(2024,扩展Transformer和数据,SDXL,SD2,DiT与 UNet)基于扩散的文本到图像生成的可扩展性
On the Scalability of Diffusion-based Text-to-Image Generation
公和众和号:EDPJ(进 Q 交流群:922230617 或加 VX:CV_EDPJ 进 V 交流群)

目录
0. 摘要
3. 扩展 Denoising 骨干
3.1. 现有的 UNet 设计
3.2. UNet 的受控对比
3.3. UNet 设计消融
3.4. 与 Transformer 的比较
4. 数据集的扩展
4.1. 数据集策划
4.2. 数据清洗
4.3. 通过合成标题扩展知识
4.4. 数据扩展提高了训练效率
5. 更多扩展性质
6. 结论
0. 摘要
扩大模型和数据规模对 LLM 的发展非常成功。然而,扩散型文本到图像(T2I)模型的扩展规律尚未完全探索。如何有效地扩展模型以在降低成本的情况下获得更好的性能尚不清楚。不同的训练设置和昂贵的训练成本使得公平的模型比较极为困难。在这项工作中,我们通过对去噪骨干和训练集进行广泛和严格的消融实验,包括在数据集上训练缩放 UNet 和 Transformer 变体,范围从 0.4B 到 4B 参数,并涵盖高达 600M 图像。对于模型的扩展,我们发现交叉注意力的位置和数量区分了现有 UNet 设计的性能。增加 Transformer 块对于改善文本-图像对齐比增加通道数量更具参数效率。然后,我们确定了一种高效的 UNet 变体,比 SDXL 的 UNet 小 45%,速度快 28%。在数据扩展方面,我们表明训练集的质量和多样性比简单的数据集大小更重要。增加标题密度和多样性可以提高文本-图像对齐性能和学习效率。最后,我们提供了用于预测文本-图像对齐性能的扩展函数,作为模型大小、计算和数据集大小的函数。

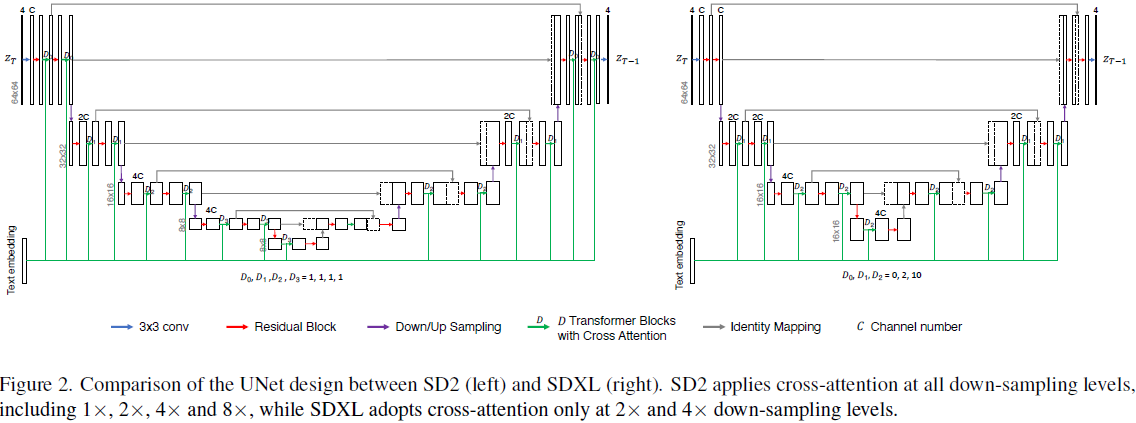
3. 扩展 Denoising 骨干
3.1. 现有的 UNet 设计
图 2 给出了 SD2 和 SDXL 的 UNet 的比较。 SDXL 在多个方面改进了 SD2:
- 更少的下采样率。SD2 使用(1, 2, 4, 4)作为倍率,以增加不同下采样级别的通道数。DeepFloyd 采用(1, 2, 3, 4)来减少计算量,而 SDXL 使用(1, 2, 4),完全移除了第四个下采样级别。
- 只在较低分辨率下进行交叉关注。交叉关注仅在特定的下采样率下计算,例如,SD2 将交叉关注应用于下采样率(1×、2×、4×),而 SDXL 仅在 2× 和 4× 下采样级别集成文本嵌入。
- 在较低分辨率下进行更多的计算。SDXL 在 2× 和 4× 下采样级别应用更多的 Transformer 块,而 SD2 在所有三个下采样级别应用统一的单一 Transformer 块。
3.2. UNet 的受控对比
训练。我们在我们的策划数据集 LensArt上 训练模型,该数据集包含 250M 个文本-图像对(详见第 4 节)。我们使用 SDXL 的 VAE 和 OpenCLIP-H [20] 文本编码器(1024 维),没有添加额外的嵌入层或其他条件。我们以 256×256 分辨率训练所有模型,批量大小为 2048,最多 600K 步。我们遵循 LDM [34] 的 DDPM 调度设置。我们使用 AdamW [27] 优化器进行 10K 步热身,然后学习率保持 8e-5 不变。我们采用 BF16 进行混合精度训练,并为大型模型启用 FSDP。
推断和评估。我们在推断中使用 DDIM 采样器 [37] 在 50 个步骤中固定种子和 CFG 比例(7.5)。为了了解训练动态,我们在训练期间监控五个指标的演变。我们发现训练早期的指标可以帮助预测最终模型的性能。具体来说,我们使用以下指标来衡量构图能力和图像质量:
- TIFA [19],通过视觉问答(VQA)衡量生成图像对其文本输入的忠实度。它包含由语言模型生成的 4K 个收集提示和相应的问答对。通过检查现有的 VQA 模型是否可以使用生成的图像回答这些问题来计算图像忠实度。TIFA 允许对生成的图像进行细粒度和可解释的评估。
- ImageReward [40],用于近似人类偏好。我们计算在 MSCOCO-10K 提示下生成的图像的平均 ImageReward 分数。尽管 ImageReward 不是一个归一化分数,但其分数在 [-2, 2] 的范围内,对图像的平均评分提供了有意义的统计信息,以便允许跨模型进行比较。
- 由于空间限制,我们主要展示 TIFA 和 ImageReward,并在附录中提供其他指标(CLIP分数[14, 32],FID,HPSv2 [39])的结果。
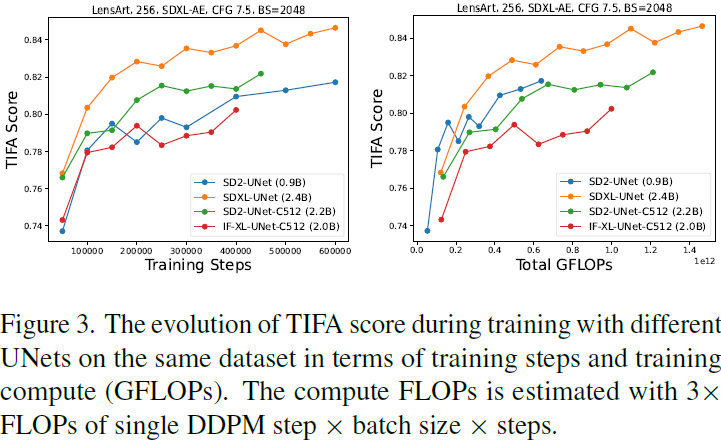
SDXL vs SD2 vs IF-XL。我们在上述受控设置中比较了 SDXL [31]、DeepFloyd-IF [9]、SD2 [34] 及其扩展版本的几种现有 UNet 模型的设计。具体来说,我们比较了a)SD2 UNet(0.9B)b)具有 512 个初始通道的 SD2 UNet(2.2B)c)SDXL 的 UNet(2.4B)d)具有 512 通道的 2.0B 的 DeepFloyd 的 IF-XL UNet。
- 图 3 显示了朴素扩展的 SD2-UNet(C512,2.2B)在相同的训练步骤下比基础 SD2 模型取得更好的 TIFA 分数。然而,就训练 FLOPs 而言,收敛速度较慢,这表明增加通道数是一种有效但不是高效的方法。
- SDXL 的 UNet 在 150K 步内实现了 0.82 的 TIFA,比 SD2 UNet 快 6 倍,比 SD2-C512 快 3 倍。尽管其训练迭代速度(FLOPS)比 SD2 慢 2 倍,但它仍以 2 倍的降低训练成本实现了相同的 TIFA 分数。
- SDXL UNet 还可以获得比其他模型高得多的 TIFA 分数(0.84)。
- 因此,SDXL 的 UNet 设计在性能和训练效率方面明显优于其他模型,推动了帕累托前沿。
3.3. UNet 设计消融
现在我们已经验证了 SDXL 比 SD2 和 DeepFloyd 变体具有更好的 UNet 设计。问题是它为什么表现出色,以及如何有效地进一步改进它。在这里,我们通过探索其设计空间来研究如何改进 SDXL 的 UNet。
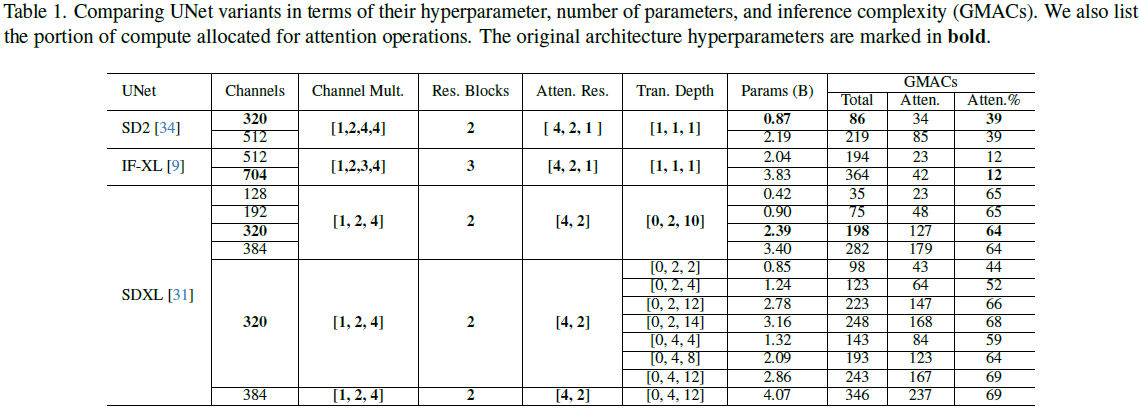
搜索空间。表 1 显示了不同的 UNet 配置及其在 256 分辨率下的计算复杂度。我们主要变化初始通道和 transformer 深度。为了理解设计空间的每个维度的影响,我们选择了一些变体模型并使用相同的配置对它们进行训练。这构成了我们 UNet 架构的主要 “搜索空间”。关于 VAE、训练迭代次数和 batch 大小的更多消融可以在附录中找到。
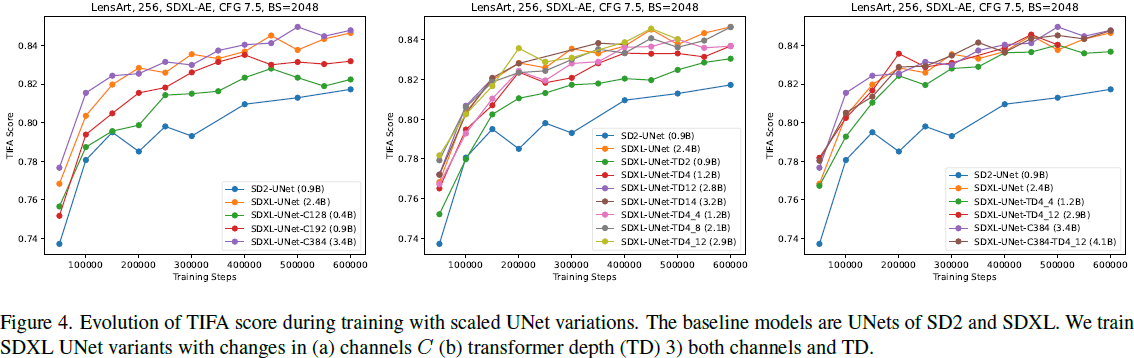
初始通道的影响。我们用不同的通道数量训练以下 SDXL UNet 变体:128、192 和 384,对应的参数分别为 0.4B、0.9B 和 3.4B。
- 图 4(a)显示,将通道数从 320 减少到 128 的 SDXL UNet 仍然可以优于带有 320 个通道的 SD2 UNet,这表明可以通过合适的架构设计,实现更少的通道数有更好的质量。然而,与 320 个通道的 SDXL UNet 相比,TIFA(也称为 ImageReward/CLIP)分数较差,这表明了通道在视觉质量中的重要性。
- 将 SDXL UNet 通道数从 320 增加到 384,参数数量从 2.4B 增加到 3.4B,它在 600K 训练步骤时也比基线 320 个通道获得更好的指标。
- 注意,初始通道数 C 实际上与 UNet 的其他超参数相关联,例如,1)时间步长嵌入 T 的维度是 4C;2)注意力头的数量与通道数成线性关系,即 C/4。如表 1 所示,当 C 变化时,注意力层的计算比例保持稳定(64%)。这解释了为什么增加 UNet 的宽度也会带来对齐改进,如图 4 所示。
Transformer Depth 的影响。Transformer Depth(TD)设置控制了特定输入分辨率下的 Transformer 块数量。SDXL 在 2× 和 4× 下采样级别分别应用了 2 个和 10 个 Transformer 块。为了理解其影响,我们使用不同的 TD 训练了表 1 中显示的变体,参数范围从 0.9B 到 3.2B。具体地,我们首先在 4× 下采样率上改变 TD,得到 TD2、TD4、TD12 和 TD14,然后我们进一步在 2× 下采样率上改变深度,得到 TD4_4、TD4_8 和 TD4_12。注意,随着 TD 的增加,注意力操作的部分也相应增加。
- 图4(b)显示,将 4× 下采样率上的 TD 从 2 增加到 14 会持续提高 TIFA 分数。
- 从 TD4 和 TD4_4 的比较中,我们可以看到在 2× 分辨率下增加 Transformer 深度(2 → 4)也会提高 TIFA 分数。
- TD4_4 在与 SDXL 的 UNet 相比具有竞争性能的同时,参数减少了 45%,推理计算量减少了 28%。
- 在附录中,我们展示了相对于 SDXL UNet,TD4_4 在墙钟(wall-clock)训练时间方面以 1.7 倍的速度实现了相同的 TIFA 分数。TD4_8 几乎与 SDXL 的 UNet 具有相同的性能,但参数减少了 13%。
- 由于文本-图像对齐(TIFA)主要涉及图像中的大对象,因此在效率考虑之外,将更多的交叉计算分配给较低分辨率或全局图像级别是有帮助的。
同时扩展通道和 Transformer 深度。鉴于通道和 Transformer 深度的影响,我们进一步探索了扩大通道数量(从 320 增加到 384)和 Transformer 深度([0,2,10] → [0,4,12])的效果。图 4(c)显示,在训练过程中,它的 TIFA 分数略高于 SDXL-UNet。然而,与仅增加通道或 Transformer 深度相比的优势并不明显,这意味着在诸如 TIFA 之类的指标下,模型继续扩展的性能存在限制。
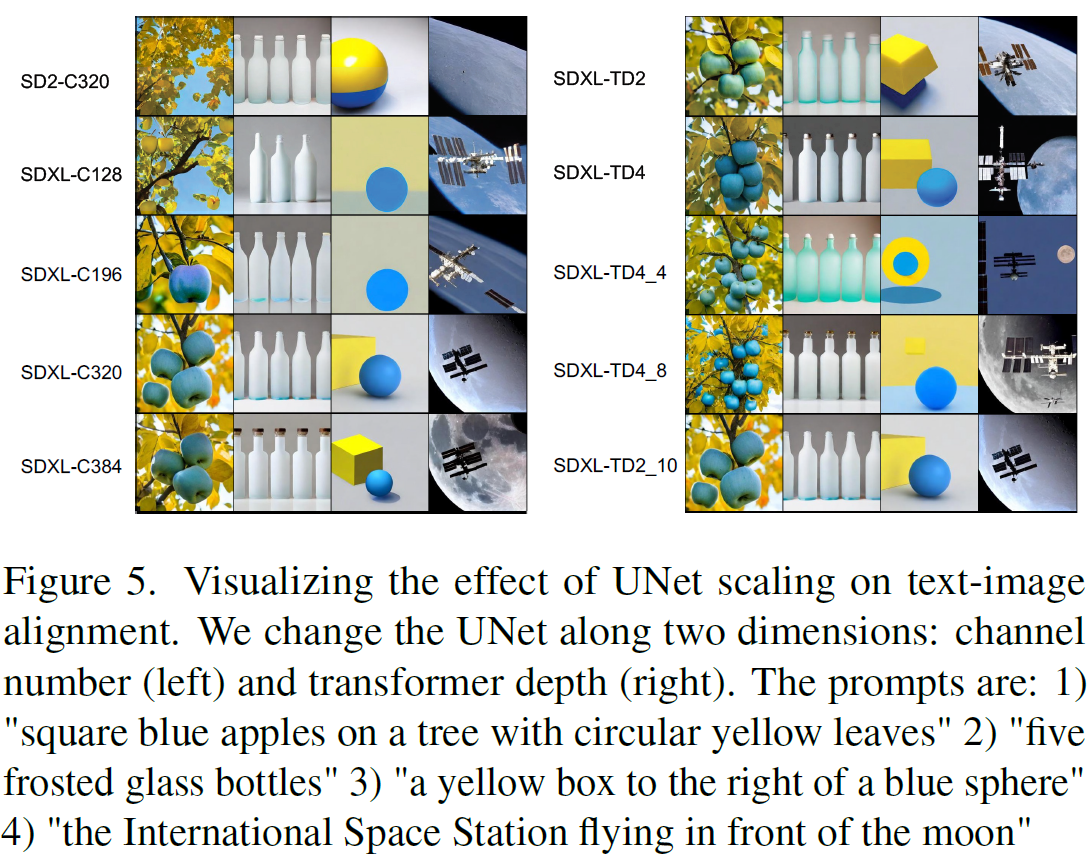
可视化 UNet 扩展效果。图 5 显示了使用相同提示生成的不同 UNet 生成的图像。我们可以看到,随着通道数或 Transformer 深度的增加,图像与给定的提示(例如,颜色、计数、空间、对象)更加对齐。某些 UNet 变体生成的图像比原始的 SDXL UNet(C320)更好,即,SDXL-C384 和 SDXL-TD4_8 都以更准确的方式生成第四个提示的图像。
3.4. 与 Transformer 的比较
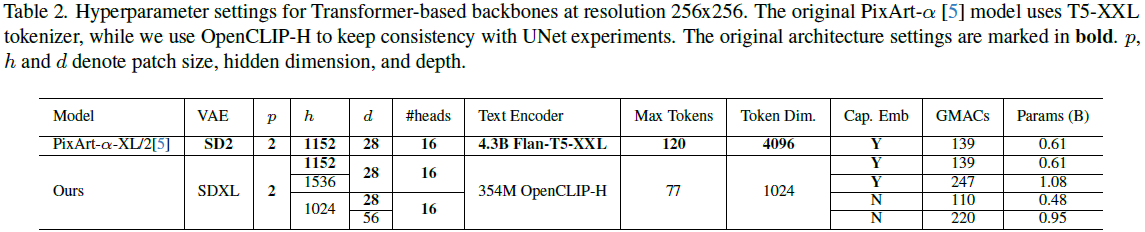
DiT [30] 表明,增加 Transformer 的复杂度可以在 ImageNet 上实现类别条件图像生成的一致性改进图像保真度。PixArt-α [5] 将 DiT 扩展到具有类似骨干结构的文本条件图像生成。然而,在受控设置中与 UNet 进行公平比较还存在不足。为了与 UNet 进行比较并了解其扩展性,我们训练了多个缩放版本的 PixArt-α,保持其他组件和设置与之前的消融相同。表 2 显示了我们缩放变体的配置。与原始 PixArt-α 模型的区别在于:1)我们使用 SDXL 的 VAE 代替 SD2 的 VAE;2)我们使用 OpenCLIP-H 文本编码器代替 T5-XXL [7],token 嵌入维度从 4096 减少到 1024,token 长度为 77 而不是 120。
消融空间。我们在以下维度上对 PixArt-α 模型进行了消融:
- 隐藏维度 h:PixArt-α 继承了 DiT-XL/2 [30] 的设计,具有 1152 维度。我们还考虑了 1024 和 1536。
- Transformer 深度 d:我们将 Transformer 深度从 28 扩展到 56。
- 标题(caption)嵌入:标题嵌入层将文本编码器的输出映射到维度h。当隐藏维度与文本嵌入相同时(即 1024),我们可以跳过标题嵌入直接使用 token 嵌入。
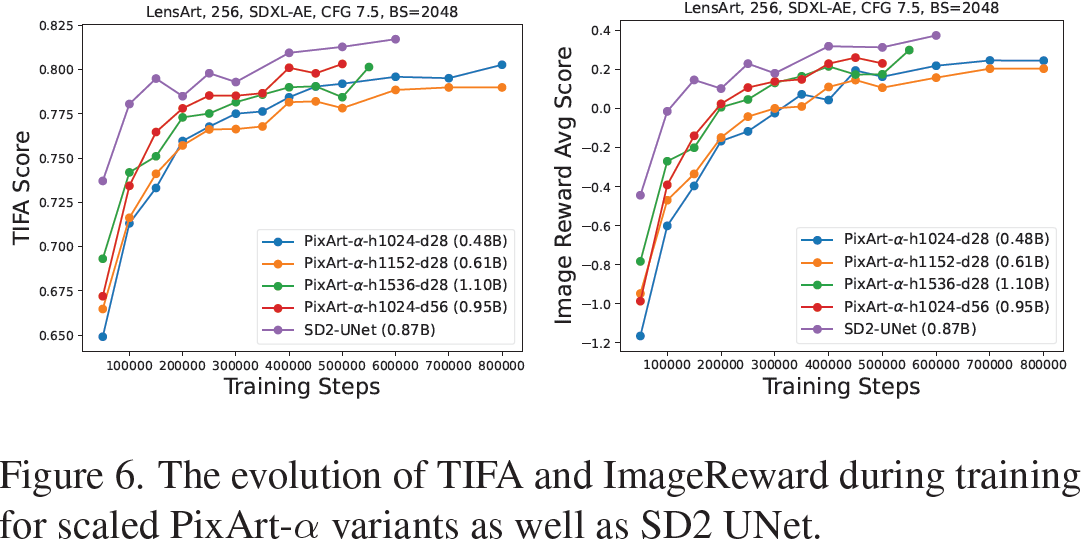
模型扩展的效果。如图 6 所示,扩展隐藏维度 h 和模型深度 d 都会导致文本-图像对齐和图像保真度的提高,而扩展深度 d 会线性改变模型的计算量和大小。d56 和 h1536 变体都以与基线 d28 模型相似的参数大小和计算量实现了约 1.5 倍更快的收敛速度。
与 UNet 的比较。相对于在相同步骤中训练的 SD2-UNet,PixArt-α 变体的 TIFA 和 ImageReward 分数较低,例如,SD2 UNet 在 250K 步时达到 0.80 TIFA 和 0.2 ImageReward,而 0.9B PixArt-α变体达到 0.78 和 0.1。PixArt-α [5] 还报告说,训练过程中没有使用 ImageNet 预训练会导致生成的图像与使用预训练 DiT 权重初始化的模型相比出现失真,后者在 ImageNet 上训练了 7M 步 [30]。尽管 DiT [30] 证明了 UNet 并不是扩散模型的必需品,但 PixArt-α 变体需要更长的迭代次数和更多的计算才能达到与 UNet 相似的性能。我们将此改进留待未来工作,并期待架构改进能够缓解这个问题,例如 [11, 12, 41] 中所做的工作。
4. 数据集的扩展
4.1. 数据集策划
我们策划了名为 LensArt 和 SSTK 的数据集。
- LensArt 是从 10 亿个有噪的网络图像文本对中获取的 2.5 亿个图像文本对。我们应用了一系列自动过滤器来消除数据噪声,包括但不限于不安全内容、低审美图像、重复图像和小图像。
- SSTK 是另一个内部数据集,约有 3.5 亿条清理后的数据。
- 表 3 显示了数据集的统计信息。更详细的分析可以在附录中看到。

4.2. 数据清洗
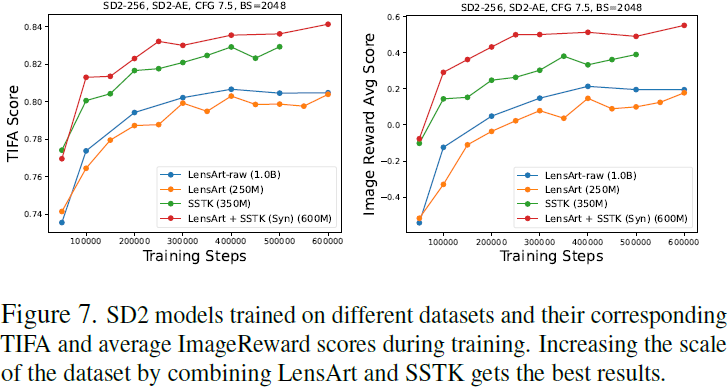
训练数据的质量是数据扩展的前提条件。与使用有噪数据源训练相比,高质量的子集不仅可以提高图像生成质量,还可以保留图像文本对齐。LensArt 比其未经筛选的 10 亿数据源小 4 倍,移除了数亿条有噪数据。然而,使用这个高质量子集训练的模型将生成图像的平均审美分数 [23] 从 5.07 提高到 5.20。这是因为 LensArt 的平均审美分数为 5.33,高于 LensArt-raw 中的 5.00。此外,如图 7 所示,使用 LensArt 训练的 SD2 模型在 TIFA 分数上与使用原始版本训练的模型相比达到了类似的水平,表明过滤不会损害图像文本对齐。原因是在激进的过滤下仍保留了足够的常识知识,同时消除了大量的重复和长尾数据。

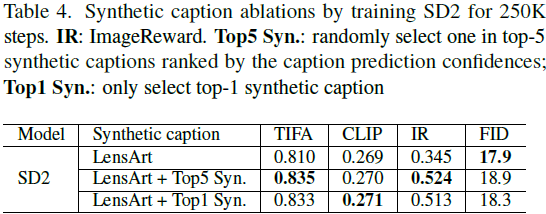
4.3. 通过合成标题扩展知识
为了增加较小但质量较高的数据的有效文本监督,我们采用了一种内部图像标题模型,类似于 BLIP2 [24],来生成合成标题。如图 9 所示,标题模型为每个图像生成五个通用描述,按预测置信度排序。其中一个合成标题和原始 alt-text 以 50% 的概率随机选取与图像配对进行模型训练。因此,我们将图像文本对加倍,并显著增加了图像-名词对,如表 3 所示。通过合成标题扩展的文本监督,使图像文本对齐和保真度得到一致提升,如表 4 所示。具体来说,LensArt 的消融表明,合成标题显著提高了 ImageReward 分数。此外,我们发现随机从前 5 个合成标题中选择一个略优于始终选择前 1 个,这被采用为合成标题的默认训练方案。与 PixArt-α 不同,后者始终用长合成标题替换原始标题,我们提供了一种通过随机翻转标题来增加图像文本对的替代方法,这与 DALL-E3 的标题增强工作一致 [3]。
4.4. 数据扩展提高了训练效率
组合数据集。随着数据集规模的增加,文本图像对齐和图像质量可以进一步提高。在这里,我们比较了在不同数据集上训练的 SD2 模型,并比较了它们的收敛速度:具有合成标题的 1)LensArt 2)SSTK 和 3)LensArt + SSTK 。我们还将使用未经筛选的 LensArt-raw 进行训练作为基线。图7 显示,与仅在 LensArt 或 SSTK 上训练的模型相比,将 LensArt 和 SSTK 组合起来可以显著提高收敛速度和两个指标的上限。使用 LensArt + SSTK 训练的 SDXL 模型在 100K 步时达到了 0.82+ TIFA 分数,比仅使用 LensArt 训练的 SDXL 快 2.5 倍。
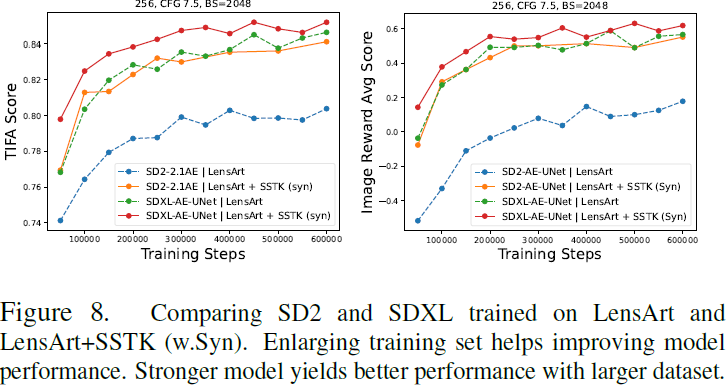
在更大数据集上,高级模型表现更佳。图 8 显示,当在扩展(组合)数据集上训练时,SD2 模型可以获得显著的性能提升。即使在使用扩展数据集训练时,SDXL 仍然比 SD2 模型获得性能提升,这表明容量较大的模型在数据集规模增加时具有更好的性能。
5. 更多扩展性质
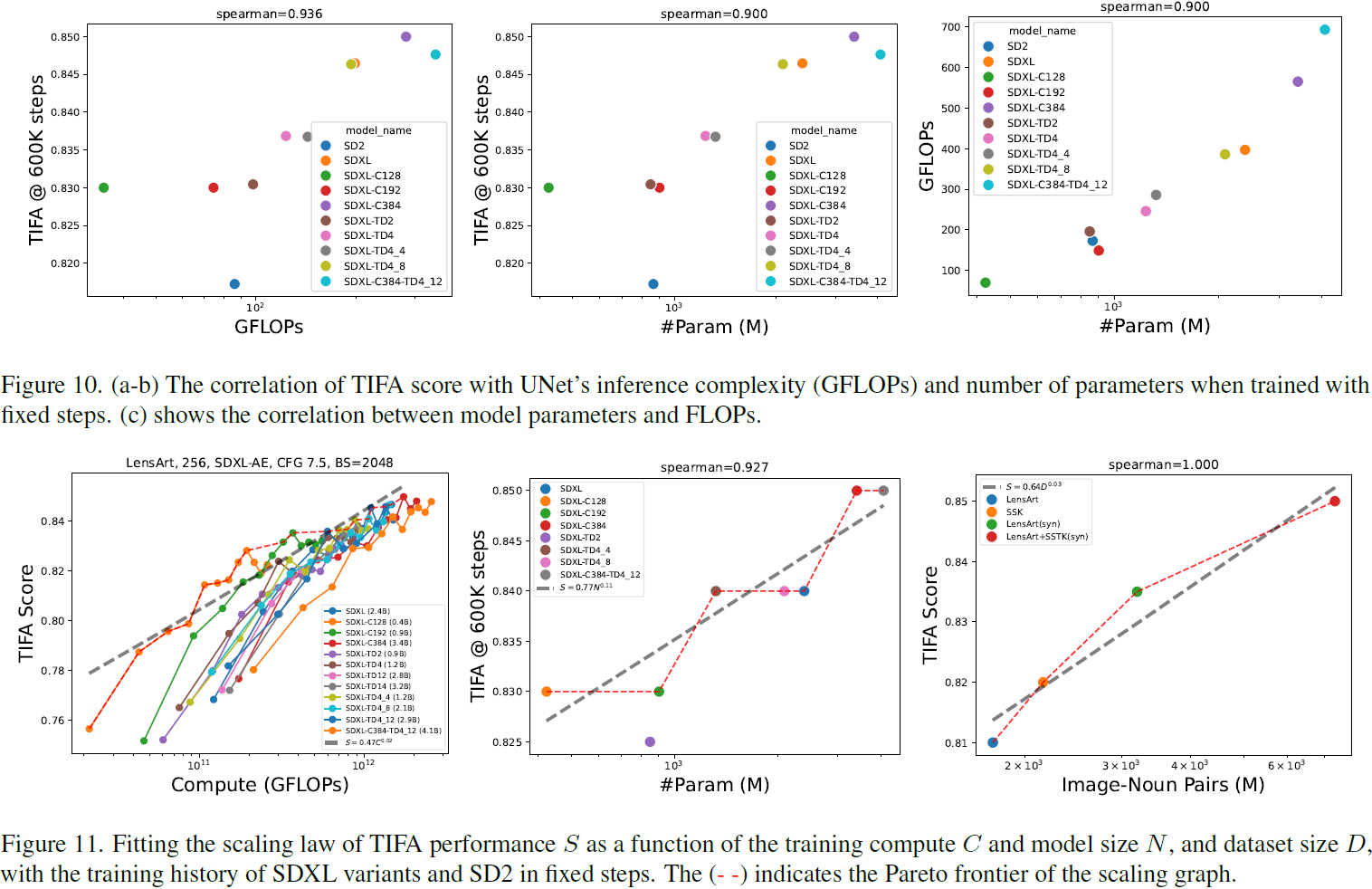
性能与模型 FLOPs 之间的关系。对于所有检验的 SD2 和 SDXL 变体,图 10(a-b)显示了在固定步数(即,600K)获得的 TIFA 分数与模型计算复杂度(GFLOPs)以及模型大小(#Params)之间的相关性。我们看到 TIFA 分数与 FLOPs 的相关性稍微好于参数,表明在训练预算充足时,模型计算的重要性,这与我们在第 3 节中的发现一致。
性能与数据量之间的关系。图11(c)显示了 SD2 的 TIFA 分数与数据集大小(以图像-名词对的数量表示)之间的相关性。每个图像-名词对定义为一个图像与其标题中的一个名词配对。它衡量了细粒度文本单元与图像之间的交互。当扩展清理后的数据时,我们看到 TIFA 与图像-名词对的规模呈线性相关。与具有类似数量的图像-名词对的 LensArt-raw 相比,LensArt+SSTK 要好得多,这表明了数据质量的重要性。
数值缩放定律。LLMs 的缩放定律 [17, 21] 揭示了 LLM 的性能作为数据集大小、模型大小和计算预算的函数具有精确的幂律缩放。在这里,我们为 SDXL 变体和 SD2 拟合了类似的缩放函数。TIFA 分数 S 可以是总计算 C(GFLOPs)、模型参数大小 N(M参数)和数据集大小 D(M图像-名词对)的函数,如图 11 所示。具体来说,通过帕累托边界数据点,我们可以拟合幂律函数为 S = 0.47C^0.02,S = 0.77N^0.11 和 S = 0.64D^0.03,它们在给定充分训练的情况下近似于性能范围。与 LLMs 类似,我们看到较大的模型更具样本效率,而较小的模型更具计算效率。
低分辨率下的模型评估。人们可能会想知道模型的相对性能是否会在高分辨率训练时发生变化,从而缓解模型之间的差距。在附录中,我们展示了持续训练 512 分辨率的模型略微改善了它们的 256 分辨率指标,但没有明显变化。尽管可以通过高质量的微调来改善图像质量和审美 [8],但在相同数据上训练时,较差的模型很难超越,特别是当高分辨率数据远少于其低分辨率版本时。大多数构图能力是在低分辨率下开发的,这使我们能够在低分辨率训练的早期阶段评估模型的性能。
6. 结论
我们对基于扩散的 T2I 模型的扩展性质进行了系统研究,包括扩展去噪骨干和数据集的影响。我们的研究证明了通过适当扩展现有的大规模数据集,可以改善 T2I 模型的性能,从而提高了文本-图像对齐和图像质量,以及训练效率。我们希望这些发现能够使社区更多地追求扩展性能更高的模型。
相关文章:
(2024,扩展Transformer和数据,SDXL,SD2,DiT与 UNet)基于扩散的文本到图像生成的可扩展性
On the Scalability of Diffusion-based Text-to-Image Generation 公和众和号:EDPJ(进 Q 交流群:922230617 或加 VX:CV_EDPJ 进 V 交流群) 目录 0. 摘要 3. 扩展 Denoising 骨干 3.1. 现有的 UNet 设计 3.2. UNe…...

redis_watchDog机制
文章目录 介绍机制介绍任务开始任务释放 介绍 redis的watchDog机制实现了超时续约的功能,简单来说就是在获取锁成功以后,开启一个定时任务,这个任务每隔一段时间(relaseTime / 3),重置超时时间,避免的因业务阻塞导致锁…...
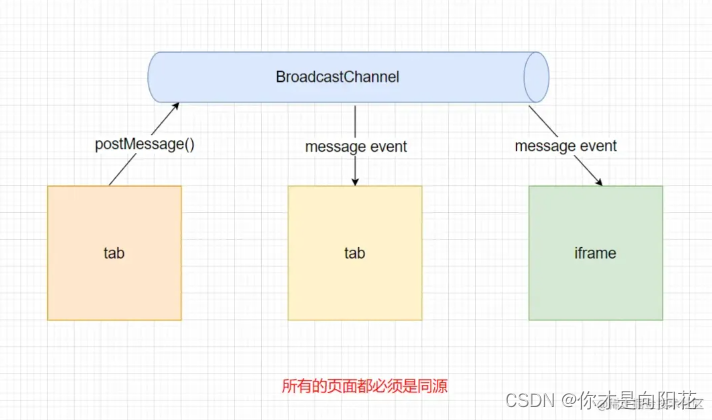
浏览器跨标签页通信的方式都有哪些
跨标签页的实际应用场景: 1. 共享登录状态: 用户登录后,多个标签页中需要及时获取到登录状态,以保持一致的用户信息。这种情况,可以使用浏览器的 localStorage 或者 sessionStorage 来存储登录状态,并通过…...
Javascript 无处不在的二分搜索
我们知道二分查找算法。二分查找是最容易正确的算法。我提出了一些我在二分搜索中收集的有趣问题。有一些关于二分搜索的请求。我请求您遵守准则:“我真诚地尝试解决问题并确保不存在极端情况”。阅读完每个问题后,最小化浏览器并尝试解决它。 …...

JavaScript 流程控制-分支
一、流程控制 流程控制主要有三种结构,分别是顺序结构、分支结构和循环结构。 二、顺序流程控制 顺序结构,没有特定的语法结构,程序会按照代码的先后顺序,依次执行, 三、分支流程控制 if 语句 1、分支结构 由上到下…...
ctfhub-ssrf(2)
1.URL Bypass 题目提示:请求的URL中必须包含http://notfound.ctfhub.com,来尝试利用URL的一些特殊地方绕过这个限制吧 打开环境发现URL中必须包含http://notfound.ctfhub.com,先按照之前的经验查看127.0.0.1/flag.php,发现没什么反应,按照题…...

python中中英文打印对齐解决方案
在python中,有时候会出现中英文混合输出的情形,但是由于中文默认是全角格式(一个中文字符占用两个字符宽度),这会对python原生的print函数带来一些障碍。尤其是用户用print对齐输出的时候,这种差异会导致文…...

Objective-C网络数据捕获:使用MWFeedParser库下载Stack Overflow示例
概述 Objective-C开发中,网络数据捕获是一项常见而关键的任务,特别是在处理像RSS源这样的实时网络数据流时。MWFeedParser库作为一个优秀的解析工具,提供了简洁而强大的解决方案。本文将深入介绍如何利用MWFeedParser库,以高效、…...
MATLAB数据类型和运算符+矩阵创建
个人主页:学习前端的小z 个人专栏:HTML5和CSS3悦读 本专栏旨在分享记录每日学习的前端知识和学习笔记的归纳总结,欢迎大家在评论区交流讨论! 文章目录 ✍一、MATLAB数据类型和运算符💎1 MATLAB的数据类型🌹…...

UE5下载与安装
官方网站:https://www.unrealengine.com/zh-CN 1、下载启动程序安装包。 登录官网后,点击首页右侧下载按钮下载Epic Games启动程序的安装包,如下图: 2、安装启动程序。 双击步骤1所下载安装软件,如下图:…...

RabbitMQ和Minio实现头像存储
使用 RabbitMQ 处理用户头像上传任务,同时将用户头像存储在 Minio 中是一个常见的应用场景。该示例将展示如何在 Spring Boot 项目中使用 RabbitMQ 和 Minio 实现此功能。示例包括两个部分:一是将头像上传任务推送到 RabbitMQ 队列中;二是从队…...
react结合Redux实现全局状态管理
React与Redux结合使用,可以为React应用提供集中式的状态管理和复杂的业务逻辑处理能力。以下是React中使用Redux的基本步骤和关键概念: 安装所需库 确保已经安装了React和ReactDOM。然后安装Redux及其配套库: npm install redux react-redu…...
2024面试软件测试,常见的面试题(上)
一、综合素质 1、自我介绍 面试官您好,我叫XXX,一直从事车载软件测试,负责最多的是中控方面。 以下是我的一些优势: 车载的测试流程我是熟练掌握的,且能够独立编写测试用例。 平时BUG提交会使用到Jira,类似…...

【VUE】Vue项目打包报告生成:让性能优化触手可及
Vue项目打包报告生成:让性能优化触手可及 Vue.js是一款流行的前端框架,开发者在使用Vue.js构建项目时,生产环境的性能优化尤为重要。为了帮助开发者分析和优化打包出来的资源,生成打包报告是一个不可或缺的步骤。本文将介绍几种在…...
git简单实践
拉取远程仓库 git clone -b main gitgithub.com:xianbingC/MultiQueueThreadpool.git创建开发分支 git checkout -b c11 # 创建本地分支C11并切换过去 git push origin c11 # 提交到远程,并在远程仓库创建该分支提交代码 第一次提交会提示设置邮箱和用户名&am…...
华为云服务镜像手动更换
操作步骤: 1、进入华为云首页点击云容器引擎CCE; 2、选择你所要更换镜像的环境【这里以dev环境演示】; 3、点击dev环境后选择顶部的命名空间,点击【工作负载】中右侧栏的【升级】按钮; 4、点【更换镜像】选择你在test…...
Python 天气预测
Python天气预测通常涉及到数据采集、数据预处理、选择和训练模型、以及预测和可视化等步骤。以下是使用Python进行天气预测的一般流程: 数据采集 使用爬虫技术从天气网站(如Weather Underground、中国天气网等)爬取历史天气数据,…...

计算机视觉——基于OpenCV和Python进行模板匹配
模板匹配? 模板匹配是它允许在一幅较大的图像中寻找是否存在一个较小的、预定义的模板图像。这项技术的应用非常广泛,包括但不限于图像识别、目标跟踪和场景理解等。 目标和原理 模板匹配的主要目标是在一幅大图像中定位一个或多个与模板图像相匹配的…...
2024-Java-Maven学习笔记
Maven Maven是一个Java项目管理和构建工具,作用:定义(规范)项目结构、项目依赖、使用统一的方式自动化构建(clean、compile)。 提供了一套依赖管理机制:利用仓库统一管理jar包,利用…...
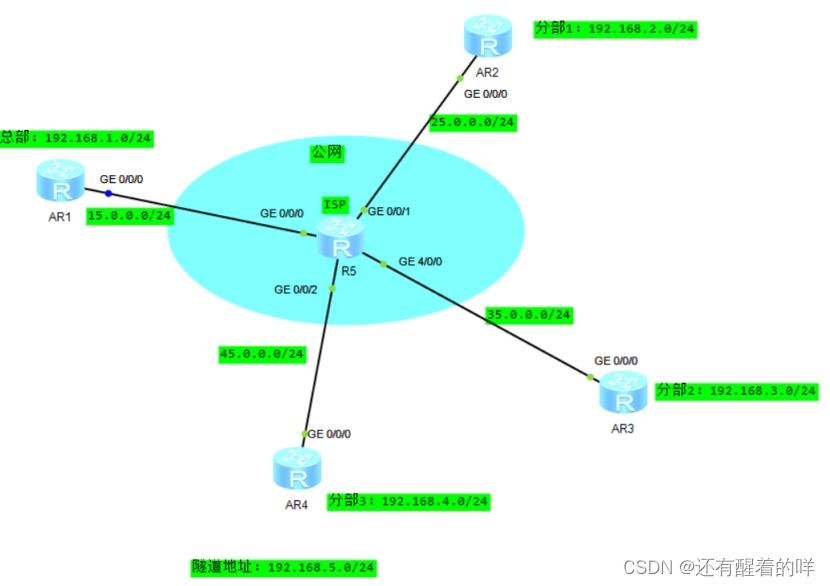
【HCIP学习】OSPF协议基础
一、OSPF基础 1、技术背景(RIP中存在的问题) RIP中存在最大跳数为15的限制,不能适应大规模组网 周期性发送全部路由信息,占用大量的带宽资源 路由收敛速度慢 以跳数作为度量值 存在路由环路可能性 每隔30秒更新 2、OSPF协议…...

elmentui树形表格使用Sortable拖拽展开行时拖拽bug
1、使用elemntui的el-table使用Sortable进行拖拽,如下 const el this.$el.querySelector(.el-table__body-wrapper tbody) Sortable.create(el, {onEnd: (event) > {const { oldIndex, newIndex } event//拿到更新前后的下标即可完成数据的更新} })2、但是我这…...

【笔试训练】day6
1.大数加法 思路: 高精度板子,停留一下都是罪过! 代码: class Solution { public:string solve(string s, string t) {vector<int> a;vector<int> b;for(int is.size()-1;i>0;i--)a.push_back(s[i]-0);for(int …...

标准版uni-app移动端页面添加/开发操作流程
页面简介 uni-app项目中,一个页面就是一个符合Vue SFC规范的.vue文件或.nvue文件。 .vue页面和.nvue页面,均全平台支持,差异在于当uni-app发行到App平台时,.vue文件会使用webview进行渲染,.nvue会使用原生进行渲染。…...

VMware 安装配置 Ubuntu(最新版、超详细)
Linux 系列教程: VMware 安装配置 Ubuntu(最新版、超详细)FinalShell 远程连接 Linux(Ubuntu)系统Ubuntu 系统安装 VS Code 并配置 C 环境 文章目录 1. 下载安装 VMware2. 检查网络适配器3. Ubuntu 下载4. 创建虚拟机5…...
clickhouse ttl不生效
现象: 日志保留31天, 但是发现1年前的数据还有。 表结构: CREATE TABLEads_xxxx_metrics_1m_local (static_time String COMMENT 统计时间,......) ENGINE ReplacingMergeTree (process_time) PARTITION BYtoYYYYMMDD (toDate (static_tim…...

前端打包webpack vite
起步 | webpack 中文文档 | webpack中文文档 | webpack中文网 npm run build 1webpack: mkdir webpack-demo cd webpack-demo npm init -y npm install webpack webpack-cli --save-dev vite : 快速上手 | Vue.js...
Cesium之home键开关及相机位置设置
显隐控制 设置代码中的homeButton var TDT_IMG_C "https://{s}.tianditu.gov.cn/img_c/wmts?servicewmts&requestGetTile&version1.0.0" "&LAYERimg&tileMatrixSetc&TileMatrix{TileMatrix}&TileRow{TileRow}&TileCol{TileCol}…...
nginx根据二级目录转发服务以及带/和不带/的区别
在nginx中配置proxy_pass代理转发时,如果在proxy_pass后面的url加/,表示绝对根路径;如果没有/,表示相对路径,把匹配的路径部分也给代理走。具体实例如下 1.配置文件location带/且proxy_pass带/ server {listen 80;se…...
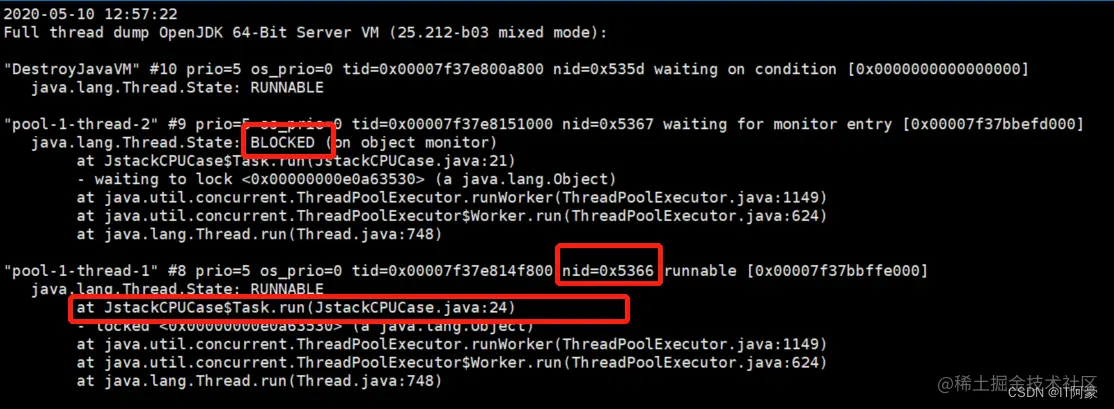
JVM 性能调优命令(jps,jinfo,jstat,jstack,jmap)
常用命令:jps、jinfo、jstat、jstack、jmap jps jps查看java进程及相关信息 jps -l 输出jar包路径,类全名 jps -m 输出main参数 jps -v 输出JVM参数jps命令示例 显示本机的Java虚拟机进程: # jps 15729 jar 92153 Jps 90267 Jstat显示主类…...
探索 IntelliJ IDEA 2024.1最新变化:全面升级助力编码效率
探索 IntelliJ IDEA 2024.1最新变化:全面升级助力编码效率 文章目录 探索 IntelliJ IDEA 2024.1最新变化:全面升级助力编码效率摘要引言 IntelliJ IDEA 2024.1 最新变化关键亮点全行代码补全 Ultimate对 Java 22 功能的支持新终端 Beta编辑器中的粘性行 …...
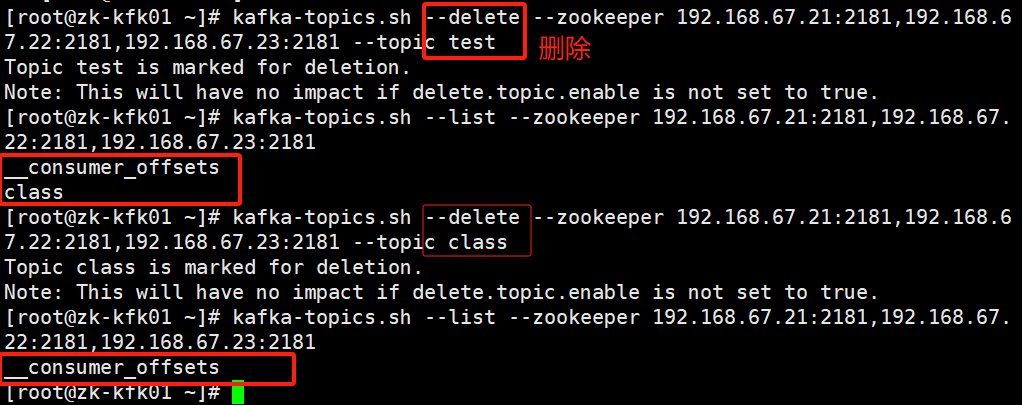
【Kafka】Zookeeper集群 + Kafka集群
Zookeeper 概述 Zookeeper是一个开源的分布式的,为分布式框架提供协调服务的Apache项目。 Zookeeper 工作机制★★★ Zookeeper从设计模式角度来理解: 1)是一个基于观察者模式设计的分布式服务管理框架; 它负责存储和管理大家都关…...
递归 python
↵一、简单理解 解决问题的一种方法,它将问题不断的分成更小的子问题,直到子问题可以用普通的方法解决。通常情况下,递归会使用一个不停调用自己的函数。 【注】:每一次递归调用都是在解决一个更小的问题,如此进行下…...

解读科技智慧公厕改变生活的革命性创新之路
公共厕所,作为城市基础设施的一部分,一直以来都备受人们诟病。脏乱差、设施老旧、管理混乱,成为公共厕所长期存在的问题。然而,随着科技的不断进步,智慧公厕应运而生,为解决公厕难题,智慧公厕源…...
鸿蒙ArkTS小短剧开源项目进行中
鸿蒙小短剧开源项目进行中 短剧项目名称:CCShort-TV 短剧项目名称:CCShort-TV 使用ArtTS语言,API9以上,HarmonyOS系统的短剧开源代码,使用GSYVideoPlayer作为核心播放器的小短剧。主要以ArkTS,ArkUI编写为…...

基于STM32的RFID智能门锁系统
本文针对RFID技术,着重研究了基于单片机的智能门锁系统设计。首先,通过链接4*4按键模块与主控STM32,实现了多种模式,包括刷卡开锁、卡号权限管理、密码开锁、修改密码、显示实时时间等功能。其次,采用RC522模块与主控S…...
消息队列的简介
什么是消息队列? 消息队列就是用于不同系统 不同服务之间异步地传递信息,就是不用生产者和消费者同时在线或者直接连接,消息存储在队列中,直到消费者准备处理 消息队列的核心概念: 生产者:发送消息的一方 消费者:处理消息的一方 队列:存储队列的一方 优点: 1解耦: 生产者和消费…...
一个开箱即用的物联网项目,开源免费可商用
一、平台简介 今天给大家推荐一款开源的物联网项目,简单易用,非常适合中小团队和个人使用,项目代码和文档完全开源,个人和公司都可以应用于商业项目,只需要保留开源协议文件即可。 本项目可应用于智能家居、农业监测…...
成为程序员后你都明白了什么呢?
成为程序员后你都明白了什么? 简介:探讨成为程序员后的收获和体会,以及对未来的展望。 方向一:技术成长 在技术成长方面,我认识到编程不仅仅是一种技能,更是一种思维方式。在不断地学习和实践中…...
Rust常见陷阱 | 算术溢出导致的 panic
Rust作为一种内存安全性语言,对于算术运算中的溢出处理特别严格。由于Rust默认会在debug模式下进行算术操作的溢出检查,任何溢出行为都会导致panic,这样能够帮助开发者在调试阶段发现潜在的溢出错误。尽管在release模式下,溢出会导致值的截断,并不会引起panic,但忽视这一…...
SRS服务接入华为云CDN
一、srs配置 正常的标准配置即可,需打开hls推流即可,一般配置中默认打开 二、华为云cdn配置 1.登录华为云,找内容分发网络cdn 2.点击域名管理,点击添加域名 3.配置加速域名 4.选择点播加速 5.添加源站 配置源站地址…...
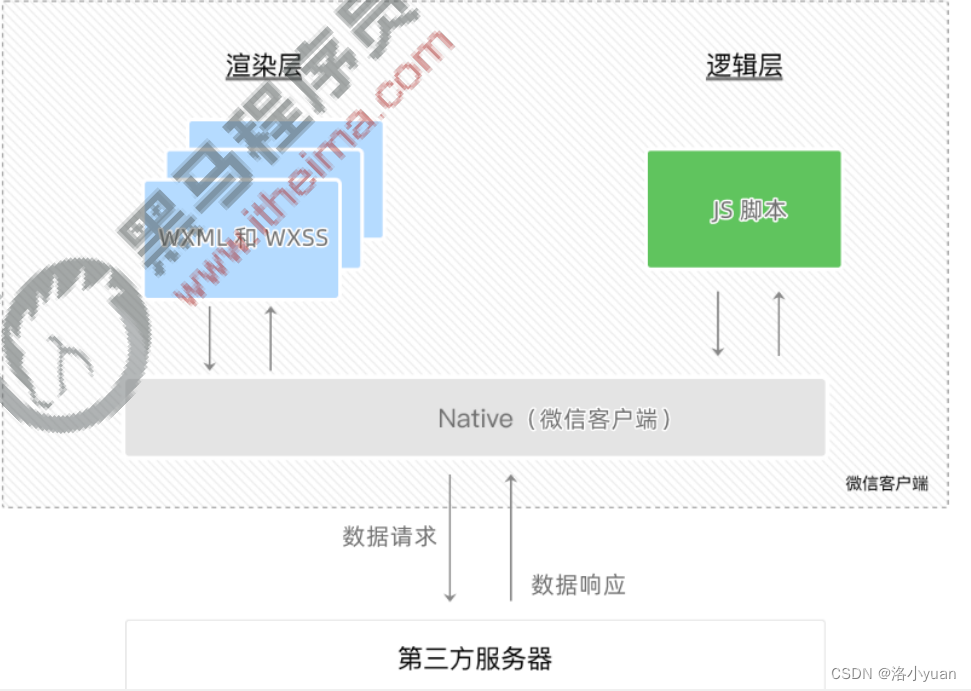
微信小程序----微信小程序基础
能够知道如何创建小程序项目能够清楚小程序项目的基本组成结构能够知道小程序页面由几部分组成能够知道小程序中常见的组件如何使用能够知道小程序如何进行协同开发和发布 一.小程序简介 1. 小程序与普通网页开发的区别 1. 运行环境不同 网页运行在浏览器环境中小程序运行在…...

牛客周赛 Round 39(A,B,C,D,E,F,G)
比赛链接 官方题解(视频) B题是个贪心。CD用同余最短路,预处理的完全背包,多重背包都能做,比较典型。E是个诈骗,暴力就完事了。F是个线段树。G是个分类大讨论,出题人钦定的本年度最佳最粪 题目…...
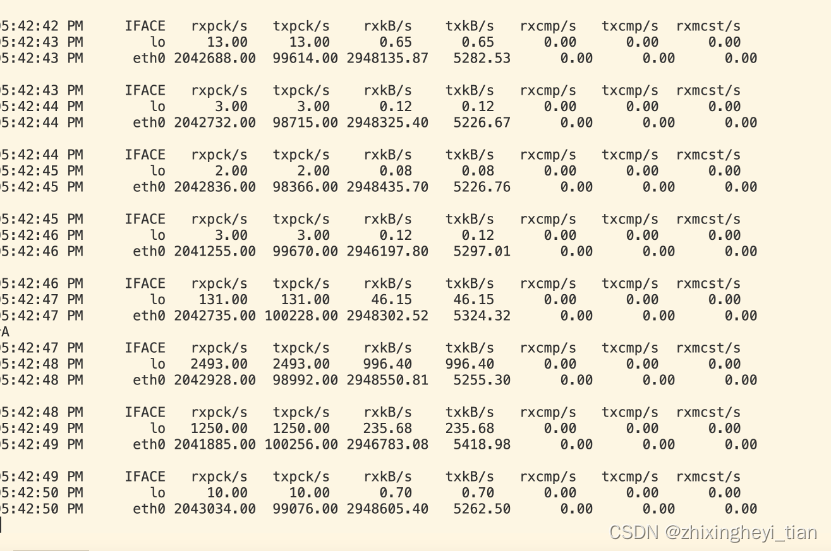
性能优化工具
CPU 优化的各类工具 network netperf 服务端: $ netserver Starting netserver with host IN(6)ADDR_ANY port 12865 and family AF_UNSPEC$ cat netperf.sh #!/bin/bash count$1 for ((i1;i<count;i)) doecho "Instance:$i-------"# 下方命令可以…...

【简单介绍下R-Tree】
🌈个人主页: 程序员不想敲代码啊 🏆CSDN优质创作者,CSDN实力新星,CSDN博客专家 👍点赞⭐评论⭐收藏 🤝希望本文对您有所裨益,如有不足之处,欢迎在评论区提出指正,让我们共…...

比特币叙事大转向
作者:David Lawant 编译:秦晋 要理比特币解减半动态,最关键的图表是下面这张,而不是价格图表。它显示了自 2012 年以来,矿业总收入与比特币现货交易量的比例,并标注了三个减半日期。 虽然矿工仍然是比特币生…...
Spring的事务传播机制有哪些
Spring的事务传播机制有哪些? Spring的事务传播机制用于控制在多个事务方法相互调用时事务的行为。 在复杂的业务场景中,多个事务方法之间的调用可能会导致事务的不一致,如出现数据丢失、重复提交等问题,使用事务传播机制可以避…...
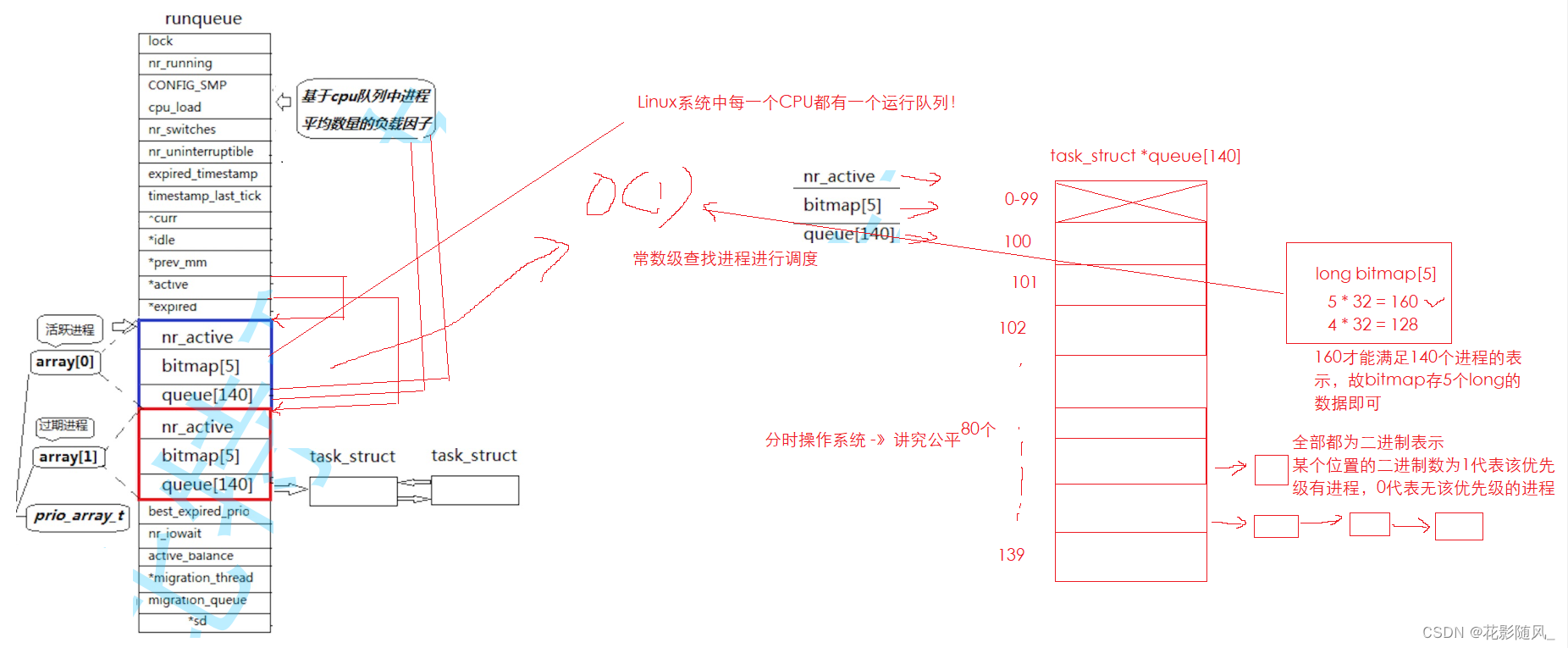
【Linux系统】地址空间 Linux内核进程调度队列
1.进程的地址空间 1.1 直接写代码,看现象 1 #include<stdio.h>2 #include<unistd.h>3 4 int g_val 100;5 6 int main()7 {8 int cnt 0;9 pid_t id fork();10 if(id 0)11 {12 while(1)13 {14 printf(&…...
centos搭建yum源
目录 1.createrepo简介 2.repo搭建思路 3.安装 4.使用 1.createrepo简介 createrepo 是一个用于创建 RPM 包的工具,它可以帮助你创建一个本地的 YUM 仓库。createrepo 并不是用于运行 YUM 仓库服务的软件,而是用来生成仓库的元数据,使得 YUM 可以理解和使用这个仓库。 …...
使用Docker搭建一主二从的redis集群
文章目录 一、根据基础镜像构建三个docker容器二、构建master机三、配置slave机四、测试 本文使用 主机指代 物理机、 master机指代“一主二从”中的 一主, slave机指代“一主二从”中的 二从 一、根据基础镜像构建三个docker容器 根据本文第一章(…...
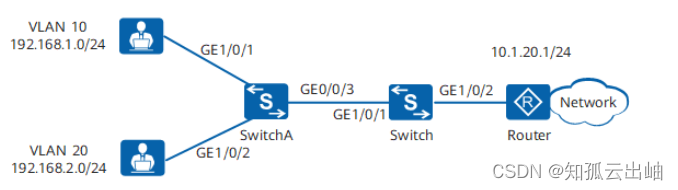
华为配置通过流策略实现流量统计
配置通过流策略实现流量统计示例 组网图形 图1 配置流策略实现流量统计组网图 设备 接口 接口所属VLAN 对应的三层接口 IP地址 SwitchA GigabitEthernet1/0/1 VLAN 10 - - GigabitEthernet1/0/2 VLAN 20 - - GigabitEthernet1/0/3 VLAN 10、VLAN 20 - - S…...
解决el-dialog弹框出现后页面滚动条可滚动问题
<el-dialogtitle"提示" //title属性用于定义标题,它是可选的,默认值为空:visible.sync"dialogVisible" //是否显示 Dialogwidth"30%":before-close"handleClose" //关闭前的回调,会暂停 Dialog 的…...

基于微信小程序+JAVA Springboot 实现的【智慧乡村旅游服务平台】app+后台管理系统 (内附设计LW + PPT+ 源码+ 演示视频 下载)
项目名称 项目名称: 基于微信小程序的智慧乡村旅游服务平台的设计与实现 项目技术栈 该项目采用了以下核心技术栈: 后端框架/库: Java SSM框架数据库: MySQL前端技术: 微信开发者工具、uni-app其他技术:…...

谷歌全力反击 OpenAI:Google I/O 2024 揭晓 AI 新篇章,一场激动人心的技术盛宴
🚀 谷歌全力反击 OpenAI:Google I/O 2024 揭晓 AI 新篇章,一场激动人心的技术盛宴! 在这个人工智能的全新时代,只有谷歌能让你眼前一亮!来自全球瞩目的 Google I/O 2024 开发者大会,谷歌用一场…...
第10章:新建MDK工程-寄存器版
0. 《STM32单片机自学教程》专栏 本文作为专栏《STM32单片机自学教程》专栏其中的一部分,返回专栏总纲,阅读所有文章,点击Link: STM32单片机自学教程-[目录总纲]_stm32 学习-CSDN博客...

vue项目打包后也能配置静态资源路径
根目录public下新建config.json配置文件,如: {"VITE_URL_3DTILES_BIG":"http://192.168.1.1:88/abu1/tW4fYCyXi/tileset.json","VITE_URL_3DTILES_SMALL":"http://192.168.1.1:181/3dtile_200/tileset.json",&…...
EasyExcel自定义数据格式化
自定格式常量类 public class ExcelFormatConstants {public static final String DATE_FORMAT "yyyy-MM-dd";public static final String NUMBER_FORMAT_DEFAULT "#,##0.00";public static final String NUMBER_FORMAT_FOUR_DECIMAL "#,##0.0000…...
摸鱼大数据——Linux搭建大数据环境(Hadoop高可用环境搭建)六
Hadoop高可用环境搭建 确定提前安装好了hadoop和zookeeper 1.删除原有数据文件 三台机器都要进行删除 可以使用CRT发送交互到所有会话 rm -rf /export/data/hadoop-3.3.0 2.安装软件 三台机器都要进行安装 注意: 如果网络较慢安装失败,那就重复安装即可 # 实现多个服务的通讯 …...
vue2人力资源项目9权限管理
页面搭建 <template><div class"container"><div class"app-container"><el-button size"mini" type"primary">添加权限</el-button><el-table-column label"名称" /><el-table-co…...
EIP-4844对Polygon的意义
1. 引言 Dencun 升级引入了L2新资源,并降低了与calldata相关的交易手续费。 本文要点为: EIP-4844 引入了 blobspace —— 一种用于高效管理大型二进制对象 (large binary objects,BLOB) 的数据库存储概念。Blobs 将降低rollups的交易成本…...

前端学习第一课
AJAX 事先说明,这只是记录,并不是从零到一的教学内容,如果想要学习的话,可以跳过本文章了 ok,转回正题,正如上面所说,这只是记录。其实我是有一定的前端基础的,也做过涉及相关的开发…...

前端启若依项目 后端配置 若依
...
CSAP_MAT_BOM_MAINTAIN修改时,字段内容为空,不生效处理
在函数CSAP_MAT_BOM_MAINTAIN修改BOM时,将字段内容改为空时,不会生效的时候,需要在调用前,调用函数CALO_INIT_API,传入参数data_reset_sign 为空,即可。 CALL FUNCTION CALO_INIT_APIEXPORTINGdata_reset_s…...