Redis从入门到实战 - 高级篇(中)
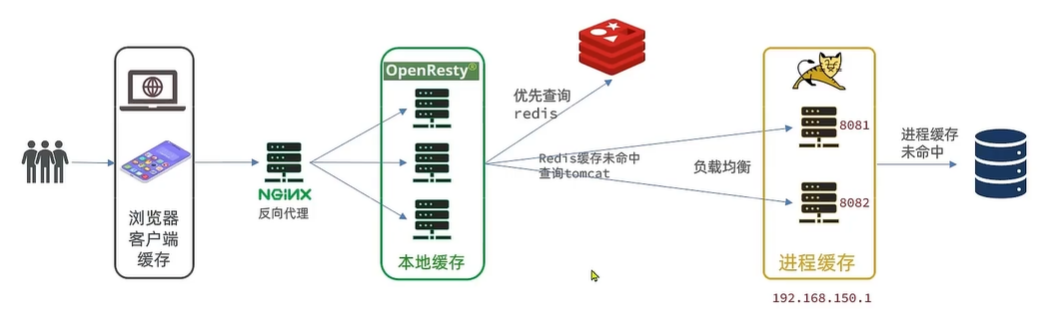
一、多级缓存
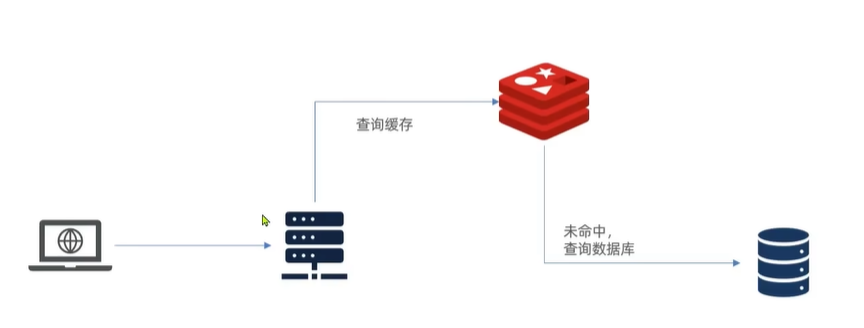
1. 传统缓存的问题
传统的缓存策略一般是请求到达Tomcat后,先查询Redis,如果未命中则查询数据库,存在下面的问题:
- 请求要经过Tomcat处理,Tomcat的性能成为整个系统的瓶颈
- Redis缓存失效时,会对数据库产生冲击
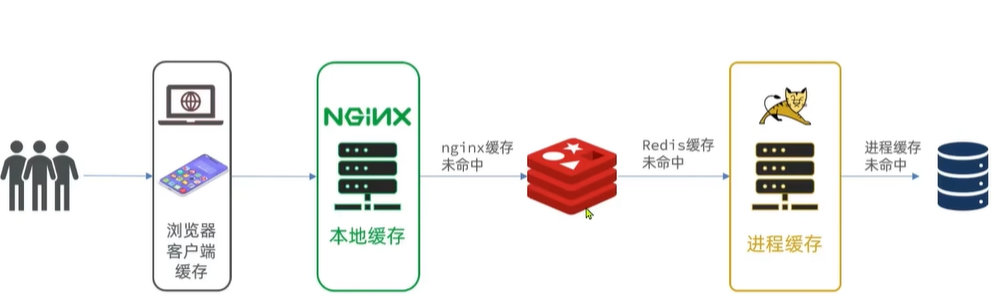
2. 多级缓存方案
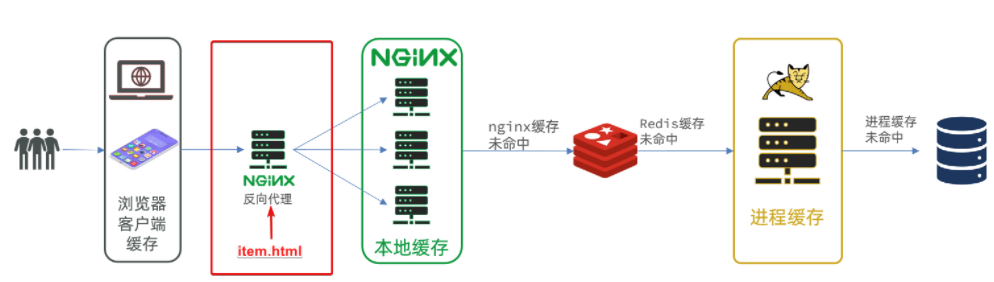
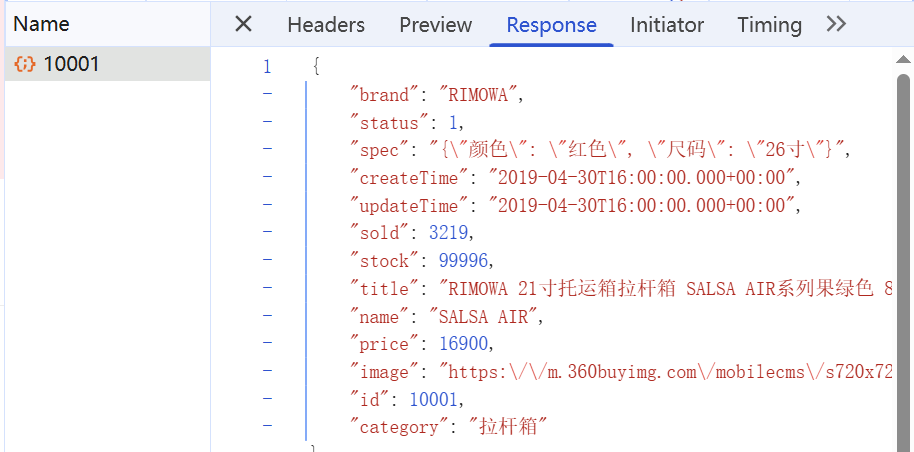
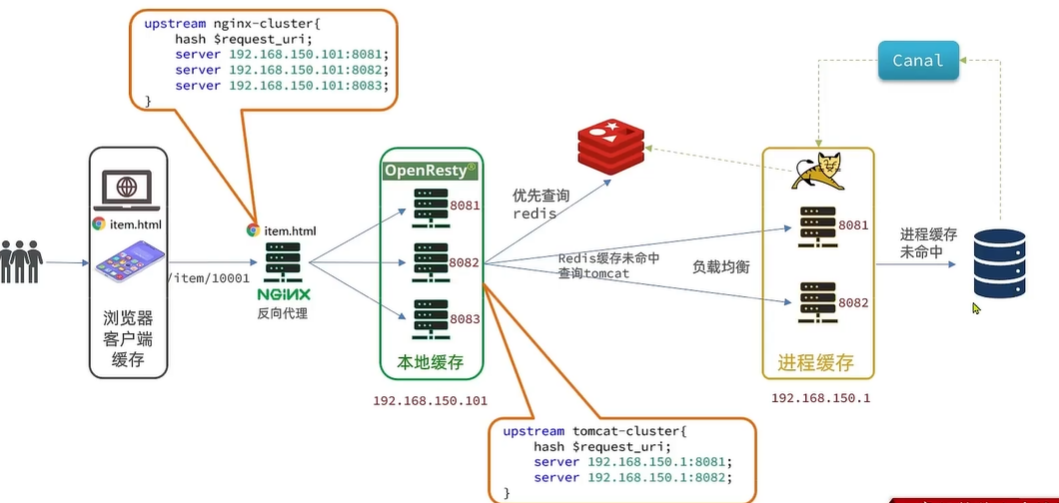
多级缓存就是充分利用请求处理的每个环节,分别添加缓存,减轻Tomcat压力,提升服务性能:
用作缓存的Nginx是业务Nginx,需要部署为集群,再由专门的Nginx用来做反向代理:
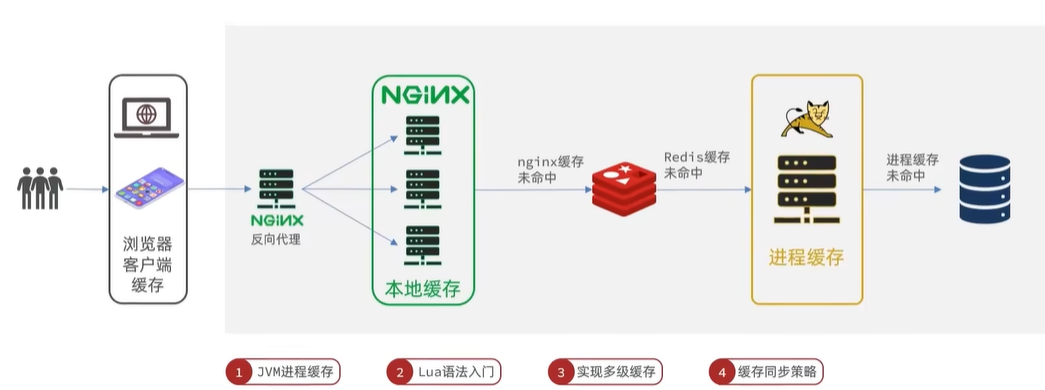
3. JVM进程缓存
3.1 导入商品案例
(1)安装MySQL
后期做数据同步需要用到MySQL的主从功能,所以需要在虚拟机中利用Docker来运行一个MySQL容器。
①为了方便后期配置MySQL,先准备两个目录,用于挂载容器的数据和配置文件目录:
# 进入/tmp目录
cd /tmp
# 创建文件夹
mkdir mysql
# 进入mysql目录
cd mysql②进入mysql目录后,执行下面的Docker命令:
docker run \-p 3306:3306 \--name mysql \-v $PWD/conf:/etc/mysql/conf.d \-v $PWD/logs:/logs \-v $PWD/data:/var/lib/mysql \-e MYSQL_ROOT_PASSWORD=123 \--privileged \-d \mysql:5.7③在/tmp/mysql/conf目录下添加一个my.cnf文件,作为mysql的配置文件:
# 创建文件
touch /tmp/mysql/conf/my.cnf文件内容如下:
[mysqld]
skip-name-resolve
character_set_server=utf8
datadir=/var/lib/mysql
server-id=1000④重启容器
docker restart mysql(2)导入SQL
①利用Navicat客户端连接MySQL,导入课前资料提供的sql文件:
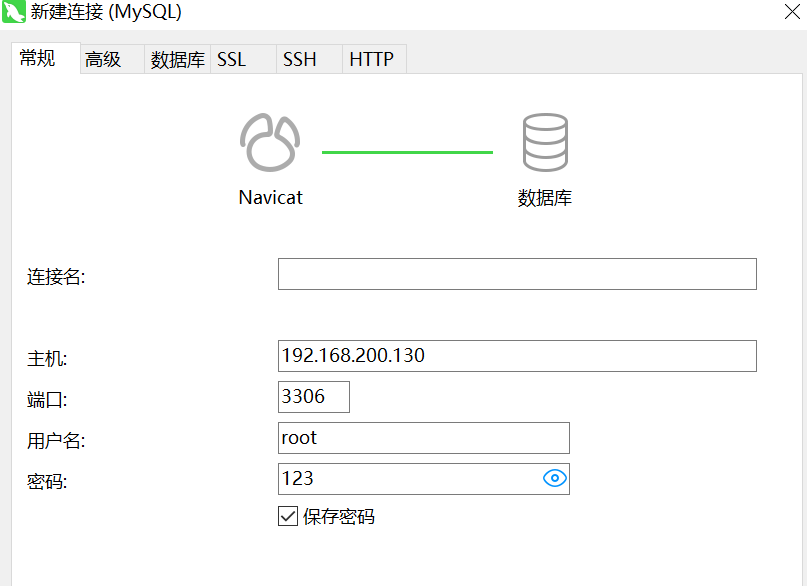
新建数据库:
运行SQL文件:
其中包含两张表:
- tb_item:商品表,包含商品的基本信息
- tb_item_stock:商品库存表,包含商品的库存信息
之所以将库存分离出来,是因为库存是更新比较频繁的信息,写操作比较多,而其他信息的修改频率非常低。
(3)导入Demo工程
①导入课前资料提供的工程
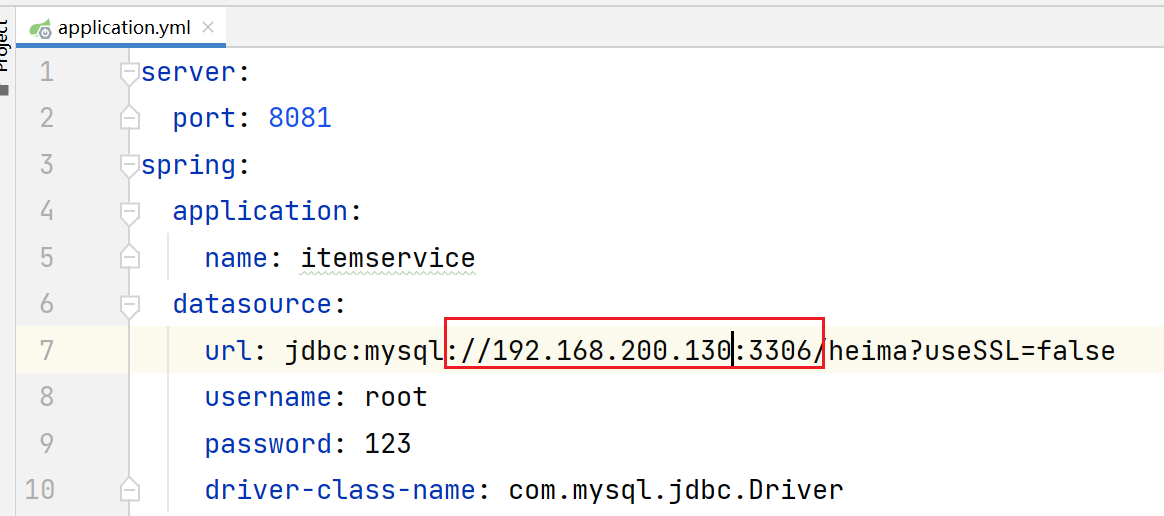
修改数据库连接地址:
修改配置文件中lombok的版本:
<dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><version>1.18.30</version></dependency>启动项目,进行测试:
(4)导入商品查询页面
商品查询是购物页面,与商品管理的页面是分离的。
部署方式如图:
我们需要准备一个反向代理的nginx服务器,如上图红框所示,将静态的商品页面存放到nginx目录中。页面需要的数据通过ajax向服务端(nginx业务集群)查询。
①找到课前资料中的nginx目录,放到一个非中文的目录下,运行这个nginx服务

若存在下面的问题:
2025/05/18 20:54:22 [notice] 19076#7520: signal process started
2025/05/18 20:55:27 [emerg] 22404#14572: bind() to 0.0.0.0:80 failed (10013: An attempt was made to access a socket in a way forbidden by its access permissions)修改nginx的监听端口

②访问http://localhost:81/item.html?id=10001
(5)反向代理
现在,页面是假数据展示的。我们需要向服务器发送ajax请求,查询商品数据。
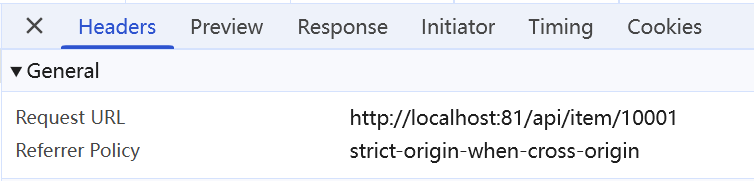
这个请求地址是81端口,所以被当前的nginx反向代理了。
查看nginx的conf目录下的nginx.conf文件,其中的关键配置如下:
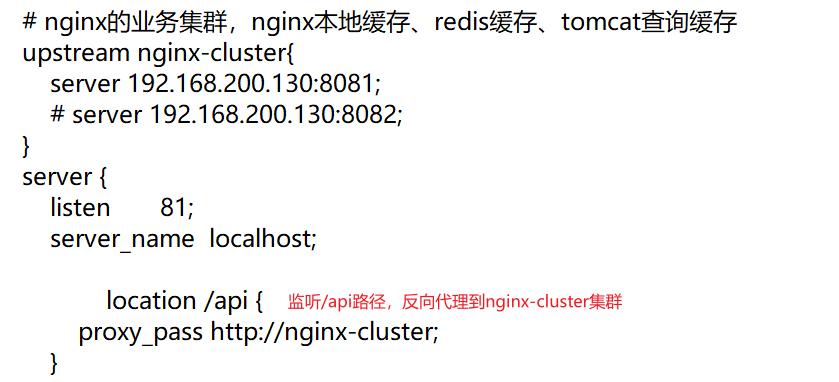
其中,192.168.200.130是虚拟机的IP地址,也就是nginx业务集群部署的地方

3.2 初始Caffeine
本地进程缓存
缓存在日常开发中起着至关重要的作用,由于是存储在内存中,数据的读取速度非常快,能大量减少对数据库的访问,减少数据库的压力。我们把缓存分为两类:
分布式缓存,例如Redis:
- 优点:存储容量大、可靠性更好、可以在集群间共享
- 缺点:访问缓存有网络开销
- 场景:缓存数据量较大、可靠性要求高、需要在集群间共享
进程本地缓存,例如HashMap、GuavaCache:
- 优点:读取本地内存,没有网络开销,速度更快
- 缺点:存储容量有限、可靠性较低、无法共享
- 场景:性能要求较高,缓存数据量较小
Caffeine
Caffeine是一个基于Java8开发的,提供了近乎最佳命中率的高性能的本地缓存库。目前Spring内部的缓存使用的就是Caffeine。Github地址:GitHub - ben-manes/caffeine: A high performance caching library for Java
Caffeine示例
可以通过item-service项目中的单元测试来学习Caffine的使用:
@Testvoid testBasicOps() {// 创建缓存对象Cache<String, String> cache = Caffeine.newBuilder().build();// 存数据cache.put("gf", "迪丽热巴");// 取数据,不存在则返回nullString gf = cache.getIfPresent("gf");System.out.println("gf = " + gf);// 取数据,不存在则去数据库查询String defaultGF = cache.get("defaultGF", key -> {// 这里可以去数据库根据 key查询valuereturn "柳岩";});System.out.println("defaultGF = " + defaultGF);}Caffeine提供了三种缓存驱逐策略:
- 基于容量:设置缓存的数量上限
// 创建缓存对象Cache<String, String> cache = Caffeine.newBuilder()// 设置缓存大小上限为 1.maximumSize(1).build();- 基于时间:设置缓存的有效时间
// 创建缓存对象Cache<String, String> cache = Caffeine.newBuilder()// 设置缓存有效期为10秒,从最后一次写入开始计时.expireAfterWrite(Duration.ofSeconds(10)).build();- 基于引用:设置缓存为软引用或弱引用,利用GC来回收缓存数据。性能较差,不建议使用
在默认情况下,当一个缓存元素过期时,Caffeine不会自动立即将其清理和驱逐。而是在一次读或写操作后,或者在空闲时间完成对失效数据的驱逐。
/*基于大小设置驱逐策略:*/@Testvoid testEvictByNum() throws InterruptedException {// 创建缓存对象Cache<String, String> cache = Caffeine.newBuilder()// 设置缓存大小上限为 1.maximumSize(1).build();// 存数据cache.put("gf1", "柳岩");cache.put("gf2", "范冰冰");cache.put("gf3", "迪丽热巴");// 延迟10ms,给清理线程一点时间Thread.sleep(10L);// 获取数据System.out.println("gf1: " + cache.getIfPresent("gf1"));System.out.println("gf2: " + cache.getIfPresent("gf2"));System.out.println("gf3: " + cache.getIfPresent("gf3"));}/*基于时间设置驱逐策略:*/@Testvoid testEvictByTime() throws InterruptedException {// 创建缓存对象Cache<String, String> cache = Caffeine.newBuilder().expireAfterWrite(Duration.ofSeconds(1)) // 设置缓存有效期为 10 秒.build();// 存数据cache.put("gf", "柳岩");// 获取数据System.out.println("gf: " + cache.getIfPresent("gf"));// 休眠一会儿Thread.sleep(1200L);System.out.println("gf: " + cache.getIfPresent("gf"));}3.3 实现进程缓存
案例:实现商品的查询的本地进程缓存
利用Caffeine实现下列需求:
- 给根据id查询商品的业务添加缓存,缓存未命中时查询数据库
- 给根据id查询商品库存的业务添加缓存,缓存未命中时查询数据库
- 缓存初始大小为100
- 缓存上限为10000
①添加配置类CaffeineConfig
package com.heima.item.config;import com.github.benmanes.caffeine.cache.Cache;
import com.github.benmanes.caffeine.cache.Caffeine;
import com.heima.item.pojo.Item;
import com.heima.item.pojo.ItemStock;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;@Configuration
public class CaffeineConfig {/*** 商品缓存* @return*/@Beanpublic Cache<Long, Item> itemCache() {return Caffeine.newBuilder().initialCapacity(100).maximumSize(10_000).build();}/*** 商品库存缓存* @return*/@Beanpublic Cache<Long, ItemStock> stockCache() {return Caffeine.newBuilder().initialCapacity(100).maximumSize(10_000).build();}
}
②改造itemController
@GetMapping("/{id}")public Item findById(@PathVariable("id") Long id){return itemCache.get(id, key -> itemService.query().ne("status", 3).eq("id", key).one());}@GetMapping("/stock/{id}")public ItemStock findStockById(@PathVariable("id") Long id){return stockCache.get(id, key -> stockService.getById(key));}③启动项目进行测试,各请求两次(第二次请求走进程本地缓存)
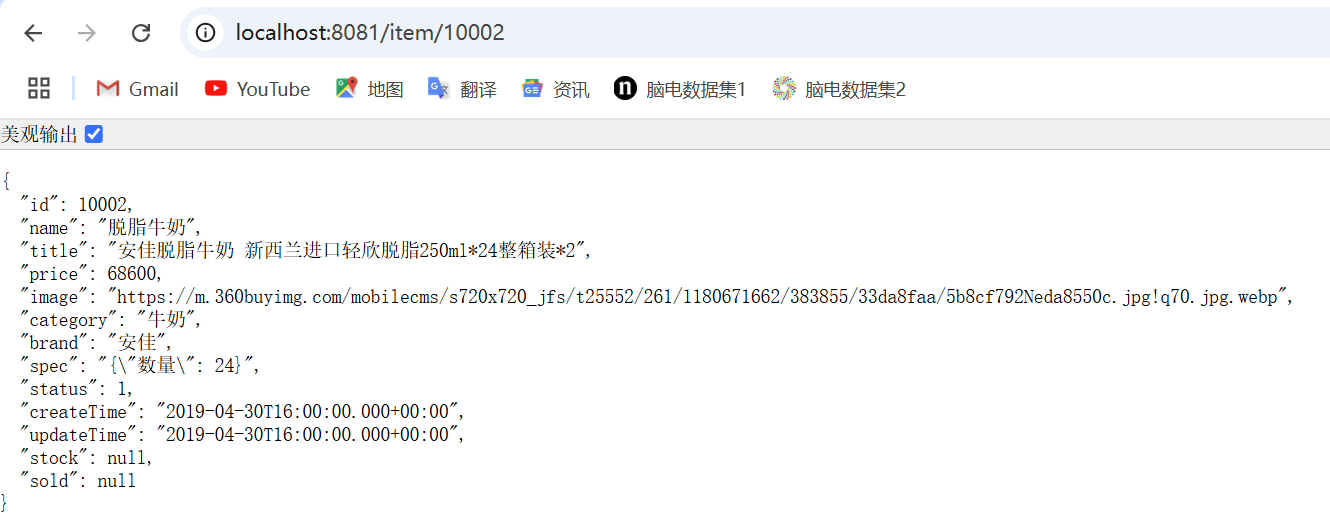
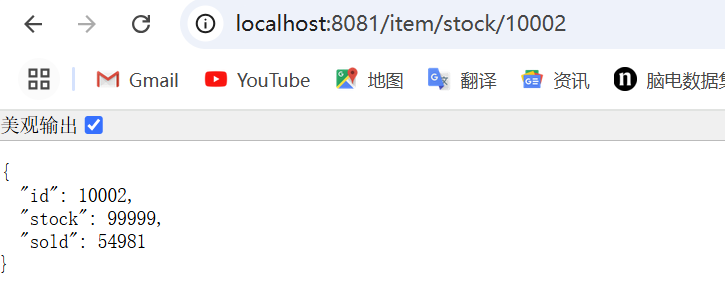
http://localhost:8081/item/10002
http://localhost:8081/item/stock/10002

4. Lua语法入门
4.1 初识Lua
Lua是一种轻量小巧的脚本语言,用标准C语言编写并以源代码形式开放,其设计目的是为了嵌入应用程序中,从而为应用程序提供灵活的扩展和定制功能。
官网:The Programming Language Lua

HelloWorld
1. 在Linux虚拟机的任意目录下,新建一个hello.lua文件
touch hello.lua2. 添加下面的内容
print("Hello World!")3. 运行
lua hello.lua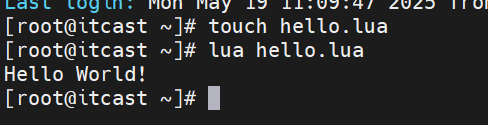
4.2 变量和循环
数据类型
| 数据类型 | 描述 |
| nil | 这个最简单,只有值nil属于该类,表示一个无效值(在条件表达式中相当于false) |
| boolean | 包含两个值:false和true |
| number | 表示双精度类型的实浮点数 |
| string | 字符串由一对双引号或单引号来表示 |
| function | 由 C 或 Lua 编写的函数 |
| table | Lua中的表(table)其实是一个“关联数组”(associative arrays),数组的索引可以是数字、字符串或表类型。在Lua里,table的创建是通过“构造表达式”来完成,最简单构造表达式是{},用来创建一个空表 |
可以利用type函数测试给定变量或值的类型:

变量
Lua声明变量的时候,并不需要指定数据类型:
-- 声明字符串
local str = 'hello'
-- 声明数字
local num = 21
-- 声明布尔类型
local flag = true
-- 声明数组 key为索引的table
local arr = {'java', 'python', 'lua'}
-- 声明table,类似java的map
local map = {name='Jack', age=21}访问table:
-- 访问数组,lua数组的角标从1开始
print(arr[1])
-- 访问table
print(map['name'])
print(map.name)循环
数组、table都可以利用for循环来遍历:
遍历数组:
-- 声明数组 key为索引的table
local arr = {'java', 'python', 'lua'}
-- 遍历数组
for index,value in ipairs(arr) doprint(index, value)
end遍历table:
-- 声明map,也就是table
local map = {name='Jack', age=21}
-- 遍历table
for key, value in pairs(map) doprint(key, value)
end4.3 条件控制、函数
函数
定义函数的语法:
function 函数名(argument1, argument2, ..., argumentn)-- 函数体return 返回值
end例如,定义一个函数,用来打印数组:
function printArr(arr)for index, value in ipairs(arr) doprint(value)end
end条件控制
类似Java的条件控制,例如if、else语法:
if(布尔表达式)
then-- [布尔表达式 为true时 执行该语句块 --]
else--[布尔表达式 为false时 执行该语句块 --]
end与java不同,布尔表达式中的逻辑运算是基于英文单词:
| 操作符 | 描述 | 实例 |
| and | 逻辑与操作符。若A为false,则返回A,否则返回B | (A and B)为false |
| or | 逻辑或操作符。若A为true,则返回A,否则返回B | (A or B)为true |
| not | 逻辑非操作符。与逻辑运算结果相反,如果条件为true,逻辑非为false | not(A and B)为true |
案例:自定义函数,打印table
需求:自定义一个函数,可以打印table,当参数为nil时,打印错误信息
local function printArr(arr)if (not arr) thenprint('数组不能为空!')return nilendfor index, value ipairs(arr) doprint(value)end
end5. 多级缓存
5.1 安装OpenResty
①安装OpenResty的依赖开发库,执行命令
yum install -y pcre-devel openssl-devel gcc --skip-broken
②安装OpenResty仓库,这样就可以便于未来安装或更新我们的软件包(通过yum check-update命令)
yum-config-manager --add-repo https://openresty.org/package/centos/openresty.repo
如果提示说命令不存在,则运行:
yum install -y yum-utils 然后再重复上面的命令
③安装OpenResty
yum install -y openresty
④安装opm工具。opm是OpenResty的一个管理工具,可以帮助我们安装一个第三方的Lua模块。如果你想安装命令行工具opm,那么可以像下面这样安装openresty-opm包
yum install -y openresty-opm
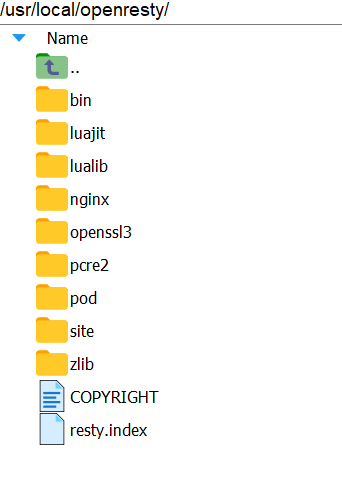
⑤目录结构。默认情况下,OpenResty安装的目录是:/usr/local/openresty。OpenResty就是再Nginx基础上继承了一些Lua模块
⑥配置nginx的环境变量
打开配置文件
vi /etc/profile在最下面加入两行
export NGINX_HOME=/usr/local/openresty/nginx
export PATH=${NGINX_HOME}/sbin:$PATH
NGINX_HOME:后面是OpenResty安装目录下的nginx的目录
然后让配置生效
source /etc/profile⑦修改nginx的配置文件。修改 /usr/local/openresty/nginx/conf/nginx.conf 文件,内容如下:(注释太多,影响后续编辑)
#user nobody;
worker_processes 1;
error_log logs/error.log;events {worker_connections 1024;
}http {include mime.types;default_type application/octet-stream;sendfile on;keepalive_timeout 65;server {listen 8081;server_name localhost;location / {root html;index index.html index.htm;}error_page 500 502 503 504 /50x.html;location = /50x.html {root html;}}
}⑧在Linux的控制台输入命令以启动nginx
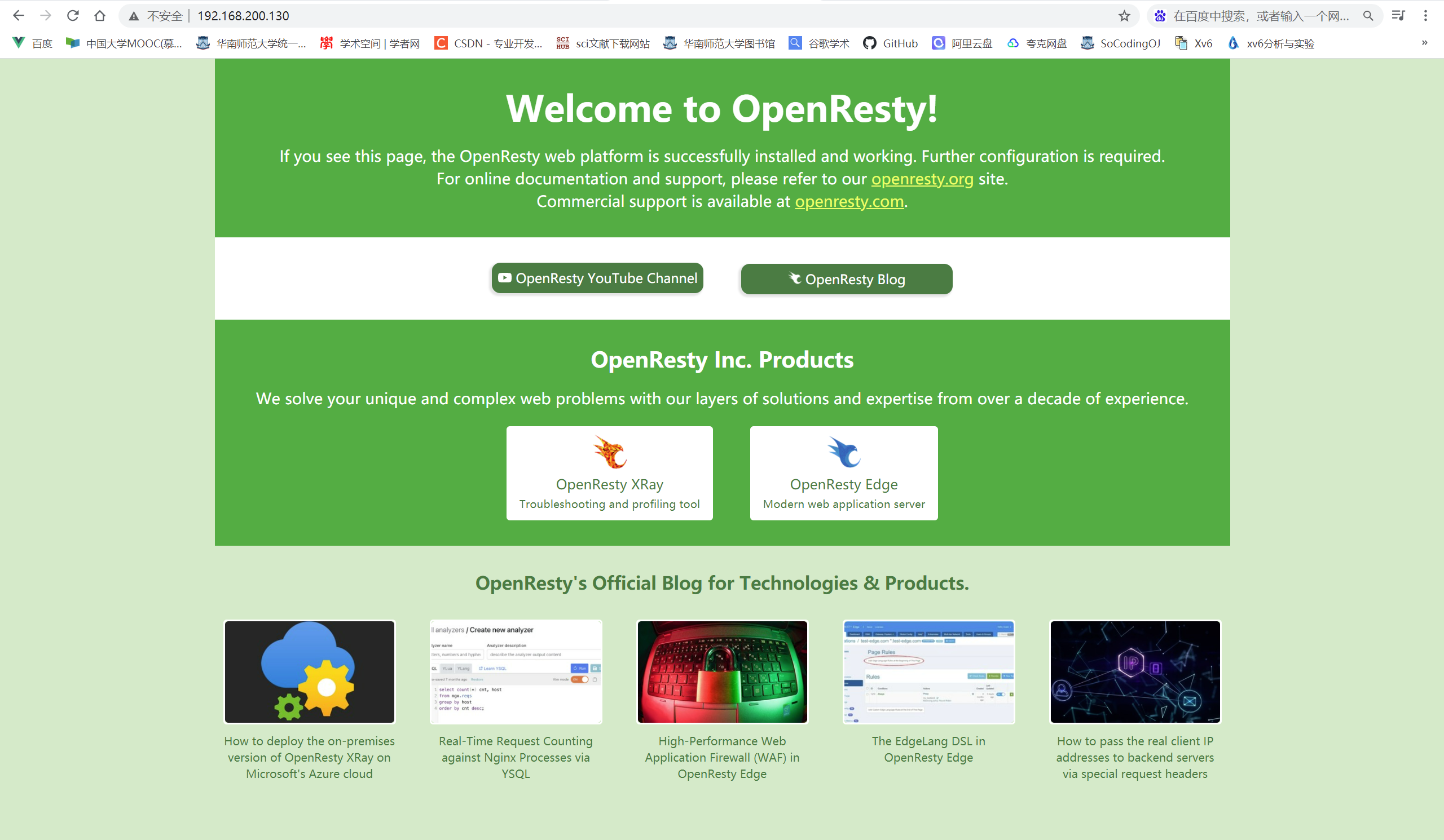
nginx访问页面:http://192.168.200.130:8081,注意ip地址换为你自己的虚拟机IP
5.2 OpenResty快速入门
初识OpenResty
OpenResty是一个基于Nginx的高性能Web平台,用于方便地搭建能够处理高并发、扩展性极高的动态Web应用、Web服务和动态网关。具备下列特点:
- 具备Nginx的完整功能
- 基于Lua语言进行扩展,集成了大量精良的Lua库、第三方模块
- 允许使用Lua自定义业务逻辑、自定义库
官方网站:OpenResty® - 开源官方站
案例:OpenResty快速入门,实现商品详情页数据查询
商品详情页面目前展示的是假数据,在浏览器的控制台可以看到查询商品信息的请求:
而这个请求最终被反向代理到虚拟机的OpenResty集群:

需求:在OpenResty中接收这个请求,并返回一段商品的假数据
步骤①:在nginx.conf的http下面,添加对OpenResty的Lua模块的加载:
# 加载lua 模块
lua_package_path "/usr/local/openresty/lualib/?.lua;;";
# 加载c模块
lua_package_cpath "/usr/local/openresty/lualib/?.so;;"; ②在nginx.conf的server下面,添加对/api/item这个路径的监听
location /api/item {# 响应类型,这里返回jsondefault_type application/json;# 响应数据由 lua/item.lua这个文件来决定content_by_lua_file lua/item.lua;}
#user nobody;
worker_processes 1;
error_log logs/error.log;events {worker_connections 1024;
}http {include mime.types;default_type application/octet-stream;sendfile on;keepalive_timeout 65;# 加载lua 模块lua_package_path "/usr/local/openresty/lualib/?.lua;;";# 加载c模块 lua_package_cpath "/usr/local/openresty/lualib/?.so;;"; server {listen 8081;server_name localhost;location /api/item {# 响应类型,这里返回jsondefault_type application/json;# 响应数据由 lua/item.lua这个文件来决定content_by_lua_file lua/item.lua;}location / {root html;index index.html index.htm;}error_page 500 502 503 504 /50x.html;location = /50x.html {root html;}}
}
②新建/lua/item.lua文件
![]()
内容如下:注意不能换行
-- 返回假数据,这里的ngx.say()函数,就是写数据到Response中
ngx.say('{"id": 10001,"name": "SALSA AIR","title": "RIMOWA 26寸托运箱拉杆箱 SALSA AIR系列果绿色 820.70.36.4","price": 21900,"image": "https://m.360buyimg.com/mobilecms/s720x720_jfs/t6934/364/1195375010/84676/e9f2c55f/597ece38N0ddcbc77.jpg!q70.jpg.webp","category": "拉杆箱","brand": "RIMOWA","spec": "","status": 1,"createTime": "2019-04-30T16:00:00.000+00:00","updateTime": "2019-04-30T16:00:00.000+00:00","stock": 2999,"sold": 31290}')Vue打不开的可以在这里copy:
③重新加载配置
nginx -s reload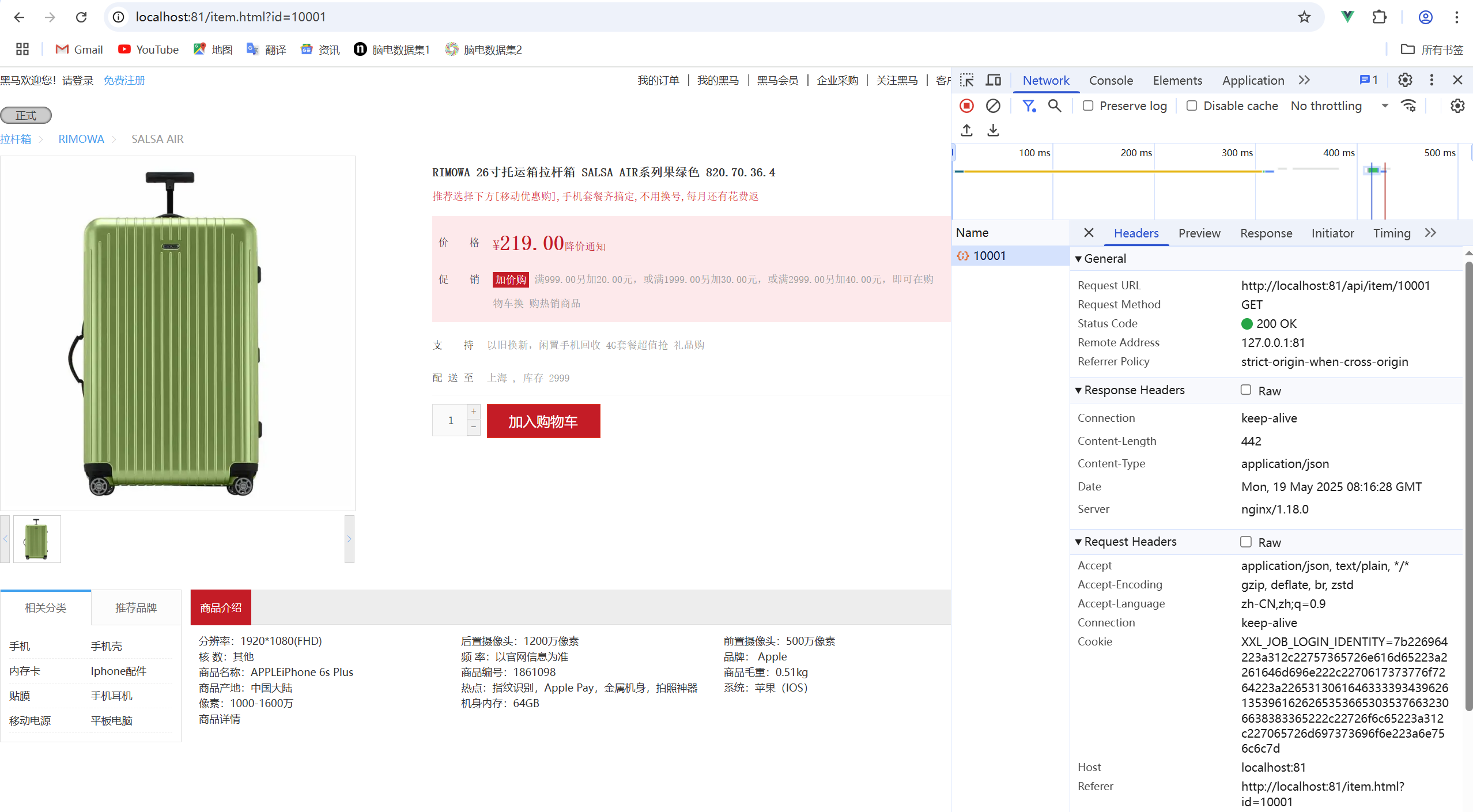
5.3 请求参数处理
OpenResty获取请求参数
OpenResty提供了各种API用来获取不同类型的请求参数:
| 参数个数 | 参数示例 | 参数解析代码示例 |
| 路径占位符 | /item/1001 | 1. 正则表达式匹配 location ~ /item/(\d+) { content_by_lua_file lua/item.lua } 2. 匹配到的参数会存入ngx.var数组中 -- 可以用角标获取 local id = ngx.var[1] |
| 请求头 | id:1001 | -- 获取请求头,返回值是table类型 local headers = ngx.get_headers() |
| Get请求参数 | ?id=1001 | -- 获取GET请求参数,返回值是table类型 local getParams = ngx.req.get_uri_args() |
| Post表单参数 | id=1001 | -- 读取请求体 ngx.req.read_body() -- 获取POST表单参数,返回值是table类型 local postParams = ngx.req.get_pos_args() |
| JSON参数 | {"id": 1001} | -- 读取请求体 ngx.req.read_body() -- 获取body中的json参数,返回值是string类型 local josnBody = ngx.req.get_body_data() |
案例:获取请求路径中的商品id信息,拼接到json结果中返回
在查询商品信息的请求中,通过路径占位符的方式,传递了商品id到后台:
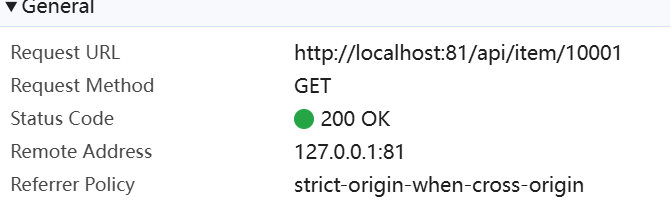
需求:在OpenResty中接收这个请求,并获取路径中的id信息,拼接到结果的json字符串中返回
①修改nginx.conf
#user nobody;
worker_processes 1;
error_log logs/error.log;events {worker_connections 1024;
}http {include mime.types;default_type application/octet-stream;sendfile on;keepalive_timeout 65;# 加载lua 模块lua_package_path "/usr/local/openresty/lualib/?.lua;;";# 加载c模块 lua_package_cpath "/usr/local/openresty/lualib/?.so;;"; server {listen 8081;server_name localhost;location ~ /api/item/(\d+) {# 响应类型,这里返回jsondefault_type application/json;# 响应数据由 lua/item.lua这个文件来决定content_by_lua_file lua/item.lua;}location / {root html;index index.html index.htm;}error_page 500 502 503 504 /50x.html;location = /50x.html {root html;}}
}
②修改item.lua
-- 获取路径参数
local id = ngx.var[1]
-- 返回假数据,这里的ngx.say()函数,就是写数据到Response中
ngx.say('{"id": ' .. id .. ',"name": "SALSA AIR","title": "RIMOWA 26寸托运箱拉杆箱 SALSA AIR系列果绿色 820.70.36.4","price": 21900,"image": "https://m.360buyimg.com/mobilecms/s720x720_jfs/t6934/364/1195375010/84676/e9f2c55f/597ece38N0ddcbc77.jpg!q70.jpg.webp","category": "拉杆箱","brand": "RIMOWA","spec": "","status": 1,"createTime": "2019-04-30T16:00:00.000+00:00","updateTime": "2019-04-30T16:00:00.000+00:00","stock": 2999,"sold": 31290}')③重新加载配置文件,发起请求
nginx -s reload
5.4 查询Tomcat
案例:获取请求路径中的商品id信息,根据id向Tomcat查询商品信息
这里要修改item.lua,满足下面的需求:
- 获取请求参数中的id
- 根据id向Tomcat服务发送请求,查询商品信息
- 根据id向Tomcat服务发送请求,查询库存信息
- 组装商品信息、库存信息,序列化为JSON格式并返回
nginx内部发送http请求
nginx提供了内部API用于发送http请求:
local resp = ngx.location.capture("/path", {method = ngx.HTTP_GET, -- 请求方式args = {a=1,b=2}, -- get方式传参数body="c=3&d=4" -- post方式传参数
})返回的响应内容包括:
- resp.status:响应状态码
- resp.header:响应头,是一个table
- resp.body:响应体,就是响应数据
注意:这里的path是路径,并不包含IP和端口。这个请求会被nginx内部的server监听并处理。
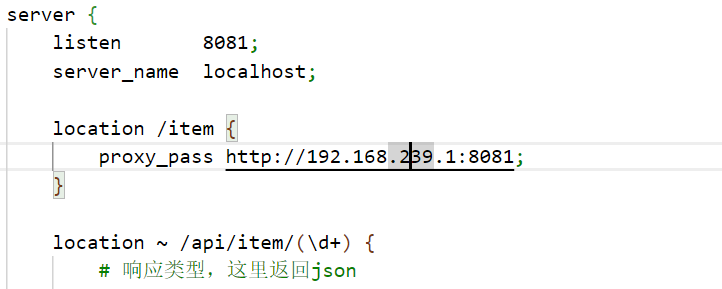
但是我们希望这个请求发送到Tomcat服务器,所以需要编写一个server来对这个路径做反向代理:
location /path {# 这里是windows电脑的ip和Java服务端口,需要确保windows防火墙处于关闭状态proxy_pass http://192.168.200.1:8081;windows的IPv4地址可以通过ipconfig命令来查看(如192.168.200.1)
封装http查询的函数
我们可以把http查询的请求封装为一个函数,放到OpenResty函数库中,方便后期使用。
①在/usr/local/openresty/lualib目录下创建common.lua文件:

②在common.lua中封装http查询的函数
-- 封装函数,发送http请求,并解析响应
local function read_http(path, params)local resp = ngx.location.capture(path,{method = ngx.HTTP_GET,args = params,})if not resp then-- 记录错误信息,返回404ngx.log(ngx.ERR, "http not found, path: ", path , ", args: ", args)ngx.exit(404)endreturn resp.body
end
-- 将方法导出
local _M = { read_http = read_http
}
return _MJSON结果处理
OpenResty提供了一个cjson的模块用来处理JSON的序列化和反序列化
官方地址:https://github.com/openresty/lua-cjson/
①引入cjson模块:
local cjson = require('cjson')②序列化:
local obj = {name = 'jack',age = 21
}
local json = cjson.encode(obj)③反序列化:
local json = '{"name": "jack", "age": 21}'
-- 反序列化
local obj = cjson.decode(json)
print(obj.name)③改造item.lua
-- 导入common函数库
local common = require('common')
local read_http = common.read_http-- 导入cjson库
local cjson = require('cjson')-- 获取路径参数
local id = ngx.var[1]-- 查询商品信息
local itemJson = read_http("/item/" .. id, nil)-- 查询库存信息
local stockJson = read_http("/item/stock/" .. id, nil)-- JSON转化为lua的table
local item = cjson.decode(itemJson)
local stock = cjson.decode(stockJson)
-- 组合数据
item.stock = stock.stock
item.sold = stock.sold-- 返回假数据,这里的ngx.say()函数,就是写数据到Response中
ngx.say(cjson.encode(item))④重新加载配置
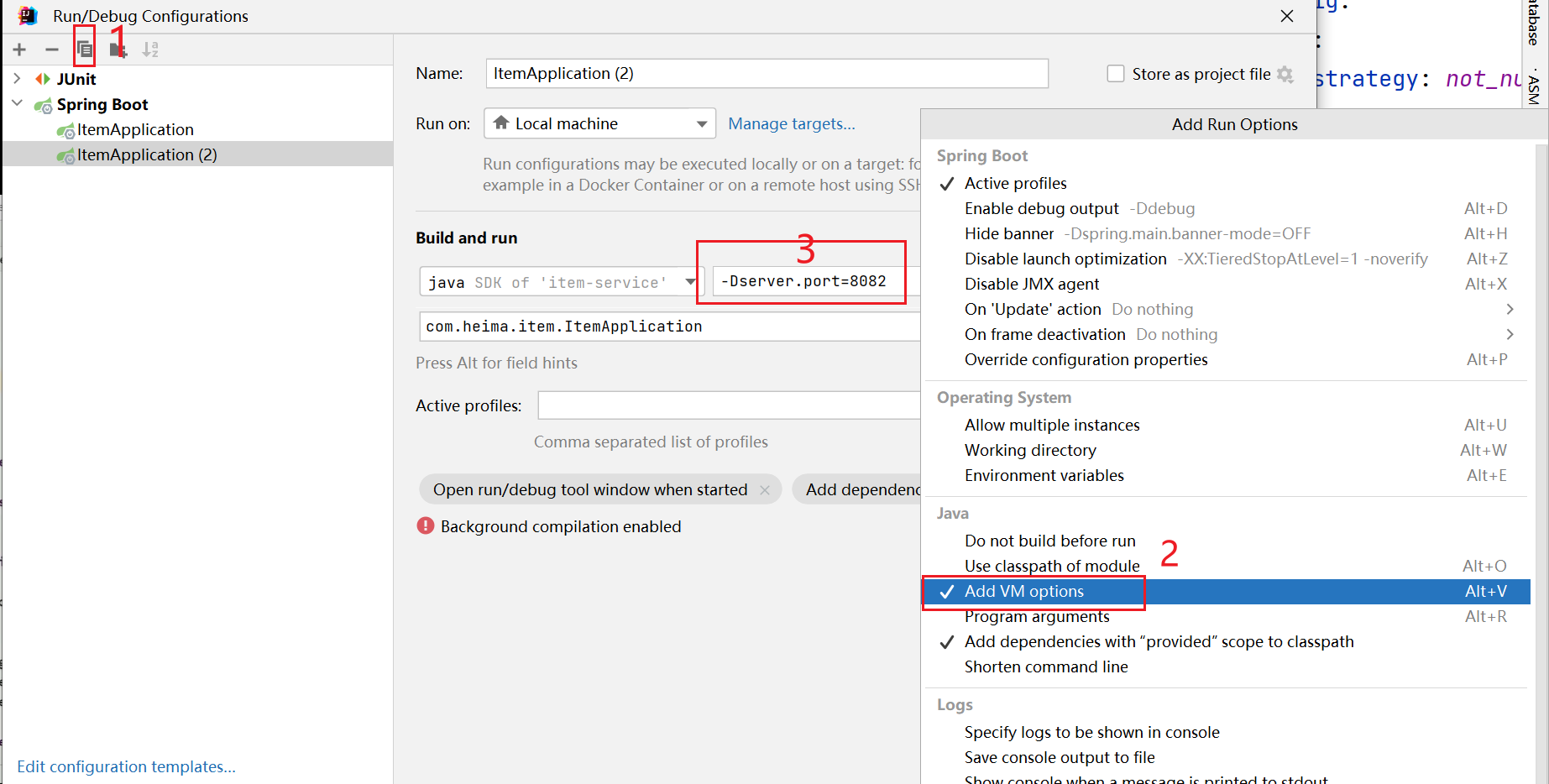
nginx -s reload⑤启动itemApplication进行测试
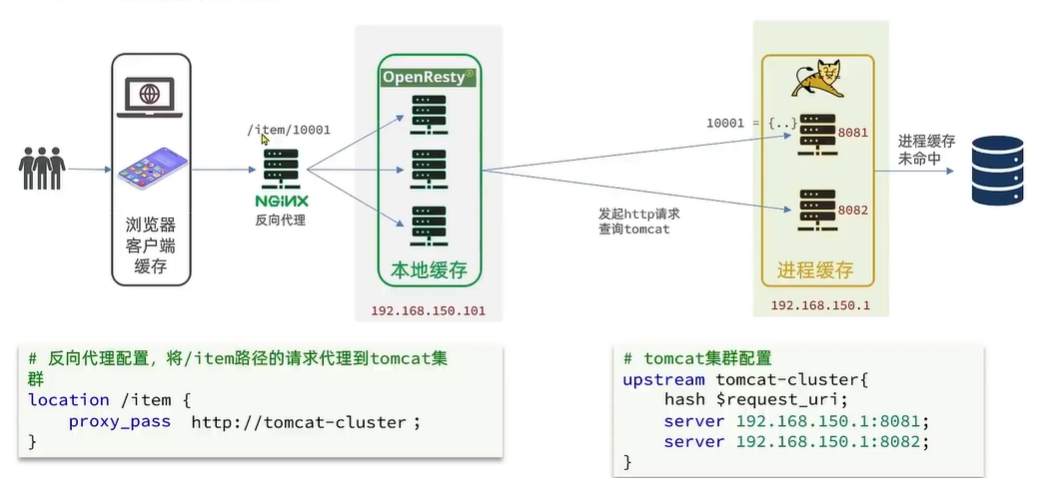
Tomcat集群的负载均衡
步骤①:修改nginx.conf
#user nobody;
worker_processes 1;
error_log logs/error.log;events {worker_connections 1024;
}http {include mime.types;default_type application/octet-stream;sendfile on;keepalive_timeout 65;# 加载lua 模块lua_package_path "/usr/local/openresty/lualib/?.lua;;";# 加载c模块 lua_package_cpath "/usr/local/openresty/lualib/?.so;;"; upstream tomcat-cluster {hash $request_uri;server 192.168.239.1:8081;server 192.168.239.1:8081;}server {listen 8081;server_name localhost;location /item {proxy_pass http://tomcat-cluster;}location ~ /api/item/(\d+) {# 响应类型,这里返回jsondefault_type application/json;# 响应数据由 lua/item.lua这个文件来决定content_by_lua_file lua/item.lua;}location / {root html;index index.html index.htm;}error_page 500 502 503 504 /50x.html;location = /50x.html {root html;}}
}
②重新加载nginx配置
nginx -s reload③启动两台Tomcat进行测试

5.5 Redis缓存预热
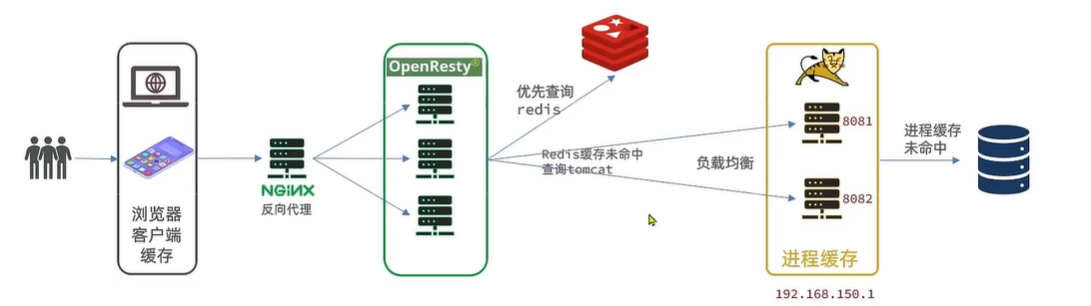
冷启动与缓存预热
- 冷启动:服务刚刚启动时,Redis中并没有缓存,如果所有商品数据都在第一次查询时添加缓存,可能会给数据库带来较大压力
- 缓存预热:在实际开发中,我们可以利用大数据统计用户访问的热点数据,在项目启动时将这些热点数据提前查询并保存到redis中。
我们数据量较少,可以在启动时将所有数据都放入缓存中
缓存预热
步骤①:利用Docker安装redis
docker run --name redis -p 6379:6379 -d redis redis-server --appendonly yes②在item-service服务中引入Redis依赖 pom.xml
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-redis</artifactId></dependency>③配置Redis地址 application.yml
spring:redis:host: 192.168.200.130④编写初始化类
package com.heima.item.config;import com.fasterxml.jackson.databind.ObjectMapper;
import com.heima.item.pojo.Item;
import com.heima.item.pojo.ItemStock;
import com.heima.item.service.IItemService;
import com.heima.item.service.IItemStockService;
import org.springframework.beans.factory.InitializingBean;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.redis.core.StringRedisTemplate;
import org.springframework.stereotype.Component;import java.util.List;@Component
public class RedisHandler implements InitializingBean {@Autowiredprivate StringRedisTemplate redisTemplate;@Autowiredprivate IItemService itemService;@Autowiredprivate IItemStockService stockService;private static final ObjectMapper MAPPER = new ObjectMapper();@Overridepublic void afterPropertiesSet() throws Exception {// 初始化缓存// 1. 查询商品信息List<Item> itemList = itemService.list();// 2. 放入缓存for (Item item : itemList) {// 2.1 item序列化为JSONString json = MAPPER.writeValueAsString(item);// 2.2 存入redisredisTemplate.opsForValue().set("item:id:" + item.getId(), json);}// 3. 查询商品库存List<ItemStock> itemStockList = stockService.list();// 4. 放入缓存for (ItemStock stock : itemStockList) {// 4.1 stock序列化为JSONString json = MAPPER.writeValueAsString(stock);// 4.2 存入redisredisTemplate.opsForValue().set("item:stock:id:" + stock.getId(), json);}}
}
⑤启动ItemApplication


5.6 查询Redis缓存
OpenResty提供了操作Redis的模块,我们只要引入该模块就能直接使用:
①引入Redis模块,并初始化Redis对象(common.lua)
-- 引入redis模块
local redis = require("resty.redis")
-- 初始化Redis对象
local red = redis:new()
-- 设置Redis超时时间
red:set_timeouts(1000, 1000, 1000)②封装函数,用来释放Redis连接,其实就是放入连接池
-- 关闭redis连接的工具方法,其实是放入连接池
local function close_redis(red)local pool_max_idle_time = 10000 -- 连接的空闲时间,单位是毫秒local pool_size = 100 --连接池大小local ok, err = red:set_keepalive(pool_max_idle_time, pool_size)if not ok thenngx.log(ngx.ERR, "放入redis连接池失败: ", err)end
end③封装函数,从Redis读取数据并返回
-- 查询redis的方法 ip和port是redis地址,key是查询的key
local function read_redis(ip, port, key)-- 获取一个连接local ok, err = red:connect(ip, port)if not ok thenngx.log(ngx.ERR, "连接redis失败 : ", err)return nilend-- 查询redislocal resp, err = red:get(key)-- 查询失败处理if not resp thenngx.log(ngx.ERR, "查询Redis失败: ", err, ", key = " , key)end--得到的数据为空处理if resp == ngx.null thenresp = nilngx.log(ngx.ERR, "查询Redis数据为空, key = ", key)endclose_redis(red)return resp
endcommon.lua完整代码:
-- 封装函数,发送http请求,并解析响应
local function read_http(path, params)local resp = ngx.location.capture(path,{method = ngx.HTTP_GET,args = params,})if not resp then-- 记录错误信息,返回404ngx.log(ngx.ERR, "http not found, path: ", path , ", args: ", args)ngx.exit(404)endreturn resp.body
end-- 引入redis模块
local redis = require("resty.redis")
-- 初始化Redis对象
local red = redis:new()
-- 设置Redis超时时间
red:set_timeouts(1000, 1000, 1000)-- 关闭redis连接的工具方法,其实是放入连接池
local function close_redis(red)local pool_max_idle_time = 10000 -- 连接的空闲时间,单位是毫秒local pool_size = 100 --连接池大小local ok, err = red:set_keepalive(pool_max_idle_time, pool_size)if not ok thenngx.log(ngx.ERR, "放入redis连接池失败: ", err)end
end-- 查询redis的方法 ip和port是redis地址,key是查询的key
local function read_redis(ip, port, key)-- 获取一个连接local ok, err = red:connect(ip, port)if not ok thenngx.log(ngx.ERR, "连接redis失败 : ", err)return nilend-- 密码认证(新增部分)local auth_ok, auth_err = red:auth("leadnews") -- 你的redis密码if not auth_ok thenngx.log(ngx.ERR, "Redis认证失败: ", auth_err)return nilend-- 查询redislocal resp, err = red:get(key)-- 查询失败处理if not resp thenngx.log(ngx.ERR, "查询Redis失败: ", err, ", key = " , key)end--得到的数据为空处理if resp == ngx.null thenresp = nilngx.log(ngx.ERR, "查询Redis数据为空, key = ", key)endclose_redis(red)return resp
end-- 将方法导出
local _M = { read_http = read_http,read_redis = read_redis
}
return _M案例:查询商品时,优先Redis缓存查询
需求:
- 修改item.lua,封装一个函数read_data,实现先查询Redis,如果未命中,再查询tomcat
- 修改item.lua,查询商品和库存时都调用read_data这个函数
①修改item.lua
-- 导入common函数库
local common = require('common')
local read_http = common.read_http
local read_redis = common.read_redis-- 导入cjson库
local cjson = require('cjson')-- 封装函数,先查询redis,再查询tomcat
function read_data(key, path, params) -- 查询redislocal resp = read_redis("127.0.0.1", 6379, key)-- 判断redis是否命中if not resp thenngx.log(ngx.ERR, "redis查询失败,尝试查询tomcat,key: ", key)-- redis查询失败,查询tomcatresp = read_http(path, params)endreturn resp
end-- 获取路径参数
local id = ngx.var[1]-- 查询商品信息
local itemJson = read_data("item:id:" .. id, "/item/" .. id, nil)-- 查询库存信息
local stockJson = read_data("item:stock:id:" .. id, "/item/stock/" .. id, nil)-- JSON转化为lua的table
local item = cjson.decode(itemJson)
local stock = cjson.decode(stockJson)
-- 组合数据
item.stock = stock.stock
item.sold = stock.sold-- 返回假数据,这里的ngx.say()函数,就是写数据到Response中
ngx.say(cjson.encode(item))重新加载nginx配置
nginx -s reload②停掉ItemApplication和ItemApplication(2),测试还能访问到数据

5.7 Nginx本地缓存
案例:在查询商品时,优先查询OpenResty的本地缓存
需求:
- 修改item.lua中的read_data函数,优先查询本地缓存,未命中时再查询Redis、Tomcat
- 查询Redis或Tomcat成功后,将数据写入本地缓存,并设置有效期
- 商品基本信息,有效期30分钟
- 库存信息,有效期1分钟
OpenResty为nginx提供了shard dict的功能,可以在nginx的多个worker之间共享数据,实现缓存功能。
①开启共享字典,在nginx.conf的http下添加配置:
# 共享字典,也就是本地缓存,名称叫做:item_cache,大小150m
lua_shared_dict item_cache 150m; 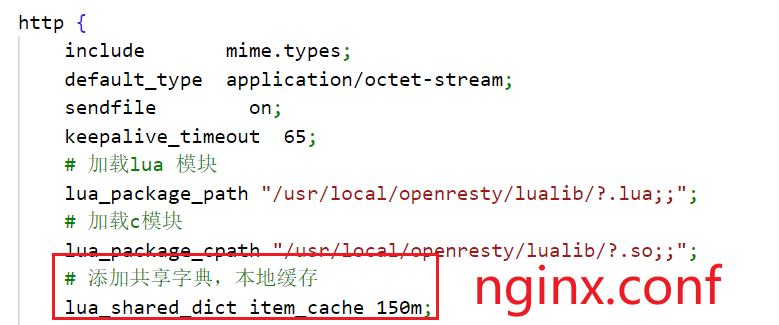
②操作共享字典:item.lua
-- 导入common函数库
local common = require('common')
local read_http = common.read_http
local read_redis = common.read_redis-- 导入cjson库
local cjson = require('cjson')
-- 导入共享字典,本地缓存
local item_cache = ngx.shared.item_cache-- 封装函数,先查询redis,再查询tomcat
function read_data(key, expire, path, params) -- 查询本地缓存local val = item_cache:get(key)if not val thenngx.log(ngx.ERR, "本地缓存查询失败,尝试查询redis,key: ", key)-- 查询redisval = read_redis("127.0.0.1", 6379, key)-- 判断redis是否命中if not val thenngx.log(ngx.ERR, "redis查询失败,尝试查询tomcat,key: ", key)-- redis查询失败,查询tomcatval = read_http(path, params)endend-- 查询成功,把数据写入本地缓存item_cache:set(key, val, expire)-- 返回数据return val
end-- 获取路径参数
local id = ngx.var[1]-- 查询商品信息
local itemJson = read_data("item:id:" .. id, 1800, "/item/" .. id, nil)-- 查询库存信息
local stockJson = read_data("item:stock:id:" .. id, 60, "/item/stock/" .. id, nil)-- JSON转化为lua的table
local item = cjson.decode(itemJson)
local stock = cjson.decode(stockJson)
-- 组合数据
item.stock = stock.stock
item.sold = stock.sold-- 返回假数据,这里的ngx.say()函数,就是写数据到Response中
ngx.say(cjson.encode(item))③重新加载配置,进行测试
nginx -s reload查看日志
[root@itcast ~]# cd /usr/local/openresty/nginx/logs/
[root@itcast logs]# tail -f error.log
访问:http://localhost:81/item.html?id=10003

6. 缓存同步
6.1 数据同步策略
缓存数据同步的常见方式有三种:
- 设置有效期:给缓存设置有效期,到期后自动删除。再次查询时更新缓存
- 优势:简单、方便
- 缺点:时效性差,缓存过期之前可能不一致
- 场景:更新频率较低,时效性要求低的业务
- 同步双写:在修改数据库的同时,直接修改缓存
- 优势:时效性强,缓存与数据库强一致
- 缺点:有代码侵入,耦合度高
- 场景:对一致性、时效性要求较高的缓存数据
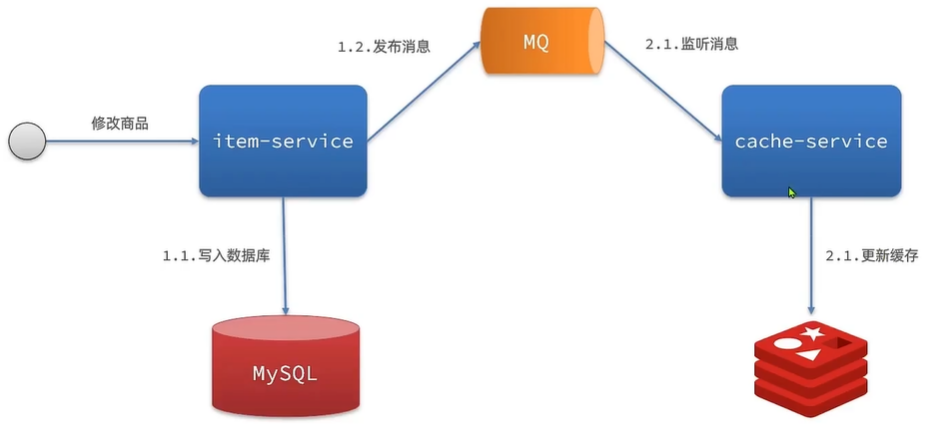
- 异步通知:修改数据库时发送事件通知,相关服务监听到通知后修改缓存数据
- 优势:低耦合,可以同时通知多个缓存服务
- 缺点:时效性一般,可能存在中间不一致状态
- 场景:时效性要求一般,有多个服务需要同步
基于MQ的异步通知
基于Canal的异步通知
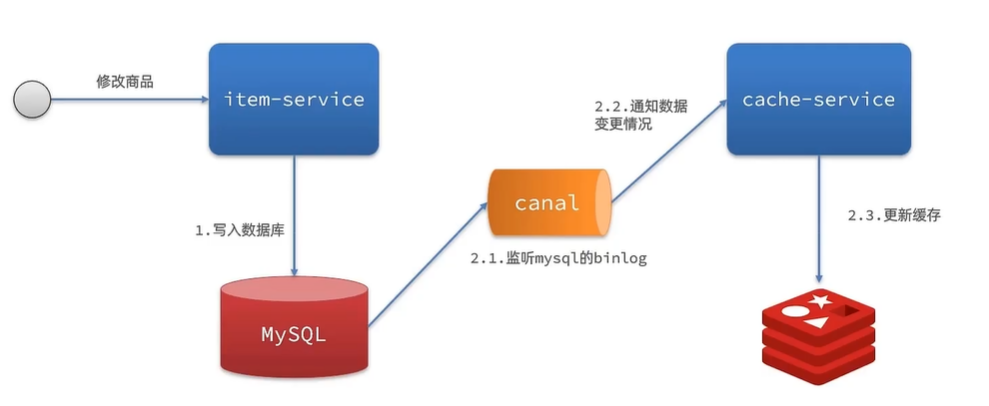
6.2 安装Canal
初识Canal
Canal,译意为管道/水道/沟渠,是阿里巴巴旗下的一款开源项目,基于Java开发。基于数据库增量日志解析,提供增量数据订阅&消费。
Github的地址:GitHub - alibaba/canal: 阿里巴巴 MySQL binlog 增量订阅&消费组件
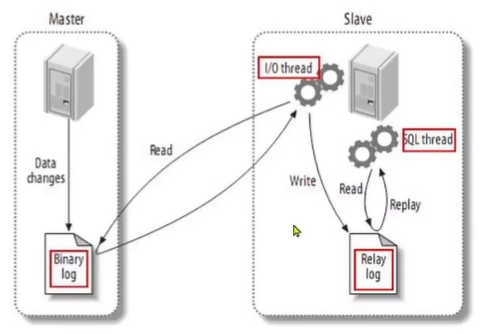
Canal是基于mysql的主从同步来实现的,MySQL主从同步的原理如下:
- MySQL master将数据变更写入二进制日志(binary log),其中记录的数据叫作binary log events
- MySQL slave将master的binary log events拷贝到它的中继日志(relay log)
- MySQL slave重放relay log中事件,将数据变更反映它自己的数据
Canal就是把自己伪装成MySQL的一个slave节点,从而监听master的binary log变化。再把得到的变化信息通知给Canal的客户端,进而完成对其他数据库的同步。
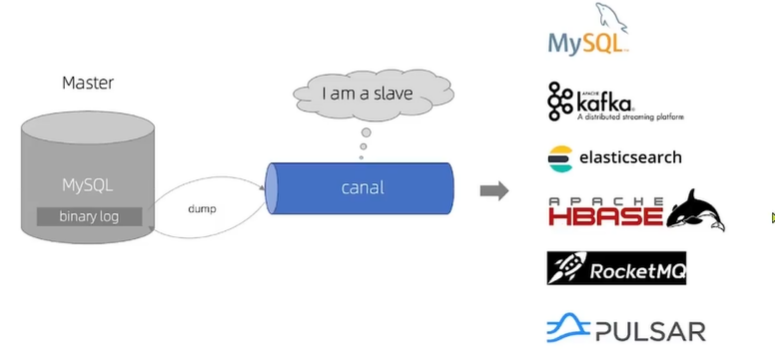
安装和配置Canal
步骤①:打开mysql容器挂载的日志文件,我的在/tmp/mysql/conf目录下,修改my.cnf文件,添加如下内容
log-bin=/var/lib/mysql/mysql-bin
binlog-do-db=heima- log-bin=/var/lib/mysql/mysql-bin:设置binary log文件的存放地址和文件名,叫作mysql-bin
- binlog-do-db=heima:指定对哪个database记录binary log events,这里记录heima这个库

②设置用户权限
添加一个仅用于数据同步的账户,出于安全考虑,仅提供对heima这个库的操作权限:
create user canal@'%' IDENTIFIED by 'canal';
GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT,SUPER ON *.* TO 'canal'@'%' identified by 'canal';
FLUSH PRIVILEGES;
重启mysql容器
docker restart mysql测试设置是否成功:在mysql控制台或者Navicat中,输入命令:
show master status;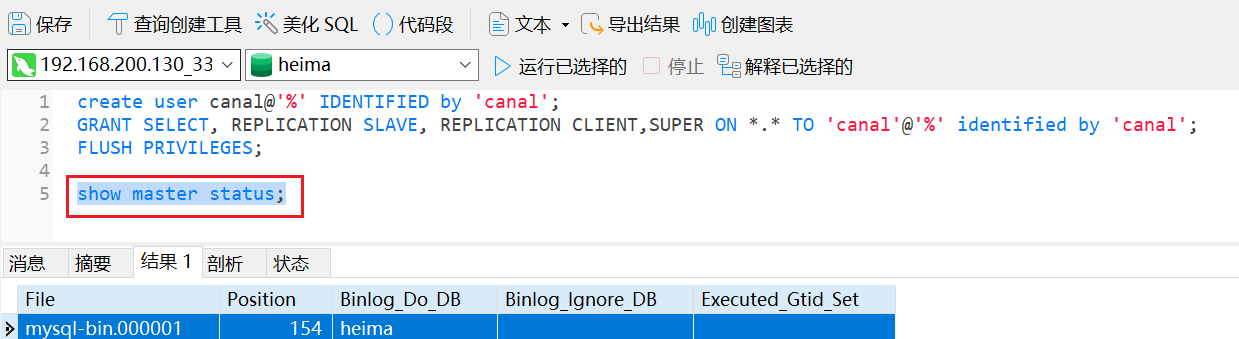
③安装Canal
创建一个网络,将MySQL、Canal、MQ放到同一个Docker网络中:
docker network create heima
让mysql加入这个网络:
docker network connect heima mysql④安装Canal
将课前资料提供的Canal镜像压缩包上传至虚拟机:
通过下面的命令导入:
docker load -i canal.tar
然后运行命令创建Canal容器:
docker run -p 11111:11111 --name canal \
-e canal.destinations=heima \
-e canal.instance.master.address=mysql:3306 \
-e canal.instance.dbUsername=canal \
-e canal.instance.dbPassword=canal \
-e canal.instance.connectionCharset=UTF-8 \
-e canal.instance.tsdb.enable=true \
-e canal.instance.gtidon=false \
-e canal.instance.filter.regex=heima\\..* \
--network heima \
-d canal/canal-server:v1.1.5说明:
- -p 11111:11111:这是canal的默认监听端口
- -e canal.instance.master.address=mysql:3306:数据库地址和端口,如果不知道mysql容器地址,可以通过docker inspect 容器id来查看
- -e canal.instance.dbUsername=canal:数据库用户名
- -e canal.instance.dbPassword=canal:数据库密码
- -e canal.instance.filter.regex=:要监听的表名称
⑤查看canal的日志:
docker logs -f canal
docker exec -it canal bash
tail -f canal-server/logs/canal/canal.log
tail -f canal-server/logs/heima/heima.log

6.3 监听Canal
Canal客户端
Canal提供了各种语言的客户端,当Canal监听到binlog变化时,会通知Canal的客户端。不过这里我们会使用Github上的第三方开源的canal-starter。
地址:GitHub - NormanGyllenhaal/canal-client: spring boot canal starter 易用的canal 客户端 canal client
步骤①:引入依赖 pom.xml
<dependency><groupId>top.javatool</groupId><artifactId>canal-spring-boot-starter</artifactId><version>1.2.1-RELEASE</version></dependency>②编写配置 application.yml
canal:destination: heima # canal实例名称,要跟canal-server运行时设置的destination一致server: 192.168.200.130:11111 # canal地址③编写监听器,监听Canal消息
Canal推送给canal-client的是被修改的这一行数据(row),而我们引入的canal-client则会帮我们把行数据封装到Item实体类中。这个过程中需要知道数据库与实体的映射关系,要用到JPA的几个注解:
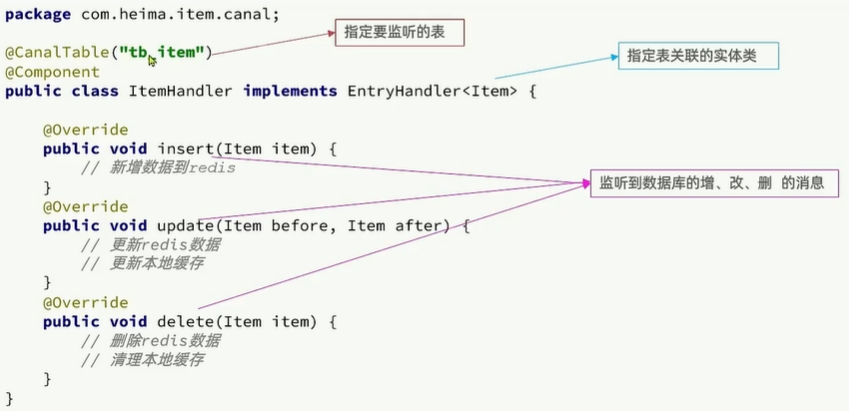
package com.heima.item.pojo;import com.baomidou.mybatisplus.annotation.IdType;
import com.baomidou.mybatisplus.annotation.TableField;
import com.baomidou.mybatisplus.annotation.TableId;
import com.baomidou.mybatisplus.annotation.TableName;
import lombok.Data;
import org.springframework.data.annotation.Id;
import org.springframework.data.annotation.Transient;import javax.persistence.Column;
import java.util.Date;@Data
@TableName("tb_item")
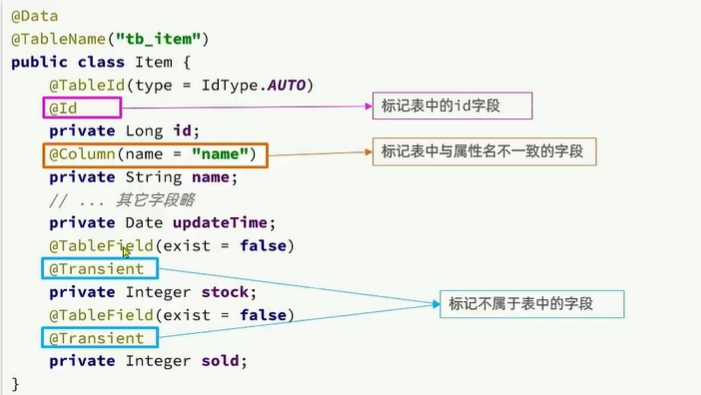
public class Item {@TableId(type = IdType.AUTO)@Idprivate Long id;//商品id@Column(name = "name")private String name;//商品名称private String title;//商品标题private Long price;//价格(分)private String image;//商品图片private String category;//分类名称private String brand;//品牌名称private String spec;//规格private Integer status;//商品状态 1-正常,2-下架private Date createTime;//创建时间private Date updateTime;//更新时间@TableField(exist = false)@Transientprivate Integer stock;@TableField(exist = false)@Transientprivate Integer sold;
}
④在RedisHandler新增两个方法
package com.heima.item.config;import com.fasterxml.jackson.core.JsonProcessingException;
import com.fasterxml.jackson.databind.ObjectMapper;
import com.heima.item.pojo.Item;
import com.heima.item.pojo.ItemStock;
import com.heima.item.service.IItemService;
import com.heima.item.service.IItemStockService;
import org.springframework.beans.factory.InitializingBean;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.redis.core.StringRedisTemplate;
import org.springframework.stereotype.Component;import java.util.List;@Component
public class RedisHandler implements InitializingBean {@Autowiredprivate StringRedisTemplate redisTemplate;@Autowiredprivate IItemService itemService;@Autowiredprivate IItemStockService stockService;private static final ObjectMapper MAPPER = new ObjectMapper();@Overridepublic void afterPropertiesSet() throws Exception {// 初始化缓存// 1. 查询商品信息List<Item> itemList = itemService.list();// 2. 放入缓存for (Item item : itemList) {// 2.1 item序列化为JSONString json = MAPPER.writeValueAsString(item);// 2.2 存入redisredisTemplate.opsForValue().set("item:id:" + item.getId(), json);}// 3. 查询商品库存List<ItemStock> itemStockList = stockService.list();// 4. 放入缓存for (ItemStock stock : itemStockList) {// 4.1 stock序列化为JSONString json = MAPPER.writeValueAsString(stock);// 4.2 存入redisredisTemplate.opsForValue().set("item:stock:id:" + stock.getId(), json);}}/*** 新增保存* @param item*/public void saveItem(Item item) {try {// 1. item序列化为JSONString json = MAPPER.writeValueAsString(item);// 2. 存入redisredisTemplate.opsForValue().set("item:id:" + item.getId(), json);} catch (JsonProcessingException e) {throw new RuntimeException(e);}}/*** 删除* @param id*/public void deleteItemById(Long id) {redisTemplate.delete("item:id:" + id);}
}
⑤新增ItemHandler
package com.heima.item.canal;import com.github.benmanes.caffeine.cache.Cache;
import com.heima.item.config.RedisHandler;
import com.heima.item.pojo.Item;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;
import top.javatool.canal.client.annotation.CanalTable;
import top.javatool.canal.client.handler.EntryHandler;@CanalTable("tb_item")
@Component
public class ItemHandler implements EntryHandler<Item> {@Autowiredprivate RedisHandler redisHandler;@Autowiredprivate Cache<Long, Item> itemCache;@Overridepublic void insert(Item item) {// 写数据到JVM进程缓存itemCache.put(item.getId(), item);// 新增数据到RedisredisHandler.saveItem(item);}@Overridepublic void update(Item before, Item after) {// 更新JVM本地缓存itemCache.put(after.getId(), after);// 更新redis数据redisHandler.saveItem(after);}@Overridepublic void delete(Item item) {// 清理JVM本地缓存itemCache.invalidate(item.getId());// 删除redis数据redisHandler.deleteItemById(item.getId());}
}
⑥启动ItemApplication和ItemApplication(2),访问:http://localhost:8081/
更新商品数据
观察控制台日志
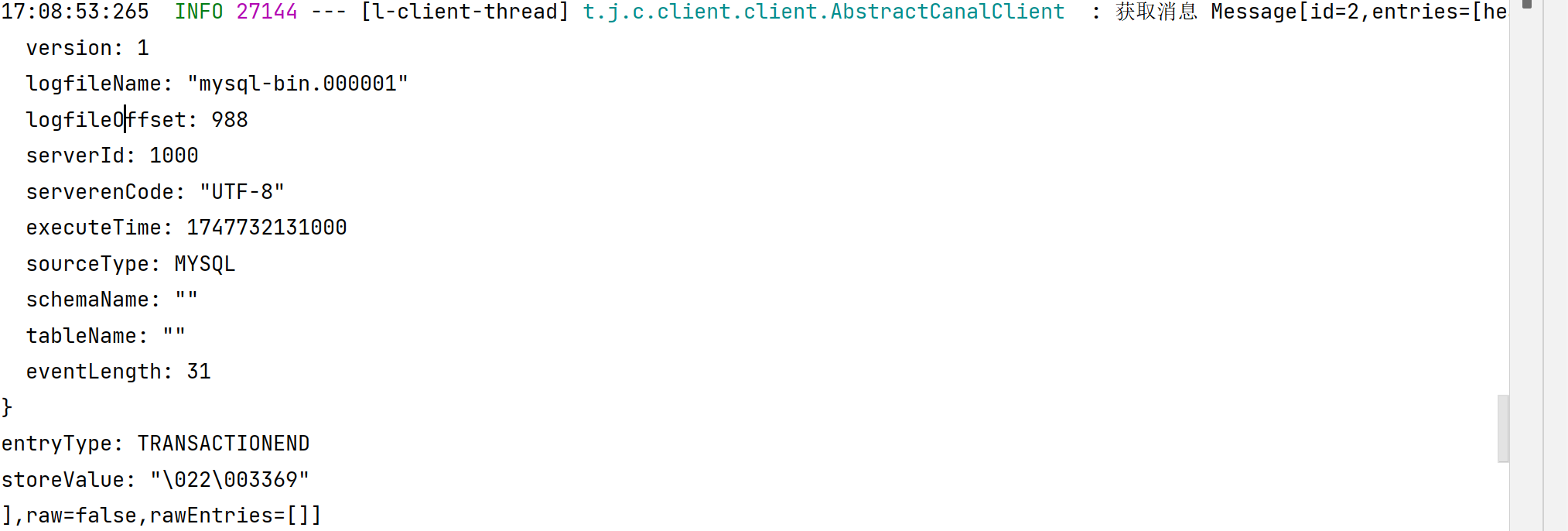
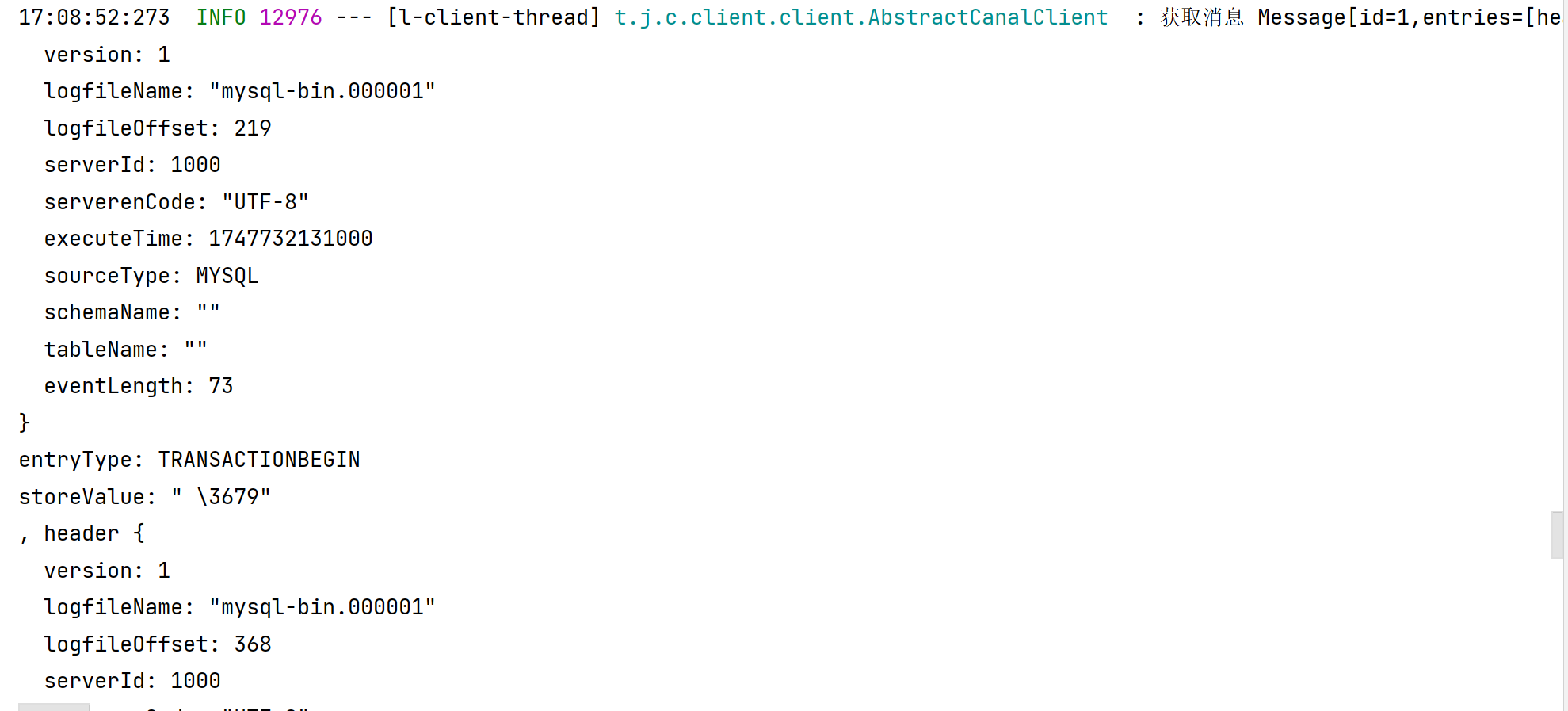
表名称监听支持的语法:
mysql 数据解析关注的表,Perl正则表达式.
多个正则之间以逗号(,)分隔,转义符需要双斜杠(\\)
常见例子:
1. 所有表:.* or .*\\..*
2. canal schema下所有表: canal\\..*
3. canal下的以canal打头的表:canal\\.canal.*
4. canal schema下的一张表:canal.test1
5. 多个规则组合使用然后以逗号隔开:canal\\..*,mysql.test1,mysql.test2 多级缓存总结
相关文章:
)
Redis从入门到实战 - 高级篇(中)
一、多级缓存 1. 传统缓存的问题 传统的缓存策略一般是请求到达Tomcat后,先查询Redis,如果未命中则查询数据库,存在下面的问题: 请求要经过Tomcat处理,Tomcat的性能成为整个系统的瓶颈Redis缓存失效时,会…...

项目计划缺乏可行性,如何制定实际可行的计划?
制定实际可行的项目计划需从明确项目目标、准确评估资源、风险管理、设定合理里程碑以及优化沟通渠道入手。其中,明确项目目标尤为关键,只有在目标清晰、具体且量化时,团队才能有效规划各项活动并衡量进展。例如,目标若模糊或过于…...

React中使用ahooks处理业务场景
// 从 ahooks 引入 useDynamicList 钩子函数,用于管理动态列表数据(增删改) import { useDynamicList } from ahooks;// 从 ant-design/icons 引入两个图标组件:减号圆圈图标和加号圆圈图标 import { MinusCircleOutlined, PlusCi…...

CNBC专访CertiK联创顾荣辉:从形式化验证到AI赋能,持续拓展Web3.0信任边界
近日,CertiK联合创始人、哥伦比亚大学教授顾荣辉接受全球知名财经媒体CNBC阿拉伯频道专访,围绕形式化验证的行业应用、AI在区块链安全中的角色,以及新兴技术风险等议题,分享了其对Web3.0安全未来的深刻洞察。 顾荣辉表示…...

基于Spring Boot与jQuery的用户管理系统开发实践✨
引言📚 用户管理系统是企业级应用的核心模块,需实现数据分页、状态管理及高效前后端交互。本文以Spring Boot为后端框架、jQuery为前端工具,构建一个结构清晰的用户管理系统,详解三层架构设计、接口规范及全栈开发流程࿰…...

StreamSaver实现大文件下载解决方案
StreamSaver实现大文件下载解决方案 web端 安装 StreamSaver.js npm install streamsaver # 或 yarn add streamsaver在 Vue 组件中导入 import streamSaver from "streamsaver"; // 确保导入名称正确完整代码修正 <!--* projectName: * desc: * author: dua…...

vue3+echarts 做温度计
参考Echarts 做的温度计_echart温度计-CSDN博客 但是现在这个写法不支持了,更新一下,然后修改了温度值和刻度及单位颜色为黑,初始化echarts写法, itemStyle: {normal: {color: #4577BA,barBorderRadius: 50,}},<div id"main14"…...

鸿蒙开发——7.ArkUI进阶:@BuilderParam装饰器的核心用法与实战解析
鸿蒙开发——7.ArkUI进阶:BuilderParam装饰器的核心用法与实战解析 ArkUI进阶:BuilderParam装饰器的核心用法与实战解析引言一、核心概念速览1.1 什么是BuilderParam?1.2 与Builder的关系 二、核心使用场景2.1 参数初始化组件2.2 尾随闭包初始…...

【数据结构】队列的完整实现
队列的完整实现 队列的完整实现github地址前言1. 队列的概念及其结构1.1 概念1.2 组织结构 2. 队列的实现接口一览结构定义与架构初始化和销毁入队和出队取队头队尾数据获取size和判空 完整代码与功能测试结语 队列的完整实现 github地址 有梦想的电信狗 前言 队列&…...

销售易史彦泽:从效率工具到增长引擎,AI加速CRM不断进化
导读:AI的加入,让CRM实现从“人适配系统”到“系统适配人”,从“管控工具”向“智能助手”跃迁,重构客户关系管理的底层逻辑。 作者 | 小葳 图片来源 | 摄图 AI应用与SaaS的关系,是当前科技与商业领域热议的话题。 当…...

开疆智能Profinet转ModbusTCP网关连接BORUNTE伯朗特系统配置案例
本案例是通过开疆智能Profinet转ModbusTCP网关将西门子PLC与BORUNTE机器人连接的配置案例。具体配置方法如下。 配置过程 Profinet设置 设置网关在Profinet一侧的参数包括(设备名称,IP地址等) 先导入GSD文件 选择GSD所在文件夹位置&#…...

从0到1搭建shopee测评自养号系统:独立IP+硬件伪装+养号周期管理
在跨境电商竞争白热化的背景下,Shopee卖家通过自养号测评实现流量与销量突破已成为行业共识。自养号测评通过模拟真实买家行为,为店铺注入精准流量,同时规避外包测评的高风险与不可控性。本文将从技术架构、运营策略、风险控制三个维度&#…...
arrow-0.1.0.jar 使用教程 - Java jar包运行方法 命令行启动步骤 常见问题解决
准备工作 首先确保你电脑上装了Java环境(JDK 8或以上版本) 把这个jar文件下载到你的电脑上,arrow-0.1.0.jar下载链接:https://pan.quark.cn/s/66d7c061c95a 运行方法 打开命令行(Windows按WinR输入cmd,M…...

请问交换机和路由器的区别?vlan 和 VPN 是什么?
交换机和路由器的区别 特性交换机(Switch)路由器(Router)工作层级数据链路层(L2,基于MAC地址)网络层(L3,基于IP地址)主要功能在局域网(LAN&#…...

如何查看与设置电脑静态IP地址:完整指南
在当今数字化时代,稳定的网络连接已成为工作生活的必需品。静态IP地址作为网络配置中的重要一环,相比动态IP具有更高的稳定性和可控性,然而,许多用户对如何查看和设置静态IP地址仍感到困惑。本文将为您提供从基础概念到实操步骤的…...

Linux网络基础全面解析:从协议分层到局域网通信原理
Linux系列 文章目录 Linux系列前言一、计算机网络背景1.1 认识网络1.2 认识协议 二、网络协议初识2.1 协议分层2.2 OSI七层模型2.3 TCP/IP协议栈2.4 网络协议栈与OS的关系2.5 网络协议在网络传输时的作用 三、网络通信局域网通信的安全隐患与应对总结 前言 Linux系统部分的学习…...

第二篇:服务与需求——让用户找到并预订服务
目录 1 服务类目与项目管理:飞书多维表格为管理中心,微搭小程序展示1.1 需求分析1.2 数据模型:微搭中的服务分类与服务项目(用于小程序展示)1.3 数据模型:多维表格中的服务分类与服务项目 总结 我们已经用了…...

【AI News | 20250520】每日AI进展
AI Repos 1、nanoDeepResearch nanoDeepResearch 是一个受 ByteDance 的 DeerFlow 项目启发,旨在从零开始构建深度研究代理的后端项目。它不依赖 LangGraph 等现有框架,通过实现一个 ReAct 代理和状态机来模拟 Deep Research 的工作流程。项目主要包含规…...

Spark Core基础与源码剖析全景手册
Spark Core基础与源码剖析全景手册 Spark作为大数据领域的明星计算引擎,其核心原理、源码实现与调优方法一直是面试和实战中的高频考点。本文将系统梳理Spark Core与Hadoop生态的关系、经典案例、聚合与分区优化、算子底层原理、集群架构和源码剖析,结合…...

抖音视频如何下载保存?高清无水印一键保存到手机!
你是不是经常在抖音上刷到超有趣的短视频,想保存下来却不知道怎么做?或者下载后发现带有烦人的水印?别担心!今天教你最简单、最快速的抖音视频下载方法,无水印、高清画质,轻松搞定! 为什么要下…...

SCAU--平衡树
3 平衡树 Time Limit:1000MS Memory Limit:65535K 题型: 编程题 语言: G;GCC;VC;JAVA;PYTHON 描述 平衡树并不是平衡二叉排序树。 这里的平衡指的是左右子树的权值和差距尽可能的小。 给出n个结点二叉树的中序序列w[1],w[2],…,w[n],请构造平衡树,…...

图的几种存储方法比较:二维矩阵、邻接表与链式前向星
图是一种非常重要的非线性数据结构,广泛应用于社交网络、路径规划、网络拓扑等领域。在计算机中表示和存储图结构有多种方法,本文将详细分析三种常见的存储方式:二维矩阵(邻接矩阵)、邻接表和链式前向星,比…...

【AS32X601驱动系列教程】MCU启动详解
在嵌入式开发领域,掌握MCU(微控制单元)的启动流程是工程师们迈向深入开发的关键一步。本文将带您深入了解MCU启动的奥秘,从编译过程到启动文件,再到链接脚本和系统时钟配置,全方位解析MCU启动流程。 在实际…...
)
计算机视觉与深度学习 | Matlab实现EMD-GWO-SVR、EMD-SVR、GWO-SVR、SVR时间序列预测(完整源码和数据)
以下是一个完整的Matlab时间序列预测实现方案,包含EMD-GWO-SVR、EMD-SVR、GWO-SVR和SVR四种方法的对比。代码包含数据生成、信号分解、优化算法和预测模型实现。 %% 主程序:时间序列预测对比实验 clc; clear; clearvars; close all;% 生成模拟时间序列数据 rng(1); % 固定随…...

Visual Studio 2022 插件推荐
Visual Studio 2022 插件推荐 Visual Studio 2022 (简称 VS2022) 是一款强大的 IDE,适合各类系统组件、框架和应用的开发。插件是接入 VS2022 最重要的扩展方式之一,它们可以大幅提升开发效率、优化代码质量,并提供强大的调试和分析功能。 …...

[luogu12541] [APIO2025] Hack! - 交互 - 构造 - 数论 - BSGS
传送门:https://www.luogu.com.cn/problem/P12541 题目大意:有一个数 n n n,你不知道是多少;你每次可以向交互库询问一个正整数集合 A A A(其中元素互不相同),交互库返回:将集合中…...
汇编指令调用(五)——内存访问)
openjdk底层(hotspot)汇编指令调用(五)——内存访问
根据前面关于aarch64架构下的编码解释可知,在src\hotspot\cpu\架构文件夹下, assembler_xx.hpp assembler_xx.cpp register_xx.hpp register_xx.cpp register_definitions_xx.cpp这些文件是有关寄存器定义以及汇编编码函数实现的文件。 对于前述的ope…...

几款常用的虚拟串口模拟器
几款常用的虚拟串口模拟器(Virtual Serial Port Emulator),适用于 Windows 系统,可用于开发和调试串口通信应用: 1. com0com (开源免费) 特点: 完全开源免费,无功能限制。 可创建多个虚拟串口…...

ChimeraX介绍
UCSF ChimeraX 是一款由美国加州大学旧金山分校(UCSF)开发的下一代分子可视化软件,是经典的 UCSF Chimera 的继任者。它集成了强大的分子结构可视化、分析、建模和动画功能,广泛应用于结构生物学、药物设计、分子建模等领域。 1. 下载安装: Download UCSF ChimeraX 2. …...

【Linux】初见,基础指令
前言 本文将讲解Linux中最基础的东西-----指令,带大家了解一下Linux中有哪些基础指令,分别有什么作用。 本文中的指令和选项并不全,只介绍较为常用的 pwd指令 语法:pwd 功能:显示当前所在位置(路径…...

链表的面试题8之环形链表
许久不见,那么这是最后倒数第三题了,这道题我们来看一下环形链表。 老规矩贴链接:141. 环形链表 - 力扣(LeetCode) 目录 倒数第k个元素 获取中间元素的问题。 双指针 来,大致看一下题目,这…...

OBS Studio:windows免费开源的直播与录屏软件
OBS Studio是一款免费、开源且跨平台的直播与录屏软件。其支持 Windows、macOS 和 Linux。OBS适用于,有直播需求的人群或录屏需求的人群。 Stars 数64,323Forks 数8413 主要特点 推流:OBS Studio 支持将视频实时推流至多个平台,如 YouTube、…...

邂逅Node.js
首先先要来学习一下nodejs的基础(和后端开发有联系的) 再然后的学习路线是学习npm,yarn,cnpm,npx,pnpm等包管理工具 然后进行模块化的使用,再去学习webpack和git(版本控制工具&…...
)
React 常见的陷阱之(如异步访问事件对象)
文章目录 前言1. 异步访问事件对象问题解决方案 2. 事件传播的误解**问题**解决方案 **3. 事件监听器未正确卸载****问题****解决方案** **4. 动态列表中的事件绑定****问题****解决方案** **5. 第三方库与 React 事件冲突****问题****解决方案** **6. 表单输入与受控组件****问…...

【LinkedList demo 内部类讲说】
LinkedList demo 内部类讲说 1. Node节点2.MyLinkedList3. LinkedListTest 测试类 1. Node节点 public class Node<T> {private Node<T> pre;private Node<T> next;private T data;public Node() {}public Node getPre() {return pre;}public void setPre(N…...
)
Sql刷题日志(day9)
一、笔试 1、limit offset:分页查询 SELECT column1, column2, ... FROM table_name LIMIT number_of_rows OFFSET start_row; --跳过前 start_row 行,返回接下来的 number_of_rows 行。 2、lag、lead:查询前后行数据 --lag函数用于访问当…...

46 python pandas
Pandas是Python数据分析的利器,也是各种数据建模的标准工具 一、什么是pandas pandas 是 Python 中用于数据处理和分析的核心库,提供了高效的数据结构(如Series和DataFrame)和数据操作工具,广泛应用于数据清洗、分析、可视化等场景。 最常用的是用来处理excel数据。 二…...

告别延迟!Ethernetip转modbustcp网关在熔炼车间监控的极速时代
熔炼车间热火朝天,巨大的热风炉发出隆隆的轰鸣声,我作为一名技术操控工,正密切关注着监控系统上跳动的各项参数。这套基于EtherNET/ip的监控系统,是我们车间数字化改造的核心,它将原本分散的控制单元整合在一起&#x…...

Prompt Tuning:高效微调大模型的新利器
Prompt Tuning(提示调优)是什么 Prompt Tuning(提示调优) 是大模型参数高效微调(Parameter-Efficient Fine-Tuning, PEFT)的重要技术之一,其核心思想是通过优化 连续的提示向量(而非整个模型参数)来适配特定任务。以下是关于 Prompt Tuning 的详细解析: 一、核心概念…...

⼆叉搜索树详解
1. ⼆叉搜索树的概念 ⼆叉搜索树⼜称⼆叉排序树,它或者是⼀棵空树,或者是具有以下性质的⼆叉树: • 若它的左⼦树不为空,则左⼦树上所有结点的值都⼩于等于根结点的值 • 若它的右⼦树不为空,则右⼦树上所有结点的值都⼤于等于根结…...

CompleteableFuture的异步任务编排
为什么会有CompleteableFuture Java 的 1.5 版本引入了 Future,可以把它简单的理解为运算结果的占位符, 它提供了两个方法来获取运算结果。 get():调用该方法线程将会无限期等待运算结果。get(longmeout, TimeUnit unit):调用该…...

珈和科技贺李德仁院士荣膺国际数字地球学会会士:以时空智能赋能可持续发展目标 绘就数字地球未来蓝图
4月22日,第十四届国际数字地球会议在重庆盛大启幕。在这场在全球范围内数字地球领域具有国际影响力的学术盛会上,国际数字地球学会向珈和科技的企业顾问,2023年度国家最高科学技术奖得主李德仁院士授予了“国际数字地球学会会士”最高荣誉称号…...

【CodeBuddy 】从0到1,打造一个“牛马打鸡血仪”
【CodeBuddy 】从0到1,打造一个“牛马打鸡血仪” 我正在参加CodeBuddy「首席试玩官」内容创作大赛,本文所使用的 CodeBuddy 免费下载链接:腾讯云代码助手 CodeBuddy - AI 时代的智能编程伙伴 🌟嗨,我是LucianaiB&#…...

BI是什么意思?一文讲清BI的概念与应用!
目录 一、BI 是什么意思 1. BI 的定义 2. BI 的发展历程 3. BI 的核心组件 二、BI 的应用场景 1. 销售与市场营销 2. 财务管理 编辑3. 人力资源管理 4. 生产与运营管理 编辑三、选择合适的 BI 工具 1. 考虑企业的需求和规模 2. 评估工具的功能和性能 3. 关注工…...

可编辑PPT | 华为安全架构设计方法指南华为数字化转型架构解决方案
这份文档是华为的安全架构设计方法指南,它详细介绍了安全架构设计的重要性、方法和流程。文档强调安全架构是软件研发技术体系中的关键DFX能力,与可靠性、性能等并列,尤其在云计算和复杂网络环境下,安全性设计显得尤为重要。华为的…...
)
1.6 提示词工程(二)
目录 3.2 提供参考文本 3.2.1 使用参考文本来构建答案 3.2.2 指导模型用引用的文本回答问题 3.3 把复杂的任务拆分成简单的子任务 3.3.1 利用意图分类确定与用户查询最相关的指令 3.3.2 针对需要长时间对话的应用程序,应概括或过滤之前的对话内容 …...

WIFI信号状态信息 CSI 深度学习之数据集
Building occupant activity sensing dataset based on WIFI CSI(WiSA) 所有的数据以及实验参数都上传到了figshare中并配备详细说明,供参考。 论文链接:WiSA: Privacy-enhanced WiFi-based activity intensity recognition in …...

基于服务器的 DPI 深度分析解决方案
一、传统网络流量分析的瓶颈与挑战 在企业网络管理体系中,传统流量分析模式高度依赖网络设备作为数据采集核心节点,无论是基于 NetFlow/IPFIX 等流协议的流量分析,还是通过端口镜像技术实现的流量监控,均以交换机、路由器等网络设…...
:线性动态规划)
动态规划(5):线性动态规划
引言 所谓线性动态规划,通常指状态定义和转移具有线性结构的动态规划问题,其状态通常可以用一维数组表示,状态转移主要依赖于相邻或前面有限个状态。这类问题的特点是状态空间呈线性排列,每个状态只与有限个前置状态相关,使得问题结构相对简单,更容易理解和掌握。 一维…...
)
c语言- 如何构建CMake项目(Linux/VSCode)
目录 linux(vscode)构建C语言CMake项目 1. 检查linux是否下载cmake,否则执行下列代码 2. 在vscode下载cmake的插件CMake Tools 3. 构建项目(项目结构) 4. 进行cmake配置 1. 在VS Code中按下ctrl shift p键&…...