单片机_简单AI模型训练与部署__从0到0.9
IDE: CLion
MCU: STM32F407VET6
一、导向
以求知为导向,从问题到寻求问题解决的方法,以兴趣驱动学习。
虽从0,但不到1,剩下的那一小步将由你迈出。本篇主要目的是体验完整的一次简单AI模型部署流程,从数据采集到模型创建与训练,再到部署单片机上。选定的训练方向也非常简单,既不是手势识别、语音识别等这些较为复杂的模型,也不是使用一些第三方的预训练模型,而是简简单单地“调包”搭建一个判断输入数字大小的小模型,比如在判断输入数据是否小于24。最终生成的C代码其内存、存储占用均为10KB,也可缩减至不到1KB
既然是“从零开始”,那么就不需要介绍太多复杂的术语解释,但一些基本的概念还是需要了解的。该篇最主要的目的就是体验,不需要知道太多为什么,真正上手实践后,再自行学习。
此处所指的单片机是STM32系列(stm32f407vet6)
二、流程
1,STM32CubeMX的AI插件
想要触碰一个未曾熟知的领域,最重要的是要搜集信息,了解要干什么、怎么干,然后简单体验一番。那么第一步来了,我们的问题很简单,stm32单片机上怎么跑AI。带着这个问题我们使用搜索引擎可以得到一些博客,什么模型搭建、部署什么的可能也听不大懂。
但从这些博客里我们可以找到一个共同点,那就是都使用到了STM32CubeMX,虽然AI模型相关的不太懂,但这个工具软件可太熟了。
从这里我们可以获取另一个关键点,就目前所获取的信息来看stm32单片机上跑AI应是依赖STM32CubeMX的AI插件的。至于怎么配置这个AI插件,相关的博客有很多

2,AI模型
当你兴冲冲地使用CubeMX上的AI插件时,你可能会发现,缺少一件东西——AI模型
回想到前面回答中,通义(通义千问)说过导入模型
虽然网上相关博客有不少,什么手势识别、神经网络算法等等,但几乎没有几个是直接给你一个AI模型的,要么是到官网的github上找,要么是什么云盘。总之对于初学者而言,是有一些麻烦的
接下来继续发挥“不会就问”的精神
通义给了我们四个方案,但无论是官方给的,还是用什么第三方的,亦或者使用预训练模型的,总之都是有一些难度的。四种方案你可以逐一尝试,尝试下来后,你可能会发现预训练、官方模型库、第三方库这些方案太难了,因为涉及到大量陌生知识。





自己训练模型看着比较可行,因为从下面可以看到,自己训练一个简单模型就两步,收集数据和python编程来训练模型。无论是收集数据,还是编程,似乎都是非常清晰的过程。
当然,上面的结论也是问出来的。当通义给你一个问题的回答,而你对其中的一些概念又含混不清的时候,你可以把自己的猜测反问给通义,且不必担心通义出言不逊。
反问后,无论你的猜测是否正确,你最终都会被指导一个正确的方向。
既然确定了步骤,不妨问问更细节的一些东西,这里需要自行提问,下面提供一个简单的示例




3,数据采集
前面说过,既然是初学者,那么一切从简,怎么简单怎么来。这里先说一个前置信息,AI模型训练需要的数据集,一般是保存在.csv文件里的,打开后你会发现这跟Excel表格大差不差。
使用记事本打开后,你会发现头部会有一些标签,数据是按照列来排布的
左边那一列是输入的数据,右边那一列是输出的结果,当然也可以称为类别
训练AI模型时,会用你收集到的这个数据集训练,以图中这个数据为例(二分类问题),给它左边的输入数据,让AI模型输出,然后与数据集中的右边的输出对比,来判断AI预测的结果,之后AI再不断调整权重、参数什么的,让预测更加精准。

这些前置信息,你自己也是可以收集的。这里,我们是需要一个数据集来帮我们训练,也知道数据集长成什么样子。从一些博客或者AI我们可以了解到,一般的数据集都是什么图像相关的,什么矩阵、像素、灰度之类的,那显然还是有些难度的。
所以接下来,我们讨论更简单的情况,就是给AI一个数据,让它判断是不是小于一个数,小于就输出1,大于就输出0。是不是简单很多了?
4、训练模型
我们首先要清楚,STM32上跑的这个AI模型其实是神经网络模型,它们之间的关系是这样的:
AI(人工智能)> 机器学习 > 深度学习 > 神经网络模型(非传统神经网络)
总之经过一系列问询之后,我们可以选择Keras 和TensorFlow Lite。这是一个神经网络框架,不要害怕陌生的术语名称,它只是用于训练AI的工具(你也可以理解为库或包)。
这里我补充一点就是,STM32CubeMX其实对Keras的支持其实并不算好,我们后续真正使用的是后者。


三、采集数据
正如前面所言,为了简单体验这个流程,我们就以那个判断数字是否小于某个数为训练目的。当体验过这个简单流程后,你可以放飞自我去训练了。
这里不说怎么安装Pycharm什么的,因为这是最基本的能力。
现在我们把训练目的具体化:在0-100内,判断出这个数据是否小于24。那么我们就需要生成这样的数据,为了保真,还得让数据随机起来,且小于24的和大于24的概率还不同,以增加些许难度。
这个数据可以使用python生成,那么怎么写python脚本呢?从变量命名、标识符开始学一遍python?那是大可不必的,不需要掌握python(因为你至少已掌握了C语言),只需要知道怎么让通义生成正确的代码就行了
通义生成的代码不一定可用,你把报错信息或者调试信息给它,提供给它需求,让它不断更新代码直至生成可用的代码。这里不展开细节了,下面就是可用的python代码,如果你是新安装的pycharm,那么可能会提示安装一些库,安装软件包的过程可能会有些漫长,这都是正常现象。有时间了可以自行查资料解决
import numpy as np import pandas as pd# 参数设置 filename = 'simulated_data.csv' num_points = 100000 threshold = 24 # 触发阈值 low_value_frequency = 0.33 # 低于24的值的概率# 生成数据 np.random.seed(0) data = np.random.randint(0, 101, num_points) # 生成0到100的整型数据# 生成低于24的值 low_values = np.random.binomial(1, low_value_frequency, num_points) data[low_values == 1] = np.random.randint(0, 24, np.sum(low_values))# 标记是否触发阈值 labels = (data < threshold).astype(int)# 创建DataFrame df = pd.DataFrame({'value': data, 'label': labels})# 保存到CSV文件 df.to_csv(filename, index=False)print(f"数据已生成并保存到 {filename}")正确执行完后,当前目录下就会有一个simulated_data.csv文件。

四、训练模型
虽然听着不明觉厉,其实这里我们只用非常简单有限的步骤,因为框架已经帮我们做好了绝大部分工作了。
问询你可以描述得更加具体
总之,多次让AI改进后,可以得到了一份可以训练刚才数据的代码
import pandas as pd import numpy as np import matplotlib.pyplot as plt from keras.src.callbacks import ModelCheckpoint from keras.src.layers import GRU from sklearn.model_selection import train_test_split from tensorflow.keras.models import Sequential from tensorflow.keras.layers import Dense from tensorflow.keras.models import save_model import tensorflow as tf import subprocess# 数据加载 df = pd.read_csv('simulated_data.csv') X = df['value'].values.reshape(-1, 1) # 特征值需要reshape为2D数组 y = df['label'].values# 划分训练集和测试集 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)# 创建模型 model = Sequential([Dense(10, input_shape=(1,), activation='relu'), # 输入层(同时也是隐藏层)# Dense(1, activation='sigmoid') # 输出层# GRU(16, input_shape=(1, 1), return_sequences=False), # 添加GRU层,32个单元,输入形状为 (1, 1),不返回序列Dense(18, activation='relu'), # 添加一个全连接层,32个神经元,使用ReLU激活函数Dense(1, activation='sigmoid') # 添加全连接层,输出1个节点,使用sigmoid激活函数 ])# 编译模型 model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])# 设置 ModelCheckpoint 回调函数 checkpoint = ModelCheckpoint('best_model.keras', monitor='val_accuracy', save_best_only=True, mode='max')# 训练模型 history = model.fit(X_train, y_train, validation_data=(X_test, y_test), epochs=78, batch_size=60)# 绘制训练过程中的损失 plt.figure(figsize=(12, 6)) plt.plot(history.history['loss'], label='Training Loss') plt.plot(history.history['val_loss'], label='Validation Loss') plt.title('Model Loss') plt.xlabel('Epochs') plt.ylabel('Loss') plt.legend() plt.show()# 绘制训练过程中的准确率 plt.figure(figsize=(12, 6)) plt.plot(history.history['accuracy'], label='Training Accuracy') plt.plot(history.history['val_accuracy'], label='Validation Accuracy') plt.title('Model Accuracy') plt.xlabel('Epochs') plt.ylabel('Accuracy') plt.legend() plt.show()# 模型保存 save_model(model, 'model/stm32_model.keras') # 将 .keras 模型转换为 .tflite 格式 converter = tf.lite.TFLiteConverter.from_keras_model(model)# # 使用 Select TF Ops,虽然允许把Keras转为TFLite模型,但是CubeMX的AI插件不支持 # converter.target_spec.supported_ops = [ # tf.lite.OpsSet.TFLITE_BUILTINS, # 支持 TFLite 内置操作 # tf.lite.OpsSet.SELECT_TF_OPS # 支持 TensorFlow 原生操作 # ] # # 禁用实验性降低张量列表操作 # converter._experimental_lower_tensor_list_ops = Falsetflite_model = converter.convert()# 保存 TFLite 模型 with open('model/stm32_model.tflite', 'wb') as f:f.write(tflite_model) print("TFLite 模型已保存")# # 下面出了问题 # # 加载最佳模型 # best_model = tf.keras.models.load_model('best_model.keras') # # # 保存最佳模型 # save_model(best_model, 'model/stm32_best_model.keras') # # # 将 .keras 模型转换为 .tflite 格式 # # 转换模型 # tflite_model = converter.convert() # # # 保存 TFLite 模型 # with open('model/stm32_best_model.tflite', 'wb') as f: # f.write(tflite_model) # # print("TFLite best模型已保存")这个代码,即便你安装了所有软件包可能还会报错,这都是正常现象,可以不用管它

训练模型这一步,步骤非常清晰明了
①加载数据
②创建模型
这里面可以看到三个函数,也就是三层神经网络,你想要增加,就再添加一个函数即可。只不过经过我的测试和官方文档说明,无法使用更加复杂的层,比如GRU层(陌生术语稍微过一下就行,暂时可以不必深究)
③编译模型
回调函数先不用管它,可加可不加
④训练模型
这里只要注意这两个参数即可,一个是epochs,另一个是batch_size。前者是训练轮数,后者是每批次训练的数据量
⑤评估模型
这里其实就是图形化显示训练的结果,什么准确率、损失什么的
⑥保存模型
这里可以看到,一开始模型格式为.keras,后面就编程了.tflite。原因就是前者格式STM32CubeMX的AI插件经常无法正常加载,报一些奇奇怪怪的错。







既然这样,我们看看运行之后是什么样子的
如果这是你的第一个AI模型,成就感满满了不是
右边的第二张图(还有一张在小窗口里),可以看到随着训练轮次增加,准确率也逐渐增加
我们单看某一次的,可以发现正确率已经达到0.9988了,因为问题比较简单嘛。有时会达到1.00




五、部署推理
既然模型已经训练完毕,接下来我们就可以在本地部署,然后进行推理看看效果怎么样。(加载训练好的模型,然后输入数据,看看AI的输出是什么样的)
不过在此之前我们还要生成100个模拟数据,当做实际中的数据,用于验证模型的推理效果。
import numpy as np import pandas as pd# 参数设置 filename = 'simulated_data1.csv' num_points = 100 threshold = 24 # 触发阈值 low_value_frequency = 0.33 # 低于24的值的概率# 生成数据 np.random.seed(0) data = np.random.randint(0, 101, num_points) # 生成0到100的整型数据# 生成低于24的值 low_values = np.random.binomial(1, low_value_frequency, num_points) data[low_values == 1] = np.random.randint(0, 24, np.sum(low_values))# 标记是否触发阈值 labels = (data < threshold).astype(int)# 创建DataFrame df = pd.DataFrame({'value': data, 'label': labels})# 保存到CSV文件 df.to_csv(filename, index=False)print(f"数据已生成并保存到 {filename}")
然后就是推理(预测)了
import numpy as np from tensorflow.keras.models import load_model import pandas as pd import matplotlib.pyplot as plt# 设置 matplotlib 使用的字体 plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签 plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号# 加载模型 model = load_model('model/stm32_model.keras')# 加载验证数据集 df = pd.read_csv('simulated_data1.csv') X_test = df['value'].values.reshape(-1, 1, 1) y_test = df['label'].values# 进行推理 predictions = model.predict(X_test) predicted_labels = (predictions > 0.5).astype(int)# 输出详细结果 for i, value in enumerate(df['value']):print(f"输入数据: {value:.2f}, 预测结果: {predicted_labels[i][0]}, 实际标签: {y_test[i]}")# 计算准确率 accuracy = np.mean(predicted_labels.squeeze() == y_test) print(f"模型准确率: {accuracy * 100:.2f}%")# 可视化预测结果和真实标签的对比 plt.figure(figsize=(12, 6)) plt.plot(y_test, label='真实标签', marker='o') plt.plot(predicted_labels.squeeze(), label='预测结果', marker='x') plt.title('真实标签 vs 预测结果') plt.xlabel('样本索引') plt.ylabel('标签') plt.legend() plt.show()
我们可以看到推理后的结果,这根本就难不倒它嘛

六、加载模型
既然前面已经把模型训练了出来,接下来就可以把模型部署到单片机上了。下面先介绍一些分析模型时的问题
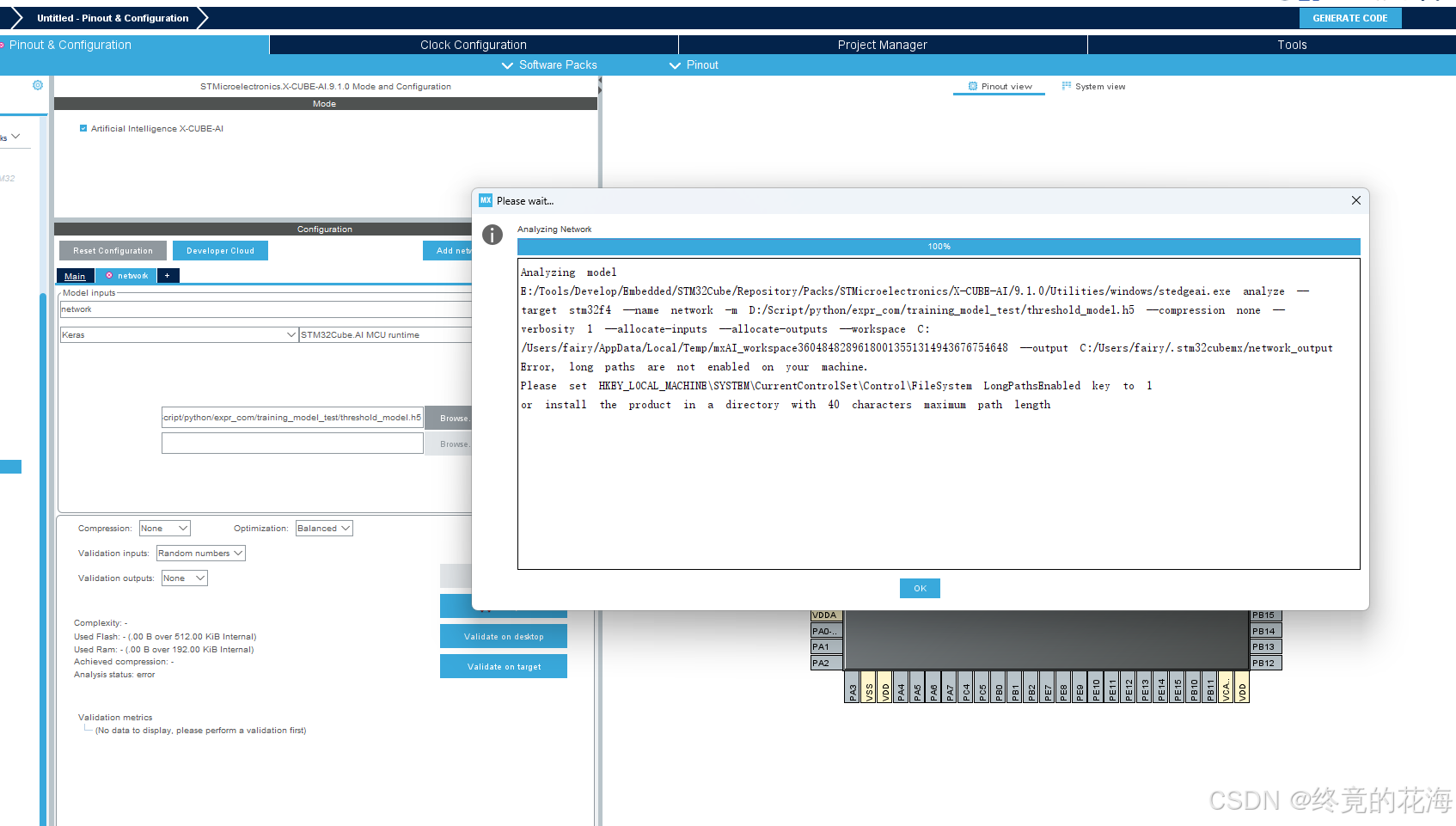
遇到这个提示后
- 在注册表编辑器中,找到路径
HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Control\FileSystem。修改或添加
LongPathsEnabled值:
- 在
FileSystem文件夹中查找名为LongPathsEnabled的DWORD (32-bit) 值。- 如果存在,双击它并将其值设置为
1。- 如果不存在,右键点击
FileSystem文件夹,选择新建->DWORD (32-bit) 值,命名为LongPathsEnabled,然后将其值设置为1。- 然后重启
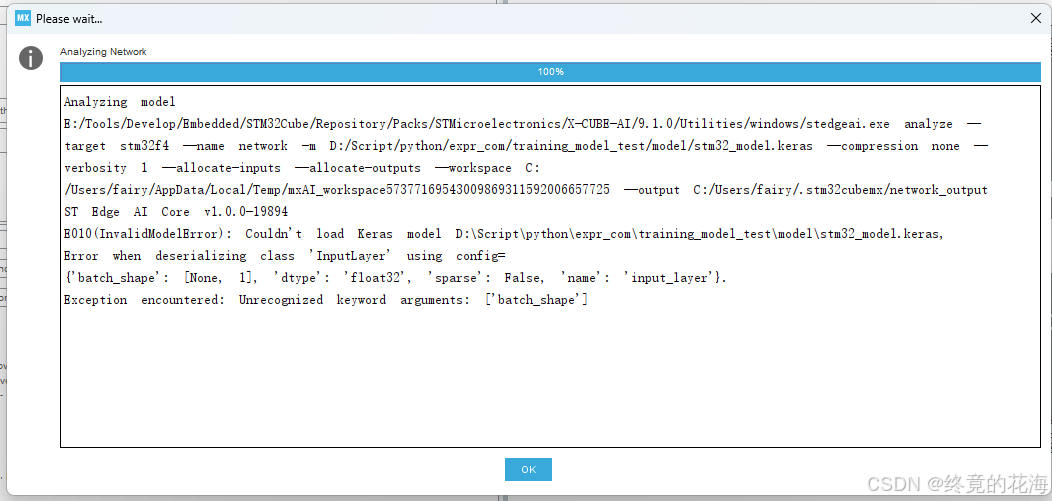
发生下面这个问题,比较奇葩,虽然提示说我们引入了batch_shape,但实际上我们没有显式引用。但只要把模型转为TFLite格式,同时不能直接使用GRU等高级层。
即便……你使用Select TF Ops,虽然可以转为TFLite模型,但是Cube的AI插件不能转换
# 模型保存
save_model(model, 'model/stm32_model.keras')
# 将 .keras 模型转换为 .tflite 格式
converter = tf.lite.TFLiteConverter.from_keras_model(model)
# 使用 Select TF Ops
converter.target_spec.supported_ops = [tf.lite.OpsSet.TFLITE_BUILTINS, # 支持 TFLite 内置操作tf.lite.OpsSet.SELECT_TF_OPS # 支持 TensorFlow 原生操作
]# 禁用实验性降低张量列表操作
converter._experimental_lower_tensor_list_ops = False
tflite_model = converter.convert()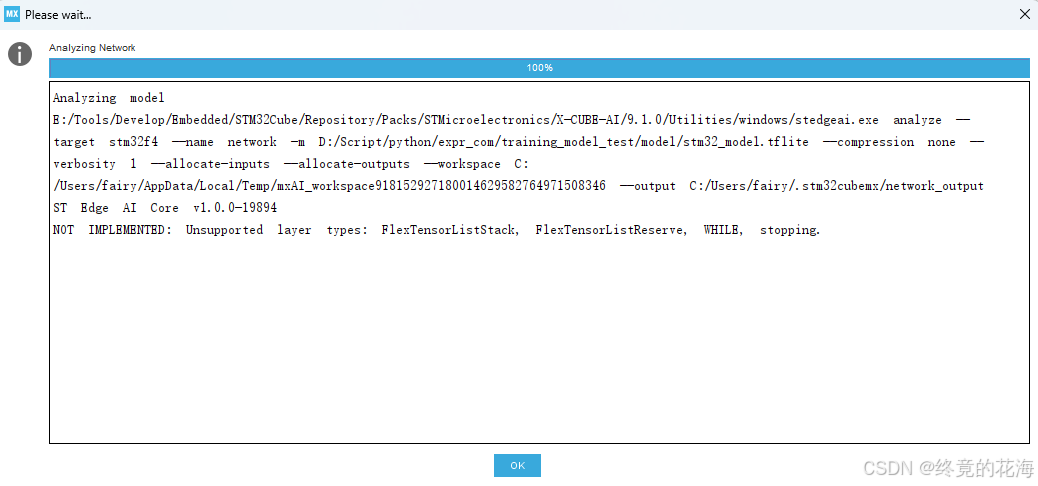
每次加载模型都要重新分析一遍
1,生成C代码
①添加AI插件
这一步有太多博客介绍了,我就说一点,把下面那个Device也勾选上,选择最后一个应用模板即可。官方文档里也很详细
②添加模型
③分析模型
点击分析即可,分析成功后应如下
我们可以看到最后一句,由于前面训练模型时也是这样,输入和输出只有一个,这里输入和输出也是一个4字节(实际为float32)
如果你想要知道模型的详细情况,可以选择这个选项,当然这都是后面了,可以自己尝试
④生成的文件
生成的模型代码就是这个文件夹了
以及Middlewares下面的这个AI库








2,移植库
如果你移植很熟练的话,这一步也没什么难度。不过要说明的是,我的工程是cmake工程,移动文件后,只需要修改CMakelists就行了。如果是Keil或者IAR的话,需要手动图形化添加。
不管是哪种,目的都一样,先把官方提供的AI库(是整个AI目录而不仅仅是Lib目录)添加到工程里,就是下面这个静态库.a
在CMakelists里就是这样,前面是什么不重要,重要的是这个库前面要加上“:”,为什么呢?我从CubeMX生成工程的CMakelists里扒出来的就是这样(疑惑的话可以多问问通义等)
target_link_libraries(libai INTERFACE :NetworkRuntime910_CM4_GCC.a) target_link_libraries(libai PRIVATE libdrivers)移植后,这个库的头文件也要包含进来,ST/AI/Inc
然后是这个X-CUBE-AI,具体过程我不描述了,移植需要多尝试、去练,讲求的是经验
总之,就两个东西,一个是官方的库,另一个是资源文件


3,使用
前面选择软件包时,由于勾选了应用模板,所以会给我们生成。这些文件中,我们只要考虑这两个文件即可
从这个头文件里可以看到,它提供了两个接口,一个是初始化,另一个是AI处理。
到资源文件中,我们可以看到这两个函数是空的,我们先补充初始化函数,直接这样添加就行了,不用管什么错误判断,因为实际上这个ai_boostrap接口就已经做好了
void MX_X_CUBE_AI_Init(void) {ai_boostrap(data_activations0); }至于函数处理,我们可以不用void MX_X_CUBE_AI_Process(void);
我们自己编写一个简单的接口,输入数据,然后返回数据。为什么前面要加上float强制转换呢?因为这个指针类型其实就是void*
float process_data_float(float input) {*(float *)data_ins[0]=input;ai_run();return *(float *)data_outs[0]; }从这个函数可以清晰地看出,把接收的数据存放进data_ins[0]指向的缓冲区,然后调用ai_run进行AI推理,之后返回data_outs[0]得到推理的结果。无论是data_ins[0]还是data_outs[0]其实都是指针,所以前面要用“*”把指针指向的缓冲区的值取出来或者修改。
接着,我们在某个按键处理中调用这个函数,输入的是从0累加到150的数据供它验证
input = 0;for (int i = 0; i < 500; ++i){result = process_data_float(input);printf("index:%f result:%f\r\n", input, result);input += 0.3;}按下按键后,串口打印的结果也符合推理结果,小于24的为1,大于24的为0。在24附近出现波动的原因也很简单,因为我提供的数据集里并没有出现浮点数,全是0-100的整数,并且模型训练轮次和数据量都比较小。
Tips:
这三行代码我想了好久才想出来,前面定义data_ins和data_outs时不是有个int8_t,这个东西把我误导了许久,问通义,它说什么标准化、偏移量、量化之类的,总之告诉我输入数据和输出数据就是一个字节(int8_t)。后来我使用CubeMX另几个选项生成模板,并查看官方手册
最终才确定转换的模型输入数据和输出数据确实是float32而不是量化后的int8_t,然后大胆尝试,强制把ai_input[0].data(也就是data_ins[0])转换为float32,才得到正确的结果


七、跨越
AI模型转为C代码可以不使用CubeMX的这个插件,但那样占用可能会很高,对于STM32平台,无论是操作的便捷性还是针对STM32的性能优化,都是使用官方的比较合适。如果是其他单片机,那么直接使用由TensorFlow Lite训练的模型转换的C代码,占用也不会很高,因为它专门用于嵌入式平台。
至于神经网络、CNN、LVTM、图像识别什么的,从0.9到∞,需要靠自己主动学习了。
相关文章:

单片机_简单AI模型训练与部署__从0到0.9
IDE: CLion MCU: STM32F407VET6 一、导向 以求知为导向,从问题到寻求问题解决的方法,以兴趣驱动学习。 虽从0,但不到1,剩下的那一小步将由你迈出。本篇主要目的是体验完整的一次简单AI模型部署流程&#x…...

Java-08 深入浅出 MyBatis - 多对多模型 SqlMapConfig 与 Mapper 详细讲解测试
点一下关注吧!!!非常感谢!!持续更新!!! 大数据篇正在更新!https://blog.csdn.net/w776341482/category_12713819.html 目前已经更新到了: MyBatisÿ…...
)
单元测试、集成测试、系统测试、验收测试、压力测试、性能测试、安全性测试、兼容性测试、回归测试(超详细的分类介绍及教学)
目录 1.单元测试 实现单元测试的方法: 注意事项: 2.集成测试 需注意事项: 实现集成测试的方法: 如何实现高效且可靠的集成测试: 3.系统测试 实现系统测试的方法: 须知注意事项: 4.验收测试 实现验…...

整车安全需求考量的多维度深度剖析
在汽车工程领域,整车安全需求的确定是一项复杂且系统的工程,其涵盖了多个关键维度的综合考量。从需求的萌生到最终的落地实施,每一个环节都紧密相扣,涉及众多技术细节与实际操作的权衡。 一、需求来源的多渠道挖掘 整车安全需求的来源广泛,其中 TARA(威胁分析与风险评估)…...

虚幻引擎---初识篇
一、学习途径 虚幻引擎官方文档:https://dev.epicgames.com/documentation/zh-cn/unreal-engine/unreal-engine-5-5-documentation虚幻引擎在线学习平台:https://dev.epicgames.com/community/unreal-engine/learning哔哩哔哩:https://www.b…...
)
Oracle - 多区间按权重取值逻辑 ,分时区-多层级-取配置方案(二)
Oracle - 多区间按权重取值逻辑 ,分时区-多层级-取配置方案https://blog.csdn.net/shijianduan1/article/details/133386281 某业务配置表,按配置的时间区间及组织层级取方案,形成报表展示出所有部门方案的取值; 例如࿰…...

线性代数的发展简史
线性代数的发展简史 线性代数作为数学的一个重要分支,其发展历史悠久而丰富。从古代文明中的基础计算到现代复杂的理论体系,线性代数经历了多个阶段的演变。 古代的起源 线性代数的雏形可以追溯到古埃及、古希腊、古印度和古代中国时期。这些早期文明…...

git使用详解
一、git介绍 1、git简介 Git 是一个开源的分布式版本控制系统(最先进的,没有之一),用于敏捷高效地处理任何或小或大的项目。 Git 是 Linus Torvalds 为了帮助管理 Linux 内核开发而开发的一个开放源码的版本控制软件。 Git 与常用…...

ros2学习日记_241124_ros相关链接
前言 提醒: 文章内容为方便作者自己后日复习与查阅而进行的书写与发布,其中引用内容都会使用链接表明出处(如有侵权问题,请及时联系)。 其中内容多为一次书写,缺少检查与订正,如有问题或其他拓展…...

【SQL】【数据库】语句翻译例题
SQL自然语言到SQL翻译知识点 以下是将自然语言转化为SQL语句的所有相关知识点,分门别类详细列出,并结合技巧说明。 1. 数据库操作 创建数据库 自然语言:创建一个名为“TestDB”的数据库。 CREATE DATABASE TestDB;技巧:识别**“创…...
)
图书管理系统(源码+数据库+报告)
基于SpringBoot的图书管理系统,系统包含两种角色:管理员、用户,系统分为前台和后台两大模块,主要功能如下。 前台: - 首页:展示系统推荐、热门图书等信息。 - 论坛:提供用户交流讨论的平台。 - 公告信息&a…...

python中lxml 库之 etree 使用详解
目录 一、 etree 介绍二、xpath 解析 html/xml1、第一步就是使用 etree 连接 html/xml 代码/文件。2、 xpath 表达式定位① xpath结合属性定位② xpath文本定位及获取③ xpath层级定位④ xpath索引定位⑤ xpath模糊匹配 一、 etree 介绍 lxml 库是 Python 中一个强大的 XML 处…...
-基础入门之vue-nuxt反向代理)
vue3(十九)-基础入门之vue-nuxt反向代理
一、反向代理 1、下载 nuxtjs/proxy 使用 npm npm install nuxtjs/proxy 或使用 yarn yarn add nuxtjs/proxy 2、配置 nuxt.config.js 文件 export default {modules: [nuxtjs/axios,nuxtjs/proxy],axios: {baseURL: /,proxy: true},proxy: {/api/: {target: https://i.maoya…...

Unity3D 截图
使用 Unity3D 自带的截图接口,制作截图工具。 截图 有时候我们想对 Unity 的窗口进行截图,如果直接使用一些截图工具,很难截取到一张完整分辨率的图片(例如,我们想要截取一张 1920 * 1080 的图片)。 其实…...
lnq(x)还是q(x)lnq(x)?)
【机器学习】近似分布的熵到底是p(x)lnq(x)还是q(x)lnq(x)?
【1】通信的定义 信息量(Information Content)是信息论中的一个核心概念,用于定量描述一个事件发生时所提供的“信息”的多少。它通常用随机变量 𝑥的概率分布来定义。事件 𝑥发生所携带的信息量由公式给出࿱…...

C语言:深入理解指针
一.内存和地址 我们知道计算机上CPU(中央处理器)在处理数据的时候,需要的数据是在内存中读取的,处理后的数据也会放回内存中,那我们买电脑的时候,电脑上内存是 8GB/16GB/32GB 等,那这些内存空间…...

Vue实训---4-使用Pinia实现menu菜单展示/隐藏
0.menu菜单展示/隐藏实现方法 Menu 菜单 | Element Plus中,当:collapse"isCollapse"其中isCollapse的值为true时菜单栏隐藏,当isCollapse的值为false时菜单栏显示。接下来使用pinia实现CommonAside.vue和CommonHeader.vue组件之间数据的共享&…...

Fakelocation Server服务器/专业版 Centos7
前言:需要Centos7系统 Fakelocation开源文件系统需求 Centos7 | Fakelocation | 任务一 更新Centos7 (安装下载不再赘述) sudo yum makecache fastsudo yum update -ysudo yum install -y kernelsudo reboot//如果遇到错误提示为 Another app is curre…...
掌握网络安全技术)
网络安全,文明上网(4)掌握网络安全技术
前言 在数字化时代,个人信息和企业数据的安全变得尤为重要。为了有效保护这些宝贵资产,掌握一系列网络安全技术是关键。 核心技术及实施方式 1. 网络监控与过滤系统: 这些系统构成了网络防御体系的基石,它们负责监控网络通信&…...

Ettus USRP X410
总线连接器: 以太网 RF频率范围: 1 MHz 至 7.2 GHz GPSDO: 是 输出通道数量: 4 RF收发仪瞬时带宽: 400 MHz 输入通道数量: 4 FPGA: Zynq US RFSoC (ZU28DR) 1 MHz to 7.2 GHz,400 MHz带宽,GPS驯服OCXO,USRP软件无线电设备 Ettus USRP X410集…...

在SQLyog中导入和导出数据库
导入 假如我要导入一个xxx.sql,我就先创建一个叫做xxx的数据库。 然后右键点击导入、执行SQL脚本 选择要导入的数据库文件的位置,点击执行即可 注意: 导入之后记得刷新一下导出 选择你要导出的数据库 右键选择:备份/导出、…...

一文了解Spring提供的几种扩展能力
基于 spring bean 的扩展 1. BeanPostProcessor spring 提供的针对 bean 的初始化过程时提供的扩展能力,从方法名也很容易看出,提供的两个方法分别是为 bean 对象提供了初始化之前以及初始化之后的扩展能力。 package com.wyl.conf;import org.spring…...

VXLAN说明
1. 什么是 VXLAN ? VXLAN(Virtual Extensible LAN,虚拟扩展局域网)是一种网络虚拟化技术,旨在通过在现有的物理网络上实现虚拟网络扩展,从而克服传统 VLAN 的一些限制。 VXLAN 主要用于数据中心、云计算环…...

MyBatis基本使用
一、向SQL语句传参: 1.MyBatis日志输出配置: mybatis配置文件设计标签和顶层结构如下: 可以在mybatis的配置文件使用settings标签设置,输出运过程SQL日志,通过查看日志,可以判定#{}和${}的输出效果 settings设置项: logImpl指定 MyBatis 所用日志的具…...
调度算法)
Linux笔记---进程:进程切换与O(1)调度算法
1. 补充概念 1.1 并行与并发 竞争性:系统进程数目众多,而CPU资源只有少量,甚至只有1个,所以进程之间是具有竞争属性的。为了高效完成任务,更合理竞争相关资源,便具有了优先级。独立性:多进程运…...
)
Flink学习连载第二篇-使用flink编写WordCount(多种情况演示)
使用Flink编写代码,步骤非常固定,大概分为以下几步,只要牢牢抓住步骤,基本轻松拿下: 1. env-准备环境 2. source-加载数据 3. transformation-数据处理转换 4. sink-数据输出 5. execute-执行 DataStream API开发 //n…...

[AutoSar]BSW_Diagnostic_007 BootLoader 跳转及APP OR boot response 实现
目录 关键词平台说明背景一、Process Jump to Bootloader二、相关函数和配置2.1 Dcm_GetProgConditions()2.2 Dcm_SetProgConditions() 三、如何实现在APP 还是BOOT 中对10 02服务响应3.1 配置3.2 code 四、报文五、小结 关键词 嵌入式、C语言、autosar、OS、BSW、UDS、diagno…...
)
用 Python 写了一个天天酷跑(附源码)
Hello,大家好,给大家说一下,我要开始装逼了 这期写个天天酷跑玩一下叭! 制作一个完整的“天天酷跑”游戏涉及很多方面,包括图形渲染、物理引擎、用户输入处理、游戏逻辑等。由于Python是一种高级编程语言,…...
光线)
WebGL进阶(九)光线
理论基础: 点光源 符合向量定义,末减初。 平行光 环境光 效果: 点光源 平行光 环境光 源码: 点光源 // 顶点着色器程序let vertexstring attribute vec4 a_position; // 顶点位置属性uniform mat4 u_formMatrix; // 用于变换…...
:Springboot整合全文检索引擎TermInSetQuery应用实例附源码)
Lucene(2):Springboot整合全文检索引擎TermInSetQuery应用实例附源码
前言 本章代码已分享至Gitee: https://gitee.com/lengcz/springbootlucene01 接上文。Lucene(1):Springboot整合全文检索引擎Lucene常规入门附源码 如何在指定范围内查询。从lucene 7 开始,filter 被弃用,导致无法进行调节过滤。 TermInSetQuery 指定…...
 UI性能优化)
HarmonyOS(57) UI性能优化
性能优化是APP开发绕不过的话题,那么在HarmonyOS开发过程中怎么进行性能优化呢?今天就来总结下相关知识点。 UI性能优化 1、避免在组件的生命周期内执行高耗时操作2、合理使用ResourceManager3、优先使用Builder方法代替自定义组件4、参考资料 1、避免在…...

机器学习周志华学习笔记-第5章<神经网络>
机器学习周志华学习笔记-第5章<神经网络> 卷王,请看目录 5模型的评估与选择5.1 神经元模型5.2 感知机与多层网络5.3 BP(误逆差)神经网络算法 5.4常见的神经网络5.4.1 RBF网络(Radial Basis Function Network,径向基函数网络࿰…...

SQL进阶技巧:如何进行数字范围统计?| 货场剩余货位的统计查询方法
目录 0 场景描述 1 剩余空位区间和剩余空位编号统计分析 2 查找已用货位区间 3 小结 0 场景描述 这是在做一个大型货场租赁系统时遇到的问题,在计算货场剩余存储空间时,不仅仅需要知道哪些货位是空闲的,还要能够判断出哪些货位之间是连续的。因为在新货物入场时,可…...
XADC IP核)
Xilinx IP核(3)XADC IP核
文章目录 1. XADC介绍2.输入要求3.输出4.XADC IP核使用5.传送门 1. XADC介绍 xadc在 所有的7系列器件上都有支持,通过将高质量模拟模块与可编程逻辑的灵活性相结合,可以为各种应用打造定制的模拟接口,XADC 包括双 12 位、每秒 1 兆样本 (MSP…...

现代大数据架构设计与实践:从数据存储到处理的全面解读
1. 引言 随着信息技术的不断发展,数据已经成为企业和组织最宝贵的资产之一。大数据的应用已经渗透到各个行业,无论是电商、金融,还是医疗、物流,如何有效管理、存储和处理海量的数据已经成为企业成功的关键之一。本文将深入探讨现代大数据架构的设计理念与技术实践,从数据…...

详细教程-Linux上安装单机版的Hadoop
1、上传Hadoop安装包至linux并解压 tar -zxvf hadoop-2.6.0-cdh5.15.2.tar.gz 安装包: 链接:https://pan.baidu.com/s/1u59OLTJctKmm9YVWr_F-Cg 提取码:0pfj 2、配置免密码登录 生成秘钥: ssh-keygen -t rsa -P 将秘钥写入认…...

前端项目支持tailwindcss写样式
安装 npm install -D tailwindcss npx tailwindcss init配置 tailwind.config.js //根据个人需求填写,比如vue简单配置 /** type {import(tailwindcss).Config} */ module.exports {darkMode: "class",corePlugins: {preflight: false},content: [&quo…...

工程师 - 智能家居方案介绍
1. 智能家居硬件方案概述 智能家居硬件方案是实现家庭自动化的重要组件,通过集成各种设备来提升生活的便利性、安全性和效率。这些方案通常结合了物联网技术,为用户提供智能化、自动化的生活体验。硬件方案的选择直接影响到智能家居系统的性能、兼容性、…...

H.264/H.265播放器EasyPlayer.js网页全终端安防视频流媒体播放器关于iOS不能系统全屏
在数字化时代,流媒体播放器已成为信息传播和娱乐消遣的主流载体。随着技术的进步,流媒体播放器的核心技术和发展趋势不断演变,影响着整个行业的发展方向。 EasyPlayer播放器属于一款高效、精炼、稳定且免费的流媒体播放器,可支持…...
)
2.langchain中的prompt模板 (FewShotPromptTemplate)
本教程将介绍如何使用 LangChain 库中的 PromptTemplate 和 FewShotPromptTemplate 来构建和运行提示(prompt),并通过示例数据展示其应用。 安装依赖 首先,确保你已经安装了 langchain 和相关依赖: pip install lan…...

TCP/IP
1、浏览器输入网址后发生了什么 1)应用层:浏览器解析ULR,生成发送给web服务器的请求信息,HTTP请求报文生成,委托给操作系统将消息发送给web服务器,发送之前需要查询服务器域名对应的IP地址(需要…...

详细探索xinput1_3.dll:功能、问题与xinput1_3.dll丢失的解决方案
本文旨在深入探讨xinput1_3.dll这一动态链接库文件。首先介绍其在计算机系统中的功能和作用,特别是在游戏和输入设备交互方面的重要性。然后分析在使用过程中可能出现的诸如文件丢失、版本不兼容等问题,并提出相应的解决方案,包括重新安装相关…...

Spring:AOP切入点表达式
对于AOP中切入点表达式,我们总共会学习三个内容,分别是语法格式、通配符和书写技巧。 语法格式 首先我们先要明确两个概念: 切入点:要进行增强的方法切入点表达式:要进行增强的方法的描述方式 对于切入点的描述,我们其实是有两中方式的&a…...
)
STM32的中断(什么是外部中断和其他中断以及中断号是什么)
一、什么是EXTI 和NVIC EXTI(External Interrupt/Event Controller)EXTI 是外部中断/事件控制器,它负责处理外部信号变化,并将信号传递给中断控制器(如 NVIC)。主要负责以下功能: 外部事件检测…...

MySQL底层概述—1.InnoDB内存结构
大纲 1.InnoDB引擎架构 2.Buffer Pool 3.Page管理机制之Page页分类 4.Page管理机制之Page页管理 5.Change Buffer 6.Log Buffer 1.InnoDB引擎架构 (1)InnoDB引擎架构图 (2)InnoDB内存结构 (1)InnoDB引擎架构图 下面是InnoDB引擎架构图,主要分为内存结构和磁…...

Linux 下进程基本概念与状态
文章目录 一、进程的定义二、 描述进程-PCBtask_ struct内容分类 三、 进程状态 一、进程的定义 狭义定义:进程是正在运行的程序的实例(an instance of a computer program that is being executed)。广义定义:进程是一个具有一定…...

Go语言链接Redis数据库
1.使用go get命令安装go-redis/v8库: 我这里使用的vscode工具安装: go get github.com/go-redis/redis/v82.创建Redis客户端实例 使用以下Go代码连接到Redis服务器并执行命令: package mainimport ("context""fmt"&q…...

SQL 分页查询详解
在处理大型数据集时,分页查询是一种常见的技术,用于将数据分成多个小块,以便逐步加载和显示。这不仅可以提高应用的性能,还可以提升用户体验,避免一次性加载过多数据导致页面加载缓慢或资源消耗过大。本文将详细介绍 S…...

ACP科普:风险价值矩阵
风险价值矩阵(Risk-Value Matrix)是一种常用的工具,用于在项目管理中帮助团队识别、评估和优先处理风险。它通过将风险和价值两个因素进行结合,帮助决策者明确哪些风险需要优先关注和处理,从而有效地管理项目的不确定性…...
_UDP网络编程实现网络字典)
计算机网络socket编程(2)_UDP网络编程实现网络字典
个人主页:C忠实粉丝 欢迎 点赞👍 收藏✨ 留言✉ 加关注💓本文由 C忠实粉丝 原创 计算机网络socket编程(2)_UDP网络编程实现网络字典 收录于专栏【计算机网络】 本专栏旨在分享学习计算机网络的一点学习笔记,欢迎大家在评论区交流讨…...