MapReduce-WordCount实现按照value降序排序、字符小写、识别不同标点
要求:
输入文件的按照空格、逗号、点号、双引号等分词
输入文件的大写字母全部换成小写
文件输出要求按照value值降序排序
Hadoop给的wordcount示例代码以及代码理解
基于map reduce的word count个人理解:输入的文件经过map reduce框架处理后,将文件分成几份,对于每份文件由独立的job来执行,针对每个job,输入的文件由map按行处理得到相应的输出,中间经过一次shuffle操作,最后经过reduce操作得到输出,输出是按照key的升序排列的。
一、创建项目
1、打开idea
cd export/servers/IDEA/bin #然后回车
./idea.sh2、创建项目
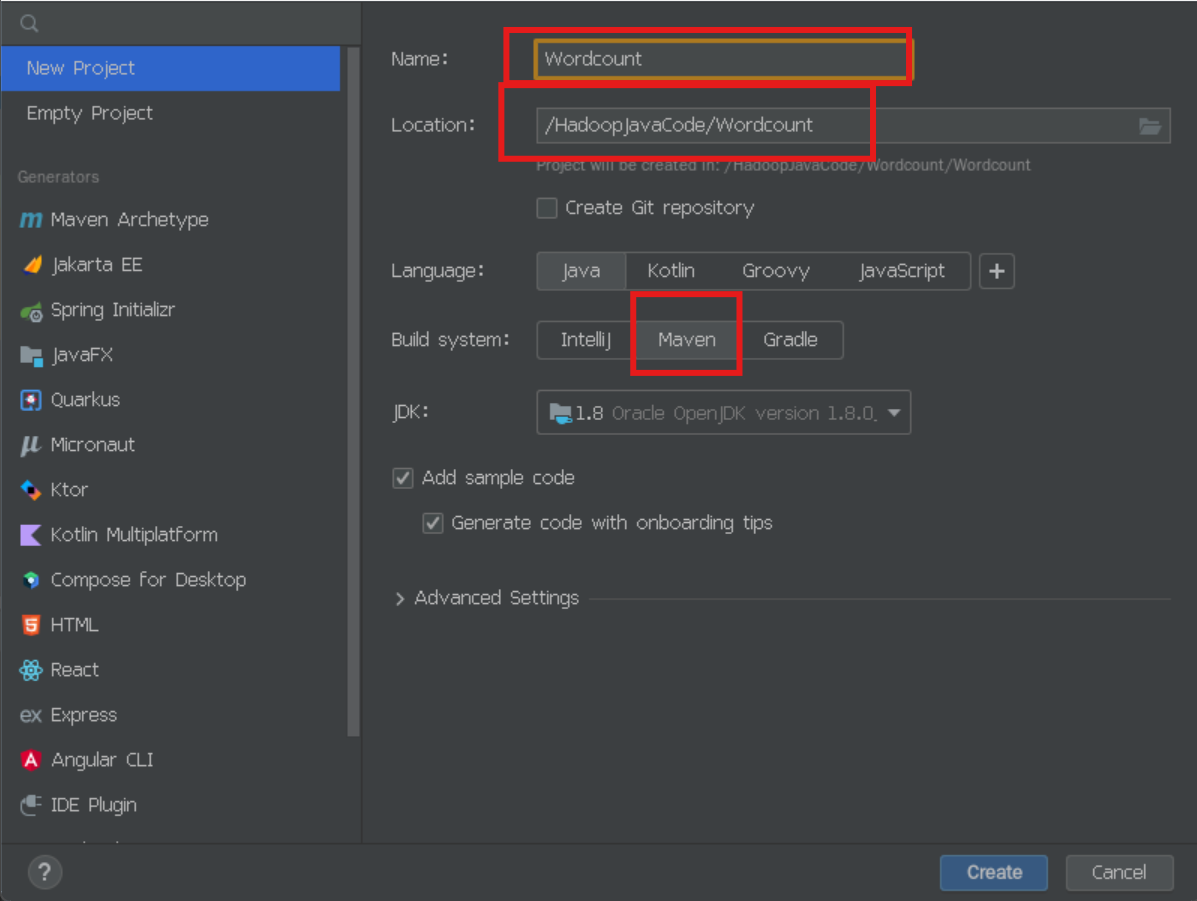
3、配置项目以及写项目
目录结构
Wordcount/
├── .idea/ # IDE(IntelliJ)配置文件(无需手动修改)
├── src/
│ ├── main/
│ │ ├── java/ # 主代码目录
│ │ │ └── org/example/
│ │ │ ├── SortReducer # 排序Reducer类
│ │ │ ├── WordCount # 主程序入口
│ │ │ ├── WordCountMapper # Mapper类
│ │ │ └── WordCountReducer # Reducer类
│ │ └── resources/ # 配置文件目录(如log4j.properties)
│ └── test/ # 测试代码目录(可选)
├── target/ # 编译输出目录(由Maven自动生成)
│ ├── classes/ # 编译后的.class文件
│ └── generated-sources/ # 生成的代码(如Protocol Buffers)
├── .gitignore # Git忽略规则
└── pom.xml # 项目依赖和构建配置
配置pom.xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><groupId>org.example</groupId><artifactId>WordCount</artifactId><version>1.0-SNAPSHOT</version><properties><project.build.sourceEncoding>UTF-8</project.build.sourceEncoding><maven.compiler.source>1.8</maven.compiler.source><maven.compiler.target>1.8</maven.compiler.target><hadoop.version>2.7.7</hadoop.version></properties><dependencies><!-- Hadoop 2.7.7 依赖 --><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-common</artifactId><version>${hadoop.version}</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-mapreduce-client-core</artifactId><version>${hadoop.version}</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-client</artifactId><version>${hadoop.version}</version></dependency></dependencies><build><plugins><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-compiler-plugin</artifactId><version>3.8.1</version></plugin><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-assembly-plugin</artifactId><version>3.3.0</version><configuration><descriptorRefs><descriptorRef>jar-with-dependencies</descriptorRef></descriptorRefs><archive><manifest><mainClass>org.example.WordCount</mainClass></manifest></archive></configuration><executions><execution><phase>package</phase><goals><goal>single</goal></goals></execution></executions></plugin></plugins></build><!-- 必须添加的仓库配置 --><repositories><!-- 阿里云镜像(优先) --><repository><id>aliyun</id><url>https://maven.aliyun.com/repository/public</url></repository><!-- Apache 归档仓库(备用) --><repository><id>apache-releases</id><url>https://repository.apache.org/content/repositories/releases/</url></repository></repositories>
</project>有些要改成自己的hadoop版本 我的是hadoop2.7.7版本 可以把这个代码复制然后问ai帮你改一下版本 改成你hadoop的版本
然后先点右边的maven 更新配置 先卸载clean,再点install
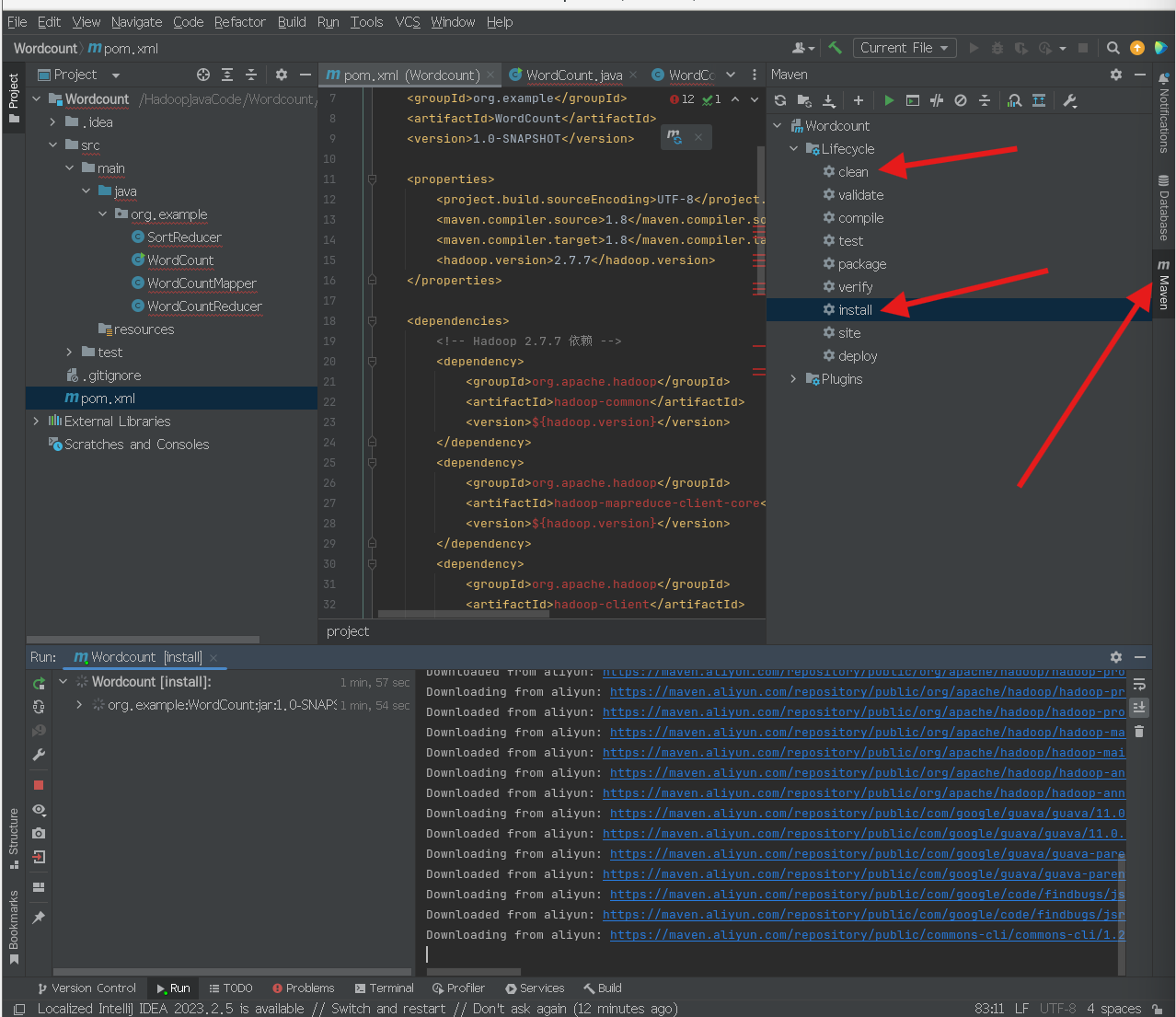
然后再打开idea控制栏 然后选择Terminal
安装Maven
cd ~/.m2/repository/org/apache/hadoopsudo yum install maven
#完成后
mvn -v
#查看安装好了没有 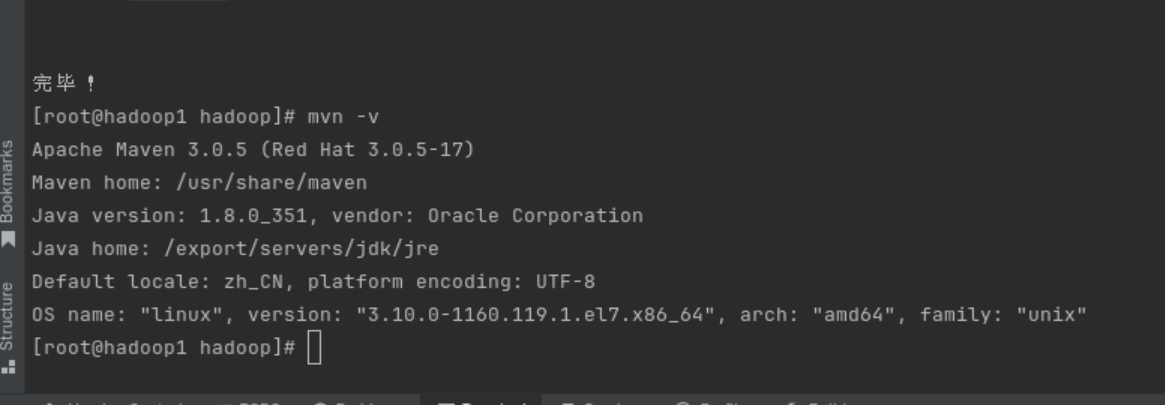
在src/main/org.example下面创建五个类
分别为:WordCountMapper、WordCountReducer、SortMapper、SortReducer、WordCount
package org.example;import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;import java.io.IOException;
import java.util.StringTokenizer;/*** Mapper类:负责分词和初步统计* 输入:<行号, 行内容>* 输出:<单词, 1>*/
public class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable> {private final static IntWritable one = new IntWritable(1);private final Text word = new Text();@Overrideprotected void map(LongWritable key, Text value, Context context)throws IOException, InterruptedException {// 定义分词分隔符:空格、逗号、点号、双引号等String delimiters = " \t\n\r\f\",.:;?![](){}<>'";// 将整行转为小写String line = value.toString().toLowerCase();// 使用StringTokenizer分词StringTokenizer tokenizer = new StringTokenizer(line, delimiters);while (tokenizer.hasMoreTokens()) {word.set(tokenizer.nextToken());context.write(word, one); // 输出<单词, 1>}}
}package org.example;import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;import java.io.IOException;/*** Reducer类:统计词频* 输入:<单词, [1,1,...]>* 输出:<单词, 总次数>*/
public class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable> {private final IntWritable result = new IntWritable();@Overrideprotected void reduce(Text key, Iterable<IntWritable> values, Context context)throws IOException, InterruptedException {int sum = 0;for (IntWritable val : values) {sum += val.get();}result.set(sum);context.write(key, result); // 输出<单词, 总次数>}
}
package org.example;import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;import java.io.IOException;public class SortMapper extends Mapper<LongWritable, Text, IntWritable, Text> {private final IntWritable count = new IntWritable();private final Text word = new Text();@Overrideprotected void map(LongWritable key, Text value, Context context)throws IOException, InterruptedException {// 输入格式: word\tcountString[] parts = value.toString().split("\t");if (parts.length == 2) {word.set(parts[0]);count.set(Integer.parseInt(parts[1]));context.write(count, word); // 输出: <count, word>}}
}package org.example;import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;import java.io.IOException;
import java.util.ArrayList;
import java.util.Collections;
import java.util.Comparator;
import java.util.List;
import java.util.Map;
import java.util.TreeMap;public class SortReducer extends Reducer<IntWritable, Text, Text, IntWritable> {// 使用List+自定义排序替代TreeMap,解决相同词频被覆盖的问题private final List<WordFrequency> wordFrequencies = new ArrayList<>();private final Text outputKey = new Text();private final IntWritable outputValue = new IntWritable();// 自定义数据结构存储单词和词频private static class WordFrequency {final String word;final int frequency;WordFrequency(String word, int frequency) {this.word = word;this.frequency = frequency;}}@Overrideprotected void reduce(IntWritable key, Iterable<Text> values, Context context) {int frequency = key.get();// 处理相同词频的不同单词for (Text val : values) {wordFrequencies.add(new WordFrequency(val.toString(), frequency));// 内存保护:限制最大记录数(根据集群内存调整)if (wordFrequencies.size() > 100000) {context.getCounter("SORT", "TRUNCATED_RECORDS").increment(1);break;}}}@Overrideprotected void cleanup(Context context) throws IOException, InterruptedException {// 按词频降序、单词升序排序Collections.sort(wordFrequencies, new Comparator<WordFrequency>() {@Overridepublic int compare(WordFrequency wf1, WordFrequency wf2) {int freqCompare = Integer.compare(wf2.frequency, wf1.frequency);return freqCompare != 0 ? freqCompare : wf1.word.compareTo(wf2.word);}});// 输出结果(可限制Top N)int outputCount = 0;for (WordFrequency wf : wordFrequencies) {if (outputCount++ >= 1000) break; // 可选:限制输出数量outputKey.set(wf.word);outputValue.set(wf.frequency);context.write(outputKey, outputValue);}// 调试信息context.getCounter("SORT", "TOTAL_WORDS").increment(wordFrequencies.size());context.getCounter("SORT", "UNIQUE_FREQUENCIES").increment(wordFrequencies.stream().mapToInt(wf -> wf.frequency).distinct().count());}
}package org.example;import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;import java.util.Arrays;public class WordCount {public static void main(String[] args) throws Exception {System.out.println("Received args: " + Arrays.toString(args));// 参数处理:取最后两个参数if (args.length < 2) {System.err.println("Usage: hadoop jar YourJar.jar [mainClass] <input path> <output path>");System.exit(-1);}String inputPath = args[args.length - 2];String outputPath = args[args.length - 1];Configuration conf = new Configuration();Path tempOutput = new Path("/temp_wordcount_output");try {// ========== Job1: 词频统计 ==========Job job1 = Job.getInstance(conf, "Word Count");job1.setJarByClass(WordCount.class);job1.setMapperClass(WordCountMapper.class);job1.setCombinerClass(WordCountReducer.class);job1.setReducerClass(WordCountReducer.class);job1.setOutputKeyClass(Text.class);job1.setOutputValueClass(IntWritable.class);FileInputFormat.addInputPath(job1, new Path(inputPath));FileOutputFormat.setOutputPath(job1, tempOutput);if (!job1.waitForCompletion(true)) {System.exit(1);}// ========== Job2: 排序 ==========Job job2 = Job.getInstance(conf, "Word Count Sort");job2.setJarByClass(WordCount.class);job2.setMapperClass(SortMapper.class);job2.setReducerClass(SortReducer.class);// 关键修改:设置正确的类型job2.setMapOutputKeyClass(IntWritable.class);job2.setMapOutputValueClass(Text.class);job2.setOutputKeyClass(Text.class);job2.setOutputValueClass(IntWritable.class);FileInputFormat.addInputPath(job2, tempOutput);FileOutputFormat.setOutputPath(job2, new Path(outputPath));System.exit(job2.waitForCompletion(true) ? 0 : 1);} finally {try {tempOutput.getFileSystem(conf).delete(tempOutput, true);} catch (Exception e) {System.err.println("警告: 临时目录删除失败: " + tempOutput);}}}
}4、idea打包java可执行jar包
方法一:打包Jar包
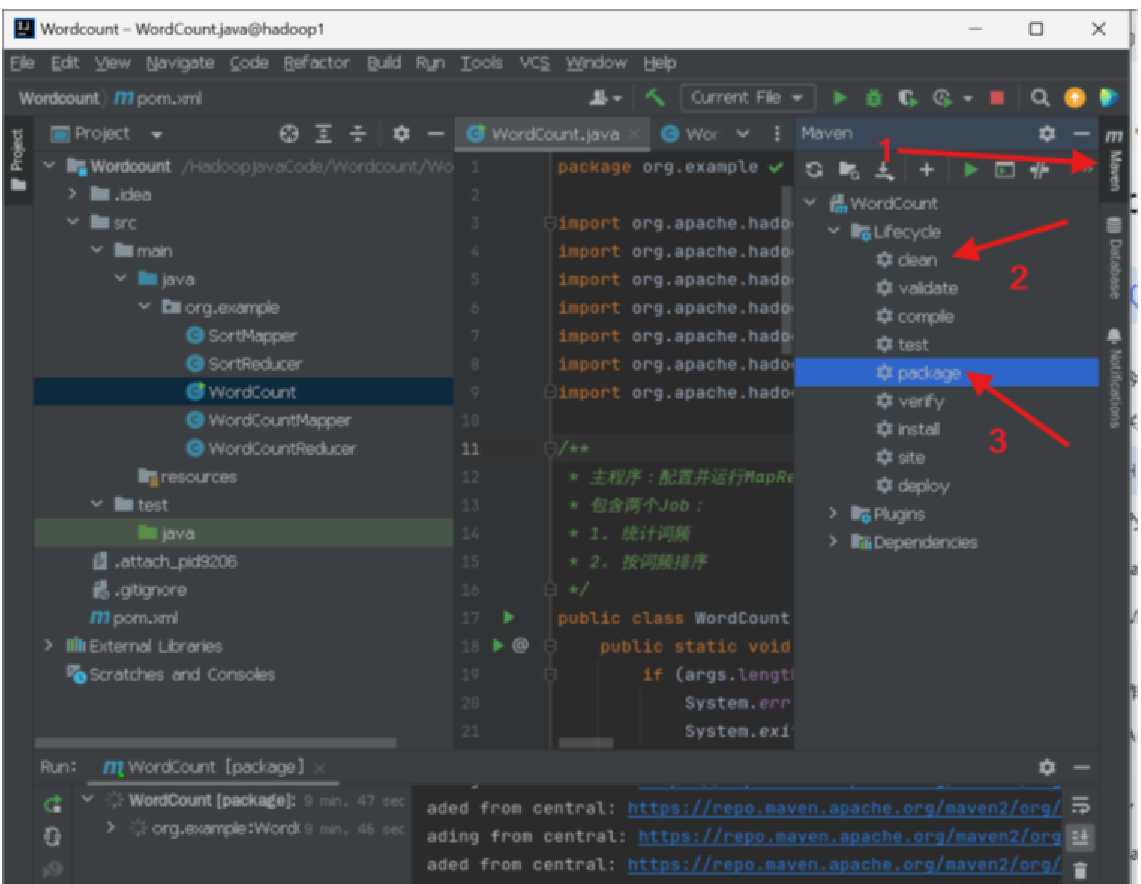
这样就打包好了
5、运行jar包
5.1启动hadoop集群
#启动h1
start-dfs.sh #回车
start-yarn.sh #回车
jps #回车#启动h1
start-dfs.sh #回车
start-yarn.sh #回车
jps #回车#启动h3
start-dfs.sh #回车
start-yarn.sh #回车
jps #回车5.2 运行jar包
首先在/export/data下上传这个文件 wordcount.txt
cd /export/data #然后上传这个文件 wordcount.txt
#创建目录
hadoop fs -mkdir -p /input
#上传到hdfs上
hadoop fs -put /export/data/wordcount.txt /input/
#验证上传
hadoop fs -ls /input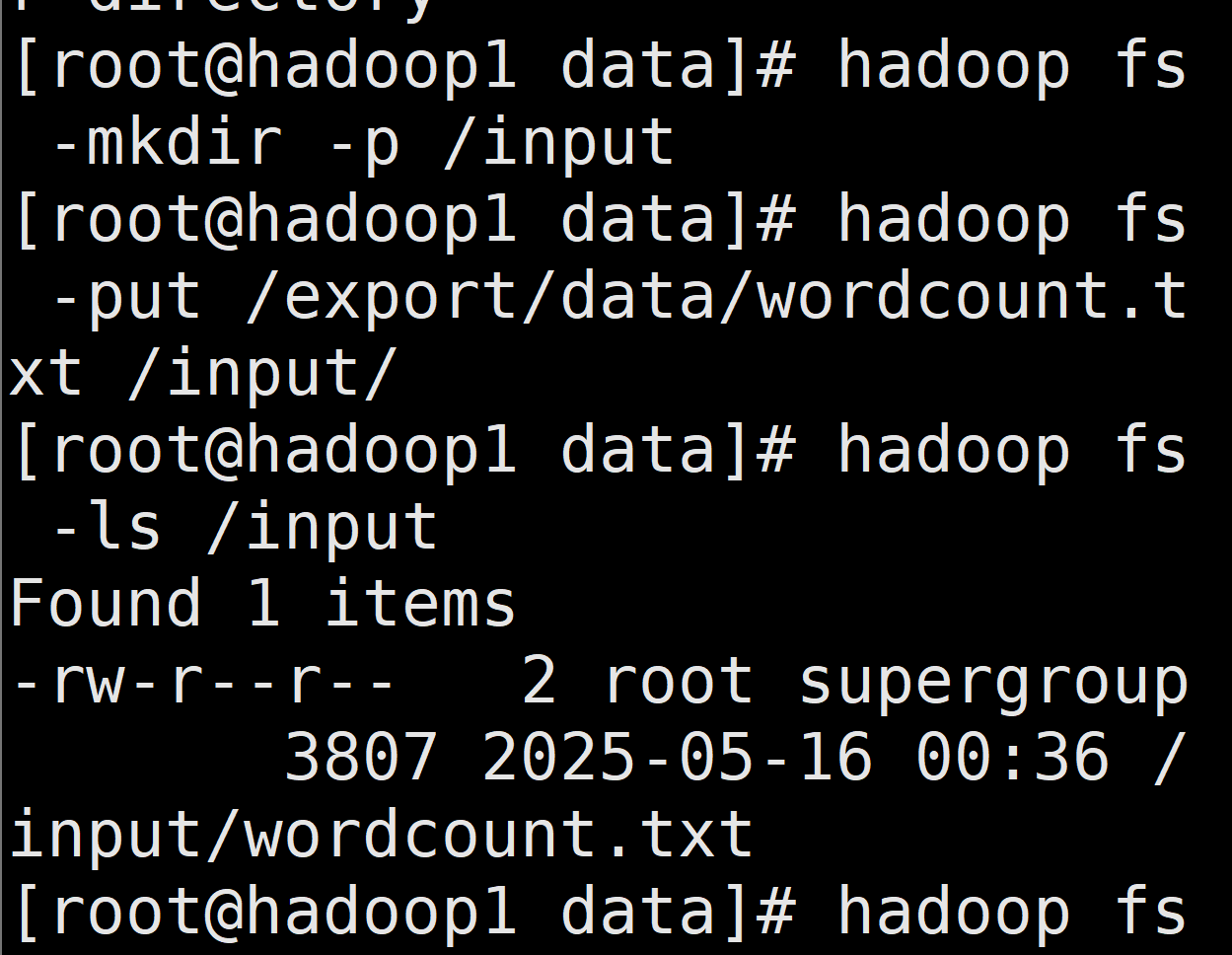
切换目录
cd /HadoopJavaCode/Wordcount/Wordcount清理并打包jar包:
mvn clean package确保HDFS目录:
hadoop fs -rm -r /temp_wordcount_output # 删除可能存在的临时目录
hadoop fs -ls /input/wordcount.txt # 确认输入文件存在运行作业:
hadoop jar target/WordCount-1.0-SNAPSHOT-jar-with-dependencies.jar \org.example.WordCount \/input/wordcount.txt \/output_wordcount
查看结果
# 查看输出目录内容
hadoop fs -ls /output_wordcount# 查看实际结果(显示前20行)
hadoop fs -cat /output_wordcount/part-r-00000 | head -20 
查看结果
hadoop fs -cat /output_wordcount/part-r-00000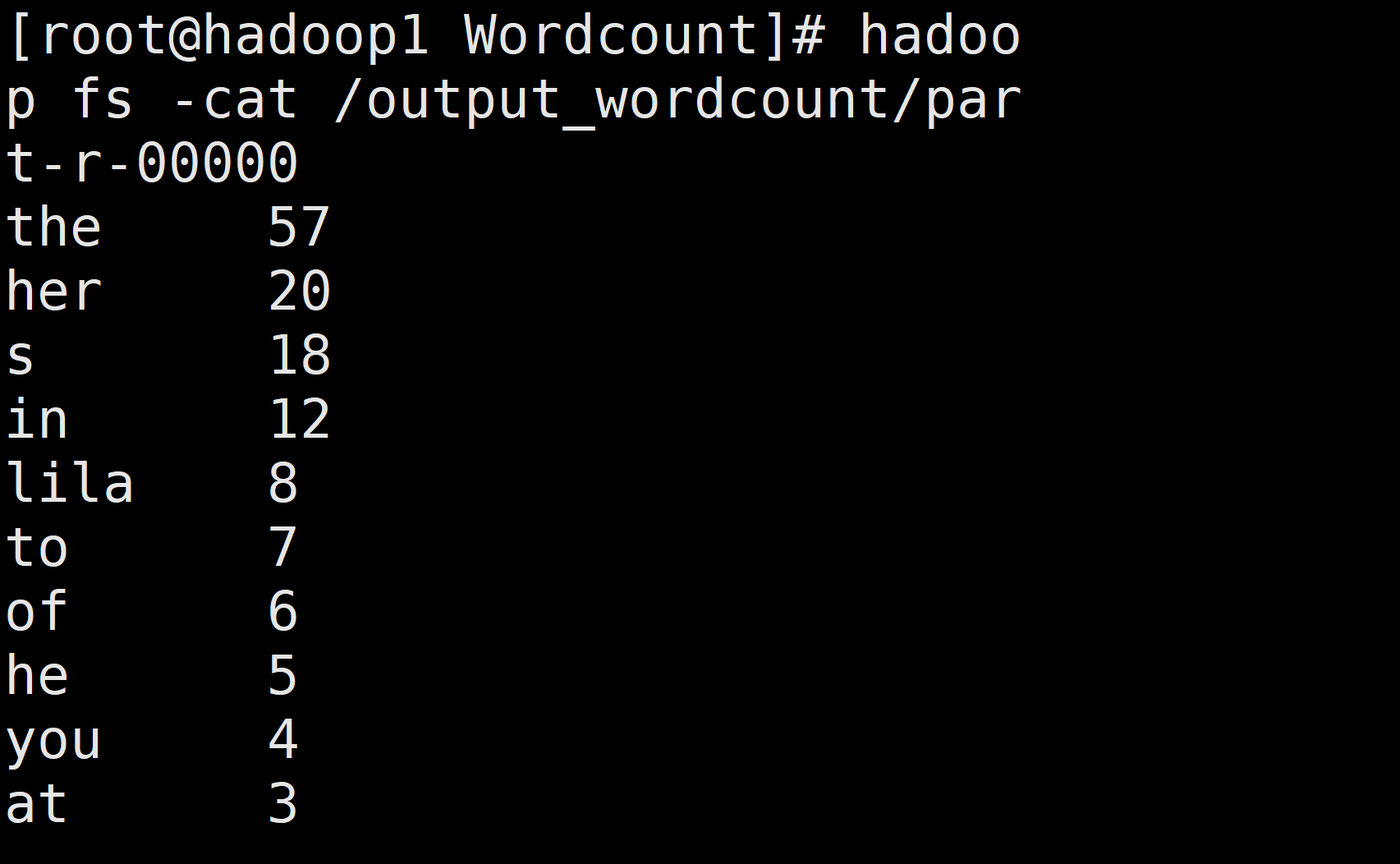
相关文章:

MapReduce-WordCount实现按照value降序排序、字符小写、识别不同标点
要求: 输入文件的按照空格、逗号、点号、双引号等分词 输入文件的大写字母全部换成小写 文件输出要求按照value值降序排序 Hadoop给的wordcount示例代码以及代码理解 基于map reduce的word count个人理解:输入的文件经过map reduce框架处理后&#…...

c++线段树之单点修改区间最大子段和-----P4513 小白逛公园
题目大意 单点修改查询区间最大字段和 解题思路 如果线段树节点存储的是‘区间最大子段和’,如何合并? 简单的加法或求极值都不行,仔细分析可得,父节点最大字段和可能为: 左子树最大子段和右子树最大子段和左子树最…...
)
[Java实战]Spring Boot整合Elasticsearch(二十六)
[Java实战]Spring Boot整合Elasticsearch(二十六) 摘要:本文通过完整的实战演示,详细讲解如何在Spring Boot项目中整合Elasticsearch,实现数据的存储、检索和复杂查询功能。包含版本适配方案、Spring Data Elasticsea…...

【深度学习新浪潮】大模型在哪些垂域已经有比较好的落地?
AI大模型在多个垂直领域已实现显著落地,以下结合可验证案例与行业数据展开说明: 一、医疗健康:精准诊断与个性化治疗 呼吸系统疾病诊断 国家呼吸医学中心研发的LungDiag模型,基于公开临床数据集训练,在预印本研究中对肺炎、肺癌等10种疾病的辅助诊断准确率达92%。医联Med…...

软件测试全攻略:从概念到实践
目录 测试指南针--概念篇 1. 什么是软件测试? 2. 软件测试和软件开发的关系是什么? 3. 测试需要哪些能力? 4. 测试流程是什么样的? 5. 什么是单元测试和集成测试? 6. 软件的生命周期是什么样的? 需求…...

linux hungtask detect机制分析
1,机制概述 hungtask detect 是 Linux 内核用于检测长时间阻塞("hung")任务的机制,主要针对因死锁、死循环或资源竞争导致无法调度的任务 触发条件:任务在 TASK_UNINTERRUPTIBLE 状态持续超过预设阈值…...

影刀处理 Excel:智能工具带来的高效变革
1. 高效的数据处理能力 1.1 快速读取与写入数据 影刀在处理 Excel 数据时展现出显著的读取与写入速度优势。传统方法处理大型 Excel 文件时,读取速度可能仅为每秒 100 行左右,而影刀通过优化底层代码和采用高效的文件解析算法,读取速度可达…...

2021ICPC四川省赛个人补题ABDHKLM
Dashboard - The 2021 Sichuan Provincial Collegiate Programming Contest - Codeforces 过题难度: A K D M H B L 铜奖 5 594 银奖 6 368 金奖 8 755 codeforces.com/gym/103117/problem/A 模拟出牌的过程,打表即可 // Code Start Here int t…...

HarmonyOS 影视应用APP开发--配套的后台服务go-imovie项目介绍及使用
网上有小伙伴对影视应用感兴趣,也想搞个自己的免费观影APP玩玩儿。前期博主开源的有uniapp版本和harmonyOS原生版本影视客户端,但是对博主开源的这个影视后台接口服务不太了解,不知道怎么用起来。这里总结介绍下该go-imove后台接口服务项目介…...
)
JAVA SE 多线程(上)
文章目录 📕1. Thread类及常见方法✏️1.1 创建线程✏️1.2 Thread 的常见构造方法✏️1.3 Thread 的几个常见属性✏️1.4 启动一个线程---start()✏️1.5 中断一个线程---interrupt()✏️1.6 等待一个线程---join()✏️1.7 获取当前线程引用✏️1.8 休眠当前线程 &…...

基于Bootstrap 的网页html css 登录页制作成品
目录 前言 一、网页制作概述 二、登录页面 2.1 HTML内容 2.2 CSS样式 三、技术说明书 四、页面效果图 前言 Bootstrap是一个用于快速开发Web应用程序和网站的前端框架,由Twitter的设计师Mark Otto和Jacob Thornton合作开发。 它基于HTML、CSS和JavaScri…...
AUTOSAR图解==>AUTOSAR_SRS_Transformer
AUTOSAR Transformer 详解 基于AUTOSAR标准的Transformer组件技术解析 目录 1. AUTOSAR Transformer 概述 1.1 Transformer的作用1.2 Transformer在AUTOSAR中的位置2. Transformer架构设计 2.1 整体架构2.2 类结构设计2.3 交互流程3. Transformer类型与实现 3.1 SOME/IP Transf…...

iOS APP启动页及广告页的实现
iOS APP启动页及广告页的实现涉及UI布局、数据加载、倒计时控制、广告跳转等多个关键环节。以下是我的一些使用心得: 1. UI实现方案 双Window方案 原理:同时创建两个Window,主Window位于底层,广告Window覆盖在其上。通过切换mak…...

图绘Linux:基础指令脉络阁
目录 Linux命令行介绍 目录操作 ls 目录所含文件信息 ls 常用选项 pwd 在那个目录下 cd 进入目录 mkdir 创建目录 文件操作 touch 创建普通文件 echo向文件写入 cat 输出文件内容 cp 拷贝文件/目录 mv剪切重命名 rm 删除文件/目录 查找 * 匹配符 man 查找指令 …...

数字格式化库 accounting.js的使用说明
accounting.js 是一个用于格式化数字、货币和金额的轻量级库,特别适合财务和会计应用。以下是其详细使用说明: 安装与引入 通过 npm 安装: bash 复制 下载 npm install accounting 引入: javascript 复制 下载 const accounting …...

ngx_http_proxy_protocol_vendor_module 模块
一、前置要求 启用 PROXY 协议 在 listen 指令中添加 proxy_protocol 参数,例如: server {listen 80 proxy_protocol;listen 443 ssl proxy_protocol;… }商业订阅 本模块仅在 Nginx 商业版中提供。 二、示例配置 http {# 将 GCP 的 PSC 连接 ID 添…...
)
C++11-(2)
文章目录 (一)C11新增功能1.1 引用折叠1.1.1 在模板中使用引用折叠的场景1.1.2 引用折叠是如何实现的 1.2 完美转发1.3 lambda表达式语法1.3.1 定义1.3.2 lambda的使用场景1.3.3 捕捉列表1.3.4 mutable语法1.3.5 lambda的原理 (一)…...

LeetCode算 法 实 战 - - - 双 指 针 与 移 除 元 素、快 慢 指 针 与 删 除 有 序 数 组 中 的 重 复 项
LeetCode算 法 实 战 - - - 双 指 针 与 移 除 元 素、快 慢 指 针 与 删 除 有 序 数 组 中 的 重 复 项 第 一 题 - - - 移 除 元 素方 法 一 - - - 双 重 循 环方 法 二 - - - 双 指 针方 法 三 - - - 相 向 双 指 针(面 对 面 移 动) 第 二 题 - - -…...
:阅读与注释重要的基类控件 QWidget,这是其精简版,完整注释版为篇 37)
QT6 源(106):阅读与注释重要的基类控件 QWidget,这是其精简版,完整注释版为篇 37
(1)原篇幅 37 为最开始整理,整理的不是太完善。重点不突出。故重新整理,但删除了大量的注释,重在突出本 QWidget类的内部逻辑,更易观察其包含了哪些内容。至于不理解的成员函数与属性,内容已不太…...

【Bluedroid】蓝牙HID DEVICE错误报告处理全流程源码解析
本文基于Android蓝牙协议栈代码,深入解析HID设备在接收非法指令(如无效的SET_REPORT)时的错误处理全流程,涵盖错误映射、协议封装、传输控制三大核心模块。重点剖析以下机制: HID协议规范错误码的动态转换策略 控制通…...

Day29 类的装饰器
类也有修饰器,他的逻辑类似:接收一个类,返回一个修改后的类。例如 添加新的方法或属性(如示例中的 log 方法)。修改原有方法(如替换 init 方法,添加日志)。甚至可以返回一个全新的类…...
)
学习黑客Active Directory 入门指南(二)
Active Directory 入门指南(二):深入逻辑结构与物理组件 🌳🏢 大家好!欢迎回到 “Active Directory 入门指南” 系列的第二篇。在上一篇中,我们初步认识了Active Directory,了解了其…...

为什么el-select组件在下拉选择后无法赋值
为什么el-select组件在下拉选择后无法赋值 https://blog.csdn.net/ZHENGCHUNJUN/article/details/127325558 这个链接解决了大模型无法解决的问题 大模型能够写基础且高级一些的代码,但是遇到再深入一些的问题,还是得问百度。对于我这种小白来说问题原因…...
)
FreeRTOS的学习记录(临界区保护,调度器挂起与恢复)
临界区 在 FreeRTOS 中,临界区(Critical Section) 是指程序中一段必须以原子方式执行的代码区域,在此区域内不允许发生任务切换或中断干扰,以保护共享资源或执行关键操作。FreeRTOS 提供了多种机制来实现临界区&#…...

给个人程序加上MCP翅膀
背景 最近MCP这个词真是到处都是,看起来特别高大上。我平时没事的时候也一直在关注这方面的技术,知道它是怎么一回事,也懂该怎么去实现。但可惜一直抽不出时间来自己动手搞一个MCP服务。网上关于MCP的教程一搜一大把,但基本上都是…...
)
2023年河南CCPC(ABCEFHK)
文章目录 2023河南CCPCA. 小水獭游河南(字符串)B. Art for Rest(数组切割)C. Toxel与随机数生成器(水)E. 矩阵游戏(dp)F. Art for Last(区间最小差分)H. Travel Begins(数学思维)K. 排列与质数(规律)总结 2023河南CCPC A. 小水獭…...

【 Redis | 实战篇 秒杀优化 】
目录 前言: 1.分布式锁 1.1.分布式锁的原理与方案 1.2.Redis的String结构实现分布式锁 1.3.锁误删问题 1.4.锁的原子性操作问题 1.5.Lua脚本解决原子性问题 1.6.基于String实现分布式锁存在的问题 1.7.Redisson分布式锁 2.秒杀优化 3.秒杀的异步优化 3.1…...

【Spring】核心机制:IOC与DI深度解析
目录 1.前言 2.正文 2.1三层架构 2.2Spring核心思想(IOC与AOP) 2.3两类注解:组件标识与配置 2.3.1五大类注解 2.3.1.1Controller 2.3.1.2Service 2.3.1.3Repository 2.3.1.4Configuration 2.3.1.5Component 2.3.2方法注解&#x…...

1-机器学习的基本概念
文章目录 一、机器学习的步骤Step1 - Function with unknownStep2 - Define Loss from Training DataStep3 - Optimization 二、机器学习的改进Q1 - 线性模型有一些缺点Q2 - 重新诠释机器学习的三步Q3 - 机器学习的扩展Q4 - 过拟合问题(Overfitting) 一、…...

ARM A64 STR指令
ARM A64 STR指令 1 STR (immediate)1.1 Post-index1.1.1 32-bit variant1.1.2 64-bit variant 1.2 Pre-index1.2.1 32-bit variant1.2.2 64-bit variant 1.3 Unsigned offset1.3.1 32-bit variant1.3.2 64-bit variant 1.4 Assembler symbols 2 STR (register)2.1 32-bit varia…...
` 和 `关卡蓝图(Level Blueprint)`的关系)
虚幻引擎5-Unreal Engine笔记之`GameMode`、`关卡(Level)` 和 `关卡蓝图(Level Blueprint)`的关系
虚幻引擎5-Unreal Engine笔记之GameMode、关卡(Level) 和 关卡蓝图(Level Blueprint)的关系 code review! 文章目录 虚幻引擎5-Unreal Engine笔记之GameMode、关卡(Level) 和 关卡蓝图(Level B…...

软件工具:批量图片区域识别+重命名文件的方法,发票识别和区域选择方法参考,基于阿里云实现
基于阿里云的批量图片区域识别与重命名解决方案 图像识别重命名 应用场景 企业档案管理:批量处理扫描的合同、文件等图片,根据合同编号、文件标题等关键信息重命名文件医疗影像处理:识别X光、CT等医学影像中的患者ID、检查日…...

.NET外挂系列:1. harmony 基本原理和骨架分析
一:背景 1. 讲故事 为什么要开这么一个系列,是因为他可以对 .NET SDK 中的方法进行外挂,这种技术对解决程序的一些疑难杂症特别有用,在.NET高级调试 领域下大显神威,在我的训练营里也是花了一些篇幅来说这个…...
:概念、实现与应用)
深入理解位图(Bit - set):概念、实现与应用
目录 引言 一、位图概念 (一)基本原理 (二)适用场景 二、位图的实现(C 代码示例) 三、位图应用 1. 快速查找某个数据是否在一个集合中 2. 排序 去重 3. 求两个集合的交集、并集等 4. 操作系…...
)
React Flow 边事件处理实战:鼠标事件、键盘操作及连接规则设置(附完整代码)
本文为《React Agent:从零开始构建 AI 智能体》专栏系列文章。 专栏地址:https://blog.csdn.net/suiyingy/category_12933485.html。项目地址:https://gitee.com/fgai/react-agent(含完整代码示例与实战源)。完整介绍…...

【计算机网络】第一章:计算机网络体系结构
本篇笔记课程来源:王道计算机考研 计算机网络 【计算机网络】第一章:计算机网络体系结构 一、计算机网络的概念1. 理论2. 计算机网络、互连网、互联网的区别 二、计算机网络的组成、功能1. 组成2. 功能 三、交换技术1. 电路交换2. 报文交换3. 分组交换4.…...

实战设计模式之状态模式
概述 作为一种行为设计模式,状态模式允许对象在其内部状态改变时,改变其行为。这种模式通过将状态逻辑从对象中分离出来,并封装到独立的状态类中来实现。每个状态类代表一种特定的状态,拥有自己的一套行为方法。当对象的状态发生变…...
日期计算器的实现)
[C++入门]类和对象中(2)日期计算器的实现
目录 一、运算符重载 1、格式 2、简单举例 2、前置,后置 3、日期生成器的实现 1、声明与定义 1、友元函数 2、print函数 3、运算符重载 4、GetMonthDay 5、,-,,-的实现 6、重载流操作符 2、实现 3、定义源码 一、运算…...

数据质量问题的形成与解决
在数字化时代,数据已成为企业和组织发展的核心资产,数据质量的高低直接影响着决策的准确性、业务的高效性以及系统的稳定性。然而,数据质量问题频发,严重阻碍了数据价值的充分发挥。 一、数据质量问题的成因分析 1.信息因素 元数…...
论文阅读(四):Agglomerative Transformer for Human-Object Interaction Detection
论文来源:ICCV(2023) 项目地址:https://github.com/six6607/AGER.git 1.研究背景 人机交互(HOI)检测需要同时定位人与物体对并识别其交互关系,核心挑战在于区分相似交互的细微视觉差异&#…...

【机器学习】工具入门:飞牛启动Dify Ollama Deepseek
很久没有更新文章了,最近正好需要研究一些机器学习的东西,打算研究一下 difyOllama 以下是基于FN 的dify本地化部署,当然这也可能是全网唯一的飞牛部署dify手册 部署 官方手册:https://docs.dify.ai/en/getting-started/install-self-hos…...

课外活动:再次理解页面实例化PO对象的魔法方法__getattr__
课外活动:再次理解页面实例化PO对象的魔法方法__getattr__ 一、动态属性访问机制解析 1.1 核心实现原理 class Page:def __getattr__(self, loc):"""魔法方法拦截未定义属性访问"""if loc not in self.locators.keys():raise Exce…...

面试题总结二
1.mybatis三个范式 第一范式:表中字段不能再分,每行数据都是唯一的第二范式:满足第一范式,非主键字段只依赖于主键第三范式:满足第二范式,非主键字段没有传递依赖 2.MySQL数据库引擎有哪些 InnoDB&#…...

代码随想录算法训练营第六十六天| 图论11—卡码网97. 小明逛公园,127. 骑士的攻击
继续补,又是两个新算法,继续进行勉强理解,也是训练营最后一天了,六十多天的刷题告一段落了! 97. 小明逛公园 97. 小明逛公园 感觉还是有点难理解原理 Floyd 算法对边的权值正负没有要求,都可以处理。核心…...

编程技能:字符串函数07,strncat
专栏导航 本节文章分别属于《Win32 学习笔记》和《MFC 学习笔记》两个专栏,故划分为两个专栏导航。读者可以自行选择前往哪个专栏。 (一)WIn32 专栏导航 上一篇:编程技能:字符串函数06,strcat 回到目录…...
)
[Java实战]Spring Boot整合RabbitMQ:实现异步通信与消息确认机制(二十七)
[Java实战]Spring Boot整合RabbitMQ:实现异步通信与消息确认机制(二十七) 摘要:本文通过完整案例演示Spring Boot与RabbitMQ的整合过程,深入讲解异步通信原理与消息可靠性保证机制。包含交换机类型选择、消息持久化配…...

数据库中关于查询选课问题的解法
前言 今天上午起来复习了老师上课讲的选课问题。我总结了三个解法以及一点注意事项。 选课问题介绍 简单来说就是查询某某同学没有选或者选了什么课。然后查询出该同学的姓名,学号,课程号,课程名之类的。 sql文件我上传了。大家可以尝试练…...

用 UniApp 开发 TilePuzzle:一个由 CodeBuddy 主动驱动的拼图小游戏
我正在参加CodeBuddy「首席试玩官」内容创作大赛,本文所使用的 CodeBuddy 免费下载链接:腾讯云代码助手 CodeBuddy - AI 时代的智能编程伙伴 起心动念:从一个小游戏想法开始 最近在使用 UniApp 做练手项目的时候,我萌生了一个小小…...

golang 安装gin包、创建路由基本总结
文章目录 一、安装gin包和热加载包二、路由简单场景总结 一、安装gin包和热加载包 首先终端新建一个main.go然后go mod init ‘项目名称’执行以下命令 安装gin包 go get -u github.com/gin-gonic/gin终端安装热加载包 go get github.com/pilu/fresh终端输入fresh 运行 &…...

组态王|组态王中如何添加西门子1200设备
哈喽,你好啊,我是雷工! 最近使用组态王采集设备数据,设备的控制器为西门子的1214CPU, 这里边实施边记录,以下为在组态王中添加西门子1200PLC的笔记。 1、新建 在组态王工程浏览器中选择【设备】→点击【新建】。 2、选择设备 和设备建立通讯要通过对应的设备驱动。 在…...