论文解读:ICLR2025 | D-FINE
[2410.13842] D-FINE: Redefine Regression Task in DETRs as Fine-grained Distribution Refinement
D-FINE 是一款功能强大的实时物体检测器,它将 DETRs 中的边界框回归任务重新定义为细粒度分布细化(FDR),并引入了全局最优定位自蒸馏(GO-LSD),在不引入额外推理和训练成本的情况下表现出了最佳性能。
📌文章针对目前存在的问题:
- YOLO系列和DETRs系列虽然在实时性和性能方面都取得了不错的效果,但是仍然有一些问题没有解决,一个最关键的就是边界框回归问题,没有考虑对于模糊和不确定的边界是如何进行回归建模的,关于边界框回归,大家可以去看往期的博客:目标检测中的损失函数(一) | IoU GIoU DIoU CIoU EIoU Focal-EIoU_yolo的损失函数-CSDN博客文章浏览阅读1.1k次,点赞7次,收藏20次。目标检测中的边界框回归损失函数_yolo的损失函数
https://blog.csdn.net/Jacknbv/article/details/147366898?spm=1001.2014.3001.5501目标检测中的损失函数(二) | BIoU RIoU α-IoU_bounded iou loss-CSDN博客文章浏览阅读793次,点赞30次,收藏12次。目标检测中的损失函数_bounded iou loss
- 另外一个问题就是老生常谈的问题:实时检测的效率问题,这会受到计算资源和模型参数的限制
✨论文的主要贡献:
- 提出了一种新的实时对象检测器D-FINE,解决了固定坐标回归中优化困难的问题、无法对定位不确定性进行建模的问题,以及需要以更低的训练成本实现有效提炼的问题,D-FINE最重要的就是下面这两个组件了
- Fine-grained Distribution Refinement (FDR) 将边界框回归从预测固定坐标转化为对概率分布的建模,提供了一种更精细的中间表示
- Global Optimal Localization Self-Distillation (GO-LSD),将定位知识从更深的层转移到较浅的层,额外的训练成本可以忽略不计
🔔在文章的相关工作这里,主要介绍了实时/端到端的目标检测、基于分布的目标检测知识蒸馏,其中localization distillation (LD)(定位蒸馏)是把用于分类head的knowledge distillation (KD)用于目标检测的定位head。自蒸馏是KD的一个特例,它使早期层次能够从模型自身的精炼输出中学习,由于不需要单独培训教师模型,因此需要的额外训练成本要少得多。
💡重点关注FDR和GO-LSD是怎么做的?
✨Fine-grained Distribution Refinement (FDR)
FDR迭代地优化由解码器层生成的细粒度分布。最初,第一个解码器层通过传统的边界盒回归头和D-FINE头(两个头都是MLP,只是输出维度不同)预测初步的边界盒和初步的概率分布。每个边界框与四个分布相关联,每个边对应一个分布。初始边界框用作参考框,而后续层则通过以残差方式调整分布来细化它们。然后应用改进的分布来调整相应的初始边界框的四个边,随着每次迭代逐步提高其精度。
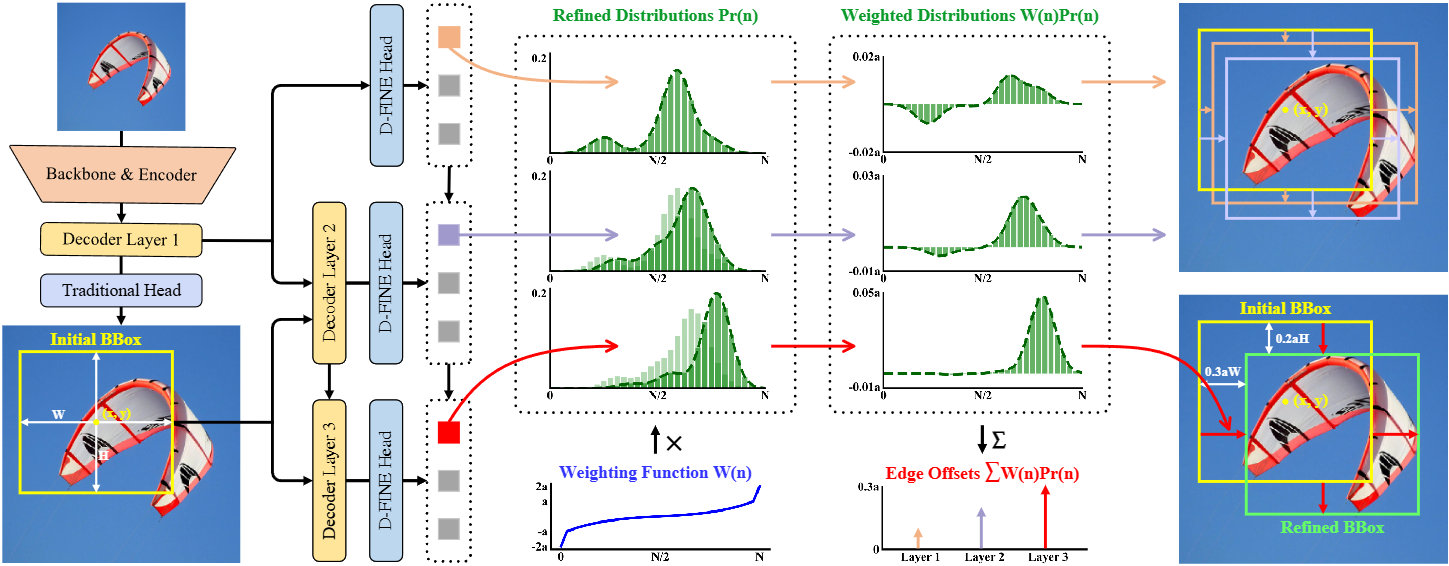

FDR 模块不是直接输出新的概率分布,而是输出一个残差,这个残差会与上一层的概率分布相加,从而得到当前层更新后的概率分布。这样做的好处是可以通过逐步调整残差的方式,对概率分布进行更精细的优化,使得模型能够逐层调整边界框,逐步收敛到更精确的位置。
权重函数W(n)的作用是让模型对接近真实位置的偏移值进行更小的调整,而对远离真实位置的边界偏移赋予更大的权重1。通过这种方式,模型可以更加关注那些需要更多调整的边界偏移,从而提高对物体边界的定位精度。分布的加权和产生边偏移,然后按初始边界框的高度H和宽度W缩放这些边偏移,以确保调整与框大小成比例。
总体而言,FDR 通过这种基于残差更新和加权的概率分布细化方式,将传统的边界框预测转变为一个迭代细化的概率分布过程,从而显著提升了模型的定位精度,增强了对物体边界细致定位的能力,并且能够更好地处理定位的不确定性。
✨Global Optimal Localization Self-Distillation (GO-LSD)
GO-LSD利用最后一层的精细分布预测将定位知识提取到较浅的层中。该过程首先将匈牙利匹配算法 (https://onlinelibrary.wiley.com/doi/abs/10.1002/nav.3800020109 End-to-End Object Detection with Transformers | SpringerLink) 应用于每个层的预测,确定模型每个阶段的局部边界框匹配。为了进行全局优化,GO-LSD将所有层的匹配索引聚合到一个统一的联合集。这个联合集结合了跨层的最精确的候选预测,确保它们都从蒸馏过程中受益。除了优化全局匹配,GO-LSD还在训练期间优化不匹配的预测,以提高整体稳定性,从而提高整体性能。虽然通过这个联合集优化了定位,但是分类任务仍然遵循一对一的匹配原则,确保没有冗余框。这种严格的匹配意味着联合集中的一些预测具有很好的局部性,但置信度较低。这些低置信度的预测通常代表具有精确定位的候选框,但仍然需要有效地提取。
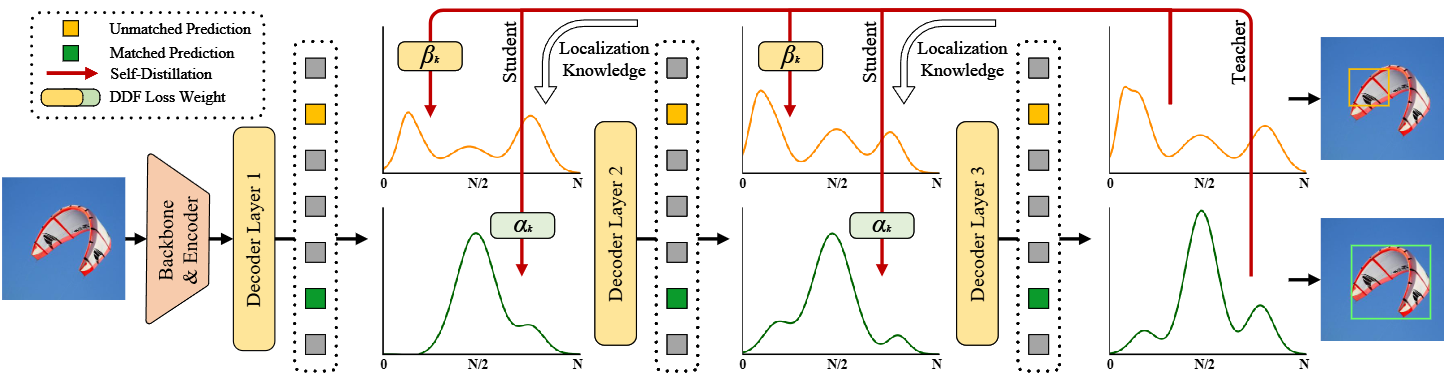
🥯针对上述这个问题,文章引入Decoupled Distillation Focal (DDF)损失去解决,这个损失是使用解耦加权策略来确保高IoU且低置信度的预测能被赋予适当的权重。DDF损失还根据匹配和不匹配预测的数量对它们进行加权,平衡它们的总体贡献和单个损失,使蒸馏更加稳定和有效。
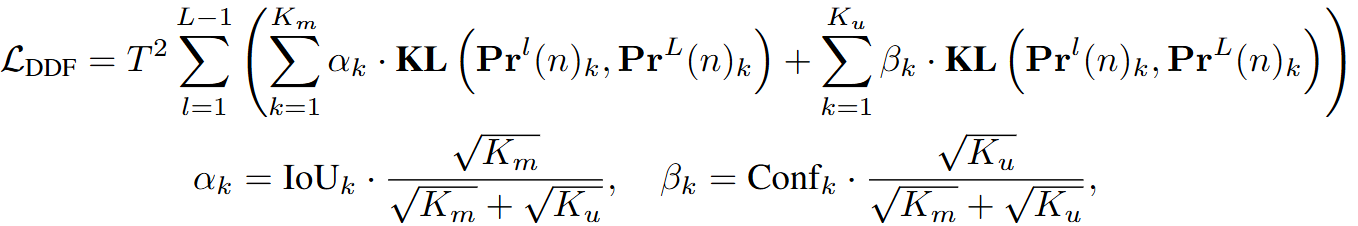
KL散度也叫相对熵,是衡量两个概率分布差异的指标,T是用于平滑logits的温度参数,第k个匹配预测的蒸馏损失通过进行加权,
和
分别是匹配和未匹配预测的数量,对于第k个不匹配的预测,权重是
,
表示的是分类的置信度。
整体上是一个累加求和的形式,主要通过计算不同层级特征(从第1层到第L−1层 )与最后一层(第L层 )特征之间的 KL散度,并结合相应权重来得到损失值。
🧶实验
D-FINE在COCO和Objects365数据集上表现出色,参考下面的表格
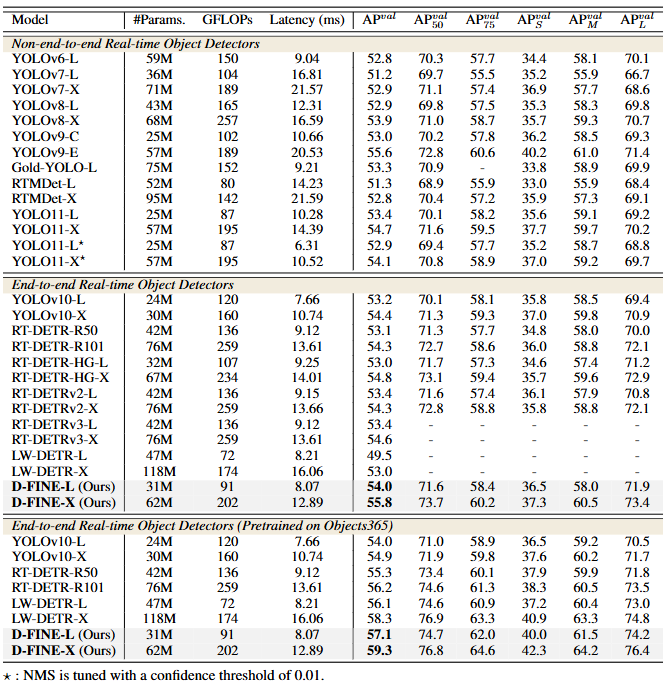
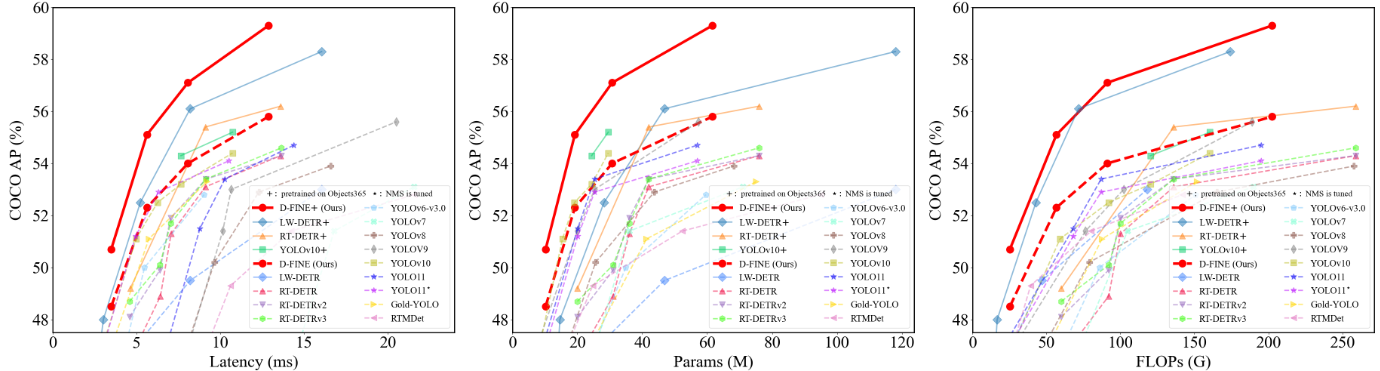
将FDR和GO-LSD无缝集成到任何DETR体系结构中,在不增加参数数量和计算负担的情况下显著提高性能在COCO数据集上进行了测试。
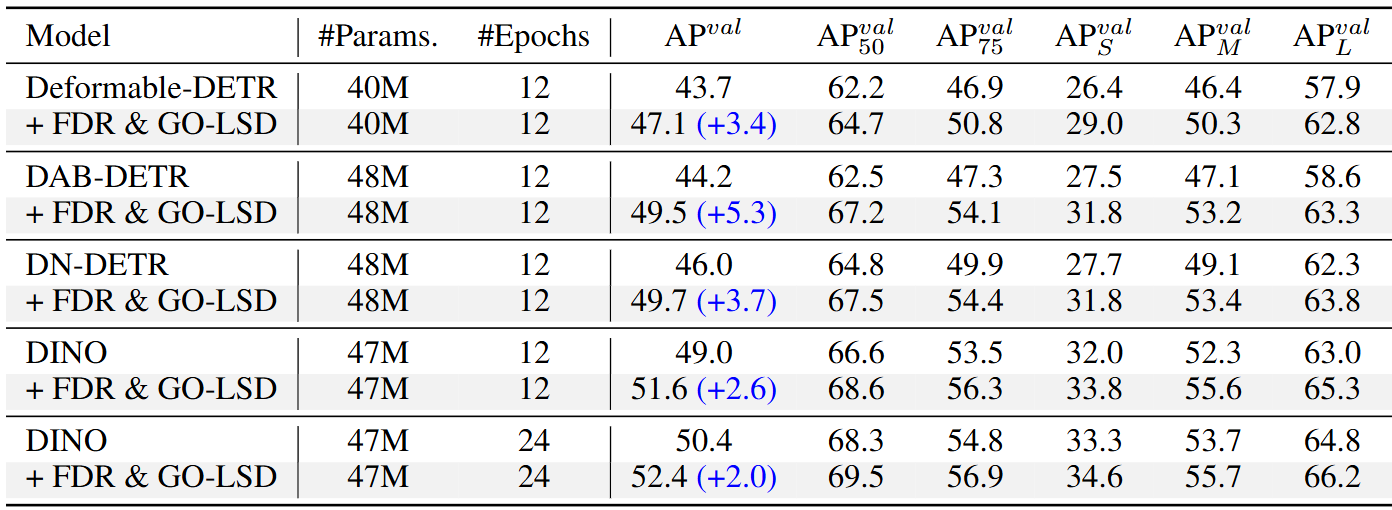
对于预训练,将Objects365 训练集的图像与验证集相结合,不包括前 5k 张图像。为了进一步提高训练效率,预先将所有分辨率超过640 × 640的图像调整为640 × 640。使用标准 COCO2017 数据拆分策略、COCO train2017 的训练和 COCO val2017 的评估。

🛒消融实验
D-FINE选择以RT-DETR-HGNetv2-L作为架构
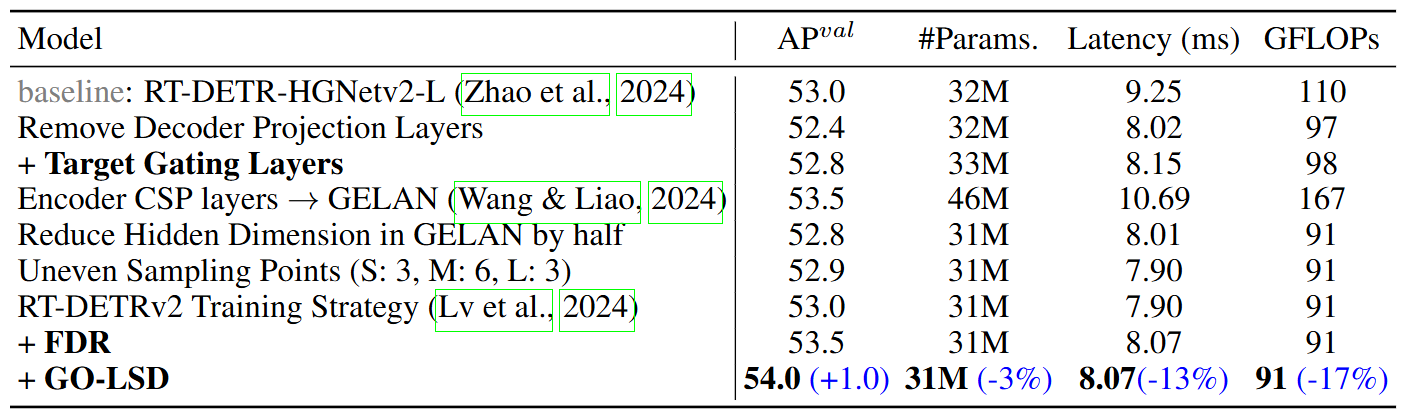 将Target Gating Layer放置在解码器的交叉注意力模块之后代替残差连接,允许查询跨层动态地将焦点切换到不同的目标上,从而有效地防止信息纠缠。
将Target Gating Layer放置在解码器的交叉注意力模块之后代替残差连接,允许查询跨层动态地将焦点切换到不同的目标上,从而有效地防止信息纠缠。
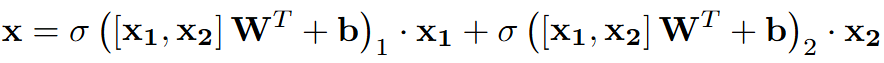
表示先前的queries,
表示交叉注意力的结果,
就是sigmoid激活函数,
是表示串行操作。
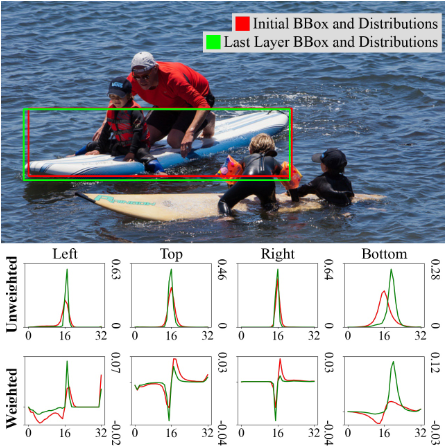
将编码器的CSP层使用GELAN层替换,为了缓解模型复杂度,降低了GELAN的隐藏层维数。RT-DETRv2的训练策略主要就是针对不同D-FINE模型的基础超参数的选择,参考下面的表格:

文章讨论了a、c、N和T超参数的取值影响,当c非常大时,加权函数以相等的间隔逼近线性函数,太大或太小的a值可能会降低精细度或限制灵活性,从而对定位精度产生不利影响。
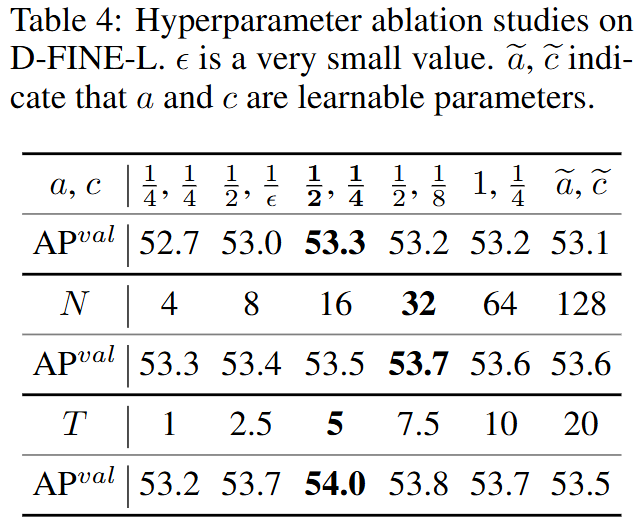
文章比较了不同的蒸馏方法的性能,GPU使用了四张NVIDIA RTX 4090。
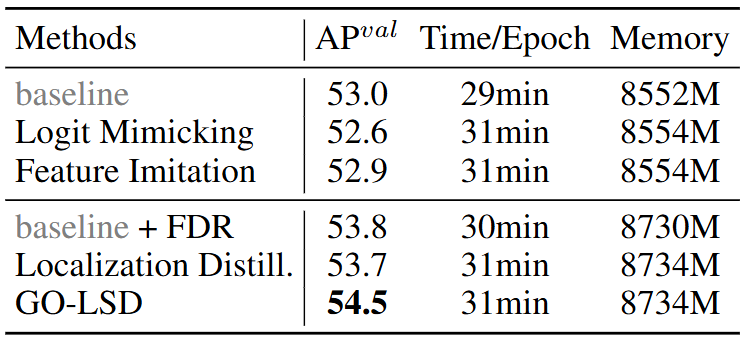
来看一下FDR的可视化效果,红色曲线表示初始分布,而绿色曲线表示最终的精细分布。加权分布强调精确预测附近的更精细调整,并允许对较大调整进行快速更改,进一步说明FDR如何细化初始边界框的偏移,从而导致越来越精确的定位。
- D-FINE是一种强大的实时对象检测器,它通过FDR和GO-LSD重新定义 DETR 模型中的边界框回归任务。COCO 数据集上的实验结果表明,D-FINE 达到了最先进的准确性和效率,超过了所有现有的实时检测器。
- D-FINE 模型和其他小模型的性能差距仍然很小,一个可能的原因是浅层解码器层可能会产生不太准确的最后一层预测,从而限制了将定位知识提取到早期层的有效性
- 未来的研究可以进一步探索更先进的架构设计或新颖的训练范例,以在保持轻量级推理的同时增强较轻模型的定位能力
相关文章:

论文解读:ICLR2025 | D-FINE
[2410.13842] D-FINE: Redefine Regression Task in DETRs as Fine-grained Distribution Refinement D-FINE 是一款功能强大的实时物体检测器,它将 DETRs 中的边界框回归任务重新定义为细粒度分布细化(FDR),并引入了全局最优定位…...

Kafka 生产者工作流程详解
以下是 Kafka 生产者工作流程的清晰分步解释,结合关键机制与用户数据: 1. 生产者初始化与数据发送 主线程创建生产者对象,调用 send(ProducerRecord) 发送消息。 拦截器(可选):可添加自定义逻辑(…...

leetcode 239. 滑动窗口最大值
暴力解法是一种简单直接的方法,虽然效率较低,但可以帮助你更好地理解问题的逻辑。以下是使用暴力解法解决“滑动窗口最大值”问题的 C 实现。 暴力解法的思路 遍历每个滑动窗口: 使用一个外层循环,从数组的起始位置开始ÿ…...
)
第3章 自动化测试:从单元测试到硬件在环(HIL)
在前两章中,我们已完成从环境搭建到流水线编译的自动化配置。为了真正保障软件质量、降低回归风险,本章将聚焦测试自动化,涵盖从最基础的单元测试,到集成测试,再到硬件在环(Hardware-in-the-Loop, HIL)测试的全流程。通过脚本驱动、测试报告可视化和与 CI 平台深度集成,…...

flutter 配置 安卓、Ios启动图
android 配置启动图 launch_background.xml <?xml version"1.0" encoding"utf-8"?> <!-- Modify this file to customize your launch splash screen --> <layer-list xmlns:android"http://schemas.android.com/apk/res/android&…...

实验八 基于Python的数字图像问题处理
一、实验目的 培养利用图像处理技术解决实际问题的能力。 培养利用图像处理技术综合设计实现的能力。 掌握在Python环境下解决实际问题的能力。 熟练掌握使用cv2库对图像进行处理 熟练掌握使用区域生长法提取图片中感兴趣的区域 二、实验内容 本次实验内容为…...

Dockerfile学习指南
目录 一、Dockerfile 本质与价值 二、基础语法结构 1. 指令格式 2. 核心指令详解 三、构建流程解析 1. 典型构建过程 2. 分层构建原理 四、高级特性 1. 多阶段构建 2. 环境变量管理 3. 健康检查 五、最佳实践指南 1. 优化建议 2. 安全实践 六、典型应用场景 1. …...

数据库原理及其应用 第六次作业
题目 参考答案 题目1. 教材P148第1题 问题:什么是数据库的安全性? 答案:数据库的安全性是指保护数据库以防止不合法的使用所造成的数据泄露、更改或破坏 。它通过用户身份鉴别、存取控制(包括自主存取控制和强制存取控制&#x…...

c/c++的opencv的轮廓匹配初识
OpenCV 轮廓匹配:形状识别与比较 📐✨ 轮廓匹配是计算机视觉中一个重要的技术,它允许我们比较两个形状的相似度。OpenCV 提供了强大的函数来实现这一功能,核心是 cv::matchShapes()。本文将引导你了解轮廓匹配的基本原理、OpenCV…...

Oracle APEX IR报表下载CSV文件的方法
目录 0. 准备工作 1. 下载--自定义SQL 2. 下载--检索结果 0. 准备工作 -- 建表 CREATE TABLE T_DL_EMP(EMPNO NUMBER(4) NOT NULL -- 雇员编号,由四个数字组成。, ENAME VARCHAR2(10) -- 雇员姓名,由10个字符组成。, JOB …...

JVM 双亲委派机制
一、从 JDK 到 JVM:Java 运行环境的基石 在 Java 开发领域,JDK(Java Development Kit)是开发者的核心工具包。它不仅包含了编译 Java 代码的工具(如 javac),还内置了 JRE(Java Run…...

shell脚本之条件判断,循环控制,exit详解
if条件语句的语法及案例 一、基本语法结构 1. 单条件判断 if [ 条件 ]; then命令1命令2... fi2. 双分支(if-else) if [ 条件 ]; then条件为真时执行的命令 else条件为假时执行的命令 fi3. 多分支(if-elif-else) if [ 条件1 ]…...

什么是私有IP地址?如何判断是不是私有ip地址
在互联网的世界中,IP地址是设备之间通信的基础标识。无论是浏览网页、发送邮件还是在线游戏,IP地址都扮演着至关重要的角色。然而,并非所有的IP地址都是公开的,有些IP地址被保留用于内部网络,这就是我们所说的私有IP地…...

BGP路由策略 基础实验
要求: 1.使用Preva1策略,确保R4通过R2到达192.168.10.0/24 2.用AS_Path策略,确保R4通过R3到达192.168.11.0/24 3.配置MED策略,确保R4通过R3到达192.168.12.0/24 4.使用Local Preference策略,确保R1通过R2到达192.168.1.0/24 …...
)
Java 原生网络编程(BIO | NIO | Reactor 模式)
1、基本常识 Socket 是应用层与 TCP/IP 协议族通信的中间软件抽象层,是一组接口,使用了门面模式对应用层隐藏了传输层以下的实现细节。TCP 用主机的 IP 地址加上主机端口号作为 TCP 连接的端点,该端点叫做套接字 Socket。 比如三次握手&…...

大语言模型 11 - 从0开始训练GPT 0.25B参数量 MiniMind2 准备数据与训练模型 DPO直接偏好优化
写在前面 GPT(Generative Pre-trained Transformer)是目前最广泛应用的大语言模型架构之一,其强大的自然语言理解与生成能力背后,是一个庞大而精细的训练流程。本文将从宏观到微观,系统讲解GPT的训练过程,…...
)
【Java ee初阶】HTTP(4)
构造HTTP请求 1)开发中,前后端交互。浏览器运行的网页中,构造出HTTP请求 2)调试阶段,通过构造HTTP请求测试服务器 朴素的方案: 通过tcp socket 的方式构造HTTP请求 按照HTTP请求格式,往TCP…...

永久免费!专为 Apache Doris 打造的可视化数据管理工具 SelectDB Studio V1.1.0 重磅发布!
作为全球领先的开源实时数据仓库, Apache Doris Github Stars 已超过 13.6k,并在 5000 余家中大型企业生产环境得到广泛应用,支撑业务核心场景,成为众多企业数据分析基础设施不可或缺的重要基座。过去,Apache Doris 用…...
React中useDeferredValue与useTransition终极对比。
文章目录 前言一、核心差异对比二、代码示例对比1. useDeferredValue:延迟搜索结果更新2. useTransition:延迟路由切换 三、应用场景总结四、注意事项五、原理剖析1. 核心机制对比2. 关键差异3. 代码实现原理 总结 前言 在React的并发模式下,…...

Git 项目切换到新的远程仓库地址
已存在的 Git 项目切换到新的远程仓库地址,比如你要换成: gitgithub.com:baoing/test-app.git步骤如下: 查看当前的远程仓库地址(可选) git remote -v你会看到类似: origin gitgithub.com:old-user/old…...

科技晚报 AI 速递:今日科技热点一览 丨 2025 年 5 月 17 日
科技晚报AI速递:今日科技热点一览 丨2025年5月17日 我们为您汇总今日的科技领域最新动向,带您快速了解前沿技术、突破性研究及行业趋势。 黄仁勋劝特朗普:AI 芯片出口规则得改,中国紧追其后:英伟达 CEO 黄仁勋在华盛顿 “山与谷论…...

基于OpenCV的SIFT特征和FLANN匹配器的指纹认证
文章目录 引言一、概述二、代码解析1. 图像显示函数2. 核心认证函数3. 匹配点筛选4. 认证判断 三、主程序四、技术要点五、总结 引言 在计算机视觉领域,图像特征匹配是一个非常重要的技术,广泛应用于物体识别、图像拼接、运动跟踪等场景。今天将介绍一个…...

【Linux】共享内存
🌻个人主页:路飞雪吖~ 🌠专栏:Linux 目录 ☃️共享内存 🪄 shmget函数 用来创建共享内存 ✨共享内存的管理指令: 🌠 shmid VS key ✨共享内存函数 🍔 shmget() 创建共享内存 &a…...

Cookie、Session、Token
Cookie 1. 什么是cookie? Cookie 是一种由服务器发送到客户端浏览器的小数据片段,用于存储用户的状态信息。例如,用户登录状态或用户偏好设置可以通过Cookie进行管理。计算机cookie更正式地称为 HTTP cookie、网络 cookie、互联网 cookie 或浏览器 coo…...

设计模式Java
UML类图 概述 类图(Class diagram)是显示了模型的静态结构,特别是模型中存在的类、类的内部结构以及它们与其他类的关系等。类图不显示暂时性的信息。类图是面向对象建模的主要组成部分。 类图的作用 在软件工程中,类图是一种静态的结构图,…...

Word文档图片排版与批量处理工具推荐
先放下载链接:夸克网盘下载 前几天给大家推荐了 Excel 图片调整软件,当时好多小伙伴问有没有 Word 相关的软件。我在网上找了一圈都没找到合适的,最后在我好久之前记录的一个文档里发现了,这不,马上就来给大家推荐,有…...

[案例五] 实体——赋值质量
最近翻阅了实验室其他人编写的一个“质量赋值”功能,能够直接为实体或组件设定质量。出于好奇,我对其进行了分析。由于自己平时没有用到该功能,所以也借此机会学习一下。 在分析过程中,我发现NX 官方其实并没有提供直接修改质量的功能。一般来说,质量是通过“密度 体积”…...
)
手撕四种常用设计模式(工厂,策略,代理,单例)
工厂模式 一、工厂模式的总体好处 解耦:客户端与具体实现类解耦,符合“开闭原则”。统一创建:对象创建交由工厂处理,便于集中控制。增强可维护性:新增对象种类时不需要大改动调用代码。便于扩展:易于管理…...
)
C# 深入理解类(静态函数成员)
静态函数成员 除了静态字段,还有静态函数成员。 如同静态字段,静态函数成员独立于任何类实例。即使没有类的实例,仍然可以调用静 态方法。静态函数成员不能访问实例成员,但能访问其他静态成员。 例如,下面的类包含一…...

数据类型转换
文章目录 基本数据类型(primitive type)整数类型:浮点类型字符类型boolean类型 类型转换类型转换注意点 基本数据类型(primitive type) 整数类型: byte占1个字节范围:-128-127 short占…...

深入理解 TypeScript 中的 unknown 类型:安全处理未知数据的最佳实践
在 TypeScript 的类型体系中,unknown 是一个极具特色的类型。它与 any 看似相似,却在安全性上有着本质差异。本文将从设计理念、核心特性、使用场景及最佳实践等方面深入剖析 unknown,帮助开发者在处理动态数据时既能保持灵活性,又…...

AI:人形机器人的应用场景以及商业化落地潜力分析
应用场景分析 人形机器人的设计使其能够适应人类环境,执行多样化任务。以下是未来主要的应用场景及其详细分析: 医疗与护理 具体应用: 老年护理:协助老年人穿衣、洗澡、喂食,或提供情感陪伴。康复辅助:帮助…...

JavaScript入门【3】面向对象
1.对象: 1.概述: 在js中除了5中基本类型之外,剩下得都是对象Object类型(引用类型),他们的顶级父类是Object;2.形式: 在js中,对象类型的格式为key-value形式,key表示属性,value表示属性的值3.创建对象的方式: 方式1:通过new关键字创建(不常用) let person new Object();// 添…...

亲测有效!OGG 创建抽取进程报错 OGG-08241,如何解决?
前言 今天在测试 OGG 一个功能的时候,需要重新初始化 oggca,所以重装了一下 OGG。重建完之后重新添加抽取进程报错,一直无法添加成功: 经过一翻分析,找到了解决方案,本文记录一下解决过程。 问题描述 OG…...

【第二篇】 初步解析Spring Boot
简介 SpringBoot是由Pivotal团队提供的全新框架,其设计目的是为了用来简化Spring应用的初始搭建以及开发过程的。本文章将详细介绍SpringBoot为什么能够简化项目的搭建以及普通的Spring程序的开发。文章内容若存在错误或需改进的地方,欢迎大家指正&#…...

JVM 机制
目录 一、什么是 JVM: 二、JVM 的运行流程: 三、JVM 内存区域划分: 1、( 1 ) 程序计数器: 1、( 2 ) 元数据区: 1、( 3 ) 栈: 1、( 4 ) 堆: 四、类加载: 1、什么时候会触…...

Java泛型详解
文章目录 1. 引言1.1 什么是泛型1.2 为什么需要泛型1.3 泛型的优势2. 泛型基础2.1 泛型类多个类型参数2.2 泛型方法2.3 泛型接口2.4 类型参数命名约定3. 类型擦除3.1 什么是类型擦除3.2 类型擦除的影响1. 无法获取泛型类型参数的实际类型2. 无法创建泛型类型的数组3. 无法使用`…...

机器学习,深度学习,神经网络,深度神经网络之间有何区别?
先说个人观点:机器学习>神经网络>深度学习≈深度神经网络。深度学习是基于深度神经网络的,深度神经网络和浅层神经网络都是神经网络,而机器学习是包括神经网络在内的算法。 一、机器学习 先说涵盖范围最广的机器学习。机器学习&#…...

AtomicInteger
AtomicInteger 是 Java 并发包 (java.util.concurrent.atomic) 中的一个原子类,用于在多线程环境下对整数进行原子操作。 核心特性 原子性 提供线程安全的原子操作(如自增、加法、比较并交换等),确保在多线程环境中操作不会被中…...
详解:原理、应用与实施)
威布尔比例风险模型(Weibull Proportional Hazards Model, WPHM)详解:原理、应用与实施
威布尔比例风险模型(Weibull Proportional Hazards Model, WPHM)详解:原理、应用与实施 一、核心原理:从威布尔分布到比例风险模型 1. 威布尔分布的数学本质 威布尔分布通过两个关键参数(形状参数 (k) 和尺度参数 (\…...

Dubbo:Docker部署Zookeeper、Dubbo Admin的详细教程和SpringBoot整合Dubbo的实战与演练
🪁🍁 希望本文能给您带来帮助,如果有任何问题,欢迎批评指正!🐅🐾🍁🐥 文章目录 一、背景二、Dubbo概述三、Dubbo与SpringCloud的关系四、Dubbo技术架构五、Docker安装Zoo…...

Windows 上安装下载并配置 Apache Maven
1. 下载 Maven 访问官网: 打开 Apache Maven 下载页面。 选择版本: 下载最新的 Binary zip archive(例如 apache-maven-3.9.9-bin.zip)。 注意:不要下载 -src 版本(那是源码包)。 2. 解压 Mave…...

Unbuntu 命令
Ubuntu 命令速查表 分类命令功能描述示例/常用选项文件与目录ls列出目录内容ls -a(显示隐藏文件); ls -lh(详细列表易读大小) cd切换目录cd ~(主目录); cd ..(上级…...

机器学习-人与机器生数据的区分模型测试-数据处理1
附件为训练数据,总体的流程可以作为参考。 导入依赖 import pandas as pd import os import numpy as np from sklearn.model_selection import train_test_split,GridSearchCV from sklearn.ensemble import RandomForestClassifier,VotingClassifier from skle…...
:认识管道)
【Linux】进程间通信(一):认识管道
📝前言: 这篇文章我们来讲讲进程间通信——认识管道 🎬个人简介:努力学习ing 📋个人专栏:Linux 🎀CSDN主页 愚润求学 🌄其他专栏:C学习笔记,C语言入门基础&a…...

AMD Vivado™ 设计套件生成加密比特流和加密密钥
概括 重要提示:有关使用AMD Vivado™ Design Suite 2016.4 及更早版本进行 eFUSE 编程的重要更新,请参阅AMD设计咨询 68832 。 本应用说明介绍了使用AMD Vivado™ 设计套件生成加密比特流和加密密钥(高级加密标准伽罗瓦/计数器模式 (AES-GCM)…...
)
第三十四节:特征检测与描述-SIFT/SURF 特征 (专利算法)
一、特征检测:计算机视觉的基石 在计算机视觉领域中,特征检测与描述是实现图像理解的核心技术。就像人类通过识别物体边缘、角点等特征来认知世界,算法通过检测图像中的关键特征点来实现: 图像匹配与拼接 物体识别与跟踪 三维重建 运动分析 其中,SIFT(Scale-Invariant F…...

【AI】SpringAI 第二弹:基于多模型实现流式输出
目录 一、基于多模型实现流式输出 1.1 什么是流式输出 1.2 多模型引入 1.3 代码实现 1.3.1 流式输出的API介绍 1.3.2 Flux 源码分析 二、了解 Reactor 模型 三、SSE 协议 一、基于多模型实现流式输出 1.1 什么是流式输出 流式输出(Streaming Output)是指数据在生成过程…...

SQL语句执行问题
执行顺序 select [all|distinct] <目标列的表达式1> AS [别名], <目标列的表达式2> AS [别名]... from <表名1或视图名1> [别名],<表名2或视图名2> [别名]... [where <条件表达式>] [group by <列名>] [having <条件表达式>] [ord…...

模型量化AWQ和GPTQ哪种效果好?
环境: AWQ GPTQ 问题描述: 模型量化AWQ和GPTQ哪种效果好? 解决方案: 关于AWQ(Adaptive Weight Quantization)和GPTQ(Generative Pre-trained Transformer Quantization)这两种量化方法的…...