Flink学习连载第二篇-使用flink编写WordCount(多种情况演示)
使用Flink编写代码,步骤非常固定,大概分为以下几步,只要牢牢抓住步骤,基本轻松拿下:
1. env-准备环境
2. source-加载数据
3. transformation-数据处理转换
4. sink-数据输出
5. execute-执行
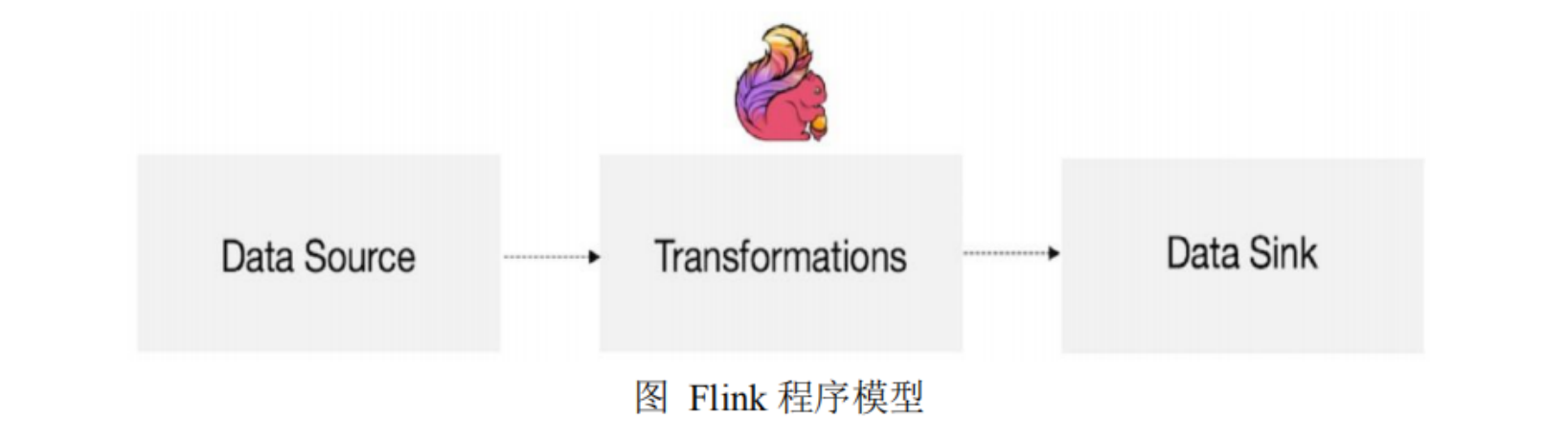
DataStream API开发
//nightlies.apache.org/flink/flink-docs-release-1.13/docs/dev/datastream/overview/
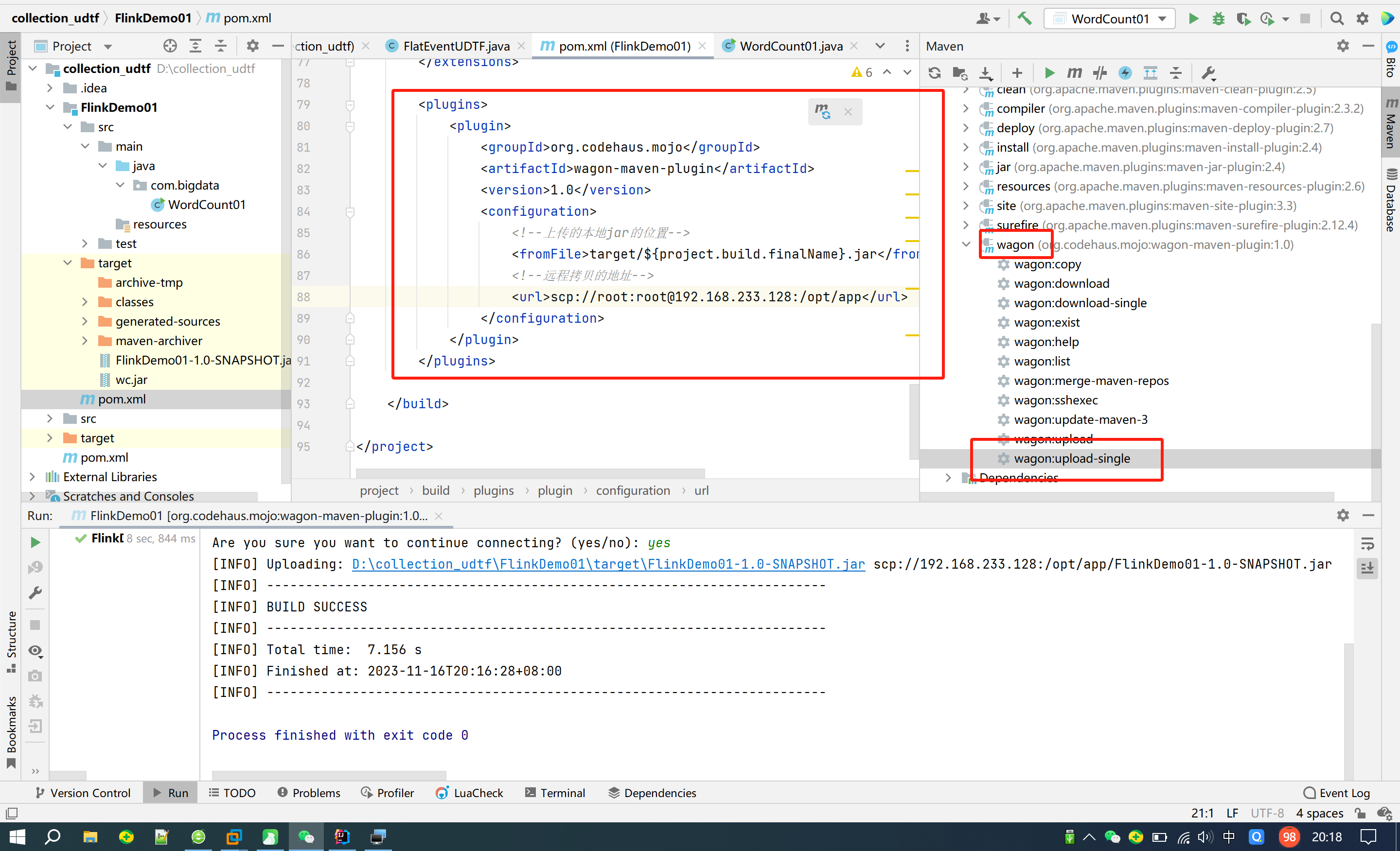
0. 添加依赖
<properties><flink.version>1.13.6</flink.version>
</properties><dependencies><dependency><groupId>org.apache.flink</groupId><artifactId>flink-streaming-java_2.11</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-java</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-clients_2.11</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-table-api-java-bridge_2.11</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-table-planner-blink_2.11</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-shaded-hadoop-2-uber</artifactId><version>2.7.5-10.0</version></dependency><dependency><groupId>log4j</groupId><artifactId>log4j</artifactId><version>1.2.17</version></dependency><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><version>1.18.24</version></dependency></dependencies><build><extensions><extension><groupId>org.apache.maven.wagon</groupId><artifactId>wagon-ssh</artifactId><version>2.8</version></extension></extensions><plugins><plugin><groupId>org.codehaus.mojo</groupId><artifactId>wagon-maven-plugin</artifactId><version>1.0</version><configuration><!--上传的本地jar的位置--><fromFile>target/${project.build.finalName}.jar</fromFile><!--远程拷贝的地址--><url>scp://root:root@bigdata01:/opt/app</url></configuration></plugin></plugins></build>-
编写代码
package com.bigdata.day01;import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;public class WordCount01 {/*** 1. env-准备环境* 2. source-加载数据* 3. transformation-数据处理转换* 4. sink-数据输出* 5. execute-执行*/public static void main(String[] args) throws Exception {// 导入常用类时要注意 不管是在本地开发运行还是在集群上运行,都这么写,非常方便StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();// 这个是 自动 ,根据流的性质,决定是批处理还是流处理//env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);// 批处理流, 一口气把数据算出来// env.setRuntimeMode(RuntimeExecutionMode.BATCH);// 流处理,默认是这个 可以通过打印批和流的处理结果,体会流和批的含义env.setRuntimeMode(RuntimeExecutionMode.STREAMING);// 获取数据 多态的写法 DataStreamSource 它是 DataStream 的子类DataStream<String> dataStream01 = env.fromElements("spark flink kafka", "spark sqoop flink", "kakfa hadoop flink");DataStream<String> flatMapStream = dataStream01.flatMap(new FlatMapFunction<String, String>() {@Overridepublic void flatMap(String line, Collector<String> collector) throws Exception {String[] arr = line.split(" ");for (String word : arr) {// 循环遍历每一个切割完的数据,放入到收集器中,就可以形成一个新的DataStreamcollector.collect(word);}}});//flatMapStream.print();// Tuple2 指的是2元组DataStream<Tuple2<String, Integer>> mapStream = flatMapStream.map(new MapFunction<String, Tuple2<String, Integer>>() {@Overridepublic Tuple2<String, Integer> map(String word) throws Exception {return Tuple2.of(word, 1); // ("hello",1)}});DataStream<Tuple2<String, Integer>> sumResult = mapStream.keyBy(new KeySelector<Tuple2<String, Integer>, String>() {@Overridepublic String getKey(Tuple2<String, Integer> tuple2) throws Exception {return tuple2.f0;}// 此处的1 指的是元组的第二个元素,进行相加的意思}).sum(1);sumResult.print();// 执行env.execute();}
}查看本机的CPU的逻辑处理器的数量,逻辑处理器的数量就是你的分区数量。
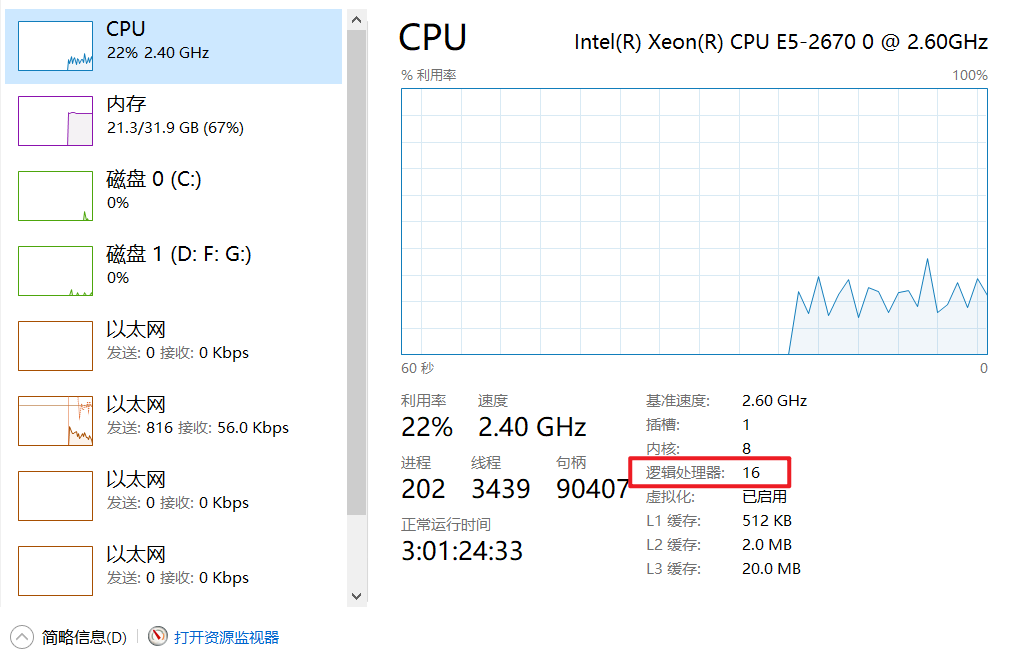
12> spark
13> kakfa
11> spark
11> flink
11> kafka
13> hadoop
12> sqoop
13> flink
12> flink前面的数字是分区数,默认跟逻辑处理器的数量有关系。对结果进行解释:
什么是批,什么是流?
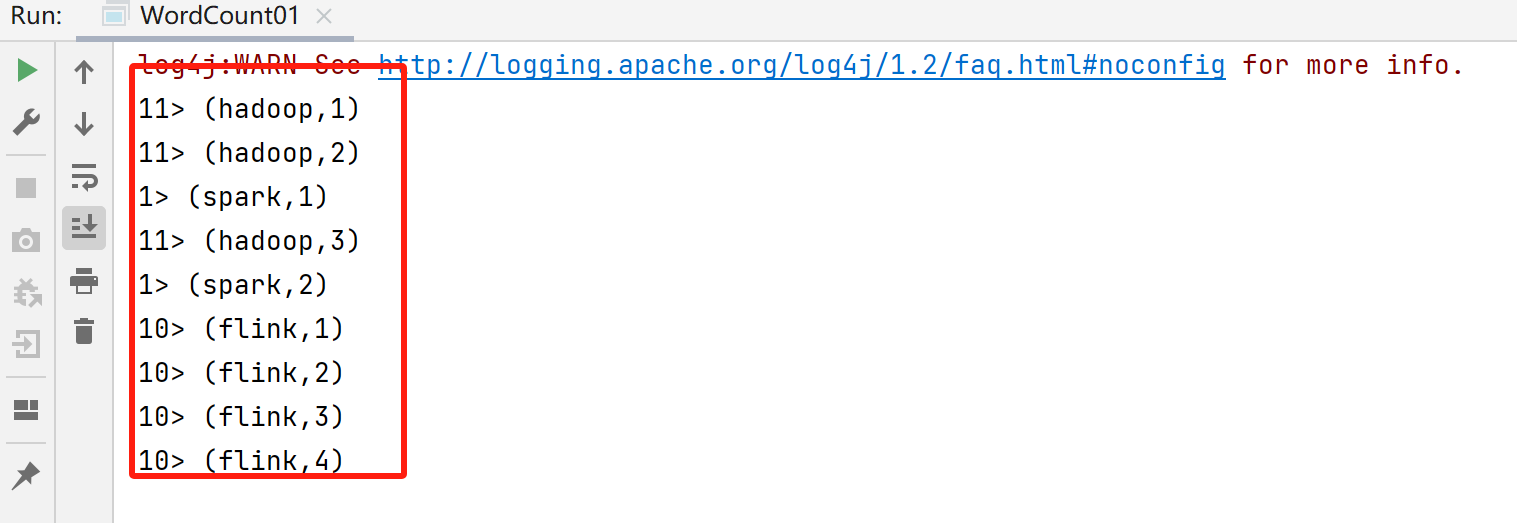
批处理结果:前面的序号代表分区
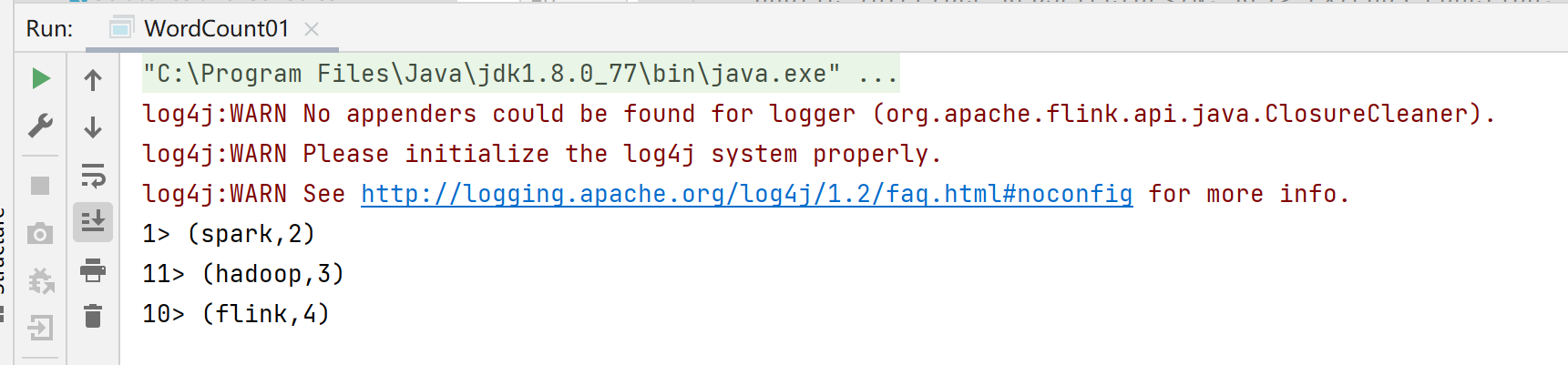
流处理结果:
也可以通过如下方式修改分区数量:
env.setParallelism(2);关于并行度的代码演示:
系统以及算子都可以设置并行度,或者获取并行度
package com.bigdata.day01;import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;public class WordCount01 {/*** 1. env-准备环境* 2. source-加载数据* 3. transformation-数据处理转换* 4. sink-数据输出* 5. execute-执行*/public static void main(String[] args) throws Exception {// 导入常用类时要注意 不管是在本地开发运行还是在集群上运行,都这么写,非常方便StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();// 这个是 自动 ,根据流的性质,决定是批处理还是流处理//env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);// 批处理流, 一口气把数据算出来// env.setRuntimeMode(RuntimeExecutionMode.BATCH);// 流处理,默认是这个 可以通过打印批和流的处理结果,体会流和批的含义env.setRuntimeMode(RuntimeExecutionMode.STREAMING);// 将任务的并行度设置为2// env.setParallelism(2);// 通过这个获取系统的并行度int parallelism = env.getParallelism();System.out.println(parallelism);// 获取数据 多态的写法 DataStreamSource 它是 DataStream 的子类DataStream<String> dataStream01 = env.fromElements("spark flink kafka", "spark sqoop flink", "kakfa hadoop flink");DataStream<String> flatMapStream = dataStream01.flatMap(new FlatMapFunction<String, String>() {@Overridepublic void flatMap(String line, Collector<String> collector) throws Exception {String[] arr = line.split(" ");for (String word : arr) {// 循环遍历每一个切割完的数据,放入到收集器中,就可以形成一个新的DataStreamcollector.collect(word);}}});// 每一个算子也有自己的并行度,一般跟系统保持一致System.out.println("flatMap的并行度:"+flatMapStream.getParallelism());//flatMapStream.print();// Tuple2 指的是2元组DataStream<Tuple2<String, Integer>> mapStream = flatMapStream.map(new MapFunction<String, Tuple2<String, Integer>>() {@Overridepublic Tuple2<String, Integer> map(String word) throws Exception {return Tuple2.of(word, 1); // ("hello",1)}});DataStream<Tuple2<String, Integer>> sumResult = mapStream.keyBy(new KeySelector<Tuple2<String, Integer>, String>() {@Overridepublic String getKey(Tuple2<String, Integer> tuple2) throws Exception {return tuple2.f0;}// 此处的1 指的是元组的第二个元组,进行相加的意思}).sum(1);sumResult.print();// 执行env.execute();}
}
- 打包、上传
文件夹不需要提前准备好,它可以帮我创建
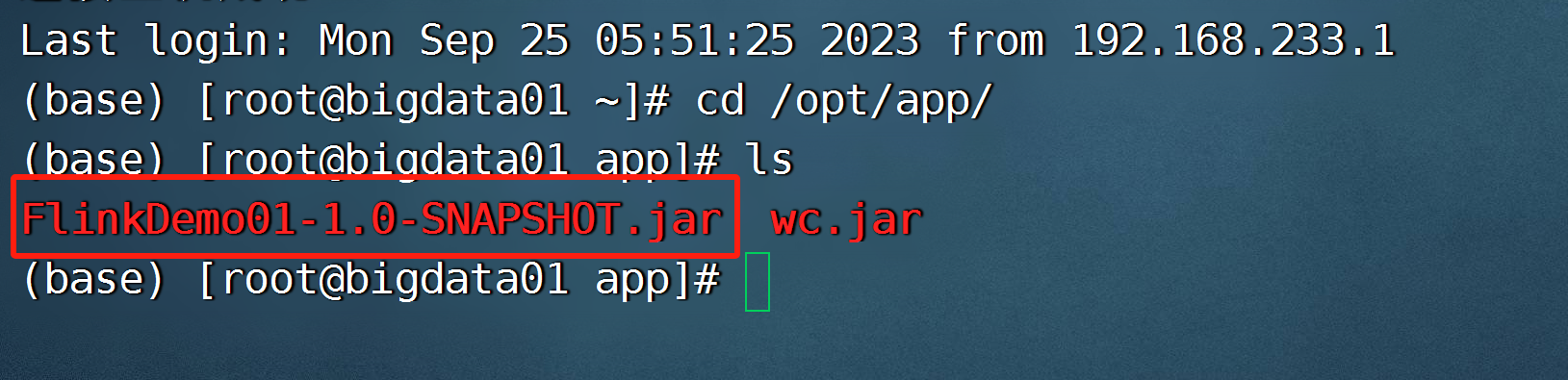
- 提交我们自己开发打包的任务
flink run -c com.bigdata.day01.WordCount01 /opt/app/FlinkDemo-1.0-SNAPSHOT.jar
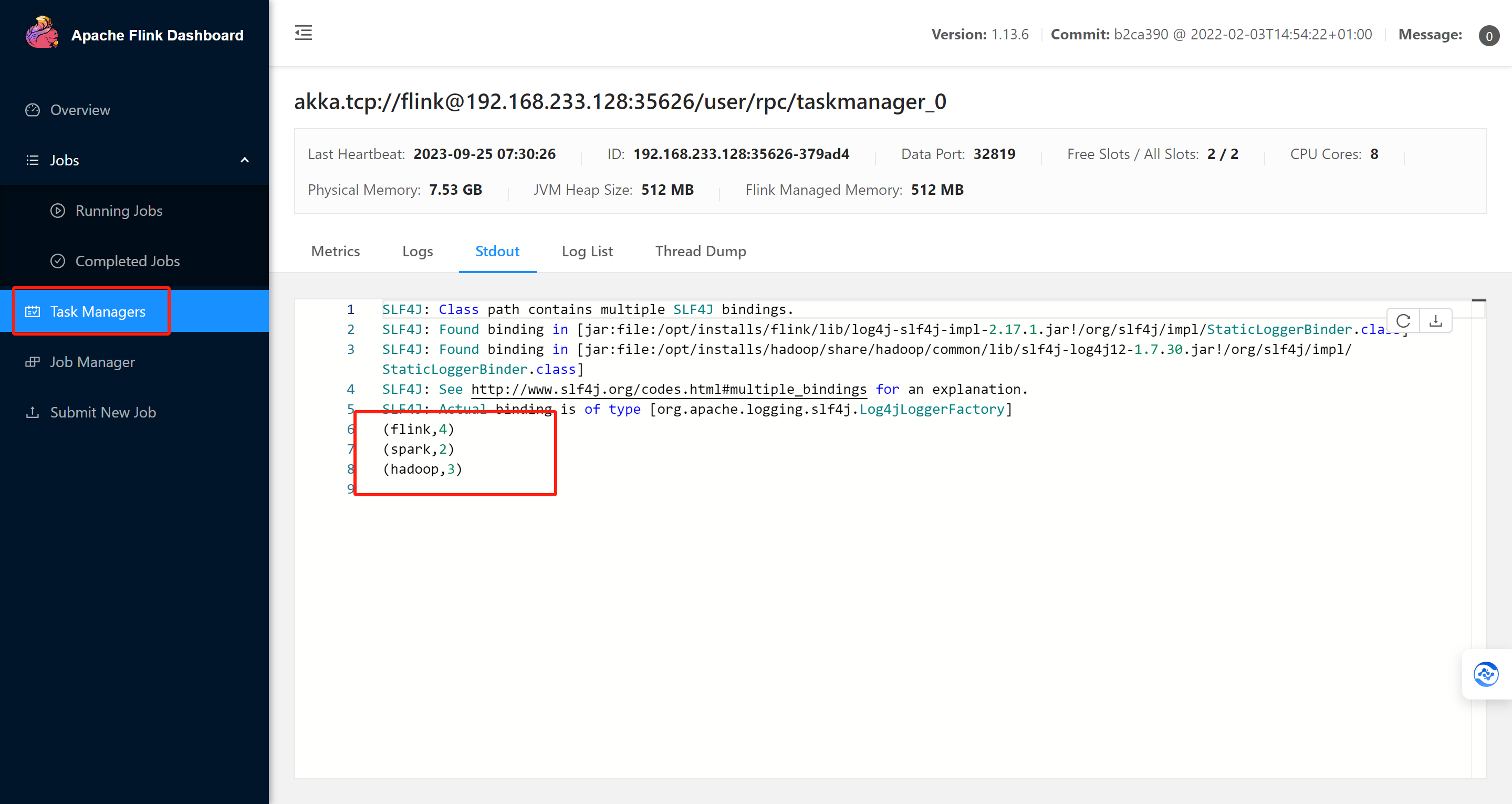
去界面中查看运行结果:
因为你这个是集群运行的,所以标准输出流中查看,假如第一台没有,去第二台查看,一直点。
获取主函数参数工具类
可以通过外部传参的方式给定一个路径
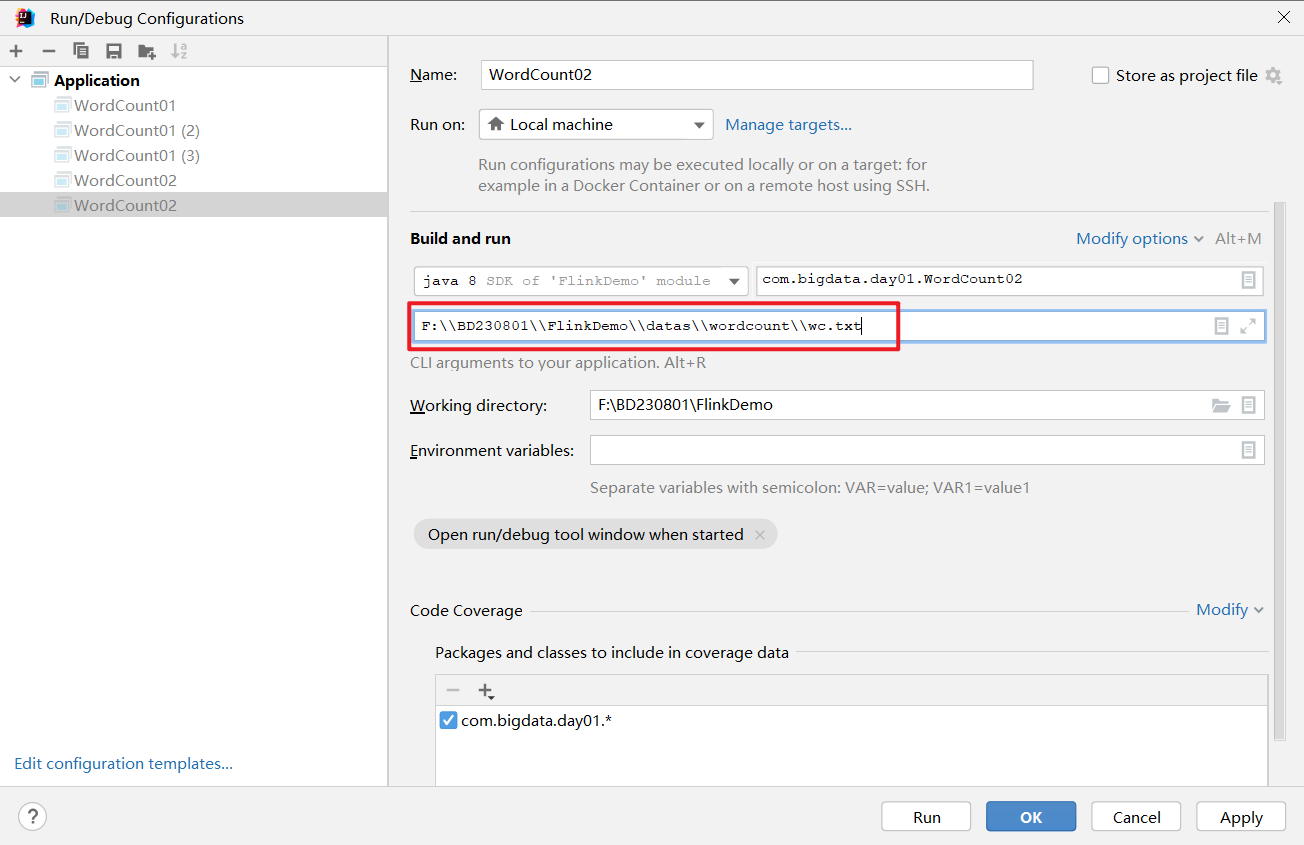
以下代码可以做到,假如给定路径,就获取路径的数据,假如没给,就读取默认数据:
package com.bigdata.day01;import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;public class WordCount02 {/*** 1. env-准备环境* 2. source-加载数据* 3. transformation-数据处理转换* 4. sink-数据输出* 5. execute-执行*/public static void main(String[] args) throws Exception {// 导入常用类时要注意 不管是在本地开发运行还是在集群上运行,都这么写,非常方便StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();// 这个是 自动 ,根据流的性质,决定是批处理还是流处理//env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);// 批处理流, 一口气把数据算出来// env.setRuntimeMode(RuntimeExecutionMode.BATCH);// 流处理,默认是这个 可以通过打印批和流的处理结果,体会流和批的含义env.setRuntimeMode(RuntimeExecutionMode.STREAMING);// 将任务的并行度设置为2// env.setParallelism(2);// 通过这个获取系统的并行度int parallelism = env.getParallelism();System.out.println(parallelism);// 获取数据 多态的写法 DataStreamSource 它是 DataStream 的子类// 连着写的本质就是 因为每一个算子的返回值都是DataStream的子类,所以可以这么写// 以下代码中路径是写死的,能不能通过外部传参进来,当然可以! agrsDataStream<String> dataStream = null;System.out.println(args.length);if(args.length !=0){String path = args[0];dataStream = env.readTextFile(path);}else{dataStream = env.fromElements("spark flink kafka", "spark sqoop flink", "kakfa hadoop flink");}dataStream.flatMap(new FlatMapFunction<String, String>() {@Overridepublic void flatMap(String line, Collector<String> collector) throws Exception {String[] arr = line.split(" ");for (String word : arr) {// 循环遍历每一个切割完的数据,放入到收集器中,就可以形成一个新的DataStreamcollector.collect(word);}}}).map(new MapFunction<String, Tuple2<String, Integer>>() {@Overridepublic Tuple2<String, Integer> map(String word) throws Exception {return Tuple2.of(word, 1); // ("hello",1)}}).keyBy(new KeySelector<Tuple2<String, Integer>, String>() {@Overridepublic String getKey(Tuple2<String, Integer> tuple2) throws Exception {return tuple2.f0;}// 此处的1 指的是元组的第二个元组,进行相加的意思}).sum(1).print();// 执行env.execute();}
}
flink run -c com.bigdata.day01.Demo02 FlinkDemo-1.0-SNAPSHOT.jar /home/wc.txt
这样做,跟我们以前的做法还是不一样。以前的运行方式是这样的
flink run /opt/installs/flink/examples/batch/WordCount.jar --input /home/wc.txt
这个写法,传递参数的时候,带有--字样,而我们的没有。
以上代码进行升级,我想将参数前面追加一个 --input 这样,怎么写?
ParameterTool parameterTool = ParameterTool.fromArgs(args);
if(parameterTool.has("output")){path = parameterTool.get("output");
}在代码中的使用:
ParameterTool parameterTool = ParameterTool.fromArgs(args);String output = "";if (parameterTool.has("output")) {output = parameterTool.get("output");System.out.println("指定了输出路径使用:" + output);} else {output = "hdfs://node01:9820/wordcount/output47_";System.out.println("可以指定输出路径使用 --output ,没有指定使用默认的:" + output);}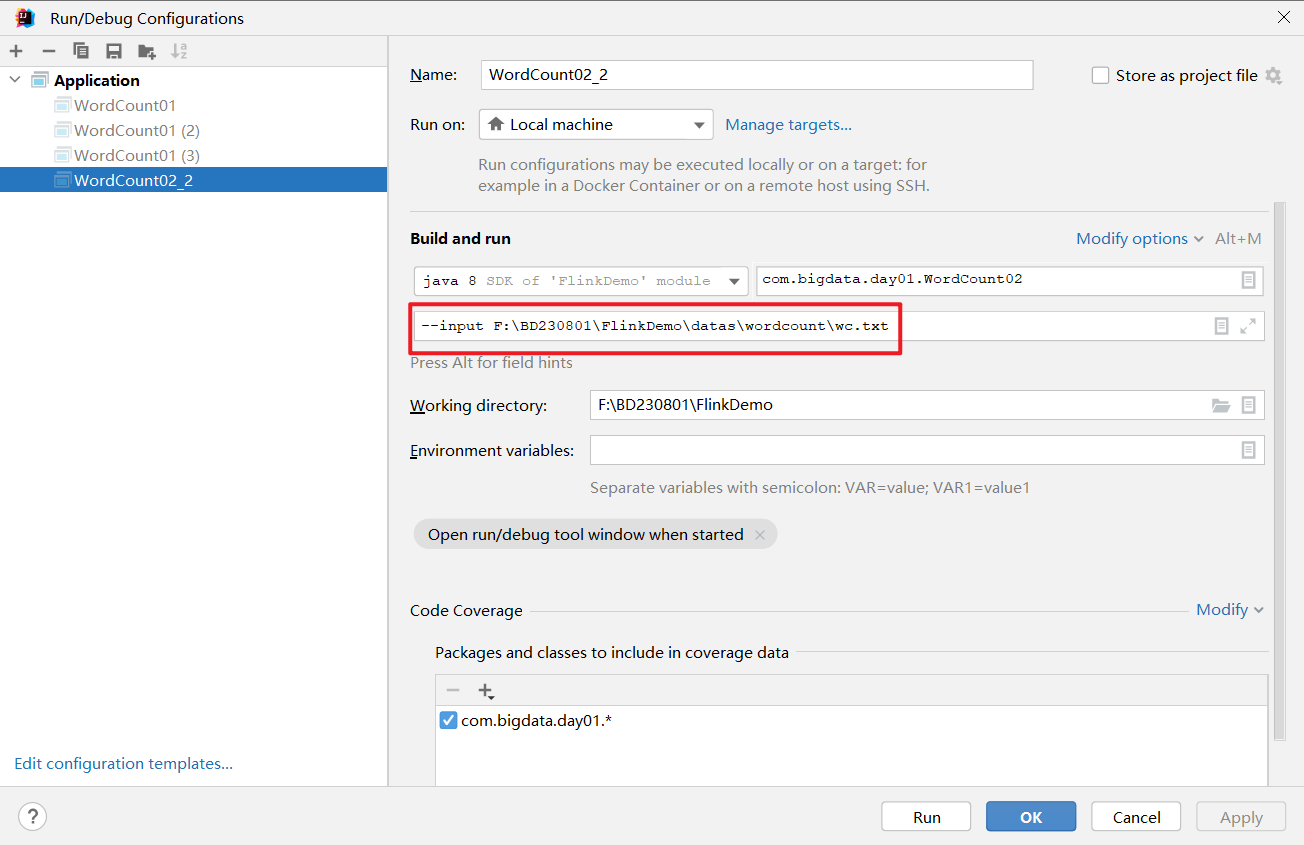
升级过的代码:
package com.bigdata.day01;import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.api.java.utils.ParameterTool;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;public class WordCount02 {/*** 1. env-准备环境* 2. source-加载数据* 3. transformation-数据处理转换* 4. sink-数据输出* 5. execute-执行*/public static void main(String[] args) throws Exception {// 导入常用类时要注意 不管是在本地开发运行还是在集群上运行,都这么写,非常方便StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();// 这个是 自动 ,根据流的性质,决定是批处理还是流处理//env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);// 批处理流, 一口气把数据算出来// env.setRuntimeMode(RuntimeExecutionMode.BATCH);// 流处理,默认是这个 可以通过打印批和流的处理结果,体会流和批的含义env.setRuntimeMode(RuntimeExecutionMode.STREAMING);// 将任务的并行度设置为2// env.setParallelism(2);// 通过这个获取系统的并行度int parallelism = env.getParallelism();System.out.println(parallelism);// 获取数据 多态的写法 DataStreamSource 它是 DataStream 的子类// 连着写的本质就是 因为每一个算子的返回值都是DataStream的子类,所以可以这么写// 以下代码中路径是写死的,能不能通过外部传参进来,当然可以! agrsDataStream<String> dataStream = null;System.out.println(args.length);if(args.length !=0){String path ;ParameterTool parameterTool = ParameterTool.fromArgs(args);if(parameterTool.has("input")){path = parameterTool.get("input");}else{path = args[0];}dataStream = env.readTextFile(path);}else{dataStream = env.fromElements("spark flink kafka", "spark sqoop flink", "kakfa hadoop flink");}dataStream.flatMap(new FlatMapFunction<String, String>() {@Overridepublic void flatMap(String line, Collector<String> collector) throws Exception {String[] arr = line.split(" ");for (String word : arr) {// 循环遍历每一个切割完的数据,放入到收集器中,就可以形成一个新的DataStreamcollector.collect(word);}}}).map(new MapFunction<String, Tuple2<String, Integer>>() {@Overridepublic Tuple2<String, Integer> map(String word) throws Exception {return Tuple2.of(word, 1); // ("hello",1)}}).keyBy(new KeySelector<Tuple2<String, Integer>, String>() {@Overridepublic String getKey(Tuple2<String, Integer> tuple2) throws Exception {return tuple2.f0;}// 此处的1 指的是元组的第二个元组,进行相加的意思}).sum(1).print();// 执行env.execute();}
}
DataStream (Lambda表达式-扩展 了解)
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;import java.util.Arrays;/*** Desc 演示Flink-DataStream-流批一体API完成批处理WordCount* 使用Java8的lambda表示完成函数式风格的WordCount*/
public class WordCount02 {public static void main(String[] args) throws Exception {//TODO 1.env-准备环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();//env.setRuntimeMode(RuntimeExecutionMode.STREAMING);//指定计算模式为流//env.setRuntimeMode(RuntimeExecutionMode.BATCH);//指定计算模式为批env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);//自动//不设置的话默认是流模式defaultValue(RuntimeExecutionMode.STREAMING)//TODO 2.source-加载数据DataStream<String> dataStream = env.fromElements("flink hadoop spark", "flink hadoop spark", "flink hadoop", "flink");//TODO 3.transformation-数据转换处理//3.1对每一行数据进行分割并压扁/*public interface FlatMapFunction<T, O> extends Function, Serializable {void flatMap(T value, Collector<O> out) throws Exception;}*//*DataStream<String> wordsDS = dataStream.flatMap(new FlatMapFunction<String, String>() {@Overridepublic void flatMap(String value, Collector<String> out) throws Exception {String[] words = value.split(" ");for (String word : words) {out.collect(word);}}});*///注意:Java8的函数的语法/lambda表达式的语法: (参数)->{函数体}DataStream<String> wordsDS = dataStream.flatMap((String value, Collector<String> out) -> {String[] words = value.split(" ");for (String word : words) {out.collect(word);}}).returns(Types.STRING);//3.2 每个单词记为<单词,1>/*public interface MapFunction<T, O> extends Function, Serializable {O map(T value) throws Exception;}*//*DataStream<Tuple2<String, Integer>> wordAndOneDS = wordsDS.map(new MapFunction<String, Tuple2<String, Integer>>() {@Overridepublic Tuple2<String, Integer> map(String value) throws Exception {return Tuple2.of(value, 1);}});*/DataStream<Tuple2<String, Integer>> wordAndOneDS = wordsDS.map((String value) -> Tuple2.of(value, 1)).returns(Types.TUPLE(Types.STRING, Types.INT));//3.3分组//注意:DataSet中分组用groupBy,DataStream中分组用keyBy//KeyedStream<Tuple2<String, Integer>, Tuple> keyedDS = wordAndOneDS.keyBy(0);/*public interface KeySelector<IN, KEY> extends Function, Serializable {KEY getKey(IN value) throws Exception;}*//*KeyedStream<Tuple2<String, Integer>, String> keyedDS = wordAndOneDS.keyBy(new KeySelector<Tuple2<String, Integer>, String>() {@Overridepublic String getKey(Tuple2<String, Integer> value) throws Exception {return value.f0;}});*/KeyedStream<Tuple2<String, Integer>, String> keyedDS = wordAndOneDS.keyBy((Tuple2<String, Integer> value) -> value.f0);//3.4聚合SingleOutputStreamOperator<Tuple2<String, Integer>> result = keyedDS.sum(1);//TODO 4.sink-数据输出result.print();//TODO 5.execute-执行env.execute();}
}此处有一个大坑,就是使用完lambda表达式以后,需要添加一个returns(Types.STRING); 否则报错,这样的话,使用lambda也不是特别快了。
连着写的版本如下:
package com.bigdata.day01;import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.api.java.utils.ParameterTool;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;public class WordCount03 {/*** 1. env-准备环境* 2. source-加载数据* 3. transformation-数据处理转换* 4. sink-数据输出* 5. execute-执行*/public static void main(String[] args) throws Exception {// 导入常用类时要注意 不管是在本地开发运行还是在集群上运行,都这么写,非常方便StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();// 这个是 自动 ,根据流的性质,决定是批处理还是流处理//env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);// 批处理流, 一口气把数据算出来// env.setRuntimeMode(RuntimeExecutionMode.BATCH);// 流处理,默认是这个 可以通过打印批和流的处理结果,体会流和批的含义//env.setRuntimeMode(RuntimeExecutionMode.STREAMING);// 将任务的并行度设置为2// env.setParallelism(2);// 通过这个获取系统的并行度int parallelism = env.getParallelism();System.out.println(parallelism);// 获取数据 多态的写法 DataStreamSource 它是 DataStream 的子类// 连着写的本质就是 因为每一个算子的返回值都是DataStream的子类,所以可以这么写// 以下代码中路径是写死的,能不能通过外部传参进来,当然可以! agrsDataStream<String> dataStream = null;System.out.println(args.length);if(args.length !=0){String path ;ParameterTool parameterTool = ParameterTool.fromArgs(args);if(parameterTool.has("input")){path = parameterTool.get("input");}else{path = args[0];}dataStream = env.readTextFile(path);}else{dataStream = env.fromElements("spark flink kafka", "spark sqoop flink", "kakfa hadoop flink");}dataStream.flatMap((String line, Collector<String> collector) -> {String[] arr = line.split(" ");for (String word : arr) {// 循环遍历每一个切割完的数据,放入到收集器中,就可以形成一个新的DataStreamcollector.collect(word);}}).returns(Types.STRING).map((String word)-> {return Tuple2.of(word, 1); // ("hello",1)}).returns(Types.TUPLE(Types.STRING, Types.INT)).keyBy((Tuple2<String, Integer> tuple2)-> {return tuple2.f0;}).sum(1).print();// 执行env.execute();}
}相关文章:
)
Flink学习连载第二篇-使用flink编写WordCount(多种情况演示)
使用Flink编写代码,步骤非常固定,大概分为以下几步,只要牢牢抓住步骤,基本轻松拿下: 1. env-准备环境 2. source-加载数据 3. transformation-数据处理转换 4. sink-数据输出 5. execute-执行 DataStream API开发 //n…...

[AutoSar]BSW_Diagnostic_007 BootLoader 跳转及APP OR boot response 实现
目录 关键词平台说明背景一、Process Jump to Bootloader二、相关函数和配置2.1 Dcm_GetProgConditions()2.2 Dcm_SetProgConditions() 三、如何实现在APP 还是BOOT 中对10 02服务响应3.1 配置3.2 code 四、报文五、小结 关键词 嵌入式、C语言、autosar、OS、BSW、UDS、diagno…...
)
用 Python 写了一个天天酷跑(附源码)
Hello,大家好,给大家说一下,我要开始装逼了 这期写个天天酷跑玩一下叭! 制作一个完整的“天天酷跑”游戏涉及很多方面,包括图形渲染、物理引擎、用户输入处理、游戏逻辑等。由于Python是一种高级编程语言,…...
光线)
WebGL进阶(九)光线
理论基础: 点光源 符合向量定义,末减初。 平行光 环境光 效果: 点光源 平行光 环境光 源码: 点光源 // 顶点着色器程序let vertexstring attribute vec4 a_position; // 顶点位置属性uniform mat4 u_formMatrix; // 用于变换…...
:Springboot整合全文检索引擎TermInSetQuery应用实例附源码)
Lucene(2):Springboot整合全文检索引擎TermInSetQuery应用实例附源码
前言 本章代码已分享至Gitee: https://gitee.com/lengcz/springbootlucene01 接上文。Lucene(1):Springboot整合全文检索引擎Lucene常规入门附源码 如何在指定范围内查询。从lucene 7 开始,filter 被弃用,导致无法进行调节过滤。 TermInSetQuery 指定…...
 UI性能优化)
HarmonyOS(57) UI性能优化
性能优化是APP开发绕不过的话题,那么在HarmonyOS开发过程中怎么进行性能优化呢?今天就来总结下相关知识点。 UI性能优化 1、避免在组件的生命周期内执行高耗时操作2、合理使用ResourceManager3、优先使用Builder方法代替自定义组件4、参考资料 1、避免在…...

机器学习周志华学习笔记-第5章<神经网络>
机器学习周志华学习笔记-第5章<神经网络> 卷王,请看目录 5模型的评估与选择5.1 神经元模型5.2 感知机与多层网络5.3 BP(误逆差)神经网络算法 5.4常见的神经网络5.4.1 RBF网络(Radial Basis Function Network,径向基函数网络࿰…...

SQL进阶技巧:如何进行数字范围统计?| 货场剩余货位的统计查询方法
目录 0 场景描述 1 剩余空位区间和剩余空位编号统计分析 2 查找已用货位区间 3 小结 0 场景描述 这是在做一个大型货场租赁系统时遇到的问题,在计算货场剩余存储空间时,不仅仅需要知道哪些货位是空闲的,还要能够判断出哪些货位之间是连续的。因为在新货物入场时,可…...
XADC IP核)
Xilinx IP核(3)XADC IP核
文章目录 1. XADC介绍2.输入要求3.输出4.XADC IP核使用5.传送门 1. XADC介绍 xadc在 所有的7系列器件上都有支持,通过将高质量模拟模块与可编程逻辑的灵活性相结合,可以为各种应用打造定制的模拟接口,XADC 包括双 12 位、每秒 1 兆样本 (MSP…...

现代大数据架构设计与实践:从数据存储到处理的全面解读
1. 引言 随着信息技术的不断发展,数据已经成为企业和组织最宝贵的资产之一。大数据的应用已经渗透到各个行业,无论是电商、金融,还是医疗、物流,如何有效管理、存储和处理海量的数据已经成为企业成功的关键之一。本文将深入探讨现代大数据架构的设计理念与技术实践,从数据…...

详细教程-Linux上安装单机版的Hadoop
1、上传Hadoop安装包至linux并解压 tar -zxvf hadoop-2.6.0-cdh5.15.2.tar.gz 安装包: 链接:https://pan.baidu.com/s/1u59OLTJctKmm9YVWr_F-Cg 提取码:0pfj 2、配置免密码登录 生成秘钥: ssh-keygen -t rsa -P 将秘钥写入认…...

前端项目支持tailwindcss写样式
安装 npm install -D tailwindcss npx tailwindcss init配置 tailwind.config.js //根据个人需求填写,比如vue简单配置 /** type {import(tailwindcss).Config} */ module.exports {darkMode: "class",corePlugins: {preflight: false},content: [&quo…...

工程师 - 智能家居方案介绍
1. 智能家居硬件方案概述 智能家居硬件方案是实现家庭自动化的重要组件,通过集成各种设备来提升生活的便利性、安全性和效率。这些方案通常结合了物联网技术,为用户提供智能化、自动化的生活体验。硬件方案的选择直接影响到智能家居系统的性能、兼容性、…...

H.264/H.265播放器EasyPlayer.js网页全终端安防视频流媒体播放器关于iOS不能系统全屏
在数字化时代,流媒体播放器已成为信息传播和娱乐消遣的主流载体。随着技术的进步,流媒体播放器的核心技术和发展趋势不断演变,影响着整个行业的发展方向。 EasyPlayer播放器属于一款高效、精炼、稳定且免费的流媒体播放器,可支持…...
)
2.langchain中的prompt模板 (FewShotPromptTemplate)
本教程将介绍如何使用 LangChain 库中的 PromptTemplate 和 FewShotPromptTemplate 来构建和运行提示(prompt),并通过示例数据展示其应用。 安装依赖 首先,确保你已经安装了 langchain 和相关依赖: pip install lan…...

TCP/IP
1、浏览器输入网址后发生了什么 1)应用层:浏览器解析ULR,生成发送给web服务器的请求信息,HTTP请求报文生成,委托给操作系统将消息发送给web服务器,发送之前需要查询服务器域名对应的IP地址(需要…...

详细探索xinput1_3.dll:功能、问题与xinput1_3.dll丢失的解决方案
本文旨在深入探讨xinput1_3.dll这一动态链接库文件。首先介绍其在计算机系统中的功能和作用,特别是在游戏和输入设备交互方面的重要性。然后分析在使用过程中可能出现的诸如文件丢失、版本不兼容等问题,并提出相应的解决方案,包括重新安装相关…...

Spring:AOP切入点表达式
对于AOP中切入点表达式,我们总共会学习三个内容,分别是语法格式、通配符和书写技巧。 语法格式 首先我们先要明确两个概念: 切入点:要进行增强的方法切入点表达式:要进行增强的方法的描述方式 对于切入点的描述,我们其实是有两中方式的&a…...
)
STM32的中断(什么是外部中断和其他中断以及中断号是什么)
一、什么是EXTI 和NVIC EXTI(External Interrupt/Event Controller)EXTI 是外部中断/事件控制器,它负责处理外部信号变化,并将信号传递给中断控制器(如 NVIC)。主要负责以下功能: 外部事件检测…...

MySQL底层概述—1.InnoDB内存结构
大纲 1.InnoDB引擎架构 2.Buffer Pool 3.Page管理机制之Page页分类 4.Page管理机制之Page页管理 5.Change Buffer 6.Log Buffer 1.InnoDB引擎架构 (1)InnoDB引擎架构图 (2)InnoDB内存结构 (1)InnoDB引擎架构图 下面是InnoDB引擎架构图,主要分为内存结构和磁…...

Linux 下进程基本概念与状态
文章目录 一、进程的定义二、 描述进程-PCBtask_ struct内容分类 三、 进程状态 一、进程的定义 狭义定义:进程是正在运行的程序的实例(an instance of a computer program that is being executed)。广义定义:进程是一个具有一定…...

Go语言链接Redis数据库
1.使用go get命令安装go-redis/v8库: 我这里使用的vscode工具安装: go get github.com/go-redis/redis/v82.创建Redis客户端实例 使用以下Go代码连接到Redis服务器并执行命令: package mainimport ("context""fmt"&q…...

SQL 分页查询详解
在处理大型数据集时,分页查询是一种常见的技术,用于将数据分成多个小块,以便逐步加载和显示。这不仅可以提高应用的性能,还可以提升用户体验,避免一次性加载过多数据导致页面加载缓慢或资源消耗过大。本文将详细介绍 S…...

ACP科普:风险价值矩阵
风险价值矩阵(Risk-Value Matrix)是一种常用的工具,用于在项目管理中帮助团队识别、评估和优先处理风险。它通过将风险和价值两个因素进行结合,帮助决策者明确哪些风险需要优先关注和处理,从而有效地管理项目的不确定性…...
_UDP网络编程实现网络字典)
计算机网络socket编程(2)_UDP网络编程实现网络字典
个人主页:C忠实粉丝 欢迎 点赞👍 收藏✨ 留言✉ 加关注💓本文由 C忠实粉丝 原创 计算机网络socket编程(2)_UDP网络编程实现网络字典 收录于专栏【计算机网络】 本专栏旨在分享学习计算机网络的一点学习笔记,欢迎大家在评论区交流讨…...
MDK-ARM各种优化选项详细说明、实际应用及拓展内容)
(Keil)MDK-ARM各种优化选项详细说明、实际应用及拓展内容
参考 MDK-ARM各种优化选项详细说明、实际应用及拓展内容 本文围绕MDK-ARM优化选项,以及相关拓展知识(微库、实际应用、调试)进行讲述,希望对你今后开发项目有所帮助。 1 总述 我们所指的优化,主要两方面: 1.代码大小(Size) 2.代码性能(运行时间) 在MDK-ARM中,优…...

mac2024 安装node和vue
以下是使用 Node.js 官方 .pkg 安装包 安装 Node.js 和 Vue CLI 的完整流程,包括如何重新设置 npm 的环境,以避免权限问题。 安装 Node.js 步骤 1.1:下载 Node.js 安装包 1. 打开 Node.js 官网。 2. 下载 LTS(长期支持…...
)
在win10环境部署opengauss数据库(包含各种可能遇到的问题解决)
适用于windows环境下通过docker desktop实现opengauss部署,请审题。 文章目录 前言一、部署适合deskdocker的环境二、安装opengauss数据库1.配置docker镜像源2.拉取镜像源 总结 前言 注意事项:后面docker拉取镜像源最好电脑有科学上网工具如果没有科学上…...

Docker1:认识docker、在Linux中安装docker
欢迎来到“雪碧聊技术”CSDN博客! 在这里,您将踏入一个专注于Java开发技术的知识殿堂。无论您是Java编程的初学者,还是具有一定经验的开发者,相信我的博客都能为您提供宝贵的学习资源和实用技巧。作为您的技术向导,我将…...

鸿蒙开发-音视频
Media Kit 特点 一般场合的音视频处理,可以直接使用系统集成的Video组件,不过外观和功能自定义程度低Media kit:轻量媒体引擎,系统资源占用低支持音视频播放/录制,pipeline灵活拼装,插件化扩展source/demu…...

Vue3学习笔记
目录 Vue3Vue3优势Vue3组合式API & Vue2选项式APIcreate-vue使用create-vue创建项目 项目目录和关键文件组合式API-setup选项组合式API-reactive和ref函数reactive()ref() 组合式API-computed组合式API-watch基础使用immdiate和deep配置精确侦听对象的某个属性 组合式API-生…...

node + Redis + svg-captcha 实现验证码
目录 前提说明 Redis链接与封装 svg-captcha使用步骤 封装中间件验证 前端接收 扩展【svg API】 svgCaptcha.create(options) svgCaptcha.createMathExpr(options) svgCaptcha.loadFont(url) svgCaptcha.options svgCaptcha.randomText([size|options]) svgCaptcha(…...

dubbo-go框架介绍
框架介绍 什么是 dubbo-go Dubbo-go 是 Apache Dubbo 的 go 语言实现,它完全遵循 Apache Dubbo 设计原则与目标,是 go 语言领域的一款优秀微服务开发框架。dubbo-go 提供: API 与 RPC 协议:帮助解决组件之间的 RPC 通信问题&am…...

玛哈特矫平机:工业制造中的平整利器
在日新月异的工业制造领域,每一个细节都至关重要。而在这其中,矫平机以其独特的功能和卓越的性能,成为了不可或缺的重要工具。它就像一位技艺高超的工匠,精心雕琢着每一件工业产品,赋予它们平整、光滑的表面。 矫平机…...
)
IDEA 2024安装指南(含安装包以及使用说明 cannot collect jvm options 问题 四)
汉化 setting 中选择插件 完成 安装出现问题 1.可能是因为之前下载过的idea,找到连接中 文件,卸载即可。...

Jmeter中的定时器
4)定时器 1--固定定时器 功能特点 固定延迟:在每个请求之间添加固定的延迟时间。精确控制:可以精确控制请求的发送频率。简单易用:配置简单,易于理解和使用。 配置步骤 添加固定定时器 右键点击需要添加定时器的请求…...

共享单车管理系统项目学习实战
前言 Spring Boot Vue前后端分离 前端:Vue(CDN) Element axios(前后端交互) BaiDuMap ECharts(图表展示) 后端:Spring Boot Spring MVC(Web) MyBatis Plus(数据库) 数据库:MySQL 验证码请求 git提交 cd C:/Users/Ustini…...

学Linux的第九天--磁盘管理
目录 一、磁盘简介 (一)、认知磁盘 (1)结构 (2)物理设备的命名规则 (二)、磁盘分区方式 MBR分区 MBR分区类型 扩展 GPT格式 lsblk命令 使用fdisk管理分区 使用gdisk管理分…...

CLIP-Adapter: Better Vision-Language Models with Feature Adapters 论文解读
abstract 大规模对比视觉-语言预训练在视觉表示学习方面取得了显著进展。与传统的通过固定一组离散标签训练的视觉系统不同,(Radford et al., 2021) 引入了一种新范式,该范式在开放词汇环境中直接学习将图像与原始文本对齐。在下游任务中,通…...

D74【 python 接口自动化学习】- python 基础之HTTP
day74 http基础定义 学习日期:20241120 学习目标:http定义及实战 -- http基础介绍 学习笔记: HTTP定义 HTTP 是一个协议(服务器传输超文本到浏览器的传送协议),是基于 TCP/IP 通信协议来传递数据&…...
)
维护表空间和数据文件(一)
学习目标 定义表空间和数据文件的用途创建表空间管理表空间使用Oracle管理文件(OMF)创建和管理表空间获取表空间信息 表空间和数据文件 Oracle逻辑上将数据存储在表空间中,物理上将数据存储在数据文件中。 Tablespaces: 一次只…...

H.265流媒体播放器EasyPlayer.js H5流媒体播放器关于如何查看手机端的日志信息并保存下来
现今流媒体播放器的发展趋势将更加多元化和个性化。人工智能的应用将深入内容创作、用户体验优化等多个方面,带来前所未有的个性化体验。 EasyPlayer.js H.265流媒体播放器属于一款高效、精炼、稳定且免费的流媒体播放器,可支持多种流媒体协议播放&#…...

Apple Vision Pro开发003-PolySpatial2.0新建项目
unity6.0下载链接:Unity 实时开发平台 | 3D、2D、VR 和 AR 引擎 一、新建项目 二、导入开发包 com.unity.polyspatial.visionos 输入版本号 2.0.4 com.unity.polyspatial(单独导入),或者直接安装 三、对应设置 其他的操作与之前的版本相同…...

解决 npm xxx was blocked, reason: xx bad guy, steal env and delete files
问题复现 今天一位朋友说,vue2的老项目安装不老依赖,报错内容如下: npm install 451 Unavailable For Legal Reasons - GET https://registry.npmmirror.com/vab-count - [UNAVAILABLE_FOR_LEGAL_REASONS] vab-count was blocked, reas…...

leetcode 面试150之 156.LUR 缓存
请你设计并实现一个满足 LRU (最近最少使用) 缓存 约束的数据结构。 实现 LRUCache 类: LRUCache(int capacity) 以 正整数 作为容量 capacity 初始化 LRU 缓存int get(int key) 如果关键字 key 存在于缓存中,则返回关键字的值,否则返回 -…...

Vue 动态给 data 添加新属性深度解析:问题、原理与解决方案
在 Vue 中,动态地向 data 中添加新的属性是一个常见的需求,但它也可能引发一些问题,尤其是关于 响应式更新 和 数据绑定 的问题。Vue 的响应式系统通过 getter 和 setter 来追踪和更新数据,但 动态添加新属性 时,Vue 并不会自动为这些新属性创建响应式链接。 1. 直接向 V…...
)
Unity类银河战士恶魔城学习总结(P141 Finalising ToolTip优化UI显示)
【Unity教程】从0编程制作类银河恶魔城游戏_哔哩哔哩_bilibili 教程源地址:https://www.udemy.com/course/2d-rpg-alexdev/ UI部分暂时完结!!! 本章节优化了UI中物品描述的显示效果,技能描述的显示效果 并且可以批…...

面试:请阐述MySQL配置文件my.cnf中参数log-bin和binlog-do-db的作用
大家好,我是袁庭新。星球里的小伙伴去面试,面试官问:MySQL配置文件my.cnf中参数log-bin和binlog-do-db的作用?一脸懵逼~不知道该如何回答。 在MySQL的配置文件my.cnf中,log-bin和binlog-do-db是与二进制日志…...

监控报警系统的指标、规则与执行闭环
随笔 从千万粉丝“何同学”抄袭开源项目说起,为何纯技术死路一条? 数据源的统一与拆分 监控报警系统的指标、规则与执行闭环 java 老矣,尚能饭否? 一骑红尘妃子笑,无人知是荔枝来! 有所依 我们如何知道系统交易…...

玩转数字与运算:用C语言实现24点游戏的扑克牌魅力
✅作者简介:2022年博客新星 第八。热爱国学的Java后端开发者,修心和技术同步精进。 🍎个人主页:Java Fans的博客 🍊个人信条:不迁怒,不贰过。小知识,大智慧。 💞当前专栏…...