时间序列预测的迁移学习
在本文中,我们将了解如何将迁移学习应用于时间序列预测,以及如何在多样化的时间序列数据集上训练一次预测模型,之后无需训练即可在不同数据集上进行预测。我们将使用开源 Darts 库,仅用几行代码即可完成所有这些操作。你可以点击此处一个包含复现结果所需所有内容的独立笔记本。
时间序列预测在供应链、能源、农业、控制、IT 运营、金融等领域应用广泛。长期以来,表现最优的方法是指数平滑法或 ARIMA 等相对复杂的统计方法。但近年来,机器学习和深度学习在许多预测任务与竞赛中开始超越这些经典方法。
机器学习模型的显著特点在于,其参数可在大量序列上进行估算,这与传统方法通常一次仅估算一个序列不同。尽管机器学习潜力巨大,但其应用仍面临实际挑战:一方面,需要足够数据训练,这在某些场景下会引发冷启动问题,即数据不足时模型难以有效工作;另一方面,即便数据充足,模型训练也更复杂 —— 虽然借助 Darts 等工具可简化训练代码,但训练大型模型仍需耗时的超参数调优、特定硬件(如 GPU),或对数据与模型管理的基础设施及流程进行调整。
在本文中,我将探讨迁移学习在时间序列预测中的应用。我会在一个庞大且多样的时间序列数据集上训练深度学习模型,并观察其预测不同数据集里各类时间序列的表现。这一过程本身就颇具价值,因为它意味着来自人口统计、金融、工业等不同领域的时间序列可能共享某些共同特征。从元学习(或 “学习如何学习”)角度看,这也符合对 “学习任务” 的定义 —— 模型可在推理时适应新任务(如预测新时间序列),而无需重新训练。
除易用性外,在需最小化推理时间的场景中,使用无需训练的模型优势显著。以神经网络为例,其推理时间通常很短,仅需前向传播。在本文中,我将训练一个大型模型,它仅需几毫秒即可完成对未知新时间序列的预测。
我将使用 Darts 开源 Python 时间序列库,仅用几行代码就能完成模型训练与使用。Darts 功能丰富,可用于训练多变量序列(每个时间序列包含多个维度)模型、提供概率预测,还能纳入外部数据(协变量)。本文中,我仅用其对大量单变量时间序列进行预测。我会在文中提供关键代码片段,并 在此处 附上用于复现结果的完整笔记本(含所需数据集下载方式)。
航班乘客(Air Passengers)
让我们首先加载包含不同航空公司乘客数量的数据集:
air_train, air_test = load_air()这里虽未展示 load_air () 函数,但它会返回两个列表,每个列表包含 301 个月度 TimeSeries 对象。其中,air_train 列表包含序列的训练部分(平均长度约为 137 个月),air_test 列表则包含最近 18 个月的数据,我将其作为验证集。(注意:一个好的做法是再留出一个测试集,在最终模型选定之前不触碰它)。
我在此使用 18 个月的预测范围,这与 M3 和 M4 竞赛中用于月度序列的范围一致(我会在本文后面使用它们的数据集)。此外,我将采用对称平均绝对百分比误差(sMAPE)作为误差指标,评估预测质量。
下面,我来绘制一些训练序列:
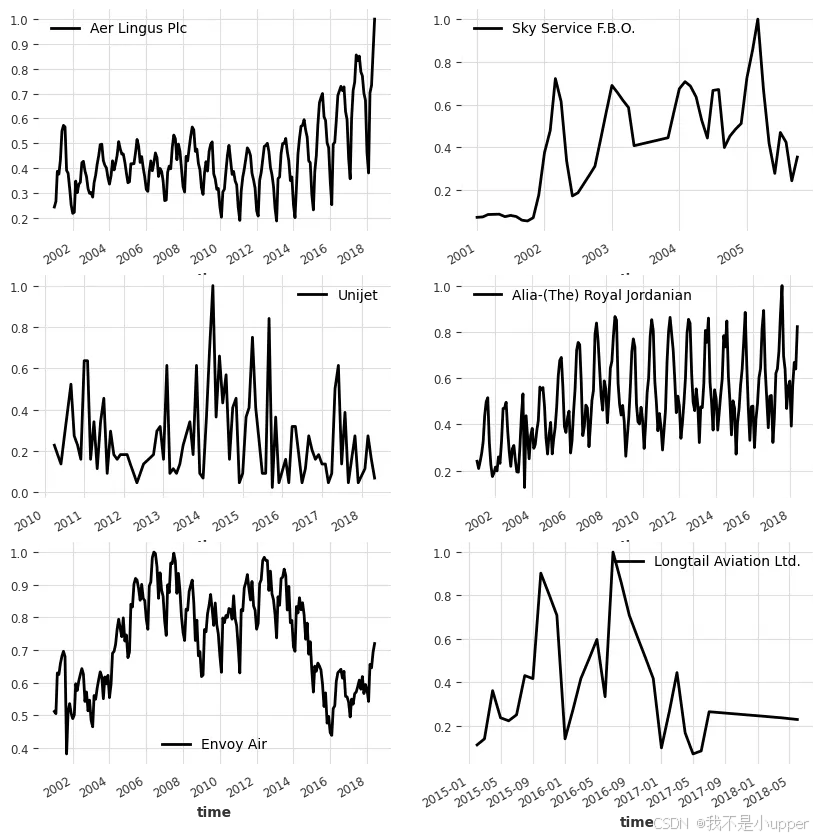
这是构成我们训练数据集的几个航空运输序列(不同航空公司)。大多数序列看起来差异很大,甚至没有相同的时间轴。例如,某些序列从 2001 年 1 月开始,而另一些则从 2010 年 4 月开始。你可以看到,这些训练序列的最大值均为 1—— 我使用了 Darts 缩放器(封装了 scikit-learn 的 MaxAbsScaler),将每个序列除以其最大绝对值。这种缩放不会影响对称平均绝对百分比误差(sMAPE),因此为了简化,这里仅处理缩放后的序列。在实际应用中,我需要对预测结果调用 scaler.inverse_transform (),将其转换回原始值域。
用局部模型预测航空旅客量
现在,我尝试用 “经典” 方法为 300 个时间序列各拟合一个模型进行预测。我们将这种在单个序列上训练的模型称为局部模型。下面,我先编写两个小函数,以便后续使用。首先,eval_forecasts () 计算所有测试序列(300 个)预测误差的中位数 sMAPE,并展示误差分布。
def eval_forecasts(pred_series: List[TimeSeries], test_series: List[TimeSeries]
) -> List[float]:print("computing sMAPEs...")smapes = smape(test_series, pred_series)plt.figure()plt.hist(smapes, bins=50)plt.ylabel("Count")plt.xlabel("sMAPE")plt.title("Median sMAPE: %.3f" % np.median(smapes))plt.show()plt.close()return smapes其次,eval_local_model()迭代所有序列,并为每个序列构建一个(本地)模型,将其拟合到序列的训练部分,并存储预测结果。然后调用此函数eval_forecasts()显示所有序列的 sMAPE 误差。函数返回所有误差的列表以及总耗时。
def eval_local_model(train_series: List[TimeSeries], test_series: List[TimeSeries], model_cls, **kwargs
) -> Tuple[List[float], float]:preds = []start_time = time.time()for series in tqdm(train_series):model = model_cls(**kwargs)model.fit(series)pred = model.predict(n=HORIZON)preds.append(pred)elapsed_time = time.time() - start_timesmapes = eval_forecasts(preds, test_series)return smapes, elapsed_time获取一些预测
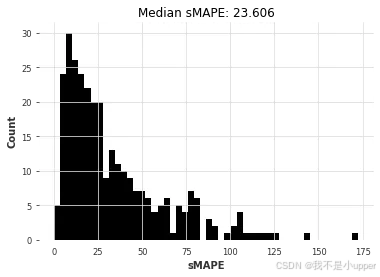
现在我们可以在这个数据集上尝试第一个预测模型。作为第一步,通常最好先看看一个(非常)简单的模型(盲目地重复训练序列的最后一个值)的表现如何。这可以在 Darts 中使用NaiveSeasonal模型来实现:
naive1_smapes, naive1_time = eval_local_model(air_train, air_test, NaiveSeasonal, K=1)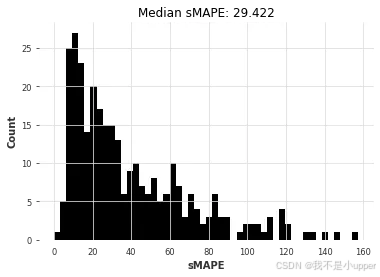
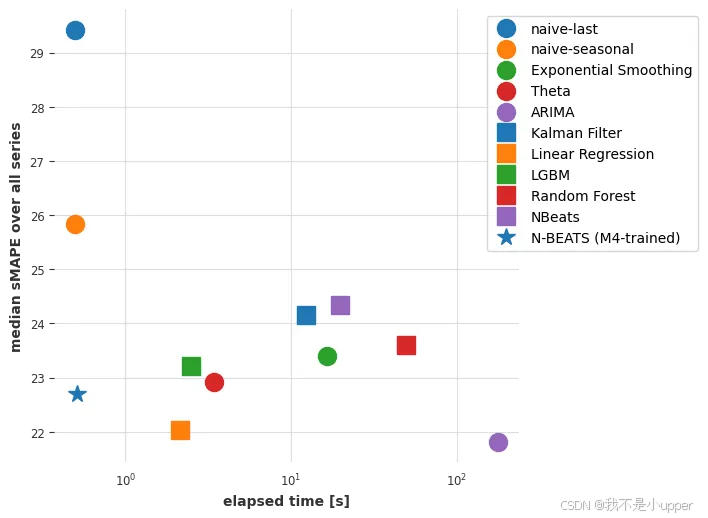
因此,最朴素的模型得出的中值 sMAPE 约为 29.4。我们能否利用大多数月度序列的季节性为 12 这一事实,用一个“不那么朴素”的模型来做得更好?
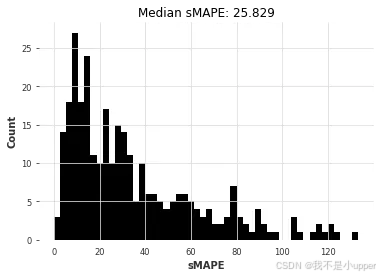
naive12_smapes, naive12_time = eval_local_model(air_train, air_test, NaiveSeasonal, K=12
)
这样就好多了。我们来试试指数平滑(ExponentialSmoothing)(默认情况下,对于月度序列,它将使用季节性 12)。
ets_smapes, ets_time = eval_local_model(air_train, air_test, ExponentialSmoothing)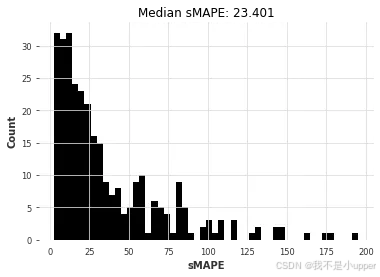
看的出来效果真的是太棒了!现在我希望读者们能明白这有多简单。我们再尝试几个模型:
theta_smapes, theta_time = eval_local_model(air_train, air_test, Theta, theta=1.5)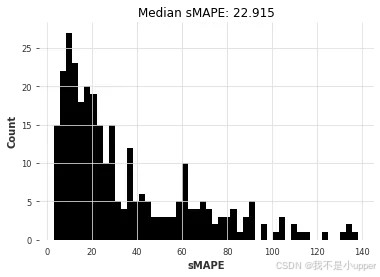
arima_smapes, arima_time = eval_local_model(air_train, air_test, ARIMA, p=12, d=1, q=1)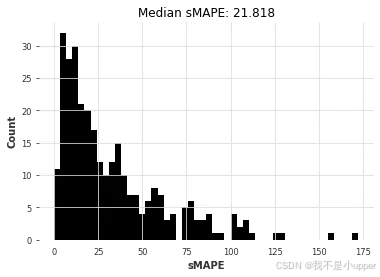
对比可以看出,ARIMA 胜出。让我们绘制每个模型获得的(中位数)误差与拟合和预测所需时间的关系图:
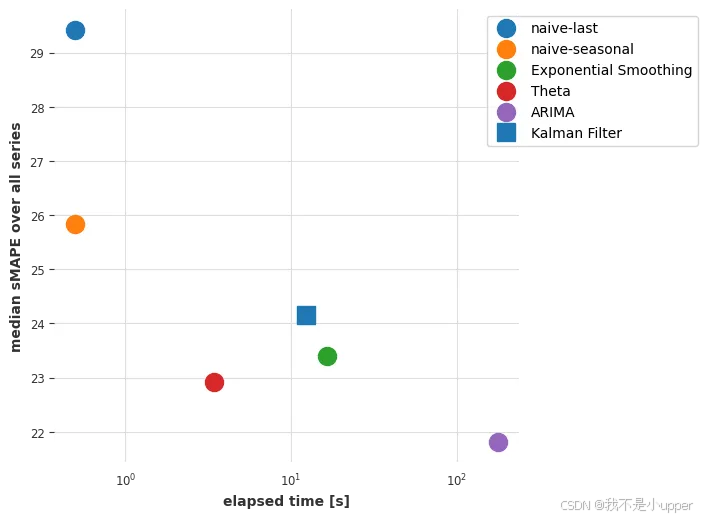
ARIMA 的结果最好,但它也是(迄今为止)最耗时的模型。Theta 方法提供了一个有趣的权衡,它具有良好的预测精度,并且比 ARIMA 快大约 50 倍。我们能否通过考虑全局模型(即只对所有时间序列进行一次联合训练的模型)来找到更好的折衷方案?
利用全球模型预测航空旅客数量
在本节中,我们将使用“全局模型”——即同时在多个序列上进行训练的模型。Darts 本质上有两种全局模型:
RegressionModels它们是类似 sklearn 的回归模型的包装器。- 基于 PyTorch 的模型,提供各种深度学习模型。
这两种模型都可以通过“表格化”数据在多个系列上进行训练——即从所有训练系列中获取许多(输入、输出)子切片,并以监督的方式训练机器学习模型,根据输入预测输出。
我们首先定义一个eval_global_model()与 类似eval_local_model()但针对全局模型的函数。
def eval_global_model(train_series: List[TimeSeries], test_series: List[TimeSeries], model_cls, **kwargs
) -> Tuple[List[float], float]:start_time = time.time()model = model_cls(**kwargs)model.fit(train_series)preds = model.predict(n=HORIZON, series=train_series)elapsed_time = time.time() - start_timesmapes = eval_forecasts(preds, test_series)return smapes, elapsed_time使用RegressionModel
Darts 中的预测模型可以与任何“兼容 scikit-learn”的回归模型结合使用,从而获得预测结果。与深度学习相比,它们代表了良好的全局模型,因为它们通常没有太多超参数,并且训练速度更快。此外,Darts 还提供了一些预打包的回归模型,例如LinearRegressionModel和LightGBMModel。
我们现在将使用我们的函数eval_global_models()并尝试一些回归模型。
读者们可以参考API 文档了解如何使用这些模型。重要的参数是lags和output_chunk_length。它们分别决定了模型使用的回溯窗口和“前瞻窗口”的长度,并且对应于用于训练的输入/输出子切片的长度。例如lags=24, 和output_chunk_length=12表示模型将使用过去的 24 个滞后值来预测接下来的 12 个滞后值。在我们的例子中,由于最短的训练序列长度为 36,因此 必须为lags + output_chunk_length <= 36。(请注意,lags也可以是一个整数列表,表示模型将使用的各个滞后值,而不是窗口长度)。
让我们尝试一下线性回归:
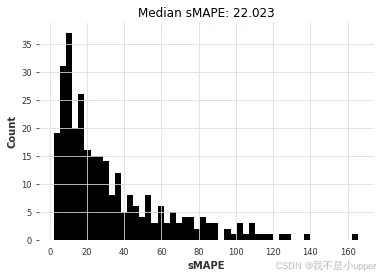
lr_smapes, lr_time = eval_global_model(air_train, air_test, LinearRegressionModel, lags=30, output_chunk_length=1
)
LGBM:
lgbm_smapes, lgbm_time = eval_global_model(air_train, air_test, LightGBMModel, lags=35, output_chunk_length=1, objective="mape"
)随机森林:
rf_smapes, rf_time = eval_global_model(air_train, air_test, RandomForest, lags=30, output_chunk_length=1
)
使用深度学习
接下来,我们将在数据集上训练一个 N-BEATS 模型air。同样,读者可以参考API 文档获取超参数的文档。以下超参数应该是一个很好的起点:
# Slicing hyper-params:
IN_LEN = 30
OUT_LEN = 4# Architecture hyper-params:
NUM_STACKS = 20
NUM_BLOCKS = 1
NUM_LAYERS = 2
LAYER_WIDTH = 136
COEFFS_DIM = 11# Training settings:
LR = 1e-3
BATCH_SIZE = 1024
MAX_SAMPLES_PER_TS = 10
NUM_EPOCHS = 10现在让我们构建模型,进行训练,并得到一些预测结果。在(速度较慢的)Colab GPU 上,训练大约需要一两分钟。
# reproducibility
np.random.seed(42)
torch.manual_seed(42)start_time = time.time()nbeats_model_air = NBEATSModel(input_chunk_length=IN_LEN,output_chunk_length=OUT_LEN,num_stacks=NUM_STACKS,num_blocks=NUM_BLOCKS,num_layers=NUM_LAYERS,layer_widths=LAYER_WIDTH,expansion_coefficient_dim=COEFFS_DIM,loss_fn=SmapeLoss(),batch_size=BATCH_SIZE,optimizer_kwargs={"lr": LR},# remove this one if your notebook does run in a GPU environment:pl_trainer_kwargs={"enable_progress_bar": True,"accelerator": "gpu","gpus": -1,"auto_select_gpus": True,},
)nbeats_model_air.fit(air_train, num_loader_workers=4, epochs=NUM_EPOCHS
)# get predictions
nb_preds = nbeats_model_air.predict(series=air_train, n=HORIZON)
nbeats_elapsed_time = time.time() - start_timenbeats_smapes = eval_forecasts(nb_preds, air_test)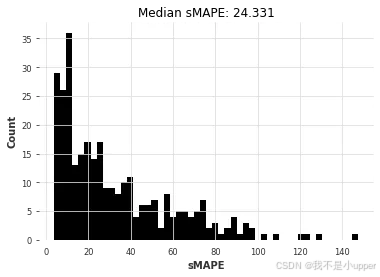
让我们再次比较一下我们的模型:
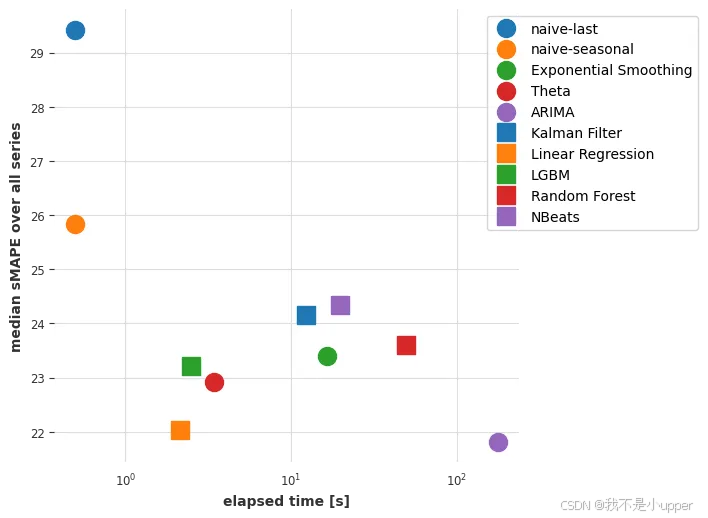
因此,看起来,对所有序列进行联合训练的线性回归模型现在在准确率和速度之间实现了最佳平衡(在相似准确率的情况下,比 ARIMA 快约 85 倍)。线性回归通常是最佳选择!
我们的深度学习模型 N-BEATS 表现不佳。需要注意的是,我们尚未尝试针对这个问题进行明确的调优,这或许能带来更准确的结果。与其花时间进行调优,不如在下一节中,看看在完全不同的数据集上训练它是否能取得更好的效果。
使用 N-BEATS 模型进行迁移学习
深度学习模型通常在大型数据集上训练时表现更佳。让我们尝试加载 M4 竞赛数据集中全部 48,000 个月度时间序列,并在这个更大的数据集上再次训练我们的模型。
m4_train, _ = load_m4()我们现在将再次尝试训练 N-BEATS 模型,但使用这个更大的数据集。
默认情况下,从给定序列中训练基于 ML 的预测模型所生成的(输入、输出)训练样本的数量与序列数量乘以其长度成正比。M4 数据集包含 48,000 个序列,平均长度约为 216 个时间步长。因此,如果我们保留默认参数,最终将得到约 10M 个数量级的训练样本。为了在一定程度上限制每个时期所需的时间,我们将限制每个序列使用的训练样本数量。这是在fit()使用参数调用时完成的max_samples_per_ts。我们添加了一个新的超参数MAX_SAMPLES_PER_TS来捕获它。注意:如果我们想要更好地控制生成(输入、输出)训练示例以训练模型的方式,我们可以调用fit_from_dataset()而不是fit()并提供darts.utils.data.TrainingDataset我们选择的实现。
由于 M4 训练系列都稍长一些,我们也可以使用稍长一些的input_chunk_length。
# Slicing hyper-params:
IN_LEN = 36
OUT_LEN = 4# Architecture hyper-params:
NUM_STACKS = 20
NUM_BLOCKS = 1
NUM_LAYERS = 2
LAYER_WIDTH = 136
COEFFS_DIM = 11# Training settings:
LR = 1e-3
BATCH_SIZE = 1024
MAX_SAMPLES_PER_TS = (10 # <-- new parameter, limiting the number of training samples per series
)
NUM_EPOCHS = 5现在我们可以再次构建和训练我们的模型:
# reproducibility
np.random.seed(42)
torch.manual_seed(42)nbeats_model_m4 = NBEATSModel(input_chunk_length=IN_LEN,output_chunk_length=OUT_LEN,batch_size=BATCH_SIZE,num_stacks=NUM_STACKS,num_blocks=NUM_BLOCKS,num_layers=NUM_LAYERS,layer_widths=LAYER_WIDTH,expansion_coefficient_dim=COEFFS_DIM,loss_fn=SmapeLoss(),optimizer_kwargs={"lr": LR},pl_trainer_kwargs={"enable_progress_bar": True,"accelerator": "gpu","gpus": -1,"auto_select_gpus": True,},
)# Train
nbeats_model_m4.fit(m4_train,num_loader_workers=4,epochs=NUM_EPOCHS,max_samples_per_ts=MAX_SAMPLES_PER_TS,
)我们现在可以使用 M4 训练的模型来预测航空旅客序列。由于我们在这里以迁移学习的方式使用该模型,因此我们只计算推理部分(假设该模型已预先训练过)。
start_time = time.time()
preds = nbeats_model_m4.predict(series=air_train, n=HORIZON) # get forecasts
nbeats_m4_elapsed_time = time.time() - start_time
nbeats_m4_smapes = eval_forecasts(preds, air_test)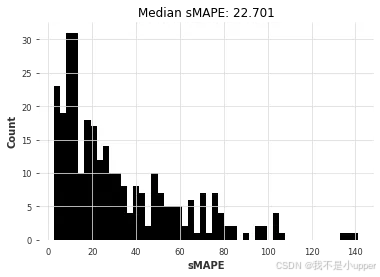
让我们再次比较一下所有模型:
虽然准确率并非绝对最佳,但我们在 M4 上预训练的 N-BEATS 模型达到了相当高的准确率。这非常了不起,因为该模型从未在我们要求其预测的任何航空旅客序列上进行过训练!使用 N-BEATS 的预测步骤比我们使用 ARIMA 所需的拟合预测步骤快约 350 倍,比线性回归的拟合预测步骤快约 4 倍。为了好玩,我们还可以手动检查该模型在其他系列上的表现——例如,每月牛奶产量系列darts.datasets:
from darts.datasets import MonthlyMilkDatasetseries = MonthlyMilkDataset().load().astype(np.float32)
train, val = series[:-24], series[-24:]scaler = Scaler(scaler=MaxAbsScaler())
train = scaler.fit_transform(train)
val = scaler.transform(val)
series = scaler.transform(series)
pred = nbeats_model_m4.predict(series=train, n=24)series.plot(label="actual")
pred.plot(label="0-shot forecast")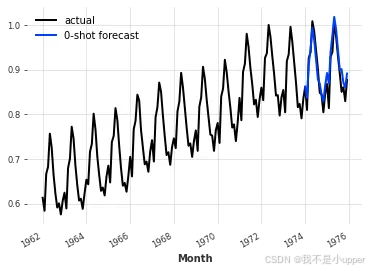
看来这个模型在月度序列上表现相当出色。这是 N-BEATS 的特性吗?或者如果我们在 M4 上训练其他全局模型(例如线性回归或 LGBM),然后在航空旅客序列上进行评估,会不会得到类似的结果?
尝试将迁移学习与其他全局模型结合
我们先尝试一下LinearRegressionModel
lr_model_m4 = LinearRegressionModel(lags=30, output_chunk_length=1)
lr_model_m4.fit(m4_train)tic = time.time()
preds = lr_model_m4.predict(n=HORIZON, series=air_train)
lr_time_transfer = time.time() - ticlr_smapes_transfer = eval_forecasts(preds, air_test)
再加上LightGBMModel
lgbm_model_m4 = LightGBMModel(lags=30, output_chunk_length=1, objective="mape")
lgbm_model_m4.fit(m4_train)tic = time.time()
preds = lgbm_model_m4.predict(n=HORIZON, series=air_train)
lgbm_time_transfer = time.time() - ticlgbm_smapes_transfer = eval_forecasts(preds, air_test)
Finally, let’s plot these new results as well:
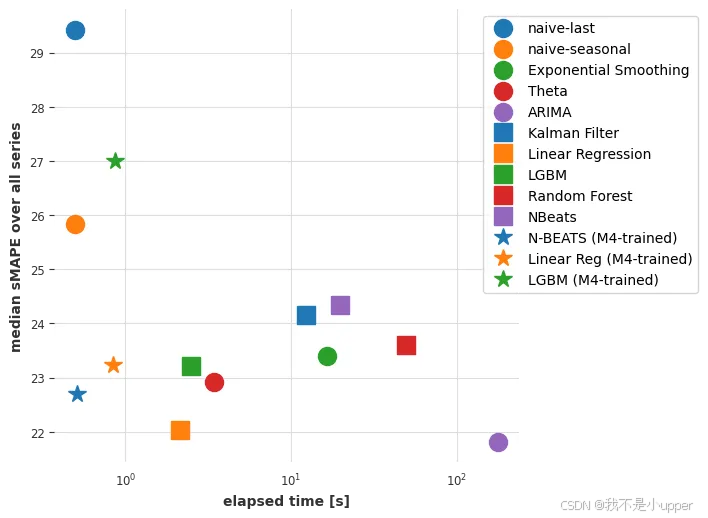
线性回归也提供了相当不错的性能。它的速度稍慢一些,可能只是因为 N-BEATS 的推理是跨时间序列批次高效批处理的,并且在 GPU 上执行。
回顾:在 M3 数据集上使用相同的模型
好了,现在,我们用航空乘客数据集测试一下结果怎么样?让我们在新的数据集上重复整个过程看看效果 :) 你会发现,实际上只需要几行代码。我们将使用 M3 预测竞赛中的 1,400 个月序列作为新的“测试”数据集。以下是运行和测试所有模型所需的全部代码:
# load M3 dataset
m3_train, m3_test = load_m3()# naive last
naive1_smapes_m3, naive1_time_m3 = eval_local_model(m3_train, m3_test, NaiveSeasonal, K=1
)# naive seasonal
naive12_smapes_m3, naive12_time_m3 = eval_local_model(m3_train, m3_test, NaiveSeasonal, K=12
)# Exponential smoothing
ets_smapes_m3, ets_time_m3 = eval_local_model(m3_train, m3_test, ExponentialSmoothing)# Theta
theta_smapes_m3, theta_time_m3 = eval_local_model(m3_train, m3_test, Theta)# ARIMA
arima_smapes_m3, arima_time_m3 = eval_local_model(m3_train, m3_test, ARIMA, p=12, d=1, q=0
)# Kalman filter
kf_smapes_m3, kf_time_m3 = eval_local_model(m3_train, m3_test, KalmanForecaster, dim_x=12
)# Linear regression
lr_smapes_m3, lr_time_m3 = eval_global_model(m3_train, m3_test, LinearRegressionModel, lags=30, output_chunk_length=1
)# LGBM
lgbm_smapes_m3, lgbm_time_m3 = eval_global_model(m3_train, m3_test, LightGBMModel, lags=35, output_chunk_length=1, objective="mape"
)# Get forecasts with our pre-trained N-BEATS
start_time = time.time()
preds = nbeats_model_m4.predict(series=m3_train, n=HORIZON)
nbeats_m4_elapsed_time_m3 = time.time() - start_time
nbeats_m4_smapes_m3 = eval_forecasts(preds, m3_test)# Get forecasts with our pre-trained linear regression model
start_time = time.time()
preds = lr_model_m4.predict(series=m3_train, n=HORIZON)
lr_m4_elapsed_time_m3 = time.time() - start_time
lr_m4_smapes_m3 = eval_forecasts(preds, m3_test)# Get forecasts with our pre-trained LightGBM model
start_time = time.time()
preds = lgbm_model_m4.predict(series=m3_train, n=HORIZON)
lgbm_m4_elapsed_time_m3 = time.time() - start_time
lgbm_m4_smapes_m3 = eval_forecasts(preds, m3_test)现在,对它们进行比较:
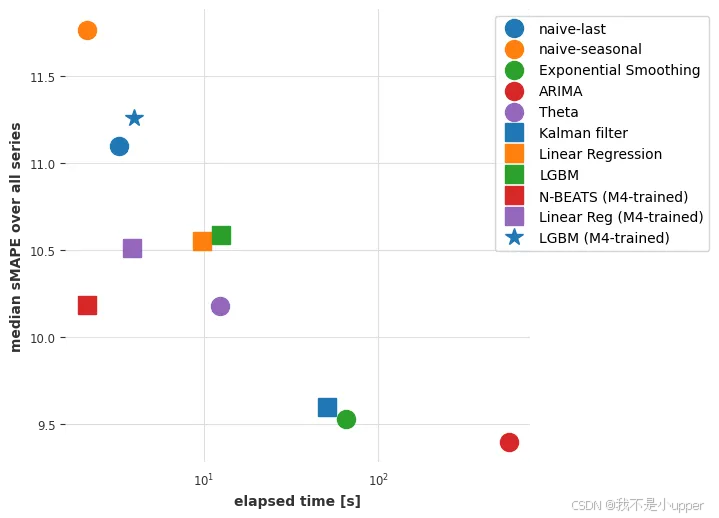
预训练的 N-BEATS 模型也获得了合理的准确率,尽管不如最准确的模型。需要注意的是,在 3 个最准确的模型中,有两个模型(指数平滑法和卡尔曼滤波器)在用于航空旅客序列时表现不佳。ARIMA 表现最佳,但速度比 N-BEATS 慢约 170 倍,后者无需任何训练,每个时间序列大约需要 15 毫秒即可生成预测结果。需要注意的是,这个 N-BEATS 模型从未在我们要求它预测的任何序列上进行过训练。
结论
迁移学习和元学习在时间序列预测领域无疑是一条充满趣味却尚未被充分探索的路径。它们何时能够大显身手?何时可能遭遇滑铁卢?微调操作是否真的能雪中送炭?究竟该在怎样的场景下启用它们?这些问题仍有许多等待破解,但我希望通过实际验证表明,借助 Darts 模型能够轻松开启相关领域的探索之旅。
那么,究竟哪种方法最契合你的应用场景呢?和往常一样,答案取决于具体情况。如果你主要面对的是拥有充足历史记录的孤立序列,那么像 ARIMA 这样的经典方法将大有用武之地。即便处理更大规模的数据集,倘若计算能力并非瓶颈,这类方法也能为单变量序列提供实用且易于上手的解决方案。另一方面,若你需要处理海量序列或多变量序列,机器学习方法与全局模型往往是更优选择 —— 它们能够精准捕捉不同时间序列中的模式规律,并且通常具备更高的运行效率。千万不要小觑基于线性回归的模型!倘若你有理由相信需要捕捉更为复杂的模式,或者推理速度对你而言至关重要,那么不妨大胆尝试深度学习方法。N - BEATS 已在元学习场景中展现出独特价值,但这种创新思路同样可能适用于其他模型。
相关文章:

时间序列预测的迁移学习
在本文中,我们将了解如何将迁移学习应用于时间序列预测,以及如何在多样化的时间序列数据集上训练一次预测模型,之后无需训练即可在不同数据集上进行预测。我们将使用开源 Darts 库,仅用几行代码即可完成所有这些操作。你可以点击此…...

react中运行 npm run dev 报错,提示vite.config.js出现错误 @esbuild/win32-x64
在React项目中运行npm run dev时,如果遇到vite.config.js报错,提示esbuild/win32-x64在另一个平台中被使用,通常是由于依赖冲突或缓存问题导致的。解决方法是删除node_modules文件夹,并重新安装依赖。 如下图: 解决办…...

量子计算模拟:从理论到实践
量子计算作为现代物理学与计算机科学的前沿交叉领域,正逐渐从纯理论研究走向实际应用。本文将介绍一个基于Python的量子计算模拟框架,重点探讨量子比特、量子门操作以及量子态的演化等核心概念,并通过可视化手段直观展示量子态的特性。 量子…...

143.重排链表的尝试
listnode* p0cur,cur->nextq;p0->next有没有改变 ChatGLM 让我们逐步分析这段代码,看看 p0->next 是否发生了改变。 假设我们有一个链表,cur 是当前节点,q 是另一个节点。代码如下: 代码生成完成 C代码 首先&#…...

精准识别记忆细胞!Elabscience PE Anti-Human/Mouse CD44 抗原特异性抗体
概述 CD44 是一种广泛表达的细胞表面黏附分子,参与细胞迁移、炎症反应及肿瘤转移等关键生物学过程。Elabscience 推出的PE Anti-Human/Mouse CD44 Antibody [IM7](货号:E-AB-F1100D)是一款高特异性、高灵敏度的流式抗体ÿ…...

OpenCV CUDA模块特征检测与描述------一种基于快速特征点检测和旋转不变的二进制描述符类cv::cuda::ORB
操作系统:ubuntu22.04 OpenCV版本:OpenCV4.9 IDE:Visual Studio Code 编程语言:C11 算法描述 cv::cuda::ORB 是 OpenCV 库中 CUDA 模块的一部分,它提供了一种基于快速特征点检测和旋转不变的二进制描述符的方法,用于…...
函数createBoxFilter())
OpenCV CUDA模块特征检测与描述------创建一个 盒式滤波器(Box Filter)函数createBoxFilter()
操作系统:ubuntu22.04 OpenCV版本:OpenCV4.9 IDE:Visual Studio Code 编程语言:C11 算法描述 cv::cuda::createBoxFilter 是 OpenCV CUDA 模块中的一个工厂函数,用于创建一个 盒式滤波器(Box Filter)&…...

【八股战神篇】Spring高频面试题汇总
专栏简介 Bean 的生命周期了解么? 延伸 谈谈自己对于 Spring IoC 的了解 延伸 什么是动态代理? 延伸 动态代理和静态代理的区别 延伸 Spring AOP的执行流程 延伸 Spring的事务什么情况下会失效? 延伸 专栏简介 八股战神篇专栏是基于各平台共上千篇面经,上万道…...

高阶数据结构——红黑树实现
目录 1.红黑树的概念 1.1 红黑树的规则: 1.2 红黑树的效率 2.红黑树的实现 2.1 红黑树的结构 2.2 红黑树的插入 2.2.1 不旋转只变色(无论c是p的左还是右,p是g的左还是右,都是一样的变色处理方式) 2.2.2 单旋变色…...

java综合交易所13国语言,股票,区块链,外汇,自带客服系统运营级,有测试
这套pc和H5是一体的,支持测试,目前只有外汇和区块链,某站居然有人卖3.8w,还觉得自己这个价格很好 自带客服系统,虽然是老的,但是可玩性还是很高的,也支持c2c,理财,质押&a…...

六:操作系统虚拟内存之缺页中断
深入理解操作系统:缺页中断 (Page Fault) 的处理流程 在上一篇文章中,我们介绍了虚拟内存和按需调页 (Demand Paging) 的概念。虚拟内存为每个进程提供了巨大的、独立的虚拟地址空间,并通过页表 (Page Table) 将虚拟页面 (Virtual Page) 映射…...
安装教程详解:第二篇)
iOS 15.4.1 TrollStore(巨魔商店)安装教程详解:第二篇
🚀 iOS 15.4.1 TrollStore(巨魔商店)安装教程详解 ✨ 前言🛠️ 如何安装 TrollStore?第一步:打开 Safari 浏览器第二步:选择对应系统版本安装方式第三步:访问地址,下载配…...
)
【JAVA】比较器Comparator与自然排序(28)
JAVA 核心知识点详细解释 Java中比较器Comparator的概念和使用方法 概念 Comparator 是 Java 中的一个函数式接口,位于 java.util 包下。它用于定义对象之间的比较规则,允许我们根据自定义的逻辑对对象进行排序。与对象的自然排序(实现 Comparable 接口)不同,Comparat…...
)
bitbar环境搭建(ruby 2.4 + rails 5.0.2)
此博客为武汉大学WA学院网络安全课程,理论课大作业Web环境搭建。 博主搭了2天!!!血泪教训是还是不能太相信ppt上的教程。 一开始尝试了ppt上的教程,然后又转而寻找网络资源 cs155源代码和docker配置,做到…...

Spring Boot接口通用返回值设计与实现最佳实践
一、核心返回值模型设计(增强版) package com.chat.common;import com.chat.util.I18nUtil; import com.chat.util.TraceUtil; import lombok.AllArgsConstructor; import lombok.Data; import lombok.Getter;import java.io.Serializable;/*** 功能: 通…...

线上 Linux 环境 MySQL 磁盘 IO 高负载深度排查与性能优化实战
目录 一、线上告警 二、问题诊断 1. 系统层面排查 2. 数据库层面分析 三、参数调优 1. sync_binlog 参数优化 2. innodb_flush_log_at_trx_commit 参数调整 四、其他优化建议 1. 日志文件位置调整 2. 生产环境核心参数配置模板 3. 突发 IO 高负载应急响应方案 五、…...

React--函数组件和类组件
React 中的函数组件和类组件是两种定义组件的方式,它们有以下主要区别: 1. 语法与定义方式 函数组件: 是 JavaScript 函数,接收 props 作为参数,返回 JSX。 const MyComponent (props) > {return <div>Hell…...
)
GitHub 趋势日报 (2025年05月20日)
本日报由 TrendForge 系统生成 https://trendforge.devlive.org/ 🌐 本日报中的项目描述已自动翻译为中文 📈 今日整体趋势 Top 10 排名项目名称项目描述今日获星总星数语言1virattt/ai-hedge-fundAI对冲基金团队⭐ 1781⭐ 31163Python2public-apis/pub…...
和uni.openSetting())
uni.getLocation()和uni.openSetting()
文章目录 环境背景问题分析问题1问题2 uni.getLocation()和uni.openSetting()的区别和联系其它uni.getLocation()的failuni.openSetting()的authSetting对象 参考 环境 Windows 11 专业版HBuilder X 4.65微信开发者工具 Stable 1.06.2412050 背景 在小程序开发中,…...

医疗行业数据共享新实践:如何用QuickAPI打通诊疗全流程数据壁垒
在医疗行业,数据的高效流转直接影响诊疗效率和患者体验。某三甲医院在数字化转型中发现,虽然已积累大量核心业务数据,但各科室系统间的数据互通仍存在明显瓶颈——检验科的报告无法实时同步至门诊系统,药房库存数据与采购系统脱节…...

管理会议最佳实践:高效协同与价值最大化
1.会前准备:明确目标与计划 1.1 明确会议目的 1.1.1 必要性评估 开会前需自问是否真的需要开会,若问题可通过邮件、文档或异步沟通解决,则应避免开会,以节省时间和资源。 1.1.2 目标定义 清晰定义会议目标,如决策、信息同步、创意讨论等,并提前告知参与者,使大家明确参…...

万物智联,重塑未来:鸿蒙操作系统的实战突破与生态崛起
鸿蒙操作系统(HarmonyOS)作为华为自主研发的分布式操作系统,自2019年发布以来,已从技术探索迈入大规模商用阶段。截至2025年,鸿蒙系统不仅成为全球第二大移动操作系统,更在政企数字化、工业制造、金融科技等…...

人工智能路径:技术演进下的职业发展导航
当生成式AI能够自主完成创意设计、商业分析和代码编写时,职业发展的传统路径正在被重新测绘。人工智能路径不再是一条预设的直线,而演变为包含多重可能性的动态网络——未来的职业成功,将取决于在技术变革中持续定位自身价值节点的能力。 一…...
)
深入理解Java虚拟机之垃圾收集器篇(垃圾回收器的深入解析待完成TODO)
目录 **一. 如何判断对象的存亡**引用计数算法:可达性分析算法: **二. Java中的四种引用****三. 垃圾回收算法****1. 标记 - 清除算法****2. 标记 - 复制算法****3. 标记 - 整理算法****4. 分代收集理论**(了解即可) **四. 十种主流垃圾收集器****3.1 Serial 收集器****3.2 Par…...

牛客网 NC16407 题解:托米航空公司的座位安排问题
牛客网 NC16407 题解:托米航空公司的座位安排问题 题目分析 解题思路 本题可以采用深度优先搜索(DFS)来解决: 从左上角开始,按行优先顺序遍历每个座位对于每个座位,有两种选择: 选择该座位(如果满足条件…...
滤波器掩模的注意事项)
拉普拉斯高斯(LoG)滤波器掩模的注意事项
目录 问题: 解答: 一、高斯函数归一化:消除幅度偏差 1. 归一化的定义 2. 为何必须归一化? 二、拉普拉斯系数和为零:抑制直流项干扰 1. 拉普拉斯算子的特性 2. 系数和不为零的后果 三、直流项如何影响零交叉点&…...

OSPF基础实验-多区域
互联接口、IP地址如下图所示,所有设备均创建Loopback0,其IP地址为10.0.x.x/24,其中x为设备编号。 R1、R3的所有接口以及R2的GE0/0/4接口属于OSPF区域2,R2、R4的Loopback0接口及互联接口属于OSPF区域0,R4、R5的互联接口…...

ERP 与 WMS 对接深度解析:双视角下的业务与技术协同
在企业数字化运营的复杂体系中,ERP(企业资源规划)与 WMS(仓储管理系统)的有效对接,已成为优化供应链管理、提升运营效率的关键环节。本文将从 ERP 和 WMS 两个核心视角出发,深度剖析两者对接过程…...

基于 Node.js 的 HTML 转 PDF 服务
这是一个基于 Node.js 开发的 Web 服务,主要功能是将 HTML 内容转换为 PDF 文件。项目使用了 Express 作为 Web 框架,Puppeteer 作为 PDF 生成引擎,提供了简单易用的 API 接口。前端开发人员提供了一个简单而强大的 HTML 转 PDF 解决方案&…...
的使用:ArrayBlockingQueue类、LinkedBlockingQueue类)
Java阻塞队列(BlockingQueue)的使用:ArrayBlockingQueue类、LinkedBlockingQueue类
1、阻塞队列的介绍 Java 中的阻塞队列(BlockingQueue) 是多线程编程中用于协调生产者和消费者线程的重要工具,属于 java.util.concurrent 包。它的核心特点是:当队列为空时,消费者线程会被阻塞,直到队列中有新元素;当队列满时,生产者线程会被阻塞,直到队列有空闲…...

esp32cmini SK6812 2个方式
1 #include <SPI.h> // ESP32-C系列的SPI引脚 #define MOSI_PIN 7 // ESP32-C3/C6的SPI MOSI引脚 #define NUM_LEDS 30 // LED灯带实际LED数量 - 确保与实际数量匹配! #define SPI_CLOCK 10000000 // SPI时钟频率 // 颜色结构体 st…...

2025年 PMP 6月 8月 专题知识
2025年 PMP 6月 8月 专题知识 文章目录 2025年 PMP 6月 8月 专题知识三点估算1. 概念:2. 原理: 决策树1. 概念:2. 步骤: 真题 三点估算 1. 概念: 三点估算常用于估算活动持续时间(也可以用于估算成本);源自计划评审技术(PERT&am…...

一文理解TCP与UDP
Socket套接字 Socket套接字,是由系统提供用于网络通信的技术,是基于TCP/IP协议的网络通信的基本操作单元。 基于Socket套接字的网络程序开发就是网络编程。 Socket套接字主要针对传输层协议划分为如下三类: 流套接字:使用传输层…...

智能指针RAII
引入:智能指针的意义是什么? RAll是一种利用对象生命周期来控制程序资源(如内存、文件句柄、网络连接、互斥量等等)的简单技术。 在对象构造时获取资源,接着控制对资源的访问使之在对象的生命周期内始终保持有效&#…...

AI护航化工:《山西省危化品视频智能分析指南》下的视频分析重构安全体系
化工和危化品行业的AI智能视频分析应用:构建安全与效率新范式 一、行业背景与挑战 化工和危化品行业是国民经济的重要支柱,但生产过程涉及高温、高压、易燃易爆等高风险场景。传统安全监管依赖人工巡检和固定监控设备,存在效率低、盲区多、…...
-学习记录4)
GitHub SSH Key 配置详细教程(适合初学者,Windows版)-学习记录4
GitHub SSH Key 配置详细教程(适合初学者,Windows版) 本教程适用于在 Windows 系统下,将本地 Git 仓库通过 SSH 方式推送到 GitHub,适合没有配置过 SSH key 的初学者。 1. 检查是否已有 SSH key 打开 Git Bash 或 Po…...

初识Linux · NAT 内网穿透 内网打洞 代理
目录 前言: 内网穿透和打洞 NAPT表 内网穿透 内网打洞 正向/反向代理 前言: 本文算是网络原理的最后一点补充,为什么说是补充呢,因为我们在前面第一次介绍NAT的时候详细介绍的是报文从子网到公网,却没有介绍报文…...

docker-compose使用详解
Docker-Compose 是 Docker 官方提供的容器编排工具,用于简化多容器应用的定义、部署和管理。其核心功能是通过 YAML 配置文件(docker-compose.yml)定义服务、网络和存储卷,并通过单一命令实现全生命周期的管理。以下从核心原理、安…...

使用计算机视觉实现目标分类和计数!!超详细入门教程
什么是物体计数和分类 在当今自动化和技术进步的时代,计算机视觉作为一项关键工具脱颖而出,在物体计数和分类任务中提供了卓越的功能。 无论是在制造、仓储、零售,还是在交通监控等日常应用中,计算机视觉系统都彻底改变了我们感知…...

并发编程中的对象组合的哲学
文章目录 引言对象组合与安全委托实例封闭技术基于监视器模式的对象访问对象不可变性简化委托原子维度的访问现有容器的并发安全的封装哲学使用继承使用组合小结参考引言 本文将介绍通过封装技术,保证开发者不对整个程序进行分析的情况下,就可以明确一个类是否是线程安全的,…...
)
03-Web后端基础(Maven基础)
1. 初始Maven 1.1 介绍 Maven 是一款用于管理和构建Java项目的工具,是Apache旗下的一个开源项目 。 Apache 软件基金会,成立于1999年7月,是目前世界上最大的最受欢迎的开源软件基金会,也是一个专门为支持开源项目而生的非盈利性…...

禁忌搜索算法:从原理到实战的全解析
禁忌搜索算法:从原理到实战的全解析 一、算法起源与核心思想 禁忌搜索(Tabu Search, TS)由美国工程院院士Fred Glover于1986年正式提出,其灵感源于人类的记忆机制——通过记录近期的搜索历史(禁忌表)&…...

从加密到信任|密码重塑车路云一体化安全生态
目录 一、密码技术的核心支撑 二、典型应用案例 三、未来发展方向 总结 车路云系统涉及海量实时数据交互,包括车辆位置、传感器信息、用户身份等敏感数据。其安全风险呈现三大特征: 开放环境威胁:V2X(车与万物互联࿰…...

【ffmpeg】SPS与PPS的概念
PPS(Picture Parameter Set)详解 PPS(图像参数集)是H.264/H.265视频编码标准中的关键数据结构,与SPS(序列参数集)共同组成视频的解码配置信息,直接影响视频的正确解码和播放。以下是…...

Java垃圾回收与JIT编译优化
1. Java中的垃圾回收 垃圾回收是Java内存管理的核心,负责自动回收不再被应用程序引用的对象内存,从而防止内存泄漏并优化资源使用。以下详细介绍垃圾回收的机制、算法及优化实践。 1.1 垃圾回收的必要性 垃圾回收解决了手动内存管理中的常见问题,如内存泄漏和悬空指针。它…...

mmaction2——tools文件夹下
build_rawframes.py 用法示例 python tools/data/build_rawframes.py data/videos data/frames --task rgb --level 2 --ext mp4 --use-opencv --num-worker 8总结: 只需要 RGB 帧,推荐 --use-opencv,简单高效,无需额外依赖。 …...

论文阅读:Next-Generation Database Interfaces:A Survey of LLM-based Text-to-SQL
地址:Next-Generation Database Interfaces: A Survey of LLM-based Text-to-SQL 摘要 由于用户问题理解、数据库模式解析和 SQL 生成的复杂性,从用户自然语言问题生成准确 SQL(Text-to-SQL)仍是一项长期挑战。传统的 Text-to-SQ…...

Devicenet主转Profinet网关助力改造焊接机器人系统智能升级
某汽车零部件焊接车间原有6台焊接机器人(采用Devicenet协议)需与新增的西门子S7-1200 PLC(Profinet协议)组网。若更换所有机器人控制器或上位机系统,成本过高且停产周期长。 《解决方案》 工程师选择稳联技术转换网关…...

【HTML-5】HTML 实体:完整指南与最佳实践
1. 什么是 HTML 实体? HTML 实体是一种在 HTML 文档中表示特殊字符的方法,这些字符如果直接使用可能会与 HTML 标记混淆,或者无法通过键盘直接输入。实体由 & 符号开始,以 ; 分号结束。 <p>这是一个小于符号的实体&am…...

MySQL 索引详解与原理分析
MySQL 索引详解与原理分析 一、什么是索引? 索引(Index)是数据库表中一列或多列的值进行排序的一种数据结构,可以加快数据的检索速度。索引类似于书本的目录,通过目录可以快速定位到想要的内容,而不用全书…...