一个位段成员存储时就从下一个字节开始存
根据上面两点假设,得到如下结果:

经过vs2022调试观察,发现vs2022的位段存储就是基于上面两点假设

位段的跨平台问题
1. int 位段被当成有符号数还是无符号数是不确定的。
2. 位段中最大位的数目不能确定。
(比如 int 整数, 16位机器最大16,32位机器最大32,写成27,在16位机器会出问题)
3. 位段中的成员在内存中从左向右分配,还是从右向左分配标准尚未定义。
4. 当一个结构包含两个位段,第二个位段成员比较大,无法容纳于第一个位段剩余的位时,是舍弃剩余的位还是利用,这是不确定的。
总结:
跟结构相比,位段可以达到同样的效果,但是可以很好的节省空间,但是有跨平台的问题存在。
位段的应用
网络中常用到,后期网络部分的博客会有介绍
枚举
枚举类型的定义
enum Day//星期
{Mon,Tues,Wed,Thur,Fri,Sat,Sun
};enum Sex//性别
{MALE,FEMALE,SECRET
};enum Color//颜色
{RED,GREEN,BLUE
};
枚举类型中包含的成员就是一个个常量,叫做枚举常量,枚举常量是有取值的,默认从0开始,依次递增一
#include <stdio.h>
enum Day//星期
{Mon,Tues,Wed,Thur,Fri,Sat,Sun
};
int main()
{printf("%d\n", Mon); //0printf("%d\n", Tues); //1printf("%d\n", Wed); //2 printf("%d\n", Thur); //3printf("%d\n", Fri); //4printf("%d\n", Sat); //5printf("%d\n", Sun); //6return 0;
}
当然我们在定义枚举变量的时候可以赋初值,从被赋初值的枚举常量开始往后的值都是递增1
#include <stdio.h>
enum Day//星期
{Mon,Tues,Wed = 3,Thur,Fri,Sat,Sun
};
int main()
{enum Day d = Fri;printf("%d\n", Mon); //0printf("%d\n", Tues); //1printf("%d\n", Wed); //3printf("%d\n", Thur); //4printf("%d\n", Fri); //5printf("%d\n", Sat); //6printf("%d\n", Sun); //7return 0;
}
枚举的优点
1. 增加代码的可读性和可维护性
比如switch - case 进行分支判定时,可以用枚举常量代替0,1, 2等数字,可以很直观的看出某个分支的含义!
2. 和#define定义的标识符比较枚举有类型检查,更加严谨。
C语言对类型的检查不是很严格,但是C++对类型的检查更加严格,
#include <stdio.h>
enum Day//星期
{Mon,Tues,Wed = 3,Thur,Fri,Sat,Sun
};
int main()
{enum Day d = 5; //errreturn 0;
}
3. 防止了命名污染(封装)
4. 便于调试
#define定义的标识符和宏都是在编译阶段就完成替换的,而调试是将代码已经编译成了二进制程序,此时都完成了替换,调试起来的代码和最开始的就不一样了!
5. 使用方便,一次可以定义多个常量
联合体(共用体)
联合类型的定义
联合也是一种特殊的自定义类型 这种类型定义的变量也包含一系列的成员,特征是这些成员公用同一块空间(所以联合也叫共用体)
#include <stdio.h>
//定义一个联合体类型
union Un
{char c;int i;
};
int main()
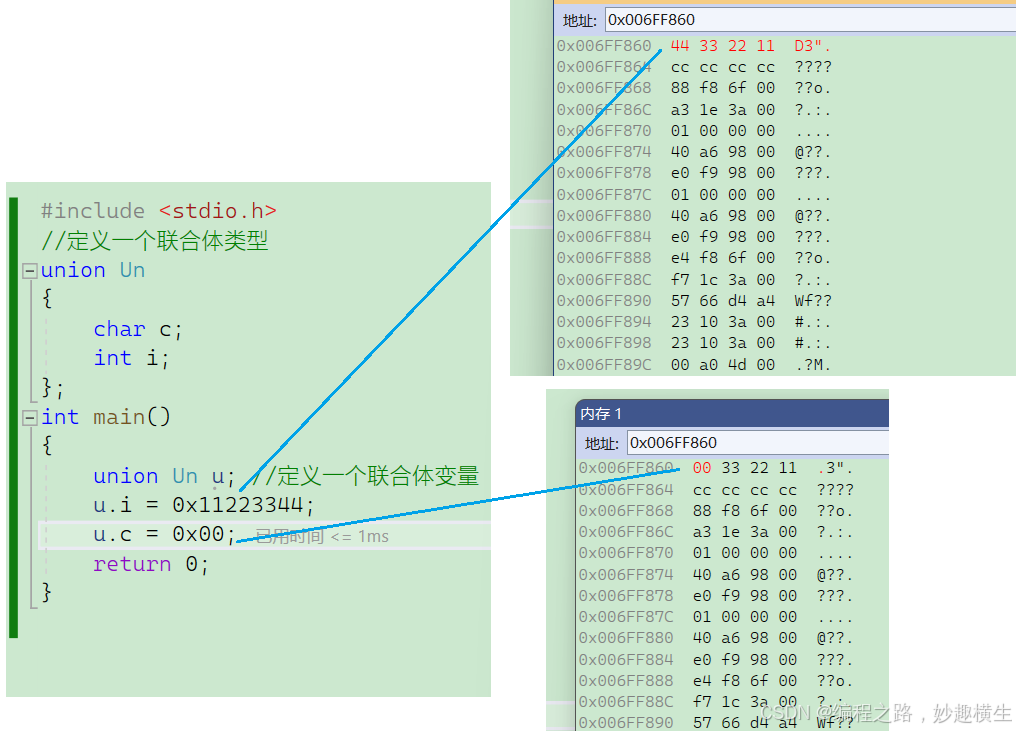
{union Un u; //定义一个联合体变量printf("%d\n", sizeof(u)); //4printf("%p\n", &u); //00AFFB78printf("%p\n", &u.c); //00AFFB78printf("%p\n", &u.i); //00AFFB78return 0;
}
注:取地址永远取出的是最低一个字节的地址

联合体的特点
● 由于联合成员公用一块空间,因此同一时刻只能使用其中一个联合成员
● 对一个联合成员的修改可能会影响另一个联合成员
联合体的大小
● 联合的大小至少是最大成员的大小
● 当最大成员大小不是最大对齐数的整数倍的时候,就要对齐到最大对齐数的整数倍
● 对齐数 = 编译器的默认对齐数 和 联合体成员大小 的较小值
#include <stdio.h>
union Un1
{char arr[5];int i;
};
int main()
{printf("%d\n", sizeof(union Un1)); //8return 0;
}联合体的大小至少是最大成员的大小,也就是数组大小是5,arr虽然是数组,但其实被看成一个一个的char, 所以对齐数是1,i 的对齐数是4,所以最大对齐数就是4,因此最终联合体的大小不是5,应该是8
联合体的应用
判断机器大小端
●大端: 数据的高字节保存在内存的低地址中, 数据的低字节保存在内存的高地址中
●小端: 数据的低字节保存在内存的低地址中, 数据的高字节保存在内存的高地址中
#include <stdio.h>
int check_sys()
{union Un{char c;int i;}u;u.i = 1;//小端: 01 00 00 00//大端: 00 00 00 01return u.c;
}
int main()
{int ret = check_sys();if (ret == 1)printf("小端\n");elseprintf("大端\n");return 0;
}
相关文章:

自定义类型: 结构体、枚举 、联合
目录 结构体 结构体类型的声明 匿名结构体 结构的自引用 结构体变量的定义和初始化 结构体成员变量的访问 结构体内存对齐 结构体传参 位段 位段类型的声明 位段的内存分配 位段的跨平台问题 位段的应用 枚举 枚举类型的定义 枚举的优点 联合体(共用体) 联合…...

力扣98:验证二叉搜索树
给你一个二叉树的根节点 root ,判断其是否是一个有效的二叉搜索树。 有效 二叉搜索树定义如下: 节点的左 子树 只包含 小于 当前节点的数。节点的右子树只包含 大于 当前节点的数。所有左子树和右子树自身必须也是二叉搜索树。 示例 1: 输入…...

Java Stream reduce 函数,聚合数据
Stream.reduce() 是 Stream 的一个聚合方法,它可以把一个 Stream 的所有元素按照自定义聚合逻辑,聚合成一个结果。 先看一个简单数字求和: public class Main {public static void main(String[] args){int sum Stream.of(1, 2…...

npm install -g@vue/cli报错解决:npm error code ENOENT npm error syscall open
这里写目录标题 报错信息1解决方案 报错信息2解决方案 报错信息1 使用npm install -gvue/cli时,发生报错,报错图片如下: 根据报错信息可以知道,缺少package.json文件。 解决方案 缺什么补什么,这里我们使用命令npm…...
部署前后端分离项目(MAC环境))
阿里云服务器(centos7.6)部署前后端分离项目(MAC环境)
Jdk17安装部署 下载地址:https://www.oracle.com/java/technologies/downloads/ 选择自己需要的jdk版本进行下载。 通过mac终端scp命令上传下载好的jdk17到服务器的/usr/local目录下 scp -r Downloads/jdk-17.0.13_linux-x64_bin.tar.gz 用户名服务器ip地址:/us…...

【机器学习】机器学习基础
什么是机器学习? 机器学习(Machine Learning, ML)是一种人工智能(AI)的分支,指计算机通过数据学习规律并做出预测或决策,而无需明确编程。它的核心目标是让机器能够从经验中学习,逐…...
)
BUUCTF—Reverse—Java逆向解密(10)
程序员小张不小心弄丢了加密文件用的秘钥,已知还好小张曾经编写了一个秘钥验证算法,聪明的你能帮小张找到秘钥吗? 注意:得到的 flag 请包上 flag{} 提交 需要用专门的Java反编译软件:jd-gui 下载文件,发现是个class文…...

基于JSP+MySQL的网上招聘系统的设计与实现
摘要 在这样一个经济飞速发展的时代,人们的生存与生活问题已成为当代社会需要关注的一个焦点。对于一个刚刚 踏入社会的年轻人来说,他对就业市场和形势了解的不够详细,同时对自己的职业规划也很模糊,这就导致大量的 时间被花费在…...

js 中 file 文件 应用
文章目录 文件上传File 对象基本属性文件上传大文件上传文件格式校验通过 type 属性校验图片格式通过文件名扩展名校验 文件解析一、处理图片文件流(以 Blob 格式接收文件流为例)二、处理文本文件流三、处理 PDF 文件流(借助 PDF.js 库来展示…...

Java 泛型详细解析
泛型的定义 泛型类的定义 下面定义了一个泛型类 Pair,它有一个泛型参数 T。 public class Pair<T> {private T start;private T end; }实际使用的时候就可以给这个 T 指定任何实际的类型,比如下面所示,就指定了实际类型为 LocalDate…...

「Mac畅玩鸿蒙与硬件33」UI互动应用篇10 - 数字猜谜游戏
本篇将带你实现一个简单的数字猜谜游戏。用户输入一个数字,应用会判断是否接近目标数字,并提供提示“高一点”或“低一点”,直到用户猜中目标数字。这个小游戏结合状态管理和用户交互,是一个入门级的互动应用示例。 关键词 UI互…...

自然语言处理期末试题汇总
建议自己做,写完再来对答案。答案可能存在极小部分错误,不保证一定正确。 一、选择题 1-10、C A D B D B C D A A 11-20、A A A C A B D B B A 21-30、B C C D D A C A C B 31-40、B B B C D A B B A A 41-50、B D B C A B B B B C 51-60、A D D …...

记录Threadlocal使用
编写ThreadLocal工具类 package com.jjking.jplan.context;public class BaseContext<T> {public static final ThreadLocal threadLocal new ThreadLocal();//存储用户public static void set(Object t) {threadLocal.set(t);}//获取用户public static <T> T ge…...

利用 SpringBoot 开发的新冠密接者跟踪系统:医疗机构疫情防控辅助方案
摘 要 信息数据从传统到当代,是一直在变革当中,突如其来的互联网让传统的信息管理看到了革命性的曙光,因为传统信息管理从时效性,还是安全性,还是可操作性等各个方面来讲,遇到了互联网时代才发现能补上自古…...

vue 2 父组件根据注册事件,控制相关按钮显隐
目标效果 我不注册事件,那么就不显示相关的按钮 注册了事件,才会显示相关内容 实现思路 组件在 mounted 的时候可以拿到父组件注册监听的方法 拿到这个就可以做事情了 mounted() {console.log(this.$listeners, this.$listeners);this.show.search !…...
)
【深度学习基础】一篇入门模型评估指标(分类篇)
🌈 个人主页:十二月的猫-CSDN博客 🔥 系列专栏: 🏀深度学习_十二月的猫的博客-CSDN博客 💪🏻 十二月的寒冬阻挡不了春天的脚步,十二点的黑夜遮蔽不住黎明的曙光 目录 1. 前言 2. 模…...

hls视频流学习
hls格式播放的依赖安装: <!-- 新增hls播放库 -->npm install hls.js 组件封装: <template><div class"hls-player-cls"><video ref" video" controls style"width: 100%; max-width: 800px;">…...

【electron-vite】搭建electron+vue3框架基础
一、拉取项目 electron-vite 中文文档地址: https://cn-evite.netlify.app/guide/ 官网网址:https://evite.netlify.app/ 版本 vue版本:vue3 构建工具:vite 框架类型:Electron JS语法:TypeScript &…...

第三方Express 路由和路由中间件
文章目录 1、Express 应用使用回调函数的参数: request 和 response 对象来处理请求和响应的数据。2、Express路由1.路由方法2.路由路径3.路由处理程序 3. 模块化路由4. Express中间件1.中间件简介2.中间件分类3.自定义中间件 1、Express 应用使用回调函数的参数&am…...

WPF 常用的5个布局容器控件介绍
1. Grid Grid 是最常用的布局容器之一,它允许开发者以表格的方式对控件进行组织和布局。Grid 使用行和列来划分区域,可以精确控制控件的位置和大小。 特点: 行列定义:Grid 使用 RowDefinitions 和 ColumnDefinitions 来定义行和…...
)
【JAVA] 杂谈: java中的拷贝(克隆方法)
这篇文章我们来介绍什么是拷贝,并且实现浅拷贝到深拷贝。 目录 一、浅拷贝 1.1 clone 方法 1.2 实现浅拷贝: 1.2.1 重写 clone方法 1.2.2 实现接口 Cloneable 1.2.3 调用克隆方法 1.2.4 原理图: 1.3 浅拷贝的不足 1.3.1 增加引用…...

同时多平台git配置:GitHub和Gitee生成不同的SSH Key
文章目录 GitHub和Gitee生成不同的SSH Key步骤1:生成SSH Key步骤2:配置SSH配置文件步骤3:查看SSH公钥步骤4:将SSH公钥添加到GitHub和Gitee步骤5:测试SSH连接步骤6:添加remote远程库 GitHub和Gitee生成不同的…...

flink1.6集成doris,并从mysql同步数据到doris
使用 Apache Flink 1.6 集成 Doris,并从 MySQL 同步数据到 Doris 是一个复杂的任务,但可以通过以下步骤实现。Doris 是一个现代化的 MPP(大规模并行处理)SQL 数据库,支持实时分析和交互式查询。Flink 可以作为实时数据…...

手搓一个不用中间件的分表策略
场景:针对一些特别的项目,不用中间件,以月为维度进行分表,代码详细设计方案 1. 定义分片策略 首先,定义一个分片策略类,用于决定数据存储在哪个分表中 import java.time.LocalDate; import java.time.fo…...

AI前景分析展望——GPTo1 SoraAI
引言 人工智能(AI)领域的飞速发展已不仅仅局限于学术研究,它已渗透到各个行业,影响着从生产制造到创意产业的方方面面。在这场技术革新的浪潮中,一些领先的AI模型,像Sora和OpenAI的O1,凭借其强大…...

损失函数Hinge Loss介绍
Hinge Loss 是一种损失函数,广泛用于 支持向量机(SVM, Support Vector Machine) 和一些分类问题中。它特别适合用于 二分类问题,主要目标是让模型的预测值(通常是经过线性变换的原始分数)与真实标签之间的间隔尽可能大,从而提高分类的鲁棒性。 Hinge Loss 的定义 Hinge…...
以及协方差矩阵:解析与应用)
多维高斯分布(Multivariate Gaussian Distribution)以及协方差矩阵:解析与应用
多维高斯分布:全面解析及其应用 1. 什么是多维高斯分布? 多维高斯分布(Multivariate Gaussian Distribution),也称多元正态分布,是高斯分布在高维空间中的推广。它描述了随机向量 ( x ( x 1 , x 2 , … ,…...

前端开发常用快捷键
浏览器 ctrl e 光标定位在搜索框ctrl r 刷新ctrl t 新打开tabctrl tab 向右切换tabctrl shift tab 向左切换tab vscode ctrl p 全局搜索文件ctrl f 当前文件搜索alt 光标左键向下拖动:竖向选中多行文本ctrl b 切换侧边栏显示隐藏ctrl shift p 显示命…...

用MATLAB符号工具建立机器人的动力学模型
目录 介绍代码功能演示拉格朗日方法回顾求解符号表达式数值求解 介绍 开发机器人过程中经常需要用牛顿-拉格朗日法建立机器人的动力学模型,表示为二阶微分方程组。本文以一个二杆系统为例,介绍如何用MATLAB符号工具得到微分方程表达式,只需要…...

全面解析 MySQL 常见问题的排查与解决方法
目录 前言1. 查看 MySQL 日志信息1.1 日志文件的种类与路径1.2 查看日志内容的方法1.3 日志分析的关键点 2. 查看 MySQL 服务状态2.1 查看服务状态2.2 检查进程运行情况2.3 常见启动失败问题与解决 3. 检查 MySQL 配置信息3.1 配置文件的路径与内容3.2 验证配置文件的正确性 4.…...

泷羽Sec-星河飞雪-BurpSuite之解码、日志、对比模块基础使用
免责声明 学习视频来自 B 站up主泷羽sec,如涉及侵权马上删除文章。 笔记的只是方便各位师傅学习知识,以下代码、网站只涉及学习内容,其他的都与本人无关,切莫逾越法律红线,否则后果自负。 泷羽sec官网:http…...
.mean()等进行统计,pd.DataFrame.groupby() 分组统计)
【小白学机器学习34】基础统计2种方法:用numpy的方法np().mean()等进行统计,pd.DataFrame.groupby() 分组统计
目录 1 用 numpy 快速求数组的各种统计量:mean, var, std 1.1 数据准备 1.2 直接用np的公式求解 1.3 注意问题 1.4 用print() 输出内容,显示效果 2 为了验证公式的背后的理解,下面是详细的展开公式的求法 2.1 均值mean的详细 2.2 方差…...

【C++】stack和queue
目录 1. stack的介绍和使用 1.1 stack的介绍 1.2 stack的使用 2. queue的介绍和使用 2.1 queue的介绍 2.2 queue的使用 3. 容器适配器 3.1 什么是适配器 3.2 STL标准库中stack和queue的底层结构 3.3 deque的简单介绍(了解) 3.3.1 deque的原理介绍 3.3.2 deque优势与…...

向量的内积和外积 为什么这样定义
向量的内积和外积 为什么这样定义 flyfish 定义、公理与证明的区别 定义: 定义是人为规定的,用于描述概念的含义。例如,内积和外积是根据实际需求定义的,目的是描述几何和代数性质。定义不需要证明。 公理: 公理是数…...

简述循环神经网络RNN
1.why RNN CNN:处理图像之间没有时间/先后关系 RNN:对于录像,图像之间也许有时间/先后顺序,此时使用CNN效果不会很好,同理和人类的语言相关的方面时间顺序就更为重要了 2.RNN和CNN之间的关联 RNN和CNN本质上其实一…...
】进程通信(IPC))
【Electron学习笔记(四)】进程通信(IPC)
进程通信(IPC) 进程通信(IPC)前言正文1、渲染进程→主进程(单向)2、渲染进程⇌主进程(双向)3、主进程→渲染进程 进程通信(IPC) 前言 在Electron框架中&…...

APP自动化测试框架的开发
基于appium的APP自动化测试框架的开发流程概览 1. 环境搭建 安装Appium Server 下载与安装:可以从Appium官方网站(Redirecting)下载安装包。对于Windows系统,下载.exe文件后双击安装;对于Mac系统,下载.dmg…...

【深度学习】各种卷积—卷积、反卷积、空洞卷积、可分离卷积、分组卷积
在全连接神经网络中,每个神经元都和上一层的所有神经元彼此连接,这会导致网络的参数量非常大,难以实现复杂数据的处理。为了改善这种情况,卷积神经网络应运而生。 一、卷积 在信号处理中,卷积被定义为一个函数经过翻转…...

pytorch 融合 fuse 学习笔记
目录 fuse_lora 作用是什么 fuse_modules源码解读 fuse_lora 作用是什么 在深度学习模型微调场景下(与 LoRA 相关) 参数融合功能 在使用 LoRA(Low - Rank Adaptation)对预训练模型进行微调后,fuse_lora函数的主要作…...

41 基于单片机的小车行走加温湿度检测系统
目录 一、主要功能 二、硬件资源 三、程序编程 四、实现现象 一、主要功能 基于51单片机,采样DHT11温湿度传感器检测温湿度,滑动变阻器连接数码转换器模拟电量采集传感器, 电机采样L298N驱动,各项参数通过LCD1602显示&#x…...

GitLab: You cannot create a branch with a SHA-1 or SHA-256 branch name
最近在迁移git库,把代码从gerrit迁移到gitlab,有几个库报错如下: GitLab: You cannot create a branch with a SHA-1 or SHA-256 branch name ! [remote rejected] refs/users/73/373/edit-95276/1 -> refs/users/73/373/edit-95276/1 (p…...
YOLOv9改进,YOLOv9引入TransNeXt中的ConvolutionalGLU模块,CVPR2024,二次创新RepNCSPELAN4结构
摘要 由于残差连接中的深度退化效应,许多依赖堆叠层进行信息交换的高效视觉Transformer模型往往无法形成足够的信息混合,导致视觉感知不自然。为了解决这个问题,作者提出了一种聚合注意力(Aggregated Attention),这是一种基于仿生设计的token混合器,模拟了生物的中央凹…...
)
TorchMoji使用教程/环境配置(2024)
TorchMoji使用教程/环境配置(2024) TorchMoji简介 这是一个基于pytorch库,用于将文本分类成不同的多种emoji表情的库,适用于文本的情感分析 配置流程 从Anaconda官网根据提示安装conda git拉取TorchMoji git clone https://gi…...

uniapp运行时,同步资源失败,未得到同步资源的授权,请停止运行后重新运行,并注意手机上的授权提示。
遇到自定义基座调试时安装无效或无反应?本文教你用 ADB 工具快速解决:打开 USB 调试,连接设备,找到应用包名,一键卸载问题包,清理干净后重新运行调试基座,轻松搞定! 问题场景&#…...

uniapp中父组件调用子组件方法
实现过程(setup语法糖形式下) 在子组件完成方法逻辑,并封装。在子组件中使用defineExpose暴露子组件的该方法。在父组件完成子组件ref的绑定。通过ref调用子组件暴露的方法。 子组件示例 <template> </template><script se…...

腾讯云 AI 代码助手:单元测试应用实践
引言 在软件开发这一充满创造性的领域中,开发人员不仅要构建功能强大的软件,还要确保这些软件的稳定性和可靠性。然而,开发过程中并非所有任务都能激发创造力,有些甚至是重复且乏味的。其中,编写单元测试无疑是最令人…...

ArcGIS栅格影像裁剪工具
1、前言 在最近的栅格转矢量处理过程中,发现二值化栅格规模太大,3601*3601,并且其中的面元太过细碎,通过arcgis直接栅格转面有将近几十万的要素,拿这样的栅格数据直接运行代码,发现速度很慢还难以执行出来结…...

VueWordCloud标签云初实现
文章目录 VueWordCloud学习总结安装初使用在组件中注册该组件简单使用项目中实现最终实现效果 VueWordCloud学习总结 本次小组官网的项目中自己要负责标签模块,想要实现一个标签云的效果,搜索了很多,发现vue有一个VueWordCloud库,…...
)
AI数据分析工具(二)
豆包-免费 优点 强大的数据处理能力: 豆包能够与Excel无缝集成,支持多种数据类型的导入,包括文本、数字、日期等,使得数据整理和分析变得更加便捷。豆包提供了丰富的数据处理功能,如数据去重、填充缺失值、转换格式等…...
)
sizeof和strlen区分,(好多例子)
sizeof算字节大小 带\0 strlen算字符串长度 \0之前...