Java 原生网络编程(BIO | NIO | Reactor 模式)
1、基本常识
Socket 是应用层与 TCP/IP 协议族通信的中间软件抽象层,是一组接口,使用了门面模式对应用层隐藏了传输层以下的实现细节。TCP 用主机的 IP 地址加上主机端口号作为 TCP 连接的端点,该端点叫做套接字 Socket。
比如三次握手,调用 Socket.connect() 就能完成,应用开发者无须关心如何具体实现三次握手。
长连接与短连接没有哪一个更好之说,只是结合具体业务使用哪一个更合适。
任何网络通信编程关注的三件事:
- 连接(客户端连接服务器,服务器接收客户端的连接)
- 读网络数据
- 写网络数据
常见的网络编程方式有三种:
- BIO:阻塞式 IO,当线程无法读取到数据或无法写入数据时,线程会进入阻塞状态
- NIO:非阻塞式 IO,也称 IO 多路复用,即一个线程为多个客户端执行读写操作。当一个客户端无法读写数据即将陷入阻塞状态之前,线程会切换到其他客户端的读写工作中,避免阻塞带来的效率低下问题
- AIO:异步 IO,Linux 的异步 IO 实际上是通过 NIO 实现的,而 Windows 才提供了真正的异步 IO,因此在 Linux 和 Java 这一侧关注的是 BIO 与 NIO
2、BIO
服务端通过 ServerSocket 获取到客户端的连接 Socket,为每个连接分配一个单独的线程,通过 IO 流进行同步阻塞式通信:
public class Server {// 别用 CachedThreadPool,与 new Thread() 没啥区别private static ExecutorService executorService = Executors.newFixedThreadPool(Runtime.getRuntime().availableProcessors() * 2);public static void main(String[] args) {ServerSocket serverSocket = null;try {serverSocket = new ServerSocket();serverSocket.bind(new InetSocketAddress(10001));System.out.println("Start server...");while (true) {executorService.submit(new ServerTask(serverSocket.accept()));}} catch (IOException e) {e.printStackTrace();} finally {try {if (serverSocket != null) {serverSocket.close();}} catch (IOException e) {e.printStackTrace();}}}static class ServerTask implements Runnable {private Socket socket;public ServerTask(Socket socket) {this.socket = socket;}@Overridepublic void run() {try (ObjectInputStream objectInputStream = new ObjectInputStream(socket.getInputStream());ObjectOutputStream objectOutputStream = new ObjectOutputStream(socket.getOutputStream())) {String userName = objectInputStream.readUTF();objectOutputStream.writeUTF("Hello," + userName);objectOutputStream.flush();} catch (IOException e) {e.printStackTrace();}}}
}
客户端使用 Socket 连接绑定服务器端口后与服务器通信:
public class Client {public static void main(String[] args) throws IOException {Socket socket = new Socket();socket.connect(new InetSocketAddress("127.0.0.1", 10001));try (ObjectOutputStream objectOutputStream = new ObjectOutputStream(socket.getOutputStream());ObjectInputStream objectInputStream = new ObjectInputStream(socket.getInputStream())) {objectOutputStream.writeUTF("James");objectOutputStream.flush();System.out.println(objectInputStream.readUTF());} finally {socket.close();}}
}
3、NIO
首先要清楚一点,在配置参数相同的情况下,单次网络通信,BIO 的效率是比 NIO 高的,但是由于 NIO 中一个服务端线程可以与多个客户端通信,所以 NIO 这个 IO 多路复用的机制,总体上比 BIO 效率更高。从成本角度考虑,NIO 节省成本,而 BIO 则是以成本换效率。
3.1 三大核心组件
NIO 的三大核心组件:
- Selector:选择器,也称为轮询代理器或事件订阅器,可以在一个单独的线程中操作 Selector 选择不同的 Channel,从而实现在一个线程中管理多个通道。应用程序向 Selector 注册需要其关注的 Channel 以及 Channel 感兴趣的 IO 事件,Selector 内则保存已经注册的 Channel 的容器
- Channels:通道,是应用程序与操作系统读写数据的渠道,通道中的数据总是先读到 Buffer 或从 Buffer 写入。Selector 注册的是 SelectableChannel,其子类 ServerSocketChannel 支持应用程序向操作系统注册 IO 多路复用的端口监听,同时支持 TCP 和 UDP;而另一个子类 SocketChannel 则是 TCP Socket 的监听通道
- Buffer:本质上就是一个数组,其内存被包装成 Buffer 对象并提供了方便访问该内存的方法。仅与 Channel 做数据交换。
3.2 重要概念 SelectionKey
除此之外还有一个重要概念 SelectionKey,表示 SelectableChannel 在 Selector 中注册的标识。Channel 向 Selector 注册时,会创建 SelectionKey 建立 Channel 与 Selector 的联系,同时维护 Channel 事件。
SelectionKey 有四种类型:
- OP_READ:操作系统读缓冲区可读,并非所有时刻都有数据可读,因此需要注册该操作
- OP_WRITE:操作系统写缓冲区有空闲空间,一般情况下都有空闲空间,因此没必要注册该类型,否则浪费 CPU;但如果是写密集型的任务,比如下载文件,缓冲区可能会满,此时就需要注册该操作类型,并在写完后取消注册
- OP_CONNECT:只给客户端使用,在 SocketChannel.connect() 连接成功后就绪
- OP_ACCEPT:只给服务器使用,在接收到客户端连接请求时就绪
这四种类型也再次阐明了网络编程关注的三件事:连接(客户端连接服务器,服务器接收客户端的连接)、读、写网络数据。
不同的 Channel 允许注册的事件类型不同:
- 服务器 ServerSocketChannel:仅 OP_ACCEPT
- 服务器 SocketChannel:OP_READ、OP_WRITE
- 客户端 SocketChannel:OP_READ、OP_WRITE 和 OP_CONNECT
3.3 Buffer
缓冲区本质上是一块可以写入数据,然后可以从中读取数据的内存(其实就是数组),这块内存被包装成 NIO Buffer 对象,并提供了一组方法,用来方便的访问该块内存。
Buffer 位于 Channel 和应用程序之间。应用程序对外写数据时,是写到 Buffer,由 Channel 将 Buffer 中的数据读出并发送出去;读也是类似的,数据是先从 Channel 读到 Buffer 后,应用程序再读 Buffer 中的数据。
Buffer 有三个重要属性:
- capacity:内存容量,只能写 capacity 个 byte、long、char 类型数据,Buffer 满了之后需要通过读数据或清除数据将其清空后,才能继续写数据
- position:表示操作数据的位置,写模式下,每写完一个数据会向下移动一个单位,最大为 capacity - 1;读模式下,每读完一个数据会向前移动到下一个可读的位置。读写模式切换时,position 会被重置为 0
- limit:写模式下表示最多能向 Buffer 中写多少数据,此时 limit 等于 capacity;读模式下表示最多能读到多少数据,切换到读模式时,limit 会被置为写模式下的 position,即可读取此前所有写入的数据
Buffer 既可以读也可以写,需要通过 flip() 从写模式切换到读模式,而当读完数据后,可以通过 clear() 或 compact() 清理缓冲区并切换成写模式,其中前者会清空整个缓冲区,而后者则只清除已经读取过的数据。
完整的通信结构如下:
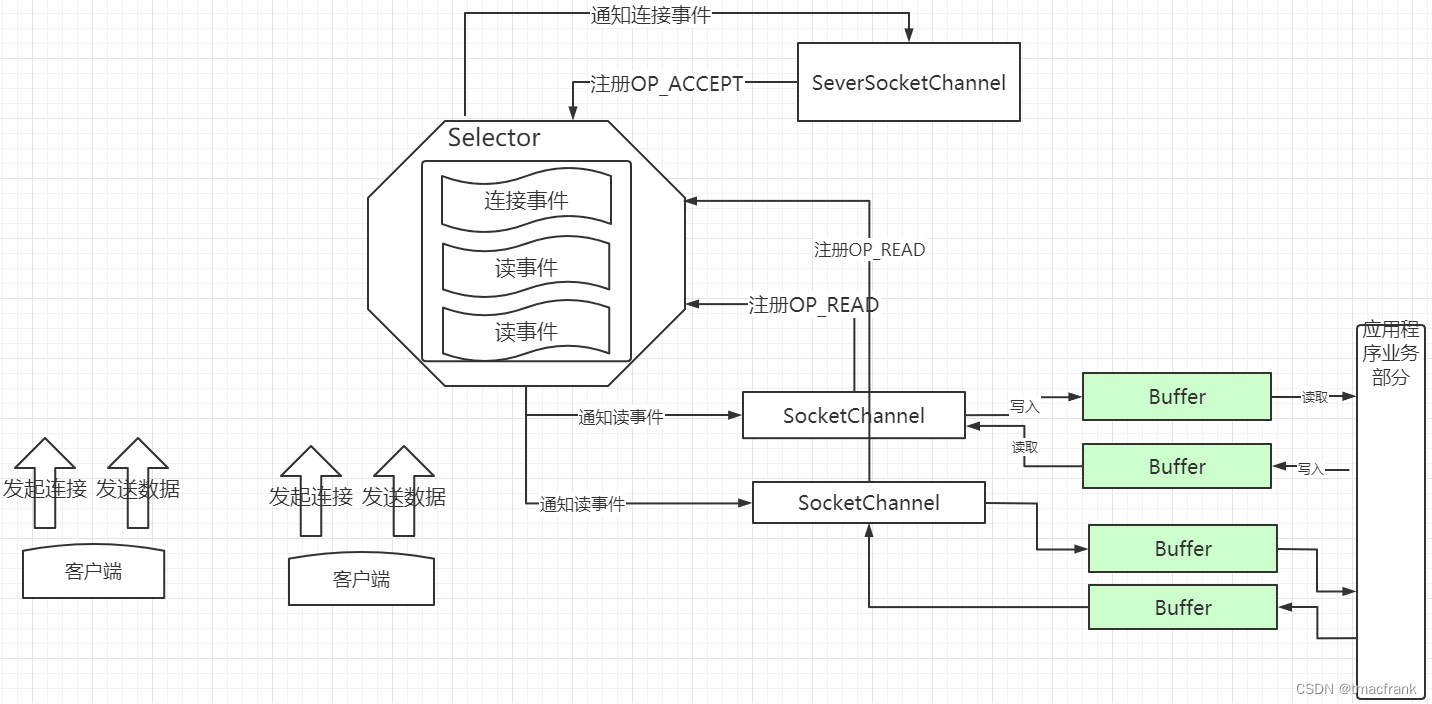
大致步骤:
- 服务端 ServerSocketChannel 向 Selector 注册 OP_ACCEPT
- 客户端连接服务器,Selector 会通知 ServerSocketChannel 连接事件,此时 ServerSocketChannel 可以产生一个 SocketChannel 与客户端进行通信,并注册 OP_READ
- 客户端发送数据,Selector 会通知服务端的 SocketChannel 读取数据,这些数据会被写入 Buffer,服务器的应用程序可以从 Buffer 中读取这些数据
- 当服务器的应用程序发送应答消息给客户端时,是向 Buffer 中写入数据,SocketChannel 会从 Buffer 中读取这些数据并发送出去
BIO 时,假如分三次向对端写 100 个字节,那么就要进行三次系统调用。而使用 NIO,可以将 100 个字节写入 Buffer,从 Buffer 读取数据再进行一次系统调用就可以发送数据了。由于系统调用会消耗大量系统资源,所以 NIO 是提升了性能的。类似的,BIO 在读取数据时,不论从系统读取到多少数据都要经过一次系统调用交给应用程序,而 NIO 可以将从操作系统读取的数据先存入 Buffer 中,然后从 Buffer 通过一次系统调用传输给应用程序。
3.4 NIO 编程实践
基础使用代码见 GitHub 上相关章节,注意事项见课程文档。这里主要说一下在读写数据时为什么一般不注册写事件 OP_WRITE。
一般情况下,服务器在写数据时,是不注册 OP_WRITE 直接通过 SocketChannel.write() 写的:
private void handleInput(SelectionKey key) throws IOException {// 由于 SelectionKey 是可以取消的,因此使用前需要先判断是否可用if (key.isValid()) {if (key.isAcceptable()) {// 只有 ServerSocketChannel 才关注 OP_ACCEPTServerSocketChannel ssc = (ServerSocketChannel) key.channel();// 获取和客户端通信的 SocketSocketChannel sc = ssc.accept();System.out.println("有客户端连接");sc.configureBlocking(false);sc.register(selector, SelectionKey.OP_READ);}// 读数据if (key.isReadable()) {SocketChannel sc = (SocketChannel) key.channel();// 如果要读取的数据多于 1024 字节,那么读事件会被触发多次直到读完ByteBuffer buffer = ByteBuffer.allocate(1024);int readBytes = sc.read(buffer);if (readBytes > 0) {// 因为 Channel 写入了 Buffer,因此读的时候需要进行模式切换buffer.flip();// 读取数据做业务处理byte[] bytes = new byte[readBytes];buffer.get(bytes);String message = new String(bytes, "UTF-8");System.out.println("服务器收到消息: " + message);String result = Const.response(message);// 发送应答消息doWrite(sc, result);} else if (readBytes < 0) {// 小于 0 说明链路已经关闭,释放资源key.cancel();sc.close();}}}}private void doWrite(SocketChannel sc, String result) throws IOException {byte[] bytes = result.getBytes();ByteBuffer writeBuffer = ByteBuffer.allocate(bytes.length);// 将字节数组复制到 writeBufferwriteBuffer.put(bytes);// 切换到读模式writeBuffer.flip();sc.write(writeBuffer);}
假如想在 OP_WRITE 下向客户端写数据,就要修改为如下这样:
private void handleInput(SelectionKey key) throws IOException {// 由于 SelectionKey 是可以取消的,因此使用前需要先判断是否可用if (key.isValid()) {...// 添加写数据逻辑if (key.isWritable()) {System.out.println("writable...");SocketChannel sc = (SocketChannel) key.channel();ByteBuffer attachment = (ByteBuffer) key.attachment();if (attachment.hasRemaining()) {System.out.println("write :" + sc.write(attachment) + " byte");} else {// 写完数据后要取消对写事件的注册,否则系统会一直通知写事件key.interestOps(SelectionKey.OP_READ);}}}}private void doWrite(SocketChannel sc, String result) throws IOException {byte[] bytes = result.getBytes();ByteBuffer writeBuffer = ByteBuffer.allocate(bytes.length);// 将字节数组复制到 writeBufferwriteBuffer.put(bytes);// 切换到读模式writeBuffer.flip();
// sc.write(writeBuffer);// register() 注册哪一个事件就只关注该事件,因此这里在注册写事件时不要忘了读,同时将 writeBuffer// 作为附件也一并注册sc.register(selector, SelectionKey.OP_WRITE | SelectionKey.OP_READ, writeBuffer);}
之所以在写完之后要取消对写事件的关注,主要是因为读写事件的触发机制是不一样的。当客户端向服务器发送数据时,服务端有数据可读,就会触发 OP_READ 事件。
而 OP_WRITE 则不同,当通信双方 Socket 连接成功后,操作系统会为每个 Socket 创建两个操作系统级别的缓存(注意并不是应用程序中用到的 Buffer,应用程序是感知不到这个缓存的,这个缓存在操作系统内核中),一个输出缓存,一个输入缓存。当输入缓存中有对端发来的数据时,就会触发 OP_READ 事件,而输出缓存中,只要有空闲空间,就会一直不停的触发 OP_WRITE。
通常都是要写的数据非常多,数据量大于缓冲区需要多次写的时候,才注册 OP_WRITE。
3.5 Reactor 模式
Reactor 翻译为“反应器”,可以延伸为“倒置”、“控制逆转”,即事件处理程序不调用反应器,而是向反应器注册一个事件处理器,当事件到来时调用事件处理程序做出反应。这种控制逆转又称为“好莱坞法则”。
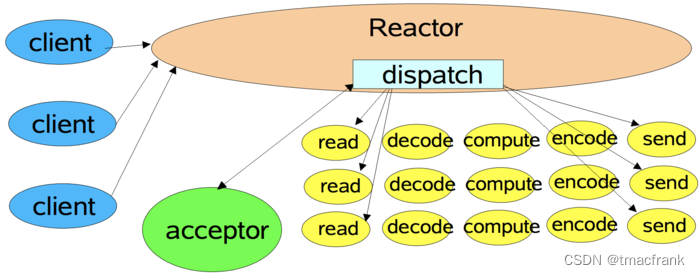
NIO 的 Selector 就扮演着 Reactor 的角色。Reactor 模式又可以分为三种流程:
- 单线程 Reactor 模式:服务器全程只使用一个线程,即 IO 操作(accept、read、write)与业务操作(decode、compute、encode)都在一个线程上处理。这样有一个问题增大 IO 响应的时间。示意图如下:
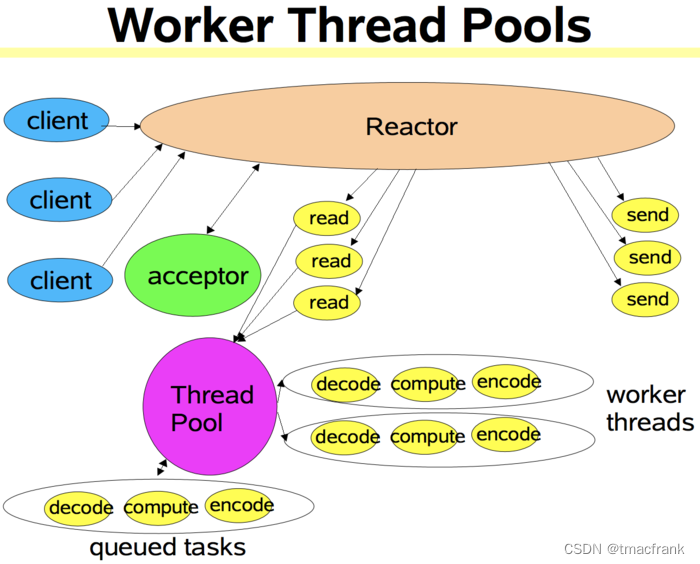
- 单线程 Reactor,工作者线程池:添加工作者线程池,将非 IO 操作从 Reactor 线程中移出交给工作者线程池执行。这种模式在处理大并发、大数据量的业务时是不合适的。因为面对成百上千的 IO 操作,一个线程的处理能力始终是有限的。再比如读取 10M 的数据,在读取时其他 IO 操作是无法进行的。示意图如下:
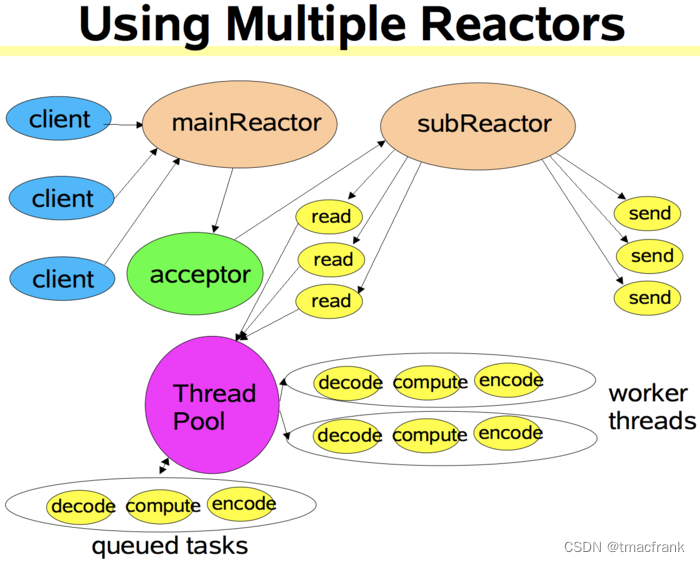
- 多 Reactor 线程模式:针对第二种模式的缺点,再引入一个 Reactor 线程池。Reactor 线程池中的每一 Reactor 线程都会有自己的 Selector、线程和分发的事件循环逻辑。mainReactor 可以只有一个,但 subReactor 一般会有多个。mainReactor 线程主要负责接收客户端的连接请求,然后将接收到的 SocketChannel 传递给 subReactor,由 subReactor 来完成和客户端的通信。示意图如下:
Reactor 模式看似与观察者模式很像,二者的主要区别是观察者模式与单个事件源关联,而反应器模式则与多个事件源关联。当一个主体发生改变时,所有依属体都得到通知。
相关文章:
)
Java 原生网络编程(BIO | NIO | Reactor 模式)
1、基本常识 Socket 是应用层与 TCP/IP 协议族通信的中间软件抽象层,是一组接口,使用了门面模式对应用层隐藏了传输层以下的实现细节。TCP 用主机的 IP 地址加上主机端口号作为 TCP 连接的端点,该端点叫做套接字 Socket。 比如三次握手&…...

大语言模型 11 - 从0开始训练GPT 0.25B参数量 MiniMind2 准备数据与训练模型 DPO直接偏好优化
写在前面 GPT(Generative Pre-trained Transformer)是目前最广泛应用的大语言模型架构之一,其强大的自然语言理解与生成能力背后,是一个庞大而精细的训练流程。本文将从宏观到微观,系统讲解GPT的训练过程,…...
)
【Java ee初阶】HTTP(4)
构造HTTP请求 1)开发中,前后端交互。浏览器运行的网页中,构造出HTTP请求 2)调试阶段,通过构造HTTP请求测试服务器 朴素的方案: 通过tcp socket 的方式构造HTTP请求 按照HTTP请求格式,往TCP…...

永久免费!专为 Apache Doris 打造的可视化数据管理工具 SelectDB Studio V1.1.0 重磅发布!
作为全球领先的开源实时数据仓库, Apache Doris Github Stars 已超过 13.6k,并在 5000 余家中大型企业生产环境得到广泛应用,支撑业务核心场景,成为众多企业数据分析基础设施不可或缺的重要基座。过去,Apache Doris 用…...
React中useDeferredValue与useTransition终极对比。
文章目录 前言一、核心差异对比二、代码示例对比1. useDeferredValue:延迟搜索结果更新2. useTransition:延迟路由切换 三、应用场景总结四、注意事项五、原理剖析1. 核心机制对比2. 关键差异3. 代码实现原理 总结 前言 在React的并发模式下,…...

Git 项目切换到新的远程仓库地址
已存在的 Git 项目切换到新的远程仓库地址,比如你要换成: gitgithub.com:baoing/test-app.git步骤如下: 查看当前的远程仓库地址(可选) git remote -v你会看到类似: origin gitgithub.com:old-user/old…...

科技晚报 AI 速递:今日科技热点一览 丨 2025 年 5 月 17 日
科技晚报AI速递:今日科技热点一览 丨2025年5月17日 我们为您汇总今日的科技领域最新动向,带您快速了解前沿技术、突破性研究及行业趋势。 黄仁勋劝特朗普:AI 芯片出口规则得改,中国紧追其后:英伟达 CEO 黄仁勋在华盛顿 “山与谷论…...

基于OpenCV的SIFT特征和FLANN匹配器的指纹认证
文章目录 引言一、概述二、代码解析1. 图像显示函数2. 核心认证函数3. 匹配点筛选4. 认证判断 三、主程序四、技术要点五、总结 引言 在计算机视觉领域,图像特征匹配是一个非常重要的技术,广泛应用于物体识别、图像拼接、运动跟踪等场景。今天将介绍一个…...

【Linux】共享内存
🌻个人主页:路飞雪吖~ 🌠专栏:Linux 目录 ☃️共享内存 🪄 shmget函数 用来创建共享内存 ✨共享内存的管理指令: 🌠 shmid VS key ✨共享内存函数 🍔 shmget() 创建共享内存 &a…...

Cookie、Session、Token
Cookie 1. 什么是cookie? Cookie 是一种由服务器发送到客户端浏览器的小数据片段,用于存储用户的状态信息。例如,用户登录状态或用户偏好设置可以通过Cookie进行管理。计算机cookie更正式地称为 HTTP cookie、网络 cookie、互联网 cookie 或浏览器 coo…...

设计模式Java
UML类图 概述 类图(Class diagram)是显示了模型的静态结构,特别是模型中存在的类、类的内部结构以及它们与其他类的关系等。类图不显示暂时性的信息。类图是面向对象建模的主要组成部分。 类图的作用 在软件工程中,类图是一种静态的结构图,…...

Word文档图片排版与批量处理工具推荐
先放下载链接:夸克网盘下载 前几天给大家推荐了 Excel 图片调整软件,当时好多小伙伴问有没有 Word 相关的软件。我在网上找了一圈都没找到合适的,最后在我好久之前记录的一个文档里发现了,这不,马上就来给大家推荐,有…...

[案例五] 实体——赋值质量
最近翻阅了实验室其他人编写的一个“质量赋值”功能,能够直接为实体或组件设定质量。出于好奇,我对其进行了分析。由于自己平时没有用到该功能,所以也借此机会学习一下。 在分析过程中,我发现NX 官方其实并没有提供直接修改质量的功能。一般来说,质量是通过“密度 体积”…...
)
手撕四种常用设计模式(工厂,策略,代理,单例)
工厂模式 一、工厂模式的总体好处 解耦:客户端与具体实现类解耦,符合“开闭原则”。统一创建:对象创建交由工厂处理,便于集中控制。增强可维护性:新增对象种类时不需要大改动调用代码。便于扩展:易于管理…...
)
C# 深入理解类(静态函数成员)
静态函数成员 除了静态字段,还有静态函数成员。 如同静态字段,静态函数成员独立于任何类实例。即使没有类的实例,仍然可以调用静 态方法。静态函数成员不能访问实例成员,但能访问其他静态成员。 例如,下面的类包含一…...

数据类型转换
文章目录 基本数据类型(primitive type)整数类型:浮点类型字符类型boolean类型 类型转换类型转换注意点 基本数据类型(primitive type) 整数类型: byte占1个字节范围:-128-127 short占…...

深入理解 TypeScript 中的 unknown 类型:安全处理未知数据的最佳实践
在 TypeScript 的类型体系中,unknown 是一个极具特色的类型。它与 any 看似相似,却在安全性上有着本质差异。本文将从设计理念、核心特性、使用场景及最佳实践等方面深入剖析 unknown,帮助开发者在处理动态数据时既能保持灵活性,又…...

AI:人形机器人的应用场景以及商业化落地潜力分析
应用场景分析 人形机器人的设计使其能够适应人类环境,执行多样化任务。以下是未来主要的应用场景及其详细分析: 医疗与护理 具体应用: 老年护理:协助老年人穿衣、洗澡、喂食,或提供情感陪伴。康复辅助:帮助…...

JavaScript入门【3】面向对象
1.对象: 1.概述: 在js中除了5中基本类型之外,剩下得都是对象Object类型(引用类型),他们的顶级父类是Object;2.形式: 在js中,对象类型的格式为key-value形式,key表示属性,value表示属性的值3.创建对象的方式: 方式1:通过new关键字创建(不常用) let person new Object();// 添…...

亲测有效!OGG 创建抽取进程报错 OGG-08241,如何解决?
前言 今天在测试 OGG 一个功能的时候,需要重新初始化 oggca,所以重装了一下 OGG。重建完之后重新添加抽取进程报错,一直无法添加成功: 经过一翻分析,找到了解决方案,本文记录一下解决过程。 问题描述 OG…...

【第二篇】 初步解析Spring Boot
简介 SpringBoot是由Pivotal团队提供的全新框架,其设计目的是为了用来简化Spring应用的初始搭建以及开发过程的。本文章将详细介绍SpringBoot为什么能够简化项目的搭建以及普通的Spring程序的开发。文章内容若存在错误或需改进的地方,欢迎大家指正&#…...

JVM 机制
目录 一、什么是 JVM: 二、JVM 的运行流程: 三、JVM 内存区域划分: 1、( 1 ) 程序计数器: 1、( 2 ) 元数据区: 1、( 3 ) 栈: 1、( 4 ) 堆: 四、类加载: 1、什么时候会触…...

Java泛型详解
文章目录 1. 引言1.1 什么是泛型1.2 为什么需要泛型1.3 泛型的优势2. 泛型基础2.1 泛型类多个类型参数2.2 泛型方法2.3 泛型接口2.4 类型参数命名约定3. 类型擦除3.1 什么是类型擦除3.2 类型擦除的影响1. 无法获取泛型类型参数的实际类型2. 无法创建泛型类型的数组3. 无法使用`…...

机器学习,深度学习,神经网络,深度神经网络之间有何区别?
先说个人观点:机器学习>神经网络>深度学习≈深度神经网络。深度学习是基于深度神经网络的,深度神经网络和浅层神经网络都是神经网络,而机器学习是包括神经网络在内的算法。 一、机器学习 先说涵盖范围最广的机器学习。机器学习&#…...

AtomicInteger
AtomicInteger 是 Java 并发包 (java.util.concurrent.atomic) 中的一个原子类,用于在多线程环境下对整数进行原子操作。 核心特性 原子性 提供线程安全的原子操作(如自增、加法、比较并交换等),确保在多线程环境中操作不会被中…...
详解:原理、应用与实施)
威布尔比例风险模型(Weibull Proportional Hazards Model, WPHM)详解:原理、应用与实施
威布尔比例风险模型(Weibull Proportional Hazards Model, WPHM)详解:原理、应用与实施 一、核心原理:从威布尔分布到比例风险模型 1. 威布尔分布的数学本质 威布尔分布通过两个关键参数(形状参数 (k) 和尺度参数 (\…...

Dubbo:Docker部署Zookeeper、Dubbo Admin的详细教程和SpringBoot整合Dubbo的实战与演练
🪁🍁 希望本文能给您带来帮助,如果有任何问题,欢迎批评指正!🐅🐾🍁🐥 文章目录 一、背景二、Dubbo概述三、Dubbo与SpringCloud的关系四、Dubbo技术架构五、Docker安装Zoo…...

Windows 上安装下载并配置 Apache Maven
1. 下载 Maven 访问官网: 打开 Apache Maven 下载页面。 选择版本: 下载最新的 Binary zip archive(例如 apache-maven-3.9.9-bin.zip)。 注意:不要下载 -src 版本(那是源码包)。 2. 解压 Mave…...

Unbuntu 命令
Ubuntu 命令速查表 分类命令功能描述示例/常用选项文件与目录ls列出目录内容ls -a(显示隐藏文件); ls -lh(详细列表易读大小) cd切换目录cd ~(主目录); cd ..(上级…...

机器学习-人与机器生数据的区分模型测试-数据处理1
附件为训练数据,总体的流程可以作为参考。 导入依赖 import pandas as pd import os import numpy as np from sklearn.model_selection import train_test_split,GridSearchCV from sklearn.ensemble import RandomForestClassifier,VotingClassifier from skle…...
:认识管道)
【Linux】进程间通信(一):认识管道
📝前言: 这篇文章我们来讲讲进程间通信——认识管道 🎬个人简介:努力学习ing 📋个人专栏:Linux 🎀CSDN主页 愚润求学 🌄其他专栏:C学习笔记,C语言入门基础&a…...

AMD Vivado™ 设计套件生成加密比特流和加密密钥
概括 重要提示:有关使用AMD Vivado™ Design Suite 2016.4 及更早版本进行 eFUSE 编程的重要更新,请参阅AMD设计咨询 68832 。 本应用说明介绍了使用AMD Vivado™ 设计套件生成加密比特流和加密密钥(高级加密标准伽罗瓦/计数器模式 (AES-GCM)…...
)
第三十四节:特征检测与描述-SIFT/SURF 特征 (专利算法)
一、特征检测:计算机视觉的基石 在计算机视觉领域中,特征检测与描述是实现图像理解的核心技术。就像人类通过识别物体边缘、角点等特征来认知世界,算法通过检测图像中的关键特征点来实现: 图像匹配与拼接 物体识别与跟踪 三维重建 运动分析 其中,SIFT(Scale-Invariant F…...

【AI】SpringAI 第二弹:基于多模型实现流式输出
目录 一、基于多模型实现流式输出 1.1 什么是流式输出 1.2 多模型引入 1.3 代码实现 1.3.1 流式输出的API介绍 1.3.2 Flux 源码分析 二、了解 Reactor 模型 三、SSE 协议 一、基于多模型实现流式输出 1.1 什么是流式输出 流式输出(Streaming Output)是指数据在生成过程…...

SQL语句执行问题
执行顺序 select [all|distinct] <目标列的表达式1> AS [别名], <目标列的表达式2> AS [别名]... from <表名1或视图名1> [别名],<表名2或视图名2> [别名]... [where <条件表达式>] [group by <列名>] [having <条件表达式>] [ord…...

模型量化AWQ和GPTQ哪种效果好?
环境: AWQ GPTQ 问题描述: 模型量化AWQ和GPTQ哪种效果好? 解决方案: 关于AWQ(Adaptive Weight Quantization)和GPTQ(Generative Pre-trained Transformer Quantization)这两种量化方法的…...

Github 2025-05-17 Rust开源项目日报 Top10
根据Github Trendings的统计,今日(2025-05-17统计)共有10个项目上榜。根据开发语言中项目的数量,汇总情况如下: 开发语言项目数量Rust项目10Dart项目1RustDesk: 用Rust编写的开源远程桌面软件 创建周期:1218 天开发语言:Rust, Dart协议类型:GNU Affero General Public Li…...

借助 CodeBuddy 打造我的图标预览平台 —— IconWiz 开发实录
我正在参加CodeBuddy「首席试玩官」内容创作大赛,本文所使用的 CodeBuddy 免费下载链接:腾讯云代码助手 CodeBuddy - AI 时代的智能编程伙伴 想做一款自己的图标预览平台 这段时间我在做前端 UI 设计时,常常需要到处找图标素材,复…...
)
KL散度 (Kullback-Leibler Divergence)
KL散度,也称为相对熵 (Relative Entropy),是信息论中一个核心概念,用于衡量两个概率分布之间的差异。给定两个概率分布 P ( x ) P(x) P(x) 和 Q ( x ) Q(x) Q(x)(对于离散随机变量)或 p ( x ) p(x) p(x) 和 q ( x …...

【Linux网络】NAT和代理服务
NAT 之前我们讨论了,IPv4协议中,IP地址数量不充足的问题。 原始报文途径路由器WAN口时,对报文中的源IP进行替换的过程,叫做NAT。 NAT技术当前解决IP地址不够用的主要手段,是路由器的一个重要功能: NAT能…...

DeepSeek赋能电商,智能客服机器人破解大型活动人力困境
1. DeepSeek 与电商客服结合的背景 1.1 电商行业客服需求特点 电商行业具有独特的客服需求特点,这些特点决定了智能客服机器人在该行业的必要性和重要性。 高并发性:电商平台的用户数量庞大,尤其是在促销活动期间,用户咨询量会…...
)
Unity序列化字段、单例模式(Singleton Pattern)
一、序列化字段 在Unity中,序列化字段是一个非常重要的概念,主要用于在Unity编辑器中显示和编辑类的成员变量,或者在运行时将对象的状态保存到文件或网络中。 1.Unity序列化字段的作用 在编辑器中显示和编辑字段:默认情况下&…...

一个可拖拉实现列表排序的WPF开源控件
从零学习构建一个完整的系统 推荐一个可通过拖拉,来实现列表元素的排序的WPF控件。 项目简介 gong-wpf-dragdrop是一个开源的.NET项目,用于在WPF应用程序中实现拖放功能,可以让开发人员快速、简单的实现拖放的操作功能。 可以在同一控件内…...

hadoop.proxyuser.代理用户.授信域 用来干什么的
在Hadoop的core-site.xml文件中存在三个可选配置,如下 <property><name>hadoop.proxyuser.root.hosts</name><value>*</value> </property> <property><name>hadoop.proxyuser.root.groups</name><value…...

python 自动化教程
文章目录 前言整数变量字符串变量列表变量算术操作比较操作逻辑操作if语句for循环遍历列表while循环定义函数调用函数导入模块使用模块中的函数启动Chrome浏览器打开网页定位元素并输入内容提交表单关闭浏览器发送GET请求获取网页内容使…...

C++学习:六个月从基础到就业——C++11/14:列表初始化
C学习:六个月从基础到就业——C11/14:列表初始化 本文是我C学习之旅系列的第四十三篇技术文章,也是第三阶段"现代C特性"的第五篇,主要介绍C11/14中的列表初始化特性。查看完整系列目录了解更多内容。 引言 在C11之前&a…...

城市静音革命:当垃圾桶遇上缓冲器
缓冲垃圾桶的核心原理是通过机械或液压装置实现垃圾桶盖的缓慢闭合,包含以下技术要点:能量吸收机制液压式:通过活塞挤压油液产生阻尼力,将动能转化为热能耗散弹簧式:利用弹性变形储存和释放能量,配合摩…...

数据库的规范化设计方法---3种范式
第一范式(1NF):确保表中的每个字段都是不可分割的基本数据项。 第二范式(2NF):在满足1NF的基础上,确保非主属性完全依赖于主键。 第三范式(3NF):在满足2NF的基…...

p024基于Django的网上购物系统的设计与实现
开发语言:Python框架:djangoPython版本:python3.7.7数据库:mysql 5.7数据库工具:Navicat11开发软件:PyCharm 系统展示 管理员登录 管理员功能界面 用户管理 商品类型管理 商品信息管理 系统管理 订单管理…...

C++跨平台开发:挑战与应对策略
C跨平台开发:挑战与应对策略 在如今设备多样、操作系统碎片化的开发环境中,跨平台能力已成为衡量软件生命力与团队工程效率的重要指标。C 作为高性能系统级语言,在游戏引擎、嵌入式系统、实时渲染等领域依旧坚挺。然而,实现“一次…...