使用 Docker Desktop 安装 Neo4j 知识图谱
一、简介
Neo4j是一个高性能的,基于java开发的,NOSQL图形数据库,它将结构化数据存储在网络上而不是表中;它是一个嵌入式的、基于磁盘的、具备完全的事务特性的Java持久化引擎。
Neo4j分为企业版和社区版,企业版可以创建多个数据库,链接多个数据库,但是收费……;社区版只能链接一个数据库,所以社区版不支持创建数据库命令。
Neo4j部署后默认创建名字为 neo4j 的数据库,可以直接链接这个数据库。
二、使用 Docker 安装 Neo4j
官网文档:https://neo4j.com/docs/
官网下载地址:https://neo4j.com/download-center
国内镜像地址(所有版本都有):https://we-yun.com/doc/neo4j/
1、安装 Docker Desktop
请看这里:Docker Desktop 安装使用教程
2、使用 Docker Desktop 安装 Neo4j 镜像
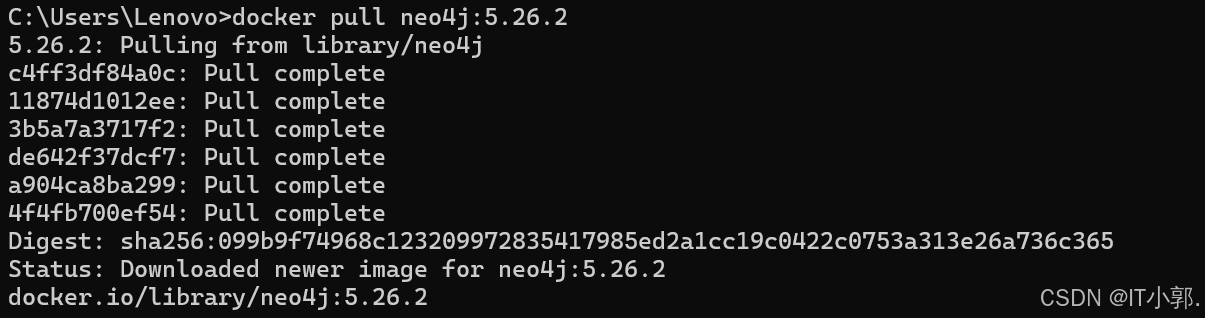
# 拉取 Neo4j 镜像
docker pull neo4j:5.26.2
# 启动 并 设置 neo4j 挂载
docker run -it -d -p 7474:7474 -p 7687:7687 -v /home/neo4j/data:/data -v /home/neo4j/logs:/logs -v /home/neo4j/conf:/var/lib/neo4j/conf -v /home/neo4j/import:/var/lib/neo4j/import -v /home/neo4j/plugins:/var/lib/neo4j/plugins -e NEO4J_AUTH=neo4j/password --name neo4j neo4j:5.26.2


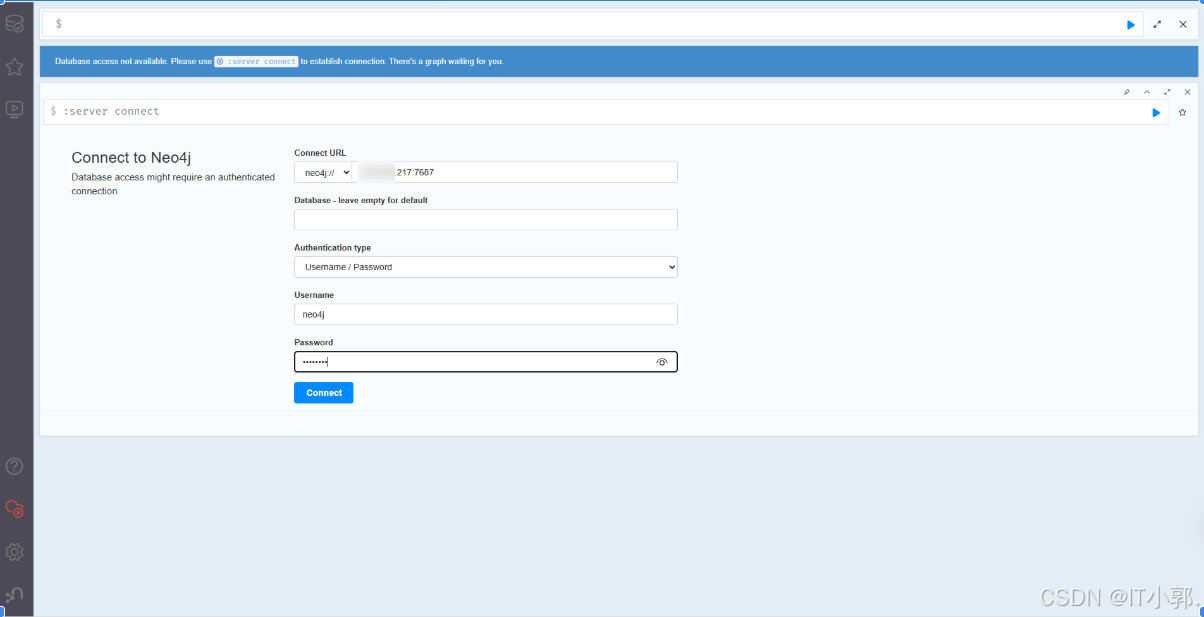
3、访问界面
访问地址:
http://localhost:7474/browser/
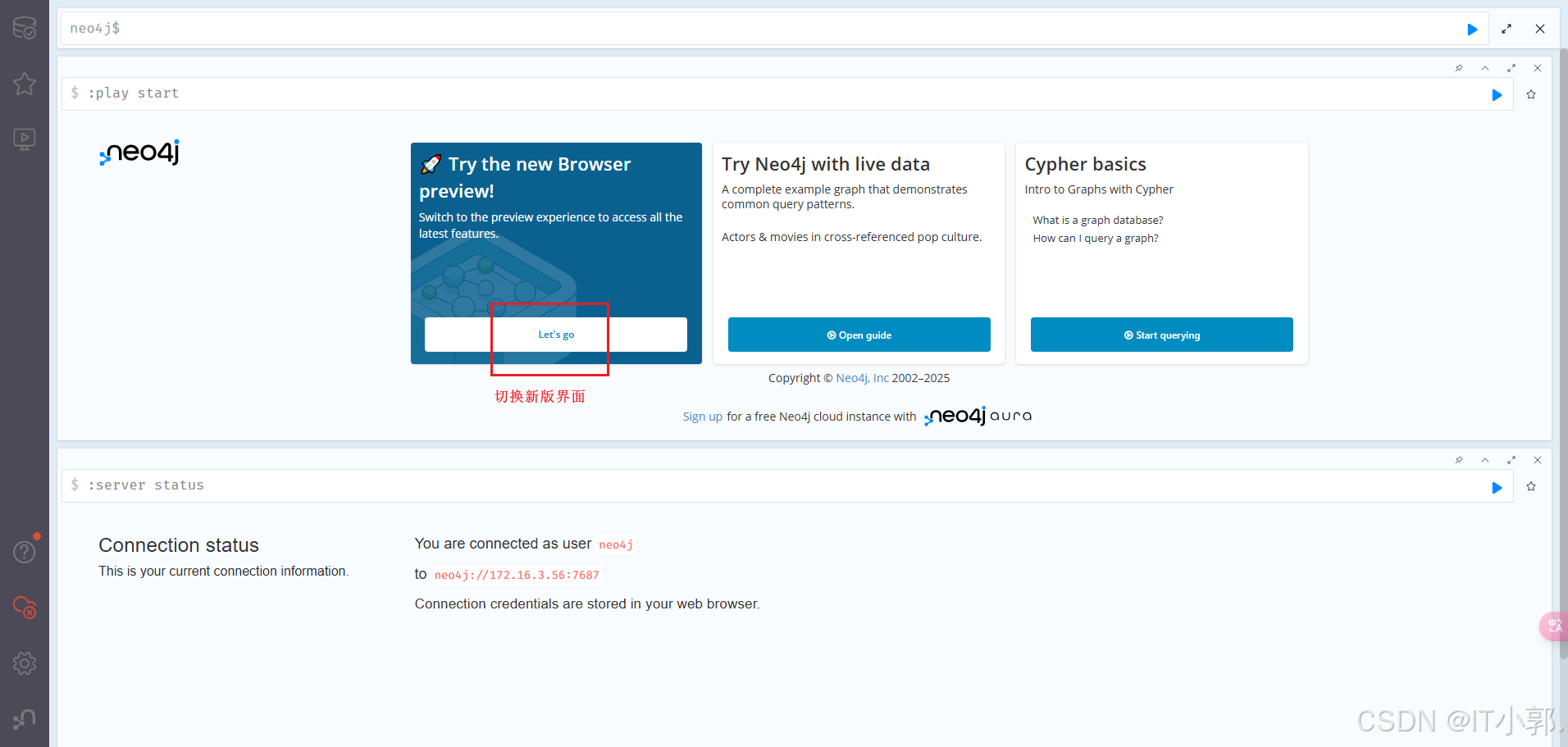
4、Cypher 和 使用 Neo4J
在这里有的小伙伴就会想我不太会使用Docker 能不能安装其他版本的呀?当然这个也是有的,小编之前也有写过一篇关于本地安装和怎么使用Neo4J的详细文章,大家有需要可以通过下面链接进行学习。
请看这里:Noe4J 超级详细的安装与使用
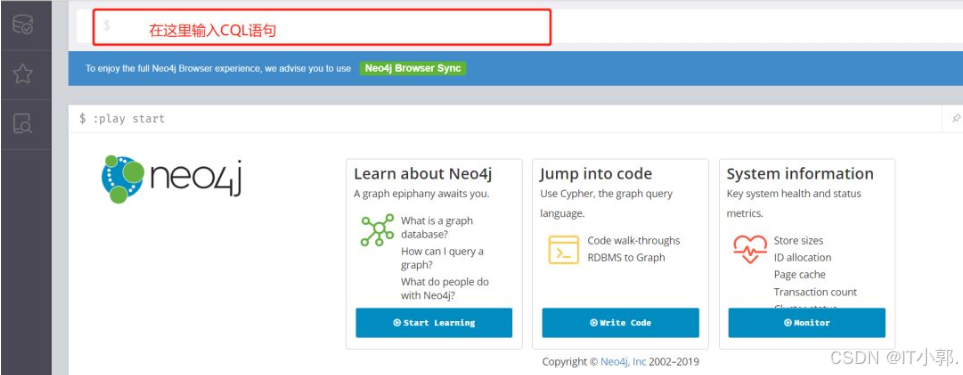
4.1、输入 CQL语句
没错,就是在大家最喜欢的美元符号那里输入 CQL语句的。这里我们拿学生和老师举例来说明。
4.2、增加节点
Neo4j使用的是create 命令进行增加,就类似与MySQL中的insert。
语法如下:
create (node-name:label-name)
create (node-name:label-name { property1-name:property1-Value, …, property3-name:property3-Value})
- node - name:它是我们要创建的节点名称
- label - name:它是我们要创建的标签名称
- property1 - name:就是属性名称
- property1 - Value:就是属性值
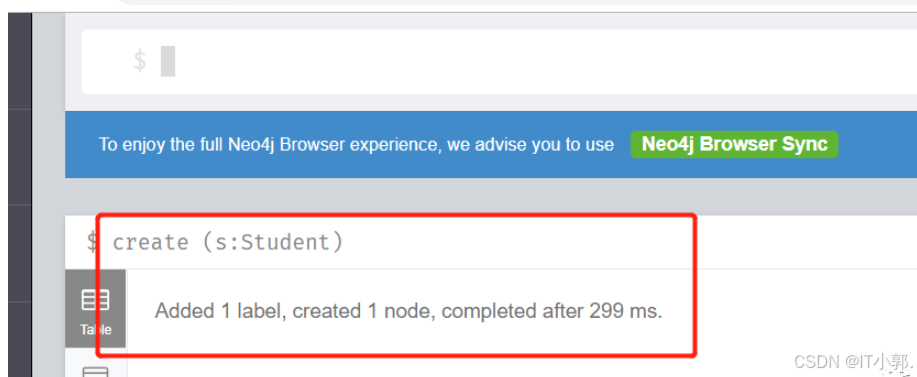
1. 创建一个学生节点(只有节点,没有属性):
create (s:Student)
在美元符号输入完上面的CQL后,回车 或者 点击右侧的三角号执行按钮,会看到如下结果:
2.创建一个学生节点(创建具有属性的节点)
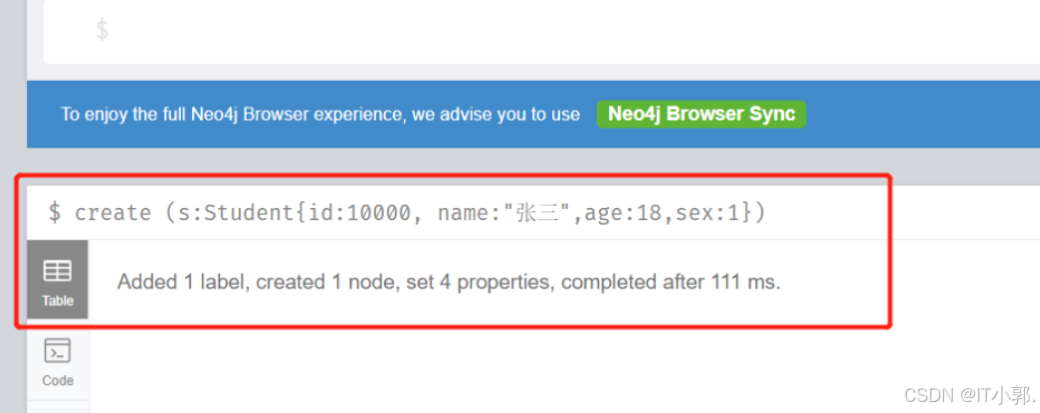
创建一个id为10000,名字为张三,年龄为18岁,性别为男的学生节点
create (s:Student{id:10000, name:"张三",age:18,sex:1})
执行后,会看到如下的结果:
4.3、查询
我们在上一步创建了没有属性的节点和有属性的节点,那么问题来了,我们怎么查看呢?查询咯~
Neo4j使用的是match … return … 命令进行查询,就类似与MySQL中的select。
我们查询刚刚创建的节点信息。
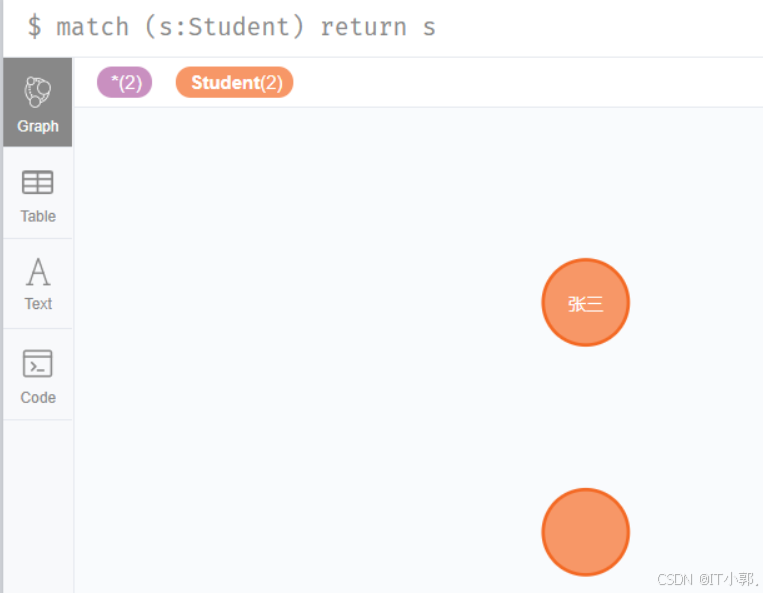
1.全部查询学生
match (s:Student) return s
从上图可以看到我们刚刚创建的两个节点,一个是没有属性节点,一个是有属性的节点。两个节点是以图的形式展示,我们也可以切换左边的Graph(图)、Table(表格)、Text(文本)等来以不同的形式展示。
2.查询全部或者部分字段
只需要把要展示的字段以节点名 + 点号 + 属性字段 拼接即可,如下:
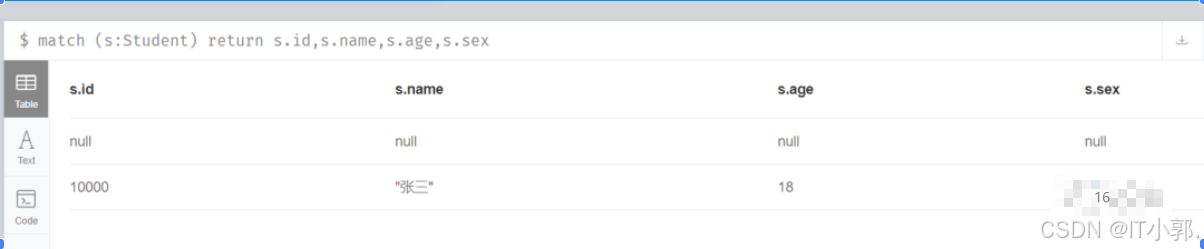
match (s:Student) return s.id,s.name,s.age,s.sex
这样就清楚的看到我们插入的学生属性信息。因为有一个是没有属性的节点,所以表格中第2行显示的各个值都是null。
3.查询满足年龄age等于18的学生信息
match (s:Student) where s.age=18 return s.id,s.name,s.age,s.sex

怎么样,这条件查询 是不是和MySQL的很相似。当然还有排序、分组、联合、分页等。为了能更好的演示这几种,我们先插入一部分数据,逐条插入:
create (s:Student{id:10001, name:"李四",age:18,sex:1}) return screate (s:Student{id:10002, name:"王五",age:19,sex:1}) return screate (s:Student{id:10003, name:"赵六",age:20,sex:1}) return screate (s:Student{id:10004, name:"周七",age:17,sex:0}) return screate (s:Student{id:10005, name:"孙八",age:23,sex:1}) return screate (s:Student{id:10006, name:"吴九",age:15,sex:1}) return screate (s:Student{id:10007, name:"郑十",age:19,sex:0}) return screate (s:Student{id:10008, name:"徐十一",age:18,sex:1}) return screate (s:Student{id:10009, name:"朱十二",age:21,sex:1}) return screate (s:Student{id:10010, name:"谭十三",age:22,sex:1}) return s
这个我们在create 的语句后面加上了return,意思就是我插入完你要把数据返回给我看下,如下:
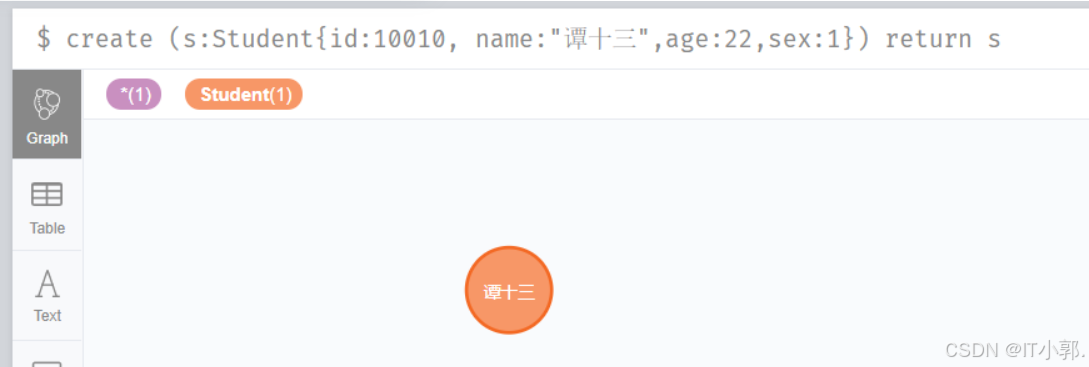
这样,我们的数据就造好了,我们可以先查询全部的看下:
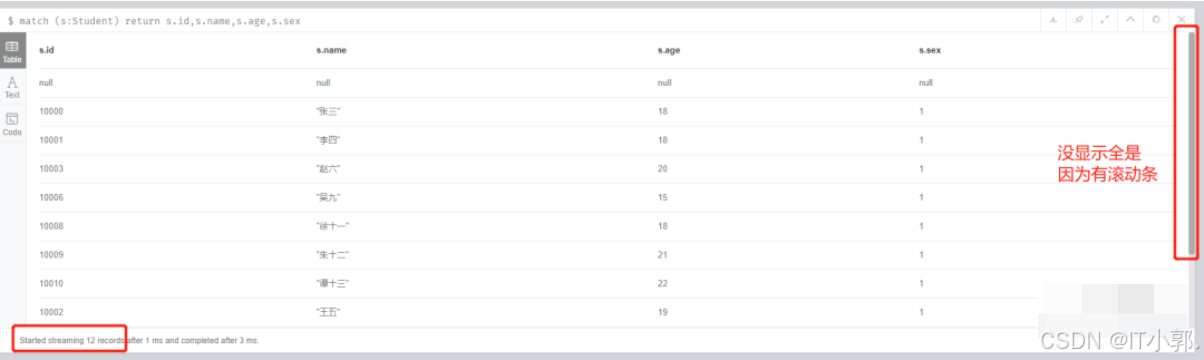
match (s:Student) return s.id,s.name,s.age,s.sex
图中的左下角我们可以看到一共有12条数据。一条没有属性的 + 11条有属性的。
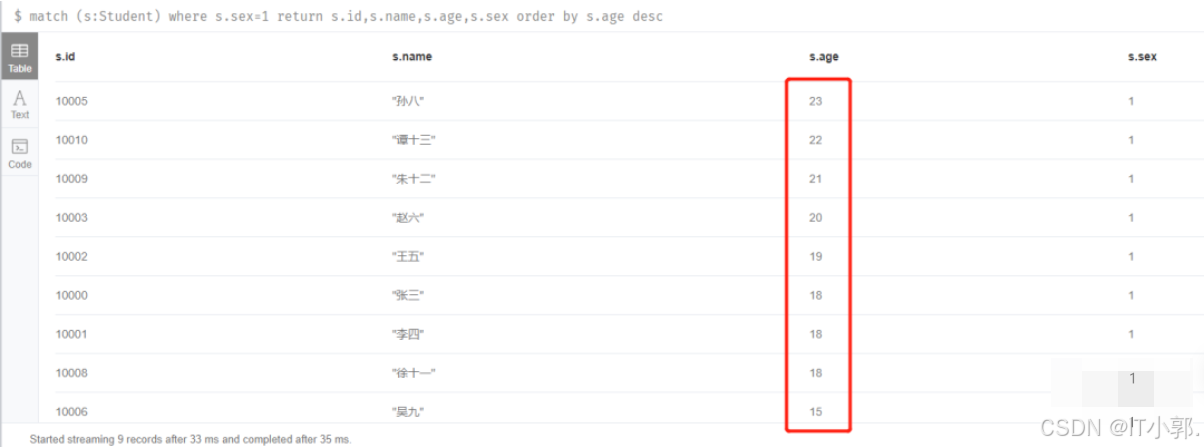
4.查询出所有的男生(sex=1)并按年龄倒叙排序
match (s:Student) where s.sex=1 return s.id,s.name,s.age,s.sex order by s.age desc
很清晰,是以age倒叙排序的。
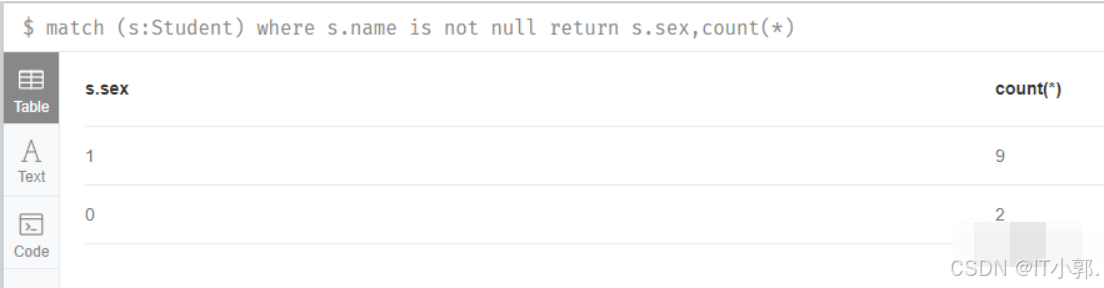
5.查询出名字不为null,且按性别分组
这里要注意一点,CQL中的分组和SQL是有所差异的,在CQL中不用显式的写group by分组字段,由解释器自动决定:即未加聚合函数的字段自动决定为分组字段。
match (s:Student) where s.name is not null return s.sex,count(*)
不难看出,上面是按sex字段分组的。
6.union联合查询(查询性别为男或者女的,且年龄为19岁的学生)
有union,当然也有 union all,这两个的区别和SQL中也是一样的。
- union:对两个结果集进行并集操作,不包括重复行;
- union all:对两个结果集进行并集操作,包括重复行;
match (s:Student) where s.sex=1 and s.age=19 return s.id,s.name,s.sex,s.ageunion match (s:Student) where s.sex=0 and s.age=19 return s.id,s.name,s.sex,s.age

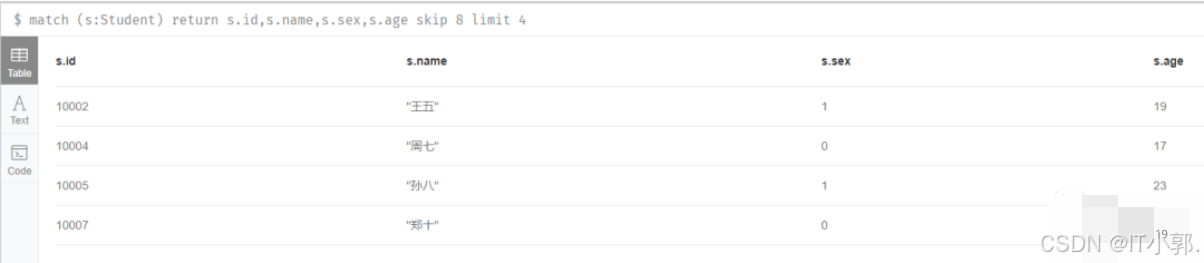
7.分页查询(每页4条,查询第3页的数据)
match (s:Student) return s.id,s.name,s.sex,s.age skip 8 limit 4
CQL中的skip表示跳过多少条,limit表示获取多少条。每页4条,查询第三页的数据,也就是跳过前8条,查询4条,或者说从第8条开始,不包括第8条,然后再查询4条。
8.in操作(查询id为10001和10005的两个数据)
match (s:Student) where s.id in [10001,10005] return s.id,s.name,s.sex,s.age
这里 用的是中括号,和SQL中是有区别的。

4.4、增加关系
创建关系的语法如下:
match (node1-label-name:node1-name),(node2-label-name:node2-name) where condition create (node1-label-name)-[relationship-label-name:relationship-name] ->(node2-label-name)
match (node1-label-name:node1-name),(node2-label-name:node2-name) where condition create (node1-label-name)-[relationship-label-name:relationship-name {relationship-properties}]->(node2-label-name)
- node1-name 表示节点名称,label1-name表示标签名称
- relationship - name 表示关系节点名称,relationship-label-name表示关系标签名称
- node2 - name 表示节点名称,label2-name表示标签名称
上面我们介绍了增加单个节点和查询的知识点。这里我们介绍下增加关系。为了存在关系,我们先创建一个老师节点。
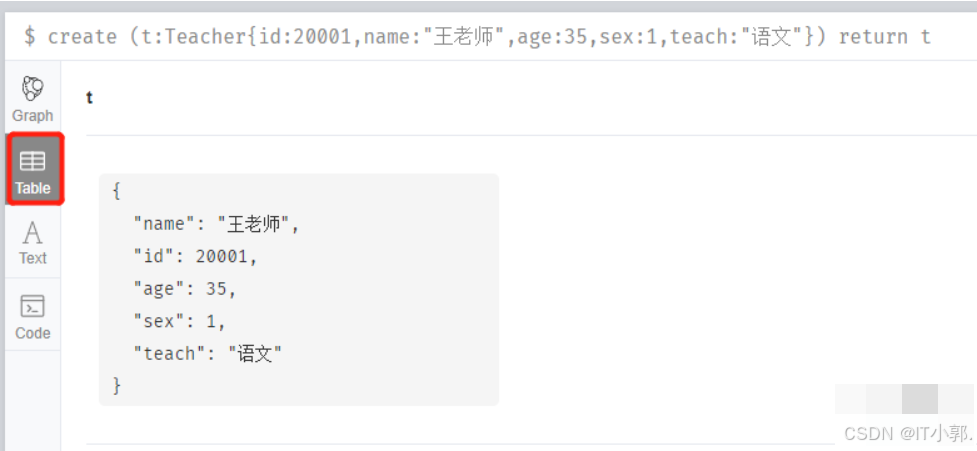
创建一个教语文的年龄为35岁的男的王老师:
create (t:Teacher{id:20001,name:"王老师",age:35,sex:1,teach:"语文"}) return t
1.假设王老师所教的班级有3个学生:张三、李四、王五,这里我们就要创建王老师 和 3个学生的关系,注意,这里是为两个现有节点创建关系。
match (t:Teacher),(s:Student) where t.id=20001 and s.id=10000 create (t)-[teach:Teach]->(s)return t,teach,s
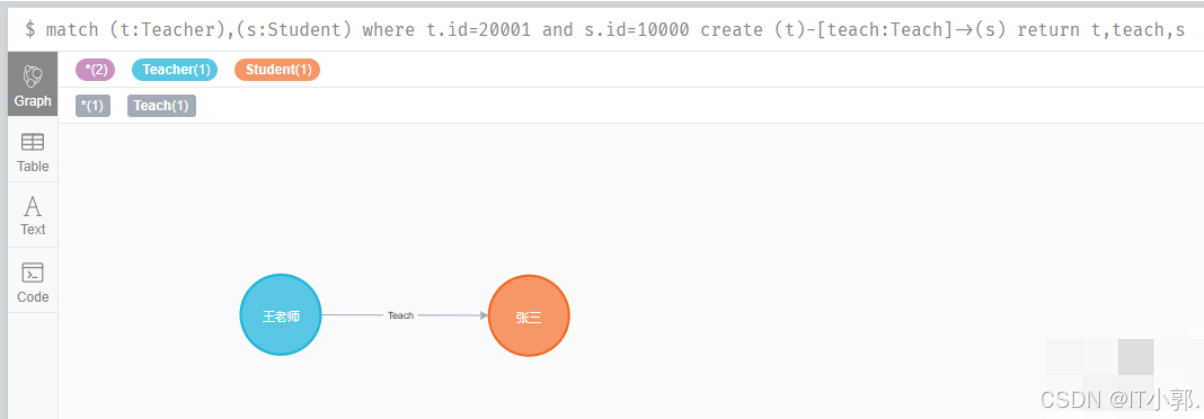
这样,王老师和张三的关系就创建了。下面,我们再继续创建王老师 和 李四、王五的关系。
match (t:Teacher),(s:Student) where t.id=20001 and s.id=10001 create (t)-[teach:Teach]->(s)return t,teach,s
match (t:Teacher),(s:Student) where t.id=20001 and s.id=10002 create (t)-[teach:Teach]->(s)return t,teach,s
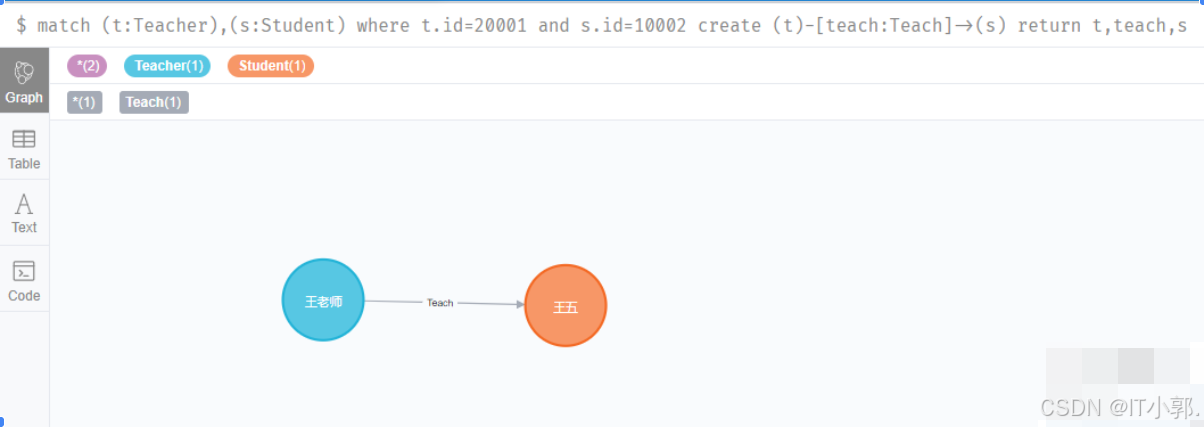
老师和学生的关系增加了,我们查询下:
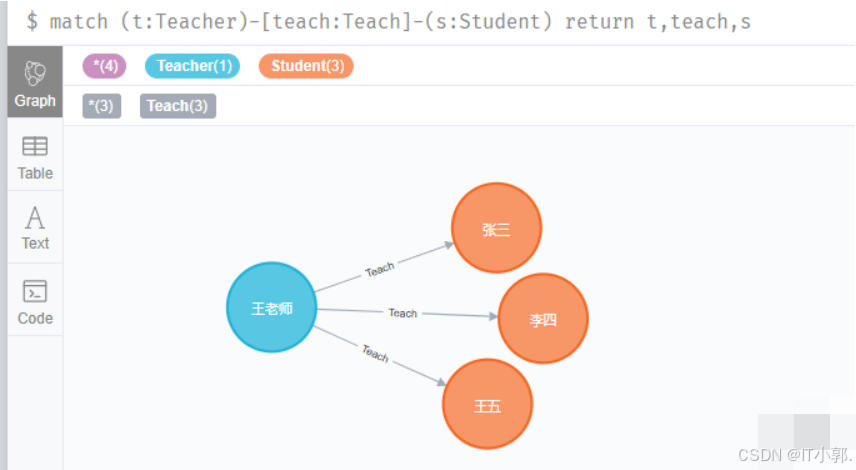
match (t:Teacher)-[teach:Teach]-(s:Student) return t,teach,s
这关系就很显然了吧。王老师教张三、李四、王五。
2.我们给广东和深圳创建关系,深圳是属于广东省的。但是并没有广东省份节点和深圳市节点,没错,我们就是为两个不存在的节点创建关系。
create (c:City{id:30000,name:"深圳市"})-[belongto:BelongTo{type:"属于"}]->(p:Province{id:40000,name:"广东省"})

我们查询下我们创建的深圳和广东的关系。
match (c:City{id:30000,name:"深圳市"})-[belongto:BelongTo{type:"属于"}]->(p:Province{id:40000,name:"广东省"}) return c,belongto,p
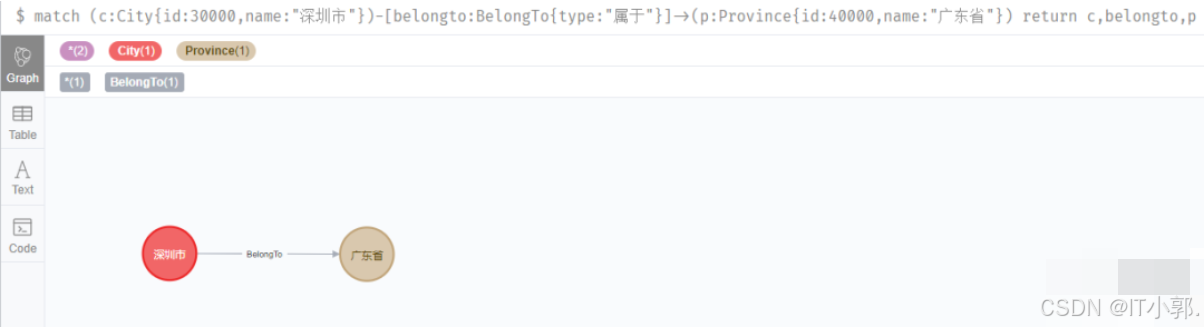
当然,属性都非必填的,只是为了更加准确。
如果我们要查询Neo4j中全部的关系需要怎么写CQL呢,如下:
match (a)-[b]-(c) return a,b,c

4.5、修改
Neo4j中的修改也和SQL中的是很相似的,都是用set子句。和es一样,Neo4j CQL set子句也可以向现有节点或关系添加新属性。
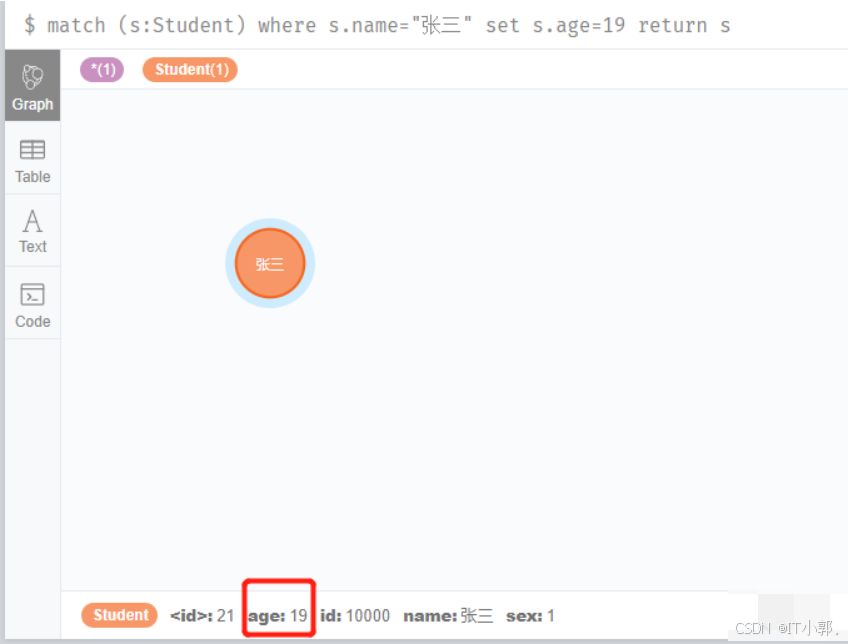
通过上面的查询,我们已经熟记了学生张三的年龄是18岁,2020年了,张三也长大了一岁,所以我们就需要把张三的年龄改为19。
match (s:Student) where s.name="张三" set s.age=19 return s
从图中的红色框中我们可以清晰的看到张三的年龄已经更新到19了:
4.6、删除
Neo4j中的删除也和SQL中的是很相似的,都是delete,当然,除了delete删除,还有remove删除。
1.删除单个节点
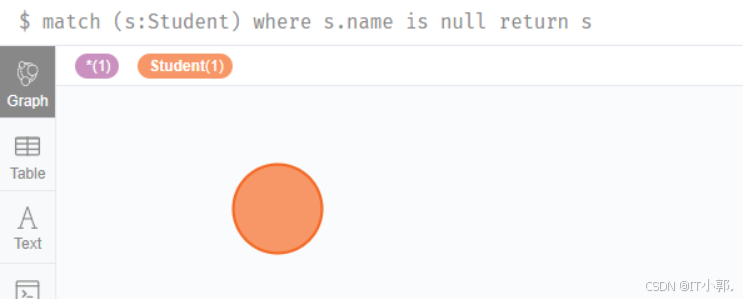
这里以删除学生节点中没有属性的来举例:
先查询下学生中没有属性的节点
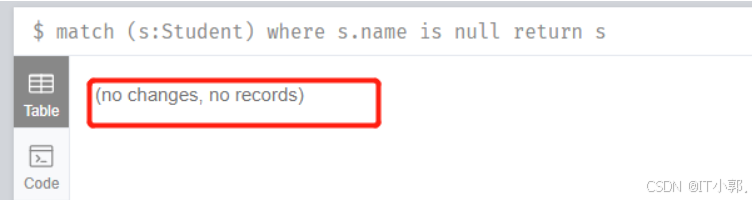
match (s:Student) where s.name is null return s
然后我们再删除这个节点:
match (s:Student) where s.name is null delete s
把上面查询的CQL中的return 改为 delete 就OK了。
执行完上面的删除CQL后,我们再重新查询下:
发现已经不存在没有属性的学生节点了,这说明我们已经删除成功了。
2.删除带关系的节点
这里我们以删除广东和深圳的关系来举例:
match (c:City{id:30000,name:"深圳市"})-[belongto]->(p:Province{id:40000,name:"广东省"}) return c,belongto,p
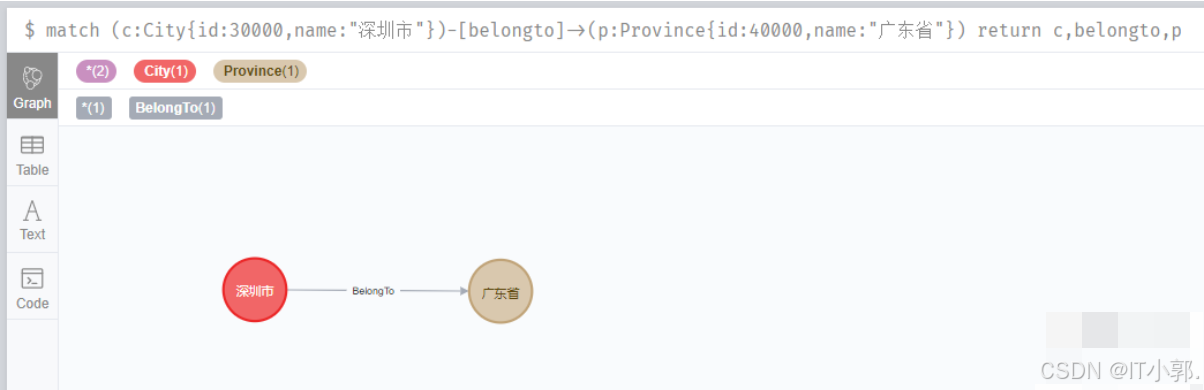
这个时候是有数据的。
然后我们执行下面的删除CQL,把上面的查询CQL中的return 改为 delete哦:
match (c:City{id:30000,name:"深圳市"})-[belongto]->(p:Province{id:40000,name:"广东省"}) delete c,belongto,p
执行完上面的删除CQL后我,我们重新再查询下:

发现已经不存在广东和深圳这两个节点以及关系了。
3.删除全部节点已经关系
这里这个CQL主要用作测试的,生产环境可不要执行,否则,真的是从删库到跑路了~
match (n) detach delete n
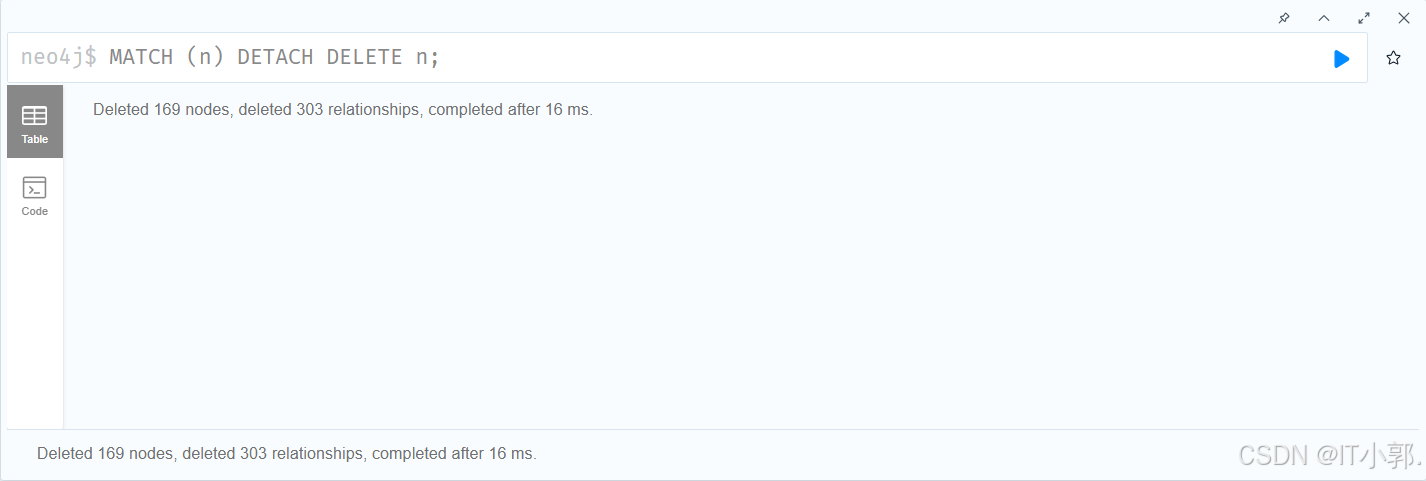
4.删除节点或关系的现有属性
可以通过remove来删除节点或关系的现有属性。
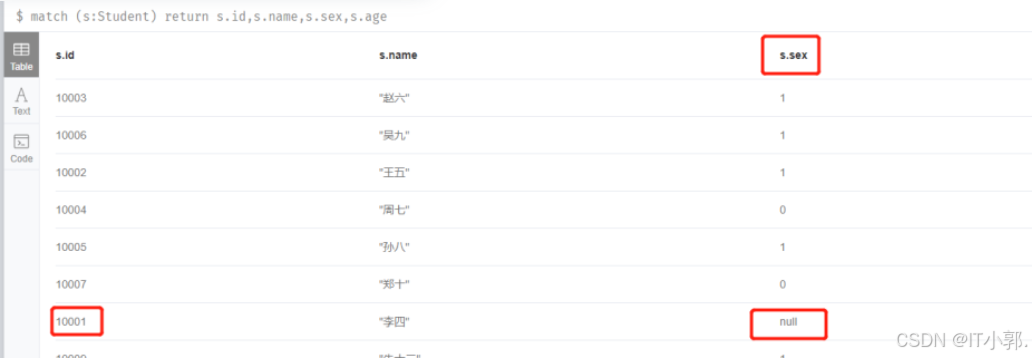
例如,我们删除学生李四节点中的sex属性:
match (s:Student{id:10001}) remove s.sex
执行完上面的remove CQL后,我们重新查询下:
看到李四的sex属性为null了。
5、将 CSV 数据导入 Neo4j
官网文档: https://neo4j.com/docs/getting-started/data-import/csv-import/
LOAD CSV可以处理本地和远程文件,并且每个文件都有一些关联的语法。 这可能是一件很容易错过的事情,并最终导致访问错误,因此此处对规则进行了说明。
出于安全原因,默认情况下,本地文件只能从 Neo4j 导入目录读取,该目录因作系统而异。 每个作系统的文件位置都列在我们的 Neo4j作手册 → 文件位置 中。 建议将文件放在 Neo4j 的 import 目录中,因为它可以保证环境安全。 但是,如果您需要访问其他位置的文件,您可以在我们的 Cypher 手册 → LOAD CSV 介绍中找到要更改的设置。
例子
//Example 1 - file directly placed in import directory (import/data.csv)
LOAD CSV FROM "file:///data.csv"//Example 2 - file placed in subdirectory within import directory (import/northwind/customers.csv)
LOAD CSV FROM "file:///northwind/customers.csv"
Web 托管文件可以直接使用其 URL 进行引用,例如 . 但是,必须设置权限,以便外部源可以读取文件。 要从本地文件系统读取文件,您需要检查配置设置是否设置为 。 有关与联机文件导入相关的访问的更多信息,请参阅此知识库文章。 但请记住,在 Neo4j v5 中,配置设置已重命名,并已更改为https://host/path/data.csvdbms.security.allow_csv_import_from_file_urlstruedbms.directories.importserver.directories.import
例子
//Example 1 - website
LOAD CSV FROM 'https://data.neo4j.com/northwind/customers.csv'//Example 2 - Google
LOAD CSV WITH HEADERS FROM 'https://docs.google.com/spreadsheets/d/<yourFilePath>/export?format=csv'
6、使用 Python 导入 Neo4j
由于 使用 LOAD CSV 命令比较麻烦,并且在实际的工作中,都不会这样去操作,而是使用代码连接数据库进行开发。我这里使用了Python 连接Neo4j 进行数据库操作。
根据这些信息,以下是修正后的代码,确保使用Bolt协议和正确的端口:
Python脚本尝试通过Bolt协议连接到Neo4j数据库,但是连接失败,并且错误提示中提到“looks like HTTP”。这通常意味着以下几个问题之一:
- 1、端口错误:你使用的端口可能是HTTP端口(7474),而Bolt协议通常使用的是7687端口。确保你使用的是正确的Bolt端口。
- 2、协议错误:如果你确实想要使用Bolt协议,确保URI以bolt://开头,而不是http://。
- 3、网络问题:网络配置可能阻止了连接,例如防火墙设置或网络策略。
- 4、Neo4j配置:Neo4j服务器可能没有配置为监听Bolt端口。
1.使用Bolt协议查询Neo4j
通过这种方式可以查询出上面我们在Neo4j 直接查询得出来的结果,只是这种会输出到控制台,这里只是一个小案例,大家可以通过实际需求进行修改
from neo4j import GraphDatabase# 连接信息
uri = "bolt://xx.xx.xx.xxx:7687" # Neo4j 连接地址,使用Bolt协议
username = "neo4j" # 用户名
password = "password" # 数据库密码# 创建驱动实例
driver = GraphDatabase.driver(uri, auth=(username, password))# 定义一个函数来执行查询
def get_students(driver):with driver.session() as session:# Cypher查询query = "MATCH (s:Student) RETURN s.id, s.name, s.age, s.sex"# 执行查询并获取结果results = session.run(query)# 打印结果for record in results:print(record["s.id"], record["s.name"], record["s.age"], record["s.sex"])# 调用函数执行查询
get_students(driver)# 关闭连接
driver.close()2.使用Bolt协议 导入数据到 Neo4j,并创建关系
通过这种方式可以连接到 Neo4j ,任何创建并批量导入CSV的数据,这种方式比起LOAD CSV 命令简单很多,同时还可以在代码中对数据进行一些复杂处理后在导入,不用我们手动处理。
import csv
from neo4j import GraphDatabase# 连接信息
uri = "bolt://xx.xx.xx.xxx:7687" # Neo4j 连接地址,使用Bolt协议
username = "neo4j" # 用户名
password = "password" # 数据库密码# 创建驱动实例
driver = GraphDatabase.driver(uri, auth=(username, password))# 定义一个函数来执行查询
def create_artists_and_relationships(driver, csv_file_path):with driver.session() as session:# 读取CSV文件with open(csv_file_path, mode='r', encoding='utf-8') as file:reader = csv.DictReader(file)for row in reader:# 构建Cypher语句创建Artists节点create_artist_query = ("CREATE (a:Artists {ID: $ID, Name:$Name, Genre: $Genre}) ""RETURN a")#ID, Name, Genreartist_params = {"ID": int(row['ID']),"Name": row['Name'],"Genre": row['Genre']}# 执行创建Artists节点的Cypher语句artist_node = session.run(create_artist_query, **artist_params).single()[0]# 如果CSV中有指定父级列,创建关系if 'Parent' in row and row['Parent']:parent_ids = row['Parent'].split(',') # 假设父级ID以逗号分隔for parent_id in parent_ids:if parent_id: # 确保parent_id不是空字符串# 构建Cypher语句创建关系create_relationship_query = ("MATCH (a:Artists {ID: $artist_id}), (p:Artists {ID:$parent_id}) ""CREATE (a)-[:CHILD_OF]->(p)")relationship_params = {"artist_id": artist_params['ID'],"parent_id": int(parent_id)}# 执行创建关系的Cypher语句session.run(create_relationship_query, **relationship_params)# 调用函数执行查询
csv_file_path = r'C:\Downloads\artists.csv' # 替换为你的CSV文件路径
create_artists_and_relationships(driver, csv_file_path)# 关闭连接
driver.close()到这里整篇关于Docker 安装 Neo4j ,以及怎么用使用 Neo4j 还有用 Python 怎么连接并操作Neo4j 就讲完了。
相关文章:

使用 Docker Desktop 安装 Neo4j 知识图谱
一、简介 Neo4j是一个高性能的,基于java开发的,NOSQL图形数据库,它将结构化数据存储在网络上而不是表中;它是一个嵌入式的、基于磁盘的、具备完全的事务特性的Java持久化引擎。 Neo4j分为企业版和社区版,企业版可以创…...

从构想到交付:专业级软开发流程详解
目录 一、软件开发生命周期(SDLC)标准化流程 1. 需求工程阶段(Requirement Engineering) 2. 系统设计阶段(System Design) 3. 开发阶段(Implementation) 4. 测试阶段&a…...

时源芯微| KY键盘接口静电浪涌防护方案
KY键盘接口静电浪涌防护方案通过集成ESD保护元件、电阻和连接键,形成了一道有效的防护屏障。当键盘接口受到静电放电或其他浪涌冲击时,该方案能够迅速将过电压和过电流引导至地,从而保护后续电路免受损害。 ESD保护元件是方案中的核心部分&a…...

数据库故障排查指南:从理论到实践的深度解析
数据库作为现代信息系统的核心组件,承载着数据存储、查询和事务处理等关键任务。然而,数据库系统在运行过程中可能遭遇各种故障,从硬件故障到软件配置问题,从性能瓶颈到安全漏洞,这些问题都可能影响业务的连续性和数据…...
)
电脑开机提示按f1原因分析及解决方法(6种解决方法)
经常有网友问到一个问题,我电脑开机后提示按f1怎么解决?不管理是台式电脑,还是笔记本,都有可能会遇到开机需要按F1,才能进入系统的问题,引起这个问题的原因比较多,今天小编在这里给大家列举了比较常见的几种电脑开机提示按f1的解决方法。 电脑开机提示按f1原因分析及解决…...

常用的Java工具库
1. Collections 首先是 java.util 包下的 Collections 类。这个类主要用于操作集合,我个人非常喜欢使用它。以下是一些常用功能: 1.1 排序 在工作中,经常需要对集合进行排序。让我们看看如何使用 Collections 工具实现升序和降序排列&…...
在企业报表中的报表数据中心里计算某张报表时,一直计算不出数据的解决办法。)
NC65开发环境(eclipse启动)在企业报表中的报表数据中心里计算某张报表时,一直计算不出数据的解决办法。
NC65开发环境(eclipse启动)在企业报表中的报表数据中心里计算某张报表时,一直计算不出数据的解决办法。 如下图,在报表数据中心,针对现金内部往来明细表计算5月的数据,然后报表下面一张显示计算,…...

React 第三十九节 React Router 中的 unstable_usePrompt Hook的详细用法及案例
React Router 中的 unstable_usePrompt 是一个用于在用户尝试离开当前页面时触发确认提示的自定义钩子,常用于防止用户误操作导致数据丢失(例如未保存的表单)。 一、unstable_usePrompt用途 防止意外离开页面:当用户在当前页面有…...
《P4391 [BalticOI 2009] Radio Transmission 无线传输 题解》
题目描述 给你一个字符串 s1,它是由某个字符串 s2 不断自我连接形成的(保证至少重复 2 次)。但是字符串 s2 是不确定的,现在只想知道它的最短长度是多少。 输入格式 第一行一个整数 L,表示给出字符串的长度。…...
)
使用ECS搭建云上博客wordpress(ALMP)
一、需求分析与技术选型 1. 架构组成及含义 本文使用ECS云服务器,采用ALMP架构搭建wordpress。组件具体的含义如下表: 组件作用WordPress中的功能体现Linux操作系统基础,提供稳定运行环境支持PHP运行和服务器管理ApacheWeb服务器ÿ…...

Scratch游戏 | 企鹅大乱斗
有没有过无聊到抓狂的时刻?试试这款 企鹅大乱斗 吧!超简单的玩法,让你瞬间告别无聊! 🎮 玩法超简单 等待屏幕出现 ”Go!” 疯狂点击,疯狂拍打企鹅! 💥 游戏特色 解压神器&#x…...

深入理解SpringBoot中的SpringCache缓存技术
深入理解SpringBoot中的SpringCache缓存技术 引言 在现代应用开发中,缓存技术是提升系统性能的重要手段之一。SpringBoot提供了SpringCache作为缓存抽象层,简化了缓存的使用和管理。本文将深入探讨SpringCache的核心技术点及其在实际业务中的应用场景。…...

URP相机如何将场景渲染定帧模糊绘制
1)URP相机如何将场景渲染定帧模糊绘制 2)为什么Virtual Machine会随着游戏时间变大 3)出海项目,打包时需要勾选ARMv7吗 4)Unity是手动还是自动调用GC.Collect 这是第431篇UWA技术知识分享的推送,精选了UWA社…...

嵌入式中深入理解C语言中的指针:类型、区别及应用
在嵌入式开发中,C语言是一种基础且极为重要的编程语言,其中指针作为一个非常强大且灵活的工具,广泛应用于内存管理、动态数据结构的实现以及函数参数的传递等方面。然而,尽管指针的使用极为常见,很多开发者在掌握其基本使用后,往往对指针的深入理解还不够。本文将深入分析…...

.NET程序启动就报错,如何截获初期化时的问题json
一:背景 1. 讲故事 前几天训练营里的一位朋友在复习课件的时候,程序一跑就报错,截图如下: 从给出的错误信息看大概是因为json格式无效导致的,在早期的训练营里曾经也有一例这样的报错,最后定位下来是公司…...
)
WeakAuras Lua Script ICC (BarneyICC)
WeakAuras Lua Script ICC (BarneyICC) https://wago.io/BarneyICC/69 全量英文字符串: !WA:2!S33c4TXX5bQv0kobjnnMowYw2YAnDKmPnjnb4ljzl7sqcscl(YaG6HvCbxaSG7AcU76Dxis6uLlHNBIAtBtRCVM00Rnj8Y1M426ZH9XDxstsRDR)UMVCTt0DTzVhTjNASIDAU…...

Sunsetting 创建 React App
🤖 作者简介:水煮白菜王,一位前端劝退师 👻 👀 文章专栏: 前端专栏 ,记录一下平时在博客写作中,总结出的一些开发技巧和知识归纳总结✍。 感谢支持💕💕&#…...

Python笔记:c++内嵌python,c++主窗口如何传递给脚本中的QDialog,使用的是pybind11
1. 问题描述 用的是python 3.8.20, qt版本使用的是5.15.2, PySide的版本是5.15.2, pybind11的版本为2.13.6 网上说在python脚本中直接用PySide2自带的QWinWidget,如from PySide2.QtWinExtras import QWinWidget,但我用的版本中说没有QWinWidget&#x…...

环境配置与MySQL简介
目录 1 环境配置 2 MySQL简介 1 环境配置 本专栏使用CentOS7进行讲解。首先我们查看系统中是否已经安装了MySQL,可以使用rpm -qa 命令查看系统安装包/压缩包 列表 这只是看我们是否下载过对应安装包,不一定就安装了。如果我们需要重新下载,…...

Unity3D游戏内存管理优化指南
前言 Unity3D 的内存管理机制较为复杂,开发者需要理解其内存分布以避免内存泄漏和性能问题。以下是 Unity3D 游戏内存分布的核心概览,结合托管堆、本地堆、资源内存等关键模块: 对惹,这里有一个游戏开发交流小组,大家…...

深度解析 Sora:从技术原理到多场景实战的 AI 视频生成指南【附学习资料包下载】
一、技术架构与核心能力解析 1.1 时空建模体系的创新突破 Sora 在视频生成领域的核心优势源于其独特的时空建模架构。区别于传统将视频拆解为单帧处理的模式,Sora 采用时空 Patch 嵌入技术,将连续视频序列分割为 32x32 像素的时空块(每个块包含相邻 3 帧画面),通过线性投…...

Maven构建流程详解:如何正确管理微服务间的依赖关系-当依赖的模块更新后,我应该如何重新构建主项目
文章目录 一、前言二、Maven 常用命令一览三、典型场景说明四、正确的构建顺序正确做法是: 五、为什么不能只在 A 里执行 clean install?六、进阶推荐:使用多模块项目(Multi-module Project)七、总结 一、前言 在现代…...

zookeeper本地部署
下载源码本地运行 zookeeper下载地址 更改配置 运行命令 如果本地启动zookeeper时出现了端口被占用的情况,在 conf 下的 zoo.cfg 文件中加入 admin.serverPort“端口号”...
:移情阶段的深度博弈——如何避开客户访谈的认知陷阱)
精益数据分析(59/126):移情阶段的深度博弈——如何避开客户访谈的认知陷阱
精益数据分析(59/126):移情阶段的深度博弈——如何避开客户访谈的认知陷阱 在创业的移情阶段,客户访谈是挖掘真实需求的核心手段,但人类认知偏差往往导致数据失真。今天,我们结合《精益数据分析》的方法论…...
(2))
一文理解扩散模型(生成式AI模型)(2)
第二期内容主要是扩散模型的架构,其中包括用于扩散模型的U-Net架构和用于扩散模型的transformer架构。(transformer架构非常重要) 扩散模型需要训练一个神经网络来学习加噪数据的分数函数,或者学习加在数据上的噪声(这对应上文所展示的扩散模型的两种训…...

【Java面试题】——this 和 super 的区别
🎁个人主页:User_芊芊君子 🎉欢迎大家点赞👍评论📝收藏⭐文章 🔍系列专栏:【Java】内容概括 【前言】 在Java的世界里,this和 super是两个非常重要且容易混淆的关键字。无论是在日常…...

数据结构基础排序算法
选择排序 选择排序的基本思路:从待排序元素中选取最大(或最小)的一个元素加入到已完成排序的末尾。 #include <stdio.h>#define ARR_LEN(arr) (sizeof(arr) / sizeof(arr[0])) #define SWAP(arr, i, j ) { \ int tmp arr[i]; …...

数据结构中的高级排序算法
希尔排序 你可以将希尔排序理解成——先通过几次分组的、较小的组间插入排序将原数组变得有序,最后再进行一次序列基本有序的完整插入排序。 #include <stdio.h>#define ARR_LEN(arr) (sizeof(arr) / sizeof(arr[0]))void print_arr(int arr[], int len) {for…...

家庭宽带的内网穿透实践
家庭宽带的内网穿透实践 龙生龙,凤生凤,老鼠的儿子会打洞。我们今天来学习 “打洞” ! 背景 众所周知,当前运营商在IPv4环境下面,由于地址资源不够,启用了大内网策略。导致家庭宽带到路由器这一层都分配了…...

LabVIEW在电子电工教学中的应用
在电子电工教学领域,传统教学模式面临诸多挑战,如实验设备数量有限、实验过程存在安全隐患、教学内容更新滞后等。LabVIEW 作为一款功能强大的图形化编程软件,为解决这些问题提供了创新思路,在电子电工教学的多个关键环节发挥着重…...

算法每日刷题 Day6 5.14:leetcode数组1道题,用时30min,明天按灵茶山艾府题单开刷,感觉数组不应该单算
14. 977.有序数组的平方(简单,学习,双指针) 977. 有序数组的平方 - 力扣(LeetCode) 思想 法一: 1.平方赋值到另一个数组sort排序 法二: 1.寻找负数和非负数的分界线(学习代码如何写?),[0,neg]负数,[neg1…...

JS逆向实战四:某查查请求头逆向解密
声明:本文章中所有内容仅供学习交流使用,不用于其他任何目的,不提供完整代码,抓包内容、敏感网址、数据接口等均已做脱敏处理,严禁用于商业用途和非法用途,否则由此产生的一切后果均与作者无关!…...

QT之QComboBox组件
欢迎来到 破晓的历程的 博客 ⛺️不负时光,不负己✈️ 文章目录 1.引言2.初见QComboBox3.核心功能和常用方法1. 添加和删除选项2. 获取和设置当前值3. 可编辑模式4. 数据绑定 4.信号与槽5.应用场景6.使用示例7.总结 1.引言 在记事本项目中,不同的编码设…...

数值积分知识
数值积分 对于增加插值节点序列: { x i } i 0 n \left\{x_i\right\}_{i0}^{n} {xi}i0n,由插值定理给出: f ( x ) ∑ i 0 n y i l i ( x ) f ( n 1 ) ( ξ ) ( n 1 ) ! ∏ i 0 n ( x − x i ) f(x)\sum_{i0}^{n}y_i l_i(x)\frac{f…...

代码随想录训练营第二十三天| 572.另一颗树的子树 104.二叉树的最大深度 559.N叉树的最大深度 111.二叉树的最小深度
572.另一颗树的子树: 状态:已做出 思路: 这道题目当时第一时间不是想到利用100.相同的树思路来解决,而是先想到了使用kmp,不过这个题目官方题解确实是有kmp解法的,我使用的暴力解法,kmp的大致思…...

力扣-105.从前序与中序遍历序列构造二叉树
题目描述 给定两个整数数组 preorder 和 inorder ,其中 preorder 是二叉树的先序遍历, inorder 是同一棵树的中序遍历,请构造二叉树并返回其根节点。 class Solution { public:TreeNode* buildTree(vector<int>& preorder, vecto…...

【Linux网络】————详解TCP三次握手四次挥手
作者主页: 作者主页 本篇博客专栏:Linux 创作时间 :2025年5月14日 一、TCP三次握手四次挥手介绍 TCP使用三次握手来进行建立连接,四次挥手来终止连接,为何连接还要这么麻烦呢,那是因为这样可以确保建立…...
部署加速方法——PagedAttention)
LLM(大语言模型)部署加速方法——PagedAttention
一、vLLM 用于大模型并行推理加速 存在什么问题? vLLM 用于大模型并行推理加速,其中核心改进是PagedAttention算法,在 vLLM 中,我们发现 LLM 服务的性能受到内存的瓶颈。在自回归解码过程中,LLM 的所有输入标记都会生…...

附加:TCP如何保障数据传输
附加:TCP如何保障数据传输 LS-NET-012-TCP的交互过程详解 TCP 如何保障数据传输 TCP(Transmission Control Protocol,传输控制协议)是互联网核心协议之一,负责在IP网络上提供可靠的、面向连接的数据传输服务。它位于T…...

【python机器学习】Day 25 异常处理
知识点: 异常处理机制debug过程中的各类报错try-except机制try-except-else-finally机制 在即将进入深度学习专题学习前,我们最后差缺补漏,把一些常见且重要的知识点给他们补上,加深对代码和流程的理解。 借助ai写代码的时候&…...

idea springboot 配置文件 中文显示
这里一定要注意编码。如果使用的是中文,则有可能出现乱码, 请单击IDEA菜单栏中的“File→→Settings→Editor→File Encodings”命令, 然后将 Properties Files(*.properties)下的“Default encoding for properties files"设置为UTF-8,…...
)
day20-线性表(链表II)
一、调试器 1.1 gdb(调试器) 在程序指定位置停顿 1.1.1 一般调试 gcc直接编译生成的是发布版(Release) gcc -g //-g调式版本,(体积大,内部有源码)(DeBug&#…...

深入剖析某App视频详情逆向:聚焦sig3参数攻克
深入剖析某手App视频详情逆向:聚焦sig3参数攻克 一、引言 在当今互联网信息爆炸的时代,短视频平台如某手,已成为人们获取信息、娱乐消遣的重要渠道。对于技术爱好者和研究人员而言,深入探索其内部机制,特别是视频详情…...

数据结构与算法-双向链表专题
目录 一. 双向链表的结构 二.双向链表的使用 2.1 创建节点 2.2 初始化 2.3 打印 2.4 尾插 2.5 头插 2.6 尾删 2.7 头删 2.8 在指定位置pos之后插入数据 2.9 查找数据 2.10 删除pos位置的节点 2.11 销毁链表 一. 双向链表的结构 在List.h的头文件中对链表的结构进行创建 #prag…...

为什么要选择七彩喜数字康养平台?加盟后有何优势?
一.七彩喜数字康养平台 1.技术领先性 七彩喜依托“端-网-云-脑”四层技术架构,整合毫米波雷达、AI算法引擎、区块链等前沿技术,解决传统养老的隐私泄露、设备孤岛等痛点。 比如非接触式健康监测系统通过毫米波雷达实现跌倒检测准确率&#…...

vscode调试c/c++
1. 调试配置选择 调试 C 程序:选择 "Debug C Program"(调用 gcc 编译)。 调试 C 程序:选择 "Debug C Program"(调用 g 编译)。 2. 调试步骤 打开代码文件:确保当前编辑器…...

进阶数据结构: AVL树
嘿,各位技术潮人!好久不见甚是想念。生活就像一场奇妙冒险,而编程就是那把超酷的万能钥匙。此刻,阳光洒在键盘上,灵感在指尖跳跃,让我们抛开一切束缚,给平淡日子加点料,注入满满的pa…...

C# 调试技巧——日志记录,NuGet内断点
在C#中,Debug.WriteLine()、Trace.WriteLine() 和 Console.WriteLine() 都用于输出信息,但它们的用途和适用场景有显著区别。以下是它们的核心差异总结: Debug.WriteLine()主要适用于控制台程序,输出到控制台Trace.WriteLine() …...

模糊数学方法之模糊贴近度
模糊数学方法之模糊贴近度 一、概述 二、代码实现(内含注释) #程序文件ex14_3.py # 本段带代码主要是用于判断b是属于a中的哪个种类的 # 通过计算贴近度的形式来实现的 import numpy as np a np.array([[0.4,0.3,0.5,0.3],[0.3,0.3,0.4,0.4],[0.2,0.3…...

Spring AI 集成 Mistral AI:构建高效多语言对话助手的实战指南
Spring AI 集成 Mistral AI:构建高效多语言对话助手的实战指南 前言 在人工智能应用开发领域,选择合适的大语言模型(LLM)与开发框架至关重要。Mistral AI 凭借其高效的多语言模型(如 Mistral-7B、Mixtral-8x7B 等&am…...