Graph Representation Learning【图最短路径优化/Node2vec/Deepwalk】
文章目录
- Q1:
- 网络性质:
- 1.数据读取与邻接表构建:
- 2.基本特征和连通性:
- 算法思路:
- 1. 广度优先搜索(BFS)标记前驱:
- 2. 回溯生成所有最短路径:
- 实验结果:
- 复杂度分析:
- Q2:
- 算法思路:
- 初始化
- 实验结果:
- 复杂度分析:
- Q3:
- 图表示学习:
- 实验结果:
- 结果分析:
- ps:为什么不同距离度量的样本区分度大有不同?
- 别的尝试:
- 参考:
Q1:
DDI网络构建无向图并找出指定节点i和j的所有最短距离
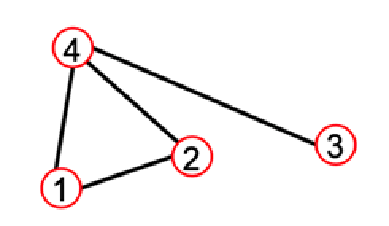
DDI网络可表示为:
G s m a l l = ( V s m a l l , E s m a l l ) V s m a l l = { 1 , 2 , 3 , 4 } E s m a l l = { ( 1 , 2 ) , ( 1 , 3 ) , ( 1 , 4 ) , ( 3 , 4 ) } G_{small}=(V_{small},E_{small})\\ V_{small}=\{1,2,3,4\} \\E_{small}=\{(1,2),(1,3),(1,4),(3,4)\} Gsmall=(Vsmall,Esmall)Vsmall={1,2,3,4}Esmall={(1,2),(1,3),(1,4),(3,4)}
网络性质:
无向无权的大规模稀疏图,我们一般用邻接表存储:
1.数据读取与邻接表构建:
遍历所有边,为每个节点维护其邻接节点列表。对于边 ( (u, v) ),将 ( v ) 加入 ( u ) 的邻接列表,并将 ( u ) 加入 ( v ) 的邻接列表。
Adj [ u ] ← Adj [ u ] ∪ { v } , Adj [ v ] ← Adj [ v ] ∪ { u } \text{Adj}[u] \leftarrow \text{Adj}[u] \cup \{v\}, \quad \text{Adj}[v] \leftarrow \text{Adj}[v] \cup \{u\} Adj[u]←Adj[u]∪{v},Adj[v]←Adj[v]∪{u}
2.基本特征和连通性:
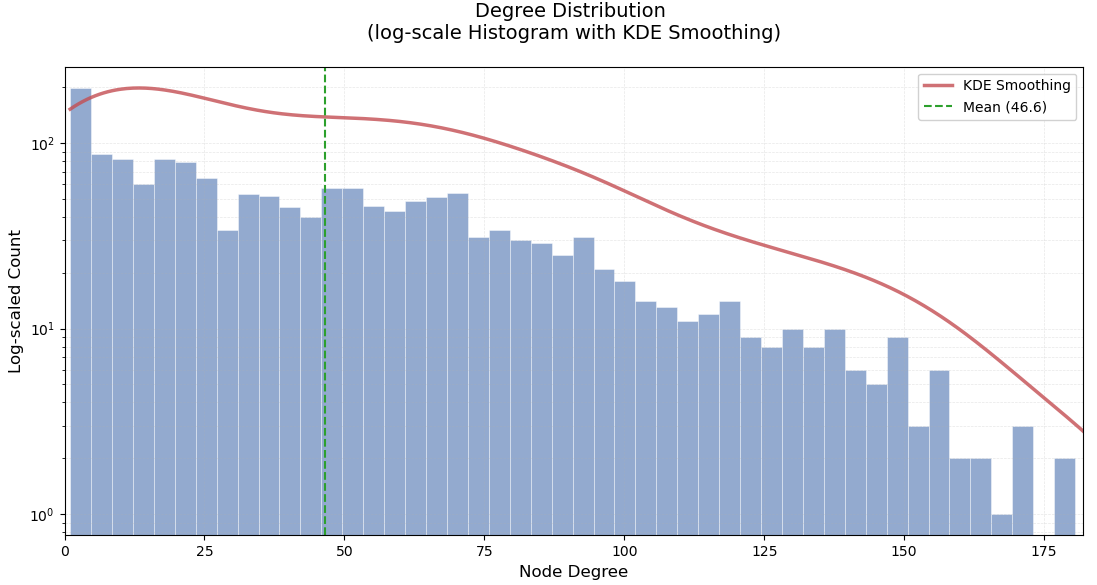
通过dfs得到图的连通性结果如下

-
每个节点平均连接到大约47个其他节点
-
这意味着整个图是一个单一的连通组件,没有孤立的子图,整个网络是完全连通的,任何两个节点之间都存在路径相连
以下为度数分布图:
算法思路:
- 寻找两点之间的所有最短路径,使用**
BFS+回溯**, 因为由上面的分析可知,图的平均度数很高,较为密集,最短路径长度较短,所以递归深度不会太高。 - 但是在路径回溯阶段,虽然直观易实现,但在最短路径数量较多的情况下,递归深度和调用栈开销可能迅速增长,性能下降甚至栈溢出。所以先使用显式栈进行迭代回溯。
- 在回溯过程中,某些节点的路径可能会被多次访问。记忆化缓存可以保存已经计算过的路径,避免再次计算。
1. 广度优先搜索(BFS)标记前驱:
- 初始化距离 (
d[s] = 0),其余节点 (d[v] = inf)。 - 使用队列逐层扩展,更新节点的最短距离和前驱节点:
∀ v ∈ Adj [ u ] , 若 d [ v ] > d [ u ] + 1 ⟹ d [ v ] ← d [ u ] + 1 , prev [ v ] ← { u } 若 d [ v ] = d [ u ] + 1 ⟹ prev [ v ] ← prev [ v ] ∪ { u } \forall v \in \text{Adj}[u], \quad \text{若 } d[v] > d[u] + 1 \implies d[v] \leftarrow d[u] + 1, \ \text{prev}[v] \leftarrow \{u\} \\ \text{若 } d[v] = d[u] + 1 \implies \text{prev}[v] \leftarrow \text{prev}[v] \cup \{u\} ∀v∈Adj[u],若 d[v]>d[u]+1⟹d[v]←d[u]+1, prev[v]←{u}若 d[v]=d[u]+1⟹prev[v]←prev[v]∪{u} - 当队列为空时结束。
2. 回溯生成所有最短路径:
从终点 ( t ) 启动,使用显式栈模拟递归过程,逐步构建所有从起点 ( s ) 到终点 ( t ) 的最短路径。与传统的回溯方法不同,这里我们利用记忆化搜索来缓存计算过的路径,以减少不必要的重复计算。
- 使用栈中元素表示当前遍历状态:
(当前节点, 当前路径)。 - 如果当前节点是起点
s,则路径已经完整,逆序将路径加入结果集中。 - 如果当前节点不是起点,首先检查该节点是否已经有缓存路径(通过
memo字典)。如果有,则直接从缓存中取出路径;否则,遍历当前节点的前驱节点,将所有可能的路径推入栈中。
实验结果:
对于(8,309)、(67,850)、(990,1256)药物的最短路径:

使用time模块:对于最短路径较多的用时较少。


复杂度分析:
- BFS会遍历所有边和节点来计算最短路径,并且回溯最短路径时涉及到路径构建
- 实际最坏时间复杂度比没有缓存时更低,但是由于使用了记忆化搜索,减少了重复计算
O ( E + ( V + E ) + K ⋅ L ) V 为节点数, E 为边数, K 是路径数量 , L 是路径最大长度 O(E + (V + E) + K \cdot L)~~~~~\\V为节点数,E为边数,K是路径数量,L是路径最大长度 O(E+(V+E)+K⋅L) V为节点数,E为边数,K是路径数量,L是路径最大长度
Q2:
计算所有正负药物对的最短距离并可视化对比两类样本的结果
| 列表 | 数据含义 | 药物对的数量 |
|---|---|---|
| DDIpos | DDI网络中存在相互作用的药物对(正样本) | 1601 |
| DDIneg | DDI网络中没有相互作用的药物对(负样本) | 1601 |
算法思路:
- 不同于Q1寻找所有的最短路径, 要计算大量节点间的最短距离,所以我们之间使用BFS即可,考虑到效率,特别是在查询较长路径时,尝试双向广度优先搜索。
- 从起点和终点同时开始搜索,直到两者相遇。这样可以显著减少搜索的空间,尤其是对于大的图,因为搜索空间的半径会从两个方向扩展,通常比从一个方向全图扩展要小。
-
初始化
定义两个队列
Q_s、Q_t,分别从起点s和终点t启动:
dist ( s , s ) = 0 , dist ( t , t ) = 0 \text{dist}(s, s) = 0,\quad \text{dist}(t, t) = 0 dist(s,s)=0,dist(t,t)=0 -
交替扩展搜索队列:
-
从
Q_s中取出节点u及其当前距离d_s,对每个邻居w:w ∉ visited s ⇒ 加入 Q s , dist ( s , w ) = d s + 1 w \notin \text{visited}_s \Rightarrow \text{加入 } Q_s,\quad \text{dist}(s, w) = d_s + 1 w∈/visiteds⇒加入 Qs,dist(s,w)=ds+1
-
从
Q_t中取出节点v及其当前距离d_t,对每个邻居w':w ′ ∉ visited t ⇒ 加入 Q t , dist ( t , w ′ ) = d t + 1 w' \notin \text{visited}_t \Rightarrow \text{加入 } Q_t,\quad \text{dist}(t, w') = d_t + 1 w′∈/visitedt⇒加入 Qt,dist(t,w′)=dt+1
-
-
路径相遇判定:
当存在某个节点
x ∈ visited s ∩ visited t x \in \text{visited}_s \cap \text{visited}_t x∈visiteds∩visitedt
最短路径长度为:
dist ( s , t ) = dist ( s , x ) + dist ( t , x ) \text{dist}(s, t) = \text{dist}(s, x) + \text{dist}(t, x) dist(s,t)=dist(s,x)+dist(t,x) -
不可达判断:
若两个队列均为空仍未相遇,说明s到t不可达。
实验结果:
正负样本对的距离柱状图如下:
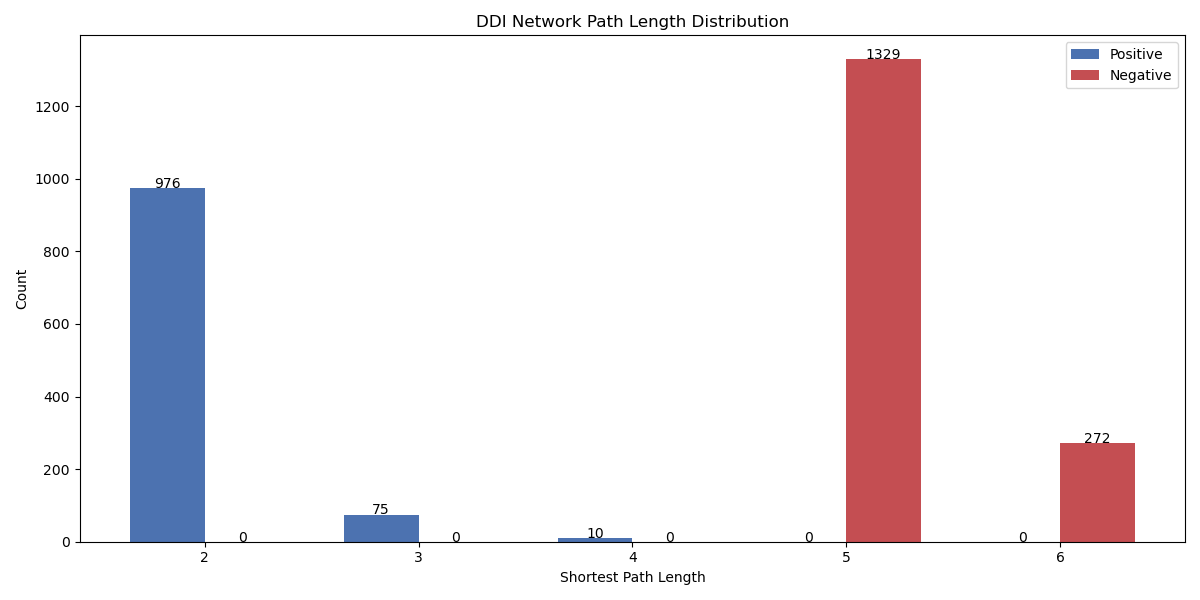
正样本对最短距离几乎都分布在24,负样本对分布在56。
复杂度分析:
最短路径长度为 d,即
d i s t ( s , t ) = d dist(s,t)=d dist(s,t)=d
分别从 ( s )、( t ) 同时扩展,搜索深度减半
假设图的平均度为 𝑑 ˉ ,则 B F S 深度为 𝑘 时,节点数量近似为 𝑂 ( 𝑑 ˉ k ) 搜索节点数近似为: O ( d ˉ d / 2 ) 假设图的平均度为 \bar𝑑 ,则 BFS 深度为 𝑘 时,节点数量近似为 𝑂(\bar𝑑^k)\\搜索节点数近似为:O(\bar{d}^{d/2}) 假设图的平均度为dˉ,则BFS深度为k时,节点数量近似为O(dˉk)搜索节点数近似为:O(dˉd/2)
-
最坏情况:要遍历整个图,时间复杂度仍为
O ( V + E ) V 为节点数, E 为边数 O(V + E) ~~~~~V为节点数,E为边数 O(V+E) V为节点数,E为边数 -
平均情况:因搜索深度减半,效率提高:
O ( d ˉ d / 2 ) O(\bar{d}^{d/2}) O(dˉd/2)
Q3:
对药物节点进行embedding并在嵌入空间计算可视化表征向量的欧式距离/余弦距离,并进行分析比较
图表示学习:
-
Deepwalk:一张图上随机生成节点序列,用这些节点序列以Word2vec方法生成embedding。对比Word2vec,把每一个“词”看做节点,得到每个节点的embedding后求两两embedding的余弦相似度,得到top N的近邻排序推荐给目标节点。
-
Node2vec:添加控制游走方向的参数,BFS更体现结构性,DFS更体现同质性(远端节点)

-
参数p:控制“回头"概率
-
参数q:控制偏向BFS or DFS
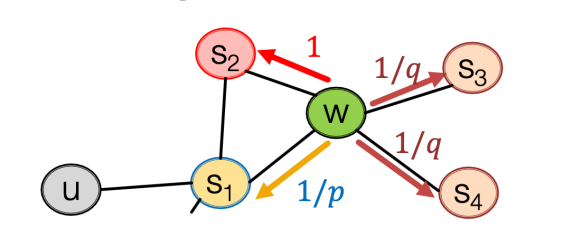
-
实验结果:
-
节点嵌入:
dimensions=128,walk_length=30,num_walk=100 -
node2vec: 超参设置不同,对比实验结果如下:

boxplot绘制直观展示:
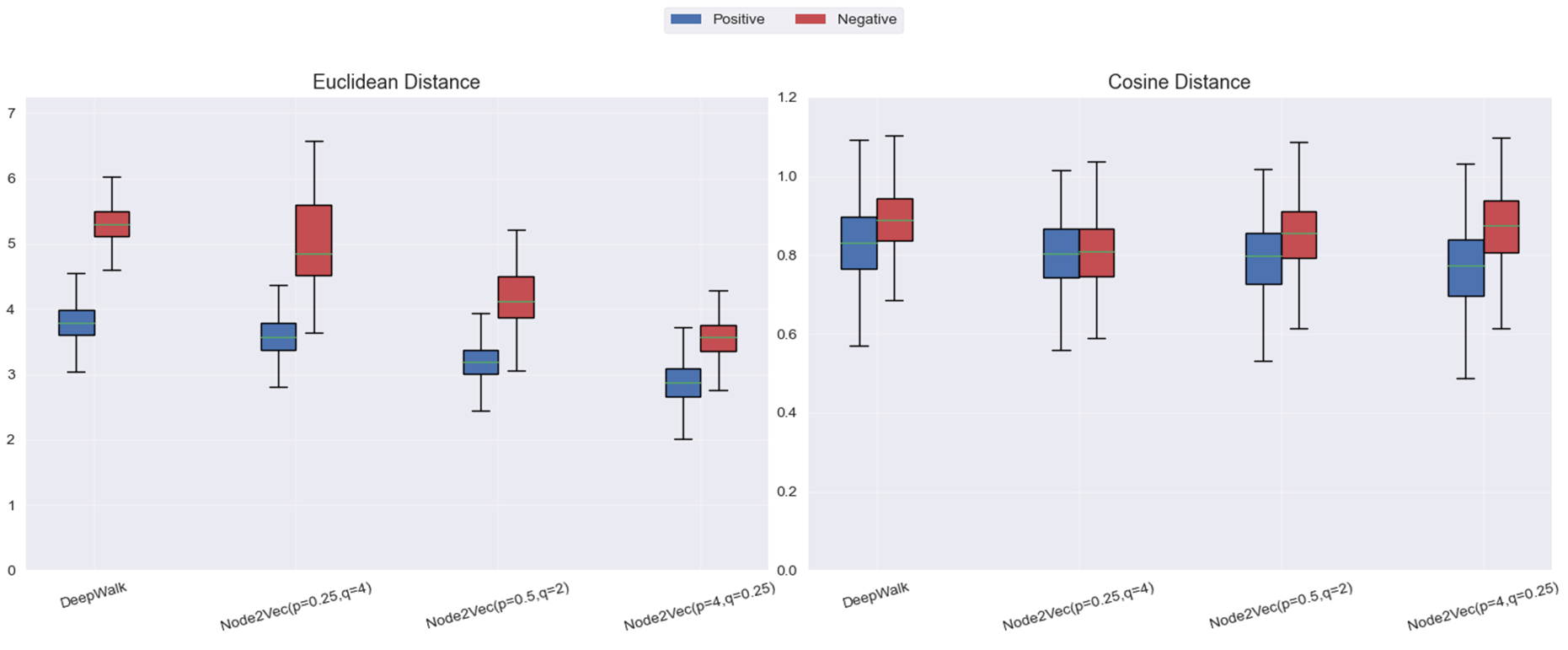
结果分析:
- Deepwalk:采用 均匀 的随机步长探索邻域。这样,DeepWalk 强调的是 节点之间的共现频率,由于没有对邻域进行加权或偏向某一类邻域结构,DeepWalk 对 直接连接节点对 的敏感度相对较低,无法很好地区分 局部 邻域的细节。
- Node2vec:
- 当 p 值较小,q 值较大时,Node2Vec 强调 局部邻域结构。此时,模型倾向于对 直接连接的节点对 给予较高的权重,使得正样本(直接连接的节点对)的欧氏距离显著小于负样本。这使得 局部结构 更容易被区分。虽然这种设置能够有效提高欧氏距离的区分度,但 余弦距离 的区分度相对较弱,因为它对空间的聚集性不如欧氏距离敏感。
- 当 p 值较大,q 值较小时,Node2Vec 强调 全局结构,类似于 深度优先搜索(DFS)。在这种设置下,Node2Vec 更倾向于 捕捉较远的、非直接连接节点的关系,从而使得正负样本在 余弦距离 上的分布更加分散,区分度更佳。但与此同时,由于较大 p 值导致的 探索全局结构,负样本和正样本的 欧氏距离 变得相对较小,且整体的聚集度较高。
ps:为什么不同距离度量的样本区分度大有不同?
如果主要关注近邻节点,直接相连的节点关注度较高,欧氏距离更容易区分,而余弦距离 的区分度较弱,因为余弦距离对相似性度量的需求更加依赖于 整体方向,而不单单是相对距离。但是如果更倾向捕捉到节点在 全局图结构中的角色,正负样本的 欧氏距离 会趋于较小,因为这时节点间的连接不再仅限于直接邻域。
别的尝试:
- 鉴于图神经网络具备端到端训练的能力,后尝试采用生成式模型来学习节点的表示(embedding),GAE 与 VGAE 本质上建模的是图数据的生成过程,因此在理论上具备较强的表达能力。
- 但是,查阅到文献中普遍指出这类模型依赖于节点的属性信息作为输入特征。而在本实验中,图中仅包含节点及其连接关系,缺乏节点特征,因此只能使用全1或one-hot等虚拟特征作为替代。在这种特征缺失的情况下,模型难以从输入中学习到有效的结构区分信息,最终导致 GAE/VGAE 的实验表现明显低于Node2Vec 方法。
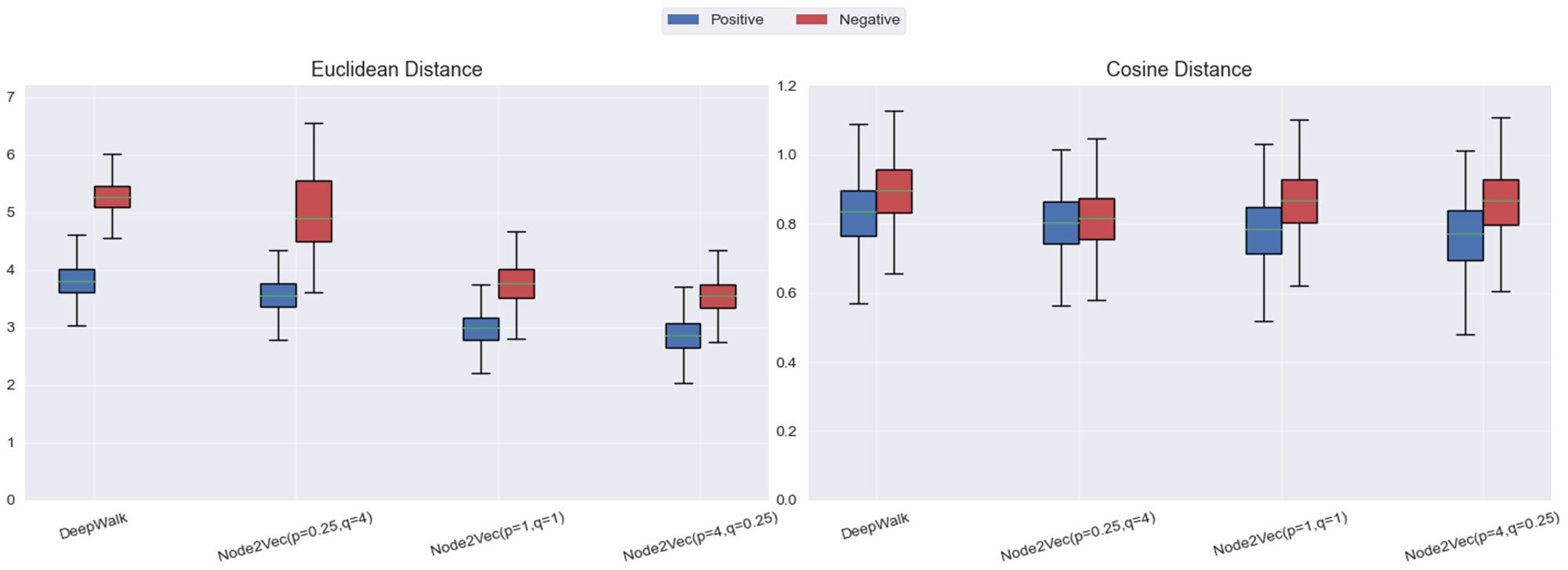
参考:
[1] CS224W | Home (stanford.edu)
[2] 1.1 - Why Graphs_哔哩哔哩_bilibili
[3] Graph Embedding - (maelfabien.github.io)
[4] rfp0191-wangAemb.pdf (kdd.org)
相关文章:

Graph Representation Learning【图最短路径优化/Node2vec/Deepwalk】
文章目录 Q1:网络性质:1.数据读取与邻接表构建:2.基本特征和连通性: 算法思路:1. 广度优先搜索(BFS)标记前驱:2. 回溯生成所有最短路径: 实验结果:复杂度分析: Q2&#x…...

ZYNQ Overlay硬件库使用指南:用Python玩转FPGA加速
在传统的FPGA开发中,硬件设计需要掌握Verilog/VHDL等硬件描述语言,这对软件开发者而言门槛较高。Xilinx的PYNQ框架通过Overlay硬件库彻底改变了这一现状——开发者只需调用Python API即可控制FPGA的硬件模块,实现硬件加速与灵活配置。本文将深入探讨ZYNQ Overlay的核心概念、…...

Git基础使用方法与命令总结
Git 是一个分布式版本控制系统,用于跟踪代码或文件的修改历史。以下是 Git 的基础使用方法和常用命令,适合快速上手: 1. 安装与配置 安装 Git 下载地址:https://git-scm.com/downloads(支持 Windows/macOS/Linux&…...

rust语言,与c,go语言一样也是编译成二进制文件吗?
是的,Rust 和 C、Go 一样,默认情况下会将代码编译成二进制可执行文件(如 ELF、PE、Mach-O 等格式),但它们的编译过程和运行时特性有所不同: 1. Rust(类似 C,直接编译为机器码&#x…...

从银行排队到零钱支付:用“钱包经济学”重构Java缓存认知
"当你的系统还在频繁访问数据库银行时,聪明的开发者早已学会用钱包零钱策略实现毫秒级响应——本文将用理财思维拆解缓存设计精髓,教你如何让代码学会小额快付的架构艺术。" 【缓存】作为程序员必须理解的概念之一,让我们用 「钱…...

Json rpc 2.0比起传统Json在通信中的优势
JSON-RPC 2.0 相较于直接使用传统 JSON 进行通信,在协议规范性、开发效率、通信性能等方面具有显著优势。以下是核心差异点及技术价值分析: 一、结构化通信协议,降低开发成本 传统 JSON 通信需要开发者自定义数据结构和处理逻辑,…...

无缝部署您的应用程序:将 Jenkins Pipelines 与 ArgoCD 集成
在 DevOps 领域,自动化是主要目标之一。这包括自动化软件部署方式。与其依赖某人在部署软件的机器上进行 rsync/FTP/编写软件,不如使用 CI/CD 的概念。 CI,即持续集成,是通过代码提交创建工件的步骤。这可以是 Docker 镜像&#…...
 2-5-1 GB/T 25070—2019 附录B (资料性附录)第三级系统安全保护环境设计示例)
网络安全-等级保护(等保) 2-5-1 GB/T 25070—2019 附录B (资料性附录)第三级系统安全保护环境设计示例
################################################################################ 文档标记说明: 淡蓝色:时间顺序标记。 橙色:为网络安全标准要点。 引用斜体:为非本文件内容,个人注解说明。 加粗标记:…...

精准掌控张力动态,重构卷对卷工艺设计
一、MapleSim Web Handling Library仿真和虚拟调试解决方案 在柔性材料加工领域,卷对卷(Roll-to-Roll)工艺的效率与质量直接决定了产品竞争力。如何在高动态生产场景中实现张力稳定、减少断裂风险、优化加工速度,是行业长期面临的…...

怎么使用python进行PostgreSQL 数据库连接?
使用Python连接PostgreSQL数据库 在Python中连接PostgreSQL数据库,最常用的库是psycopg2。以下是详细的使用指南: 安装psycopg2 首先需要安装psycopg2库: pip install psycopg2 # 或者使用二进制版本(安装更快) pi…...

SQL Server权限设置的几种方法
SQL Server 的权限设置是数据库安全管理的核心,正确配置权限可以有效防止数据泄露、误操作和恶意篡改。下面详细介绍 SQL Server 权限设置的方法,涵盖从登录名创建到用户授权的完整流程。 一、权限设置的基本概念 SQL Server 的权限体系主要包括以下几…...
 - Neo4j安装教程(Windows))
Neo4j(一) - Neo4j安装教程(Windows)
文章目录 前言一、JDK与Neo4j版本对应关系二、JDK11安装及配置1. JDK11下载2. 解压3. 配置环境变量3.1 打开系统属性设置3.2 新建系统环境变量3.3 编辑 PATH 环境变量3.4 验证环境变量是否配置成功 三、Neo4j安装(Windows)1. 下载并解压Neo4j安装包1.1 下…...

idea启用lombok
有lombok的项目在用idea打开的时候会提示启用lombok,但是。。。不小心就落下了...

uniapp婚纱预约小程序
uniapp婚纱预约小程序,这套设计bug很多,是一个半成品,一个客户让我修改,很多问题,页面显示不了,评论不能用,注册不能用,缺少表,最后稍微改一下,但是也有小问题…...

基于OpenCV的SIFT特征匹配指纹识别
文章目录 引言一、概述二、关键代码解析1. SIFT特征提取与匹配2. 指纹身份识别3. 姓名映射 三、使用示例四、技术分析五、完整代码六、总结 引言 指纹识别是生物特征识别技术中最常用的方法之一。本文将介绍如何使用Python和OpenCV实现一个简单的指纹识别系统,该系…...

Vue3 加快页面加载速度 使用CDN外部库的加载 提升页面打开速度 服务器分发
介绍 CDN(内容分发网络)通过全球分布的边缘节点,让用户从最近的服务器获取资源,减少网络延迟,显著提升JS、CSS等静态文件的加载速度。公共库(如Vue、React、Axios)托管在CDN上,减少…...

C++23:ranges::iota、ranges::shift_left和ranges::shift_right详解
文章目录 引言ranges::iota定义与功能使用场景代码示例 ranges::shift_left定义与功能使用场景代码示例 ranges::shift_right定义与功能使用场景代码示例 总结 引言 C23作为C编程语言的一个重要版本,为开发者带来了许多新的特性和改进。其中,ranges::io…...

Spring 框架中适配器模式的五大典型应用场景
Spring 框架中适配器模式的应用场景 在 Spring 框架中,适配器模式(Adapter Pattern)被广泛应用于将不同组件的接口转化为统一接口,从而实现组件间的无缝协作。以下是几个典型的应用场景: 1. HandlerAdapter - MVC 请…...
ScrollList滚动数据列表)
【Unity】 HTFramework框架(六十五)ScrollList滚动数据列表
更新日期:2025年5月16日。 Github 仓库:https://github.com/SaiTingHu/HTFramework Gitee 仓库:https://gitee.com/SaiTingHu/HTFramework 索引 一、ScrollList滚动数据列表二、使用ScrollList1.快捷创建ScrollList2.ScrollList的属性3.自定义…...

Android SwitchButton 使用详解:一个实际项目的完美实践
Android SwitchButton 使用详解:一个实际项目的完美实践 引言 在最近开发的 Android 项目中,我遇到了一个需要自定义样式开关控件的需求。经过多方比较,最终选择了功能强大且高度可定制的 SwitchButton 控件。本文将基于实际项目中的使用案…...

【C++ 基础数论】质数判断
质数判断 质数:对于所有大于 1 的自然数而言,如果该数除 1 和自身以外没有其它因数 / 约数,则该数被称为为质数,质数也叫素数。 如何判定一个数是否为质数呢? 一个简单的方法是 试除法 : 对于一个数 n&…...
)
【数据结构】手撕AVL树(万字详解)
目录 AVL树的概念为啥要有AVL树?概念 AVL树节点的定义AVL树的插入AVL树的旋转左单旋右单旋左右双旋右左双旋 AVL树的查找AVL树的验证end AVL树的概念 为啥要有AVL树? 在上一章节的二叉搜索树中,我们在插入节点的操作中。有可能一直往一边插…...

Chrome代理IP配置教程常见方式附问题解答
在网络隐私保护和跨境业务场景中,为浏览器配置代理IP已成为刚需。无论是访问地域限制内容、保障数据安全,还是管理多账号业务,掌握Chrome代理配置技巧都至关重要。本文详解三种主流代理设置方式,助你快速实现精准流量管控。 方式一…...

SpringBoot + Shiro + JWT 实现认证与授权完整方案实现
SpringBoot Shiro JWT 实现认证与授权完整方案 下面博主将详细介绍如何使用 SpringBoot 整合 Shiro 和 JWT 实现安全的认证授权系统,包含核心代码实现和最佳实践。 一、技术栈组成 技术组件- 作用版本要求SpringBoot基础框架2.7.xApache Shiro认证和授权核心1.…...

深入解析VPN技术原理:安全网络的护航者
在当今信息化迅速发展的时代,虚拟私人网络(VPN)技术成为了我们在互联网时代保护隐私和数据安全的重要工具。VPN通过为用户与网络之间建立一条加密的安全通道,确保了通讯的私密性与完整性。本文将深入解析VPN的技术原理、工作机制以…...

OceanBase 的系统变量、配置项和用户变量有何差异
在继续阅读本文之前,大家不妨先思考一下,数据库中“系统变量”、“用户变量”以及“配置项”这三者之间有何不同。如果感到有些模糊,那么本文将是您理清这些概念的好帮手。 很多用户在使用OceanBase数据库中的“配置项”和“系统变量”&#…...

ReinboT:通过强化学习增强机器人视觉-语言操控能力
25年5月来自浙大和西湖大学的论文“ReinboT: Amplifying Robot Visual-Language Manipulation with Reinforcement Learning”。 视觉-语言-动作 (VLA) 模型通过模仿学习在一般机器人决策任务中展现出巨大潜力。然而,训练数据的质量参差不齐通常会限制这些模型的性…...

MySQL联表查询:多表关联与嵌套查询指南
引言 各位数据库爱好者们好!今天我们要挑战MySQL查询技能的高阶关卡——复杂查询 🚀。在真实业务场景中,数据往往分散在多个表中,就像拼图的各个碎片,只有掌握了多表查询的"拼图技巧",才能将它们…...
)
QBasic 一款古老的编程语言在现代学习中的价值(附程序)
QBasic(Quick Beginner’s All-purpose Symbolic Instruction Code)是微软公司于 1991 年推出的一款简单易学的编程语言,作为BASIC语言的变种,它曾广泛应用于教育领域和初学者编程入门。尽管在当今Python、Java等现代编程语言主导…...

基于Backtrader库的均线策略实现与回测
本文将通过Python语言和强大的Backtrader库,详细介绍如何实现一个基于均线的简单交易策略,并进行历史数据的回测。将一步步构建这个策略,从数据获取、策略定义到回测结果分析,帮助你深入理解并掌握这一过程。 一、环境配置与库安装 1.1 安装必要的Python库 确保你已经安…...
面试题)
Elasticsearch 分词与字段类型(keyword vs. text)面试题
Elasticsearch 分词与字段类型(keyword vs. text)面试题 🔍 目录 基础概念底层存储查询影响多字段聚合与排序分词器实战排查总结基础概念 💡 问题1:Elasticsearch 中的 keyword 和 text 类型有什么区别? 👉 查看参考答案 对比项keywordtext分词(Analysis)❌ 不进…...

Java 后端给前端传Long值,精度丢失的问题与解决
为什么后端 Long 类型 ID 要转为 String? 在前后端分离的开发中,Java 后端通常使用 Long 类型作为主键 ID(如雪花算法生成的 ID)。但如果直接将 Long 返回给前端,可能会导致前端精度丢失的问题,特别是在 J…...

【C++】 —— 笔试刷题day_29
一、排序子序列 题目解析 一个数组的连续子序列,如果这个子序列是非递增或者非递减的;这个连续的子序列就是排序子序列。 现在给定一个数组,然后然我们判断这个子序列可以划分成多少个排序子序列。 例如:1 2 3 2 2 1 可以划分成 …...

高光谱遥感图像处理之数据分类的fcm算法
基于模糊C均值聚类(FCM)的高光谱遥感图像分类MATLAB实现示例 %% FCM高光谱图像分类示例 clc; clear; close all;%% 数据加载与预处理 % 加载示例数据(此处使用公开数据集Indian Pines的简化版) load(indian_pines.mat); % 包含变…...

衡量 5G 和未来网络的安全性
大家读完觉得有帮助记得关注和点赞!!! 抽象 在当今日益互联和快节奏的数字生态系统中,移动网络(如 5G)和未来几代(如 6G)发挥着关键作用,必须被视为关键基础设施。确保其…...

【Vite】前端开发服务器的配置
定义一些开发服务器的行为和代理规则 服务器的基本配置 server: {host: true, // 监听所有网络地址port: 8081, // 使用8081端口open: true, // 启动时自动打开浏览器cors: true // 启用CORS跨域支持 } 代理配置 proxy: {/api: {target: https://…...
)
文章记单词 | 第85篇(六级)
一,单词释义 verb /vɜːrb/- n. 动词wave /weɪv/- v. 挥手;波动;挥舞 /n. 波浪;波;挥手add /d/- v. 增加;添加;补充说liberal /ˈlɪbərəl/- adj. 自由的;开明的;慷…...

通过实例讲解螺旋模型
目录 一、螺旋模型的核心概念 二、螺旋模型在电子商城系统开发中的应用示例 第 1 次螺旋:项目启动与风险初探...
Android各版本新特性)
(面试)Android各版本新特性
Android 6.0 (Marshmallow, API 23) 运行时权限管理:用户可在应用运行时动态授予或拒绝权限,取代安装时统一授权4。Doze模式与应用待机:优化后台耗电,延长设备续航5。指纹识别支持:原生API支持指纹身份验证。 Android…...

如何有效的开展接口自动化测试?
🍅 点击文末小卡片,免费获取软件测试全套资料,资料在手,涨薪更快 一、简介 接口自动化测试是指使用自动化测试工具和脚本对软件系统中的接口进行测试的过程。其目的是在软件开发过程中,通过对接口的自动化测试来提高测…...

当 PyIceberg 和 DuckDB 遇见 AWS S3 Tables:打造 Serverless 数据湖“开源梦幻组合”
引言 在一些大数据分析场景比如电商大数据营销中,我们需要快速分析存储海量用户行为数据(如浏览、加购、下单),以进行用户行为分析,优化营销策略。传统方法依赖 Spark/Presto 集群或 Redshift 查询 S3 上的 Parquet/O…...

泰迪杯特等奖案例深度解析:基于MSER-CNN的商品图片字符检测与识别系统设计
(第四届泰迪杯数据挖掘挑战赛特等奖案例全流程拆解) 一、案例背景与核心挑战 1.1 行业痛点与场景需求 在电商平台中,商品图片常包含促销文字(如“3折起”“限时秒杀”),但部分商家采用隐蔽文字误导消费者(如“起”字极小或位于边角)。传统人工审核效率低(日均处理量…...

开发工具指南
后端运维场用工具 工具文档简介1panel安装指南运维管理面板网盘功能介绍网盘jenkins可以通过1panel 进行安装jpom辅助安装文档后端项目发布工具...
)
将 Element UI 表格元素导出为 Excel 文件(处理了多级表头和固定列导出的问题)
import { saveAs } from file-saver import XLSX from xlsx /*** 将 Element UI 表格元素导出为 Excel 文件* param {HTMLElement} el - 要导出的 Element UI 表格的 DOM 元素* param {string} filename - 导出的 Excel 文件的文件名(不包含扩展名)*/ ex…...
)
图像对比度调整(局域拉普拉斯滤波)
一、背景介绍 之前刷对比度相关调整算法,找到效果不错,使用局域拉普拉斯做图像对比度调整,尝试复现和整理了下相关代码。 二、实现流程 1、基本原理 对输入图像进行高斯金字塔拆分,对每层的每个像素都针对性处理,生产…...

【控制波形如何COPY并无痛使用】
控制波形如何COPY并无痛使用 波形分析思路概况记录波形 波形分析 通过逻辑分析仪可以解析到设备的控制波形,在一些对于电机控制类的设备上显得尤为重要。通过分析不同波形,将PWM的波形存储到程序中得以实现,并建立合理的数据结构。 思路概…...

CSDN-2024《AGP-Net: Adaptive Graph Prior Network for Image Denoising》
推荐深蓝学院的《深度神经网络加速:cuDNN 与 TensorRT》,课程面向就业,细致讲解CUDA运算的理论支撑与实践,学完可以系统化掌握CUDA基础编程知识以及TensorRT实战,并且能够利用GPU开发高性能、高并发的软件系统…...

使用IDEA开发Spark Maven应用程序【超详细教程】
一、创建项目 创建maven项目 二、修改pom.xml文件 创建好项目后,在pom.xml中改为: <?xml version"1.0" encoding"UTF-8"?> <project xmlns"http://maven.apache.org/POM/4.0.0"xmlns:xsi"http://www.w…...

深入探索MCP通信:构建高效的MCP Client
在现代软件开发中,高效的通信机制是构建复杂系统的关键。MCP(Model-Controller-Proxy)架构作为一种新兴的开发模式,提供了强大的工具来实现客户端与服务器之间的高效通信。本文将通过实际代码示例,详细探讨如何使用MCP…...

【第76例】IPD流程实战:华为业务流程架构BPA进化的4个阶段
目录 简介 第一个阶段,业务流程架构BPA1.0 第二个阶段,业务流程架构BPA2.0 BPA3.0、4.0 作者简介 简介 不管业务是复杂还是简单,企业内外的所有事情、所有业务都最终会归于流程。 甚至是大家经常说的所谓的各种方法论,具体的落脚点还是在流程上。 比如把大象放进冰…...