当 PyIceberg 和 DuckDB 遇见 AWS S3 Tables:打造 Serverless 数据湖“开源梦幻组合”
引言
在一些大数据分析场景比如电商大数据营销中,我们需要快速分析存储海量用户行为数据(如浏览、加购、下单),以进行用户行为分析,优化营销策略。传统方法依赖 Spark/Presto 集群或 Redshift 查询 S3 上的 Parquet/ORC 文件,这对于需要快速迭代、按需执行的分析来说,成本高、运维复杂且响应不够敏捷。
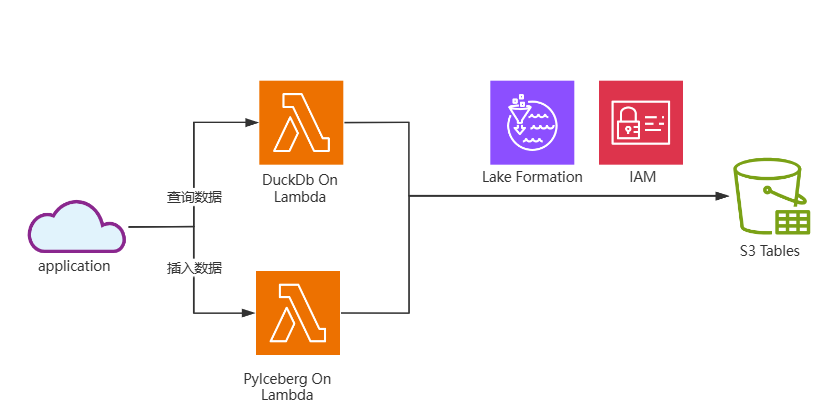
本文将介绍一种现代化的 Serverless 解决方案:利用 S3 Tables(内置优化的 Apache Iceberg 支持)作为存储基础,并结合 PyIceberg 的便捷性与 DuckDB 的高性能嵌入式分析能力,直接在 AWS Lambda 等环境中实现对 S3 数据的低成本、高效率即时查询,彻底摆脱集群运维的负担,加速您的用户行为分析。关键工具及技术点:
- S3 Tables:在 S3 上为表格数据(采用内建优化的 Apache Iceberg 格式)设计的、具备自动性能优化的智能对象存储。
- Lambda:提供按需运行代码的无服务器计算能力
- PyIceberg:Iceberg 官方开源项目,提供简洁的 Python API 来操作 Iceberg 表
- DuckDB:高性能嵌入式分析引擎,支持 Iceberg rest catalog 接口
|
|
核心实践
使用 PyIceberg 创建和插入 S3 Tables
首先,安装 python 依赖
pip install pyiceberg[s3fs, pyarrow]创建表和插入表的核心代码如下,通过 pyiceberg 对接 S3 Tables 的 rest catalog api 来实现 catalog 的获取,从而实现表的创建、列出,以及数据的插入等操作。
from pyiceberg.catalog import load_catalog
import pyarrow as pa
rest_catalog = load_catalog("catalog_name",**{"type": "rest","warehouse": "arn:aws:s3tables:us-west-2:${awsAccountId}:bucket/testtable","uri": "https://s3tables.us-west-2.amazonaws.com/iceberg","rest.sigv4-enabled": "true","rest.signing-name": "s3tables","rest.signing-region": "us-west-2","py-io-impl": "pyiceberg.io.fsspec.FsspecFileIO"}
)
# 新建namespace
rest_catalog.create_namespace("namespace_example")
# 新建表
rest_catalog.create_table("namespace_example.test_table",schema=pa.schema([("id", pa.int32()),("data", pa.string()),])
)
# 打印表列表
tables_list = rest_catalog.list_tables("namespace_example")
print(tables_list)
# 获取表对象
table = rest_catalog.load_table("namespace_example.test_table")
df = pa.Table.from_pylist([{"id": 303, "data": 'test insert icb'}], schema=table.schema().as_arrow()
)
#插入表
table.append(df)
# 读取表并打印
for row in table.scan().to_arrow().to_pylist():
print(row)
可以先通过本地配置 AWS CLI 权限然后运行代码进行测试,然后通过 docker 的方式部署 Lambda。
参考 Dockerfile:
FROM public.ecr.aws/lambda/python:3.12
COPY requirements.txt ${LAMBDA_TASK_ROOT}
RUN pip install -r requirements.txt
COPY lambda_function.py ${LAMBDA_TASK_ROOT}
CMD [ "lambda_function.handler" ]
使用 DuckDB 在 S3 Tables 进行复杂数据分析查询
这里使用 1.2.1 版本的 DuckDB,通过 pip install duckdb==1.2.1 来安装,DuckDB 最新的夜间版本插件支持了 Apache Iceberg REST 目录,而 S3 Tables 也有 REST 目录接口。可以通过在 Lambda 上部署 DuckDB 来读取查询分析 S3 Tables 里面的数据。也可以把 DuckDB 嵌入到您的应用程序中直接查询 S3 Tables。
DuckDB 的 Lambda 实现代码如下,结合了 boto3 的 S3 Tables 客户端,通过 api 把 S3 Tables 里面的桶加载到 DuckDB 的 catalog 中,后续就可以直接通过 sql 来进行查询了。Lambda 的入口函数接收 sql,然后返回 sql 的执行结果,示例 sql: Select * from bucketname.namespace.tablename 就可以直接查询出对应桶里面的表的数据了,需要注意的是在 DuckDB 里面一般通过 DETACH 和 ATTACH 来获取最新的 catalog 表元数据。
import os
import duckdb
import boto3
os.environ['HOME'] = '/tmp'
con = duckdb.connect(database=':memory:', config={'memory_limit': '9GB','worker_threads': 5,'temp_directory':'/tmp/file/overmem'})
# 验证设置
con.execute("""
FORCE INSTALL aws FROM core_nightly;
FORCE INSTALL httpfs FROM core_nightly;
FORCE INSTALL iceberg FROM core_nightly;
CREATE SECRET (TYPE s3,PROVIDER credential_chain
);
""")
s3tables = boto3.client('s3tables')
table_buckets = s3tables.list_table_buckets(maxBuckets=1000)['tableBuckets']
def handler(event, context):for table_bucket in table_buckets:name = table_bucket['name']arn = table_bucket['arn']try:con.execute(f"DETACH {name};")except:passcon.execute(f"""ATTACH '{arn}' AS {name} (TYPE iceberg,ENDPOINT_TYPE s3_tables);""")sql = event.get("sql")try:result = con.execute(sql).fetchall()return {"statusCode": 200,"result": result}except Exception as e:return {"statusCode": 500,"error": str(e)}
Dockerfile 可以参考插入部分的 Dockerfile,通过镜像部署到 Lambda,并设置好对应的 IAM 角色权限以及 Lambda 的超时以及内存设置。这里代码通过 duckdb.connect(database=’:memory:’, config={‘memory_limit’: ‘9GB’,’worker_threads’: 5,’temp_directory’:’/tmp/file/overmem’})来设置最大内存的使用和工作的线程数,这个可以根据实际的需要来调整
数据分析实践
测试数据集:电商用户行为数据,总量 13 亿数据,字段如下:
user_id STRING ‘用户ID(非真实ID),经抽样&字段脱敏处理后得到’
item_id STRING ‘商品ID(非真实ID),经抽样&字段脱敏处理后得到’
item_category STRING ‘商品类别ID(非真实ID),经抽样&字段脱敏处理后得到’
behavior_type STRING ‘用户对商品的行为类型,包括浏览、收藏、加购物车、购买,pv,fav,cart,buy)’
behavior_time STRING ‘行为时间,精确到小时级别’
测试 sql:用户行为数据漏斗分析
WITH user_behavior_counts AS (SELECTuser_id,SUM(CASE WHEN behavior_type = 'pv' THEN 1 ELSE 0 END) AS view_count,SUM(CASE WHEN behavior_type = 'fav' THEN 1 ELSE 0 END) AS favorite_count,SUM(CASE WHEN behavior_type = 'cart' THEN 1 ELSE 0 END) AS cart_count,SUM(CASE WHEN behavior_type = 'buy' THEN 1 ELSE 0 END) AS purchase_countFROM testtable.testdb.commerce_shoppingGROUP BY user_id
),
funnel_stages AS (SELECTCOUNT(DISTINCT user_id) AS total_users,COUNT(DISTINCT CASE WHEN view_count > 0 THEN user_id END) AS users_with_views,COUNT(DISTINCT CASE WHEN favorite_count > 0 THEN user_id END) AS users_with_favorites,COUNT(DISTINCT CASE WHEN cart_count > 0 THEN user_id END) AS users_with_cart_adds,COUNT(DISTINCT CASE WHEN purchase_count > 0 THEN user_id END) AS users_with_purchasesFROM user_behavior_counts
)
SELECTtotal_users,users_with_views,users_with_favorites,users_with_cart_adds,users_with_purchases,ROUND(100.0 * users_with_views / total_users, 2) AS view_rate,ROUND(100.0 * users_with_favorites / users_with_views, 2) AS view_to_favorite_rate,ROUND(100.0 * users_with_cart_adds / users_with_favorites, 2) AS favorite_to_cart_rate,ROUND(100.0 * users_with_purchases / users_with_cart_adds, 2) AS cart_to_purchase_rate,ROUND(100.0 * users_with_purchases / total_users, 2) AS overall_conversion_rate
FROM funnel_stages;
Lambda 测试结果:消耗内存 1934M
用时:37s
关键优势
将 PyIceberg 和 DuckDB 运行在 AWS Lambda 上来访问 S3 上的 Iceberg 表,这种 Serverless 数据湖模式主要的优势如下:
- 低门槛:主要依赖 python 和 sql,这两种是数据开发领域最常见的技能,大大降低了学习和使用的门槛,同时基础设施 0 依赖且易于部署,不需要投入基础设施运维。
- 高性价比:Lambda 按实际计算时间付费且自动伸缩,而 S3 的存储成本也较为低廉。加上 DuckDB 高性能的特性,这意味着更短的 Lambda 执行时间,进一步降低成本。
- 开源与灵活性:核心组件 Apache Iceberg、DuckDB 和 PyIceberg 均为广泛应用的开源项目。受益于活跃的开源社区支持,可以获得持续的功能更新、问题修复和丰富的学习资源。
典型应用场景
- 低成本海量分析负载:对于需要控制成本,但仍需进行有效数据分析的场景,如中小型企业或特定项目预算有限的情况。
- 非频繁或突发性查询:如定期的报表生成、临时的业务数据洞察、偶尔进行的数据探索等,这些场景下按需付费的 Lambda + DuckDB 极具优势。
- 事件驱动的数据处理:由 S3 事件触发 Lambda (PyIceberg) 进行数据验证、转换和加载到 Iceberg 表,后续可由另一个 Lambda (DuckDB) 进行即时查询或聚合。
- 交互式查询接口后端:通过 API Gateway 暴露一个 Lambda (DuckDB) 端点,为内部用户或应用提供一个低成本的 SQL 查询接口,用于查询特定范围的数据。
- 快速原型验证:在开发或研究阶段,快速搭建一个功能完备的数据湖查询环境,用于验证想法或进行小规模实验。
相关文章:

当 PyIceberg 和 DuckDB 遇见 AWS S3 Tables:打造 Serverless 数据湖“开源梦幻组合”
引言 在一些大数据分析场景比如电商大数据营销中,我们需要快速分析存储海量用户行为数据(如浏览、加购、下单),以进行用户行为分析,优化营销策略。传统方法依赖 Spark/Presto 集群或 Redshift 查询 S3 上的 Parquet/O…...

泰迪杯特等奖案例深度解析:基于MSER-CNN的商品图片字符检测与识别系统设计
(第四届泰迪杯数据挖掘挑战赛特等奖案例全流程拆解) 一、案例背景与核心挑战 1.1 行业痛点与场景需求 在电商平台中,商品图片常包含促销文字(如“3折起”“限时秒杀”),但部分商家采用隐蔽文字误导消费者(如“起”字极小或位于边角)。传统人工审核效率低(日均处理量…...

开发工具指南
后端运维场用工具 工具文档简介1panel安装指南运维管理面板网盘功能介绍网盘jenkins可以通过1panel 进行安装jpom辅助安装文档后端项目发布工具...
)
将 Element UI 表格元素导出为 Excel 文件(处理了多级表头和固定列导出的问题)
import { saveAs } from file-saver import XLSX from xlsx /*** 将 Element UI 表格元素导出为 Excel 文件* param {HTMLElement} el - 要导出的 Element UI 表格的 DOM 元素* param {string} filename - 导出的 Excel 文件的文件名(不包含扩展名)*/ ex…...
)
图像对比度调整(局域拉普拉斯滤波)
一、背景介绍 之前刷对比度相关调整算法,找到效果不错,使用局域拉普拉斯做图像对比度调整,尝试复现和整理了下相关代码。 二、实现流程 1、基本原理 对输入图像进行高斯金字塔拆分,对每层的每个像素都针对性处理,生产…...

【控制波形如何COPY并无痛使用】
控制波形如何COPY并无痛使用 波形分析思路概况记录波形 波形分析 通过逻辑分析仪可以解析到设备的控制波形,在一些对于电机控制类的设备上显得尤为重要。通过分析不同波形,将PWM的波形存储到程序中得以实现,并建立合理的数据结构。 思路概…...

CSDN-2024《AGP-Net: Adaptive Graph Prior Network for Image Denoising》
推荐深蓝学院的《深度神经网络加速:cuDNN 与 TensorRT》,课程面向就业,细致讲解CUDA运算的理论支撑与实践,学完可以系统化掌握CUDA基础编程知识以及TensorRT实战,并且能够利用GPU开发高性能、高并发的软件系统…...

使用IDEA开发Spark Maven应用程序【超详细教程】
一、创建项目 创建maven项目 二、修改pom.xml文件 创建好项目后,在pom.xml中改为: <?xml version"1.0" encoding"UTF-8"?> <project xmlns"http://maven.apache.org/POM/4.0.0"xmlns:xsi"http://www.w…...

深入探索MCP通信:构建高效的MCP Client
在现代软件开发中,高效的通信机制是构建复杂系统的关键。MCP(Model-Controller-Proxy)架构作为一种新兴的开发模式,提供了强大的工具来实现客户端与服务器之间的高效通信。本文将通过实际代码示例,详细探讨如何使用MCP…...

【第76例】IPD流程实战:华为业务流程架构BPA进化的4个阶段
目录 简介 第一个阶段,业务流程架构BPA1.0 第二个阶段,业务流程架构BPA2.0 BPA3.0、4.0 作者简介 简介 不管业务是复杂还是简单,企业内外的所有事情、所有业务都最终会归于流程。 甚至是大家经常说的所谓的各种方法论,具体的落脚点还是在流程上。 比如把大象放进冰…...

25-05-16计算机网络学习笔记Day1
深入剖析计算机网络:今日学习笔记总结 本系列博客源自作者在大二期末复习计算机网络时所记录笔记,看的视频资料是B站湖科大教书匠的计算机网络微课堂,每篇博客结尾附书写笔记(字丑见谅哈哈) 视频链接地址 一、计算机网络基础概念 …...

车道线检测----CLRNet
继续更新本系列,本文CLRNet,文章主要目的是弄懂论文关键部分,希望对文章细节有一个深刻的理解,有帮助的话,请收藏支持。 CLRNet:用于车道检测的跨层精炼网络 摘要 车道在智能车辆的视觉导航系统中至关重要…...

maven和npm区别是什么
这是一个很容易搞糊涂新手的问题,反正我刚开始从课堂的知识转向项目网站开发时,被这些问题弄得晕头转向,摸不着头脑,学的糊里糊涂,所以,写了这么久代码,也总结一下,为后来者传授下经…...
)
【SpringBoot】从零开始全面解析SpringMVC (二)
本篇博客给大家带来的是SpringBoot的知识点, 本篇是SpringBoot入门, 介绍SpringMVC相关知识. 🐎文章专栏: JavaEE进阶 🚀若有问题 评论区见 👉gitee链接: 薯条不要番茄酱 ❤ 欢迎大家点赞 评论 收藏 分享 如果你不知道分享给谁,那就分享给薯条…...

Python连接redis
第一步安装redis Releases microsoftarchive/redis 安装时勾上所有能勾上的选项下一步即可 在CMD中pip install redis 安装redis pip install redis -i https://pypi.tuna.tsinghua.edu.cn/simple 配置redis 在redis安装目录下找到 修改 line 57 bind 0.0.0.0 line…...

Unity3D Overdraw性能优化详解
前端 在 Unity3D 开发中,Overdraw(过度绘制) 是一个常见的性能问题,尤其在移动端设备上可能导致严重的帧率下降。以下是关于 Overdraw 的详细解析和优化方法: 对惹,这里有一个游戏开发交流小组࿰…...

uni-app 中适配 App 平台
文章目录 前言✅ 1. App 使用的 Runtime 架构:**WebView 原生容器(plus runtime)**📌 技术栈核心: ✅ 2. WebView Native 的通信机制详解(JSBridge)📤 Web → Native 调用…...

[CSS3]属性增强1
字体图标 使用字体图标可以实现简洁的图标效果, 字体图标展示的是图标, 本质是字体, 适合简单, 颜色单一的图标 优势 灵活性: 灵活的修改样式, 比如尺寸, 颜色等轻量级: 体积小, 渲染快, 降低服务器请求次数兼容性: 几乎兼容所有主流浏览器使用方便: 下载字体包使用字体图标…...
)
【Python+flask+mysql】网易云数据可视化分析(全网首发)
网易云数据可视化分析 项目概述 网易云数据可视化分析系统是一个基于Flask框架开发的Web应用,旨在对网易云音乐平台的用户、歌曲、专辑、歌单等数据进行全面的可视化分析。该系统通过直观的图表、表格和词云等形式,展示网易云音乐的数据分布特征&#…...

项目版本管理和Git分支管理方案
文章目录 一、团队协作1.项目团队与职责2.项目时间线与里程碑3.风险评估与应对措施4.跨团队同步会议(定期)跨团队同步会议(双周) 5.版本升级决策树6.边界明确与路标制定a.功能边界划分b.项目路标制定b1、项目路标制定核心要素b2. 路标表格模板…...

Java 21 + Spring Boot 3.5:AI驱动的高性能框架实战
简介 在微服务架构日益普及的今天,如何构建一个既高性能又具备AI驱动能力的后端系统成为开发者关注的焦点。本篇文章将深入探讨Java 21与Spring Boot 3.5的结合,展示如何通过Vector API和JIT优化实现单线程性能提升30%,并利用飞算JavaAI生成智能重试机制和超时控制代码,解…...

【MySQL】索引太多会怎样?
在 MySQL 中,虽然索引可以显著提高查询效率,但过多的索引(如超过 5-6 个)会带来以下弊端: 1. 存储空间占用增加 每个索引都需要额外的磁盘空间存储索引树(BTree)。对于大表来说,多个…...

Flask 是否使用类似 Spring Boot 的核心注解机制
Flask 和 Spring Boot 架构风格不同:Spring Boot 是“注解驱动的全家桶框架”,而 Flask 是“微核心 + 显式扩展的 Python 微框架”。因此: ❌ Flask 没有类似 Spring Boot 的“核心注解机制”(如 @SpringBootApplication),而是使用函数装饰器(decorator)作为核心语法特…...

学习threejs,使用Physijs物理引擎,各种constraint约束限制
👨⚕️ 主页: gis分享者 👨⚕️ 感谢各位大佬 点赞👍 收藏⭐ 留言📝 加关注✅! 👨⚕️ 收录于专栏:threejs gis工程师 文章目录 一、🍀前言1.1 ☘️Physijs 物理引擎1.1.1 ☘️…...

城市排水管网流量监测系统解决方案
一、方案背景 随着工业的不断发展和城市人口的急剧增加,工业废水和城市污水的排放量也大量增加。目前,我国已成为世界上污水排放量大、增加速度快的国家之一。然而,总体而言污水处理能力较低,有相当部分未经处理的污水直接或间接排…...
)
redis数据结构-11(了解 Redis 持久性选项:RDB 和 AOF)
了解 Redis 持久性选项:RDB 和 AOF Redis 提供了多个持久性选项,以确保数据持久性并防止在服务器发生故障或重启时丢失数据。了解这些选项对于为您的特定使用案例选择正确的策略、平衡性能和数据安全至关重要。本章节将深入探讨 Redis 中的两种主要持久…...

掌握 Kotlin Android 单元测试:MockK 框架深度实践指南
掌握 Kotlin Android 单元测试:MockK 框架深度实践指南 在 Android 开发中,单元测试是保障代码质量的核心手段。但面对复杂的依赖关系和 Kotlin 语言特性,传统 Mock 框架常显得力不从心。本文将带你深入 MockK —— 一款专为 Kotlin 设计的 …...

2025/5/16
第一题 A. 例题4.1.2 潜水 题目描述 在马其顿王国的ohide湖里举行了一次潜水比赛。 其中一个项目是从高山上跳下水,再潜水达到终点。 这是一个团体项目,一支队伍由n人组成。在潜水时必须使用氧气瓶,但是每只队伍只有一个氧气瓶。 最多两…...
 and ‘kspDebugKotlin‘ (21).)
Detected for tasks ‘compileDebugJavaWithJavac‘ (17) and ‘kspDebugKotlin‘ (21).
1.报错 在导入Android源码的时候出现以下错误:Inconsistent JVM-target compatibility detected for tasks compileDebugJavaWithJavac (17) and kspDebugKotlin (21).。 Execution failed for task :feature-repository:kspDebugKotlin. > Inconsistent JVM-ta…...

嵌入式单片机中STM32F1演示寄存器控制方法
该文以STM32F103C8T6为示例,演示如何使用操作寄存器的方法点亮(关闭LED灯),并讲解了如何调试,以及使用宏定义。 第一:操作寄存器点亮LED灯。 (1)首先我们的目的是操作板子上的LED2灯,对其实现点亮和关闭操作。打开STM32F103C8T6的原理图,找到LED2的位置。 可以看到…...
)
【带文档】网上点餐系统 springboot + vue 全栈项目实战(源码+数据库+万字说明文档)
📌 一、项目概括 本系统共包含三个角色: 管理员:系统运营管理者 用户:点餐消费用户 美食店:上传菜品与处理订单的店铺账号 通过对这三类角色的权限与业务分工设计,系统实现了点餐流程的全链路数字化&a…...
)
Spring Cloud:Gateway(统一服务入口)
Api 网关 也是一种服务,就是通往后端的唯一入口,类似于整个微服务架构的门面,所有的外部客户端进行访问,都需要经过它来进行过滤和调度,类似于公司的前台 而Spring Cloud Gateway就是Api网关的一种具体实现 网关的核心…...

Perl测试起步:从零到精通的完整指南
阅读原文 5.2 为什么你的Perl代码总是出问题?因为你还没开始测试! "我的代码昨天还能运行,今天就莫名其妙报错了!"、"我只是改了一个小功能,结果整个系统都崩溃了"、"这段代码不是我写的&am…...

【前端优化】vue2 webpack4项目升级webpack5,大大提升运行速度
记录一下过程 手里有个老项目,vue2webpack4 项目很大,每次运行、运行都要将近10分钟 现在又要往里面写很多东西,再不优化,开发着会更难受,所以决定先将它升级至webpack5 最初失败的尝试 直接在项目里安装了webpack5 但…...

【蓝桥杯省赛真题50】python字母比较 第十五届蓝桥杯青少组Python编程省赛真题解析
python字母比较 第十五届蓝桥杯青少年组python比赛省赛真题详细解析 博主推荐 所有考级比赛学习相关资料合集【推荐收藏】1、Python比赛 信息素养大赛Python编程挑战赛 蓝桥杯python选拔赛真题详解...

学习以任务为中心的潜动作,随地采取行动
25年5月来自香港大学、OpenDriveLab 和智元机器人的论文“Learning to Act Anywhere with Task-centric Latent Actions”。 通用机器人应该在各种环境中高效运行。然而,大多数现有方法严重依赖于扩展动作标注数据来增强其能力。因此,它们通常局限于单一…...

《数据结构初阶》【二叉树 精选9道OJ练习】
【二叉树 精选9道OJ练习】目录 前言:二叉树的OJ练习[144. 二叉树的前序遍历](https://leetcode.cn/problems/binary-tree-preorder-traversal/)题目介绍方法一:[104. 二叉树的最大深度](https://leetcode.cn/problems/maximum-depth-of-binary-tree/)题目…...

协议不兼容?Profinet转Modbus TCP网关让恒压供水系统通信0障碍
在现代工业自动化领域中,通信协议扮演着至关重要的角色。ModbusTCP和Profinet是两种广泛使用的工业通信协议,它们各自在不同的应用场合中展现出独特的优势。本文将探讨如何通过开疆智能Profinet转Modbus TCP的网关,在恒压供水系统中实现高效的…...

基于大模型预测的脑出血全流程诊疗技术方案
目录 一、系统架构设计技术架构图二、核心算法实现1. 多模态数据融合算法伪代码2. 风险预测模型实现三、关键模块流程图1. 术前风险预测流程图2. 术中决策支持流程图3. 并发症预测防控流程图四、系统集成方案1. 数据接口规范五、性能优化策略1. 推理加速方案2. 分布式训练架构六…...

掌握 LangChain 文档处理核心:Document Loaders 与 Text Splitters 全解析
🐇明明跟你说过:个人主页 🏅个人专栏:《深度探秘:AI界的007》 🏅 🔖行路有良友,便是天堂🔖 目录 一、引言 1、什么是LangChain 2、LangChain 在智能应用中的作用 …...

Oracle — 总结
Oracle 公司及产品概述 公司背景 Oracle(甲骨文)是全球领先的数据库软件和服务提供商,成立于1977年,核心产品包括: Oracle Database:关系型数据库管理系统(RDBMS)。Java:…...

【Vue 3全栈实战】从响应式原理到企业级架构设计
目录 🌟 前言🏗️ 技术背景与价值🩹 当前技术痛点🛠️ 解决方案概述👥 目标读者说明 🧠 一、技术原理剖析📊 核心概念图解💡 核心作用讲解🔧 关键技术模块说明⚖️ 技术选…...

升级kafka4.0.0,无ZK版本
设备规划: 172.20.192.47 kafka-0 172.20.192.48 kafka-1 172.20.192.49 kafka-2 单机块7TB Nvme磁盘一共9块 # 格式化成GPT分区 sudo parted /dev/nvme0n1 --script mklabel gpt sudo parted /dev/nvme1n1 --script mklabel gpt sudo parted /dev/nvme2n1 --s…...
等差矩阵))
GESP2025年3月认证C++二级( 第三部分编程题(1)等差矩阵)
参考程序: #include <bits/stdc.h> using namespace std;int n, m; // 声明矩阵的行数 n 和列数 mint main() {// 输入两个正整数 n 和 mscanf("%d%d", &n, &m);// 遍历每一行for (int i 1; i < n; i)// 遍历每一列for (int j 1; j &…...

Linux系统启动相关:vmlinux、vmlinuz、zImage,和initrd 、 initramfs,以及SystemV 和 SystemD
目录 一、vmlinux、vmlinuz、zImage、bzImage、uImage 二、initrd 和 initramfs 1、initrd(Initial RAM Disk) 2、initramfs(Initial RAM Filesystem) 3、initrd vs. initramfs 对比 4. 如何查看和生成 initramfs 三、Syste…...

单序列双指针---初阶篇
目录 相向双指针 344. 反转字符串 125. 验证回文串 1750. 删除字符串两端相同字符后的最短长度 2105. 给植物浇水 II 977. 有序数组的平方 658. 找到 K 个最接近的元素 1471. 数组中的 k 个最强值 167. 两数之和 II - 输入有序数组 633. 平方数之和 2824. 统计和小于…...

K8s CoreDNS 核心知识点总结
文章目录 一、章节介绍背景与主旨核心知识点及面试频率 二、知识点详解1. CoreDNS 概述2. 工作原理(高频考点)服务发现流程 3. 配置与插件系统(高频考点)核心配置文件:Corefile常用插件 4. Pod DNS策略(中频…...

Java视频流RTMP/RTSP协议解析与实战代码
在Java中实现视频直播的输入流处理,通常需要结合网络编程、多媒体处理库以及流媒体协议(如RTMP、HLS、RTSP等)。以下是实现视频直播输入流的关键步骤和技术要点: 1. 视频直播输入流的核心组件 网络输入流:通过Socket或…...

卓力达电铸镍网:精密制造与跨领域应用的创新典范
目录 引言 一、电铸镍网的技术原理与核心特性 二、电铸镍网的跨领域应用 三、南通卓力达电铸镍网的核心优势 四、未来技术展望 引言 电铸镍网作为一种兼具高精度与高性能的金属网状材料,通过电化学沉积工艺实现复杂结构的精密成型,已成为航空航天、电…...

label-studio功能常用英文翻译
Projects 项目 Settings 设置 Labeling Interface 标注界面 1、Computer Vision 计算机视觉 Semantic Segmentation with Polygons 多边形语义分割 Semantic Segmentation with Masks 掩码语义分割 Object Detection with Bounding Boxes 边界框目标检测 Keypoint Label…...