ReinboT:通过强化学习增强机器人视觉-语言操控能力
25年5月来自浙大和西湖大学的论文“ReinboT: Amplifying Robot Visual-Language Manipulation with Reinforcement Learning”。
视觉-语言-动作 (VLA) 模型通过模仿学习在一般机器人决策任务中展现出巨大潜力。然而,训练数据的质量参差不齐通常会限制这些模型的性能。另一方面,离线强化学习 (RL) 擅长从混合质量数据中学习稳健的策略模型。本文介绍强化的机器人 GPT (ReinboT),这是一种端到端 VLA 模型,它集成 RL 最大化累积奖励的原理。ReinboT 通过预测能够捕捉操作任务细微差别的密集回报,从而对数据质量分布有了更深入的理解。密集回报预测能力使机器人能够生成更稳健的决策动作,以最大化未来利益为导向。
近年来,针对机器人通用具身智能的视觉-语言-动作 (VLA) 模型研究蓬勃发展 (Brohan,2022;2023)。VLA 模型通常基于模仿学习范式,即使用预训练的视觉-语言模型,并利用下游机器人数据进行后训练 (Ding,2024;Zhao,2025b)。虽然通过大量的机器人训练数据,VLA 模型的语义泛化能力有所提升,但其在下游任务的操作精度方面仍然存在关键差距 (Brohan,2023;Black;Li,2024)。限制 VLA 模型性能的一个重要原因是训练数据源的质量通常参差不齐,即使它们来自成功的演示 (Hejna,2024)。尽管最近的模仿学习方法可以有效地复制演示的分布(Vuong,2023;Brohan,2023;Zhang,2025),但它们难以区分不均匀的数据质量和充分利用混合质量数据(Bai,2025)。另一方面,离线强化学习 (RL) 算法旨在利用先前收集的数据,而无需在线数据收集(Levine,2020)。尽管最初尝试将 VLA 与 RL 相结合(Mark,2024;Zhai,2024;Zhao,2025a;Guo,2025),但对于视觉-语言操作任务广泛适用密集奖励的设计以及将 RL 收益最大化概念融入 VLA 模型仍未得到充分探索。
基于序列建模的离线强化学习。自 Transformer (Vaswani,2017) 作为一种高效的序列建模模型出现以来,大量研究(Chen,2021;Yamagata,2022;Janner,2021;Zhuang,2024;Shafiullah,2022;Hu,2024)探索了序列模型作为智体策略在强化学习决策任务中的应用。Decision Transformer (Chen,2021) (DT) 通过监督学习范式在离线数据集上训练上下文条件策略模型,以历史观测值和 ReturnToGo 为条件,并输出策略模型应执行的操作。 Reinformer (Zhuang et al., 2024) 在 DT 的基础上进一步引入了最大化回报的概念。在训练过程中,Reinformer 不仅预测离线数据中以 ReturnToGo 为条件的动作,还预测策略模型后续在观察下可能获得的最大化 ReturnToGo。
VLA 模型与强化学习的融合。近期研究初步将 VLA 与 RL 相结合,旨在研究如何进一步提升 VLA 模型的操作精度和适应性,同时保留其在规模和泛化方面的最佳优势。在这些研究成果中,奖励信号的来源要么是目标是否达成的稀疏形式(Chebotar,2023;Nakamoto;Mark,2024),要么是达到目标所需的步数(Yang,2023),要么借助 LLM 模型和其他预训练视觉模型计算距离目标的距离(Zhang,2024)。然而,这些奖励设计要么面临强化学习中尚未完全解决的信用分配问题(Sutton,1984),要么受限于 LLM 的幻觉问题(Zhang,2023)。在与强化学习算法结合方面,这些工作主要对现有经过模仿学习的 VLA 模型进行微调,包括引入 Q 函数修正动作分布(Nakamoto, 2024)、筛选出高价值的动作微调策略(Mark et al.,2024;Zhang et al.,2024)以及根据人类的偏好进行微调(Chen et al.,2025)。此外,最近的一项工作(Chebotar et al.,2023)利用自回归 Q 函数来学习视觉语言操作,但其模型的序列长度和推理时间随着动作维度的增加而显著增加。
为此,本文提出强化的机器人 GPT(ReinboT),这是一种端到端 VLA 模型,用于实现 RL 最大化密集回报的概念。具体而言,高效且自动地将长视界操作任务轨迹分解为仅包含单个子目标的多个轨迹段,并设计一个能够捕捉操作任务特征的密集奖励。事实上,复杂的机器人操作任务需要考虑许多因素,例如跟踪目标、降低能耗以及保持灵活稳定的行为。因此,所提出的奖励密集化方法的设计原理基于这些考虑,并且广泛应用于各种操作任务。
VLA 模型的模仿学习
GR-1 (Wu et al. 2023) 是一个典型的 VLA 模仿学习模型,它证明视觉机器人操作可以显著受益于大规模视频生成预训练。得益于其灵活的设计,GR-1 可以在大规模视频数据集上进行预训练后,无缝地在机器人数据上进行微调。GR-1 是一个 GPT 风格的模型,以语言指令 l、历史图像观测值 o_t−h:t 和本体感觉 s_t−h:t 作为输入。它以端到端的方式预测机器人动作和未来图像 ⟨oˆ_t+1, aˆ_t⟩ = π(l, ⟨o, s⟩_t−h:t)。
最大回报序列建模
序列模型 DT (Chen,2021) 根据历史轨迹和 ReturnToGo 最大化动作的可能性,本质上将离线强化学习转化为监督序列建模。
Reinformer (Zhuang et al., 2024) 将最大化收益的目标融入序列模型。具体来说,Reinformer 预测当前状态在数据集所代表的数据分布中可能获得的最大收益,而不是当前轨迹的真实 ReturnToGo 收益。Reinformer 通过最小化预期回归损失隐式地实现了这一点。
相比于 DT,Reinformer 的一个优势在于推理时无需指定 ReturnToGo 的初始值以及环境返回的奖励,而是通过两种模型推理,自回归地预测下一步的最大ReturnToGo值和动作。
本文旨在构建一个端到端 VLA 模型,将最大化密集奖励的原则融入机器人视觉运动控制中,如图所示。首先,在设计密集奖励时考虑四个主要因素,以捕捉机器人长视域操作任务的本质。然后,详细阐述了如何构建一个端到端强化学习 VLA 模型和测试执行流程。最后,讨论并分析所提出的 ReinboT 如何有机地整合强化学习最大化奖励的原则。
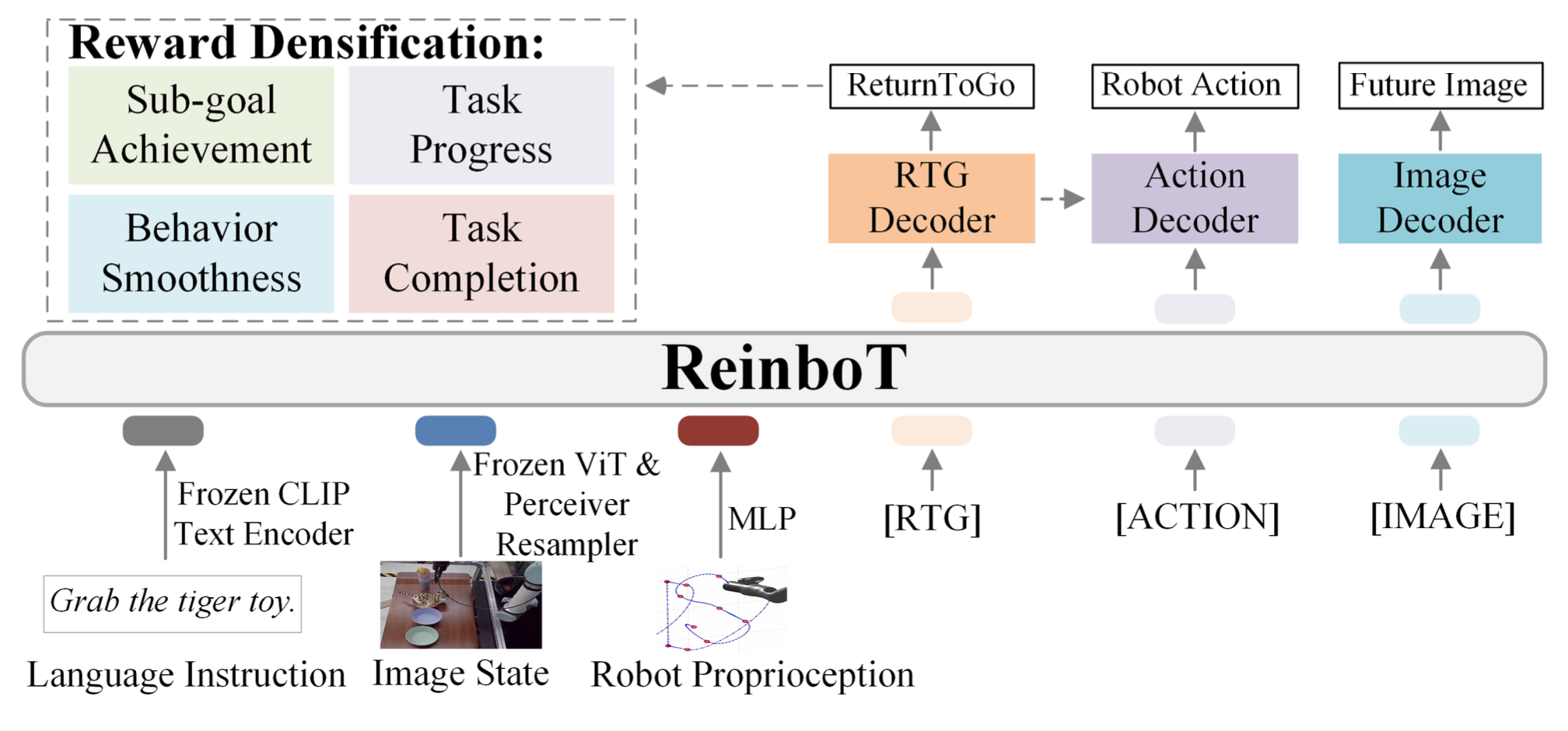
奖励密集化
对于长视域视觉-语言操作任务,VLA 模型通常需要在遵循目标的同时,以最小的能量成本保持鲁棒稳定的行为。因此,主要围绕这一原则设计一个广泛适用的密集奖励机制,以捕捉操作任务的本质。直观地讲,在机器人轨迹中,最小化状态距离的奖励是一种简单有效的方案,可以鼓励机器人直接移动到目标状态。然而,这种奖励仅限于任务仅包含一个目标的情况。对于需要操作具有多个子目标的长视域任务,这种奖励会引导机器人直接移动到最终目标状态,从而造成失败 (Zhao et al., 2024)。
因此,首先采用启发式方法 (James & Davison, 2022; Shridhar et al., 2023) 将长视域操作任务划分为多个子目标序列,并为每个序列设计一个密集奖励。启发式过程会迭代每个演示轨迹中的状态,并确定该状态是否应被视为临界状态。判断基于两个主要约束:关节速度接近于零以及夹持器状态的变化。直观地讲,临界状态发生在机器人达到预抓取姿势或转换到新任务阶段时,或者抓取或释放目标时。因此,将临界状态作为子目标是一个自然而合理的选择。
子目标达成。图像状态 o_t 和本体感知 s_t 都包含丰富的环境感知信息。因此,子目标达成奖励 r_1 涵盖本体感知跟踪、像素强度、图像视觉质量和图像特征点。
利用均方误差(MSE)计算图像状态o_t(以及本体感觉s_t)与子目标图像状态o∗_t(以及子目标本体感觉s∗_t)的直接差异,并利用结构相似度指数(SSIM)衡量图像的视觉质量。用于计算奖励的 Oriented FAST and Rotated BRIEF (ORB) (Rublee et al., 2011)算法专注于图像特征点的提取和匹配。具体而言,首先在当前图像状态和子目标图像状态上检测关键点,进行特征匹配和匹配点筛选,最后通过匹配点数量计算相似度。
任务进度。考虑到划分为多个子目标序列对整体轨迹的影响不同,后面的序列更接近最终目标状态,为了体现这一点,设计任务进度奖励r_2:r_2 = n(s_t) / |{s^∗}| 。子目标序列越接近最终目标状态,任务进度奖励越大。
行为平滑度。为了促进运动轨迹平滑自然,主要考虑抑制机械臂运动的关节速度 q̇ 和加速度 q̈ 以及动作 a_t 的变化率,从而惩罚过于剧烈僵硬的轨迹运动。行为平滑度奖励 r_3 为:
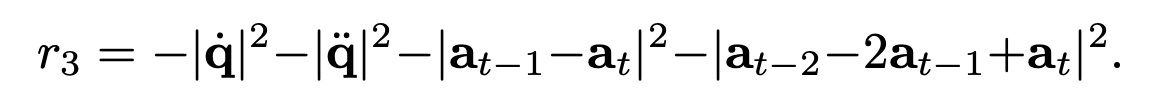
任务完成。对于视觉语言操作任务,语言指导被视为与机器人行为相匹配的目标。任务完成奖励 r_4 为: r_4 = 1 {τ is successful}.
基于这四个主要因素,一般密集奖励捕捉到长视界视觉-语言操作任务的本质。
通过利用设计的奖励信号,ReinboT 可以对训练数据的质量分布有更广泛、更深入的理解和识别,从而指导机器人执行更稳健、稳定的机器人决策动作。
端到端强化 VLA 模型
通过提出的密集奖励机制,可以得到用于长视域视觉语言操作任务的 ReturnToGo (RTG) g_t = sum(r_j)。
ReinboT 模型采用 GPT 风格的 Transformer (Radford, 2018) 作为骨干网络 π_θ,因为它可以灵活高效地使用不同类型的模态数据作为输入和输出。CLIP (Radford et al., 2021) 用于编码语言指令,ViT (Dosovitskiy et al., 2020; He et al., 2022)(以及感知器重采样器 (Jaegle et al., 2021))用于压缩和编码图像状态,MLP 用于编码本体感觉。
引入动作和图像 token 嵌入([ACTION] 和 [IMAGE]),并分别通过动作解码器 P_ω 和图像解码器 P_ν 预测机器人动作和未来图像状态。最重要的是,将 ReturnToGo 视为一种新的数据模态,并学习 ReturnToGo 预测 token 嵌入 [RTG]。通过 ReturnToGo 解码器 P_φ,根据语言指令 l、图像状态 o 和本体感觉 s 预测最大化回报。
ReinboT 模型的损失函数 L 包括 ReturnToGo 损失 L_RTG、手臂动作平滑 L1 损失 L_arm、夹持器动作交叉熵损失 L_gripper 和未来图像像素-级损失 L_image。
当设计如何利用包含 ReturnToGo 的特征信息预测动作 a 时,在 ReinboT 网络结构中做模块化设计。具体来说,首先将语言指令 l、图像状态 o_t−u+1:t 和本体感觉 s_t−u+1:t 输入到骨干网络 π_φ 中,得到 [RTG] 和 [ACTION] token 嵌入对应的特征 h^RTG_t:t+k−1 和 h^action_t:t+k−1:
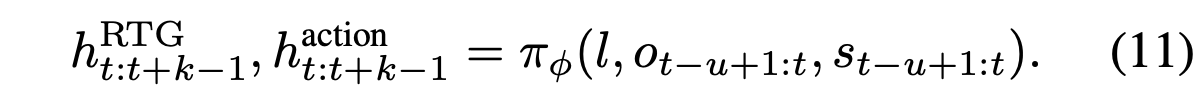
然后将特征 h^RTG_t:t+k−1 输入 ReturnToGo 解码器 P_φ,得到最后一层隐特征 gˆhidden_t:t+k−1:
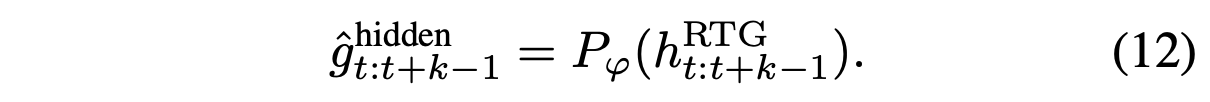
隐特征 gˆhidden_t:t+k−1 与动作特征 h^action_t:t+k−1 连接,并进一步输入动作解码器 P_ω,预测动作 aˆ_t:t+k−1:
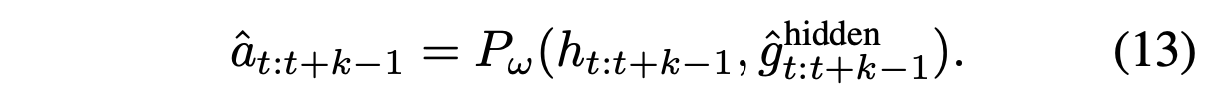
ReinboT 的模块化设计,只需单次模型推理即可获得机器人动作,从而比 Reinformer 模型具有更高的推理效率。这种设计更大的好处在于,在推理阶段,不需要像 DT 模型那样手动设置 ReturnToGo 的初始值。这对于实际部署至关重要,因为它大大减轻手动调整参数的繁琐性,并且实际部署环境在很大程度上无法直接获得奖励。ReinboT 推理流程已在如下算法 1 中进行总结。

ReinboT 的讨论与分析
与常见的端到端 VLA 模型相比,所提出的 ReinboT 最显著的特点是额外引入 ReturnToGo 损失,并且动作会受到 ReturnToGo tokens gˆhidden_t:t+k−1(13)的影响。随后将分析该框架如何实现强化学习的回报最大化,以及与经典强化学习中回报最大化的区别和优势。
以某个日期点(l, ⟨o, s⟩_t−h+1 , g_t, a_t)为例。ReturnToGo 的损失基于预期回归实现,其关键参数为 m。当 m = 0.5 时,预期回归退化为 MSE,预测的 ReturnToGo tokens gˆ_t 趋近于真实值 g_t。此时,ReinboT 退化为模仿学习的范式,也就是常见的带有 ReturnToGo token 预测的端到端 VLA 模型。当 m > 0.5 时,预期回归会预测 gˆ_t 大于 g_t,这被称为收益最大化。这种最大化的收益引导 ReinboT 预测更优的行为。然而,盲目增加 m 会导致模型对训练数据分布中可实现的最大收益做出过于乐观的估计。相关理论分析参见 Reinformer (Zhuang et al., 2024)。
在经典的强化学习算法中,最大化 Q 值被用来实现最佳策略模型。这意味着在 VLA 中应用强化学习需要引入额外的强化学习损失函数。这样的添加可能会对 Transformer 等模型的学习过程造成障碍 (Mishra,2018;Parisotto,2020;Davis,2021)。相比之下,本文回报条件最大化避免纳入 RL 特定损失的需要。
首先构建一个基于 CALVIN (Mees et al., 2022) 的混合质量数据集,其中包含长期操控任务,以检查所提出的 ReinboT 和基线算法的性能。该数据集包含少量带有 CALVIN A/B/C 语言指令的数据(每个任务约 50 条轨迹)和大量不带有语言指令的自主数据。除了 CALVIN 中人类遥控操作在没有语言指令的情况下收集的原始数据(超过 20,000 条轨迹)之外,自主数据还包含由训练的 VLA 行为策略 RoboFlamingo (Li et al., b) 与环境 CALVIN D(超过 10,000 条轨迹)交互产生的失败数据。为了促进数据多样性,在交互过程中向 RoboFlamingo 策略模型的动作添加不同程度的高斯噪声(0.05、0.1 和 0.15)。其研究在此混合质量数据上进行训练,然后用语言指令对少量数据进行微调,最后在 CALVIN D 上测试泛化性能。
为了全面评估所提出的 ReinboT 模型的有效性,考虑了一些具有代表性的基线算法和奖励设计方法,包括 RoboFlamingo (Li et al., b)、GR-1 (Wu et al.)、PIDM (Tian et al., 2024)(三种模仿学习类型)、GR-MG (Li et al., 2025)(分层模仿学习类型)和 RWR (Peters & Schaal, 2007)(离线 RL 类型)。“带注释的数据”意味着该模型仅在少量带有文本注释的数据上进行训练(每个任务约 50 条轨迹)。“稀疏”意味着利用稀疏奖励,即成功轨迹的最后三步的奖励为 1,其余为 0(Nakamoto et al.)。 “sub-goal, sparse”表示使用稀疏奖励,即成功轨迹的最后三步和子目标状态的奖励为 1,其余为 0。“dense, single” 表示使用本文提出的密集奖励,在计算 ReturnToGo 损失时使用最终计算出的单维标量回报。“dense, full” 表示使用本文提出的密集奖励,预测的 ReturnToGo 是一个包含计算的单维标量回报和每个回报分量的向量。
对现实世界的任务进行评估,以检验所提出的 ReinboT 是否可以在现实场景中执行有效的少样本学习和泛化。具体来说,考虑在机械臂 UR5 上拾取和放置杯子、碗和毛绒玩具等物体的任务。收集的成功轨迹总数约为 530,并且首先在这些数据上训练模型。对于少样本学习评估,考虑三个物体抓取和放置任务。每个任务仅包含 30 条成功轨迹,并且模型在这三个任务上进行微调。对于 OOD 泛化评估,考虑具有未见过的指令、背景、干扰项和被操纵物体的场景。如图所示:

相关文章:

ReinboT:通过强化学习增强机器人视觉-语言操控能力
25年5月来自浙大和西湖大学的论文“ReinboT: Amplifying Robot Visual-Language Manipulation with Reinforcement Learning”。 视觉-语言-动作 (VLA) 模型通过模仿学习在一般机器人决策任务中展现出巨大潜力。然而,训练数据的质量参差不齐通常会限制这些模型的性…...

MySQL联表查询:多表关联与嵌套查询指南
引言 各位数据库爱好者们好!今天我们要挑战MySQL查询技能的高阶关卡——复杂查询 🚀。在真实业务场景中,数据往往分散在多个表中,就像拼图的各个碎片,只有掌握了多表查询的"拼图技巧",才能将它们…...
)
QBasic 一款古老的编程语言在现代学习中的价值(附程序)
QBasic(Quick Beginner’s All-purpose Symbolic Instruction Code)是微软公司于 1991 年推出的一款简单易学的编程语言,作为BASIC语言的变种,它曾广泛应用于教育领域和初学者编程入门。尽管在当今Python、Java等现代编程语言主导…...

基于Backtrader库的均线策略实现与回测
本文将通过Python语言和强大的Backtrader库,详细介绍如何实现一个基于均线的简单交易策略,并进行历史数据的回测。将一步步构建这个策略,从数据获取、策略定义到回测结果分析,帮助你深入理解并掌握这一过程。 一、环境配置与库安装 1.1 安装必要的Python库 确保你已经安…...
面试题)
Elasticsearch 分词与字段类型(keyword vs. text)面试题
Elasticsearch 分词与字段类型(keyword vs. text)面试题 🔍 目录 基础概念底层存储查询影响多字段聚合与排序分词器实战排查总结基础概念 💡 问题1:Elasticsearch 中的 keyword 和 text 类型有什么区别? 👉 查看参考答案 对比项keywordtext分词(Analysis)❌ 不进…...

Java 后端给前端传Long值,精度丢失的问题与解决
为什么后端 Long 类型 ID 要转为 String? 在前后端分离的开发中,Java 后端通常使用 Long 类型作为主键 ID(如雪花算法生成的 ID)。但如果直接将 Long 返回给前端,可能会导致前端精度丢失的问题,特别是在 J…...

【C++】 —— 笔试刷题day_29
一、排序子序列 题目解析 一个数组的连续子序列,如果这个子序列是非递增或者非递减的;这个连续的子序列就是排序子序列。 现在给定一个数组,然后然我们判断这个子序列可以划分成多少个排序子序列。 例如:1 2 3 2 2 1 可以划分成 …...

高光谱遥感图像处理之数据分类的fcm算法
基于模糊C均值聚类(FCM)的高光谱遥感图像分类MATLAB实现示例 %% FCM高光谱图像分类示例 clc; clear; close all;%% 数据加载与预处理 % 加载示例数据(此处使用公开数据集Indian Pines的简化版) load(indian_pines.mat); % 包含变…...

衡量 5G 和未来网络的安全性
大家读完觉得有帮助记得关注和点赞!!! 抽象 在当今日益互联和快节奏的数字生态系统中,移动网络(如 5G)和未来几代(如 6G)发挥着关键作用,必须被视为关键基础设施。确保其…...

【Vite】前端开发服务器的配置
定义一些开发服务器的行为和代理规则 服务器的基本配置 server: {host: true, // 监听所有网络地址port: 8081, // 使用8081端口open: true, // 启动时自动打开浏览器cors: true // 启用CORS跨域支持 } 代理配置 proxy: {/api: {target: https://…...
)
文章记单词 | 第85篇(六级)
一,单词释义 verb /vɜːrb/- n. 动词wave /weɪv/- v. 挥手;波动;挥舞 /n. 波浪;波;挥手add /d/- v. 增加;添加;补充说liberal /ˈlɪbərəl/- adj. 自由的;开明的;慷…...

通过实例讲解螺旋模型
目录 一、螺旋模型的核心概念 二、螺旋模型在电子商城系统开发中的应用示例 第 1 次螺旋:项目启动与风险初探...
Android各版本新特性)
(面试)Android各版本新特性
Android 6.0 (Marshmallow, API 23) 运行时权限管理:用户可在应用运行时动态授予或拒绝权限,取代安装时统一授权4。Doze模式与应用待机:优化后台耗电,延长设备续航5。指纹识别支持:原生API支持指纹身份验证。 Android…...

如何有效的开展接口自动化测试?
🍅 点击文末小卡片,免费获取软件测试全套资料,资料在手,涨薪更快 一、简介 接口自动化测试是指使用自动化测试工具和脚本对软件系统中的接口进行测试的过程。其目的是在软件开发过程中,通过对接口的自动化测试来提高测…...

当 PyIceberg 和 DuckDB 遇见 AWS S3 Tables:打造 Serverless 数据湖“开源梦幻组合”
引言 在一些大数据分析场景比如电商大数据营销中,我们需要快速分析存储海量用户行为数据(如浏览、加购、下单),以进行用户行为分析,优化营销策略。传统方法依赖 Spark/Presto 集群或 Redshift 查询 S3 上的 Parquet/O…...

泰迪杯特等奖案例深度解析:基于MSER-CNN的商品图片字符检测与识别系统设计
(第四届泰迪杯数据挖掘挑战赛特等奖案例全流程拆解) 一、案例背景与核心挑战 1.1 行业痛点与场景需求 在电商平台中,商品图片常包含促销文字(如“3折起”“限时秒杀”),但部分商家采用隐蔽文字误导消费者(如“起”字极小或位于边角)。传统人工审核效率低(日均处理量…...

开发工具指南
后端运维场用工具 工具文档简介1panel安装指南运维管理面板网盘功能介绍网盘jenkins可以通过1panel 进行安装jpom辅助安装文档后端项目发布工具...
)
将 Element UI 表格元素导出为 Excel 文件(处理了多级表头和固定列导出的问题)
import { saveAs } from file-saver import XLSX from xlsx /*** 将 Element UI 表格元素导出为 Excel 文件* param {HTMLElement} el - 要导出的 Element UI 表格的 DOM 元素* param {string} filename - 导出的 Excel 文件的文件名(不包含扩展名)*/ ex…...
)
图像对比度调整(局域拉普拉斯滤波)
一、背景介绍 之前刷对比度相关调整算法,找到效果不错,使用局域拉普拉斯做图像对比度调整,尝试复现和整理了下相关代码。 二、实现流程 1、基本原理 对输入图像进行高斯金字塔拆分,对每层的每个像素都针对性处理,生产…...

【控制波形如何COPY并无痛使用】
控制波形如何COPY并无痛使用 波形分析思路概况记录波形 波形分析 通过逻辑分析仪可以解析到设备的控制波形,在一些对于电机控制类的设备上显得尤为重要。通过分析不同波形,将PWM的波形存储到程序中得以实现,并建立合理的数据结构。 思路概…...

CSDN-2024《AGP-Net: Adaptive Graph Prior Network for Image Denoising》
推荐深蓝学院的《深度神经网络加速:cuDNN 与 TensorRT》,课程面向就业,细致讲解CUDA运算的理论支撑与实践,学完可以系统化掌握CUDA基础编程知识以及TensorRT实战,并且能够利用GPU开发高性能、高并发的软件系统…...

使用IDEA开发Spark Maven应用程序【超详细教程】
一、创建项目 创建maven项目 二、修改pom.xml文件 创建好项目后,在pom.xml中改为: <?xml version"1.0" encoding"UTF-8"?> <project xmlns"http://maven.apache.org/POM/4.0.0"xmlns:xsi"http://www.w…...

深入探索MCP通信:构建高效的MCP Client
在现代软件开发中,高效的通信机制是构建复杂系统的关键。MCP(Model-Controller-Proxy)架构作为一种新兴的开发模式,提供了强大的工具来实现客户端与服务器之间的高效通信。本文将通过实际代码示例,详细探讨如何使用MCP…...

【第76例】IPD流程实战:华为业务流程架构BPA进化的4个阶段
目录 简介 第一个阶段,业务流程架构BPA1.0 第二个阶段,业务流程架构BPA2.0 BPA3.0、4.0 作者简介 简介 不管业务是复杂还是简单,企业内外的所有事情、所有业务都最终会归于流程。 甚至是大家经常说的所谓的各种方法论,具体的落脚点还是在流程上。 比如把大象放进冰…...

25-05-16计算机网络学习笔记Day1
深入剖析计算机网络:今日学习笔记总结 本系列博客源自作者在大二期末复习计算机网络时所记录笔记,看的视频资料是B站湖科大教书匠的计算机网络微课堂,每篇博客结尾附书写笔记(字丑见谅哈哈) 视频链接地址 一、计算机网络基础概念 …...

车道线检测----CLRNet
继续更新本系列,本文CLRNet,文章主要目的是弄懂论文关键部分,希望对文章细节有一个深刻的理解,有帮助的话,请收藏支持。 CLRNet:用于车道检测的跨层精炼网络 摘要 车道在智能车辆的视觉导航系统中至关重要…...

maven和npm区别是什么
这是一个很容易搞糊涂新手的问题,反正我刚开始从课堂的知识转向项目网站开发时,被这些问题弄得晕头转向,摸不着头脑,学的糊里糊涂,所以,写了这么久代码,也总结一下,为后来者传授下经…...
)
【SpringBoot】从零开始全面解析SpringMVC (二)
本篇博客给大家带来的是SpringBoot的知识点, 本篇是SpringBoot入门, 介绍SpringMVC相关知识. 🐎文章专栏: JavaEE进阶 🚀若有问题 评论区见 👉gitee链接: 薯条不要番茄酱 ❤ 欢迎大家点赞 评论 收藏 分享 如果你不知道分享给谁,那就分享给薯条…...

Python连接redis
第一步安装redis Releases microsoftarchive/redis 安装时勾上所有能勾上的选项下一步即可 在CMD中pip install redis 安装redis pip install redis -i https://pypi.tuna.tsinghua.edu.cn/simple 配置redis 在redis安装目录下找到 修改 line 57 bind 0.0.0.0 line…...

Unity3D Overdraw性能优化详解
前端 在 Unity3D 开发中,Overdraw(过度绘制) 是一个常见的性能问题,尤其在移动端设备上可能导致严重的帧率下降。以下是关于 Overdraw 的详细解析和优化方法: 对惹,这里有一个游戏开发交流小组࿰…...

uni-app 中适配 App 平台
文章目录 前言✅ 1. App 使用的 Runtime 架构:**WebView 原生容器(plus runtime)**📌 技术栈核心: ✅ 2. WebView Native 的通信机制详解(JSBridge)📤 Web → Native 调用…...

[CSS3]属性增强1
字体图标 使用字体图标可以实现简洁的图标效果, 字体图标展示的是图标, 本质是字体, 适合简单, 颜色单一的图标 优势 灵活性: 灵活的修改样式, 比如尺寸, 颜色等轻量级: 体积小, 渲染快, 降低服务器请求次数兼容性: 几乎兼容所有主流浏览器使用方便: 下载字体包使用字体图标…...
)
【Python+flask+mysql】网易云数据可视化分析(全网首发)
网易云数据可视化分析 项目概述 网易云数据可视化分析系统是一个基于Flask框架开发的Web应用,旨在对网易云音乐平台的用户、歌曲、专辑、歌单等数据进行全面的可视化分析。该系统通过直观的图表、表格和词云等形式,展示网易云音乐的数据分布特征&#…...

项目版本管理和Git分支管理方案
文章目录 一、团队协作1.项目团队与职责2.项目时间线与里程碑3.风险评估与应对措施4.跨团队同步会议(定期)跨团队同步会议(双周) 5.版本升级决策树6.边界明确与路标制定a.功能边界划分b.项目路标制定b1、项目路标制定核心要素b2. 路标表格模板…...

Java 21 + Spring Boot 3.5:AI驱动的高性能框架实战
简介 在微服务架构日益普及的今天,如何构建一个既高性能又具备AI驱动能力的后端系统成为开发者关注的焦点。本篇文章将深入探讨Java 21与Spring Boot 3.5的结合,展示如何通过Vector API和JIT优化实现单线程性能提升30%,并利用飞算JavaAI生成智能重试机制和超时控制代码,解…...

【MySQL】索引太多会怎样?
在 MySQL 中,虽然索引可以显著提高查询效率,但过多的索引(如超过 5-6 个)会带来以下弊端: 1. 存储空间占用增加 每个索引都需要额外的磁盘空间存储索引树(BTree)。对于大表来说,多个…...

Flask 是否使用类似 Spring Boot 的核心注解机制
Flask 和 Spring Boot 架构风格不同:Spring Boot 是“注解驱动的全家桶框架”,而 Flask 是“微核心 + 显式扩展的 Python 微框架”。因此: ❌ Flask 没有类似 Spring Boot 的“核心注解机制”(如 @SpringBootApplication),而是使用函数装饰器(decorator)作为核心语法特…...

学习threejs,使用Physijs物理引擎,各种constraint约束限制
👨⚕️ 主页: gis分享者 👨⚕️ 感谢各位大佬 点赞👍 收藏⭐ 留言📝 加关注✅! 👨⚕️ 收录于专栏:threejs gis工程师 文章目录 一、🍀前言1.1 ☘️Physijs 物理引擎1.1.1 ☘️…...

城市排水管网流量监测系统解决方案
一、方案背景 随着工业的不断发展和城市人口的急剧增加,工业废水和城市污水的排放量也大量增加。目前,我国已成为世界上污水排放量大、增加速度快的国家之一。然而,总体而言污水处理能力较低,有相当部分未经处理的污水直接或间接排…...
)
redis数据结构-11(了解 Redis 持久性选项:RDB 和 AOF)
了解 Redis 持久性选项:RDB 和 AOF Redis 提供了多个持久性选项,以确保数据持久性并防止在服务器发生故障或重启时丢失数据。了解这些选项对于为您的特定使用案例选择正确的策略、平衡性能和数据安全至关重要。本章节将深入探讨 Redis 中的两种主要持久…...

掌握 Kotlin Android 单元测试:MockK 框架深度实践指南
掌握 Kotlin Android 单元测试:MockK 框架深度实践指南 在 Android 开发中,单元测试是保障代码质量的核心手段。但面对复杂的依赖关系和 Kotlin 语言特性,传统 Mock 框架常显得力不从心。本文将带你深入 MockK —— 一款专为 Kotlin 设计的 …...

2025/5/16
第一题 A. 例题4.1.2 潜水 题目描述 在马其顿王国的ohide湖里举行了一次潜水比赛。 其中一个项目是从高山上跳下水,再潜水达到终点。 这是一个团体项目,一支队伍由n人组成。在潜水时必须使用氧气瓶,但是每只队伍只有一个氧气瓶。 最多两…...
 and ‘kspDebugKotlin‘ (21).)
Detected for tasks ‘compileDebugJavaWithJavac‘ (17) and ‘kspDebugKotlin‘ (21).
1.报错 在导入Android源码的时候出现以下错误:Inconsistent JVM-target compatibility detected for tasks compileDebugJavaWithJavac (17) and kspDebugKotlin (21).。 Execution failed for task :feature-repository:kspDebugKotlin. > Inconsistent JVM-ta…...

嵌入式单片机中STM32F1演示寄存器控制方法
该文以STM32F103C8T6为示例,演示如何使用操作寄存器的方法点亮(关闭LED灯),并讲解了如何调试,以及使用宏定义。 第一:操作寄存器点亮LED灯。 (1)首先我们的目的是操作板子上的LED2灯,对其实现点亮和关闭操作。打开STM32F103C8T6的原理图,找到LED2的位置。 可以看到…...
)
【带文档】网上点餐系统 springboot + vue 全栈项目实战(源码+数据库+万字说明文档)
📌 一、项目概括 本系统共包含三个角色: 管理员:系统运营管理者 用户:点餐消费用户 美食店:上传菜品与处理订单的店铺账号 通过对这三类角色的权限与业务分工设计,系统实现了点餐流程的全链路数字化&a…...
)
Spring Cloud:Gateway(统一服务入口)
Api 网关 也是一种服务,就是通往后端的唯一入口,类似于整个微服务架构的门面,所有的外部客户端进行访问,都需要经过它来进行过滤和调度,类似于公司的前台 而Spring Cloud Gateway就是Api网关的一种具体实现 网关的核心…...

Perl测试起步:从零到精通的完整指南
阅读原文 5.2 为什么你的Perl代码总是出问题?因为你还没开始测试! "我的代码昨天还能运行,今天就莫名其妙报错了!"、"我只是改了一个小功能,结果整个系统都崩溃了"、"这段代码不是我写的&am…...

【前端优化】vue2 webpack4项目升级webpack5,大大提升运行速度
记录一下过程 手里有个老项目,vue2webpack4 项目很大,每次运行、运行都要将近10分钟 现在又要往里面写很多东西,再不优化,开发着会更难受,所以决定先将它升级至webpack5 最初失败的尝试 直接在项目里安装了webpack5 但…...

【蓝桥杯省赛真题50】python字母比较 第十五届蓝桥杯青少组Python编程省赛真题解析
python字母比较 第十五届蓝桥杯青少年组python比赛省赛真题详细解析 博主推荐 所有考级比赛学习相关资料合集【推荐收藏】1、Python比赛 信息素养大赛Python编程挑战赛 蓝桥杯python选拔赛真题详解...

学习以任务为中心的潜动作,随地采取行动
25年5月来自香港大学、OpenDriveLab 和智元机器人的论文“Learning to Act Anywhere with Task-centric Latent Actions”。 通用机器人应该在各种环境中高效运行。然而,大多数现有方法严重依赖于扩展动作标注数据来增强其能力。因此,它们通常局限于单一…...