AMO——下层RL与上层模仿相结合的自适应运动优化:让人形行走操作(loco-manipulation)兼顾可行性和动力学约束
前言
自从去年24年Q4,我司侧重具身智能的场景落地与定制开发之后
- 去年Q4,每个月都会进来新的具身需求
- 今年Q1,则每周都会进来新的具身需求
- Q2的本月起,一周不止一个需求
特别是本周,几乎每天都有国企、名企通过我司找到我们,比如钢筋绑扎等等各行各业
使得我们,包括我自己没有一刻停得下来,比如我个人的工作之一就是针对各种项目的各个场景寻找最优的解决方案
比如不在只是单纯的上半身操作,或者下肢行走,而遇到了越来越多的loco-manipulation问题——既涉及运动控制 也涉及操作,最简单的比如搬运箱子,以及从地面拾取物品
如此,不可避免的会关注CMU、UC San Diego、斯坦福等高校的各个团队的最新前沿进展
UCSD的Xiaolong Wang团队发布了最新的这个AMO工作《AMO: Adaptive Motion Optimization for Hyper-Dexterous Humanoid Whole-Body Control》——25年5.6日提交到的arXiv,个人觉得很有新意,故本文来解读下,且还会顺带解读另一个有些相似的动作:来自CMU的FALCON
第一部分
1.1 引言与相关工作
1.1.1 引言
如AMO论文所述,由于动态人形全身控制具有高维度、高度非线性以及丰富接触的特性。传统的基于模型的最优控制方法需要对机器人及环境进行精确建模,具备高计算能力,并且需要采用reduced-order模型以获得可实现的计算结果,这对于在现实世界中利用过度驱动人形机器人全部自由度(29)的问题来说是不可行的
近年来,强化学习(RL)与仿真到现实(sim-to-real)技术的结合在实现现实世界中的人形机器人行走-操作(loco-manipulation)任务方面展现出巨大潜力 [42-Mobile-television]
尽管这些方法实现了高自由度(DoF)人形机器人的强健实时控制,但通常依赖于大量人类专业知识和奖励函数的手动调整,以确保稳定性和性能
- 为了解决这一限制,研究人员将动作模仿框架与强化学习结合,利用重定向的人体动作捕捉(MoCap)轨迹来定义奖励目标,引导策略学习 [10-Exbody,28-Omnih2o]
然而,这类轨迹通常在运动学上可行,却未能考虑目标人形平台的动态约束,从而在仿真动作与硬件可执行行为之间引入了体现差距(embodiment gap)
- 另一种方法则将轨迹优化(TO)与强化学习结合,以弥合这一差距
38-Reinforcement learning for robust parameterized locomotion control of bipedal robots
41-Opt2skill: Imitating dynamicallyfeasible whole-body trajectories for versatile humanoid
loco-manipulation
尽管上述这些方法推动了人形机器人行走-操作能力,当前的方法仍然局限于简化的运动模式,而未能实现真正的全身灵巧性,原因在于
- 基于动作捕捉的方法存在固有的运动学偏差:其参考数据集主要包含双足步态序列(如行走、转向),却缺乏对实现高度灵巧操作至关重要的手臂-躯干协调动作
- 相反,基于轨迹优化TO的方法则面临互补的局限性——它们依赖于有限的运动基元库,并且在实时应用中的计算效率低下,阻碍了策略的泛化能力。这在需要对非结构化输入做出快速适应的动态场景中(如反应式远程操作或环境扰动)严重制约了实际部署
为弥合这一差距,作者提出了自适应运动优化(AMO)——一种用于人形机器人实时全身控制的分层框架,通过两项协同创新实现:
- 混合运动合成:通过融合来自动作捕捉数据的手臂轨迹与概率采样的躯干朝向,构建混合上半身指令集,从系统上消除训练分布中的运动学偏差
这些指令驱动具备动力学感知的轨迹优化器,生成既满足运动学可行性又满足动力学约束的全身参考动作,从而构建了AMO数据集——首个专为灵巧行走操作设计的人形机器人动作库 - 可泛化策略训练:虽然直接将指令映射到动作的离散查找表是一种简单的解决方案,但此类方法本质上仅限于离散的、分布内场景
AMO网络则学习连续映射,实现了在连续输入空间及分布外(O.O.D)远程操作指令之间的稳健插值,同时保持实时响应能力
在部署过程中,作者首先从VR远程操作系统中提取稀疏姿态,并通过多目标逆向运动学输出上半身目标。训练好的AMO网络和RL策略共同输出机器人的控制信号
1.1.2 相关工作
第一,对于人形机器人全身控制
由于人形机器人具有高自由度和非线性,全身控制依然是一个具有挑战性的问题
- 此前,这一问题主要通过动力学建模和基于模型的控制方法实现
14- The mit humanoid robot: Design,motion planning, and control for acrobatic behaviors
16-Synchronized humanhumanoid motion imitation. IEEE Robotics and Automation Letters
18-Whole body humanoid control from human motion descriptors
19-Wholebody geometric retargeting for humanoid robots
31-The development of honda humanoid robot
32-Anymal-a highly mobile and dynamic quadrupedal robot
34-A simple modeling for a biped walking pattern generation
35-Development of wabot 1
51-Dynamic walk of a biped
52-Whole-body control of humanoid robots
56-A multimode teleoperation framework for humanoid loco-manipulation: An application for the icub robot
72-Hybrid zero dynamics of planar biped walkers
75-Simbicon: Simple biped locomotion control - 近年来,深度强化学习方法已在实现足式机器人鲁棒行走性能方面展现出潜力
3-Legged locomotion in challenging terrains using egocentric vision
7-Legs as manipulator: Pushing quadrupedal agility beyond locomotion
8-Extreme parkour with legged robots
20-Learning vision-based bipedal locomotion for challenging terrain
21-Adversarial motion priors make good substitutes for complex reward functions
22- Learning deep sensorimotor policies for vision-based autonomous drone racing
23-Minimizing energy consumption leads to the emergence of gaits in legged robots
26-Opt-mimic: Imitation of optimized trajectories for dynamic quadruped behaviors
37-Rma: Rapid motor adaptation for legged robots
38-Reinforcement learning for robust parameterized locomotion control of bipedal robots
39-Reinforcement learning for versatile, dynamic, and robust bipedal locomotion control
40-Berkeley humanoid: A research platform for learning-based control
46- Learning to jump from pixels
47-Rapid locomotion via reinforcement learning
61- Learning humanoid locomotion with transformers
67-Blind bipedal stair traversal via sim-to-real reinforcement learning
73-Generalized animal imitator: Agile locomotion with versatile motion prior
74-Neural volumetric memory for visual locomotion control
79- Robot parkour learning
总之,研究者们已经针对四足机器人
[7,8,22,27-Umi on legs: Making manipulation policies mobile with manipulation-centric whole-body controllers]
和人形机器人 [9-Exbody,24-Humanplus,29-H2O,33- Exbody2],从高维输入出发研究了全身控制
当然了,其中的
[24-Humanplus] 分别训练了一个 transformer 用于控制,另一个用于模仿学习
[9-Exbody] 仅鼓励上半身模仿动作,而下半身控制则被解耦
[29-H2O] 针对下游任务训练了目标条件策略
所有 [9,24,29] 仅展示了有限的全身控制能力,其约束让人形机器人保持躯干和骨盆静止
而[33-Exbody2] 展示了人形机器人的富有表现力的全身动作,但并未强调利用全身控制来扩展机器人行走-操作任务空间
第二,对于人形机器人的远程操作
人形机器人的远程操作对于实时控制和机器人数据采集至关重要
此前在人形机器人远程操作方面的工作包括 [11,24,28,29,42,64]
- 例如
24-Humanplus
29-H2O
使用第三人称RGB相机获取人类操作员的关键点。有些工作使用虚拟现实VR为操作员提供以自我为中心的观察视角 - [11] 利用 AppleVisionPro 控制带有灵巧手的主动头部和上半身
- [42] 使用 Vision Pro 控制头部和上半身,同时通过踏板进行行走控制。人形机器人的全身控制要求远程操作员为机器人提供物理可实现的全身坐标
第三,行走操作模仿学习
模仿学习已被研究用于帮助机器人自主完成任务。现有的工作可根据演示来源分为
- 从真实机器人专家数据学习
4-RT-1
5-RT-2
12-diffusion policy
13-UMI
25-Mobile ALOHA
36-Droid: A large-scale in-thewild robot manipulation dataset
54-Openx-embodiment
55-The surprising effectiveness of representation learning for visual imitation
65-Yell at your robot
66-Perceiver-actor
76- 3d diffusion policy
78-ALOHA ACT - 从游戏数据学习
15-From play to policy:Conditional behavior generation from uncurated robot data
50-Alan : Autonomously exploring robotic agents in the real world
70- Mimicplay: Long-horizon imitation learning by watching human play - 从人类演示学习
9-Exbody
21-Adversarial motion priors make good substitutes for complex reward functions
24-Humanplus
26-Opt-mimic
29-H2O
57-Learning agile robotic locomotion skills by imitating animals
58-AMP: adversarial motion priors for stylized physics-based character control
71-Unicon: Universal neural controller for physicsbased character motion
73-Generalized animal imitator: Agile locomotion with versatile motion prior
这些模仿学习研究主要局限于操作技能,而针对行走操作的模仿学习研究非常少。[25]研究了基于轮式机器人的行走操作模仿学习
本文利用模仿学习使人形机器人能够自主完成行走操作任务
1.2 自适应运动优化
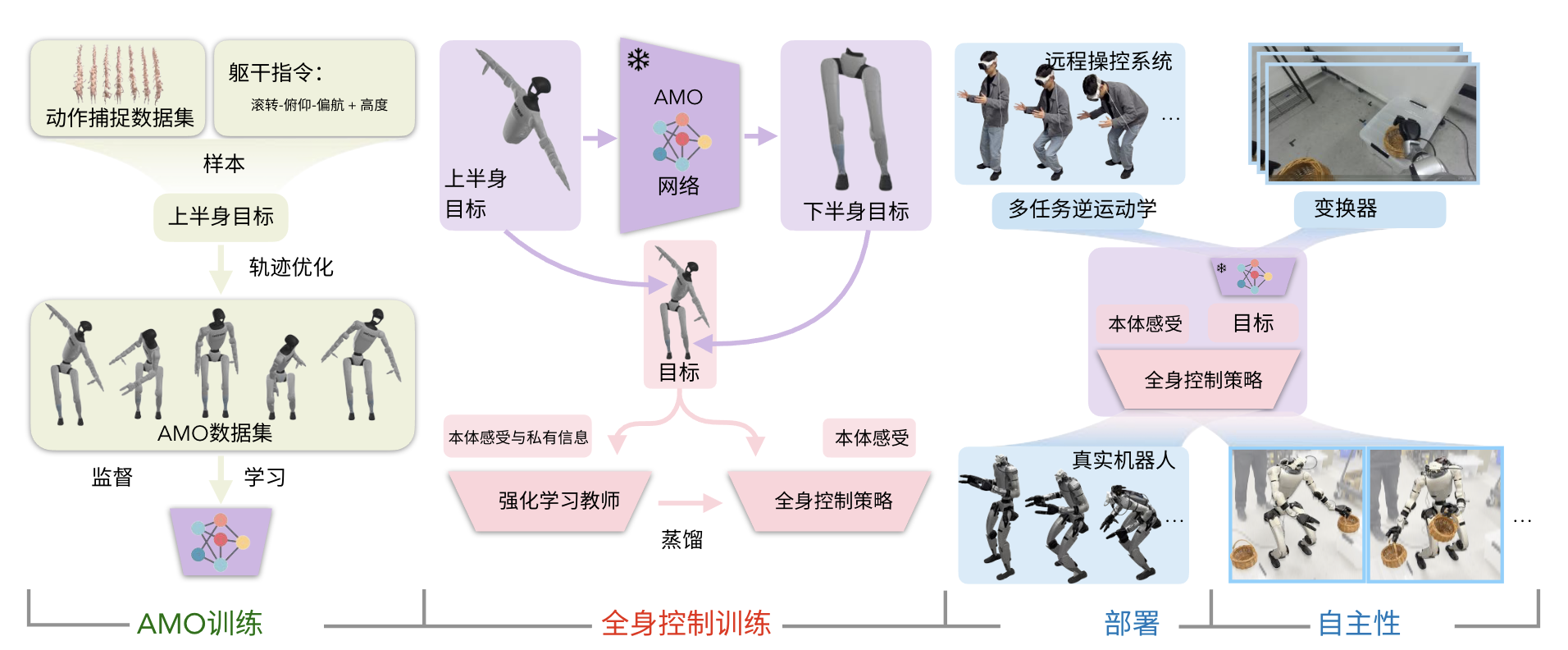
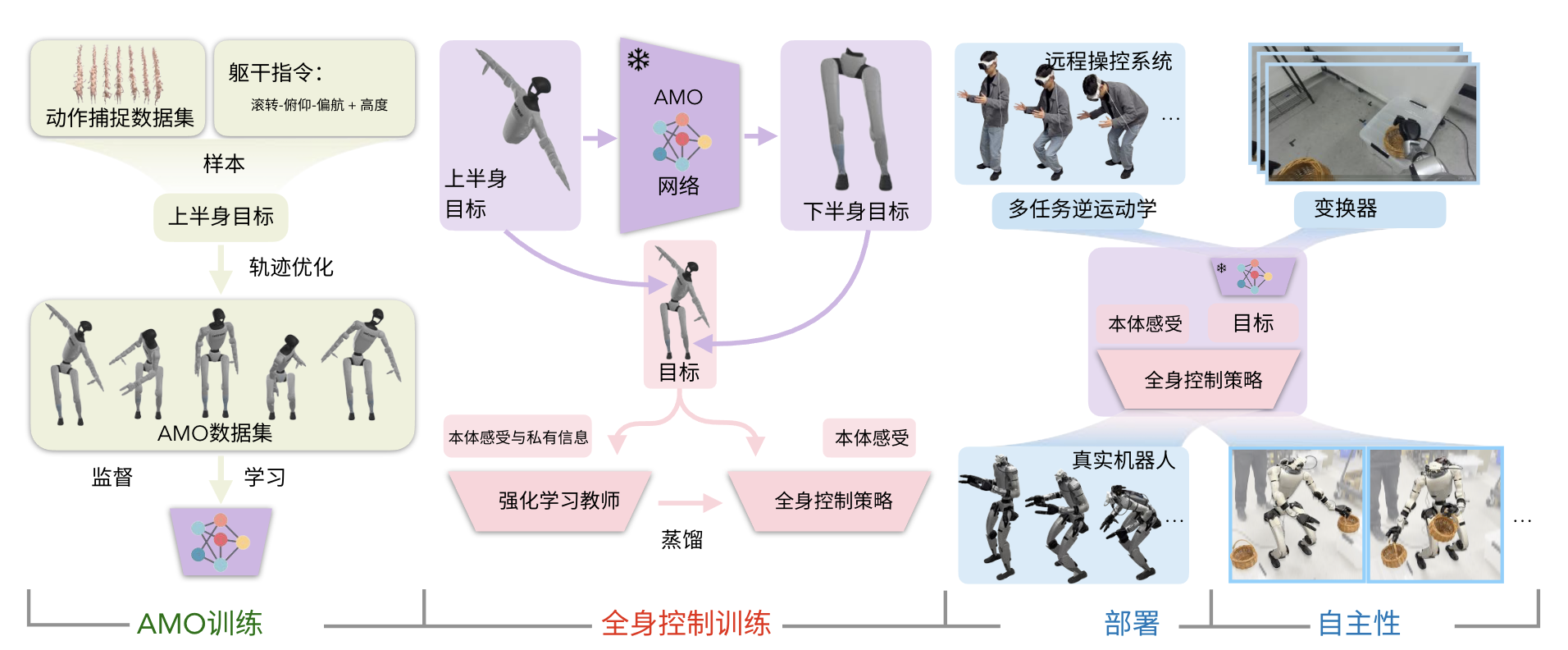
AMO定位于自适应运动优化,是一个实现无缝全身控制的框架,如图2所示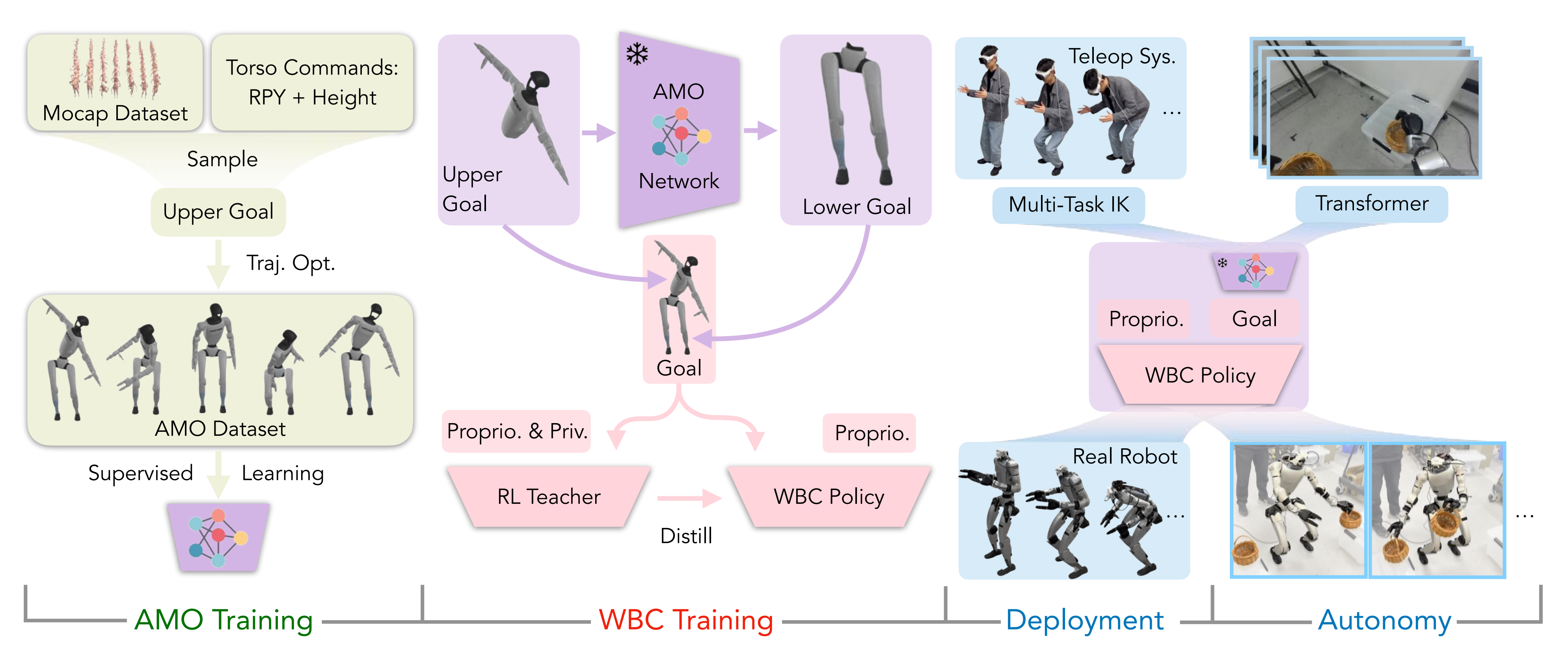
系统被分解为四个阶段:
- 通过轨迹优化收集AMO数据集进行AMO模块训练
- 通过在仿真中采用师生蒸馏进行强化学习(RL)策略训练
- 通过逆运动学(IK)和重定向实现真实机器人远程操作
- 结合transformer,通过模仿学习(IL)进行真实机器人自主策略训练
1.2.0 问题表述与符号定义
作者针对人形机器人全身控制的问题,重点关注两种不同的设置:远程操作和自主控制
- 在遥操作环境中,整体控制问题被表述为学习一个目标条件策略
,其中
表示目标空间
表示观测空间
表示动作空间
目标条件遥操作策略接收来自遥操作员的控制信号
,其中
表示操作员的头部和手部关键点姿态
而指定底座速度
包括视觉和本体感觉数据:
由上半身和下半身的关节角度指令组成:
进一步讲,目标条件化策略采用分层设计:
- 上层策略
输出上半身的动作,以及中间控制信号
,其中
指令躯干方向,
指令基座高度
- 下层策略
利用此中间控制信号、速度指令和本体感觉观测生成下半身的动作
- 在自主环境中,学习到的策略
仅基于观测生成动作,无需人为输入
进一步而言,自主策略与遥操作策略采用相同的分层设计
下层策略是相同的:
而上层策略则独立于人类输入生成动作和中间控制
1.2.1 适应模块预训练
在AMO的系统规范中,下层策略遵循形式为的指令。跟随速度指令
的运动能力可以通过在仿真环境中随机采样定向向量,并采用与[8, 9-Exbody] 相同的策略轻松学习
然而,学习躯干和高度跟踪技能则并非易事,因为它们需要全身协调。与运动任务不同,在运动任务中可以基于Raibert 启发式[62]设计足部跟踪奖励以促进技能学习,而对于引导机器人完成全身控制,则缺乏类似的启发式方法
一些工作[28-Omnih2o, 33-Exbody2]通过跟踪人类参考来训练此类策略。然而,他们的策略并未在人体姿态与全身控制指令之间建立联系
为了解决这个问题,作者提出了一种自适应运动优化(adaptive motion optimization,简称AMO)模块
AMO 模块表示为。当接收到来自上层的全身控制指令
,
后,它将这些指令转换为所有下肢执行器的关节角参考值,供下层策略显式跟踪

为了训练这个自适应模块
- 首先,通过随机采样上层指令并执行基于模型的轨迹优化来收集AMO 数据集,以获得下肢关节角
轨迹优化可以被表述为一个多接触最优控制问题(MCOP),其代价函数如下
其中包括对状态和控制
的正则化、目标跟踪项Lrpy 和Lh,以及用于在进行全身控制时确保平衡的质心(CoM)正则化项
- 在收集数据集时,作者
由于作者没有考虑行走场景,机器人的双脚都被认为与地面接触
参考数据被通过 Crocoddyl [48,49] 使用受控制约的可行性驱动微分动态规划(BoxFDDP)生成
1.2.2 底层策略训练
使用大规模并行仿真在IsaacGym[44] 中训练他们的低层策略。低层策略旨在跟踪和
,同时利用本体感觉观测
,其定义如下
- 上述公式包含了基座朝向
、基座角速度
、当前位置、速度和上一次的位置目标
- 值得注意的是,下层策略的观测包括了上半身执行器的状态,以实现更好的上下半身协调
是步态循环信号,其定义方式与[45, 77] 类似
是由AMO 模块生成的下半身参考关节角度
下层动作空间是一个15 维向量,由双腿的2 ∗6个目标关节位置和腰部电机的3 个目标关节位置组成
作者选择使用教师-学生框架来训练他们的低层策略
- 首先训练一个能够在仿真中观察特权信息的教师策略,使用现成的PPO[63]
进一步而言,教师策略可以表述为
额外的特权观测定义如下
其中包括如下真实值:
基座速度
躯干姿态
以及基座高度
而在跟踪其对应目标时,这些值在现实世界中并不容易获得
是脚与地面之间的接触信号。教师RL训练过程详见原论文的附录B
- 然后,通过监督学习将教师策略蒸馏到学生策略中。学生策略仅观察现实中可用的信息,可以用于远程操作和自主任务
进一步而言,学生策略可以写成
为了用现实世界中可获取的观察结果来补偿,学生策略利用了 25 步的本体感觉观察历史作为额外的输入信号:
1.2.3 遥操作高层策略实现
远程操作上层策略为全身控制生成一系列指令,包括手臂和手的运动、躯干方向以及底座高度
作者选择采用基于优化的方法来实现该策略,以达到操作任务所需的精度
- 具体来说,手部运动通过重定向生成,而其他控制信号则通过逆运动学(IK)计算
他们的手部重定向实现基于 dex-retargeting [60]。关于重定向公式的更多细节见附录A
在他们的全身控制框架中,他们将传统的逆运动学(IK)扩展为多目标加权逆运动学,通过最小化与三个关键目标(头部、左手腕和右手腕)的6维距离,实现对这些目标的精确控制——机器人调动所有上半身执行器,同时对齐这三个目标
形式化地,目标是
- 如下图图3所示
优化变量包含了机器人上半身所有驱动自由度(DoFs):
、
和
。除了电机指令外,还会求解一个中间指令以实现全身协调:用于躯干姿态和高度控制的
为了确保上半身控制的平滑性,姿态代价在优化变量的不同组成部分上赋予了不同的权重:
这鼓励策略优先使用上半身驱动器来完成较简单的任务
然而,对于需要全身运动的任务,如弯腰拾取或够取远处目标,会生成额外的控制信号并发送给下层策略
下层策略协调其电机角度以满足上层策略的要求,实现全身目标到达。他们的IK实现采用了Levenberg-Marquardt(LM)算法[68],并基于Pink[6]
1.2.4 自主上层策略训练:基于模仿学习
作者通过模仿学习来训练自主上层策略
- 首先,人类操作员对机器人进行远程操作——使用目标条件策略,记录观测和动作作为示范
- 然后采用以DinoV2 [17, 53] 视觉编码器为策略骨干的ACT [78]。视觉观测包括两张立体图像
和
DinoV2 将每张图片分割为16 × 22 个patch,并为每个patch 生成一个384 维的视觉token,得到的组合视觉token 形状为2 × 16 × 22 × 384
该视觉token 与通过投影获得的状态token 拼接在一起
其中,是上半身本体感觉观测,
构成了上一次发送给下层策略的指令
由于作者的解耦系统设计,上层策略观测到的是这些下层策略指令,而不是直接的下半身本体感觉
策略的输出表示为
包括所有上半身关节角度以及下层策略的中间控制信号
1.3 评估
在本节中,作者旨在通过在仿真和现实世界中的实验来回答以下问题:
- AMO 在跟踪运动指令和躯干指令(rpy, h)方面的表现如何?
- AMO 与其他 WBC 策略相比如何?
- AMO系统在真实环境中的表现如何?
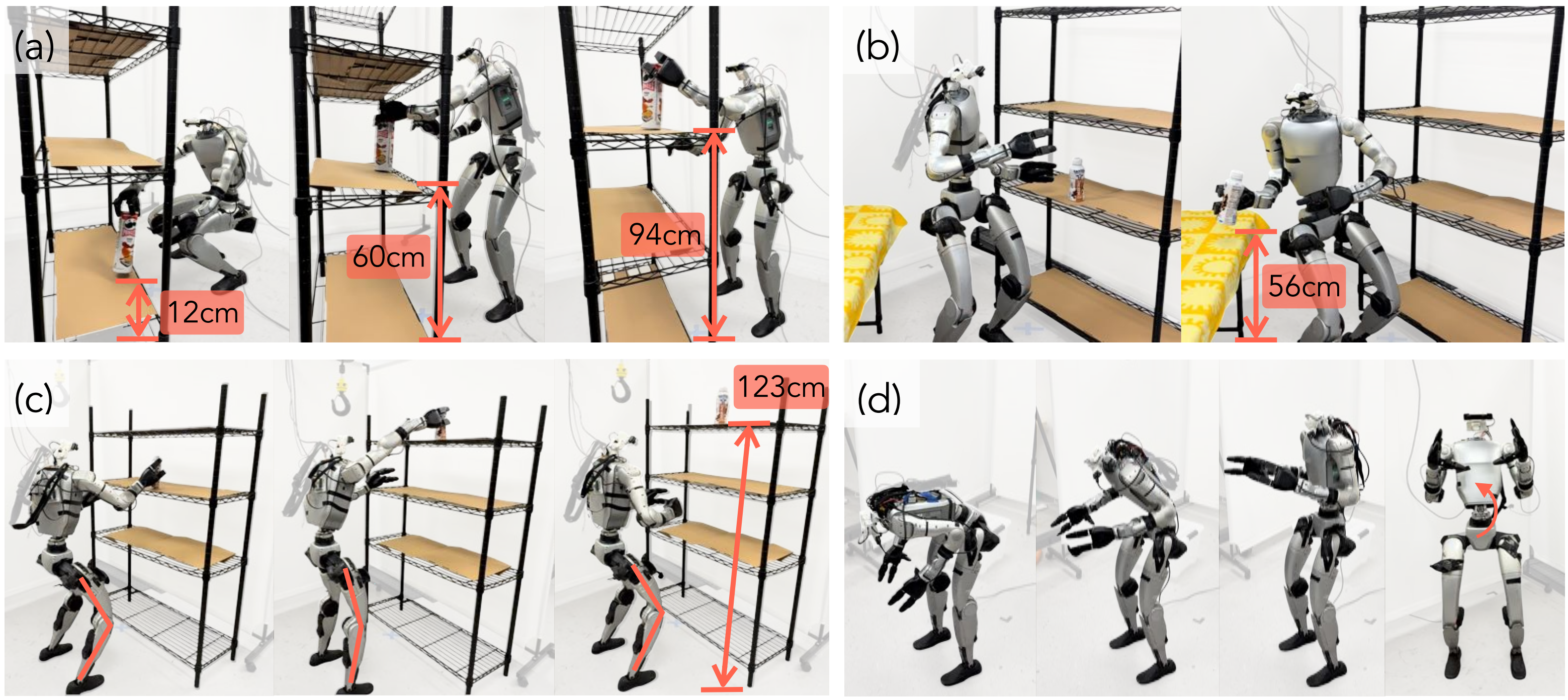
作者在IsaacGym仿真器[44]中进行了模拟实验。真实机器人搭建如图3所示『遥操作系统概览。操作员提供三个末端执行器目标:头部、左手腕和右手腕的位姿。多目标逆运动学(IK)通过同时匹配三个加权目标来计算上层目标和中间目标。中间目标(rpy,h)被输入到AMO,并转换为下层目标』
- 该机器人是在Unitree G1[1]基础上改装,并配备了两个Dex3-1灵巧手。该平台具有29个全身自由度,每只手有7个自由度
- 且作者定制了一个带有三个驱动自由度的主动头部,用于映射人类操作员的头部运动,并安装了一台ZED Mini[2]相机用于立体视觉流传输
1.3.1 AMO在跟踪运动指令和躯干指令rpy, h方面的表现如何?
表II展示了AMO性能的评估,并将其与以下基线方法进行了比较:
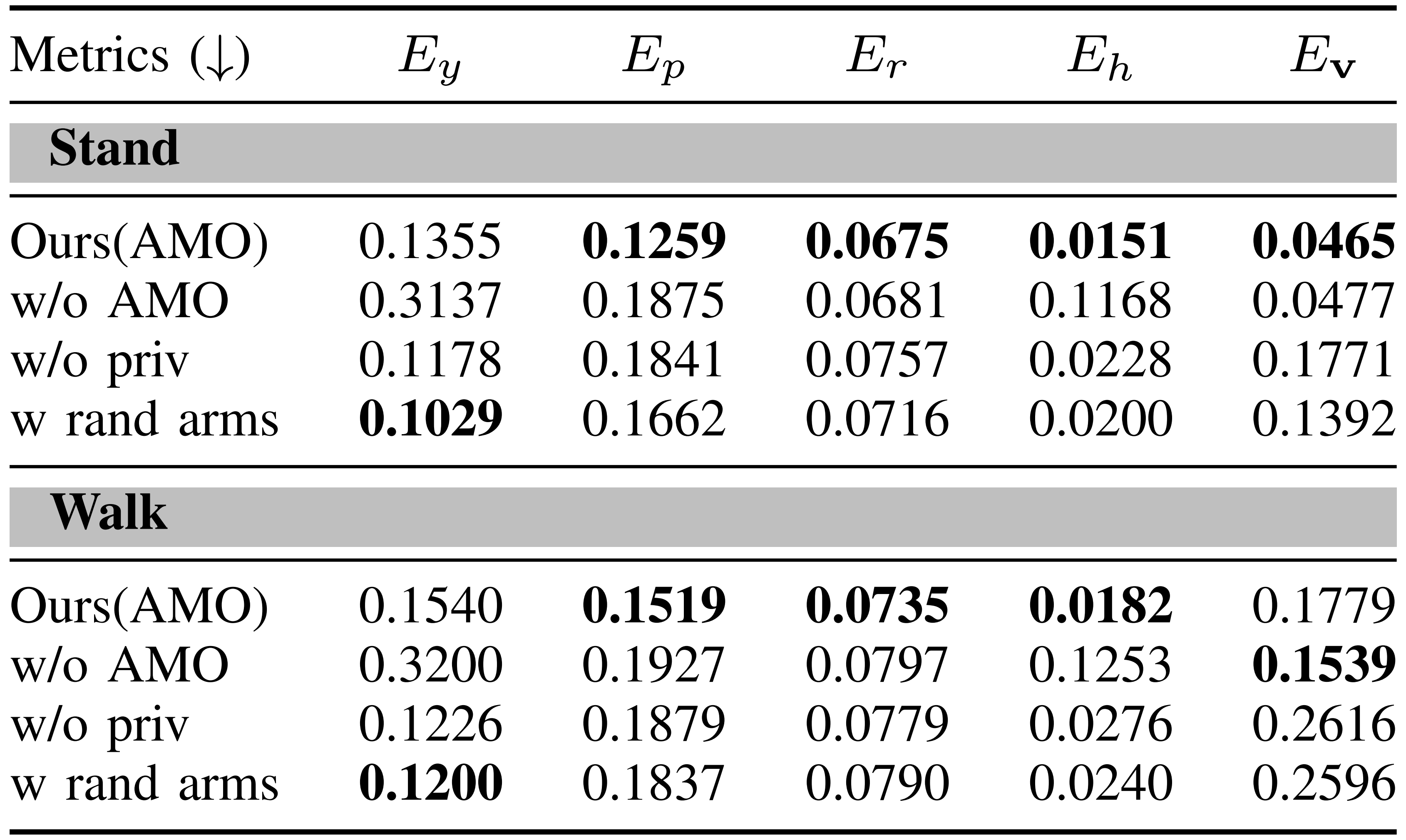
- w/o AMO:该基线遵循与Ours(AMO) 相同的强化学习训练方案,但有两个关键修改
首先,它在观察空间中排除了AMO 输出
其次,它不是对偏离 - w/o priv:该基线在训练时不包含额外的特权观测
- w rand arms:在该基线中,手臂关节角度不是通过从MoCap 数据集中采样的人体参考设置的,而是在各自的关节限制范围内均匀随机采样赋值
性能评估采用以下指标:
- 躯干方向追踪精度
躯干方向追踪通过,
,
进行测量
结果表明
AMO 在横滚和俯仰方向上实现了更高的追踪精度。在俯仰追踪方面的提升最为显著,其他基线方法难以保持精度,而AMO显著降低了追踪误差
w rand arms 表现出最低的偏航追踪误差,这可能是因为随机手臂运动使机器人能够探索更广泛的姿态范围
然而,AMO 在偏航追踪方面并不一定表现突出,因为与横滚和俯仰相比,躯干偏航旋转引起的质心位移较小。因此,偏航追踪精度可能无法充分反映AMO 在生成自适应和稳定姿态方面的能力
尽管如此,值得注意的是,w/o AMO 在偏航追踪方面表现不佳,这表明AMO 为实现稳定的偏航控制提供了关键的参考信息 - 高度跟踪精度
结果显示,AMO 实现了最低的高度跟踪误差。值得注意的是,w/oAMO 报告的误差显著高于所有其他基线,表明其几乎无法跟踪高度指令
与躯干跟踪不同,躯干跟踪中至少有一个腰部电机角度与指令成正比,而高度跟踪则需要多个下肢关节的协调调整
缺乏来自 AMO 的参考信息,策略无法学习高度指令与相应电机角度之间的变换关系,从而难以掌握这一技能 - 线速度跟踪精度
AMO模块基于双支撑姿态下的全身控制生成参考姿态,这意味着它未考虑行走过程中因摆脚产生的姿态变化
尽管存在这一限制,AMO仍能实现稳定的行走,并保持较低的跟踪误差,展现出其鲁棒性
// 待更
相关文章:
兼顾可行性和动力学约束)
AMO——下层RL与上层模仿相结合的自适应运动优化:让人形行走操作(loco-manipulation)兼顾可行性和动力学约束
前言 自从去年24年Q4,我司侧重具身智能的场景落地与定制开发之后 去年Q4,每个月都会进来新的具身需求今年Q1,则每周都会进来新的具身需求Q2的本月起,一周不止一个需求 特别是本周,几乎每天都有国企、名企通过我司找到…...

大模型——多模态检索的RAG系统架构设计
文章目录 1. 系统架构设计核心组件 2. 跨模态向量空间对齐方案方法一:预训练对齐模型(如CLIP)方法二:跨模态投影网络方法三:联合微调 3. 混合检索策略4. 关键问题解决Q: 如何解决模态间向量尺度不一致?Q: 如…...

BUUCTF——Kookie
BUUCTF——Kookie 进入靶场 一个登录页面 左上角提示让以admin身份登录 找到了cookie 应该与cookie相关 测试了一下admin admin没登上 We found the account cookie / monster 回头看了一下 这个是不是账号密码 测试一下 成功登入 但是没有flag 应该还是跟cookie相关 …...

代码随想录算法训练营
力扣684.冗余连接【medium】 力扣.冗余连接Ⅱ【hard】 一、力扣684.冗余连接【medium】 题目链接:力扣684.冗余连接 left x300 视频链接:代码随想录 题解链接:灵茶山艾府 1、思路 可以从前向后遍历每一条边(因为优先让前面的边连上…...

服务器磁盘不同格式挂载区别
在Linux系统中,磁盘不同格式挂载的核心区别主要体现在文件系统类型和挂载方式两个方面,以下为具体差异分析: 一、文件系统类型区别 磁盘格式即文件系统类型的选择直接影响挂载后的性能和功能: 常见文件系统比较 e…...

AI智能分析网关V4人员摔倒检测打造医院/工厂等多场景智能安全防护体系
一、方案背景 随着全球老龄化加剧,我国老年人口占比持续攀升,老年人摔倒伤亡事件频发,居家、养老机构等场景的摔倒防控成为社会焦点。同时,工厂、医院、学校等人员密集场所也易发生意外摔倒安全事故。传统人工监控存在视觉疲劳…...

window 显示驱动开发-准备 DMA 缓冲区
显示微型端口驱动程序必须及时准备 DMA 缓冲区。 当 GPU 处理 DMA 缓冲区时,通常调用显示微型端口驱动程序来准备下一个 DMA 缓冲区,以便提交到 GPU。 若要防止 GPU 耗尽,显示微型端口驱动程序在准备和提交后续 DMA 缓冲区时所花费的时间必须…...
)
程序设计实践--排序(1)
1、插入排序(一个数组) #include<bits/stdc.h> using namespace std; const int N1e35; int a[N]; int n; int main(){cin>>n;for(int i1;i<n;i){cin>>a[i];}for(int i1;i<n;i){int va[i];int ji-1;while(j>1&am…...

window 显示驱动开发-GDI 硬件加速
Windows 7 引入的 GDI 硬件加速功能在图形处理单元 (GPU) 上提供加速的核心图形设备接口 (GDI) 操作。 若要指示 GPU 和驱动程序支持此功能,显示微型端口驱动程序必须将DXGKDDI_INTERFACE_VERSION设置为 > DXGKDDI_INTERFACE_VERSION_WIN7。 显示微型端口驱动程…...

驱动开发硬核特训 · Day 31:理解 I2C 子系统的驱动模型与实例剖析
📚 训练目标: 从驱动模型出发,掌握 I2C 子系统的核心结构;分析控制器与从设备的注册流程;结合 AT24 EEPROM 驱动源码与设备树实例,理解 i2c_client 与 i2c_driver 的交互;配套高质量练习题巩固理…...

网络安全之网络攻击spring临时文件利用
0x00 传统攻击流程 我们之前传统的攻击流程由以下几个步骤来完成 攻击者找到可以控制目标JDBC连接fakeServer的地方目标向fakeServer发起连接请求fakeServer向目标下发恶意数据包目标解析恶意数据包并完成指定攻击行为(文件读取、反序列化),…...
:定义、优势与重要性)
统一端点管理(UEM):定义、优势与重要性
统一终端管理(UEM)是一种通过单一平台集中管理、监控和保护企业所有终端设备(如笔记本电脑、移动设备、服务器、物联网设备等)的综合性策略。其核心在于跨操作系统(Windows、macOS、iOS、Android等)实现…...

什么是Rootfs
Rootfs (Root Filesystem) 详解 buildroot工具构建了一个名为"rootfs.tar"的根文件系统压缩包。 什么是rootfs Rootfs(Root Filesystem,根文件系统)是操作系统启动后挂载的第一个文件系统,它包含系统正常运行所需的基…...

黑马Java基础笔记-13常用查找算法
查找算法 基本查找(也叫顺序查找,线性查找) 二分查找(需要有序数据) public static int binarySearch(int[] arr, int number){//1.定义两个变量记录要查找的范围int min 0;int max arr.length - 1;//2.利用循环不断的去找要查找的数据wh…...
 任意文件上传漏洞)
#渗透测试#批量漏洞挖掘#LiveBos UploadFile(CVE-2021-77663-2336) 任意文件上传漏洞
免责声明 本教程仅为合法的教学目的而准备,严禁用于任何形式的违法犯罪活动及其他商业行为,在使用本教程前,您应确保该行为符合当地的法律法规,继续阅读即表示您需自行承担所有操作的后果,如有异议,请立即停…...

Git 和 GitHub 学习指南本地 Git 配置、基础命令、GitHub 上传流程、企业开发中 Git 的使用流程、以及如何将代码部署到生产服务器
Windows 上 Git 安装与配置 下载安装:访问 Git 官方网站下载适用于 Windows 的安装程序。运行安装包时会出现许可协议、安装目录、组件选择等界面(如下图)。在“Select Components”页面建议勾选 Git Bash Here 等选项,以便在资源…...

SUI批量转账几种方法介绍
一、Sui区块链简介 Sui是由前Meta(Facebook)工程师创建的下一代Layer 1区块链,采用基于Move编程语言的新型智能合约平台。Sui的设计专注于高吞吐量、低延迟和可扩展性,使其特别适合需要处理大量交易的场景。 Sui的核心特点&…...

Vue2到Vue3迁移问题解析
1. 响应式系统的变化 问题:Vue3 使用 Proxy 替代 Object.defineProperty,导致部分 Vue2 的响应式写法失效。解析: 数组直接索引修改:// Vue2:需使用 Vue.set 或 splice this.$set(this.items, 0, new value); this.it…...

【解决】rpm 包安装成功,但目录不存在问题
开发平台:RedHat 8 一、问题描述 [rootproxy ~]# rpmbuild -ba /root/rpmbuild/SPECS/nginx.spec # rpmbuild 制作 .rpm 包 [rootproxy ~]# yum -y install /root/rpmbuild/RPMS/x86_64/nginx-1.22.1-1.x86_64.rpm # 安装 .rpm包 …...
)
深度学习框架显存泄漏诊断手册(基于PyTorch的Memory Snapshot对比分析方法)
点击 “AladdinEdu,同学们用得起的【H卡】算力平台”,H卡级别算力,按量计费,灵活弹性,顶级配置,学生专属优惠。 一、显存泄漏:深度学习开发者的"隐形杀手" 在深度学习模型的训练与推…...
和DistributedDataParallel(DDP))
PyTorch中单卡训练、DataParallel(DP)和DistributedDataParallel(DDP)
PyTorch中提供了单卡训练、DataParallel(DP)和DistributedDataParallel(DDP),下面是相关原理与实现代码。 代码下载链接:git代码链接 一、单卡训练 原理 单卡训练是最基础的模型训练方式,使用…...
)
Redis从入门到实战 - 高级篇(中)
一、多级缓存 1. 传统缓存的问题 传统的缓存策略一般是请求到达Tomcat后,先查询Redis,如果未命中则查询数据库,存在下面的问题: 请求要经过Tomcat处理,Tomcat的性能成为整个系统的瓶颈Redis缓存失效时,会…...

项目计划缺乏可行性,如何制定实际可行的计划?
制定实际可行的项目计划需从明确项目目标、准确评估资源、风险管理、设定合理里程碑以及优化沟通渠道入手。其中,明确项目目标尤为关键,只有在目标清晰、具体且量化时,团队才能有效规划各项活动并衡量进展。例如,目标若模糊或过于…...

React中使用ahooks处理业务场景
// 从 ahooks 引入 useDynamicList 钩子函数,用于管理动态列表数据(增删改) import { useDynamicList } from ahooks;// 从 ant-design/icons 引入两个图标组件:减号圆圈图标和加号圆圈图标 import { MinusCircleOutlined, PlusCi…...

CNBC专访CertiK联创顾荣辉:从形式化验证到AI赋能,持续拓展Web3.0信任边界
近日,CertiK联合创始人、哥伦比亚大学教授顾荣辉接受全球知名财经媒体CNBC阿拉伯频道专访,围绕形式化验证的行业应用、AI在区块链安全中的角色,以及新兴技术风险等议题,分享了其对Web3.0安全未来的深刻洞察。 顾荣辉表示…...

基于Spring Boot与jQuery的用户管理系统开发实践✨
引言📚 用户管理系统是企业级应用的核心模块,需实现数据分页、状态管理及高效前后端交互。本文以Spring Boot为后端框架、jQuery为前端工具,构建一个结构清晰的用户管理系统,详解三层架构设计、接口规范及全栈开发流程࿰…...

StreamSaver实现大文件下载解决方案
StreamSaver实现大文件下载解决方案 web端 安装 StreamSaver.js npm install streamsaver # 或 yarn add streamsaver在 Vue 组件中导入 import streamSaver from "streamsaver"; // 确保导入名称正确完整代码修正 <!--* projectName: * desc: * author: dua…...

vue3+echarts 做温度计
参考Echarts 做的温度计_echart温度计-CSDN博客 但是现在这个写法不支持了,更新一下,然后修改了温度值和刻度及单位颜色为黑,初始化echarts写法, itemStyle: {normal: {color: #4577BA,barBorderRadius: 50,}},<div id"main14"…...

鸿蒙开发——7.ArkUI进阶:@BuilderParam装饰器的核心用法与实战解析
鸿蒙开发——7.ArkUI进阶:BuilderParam装饰器的核心用法与实战解析 ArkUI进阶:BuilderParam装饰器的核心用法与实战解析引言一、核心概念速览1.1 什么是BuilderParam?1.2 与Builder的关系 二、核心使用场景2.1 参数初始化组件2.2 尾随闭包初始…...

【数据结构】队列的完整实现
队列的完整实现 队列的完整实现github地址前言1. 队列的概念及其结构1.1 概念1.2 组织结构 2. 队列的实现接口一览结构定义与架构初始化和销毁入队和出队取队头队尾数据获取size和判空 完整代码与功能测试结语 队列的完整实现 github地址 有梦想的电信狗 前言 队列&…...

销售易史彦泽:从效率工具到增长引擎,AI加速CRM不断进化
导读:AI的加入,让CRM实现从“人适配系统”到“系统适配人”,从“管控工具”向“智能助手”跃迁,重构客户关系管理的底层逻辑。 作者 | 小葳 图片来源 | 摄图 AI应用与SaaS的关系,是当前科技与商业领域热议的话题。 当…...

开疆智能Profinet转ModbusTCP网关连接BORUNTE伯朗特系统配置案例
本案例是通过开疆智能Profinet转ModbusTCP网关将西门子PLC与BORUNTE机器人连接的配置案例。具体配置方法如下。 配置过程 Profinet设置 设置网关在Profinet一侧的参数包括(设备名称,IP地址等) 先导入GSD文件 选择GSD所在文件夹位置&#…...

从0到1搭建shopee测评自养号系统:独立IP+硬件伪装+养号周期管理
在跨境电商竞争白热化的背景下,Shopee卖家通过自养号测评实现流量与销量突破已成为行业共识。自养号测评通过模拟真实买家行为,为店铺注入精准流量,同时规避外包测评的高风险与不可控性。本文将从技术架构、运营策略、风险控制三个维度&#…...
arrow-0.1.0.jar 使用教程 - Java jar包运行方法 命令行启动步骤 常见问题解决
准备工作 首先确保你电脑上装了Java环境(JDK 8或以上版本) 把这个jar文件下载到你的电脑上,arrow-0.1.0.jar下载链接:https://pan.quark.cn/s/66d7c061c95a 运行方法 打开命令行(Windows按WinR输入cmd,M…...

请问交换机和路由器的区别?vlan 和 VPN 是什么?
交换机和路由器的区别 特性交换机(Switch)路由器(Router)工作层级数据链路层(L2,基于MAC地址)网络层(L3,基于IP地址)主要功能在局域网(LAN&#…...

如何查看与设置电脑静态IP地址:完整指南
在当今数字化时代,稳定的网络连接已成为工作生活的必需品。静态IP地址作为网络配置中的重要一环,相比动态IP具有更高的稳定性和可控性,然而,许多用户对如何查看和设置静态IP地址仍感到困惑。本文将为您提供从基础概念到实操步骤的…...

Linux网络基础全面解析:从协议分层到局域网通信原理
Linux系列 文章目录 Linux系列前言一、计算机网络背景1.1 认识网络1.2 认识协议 二、网络协议初识2.1 协议分层2.2 OSI七层模型2.3 TCP/IP协议栈2.4 网络协议栈与OS的关系2.5 网络协议在网络传输时的作用 三、网络通信局域网通信的安全隐患与应对总结 前言 Linux系统部分的学习…...

第二篇:服务与需求——让用户找到并预订服务
目录 1 服务类目与项目管理:飞书多维表格为管理中心,微搭小程序展示1.1 需求分析1.2 数据模型:微搭中的服务分类与服务项目(用于小程序展示)1.3 数据模型:多维表格中的服务分类与服务项目 总结 我们已经用了…...

【AI News | 20250520】每日AI进展
AI Repos 1、nanoDeepResearch nanoDeepResearch 是一个受 ByteDance 的 DeerFlow 项目启发,旨在从零开始构建深度研究代理的后端项目。它不依赖 LangGraph 等现有框架,通过实现一个 ReAct 代理和状态机来模拟 Deep Research 的工作流程。项目主要包含规…...

Spark Core基础与源码剖析全景手册
Spark Core基础与源码剖析全景手册 Spark作为大数据领域的明星计算引擎,其核心原理、源码实现与调优方法一直是面试和实战中的高频考点。本文将系统梳理Spark Core与Hadoop生态的关系、经典案例、聚合与分区优化、算子底层原理、集群架构和源码剖析,结合…...

抖音视频如何下载保存?高清无水印一键保存到手机!
你是不是经常在抖音上刷到超有趣的短视频,想保存下来却不知道怎么做?或者下载后发现带有烦人的水印?别担心!今天教你最简单、最快速的抖音视频下载方法,无水印、高清画质,轻松搞定! 为什么要下…...

SCAU--平衡树
3 平衡树 Time Limit:1000MS Memory Limit:65535K 题型: 编程题 语言: G;GCC;VC;JAVA;PYTHON 描述 平衡树并不是平衡二叉排序树。 这里的平衡指的是左右子树的权值和差距尽可能的小。 给出n个结点二叉树的中序序列w[1],w[2],…,w[n],请构造平衡树,…...

图的几种存储方法比较:二维矩阵、邻接表与链式前向星
图是一种非常重要的非线性数据结构,广泛应用于社交网络、路径规划、网络拓扑等领域。在计算机中表示和存储图结构有多种方法,本文将详细分析三种常见的存储方式:二维矩阵(邻接矩阵)、邻接表和链式前向星,比…...

【AS32X601驱动系列教程】MCU启动详解
在嵌入式开发领域,掌握MCU(微控制单元)的启动流程是工程师们迈向深入开发的关键一步。本文将带您深入了解MCU启动的奥秘,从编译过程到启动文件,再到链接脚本和系统时钟配置,全方位解析MCU启动流程。 在实际…...
)
计算机视觉与深度学习 | Matlab实现EMD-GWO-SVR、EMD-SVR、GWO-SVR、SVR时间序列预测(完整源码和数据)
以下是一个完整的Matlab时间序列预测实现方案,包含EMD-GWO-SVR、EMD-SVR、GWO-SVR和SVR四种方法的对比。代码包含数据生成、信号分解、优化算法和预测模型实现。 %% 主程序:时间序列预测对比实验 clc; clear; clearvars; close all;% 生成模拟时间序列数据 rng(1); % 固定随…...

Visual Studio 2022 插件推荐
Visual Studio 2022 插件推荐 Visual Studio 2022 (简称 VS2022) 是一款强大的 IDE,适合各类系统组件、框架和应用的开发。插件是接入 VS2022 最重要的扩展方式之一,它们可以大幅提升开发效率、优化代码质量,并提供强大的调试和分析功能。 …...

[luogu12541] [APIO2025] Hack! - 交互 - 构造 - 数论 - BSGS
传送门:https://www.luogu.com.cn/problem/P12541 题目大意:有一个数 n n n,你不知道是多少;你每次可以向交互库询问一个正整数集合 A A A(其中元素互不相同),交互库返回:将集合中…...
汇编指令调用(五)——内存访问)
openjdk底层(hotspot)汇编指令调用(五)——内存访问
根据前面关于aarch64架构下的编码解释可知,在src\hotspot\cpu\架构文件夹下, assembler_xx.hpp assembler_xx.cpp register_xx.hpp register_xx.cpp register_definitions_xx.cpp这些文件是有关寄存器定义以及汇编编码函数实现的文件。 对于前述的ope…...

几款常用的虚拟串口模拟器
几款常用的虚拟串口模拟器(Virtual Serial Port Emulator),适用于 Windows 系统,可用于开发和调试串口通信应用: 1. com0com (开源免费) 特点: 完全开源免费,无功能限制。 可创建多个虚拟串口…...

ChimeraX介绍
UCSF ChimeraX 是一款由美国加州大学旧金山分校(UCSF)开发的下一代分子可视化软件,是经典的 UCSF Chimera 的继任者。它集成了强大的分子结构可视化、分析、建模和动画功能,广泛应用于结构生物学、药物设计、分子建模等领域。 1. 下载安装: Download UCSF ChimeraX 2. …...